Elasticsearch index 设置 false,为什么还可以被检索到?
在 Elasticsearch 中,mapping 定义了索引中的字段类型及其处理方式。
近期有球友提问,为什么设置了 index: false 的字段仍能被检索。
本文将详细探讨这个问题,并引入列式存储的概念,帮助大家更好地理解 Elasticsearch 的存储和查询机制。

1、问题描述
我们创建了一个名为 my-index-000001 的索引,并为其添加了一个名为 employee-id 的字段,该字段的 index 属性被设置为 false。
按理说,这个字段不应该被索引,也不应能被检索,但在执行查询时,却能检索到该字段。这是为什么呢?
PUT /my-index-000001
{"mappings": {"properties": {"employee-id": {"type": "keyword","index": false}}}
}POST /my-index-000001/_doc/1
{"employee-id": "1111"
}POST /my-index-000001/_search
{"query": {"term": {"employee-id": "1111"}}
}问题来源:https://t.zsxq.com/GuwKP
2、原因分析
在 Elasticsearch 中,index 选项控制字段值是否被索引。
默认情况下,所有字段都是被索引的 (index: true)。当 index 设置为 false 时,字段不会被索引,因此不能通过常规查询方法高效地检索该字段。
https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-index.html
然而,对于某些特定类型的字段,即使设置了 index: false,它们仍然可以通过 doc_values 进行查询。
这其实就是咱们的问题所在!
这些特定字段类型包括:
数值类型(Numeric types)
日期类型(Date types)
布尔类型(Boolean type)
IP 类型(IP type)
地理点类型(Geo_point type)
关键字类型(Keyword type)
对于这些类型的字段,即使 index 设置为 false,只要 doc_values 启用,它们仍然可以被查询。
查询效率会较低,因为需要对整个索引进行全扫描(full scan)。
3、列式存储概述
列式存储(Columnar Storage)是指将每个字段的数据独立存储,这种存储方式不同于传统的行式存储。
在数据仓库和大数据处理系统中,列式存储优化了读取和分析操作。
以下是一些常见的列式存储格式及其应用:
Parquet:广泛用于 Apache Hadoop 生态系统中的数据处理,提供高效的存储和压缩。
ORC(Optimized Row Columnar):主要用于 Apache Hive 和 Hadoop 生态系统,提供优化的列存储格式。
Cassandra:分布式数据库系统,采用行和列的混合存储方式,支持列级别的高效查询。

