Java-01-基础篇-04 Java集合-04-HashMap (源码)
目录
一,HashMap
1.1 HashMap 属性分析
1.2 HashMap 构造器
1.3 HashMap 内置的 Node 类
1.4 HashMap 内置的 KeySet 类
1.5 HashMap 内置的 Values 类
1.6 HashMap 内置的 EntrySet 类
1.7 HashMap 内置的 UnsafeHolder 类
1.8 HashMap 相关的迭代器
1.9 HashMap 相关的分割器
1.10 Hash 内置的 TreeNode 类
1.10.1 TreeNode 属性分析
1.10.2 TreeNode 构造器
1.10.3 查看根节点
1.10.4 moveRootToFront
1.10.5 find
1.10.6 getTreeNode
1.10.7 tieBreakOrder
1.10.8 treeify 树结构化处理
1.10.9 untreeify 链表化处理
1.10.10 putTreeVal
1.10.11 removeTreeNode & 红黑树转链表
1.10.12 split
1.10.13 rotateLeft
1.10.14 rotateRight
1.10.15 balanceInsertion
1.10.16 balanceDeletion
1.10.17 checkInvariants
1.11 HashMap 新增业务
1.12 hash处理
1.13 putVal
1.14 链表转红黑树
1.15 HashMap 删除业务
上一篇Map 接口:Java-01-基础篇 Java集合-01-Map-CSDN博客
一,HashMap
1.1 HashMap 属性分析
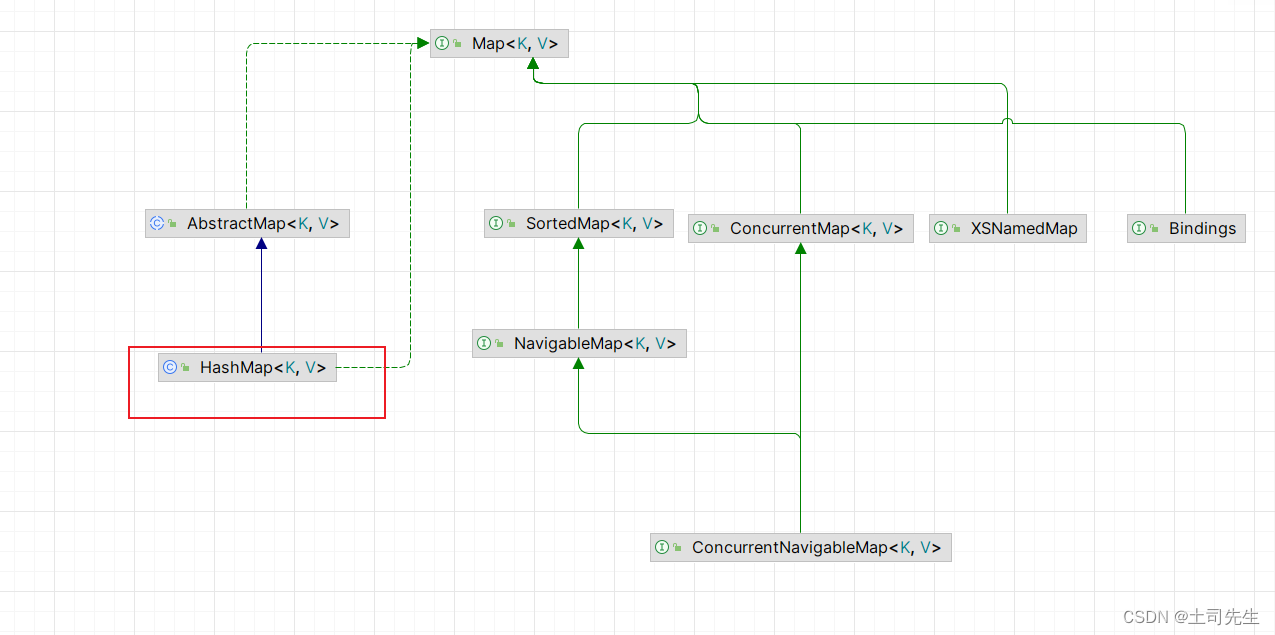
public class HashMap<K,V> extends AbstractMap<K,V>implements Map<K,V>, Cloneable, Serializable {@java.io.Serialprivate static final long serialVersionUID = 362498820763181265L;/** 默认初始容量 */static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16/*** HashMap最大容量 * 常用于构造函数中指定的最大值。必须是小于等于2的30次方的2的幂(即1073741824)。*/static final int MAXIMUM_CAPACITY = 1 << 30;/*** 默认负载因子:0.75;当容量填充到75%;进行扩容*/static final float DEFAULT_LOAD_FACTOR = 0.75f;/*** 树化阈值;链表将转换成红黑树以提高性能。该值必须大于2,且通常设为8,以与树节点删除时的假设相匹配,即在缩减时会转换回普通链表。* 大于8 链表转树*/static final int TREEIFY_THRESHOLD = 8;/** 去树化阈值:小于6时,进行树结构转至链表结构; */static final int UNTREEIFY_THRESHOLD = 6;/** 最小树化容量:64 */static final int MIN_TREEIFY_CAPACITY = 64;/** HashMap 的主数据,该数组的长度始终是 2 的幂,以确保哈希值分布均匀。*/transient Node<K,V>[] table;/** entrySet 缓存了 HashMap 中的 entrySet() 视图。这使得在多次调用 entrySet() 方法时不会重复创建新的集合视图。*/transient Set<Map.Entry<K,V>> entrySet;/** HashMap 数量大小 */transient int size;/** HashMap 读写次数 */transient int modCount;/*** 元素数量达到这个值时,哈希表会进行扩容。* 计算公式为:capacity * loadFactor。* 如果 table 数组还没有被分配,那么这个字段表示初始数组容量,或者为零。* 表示使用默认初始容量(16)*/ int threshold;/*** 哈希表的负载因子*/final float loadFactor;/* 忽略其他代码 */
}1.2 HashMap 构造器
设置默认加载因子为:16
public HashMap() {this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted}创建一个的指定初始化容量大小 HashMap
public HashMap(int initialCapacity) {this(initialCapacity, DEFAULT_LOAD_FACTOR);}创建一个指定初始化容量和加载因子大小
public HashMap(int initialCapacity, float loadFactor) {if (initialCapacity < 0)throw new IllegalArgumentException("Illegal initial capacity: " +initialCapacity);if (initialCapacity > MAXIMUM_CAPACITY)initialCapacity = MAXIMUM_CAPACITY;if (loadFactor <= 0 || Float.isNaN(loadFactor))throw new IllegalArgumentException("Illegal load factor: " +loadFactor);this.loadFactor = loadFactor;this.threshold = tableSizeFor(initialCapacity);}将指定的 Map 集合添加到新创建的 HashMap 中;设置加载因子为16;
public HashMap(Map<? extends K, ? extends V> m) {this.loadFactor = DEFAULT_LOAD_FACTOR;putMapEntries(m, false);}1.3 HashMap 内置的 Node 类
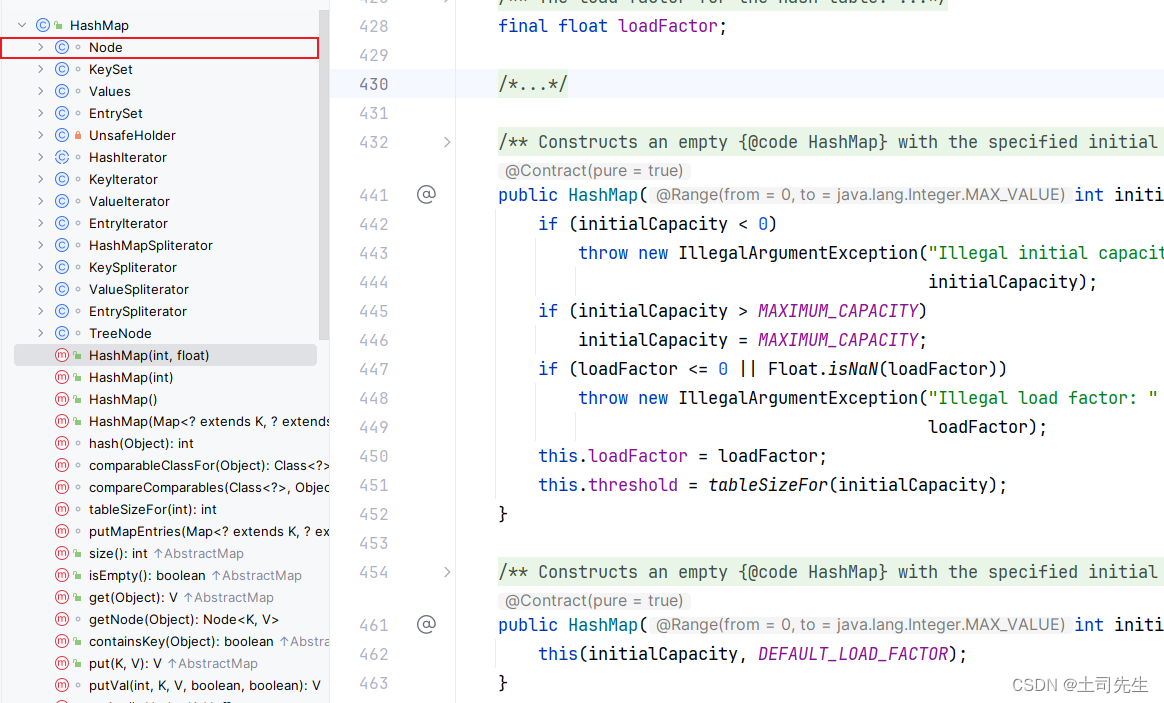
/*** 从继承结构可以看出该节点类是支持键值映射的特性*/
static class Node<K,V> implements Map.Entry<K,V> {final int hash;final K key;V value;Node<K,V> next;Node(int hash, K key, V value, Node<K,V> next) {this.hash = hash;this.key = key;this.value = value;this.next = next;}public final K getKey() { return key; }public final V getValue() { return value; }public final String toString() { return key + "=" + value; }/*** ^ 异或操作在二进制级别对两个数的每一位执行异或运算。即当两位相同时结果为 0,两位不同时结果为 1* 键和值的异或运算:* 哈希码分布更均匀:* 简单且高效:异或操作相对简单且高效,可以快速计算出结果* 对称性和混淆:异或操作的对称性和混淆特性使得它适合作为组合哈希码的方法。通过混淆键和值的哈希码,可以有效减少不同键值对生成相同哈希码的概率。*/public final int hashCode() {return Objects.hashCode(key) ^ Objects.hashCode(value);}public final V setValue(V newValue) {V oldValue = value;value = newValue;return oldValue;}public final boolean equals(Object o) {if (o == this)return true;return o instanceof Map.Entry<?, ?> e&& Objects.equals(key, e.getKey())&& Objects.equals(value, e.getValue());}}
这个Node 就是用来表示HashMap 里面的链表作用,每当HashCode 冲突时,hashMap 底层通过Node 来进行存储形成一个链表。这里的节点都是通过next进行连接。
1.4 HashMap 内置的 KeySet 类
KeySet 类是 HashMap 的一个重要内部类,通过它可以将 HashMap 的键视为一个集合进行操作。它提供了对 HashMap 键集合的便捷操作,同时确保这些操作会影响底层的 HashMap。
final class KeySet extends AbstractSet<K> {public final int size() { return size; }public final void clear() { HashMap.this.clear(); }public final Iterator<K> iterator() { return new KeyIterator(); }public final boolean contains(Object o) { return containsKey(o); }public final boolean remove(Object key) {return removeNode(hash(key), key, null, false, true) != null;}public final Spliterator<K> spliterator() {return new KeySpliterator<>(HashMap.this, 0, -1, 0, 0);}public Object[] toArray() {return keysToArray(new Object[size]);}public <T> T[] toArray(T[] a) {return keysToArray(prepareArray(a));}public final void forEach(Consumer<? super K> action) {Node<K,V>[] tab;if (action == null)throw new NullPointerException();if (size > 0 && (tab = table) != null) {int mc = modCount;for (Node<K,V> e : tab) {for (; e != null; e = e.next)action.accept(e.key);}if (modCount != mc)throw new ConcurrentModificationException();}}}KeySet 提供用于迭代 keys 集合,是否包含,提供删除key等操作。
1.5 HashMap 内置的 Values 类
Values 类是 HashMap 的一个重要内部类,通过它可以将 HashMap 的值集合视为一个集合进行操作。它提供了对 HashMap 值集合的便捷操作,同时确保这些操作会影响底层的 HashMap。
