LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS
文章汇总
总体来看像是一种带权重的残差,但解决的如何高效问题的事情。
相比模型的全微调,作者提出固定预训练模型参数不变,在原本权重矩阵旁路添加低秩矩阵的乘积作为可训练参数,用以模拟参数的变化量。
模型架构

h = W 0 x + △ W x = W 0 x + B A x , B ∈ R d × r , A ∈ R r × k , r ≪ m i n ( d , k ) h=W_0x+\triangle Wx=W_0x+BAx,B\in \mathbb{R}^{d\times r},A\in \mathbb{R}^{r\times k},r \ll min(d,k) h=W0x+△Wx=W0x+BAx,B∈Rd×r,A∈Rr×k,r≪min(d,k)
可以从中看出来 B ∈ R d × r , A ∈ R r × k B\in\mathbb{R}^{d\times r},A\in \mathbb{R}^{r\times k} B∈Rd×r,A∈Rr×k分别是列满秩和行满秩。
因此 r a n k ( A ) = r a n k ( B ) = r , r ≪ m i n ( d , k ) rank(A)=rank(B)=r,r \ll min(d,k) rank(A)=rank(B)=r,r≪min(d,k)。
优点:
1:只优化注入的小得多的低秩矩阵,并且降低了过拟合的风险。
2:推理时可以将原权重与训练后权重合并,即 W = W 0 + B A W=W_0+BA W=W0+BA,因此在推理时不存在额外的开销。
3:当我们需要切换到另一个下游任务时,我们可以通过减去 B A BA BA然后添加不同的 B ′ A ′ B'A' B′A′来恢复 W 0 W_0 W0,这是一个内存开销很小的快速操作。
LoRA在transformer上的应用

为了简单和参数效率,我们将研究限制为仅适应下游任务的注意力权重,并冻结MLP模块(因此它们不接受下游任务的训练)
摘要
自然语言处理的一个重要范例是对一般领域数据进行大规模预训练,并适应特定的任务或领域。当我们预训练更大的模型时,重新训练所有模型参数的完全微调变得不太可行。以GPT-3 175B为例,部署独立的微调模型实例,每个实例都有175B参数,这是非常昂贵的。我们提出了低秩自适应(Low-Rank Adaptation, LoRA),它冻结了预训练的模型权重,并将可训练的秩分解矩阵注入到Transformer架构的每一层,从而大大减少了下游任务的可训练参数的数量。与经过Adam微调的GPT-3 175B相比,LoRA可以将可训练参数的数量减少10,000倍,GPU内存需求减少3倍。在RoBERTa、DeBERTa、GPT-2和GPT-3上,LoRA在模型质量方面的表现与调优相当或更好,尽管具有更少的可训练参数、更高的训练吞吐量,并且与适配器不同,没有额外的推理延迟。我们还对语言模型适应中的等级缺陷进行了实证研究,从而揭示了LoRA的有效性。我们发布了一个包来促进LoRA与PyTorch模型的集成,并在https://github.com/microsoft/LoRA上为RoBERTa、DeBERTa和GPT-2提供我们的实现和模型检查点。
1介绍
自然语言处理中的许多应用依赖于将一个大规模的预训练语言模型适应多个下游应用。这种适应通常是通过微调来完成的,微调会更新预训练模型的所有参数。微调的主要缺点是新模型包含与原始模型一样多的参数。由于每隔几个月就会训练更大的模型,对于GPT-2 (Radford等人,b)或RoBERTa large (Liu等人,2019)来说,这仅仅是一个“不便”,而对于具有1750亿个可训练参数的GPT-3 (Brown等人,2020)来说,这是一个关键的部署挑战许多人试图通过调整一些参数或学习外部模块来缓解这种情况。这样,除了每个任务的预训练模型外,我们只需要存储和加载少量的特定于任务的参数,大大提高了部署时的运行效率。然而,现有的技术经常引入推理延迟(Houlsby等人,2019;Rebuffi等人,2017)通过扩展模型深度或减少模型的可用序列长度(Li & Liang, 2021;Lester等人,2021;Hambardzumyan等,2020;Liu et al ., 2021)(第3节)。更重要的是,这些方法往往无法匹配微调基线,从而在效率和模型质量之间做出权衡。
图1:我们的重新参数化。我们只训练A和B。
我们从Li等人(2018a)那里获得灵感;Aghajanyan等人(2020)的研究表明,学习到的过度参数化模型实际上存在于低内在维上。我们假设模型适应过程中的权重变化也具有较低的“内在秩”,从而提出了低秩适应(low - rank adaptation, LoRA)方法。LoRA允许我们通过优化密集层在适应过程中变化的秩分解矩阵来间接训练神经网络中的一些密集层,同时保持预训练的权值不变,如图1所示。以GPT-3 175B为例,我们展示了即使在全秩(即d)高达12,288时,非常低的秩(即图1中的 r r r可以是1或2)也足够了,这使得LoRA既具有存储效率又具有计算效率。
LoRA具有几个关键优势。
•预先训练的模型可以共享,并用于为不同的任务构建许多小型LoRA模块。我们可以通过替换图1中的矩阵A和B来冻结共享模型并有效地切换任务,从而显著降低存储需求和任务切换开销。
•LoRA使训练更有效,并且在使用自适应优化器时将硬件进入门槛降低了3倍,因为我们不需要计算梯度或维护大多数参数的优化器状态。相反,我们只优化注入的小得多的低秩矩阵。
•我们简单的线性设计允许我们在部署时将可训练矩阵与冻结权重合并,与完全微调的模型相比,通过构建不会引入推理延迟。
•LoRA与许多先前的方法正交,并且可以与其中许多方法组合,例如前缀调优。我们在附录E中提供了一个例子。
术语和约定
我们经常引用Transformer体系结构,并对其维度使用常规术语。我们将Transformer层的输入和输出维度大小称为 d m o d e l d_{model} dmodel。我们用 W q , W k , W v , W o W_q,W_k,W_v,W_o Wq,Wk,Wv,Wo来指代自关注模块中的查询/键/值/输出投影矩阵。 W W W或 W 0 W_0 W0为预训练权矩阵, △ W \triangle W △W为适应过程中累积的梯度更新。我们用 r r r来表示LoRA模块的秩。我们遵循(Vaswani et al ., 2017;Brown et al ., 2020),并使用Adam (Loshchilov & Hutter, 2019;Kingma & Ba, 2017)进行模型优化,并使用Transformer MLP前馈维度 f f f n = 4 × d m o d e l f_{ffn}=4\times d_{model} fffn=4×dmodel。
2 问题陈述
虽然我们的建议与训练目标无关,但我们将重点放在语言建模上,作为我们的激励用例。下面是对语言建模问题的简要描述,特别是在给定特定任务提示的情况下最大化条件概率。
假设我们有一个预训练的自回归语言模型 P Φ ( y ∣ x ) P_\Phi(y|x) PΦ(y∣x),参数化为 Φ \Phi Φ。例如, P Φ ( y ∣ x ) P_\Phi(y|x) PΦ(y∣x)可以是通用的多任务学习器,如GPT (Radford等人,b;Brown等人,2020)基于Transformer架构(Vaswani等人,2017)。考虑将此预训练模型应用于下游条件文本生成任务,例如摘要、机器阅读理解(MRC)和自然语言转换为SQL (NL2SQL)。每个下游任务由上下文-目标对的训练数据集表示: Z = { ( x i , y i ) } i = 1 , . . . , N \mathcal{Z}=\{(x_i,y_i)\}_{i=1,...,N} Z={(xi,yi)}i=1,...,N,其中 x i x_i xi和 y i y_i yi都是令牌序列。例如,在NL2SQL中, x i x_i xi是一个自然语言查询, y i y_i yi是对应的SQL命令;“ x i x_i xi”是文章的内容,“ y i y_i yi”是文章的摘要。
在全微调过程中,将模型初始化为预训练的权值 Φ 0 \Phi_0 Φ0,并通过反复跟随梯度更新为 Φ 0 + △ Φ \Phi_0+\triangle \Phi Φ0+△Φ,以最大化条件语言建模目标:

完全微调的主要缺点之一是,对于每个下游任务,我们学习一组不同的参数 △ Φ \triangle \Phi △Φ,其维数 ∣ △ Φ ∣ |\triangle \Phi| ∣△Φ∣等于 ∣ Φ 0 ∣ |\Phi_0| ∣Φ0∣。因此,如果预训练的模型很大(如GPT-3的 ∣ Φ 0 ∣ |\Phi_0| ∣Φ0∣≈1750亿),存储和部署许多独立的微调模型实例可能是具有挑战性的,如果可行的话。
在本文中,我们采用了一种参数效率更高的方法,其中特定于任务的参数增量 △ Φ = △ Φ ( Θ ) \triangle \Phi=\triangle \Phi(\Theta) △Φ=△Φ(Θ)由更小的参数集 Θ \Theta Θ与 ∣ Θ ∣ ≪ ∣ Φ 0 ∣ |\Theta| \ll |\Phi_0| ∣Θ∣≪∣Φ0∣进一步编码。因此,寻找 △ Φ \triangle \Phi △Φ的任务变成了对 Θ \Theta Θ的优化:
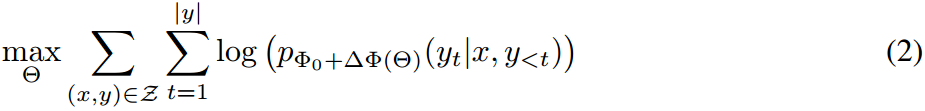
在随后的章节中,我们建议使用低秩表示来编码 △ Φ \triangle \Phi △Φ,这既节省计算又节省内存。当预训练模型为GPT-3 175B时,可训练参数 ∣ Θ ∣ |\Theta| ∣Θ∣的数量可小至 ∣ Φ 0 ∣ |\Phi_0| ∣Φ0∣的0.01%。
3.现有的解决方案还不够好吗?
我们着手解决的问题绝不是什么新问题。自从迁移学习开始以来,已经有几十项工作试图使模型适应更具有参数和计算效率。关于一些著名作品的概览,见第6节。以语言建模为例,在有效适应方面有两种突出的策略:添加适配器层(Houlsby等人,2019;Rebuffi et al ., 2017;Pfeiffer等,2021;Ruckl¨e等人,2020)或优化输入层激活的某些形式(Li & Liang, 2021;Lester等人,2021;Hambardzumyan等,2020;Liu et al, 2021)。然而,这两种策略都有其局限性,特别是在大规模和对延迟敏感的生产场景中。
适配器层引入推理延迟
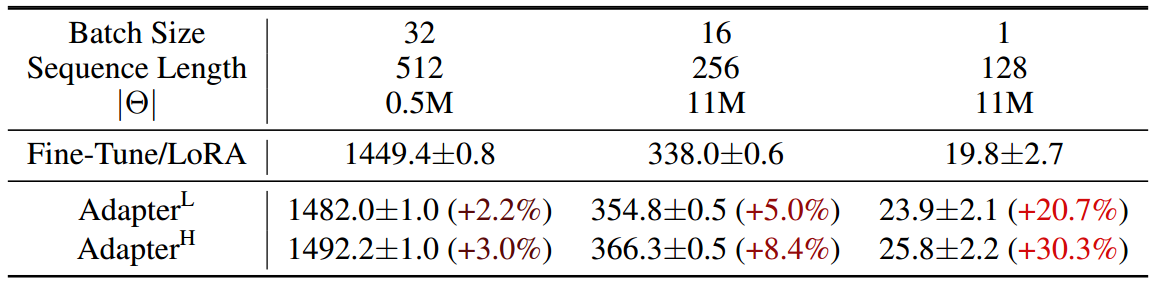
表1:GPT-2介质中单个正向传递的延迟时间(以毫秒为单位),平均超过100次试验。我们使用的是NVIDIA Quadro RTX8000。“ ∣ Θ ∣ |\Theta| ∣Θ∣”表示适配器层中可训练参数的数量。AdapterL和AdapterH是适配器调优的两个变体,我们将在5.1节中描述。在在线、短序列长度的场景中,适配器层引入的推理延迟可能非常大。详见附录B的完整研究。
适配器有许多变体。我们专注于Houlsby等人(2019)的原始设计,每个Transformer块有两个适配器层,Lin等人(2020)的最新设计,每个块只有一个适配器层,但有一个额外的LayerNorm (Ba等人,2016)。虽然可以通过修剪层或利用多任务设置来减少总体延迟(Ruckl¨e等人,2020;Pfeiffer等人,2021),没有直接的方法绕过适配器层中的额外计算。这似乎不是问题,因为适配器层被设计为具有很少的参数(有时<原始模型的1%),通过具有较小的瓶颈维度,这限制了它们可以添加的flop。然而,大型神经网络依赖于硬件并行性来保持低延迟,适配器层必须按顺序处理。这在批处理大小通常小于1的在线推理设置中会产生差异。在没有模型并行性的通用场景中,例如在单个GPU上运行GPT-2 (Radford et al, b)介质上的推理,我们看到使用适配器时延迟明显增加,即使瓶颈维度非常小(表1)。
当我们需要像Shoeybi等人(2020)那样对模型进行分片时,这个问题会变得更糟;Lepikhin等人(2020),因为额外的深度需要更多的同步GPU操作,如AllReduce和Broadcast,除非我们多次冗余存储适配器参数。
直接优化提示是很困难的
另一个方向,如前缀调优(Li & Liang, 2021),面临着不同的挑战。我们观察到前缀调优很难优化,其性能在可训练参数中呈非单调变化,证实了原论文的类似观察结果。更根本的是,为自适应保留一部分序列长度必然会减少用于处理下游任务的序列长度,我们怀疑与其他方法相比,这使得调整提示的性能降低。我们把对任务执行的研究推迟到第5节。
4.我们的方法