列式存储 VS 行式存储
在 Elasticsearch 中,doc_values 是一种列式存储机制,用于存储字段的数据,以支持高效的排序和聚合操作。
这里就是明显区别于“倒排索引”的一种正排索引技术,详细解读参见《一本书讲透 Elasticsearch》P97-P98。
Doc values 是指在文档索引时创建的存储在磁盘数据结构,它们以列式存储的方式保存与 _source 相同的数据,从而大大提高了排序和聚合操作的效率。除文本 text 和带注释的文本(annotated_text ,新类型)字段外,几乎所有字段类型都支持 doc values。
https://www.elastic.co/guide/en/elasticsearch/reference/current/doc-values.html
3.1 列式存储示例:词组数据举例
假设我们有以下文档集合,这些文档包含多个字段,包括 employee-id 雇员 id 序号和 address 地址信息:
[{"employee-id": "1111", "name": "Alice", "age": 30, "address": "123 Main St, Springfield, IL"},{"employee-id": "1112", "name": "Bob", "age": 25, "address": "456 Elm St, Springfield, IL"},{"employee-id": "1113", "name": "Charlie", "age": 35, "address": "789 Oak St, Springfield, IL"}
]列式存储如下图所示:
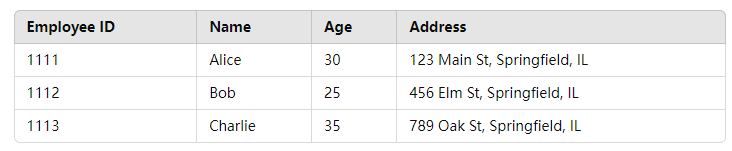
当这些文档被索引到 Elasticsearch 中时,启用了 doc_values 的字段会以列式存储的方式独立存储。
假设我们为 employee-id、address 字段启用了 doc_values,其存储结构如下:
employee-id 列存储:
"1111"
"1112"
"1113"address 列存储:
"123 Main St, Springfield, IL"
"456 Elm St, Springfield, IL"
"789 Oak St, Springfield, IL"3.2 列式存储查询行为
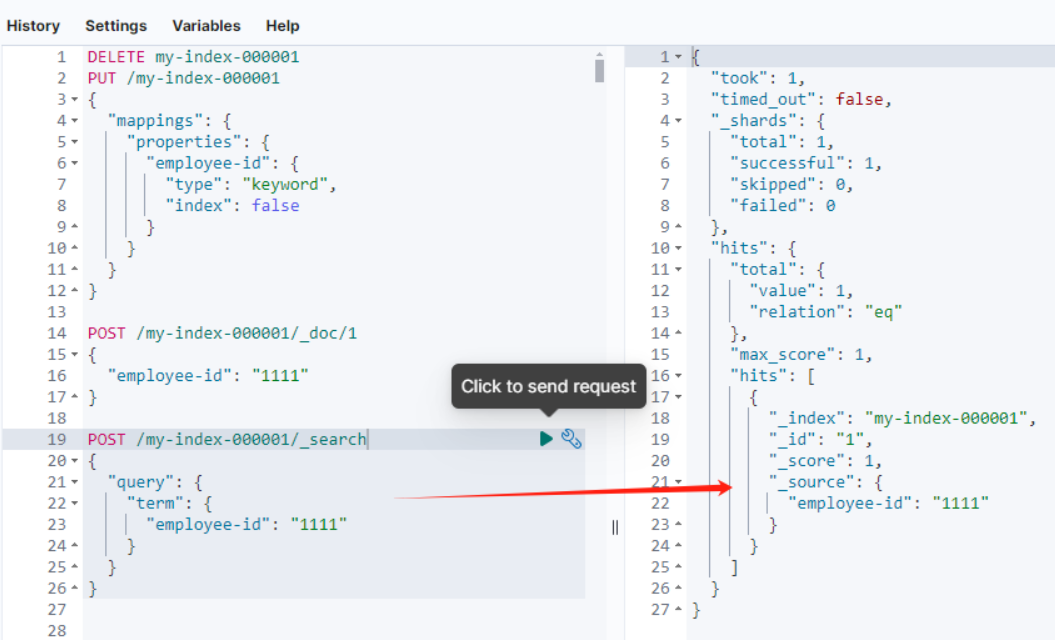
回到开篇问题,在这种情况下,如果我们对 employee-id 进行查询:
POST /my-index/_search
{"profile": true, "query": {"term": {"employee-id": "1111"}}
}由于 employee-id 字段启用了 doc_values,但没有被索引,Elasticsearch 会使用基于 doc_values 的查询机制来处理。
这个查询会遍历 employee-id 列的数据,找到匹配 "1111" 的文档。
这里就分析出了 index:false, 依然可以被检索的原因。
再进一步验证,
PUT /my-index-0606
{"mappings": {"properties": {"employee-id": {"type": "keyword","doc_values": true},"name": {"type": "text"},"age": {"type": "integer","doc_values": true},"address": {"type": "keyword","index":false}}}
}POST /my-index-0606/_bulk
{ "index": { "_id": "1" } }
{ "employee-id": "1111", "name": "Alice", "age": 30, "address": "123 Main St, Springfield, IL" }