final class Values extends AbstractCollection<V> {public final int size() { return size; }public final void clear() { HashMap.this.clear(); }public final Iterator<V> iterator() { return new ValueIterator(); }public final boolean contains(Object o) { return containsValue(o); }public final Spliterator<V> spliterator() {return new ValueSpliterator<>(HashMap.this, 0, -1, 0, 0);}public Object[] toArray() {return valuesToArray(new Object[size]);}public <T> T[] toArray(T[] a) {return valuesToArray(prepareArray(a));}public final void forEach(Consumer<? super V> action) {Node<K,V>[] tab;if (action == null)throw new NullPointerException();if (size > 0 && (tab = table) != null) {int mc = modCount;for (Node<K,V> e : tab) {for (; e != null; e = e.next)action.accept(e.value);}if (modCount != mc)throw new ConcurrentModificationException();}}}提供了值集合的迭代,包含,转换数组等等操作。
1.6 HashMap 内置的 EntrySet 类
这个类已经很明显了,KeySet 是用于存储键的集合,Values 是用于存储值的集合;EntrySet是用于存储映射实体(键值对)的集合,EntrySet 是一个Set集合。提供删除,是否包含指定元素,迭代元素等操作;代码如下:
final class EntrySet extends AbstractSet<Map.Entry<K,V>> {public final int size() { return size; }public final void clear() { HashMap.this.clear(); }public final Iterator<Map.Entry<K,V>> iterator() {return new EntryIterator();}public final boolean contains(Object o) {if (!(o instanceof Map.Entry<?, ?> e))return false;Object key = e.getKey();Node<K,V> candidate = getNode(key);return candidate != null && candidate.equals(e);}public final boolean remove(Object o) {if (o instanceof Map.Entry<?, ?> e) {Object key = e.getKey();Object value = e.getValue();return removeNode(hash(key), key, value, true, true) != null;}return false;}public final Spliterator<Map.Entry<K,V>> spliterator() {return new EntrySpliterator<>(HashMap.this, 0, -1, 0, 0);}public final void forEach(Consumer<? super Map.Entry<K,V>> action) {Node<K,V>[] tab;if (action == null)throw new NullPointerException();if (size > 0 && (tab = table) != null) {int mc = modCount;for (Node<K,V> e : tab) {for (; e != null; e = e.next)action.accept(e);}if (modCount != mc)throw new ConcurrentModificationException();}}}1.7 HashMap 内置的 UnsafeHolder 类
UnsafeHolder 故名意思是Unsafe 的拥有者,Unsafe 类是一个支持直接操作内存和原子性擦操作,并且可以跳过JVM的对象管理机制。这HashMap 中的作用体现仅仅只是在序列化的时候,对负载因子进行存储;代码如下:
private static final class UnsafeHolder {private UnsafeHolder() { throw new InternalError(); }// 创建一个unfase 实体类private static final jdk.internal.misc.Unsafe unsafe= jdk.internal.misc.Unsafe.getUnsafe();// 获取 loadFactor 负载因子字段属性的相关操作private static final long LF_OFFSET= unsafe.objectFieldOffset(HashMap.class, "loadFactor");static void putLoadFactor(HashMap<?, ?> map, float lf) {unsafe.putFloat(map, LF_OFFSET, lf); // 设置负载因子属性}}HashMap 中的序列化
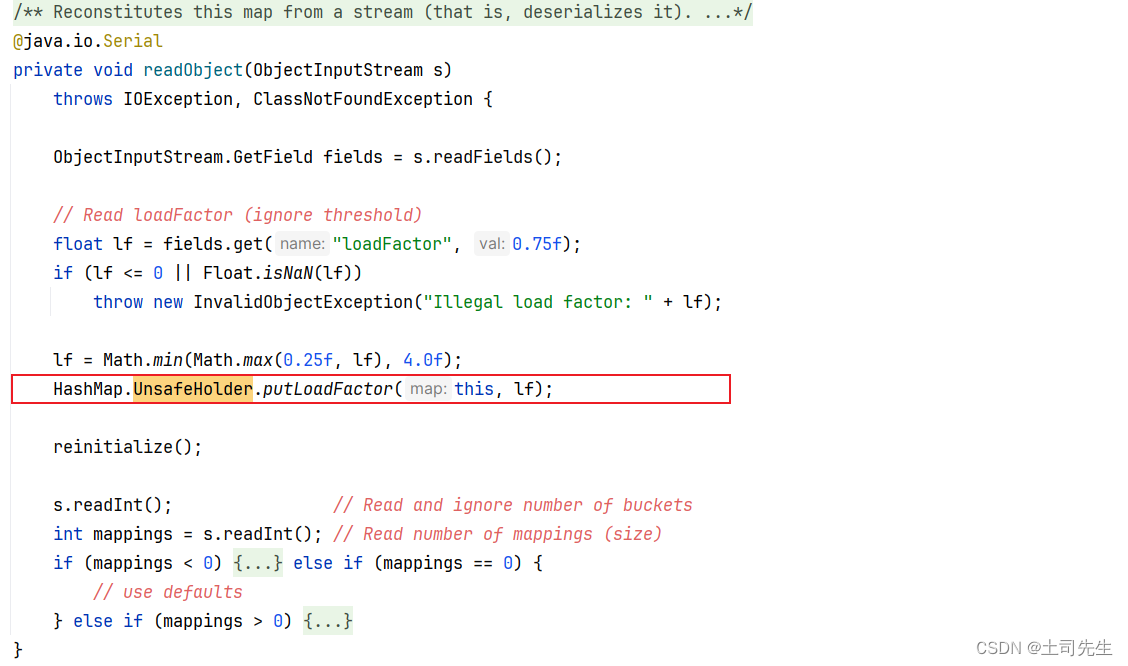
是的,整个HashMap 代码中 UnsafeHolder 类只有这一处调用了。
1.8 HashMap 相关的迭代器
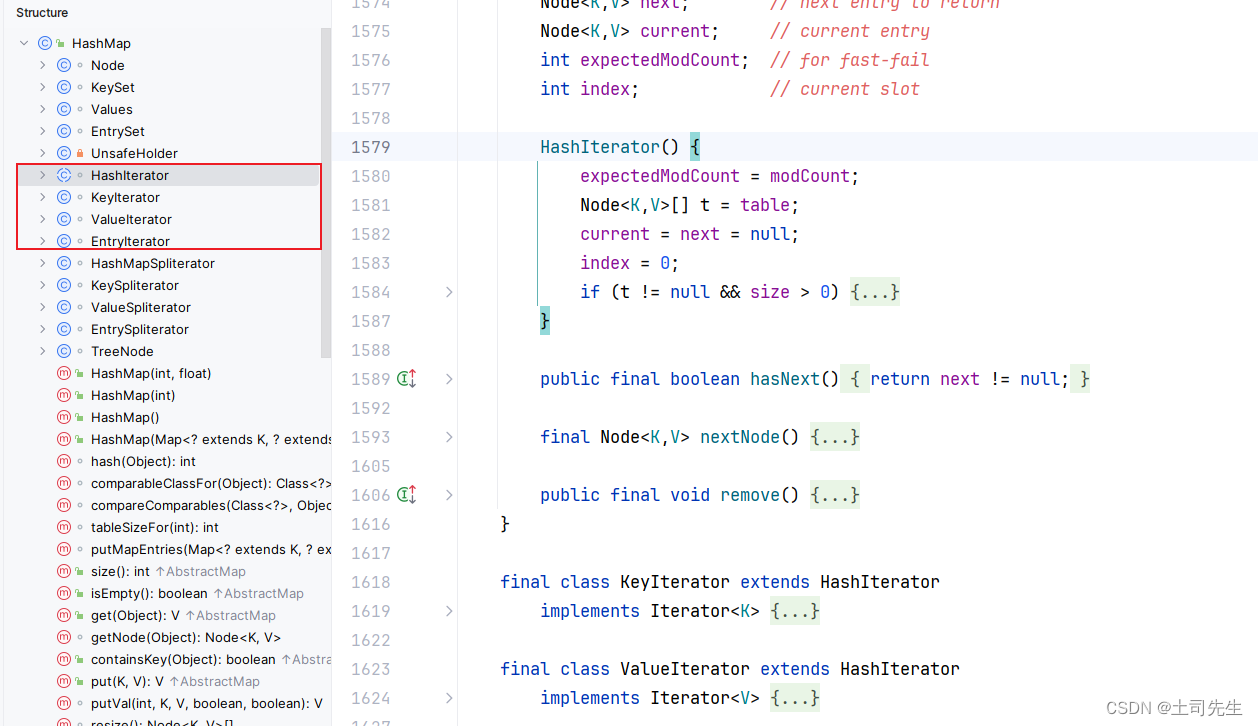
1.9 HashMap 相关的分割器
1.10 HashMap 内置的 TreeNode 类
这个类就是大名鼎鼎的红黑树结构的节点类。
当哈希表 table 属性字段中的节点数量超过树化阈值 (TREEIFY_THRESHOLD =8)时,链表结构(Node)将转成一颗红黑树结构(TreeNode)。当转变成红黑树时,其最小的初始容量是64;是原本初始容量(16)的4倍;
当HashMap 数量小于去树化阈值(UNTREEIFY_THRESHOLD = 6) 时,HashMap 将从一颗红黑树结构(TreeNode)转成链表结构(Node);
1.10.1 TreeNode 属性分析
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {/* * 指向当前节点的父节点,红黑树是一种二叉树结构,* parent 属性用于维护节点之间的父子关系,在树的插入,删除和旋转操作中会频繁使用到这个属性*/TreeNode<K,V> parent; // red-black tree links/*** 指向当前节点的左子节点,红黑树是有序二叉树* 左子节点 < 父节点* left属性在于维护左子节点的链接*/TreeNode<K,V> left;/*** 指向当前节点的右节点,红黑叔是有序二叉树* 父节点 < 右子节点* right属性在于维护右子节点的链接*/TreeNode<K,V> right;/*** 当前节点的前置节点;**/TreeNode<K,V> prev;/*** 标识当前节点的颜色。红黑树的每个节点都有一个颜色属性(红色或黑色),用于维护树的平衡。red 属性为 true 表示节点是红色,为 false 表示节点是黑色*/boolean red;/* 忽略其他代码 */}1.10.2 TreeNode 构造器
TreeNode(int hash, K key, V val, Node<K,V> next) {super(hash, key, val, next);}1.10.3 查看根节点
/*** 循环不断向上查找根节点,根节点的判断依据就是根节点本身的父节点为 null*/ final TreeNode<K,V> root() {for (TreeNode<K,V> r = this, p;;) {if ((p = r.parent) == null)return r;r = p;}}1.10.4 moveRootToFront
指定的红黑树根节点移动到哈希桶的前端。此方法确保在哈希桶中根节点总是位于最前面,以便在后续操作中更容易访问。
static <K,V> void moveRootToFront(Node<K,V>[] tab, TreeNode<K,V> root) {int n;if (root != null && tab != null && (n = tab.length) > 0) {int index = (n - 1) & root.hash;TreeNode<K,V> first = (TreeNode<K,V>)tab[index];if (root != first) {Node<K,V> rn;tab[index] = root;TreeNode<K,V> rp = root.prev;if ((rn = root.next) != null)((TreeNode<K,V>)rn).prev = rp;if (rp != null)rp.next = rn;if (first != null)first.prev = root;root.next = first;root.prev = null;}assert checkInvariants(root);}}1.10.5 find
在红黑树中查找特定键值 k。该方法通过比较哈希值和键来遍历树节点,以查找与给定键匹配的节点
final TreeNode<K,V> find(int h, Object k, Class<?> kc) {TreeNode<K,V> p = this;do {int ph, dir; K pk;TreeNode<K,V> pl = p.left, pr = p.right, q;if ((ph = p.hash) > h)p = pl;else if (ph < h)p = pr;else if ((pk = p.key) == k || (k != null && k.equals(pk)))return p;else if (pl == null)p = pr;else if (pr == null)p = pl;else if ((kc != null ||(kc = comparableClassFor(k)) != null) &&(dir = compareComparables(kc, k, pk)) != 0)p = (dir < 0) ? pl : pr;else if ((q = pr.find(h, k, kc)) != null)return q;elsep = pl;} while (p != null);return null;}
1.10.6 getTreeNode
在红黑树结构中查找特定的键值。
final TreeNode<K,V> getTreeNode(int h, Object k) {return ((parent != null) ? root() : this).find(h, k, null);}1.10.7 tieBreakOrder
在比较两个对象时进行“平局破坏”(tie-breaking),即当两个对象的比较结果相等或无法直接比较时,使用一些额外的规则来确定它们的顺序
static int tieBreakOrder(Object a, Object b) {int d;if (a == null || b == null ||(d = a.getClass().getName().compareTo(b.getClass().getName())) == 0)d = (System.identityHashCode(a) <= System.identityHashCode(b) ?-1 : 1);return d;}1.10.8 treeify 树结构化处理
将链表节点转换为红黑树节点,并将其插入到树结构中
