经典机器学习方法(7)—— 卷积神经网络CNN
- 参考:《动手学深度学习》第六章
- 卷积神经网络(convolutional neural network,CNN)是一类针对图像数据设计的神经网络,它充分利用了图像数据的特点,具有适合图像特征提取的归纳偏置,因而在图像相关任务上,它可以用相比全连接网络更少的参数量取得更好的性能。基于 CNN 的模型已经在 CV 领域处于主导地位,当今几乎所有的图像识别、目标检测或语义分割相关的学术竞赛和商业应用都以这种方法为基础
- 即使在通常使用循环神经网络的一维序列结构任务上(例如音频、文本和时间序列分析),卷积神经网络也越来越受欢迎。 通过对卷积神经网络一些巧妙的调整,它们也能在图结构数据和推荐系统中发挥作用
- 本文介绍卷积神经网络的基础结构,不涉及任何先进模型和新架构
文章目录
- 1. 从全连接层到卷积层
- 1.1 不变性
- 1.2 MLP 的局限性
- 1.3 卷积
- 1.3.1 卷积的数学定义
- 1.3.2 互相关运算
- 1.4 通道
- 2. 图像卷积
- 2.1 卷积核的特征提取能力
- 2.2 学习卷积核
- 2.3 特征映射和感受野
- 3. 填充和步幅
- 3.1 填充
- 3.2 步幅
- 4. 多输入多输出通道
- 4.1 多输入通道
- 4.2 多输出通道
- 4.3 只作用在通道上的 1X1 卷积层
- 5. 汇聚层
- 5.1 最大汇聚层与平均汇聚层
- 5.2 填充和步幅
- 5.3 多个通道
- 6. 卷积神经网络
1. 从全连接层到卷积层
- 前文 经典机器学习方法(3)—— 多层感知机 我们训练 MLP 解决了图像分类问题。为了适配 MLP 的输入形式,我们直接把尺寸为 (1,28,28) 的原始图像数据拉平成 28x28 的一维数据,这种做法破坏了图像的空间结构信息,原本图像中相近像素之间具有相互关联性,这些性质并不能被 MLP 利用
- MLP 适合处理表格数据,其中行对应样本,列对应特征,我们寻找的模式可能涉及特征之间的交互,但是我们不能预先假设任何与特征交互相关的先验结构,换句话说,MLP 不具有任何归纳偏置,其训练效率随数据维度上升而不断下降,最终导致模型不再实用
考虑一个图像分类任务,每张图像具有百万级像素,这意味着 MLP 的每次输入都有 1 0 6 10^6 106 维度,一个将其降维到 1000 的全连接层将有 1 0 9 10^9 109 个参数,这几乎和 GPT1 的总参数量相当
1.1 不变性
- 针对图像数据而言,一个设计良好的模型应当对图像的某些变换具有容忍性,这被称为模型的不变性
平移不变性:图像中的目标物体在发生平移后,模型仍然能有效识别。原始 CNN 可以通过局部连接和权值共享这两个设计实现平移不变性旋转不变性:图像中的目标物体在发生旋转后,模型仍然能有效识别。原始 CNN 不具备这种能力,需要通过数据增强(构造随机旋转的样本)和特定的网络结构(如旋转卷积和旋转不变池化)来实现尺度不变性:图像中的目标物体在放大或缩小后,模型仍然能有效识别。原始 CNN 不具备这种能力,需要通过数据增强(构造随机缩放的样本)和特定的网络结构(如多尺度特征融合)来实现
- 原始 CNN 仅具备平移不变性,它也常被称为
空间不变性,为了实现这一点,模型应当具有以下归纳偏置平移不变:不管检测对象出现在图像中的哪个位置,神经网络的前面几层应该对相同的图像区域具有相似的反应局部原则:神经网络的前面几层应该只探索输入图像中的局部区域,而不过度在意图像中相隔较远区域的关系。最后通过聚合这些局部特征,在整个图像级别进行预测
1.2 MLP 的局限性
- 设 MLP 的输入是二维图像 X ∈ R I × J \mathbf{X}\in\mathbb{R}^{I\times J} X∈RI×J,其隐藏表示为 H ∈ R I × J \mathbf{H}\in\mathbb{R}^{I\times J} H∈RI×J,用 [ X ] i , j {[\mathbf{X}]_{i, j} } [X]i,j 和 [ H ] i , j {[\mathbf{H}]_{i, j} } [H]i,j 分别表示输入图像和隐藏表示中位置 ( i , j ) (i,j) (i,j) 处的像素
注意,真实 MLP 中 X , H \mathbf{X,H} X,H 都应当是一维的,这里为了方便理解,认为无论输入还是隐藏表示都拥有二维空间结构
- 设 MLP 的权重和偏置参数分别为 W , U \mathbf{W,U} W,U 全连接层可以表示为
[ H ] i , j = [ U ] i , j + ∑ k ∑ l [ W ] i , j , k , l [ X ] k , l = [ U ] i , j + ∑ ∑ l [ V ] i , j , a , b [ X ] i + a , j + b (1) \begin{aligned} {[\mathbf{H}]_{i, j} } & =[\mathbf{U}]_{i, j}+\sum_{k} \sum_{l}[\mathbf{W}]_{i, j, k, l}[\mathbf{X}]_{k, l} \\ & =[\mathbf{U}]_{i, j}+\sum \sum^{l}[\mathbf{V}]_{i, j, a, b}[\mathbf{X}]_{i+a, j+b} \end{aligned} \tag{1} [H]i,j=[U]i,j+k∑l∑[W]i,j,k,l[X]k,l=[U]i,j+∑∑l[V]i,j,a,b[X]i+a,j+b(1) 其中从 W \mathbf{W} W 到 V \mathbf{V} V 的转换只是形式上从绝对位置索引变成相对位置索引,即有 [ V ] i , j , a , b = [ W ] i , j , i + a , j + b [\mathbf{V}]_{i, j, a, b}=[\mathbf{W}]_{i, j, i+a, j+b} [V]i,j,a,b=[W]i,j,i+a,j+b,此处索引 a , b a,b a,b 通过正负偏移覆盖了整个图像。上式意味着:隐藏表示中任意给定位置 [ H ] i , j {[\mathbf{H}]_{i, j} } [H]i,j 处的隐藏值,可以通过在 X \mathbf{X} X 中以为 ( i , j ) (i,j) (i,j) 为中心对像素进行加权求和得到,加权使用的权重为 [ V ] i , j , a , b [\mathbf{V}]_{i, j, a, b} [V]i,j,a,b - 现在将 1.1 节的两个归纳偏置引入以上全连接层计算式中。
