深度学习:使用argparse 模块
在深度学习中,结合 Bash 脚本和 argparse 模块,可以实现高效的任务自动化和参数管理。Bash 脚本可以用来调度任务和管理环境,而 argparse 模块可以用来解析命令行参数,控制深度学习模型的训练和评估过程。
1.argparse 模块
argparse 模块是 Python 标准库中的一个模块,用于解析命令行参数。它可以帮助开发者轻松地编写用户友好的命令行接口,使得程序可以通过命令行参数来接受用户输入,并根据这些输入执行相应的功能。
argparse 模块的主要功能
- 定义命令行参数:可以定义位置参数和可选参数,以及它们的类型、默认值和帮助信息。
- 解析命令行参数:自动解析命令行输入,并将其转换为相应的数据类型。
- 生成帮助和使用信息:自动生成帮助信息,用户可以通过
-h或--help选项查看。
使用 argparse 模块的步骤
- 创建 ArgumentParser 对象:这是解析器的核心对象。
- 添加参数:使用
add_argument方法添加命令行参数。 - 解析参数:使用
parse_args方法解析命令行输入。 - 使用参数:解析后的参数可以作为属性访问并在程序中使用。
示例代码
下面是一个使用 argparse 模块的基本示例:
import argparsedef main():# 创建 ArgumentParser 对象parser = argparse.ArgumentParser(description='这是一个示例程序')# 添加参数parser.add_argument('filename', type=str, help='文件的名称')parser.add_argument('--verbose', '-v', action='store_true', help='输出详细信息')parser.add_argument('--count', '-c', type=int, default=1, help='重复次数')# 解析参数args = parser.parse_args()# 使用参数if args.verbose:print(f'Processing file: {args.filename}')print(f'Repeat count: {args.count}')# 模拟处理文件for i in range(args.count):print(f'Processing {args.filename} - iteration {i + 1}')if __name__ == '__main__':main()
运行命令:
python script.py example.txt -v -c 3
输出示例:
Processing file: example.txt
Repeat count: 3
Processing example.txt - iteration 1
Processing example.txt - iteration 2
Processing example.txt - iteration 3
参数类型
- 位置参数:必须提供,按位置传递。例如,上面的
filename。 - 可选参数:不必须提供,通常以
--或-开头,例如--verbose和--count。
处理布尔选项
布尔选项通常使用 action='store_true' 或 action='store_false':
parser.add_argument('--verbose', '-v', action='store_true', help='输出详细信息')
设置默认值
可以使用 default 参数来设置默认值:
parser.add_argument('--count', '-c', type=int, default=1, help='重复次数')
帮助信息
argparse 会自动生成帮助信息。用户可以使用 -h 或 --help 选项来查看:
python script.py -h
输出:
usage: script.py [-h] [--verbose] [--count COUNT] filename这是一个示例程序positional arguments:filename 文件的名称optional arguments:-h, --help show this help message and exit--verbose, -v 输出详细信息--count COUNT, -c 重复次数
子命令
通过 add_subparsers 方法,可以轻松地处理子命令:
import argparsedef main():parser = argparse.ArgumentParser(description='带有子命令的示例程序')# 添加子命令解析器subparsers = parser.add_subparsers(dest='command', help='子命令')# 添加子命令 'foo'parser_foo = subparsers.add_parser('foo', help='foo 子命令的帮助信息')parser_foo.add_argument('--bar', type=int, required=True, help='bar 参数')# 添加子命令 'baz'parser_baz = subparsers.add_parser('baz', help='baz 子命令的帮助信息')parser_baz.add_argument('--qux', type=str, help='qux 参数')# 解析参数args = parser.parse_args()# 处理子命令if args.command == 'foo':print(f'执行 foo 子命令,bar 参数值为 {args.bar}')elif args.command == 'baz':print(f'执行 baz 子命令,qux 参数值为 {args.qux}')else:parser.print_help()if __name__ == '__main__':main()
运行命令:
python script.py foo --bar 123
python script.py baz --qux hello
输出示例:
执行 foo 子命令,bar 参数值为 123
执行 baz 子命令,qux 参数值为 hello
总结
argparse 模块是一个强大的工具,用于解析命令行参数,提供了丰富的功能来处理不同类型的参数和选项,使得命令行工具的开发更加简便和灵活。通过定义和解析参数,开发者可以方便地从命令行获取用户输入,并在程序中使用这些输入来执行相应的操作。