{ "index": { "_id": "2" } }
{ "employee-id": "1112", "name": "Bob", "age": 25, "address": "456 Elm St, Springfield, IL" }
{ "index": { "_id": "3" } }
{ "employee-id": "1113", "name": "Charlie", "age": 35, "address": "789 Oak St, Springfield, IL" }POST my-index-0606/_search
{"query": {"term": {"address": "123 Main St, Springfield, IL"}}
}得到结果如下:
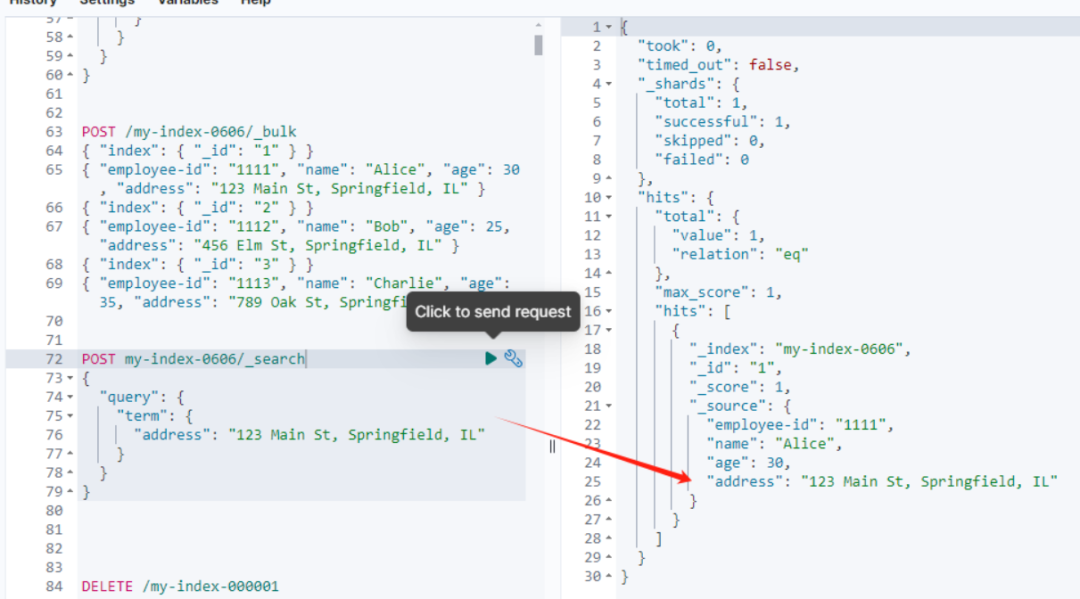
这就是基于正排索引做的轮询的结果。
3.3 列式存储的优势和劣势
优势:
列式存储使得对特定字段的聚合和排序操作更加高效,因为只需要读取相关列的数据,而不是整个文档的所有字段。
举例说明,假设我们有一个包含员工信息的索引(在之前基础上新增了字段),文档结构如下:
[{"employee-id": "1111", "name": "Alice", "age": 30, "salary": 5000, "address": "123 Main St, Springfield, IL"},{"employee-id": "1112", "name": "Bob", "age": 25, "salary": 6000, "address": "456 Elm St, Springfield, IL"},{"employee-id": "1113", "name": "Charlie", "age": 35, "salary": 7000, "address": "789 Oak St, Springfield, IL"}
]如果行式存储:读取每个文档时,所有字段数据都被加载,即使我们只关心其中一个字段的数据。
行式存储举例——计算平均薪资时,整个文档(包括 name、age、address 等)都要被读取。如下图所示:
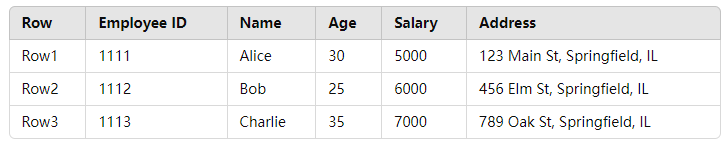
读取整行信息,有点类似 MySQL 如下操作:
SELECT * FROM employees WHERE employee-id = '1111';返回结果:
{"employee-id": "1111", "name": "Alice", "age": 30, "salary": 5000, "address": "123 Main St, Springfield, IL"}如果列式存储:只读取特定字段的数据。
列式存储举例——计算平均薪资时,只需读取 salary 列的数据即可,避免了读取无关字段的数据。如下图所示。
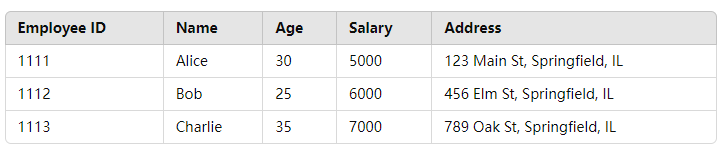
列式存储读取一列数据,有点类似 MySQL如下操作:
SELECT age FROM employees;返回结果:
[30, 25, 35]劣势:对于未被索引的字段,查询效率较低,因为需要遍历整个列的数据来匹配查询条件。
4、结论
通过这些示例,我们可以更清楚地理解 Elasticsearch 中列式存储和 doc_values 的应用。
列式存储使得对特定字段的聚合和排序操作更加高效,但对于未被索引的字段,查询效率较低,因为需要遍历整个列的数据来匹配查询条件。
希望这些解释能帮助你更好地理解 Elasticsearch 的存储和查询机制。
如果你对字段的查询和聚合有特定需求,合理使用 index 和 doc_values 设置可以大大提升性能和效率。
新时代写作与互动:《一本书讲透 Elasticsearch》读者群的创新之路

