【雷丰阳-谷粒商城 】【分布式高级篇-微服务架构篇】【11】ElasticSearch
持续学习&持续更新中…
守破离
【雷丰阳-谷粒商城 】【分布式高级篇-微服务架构篇】【11】ElasticSearch
- 简介
- 基本概念
- ElasticSearch概念-倒排索引
- 安装
- 基本命令
- Mapping-映射
- ElasticSearch7-去掉type概念
- Es-数组(数组装着Object)的扁平化处理
- ik 分词器
- SpringBoot整合
- 测试存储数据:
- 测试复杂检索
- 同步与异步调用
- 参考

简介
Elasticsearch 是一个高度可扩展且开源的全文检索和分析引擎。它可以让您快速且近实时地存储,检索以及分析海量数据。它通常用作那些具有复杂搜索功能和需求的应用的底层引擎或者技术。(我们得把MySQL中的数据给ES也存储一份,这样ES才能检索这些数据)
- https://www.elastic.co/cn/what-is/elasticsearch
- 全文搜索属于最常见的需求,开源的 Elasticsearch 是目前全文搜索引擎的首选。
- 它可以快速地储存、搜索和分析海量数据。维基百科、Stack Overflow、Github 都采用它
- Elastic 的底层是开源库 Lucene。但是,你没法直接用 Lucene,必须自己写代码去调用它的接口。
- Elastic 是 Lucene 的封装,提供了 REST API 的操作接口,开箱即用。
- REST API:天然的跨平台。
- 官方文档:https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html
- 官方中文:https://www.elastic.co/guide/cn/elasticsearch/guide/current/foreword_id.html
- 社区中文:
- https://es.xiaoleilu.com/index.html
- http://doc.codingdict.com/elasticsearch/0/


基本概念

类比MySQL数据库:索引 ============= 数据库
类型 ============= 数据表
文档 ============= 行记录(数据)
属性 ============= 列名
一个 Elasticsearch 可以 包含多个 索引 ,相应的每个索引可以包含多个 类型 。 这些不同的类型存储着多个 文档 ,每个文档又有 多个 属性 。【这些文档都是json】


ElasticSearch概念-倒排索引

比如检索“红海特工行动”,会发现,4号记录命中了一次,1/2/3/5分别命中了两次,但是,5号记录是四个单词命中了两次,3号记录是三个单词命中了两次,那么3号记录的相关性得分就更高;查询出的结果会按照相关性得分从高到低排序。
安装
老师安装在虚拟机中,由于内存原因,我安装在Windows下
elasticsearch:7.4.2
https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.4.2-windows-x86_64.zip
elasticsearch.yml:
path.data: G:\elasticsearch\data
path.logs: G:\elasticsearch\logs
http.cors.enabled: true
http.cors.allow-origin: "*"
jvm.options:
-Xms64m
-Xmx512m
kibana:7.4.2
https://artifacts.elastic.co/downloads/kibana/kibana-7.4.2-windows-x86_64.zip


基本命令
保存一个数据,保存在哪个索引的哪个类型下,指定用哪个唯一标识
PUT customer/external/1;在 customer 索引下的 external 类型下保存 1 号数据为
{ "name": "John Doe"
}

PUT 和 POST 都可以,
- POST 新增。如果不指定 id,会自动生成 id。指定 id 就会修改这个数据,并新增版本号
- PUT 可以新增可以修改。PUT 必须指定 id;由于 PUT 需要指定 id,我们一般都用来做修改操作,不指定 id 会报错。
查询文档


