MYSQL 三、mysql基础知识 4(存储过程与函数)
MySQL从5.0版本开始支持存储过程和函数。存储过程和函数能够将复杂的SQL逻辑封装在一起,应用程序无须关注存储过程和函数内部复杂的SQL逻辑,而只需要简单地调用存储过程和函数即可。
一、存储过程概述:
1.1理解:
含义:存储过程的英文是 Stored Procedure 。它的思想很简单,就是一组经过 预先编译 的 SQL 语句的封装。
执行过程:存储过程预先存储在 MySQL 服务器上,需要执行的时候,客户端只需要向服务器端发出调用 存储过程的命令,服务器端就可以把预先存储好的这一系列 SQL 语句全部执行。
1、简化操作,提高了sql语句的重用性,减少了开发程序员的压力
2 、减少操作过程中的失误,提高效率
4 、减少了 SQL 语句暴露在 网上的风险,也提高了数据查询的安全性
和视图的对比 :
它和视图有着同样的优点,清晰、安全,还可以减少网络传输量。不过它和视图不同,视图是 虚拟表 ,通常不对底层数据表直接操作,而存储过程是程序化的 SQL ,可以 直接操作底层数据表 ,相比于面向集 合的操作方式,能够实现一些更复杂的数据处理。
- 一旦存储过程被创建出来,使用它就像使用函数一样简单,我们直接通过调用存储过程名即可。
- 存储过程可以有返回值也可以没有返回值,但函数必须有返回值;
- 存储过程可以单独执行也可以被sql调用,但函数必须被sql调用;
- 存储过程可以修改表中的数据,但是函数不能修改表中的数据,只返回处理后的结果
- 存储过程是一组预定义的sql语句集合,通过循环结构和判断结构提高编程效率,减少开发人员工作量,可以实现复杂的业务逻辑;
- 函数是一种sql程序单元,对数据进行封装和处理,可以对日期、字符串等处理时封装在函数中实现,提供sql编写效率。
1.2 分类:
存储过程的参数类型可以是IN、OUT和INOUT。根据这点分类如下:
1、没有参数(无参数无返回)
2、仅仅带 IN 类型(有参数无返回)
3、仅仅带 OUT 类型(无参数有返回)
4、既带 IN 又带 OUT(有参数有返回)
5、带 INOUT(有参数有返回)
二、创建存储过程:
2.1 语法分析:
# 语法:
CREATE PROCEDURE 存储过程名(IN|OUT|INOUT 参数名 参数类型,...)
[characteristics ...]
BEGIN存储过程体
END# 类似于Java中的方法:
修饰符 返回类型 方法名(参数类型 参数名,...){方法体;
} 说明:
1、参数前面的符号的意思
IN :当前参数为输入参数,也就是表示入参;
存储过程只是读取这个参数的值。如果没有定义参数种类, 默认就是 IN ,表示输入参数。
OUT :当前参数为输出参数,也就是表示出参;
执行完成之后,调用这个存储过程的客户端或者应用程序就可以读取这个参数返回的值了。
INOUT :当前参数既可以为输入参数,也可以为输出参数
LANGUAGE SQL| [ NOT ] DETERMINISTIC| { CONTAINS SQL | NO SQL | READS SQL DATA | MODIFIES SQL DATA }| SQL SECURITY { DEFINER | INVOKER }| COMMENT 'string'
- LANGUAGE SQL :说明存储过程执行体是由SQL语句组成的,当前系统支持的语言为SQL。
- [NOT] DETERMINISTIC :指明存储过程执行的结果是否确定。DETERMINISTIC表示结果是确定的。每次执行存储过程时,相同的输入会得到相同的输出。NOT DETERMINISTIC表示结果是不确定的,相同的输入可能得到不同的输出。如果没有指定任意一个值,默认为NOT DETERMINISTIC。
- { CONTAINS SQL | NO SQL | READS SQL DATA | MODIFIES SQL DATA } :指明子程序使用SQL语句的限制。
- CONTAINS SQL表示当前存储过程的子程序包含SQL语句,但是并不包含读写数据的SQL语句;
- NO SQL表示当前存储过程的子程序中不包含任何SQL语句;
- READS SQL DATA表示当前存储过程的子程序中包含读数据的SQL语句;
- MODIFIES SQL DATA表示当前存储过程的子程序中包含写数据的SQL语句。
- 默认情况下,系统会指定为CONTAINS SQL。
- SQL SECURITY { DEFINER | INVOKER } :执行当前存储过程的权限,即指明哪些用户能够执行当前存储过程。
- DEFINER 表示只有当前存储过程的创建者或者定义者才能执行当前存储过程;
- INVOKER 表示拥有当前存储过程的访问权限的用户能够执行当前存储过程。
- 如果没有设置相关的值,则MySQL默认指定值为DEFINER。
- COMMENT 'string' :注释信息,可以用来描述存储过程。
1. BEGIN …END : BEGIN…END 中间包含了多个语句,每个语句都以( ; )号为结束符。2. DECLARE : DECLARE 用来声明变量,使用的位置在于 BEGIN …END 语句中间,而且需要在其他语句使用之前进行变量的声明。3. SET :赋值语句,用于对变量进行赋值。4. SELECT … INTO :把从数据表中查询的结果存放到变量中,也就是为变量赋值。
DELIMITER 新的结束标记
示例:DELIMITER $CREATE PROCEDURE 存储过程名(IN|OUT|INOUT 参数名 参数类型,...)
[characteristics ...]
BEGINsql语句1;sql语句2;
END $# 举例1:创建存储过程select_all_data(),查看 emps 表的所有数据DELIMITER $CREATE PROCEDURE select_all_data()
BEGINSELECT * FROM emps;
END $DELIMITER ;# 举例2:创建存储过程avg_employee_salary(),返回所有员工的平均工资DELIMITER //CREATE PROCEDURE avg_employee_salary ()
BEGINSELECT AVG(salary) AS avg_salary FROM emps;
END //DELIMITER ;# 举例3:创建存储过程show_max_salary(),用来查看“emps”表的最高薪资值。CREATE PROCEDURE show_max_salary()LANGUAGE SQLNOT DETERMINISTICCONTAINS SQLSQL SECURITY DEFINERCOMMENT '查看最高薪资'BEGINSELECT MAX(salary) FROM emps;