final void treeify(Node<K,V>[] tab) {TreeNode<K,V> root = null;for (TreeNode<K,V> x = this, next; x != null; x = next) {next = (TreeNode<K,V>)x.next;x.left = x.right = null;if (root == null) {x.parent = null;x.red = false;root = x;}else {K k = x.key;int h = x.hash;Class<?> kc = null;for (TreeNode<K,V> p = root;;) {int dir, ph;K pk = p.key;if ((ph = p.hash) > h)dir = -1;else if (ph < h)dir = 1;else if ((kc == null &&(kc = comparableClassFor(k)) == null) ||(dir = compareComparables(kc, k, pk)) == 0)dir = tieBreakOrder(k, pk);TreeNode<K,V> xp = p;if ((p = (dir <= 0) ? p.left : p.right) == null) {x.parent = xp;if (dir <= 0)xp.left = x;elsexp.right = x;root = balanceInsertion(root, x);break;}}}}moveRootToFront(tab, root);}1.10.9 untreeify 链表化处理
红黑树节点转换为普通链表节点
final Node<K,V> untreeify(HashMap<K,V> map) {Node<K,V> hd = null, tl = null;for (Node<K,V> q = this; q != null; q = q.next) {Node<K,V> p = map.replacementNode(q, null);if (tl == null)hd = p;elsetl.next = p;tl = p;}return hd;}1.10.10 putTreeVal
putTreeVal 方法是 HashMap 的红黑树版本的 putVal 方法,用于将一个新的键值对插入到红黑树中
final TreeNode<K,V> putTreeVal(HashMap<K,V> map, Node<K,V>[] tab,int h, K k, V v) {Class<?> kc = null;boolean searched = false;TreeNode<K,V> root = (parent != null) ? root() : this;for (TreeNode<K,V> p = root;;) {int dir, ph; K pk;if ((ph = p.hash) > h)dir = -1;else if (ph < h)dir = 1;else if ((pk = p.key) == k || (k != null && k.equals(pk)))return p;else if ((kc == null &&(kc = comparableClassFor(k)) == null) ||(dir = compareComparables(kc, k, pk)) == 0) {if (!searched) {TreeNode<K,V> q, ch;searched = true;if (((ch = p.left) != null &&(q = ch.find(h, k, kc)) != null) ||((ch = p.right) != null &&(q = ch.find(h, k, kc)) != null))return q;}dir = tieBreakOrder(k, pk);}TreeNode<K,V> xp = p;if ((p = (dir <= 0) ? p.left : p.right) == null) {Node<K,V> xpn = xp.next;TreeNode<K,V> x = map.newTreeNode(h, k, v, xpn);if (dir <= 0)xp.left = x;elsexp.right = x;xp.next = x;x.parent = x.prev = xp;if (xpn != null)((TreeNode<K,V>)xpn).prev = x;moveRootToFront(tab, balanceInsertion(root, x));return null;}}}1.10.11 removeTreeNode & 红黑树转链表
removeTreeNode 方法用于从红黑树中删除指定的节点,并在需要时将红黑树转换回链表。removeTreeNode 方法用于从红黑树结构中移除一个节点。它会在 HashMap 的键冲突情况下使用红黑树作为桶内的存储结构时被调用。这个方法主要处理以下步骤:找到要删除的节点、调整红黑树的平衡、更新链表指针和哈希表指针
/*** 从红黑树中删除节点* @param map 当前 hashmap 实例* @param tab 哈希表 * @param movable 是否允许在删除节点后调整树的根节点位置。*/final void removeTreeNode(HashMap<K,V> map, Node<K,V>[] tab,boolean movable) {int n;// 1. 检查哈希表是否为空或长度为零。如果是,则直接返回if (tab == null || (n = tab.length) == 0) return;/** 2. 计算节点所在桶的索引。* 初始化 first、root、succ(后置节点)、pred(前置节点)。*/int index = (n - 1) & hash;TreeNode<K,V> first = (TreeNode<K,V>)tab[index], root = first, rl;TreeNode<K,V> succ = (TreeNode<K,V>)next, pred = prev;/** 3. 更新链表指针*/// 3.1 更新链表中前置和后置节点的指针。如果前置节点为空,表示当前节点是第一个节点,则更新桶的第一个节点指向后置节点。if (pred == null) tab[index] = first = succ;elsepred.next = succ;// 3.2 如果后置节点不为空,更新后置节点的前置指针if (succ != null)succ.prev = pred;// 3.3 如果第一个节点为空,直接返回。if (first == null)return;/** 4 处理红黑树根节点*/// 4.1 获取红黑树的根节点if (root.parent != null) root = root.root();// 4.2 检查根节点是否为空或者是否需要将红黑树转回链表(即当树中节点过少时)。if (root == null|| (movable&& (root.right == null|| (rl = root.left) == null|| rl.left == null))) {// 4.3 如果需要转回链表,调用 untreeify 方法。tab[index] = first.untreeify(map); // too smallreturn;}/** 5. 查找替代节点*/TreeNode<K,V> p = this, pl = left, pr = right, replacement;// 5.1 如果节点有两个子节点,找到后置节点(右子树的最左节点),并交换颜色和位置if (pl != null && pr != null) {TreeNode<K,V> s = pr, sl;while ((sl = s.left) != null) // find successors = sl;boolean c = s.red; s.red = p.red; p.red = c; // swap colors// 5.2 更新子节点和父节点的指针TreeNode<K,V> sr = s.right;TreeNode<K,V> pp = p.parent;if (s == pr) { // p was s's direct parentp.parent = s;s.right = p;}// 5.3 如果节点只有一个子节点或者没有子节点,直接使用子节点作为替代节点。else {TreeNode<K,V> sp = s.parent;if ((p.parent = sp) != null) {if (s == sp.left)sp.left = p;elsesp.right = p;}if ((s.right = pr) != null)pr.parent = s;}p.left = null;if ((p.right = sr) != null)sr.parent = p;if ((s.left = pl) != null)pl.parent = s;if ((s.parent = pp) == null)root = s;else if (p == pp.left)pp.left = s;elsepp.right = s;if (sr != null)replacement = sr;elsereplacement = p;}else if (pl != null)replacement = pl;else if (pr != null)replacement = pr;elsereplacement = p;/** 6. 更新替代节点指针*/if (replacement != p) { // 6.1 如果替代节点不是当前节点,更新替代节点的父指针TreeNode<K,V> pp = replacement.parent = p.parent;// 6.2 如果父节点为空,将替代节点设为根节点并设为黑色。if (pp == null)(root = replacement).red = false;else if (p == pp.left)pp.left = replacement;// 6.3 否则,更新父节点的子指针。elsepp.right = replacement;p.left = p.right = p.parent = null;}/** 7. 平衡红黑树*/// 7.1 如果当前节点是红色,不需要平衡。如果是黑色,调用 balanceDeletion 方法平衡红黑树。TreeNode<K,V> r = p.red ? root : balanceDeletion(root, replacement);// 7.2 如果替代节点是当前节点,断开其与父节点的链接。if (replacement == p) { // detachTreeNode<K,V> pp = p.parent;p.parent = null;if (pp != null) {if (p == pp.left)pp.left = null;else if (p == pp.right)pp.right = null;}}// 7.3 如果允许移动根节点,将根节点移动到前面if (movable)moveRootToFront(tab, r);}removeTreeNode 方法从红黑树结构中删除一个节点,主要步骤包括:
- 更新链表指针。
- 查找替代节点。
- 更新指针以移除节点并平衡红黑树。
- 根据需要将根节点移动到哈希表桶的前面。
1.10.12 split
split 方法在 HashMap 的扩容过程中使用,用于将红黑树节点分割成两个链表或树。这个方法将一个红黑树节点数组中的元素重新分配到新的数组中,以便支持哈希表的扩容操作。
final void split(HashMap<K,V> map, Node<K,V>[] tab, int index, int bit) {TreeNode<K,V> b = this;// Relink into lo and hi lists, preserving orderTreeNode<K,V> loHead = null, loTail = null;TreeNode<K,V> hiHead = null, hiTail = null;int lc = 0, hc = 0;for (TreeNode<K,V> e = b, next; e != null; e = next) {next = (TreeNode<K,V>)e.next;e.next = null;if ((e.hash & bit) == 0) {if ((e.prev = loTail) == null)loHead = e;elseloTail.next = e;loTail = e;++lc;}else {if ((e.prev = hiTail) == null)hiHead = e;elsehiTail.next = e;hiTail = e;++hc;}}if (loHead != null) {if (lc <= UNTREEIFY_THRESHOLD)tab[index] = loHead.untreeify(map);else {tab[index] = loHead;if (hiHead != null) // (else is already treeified)loHead.treeify(tab);}}if (hiHead != null) {if (hc <= UNTREEIFY_THRESHOLD)tab[index + bit] = hiHead.untreeify(map);else {tab[index + bit] = hiHead;if (loHead != null)hiHead.treeify(tab);}}}1.10.13 rotateLeft
