微服务开发与实战Day11 - 微服务面试篇
一、分布式事务
1. CAP定理
1998年,加州大学的计算机科学及Eric Brewer提出,分布式系统有三个指标:
- Consistency(一致性)
- Availability(可用性)
- Partition tolerance(分区容错性)
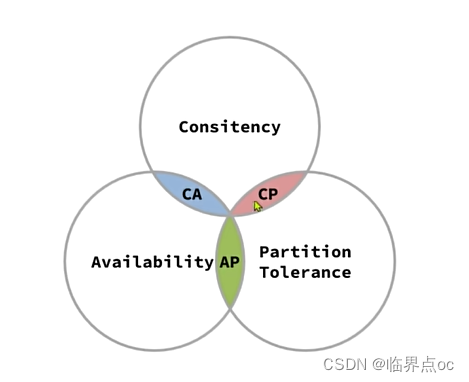
Eric Brewer说,分布式系统无法同时满足这三个指标。这个结论就叫做CAP定理。
Consistency
Consistency(一致性):用户当问分布式系统中的任意节点,得到的数据必须一致

Availability
Avaliability(可用性):用户访问分布式系统时,读或写操作总能成功。只能读不能写,或者只能写不能读,或者两者都不能执行,就说明系统弱可用或不可用。
Partition tolerance
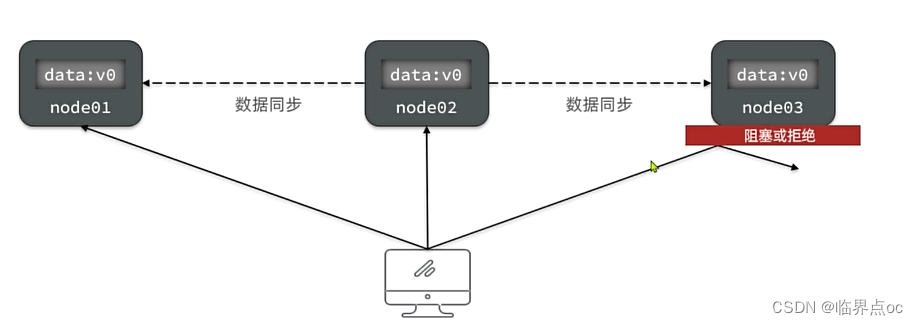
Partition(分区):因为网络故障或其他原因导致分布式系统中的部分节点与其他节点失去连接,形成独立分区。
tolerance(容错):系统要能容忍网络分区现象,出现分区时,整个系统也要持续对外提供服务。
- 如果此时只允许读,不允许写,满足所有节点一致性。但是牺牲了可用性。符合CP
- 如果此时允许任意读写,满足了可用性。但由于node3无法同步,导致数据不一致,牺牲了一致性。符合AP

2. BASE理论
BASE理论是对CAP的一种解决思路,包含三个思想:
- Basically Available(基本可用):分布式系统在出现故障时,允许损失部分可用性,即保证核心可用。
- Soft State(软状态):在一定时间内,允许出现中间状态,比如临时的不一致状态。
- Eventually Consistent(最终一致性):虽然无法保证强一致性,但是在软状态结束后,最终达到数据一致。
而分布式事务最大的问题是各个子事务的一致性问题,因此可以借鉴CAP定理和BASE理论:
- CP模式:各个子事务执行后互相等待,同时提交,同时回滚,达成强一致。但事务等待过程中,处于弱可用状态。
- AP模式:各个子事务分别执行和提交,允许出现结果不一致,然后采用弥补措施恢复数据即可,实现最终一致。
3. AT模式的脏写问题
AT模式原理
例如,一个分支业务的SQL是这样的:update tb_account set money = money - 10 where id = 1
第一阶段是记录数据快照,执行并提交事务:

第二阶段根据阶段一的结果来判断:
- 如果每一个分支事务都成功,则事务已经结束(因为阶段一已经提交),因此删除阶段一的快照即可
- 如果有任意分支事务失败,则需要根据快照恢复到更新前数据,然后删除快照。

AT模式的脏写问题
Seata AT 模式 | Apache Seata
这种模式在大多数情况下并不会有什么问题,不过在极端情况下,特别是多线程并发访问AT模式的分布式事务时,有可能出现脏写问题,如图:(丢失更新)

AT模式的写隔离
解决思路就是引入了全局锁的概念。在释放DB锁之前,先拿到全局锁。避免同一时刻有另外一个事务操作当前数据。

极端情况:

4. TCC模式
4.1 流程分析
TCC模式与AT模式非常相似,每阶段都是独立事务,不同的是TCC通过人工编码实现数据恢复。需要实现三个方法:
- Try:资源的检测和预留;
- Confirm:完成资源操作业务;要求Try成功 Confirm一定要能成功 -> 业务执行和提交
- Cancel:预留资源的释放,可以理解为try的反向操作。
举例,一个扣减用户余额的业务。假设账户A原来是100,需要余额扣减30元。
- 阶段一(Try):检测余额是否充足,如果充足则冻结金额增加30元,可用余额扣除30
初始余额:

余额充足,可以冻结:

- 阶段二(Confirm):假如要提交(Confirm),则冻结金额扣减30即可

- 阶段二(Cancel):如果要回滚(Cancel),则冻结金额扣减30,可用余额增加30

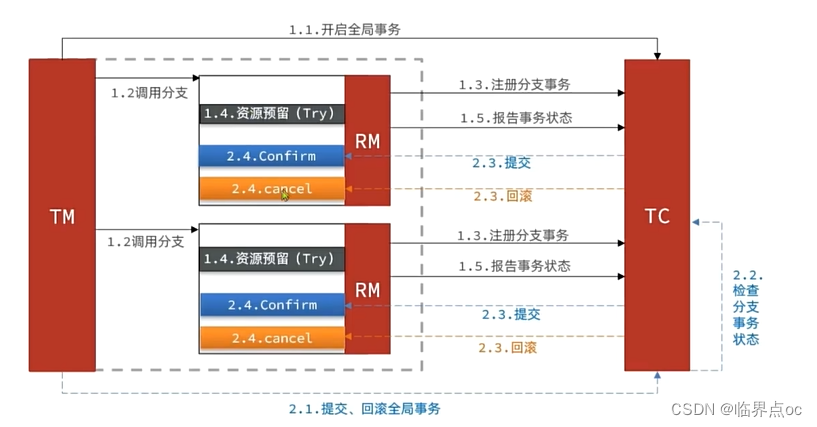
TCC模式原理
TCC的工作模型图:
4.2 事务悬挂和空回滚
假如一个分布式事务中包含两个分支事务,try阶段,一个分支成功执行,另一个分支事务阻塞:

如果阻塞时间过长,可能导致全局事务超时而触发二阶段的cancel操作。两个分支事务都会执行cancel操作:

要知道,其中一个分支是未执行try操作的,直接执行了cancel操作,反而会导致数据错误。因此,这种情况下,尽管cancel方法要执行,但其中不能做任何回滚操作,这就是空回滚。
对于整个空回滚的分支事务,将来try方法阻塞结束依然会执行。但是整个全局事务其实已经结束了,因此永远不会再有confirm或cancel,也就是说这个事务执行了一半,处于悬挂状态,这就是业务悬挂问题。
以上问题都需要我们在编写try、cancel方法时处理
TCC的优点是什么?
- 一阶段完成直接提交事务,释放数据库资源,性能好
- 相比AT模式,无需生成快照,无需使用全局锁,性能最强
- 不依赖数据库事务,而是依赖补偿操作,可以用于非事务型数据库
TCC的缺点是什么?
- 有代码侵入,需要人为编写try、Confirm和Cancel接口,麻烦
- 软状态,事务是最终一致
- 需要考虑Confirm和Cancel的失败情况,做好幂等处理、事务悬挂和空回滚处理
5. 最大努力通知
最大努力通知是一种最终一致性的分布式事务解决方案。顾名思义,就是通过消息通知的方式来通知事务参与者完成业务执行,如果执行失败会多次通知。无需任何分布式事务组件介入。

二、注册中心 - Nacos
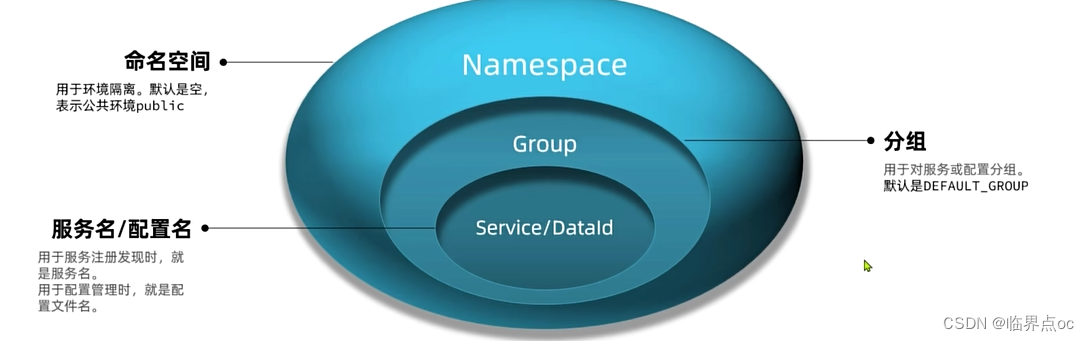
1. 环境隔离
企业实际开发中,往往会搭建多个运行环境,例如:开发环境、测试环境、发布环境。不同环境之间需要隔离。或者不同项目使用了一套Nacos,不同项目之间要做环境隔离。
1.1 创建namespace
nacos提供了一个默认的namespace,叫作public
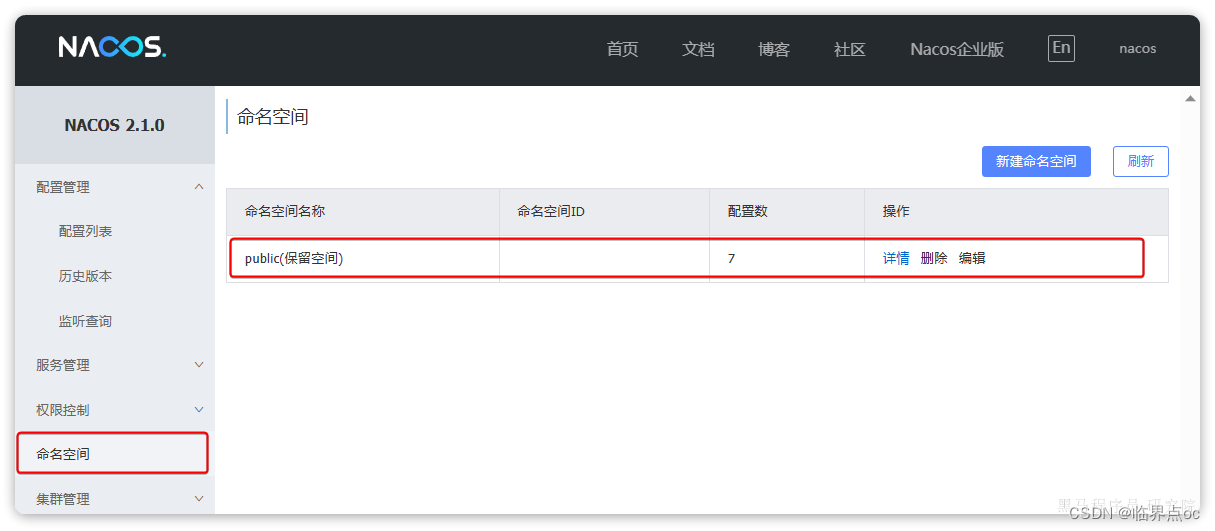
默认所有的服务和配置都属于这个namespace,当然我们也可以自己创建新的namespace:


添加完成后,可以在页面看到我们新建的namespace,并且Nacos为我们自动生成了一个命名空间id:

切换到配置列表页,发现dev这个命名空间下没有任何配置(因为我们之前添加的所有配置都在public下)

1.2 微服务配置namespace
默认情况下,所有的微服务注册发现、配置管理都是走public这个命名空间。如果要指定命名空间则需要修改application.yml文件。
比如,修改item-service服务的bootstrap.yml文件,添加服务发现配置,指定其namespace(不指定默认为public):
spring:application:name: item-service # 服务名称profiles:active: devcloud:nacos:server-addr: 192.168.150.101 # nacos地址discovery: # 服务发现配置namespace: 8c468c63-b650-48da-a632-311c75e6d235 # 设置namespace,必须用id# 。。。略重启item-service,查看服务列表,会发现item-service会在dev下:

而其它服务则出现在public下:

此时,访问http://localhost:8082/doc.html,基于swagger做测试:

会发现查询结果中缺少商品的最新价格信息。
查看cart-service运行日志:
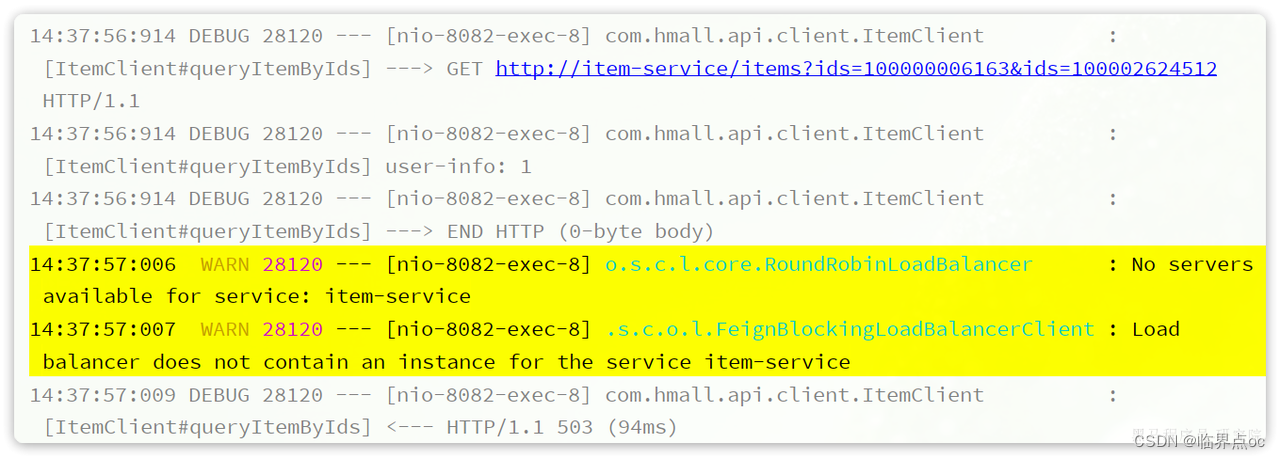
会发现cart-service服务在远程调用item-service时,并没有找到可用的实例。这证明不同namespace之间是相互隔离的,不可访问。
2. 分级模型
大厂的服务可能部署在多个不同机房,物理上被隔离为多个集群。Nacos支持对于这种集群的划分。一个服务(service)下可以有很多集群(cluster),而一个集群(cluster)下又可以包含很多实例(instance)。

任何一个微服务的实例在注册到Nacos时都会生成以下几个信息,用来确认当前实例的身份,从外到内依次是:
- namespace:命名空间
- group:分组
- service:服务名
- cluster:集群
- instance:实例,包含ip和端口
在Nacos内部会有一个服务实例的注册表,是基于Map实现的,其结构与分级模型的对应关系如下:

查看nacos控制台,会发现默认情况下所有服务的集群都是default:

如果我们要修改服务所在集群,只需要修改bootstrap.yml即可:
spring:cloud:nacos:discovery:cluster-name: BJ # 集群名称,自定义3. Eureka与Nacos
3.1 Eureka
Eureka是Netfix公司开源的一个注册中心组件,目前被集成在SpringCloudNetfix这个模块下。它的工作原理与Nacos类似。由于Eureka和Nacos的starter中提供的功能都是基于SpringCloudCommon规范,因此两者使用起来差别不大。

用IDEA打开课前资料里提供的cloud-demo项目:

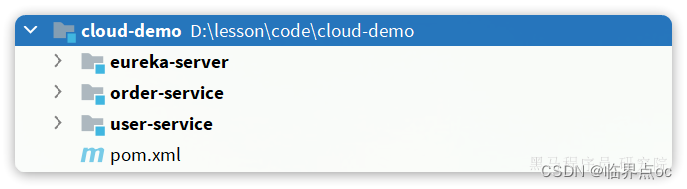
结构说明:
- eureka-service:Eureka的服务端,也就是注册中心。Eureka服务端要自己创建项目
- order-serive:订单服务,是一个服务调用者,查询订单的时候要查询用户
- user-service:用户服务,是一个服务提供者,对外暴露查询用户的接口
启动EurekaApplication后,可以在localhost:10086查看Eureka的控制台:

微服务引入Eureka的步骤:
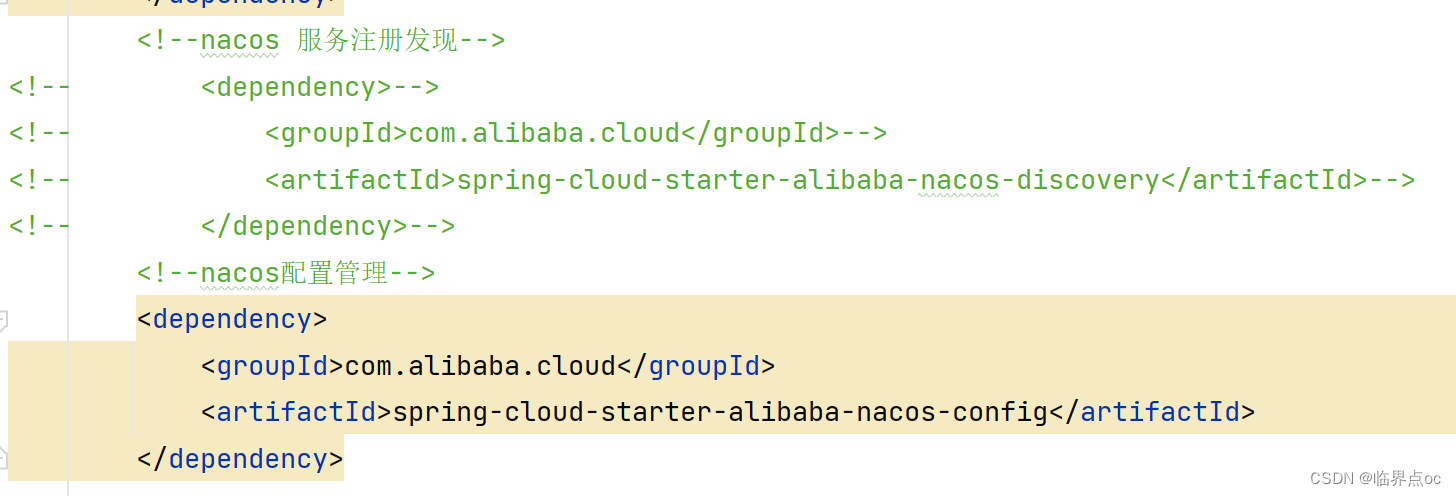
①引入eureka-client依赖
此处在hmall项目的cart-serive和item-service的pom.xml引入
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>注意要把 Nacos服务注册发现 的依赖注释掉,把Eureka的依赖放到最下面,不然可能导致依赖冲突问题

②配置eureka地址
item-service和cart-service的application.yaml
(测试完之后改回为 nacos的配置)
eureka:client:service-url:defaultZone: http://127.0.0.1:10086/eureka
在swagger接口文档中进行测试:

同时Eureka还实现了负载均衡:


3.2 Eureka与Nacos的对比
Eureka和Nacos都能起到注册中心的作用,用法基本相似,但是还是有一些区别的,例如:
- Nacos支持配置管理,而Eureka则不支持。
而且在服务注册发现上也有区别。
在Eureka中,健康检测的原理如下:
- 微服务启动时注册信息到Eureka,这点与Nacos一致。
- 微服务每隔30秒向Eureka发送心跳请求,报告自己的健康状态。Nacos中默认是5秒1次。
- Eureka如果90秒未收到心跳,则认为是服务疑似故障,可能被剔除。Nacos中则是15秒超时,30秒剔除。
- Eureka如果发现超过85%的服务都心跳异常,会认为是自己的网络异常,暂停剔除服务的功能。
- Eureka每隔60秒执行一次服务检测和清理任务。Nacos是每隔5秒执行一次。
综上,Eureka是尽量不剔除服务,避免”误杀“,宁可放过一千,也不错杀一个。这就导致当服务真的出现故障时,迟迟不会被剔除,给服务的调用者带来困扰。
不仅如此,当Eureka发现服务宕机并从服务列表中剔除以后,并不会将服务列表的变更信息推动给所有微服务,而是等待微服务自己来拉取时发现服务列表的变化。而微服务每隔30秒才会去Eureka更新一次服务列表,进一步推迟了服务宕机时被发现的时间。
而Nacos中微服务除了自己定时去Nacos中拉取服务列表外,Nacos还会在服务列表变更时主动推送最新的服务列表给所有的订阅者。
Eureka与Nacos的相似点:
- 都支持服务注册发现功能
- 都有基于心跳的健康监测功能
- 都支持集群,集群间数据同步默认是AP模式,即最高可用性
Eureka与Nacos的区别:
- Eureka的心跳是30秒一次,Nacos则是5秒一次
- Eureka如果90秒未收到心跳,则认为服务疑似故障,可能被剔除。Nacos中则是15秒超时,30秒剔除。
- Eureka每隔60秒执行一次服务检测和清理服务;Nacos是每隔5秒执行一次
- Eureka只能等微服务自己每隔30秒更新一次服务列表;Nacos既有定时更新,也有在服务变更时的广播推送
- Eureka仅有注册中心功能,而Nacos通知支持注册中心、配置管理
- Nacos集群默认采用AP模式,但也支持CP模式。Eureka采用AP模式
三、远程调用
1. 负载均衡原理
自SpringCloud2020版本开始,SpringCloud弃用Ribbon,改用Spring自己开源的Spring Cloud LoadBalancer了,我们使用的OpenFeign、Gateway都已经与其整合。
OpenFeign在整合SpringCloudLoadBalancer时,与我们手动服务发现、负载均衡的流程类似。
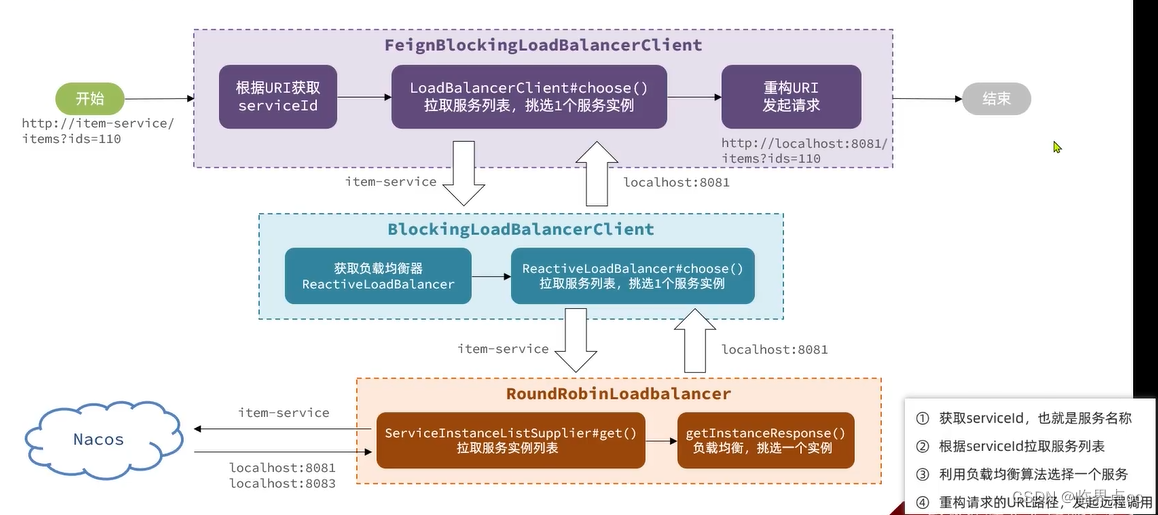
流程梳理:
Spring在整合OpenFeign时,实现了org.springframework.cloud.openfeign.loadbalancer.FeignBlockingLoadBalancerClient类,其中定义了OpenFeign发起远程调用的核心流程。也就是四步:
- 从请求的URI中获取serviceId,也就是服务名称
- 根据serviceId拉取服务列表
- 利用loadBalancerClient,根据serviceId做负载均衡,选择一个服务实例ServiceInstance(轮询)
- 用选中的ServiceInstance的ip和port替代serviceId,重构请求的URI路径,发起远程调用
而具体的负载均衡则不是由OpenFiegn组件负责。而是分成了负载均衡的接口规范,以及负载均衡的具体实现两部分。
负载均衡的接口规范是定义在Spring-Cloud-Common模块中,包含下面的接口:
- LoadBalancerClient:负载均衡客户端,职责是根据serviceId最终负载均衡,选出一个服务实例
- ReactiveLoadBalancer:负载均衡器,负责具体的负载均衡算法
OpenFeign的负载均衡是基于Spring-Cloud-Common模块的相关接口,具体如下:
BlockingLoadBalancerClient:实现了LoadBalancerClient,会根据serviceId选出负载均衡器并调用其算法实现负载均衡。
- RoundRobinLoadBalancer:基于轮询算法实现了ReactiveLoadBalancer
- RandomLoadBalancer:基于随机算法实现了ReactiveLoadBalancer
2. 切换负载均衡算法
ReactiveLoadBalancer的实现类有三个:

其中,RoundRobinLoadBalancer和RandomLoadBalalcer是由Spring-Cloud-LoadBalancer模块提供,而NacosLoadBalancer则是由Nacos-Discovery模块提供的。
默认采用的负载均衡策略是RoundRobinLoadBalancer。
2.1 修改负载均衡策略
查看源码会发现,Spring-Cloud-LoadBalancer模块中会有一个自动配置类

其中定义了默认的负载均衡器:RoundRobinLoadBalancer

这个Bean上添加了@ConditionalOnMissingBean注解,也就是说如果我们自定义了这个类型的bean,则负载均衡的策略就会被改变。
在cart-service模块中添加一个配置类:

代码如下:注意,这个配置类不能加@Configuration注解,也不要被SpringBootApplication扫描到
package com.hmall.cart.config;import com.alibaba.cloud.nacos.NacosDiscoveryProperties;
import com.alibaba.cloud.nacos.loadbalancer.NacosLoadBalancer;
import org.springframework.cloud.client.ServiceInstance;
import org.springframework.cloud.loadbalancer.core.ReactorLoadBalancer;
import org.springframework.cloud.loadbalancer.core.ServiceInstanceListSupplier;
import org.springframework.cloud.loadbalancer.support.LoadBalancerClientFactory;
import org.springframework.context.annotation.Bean;
import org.springframework.core.env.Environment;public class LoadBalancerConfiguration {@Beanpublic ReactorLoadBalancer<ServiceInstance> reactorServiceInstanceLoadBalancer(Environment environment, NacosDiscoveryProperties properties,LoadBalancerClientFactory loadBalancerClientFactory) {String name = environment.getProperty(LoadBalancerClientFactory.PROPERTY_NAME);return new NacosLoadBalancer(loadBalancerClientFactory.getLazyProvider(name, ServiceInstanceListSupplier.class), name, properties);}
}
由于这个LoadBalancerConfiguration没有加@Configuration注解,也就没有被Spring加载,因此是不会生效的。接下来,我们要在启动类上通过注解来声明这个配置。
有两种做法:
全局配置:对所有服务生效(我们选择全局配置)
@LoadBalancerClients(defaultConfiguration = LoadBalancerConfiguration.class)局部配置:只对某个服务生效
@LoadBalancerClients(@LoadBalancerClient(value = "item-service", configuration = LoadBalancerConfiguration.class)DEBUG重启测试,会发现负载均衡器的类型切换成功:

2.2 集群优先负载均衡算法
RoundRobinLoadBalancer是轮询算法,RandomLoadBalancer是随机算法,那么NacosLoadBalancer是什么负载均衡算法呢?
源码分析:
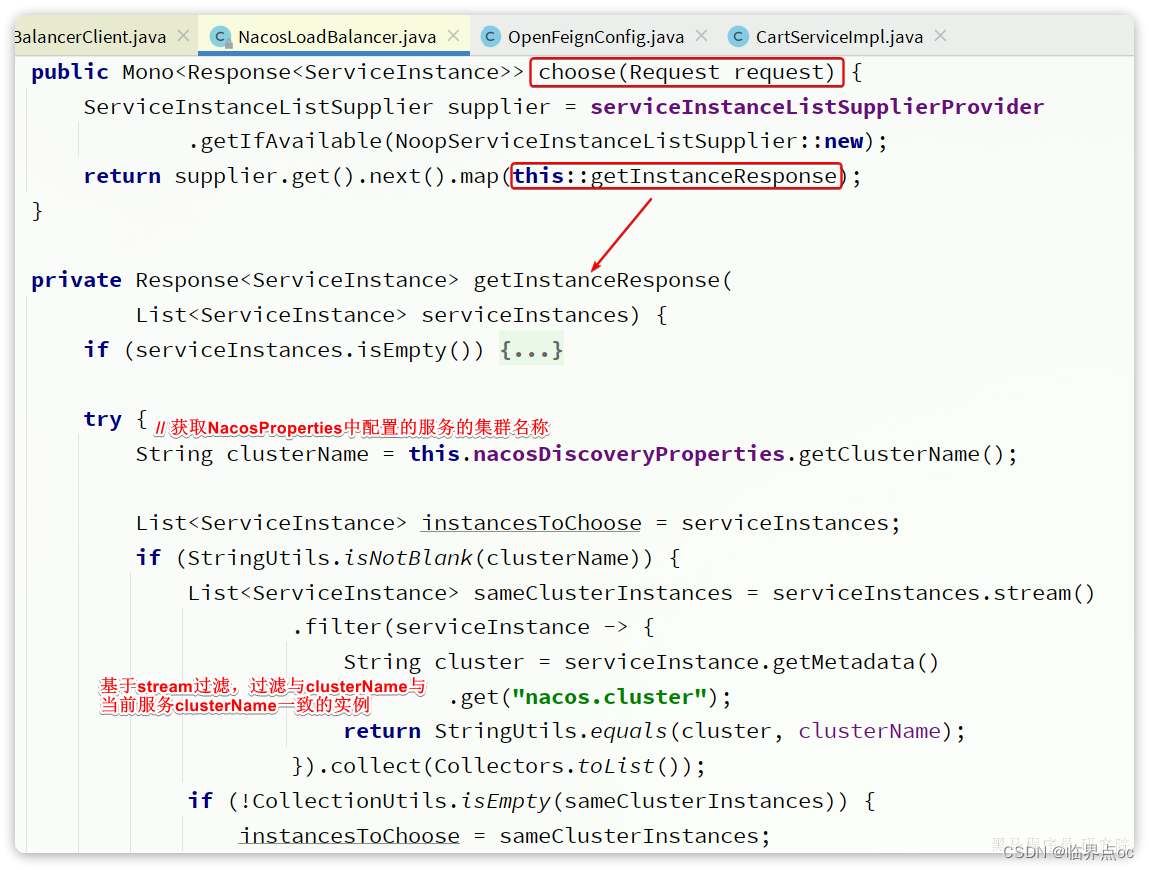
流程:
- 通过SeriveInstanceListSupplier获取服务实例列表
- 获取NacosDiscoveryProperties中的clusterName,也就是yml文件中的配置,代表当前服务实例所在集群信息
- 然后利用stream的filter过滤找到被调用的服务实例中与当前服务实例clusterName一致的。简单来说,就是服务调用者与服务提供者要在一个集群
为什么?
假如我们现在有两个机房,都部署有item-service和cart-service服务:

假如这些服务实例全部都注册到了同一个Nacos。现在,杭州机房的cart-service要调用item-service,会拉取到所有机房的item-service的实例。调用时会出现两种情况:
- 直接调用当前机房的item-service
- 调用其他机房的item-service
本机房调用几乎没有网络延迟,速度比较快。而跨机房调用,如果两个机房相距很远,会存在较大的网络延迟。因此,我们应该尽可能避免跨机房调用,优先本地集群调用。