END //DELIMITER ;# 举例4:创建存储过程show_min_salary(),查看“emps”表的最低薪资值。并将最低薪资通过OUT参数“ms”输出DELIMITER //CREATE PROCEDURE show_min_salary(OUT ms DOUBLE)BEGINSELECT MIN(salary) INTO ms FROM emps;END //DELIMITER ;# 举例5:创建存储过程show_someone_salary(),查看“emps”表的某个员工的薪资,并用IN参数empname输入员工姓名。DELIMITER //CREATE PROCEDURE show_someone_salary(IN empname VARCHAR(20))BEGINSELECT salary FROM emps WHERE ename = empname;END //DELIMITER ;# 举例6:创建存储过程show_someone_salary2(),查看“emps”表的某个员工的薪资,并用IN参数empname输入员工姓名,用OUT参数empsalary输出员工薪资。DELIMITER //CREATE PROCEDURE show_someone_salary2(IN empname VARCHAR(20),OUT empsalary DOUBLE)BEGINSELECT salary INTO empsalary FROM emps WHERE ename = empname;END //DELIMITER ;# 举例7:创建存储过程show_mgr_name(),查询某个员工领导的姓名,并用INOUT参数“empname”输入员工姓名,输出领导的姓名。DELIMITER //CREATE PROCEDURE show_mgr_name(INOUT empname VARCHAR(20))BEGINSELECT ename INTO empname FROM empsWHERE eid = (SELECT MID FROM emps WHERE ename=empname);
END //DELIMITER ;三、调用存储过程:
3.1 调用格式
存储过程有多种调用方法。存储过程必须使用CALL语句调用,并且存储过程和数据库相关,如果要执行 其他数据库中的存储过程,需要指定数据库名称,例如CALL dbname.procname。
CALL 存储过程名(实参列表)
# 1、调用in模式的参数:
CALL sp1('值');# 2、调用out模式的参数:
SET @name;
CALL sp1(@name);
SELECT @name;# 3、调用inout模式的参数:
SET @name=值;
CALL sp1(@name);
SELECT @name;3.2 代码举例
# 举例1:
DELIMITER //CREATE PROCEDURE CountProc(IN sid INT,OUT num INT)
BEGINSELECT COUNT(*) INTO num FROM fruits
WHERE s_id = sid;
END //DELIMITER ;# 调用存储过程:
mysql> CALL CountProc (101, @num);
Query OK, 1 row affected (0.00 sec)# 查看返回结果:
mysql> SELECT @num;# 该存储过程返回了指定 s_id=101 的水果商提供的水果种类,返回值存储在num变量中,使用SELECT查
看,返回结果为3。# 举例2:创建存储过程,实现累加运算,计算 1+2+…+n 等于多少。具体的代码如下:
DELIMITER //
CREATE PROCEDURE `add_num`(IN n INT)
BEGINDECLARE i INT;DECLARE sum INT;SET i = 1;SET sum = 0;WHILE i <= n DOSET sum = sum + i;SET i = i +1;END WHILE;SELECT sum;
END //
DELIMITER ;# 如果你用的是 Navicat 工具,那么在编写存储过程的时候,Navicat 会自动设置 DELIMITER 为其他符号,我们不需要再进行 DELIMITER 的操作。
直接使用 CALL add_num(50); 即可。这里我传入的参数为 50,也就是统计 1+2+…+50 的积累之和。
四、存储函数的使用
# 语法格式:
CREATE FUNCTION 函数名(参数名 参数类型,...)
RETURNS 返回值类型
[characteristics ...]BEGIN函数体 #函数体中肯定有 RETURN 语句
END说明:
在MySQL 中,存储函数的使用方法与 MySQL 内部函数的使用方法是一样的。换言之,用户自己定义的存 储函数与MySQL 内部函数是一个性质的。区别在于,存储函数是 用户自己定义 的,而内部函数是 MySQL 的 开发者定义 的。
SELECT 函数名 ( 实参列表 )
# 举例1:
# 创建存储函数,名称为email_by_name(),参数定义为空,该函数查询Abel的email,并返回,数据类型为字符串型。DELIMITER //CREATE FUNCTION email_by_name()
RETURNS VARCHAR(25)
DETERMINISTIC
CONTAINS SQLBEGINRETURN (SELECT email FROM employees WHERE last_name = 'Abel');
END //DELIMITER ;# 调用:
SELECT email_by_name();# 举例2:
# 创建存储函数,名称为email_by_id(),参数传入emp_id,该函数查询emp_id的email,并返回,数据类型为字符串型。DELIMITER //CREATE FUNCTION email_by_id(emp_id INT)
RETURNS VARCHAR(25)
DETERMINISTIC
CONTAINS SQLBEGINRETURN (SELECT email FROM employees WHERE employee_id = emp_id);
END //DELIMITER ;# 调用:
SET @emp_id = 102;
SELECT email_by_id(102);# 举例3:
# 创建存储函数count_by_id(),参数传入dept_id,该函数查询dept_id部门的员工人数,并返回,数据类型为整型。DELIMITER //CREATE FUNCTION count_by_id(dept_id INT)
RETURNS INT
LANGUAGE SQL
NOT DETERMINISTIC
READS SQL DATA
SQL SECURITY DEFINER
COMMENT '查询部门平均工资'BEGINRETURN (SELECT COUNT(*) FROM employees WHERE department_id = dept_id);
END //DELIMITER ;# 调用:
SET @dept_id = 50;
SELECT count_by_id(@dept_id);# 注意:
# 若在创建存储函数中报错“ you might want to use the less safe log_bin_trust_function_creators variable ”,有两种处理方法:方式1:加上必要的函数特性“[NOT] DETERMINISTIC”和“{CONTAINS SQL | NO SQL | READS SQL DATA |
MODIFIES SQL DATA}”方式2: mysql> SET GLOBAL log_bin_trust_function_creators = 1;| 关键字 | 调用语法 | 返回值 | 应用场景 | |
| 存储过程 | PROCEDURE | CALL 存储过程() | 理解为有 0 个或多个 | 一般用于更新 |
| 存储函数 | FUNCTION | SELECT 函数() | 只能是一个 | 一般用于查询结果为一个值并 返回时 |
五、存储过程和函数的查看、修改、删除
# 1. 使用SHOW CREATE语句查看存储过程和函数的创建信息
# 基本语法结构如下:
SHOW CREATE {PROCEDURE | FUNCTION} 存储过程名或函数名# 举例:
SHOW CREATE FUNCTION test_db.CountProc \G# 2. 使用SHOW STATUS语句查看存储过程和函数的状态信息
# 基本语法结构如下:
SHOW {PROCEDURE | FUNCTION} STATUS [LIKE 'pattern']# 这个语句返回子程序的特征,如数据库、名字、类型、创建者及创建和修改日期。[LIKE 'pattern']:匹配存储过程或函数的名称,可以省略。当省略不写时,会列出MySQL数据库中存在的所有存储过程或函数的信息。 举例:SHOW STATUS语句示例,代码如下:mysql> SHOW PROCEDURE STATUS LIKE 'SELECT%' \G
*************************** 1. row ***************************
Db: test_db
Name: SelectAllData
Type: PROCEDURE
Definer: root@localhost
Modified: 2021-10-16 15:55:07
Created: 2021-10-16 15:55:07
Security_type: DEFINER
Comment:
character_set_client: utf8mb4
collation_connection: utf8mb4_general_ci
Database Collation: utf8mb4_general_ci
1 row in set (0.00 sec)# 3. 从information_schema.Routines表中查看存储过程和函数的信息
MySQL中存储过程和函数的信息存储在information_schema数据库下的Routines表中。可以通过查询该表
的记录来查询存储过程和函数的信息。其基本语法形式如下:
SELECT * FROM information_schema.Routines
WHERE ROUTINE_NAME='存储过程或函数的名' [AND ROUTINE_TYPE = {'PROCEDURE|FUNCTION'}];# 说明:如果在MySQL数据库中存在存储过程和函数名称相同的情况,最好指定ROUTINE_TYPE查询条件来指明查询的是存储过程还是函数。
# 举例:从Routines表中查询名称为CountProc的存储函数的信息,代码如下:
SELECT * FROM information_schema.Routines
WHERE ROUTINE_NAME='count_by_id' AND ROUTINE_TYPE = 'FUNCTION' \GALTER {PROCEDURE | FUNCTION} 存储过程或函数的名 [characteristic ...]
其中,characteristic指定存储过程或函数的特性,其取值信息与创建存储过程、函数时的取值信息略有不同。
{ CONTAINS SQL | NO SQL | READS SQL DATA | MODIFIES SQL DATA }
| SQL SECURITY { DEFINER | INVOKER }
| COMMENT 'string
- CONTAINS SQL ,表示子程序包含SQL语句,但不包含读或写数据的语句。
- NO SQL ,表示子程序中不包含SQL语句。
- READS SQL DATA ,表示子程序中包含读数据的语句。
- MODIFIES SQL DATA ,表示子程序中包含写数据的语句。
- SQL SECURITY { DEFINER | INVOKER } ,指明谁有权限来执行。
- DEFINER ,表示只有定义者自己才能够执行。
- INVOKER ,表示调用者可以执行。
- COMMENT 'string' ,表示注释信息。
修改存储过程使用 ALTER PROCEDURE 语句,修改存储函数使用 ALTER FUNCTION 语句。但是,这两个语句的结构是一样的,语句中的所有参数也是一样的。
# 举例1:
# 修改存储过程CountProc的定义。将读写权限改为MODIFIES SQL DATA,并指明调用者可以执行,代码如下:ALTER PROCEDURE CountProc
MODIFIES SQL DATA
SQL SECURITY INVOKER ;# 查询修改后的信息:SELECT specific_name,sql_data_access,security_type
FROM information_schema.`ROUTINES`
WHERE routine_name = 'CountProc' AND routine_type = 'PROCEDURE';# 结果显示,存储过程修改成功。从查询的结果可以看出,访问数据的权限(SQL_DATA_ ACCESS)已经变成MODIFIES SQL DATA,安全类型(SECURITY_TYPE)已经变成INVOKER。# 举例2:
# 修改存储函数CountProc的定义。将读写权限改为READS SQL DATA,并加上注释信息“FIND NAME”,代码如下:
ALTER FUNCTION CountProc
READS SQL DATA
COMMENT 'FIND NAME' ;# 存储函数修改成功。从查询的结果可以看出,访问数据的权限(SQL_DATA_ACCESS)已经变成READS SQL DATA,函数注释(ROUTINE_COMMENT)已经变成FIND NAME。
DROP {PROCEDURE | FUNCTION } [ IF EXISTS ] 存储过程或函数的名
DROP PROCEDURE CountProc;DROP FUNCTION CountProc;
六. 关于存储过程使用的争议
阿里开发规范
【强制】禁止使用存储过程,存储过程难以调试和扩展,更没有移植性。
相关文章:
)
MYSQL 三、mysql基础知识 4(存储过程与函数)
MySQL从5.0版本开始支持存储过程和函数。存储过程和函数能够将复杂的SQL逻辑封装在一起,应用程序无须关注存储过程和函数内部复杂的SQL逻辑,而只需要简单地调用存储过程和函数即可。 一、存储过程概述: 1.1理解: 含义&am…...