2. 使用argparse 模块
python3 utils/create_indexes.py create_indexes \--waveforms_hdf5_path=$WORKSPACE"/hdf5s/waveforms/eval.h5" \--indexes_hdf5_path=$WORKSPACE"/hdf5s/indexes/eval.h5这段代码使用 argparse 模块解析命令行参数,并执行指定的操作。具体来说,代码的作用是调用一个 Python 脚本 create_indexes.py,执行 create_indexes 子命令,并传递两个参数:waveforms_hdf5_path 和 indexes_hdf5_path。下面详细分析这段代码的各个部分。
代码拆解和分析
1. 调用 Python 脚本
python3 utils/create_indexes.py create_indexes
2. 传递命令行参数
--waveforms_hdf5_path=$WORKSPACE"/hdf5s/waveforms/eval.h5" \
--indexes_hdf5_path=$WORKSPACE"/hdf5s/indexes/eval.h5"
这部分代码传递了两个命令行参数:
--waveforms_hdf5_path:指定包含波形数据的 HDF5 文件路径。--indexes_hdf5_path:指定要生成的索引 HDF5 文件路径。
这两个路径是基于环境变量 WORKSPACE 构建的,$WORKSPACE 变量表示工作空间的路径。
环境变量和路径拼接
假设 WORKSPACE 变量的值为 "/home/user/project",则上述路径在运行时会被解析为:
--waveforms_hdf5_path="/home/user/project/hdf5s/waveforms/eval.h5"--indexes_hdf5_path="/home/user/project/hdf5s/indexes/eval.h5"
create_indexes.py 脚本的实现
为了更好地理解这段代码,我们需要假设 create_indexes.py 的部分实现。通常,这个脚本会使用 argparse 模块解析命令行参数,并根据参数调用相应的函数。
示例的 create_indexes.py 实现
import argparsedef create_indexes(args):waveforms_hdf5_path = args.waveforms_hdf5_pathindexes_hdf5_path = args.indexes_hdf5_path# 假设有一个函数 load_waveforms 用于加载波形数据waveforms = load_waveforms(waveforms_hdf5_path)# 假设有一个函数 create_and_save_indexes 用于创建索引并保存到 HDF5 文件create_and_save_indexes(waveforms, indexes_hdf5_path)def load_waveforms(path):# 从 HDF5 文件中加载波形数据的示例实现import h5pywith h5py.File(path, 'r') as f:waveforms = f['waveforms'][:]return waveformsdef create_and_save_indexes(waveforms, path):# 创建索引并保存到 HDF5 文件的示例实现import h5pyindexes = generate_indexes(waveforms) # 生成索引的示例函数with h5py.File(path, 'w') as f:f.create_dataset('indexes', data=indexes)def generate_indexes(waveforms):# 假设生成索引的示例实现indexes = [i for i in range(len(waveforms))]return indexesif __name__ == '__main__':parser = argparse.ArgumentParser(description='创建索引')subparsers = parser.add_subparsers(dest='mode')parser_create_indexes = subparsers.add_parser('create_indexes')parser_create_indexes.add_argument('--waveforms_hdf5_path', type=str, required=True, help='波形数据 HDF5 文件的路径')parser_create_indexes.add_argument('--indexes_hdf5_path', type=str, required=True, help='索引 HDF5 文件的路径')args = parser.parse_args()if args.mode == 'create_indexes':create_indexes(args)else:raise ValueError('不支持的子命令')
运行代码时的过程
-
执行命令行:执行命令行
python3 utils/create_indexes.py create_indexes --waveforms_hdf5_path="/home/user/project/hdf5s/waveforms/eval.h5" --indexes_hdf5_path="/home/user/project/hdf5s/indexes/eval.h5"。 -
解析参数:
argparse模块解析命令行参数,将waveforms_hdf5_path和indexes_hdf5_path的值存储在args对象中。 -
调用函数:根据子命令
create_indexes,调用create_indexes(args)函数。 -
加载波形数据:在
create_indexes函数中,调用load_waveforms函数从指定的 HDF5 文件中加载波形数据。 -
创建并保存索引:调用
create_and_save_indexes函数,根据波形数据生成索引,并将索引保存到指定的 HDF5 文件中。
总结
这段代码展示了如何使用 argparse 模块解析命令行参数并执行特定操作。通过结合命令行参数和脚本逻辑,可以方便地实现复杂的任务自动化流程。上述示例详细解释了命令行参数的传递和处理方式,有助于更好地理解和使用 argparse 模块。
相关文章:

深度学习:使用argparse 模块
在深度学习中,结合 Bash 脚本和 argparse 模块,可以实现高效的任务自动化和参数管理。Bash 脚本可以用来调度任务和管理环境,而 argparse 模块可以用来解析命令行参数,控制深度学习模型的训练和评估过程。 1.argparse 模块 argp…...

unity text根据文本内容自动设置高度
我们经常会遇到需要根据文字数量动态修改文本框高度的需求,我们可以使用文本的行数*每行的高度来计算文本框的高度,伪代码如下: int oneLineHight 50;// 每行的像素高度 private void ResetTextHight(string str) {//设置文字内容ShowText.…...

ARM 汇编 C语言 for循环
在使用 Keil 编译基于 STM32F103 的 C 语言程序时,生成的汇编代码会有一些不同。STM32F103 是基于 ARM Cortex-M3 内核的微控制器,因为汇编语言是 ARM 汇编,而不是 x86 汇编。 示例 C 代码 假设我们有如下的简单 C 语言 for 循环代码&#x…...
java:【@ComponentScan】和【@SpringBootApplication】扫包范围的冲突
# 代码结构如下: 注意【com.chz.myBean.branch】和【com.chz.myBean.main】这两个包是没有生重叠的。 主程序【MyBeanTest1、MyBeanTest2、MyBeanTest3】这两个类是在包【com.chz.myBean.main】下 # 示例代码 【pom.xml】 <dependency><groupId>org.…...
本学期嵌入式期末考试的综合项目,我是这么出题的