假设现在的情况如下:
- cart-service所在集群是default
- item-service的8081、8083所在集群为default
- item-service的8084所在集群为BJ
cart-service访问item-service时,应该优先访问8081和8082。重启cart-service进行测试:
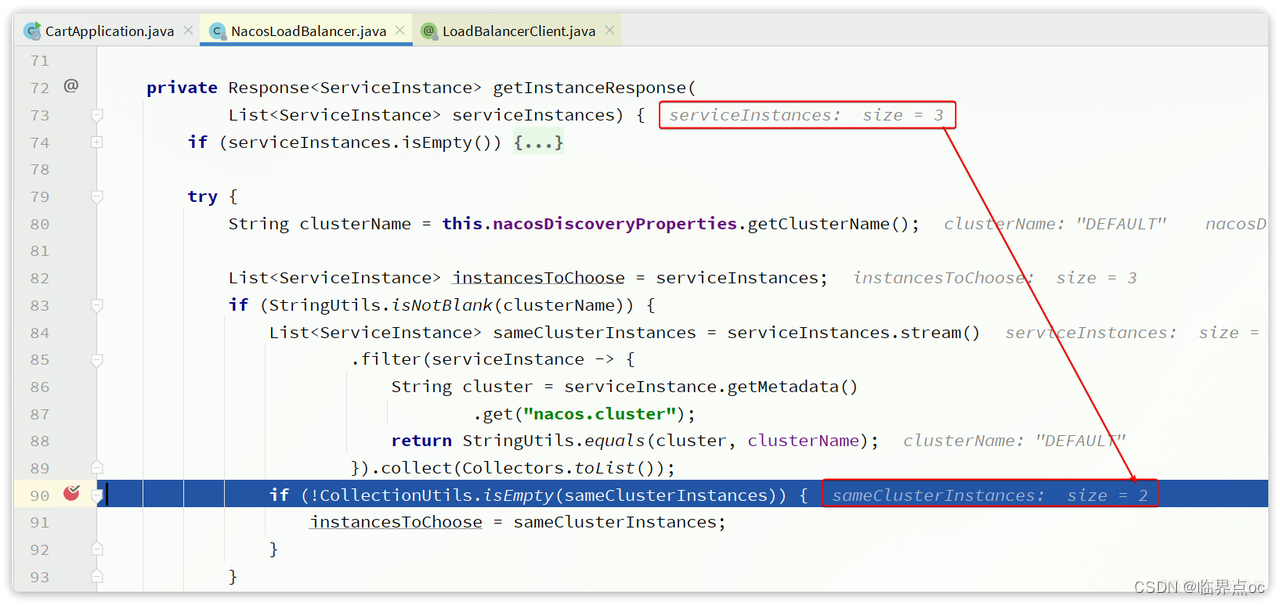
可以看到原本是3个实例,经过筛选后还剩下2个实例。
查看DEBUG控制台:

同集群还剩下两个实例,接下来就需要做负载均衡,使用的是权重算法。
权重配置
继续跟踪NacosLoadBalancer的源码:

在nacos控制台,进入item-service的服务详情页,可以看到每个实例后面都有应一个编辑按钮:
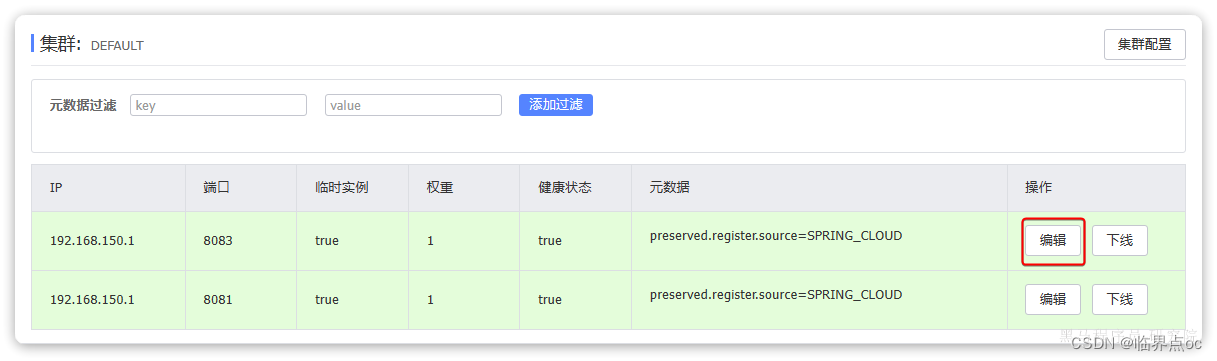
点击,可以编辑实例的权重:

我们将这里的权重修改为5,可以发现大多数请求都访问到了8083这个实例:

四、服务保护
在SpringCloud的早期版本中采用的服务保护技术叫作Hystix,不过后来被淘汰,替换为Spring Cloud Circuit Breaker,其底层实现可以是Spring Retry和Resilience4J。
不过在国内使用较多的还是SpringCloudAlibaba中的Sentinel组件。
1. 线程隔离
- 线程池隔离(Hystix默认采用):给每个服务调用业务分配一个线程池,利用线程池本身实现隔离效果
- 信号量隔离(Sentinel默认采用):不创建线程池,而是计数器模式,记录业务使用的线程数量,达到信号量上限时,禁止新的请求。
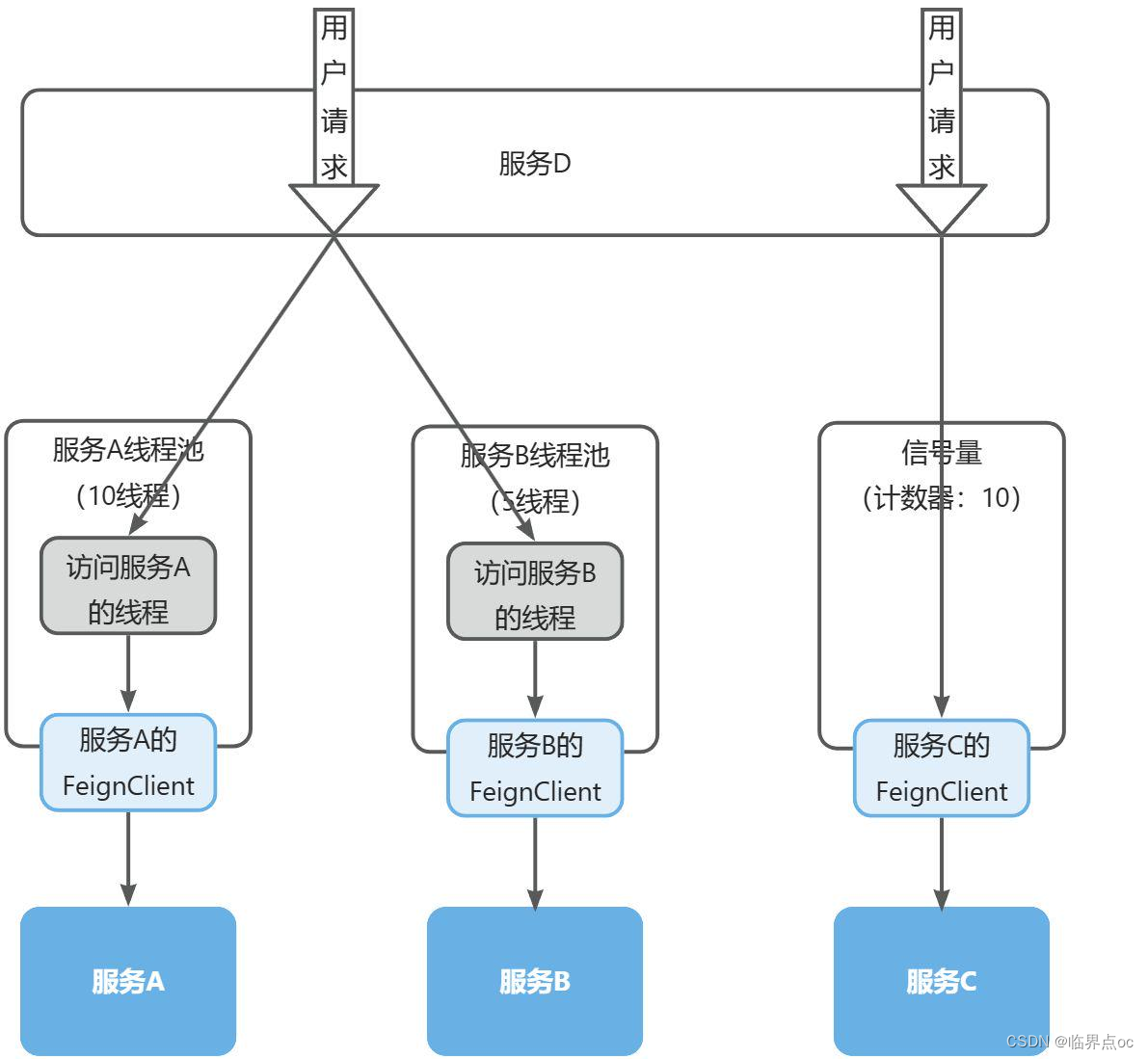
| 优点 | 缺点 | 场景 | |
| 信号量隔离 | 轻量级,无额外开销 | 不支持主动超时 不支持异步调用 | 高频调用 高扇出 |
| 线程池隔离 | 支持主动超时 支持异步调用 | 线程的额外开销比较大 | 低扇出 |
问题:Sentinel的线程隔离与Hystix的线程隔离有什么差别?
答:线程隔离可以采用线程池隔离或者信号量隔离。Hystix默认是基于线程池实现的线程隔离,每一个被隔离的业务都要创建一个独立的线程池,线程过多会带来额外的CPU开销,性能一般,但是隔离性更强。Sentinel则是基于信号量隔离的原理,这种方式不用创建线程池,性能较好,但是隔离性一般。
2. 滑动窗口算法
2.1 固定窗口计数算法

说明:
- 将时间划分为多个窗口,窗口时间跨度称为Interval,本例中为1000ms;
- 每个窗口维护1个计数器,每有1个请求就将计数器+1。限流就是设置计数器阈值,本例为3,图中红线标记
- 如果计数器超过了限流阈值,则超出阈值的请求都被丢弃。

说明:
- 第1、2秒,请求数量都小于3,没问题
- 第3秒,请求数量为5,超过阈值,超出的请求被拒绝
一种特殊场景:

说明:假如在第5、6秒,请求数量都为3,没有超过阈值,全部放行
但是,如果第5秒的三次请求都是在4.5~5秒之间进来;第6秒的请求是在5~5.5之间进来。那么第4.5~5.5之间就有6次请求!也就是说,每秒的QPS达到了6,远超阈值。
这就是固定窗口计数算法的问题,它只能统计当前某一时间窗的请求数量是否达到阈值,无法结合前后的时间窗的数据做综合统计。因此,我们就需要滑动时间窗口算法来解决。
2.2 滑动窗口计数算法
固定时间窗口算法中窗口有很多,其跨度和位置是与时间区间绑定,因此是很多固定不动的窗口。而滑动时间窗口算法中只包含1个固定跨度的窗口,但窗口是可移动的,与时间区间无关。
滑动窗口计数器算法会将一个窗口划分为n个更小的区间,例如:
- 窗口时间跨度Interval为1秒;区间数量n=2,则每隔小区间时间跨度为500ms,每个区间都有计数器
- 限流阈值依然为3,时间窗口(1秒)内请求超过阈值时,超出的请求被限流
- 窗口会根据当前请求所在时间(currentTime)移动,窗口范围是从(currentTime - Interval)之后的第一个时区开始,到currentTime所在时区结束。