更短时间更快习得更多干货!
和全球超2000+ Elastic 爱好者一起精进!
elastic6.cn——ElasticStack进阶助手

比同事抢先一步学习进阶干货!
相关文章:
Elasticsearch index 设置 false,为什么还可以被检索到?
在 Elasticsearch 中,mapping 定义了索引中的字段类型及其处理方式。 近期有球友提问,为什么设置了 index: false 的字段仍能被检索。 本文将详细探讨这个问题,并引入列式存储的概念,帮助大家更好地理解 Elasticsearch 的存储和查…...
169. 多数元素
题目 给定一个大小为 n 的数组 nums ,返回其中的多数元素。多数元素是指在数组中出现次数大于 ⌊ n/2 ⌋ 的元素。 你可以假设数组是非空的,并且给定的数组总是存在多数元素。 示例 1: 输入:nums [3,2,3]输出:3 …...

ADS基础教程19 - 电磁仿真(EM)基本概念和实操
EM介绍 一、引言二、基本概念1.EM介绍2.Momentum介绍3.FEM介绍4.Substrate介绍 三、创建Layout并进行Momentum仿真1.创建Layout2.添加Microtrip(微带线)3.添加Substrate4.Momentum仿真 四、总结 一、引言 本章节开始介绍EM的基本概念、内容以及实现具体…...
LabVIEW RT环境中因字符串拼接导致的系统崩溃问题
在LabVIEW实时操作系统(RT)环境中运行的应用程序出现字符串拼接后死机的问题,通常涉及内存管理、内存泄漏或其他资源管理问题。以下是一些指导和步骤,帮助解决这个问题: 1. 内存泄漏检测 字符串拼接会在内存中创建新…...
深层网络:层数多真的更好吗?
深层网络:层数多真的更好吗? 在深度学习的世界里,"深度"始终是一个热门话题。随着技术的发展,我们有了越来越多的方法来构建更深的神经网络,这似乎暗示着“层数越多,效果越好”。然而࿰…...
【QT5】<知识点> QT常用知识(更新中)
目录 一、更改文本颜色和格式 二、QT容器类 三、字符串与整数、浮点数之间的转换 四、QString常用功能 五、SpinBox的属性介绍 六、滑动、滚动、进度条和表盘LCD 七、时间、日期、定时器 一、更改文本颜色和格式 动态设置字体粗体:QFont对象的setBold方法动态…...

