链家房屋数据爬取与预处理-大数据采集与预处理课程设计
芜湖市链家二手房可视化平台
成品展示
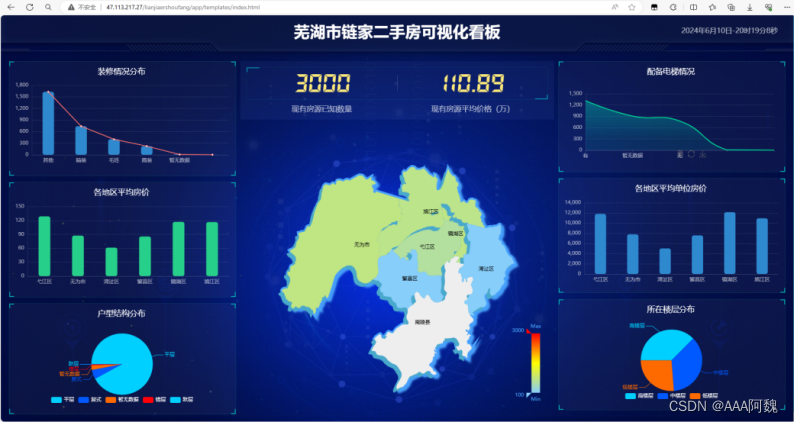
重点说明
1.数据特征数量和名称、数据量
数据特征数量:14;
名称:小区名、价格/万、地区、房屋户型、所在楼层、建筑面积/平方米、户型结构、套内面积、建筑类型、房屋朝向、建筑结构、装修情况、梯户比例、配备电梯;
数据量:3000条。
2.主要爬取和预处理的工具或库
爬取的工具:Requests、time、csv、lxml;
预处理的库:pandas、json、pyecharts;
Web开发框架:HTML、CSS、JavaScript、jQuery、Bootstrap;
3.软件模块设计(类、函数等)
#获取每一页的url
def Get_url(url):
#获取每套房详情信息的url
def Get_house_url(all_url,headers):
#获取每套房的详情信息
def Analysis_html(url_ls,headers):
#把爬取的信息存入文件
def Save_data(name, money, area, data):
4.软件产品形式
Web网站:
http://47.113.217.27/lianjiaershoufang/app/templates/index.html,欢迎访问
摘要
在当前房价高涨的市场环境下,购房者对于房价信息的获取和分析需求日益增强。作为房地产行业的领军企业之一,链家网拥有大量的房源信息和用户数据。为了更好地满足用户需求,提升购房体验,本设计计划构建一个芜湖市链家二手房可视化平台,通过爬取和预处理链家网的房屋数据,为用户提供直观、便捷的房价信息展示和分析工具。
通过使用requests库发送请求获取网页内容,使用time库控制程序的请求速度,使用lxml库解析HTML数据并保存实现对链家网站的数据爬取,使用pandas库对原始数据进行缺失值检测、添加表格头、数据类型转换、异常数据替换等操作,并对各地区房源数量、各地区房价、户型结构分布、所在楼层分布、配备电梯情况等进行分析并转换成json数据实现数据的预处理,成功构建了包含房屋属性、交易属性等关键信息的数据库。采用HTML、CSS、echarts、jQuery、BootStrap框架开发芜湖市链家二手房可视化平台,读取转换的json数据以可视化看板的形式展现给用户。
在数据采集过程中,针对数据不完整和爬虫程序触发限制等问题,提出了分区域爬取和合理控制爬取速度等有效措施。经过数据清洗与分析,确保数据质量并存储于适当格式。平台功能设计完善,部署顺利,为后续的可视化展示提供了坚实基础。
平台对各地区房源数量、各地区房价、户型结构分布、所在楼层分布、配备电梯情况等进行分析,可以让用户快速了解芜湖市二手房的关键信息,辅助用户决策。
在构建芜湖市链家二手房可视化平台的旅程中,成功地将链家网的海量房源数据转化为直观、易理解的可视化信息,为用户提供了宝贵的参考依据。通过不断的优化和迭代,确保了数据的准确性和实时性,满足了购房者在当前房价高涨市场环境下对房价信息的迫切需求。
展望未来,将继续倾听用户的声音,不断完善平台的各项功能,提升用户体验。也将积极探索新的数据源和分析方法,为用户提供更加全面、深入的房地产市场分析服务。相信,在不久的将来,芜湖市链家二手房可视化平台将成为购房者不可或缺的信息助手,帮助他们更加明智地做出购房决策。
下面是具体实现代码
(代码中的路径自己替换成自己的路径)
爬虫程序(URL自己替换成自己想爬取城市的)
import requests,time,csv
import pandas as pd
from lxml import etree#获取每一页的url
def Get_url(url):all_url=[]for i in range(1,101):all_url.append(url+'pg'+str(i)+'/') #储存每一个页面的urlreturn all_url#获取每套房详情信息的url
def Get_house_url(all_url,headers):num=0#简单统计页数for i in all_url:r=requests.get(i,headers=headers)html=etree.HTML(r.text)url_ls=html.xpath("//ul[@class='sellListContent']/li/a/@href") #获取房子的urlAnalysis_html(url_ls,headers)time.sleep(4)print("第%s页爬完了"%i)num+=1#获取每套房的详情信息
def Analysis_html(url_ls,headers):for i in url_ls: #num记录爬取成功的索引值r=requests.get(i,headers=headers)html=etree.HTML(r.text)name=(html.xpath("//div[@class='communityName']/a/text()"))[0].split() #获取房名money = html.xpath("//span[@class='total']/text()" )# 获取价格area = html.xpath("//span[@class='info']/a[1]/text()") # 获取地区data = html.xpath("//div[@class='content']/ul/li/text()")# 获取房子基本属性Save_data(name,money,area,data)#把爬取的信息存入文件
def Save_data(name, money, area, data):result=[name[0]]+money+[area]+data #把详细信息合为一个列表with open(r'../app/data/raw_data.csv','a',encoding='utf_8_sig',newline='')as f:wt=csv.writer(f)wt.writerow(result)print('已写入')f.close()if __name__=='__main__':url='https://wuhu.lianjia.com/ershoufang/'headers={"Upgrade-Insecure-Requests":"1","User-Agent":"Mozilla/5.0(Windows NT 10.0;Win64;x64) AppleWebKit/537.36(KHTML,like Gecko)Chrome""/72.0.3626.121 Safari/537.36"}all_url=Get_url(url)with open(r'../app/data/raw_data.csv', 'a', encoding='utf_8_sig', newline='') as f:#首先加入表格头table_label=['小区名','价格/万','地区','房屋户型','所在楼层','建筑面积','户型结构','套内面积','建筑类型','房屋朝向','建筑结构','装修情况','梯户比例','配备电梯']wt=csv.writer(f)wt.writerow(table_label)Get_house_url(all_url,headers)预处理程序
