李宏毅2023机器学习作业HW06解析和代码分享
ML2023Spring - HW6 相关信息:
课程主页
课程视频
Sample code
HW06 视频
HW06 PDF个人完整代码分享: GitHub | Gitee | GitCode
P.S. HW06 是在 Judgeboi 上提交的,出于学习目的这里会自定义两个度量的函数,不用深究,遵循 Suggestion 就可以达成学习的目的。
每年的数据集 size 和 feature 并不完全相同,但基本一致,过去的代码仍可用于新一年的 Homework。。
文章目录
- 任务目标(seq2seq)
- 性能指标(FID)
- 安装环境
- 定义函数计算 FID 和 AFD rate
- 数据解析
- 数据下载(kaggle)
- Gradescope
- Question 1
- 简述去噪过程
- Question 2
- 训练/推理过程的差异
- 生成图像的差异
- 为什么 DDIM 更快
- Baselines
- Simple baseline (FID ≤ 30000, AFD ≥ 0)
- Medium baseline (FID ≤ 12000, AFD ≥ 0.4)
- Strong baseline (FID ≤ 10000, AFD ≥ 0.5)
- Boss baseline(FID ≤ 9000, AFD ≥ 0.6)
- 完整的样例图对比
任务目标(seq2seq)
- Anime face generation: 动漫人脸生成
- 输入:随机数
- 输出:动漫人脸
- 实现途径:扩散模型
- 目标:生成 1000 张动漫人脸图像
性能指标(FID)
-
FID (Frechet Inception Distance)
用于衡量真实图像与生成图像之间特征向量的距离,计算步骤:

- 使用 Inception V3 模型分别提取真实图像和生成图像的特征(使用最后一层卷积层的输出)
- 计算特征的均值和方差
- 计算 Frechet 距离
-
AFD (Anime face detection) rate
用于衡量动漫人脸检测性能,用来检测提交的文件中有多少动漫人脸。
不过存在一个问题:代码中没有给出 FID 和 AFD 的计算,所以我们需要去自定义计算的函数用于学习。
安装环境
AFD rate 的计算使用预训练的 Haar Cascade 文件。anime_face_detector 库在 cuda 版本过新的时候,需要处理的步骤过多,不方便复现
安装 pytorch-fid 和 ultralytics,并下载预训练的 YOLOv8 模型(源自 Github)。
!pip install pytorch-fid ultralytics
!wget https://github.com/MagicalKyaru/yolov8_animeface/releases/download/v1/yolov8x6_animeface.pt
定义函数计算 FID 和 AFD rate
这里我们定义在 Inference 之后。
import os
import cv2
from pytorch_fid import fid_scoredef calculate_fid(real_images_path, generated_images_path):"""Calculate FID score between real and generated images.:param real_images_path: Path to the directory containing real images.:param generated_images_path: Path to the directory containing generated images.:return: FID score"""fid = fid_score.calculate_fid_given_paths([real_images_path, generated_images_path], batch_size=50, device='cuda', dims=2048)return fiddef calculate_afd(generated_images_path, save=True):"""Calculate AFD (Anime Face Detection) score for generated images.:param generated_images_path: Path to the directory containing generated images.:return: AFD score (percentage of images detected as anime faces)"""results = yolov8_animeface.predict(generated_images_path, save=save, conf=0.8, iou=0.8, imgsz=64)anime_faces_detected = 0total_images = len(results)for result in results:if len(result.boxes) > 0:anime_faces_detected += 1afd_score = anime_faces_detected / total_imagesreturn afd_score# Calculate and print FID and AFD with optional visualization
yolov8_animeface = YOLO('yolov8x6_animeface.pt')
real_images_path = './faces/faces' # Replace with the path to real images
fid = calculate_fid(real_images_path, './submission')
afd = calculate_afd('./submission')
print(f'FID: {fid}')
print(f'AFD: {afd}')
注意,使用当前函数只是为了有个度量,单以当前的YOLOv8预训练模型为例,很可能当前模型只学会了判断两个眼睛的区域是 face,但没学会判断三个眼睛图像的不是 face,这会导致 AFD 实际上偏高,所以只能作学习用途。
数据解析
-
训练数据:71,314 动漫人脸图片
数据集下载链接:https://www.kaggle.com/datasets/b07202024/diffusion/download?datasetVersionNumber=1,也可以通过命令行进行下载:
kaggle datasets download -d b07202024/diffusion注意下载完之后需要进行解压,并对应修改
Sample code中 Training Hyper-parameters 中的路径path。
数据下载(kaggle)
To use the Kaggle API, sign up for a Kaggle account at https://www.kaggle.com. Then go to the ‘Account’ tab of your user profile (
https://www.kaggle.com/<username>/account) and select ‘Create API Token’. This will trigger the download ofkaggle.json, a file containing your API credentials. Place this file in the location~/.kaggle/kaggle.json(on Windows in the locationC:\Users\<Windows-username>\.kaggle\kaggle.json- you can check the exact location, sans drive, withecho %HOMEPATH%). You can define a shell environment variableKAGGLE_CONFIG_DIRto change this location to$KAGGLE_CONFIG_DIR/kaggle.json(on Windows it will be%KAGGLE_CONFIG_DIR%\kaggle.json).-- Official Kaggle API
替换<username>为你自己的用户名,https://www.kaggle.com/<username>/account,然后点击 Create New API Token,将下载下来的文件放去应该放的位置:
- Mac 和 Linux 放在
~/.kaggle - Windows 放在
C:\Users\<Windows-username>\.kaggle
pip install kaggle
# 你需要先在 Kaggle -> Account -> Create New API Token 中下载 kaggle.json
# mv kaggle.json ~/.kaggle/kaggle.json
kaggle datasets download -d b07202024/diffusion
unzip diffusion
Gradescope
这一题我们先处理可视化部分,这个有助于我们理解自己的模型(毕竟没有官方的标准来评价生成的图像好坏)。
Question 1
采样5张图像并展示其渐进生成过程,简要描述不同时间步的差异。
修改 GaussianDiffusion 类中的 p_sample_loop() 方法:
class GaussianDiffusion(nn.Module):...# Gradescope – Question 1@torch.no_grad()def p_sample_loop(self, shape, return_all_timesteps = False, num_samples=5, save_path='./Q1_progressive_generation.png'):batch, device = shape[0], self.betas.deviceimg = torch.randn(shape, device = device)imgs = [img]samples = [img[:num_samples]] # Store initial noisy samplesx_start = None############################################# TODO: plot the sampling process #############################################for t in tqdm(reversed(range(0, self.num_timesteps)), desc = 'sampling loop time step', total = self.num_timesteps):img, x_start = self.p_sample(img, t)imgs.append(img)if t % (self.num_timesteps // 20) == 0:samples.append(img[:num_samples]) # Store samples at specific stepsret = img if not return_all_timesteps else torch.stack(imgs, dim = 1)ret = self.unnormalize(ret)self.plot_progressive_generation(samples, len(samples)-1, save_path=save_path)return retdef plot_progressive_generation(self, samples, num_steps, save_path=None):fig, axes = plt.subplots(1, num_steps + 1, figsize=(20, 4))for i, sample in enumerate(samples):axes[i].imshow(vutils.make_grid(sample, nrow=1, normalize=True).permute(1, 2, 0).cpu().numpy())axes[i].axis('off')axes[i].set_title(f'Step {i}')if save_path:plt.savefig(save_path)plt.show()
表现如下(基于 Sample code):