鸿蒙开发文件管理:【@ohos.statfs (statfs)】
statfs 该模块提供文件系统相关存储信息的功能,向应用程序提供获取文件系统总字节数、空闲字节数的JS接口。 说明: 本模块首批接口从API version 8开始支持。后续版本的新增接口,采用上角标单独标记接口的起始版本。 导入模块 import stat…...

C++和C语言到底有什么区别?
引言:C和C语言是两种非常常见的编程语言,由于其广泛的应用和灵活性,它们在计算机科学领域内受到了广泛的关注。虽然C是从C语言发展而来的,但是这两种语言在许多方面都有所不同。本文将对C和C语言进行比较和分析,以便更…...
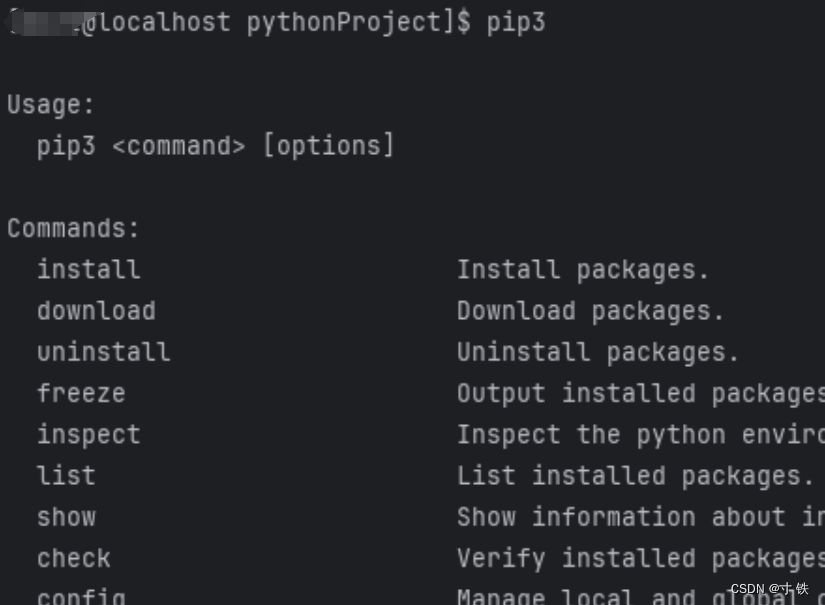
【Centos】深度解析:CentOS下安装pip的完整指南
【Centos】深度解析:CentOS下安装pip的完整指南 大家好 我是寸铁👊 总结了一篇【Centos】深度解析:CentOS下安装pip的完整指南✨ 喜欢的小伙伴可以点点关注 💝 方式1(推荐) 下载get-pip.py到本地 sudo wget https://bootstrap.p…...