import csv# 打开原始CSV文件和目标CSV文件,指定编码方式为UTF-8
with open('../app/data/raw_data.csv', 'r', newline='', encoding='utf-8') as infile, \open('../app/data/cleaned_data.csv', 'w', newline='', encoding='utf-8') as outfile:reader = csv.reader(infile)writer = csv.writer(outfile)# 跳过原始CSV文件的第一行next(reader)# 添加表格头table_label=['小区名','价格/万','地区','房屋户型','所在楼层','建筑面积','户型结构','套内面积','建筑类型','房屋朝向','建筑结构','装修情况','梯户比例','配备电梯']writer.writerow(table_label)# 删除指定列的索引columns_to_drop = [3, 5, 7, 9, 11, 13, 15, 17, 19, 21, 23, 25,26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41]for row in reader:# 删除指定列cleaned_row = [row[i] for i in range(len(row)) if i not in columns_to_drop]writer.writerow(cleaned_row)import pandas as pd# 读取csv文件的前14列
df = pd.read_csv('../app/data/cleaned_data.csv', encoding='utf-8', usecols=range(14))# 去除地区列中的 [''](使用正则表达式)
df['地区'] = df['地区'].str.replace(r"['\[\]]", '', regex=True)
# 去除建筑面积列中的㎡
df['建筑面积'] = df['建筑面积'].str.replace('㎡', '')
# 修改列名为'建筑面积/平方米'
df = df.rename(columns={'建筑面积': '建筑面积/平方米'})
# 所在楼层列只保留前三个文字
df['所在楼层'] = df['所在楼层'].str.slice(0, 3)
df['地区'] = df['地区'].replace('三山区', '弋江区')
df['所在楼层'] = df['所在楼层'].replace('22.', '高楼层')
# 将'三山区'改为'弋江区'
# 将'经济开发区'改为'鸠江区'
df['地区'] = df['地区'].replace('经济开发区', '鸠江区')# 保存修改后的数据
df.to_csv('../app/data/last_cleaned_data.csv', index=False)转换成Echarts需要的json数据程序
import pandas as pd# 读取csv文件
df = pd.read_csv('../app/data/last_cleaned_data.csv', encoding='utf-8')
# 计算价格/万列的均值
mean_price = df['价格/万'].mean()print("价格/万列的均值为:", mean_price)import pandas as pd
import json# 读取地区数据
df = pd.read_csv('../app/data/last_cleaned_data.csv', encoding='utf-8')# 统计每个地区的数量
area_counts = df['地区'].value_counts().reset_index()
area_counts.columns = ['name', 'value']# 转换为需要的格式
json_data = area_counts.to_dict(orient='records')# 保存为json文件
with open('../app/templates/wuhu_data.json', 'w', encoding='utf-8') as f:json.dump({"datas": json_data}, f, ensure_ascii=False)print("各地区房源数量统计JSON文件保存成功。")import pandas as pd# 读取 CSV 文件
df = pd.read_csv('../app/data/last_cleaned_data.csv', encoding='utf-8')# 对小区名列进行统计
counts = df['小区名'].value_counts()# 转换成指定的 JSON 格式
result = {"ciyunshuju": [{"name": name,"value": count}for name, count in counts.items()]}# 输出 JSON 文件
with open('../app/templates/ciyun.json', 'w',encoding='utf-8') as f:json.dump(result, f, ensure_ascii=False, indent=4)
print("小区名词云数据JSON文件保存成功。")import pandas as pd# 读取 CSV 文件
df = pd.read_csv('../app/data/last_cleaned_data.csv', encoding='utf-8')# 对户型结构列进行统计
counts = df['户型结构'].value_counts()# 转换成指定的 JSON 格式
result = {"huxingjiegou": [{"name": name,"value": count}for name, count in counts.items()]}# 输出 JSON 文件