简述去噪过程
去噪过程主要是指从完全噪声的图像开始,通过逐步减少噪声,最终生成一个清晰的图像。去噪过程的简单描述:
-
初始步骤(噪声):
在初始步骤中,图像是纯噪声,此时的图像没有任何结构和可辨识的特征,看起来为随机的像素点。 -
中间步骤:
模型通过多个时间步(Timesteps)将噪声逐渐减少,每一步都试图恢复更多的图像信息。-
早期阶段,图像中开始出现一些模糊的结构和形状。虽然仍然有很多噪声,但可以看到一些基本轮廓和大致的图像结构。
-
中期阶段,图像中的细节开始变得更加清晰。面部特征如眼睛、鼻子和嘴巴开始显现,噪声显著减少,图像的主要轮廓和特征逐渐清晰。
-
-
最终步骤(完全去噪):
在最后的步骤中,噪声被最大程度地去除,图像变清晰。
Question 2
DDPM(去噪扩散概率模型)在推理过程中速度较慢,而DDIM(去噪扩散隐式模型)在推理过程中至少比DDPM快10倍,并且保留了质量。请分别描述这两种模型的训练、推理过程和生成图像的差异,并简要解释为什么DDIM更快。
参考文献:
- 去噪扩散概率模型 (DDPM)
- 去噪扩散隐式模型 (DDIM)
下面是个简单的叙述,如果有需要的话,建议阅读原文进行理解。
训练/推理过程的差异
DDPM:
-
DDPM 的训练分为前向扩散和反向去噪两个部分:
前向扩散逐步给图像添加噪声。
反向去噪使用 U-Net 模型,通过最小化预测噪声和实际噪声的差异来训练,逐步去掉这些噪声。- Ho et al., 2020, To represent the reverse process, we use a U-Net backbone similar to an unmasked PixelCNN++ with group normalization throughout.
-
但需要处理大量的时间步(比如1000步),训练时间相对DDIM来说更长。
- Ho et al., 2020, We set T = 1000 for all experiments …
DDIM:
- DDIM 的训练与 DDPM 类似,但使用非马尔可夫的确定性采样过程。
- Song et al., 2020, We present denoising diffusion implicit models (DDIMs)…a non-Markovian deterministic sampling process
生成图像的差异
DDPM:
- 生成的图像质量很高,每一步去噪都会使图像变得更加清晰,但步骤多,整个过程比DDIM慢。
DDIM:
- 步骤少,生成速度快,且生成的图像质量与 DDPM 相当。
- Song et al., 2020, Notably, DDIM is able to produce samples with quality comparable to 1000 step models within 20 to 100 steps …
为什么 DDIM 更快
- 步骤更少:DDIM 在推理过程中减少了很多步骤。例如,DDPM 可能需要 1000 步,而 DDIM 可能只需要 50-100 步。
- Song et al., 2020, Notably, DDIM is able to produce samples with quality comparable to 1000 step models within 20 to 100 steps, which is a 10× to 50× speed up compared to the original DDPM. Even though DDPM could also achieve reasonable sample quality with 100× steps, DDIM requires much fewer steps to achieve this; on CelebA, the FID score of the 100 step DDPM is similar to that of the 20 step DDIM.
- 非马尔可夫采样
- Song et al., 2020, These non-Markovian processes can correspond to generative processes that are deterministic, giving rise to implicit models that produce high quality samples much faster.
- 效率:确定性的采样方式使得 DDIM 能更快地生成高质量的图像。
- Song et al., 2020, For DDIM, the generative process is deterministic, and x 0 x_0 x0 would depend only on the initial state x T x_T xT .
Baselines
实际上如果时间充足,出于学习的目的,可以对超参数或者模型架构进行调整以印证自身的想法。这篇文章是最近重新拾起的,所以只是一个简单的概述帮助理解。
另外,当前 FID 数的度量数量级和 Baseline 是不一致的,这里因为时间原因不做度量标准的还原,完成 Suggestion 和 Gradescope 就足够达成学习的目的了。
Simple baseline (FID ≤ 30000, AFD ≥ 0)
- 运行所给的 sample code
Medium baseline (FID ≤ 12000, AFD ≥ 0.4)
-
简单的数据增强
T.RandomHorizontalFlip(), T.RandomRotation(10), T.ColorJitter(brightness=0.25, contrast=0.25) -
将 timesteps 变成1000(遵循 DDPM 原论文的设置)
-
注意,设置为 1000 的话在
trainer.inference()时很可能会遇到 CUDA out of memory,这里对inference()进行简单的修改。
实际效果是针对self.ema.ema_model.sample()减少batch_size至 100,不用过多细究。def inference(self, num=1000, n_iter=10, output_path='./submission'):if not os.path.exists(output_path):os.mkdir(output_path)with torch.no_grad():for i in range(n_iter):batches = num_to_groups(num // n_iter, 100)all_images = list(map(lambda n: self.ema.ema_model.sample(batch_size=n), batches))[0]for j in range(all_images.size(0)):torchvision.utils.save_image(all_images[j], f'{output_path}/{i * 100 + j + 1}.jpg')
-
-
将 train_num_step 修改为 20000
Strong baseline (FID ≤ 10000, AFD ≥ 0.5)
- Model Arch
看了下HW06 对应的视频,从叙述上看应该指的是调整超参数:channel和dim_mults。
这里简单的将channel调整为 32。
dim_mults初始为 (1, 2, 4),增加维度改成 (1, 2, 4, 8) 又或者改变其中的值都是允许的。 - Varience Scheduler
这部分可以自己实现,下面给出比较官方的代码供大家参考比对:使用 denoising-diffusion-pytorch 中的cosine_beta_schedule(),对应的还有sigmoid_beta_schedule()。
sigmoid_beta_schedule()在训练时更适合用在分辨率大于 64x64 的图像上,当前训练集图像的分辨率为 96x96。
增加和修改的部分代码:
def cosine_beta_schedule(timesteps, s = 0.008):"""cosine scheduleas proposed in https://openreview.net/forum?id=-NEXDKk8gZ"""steps = timesteps + 1t = torch.linspace(0, timesteps, steps, dtype = torch.float64) / timestepsalphas_cumprod = torch.cos((t + s) / (1 + s) * math.pi * 0.5) ** 2alphas_cumprod = alphas_cumprod / alphas_cumprod[0]betas = 1 - (alphas_cumprod[1:] / alphas_cumprod[:-1])return torch.clip(betas, 0, 0.999)def sigmoid_beta_schedule(timesteps, start = -3, end = 3, tau = 1, clamp_min = 1e-5):"""sigmoid scheduleproposed in https://arxiv.org/abs/2212.11972 - Figure 8better for images > 64x64, when used during training"""steps = timesteps + 1t = torch.linspace(0, timesteps, steps, dtype = torch.float64) / timestepsv_start = torch.tensor(start / tau).sigmoid()v_end = torch.tensor(end / tau).sigmoid()alphas_cumprod = (-((t * (end - start) + start) / tau).sigmoid() + v_end) / (v_end - v_start)alphas_cumprod = alphas_cumprod / alphas_cumprod[0]betas = 1 - (alphas_cumprod[1:] / alphas_cumprod[:-1])return torch.clip(betas, 0, 0.999)class GaussianDiffusion(nn.Module):def __init__(...beta_schedule = 'linear',...):...if beta_schedule == 'linear':beta_schedule_fn = linear_beta_scheduleelif beta_schedule == 'cosine':beta_schedule_fn = cosine_beta_scheduleelif beta_schedule == 'sigmoid':beta_schedule_fn = sigmoid_beta_scheduleelse:raise ValueError(f'unknown beta schedule {beta_schedule}')......
beta_schedule = 'cosine' # 'sigmoid'
...Boss baseline(FID ≤ 9000, AFD ≥ 0.6)
- StyleGAN
仅供参考,从实验结果上来看,扩散模型生成的图像视觉上更清晰,而 StyleGAN 的风格更一致。