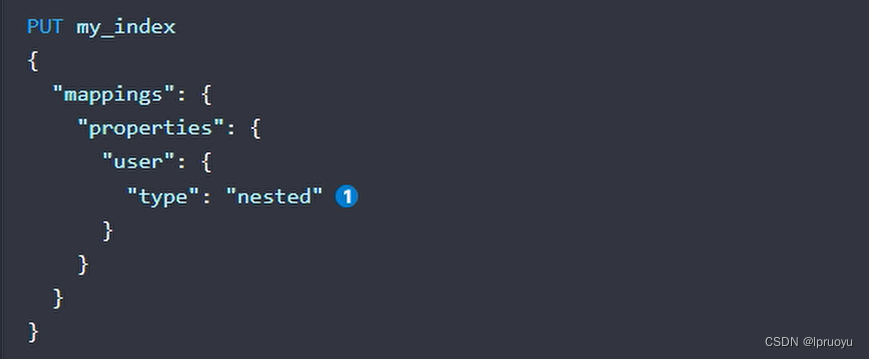
Mapping-映射

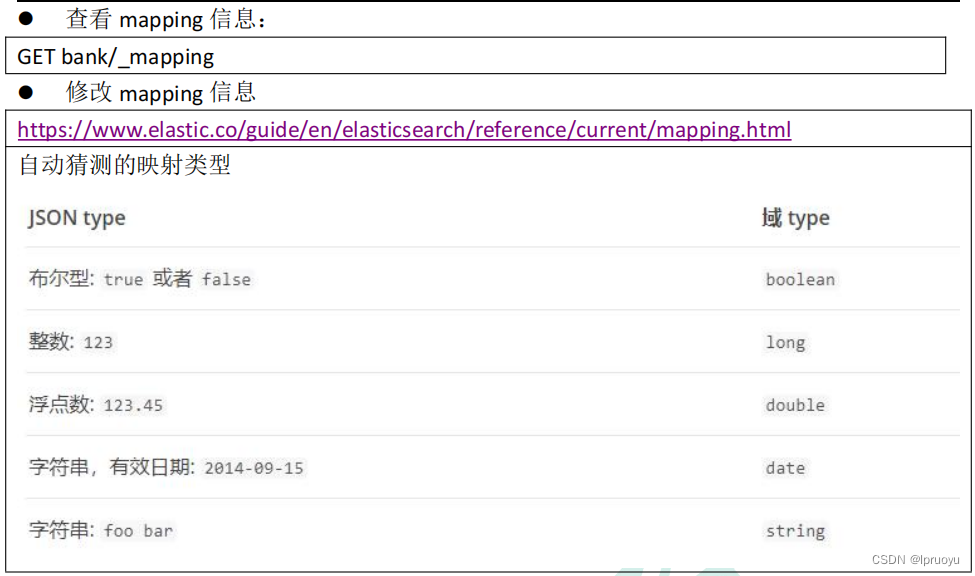
ElasticSearch7-去掉type概念

Es-数组(数组装着Object)的扁平化处理

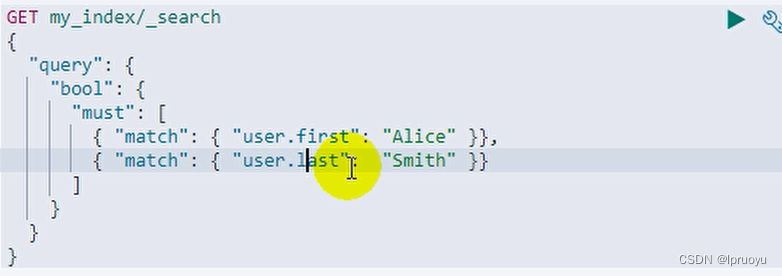
问题:

解决:修改映射再存储数据
ik 分词器
https://github.com/infinilabs/analysis-ik/releases?after=v6.4.2&page=11
放到G:\software\elasticsearch-7.4.2-windows-x86_64\elasticsearch-7.4.2\plugins目录下并解压,然后改目录名为analysis-ik

使用分词器对比:(默认分词器:standard)



能够看出不同的分词器,分词有明显的区别,所以以后定义一个索引不能再使用默认的 mapping 了,要手工建立 mapping, 因为要选择分词器。
自定义词库:
利用 nginx 发布静态资源,按照请求路径,创建对应的文件夹以及文件,放在nginx的html目录下

修改G:\software\elasticsearch-7.4.2-windows-x86_64\elasticsearch-7.4.2\plugins\analysis-ik\config\IKAnalyzer.cfg.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties><comment>IK Analyzer 扩展配置</comment><!--用户可以在这里配置自己的扩展字典 --><entry key="ext_dict"></entry><!--用户可以在这里配置自己的扩展停止词字典--><entry key="ext_stopwords"></entry><!--用户可以在这里配置远程扩展字典 --><!-- http://192.168.56.10/fenci/myword.txt 80断口是nginx端口,把这个txt放在nginx中的html目录下 --><entry key="remote_ext_dict">http://192.168.56.10/fenci/myword.txt</entry><!--用户可以在这里配置远程扩展停止词字典--><entry key="remote_ext_stopwords">words_location</entry>
</properties>
重启elasticsearch和kibana后,测试自定义的词库使用效果:

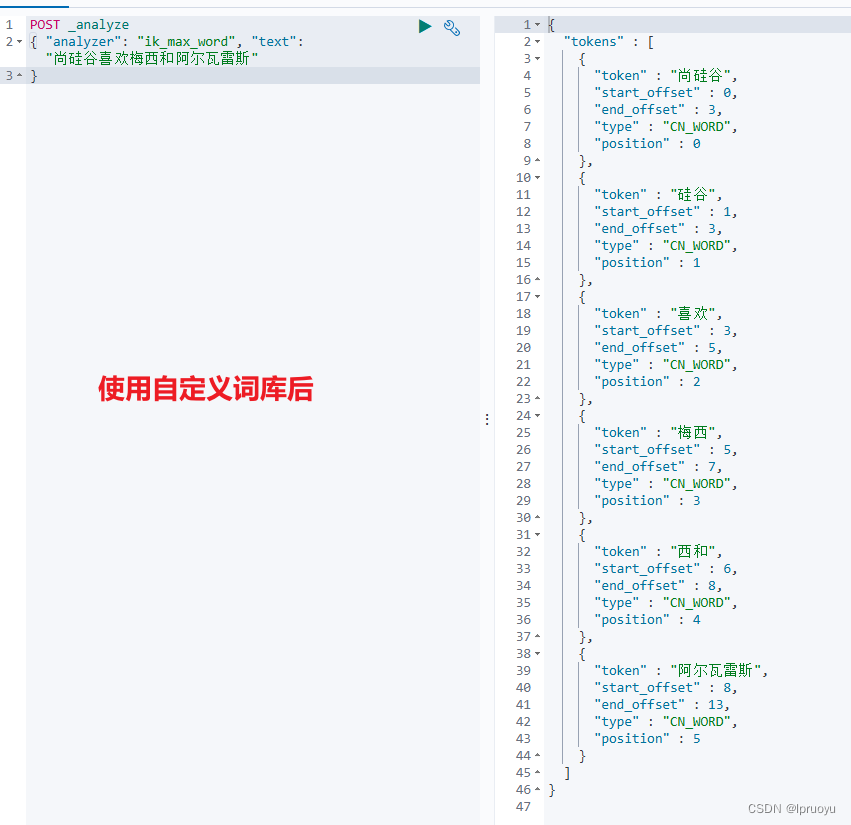
注意:
更新完成后,es 只会对新增的数据用新词分词。历史数据是不会重新分词的。如果想要历史数据重新分词。需要执行:
POST my_index/_update_by_query?conflicts=proceed
SpringBoot整合