with open('../app/templates/huxing.json', 'w',encoding='utf-8') as f:json.dump(result, f, ensure_ascii=False, indent=4)
print("户型结构分布数据JSON文件保存成功。")import json
from pyecharts import options as opts
from pyecharts.charts import WordCloud# Read data from ciyun.json
with open('../app/templates/ciyun.json', 'r', encoding='utf-8') as file:data = json.load(file)# Extract name-value pairs from the data
words = [(item['name'], item['value']) for item in data['ciyunshuju']]# Generate word cloud
wordcloud = (WordCloud().add("", words, word_size_range=[10, 30]).set_global_opts(graphic_opts=[opts.GraphicGroup(graphic_item=opts.GraphicItem(left="center", top="middle", width=500, height=300))])
)# Save word cloud as an HTML file
wordcloud.render('../app/templates/wordcloud.html')print('小区名词云图绘制成功')import pandas as pd
import json# 读取CSV文件
df = pd.read_csv('../app/data/last_cleaned_data.csv')# 将需要的列转换为数值类型,非数值的部分会被转换为NaN
df['价格/万'] = pd.to_numeric(df['价格/万'], errors='coerce')
df['建筑面积/平方米'] = pd.to_numeric(df['建筑面积/平方米'], errors='coerce')# 去除包含NaN值的行
df = df.dropna(subset=['价格/万', '建筑面积/平方米', '地区'])# 计算每平方米价格
df['每平方米价格'] = df['价格/万'] * 10000 / df['建筑面积/平方米']# 按地区分组并计算平均值
average_price_per_sqm = df.groupby('地区')['每平方米价格'].mean().reset_index()# 将平均值转换为整数
average_price_per_sqm['每平方米价格'] = average_price_per_sqm['每平方米价格'].astype(int)# 将结果转换为所需的JSON格式
result = {"diqupingjun": [{"name": row['地区'], "value": row['每平方米价格']}for index, row in average_price_per_sqm.iterrows()]
}# 将结果存储为JSON文件
with open('../app/templates/diqupingjun.json', 'w', encoding='utf-8') as f:json.dump(result, f, ensure_ascii=False, indent=4)print("各地区平均房价数据JSON数据已保存")import pandas as pd
import json# 读取CSV文件
df = pd.read_csv('../app/data/last_cleaned_data.csv')# 按地区分组并计算平均价格
average_price_per_region = df.groupby('地区')['价格/万'].mean().reset_index()# 将结果转换为JSON格式
result = {"diqujiage": [{"name": row['地区'], "value": round(row['价格/万'], 2)}for index, row in average_price_per_region.iterrows()]
}# 将结果存储为JSON文件
with open('../app/templates/diqujiage.json', 'w', encoding='utf-8') as f:json.dump(result, f, ensure_ascii=False, indent=4)print("各地区平均单位房价数据JSON数据已保存")import pandas as pd# 读取 CSV 文件
df = pd.read_csv('../app/data/last_cleaned_data.csv', encoding='utf-8')# 对户型结构列进行统计
counts = df['装修情况'].value_counts()# 转换成指定的 JSON 格式
result = {"zhuangxiu": [{"name": name,"value": count}for name, count in counts.items()]}# 输出 JSON 文件
with open('../app/templates/zhuangxiu.json', 'w',encoding='utf-8') as f:json.dump(result, f, ensure_ascii=False, indent=4)
print("装修情况数据JSON文件保存成功。")import pandas as pd# 读取 CSV 文件
df = pd.read_csv('../app/data/last_cleaned_data.csv', encoding='utf-8')# 对配备电梯列进行统计
counts = df['配备电梯'].value_counts()# 转换成指定的 JSON 格式
result = {"dianti": [{"name": name,"value": count}for name, count in counts.items()]}# 输出 JSON 文件
with open('../app/templates/dianti.json', 'w',encoding='utf-8') as f:json.dump(result, f, ensure_ascii=False, indent=4)
print("配备电梯情况JSON文件保存成功。")import pandas as pd# 读取 CSV 文件