当然,同样存在设置出现问题的情况(毕竟超参数直接延续了之前的设定。Anyway,希望对你有所帮助)
| Strong (DDPM) | Boss (StyleGAN) |
|---|---|
 |  |
class StyleGANTrainer(object):def __init__(self, folder, image_size, *,train_batch_size=16, gradient_accumulate_every=1, train_lr=1e-3, train_num_steps=100000, ema_update_every=10, ema_decay=0.995, save_and_sample_every=1000, num_samples=25, results_folder='./results', split_batches=True):super().__init__()dataloader_config = DataLoaderConfiguration(split_batches=split_batches)self.accelerator = Accelerator(dataloader_config=dataloader_config,mixed_precision='no')self.image_size = image_size# Initialize the generator and discriminatorself.gen = self.create_generator().cuda()self.dis = self.create_discriminator().cuda()self.g_optim = torch.optim.Adam(self.gen.parameters(), lr=train_lr, betas=(0.0, 0.99))self.d_optim = torch.optim.Adam(self.dis.parameters(), lr=train_lr, betas=(0.0, 0.99))self.train_num_steps = train_num_stepsself.batch_size = train_batch_sizeself.gradient_accumulate_every = gradient_accumulate_every# Initialize the dataset and dataloaderself.ds = Dataset(folder, image_size)self.dl = cycle(DataLoader(self.ds, batch_size=train_batch_size, shuffle=True, pin_memory=True, num_workers=os.cpu_count()))# Initialize the EMA for the generatorself.ema = EMA(self.gen, beta=ema_decay, update_every=ema_update_every).to(self.device)self.results_folder = Path(results_folder)self.results_folder.mkdir(exist_ok=True)self.save_and_sample_every = save_and_sample_everyself.num_samples = num_samplesself.step = 0def create_generator(self):return dnnlib.util.construct_class_by_name(class_name='training.networks.Generator',z_dim=512,c_dim=0,w_dim=512,img_resolution=self.image_size,img_channels=3)def create_discriminator(self):return dnnlib.util.construct_class_by_name(class_name='training.networks.Discriminator',c_dim=0,img_resolution=self.image_size,img_channels=3)@propertydef device(self):return self.accelerator.devicedef save(self, milestone):if not self.accelerator.is_local_main_process:returndata = {'step': self.step,'gen': self.accelerator.get_state_dict(self.gen),'dis': self.accelerator.get_state_dict(self.dis),'g_optim': self.g_optim.state_dict(),'d_optim': self.d_optim.state_dict(),'ema': self.ema.state_dict()}torch.save(data, str(self.results_folder / f'model-{milestone}.pt'))def load(self, ckpt):data = torch.load(ckpt, map_location=self.device)self.gen.load_state_dict(data['gen'])self.dis.load_state_dict(data['dis'])self.g_optim.load_state_dict(data['g_optim'])self.d_optim.load_state_dict(data['d_optim'])self.ema.load_state_dict(data['ema'])self.step = data['step']def train(self):with tqdm(initial=self.step, total=self.train_num_steps, disable=not self.accelerator.is_main_process) as pbar:while self.step < self.train_num_steps:total_g_loss = 0.total_d_loss = 0.for _ in range(self.gradient_accumulate_every):# Get a batch of real imagesreal_images = next(self.dl).to(self.device)# Generate latent vectorslatent = torch.randn([self.batch_size, self.gen.z_dim]).cuda()# Generate fake imagesfake_images = self.gen(latent, None)# Discriminator logits for real and fake imagesreal_logits = self.dis(real_images, None)fake_logits = self.dis(fake_images.detach(), None)# Discriminator lossd_loss = torch.nn.functional.softplus(fake_logits).mean() + torch.nn.functional.softplus(-real_logits).mean()# Update discriminatorself.d_optim.zero_grad()self.accelerator.backward(d_loss / self.gradient_accumulate_every)self.d_optim.step()total_d_loss += d_loss.item()# Generator logits for fake imagesfake_logits = self.dis(fake_images, None)# Generator lossg_loss = torch.nn.functional.softplus(-fake_logits).mean()# Update generatorself.g_optim.zero_grad()self.accelerator.backward(g_loss / self.gradient_accumulate_every)self.g_optim.step()total_g_loss += g_loss.item()self.ema.update()pbar.set_description(f'G loss: {total_g_loss:.4f} D loss: {total_d_loss:.4f}')self.step += 1if self.step % self.save_and_sample_every == 0:self.ema.ema_model.eval()with torch.no_grad():milestone = self.step // self.save_and_sample_everybatches = num_to_groups(self.num_samples, self.batch_size)all_images_list = list(map(lambda n: self.ema.ema_model(torch.randn([n, self.gen.z_dim]).cuda(), None), batches))all_images = torch.cat(all_images_list, dim=0)utils.save_image(all_images, str(self.results_folder / f'sample-{milestone}.png'), nrow=int(np.sqrt(self.num_samples)))self.save(milestone)pbar.update(1)print('Training complete')def inference(self, num=1000, n_iter=5, output_path='./submission'):if not os.path.exists(output_path):os.mkdir(output_path)with torch.no_grad():for i in range(n_iter):latent = torch.randn(num // n_iter, self.gen.z_dim).cuda()images = self.ema.ema_model(latent, None)for j, img in enumerate(images):utils.save_image(img, f'{output_path}/{i * (num // n_iter) + j + 1}.jpg')完整的样例图对比
| Simple | Medium | Strong | Boss |
|---|---|---|---|
 |  |  |  |
相关文章:
李宏毅2023机器学习作业HW06解析和代码分享
ML2023Spring - HW6 相关信息: 课程主页 课程视频 Sample code HW06 视频 HW06 PDF 个人完整代码分享: GitHub | Gitee | GitCode P.S. HW06 是在 Judgeboi 上提交的,出于学习目的这里会自定义两个度量的函数,不用深究,遵循 Sugge…...