- 首先考虑
平移不变性,这意味着检查对象在输入 X \mathbf{X} X 中的平移应导致隐藏表示 H \mathbf{H} H 中的平移,这意味着 V , U \mathbf{V,U} V,U 不能依赖于目标位置 ( i , j ) (i,j) (i,j),即 [ V ] i , j , a , b = [ V ] a , b [\mathbf{V}]_{i, j, a, b} = [\mathbf{V}]_{a, b} [V]i,j,a,b=[V]a,b,且 U \mathbf{U} U 是一个常数,这时 H \mathbf{H} H 的定义可以简化为
[ H ] i , j = u + ∑ a ∑ b [ V ] a , b [ X ] i + a , j + b (2) [\mathbf{H}]_{i, j}=u+\sum_{a} \sum_{b}[\mathbf{V}]_{a, b}[\mathbf{X}]_{i+a, j+b} \tag{2} [H]i,j=u+a∑b∑[V]a,b[X]i+a,j+b(2) 机器学习领域中,以上运算被称为卷积convolution,注意我们此时用系数 [ V ] a , b [\mathbf{V}]_{a, b} [V]a,b 对 ( i , j ) (i,j) (i,j) 附近的像素 ( i + a , j + b ) (i+a,j+b) (i+a,j+b) 加权计算 [ H ] i , j [\mathbf{H}]_{i, j} [H]i,j,由于 [ V ] a , b [\mathbf{V}]_{a, b} [V]a,b 不再依赖于目标位置,其参数量相比 [ V ] i , j , a , b [\mathbf{V}]_{i,j,a, b} [V]i,j,a,b 减少了很多,这就是利用归纳偏置提升模型效率的体现 - 进一步考虑
局部性。局部原则说明我们不应用偏移 ( i , j ) (i,j) (i,j) 太远的信息计算隐藏值 [ H ] i , j [\mathbf{H}]_{i, j} [H]i,j,为此我们对偏移 a , b a,b a,b 的绝对值设置上限 △ \triangle △, H \mathbf{H} H 的定义进一步简化为
[ H ] i , j = u + ∑ a = − Δ Δ ∑ b = − Δ Δ [ V ] a , b [ X ] i + a , j + b (3) [\mathbf{H}]_{i, j}=u+\sum_{a=-\Delta}^{\Delta} \sum_{b=-\Delta}^{\Delta}[\mathbf{V}]_{a, b}[\mathbf{X}]_{i+a, j+b} \tag{3} [H]i,j=u+a=−Δ∑Δb=−Δ∑Δ[V]a,b[X]i+a,j+b(3) 执行以上计算的神经网络层被称为卷积层(convolutional layer),其中 V \mathbf{V} V 被称为卷积核(convolution kernel)/滤波器(filter),亦或简单地称之为该卷积层的权重,通常该权重是可学习的参数
- 首先考虑
- 我们通过引入归纳偏置将全连接层变成了卷积层,大幅降低了需要学习的权重 U , V \mathbf{U,V} U,V 的参数量,这并不是没有代价的。归纳偏置的引入其实限制了网络的表示能力,卷积层无法汇聚长跨度信息,也无法考虑目标的绝对位置信息
- 当偏置与目标场景(图像数据)相符时,这种表示能力的限制是有益的,它相当于做了一个剪枝,避免了大量无用参数的训练,在不影响模型性能的情况下提升了训练效率
- 当偏置与目标场景(图像数据)不符时,比如当图像不满足平移不变时,模型可能难以拟合我们的训练数据
1.3 卷积
1.3.1 卷积的数学定义
- 进一步讨论之前,首先明确一下以上提到的卷积运算。首先,数学中卷积本质是一个泛函积分公式,它将两个函数 f , g : R d → R f,g:\mathbb{R}^d\to\mathbb{R} f,g:Rd→R 映射到一个数,定义为
( f ∗ g ) ( x ) = ∫ f ( z ) g ( x − z ) d z (4) (f*g)(\mathbf{x}) = \int f(\mathbf{z})g(\mathbf{x-z})d\mathbf{z} \tag{4} (f∗g)(x)=∫f(z)g(x−z)dz(4) 也就是说,卷积是当把一个函数“翻转”并移位 x \mathbf{x} x 时( g ( z ) → g ( − z ) → g ( x − z ) g(\mathbf{z})\to g(-\mathbf{z})\to g(\mathbf{x}-\mathbf{z}) g(z)→g(−z)→g(x−z) ),测量 f , g f,g f,g 之间的重叠。当自变量为离散对象时,积分就变成求和。例如,对于由索引为整数 Z \mathbb{Z} Z 的、平方可和的、无限维向量集合中抽取的向量,我们得到以下定义
( f ∗ g ) ( i ) = ∑ a f ( a ) g ( i − a ) (5) (f*g)(i) = \sum_a f(a)g(i-a) \tag{5} (f∗g)(i)=a∑f(a)g(i−a)(5) 进一步推广到二维张量的情况
( f ∗ g ) ( i , j ) = ∑ a ∑ b f ( a , b ) g ( i − a , j − b ) . (6) (f * g)(i, j)=\sum_{a} \sum_{b} f(a, b) g(i-a, j-b) . \tag{6} (f∗g)(i,j)=a∑b∑f(a,b)g(i−a,j−b).(6) 注意这个 (6) 式本质和 1.2 节的 (3) 式是一样的,我们总是可以匹配两者间的符号 - 下面给出两个例子,帮助读者直观理解卷积的物理含义