时间过得真快,临近期末,又到了老师出卷的时候。作为《嵌入式开发及应用》这门课的主讲教师,今年给学生出的题目有一点点难度,最后的综合项目要求如下所示,各位学生朋友和教师同行可以评论一下难度如何,单片…...
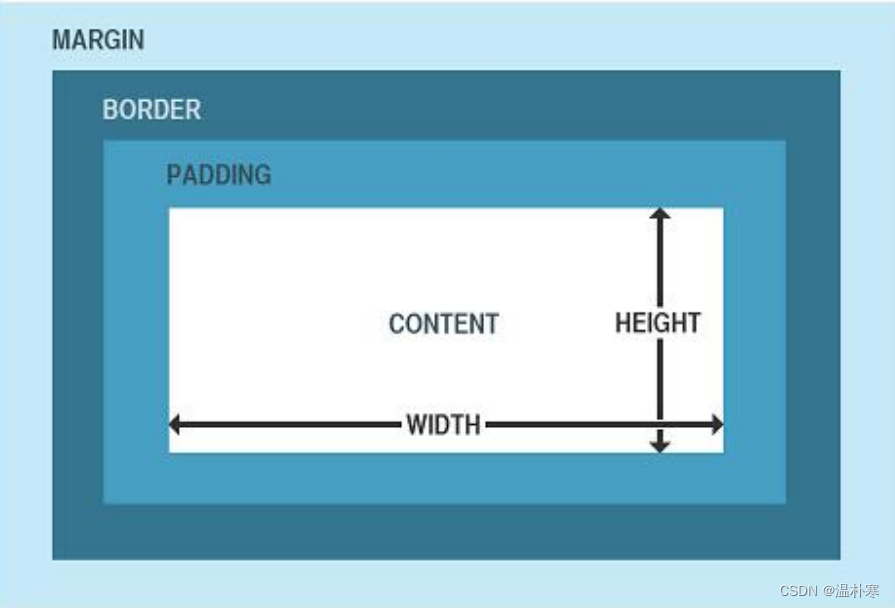
CSS概述
CSS是一种样式表语言,用于为HTML文档控制外观,定义布局。例如, CSS涉及字体、颜色、边距、高度、宽度、背景图像、高级定位等方面 。 ● 可将页面的内容与表现形式分离,页面内容存放在HTML文档中,而用 于定义表现形式…...
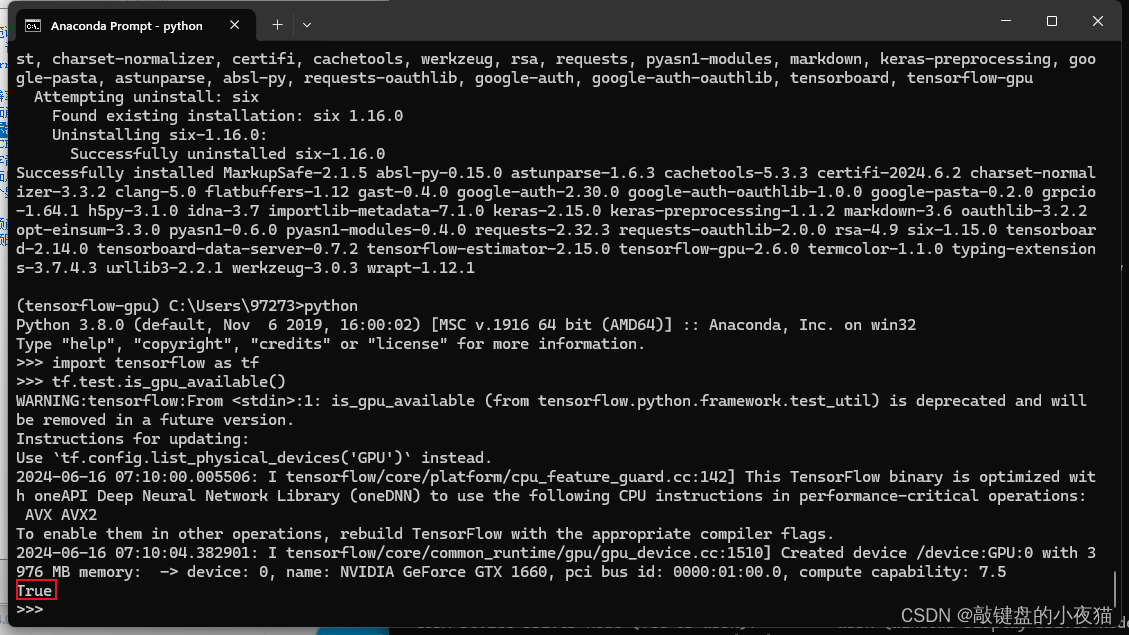
Tensorflow-GPU工具包了解和详细安装方法
目录 基础知识信息了解 显卡算力 CUDA兼容 Tensorflow gpu安装 CUDA/cuDNN匹配和下载 查看Conda driver的版本 下载CUDA工具包 查看对应cuDNN版本 下载cuDNN加速库 CUDA/cuDNN安装 CUDA安装方法 cuDNN加速库安装 配置CUDA/cuDNN环境变量 配置环境变量 核验是否安…...
【python】OpenCV GUI——Trackbar(14.2)
学习来自 OpenCV基础(12)OpenCV GUI中的鼠标和滑动条 文章目录 GUI 滑条介绍cv2.createTrackbar 介绍牛刀小试 GUI 滑条介绍 GUI滑动条是一种直观且快速的调节控件,主要用于改变一个数值或相对值。以下是关于GUI滑动条的详细介绍:…...