专业技能篇--算法
文章目录 前言经典算法思想总结一、贪心算法二、动态规划三、回溯算法四、分治算法 前言 这篇简单理解一些常见的算法。如果面试的时候问到相关的算法,能够应付一二。 经典算法思想总结 一、贪心算法 思想:贪心算法是一种在每一步选择中都采取在当前状…...

Vue中CSS动态样式绑定
Vue中CSS动态样式绑定与注意事项_vue css动态绑定-CSDN博客 在 Vue 中,你不能直接在 CSS 中直接绑定 data 中的数据,因为 CSS 不是响应式的。但是,有几种方法可以实现根据 Vue 实例中的数据来动态地改变样式: 内联样式绑定&…...

【漏洞复现】契约锁电子签章平台 add 远程命令执行漏洞(XVE-2023-23720)
0x01 产品简介 契约锁电子签章平台是上海亘岩网络科技有限公司推出的一套数字签章解决方案。契约锁为中大型组织提供“数字身份、电子签章、印章管控以及数据存证服务”于一体的数字可信基础解决方案,可无缝集成各类系统,让其具有电子化签署的能力,实现组织全程数字化办公。通…...

计算机专业是否仍是“万金油”?
身份角度一:一名曾经的计算机专业学生 随着高考的结束,我站在了人生的分岔路口,面临着大学专业的选择。在众多的选择中,计算机专业一直是我深思熟虑后的一个重要选项。然而,我并不清楚自己是否真的适合这个专业&…...

Spring 启动顺序
在 Spring 框架中,应用启动过程涉及多个步骤和组件的初始化。理解 Spring 启动顺序不仅有助于优化应用性能,还能帮助开发人员排查启动过程中可能出现的问题。本文将详细介绍 Spring 启动过程中的关键步骤和顺序。 1. Spring 启动过程概述 Spring 应用的…...

2024.06.19 刷题日记
41. 缺失的第一个正数 这个题目的通过率很低,是一道难题,类似于脑筋急转弯,确实不好想。实际上,对于一个长度为 N 的数组,其中没有出现的最小正整数只能在 [1,N1] 中。 这个结论并不好想,举个例子&#x…...