如果一个系统输入 f 是不稳定的,消耗 g 是稳定的,那么可以用卷积求这个系统的存量。下面是一个吃饭的例子,图中 f , g f,g f,g 分别表示一个人的进食曲线和食物的消化曲线。 f ( t ) f(t) f(t) 表示在t时刻吃下的食物量, g ( t ) g(t) g(t) 表示吃下事物后 t t t 时刻食物量的比例值。左上图给出了这个人在 8/10/12 点吃下三种东西的量,左下图显示了 14 点时三种食物的消化剩余比例,右侧表格列举了 14 点时三种食物的剩余量,将其求和就是卷积运算,我们可以用卷积求取任意时刻此人肚子里剩余的实物总量
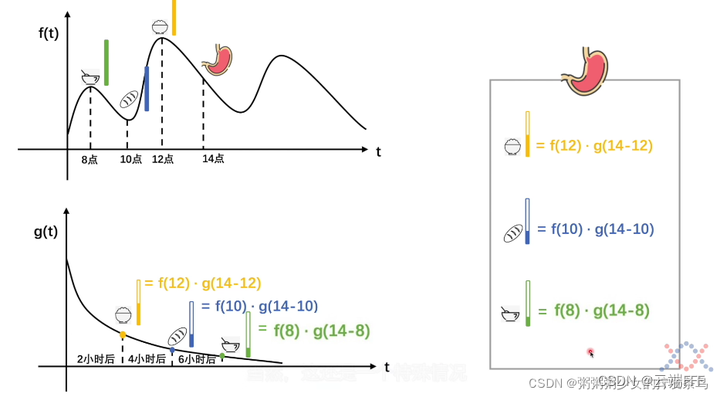
下图可视化了卷积中的 “翻转-平移” 操作
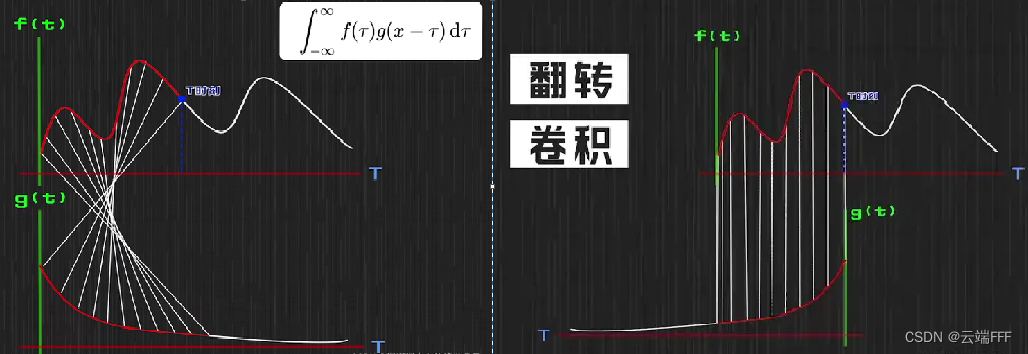
这种不稳定输入和稳定消耗的场景在信号与系统中经常用出现,一个典型场景是系统处理输入的最高速率有限,而每时每刻输入系统的信号量是不定的,这时就可以用卷积计算系统积压的未处理信息量卷积可以理解为影响因素的叠加,此时 f 表示影响源的强度,g 表示影响随时间或距离的缩放系数。一个例子是噪音的叠加,此时可以把 f f f 看作一条直路上各个坐标位置噪音源的强度, g g g 表示噪音随距离增加的衰减系数,则路上任意一点处的真实噪声强度也可以通过卷积计算。图像卷积可以看作这个例子的二维推广
1.3.2 互相关运算
- 了解了卷积的数学定义后,回头看式 (3) 给出的图像卷积运算
[ H ] i , j = u + ∑ a = − Δ Δ ∑ b = − Δ Δ [ V ] a , b [ X ] i + a , j + b [\mathbf{H}]_{i, j}=u+\sum_{a=-\Delta}^{\Delta} \sum_{b=-\Delta}^{\Delta}[\mathbf{V}]_{a, b}[\mathbf{X}]_{i+a, j+b} [H]i,j=u+a=−Δ∑Δb=−Δ∑Δ[V]a,b[X]i+a,j+b 现在尝试把它对应到 1.3.1 节的数学定义,这时原始图像 X \mathbf{X} X 相当于影响强度 f f f,卷积核 V \mathbf{V} V 相当于影响系数 g g g,忽略偏置 u u u,上式可改写为
[ H ] i , j = ∑ a = − Δ Δ ∑ b = − Δ Δ g ( a , b ) f ( i + a , j + b ) [\mathbf{H}]_{i, j}=\sum_{a=-\Delta}^{\Delta} \sum_{b=-\Delta}^{\Delta} g(a, b) f(i+a, j+b) \\ [H]i,j=a=−Δ∑Δb=−Δ∑Δg(a,b)f(i+a,j+b) 再令 a ′ = i + a , b ′ = j + b a'=i+a, b'=j+b a′=i+a,b′=j+b,把相对位置改写成绝对位置,有
[ H ] i , j = ∑ a ′ ∑ b ′ g ( a ′ − i , b ′ − j ) f ( a ′ , b ′ ) (7) [\mathbf{H}]_{i, j}=\sum_{a'} \sum_{b'} g(a'-i, b'-j) f(a', b') \tag{7} [H]i,j=a′∑b′∑g(a′−i,b′−j)f(a′,b′)(7) - 将 (7) 式和标准卷积运算 ( f ∗ g ) ( i , j ) = ∑ a ∑ b g ( i − a , j − b ) f ( a , b ) (f * g)(i, j)=\sum_{a} \sum_{b} g(i-a, j-b) f(a, b) (f∗g)(i,j)=∑a∑bg(i−a,j−b)f(a,b) 对比,可见 CNN 中的卷积并不是标准卷积,只有把卷积核水平和垂直翻转后才是标准卷积,准确地讲,CNN 中这种运算称为
互相关(cross-correlation)运算。尽管如此,由于卷积核参数是从数据中学习到的,因此无论这些层执行严格的卷积运算还是互相关运算,卷积层的输出都不会受到影响为了与深度学习文献中的标准术语保持一致,我们将继续把“互相关运算”称为卷积运算
1.4 通道
- 以上讨论中,我们都把图像视为黑白的,即只有一个灰度通道,但是彩色图片都有 R/G/B 三个通道,某些特殊图像如光电图可能含有更多通道的信息,故大多数图像都是三维张量,其中前两个轴与像素的空间位置有关,第三轴可以看作每个像素的多维表示
- 由于输入图像是三维的,我们的隐藏表示也最好采用三维张量。换句话说,对于每一个空间位置,我们想要采用一组而不是一个隐藏表示。因此,我们可以把隐藏表示想象为一系列具有二维张量的
通道channel。 这些通道有时也被称为特征映射feature maps,因为每个通道都向后续层提供一组空间化的学习特征。 直观上可以想象在靠近输入的底层,一些通道专门识别边缘,而一些通道专门识别纹理 - 为了支持输入 X \mathbf{X} X 和隐藏表示 H \mathbf{H} H 中的多个通道,我们将卷积公式调整如下
[ H ] i , j , d = ∑ a = − Δ Δ ∑ b = − Δ Δ ∑ c [ V ] a , b , c , d [ X ] i + a , j + b , c [\mathrm{H}]_{i, j, d}=\sum_{a=-\Delta}^{\Delta} \sum_{b=-\Delta}^{\Delta} \sum_{c}[\mathbf{V}]_{a, b, c, d}[\mathbf{X}]_{i+a, j+b, c} [H]i,j,d=a=−Δ∑Δb=−Δ∑Δc∑[V]a,b,c,d[X]i+a,j+b,c
2. 图像卷积
- 本节中,我们暂时忽略通道(第三维),看看卷积核是如何作用于二维图像数据,算出隐藏表示的。下面给出二维互相关运算的示意图,这里原始输入尺寸是 ( 3 , 3 ) (3,3) (3,3),卷积核尺寸 ( 2 , 2 ) (2,2) (2,2),滑动步长 ( 1 , 1 ) (1,1) (1,1)。(注意:将核函数上下左右翻转则是标准卷积运算)

