【深度强化学习】(2) Double DQN 模型解析,附Pytorch完整代码
大家好,今天和大家分享一个深度强化学习算法 DQN 的改进版 Double DQN,并基于 OpenAI 的 gym 环境库完成一个小游戏,完整代码可以从我的 GitHub 中获得:
https://github.com/LiSir-HIT/Reinforcement-Learning/tree/main/Model
1. 算法原理
1.1 DQN 原理回顾
DQN 算法的原理是指导机器人不断与环境交互,理解最佳的行为方式,最终学习到最优的行为策略,机器人与环境的交互过程如下图所示。
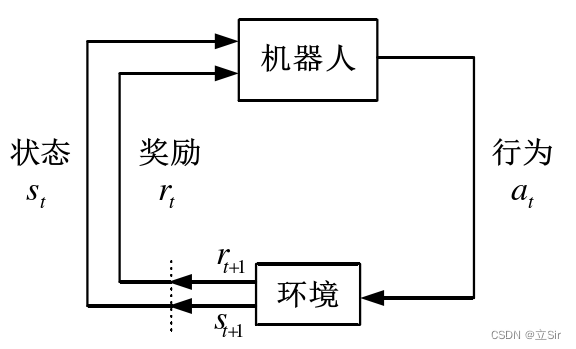
机器人与环境的交互过程是机器人在 时刻,采取动作
并作用于环境,然后环境从
时刻状态
转变到
时刻状态
,同时奖励函数对
进行评价得到奖励值
。机器人根据
不断优化行为轨迹,最终学习到最优的行为策略。
整个强化学习过程可简化为马尔可夫决策过程(MDP)。其中所有状态均具备马尔可夫性。MDP 可用一个五元组 表示,各元素意义如下:
(1)S 是有限状态集合,即机器人在环境中探索到的所有可能状态。 表示机器人在 t 时刻的状态。
(2)A 是有限动作集合,即智能体根据 采取的所有可能动作集合。
表示机器人在t 时刻状态采取的行为
(3)P 是状态转移概率,定义如下:
(4)R 是奖励函数,即机器人基于 采取
后获得的期望奖励,定义如下:
(5)γ 代表折扣因子,值域 [0,1],即未来的期望奖励在当前时刻的价值比例。
MDP 中,价值函数包括状态价值函数和动作价值函数。动作价值函数(Q 函数)表示在策略 的指导下,根据状态
,采取行为
所获得的期望回报。策略
表示状态到行为的映射,相当于机器人的决策策略,并根据不同的状态选择不同的行为,即
。机器人在策略
的指导下,Q 函数的定义如下:
式中 表示折扣奖励,定义如下:
式中 随训练过程迭代减小,
越小表示未来的奖励对当前时刻的奖励影响越小。
Q 函数的贝尔曼方程表示如下:
式中, 表示机器人在
时采取
所获得的即时奖励,等式右侧第二项表示机
器人执行策略 产生的未来累计奖励的期望。
通过选取最大动作价值函数求解最优行为策略的公式表示如下:
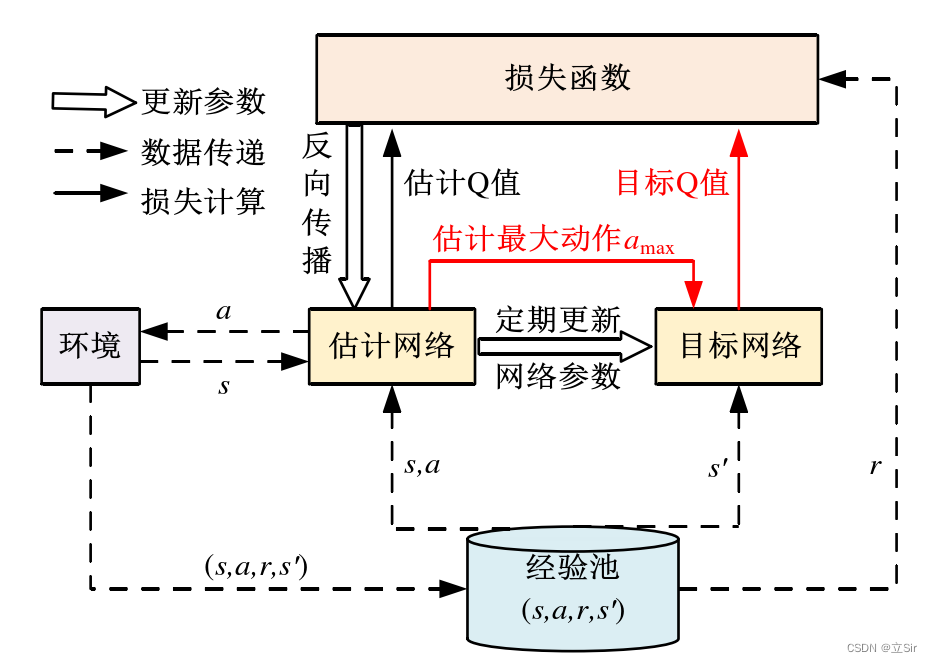
DQN 算法通过行为的奖励值构造算法训练的标签,并且其中的经验回放(Experience Replay)和目标网络有效的解决了数据相关性和非静态分布的问题。DQN 算法的结构示意图如下。