最终选择 Elasticsearch-Rest-Client(elasticsearch-rest-high-level-client):
https://www.elastic.co/guide/en/elasticsearch/client/java-rest/current/java-rest-high.html
依赖:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>com.atguigu.gulimall</groupId><artifactId>gulimall-search</artifactId><version>0.0.1-SNAPSHOT</version><name>gulimall-search</name><description>ElasticSearch检索服务</description><properties><elasticsearch.version>7.4.2</elasticsearch.version></properties><dependencies><!-- 导入es的rest-high-level-client--><dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-high-level-client</artifactId><version>7.4.2</version></dependency></dependencies>
</project>
配置类:
/*** 1、导入依赖* 2、编写配置,给容器中注入一个RestHighLevelClient* 3、参照API https://www.elastic.co/guide/en/elasticsearch/client/java-rest/current/java-rest-high.html*/
@Configuration
public class ElasticSearchConfig {public static final RequestOptions COMMON_OPTIONS;static {RequestOptions.Builder builder = RequestOptions.DEFAULT.toBuilder();
// builder.addHeader("Authorization", "Bearer " + TOKEN);
// builder.setHttpAsyncResponseConsumerFactory(
// new HttpAsyncResponseConsumerFactory
// .HeapBufferedResponseConsumerFactory(30 * 1024 * 1024 * 1024));COMMON_OPTIONS = builder.build();}@Beanpublic RestHighLevelClient esRestClient(@Value("${spring.elasticsearch.jest.uris}") String esUrl) {//TODO 修改为线上的地址//final String hostname, final int port, final String scheme/// RestClientBuilder builder = RestClient.builder(new HttpHost("192.168.56.10", 9200, "http"));// RestHighLevelClient client = new RestHighLevelClient(
// RestClient.builder(
// new HttpHost("192.168.56.10", 9200, "http")));return new RestHighLevelClient(RestClient.builder(HttpHost.create(esUrl)));}}
@EnableDiscoveryClient
@SpringBootApplication(exclude = DataSourceAutoConfiguration.class)
public class GulimallSearchApplication {public static void main(String[] args) {SpringApplication.run(GulimallSearchApplication.class, args);}}
spring:elasticsearch:jest:uris: 127.0.0.1:9200
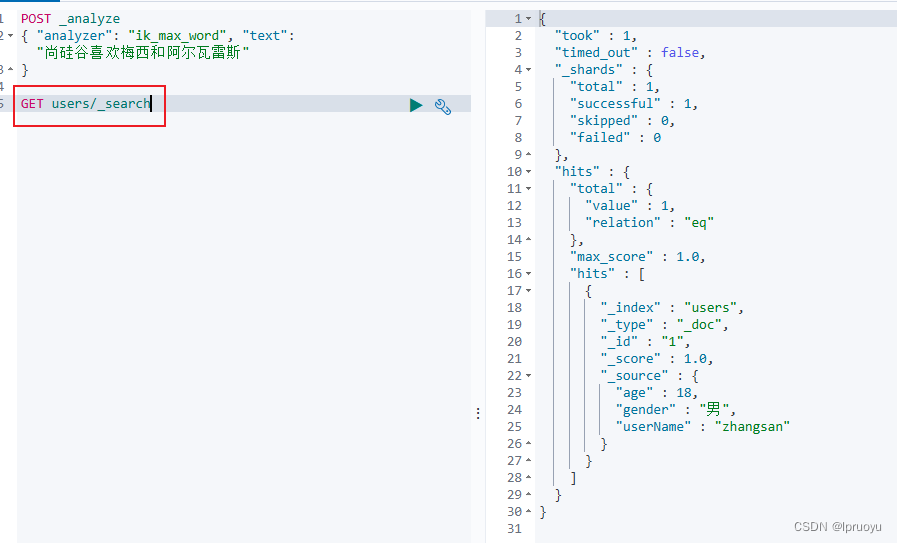
测试存储数据:
@Testpublic void indexData() throws IOException {IndexRequest indexRequest = new IndexRequest("users");indexRequest.id("1");//数据的id,如果不设置会自动生成id
// indexRequest.source("userName","zhangsan","age",18,"gender","男");User user = new User();user.setUserName("zhangsan");user.setAge(18);user.setGender("男");String jsonString = JSON.toJSONString(user);indexRequest.source(jsonString, XContentType.JSON);//要保存的内容//执行操作IndexResponse index = client.index(indexRequest, ElasticSearchConfig.COMMON_OPTIONS);//提取有用的响应数据System.out.println(index);}




将存储的东西转为JSON即可
测试复杂检索
@Testpublic void searchData() throws IOException {//1、创建检索请求SearchRequest searchRequest = new SearchRequest();//指定索引searchRequest.indices("bank");//指定DSL,检索条件//SearchSourceBuilder sourceBuilde 封装的条件SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();//1.1)、构造检索条件
// sourceBuilder.query();
// sourceBuilder.from();
// sourceBuilder.size();
// sourceBuilder.aggregation()sourceBuilder.query(QueryBuilders.matchQuery("address","mill"));//1.2)、按照年龄的值分布进行聚合TermsAggregationBuilder ageAgg = AggregationBuilders.terms("ageAgg").field("age").size(10);sourceBuilder.aggregation(ageAgg);//1.3)、计算平均薪资AvgAggregationBuilder balanceAvg = AggregationBuilders.avg("balanceAvg").field("balance");sourceBuilder.aggregation(balanceAvg);System.out.println("检索条件"+sourceBuilder.toString());searchRequest.source(sourceBuilder);//2、执行检索;SearchResponse searchResponse = client.search(searchRequest, ElasticSearchConfig.COMMON_OPTIONS);//3、分析结果 searchResponseSystem.out.println(searchResponse.toString());
// Map map = JSON.parseObject(searchResponse.toString(), Map.class);//3.1)、获取所有查到的数据SearchHits hits = searchResponse.getHits();SearchHit[] searchHits = hits.getHits();for (SearchHit hit : searchHits) {/*** "_index": "bank",* "_type": "account",* "_id": "345",* "_score": 5.4032025,* "_source":*/
// hit.getIndex();hit.getType();hit.getId();String string = hit.getSourceAsString();Accout accout = JSON.parseObject(string, Accout.class);System.out.println("accout:"+accout);}//3.2)、获取这次检索到的分析信息;Aggregations aggregations = searchResponse.getAggregations();
// for (Aggregation aggregation : aggregations.asList()) {
// System.out.println("当前聚合:"+aggregation.getName());
aggregation.get
//
// }Terms ageAgg1 = aggregations.get("ageAgg");for (Terms.Bucket bucket : ageAgg1.getBuckets()) {String keyAsString = bucket.getKeyAsString();System.out.println("年龄:"+keyAsString+"==>"+bucket.getDocCount());}Avg balanceAvg1 = aggregations.get("balanceAvg");System.out.println("平均薪资:"+balanceAvg1.getValue());// Aggregation balanceAvg2 = aggregations.get("balanceAvg");}
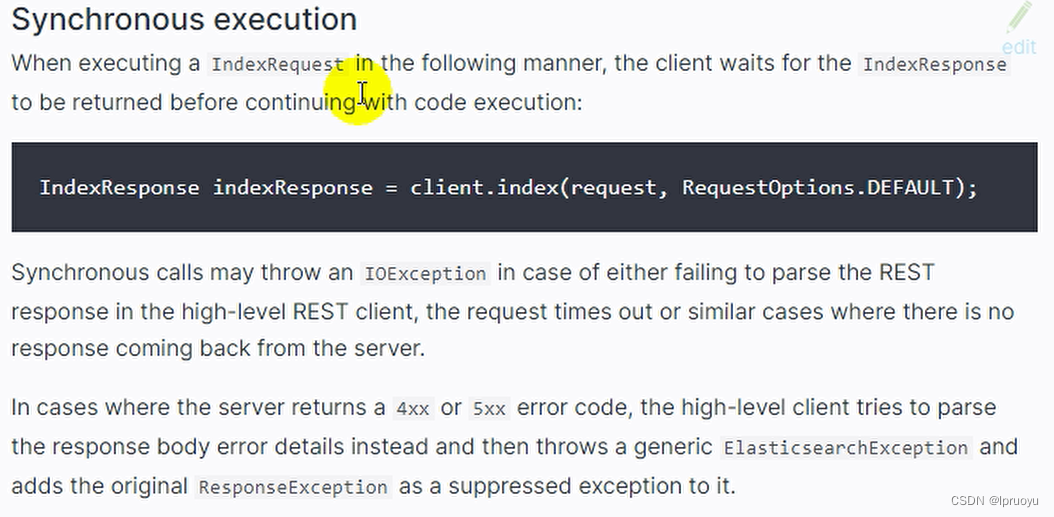
同步与异步调用