如何将AndroidStudio和IDEA的包名改为分层级目录
新版UIAndroidStudio 1、点击项目目录右上角如图所示的三个点点。 2、然后依次取消Hide empty middle package ,Flatten package的勾选 3、注意:一定要先取消hide的勾选,不然目录不会完全分级(做错了可以反过来重新设置&#x…...
北交字节联合提出ClassDiffusion: 使用显式类别引导的一致性个性化生成。
在个性化生成领域, 微调可能会引起过拟合导致模型无法生成与提示词一致的结果。针对这个问题,北交&字节联合提出ClassDiffusion,来提升个性化生成的一致性。 通过两个重要观察及理论分析提出了新的观点:一致性的损失是个性化概念语义偏移导致的, 还…...

37、matlab矩阵运算
1、前言 矩阵运算是指对矩阵的各种操作和运算,包括矩阵加法、矩阵减法、矩阵乘法、矩阵转置、求逆矩阵等。以下是常见的矩阵运算: 矩阵加法:对应位置的元素相加,要求加数和被加数的维度相同。 A B | a11 b11 | | a12 b12 | | …...

用软件实现的硬件——虚拟机
通过软件实现CPU和内存等硬件所具有的功能,并在计算机中运行循环的计算机技术称为虚拟机。使用虚拟机,就可以在一台计算机中运行多个循环出来的计算机。 近几年的计算机,除了硬件具有较高的性能外,CPU的性能也有了提升。因此&…...
[Shell编程学习路线]--shell中重定向和管道符(详细介绍)
🏡作者主页:点击! 🛠️Shell编程专栏:点击! ⏰️创作时间:2024年6月12日10点50分 🀄️文章质量:93分 ——前言—— 在Shell编程中,重定向和管道符是两个…...

Linux命令详解(1)
在Linux操作系统中,命令行界面(CLI)是一个强大的工具,它允许用户通过键入命令来与系统交互。无论是系统管理员还是普通用户,掌握一些基本的Linux命令都是非常重要的。在本文中,我们将探讨一些常用的Linux命…...

网工内推 | 深信服、中软国际技术支持工程师,最高13k*13薪
01 深信服 🔷招聘岗位:远程技术支持工程师 🔷任职要求: 一、专业能力和行业经验: ①具备友商同岗位工作经验1.5年以上,具备良好的分析和判断能力,有独立问题处理思路,具备常见协…...

实现卡片的展开缩放动画
原理,外层包裹一个元素,子元素分别是展开和收起的元素,然后对展开的元素添加动画,动画内容是随时间变化,将卡片的transform:rotateX属性进行调整,因为改变的是子元素的旋转,父元素高…...

实验:贪心算法
实验二:贪心算法 【实验目的】 应用贪心算法求解活动安排问题。 【实验性质】 验证性实验。 【实验要求】 活动安排问题是可以用贪心算法有效求解的很好的例子。 问题:有n个活动的集合A{1,2,…,n},其中每个活动都要求使用同一资源&…...

Python学习笔记12 -- 有关布尔值的详细说明
一、布尔表达式 最终值为true 或者false 二、常见形式: 1、常量:true false 2、比较运算: and ! 3、复合运算: and and or 4、其他 例:检测闰年: def specialYearMine(year):if (year%4 …...

SQL-窗口函数合集
目录 1.窗口函数简介2.窗口的定义3.相关题目示例3.1 PERCENT_RANK()2346 以百分比计算排名 3.2 FIRST_VALUE()/LAST_VALUE()/NTH_VALUE()2388 将表中的空值更改为前一个值 1.窗口函数简介 MySQL 开窗函数(Window Functions)是 MySQL 8.0 版本引入的一个…...