限流阈值依然为3,绿色小块就是请求,上面的数字是其currentTime值。
- 在1300ms时接收到一个请求,其所在时区就是1000~1500
- 按照规则,currentTime-Interval值为300ms,300ms之后的第一个时区是500~1000,因此窗口范围包含两个时区:500~1000、1000~1500,也就是粉红色框部分
- 统计窗口内的请求总数,发现是3,未达到上限。
若第1400ms又来一个请求,会落在1000~1500时区,虽然该时区请求总数是3,但是滑动窗口内总数已经达到4,因此该请求会被拒绝:

假如第1600ms又来一个请求,处于1500~2000时区,根据算法,滑动窗口位置应该是1000~1500和1500~2000这两个时区,也就是向后移动:

这就是滑动窗口计数的原理,解决了我们之前所说的问题。而且滑动窗口内划分的时区越多,这种统计就越准确。
3. 漏桶算法
漏桶算法说明:
- 将每个请求视作”水滴“放入”漏桶”进行存储;
- “漏桶”以固定速率向外“漏”出请求来执行,如果“漏桶”空了则停止“漏水”;
- 如果“漏桶”满了则多余的“水滴”会被直接丢弃;
- 可以理解为请求在桶内排队等待
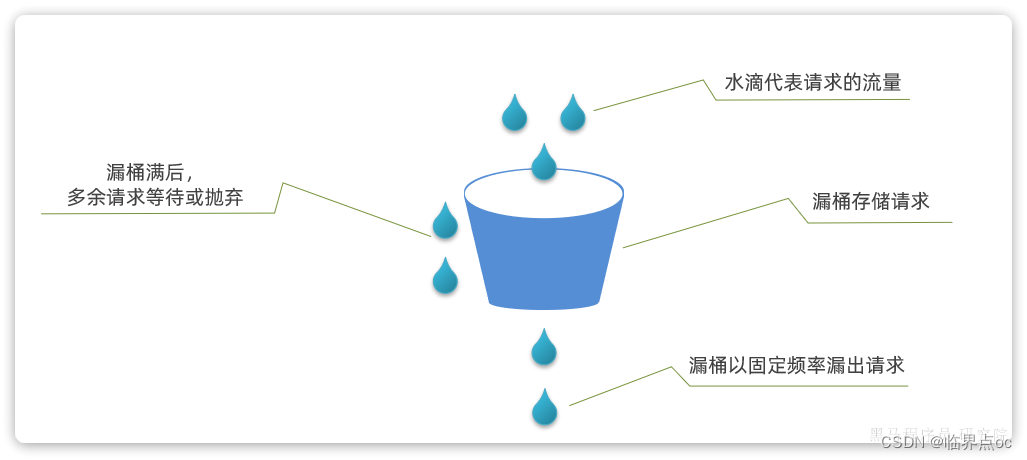
Sentinel内部基于漏桶算法实现了排队等待效果,桶的容量取决于QPS阈值以及允许等待的最大超时时间。
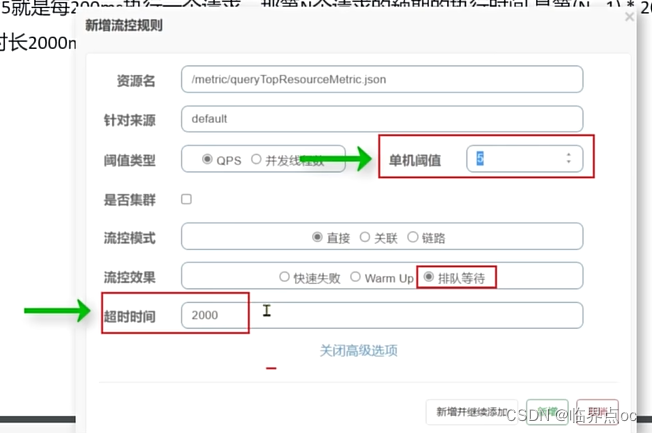
例如:限流QPS=5,队列超时时间为2000ms。我们让所有请求进入应该队列中,如同进入漏桶中。由于漏桶是固定频率执行,因此QPS为5就是每200ms执行一个请求。那第N个请求的预期的执行时间是第(N-1)*200ms。如果请求预期的执行时间超出最大时长2000ms,说明“桶满了”,新的请求则会被拒绝。

漏桶的优势就是流量整型,桶就像是一个大坝,请求就是水。并发量不断波动,就如图水流时大时小,但都会被大坝拦住。而后大坝按照固定的速度放水,避免下游被洪水淹没。
因此,不管并发量如何波动,经过漏桶处理后的请求一定是相对平滑的曲线:

Sentinel中的限流中的排队等待功能正是基于漏桶算法实现的。
4. 令牌桶算法
限流的另一种常见算法是令牌桶算法。Sentinel中的热点参数限流正是基于令牌桶算法实现的。
令牌桶算法说明:
- 以固定的速率生成令牌,存入令牌桶中,如果令牌桶满了之后,停止生成
- 请求进入后,必须先尝试从桶中获取令牌,获取到令牌后才可以被处理
- 如果令牌桶中没有令牌,则请求等待或丢弃
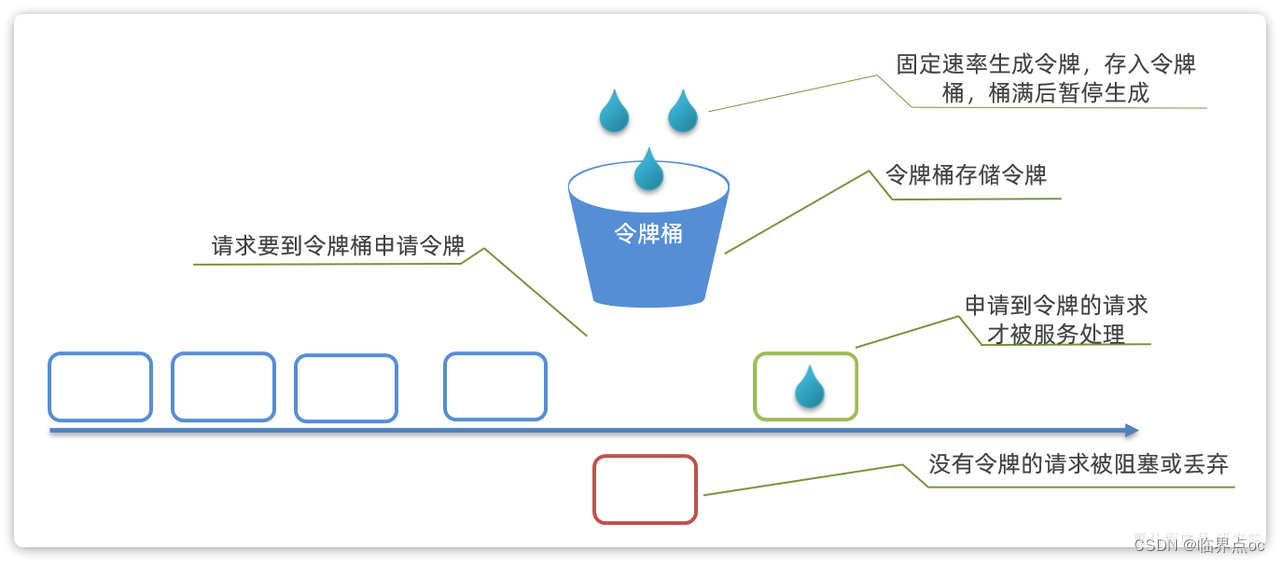
基于令牌桶算法,每秒产生的令牌数量基本就是QPS上限。
当然也有例外情况,例如:
- 某一秒令牌桶中产生了很多令牌,达到令牌桶上限N,缓存在令牌桶中,但是这一秒没有请求进入。
- 下一秒的前半秒融入了超过2N个请求,之前缓存的令牌桶的令牌耗尽,同时这一秒又生成了N个令牌,于是总共放行了2N个请求。超出了我们设定的QPS阈值。
因此,在使用令牌桶算法时,尽量不要将令牌上限设定到服务能承受的QPS上限,而是预留一定的波动空间,这样我们才能应对突发流量。
问题:Sentinel的限流与Gateway的限流有什么差别?
答:限流算法常见的有三种实现:滑动时间窗口、令牌桶算法、漏桶算法。Gateway则采用了基于Redis实现的令牌桶算法,而Sentinel内部却比较复杂:
- 默认限流模式是基于滑动时间窗口算法,另外Sentinel中 断路器的计数也是基于滑动时间窗口算法
- 限流后可以快速失败和排队等待,其中排队等待基于漏桶算法
- 而热点参数限流则是基于令牌桶算法
五、总结
1. Spring Cloud有哪些常用组件?分别是什么作用?
- Nacos:一个基于云原生技术构建的的动态服务发现、配置管理和服务管理平台,可以实现服务注册与发现、动态配置、服务路由、流量管理等功能。
- OpenFeign:一个声明式的的HTTP客户端,可以与Spring Cloud集成,简化服务之间的调用方式,开发人员只需定义接口并加上注解,OpenFeign会自动生成实现类。
- Spring Cloud Gateway:一个基于Spring Framework 5、Project Reactor和Spring Boot 2的网关服务,可以实现路由、过滤等功能,用于统一管理微服务的流量。
- Sentinel:阿里巴巴开源的一款流量控制、熔断降级和系统负载保护的库。在微服务架构中,Sentinel可以帮助开发人员保护系统的稳定性,防止雪崩效应。
- Seata:一个分布式事务解决方案,可以实现分布式事务的管理和协调,保证一致性。在微服务架构中,Seata可以帮助处理分布式事务问题。
- RabbitMQ:一个开源的消息的代理软件,可以实现消息队列的功能,用于在微服务架构中进行异步通信、解耦服务等。
- Elasticsearch:一个分布式的搜索和分析引擎,可以用于存储和搜索大规模数据。在微服务架构中,Elasticsearch可以用于日志存储、搜索等。
- SpringCloudLoadBalancer:Spring Cloud中的负载均衡组件,可以帮助开发人员实现客户端负载均衡功能,用于分布式系统中的负载均衡。
2. 服务注册发现的基本流程是怎样的?
- 服务注册:服务提供者在启动时向Nacos服务注册中心注册自己的服务信息,包括服务名称、IP地址、端口等。服务注册阶段服务提供者会发送一个心跳包,心跳包包含服务运行的信息以及服务的实例信息。
- 服务发现:服务消费者通过Nacos服务注册中心来发现需要调用的服务。Nacos维护了一份服务注册表,将各个服务的实例信息记录在其中。服务消费者可以通过查询服务注册表来发现可调用的服务实例。
- 负载均衡:在服务发现过程中,Nacos还会提供负载均衡的功能。它可以根据一定的策略(权重)选择合适的服务实例,实现负载均衡,确保请求能够分布到多个服务实例上,避免单个实例负载过重。
- 服务实例维护:在服务运行过程中,Nacos会不断地接收服务实例的心跳信息,如果某个服务实例过长时间未发送心跳或者宕机,则Nacos会将其标记为不可用,并从服务注册表中移除,保证服务调用时只会寻找可用的服务实例。
- 服务治理:除了服务注册和发现,Nacos还提供了服务治理的功能,包括动态配置管理、服务治理、流量管理等,帮助开发人员更好地管理和控制微服务架构中的各个服务。
3. Eureka和Nacos有哪些区别?
相似点:
- 都支持服务注册发现功能
- 都有基于心跳的健康监测功能
- 都支持集群,集群间数据同步默认是AP模式,即最高可用性
区别:
- Eureka的心跳是30秒1次,Nacos是5秒1次
- Eureka如果90秒未收到心跳,则认为服务疑似故障,可能被剔除。Nacos中则是15秒超时,30秒剔除。
- Eureka每隔60秒执行一次服务检测和清理任务。Nacos是每隔5秒执行一次。
- Eureka只能等微服务自己每隔30秒更新一次服务列表;Nacos既有定时更新,也有在服务变更时的广播推送
- Eureka仅有注册中心功能,而Nacos同时支持注册中心、配置管理
- Eureka和Nacos都支持集群,而且默认都是AP模式,但Eureka也可以支持CP模式。
4. Nacos的分级存储模型是什么意思?
- 在一些大型应用中,同一个服务可以部署很多实例。而这些实例可能分布在全国各地的不同机房。由于存在地域差异,网络传输的速度会有很大不同,因此在做服务治理时需要区分不同机房的实例。
- Nacos中提供了集群(cluster)的概念,来对应不同机房。也就是说,一个服务(service)下可以有很多集群(cluster),而一个集群(cluster)下又可以包含很多实例(instance)。任何一个微服务的实例在注册到Nacos时,都会从外到内生成以下几个信息:namespace、group、service、cluster、instance,这就是nacos中的服务分级模型。服务实例的注册表时基于Map实现的。
5. OpenFeign是如何实现负载均衡的?
在SpringCloud的早期版本中,负载均衡都是有Netflix公司开源的Ribbon组件来实现的,甚至Ribbon被直接集成到了Eureka-client和Nacos-Discovery中。
但是自SpringCloud2020版本开始,已经弃用Ribbon,改用Spring自己开源的Spring Cloud LoadBalancer了,我们使用的OpenFeign的也已经与其整合。
发现Spring在整合OpenFeign的时候,实现了org.springframework.cloud.openfeign.loadbalancer.FeignBlockingLoadBalancerClient类,其中定义了OpenFeign发起远程调用的核心流程。也就是四步:
-
获取请求中的serviceId
-
根据serviceId负载均衡,找出一个可用的服务实例
-
利用服务实例的ip和port信息重构url
-
向真正的url发起请求
而具体的负载均衡则是不是由OpenFeign组件负责。而是分成了负载均衡的接口规范,以及负载均衡的具体实现两部分。
负载均衡的接口规范是定义在Spring-Cloud-Common模块中,包含下面的接口:
- LoadBalancerClient:负载均衡客户端,职责是根据serviceId最终负载均衡,选出一个服务实例
- ReactiveLoadBalancer:负载均衡器,负责具体的负载均衡算法
OpenFeign的负载均衡是基于Spring-Cloud-Common模块中的负载均衡规则接口,并没有写死具体实现。这就意味着以后还可以拓展其它各种负载均衡的实现。
不过目前SpringCloud中只有Spring-Cloud-Loadbalancer这一种实现。
Spring-Cloud-Loadbalancer模块中,实现了Spring-Cloud-Common模块的相关接口,具体如下:
BlockingLoadBalancerClient:实现了LoadBalancerClient,会根据serviceId选出负载均衡器并调用其算法实现负载均衡。
- RoundRobinLoadBalancer:基于轮询算法实现了ReactiveLoadBalalcer
- RandomLoadBalancer:基于随机算法实现了ReactiveLoadBalalcer
6. 什么是服务雪崩,常见的解决方案有哪些?
服务雪崩:微服务调用链路中某个服务故障,引起整个链路中的所有微服务都不可用,这就是雪崩。
雪崩问题的产生原因:
- 微服务相互调用,服务提供者出现故障或阻塞;
- 服务调用者没有做好异常处理,导致自身故障;
- 调用链中的所有服务级联失败,导致整个集群故障
解决方案:
①尽量避免服务出现故障或阻塞
- 保证代码的健壮性
- 保证网络畅通
- 提高并发处理能力,能应对较高的并发能求
②服务调用者做好远程调用异常的后备方案,避免故障扩散
| 服务保护技术 | ||
| Sentinel | Hystrix | |
| 线程隔离 | 信号量隔离 | 线程池隔离/信号量隔离 |
| 熔断策略 | 基于慢调用比例或异常比例 | 基于异常比率 |
| 限流 | 基于QPS,支持流量整形 | 有限的支持 |
| Fallback | 支持 | 支持 |
| 控制台 | 开箱即用,可配置规则、查看秒级监控、机器发现等 | 不完善 |
| 配置方式 | 基于控制台,重启后失效 | 基于注解或配置文件,永远生效 |
- 请求限流:限制访问微服务的请求并发量,避免服务因流量激增出现故障。
- 线程隔离:也叫做舱壁模式,模拟船舱隔板的防水原理。通过限定每个业务能使用的线程数量,将故障业务隔离,避免故障扩散。
- 服务熔断:由断路器统计请求的异常比例或慢调用比例,如果超出阈值则会熔断该业务,拦截该接口的请求。熔断期间,所有请求快速失败,全都走fallback逻辑。
7. Hystix和Sentinel有什么区别和联系?
- 线程隔离可以采用线程池隔离或者信号量隔离。Hystix默认是基于线程池实现的线程隔离,每一个被隔离的业务都要创建一个独立的线程池,线程过多会带来额外的CPU开销,性能一般,但是隔离性更强。
- Sentinel则是基于信号量隔离的原理,这种方式不用创建线程池,性能较好,但是隔离性一般。
8. 限流的常见算法有哪些?
滑动窗口算法:通过统计一段时间内的请求次数来限制流量。算法维护1个固定大小的时间窗口(例如1秒),在这个时间窗口内计算请求次数,如果请求次数超过设定的阈值,则拒绝该请求。随着时间推移,滑动窗口不断向前移动,过期的请求数量被移除,新的请求数量被加入。
- 窗口时间跨度Interval大小固定,例如1秒
- 时间区间跨度为Interval / n,例如n=2,则时间区间跨度为500ms
- 窗口会随着当前请求所在时间currentTime移动,窗口范围从currentTime-Interval时刻之后的第一个时区开始,到currentTime所在时区结束。
令牌桶算法:通过令牌桶的设计来控制流量。算法维护一个固定容量的桶,以固定的速率不断往桶内放入令牌,每次请求到来时,消耗一个令牌,如果桶内的令牌数足够,则接受请求,否则拒绝请求。能够平滑限制请求的速率。
- 以固定的速率生成令牌,存入令牌桶中,如果令牌桶满了以后,多余令牌丢弃
- 请求进入后,必须先尝试从桶中获取令牌,获取到令牌后才可以被处理
- 如果令牌桶中没有令牌,则请求等待或丢弃
漏桶算法:通过一个固定容量的漏桶来控制流量。算法规定每隔请求都向漏桶中注入一个水滴,漏桶以固定速率漏水。如果漏桶被注满了,新注入的水滴就会被溢出,即请求被拒绝。如果漏桶未满,则会接受请求被按固定速率漏水,这种算法可以平滑流量防止突发请求引起系统崩溃。
- 将每个请求视作“水滴”放入“漏桶”进行存储;
- “漏桶”以固定速率向外“漏”出请求来执行,如果“漏桶”空了则停止“漏水”
- 如果“漏桶”满了则多余的“水滴”会被直接丢弃
9. 什么是CAP理论和BASE思想?
CAP理论是指分布式系统的三个指标:Consistency(一致性)、Availability(可用性)、Partition tolerance(分区容错性)。
- Consistency(一致性):用户访问分布式系统中的任意节点,得到的数据必须一致。
- Availability(可用性):用户访问分布式系统时,读或写操作总能成功。只能读不能写,或者只能写不能读,或者两者都不能执行,就说明系统弱可用或不可用。
- Partition(分区):因为网络故障或其他原因导致分布式系统中的部分节点与其他节点失去连接,形成独立分区。
- tolerance(容错):系统要能容忍网络分区现象,出现分区时,整个系统也要持续对外提供服务。
BASE思想是指Basically Available(基本可用)、Soft State(软状态)、Eventually Consistent(最终一致性)。
- Basically Available(基本可用):分布式系统在出现故障时,允许损失部分可用性,即保证核心可用。
- Soft State(软状态):在一定时间内,允许出现中间状态,比如临时的不一致状态。
- Eventually Consistent(最终一致性):虽然无法保证强一致性,但是在软状态结束后,最终达到数据一致。
简单来说,BASE思想是一种取舍的方案,不再追求完美,而是最终达成目标。因此解决分布式事务的思想也是这样,有两个方向:
- AP思想:各个子事务分别执行和提交,无需锁定数据。允许出现结果不一致,然后采用弥补措施恢复,实现最终一致即可。例如AT模式就是如此。
- CP思想:各个子事务执行后不要提交,而是等待彼此结果,然后同时提交或回滚。在这个过程中锁定资源,不允许其他人访问,数据处于不可用状态,但能保证一致性。例如XA模式。
10. 项目中碰到过分布式事务吗?怎么解决的?
答:黑马商城hmall项目中交易服务、购物车服务、库存服务分别在三个不同的微服务,每个微服务有自己独立的数据库,因此下单过程中就会跨多个数据库完成业务。虽然每个单独的业务都能在本地遵循ACID,但是它们互相之间无法感知,不知道有人失败了,无法保证最终结果的统一,也就无法遵循ACID的事务特性了。
出现分布式事务:业务跨多个服务实现,业务跨多个数据源实现。
分布式事务产生的一个重要原因,就是参与事务的多个分支事务互相无感知,不知道彼此的执行状态。因此解决分布式事务的思想非常简单:就是找一个统一的事务协调者,与多个分支事务通信,检测每个分支事务的执行状态,保证全局事务下的每一个分支事务同时成功或失败即可。
Seata的事务管理者有3个重要的角色:
- TC(Transaction Coordinator)- 事务协调者:维护全局和分支事务的状态,协调全局事务提交或回滚
- TM(Transaction Manager)- 事务管理器:定义全局事务的范围、开始全局事务、提交或回滚全局事务
- RM(Resource Manager)- 资源管理器:管理分支事务,与TC交谈以注册分支事务和报告分支事务的状态,并驱动分支事务的提交或回滚。