参考
雷丰阳: Java项目《谷粒商城》Java架构师 | 微服务 | 大型电商项目.
本文完,感谢您的关注支持!
相关文章:
【雷丰阳-谷粒商城 】【分布式高级篇-微服务架构篇】【11】ElasticSearch
持续学习&持续更新中… 守破离 【雷丰阳-谷粒商城 】【分布式高级篇-微服务架构篇】【11】ElasticSearch 简介基本概念ElasticSearch概念-倒排索引安装基本命令Mapping-映射ElasticSearch7-去掉type概念Es-数组(数组装着Object)的扁平化处理ik 分词…...

Pip换源详解
Pip换源是指将pip(Python的包管理工具)的默认源更改为其他源。以下是关于Pip换源的详细说明: 一、Pip换源的原因 访问被阻止的源:在某些地区或网络环境下,直接访问官方的Python Package Index (PyPI) 可能受到限制或…...

【Docker】——安装镜像和创建容器,详解镜像和Dockerfile
前言 在此记录一下docker的镜像和容器的相关注意事项 前提条件:已安装Docker、显卡驱动等基础配置 1. 安装镜像 网上有太多的教程,但是都没说如何下载官方的镜像,在这里记录一下,使用docker安装官方的镜像 Docker Hub的官方链…...
利用LinkedHashMap实现一个LRU缓存
一、什么是 LRU LRU是 Least Recently Used 的缩写,即最近最少使用,是一种常用的页面置换算法,选择最近最久未使用的页面予以淘汰。 简单的说就是,对于一组数据,例如:int[] a {1,2,3,4,5,6},…...

git-pull详解
NAME git-pull - Fetch from and integrate with another repository or a local branch SYNOPSIS git pull [<options>] [<repository> [<refspec>…]] DESCRIPTION Incorporates changes from a remote repository into the current branch. If the…...
、count(*) 与 count(列名) 的区别)
【SQL】count(1)、count(*) 与 count(列名) 的区别
在 SQL 中,COUNT 函数用于计算查询结果集中的行数。COUNT(1)、COUNT(*) 和 COUNT(列名) 都可以用来统计行数,但它们在实现细节和使用场景上有一些区别。以下是详细的解释: 1. COUNT(1) 定义: COUNT(1) 计算查询结果集中的行数。实现: 在执行…...