我们描述了LoRA的简单设计及其实际效益。这里概述的原则适用于深度学习模型中的任何密集层,尽管在我们的实验中,我们只关注Transformer语言模型中的某些权重,作为激励用例。
4.1低秩参数化更新矩阵
神经网络包含许多执行矩阵乘法的密集层。这些层中的权矩阵通常是全秩的。当适应一个特定的任务时,Aghajanyan等人(2020)表明,预训练的语言模型具有较低的“内在维度”,尽管随机投影到较小的子空间,但仍然可以有效地学习。受此启发,我们假设权重的更新在适应过程中也具有较低的“内在秩”。对于预训练的权重矩阵 W 0 ∈ R d × k W_0\in \mathbb{R}^{d\times k} W0∈Rd×k,我们通过用低秩分解 W 0 + △ W = W 0 + B A W_0+\triangle W=W_0+BA W0+△W=W0+BA来约束其更新,其中 B ∈ R d × r , A ∈ R r × k B\in \mathbb{R}^{d\times r},A\in \mathbb{R}^{r\times k} B∈Rd×r,A∈Rr×k,秩 r ≪ m i n ( d , k ) r \ll min(d,k) r≪min(d,k)。在训练过程中, W 0 W_0 W0被冻结,不接受梯度更新,而 A A A和 B B B包含可训练参数。注意, W 0 W_0 W0和 △ W = B A \triangle W= BA △W=BA都用相同的输入相乘,它们各自的输出向量按坐标求和。当 h = W 0 x h=W_0x h=W0x时,修正后的正向传递收益率为:
h = W 0 x + △ W x = W 0 x + B A x h=W_0x+\triangle Wx=W_0x+BAx h=W0x+△Wx=W0x+BAx
我们在图1中说明了我们的重新参数化。我们对 A A A使用随机高斯初始化,对 B B B使用零初始化,因此 △ W = B A \triangle W=BA △W=BA在训练开始时为零。然后,我们将 △ W x \triangle W x △Wx乘以 α r \frac{\alpha}{r} rα,其中 α \alpha α是 r r r中的常数。当使用Adam进行优化时,如果我们适当地缩放初始化,则调整 α \alpha α与调整学习率大致相同。因此,我们简单地将 α \alpha α设置为我们尝试的第一个 r r r,而不调整它。当我们改变 r r r时,这种缩放有助于减少重新调整超参数的需要(Yang & Hu, 2021)。
全微调的推广。更一般的微调形式允许训练预训练参数的子集。LoRA更进一步,在适应过程中不要求权重矩阵的累积梯度更新具有全秩。这意味着当将LoRA应用于所有权重矩阵并训练所有偏差时,通过将LoRA秩 r r r设置为预训练的权重矩阵的秩,我们大致恢复了完全微调的表达性。换句话说,当我们增加可训练参数的数量时,训练LoRA大致收敛于训练原始模型,而基于适配器的方法收敛于MLP,基于前缀的方法收敛于不能接受长输入序列的模型。
**没有额外的推理延迟。当部署到生产环境中时,我们可以显式地计算和存储 W = W 0 + B A W=W_0+BA W=W0+BA,并像往常一样执行推理。注意 W 0 W_0 W0和 B A BA BA都在 R d × k \mathbb{R}^{d\times k} Rd×k中。当我们需要切换到另一个下游任务时,我们可以通过减去 B A BA BA然后添加不同的 B ′ A ′ B'A' B′A′来恢复 W 0 W_0 W0,这是一个内存开销很小的快速操作。**至关重要的是,这保证在推理期间,与通过构造进行微调的模型相比,我们不会引入任何额外的延迟。
4.2 LoRA在transformer上的应用
原则上,我们可以将LoRA应用于神经网络中权矩阵的任何子集,以减少可训练参数的数量。在Transformer体系结构中,自关注模块 ( W q , W k , W v , W o ) (W_q,W_k,W_v,W_o) (Wq,Wk,Wv,Wo)和2个在MLP模块。我们将 W q W_q Wq(或 W k , W v W_k,W_v Wk,Wv)视为维度 d m o d e l × d m o d e l d_{model}\times d_{model} dmodel×dmodel的单个矩阵,尽管输出维度通常被分割成注意头。为了简单和参数效率,我们将研究限制为仅适应下游任务的注意力权重,并冻结MLP模块(因此它们不接受下游任务的训练)。在7.1节中,我们进一步研究了在Transformer中适应不同类型的注意力权重矩阵的影响。我们把适应MLP层、LayerNorm层和偏差的实证调查留给未来的工作。