左旋操作的目的是将一个节点(通常是子树的根节点)的右子节点提升为新的根节点,而原来的根节点成为新根节点的左子节点。
static <K,V> TreeNode<K,V> rotateLeft(TreeNode<K,V> root,TreeNode<K,V> p) {TreeNode<K,V> r, pp, rl;if (p != null && (r = p.right) != null) {if ((rl = p.right = r.left) != null)rl.parent = p;if ((pp = r.parent = p.parent) == null)(root = r).red = false;else if (pp.left == p)pp.left = r;elsepp.right = r;r.left = p;p.parent = r;}return root;}1.10.14 rotateRight
右旋操作的目的是将一个节点(通常是子树的根节点)的左子节点提升为新的根节点,而原来的根节点成为新根节点的右子节点
static <K,V> TreeNode<K,V> rotateRight(TreeNode<K,V> root,TreeNode<K,V> p) {TreeNode<K,V> l, pp, lr;if (p != null && (l = p.left) != null) {if ((lr = p.left = l.right) != null)lr.parent = p;if ((pp = l.parent = p.parent) == null)(root = l).red = false;else if (pp.right == p)pp.right = l;elsepp.left = l;l.right = p;p.parent = l;}return root;}1.10.15 balanceInsertion
在红黑树中插入节点后调整树以保持其平衡性
static <K,V> TreeNode<K,V> balanceInsertion(TreeNode<K,V> root,TreeNode<K,V> x) {x.red = true;for (TreeNode<K,V> xp, xpp, xppl, xppr;;) {if ((xp = x.parent) == null) {x.red = false;return x;}else if (!xp.red || (xpp = xp.parent) == null)return root;if (xp == (xppl = xpp.left)) {if ((xppr = xpp.right) != null && xppr.red) {xppr.red = false;xp.red = false;xpp.red = true;x = xpp;}else {if (x == xp.right) {root = rotateLeft(root, x = xp);xpp = (xp = x.parent) == null ? null : xp.parent;}if (xp != null) {xp.red = false;if (xpp != null) {xpp.red = true;root = rotateRight(root, xpp);}}}}else {if (xppl != null && xppl.red) {xppl.red = false;xp.red = false;xpp.red = true;x = xpp;}else {if (x == xp.left) {root = rotateRight(root, x = xp);xpp = (xp = x.parent) == null ? null : xp.parent;}if (xp != null) {xp.red = false;if (xpp != null) {xpp.red = true;root = rotateLeft(root, xpp);}}}}}}1.10.16 balanceDeletion
balanceDeletion 方法在红黑树中删除节点后调整树以保持其平衡性
static <K,V> TreeNode<K,V> balanceDeletion(TreeNode<K,V> root,TreeNode<K,V> x) {for (TreeNode<K,V> xp, xpl, xpr;;) {if (x == null || x == root)return root;else if ((xp = x.parent) == null) {x.red = false;return x;}else if (x.red) {x.red = false;return root;}else if ((xpl = xp.left) == x) {if ((xpr = xp.right) != null && xpr.red) {xpr.red = false;xp.red = true;root = rotateLeft(root, xp);xpr = (xp = x.parent) == null ? null : xp.right;}if (xpr == null)x = xp;else {TreeNode<K,V> sl = xpr.left, sr = xpr.right;if ((sr == null || !sr.red) &&(sl == null || !sl.red)) {xpr.red = true;x = xp;}else {if (sr == null || !sr.red) {if (sl != null)sl.red = false;xpr.red = true;root = rotateRight(root, xpr);xpr = (xp = x.parent) == null ?null : xp.right;}if (xpr != null) {xpr.red = (xp == null) ? false : xp.red;if ((sr = xpr.right) != null)sr.red = false;}if (xp != null) {xp.red = false;root = rotateLeft(root, xp);}x = root;}}}else { // symmetricif (xpl != null && xpl.red) {xpl.red = false;xp.red = true;root = rotateRight(root, xp);xpl = (xp = x.parent) == null ? null : xp.left;}if (xpl == null)x = xp;else {TreeNode<K,V> sl = xpl.left, sr = xpl.right;if ((sl == null || !sl.red) &&(sr == null || !sr.red)) {xpl.red = true;x = xp;}else {if (sl == null || !sl.red) {if (sr != null)sr.red = false;xpl.red = true;root = rotateLeft(root, xpl);xpl = (xp = x.parent) == null ?null : xp.left;}if (xpl != null) {xpl.red = (xp == null) ? false : xp.red;if ((sl = xpl.left) != null)sl.red = false;}if (xp != null) {xp.red = false;root = rotateRight(root, xp);}x = root;}}}}}1.10.17 checkInvariants
用于递归地检查红黑树的几个不变量,确保树的结构和颜色属性保持一致。这些不变量是红黑树能够提供高效性能的关键。
static <K,V> boolean checkInvariants(TreeNode<K,V> t) {TreeNode<K,V> tp = t.parent, tl = t.left, tr = t.right,tb = t.prev, tn = (TreeNode<K,V>)t.next;if (tb != null && tb.next != t)return false;if (tn != null && tn.prev != t)return false;if (tp != null && t != tp.left && t != tp.right)return false;if (tl != null && (tl.parent != t || tl.hash > t.hash))return false;if (tr != null && (tr.parent != t || tr.hash < t.hash))return false;if (t.red && tl != null && tl.red && tr != null && tr.red)return false;if (tl != null && !checkInvariants(tl))return false;if (tr != null && !checkInvariants(tr))return false;return true;}1.11 HashMap 新增业务
/*** 新增key-value 键值对(映射实体),如果key有旧值,则value覆盖旧值* @retrun 返回 key之前所关联的旧值,如果key没有关联值,返回null* @param key 要新增的key* @param value 要新增的value*/public V put(K key, V value) {return putVal(hash(key), key, value, false, true);}1.12 hash处理
为什么还要对 key进行一次hash 计算,而不是直接调用 key.hashCode() 方法?直接调用key.hashCode() 可能会导致哈希值分布不均匀。要直到HashMap的key 是存储在一条链表上,而具体是链表的哪个位置是通过哈希值来进行计算得到的。如果直接key.hashCode() 这样哈希值容易相同,发生冲突,导致数据分布不均匀;减低存取效率;
所以通过 hash(key) 多计算一次key的哈希值,使得哈希值不容易相同,减少哈希冲突,数据分布均匀,增加存储效率;
static final int hash(Object key) {int h;// key.hashCode() 是获取 key 的哈希码,^ 是按位异或操作return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);}这个 hash 方法通过将原始哈希码的高 16 位与低 16 位进行异或操作,来混合高位和地位的哈希值,这样做的目的是:
高位扰动:通过将高位和低位的哈希值混合,使得最终的哈希值能够更好地利用哈希表的所有位,从而减少冲突。
均匀分布:避免因为低位的简单性导致的哈希冲突,使得哈希值在哈希表上分布更均匀。
【案例说明】假设我们有一个简单的键 key1 和 key2,它们的 hashCode 分别是 0x11111111 和 0x11111110。如果不进行高位扰动,这两个键的低位哈希值很接近,容易导致哈希冲突。而经过 hash 方法处理后,这两个哈希值会变得不同,更加均匀地分布在哈希表中。
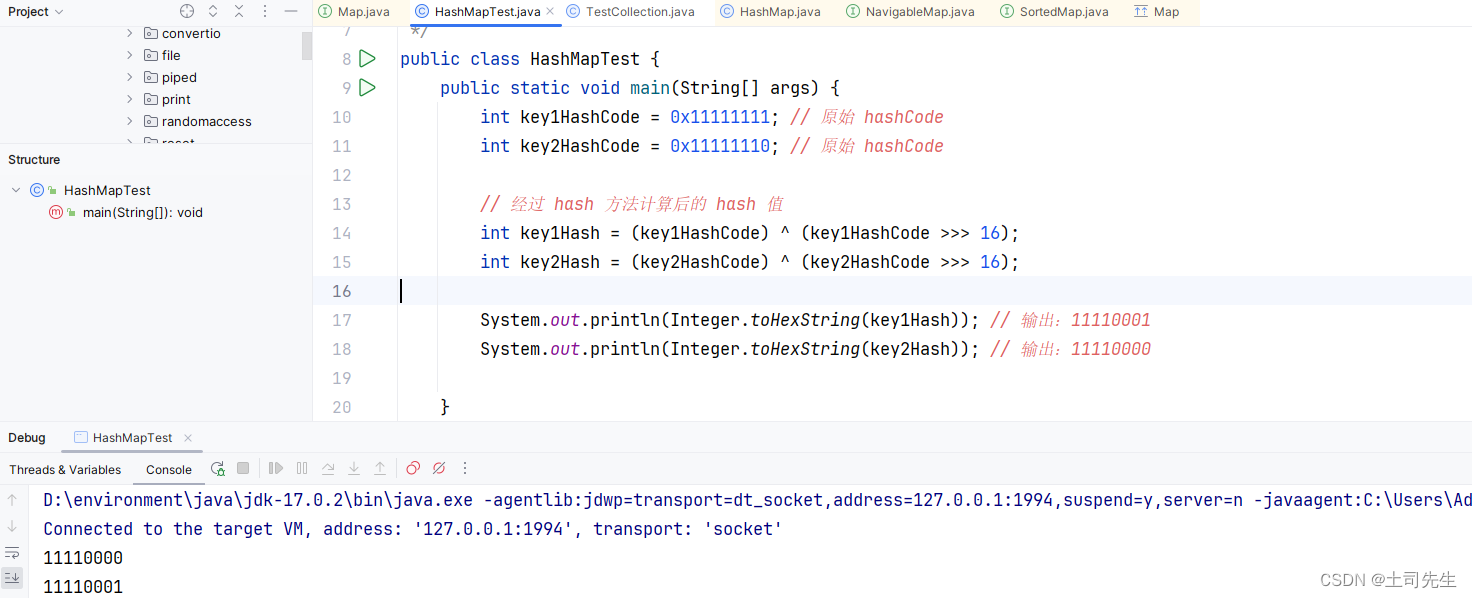
所以,hash(key) 方法通过对键的 hashCode 进行进一步处理,确保哈希值分布均匀、减少冲突、提高性能,是 HashMap 能够高效工作的关键之一。这种方法通过混合高位和低位的哈希值,使得哈希值在哈希表中更加均匀地分布,避免了简单哈希算法可能导致的冲突问题。
1.13 putVal
此时putVal 方法就是真正新增,代码如下:
/*** 新增key-value 键值对* @param hash key的哈希值* @param key 要新增的key* @param value 要新增的value* @param onlyIfAbsent 如果为 true,则只有当键不存在时才插入 (put方法传入 false)* @param evict 是否在插入节点后进行驱逐 (put方法传入 true)*/final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) {Node<K,V>[] tab; /* map集合,里面存储所有键值对 */Node<K,V> p; /* p 是键值对应位置的第一个节点,如果该位置有冲突,则 p 是链表或红黑树的根节点 */int n, i; /* n: tab map集合的长度,i: 哈希值和数组长度计算得到的索引值 */// 1. 初始化或扩容:检查 table 是否为 null 或长度为 0,如果是,则通过调用 resize 方法进行初始化或扩容,并更新 n 为新表的长度if ((tab = table) == null || (n = tab.length) == 0) n = (tab = resize()).length;/** 2. 计算索引: 通过 使用 (n - 1) & hash 计算出键在数组中的索引 i* 并检查该索引处是否为空。如果为空,则直接在该位置插入新节点。*/if ((p = tab[i = (n - 1) & hash]) == null)// 将新增的需要的数据统一封装成一个节点;tab[i] = newNode(hash, key, value, null);else { // 3. 处理冲突Node<K,V> e /* e: element 缩写;*/; K k / k: key 的缩写 表示p的key*/;// 3.1 索引处已经有其他节点(发生冲突),检查该节点 p 是否与要插入的键具有相同的哈希值和键。如果相同,则 e = p,表示该键已经存在if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k))))e = p;// 3.2 如果此时 p的节点类型是 TreeNode 红黑树节点,则调用putTreeVal插入红黑树中else if (p instanceof TreeNode)e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);// 3.3 如果索引处的节点 p 不是 TreeNode,则在链表中插入新节点else {// 遍历链表,如果找到相同的键,for (int binCount = 0; ; ++binCount) {if ((e = p.next) == null) {// 将数据封装成链表节点,并追加在p的后置节点,p.next = newNode(hash, key, value, null);// 如果当前map数量大于或等于树化阈值,则进行链表转红黑树if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1sttreeifyBin(tab, hash);break;}// 如果哈希值不同,那么键一定不同,可以直接跳过这个节点。if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))break;p = e;}}//4 更新现有节点: 如果键已经存在(e != null),则根据 onlyIfAbsent 标志更新节点的值,并返回旧值。if (e != null) {// put是传入 false, 意味着key存不存在都进行插入V oldValue = e.value;if (!onlyIfAbsent || oldValue == null)e.value = value;afterNodeAccess(e);return oldValue;}}++modCount; // 记录修改次数if (++size > threshold) // 进行扩容处理resize();afterNodeInsertion(evict); // 调用 afterNodeInsertion 进行一些插入后的处理return null;} 这段代码是 HashMap 插入操作的核心实现,它处理了哈希冲突、链表插入、树化以及扩容等一系列复杂操作,确保 HashMap 能够高效地进行键值对的插入和存储。
1.14 链表转红黑树
/*** 链表转红黑树,当 HashMap 数量大小大小等于树化阈值(64)* @param tab 哈希表* @param key的hash值*/final void treeifyBin(Node<K,V>[] tab, int hash) {int n, index; Node<K,V> e;// 进行扩容,当tab == null 或者容量小于 最小树化容量(64)if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY) resize();/** index = (n - 1) & hash 计算出 hash 在哈希表中的索引* 如果 tab[index] 位置上有节点存在(即不为空),则继续转换链表为红黑树*/else if ((e = tab[index = (n - 1) & hash]) != null) {/* hd 红黑树的头部节点,t1 红黑树的尾部节点 */TreeNode<K,V> hd = null, tl = null;do {// replacementTreeNode 转换成红黑树TreeNode<K,V> p = replacementTreeNode(e, null);if (tl == null) // 尾部节点为空,意味着这是第一个节点,所以设置给头部节点hd = p;else {// tl 不为 null,则将当前节点 p 的 prev 指向 tl,并将 tl 的 next 指向 pp.prev = tl;tl.next = p;}tl = p; 更新 tl 为当前节点 p。} while ((e = e.next) != null); // 循环链表,直到最后一个节点为止// 将哈希表索引 index 处的链表头节点替换为红黑树的头节点 hd。if ((tab[index] = hd) != null)hd.treeify(tab); // 如果 hd 不为空,则调用 hd.treeify(tab) 方法,将链表转换为红黑树结构。}} // For treeifyBinTreeNode<K,V> replacementTreeNode(Node<K,V> p, Node<K,V> next) {return new TreeNode<>(p.hash, p.key, p.value, next);}总结
- 检查和扩容:首先检查哈希表是否为空或长度是否小于最小树化容量,若是,则扩容哈希表。
- 链表转换为红黑树节点:遍历哈希表指定索引位置的链表,将链表中的每个节点转换为红黑树节点。
- 树化链表:将转换后的红黑树节点替换原链表节点,最后调用
treeify方法将链表转换为红黑树。
这个方法的目的是在链表中的节点数量达到一定阈值时,将链表转换为红黑树,以提高哈希表在大量冲突情况下的性能。
1.15 HashMap 删除业务
remove 方法是 HashMap 用于删除键值对的实现。它通过键删除相应的键值对,并返回被删除的值。
public V remove(Object key) {Node<K,V> e;// 调用 removeNode 方法,执行实际的删除操作。return (e = removeNode(hash(key), key, null, false, true)) == null ?null : e.value;} /*** 删除原始* @param hash key的hash值* @param key 要删除的key* @param value key对应的value* @param matchValue 是否需要匹配值。如果为 true,则只有键和值都匹配的节点才会被删除。* @param movable 是否允许在删除节点后移动其他节点以保持哈希表的结构。*/final Node<K,V> removeNode(int hash, Object key, Object value,boolean matchValue, boolean movable) {Node<K,V>[] tab; Node<K,V> p; int n, index;/** tab = table:获取哈希表数组。* n = tab.length:获取哈希表的长度。* (n - 1) & hash:计算键的索引。* p = tab[index]:获取对应索引位置的节点。如果哈希表为空或索引位置没有节点,则不进行任何操作。*/if ((tab = table) != null && (n = tab.length) > 0 &&(p = tab[index = (n - 1) & hash]) != null) {// 1. 查到节点 初始化目标节点 node;Node<K,V> node = null, e; K k; V v;// 1.1 检查 p 节点是否为要删除的节点(哈希值和键相等)。如果是,设置 node = p。if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k))))node = p;/** 1.2 如果 p 不是目标节点,检查 p 是否有后续节点。* 如果 p 是 TreeNode 类型,调用 getTreeNode 方法查找红黑树中的节点。* 否则,遍历链表查找目标节点。*/else if ((e = p.next) != null) {if (p instanceof TreeNode)node = ((TreeNode<K,V>)p).getTreeNode(hash, key);else {do {if (e.hash == hash &&((k = e.key) == key ||(key != null && key.equals(k)))) {node = e;break;}p = e;} while ((e = e.next) != null);}}// 2. 删除节点:如果找到了匹配的节点 node,并且值匹配(如果需要匹配值),则进行删除操作。if (node != null && (!matchValue || (v = node.value) == value ||(value != null && value.equals(v)))) {// 2.1 如果 node 是 TreeNode,调用 removeTreeNode 方法从红黑树中删除节点if (node instanceof TreeNode)((TreeNode<K,V>)node).removeTreeNode(this, tab, movable);// 2.2 如果 node 是链表的第一个节点,将 tab[index] 指向 node.next。else if (node == p)tab[index] = node.next;else // 否则,将 p.next 指向 node.next;这样循环指向由 GC进行收回p.next = node.next;// 更新修改次数 modCount 和大小 size++modCount;--size;// 调用 afterNodeRemoval 方法进行后续处理。afterNodeRemoval(node);return node; // 返回删除的节点。}}return null; // 未找到节点}
相关文章:
Java-01-基础篇-04 Java集合-04-HashMap (源码)
目录 一,HashMap 1.1 HashMap 属性分析 1.2 HashMap 构造器 1.3 HashMap 内置的 Node 类 1.4 HashMap 内置的 KeySet 类 1.5 HashMap 内置的 Values 类 1.6 HashMap 内置的 EntrySet 类 1.7 HashMap 内置的 UnsafeHolder 类 1.8 HashMap 相关的迭代器 1.9…...
开源语音合成模型ChatTTS本地部署结合内网穿透实现远程访问
文章目录 前言1. 下载运行ChatTTS模型2. 安装Cpolar工具3. 实现公网访问4. 配置ChatTTS固定公网地址 前言 本篇文章就教大家如何快速地在Windows中本地部署ChatTTS,并且我们还可以结合Cpolar内网穿透实现公网随时随地访问ChatTTS AI语言模型。 最像人声的AI来了&a…...