03-ES6新语法
1. ES6 函数 1.1 函数参数的扩展 1.1.1 默认参数 function fun(name,age17){console.log(name","age); } fn("张美丽",18); // "张美丽",18 fn("张美丽",""); // "张美丽" fn("张美丽"); // &…...

Linux中的文本编辑器vi与vim
摘要: 本文将深入探讨VI和VIM编辑器的基本概念、特点、使用方法以及它们在Linux环境中的重要性。通过对这两款强大的文本编辑器的详细分析,读者将能够更全面地理解它们的功能,并掌握如何有效地使用它们进行日常的文本编辑和处理任务。 引言&…...
)
MATLAB基础应用精讲-【数模应用】三因素方差(附R语言、MATLAB和python代码实现)
目录 几个高频面试题目 群体分布是否服从高斯分布? 数据是否不匹配? “误差”是否独立存在? 您是否真的想比较平均值? 是否存在三项因素? 这三项因素是否均属于“固定因素”,而非“随机因素”? 算法原理 EXCEL spss三因素方差分析步骤 一、spss三因素…...
Linux ubuntu安装pl2303USB转串口驱动
文章目录 1.绿联PL2303串口驱动下载2.驱动安装3.验证方法 1.绿联PL2303串口驱动下载 下载地址:https://www.lulian.cn/download/16-cn.html 也可以直接通过CSDN下载:https://download.csdn.net/download/Axugo/89447539 2.驱动安装 下载后解压找到Lin…...
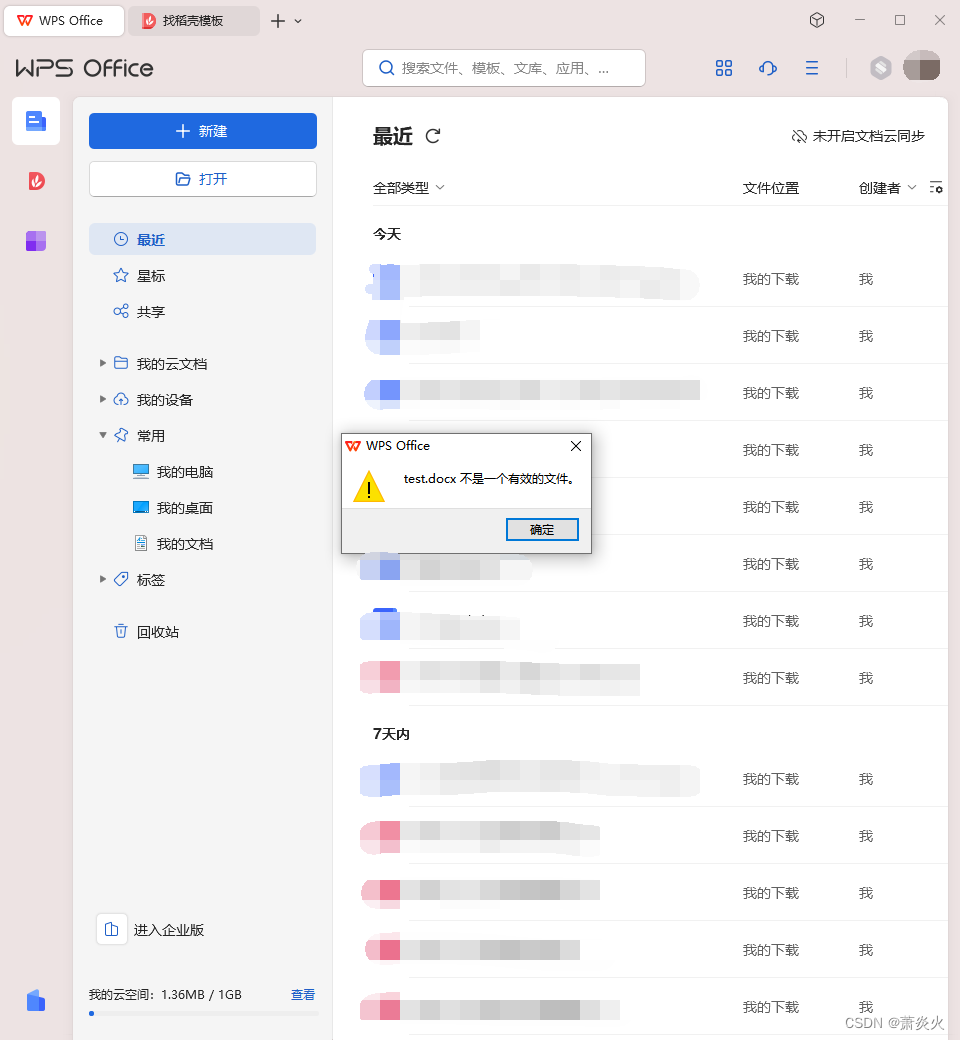
关于使用命令行打开wps word文件
前言 在学习python-docx时,想在完成运行时使用命令行打开生成的docx文件。 总结 在经过尝试后,得出以下代码: commandrstart "C:\Users\86136\AppData\Local\Kingsoft\WPS Office\12.1.0.16929\office6\wps.exe" "./result…...
将Vite添加到您现有的Web应用程序
Vite(发音为“veet”)是一个新的JavaScript绑定器。它包括电池,几乎不需要任何配置即可使用,并包括大量配置选项。哦——而且速度很快。速度快得令人难以置信。 本文将介绍将现有项目转换为Vite的过程。我们将介绍别名、填充webp…...