实际的好处和局限性
最大的好处来自内存和存储使用的减少。对于亚当训练的大型Transformer,如果 r ≪ d m o d e l r \ll d_{model} r≪dmodel ,我们将VRAM使用量减少2/3,因为我们不需要存储冻结参数的优化器状态。在GPT-3 175B上,我们将训练期间的VRAM消耗从1.2TB减少到350GB。当 r = 4 r=4 r=4并且只调整查询和值投影矩阵时,检查点大小减少了大约10,000倍(从350GB减少到35MB)4。这使我们能够使用更少的gpu进行训练,并避免I/O瓶颈。另一个好处是,我们可以在部署时以低得多的成本在任务之间切换,只需交换LoRA权重,而不是所有参数。这允许创建许多定制模型,这些模型可以在将预训练的权重存储在VRAM中的机器上动态交换。我们还观察到,在GPT-3 175B的训练过程中,与完全微调相比,速度提高了25%,因为我们不需要计算绝大多数参数的梯度。
LoRA也有其局限性。例如,如果选择将 A A A和 B B B吸收到 W W W中以消除额外的推理延迟,则在单个前向传递中批量处理具有不同 A A A和 B B B的不同任务的输入是不直接的。尽管对于延迟不重要的场景,可以不合并权重并动态选择用于批量示例的LoRA模块。
5 实证实验
在扩展到GPT-3 175B (Brown等人,2020)之前,我们评估了LoRA在RoBERTa (Liu等人,2019)、DeBERTa (He等人,2021)和GPT-2 (Radford等人,b)上的下游任务性能。我们的实验涵盖了广泛的任务,从自然语言理解(NLU)到生成(NLG)。具体来说,我们对RoBERTa和DeBERTa的GLUE (Wang et al ., 2019)基准进行了评估。我们遵循Li & Liang(2021)在GPT-2上的设置进行直接比较,并添加了WikiSQL (Zhong等人,2017)(NL到SQL查询)和SAMSum (Gliwa等人,2019)(对话摘要)在GPT-3上进行大规模实验。有关我们使用的数据集的更多细节,请参阅附录C。我们使用NVIDIA Tesla V100进行所有实验。
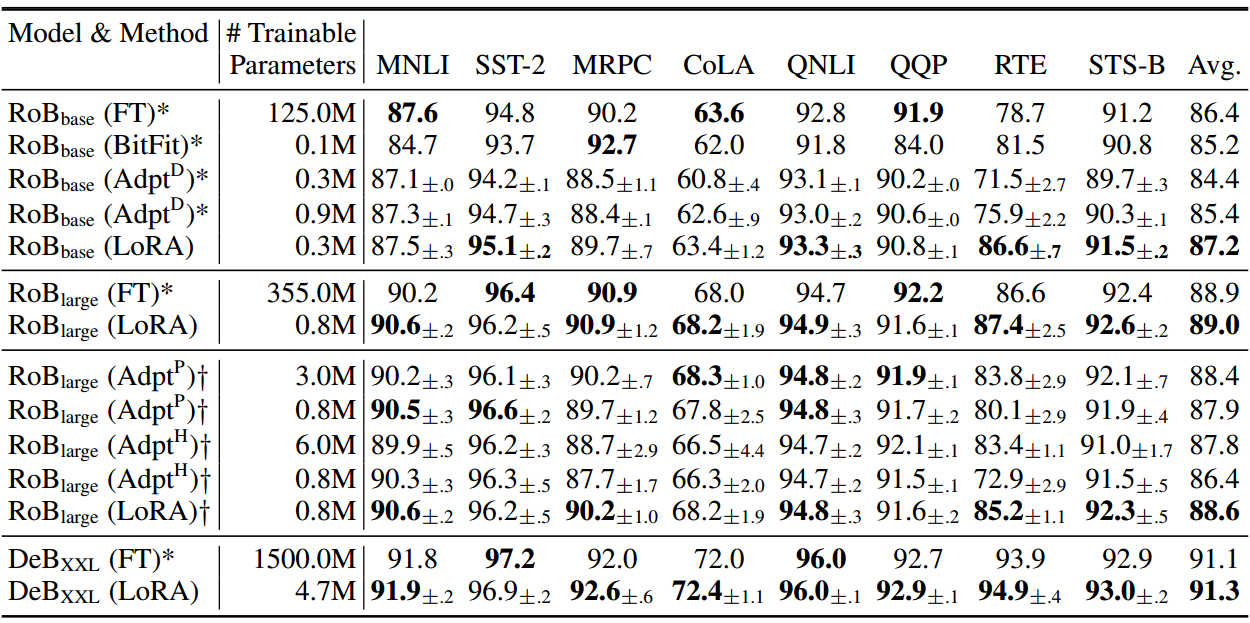
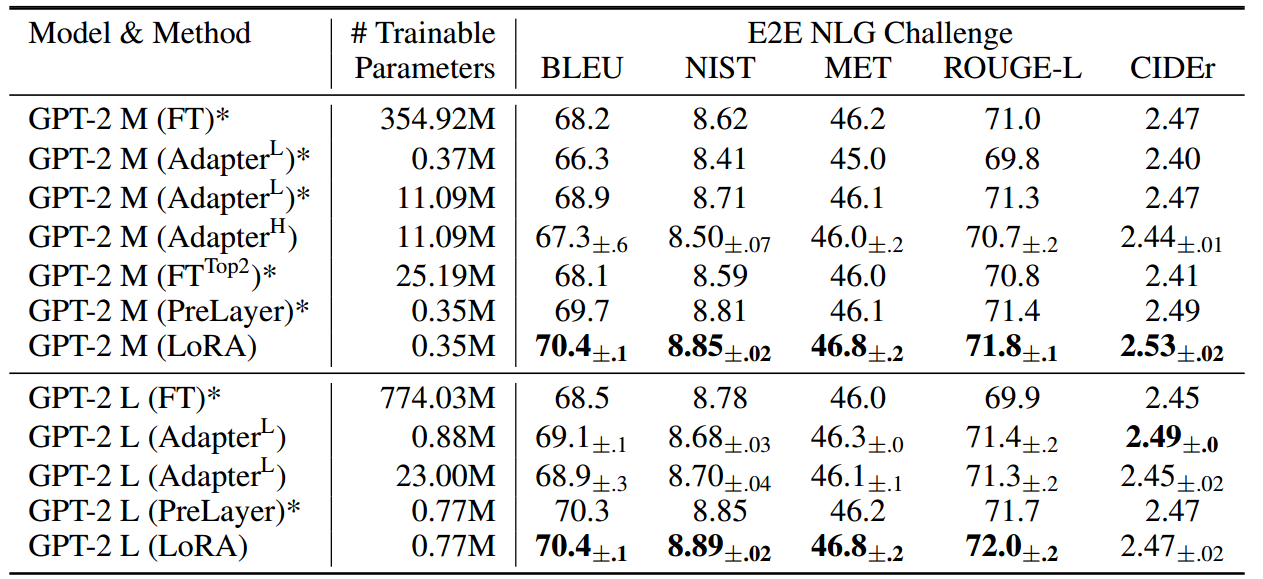
8 结论与未来工作
就所需的硬件和为不同任务托管独立实例的存储/切换成本而言,对庞大的语言模型进行微调是非常昂贵的。我们提出LoRA,一种有效的自适应策略,既不引入推理延迟,也不减少输入序列长度,同时保持高模型质量。重要的是,通过共享绝大多数模型参数,它允许在作为服务部署时快速切换任务。虽然我们关注的是Transformer语言模型,但所提出的原则通常适用于任何具有密集层的神经网络。
未来的工作有很多方向。1) LoRA可以与其他有效的自适应方法相结合,有可能提供正交改进。2)微调或LoRA背后的机制尚不清楚——**如何将预训练期间学习到的特征转化为下游任务?我们相信LoRA比全微调更容易回答这个问题。**3)我们主要依靠启发式方法来选择应用LoRA的权重矩阵。有没有更有原则的方法?4)最后, △ W \triangle W △W的rank-deficient表明 W W W也可能是rank-deficient,这也可以作为未来作品的灵感来源。
参考资料
论文下载(2021年)
https://arxiv.org/abs/2106.09685v2
代码地址
https://github.com/microsoft/LoRA
参考资料
《大规模语言模型从理论到实践》张奇 桂韬 郑锐 ⻩萱菁 著
相关文章:
LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS
文章汇总 总体来看像是一种带权重的残差,但解决的如何高效问题的事情。 相比模型的全微调,作者提出固定预训练模型参数不变,在原本权重矩阵旁路添加低秩矩阵的乘积作为可训练参数,用以模拟参数的变化量。 模型架构 h W 0 x △…...