df = pd.read_csv('../app/data/last_cleaned_data.csv', encoding='utf-8')# 对户型结构列进行统计
counts = df['所在楼层'].value_counts()# 转换成指定的 JSON 格式
result = {"louceng": [{"name": name,"value": count}for name, count in counts.items()]}# 输出 JSON 文件
with open('../app/templates/louceng.json', 'w',encoding='utf-8') as f:json.dump(result, f, ensure_ascii=False, indent=4)
print("所在楼层分布数据JSON文件保存成功。")JS部分代码
$(function () {echarts_1();echarts_2();echarts_4();echarts_31();echarts_5();echarts_6();function echarts_31() {var myChart = echarts.init(document.getElementById("fb1"));myChart.setOption({title: [{left: 'center',textStyle: {color: '#fff',fontSize: '16'}}],tooltip: {trigger: 'item',formatter: '{a} <br/>{b} : {c} ({d}%)'},legend: {orient: 'horizontal',bottom: 0,textStyle: {color: '#fff' // 设置图例字体颜色为白色},data: [] // 初始设置为空数组,等待后续动态加载},series: [{color: ['#00d0ff', '#0059ff', '#ff6a00', '#ff0008'],name: '户型结构占比',type: 'pie',center: ['50%', '50%'],startAngle: 180,endAngle: 360,data: [] // 初始设置为空数组,等待后续动态加载}]});// 读取huxing.json$.getJSON("huxing.json", function (data) {var huxing_data = data.huxingjiegou;// 使用huxing_data来渲染图表// 修改图表数据myChart.setOption({series: [{data: huxing_data.map(function (item) {return {name: item.name.trim(),value: item.value};})}],legend: {data: huxing_data.map(function (item) {return item.name.trim();})}});});
}function echarts_1() {// 基于准备好的dom,初始化echarts实例var myChart = echarts.init(document.getElementById('echart1'));// 从服务器加载JSON数据fetch('zhuangxiu.json').then(response => response.json()).then(data => {// 提取名称和对应的值var names = data.zhuangxiu.map(item => item.name.trim());var values = data.zhuangxiu.map(item => item.value);var option = {tooltip: {trigger: 'axis',axisPointer: {type: 'shadow'}},grid: {left: '0%',top: '10px',right: '0%',bottom: '4%',containLabel: true},xAxis: [{type: 'category',data: names, // 使用从JSON文件中读取的数据axisLine: {show: true,lineStyle: {color: "rgba(255,255,255,.1)",width: 1,type: "solid"},},axisTick: {show: false,},axisLabel: {interval: 0,show: true,splitNumber: 15,textStyle: {color: "rgba(255,255,255,.6)",fontSize: '12',},},}],yAxis: [{type: 'value',axisLabel: {show: true,textStyle: {color: "rgba(255,255,255,.6)",fontSize: '12',},},axisTick: {show: false,},axisLine: {show: true,lineStyle: {color: "rgba(255,255,255,.1)",width: 1,type: "solid"},},splitLine: {lineStyle: {color: "rgba(255,255,255,.1)",}}}],series: [{name: '装修类型数量',type: 'bar',data: values, // 使用从JSON文件中读取的数据barWidth: '35%', // 柱子宽度itemStyle: {normal: {color: '#2f89cf',opacity: 1,barBorderRadius: 5,}}},{name: '装修类型数量',type: 'line',data: values, // 使用从JSON文件中读取的数据itemStyle: {normal: {color: '#f56c6c',opacity: 1,}}}]};// 使用刚指定的配置项和数据显示图表。myChart.setOption(option);window.addEventListener("resize", function(){myChart.resize();});});