超多细节—app图标拖动排序实现详解
前言: 最近做了个活动需求大致类似于一个拼图游戏,非常接近于咱们日常app拖动排序的场景。所以想着好好梳理一下,改造改造干脆在此基础上来写一篇实现app拖动排序的文章,跟大家分享下这个大家每天都要接触的场景,到底…...

基于深度学习的文字识别
基于深度学习的文字识别 基于深度学习的文字识别(Optical Character Recognition, OCR)是指利用深度神经网络模型自动识别和提取图像中的文字内容。这一技术在文档数字化、自动化办公、车牌识别、手写识别等多个领域有着广泛的应用。 深度学习OCR的基本…...
Pikachu靶场--文件包含
参考借鉴 Pikachu靶场之文件包含漏洞详解_pikachu文件包含-CSDN博客 文件包含(CTF教程,Web安全渗透入门)__bilibili File Inclusion(local) 查找废弃隐藏文件 随机选一个然后提交查询 URL中出现filenamefile2.php filename是file2.php&…...

get put post delete 区别以及幂等
GET 介绍:GET请求用于从服务器获取资源,通常用于获取数据。它的参数会附加在URL的末尾,可以通过URL参数传递数据。GET请求是幂等的,即多次请求同一个URL得到的结果应该是一样的,不会对服务器端产生影响。 特点…...