cmake、make、makefile、ninga的关系
CMake是一种跨平台的构建系统,它用来管理软件的编译过程。CMake可以生成本地平台特定的构建文件,例如Makefile或者Microsoft Visual Studio项目文件,以便开发人员更轻松地在不同的平台上构建他们的项目。它的主要功能是配置和生成构建脚本&am…...
StarRocks详解
什么是StarRocks? StarRocks是新一代极速全场景MPP数据库(高并发数据库)。 StarRocks充分吸收关系型OLAP数据库和分布式存储系统在大数据时代的优秀研究成果。 1.可以在Spark和Flink里面处理数据,然后将处理完的数据写到StarRo…...

【C语言】进程间通信之管道pipe
进程间通信之管道pipe 一、进程间通信管道pipe()管道的读写行为 最后 一、进程间通信 管道pipe() 管道pipe也称为匿名管道,只有在有血缘关系的进程间进行通信。管道的本质就是一块内核缓冲区。 进程间通过管道的一端写,通过管道的另一端读。管道的读端…...
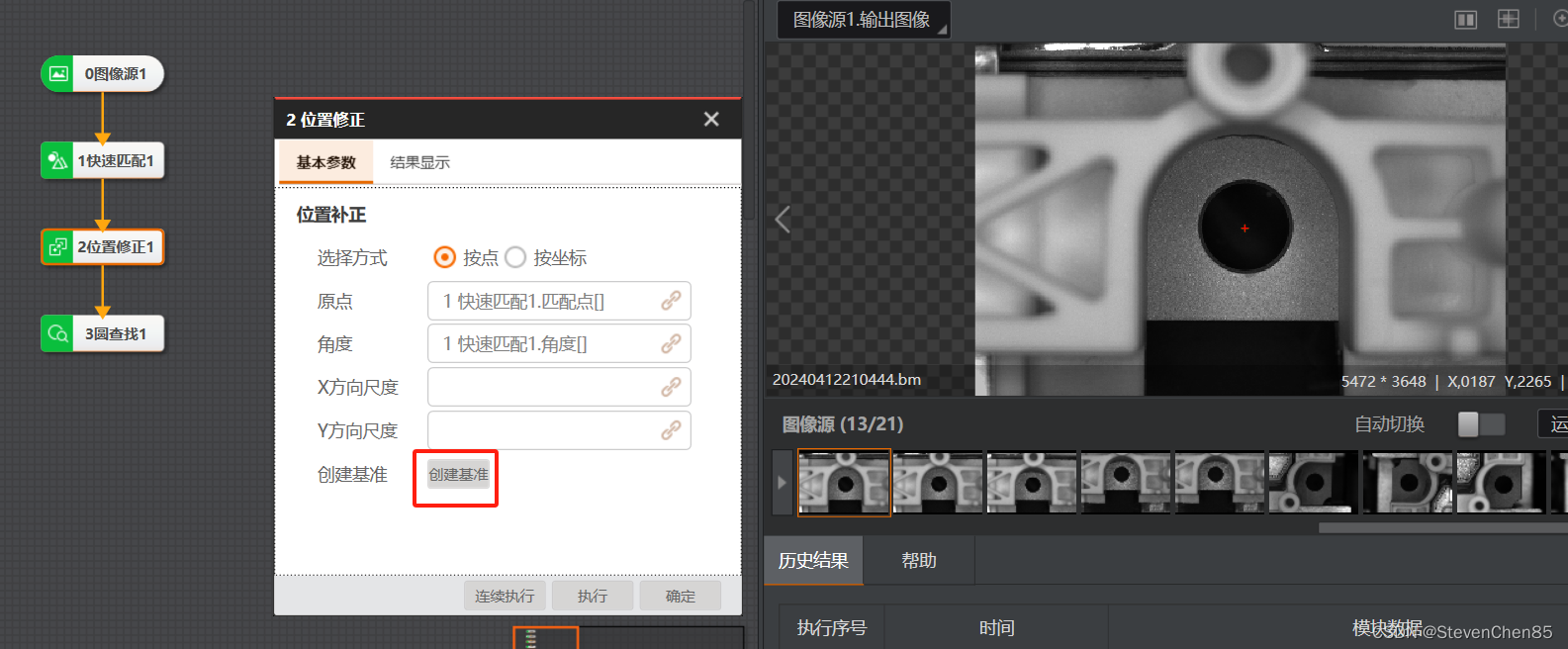
03.VisionMaster 机器视觉 位置修正 工具
VisionMaster 机器视觉 位置修正 工具 官方解释:位置修正是一个辅助定位、修正目标运动偏移、辅助精准定位的工具。可以根据模板匹配结果中的匹配点和匹配框角度建立位置偏移的基准,然后再根据特征匹配结果中的运行点和基准点的相对位置偏移实现ROI检测…...