}function echarts_2() {var myChart = echarts.init(document.getElementById('echart2'));// 从服务器加载JSON数据fetch('diqujiage.json').then(response => response.json()).then(data => {var option = {tooltip: {trigger: 'axis',axisPointer: { type: 'shadow'},formatter: function(params) {return params[0].name + ': ' + params[0].value + ' 万';}},grid: {left: '0%',top:'10px',right: '0%',bottom: '4%',containLabel: true},xAxis: [{type: 'category',data: data.diqujiage.map(item => item.name), // 使用从JSON文件中读取的地区数据axisLine: {show: true,lineStyle: {color: "rgba(255,255,255,.1)",width: 1,type: "solid"},},axisTick: {show: false,},axisLabel: {interval: 0,show: true,splitNumber: 15,textStyle: {color: "rgba(255,255,255,.6)",fontSize: '12',},},}],yAxis: [{type: 'value',axisLabel: {show:true,textStyle: {color: "rgba(255,255,255,.6)",fontSize: '12',},},axisTick: {show: false,},axisLine: {show: true,lineStyle: {color: "rgba(255,255,255,.1)",width: 1,type: "solid"},},splitLine: {lineStyle: {color: "rgba(255,255,255,.1)",}}}],series: [{type: 'bar',data: data.diqujiage.map(item => item.value), // 使用从JSON文件中读取的价格数据barWidth:'35%', //柱子宽度itemStyle: {normal: {color:'#27d08a',opacity: 1,barBorderRadius: 5,}}}]};myChart.setOption(option, true);myChart.setOption(option);window.addEventListener("resize",function(){myChart.resize();});});
}function echarts_5() {var myChart = echarts.init(document.getElementById('echart5'));// 从服务器加载JSON数据fetch('diqupingjun.json').then(response => response.json()).then(data => {// 提取地区名称和对应的平均价格var names = data.diqupingjun.map(item => item.name);var values = data.diqupingjun.map(item => item.value);var option = {tooltip: {trigger: 'axis',axisPointer: {type: 'shadow'},formatter: function(params) {return params[0].name + ': ' + params[0].value + ' 元/㎡';}},grid: {left: '0%',top: '10px',right: '0%',bottom: '2%',containLabel: true},xAxis: [{type: 'category',data: names, // 使用从JSON文件中读取的地区数据axisLine: {show: true,lineStyle: {color: "rgba(255,255,255,.1)",width: 1,type: "solid"},},axisTick: {show: false,},axisLabel: {interval: 0,show: true,splitNumber: 15,textStyle: {color: "rgba(255,255,255,.6)",fontSize: '12',},},}],yAxis: [{type: 'value',axisLabel: {show: true,textStyle: {color: "rgba(255,255,255,.6)",fontSize: '12',},},axisTick: {show: false,},axisLine: {show: true,lineStyle: {color: "rgba(255,255,255,.1)",width: 1,type: "solid"},},splitLine: {lineStyle: {color: "rgba(255,255,255,.1)",}}}],series: [{type: 'bar',data: values, // 使用从JSON文件中读取的价格数据barWidth: '35%', // 柱子宽度itemStyle: {normal: {color: '#2f89cf',opacity: 1,barBorderRadius: 5,}}}]};// 使用刚指定的配置项和数据显示图表myChart.setOption(option);window.addEventListener("resize", function() {myChart.resize();});});