DQN 的网络结构由目标网络和估计网络组成,这两个网络的结构相同但参数不同。估计网络具有最新的网络参数,计算当前状态-动作对的价值,并定期更新目标网络的参数,使其计算目标 Q 值。双网络结构打破了数据之间的相关性,使DQN 学习不同的数据分布。经验回放部分储存了智能体(机器人)的历史行为信息,其中包括多组行为序列对 ,即当前时刻状态 s ,行为 a ,奖励 r 以及下一时刻状态 s'。当 DQN 算法更新时,随机从经验池中抽取部分行为序列对进行经验回放,这种方式解决了经验池中数据相关性强和非静态分布导致的模型泛化能力差的问题。
DQN 算法通过贪婪法直接获得目标 Q 值,贪婪法通过最大化方式使 Q 值快速向可能的优化目标收敛,但易导致过估计Q 值的问题,使模型具有较大的偏差。DQN 算法过估计 Q 值的问题不适合机器人操作行为的研究,采用 Double DQN 算法解耦动作的选择和目标 Q 值的计算,以解决过估计 Q 值的问题。
1.2 Double DQN 原理
Double DQN 算法是 DQN 算法的改进版本,解决了 DQN 算法过估计行为价值的问题。DQN 算法中,某一时刻状态为非终止状态时,目标 Q 值的计算公式如下所示:
Double DQN 算法不直接通过最大化的方式选取目标网络计算的所有可能 Q 值,而是首先通过估计网络选取最大 Q 值对应的动作,公式表示如下:
然后目标网络根据 计算目标 Q 值,公式表示如下:
最后将上面两个公式结合,目标 Q 值的最终表示形式如下:
目标是最小化目标函数,即最小化估计 Q 值和目标 Q 值的差值,公式如下:
结合目标函数,损失函数定义如下:
Double DQN 的伪代码:

Double DQN 算法结构如下。在 Double DQN 框架中存在两个神经网络模型,分别是训练网络与目标网络。这两个神经网络模型的结构完全相同,但是权重参数不同;每训练一段之间后,训练网络的权重参数才会复制给目标网络。训练时,训练网络用于估计当前的 ,而目标网络用于估计
,这样就能保证真实值
的估计不会随着训练网络的不断自更新而变化过快。此外,DQN 还是一种支持离线学习的框架,即通过构建经验池的方式离线学习过去的经验。将均方误差
作为训练模型的损失函数,通过梯度下降法进行反向传播,对训练模型进行更新;若干轮经验池采样后,再将训练模型的权重赋给目标模型,以此进行 Double DQN 框架下的模型自学习。
2. 代码实现
模型构建部分的代码如下:
import torch
from torch import nn
from torch.nn import functional as F
import numpy as np
import collections # 队列
import random# ----------------------------------- #
#(1)经验回放池
# ----------------------------------- #class ReplayBuffer:def __init__(self, capacity):# 创建一个队列,先进先出,队列长度不变self.buffer = collections.deque(maxlen=capacity)# 填充经验池def add(self, state, action, reward, next_state, done):self.buffer.append((state, action, reward, next_state, done))# 随机采样batch组样本数据def sample(self, batch_size):transitions = random.sample(self.buffer, batch_size)# 分别取出这些数据,*获取list中的所有值state, action, reward, next_state, done = zip(*transitions)# 将state变成数组,后面方便计算return np.array(state), action, reward, np.array(next_state), done# 队列的长度def size(self):return len(self.buffer)# ----------------------------------- #
#(2)构造网络,训练网络和目标网络共用该结构
# ----------------------------------- #class Net(nn.Module):def __init__(self, n_states, n_hiddens, n_actions):super(Net, self).__init__()# 只有一个隐含层self.fc1 = nn.Linear(n_states, n_hiddens)self.fc2 = nn.Linear(n_hiddens, n_actions)# 前向传播def forward(self, x):x = self.fc1(x) # [b,n_states]-->[b,n_hiddens]x = self.fc2(x) # [b,n_hiddens]-->[b,n_actions]return x# ----------------------------------- #
#(3)模型构建
# ----------------------------------- #class Double_DQN:#(1)初始化def __init__(self, n_states, n_hiddens, n_actions,learning_rate, gamma, epsilon,target_update, device):# 属性分配self.n_states = n_statesself.n_hiddens = n_hiddensself.n_actions = n_actionsself.learning_rate = learning_rateself.gamma = gammaself.epsilon = epsilonself.target_update = target_updateself.device = device# 记录迭代次数self.count = 0# 实例化训练网络self.q_net = Net(self.n_states, self.n_hiddens, self.n_actions)# 实例化目标网络self.target_q_net = Net(self.n_states, self.n_hiddens, self.n_actions)# 优化器,更新训练网络的参数self.optimizer = torch.optim.Adam(self.q_net.parameters(), lr=self.learning_rate)#(2)动作选择def take_action(self, state):# numpy[n_states]-->[1, n_states]-->Tensorstate = torch.Tensor(state[np.newaxis, :])# print('--------------------------')# print(state.shape)# 如果小于贪婪系数就取最大值reward最大的动作if np.random.random() < self.epsilon:# 获取当前状态下采取各动作的rewardactions_value = self.q_net(state)# 获取reward最大值对应的动作索引action = actions_value.argmax().item()# 如果大于贪婪系数就随即探索else:action = np.random.randint(self.n_actions)return action#(3)获取每个状态对应的最大的state_valuedef max_q_value(self, state):# list-->tensor[3]-->[1,3]state = torch.tensor(state, dtype=torch.float).view(1,-1)# 当前状态对应的每个动作的reward的最大值 [1,3]-->[1,11]-->intmax_q = self.q_net(state).max().item()return max_q#(4)网络训练def update(self, transitions_dict):# 当前状态,array_shape=[b,4]states = torch.tensor(transitions_dict['states'], dtype=torch.float)# 当前状态的动作,tuple_shape=[b]==>[b,1]actions = torch.tensor(transitions_dict['actions'], dtype=torch.int64).view(-1,1)# 选择当前动作的奖励, tuple_shape=[b]==>[b,1]rewards = torch.tensor(transitions_dict['rewards'], dtype=torch.float).view(-1,1)# 下一个时刻的状态array_shape=[b,4]next_states = torch.tensor(transitions_dict['next_states'], dtype=torch.float)# 是否到达目标 tuple_shape=[b,1]dones = torch.tensor(transitions_dict['dones'], dtype=torch.float).view(-1,1)# 当前状态[b,4]-->当前状态采取的动作及其奖励[b,2]-->actions中是每个状态下的动作索引# -->当前状态s下采取动作a得到的state_valueq_values = self.q_net(states).gather(1, actions)# 获取动作索引# .max(1)输出tuple每个特征的最大state_value及其索引,[1]获取的每个特征的动作索引shape=[b]max_action = self.q_net(next_states).max(1)[1].view(-1,1)# 下个状态的state_value。下一时刻的状态输入到目标网络,得到每个动作对应的奖励,使用训练出来的action索引选取最优动作max_next_q_values = self.target_q_net(next_states).gather(1, max_action)# 目标网络计算出的,当前状态的state_valueq_targets = rewards + self.gamma * max_next_q_values * (1-dones)# 预测值和目标值的均方误差损失dqn_loss = torch.mean(F.mse_loss(q_values, q_targets))# 梯度清零self.optimizer.zero_grad()# 梯度反传dqn_loss.backward()# 更新训练网络的参数self.optimizer.step()# 更新目标网络参数if self.count % self.target_update == 0:self.target_q_net.load_state_dict(self.q_net.state_dict()) # 更新目标网络# 迭代计数+1self.count += 1
3. 案例实现
我们使用 OpenAI 中的重力摆来验证模型,动作是连续型,代表力矩;状态包含三个;目的是让杆子竖直。