Oracle 是否扼杀了开源 MySQL
Oracle 是否无意中扼杀了开源 MySQL Peter Zaitsev是一位俄罗斯软件工程师和企业家,曾在MySQL公司担任性能工程师。大约15年前,当甲骨文收购Sun公司并随后收购MySQL时,有很多关于甲骨文何时“杀死MySQL”的讨论。他曾为甲骨文进行辩护&#…...
机器学习归一化特征编码
特征缩放 因为对于大多数的机器学习算法和优化算法来说,将特征值缩放到相同区间可以使得获取性能更好的模型。就梯度下降算法而言,例如有两个不同的特征,第一个特征的取值范围为1——10,第二个特征的取值范围为1——10000。在梯度…...

抛光粉尘可爆性检测 打磨粉尘喷砂粉尘爆炸下限测试
抛光粉尘可爆性检测 抛光粉尘的可爆性检测是一种安全性能测试,用于确定加工过程中产生的粉尘在特定条件下是否会爆炸,从而对生产安全构成威胁。如果粉尘具有可爆性,那么在生产环境中就需要采取相应的防爆措施。粉尘爆炸的条件通常包括粉尘本身…...

python14 字典类型
字典类型 键值对方式,可变数据类型,所以有增删改功能 声明方式1 {} 大括号,示例 d {key1 : value1, key2 : value2, key3 : value3 ....} 声明方式2 使用内置函数 dict() 创建1)通过映射函数创建字典zip(list1,list2) 继承了序列的所有操作 …...

深入了解 .url文件中的 Prop3属性
在使用 Windows 操作系统时,我们经常会遇到以 .url 结尾的文件,它们通常被用来快速访问互联网上的特定网页。这些文件虽然看起来简单,但其中包含的 Prop3 属性却有其特殊的作用和意义。 1. Prop3 是什么? 在 .url 文件中&#x…...

vue3+vite:动态引入静态图片资源
目录 第一章 前言 第二章 vue2与vue3动态引入静态图片资源 2.1 vue2 webpack动态引入静态图片资源 2.1.1 了解 2.1.2 vue2项目动态引入静态图片资源 2.2 vue3 vite动态引入静态图片资源 2.2.1 了解 2.2.2 require vs import了解 2.2.3 vue3vite 项目动态引入静态图片…...