卷积窗口从输入张量的左上角开始,从左到右、从上到下滑动。 当卷积窗口滑动到新一个位置时,包含在该窗口中的部分张量与卷积核张量进行按元素相乘,得到的张量再求和得到一个单一的标量值,由此我们得出了这一位置的输出张量值。输出的隐藏表示尺寸为输入尺寸 ( n h , n w ) (n_h,n_w) (nh,nw) 减去卷积核大小 ( k h , k w ) (k_h, k_w) (kh,kw) 即
( n h − k h + 1 ) × ( n w − k w + 1 ) (n_h-k_h+1) \times (n_w-k_w+1) (nh−kh+1)×(nw−kw+1) 稍后,我们将看到如何通过在图像边界周围填充零来保证有足够的空间移动卷积核,从而保持输出大小不变
2.1 卷积核的特征提取能力
- 不同的卷积核可以对原始输入做出不同的处理,从而提取图像的各类特征。我们可以手工设计出提取水平特征和垂直特征的卷积核

类似地,还可以设计提取边缘特征和对图像进行一些处理的卷积核

2.2 学习卷积核
- 对于复杂的 CV 任务而言,手工设计的卷积核不一定是最合适的,注意到卷积核其实就是卷积层中的待学习权重,完全可以通过梯度下降方法通过数据驱动的形式自动学出来
- 下面给出一个学习垂直边缘检查卷积核的简单示例,为简单起见,在此使用 pytorch 内置的二维卷积层并忽略偏置
import torch from torch import nn# 构造一个二维卷积层,它具有1个输出通道和形状为(1,2)的卷积核 conv2d = nn.Conv2d(1,1, kernel_size=(1, 2), bias=False)# 构造一个黑白图像 X = torch.ones((6, 8)) # 初始化为全白 X[:, 2:6] = 0 # 中间设置一块黑区域# 构造边缘检查结果 Y = torch.zeros((6, 7)) Y[:,1] = 1 # 1代表从白色到黑色的边缘 Y[:,-2] = -1 # -1代表从黑色到白色的边缘# 这个二维卷积层使用四维输入和输出格式(批量大小、通道、高度、宽度), # 其中批量大小和通道数都为1 X = X.reshape((1, 1, 6, 8)) Y = Y.reshape((1, 1, 6, 7)) lr = 3e-2 # 学习率for i in range(10):Y_hat = conv2d(X)l = (Y_hat - Y) ** 2conv2d.zero_grad()l.sum().backward()# 迭代卷积核conv2d.weight.data[:] -= lr * conv2d.weight.gradif (i + 1) % 2 == 0:print(f'epoch {i+1}, loss {l.sum():.3f}') - 训练结束后,观察学习到的卷积核
conv2d.weight.data.reshape((1, 2)) >>> tensor([[ 0.9910, -0.9936]])
2.3 特征映射和感受野
- 如 1.4 节所述,某个通道的卷积层输出有时被称为
特征映射/特征图feature map,因为它可以被视为一个输入映射到下一层的空间维度的转换器。 在卷积神经网络中,对于某一层的任意元素 x x x,其感受野receptive field是指在前向传播期间可能影响计算的所有元素(来自所有先前层) - 注意,感受野可能大于输入的实际大小。还是以本节开头的图为例
给定 2 × 2 2\times 2 2×2 卷积核,阴影输出元素值19的感受野是输入阴影部分的四个元素。现在设上图的输入和输出分别为 X , Y \mathbf{X,Y} X,Y,现在我们在其后附加一个卷积层,该卷积层以 Y \mathbf{Y} Y 为输入,输出单个元素 z z z- z z z 在 Y \mathbf{Y} Y 上的感受野包括 Y \mathbf{Y} Y 的所有四个元素
- z z z 在 X \mathbf{X} X 上的感受野包括 X \mathbf{X} X 的所有九个输入元素
- 因此,当一个特征图中的任意元素需要检测更广区域的输入特征时,我们可以构建一个更深的网络
3. 填充和步幅
- 从以上第2节的例子可知,卷积的输出形状 ( n h − k h + 1 ) × ( n w − k w + 1 ) (n_h-k_h+1) \times (n_w-k_w+1) (nh−kh+1)×(nw−kw+1) 取决于输入尺寸 ( n h , n w ) (n_h,n_w) (nh,nw) 和卷积核大小 ( k h , k w ) (k_h, k_w) (kh,kw),这种关系可能不够灵活,比如
- 有时在连续应用卷积之后,最终得到的输出远小于输入大小,原始图像许多的边界信息丢失了,
填充padding是解决此问题最有效的方法 - 有时原始的输入的分辨率可能过高了,我们希望大幅降低图像的宽度和高度,此时
步幅stride可以提供帮助
- 有时在连续应用卷积之后,最终得到的输出远小于输入大小,原始图像许多的边界信息丢失了,
3.1 填充
- 卷积核尺寸大于 ( 1 , 1 ) (1,1) (1,1) 时,边界信息的丢失是不可避免的,虽然可能仅丢失了边缘的几个像素,但当多个卷积层堆叠时,累计丢失的像素就不可忽略的。
填充padding通过在输入图像边缘填充元素(通常填充0)来解决这个问题给出一个示例,原始输入尺寸为 ( 3 , 3 ) (3,3) (3,3),我们将其填充到 ( 5 , 5 ) (5,5) (5,5),使输出尺寸增加到 ( 4 , 4 ) (4,4) (4,4)