2024 全球软件研发技术大会官宣,50+专家共话软件智能新范式!
2024年的全球软件研发技术大会(SDCon)由CSDN和高端IT咨询与教育平台Boolan联合主办,将于7月4日至5日在北京威斯汀酒店举行。本次大会的主题为“大模型驱动软件智能化新范式”,旨在探讨大模型和开源技术的发展如何引领全球软件研发…...
opencv快速安装以及各种查看版本命令
安装opencv并查看其版本,直接通过一个可执行文件实现。 #!/bin/bashwget https://codeload.github.com/opencv/opencv/zip/3.4 -O opencv-3.4.zip && unzip opencv-3.4.zip && cd opencv-3.4 && \mkdir build && cd build &&a…...
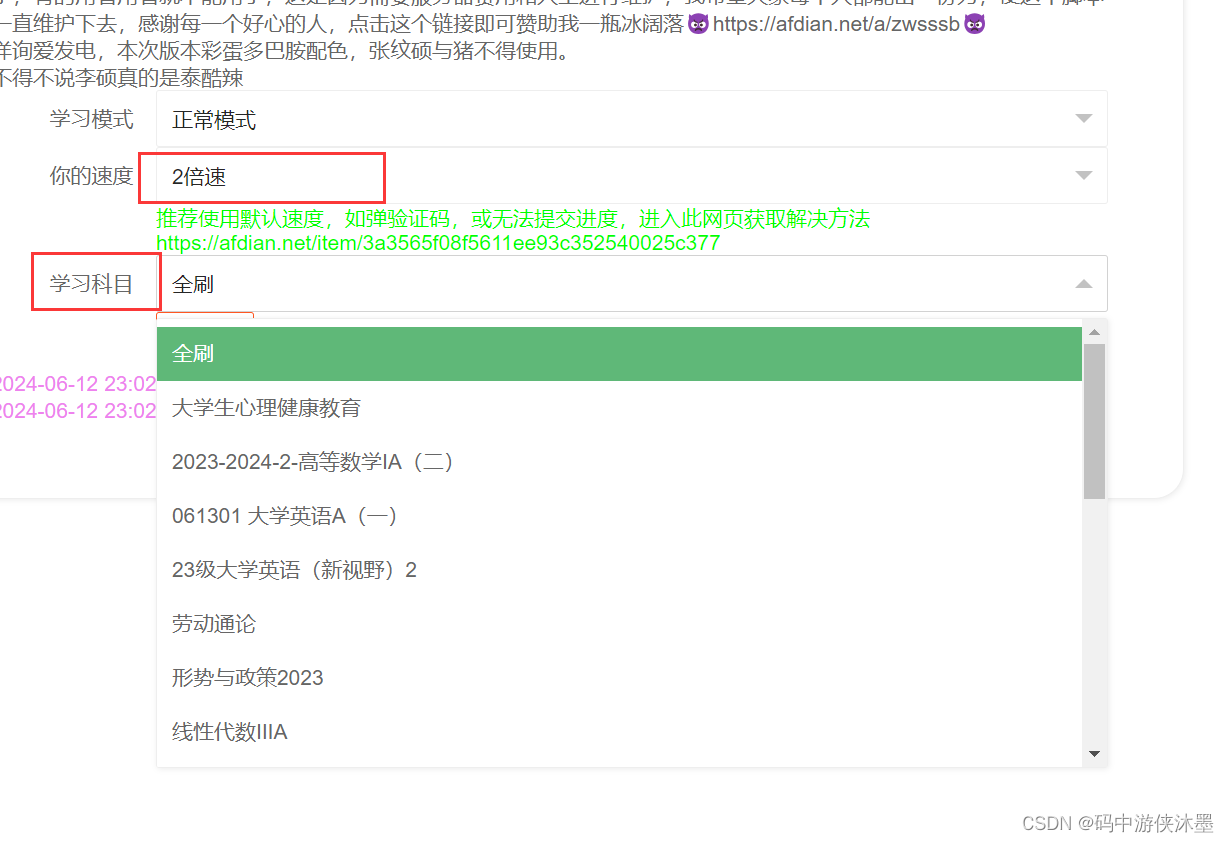
免费学习通刷课(免费高分)Pro版
文章目录 概要整体架构流程小结 概要 关于上一版的免费高分的学习通刷课,有很多人觉得还得登录太复杂了,然后我又发现了个神脚本,操作简单,可以后台挂着,但是还是建议调整速度到2倍速,然后找到你该刷的课&…...