【K8s】专题五(3):Kubernetes 配置之 ConfigMap 与 Secret 异同
以下内容均来自个人笔记并重新梳理,如有错误欢迎指正!如果对您有帮助,烦请点赞、关注、转发!欢迎扫码关注个人公众号! 目录 一、相同点 二、不同点 一、相同点 功能作用:ConfigMap 与 Secret 都用于存储…...
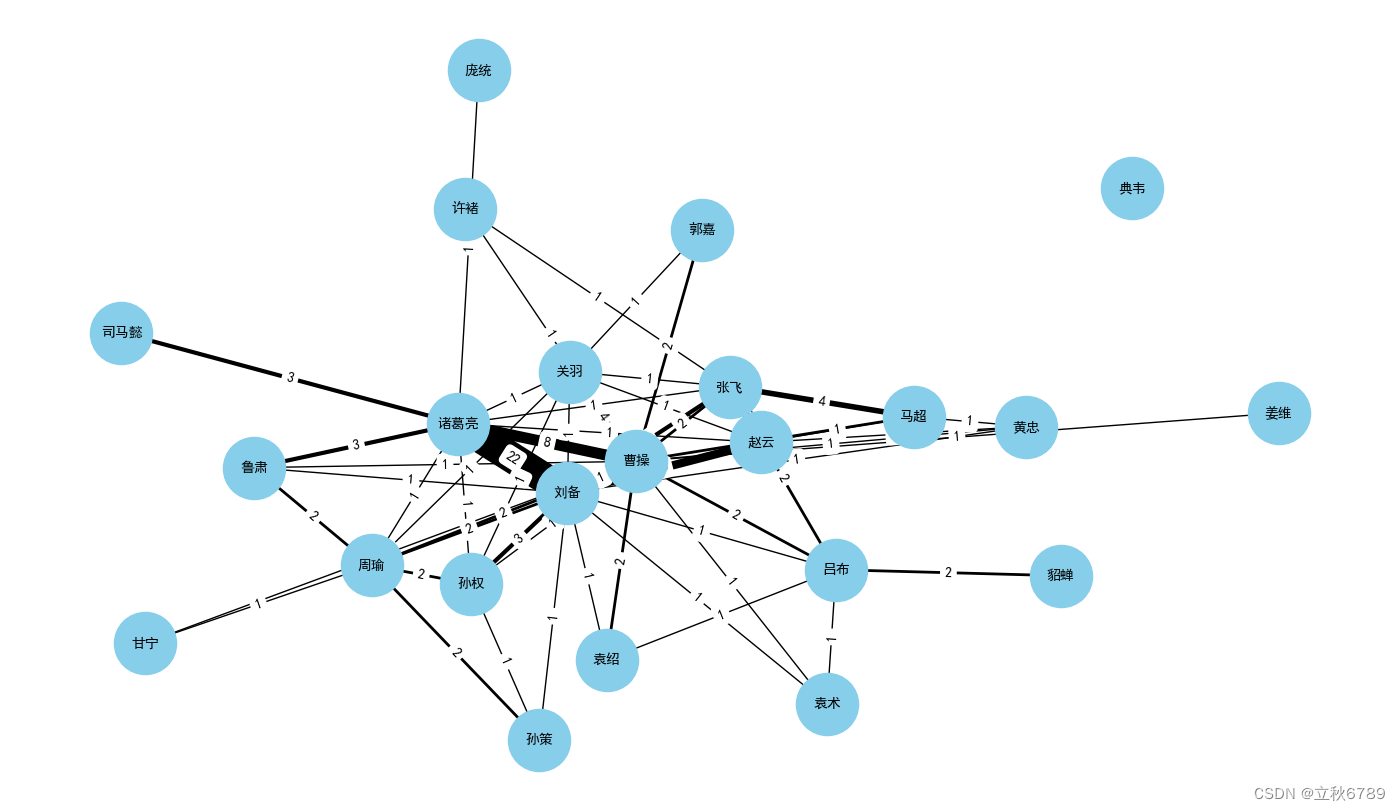
用Python分析《三国演义》中的人物关系网
用Python分析《三国演义》中的人物关系网 三国演义获取文本文本预处理分词与词频统计引入停用词后进行词频统计构建人物关系网完整代码 三国演义 《三国演义》是中国古代四大名著之一,它以东汉末年到晋朝统一之间的历史为背景,讲述了魏、蜀、吴三国之间…...
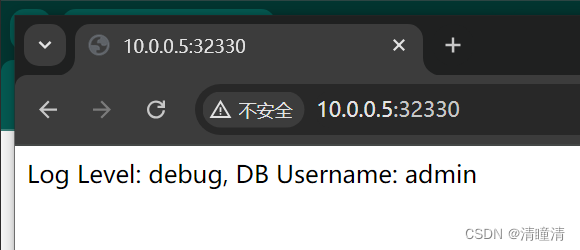
k8s上使用ConfigMap 和 Secret
使用ConfigMap 和 Secret 实验目标: 学习如何使用 ConfigMap 和 Secret 来管理应用的配置。 实验步骤: 创建一个 ConfigMap 存储应用配置。创建一个 Secret 存储敏感信息(如数据库密码)。在 Pod 中挂载 ConfigMap 和 Secret&am…...
hexo实战:(二)个人独立博客优化合集
前言 上次介绍了使用 HexoGitHub Pages,零成本搭建一个专属自己的独立博客网站。我觉得那篇文章是没有入门门槛的,不管你是什么行业,只要想打造个人 IP,又不太想受博客平台约束,那么读完后动手操作一下也能轻松完成。…...

PostgreSQL的pg_relation_filepath函数
PostgreSQL的pg_relation_filepath函数 基础信息 OS版本:Red Hat Enterprise Linux Server release 7.9 (Maipo) DB版本:16.2 pg软件目录:/home/pg16/soft pg数据目录:/home/pg16/data 端口:5777在 PostgreSQL 中&…...

Vue开发中Element UI/Plus使用指南:常见问题(如Missing required prop: “value“)及中文全局组件配置解决方案
文章目录 一、vue中使用el-table的typeindex有时不显示序号Table 表格显示索引自定义索引报错信息解决方案 二、vue中Missing required prop: “value” 报错报错原因解决方案 三、el-table的索引值index在翻页的时候可以连续显示方法一方法二 四、vue3中Element Plus全局组件配…...
安装golang
官网:All releases - The Go Programming Language (google.cn) 下载对应的版本安装即可...