- 通常,如果我们添加 p h p_h ph 行填充和 p w p_w pw 列填充,则输出形状将为
( n h − k h + p h + 1 ) × ( n w − k w + p w + 1 ) (n_h-k_h+p_h+1) \times (n_w-k_w+p_w+1) (nh−kh+ph+1)×(nw−kw+pw+1) 这意味着输出的高度和宽度分别增加 p h p_h ph 和 p w p_w pw。许多时候我们设置 p h = k h − 1 p_h=k_h-1 ph=kh−1 和 p w = k w − 1 p_w=k_w-1 pw=kw−1,使输出和输入具有相同的尺寸,这样可以在构建网络时更容易地预测每个图层的输出形状 - 卷积神经网络中卷积核的高度和宽度通常为奇数,好处是
- 我们可以在原始输入的上下、左右填充相同数量的行和列来保持空间维度
- 对于任何二维张量 X \mathbf{X} X,当所有边的填充行列数相同且输出保持空间维度时,输出 Y [ i , j ] \mathbf{Y}[i, j] Y[i,j] 是通过以输入 X [ i , j ] \mathbf{X}[i, j] X[i,j] 为中心,与卷积核进行互相关计算得到的
- 下面给出两个例子
- 创建一个高度和宽度为3的二维卷积层,并在所有侧边填充1个像素(上下共填充2 / 左右共填充2)。给定高度和宽度为8的输入,则输出的高度和宽度也是8
import torch from torch import nn# 为了方便起见,我们定义了一个计算卷积层的函数。 # 此函数初始化卷积层权重,并对输入和输出提高和缩减相应的维数 def comp_conv2d(conv2d, X):# 这里的(1,1)表示批量大小和通道数都是1X = X.reshape((1, 1) + X.shape)Y = conv2d(X)# 省略前两个维度:批量大小和通道return Y.reshape(Y.shape[2:])# 请注意,这里每边都填充了1行或1列,因此总共添加了2行或2列 conv2d = nn.Conv2d(1, 1, kernel_size=3, padding=1) X = torch.rand(size=(8, 8)) comp_conv2d(conv2d, X).shape>>> torch.Size([8, 8]) - 我们使用高度为 5,宽度为 3 的卷积核,高度和宽度两边的填充分别为2(共4)和1(共2)
conv2d = nn.Conv2d(1, 1, kernel_size=(5, 3), padding=(2, 1)) comp_conv2d(conv2d, X).shape>>> torch.Size([8, 8])
- 创建一个高度和宽度为3的二维卷积层,并在所有侧边填充1个像素(上下共填充2 / 左右共填充2)。给定高度和宽度为8的输入,则输出的高度和宽度也是8
3.2 步幅
-
在计算互相关时,卷积窗口从输入张量的左上角开始,向下、向右滑动。 在前面的例子中,我们默认每次滑动一个元素。 但是,有时候为了高效计算或是缩减采样次数,卷积窗口可以跳过中间位置,每次滑动多个元素
-
我们将每次滑动元素的数量称为
步幅stride,下图显示了垂直步幅为3,水平步幅为2的二维互相关运算。着色部分是输出元素以及用于输出计算的输入和内核张量元素

通常,当垂直步幅为 s h s_h sh、水平步幅为 s w s_w sw 时,输出形状为
⌊ ( n h − k h + p h + s h ) / s h ⌋ × ⌊ ( n w − k w + p w + s w ) / s w ⌋ . \left\lfloor\left(n_{h}-k_{h}+p_{h}+s_{h}\right) / s_{h}\right\rfloor \times\left\lfloor\left(n_{w}-k_{w}+p_{w}+s_{w}\right) / s_{w}\right\rfloor . ⌊(nh−kh+ph+sh)/sh⌋×⌊(nw−kw+pw+sw)/sw⌋. -
下面给出一个例子,将高度和宽度的步幅设置为2,从而将输入的高度和宽度减半
conv2d = nn.Conv2d(1, 1, kernel_size=3, padding=1, stride=2) comp_conv2d(conv2d, X).shape>>> torch.Size([4, 4]) -
为了简洁起见,我们称填充为 ( p h , p w ) (p_h,p_w) (ph,pw),步幅为 ( s h , s w ) (s_h, s_w) (sh,sw)。特别地,当 p h = p w = p p_h=p_w=p ph=pw=p 时,称填充为 p p p;当 s h = s w = s s_h=s_w=s sh=sw=s 时,步幅是 s s s。默认情况下,填充为0,步幅为1。实践中我们很少使用不一致的步幅或填充
4. 多输入多输出通道
- 以上 2/3 节都是基于单个输入输出通道进行讨论的,这使得我们可以将输入、卷积核和输出看作二维张量。当添加通道时,输入和输出都变成了三维张量,本节将更深入地研究具有多输入和多输出通道的卷积核
4.1 多输入通道
- 当输入包含多个通道时,需要构造一个与输入数据具有相同输入通道数的卷积核,以便与输入数据进行互相关运算。设输入数据尺寸为 ( c i , n h , n w ) (c_i, n_h,n_w) (ci,nh,nw),需要卷积核尺寸为 ( c i , k h , k w ) (c_i, k_h, k_w) (ci,kh,kw),这可以看作 c i c_i ci 个相同尺寸的卷积核,它们分别与输入的各个通道数据进行互相关运算得到 c i c_i ci 个二维输出,最后把它们按位置求和得到最终输出。如下图所示

4.2 多输出通道
- 在 1.4 节我们提到过,每个通道都向后续层提供一组空间化的学习特征,在最流行的神经网络架构中,随着神经网络层数的加深,我们常会增加输出通道的维数,通过减少空间分辨率以获得更大的通道深度
- 通道有点类似 Transformer 中的多个注意力头,直观地说,我们可以将每个通道看作对不同特征的响应,但多输出通道并不仅是学习多个单通道的检测器,因为每个通道不是独立学习的,而是为了共同使用而优化的
- 用 c i , c o c_i,c_o ci,co 分别表示输入和输出的通道数量,用 k h , k w k_h,k_w kh,kw 表示卷积核的高度和宽度,为了获得多个通道的输出,我们可以为每个输出通道创建一个形状为 ( c i , k h , k w ) (c_i, k_h, k_w) (ci,kh,kw) 的卷积核张量,这样卷积核的最终形状为 ( c o , c i , k h , k w ) (c_o, c_i, k_h, k_w) (co,ci,kh,kw)。在互相关运算中,每个输出通道先获取所有输入通道,再以对应该输出通道的卷积核计算出结果
4.3 只作用在通道上的 1X1 卷积层
- 当 k h = k w = 1 k_h=k_w=1 kh=kw=1 时,卷积核只能输入一个空间位置的像素,这种卷积核不再能提取相邻像素间的相关特征,它唯一的计算发生在通道上,可以把 1x1 卷积看作在每个像素位置的所有通道上的全连接层,将 c i c_i ci 个输入转换为 c o c_o co 个输出,如下图所示