半导体PW和NPW的一些小知识
芯片制造厂内的晶圆主要由两种,生产晶圆(PW:Product Wafer)和非生产晶圆(NPW:None Product Wafer)。 一、生产晶圆(PW) 生产晶圆的一些关键特点: 高纯度硅材料:生产晶…...
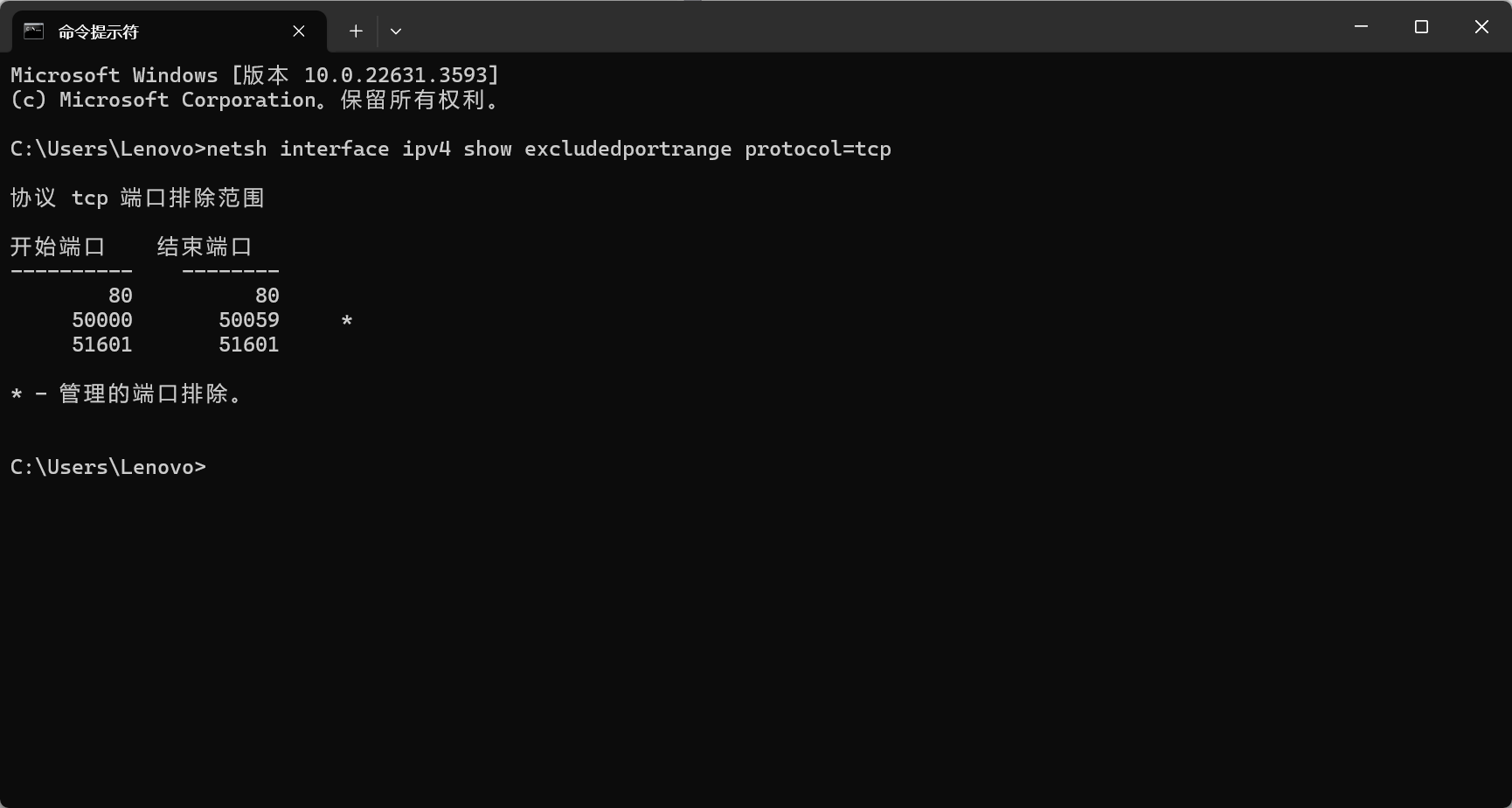
后端启动项目端口冲突问题解决
后端启动项目端口冲突 原因: Vindows Hyper-V虚拟化平台占用了端口。 解决方案一: 查看被占用的端口范围,然后选择一个没被占用的端口启动项目。netsh interface ipv4 show excludedportrange protocoltcp 解决方案二: 禁用H…...