Seata支持4种不同的分布式事务解决方案:XA、TCC、AT、SAGA。
XA模式:

AT模式:
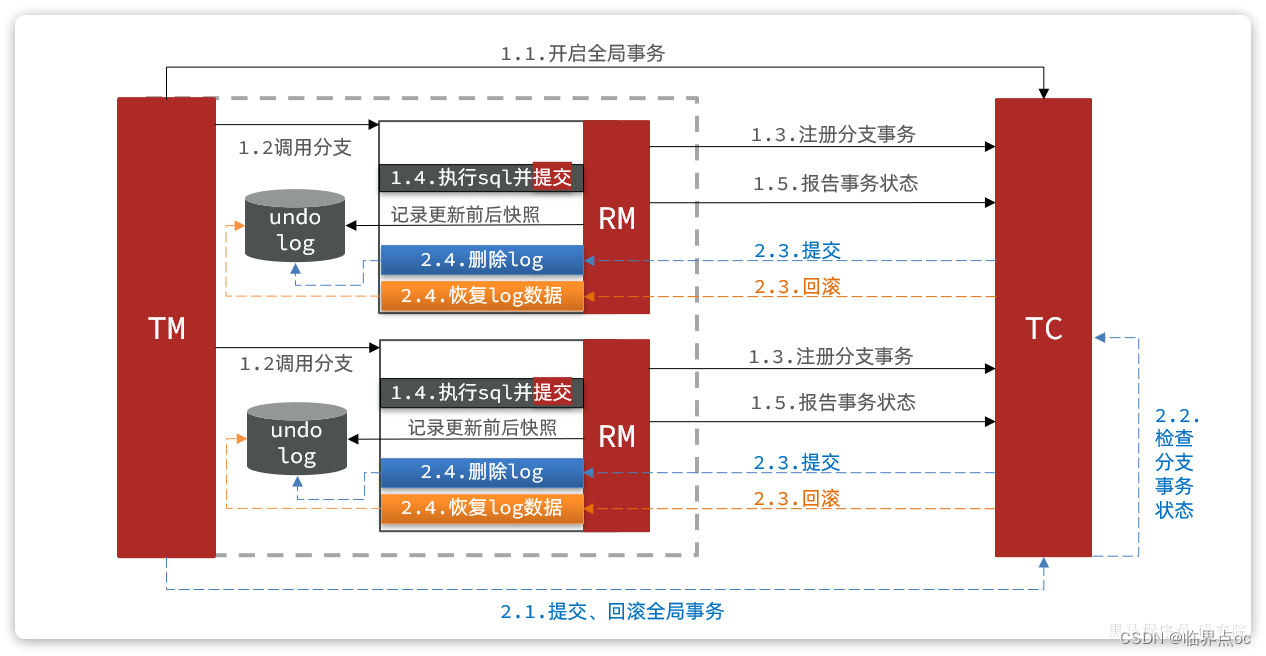
11. AT模式如何解决脏读和脏写问题的?
答:解决思路就是引入了全局锁的概念。在释放DB锁之前,先拿到全局锁,避免同一时刻有另外一个事务来操作当前数据。

12. TCC模式与AT模式相比,有哪些优缺点?
答:TCC(Try Confirm Cancel)模式和AT(Try Abort)模式都是分布式事务处理中常见的两种设计模式,各自有一些优缺点:
TCC模式的优点:
- 一阶段完成直接提交事务,释放数据库资源,性能好
- 相比AT模式,无需生成快照,无需使用全局锁,性能最强
- 不依赖数据库事务,而是依赖补偿操作,可以用于非事务型数据库
TCC模式的缺点:
- 有代码侵入,需要人为编写try、confirm、cancel接口,实现复杂
- 软状态,事务是最终一致
- 需要考虑confirm和cancel的失败情况,做好幂等处理、事务悬挂、和空回滚处理
AT模式的优点:
- AT模式比TCC模式实现起来更为简单,在一些简单的情况下可以更轻松地应用
- AT模式通过两阶段提交的原理,保证所有分支事务在提交时都能保证数据的强一致性
AT模式的缺点:
- AT模式在第二阶段需要等待所有分支事务准备就绪,可能会引起事务的长时间等待,影响性能
- AT模式中需要一个全局锁,如果全局锁出现问题,会造成整个系统事务无法正常提交或回滚
- AT模式需要维护全局事务状态,可能会增加系统资源的开销
13. RabbitMQ是如何确保消息的可靠性的?
答:确保消息的可靠性,要从发送者的可靠性、MQ的可靠性、消费者的可靠性三个方面入手。
发送者的可靠性
- 生产者重试机制:SpringAMQP提供了消息发送时的重试机制,即当RabbitTemplate与MQ连接超时后,多次重试。
- 生产者确认机制:RabbitMQ提供了生产者消息确认机制,包括Publisher Confirm和Publisher Return两种。在开启确认机制的情况下,当生产者发送消息给MQ后,MQ会根据消息处理的情况返回不同的回执。
MQ的可靠性
- 数据持久化:为了提升性能,默认情况下MQ的数据都是在内存存储的临时数据,重启后就会消失。为了保证数据的可靠性,必须配置数据持久化,包括:交换机持久化、队列持久化、消息持久化。
- LazyQueue:①接收到消息后直接存入磁盘而非内存;②消费者要消费消息时才会从磁盘中读取并加载到内存(懒加载)
消费者的可靠性
- 消费者确认机制:为了确认消费者是否成功处理消息,RabbitMQ提供了消费者确认机制(Consumer Acknowledgement)。当消费者处理消息结束后,应该向RabbitMQ发送一个回执,告知RabbitMQ自己消息处理状态:ack(成功)、nack(失败)、reject(失败并拒绝)。
- 失败重试机制:当消费者出现异常后,消息会不断requeue(重入队)到队列,再重新发送给消费者。如果消费者再次执行依然出错,消息会再次requeue到队列,再次投递,直到消息处理成功为止。
- 失败处理策略:Spring允许我们自定义重试次数耗尽后的消息处理策略,这个策略是由MessageRecovery接口来定义,它有三个不同的实现:RejectAndDontRequeueRecoverer(丢弃消息)、ImmediateRequeueMessageRecoverer(消息重新入队)、RepulishMessageRecoverer(将失败消息投递到指定交换机,如死信交换机)
- 设置定时任务作为兜底方案
14. RabbitMQ是如何解决消息堆积问题的?
- 增加消费者数量,优化消费者性能
- 消息预取限制:调整消费者的预取数量以避免一次处理过多消息而导致处理缓慢
- 增加队列的容量:调整队列设置以允许更多消息存储
- 持久化和高可用性:确保消息和队列的持久化以避免消息丢失,使用镜像队列提高可用性
- 使用死信队列:将无法处理的消息转移到死信队列,防止阻塞主队列
- 负载均衡:确保消息在消费者之间合理分配,能者多劳,避免个别消费者过载。
- 使用消息限流:控制消息的生产速度,确保不会超过消费者的处理能力
- 消息优先级:使用消息优先级确保高优先级消息优先处理
资料文档地址:Docs
相关文章:
微服务开发与实战Day11 - 微服务面试篇
一、分布式事务 1. CAP定理 1998年,加州大学的计算机科学及Eric Brewer提出,分布式系统有三个指标: Consistency(一致性)Availability(可用性)Partition tolerance(分区容错性&am…...
基于Spring Boot+VUE职称评审管理系统
1管理员功能模块 管理员登录,通过填写注册时输入的用户名、密码、角色进行登录,如图1所示。 图1管理员登录界面图 管理员登录进入职称评审管理系统可以查看首页、个人中心、用户管理、评审员管理、省份管理、评审条件管理、职称申请管理、结果公布管理、…...

MySQL 基本语法讲解及示例(上)
第一节:MySQL的基本操作 1. 创建数据库 在 MySQL 中,创建数据库的步骤如下: 命令行操作 打开 MySQL 命令行客户端或连接到 MySQL 服务器。 输入以下命令创建一个数据库: CREATE DATABASE database_name;例如,创建一…...

6.18作业
完善对话框,点击登录对话框,如果账号和密码匹配,则弹出信息对话框,给出提示”登录成功“,提供一个Ok按钮,用户点击Ok后,关闭登录界面,跳转到其他界面 如果账号和密码不匹配ÿ…...

Excel文件转换为HTML文件
文章目录 前言安装python包python代码 前言 将一个Excel文件转换为HTML文件 安装python包 使用pandas和openpyxl库来实现这个功能 pip install pandas openpyxlpython代码 1、首先使用tkinter库中的filedialog模块弹出一个对话框来选择要转换的Excel文件 2、使用pandas库…...

MySQL数据库入门
1、MySQL概述 MySQL官方网站 https://www.mysql.com/downloads/ MySQL被Oracle公司收购了,作者又重新编写了一个开源的数据库管理系统,Mariadb 2、MySQL产品&版本 2、数据库在网站架构中的角色 LAMP LNMP网站架构 3、安装MySQL-基于yum 查…...
vue element-ui 下拉框 以及 input 限制输入,小数点后保留两位 界面设计案例 和 例子:支持mp4和m3u8视频播放
vue input 限制输入,小数点后保留两位 以及 图片垂直居中显示 和 分享 git 小技巧-CSDN博客文章浏览阅读430次,点赞5次,收藏4次。error:Your local changes to the following files would be overwritten by merge:_error: your local change…...
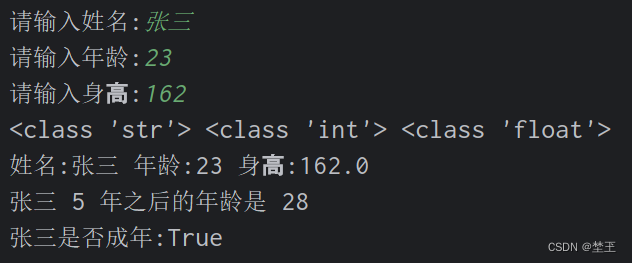
Python基础用法 之 运算符
1.算数运算符 符号作用说明举例加与“”相同 - 减与“-”相同*乘 与“ ”相同 9*218/除 与“ ”相同 9/24.5 、6/32.0//求商(整数部分) 两个数据做除法的 商 9//24%取余(余数部分) 是两个数据做除法的 余数 9%21**幂、次方2**…...
事务所管理系统的设计
管理员账户功能包括:系统首页,个人中心,管理员管理,客户管理,评论管理,基础数据管理,公告信息管理 客户账户功能包括:系统首页,个人中心,律师管理࿰…...

airsim安装
继续进行,遇到下面的报错 Cannot find path HKEY_CLASSES_ROOT\Unreal.ProjectFile\shell\rungenproj 在Git地址的issue中,搜到下面的解决方法,根因是安装Unreal Engine之后未重启电脑,文件未关联导致,或者出现重定向…...