ultralytics版本及对应的更新
Ultralytics Ultralytics 是一家专注于计算机视觉和深度学习工具的公司,尤以其开源的 YOLO (You Only Look Once) 系列深受欢迎。目前,Ultralytics 主要管理和开发 YOLOv5 和 YOLOv8。以下是各个版本的概述及其主要更新: YOLOv5 YOLOv5 是…...
进行集成和协作?)
在现代编程环境中,Perl 如何与其他流行语言(如 Python、Java 等)进行集成和协作?
在现代编程环境中,Perl 可以与其他流行语言(如 Python、Java 等)进行集成和协作。以下是一些常见的方法: 调用外部程序:Perl 可以使用系统调用来执行其他语言编写的可执行文件。这意味着可以从 Perl 中调用 Python、Ja…...

BEV 中 multi-frame fusion 多侦融合(一)
文章目录 参数设置align_dynamic_thing:为了将动态物体的点云数据从上一帧对齐到当前帧流程旋转函数平移公式filter_points_in_ego:筛选出属于特定实例的点get_intermediate_frame_info: 函数用于获取中间帧的信息,包括点云数据、传感器校准信息、自车姿态、边界框及其对应…...

“Docker操作案例实践“
目录 1. 下载nginx 2. Portainer可视化 1. 下载nginx 步骤: 搜索nginx:docker search nginx;下载镜像:docker pull nginx ;查看镜像:docker images ;后台运行 :docker run -d -na…...
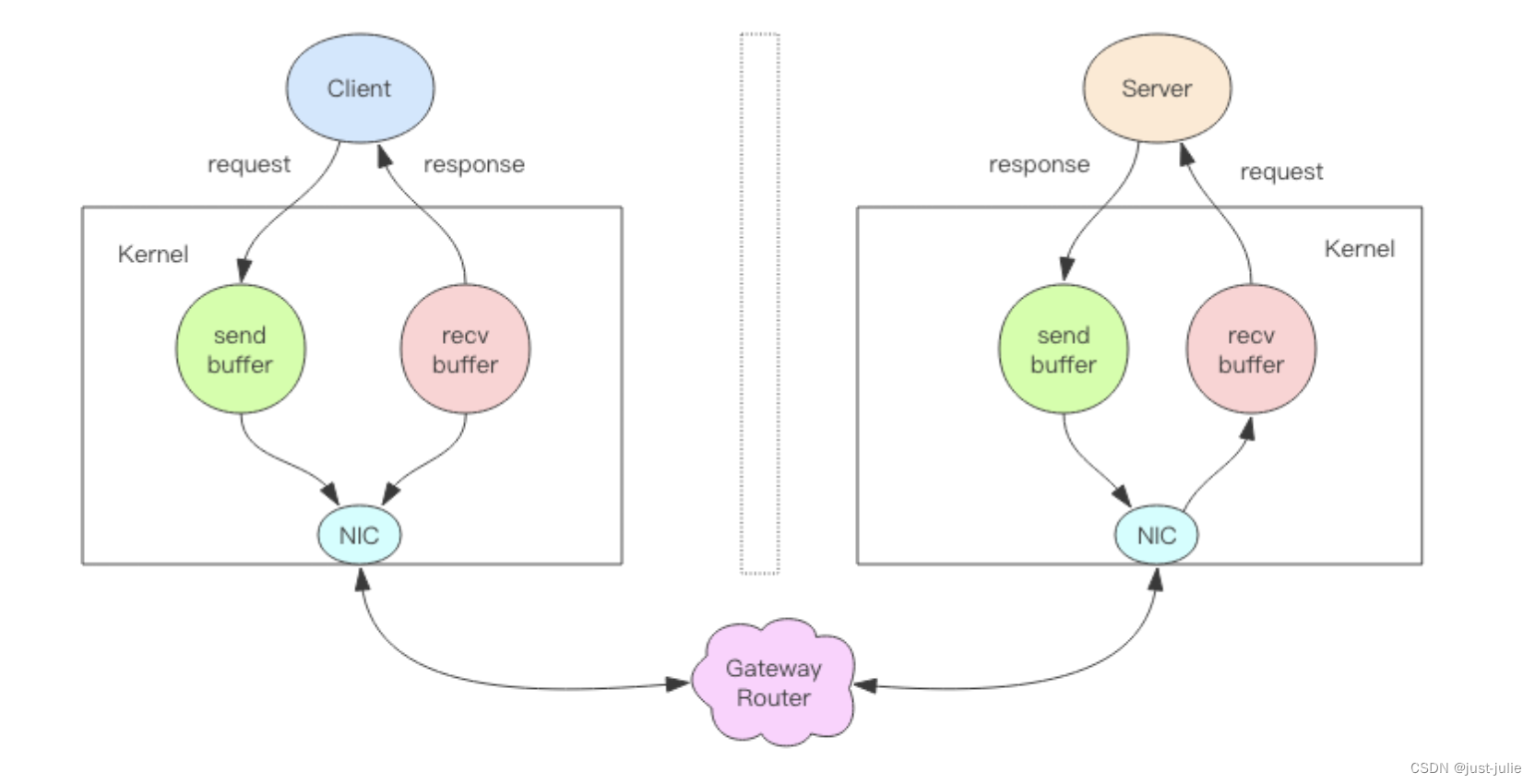
Redis 管道
Redis的消息交互 当我们使用客户端对Redis进行一次操作时,如下图所示,客户端将请求传送给服务器,服务器处理完毕后,再将响应回复给客户端,这要花费一个网络数据包来回的时间。 如果连续执行多条指令,那就会…...

ubuntu20.04安装配置openMVG+openMVS
安装 主要跟着官方教程逐步安装 openMVG https://github.com/openMVG/openMVG/blob/master/BUILD.md openMVS https://github.com/cdcseacave/openMVS/wiki/Building 注意事项 1. 库版本要求 使用版本: openMVS 2.2.0 openMVG Eigen 3.4.0 OpenCV 4.6.0 Ce…...

使用CSS常见问题解答卡片
常见问题解答卡片 效果展示 CSS 知识点 CSS 选择器的使用background 渐变背景色运用CSS 综合知识运用 页面整体布局 <div class"container"><h1>经常问的问题</h1><!-- 这里只是展示一个项目 --><div class"tab"><in…...

Kong AI Gateway 正式 GA !
Kong Gateway 3.7 版本已经重磅上线,我们给 AI Gateway 带来了一系列升级,下面是 AI Gateway 的更新亮点一览。 AI Gateway 正式 GA 在 Kong Gateway 的最新版本 3.7 中,我们正式宣布 Kong AI Gateway 达到了通用可用性(GA&…...
HTML5有哪些新特性?
目录 1.语义化标签:2.多媒体支持:3.增强型表单:4.绘图与图形:5.地理定位:6.离线应用与存储:7.性能与集成:8.语义化属性:9.改进的 DOM 操作:10.跨文档通信:11.…...
SQL Server入门-SSMS简单使用(2008R2版)-2
环境: win10,SQL Server 2008 R2 参考: SQL Server 管理套件(SSMS)_w3cschool https://www.w3cschool.cn/sqlserver/sqlserver-oe8928ks.html SQL Server存储过程_w3cschool https://www.w3cschool.cn/sqlserver/sql…...

php实现modbus CRC校验
一:计算CRC校验函数 function calculateCRC16Modbus($string) {$crcBytes [];for ($i 0; $i < strlen($string); $i 2) {$crcBytes[] hexdec(substr($string, $i, 2));}$crc 0xFFFF;$polynomial 0xA001; // This is the polynomial x^16 x^15 x^2 1fo…...