【优选算法】优先级队列 {优先级队列解决TopK问题,利用大小堆维护数据流的中位数}
一、经验总结 优先级队列(堆),常用于在集合中筛选最值或解决TopK问题。 提示:对于固定序列的TopK问题,最优解决方案是快速选择算法,时间复杂度为O(N)比堆算法O(NlogK)更优;而对于动态维护数据流…...
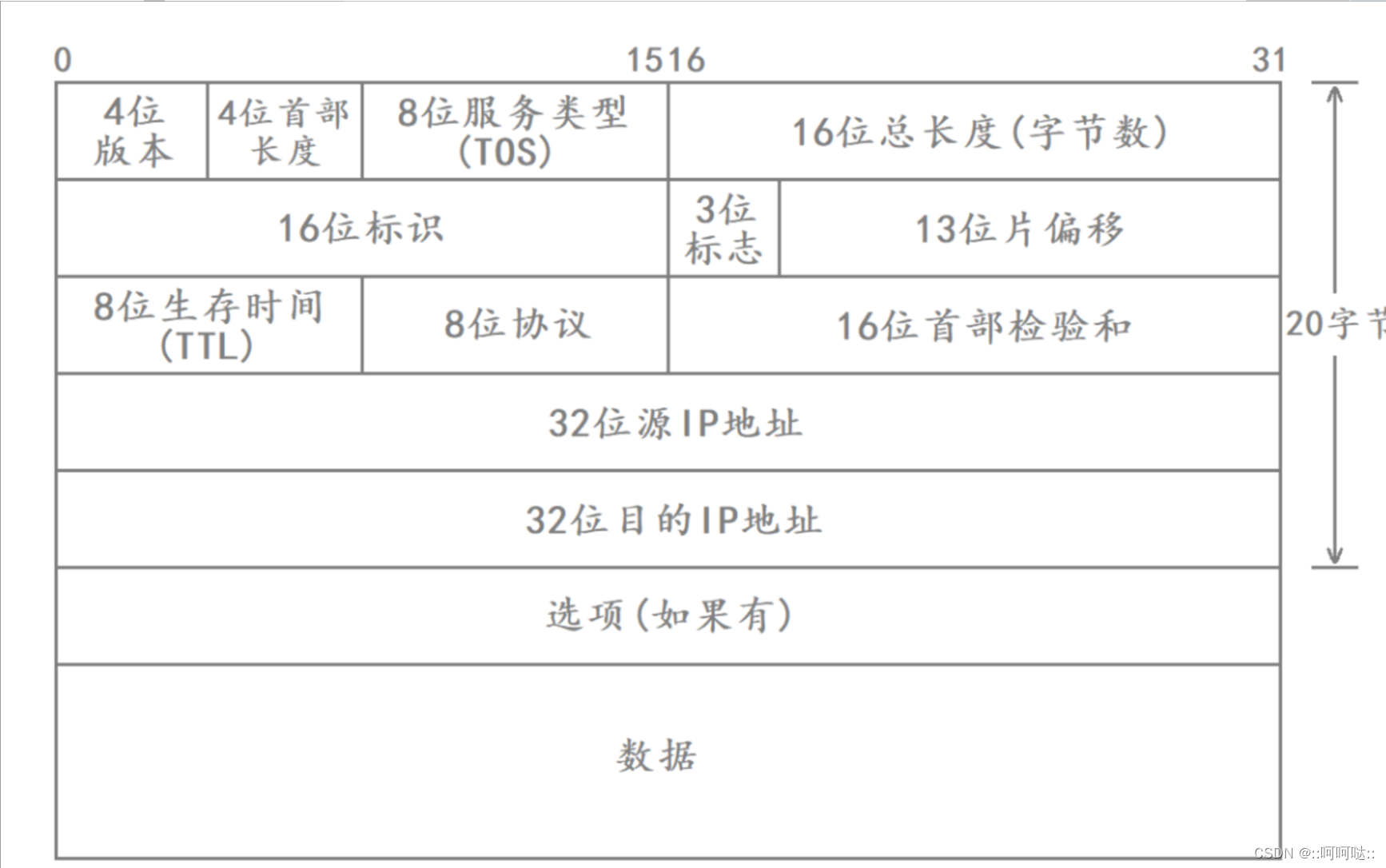
11 IP协议 - IP协议头部
什么是 IP 协议 IP(Internet Protocol)是一种网络通信协议,它是互联网的核心协议之一,负责在计算机网络中路由数据包,使数据能够在不同设备之间进行有效的传输。IP协议的主要作用包括寻址、分组、路由和转发数据包&am…...