Apache Kafka与Spring整合应用详解
引言 Apache Kafka是一种高吞吐量的分布式消息系统,广泛应用于实时数据处理、日志聚合和事件驱动架构中。Spring作为Java开发的主流框架,通过Spring Kafka项目提供了对Kafka的集成支持。本文将深入探讨如何使用Spring Kafka整合Apache Kafka,…...
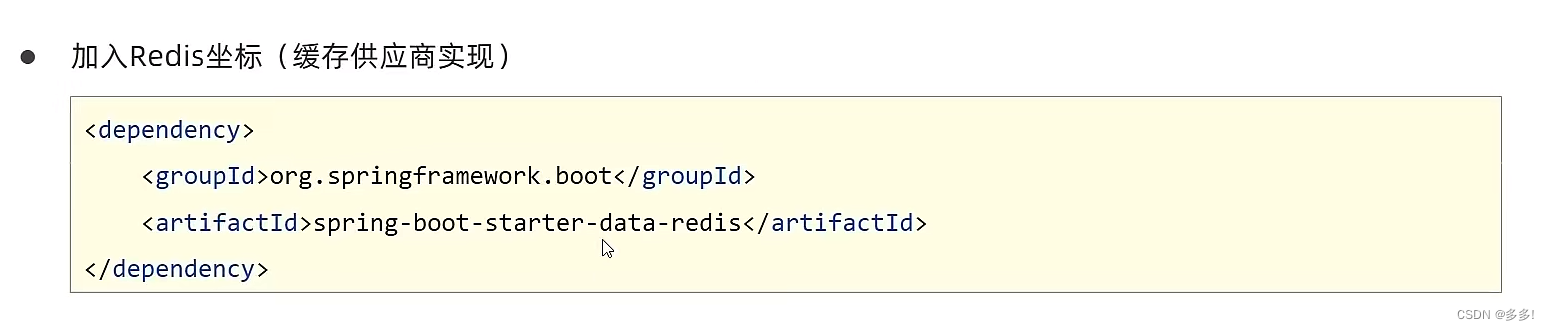
SpringBoot配置第三方专业缓存技术Redis
Redis缓存技术 Redis(Remote Dictionary Server)是一个开源的内存中数据结构存储系统,通常用作数据库、缓存和消息中间件。它支持多种数据结构,如字符串、哈希表、列表、集合、有序集合等,并提供了丰富的功能和灵活的…...
以及使用)
javascript的toFixed()以及使用
toFixed() 是 JavaScript 中数字类型(Number)的一个方法,用来将数字转换为指定小数位数的字符串表示形式。 使用方式和示例: let num 123.45678; let fixedNum num.toFixed(2); console.log(fixedNum); // 输出 "123.46&qu…...

软件功能测试和性能测试包括哪些测试内容?又有什么联系和区别?
软件功能测试和性能测试是保证软件质量和稳定性的重要手,无论是验证软件的功能正确性,还是评估软件在负载下的性能表现,这些测试都是必不可少的。 一、软件功能测试 软件功能测试是指对软件的各项功能进行验证和确认,确保软件…...
从工具产品体验对比spark、hadoop、flink
作为一名大数据开发,从工具产品的角度,对比一下大数据工具最常使用的框架spark、hadoop和flink。工具无关好坏,但人的喜欢有偏好。 目录 评价标准1 效率2 用户体验分析从用户的维度来看从市场的维度来看从产品的维度来看 3 用户体验的基本原则…...