基于大模型的 UI 自动化系统
基于大模型的 UI 自动化系统 下面是一个完整的 Python 系统,利用大模型实现智能 UI 自动化,结合计算机视觉和自然语言处理技术,实现"看屏操作"的能力。 系统架构设计 #mermaid-svg-2gn2GRvh5WCP2ktF {font-family:"trebuchet ms",verdana,arial,sans-…...

基于当前项目通过npm包形式暴露公共组件
1.package.sjon文件配置 其中xh-flowable就是暴露出去的npm包名 2.创建tpyes文件夹,并新增内容 3.创建package文件夹...

新能源汽车智慧充电桩管理方案:新能源充电桩散热问题及消防安全监管方案
随着新能源汽车的快速普及,充电桩作为核心配套设施,其安全性与可靠性备受关注。然而,在高温、高负荷运行环境下,充电桩的散热问题与消防安全隐患日益凸显,成为制约行业发展的关键瓶颈。 如何通过智慧化管理手段优化散…...

Axios请求超时重发机制
Axios 超时重新请求实现方案 在 Axios 中实现超时重新请求可以通过以下几种方式: 1. 使用拦截器实现自动重试 import axios from axios;// 创建axios实例 const instance axios.create();// 设置超时时间 instance.defaults.timeout 5000;// 最大重试次数 cons…...

什么是Ansible Jinja2
理解 Ansible Jinja2 模板 Ansible 是一款功能强大的开源自动化工具,可让您无缝地管理和配置系统。Ansible 的一大亮点是它使用 Jinja2 模板,允许您根据变量数据动态生成文件、配置设置和脚本。本文将向您介绍 Ansible 中的 Jinja2 模板,并通…...

云原生玩法三问:构建自定义开发环境
云原生玩法三问:构建自定义开发环境 引言 临时运维一个古董项目,无文档,无环境,无交接人,俗称三无。 运行设备的环境老,本地环境版本高,ssh不过去。正好最近对 腾讯出品的云原生 cnb 感兴趣&…...

HDFS分布式存储 zookeeper
hadoop介绍 狭义上hadoop是指apache的一款开源软件 用java语言实现开源框架,允许使用简单的变成模型跨计算机对大型集群进行分布式处理(1.海量的数据存储 2.海量数据的计算)Hadoop核心组件 hdfs(分布式文件存储系统)&a…...

安全突围:重塑内生安全体系:齐向东在2025年BCS大会的演讲
文章目录 前言第一部分:体系力量是突围之钥第一重困境是体系思想落地不畅。第二重困境是大小体系融合瓶颈。第三重困境是“小体系”运营梗阻。 第二部分:体系矛盾是突围之障一是数据孤岛的障碍。二是投入不足的障碍。三是新旧兼容难的障碍。 第三部分&am…...