linux系统中,pwd获取当前路径,dirname获取上一层路径;不使用 ../获取上一层路径
在实际项目中,我们通常可以使用 pwd 来获取当前路径,但是如果需要获取上一层路径,有不想使用 …/ 的方式,可以尝试使用 dirname指令 测试shell脚本 #!/bin/bash# 获取当前路径 CURRENT_PATH$PWD echo "CURRENT_PATH$CURREN…...
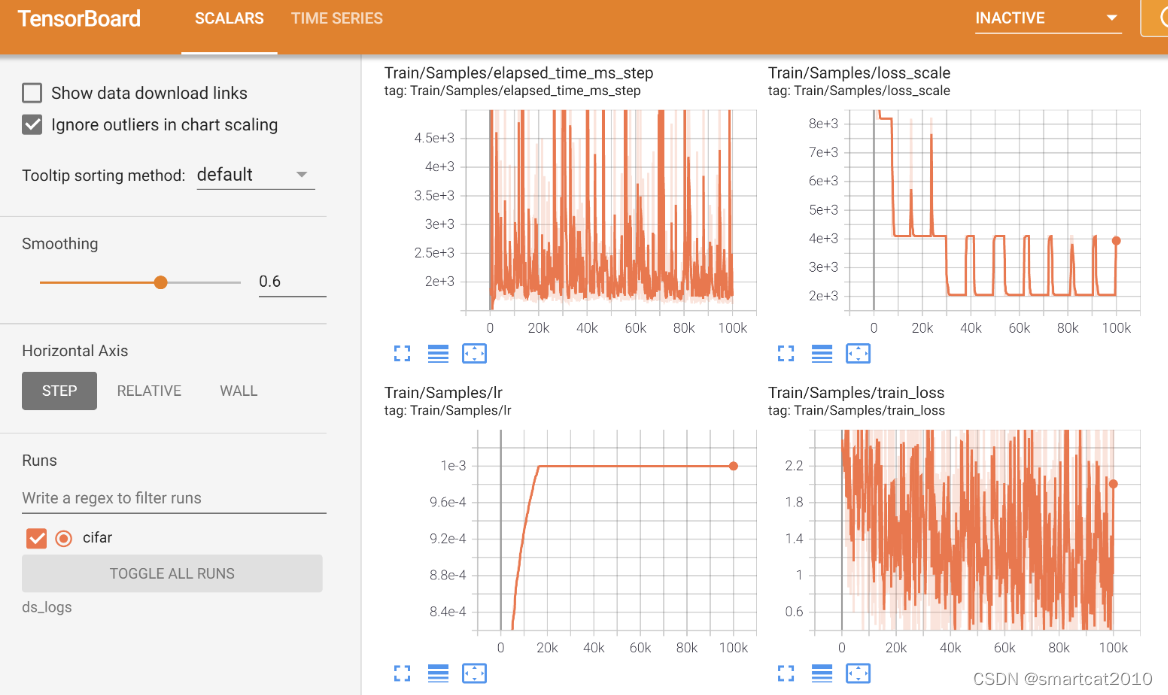
DeepSpeed Monitoring Comm. Logging
Monitoring 支持多种后端:Tensorboard、WandB、Comet、CSV文件; TensorBoard例子: 自动监控:DeepSpeed自动把重要metric记录下来。只需在配置文件里enable相应的看板后端即可: {"tensorboard": {"enabl…...
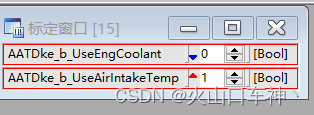
关于INCA的几个实用功能