2025年计算机毕业设计题目参考
今年最新计算机毕业设计题目参考 以下可以参考 springboot洗衣店订单管理系统 springboot美发门店管理系统 springboot课程答疑系统 springboot师生共评的作业管理系统 springboot平台的医疗病历交互系统 springboot购物推荐网站的设计与实现 springboot知识管理系统 springbo…...

ERP、CRM、SRM、PLM、HRM、OA……都是啥意思?
经常会听说一些奇怪的系统或平台名称,例如ERP、CRM、SRM、PLM、HRM、OA等。 这些系统,都是干啥用的? █ ERP(企业资源计划) 英文全称:Enterprise Resource Planning 定义:由美国Gartner Gro…...
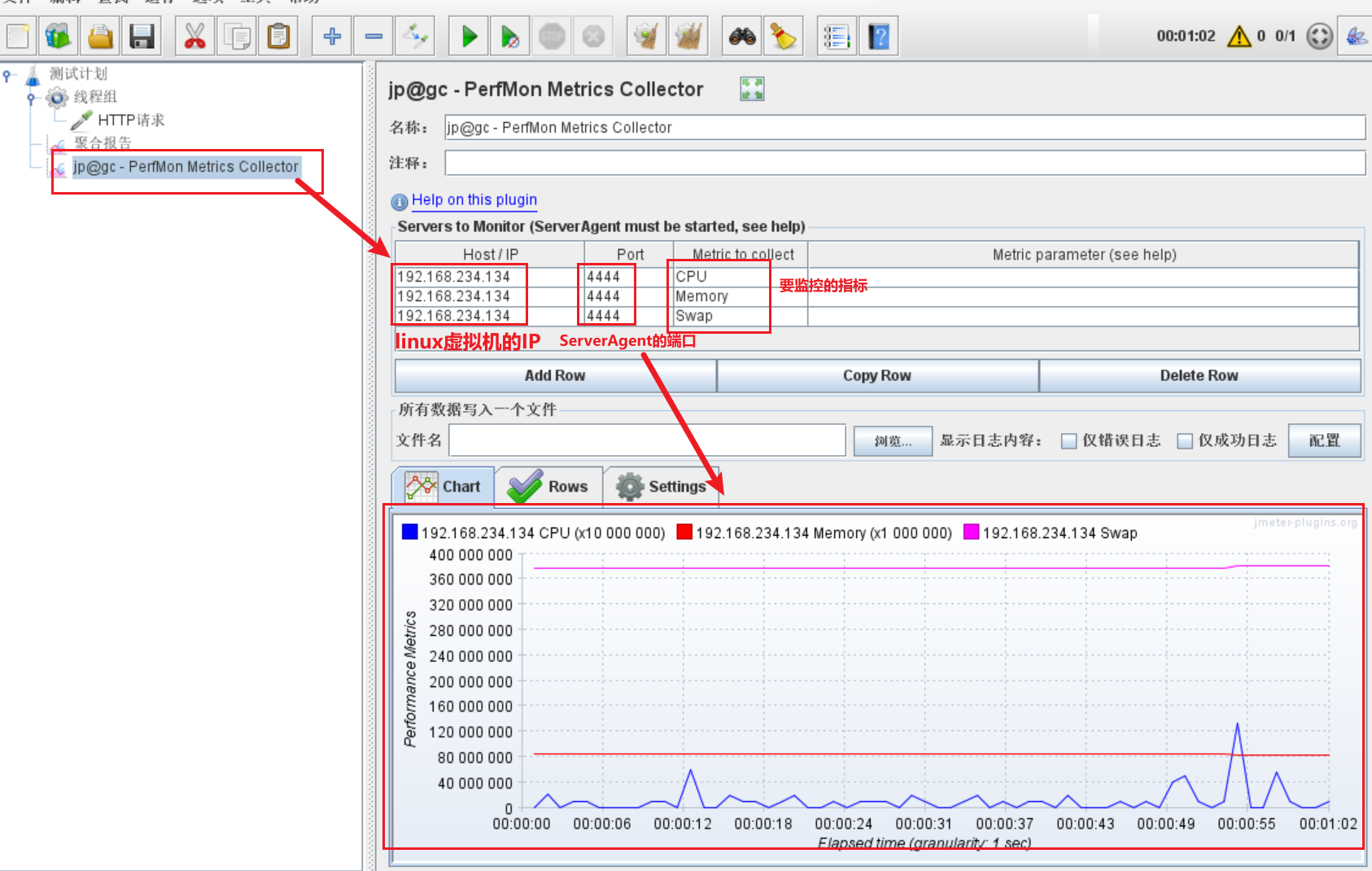
Jmeter分布式、测试报告、并发数计算、插件添加方式、常用图表
Jmeter分布式 应用场景 当单个测试机无法模拟用户要求的业务场景时,可以使用多台测试机进行模拟,就是Jmeter的分布 式测试。 Jmeter分布式执行原理 Jmeter分布测试时,选择其中一台作为控制机(Controller),…...

conda相比python好处
Conda 作为 Python 的环境和包管理工具,相比原生 Python 生态(如 pip 虚拟环境)有许多独特优势,尤其在多项目管理、依赖处理和跨平台兼容性等方面表现更优。以下是 Conda 的核心好处: 一、一站式环境管理:…...

PHP和Node.js哪个更爽?
先说结论,rust完胜。 php:laravel,swoole,webman,最开始在苏宁的时候写了几年php,当时觉得php真的是世界上最好的语言,因为当初活在舒适圈里,不愿意跳出来,就好比当初活在…...

大数据零基础学习day1之环境准备和大数据初步理解
学习大数据会使用到多台Linux服务器。 一、环境准备 1、VMware 基于VMware构建Linux虚拟机 是大数据从业者或者IT从业者的必备技能之一也是成本低廉的方案 所以VMware虚拟机方案是必须要学习的。 (1)设置网关 打开VMware虚拟机,点击编辑…...

如何在看板中有效管理突发紧急任务
在看板中有效管理突发紧急任务需要:设立专门的紧急任务通道、重新调整任务优先级、保持适度的WIP(Work-in-Progress)弹性、优化任务处理流程、提高团队应对突发情况的敏捷性。其中,设立专门的紧急任务通道尤为重要,这能…...

Cloudflare 从 Nginx 到 Pingora:性能、效率与安全的全面升级
在互联网的快速发展中,高性能、高效率和高安全性的网络服务成为了各大互联网基础设施提供商的核心追求。Cloudflare 作为全球领先的互联网安全和基础设施公司,近期做出了一个重大技术决策:弃用长期使用的 Nginx,转而采用其内部开发…...

IoT/HCIP实验-3/LiteOS操作系统内核实验(任务、内存、信号量、CMSIS..)
文章目录 概述HelloWorld 工程C/C配置编译器主配置Makefile脚本烧录器主配置运行结果程序调用栈 任务管理实验实验结果osal 系统适配层osal_task_create 其他实验实验源码内存管理实验互斥锁实验信号量实验 CMISIS接口实验还是得JlINKCMSIS 简介LiteOS->CMSIS任务间消息交互…...

并发编程 - go版
1.并发编程基础概念 进程和线程 A. 进程是程序在操作系统中的一次执行过程,系统进行资源分配和调度的一个独立单位。B. 线程是进程的一个执行实体,是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位。C.一个进程可以创建和撤销多个线程;同一个进程中…...

怎么让Comfyui导出的图像不包含工作流信息,
为了数据安全,让Comfyui导出的图像不包含工作流信息,导出的图像就不会拖到comfyui中加载出来工作流。 ComfyUI的目录下node.py 直接移除 pnginfo(推荐) 在 save_images 方法中,删除或注释掉所有与 metadata …...

PostgreSQL——环境搭建
一、Linux # 安装 PostgreSQL 15 仓库 sudo dnf install -y https://download.postgresql.org/pub/repos/yum/reporpms/EL-$(rpm -E %{rhel})-x86_64/pgdg-redhat-repo-latest.noarch.rpm# 安装之前先确认是否已经存在PostgreSQL rpm -qa | grep postgres# 如果存在࿰…...

为什么要创建 Vue 实例
核心原因:Vue 需要一个「控制中心」来驱动整个应用 你可以把 Vue 实例想象成你应用的**「大脑」或「引擎」。它负责协调模板、数据、逻辑和行为,将它们变成一个活的、可交互的应用**。没有这个实例,你的代码只是一堆静态的 HTML、JavaScript 变量和函数,无法「活」起来。 …...