环境交互和训练代码如下:
import torch
import numpy as np
import gym
from tqdm import tqdm
import matplotlib.pyplot as plt
from parsers import args
from RL_brain import ReplayBuffer, Double_DQN# GPU运算
device = torch.device("cuda") if torch.cuda.is_available() \else torch.device("cpu")# ------------------------------- #
#(1)加载环境
# ------------------------------- #env = gym.make("Pendulum-v1", render_mode="human")
n_states = env.observation_space.shape[0] # 状态数 3
act_low = env.action_space.low # 最小动作力矩 -2
act_high = env.action_space.high # 最大动作力矩 +2
n_actions = 11 # 动作是连续的[-2,2],将其离散成11个动作# 确定离散动作区间后,确定其连续动作
def dis_to_con(discrete_action, n_actions):# discrete_action代表动作索引return act_low + (act_high-act_low) * (discrete_action/(n_actions-1))# 实例化经验池
replay_buffer = ReplayBuffer(args.capacity)# 实例化 Double-DQN
agent = Double_DQN(n_states,args.n_hiddens,n_actions,args.lr,args.gamma,args.epsilon,args.target_update,device)# ------------------------------- #
#(2)模型训练
# ------------------------------- #return_list = [] # 记录每次迭代的return,即链上的reward之和
max_q_value = 0 # 最大state_value
max_q_value_list = [] # 保存所有最大的state_valuefor i in range(10): # 训练几个回合done = False # 初始,未到达终点state = env.reset()[0] # 重置环境episode_return = 0 # 记录每回合的returnwith tqdm(total=10, desc='Iteration %d' % i) as pbar:while True:# 状态state时做动作选择,返回索引action = agent.take_action(state)# 平滑处理最大state_valuemax_q_value = agent.max_q_value(state) * 0.005 + \max_q_value * 0.995# 保存每次迭代的最大state_valuemax_q_value_list.append(max_q_value)# 将action的离散索引连续化action_continuous = dis_to_con(action, n_actions)# 环境更新next_state, reward, done, _, _ = env.step(action_continuous)# 添加经验池replay_buffer.add(state, action, reward, next_state, done)# 更新状态state = next_state# 更新每回合的回报episode_return += reward# 如果经验池超数量过阈值时开始训练if replay_buffer.size() > args.min_size:# 在经验池中随机抽样batch组数据s, a, r, ns, d = replay_buffer.sample(args.batch_size)# 构造训练集transitions_dict = {'states': s,'actions': a,'next_states': ns,'rewards': r,'dones': d,}# 模型训练agent.update(transitions_dict)# 到达终点就停止if done is True: break# 保存每回合的returnreturn_list.append(episode_return)pbar.set_postfix({'step':agent.count,'return':'%.3f' % np.mean(return_list[-10:])})pbar.update(1)# ------------------------------- #
#(3)绘图
# ------------------------------- #plt.subplot(121)
plt.plot(return_list)
plt.title('return')
plt.subplot(122)
plt.plot(max_q_value_list)
plt.title('max_q_value')
plt.show()
相关文章:
【深度强化学习】(2) Double DQN 模型解析,附Pytorch完整代码
大家好,今天和大家分享一个深度强化学习算法 DQN 的改进版 Double DQN,并基于 OpenAI 的 gym 环境库完成一个小游戏,完整代码可以从我的 GitHub 中获得: https://github.com/LiSir-HIT/Reinforcement-Learning/tree/main/Model 1…...