Kubernetes面试整理-Kubernetes的主要组件有哪些?
Kubernetes 的主要组件分为控制平面组件和节点组件。以下是每个组件的详细介绍: 控制平面组件 1. API 服务器(kube-apiserver): ● 是 Kubernetes 控制平面的前端,接收、验证并处理所有的 API 请求。 ● 提供集群的管理接口,所有的集群操作都是通过 API 服务器进行的。...
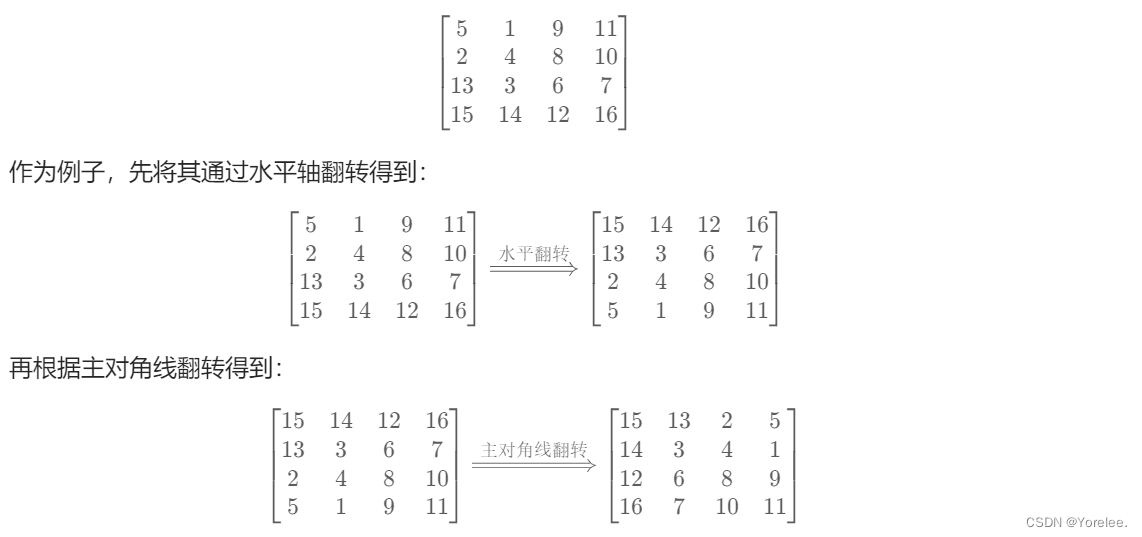
力扣hot100: 48. 旋转图像
LeetCode:48. 旋转图像 受到力扣hot100:54. 螺旋矩阵的启发,我们可以对旋转图像按层旋转,我们只需要记录四个顶点,并且本题是一个方阵,四个顶点就能完成图像的旋转操作。 1、逐层旋转 注意到࿰…...

现货库存MAX3221EEAE+T一款由ADI公司生产的高性能、低功耗 RS-232 收发器芯片,广泛应用于工业控制、通信设备和嵌入式系统中,具备高可靠性与出色的电气性能
MAX3221EEAET 是一款由ADI公司生产的高性能、低功耗 RS-232 收发器芯片,广泛应用于工业控制、通信设备和嵌入式系统中,具备高可靠性与出色的电气性能 。 核心性能参数 协议标准:完全兼容 EIA/TIA-232 标准,支持 RS-232 电…...

3大核心问题解决:B站视频处理全流程指南从下载到去水印的实战方案
3大核心问题解决:B站视频处理全流程指南从下载到去水印的实战方案 【免费下载链接】downkyi 哔哩下载姬downkyi,哔哩哔哩网站视频下载工具,支持批量下载,支持8K、HDR、杜比视界,提供工具箱(音视频提取、去水…...

如何分析和改善网站的SEO效果
如何分析和改善网站的SEO效果 在当今互联网时代,一个优秀的网站不仅需要内容丰富,还需要有良好的搜索引擎优化(SEO)效果。SEO是提升网站在搜索引擎中排名的关键手段,本文将详细探讨如何分析和改善网站的SEO效果&#…...

OpenClaw技能共享:将Qwen2.5-VL-7B定制插件发布到ClawHub
OpenClaw技能共享:将Qwen2.5-VL-7B定制插件发布到ClawHub 1. 为什么需要共享OpenClaw技能 去年我开发了一个基于Qwen2.5-VL-7B的图片分析插件,能够自动识别截图中的UI元素并生成操作指令。当我发现这个插件在团队内部被反复复制粘贴使用时,…...
Hunyuan-MT-7B GPU部署:Pixel Language Portal在单卡A10上并发处理16路实时语音翻译压测报告
Hunyuan-MT-7B GPU部署:Pixel Language Portal在单卡A10上并发处理16路实时语音翻译压测报告 1. 项目背景与核心价值 Pixel Language Portal(像素语言跨维传送门)是一款基于Tencent Hunyuan-MT-7B大模型构建的创新翻译工具。与传统翻译软件…...

告别低效查询!用SAP SE16H的‘公式’和‘分组统计’功能,5分钟搞定复杂报表数据准备
SAP SE16H高效数据加工:用内置公式与分组统计替代Excel计算 每次月底结账前,财务部的王敏总要熬夜处理几十张采购订单的统计报表。从SAP导出原始数据到Excel,用VLOOKUP匹配供应商信息,写SUMIFS公式按物料组汇总金额,最…...

linux sed/awk命令检索区间日志的问题
开发时如果需要检索一段时间内或者某个批量执行期间的所有日志,也就是区间日志时,手动检索会有一些问题:如要查询一段时间前的日志(比如归档日志),需要一页一页翻,费时且费眼睛使用grep筛选日志…...

bert-base-chinese新手必看:完形填空与语义相似度功能实测教程
bert-base-chinese新手必看:完形填空与语义相似度功能实测教程 1. 快速了解bert-base-chinese bert-base-chinese是Google发布的经典中文预训练模型,作为NLP领域的基础模型,它已经成为中文自然语言处理任务的标准选择之一。这个模型特别适合…...

OpenClaw多模型对比:Phi-3-mini-128k-instruct与Qwen在自动化任务中的表现
OpenClaw多模型对比:Phi-3-mini-128k-instruct与Qwen在自动化任务中的表现 1. 测试背景与实验设计 去年夏天,当我第一次尝试用OpenClaw自动化处理日常办公任务时,最困扰我的问题就是模型选择。不同的模型在理解能力、响应速度和资源消耗上差…...

IronCalc 性能基准测试:与传统电子表格引擎的对比分析
IronCalc 性能基准测试:与传统电子表格引擎的对比分析 【免费下载链接】IronCalc Main engine of the IronCalc ecosystem 项目地址: https://gitcode.com/gh_mirrors/ir/IronCalc IronCalc 是一个基于 Rust 语言开发的现代化开源电子表格引擎,专…...