- 注意 1x1 卷积也是一个卷积层,故其跨像素的权重是一致的,权重维度为 c i × c o c_i\times c_o ci×co,再额外加上一个偏置
5. 汇聚层
- 通常当我们处理图像时,我们希望逐渐降低隐藏表示的空间分辨率、聚集信息,这样随着我们在神经网络中层叠的上升,每个神经元对其敏感的感受野(输入)就越大。机器学习任务通常会跟全局图像的问题有关(例如,“图像是否包含一只猫呢?”),所以我们最后一层的神经元应该对整个输入的全局敏感,这需要我们逐渐聚合信息,生成越来越粗糙的映射
- 现实中,随着拍摄角度的移动,任何物体几乎不可能发生在同一像素上,我们希望模型检查的底层特征(例如 2.1 节中讨论的边缘)保持某种程度上的平移不变性,前面介绍的卷积层相比全连接层已经具有更强的平移不变性了,汇聚层可以进一步增强模型的平移不变能力
- 本节将介绍
汇聚/池化pooling层,它具有双重目的- 降低卷积层对位置的敏感性
- 降低对空间降采样表示的敏感性
5.1 最大汇聚层与平均汇聚层
- 与卷积层类似,汇聚层运算符由一个固定形状的窗口组成,该窗口根据其步幅大小在输入的所有区域上滑动,为固定形状窗口(有时称为
汇聚窗口)遍历的每个位置计算一个输出。 - 不同于卷积层中的输入与卷积核之间的互相关计算,汇聚层不包含参数。 相反,池运算是确定性的,通常有两种
最大汇聚层maximum pooling:计算汇聚窗口中所有元素的最大值平均汇聚层average pooling:计算汇聚窗口中所有元素的平均值
- 下图显示了最大汇聚层的处理过程

注意汇聚层的输入是卷积层的输出,我们可以假设上图中的输入 4 对应到原始图像输入上感受野的某个特征(随着层数叠加,感受野可以是较大的一片区间,特征也可以是高价的,比如鸟翅膀或猫尾巴),当原始图像输入发生少量平移时,以上汇聚层输入中的 4 可能偏移到左上角的 0 位置,最大汇聚层在这种情况下可以保持输出不变,这意味着更强的平移不变性
5.2 填充和步幅
- 与卷积层一样,汇聚层也可以通过设置填充和步幅改变输出形状,pytorch 中语法如下
# 定义卷积层,指定卷积核尺寸、填充和步幅 conv2d = nn.Conv2D(1, kernel_size=(3, 5), padding=(0, 1), strides=(3, 4))# 定义最大池化层,指定汇聚窗口尺寸、填充和步幅 pool2d = nn.MaxPool2d((2, 3), stride=(2, 3), padding=(0, 1))
5.3 多个通道
- 在处理多通道输入数据时,汇聚层在每个输入通道上单独运算,而不是像卷积层一样在通道上对输入进行汇总,这意味着汇聚层的输出通道数与输入通道数相同
import torch import numpy as npX = np.arange(16, dtype=np.float32).reshape((1, 1, 4, 4)) X = np.concatenate((X, X + 1), 1) # (1, 2, 4, 4) pool2d = nn.MaxPool2d(3, padding=1, stride=2) # 由于汇聚层中没有参数,所以不需要调用初始化函数 Y = pool2d(torch.tensor(X)) # (1, 2, 2, 2)
6. 卷积神经网络
- 一个完整的卷积神经网络通过交替堆叠卷积层和汇聚层提取图像特征,最后接全连接层调整维度,用于分类或回归任务。下面是经典 CNN 模型 LeNet 的结构图

- 考虑到篇幅问题,本文仅介绍 CNN 基础原理,各种经典模型的细节和 pytorch 实现将在后续其他文章介绍,链接将更新到此处。To be continue…
相关文章:
经典机器学习方法(7)—— 卷积神经网络CNN
参考:《动手学深度学习》第六章 卷积神经网络(convolutional neural network,CNN)是一类针对图像数据设计的神经网络,它充分利用了图像数据的特点,具有适合图像特征提取的归纳偏置,因而在图像相…...

经典面试题【作用域、闭包、变量提升】,带你深入理解掌握!
前言:哈喽,大家好,我是前端菜鸟的自我修养!今天给大家分享经典面试题【作用域、闭包、变量提升】,并提供具体代码帮助大家深入理解,彻底掌握!原创不易,如果能帮助到带大家࿰…...
Dockerfile实战
Dockerfile是用来快速创建自定义镜像的一种文本格式的配置文件,在持续集成和持续部署时,需要使用Dockerfile生成相关应用程序的镜像。 Dockerfile常用命令 FROM:继承基础镜像MAINTAINER:镜像制作作者的信息,已弃用&a…...

常用的开源数据集网站
Kaggle(https://www.kaggle.com/datasets):Kaggle 是一个著名的数据科学竞赛平台,也提供了大量的开放数据集供用户下载和使用。UCI Machine Learning Repository(https://archive.ics.uci.edu/datasets)&am…...

html文本被木马病毒植入vbs脚本
我在公司服务器上写了一个静态html,方便导航,结果没过多久发现html文件被修改了,在</html>标签后加了这些代码。 注:WriteData 的内容很长,被我删掉了很多,不然没法提交这个提问 <SCRIPT Lan…...

jsonl 文件介绍
jsonl文件介绍 什么是 jsonl 文件文件结构读取jsonl文件写入jsonl文件 什么是 jsonl 文件 jsonl(json lines)是一种文件格式,其中每一行都是一个单独的 json 对象。与常规的 json文件不同,jsonl文件在处理大量数据时具有优势&…...

反射机制详解
✅作者简介:大家好,我是Leo,热爱Java后端开发者,一个想要与大家共同进步的男人😉😉 🍎个人主页:Leo的博客 💞当前专栏:Java从入门到精通 ✨特色专栏ÿ…...
【数据库】七、数据库安全与保护
七、数据库安全与保护 文章目录 七、数据库安全与保护安全性访问控制数据库安全性控制用户标识和鉴别存取控制自主存取控制(DAC)存取控制方法:授权与回收GRANT授权REVOKE回收 强制存取控制(MAC) MySQL的安全设置用户管理1.创建登录用户2.修改用户密码3.修改用户名4.…...

卡尔曼滤波-剔除异常值的影响
二郎在看论文的时候,发现了一个针对卡尔曼滤波过程中,测量向量出现误差导致滤波发散的处理方法。 该方法也可以扩展到其他问题中使用,所以二郎在这里写一下。 论文原文:https://www.mdpi.com/1424-8220/20/17/4710 论文翻译对应…...
Java程序之动物声音“模拟器”
题目: 设计一个“动物模拟器”,希望模拟器可以模拟许多动物的叫声和行为,要求如下: 编写接口Animal,该接口有两个抽象方法cry()和getAnimalName(),即要求实现该接口的各种具体的动物类给出自己的叫声和种类…...

jieba中文分词器的使用
Jieba 是一个中文分词的第三方库,主要用于对中文文本进行分词。分词是将文本分割成一个个词语的过程,这在中文文本处理中尤为重要,因为中文不像英文那样有明显的空格来分隔词语。Jieba 的分词算法可以实现精确分词、全模式分词和搜索引擎模式…...