【java】【python】leetcode刷题记录--二叉树
144.二叉树的前序遍历 题目链接 前、中、后的遍历的递归做法实际上都是一样的,区别就是遍历操作的位置不同。 对于先序遍历,也就是先根,即把查看当前结点的操作放在最前面即可。 class Solution {public List<Integer> preorderTrav…...
EVA-CLIP实战
摘要 EVA-CLIP,这是一种基于对比语言图像预训练(CLIP)技术改进的模型,通过引入新的表示学习、优化和增强技术,显著提高了CLIP的训练效率和效果。EVA-CLIP系列模型在保持较低训练成本的同时,实现了与先前具有相似参数数量的CLIP模型相比更高的性能。特别地,文中提到的EV…...

限定法术施放目标
实现目标 法术只对特定 creature | gameobject 施放,否则无法施放 实现方法 conditions SourceTypeOrReferenceId:13(CONDITION_SOURCE_TYPE_SPELL_IMPLICIT_TARGET)SourceGroup:受条件影响的法术效果掩码…...

【通信原理】数字频带传输系统
二进制数字调制,解调原理:2ASK,2FSK 二进制数字调制,解调原理:2PSK,2DPSK 二进制数字已调制信号的功率谱 二进制数字调制系统的抗噪声性能 二进制调制系统的性能总结...
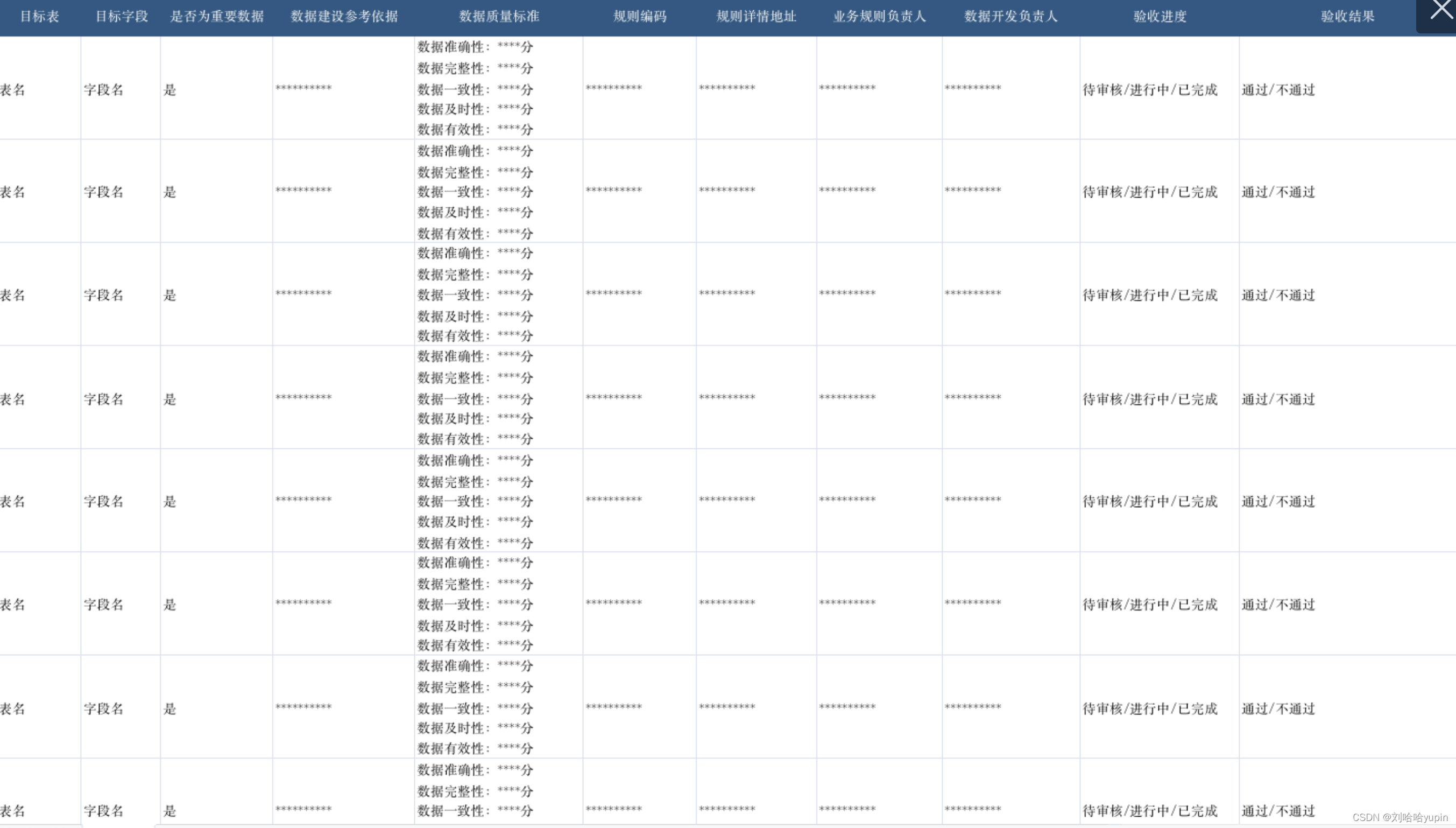
数据价值管理-数据验收标准
前情提要:数据价值管理是指通过一系列管理策略和技术手段,帮助企业把庞大的、无序的、低价值的数据资源转变为高价值密度的数据资产的过程,即数据治理和价值变现。第一讲介绍了业务架构设计的基本逻辑和思路。前面我们讲完了数据资产建设标准…...

vue3模板语法总结
1. 响应式数据 Vue 3中的数据是响应式的,即当数据发生变化时,视图会自动更新。这是通过使用JavaScript的getter和setter来实现的。 2. 组件化 Vue 3采用组件化开发方式,允许创建可复用的组件。 每个组件都有自己的作用域,并且…...
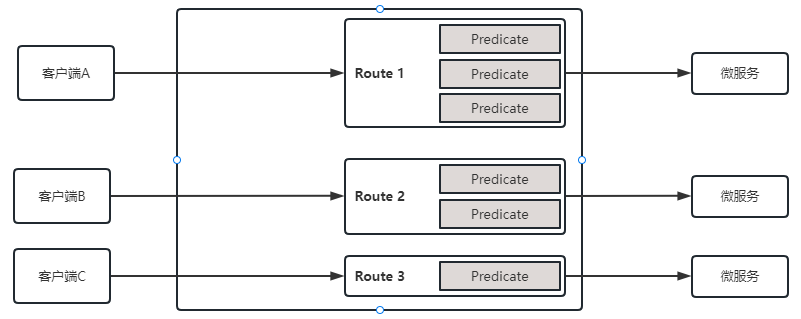
Spring Cloud 之 GateWay
前言 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家:https://www.captainbed.cn/z ChatGPT体验地址 文章目录 前言前言1、通过API网关访问服务2、Spring Cloud GateWay 最主要的功能就是路由…...

可转债全部历史因子数据,提供api支持
今天在写可转债系统,顺便下载了一下服务器的可转债数据,给大家研究使用 from trader_tool.stock_data import stock_datafrom trader_tool.lude_data_api import lude_data_apiimport osclass convertible_bond_back_test_system: 可转债回测系统…...

Python | C++ | MATLAB | Julia | R 市场流动性数学预期评估量
🎯要点 🎯市场流动性策略代码应用:🎯动量策略:滚动窗口均值策略、简单移动平均线策略、指数加权移动平均线策略、相对强弱指数、移动平均线收敛散度交叉策略、三重指数平均策略、威廉姆斯 %R 策略 | 🎯均值…...