打造精致UI界面:字体设计的妙招
字体设计是UI设计的关键模块之一。字体设计是否有效可能直接实现或破坏整个UI界面。那么,界面设计的字体设计有哪些规范呢?如何设计细节字体?本文将解释字体设计规范的可读性、可读性和可用性,并介绍UI界面中的字体设计技巧。 如…...
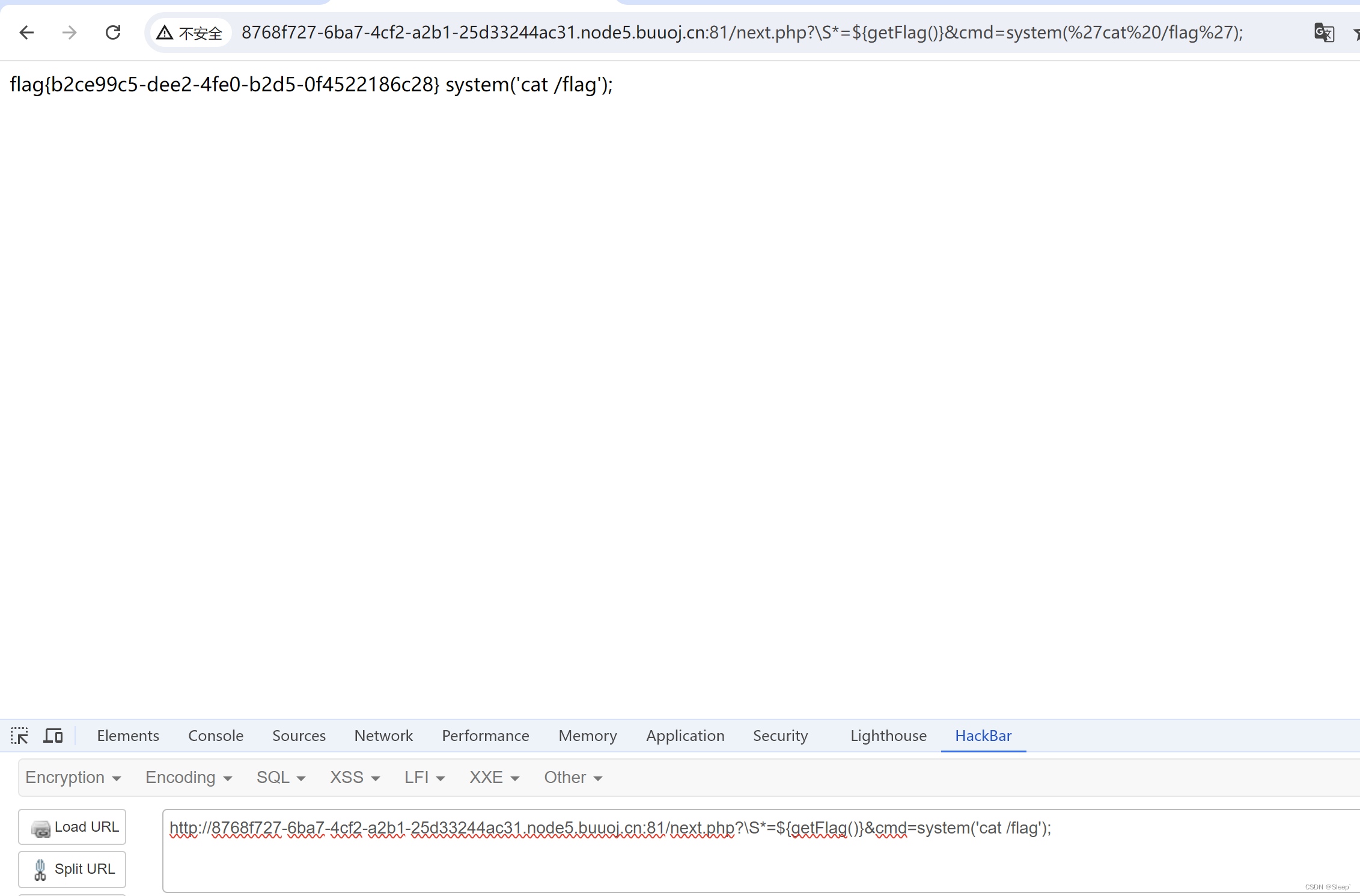
[BJDCTF2020]ZJCTF,不过如此1
打开题目可以看到一段php文件包含,源码如下 <?phperror_reporting(0); $text $_GET["text"]; $file $_GET["file"]; if(isset($text)&&(file_get_contents($text,r)"I have a dream")){echo "<br><h1>…...

全网最全 Kimi 使用手册,看完 Kimi 效率提升 80%
在当前AI文字大模型领域,ChatGPT4.0无疑是最强大。然而,最近最火爆的大模型非国产Kimi莫属。 相较于其它大模型,Kimi 最大的优势在于,超长文本输入,支持200万汉字,是全球范围内罕见的超长文本处理工具&…...
“Redis中的持久化:深入理解RDB与AOF机制“
目录 # 概念 1. RDB持久化 1.1 备份是如何执行的(RDB过程) 1.2 配置文件信息 1.3 RDB持久化操作 1.4 RDB优势 1.5 RDB劣势 1.6 RDB做备份 2. AOF持久化 2.1 AOF开启及使用 2.2 异常恢复 2.3 配置文件操作 2.4 AOF持久化流程 2.5 优点 2.6…...

PHP框架详解:Symfony框架讲解
PHP作为一种流行的服务器端编程语言,拥有众多框架,其中Symfony是备受开发者推崇的一个强大框架。本文将详细讲解Symfony框架的特点、优势及其主要组件和用法。 一、Symfony简介 Symfony是由Fabien Potencier于2005年创建的一个开源PHP框架。它基于MVC&…...
PR软件视频抠图换背景
1 新建项目 2 新建序列 在项目的右下角有个图标,新建 序列 序列是视频的制作尺寸,根据自己的需要选择 3 新建颜色遮罩 在项目的右下角--新建颜色遮罩--选择黑色--确定 4 导入视频 把要导入视频的文件夹打开,把视频拖到 项目 里 把黑色遮罩拖…...
下载依赖有问题(只有自己有问题)
有缓存! 删除node_modules 命令:npm run clean 前提是该项目支持这个命令:package.json > scripts 内有 clean 例如下面这个就没有clean,则直接手动删除 清除缓存 npm cache clean --force pnpm store prune删除lock文件 …...
vscode-关闭ts与js语义校验
1.ts与js语义校验 TypeScript(TS)和JavaScript(JS)在语义校验方面有很大的不同。TypeScript是一种静态类型检查的编程语言,它是JavaScript的一个超集,为JavaScript添加了类型系统和其他一些特性。而JavaScr…...

风控中的文本相似方法之余弦定理
一、余弦相似 一、 余弦相似概述 余弦相似性通过测量两个向量的夹角的余弦值来度量它们之间的相似性。0度角的余弦值是1,而其他任何角度的余弦值都不大于1;并且其最小值是-1。 从而两个向量之间的角度的余弦值确定两个向量是否大致指向相同的方向。结…...

Spring Boot定时任务编程指南:如何创建和配置周期性任务
🍁 作者:知识浅谈,CSDN签约讲师,CSDN博客专家,华为云云享专家,阿里云专家博主 📌 擅长领域:全栈工程师、爬虫、ACM算法 🔥 微信:zsqtcyw 联系我领取学习资料 …...

【Linux】shell脚本忽略错误继续执行
在 shell 脚本中,可以使用 set -e 命令来设置脚本在遇到错误时退出执行。如果你希望脚本忽略错误并继续执行,可以在脚本开头添加 set e 命令来取消该设置。 举例1 #!/bin/bash# 取消 set -e 的设置 set e# 执行命令,并忽略错误 rm somefile…...
:OpenBCI_GUI:从环境搭建到数据可视化(下))
脑机新手指南(八):OpenBCI_GUI:从环境搭建到数据可视化(下)
一、数据处理与分析实战 (一)实时滤波与参数调整 基础滤波操作 60Hz 工频滤波:勾选界面右侧 “60Hz” 复选框,可有效抑制电网干扰(适用于北美地区,欧洲用户可调整为 50Hz)。 平滑处理&…...

DockerHub与私有镜像仓库在容器化中的应用与管理
哈喽,大家好,我是左手python! Docker Hub的应用与管理 Docker Hub的基本概念与使用方法 Docker Hub是Docker官方提供的一个公共镜像仓库,用户可以在其中找到各种操作系统、软件和应用的镜像。开发者可以通过Docker Hub轻松获取所…...

《从零掌握MIPI CSI-2: 协议精解与FPGA摄像头开发实战》-- CSI-2 协议详细解析 (一)
CSI-2 协议详细解析 (一) 1. CSI-2层定义(CSI-2 Layer Definitions) 分层结构 :CSI-2协议分为6层: 物理层(PHY Layer) : 定义电气特性、时钟机制和传输介质(导线&#…...

STM32标准库-DMA直接存储器存取
文章目录 一、DMA1.1简介1.2存储器映像1.3DMA框图1.4DMA基本结构1.5DMA请求1.6数据宽度与对齐1.7数据转运DMA1.8ADC扫描模式DMA 二、数据转运DMA2.1接线图2.2代码2.3相关API 一、DMA 1.1简介 DMA(Direct Memory Access)直接存储器存取 DMA可以提供外设…...

鸿蒙中用HarmonyOS SDK应用服务 HarmonyOS5开发一个医院查看报告小程序
一、开发环境准备 工具安装: 下载安装DevEco Studio 4.0(支持HarmonyOS 5)配置HarmonyOS SDK 5.0确保Node.js版本≥14 项目初始化: ohpm init harmony/hospital-report-app 二、核心功能模块实现 1. 报告列表…...

相机从app启动流程
一、流程框架图 二、具体流程分析 1、得到cameralist和对应的静态信息 目录如下: 重点代码分析: 启动相机前,先要通过getCameraIdList获取camera的个数以及id,然后可以通过getCameraCharacteristics获取对应id camera的capabilities(静态信息)进行一些openCamera前的…...

Neo4j 集群管理:原理、技术与最佳实践深度解析
Neo4j 的集群技术是其企业级高可用性、可扩展性和容错能力的核心。通过深入分析官方文档,本文将系统阐述其集群管理的核心原理、关键技术、实用技巧和行业最佳实践。 Neo4j 的 Causal Clustering 架构提供了一个强大而灵活的基石,用于构建高可用、可扩展且一致的图数据库服务…...

论文浅尝 | 基于判别指令微调生成式大语言模型的知识图谱补全方法(ISWC2024)
笔记整理:刘治强,浙江大学硕士生,研究方向为知识图谱表示学习,大语言模型 论文链接:http://arxiv.org/abs/2407.16127 发表会议:ISWC 2024 1. 动机 传统的知识图谱补全(KGC)模型通过…...

EtherNet/IP转DeviceNet协议网关详解
一,设备主要功能 疆鸿智能JH-DVN-EIP本产品是自主研发的一款EtherNet/IP从站功能的通讯网关。该产品主要功能是连接DeviceNet总线和EtherNet/IP网络,本网关连接到EtherNet/IP总线中做为从站使用,连接到DeviceNet总线中做为从站使用。 在自动…...