【正则表达式】正则表达式语法规则
正则表达式语法规则1.普通字符 字符描述[ABC]匹配 […] 中的所有字符[^ABC]匹配除了 […] 中字符的所有字符[A-Z][A-Z] 表示一个区间,匹配所有大写字母,[a-z] 表示所有小写字母.匹配除换行符以外的任意字符[\s\S]匹配所有。\s 是匹配所有空白符…...
1636_isatty函数的功能
全部学习汇总: GreyZhang/g_unix: some basic learning about unix operating system. (github.com) 前面刚刚看完了一个函数和三个文件指针,一行代码懂了半行。但是继续分析我之前看到的代码还是遇到了困难,因为之前自己对于UNIX的一些基础知…...
基于Stackelberg博弈的光伏用户群优化定价模型(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

EXCEL职业版本(3)
Excel职业版本(3) 公式与函数 运算符 算数运算符 关系运算符 地址的引用 相对引用:你变它就变,如影随形 A2:A5 绝对引用:以不变应万变 $A$2 混合引用:识时务者为俊杰,根据时…...

查找Pycharm跑代码下载模型存放位置以及有关模型下载小技巧(model_name_or_path参数)
目录一、前言二、发现问题三、删除这些模型方法一:直接删除注意方法二:代码删除一、前言 当服务器连不上,只能在本地跑代码时需要使用***预训练语言模型进行处理 免不了需要把模型下载到本地 时间一长就会发现C盘容量不够 二、发现问题 正…...

JS学习笔记day04
今日内容 零、 复习昨日 一、事件 二、DOM操作 三、案例 零、 复习昨日 js 脚本语言,弱类型 引入方案: 3种 js的内容: 语法dombom 语法 变量 var 数据类型 引用类型 - 对象,JSON {key:value,key:value} 数组 var arr new Array();var arr [1,2];下标取值赋值pop() s…...

异步控制流程 遍历篇
文章目录基础方法onlyOnce 只执行一次,第二次报错once 只执行一次,第二次无效iteratorSymbol 判断是否具有迭代器并返回迭代器arrayEach 普通数组遍历baseEach 对象类型遍历symbolEach 具有迭代器类型遍历异步遍历each异步控制流程的目的: 对…...
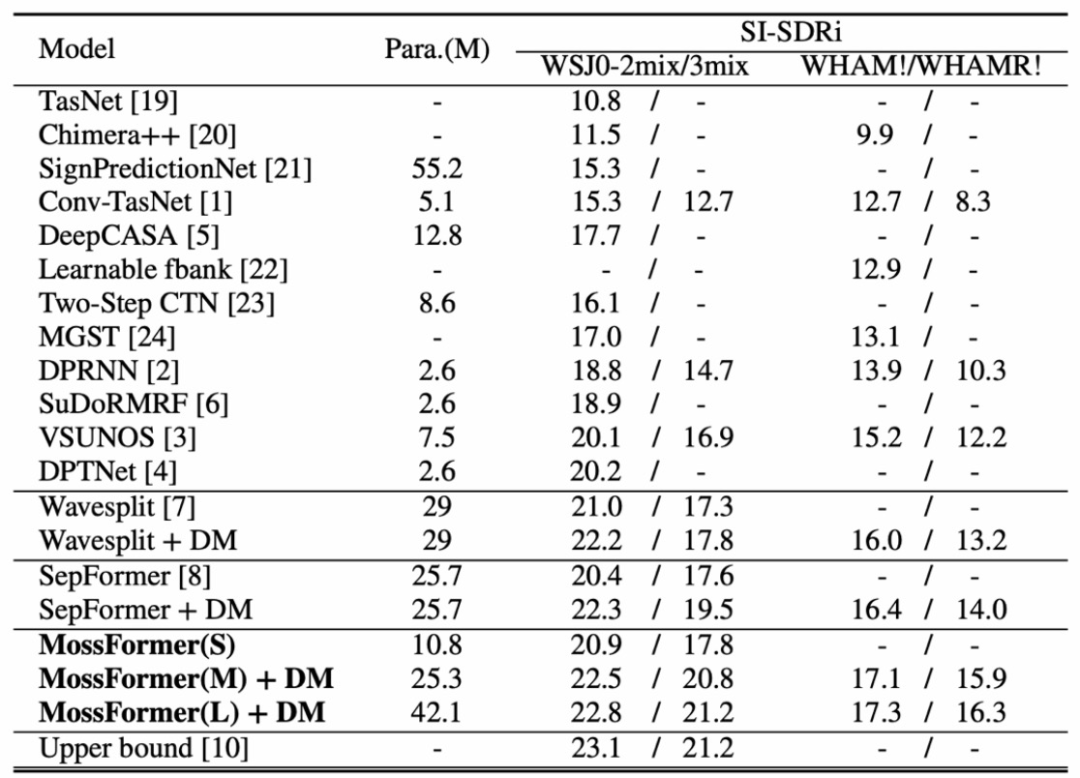
ICASSP 2023论文模型开源|语音分离Mossformer
人类能在复杂的多人说话环境中轻易地分离干扰声音,选择性聆听感兴趣的主讲人说话。但这对机器却不容易,如何构建一个能够媲美人类听觉系统的自动化系统颇具挑战性。 本文将详细解读ICASSP2023本届会议收录的单通道语音分离模型Mossformer论文࿰…...