【杂记-浅谈OSPF协议中的RouterDeadInterval】
OSPF协议中的RouterDeadInterval 一、RouterDeadInterval概述二、设置RouterDeadInterval三、RouterDeadInterval的重要性 一、RouterDeadInterval概述 RouterDeadInterval,即路由器死区间隔,它涉及到路由器如何在广播网络上发现和维护邻居关系。Router…...

Django 模版变量
1,模版变量作用 模板变量使用“{{ 变量名 }}” 来表示模板变量前后可以有空格,模板变量名称,可以由数字,字母,下划线组成,不能包含空格模板变量还支持列表,字典,对象 2,…...
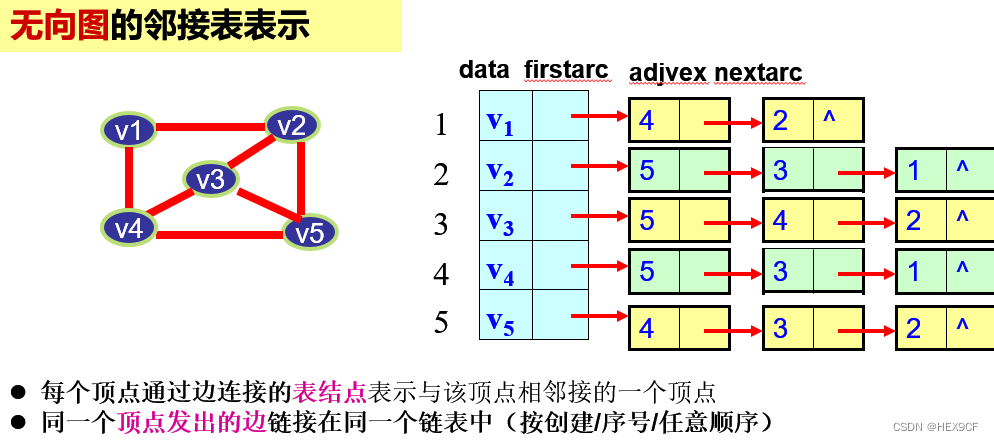
【数据结构与算法】图的存储(邻接矩阵,邻接表)详解
图的邻接矩阵数据结构 typedef enum { NDG, DG, NDN, DN } GraphKind;using VRType int; using InfoType int;typedef struct ArcCell {VRType adj;InfoType *info; } Arc[N][N];struct MGraph {ElemType vexs[N];Arc arc;int vexnum, arcnum;GraphKind kind; };ArcCell 结构…...

【深度C++】之“类与结构体”
0. 抽象数据类型 类(class) 和结构体(struct) 都是C中的自定义数据类型,是使用C实现面向对象编程思想的起点。 类的基本思想是数据抽象(data abstraction) 和封装(encapsulation&a…...

CTO的职责是什么?
看《架构思维》作者是这样讲的: CTO 到底是做什么的? 我当下的答案是:“CTO 就是一个从技术视角出发,为公司或者所在的部门做正确决策的 CEO。”怎么理解这句话呢?作为一个 CTO,其长期目标和决策优先级与…...
【GD32】从零开始学兆易创新32位微处理器——RTC实时时钟+日历例程
1 简介 RTC实时时钟顾名思义作用和墙上挂的时钟差不多,都是用于记录时间和日历,同时也有闹钟的功能。从硬件实现上来说,其实它就是一个特殊的计时器,它内部有一个32位的寄存器用于计时。RTC在低功耗应用中可以说相当重要…...

HTTP网络协议
1.HTTP (1)概念: Hyper Text Transfer Protocol,超文本传输协议规定了浏览器和服务器之间数据传输的规则。 (2)特点 基于TCP协议:面向连接,安全基于请求-响应模型的:一次请求对应一次响应HTTP协…...
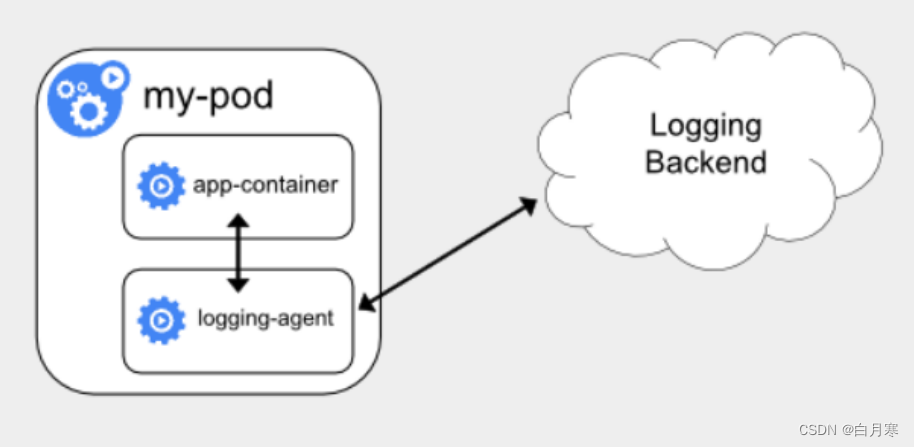
Kubernetes相关生态
1、Prometheus、Metrics Server与Kubernetes监控体系 简介: Prometheus 项目与 Kubernetes 项目一样,也来自于 Google 的 Borg 体系,它的原型系统,叫作 BorgMon,是一个几乎与 Borg 同时诞生的内部监控系统 Pro…...

C语言入门4-函数和程序结构
函数举例 读取字符串,如果字符串中含有ould则输出该字符串,否则不输出。 #include <stdio.h>// 函数声明 int getLine(char s[], int lim); int strindex(char s[], char t[]);int main() {char t[] "ould"; // 要查找的目标子字符串…...

Ubuntu系统下交叉编译openssl
一、参考资料 OpenSSL&&libcurl库的交叉编译 - hesetone - 博客园 二、准备工作 1. 编译环境 宿主机:Ubuntu 20.04.6 LTSHost:ARM32位交叉编译器:arm-linux-gnueabihf-gcc-11.1.0 2. 设置交叉编译工具链 在交叉编译之前&#x…...

【入坑系列】TiDB 强制索引在不同库下不生效问题
文章目录 背景SQL 优化情况线上SQL运行情况分析怀疑1:执行计划绑定问题?尝试:SHOW WARNINGS 查看警告探索 TiDB 的 USE_INDEX 写法Hint 不生效问题排查解决参考背景 项目中使用 TiDB 数据库,并对 SQL 进行优化了,添加了强制索引。 UAT 环境已经生效,但 PROD 环境强制索…...

cf2117E
原题链接:https://codeforces.com/contest/2117/problem/E 题目背景: 给定两个数组a,b,可以执行多次以下操作:选择 i (1 < i < n - 1),并设置 或,也可以在执行上述操作前执行一次删除任意 和 。求…...