01--VUI窗口设计 这个可以按照自己的想法设计INCA观测或标定窗口 首先进入到INCA的环境内,点击实验→加载VUI窗口 选择空的窗口 打开后如下所示: 点击UI开发模式,如下图 如下: 添加标定量、观测量、示波器 窗口的大小需要在开发…...
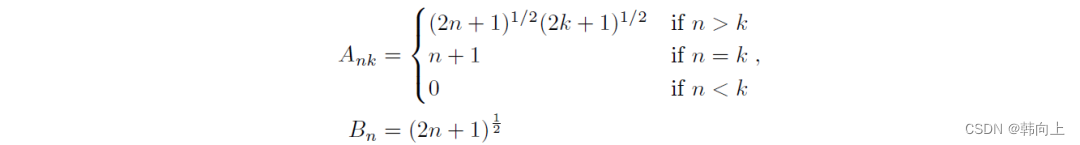
Mamaba3--RNN、状态方程、勒让德多项式
Mamaba3–RNN、状态方程、勒让德多项式 一、简单回顾 在Mamba1和Mamba2中分别介绍了RNN和状态方程。 下面从两个图和两个公式出发,对RNN和状态方程做简单的回顾: R N N : s t W s t − 1 U x t ; O t V s t RNN: s_t Ws_{t-1}Ux_t&…...
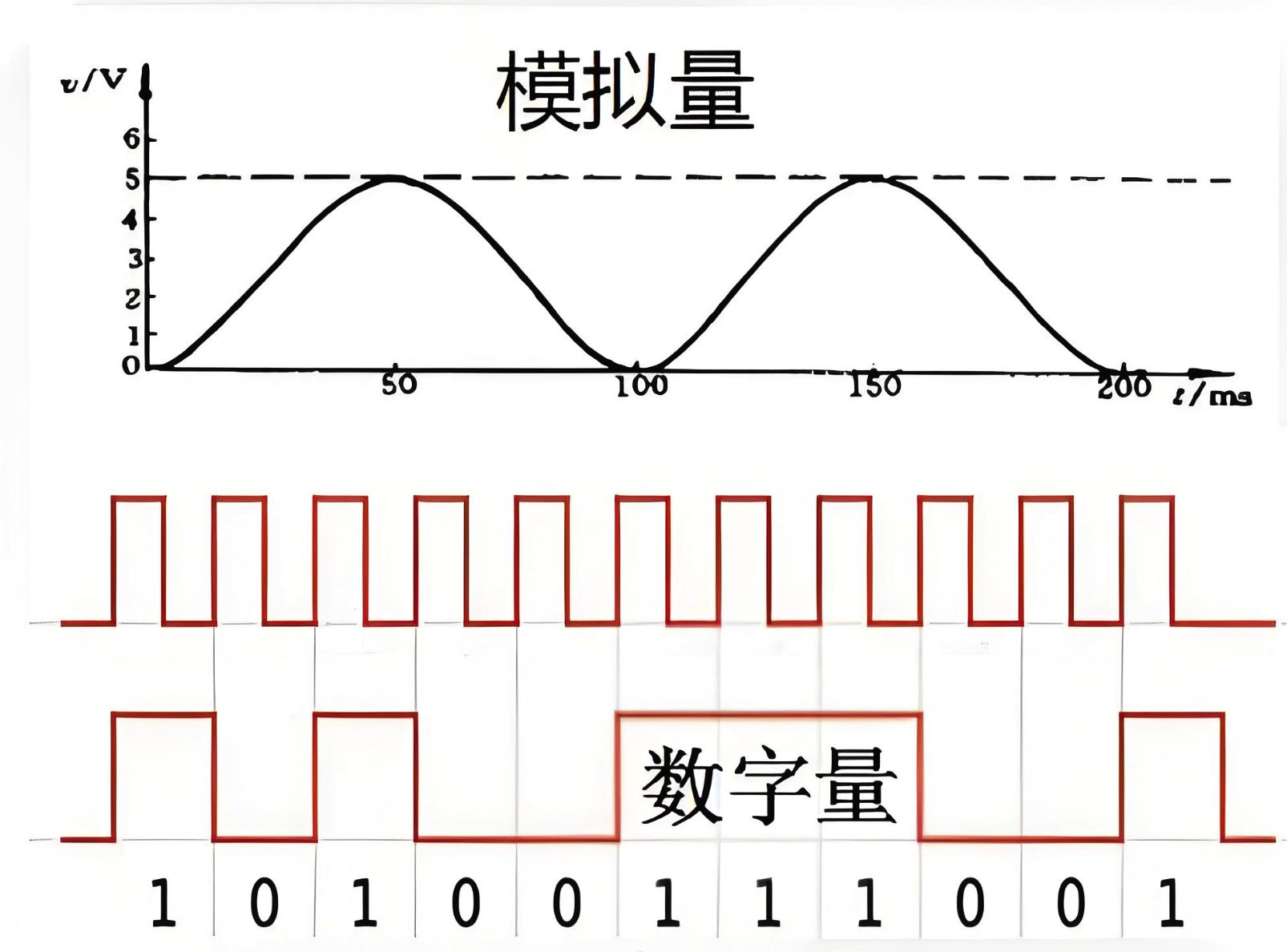
PLC模拟量和数字量到底有什么区别?
PLC模拟量和数字量的区别 在工业自动化领域,可编程逻辑控制器(PLC)是控制各种机械设备和生产过程的核心组件。PLC通过处理模拟量和数字量来实现对工业过程的精确控制。了解模拟量和数字量的区别对于设计高效、可靠的自动化系统至关重要。 1. …...