vs2019 更改工程项目名称
本地 解决方案所在的位置为:D:\Projcet 解决方案名称:hello.sln 位置:D:\Projcet\hello.sln 工程项目名称:test 位置:D:\Projcet\test (文件夹中包含头文件,源文件) 工程包含的文件: fun.h …...
FusionCompute安装和配置步骤
1. 先去华为官网下载FusionCompute的镜像 下载地址:https://support.huawei.com/enterprise/zh/distributed-storage/fusioncompute-pid-8576912/software/251713663?idAbsPathfixnode01%7C22658044%7C7919788%7C9856606%7C21462752%7C8576912 下载后放在D盘中&am…...

makefile 参数和基本使用
make 常用选项make[-f file] [options] [target]make 默认在当前目录中查找GUNmakefile、makefile 及 Makefile 文件作为make的输入文件-f 指定文件作为输入文件-v 显示版本号-n 只输出命令不执行, 一般作为测试-s 执行命令不显示命令,-w 显示执行前和执…...

golang 占位符还傻傻分不清?
xdm ,写 C/C 语言的时候有格式控制符,例如 %s , %d , %c , %p 等等 在写 golang 的时候,也是有对应的格式控制符,也叫做占位符,写这个占位符,需要有对应的数据与之对应,不能瞎搞 基本常见常用…...

manacher算法详解
例题 求一个字符串的最长回文子串的长度 O(N2)O(N^2)O(N2)的解法很容易想,就是从每个字符位置向左右同时拓展,然后检查当前是不是回文,更新长度,可以简单写一下代码 int solve(string &ss){int ans 0;int n ss.length();s…...

要做一个关于DDD的内部技术分享,记录下用到的资源,学习笔记(未完)
最后更新于2023年3月10日 14:28:08 问题建模》软件分层》具体结构,是层层递进的关系。有了问题建模,才能进行具体的软件分层的讨论,再有了分层,才能讨论在domain里面应该怎么实现具体结构。 1、问题建模:Domain、Mod…...

KDZD互感器二次负载测试仪
一、概述 电能计量综合误差过大是电能计量中普遍存在的一个关键问题。电压互感器二次回路压降引起的计量误差往往是影响电能计量综合误差的因素。所谓电压互感器二次压降引起的误差,就是指电压互感器二次端子和负载端子之间电压的幅值差相对于二次实际电压的百分数…...
在空投之后,Blur能否颠覆OpenSea的主导地位?
Mar. 2023, Daniel数据源: NFT Aggregators Overview & Aggregator Statistics Overview & Blur Airdrop一年前,通过聚合器进行的NFT交易量开始像滚雪球一样增长,有时甚至超过了直接通过市场平台的交易量。虽然聚合器的使用量从10月到…...
2023年新三板产品及服务研究报告
第一章 概述 全国中小企业股份转让系统(英语:National Equities Exchange and Quotations,缩写NEEQ),简称股转系统,是第三家全国性证券交易场所,因挂牌企业均为高科技企业而不同于原转让系统内…...
张力控制之开环模式
张力控制的相关知识也可以参看专栏的其它文章,链接如下: 张力闭环控制之传感器篇(精密调节气阀应用)_RXXW_Dor的博客-CSDN博客跳舞轮对应张力调节范围,我们可以通过改变气缸的气压方式间接改变,张力跳舞轮在收放卷闭环控制上的详细应用,可以参看下面的文章链接,这里我…...