【软件设计】详细设计说明书(word原件,项目直接套用)
软件详细设计说明书 1.系统总体设计 2.性能设计 3.系统功能模块详细设计 4.数据库设计 5.接口设计 6.系统出错处理设计 7.系统处理规定 软件全套资料:本文末个人名片直接获取或者进主页。...
优缺点,以及适用场景)
java本地缓存(map,Guava,echcache,caffeine)优缺点,以及适用场景
前言 在高并发系统环境下,jvm本地缓存扮演着至关重要的角色,合理的应用能够使系统响应迅速,提高用户体验感,而分布式缓存redis则存在着网络io,以及流量消耗问题,需要和本地缓存搭配使用,才能使…...

Monica
在 《long long ago》中,我论述了on是一个刚出生的孩子的脐带连接在其肚子g上的形象,脐带就是long的字母l和字母n,l表脐带很长,n表脐带曲转冗余和连接之性,on表一,是孩子刚诞生的意思,o是身体&a…...
:手搓截屏和帧率控制)
Python|GIF 解析与构建(5):手搓截屏和帧率控制
目录 Python|GIF 解析与构建(5):手搓截屏和帧率控制 一、引言 二、技术实现:手搓截屏模块 2.1 核心原理 2.2 代码解析:ScreenshotData类 2.2.1 截图函数:capture_screen 三、技术实现&…...

未来机器人的大脑:如何用神经网络模拟器实现更智能的决策?
编辑:陈萍萍的公主一点人工一点智能 未来机器人的大脑:如何用神经网络模拟器实现更智能的决策?RWM通过双自回归机制有效解决了复合误差、部分可观测性和随机动力学等关键挑战,在不依赖领域特定归纳偏见的条件下实现了卓越的预测准…...

阿里云ACP云计算备考笔记 (5)——弹性伸缩
目录 第一章 概述 第二章 弹性伸缩简介 1、弹性伸缩 2、垂直伸缩 3、优势 4、应用场景 ① 无规律的业务量波动 ② 有规律的业务量波动 ③ 无明显业务量波动 ④ 混合型业务 ⑤ 消息通知 ⑥ 生命周期挂钩 ⑦ 自定义方式 ⑧ 滚的升级 5、使用限制 第三章 主要定义 …...

前端倒计时误差!
提示:记录工作中遇到的需求及解决办法 文章目录 前言一、误差从何而来?二、五大解决方案1. 动态校准法(基础版)2. Web Worker 计时3. 服务器时间同步4. Performance API 高精度计时5. 页面可见性API优化三、生产环境最佳实践四、终极解决方案架构前言 前几天听说公司某个项…...

DAY 47
三、通道注意力 3.1 通道注意力的定义 # 新增:通道注意力模块(SE模块) class ChannelAttention(nn.Module):"""通道注意力模块(Squeeze-and-Excitation)"""def __init__(self, in_channels, reduction_rat…...

1688商品列表API与其他数据源的对接思路
将1688商品列表API与其他数据源对接时,需结合业务场景设计数据流转链路,重点关注数据格式兼容性、接口调用频率控制及数据一致性维护。以下是具体对接思路及关键技术点: 一、核心对接场景与目标 商品数据同步 场景:将1688商品信息…...

使用Matplotlib创建炫酷的3D散点图:数据可视化的新维度
文章目录 基础实现代码代码解析进阶技巧1. 自定义点的大小和颜色2. 添加图例和样式美化3. 真实数据应用示例实用技巧与注意事项完整示例(带样式)应用场景在数据科学和可视化领域,三维图形能为我们提供更丰富的数据洞察。本文将手把手教你如何使用Python的Matplotlib库创建引…...

HashMap中的put方法执行流程(流程图)
1 put操作整体流程 HashMap 的 put 操作是其最核心的功能之一。在 JDK 1.8 及以后版本中,其主要逻辑封装在 putVal 这个内部方法中。整个过程大致如下: 初始判断与哈希计算: 首先,putVal 方法会检查当前的 table(也就…...

【VLNs篇】07:NavRL—在动态环境中学习安全飞行
项目内容论文标题NavRL: 在动态环境中学习安全飞行 (NavRL: Learning Safe Flight in Dynamic Environments)核心问题解决无人机在包含静态和动态障碍物的复杂环境中进行安全、高效自主导航的挑战,克服传统方法和现有强化学习方法的局限性。核心算法基于近端策略优化…...

使用Spring AI和MCP协议构建图片搜索服务
目录 使用Spring AI和MCP协议构建图片搜索服务 引言 技术栈概览 项目架构设计 架构图 服务端开发 1. 创建Spring Boot项目 2. 实现图片搜索工具 3. 配置传输模式 Stdio模式(本地调用) SSE模式(远程调用) 4. 注册工具提…...