html中如何写一个提示框,css画一个提示框
在HTML中,提示框通常使用<div>元素来创建,然后使用CSS进行样式化。以下是一个示例,展示如何在HTML中写一个提示框,并使用CSS来设计其外观。 HTML 首先,创建一个HTML文件,其中包含一个提示框的结构&…...

ExoPlayer 学习笔记
https://www.51cto.com/article/777840.html ExoPlayer支持多种媒体格式和流媒体协议的播放器 播放视频:player.play()暂停视频:player.pause()停止播放:player.stop() Media3 ExoPlayer | Android media | Android Developers implem…...

汽车IVI中控开发入门及进阶(二十七):车载摄像头vehicle camera
前言: 在车载IVI、智能座舱系统中,有一个重要的应用场景就是视频。视频应用又可分为三种,一种是直接解码U盘、SD卡里面的视频文件进行播放,一种是手机投屏,就是把手机投屏软件已视频方式投屏到显示屏上显示,另外一种就是对视频采集设备(主要就是摄像头Camera)的视频源…...
Transformer模型:未来的改进方向与潜在影响
Transformer模型:未来的改进方向与潜在影响 自从2017年Google的研究者们首次提出Transformer模型以来,它已经彻底改变了自然语言处理(NLP)领域的面貌。Transformer的核心优势在于其“自注意力(Self-Attention…...

ROS 激光雷达
ROS 激光雷达 基本工作原理 激光雷达(LIDAR,Light Detection and Ranging)是一种用于测量距离的远程感应技术。它通过向目标发射激光并分析反射回来的光来测量目标与激光发射源之间的距离。激光雷达广泛应用于多种领域,包括地理…...

杂说咋说-关于城市化发展和城市治理的几点建议(浙江借鉴)
杂说咋说-关于城市化发展和城市治理的几点建议(浙江借鉴) 近年来,浙江省坚持一张蓝图绘到底,推动城市化发展和城市治理不断迈上新台阶,全省城市化水平和城市治理能力牢牢居于全国第一方阵。当前,国内外环境…...

Linux 常用命令 - which【定位可执行文件的位置】
简介 which 命令源自于英文单词 "which",用于在环境变量 PATH 所指定的路径中搜索某个可执行文件或链接(如一个系统命令)的位置,并返回第一个搜索结果。这个命令会遍历 PATH 环境变量中的所有路径,直到找到…...

js文件导出功能
效果图: 代码示例: <!DOCTYPE html> <html> <head lang"en"><meta charset"UTF-8"><title>html 表格导出道</title><script src"js/jquery-3.6.3.js"></script><st…...

C++_核心编程_多态案例二-制作饮品
#include <iostream> #include <string> using namespace std;/*制作饮品的大致流程为:煮水 - 冲泡 - 倒入杯中 - 加入辅料 利用多态技术实现本案例,提供抽象制作饮品基类,提供子类制作咖啡和茶叶*//*基类*/ class AbstractDr…...

STM32+rt-thread判断是否联网
一、根据NETDEV_FLAG_INTERNET_UP位判断 static bool is_conncected(void) {struct netdev *dev RT_NULL;dev netdev_get_first_by_flags(NETDEV_FLAG_INTERNET_UP);if (dev RT_NULL){printf("wait netdev internet up...");return false;}else{printf("loc…...

基于Uniapp开发HarmonyOS 5.0旅游应用技术实践
一、技术选型背景 1.跨平台优势 Uniapp采用Vue.js框架,支持"一次开发,多端部署",可同步生成HarmonyOS、iOS、Android等多平台应用。 2.鸿蒙特性融合 HarmonyOS 5.0的分布式能力与原子化服务,为旅游应用带来…...

第25节 Node.js 断言测试
Node.js的assert模块主要用于编写程序的单元测试时使用,通过断言可以提早发现和排查出错误。 稳定性: 5 - 锁定 这个模块可用于应用的单元测试,通过 require(assert) 可以使用这个模块。 assert.fail(actual, expected, message, operator) 使用参数…...

Nginx server_name 配置说明
Nginx 是一个高性能的反向代理和负载均衡服务器,其核心配置之一是 server 块中的 server_name 指令。server_name 决定了 Nginx 如何根据客户端请求的 Host 头匹配对应的虚拟主机(Virtual Host)。 1. 简介 Nginx 使用 server_name 指令来确定…...

select、poll、epoll 与 Reactor 模式
在高并发网络编程领域,高效处理大量连接和 I/O 事件是系统性能的关键。select、poll、epoll 作为 I/O 多路复用技术的代表,以及基于它们实现的 Reactor 模式,为开发者提供了强大的工具。本文将深入探讨这些技术的底层原理、优缺点。 一、I…...