Qt自定义日志输出
Qt自定义日志输出 简略版: #include <QApplication> #include <QDebug> #include <QDateTime> #include <QFileInfo> // 将日志类型转换为字符串 QString typeToString(QtMsgType type) {switch (type) {case QtDebugMsg: return "D…...
[C++] vector list 等容器的迭代器失效问题
标题:[C] 容器的迭代器失效问题 水墨不写bug 正文开始: 什么是迭代器? 迭代器是STL提供的六大组件之一,它允许我们访问容器(如vector、list、set等)中的元素,同时提供一个遍历容器的方法。然而…...

Java——变量作用域和生命周期
一、作用域 1、作用域简介 在Java中,作用域(Scope)指的是变量、方法和类在代码中的可见性和生命周期。理解作用域有助于编写更清晰、更高效的代码。 2、作用域 块作用域(Block Scope): 块作用域是指在…...
WPF界面设计
1、使用C#-WPF实现抽屉效果-炫酷漂亮的侧边栏导航菜单-SplitViewMD主题重绘原生控件的美观效果-提供源码Demo下载 码源地址:https://download.csdn.net/download/Prince999999/89424685 2、使用C#-WPF实现抽屉效果-菜单导航功能实现,常规的管理系统应该…...

【C#】使用JavaScriptSerializer序列化对象
在C#开发语言编程中,通常使用系统内置的JavaScriptSerializer类来序列化对象,以便将其转换为JSON格式的文本存储与后台服务通信, 在这里将为大家详细介绍一下这个过程。 文章目录 反序列化序列化忽略属性 假设处理的数据中有一个对象类, 如下 public cl…...

HTML静态网页成品作业(HTML+CSS)—— 明星吴磊介绍网页(5个页面)
🎉不定期分享源码,关注不丢失哦 文章目录 一、作品介绍二、作品演示三、代码目录四、网站代码HTML部分代码 五、源码获取 一、作品介绍 🏷️本套采用HTMLCSS,未使用Javacsript代码,共有5个页面。 二、作品演示 三、代…...

EasyRecovery2024数据恢复神器#电脑必备良品
EasyRecovery数据恢复软件,让你的数据重见天日! 大家好!今天我要给大家种草一个非常实用的软件——EasyRecovery数据恢复软件!你是不是也曾经遇到过不小心删除了重要的文件,或者电脑突然崩溃导致数据丢失的尴尬情况呢&…...

前端HTML相关知识
1.什么是HTML HTML 指的是超文本标记语言 ( HyperText Markup Language )。 超文本:是指页面内可以包含图片、链接、声音,视频等内容 标记:标签(通过标记符号来告诉浏览器网页内容该如何显示) 浏览器根据不同的HTML标签,解析成我们看到的网页 2.HTML的特点 HTML不…...

集合面试题
目录 ①HashMap的理解?以及为什么要把链表转换为红黑树?②HashMap的put?③HashMap的扩容?④加载因子为什么是0.75?⑤modcount的作用?⑥HashMap与HashTable的区别?⑥HashMap中1.7和1.8的区别&am…...
集成学习概述
概述 集成学习(Ensemble learning)就是将多个机器学习模型组合起来,共同工作以达到优化算法的目的。具体来讲,集成学习可以通过多个学习器相结合,来获得比单一学习器更优越的泛化性能。集成学习的一般步骤为:1.生产一组“个体学习…...

记录一次root过程
设备: Redmi k40s 第一步, 解锁BL(会重置手机系统!!!所有数据都会没有!!!) 由于更新了澎湃OS系统, 解锁BL很麻烦, 需要社区5级以上还要答题。 但是,这个手机…...

函数(上)(C语言)
函数(上) 一. 函数的概念二. 函数的使用1. 库函数和自定义函数(1) 库函数(2) 自定义函数的形式 2. 形参和实参3. return语句4. 数组做函数参数 一. 函数的概念 数学中我们其实就见过函数的概念,比如:一次函数ykxb,k和b都是常数&a…...