Android 常用开源库 MMKV 源码分析与理解
文章目录 前言一、MMKV简介1.mmap2.protobuf 二、MMKV 源码详解1.MMKV初始化2.MMKV对象获取3.文件摘要的映射4.loadFromFile 从文件加载数据5.数据写入6.内存重整7.数据读取8.数据删除9.文件回写10.Protobuf 实现1.序列化2.反序列化 12.文件锁1.加锁2.解锁 13.状态同步 总结参考…...
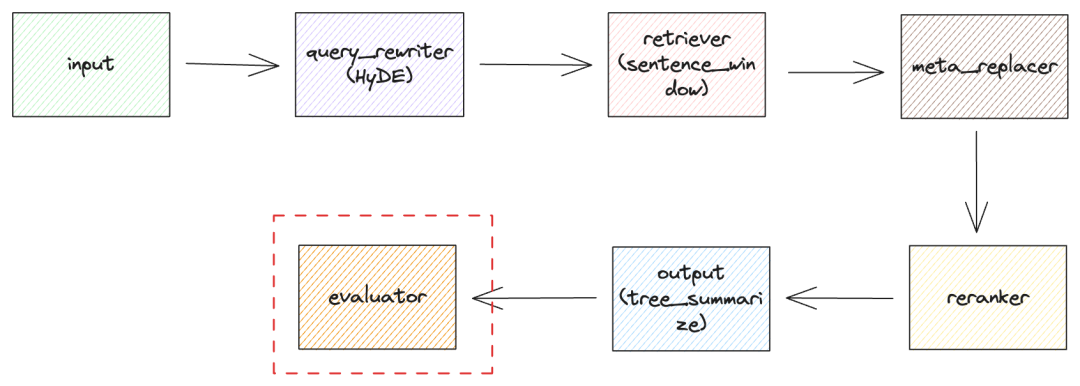
大模型高级 RAG 检索策略之流程与模块化
我们介绍了很多关于高级 RAG(Retrieval Augmented Generation)的检索策略,每一种策略就像是机器中的零部件,我们可以通过对这些零部件进行不同的组合,来实现不同的 RAG 功能,从而满足不同的需求。 今天我们…...

TCPListen客户端和TCPListen服务器
创建项目 TCPListen服务器 public Form1() {InitializeComponent();//TcpListener 搭建tcp服务器的类,基于socket套接字通信的//1创建服务器对象TcpListener server new TcpListener(IPAddress.Parse("192.168.107.83"), 3000);//2 开启服务器 设置最大…...

基于FPGA的PID算法学习———实现PID比例控制算法
基于FPGA的PID算法学习 前言一、PID算法分析二、PID仿真分析1. PID代码2.PI代码3.P代码4.顶层5.测试文件6.仿真波形 总结 前言 学习内容:参考网站: PID算法控制 PID即:Proportional(比例)、Integral(积分&…...

Redis相关知识总结(缓存雪崩,缓存穿透,缓存击穿,Redis实现分布式锁,如何保持数据库和缓存一致)
文章目录 1.什么是Redis?2.为什么要使用redis作为mysql的缓存?3.什么是缓存雪崩、缓存穿透、缓存击穿?3.1缓存雪崩3.1.1 大量缓存同时过期3.1.2 Redis宕机 3.2 缓存击穿3.3 缓存穿透3.4 总结 4. 数据库和缓存如何保持一致性5. Redis实现分布式…...

最新SpringBoot+SpringCloud+Nacos微服务框架分享
文章目录 前言一、服务规划二、架构核心1.cloud的pom2.gateway的异常handler3.gateway的filter4、admin的pom5、admin的登录核心 三、code-helper分享总结 前言 最近有个活蛮赶的,根据Excel列的需求预估的工时直接打骨折,不要问我为什么,主要…...

成都鼎讯硬核科技!雷达目标与干扰模拟器,以卓越性能制胜电磁频谱战
在现代战争中,电磁频谱已成为继陆、海、空、天之后的 “第五维战场”,雷达作为电磁频谱领域的关键装备,其干扰与抗干扰能力的较量,直接影响着战争的胜负走向。由成都鼎讯科技匠心打造的雷达目标与干扰模拟器,凭借数字射…...

图表类系列各种样式PPT模版分享
图标图表系列PPT模版,柱状图PPT模版,线状图PPT模版,折线图PPT模版,饼状图PPT模版,雷达图PPT模版,树状图PPT模版 图表类系列各种样式PPT模版分享:图表系列PPT模板https://pan.quark.cn/s/20d40aa…...

2023赣州旅游投资集团
单选题 1.“不登高山,不知天之高也;不临深溪,不知地之厚也。”这句话说明_____。 A、人的意识具有创造性 B、人的认识是独立于实践之外的 C、实践在认识过程中具有决定作用 D、人的一切知识都是从直接经验中获得的 参考答案: C 本题解…...

使用Matplotlib创建炫酷的3D散点图:数据可视化的新维度
文章目录 基础实现代码代码解析进阶技巧1. 自定义点的大小和颜色2. 添加图例和样式美化3. 真实数据应用示例实用技巧与注意事项完整示例(带样式)应用场景在数据科学和可视化领域,三维图形能为我们提供更丰富的数据洞察。本文将手把手教你如何使用Python的Matplotlib库创建引…...

JAVA后端开发——多租户
数据隔离是多租户系统中的核心概念,确保一个租户(在这个系统中可能是一个公司或一个独立的客户)的数据对其他租户是不可见的。在 RuoYi 框架(您当前项目所使用的基础框架)中,这通常是通过在数据表中增加一个…...

【Go语言基础【13】】函数、闭包、方法
文章目录 零、概述一、函数基础1、函数基础概念2、参数传递机制3、返回值特性3.1. 多返回值3.2. 命名返回值3.3. 错误处理 二、函数类型与高阶函数1. 函数类型定义2. 高阶函数(函数作为参数、返回值) 三、匿名函数与闭包1. 匿名函数(Lambda函…...

安宝特案例丨Vuzix AR智能眼镜集成专业软件,助力卢森堡医院药房转型,赢得辉瑞创新奖
在Vuzix M400 AR智能眼镜的助力下,卢森堡罗伯特舒曼医院(the Robert Schuman Hospitals, HRS)凭借在无菌制剂生产流程中引入增强现实技术(AR)创新项目,荣获了2024年6月7日由卢森堡医院药剂师协会࿰…...