零基础设计模式——行为型模式 - 责任链模式
第四部分:行为型模式 - 责任链模式 (Chain of Responsibility Pattern) 欢迎来到行为型模式的学习!行为型模式关注对象之间的职责分配、算法封装和对象间的交互。我们将学习的第一个行为型模式是责任链模式。 核心思想:使多个对象都有机会处…...

Caliper 配置文件解析:config.yaml
Caliper 是一个区块链性能基准测试工具,用于评估不同区块链平台的性能。下面我将详细解释你提供的 fisco-bcos.json 文件结构,并说明它与 config.yaml 文件的关系。 fisco-bcos.json 文件解析 这个文件是针对 FISCO-BCOS 区块链网络的 Caliper 配置文件,主要包含以下几个部…...

STM32HAL库USART源代码解析及应用
STM32HAL库USART源代码解析 前言STM32CubeIDE配置串口USART和UART的选择使用模式参数设置GPIO配置DMA配置中断配置硬件流控制使能生成代码解析和使用方法串口初始化__UART_HandleTypeDef结构体浅析HAL库代码实际使用方法使用轮询方式发送使用轮询方式接收使用中断方式发送使用中…...

Windows安装Miniconda
一、下载 https://www.anaconda.com/download/success 二、安装 三、配置镜像源 Anaconda/Miniconda pip 配置清华镜像源_anaconda配置清华源-CSDN博客 四、常用操作命令 Anaconda/Miniconda 基本操作命令_miniconda创建环境命令-CSDN博客...

华为OD机试-最短木板长度-二分法(A卷,100分)
此题是一个最大化最小值的典型例题, 因为搜索范围是有界的,上界最大木板长度补充的全部木料长度,下界最小木板长度; 即left0,right10^6; 我们可以设置一个候选值x(mid),将木板的长度全部都补充到x,如果成功…...

Spring Security 认证流程——补充
一、认证流程概述 Spring Security 的认证流程基于 过滤器链(Filter Chain),核心组件包括 UsernamePasswordAuthenticationFilter、AuthenticationManager、UserDetailsService 等。整个流程可分为以下步骤: 用户提交登录请求拦…...
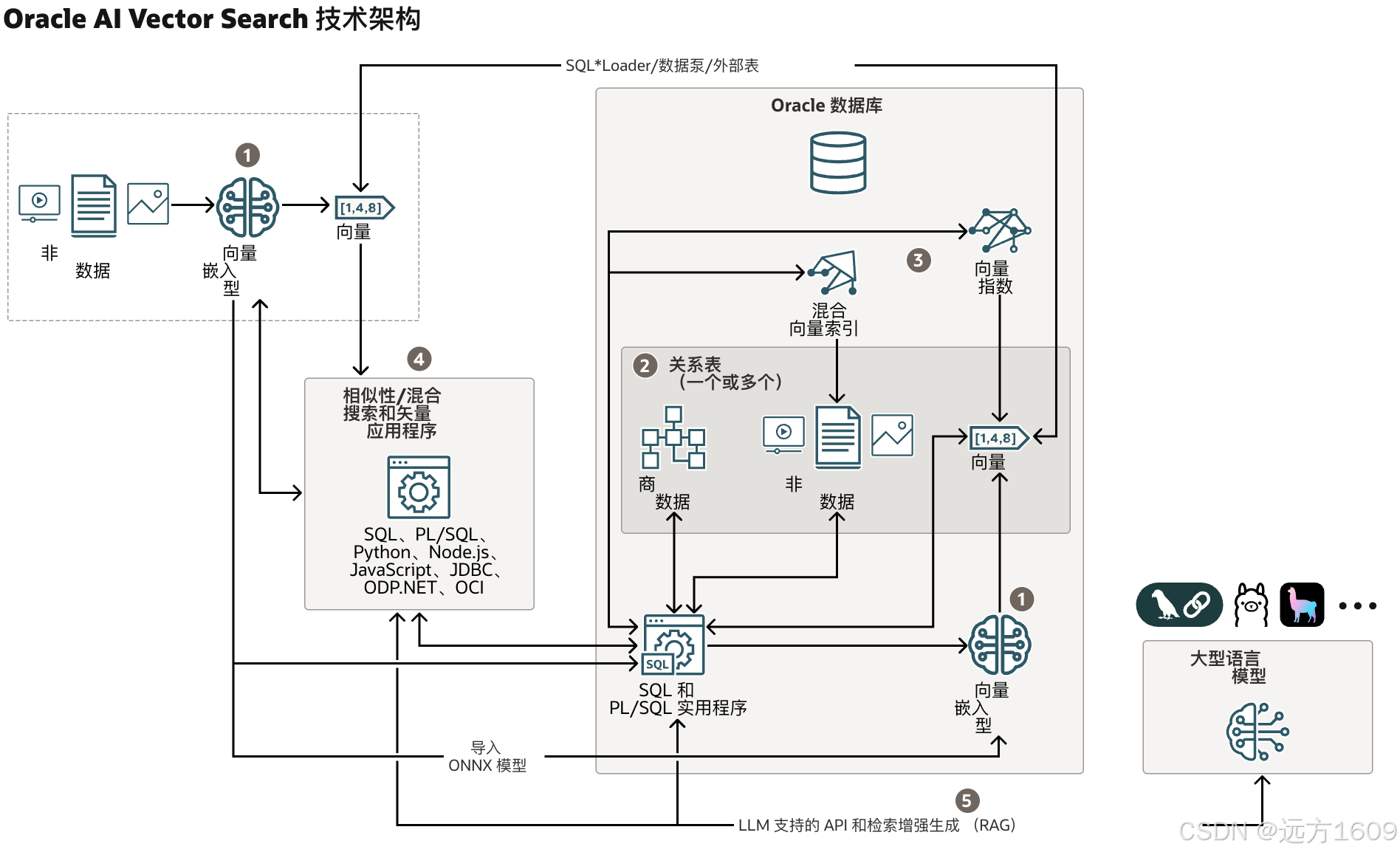
9-Oracle 23 ai Vector Search 特性 知识准备
很多小伙伴是不是参加了 免费认证课程(限时至2025/5/15) Oracle AI Vector Search 1Z0-184-25考试,都顺利拿到certified了没。 各行各业的AI 大模型的到来,传统的数据库中的SQL还能不能打,结构化和非结构的话数据如何和…...