TPAMI 2025 | 港城大团队新作:强化学习引导 ODE 轨迹,提升图像复原性能
点击上方“小白学视觉”,选择加"星标"或“置顶” 重磅干货,第一时间送达在计算机视觉领域,图像恢复一直是核心研究方向之一——从模糊的监控画面中还原清晰细节、让水下拍摄的照片重现真实色彩、给低光照的夜景图像提亮增晰&#x…...

Graphormer在药物发现中的价值:缩短先导化合物筛选周期50%以上
Graphormer在药物发现中的价值:缩短先导化合物筛选周期50%以上 1. 引言:药物研发的新利器 在药物研发领域,科学家们每年需要筛选数百万种化合物来寻找潜在的药物候选分子。传统方法不仅耗时耗力,而且成本高昂。Graphormer的出现…...

别再只用BCE了!用PyTorch实现ASL损失函数,搞定多标签分类中的样本不均衡
多标签分类新范式:PyTorch实战ASL损失函数解决样本不均衡难题 在图像标注、医学诊断或文本情感分析等多标签分类任务中,我们常常遇到一个棘手问题——某些标签的出现频率可能比其他标签高出几个数量级。想象一下,当你构建一个商品标签系统时&…...

别再手动写JSON Schema了!用智谱AI/DeepSeek的FunctionCall,5分钟搞定天气查询API对接
告别JSON Schema手写时代:用大模型FunctionCall极速对接天气API 开发聊天机器人时,最头疼的莫过于为每个新功能手动编写JSON Schema。上周我接手一个天气查询功能需求,原本预计要花半天时间定义参数结构、验证逻辑,结果用智谱AI的…...

FDTD复现Science正刊:二次谐波产生的奇妙之旅
FDTD复现Science正刊,二次谐波产生 嘿,大家好!今天来聊聊用FDTD方法复现Science正刊中二次谐波产生的相关研究,这可是个超有趣的领域。 什么是二次谐波产生? 二次谐波产生(Second Harmonic Generation&a…...

构建企业级AI客服系统:从知识库集成到无缝转人工的实战指南
1. 企业级AI客服系统架构设计 第一次搭建AI客服系统时,我犯了个典型错误——直接调用大模型API就开始开发前端界面。结果上线后才发现,当用户量超过50人时响应速度直线下降,转人工功能更是形同虚设。这个教训让我明白,企业级系统必…...

如何破解Godot游戏的黑盒:解密PCK文件中的资源宝藏
如何破解Godot游戏的黑盒:解密PCK文件中的资源宝藏 【免费下载链接】godot-unpacker godot .pck unpacker 项目地址: https://gitcode.com/gh_mirrors/go/godot-unpacker 你是否曾好奇Godot游戏内部隐藏着怎样的资源结构?当面对那些看似神秘的.pc…...
)
别再让设备突然罢工!手把手教你用MATLAB搞预测性维护(附往复泵故障诊断实战)
别再让设备突然罢工!手把手教你用MATLAB搞预测性维护(附往复泵故障诊断实战) 设备突然停机造成的损失有多严重?某化工厂曾因关键泵组突发故障导致全线停产36小时,直接经济损失超过200万元。这种场景在工业领域并不罕见…...

Winhance-zh_CN:如何免费让你的Windows系统焕然一新
Winhance-zh_CN:如何免费让你的Windows系统焕然一新 【免费下载链接】Winhance-zh_CN A Chinese version of Winhance. C# application designed to optimize and customize your Windows experience. 项目地址: https://gitcode.com/gh_mirrors/wi/Winhance-zh_C…...

从零到一:基于SkyWalking构建微服务可观测性实践
1. 为什么微服务需要可观测性? 记得去年我们团队把一个单体应用拆分成五个微服务后,突然发现线上问题排查变得异常困难。有一次用户反馈订单支付超时,我们花了整整两天时间才定位到是风控服务调用了第三方接口导致的性能瓶颈。这种经历让我深…...