面向无人机海岸带生态系统监测的语义分割基准数据集
描述:海岸带生态系统的监测是维护生态平衡和可持续发展的重要任务。语义分割技术在遥感影像中的应用为海岸带生态系统的精准监测提供了有效手段。然而,目前该领域仍面临一个挑战,即缺乏公开的专门面向海岸带生态系统的语义分割基准数据集。受…...

三分算法与DeepSeek辅助证明是单峰函数
前置 单峰函数有唯一的最大值,最大值左侧的数值严格单调递增,最大值右侧的数值严格单调递减。 单谷函数有唯一的最小值,最小值左侧的数值严格单调递减,最小值右侧的数值严格单调递增。 三分的本质 三分和二分一样都是通过不断缩…...

比较数据迁移后MySQL数据库和OceanBase数据仓库中的表
设计一个MySQL数据库和OceanBase数据仓库的表数据比较的详细程序流程,两张表是相同的结构,都有整型主键id字段,需要每次从数据库分批取得2000条数据,用于比较,比较操作的同时可以再取2000条数据,等上一次比较完成之后,开始比较,直到比较完所有的数据。比较操作需要比较…...
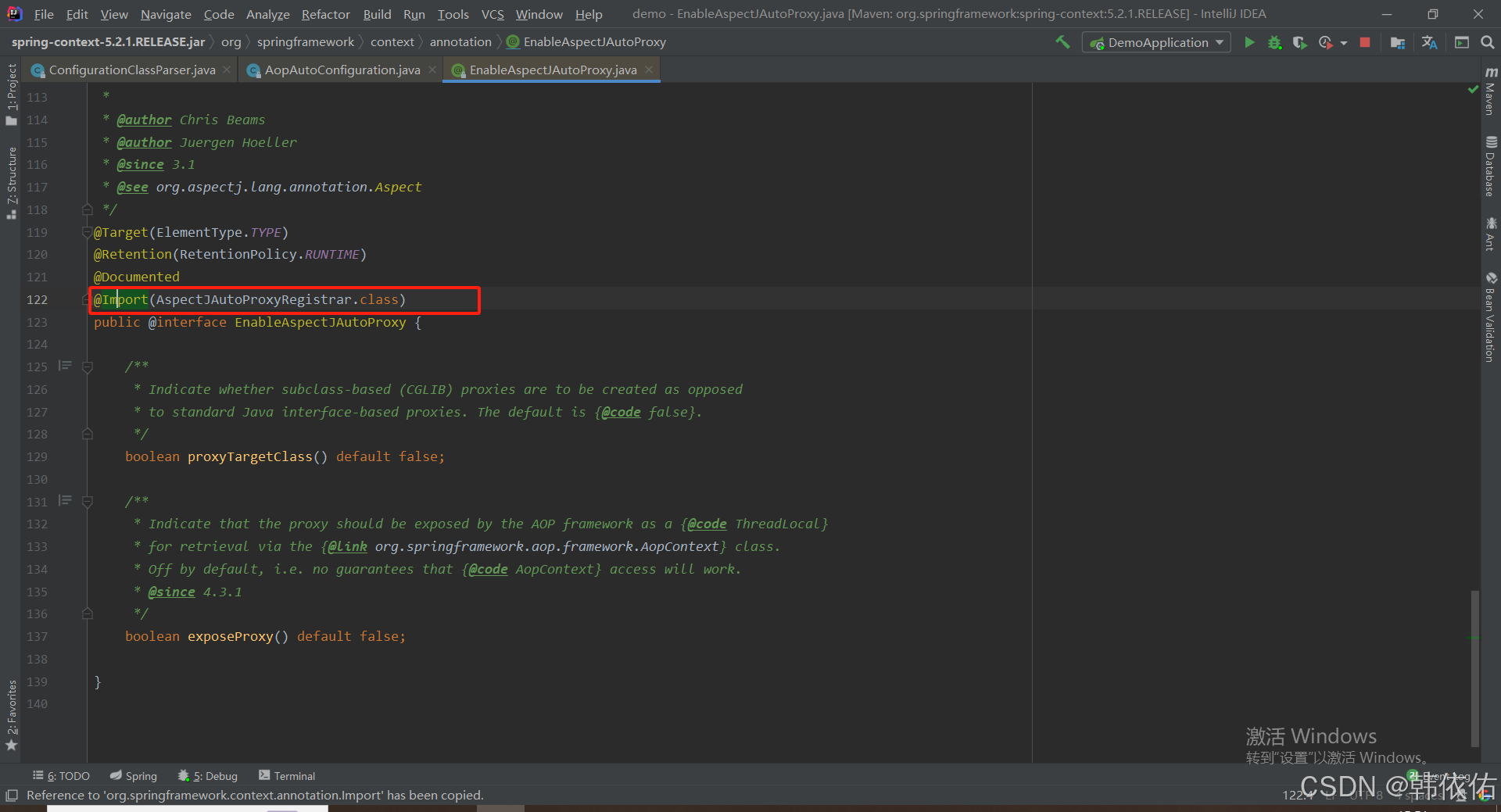
Spring AOP代理对象生成原理
代理对象生成的关键类是【AnnotationAwareAspectJAutoProxyCreator】,这个类继承了【BeanPostProcessor】是一个后置处理器 在bean对象生命周期中初始化时执行【org.springframework.beans.factory.config.BeanPostProcessor#postProcessAfterInitialization】方法时…...