python的django框架从入门到熟练【保姆式教学】第二篇
在上一篇博客中,我们介绍了Django的基础知识,并创建了一个简单的Web应用程序。在本篇教程中,我们将深入探讨Django的模型层(Model),它是Django应用程序的核心组件之一。 模型层 Django的模型层是一个对象…...

xxhash-java详解:lz4-java内置的超高速哈希算法实战
xxhash-java详解:lz4-java内置的超高速哈希算法实战 【免费下载链接】lz4-java 项目地址: https://gitcode.com/gh_mirrors/lz4/lz4-java xxhash-java是lz4-java项目中内置的超高速哈希算法实现,它为Java开发者提供了高效的哈希计算能力。作为一…...

10分钟上手ppscore:Python预测力评分工具快速入门
10分钟上手ppscore:Python预测力评分工具快速入门 【免费下载链接】ppscore Predictive Power Score (PPS) in Python 项目地址: https://gitcode.com/gh_mirrors/pp/ppscore ppscore是一个基于Python的预测力评分(Predictive Power Score, PPS&a…...

终极指南:text-generation-inference问题处理与高效解决方案
终极指南:text-generation-inference问题处理与高效解决方案 【免费下载链接】text-generation-inference text-generation-inference - 一个用于部署和提供大型语言模型(LLMs)服务的工具包,支持多种流行的开源 LLMs,适…...

2026年五大最值得了解的能源管理系统全解析
在智能工业与绿色低碳战略深度融合的背景下,能源管理系统(EMS)正从“基础监控”向“智能决策全链路优化”升级,成为企业实现高质量发展的关键支撑。据艾瑞咨询数据显示,2025年中国智能能源管理系统市场规模达192亿美元…...

多维复高斯分布PDF表达式、协方差矩阵意义探究
背景学习《空间信息论》时,对于高斯白噪情况下,雷达接收信号在已知距离和散射特性条件下,似然概率往往取决于噪声的PDF,即时间采样点为N的接收信号符合N维复高斯分布。欲推导的表达式,首先要使用N维复高斯分布的PDF表达…...

【剪映9.9 全功能绿化版】剪映免费绿色版,2026最新全部功能可用
【剪映全功能绿化版】剪映免费绿色版,2026最新全部功能可用 领取方式如下:领取方法自取⬇️(平台不让放链接)①复制完整 关键词 :“筷莱廀牢玤齾虪夺郝” ,②然后再打开手机「夸克APP 或者 夸克网盘APP」没…...

Thinkphp和Laravel框架微信小程序的 畅玩安阳旅游网站平台的景点门票民宿预订-
目录技术选型与框架整合数据库设计接口开发微信支付集成性能优化与安全测试与部署项目技术支持可定制开发之功能创新亮点源码获取详细视频演示 :文章底部获取博主联系方式!同行可合作技术选型与框架整合 ThinkPHP和Laravel均可作为后端框架实现微信小程…...
)
STM32F103C8T6定时器实战:5分钟搞定TIM2中断配置(附OLED显示效果)
STM32F103C8T6定时器实战:5分钟搞定TIM2中断配置(附OLED显示效果) 刚拿到STM32开发板时,定时器配置总是让人望而生畏。那些复杂的寄存器、晦涩的术语,还有永远理不清的时钟树...但今天我要分享的是一种极简配置法&…...

Docker 27发布90天内必须执行的4项调度加固操作:否则下一次节点故障将触发级联驱逐风暴
第一章:Docker 27调度架构演进与级联驱逐风险本质Docker 27 引入了全新的轻量级调度器(Lightweight Scheduler),取代了早期依赖 SwarmKit 的集中式调度模型。该调度器运行于每个 daemon 实例中,采用基于声明式状态同步…...
)
GPT-SoVITS vs RVC深度对比:选对工具搞定AI变声/语音合成(附效果实测)
GPT-SoVITS与RVC技术全景对比:从核心原理到场景化选型指南 在数字内容创作爆发的时代,AI语音合成技术正在重塑声音产业的边界。无论是虚拟主播的实时互动、有声读物的高效生产,还是影视配音的个性化定制,选择适合的声音克隆工具直…...