【Redis】笔记|第8节|大厂高并发缓存架构实战与优化
缓存架构 代码结构 代码详情 功能点: 多级缓存,先查本地缓存,再查Redis,最后才查数据库热点数据重建逻辑使用分布式锁,二次查询更新缓存采用读写锁提升性能采用Redis的发布订阅机制通知所有实例更新本地缓存适用读多…...
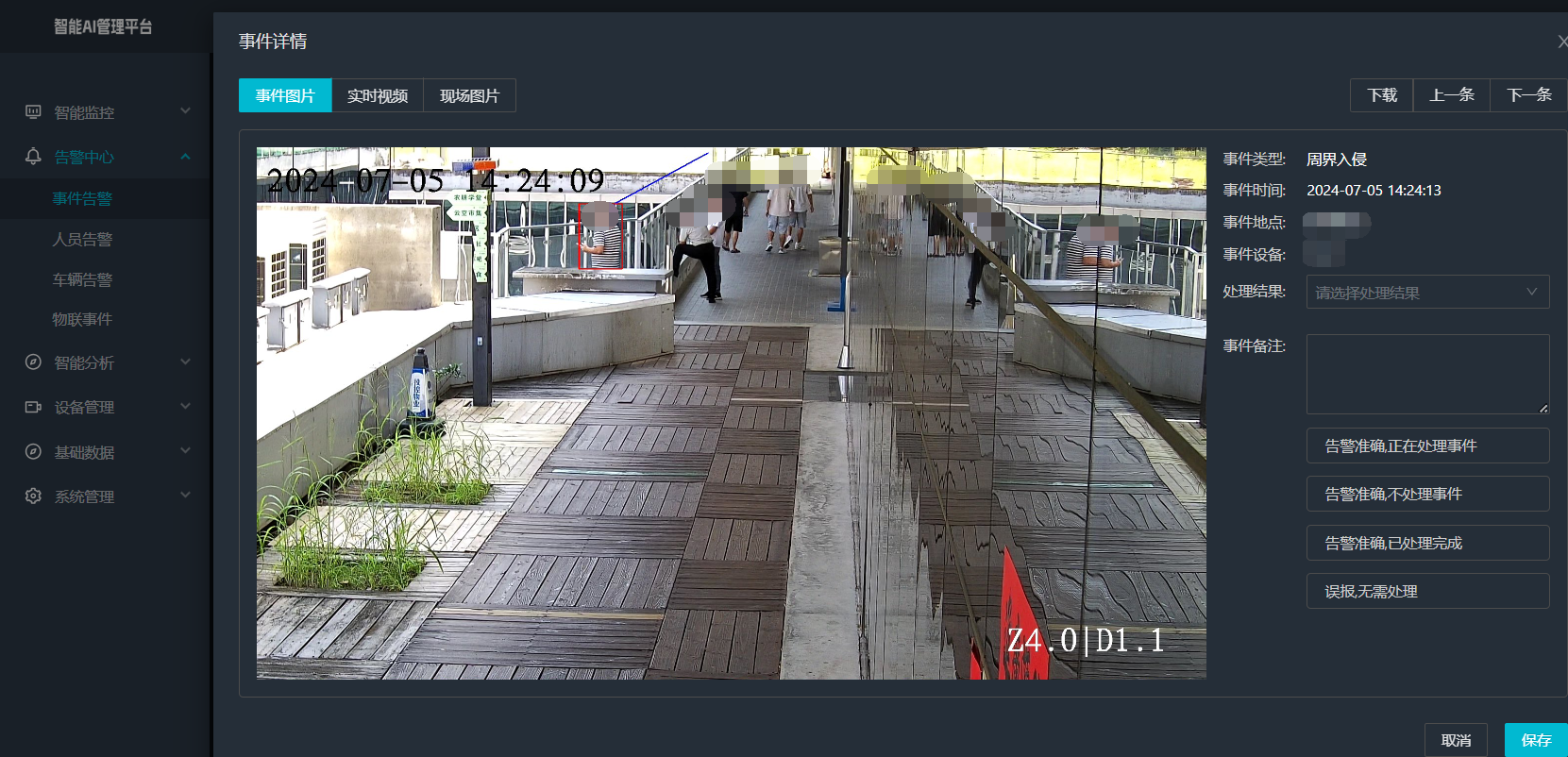
打手机检测算法AI智能分析网关V4守护公共/工业/医疗等多场景安全应用
一、方案背景 在现代生产与生活场景中,如工厂高危作业区、医院手术室、公共场景等,人员违规打手机的行为潜藏着巨大风险。传统依靠人工巡查的监管方式,存在效率低、覆盖面不足、判断主观性强等问题,难以满足对人员打手机行为精…...