}function echarts_4() {// 基于准备好的dom,初始化echarts实例var myChart = echarts.init(document.getElementById('echart4'));// 从服务器加载JSON数据fetch('dianti.json').then(response => response.json()).then(data => {// 提取名称和对应的值var names = data.dianti.map(item => item.name.trim());var values = data.dianti.map(item => item.value);var option = {tooltip: {trigger: 'axis',axisPointer: {lineStyle: {color: '#dddc6b'}}},grid: {left: '10',top: '30',right: '10',bottom: '10',containLabel: true},xAxis: [{type: 'category',boundaryGap: false,axisLabel: {textStyle: {color: "rgba(255,255,255,.6)",fontSize: 12,},},axisLine: {lineStyle: {color: 'rgba(255,255,255,.2)'}},data: names // 使用从JSON文件中读取的数据}, {axisPointer: { show: false },axisLine: { show: false },position: 'bottom',offset: 20,}],yAxis: [{type: 'value',axisTick: { show: false },axisLine: {lineStyle: {color: 'rgba(255,255,255,.1)'}},axisLabel: {textStyle: {color: "rgba(255,255,255,.6)",fontSize: 12,},},splitLine: {lineStyle: {color: 'rgba(255,255,255,.1)'}}}],series: [{// name: '安卓',type: 'line',smooth: true,symbol: 'circle',symbolSize: 5,showSymbol: false,lineStyle: {normal: {color: '#0184d5',width: 2}},areaStyle: {normal: {color: new echarts.graphic.LinearGradient(0, 0, 0, 1, [{offset: 0,color: 'rgba(1, 132, 213, 0.4)'}, {offset: 0.8,color: 'rgba(1, 132, 213, 0.1)'}], false),shadowColor: 'rgba(0, 0, 0, 0.1)',}},itemStyle: {normal: {color: '#0184d5',borderColor: 'rgba(221, 220, 107, .1)',borderWidth: 12}},data: values // 使用从JSON文件中读取的数据},{// name: 'IOS',type: 'line',smooth: true,symbol: 'circle',symbolSize: 5,showSymbol: false,lineStyle: {normal: {color: '#00d887',width: 2}},areaStyle: {normal: {color: new echarts.graphic.LinearGradient(0, 0, 0, 1, [{offset: 0,color: 'rgba(0, 216, 135, 0.4)'}, {offset: 0.8,color: 'rgba(0, 216, 135, 0.1)'}], false),shadowColor: 'rgba(0, 0, 0, 0.1)',}},itemStyle: {normal: {color: '#00d887',borderColor: 'rgba(221, 220, 107, .1)',borderWidth: 12}},data: values // 使用从JSON文件中读取的数据},]};// 使用刚指定的配置项和数据显示图表。myChart.setOption(option);window.addEventListener("resize", function(){myChart.resize();});});
}function echarts_6() {// 基于准备好的dom,初始化echarts实例var myChart = echarts.init(document.getElementById("echart6"));myChart.setOption({title: [{left: 'center',textStyle: {color: '#fff',fontSize: '16'}}],tooltip: {trigger: 'item',formatter: '{a} <br/>{b} : {c} ({d}%)'},legend: {orient: 'horizontal',bottom: 0,textStyle: {color: '#fff' // 设置图例字体颜色为白色},data: [] // 初始设置为空数组,等待后续动态加载},series: [{color: ['#00d0ff', '#0059ff', '#ff6a00', '#ff0008'],name: '所在楼层占比',type: 'pie',center: ['50%', '50%'],startAngle: 180,endAngle: 360,data: [] // 初始设置为空数组,等待后续动态加载}]});// 读取huxing.json$.getJSON("louceng.json", function (data) {var huxing_data = data.louceng;// 使用huxing_data来渲染图表// 修改图表数据myChart.setOption({series: [{data: huxing_data.map(function (item) {return {name: item.name.trim(),value: item.value};})}],legend: {data: huxing_data.map(function (item) {return item.name.trim();})}});});}})HTML、CSS、JS等代码太多不去展示。
需要web平台端程序、文档、帮忙修改程序的可以加我QQ2579562108。
相关文章:
链家房屋数据爬取与预处理-大数据采集与预处理课程设计
芜湖市链家二手房可视化平台 成品展示 重点说明 1.数据特征数量和名称、数据量 数据特征数量:14; 名称:小区名、价格/万、地区、房屋户型、所在楼层、建筑面积/平方米、户型结构、套内面积、建筑类型、房屋朝向、建筑结构、装修情况、梯户…...
一种502 bad gateway nginx/1.18.0的解决办法
背景:上线的服务突然挂掉了 step1,去后端日志查看,发现并无异常,就是请求无法被接收 step2,查看了nginx的错误日志,发现该文件为空 step3,查看了niginx的运行日志,发现了以下问题 [error] 38#…...
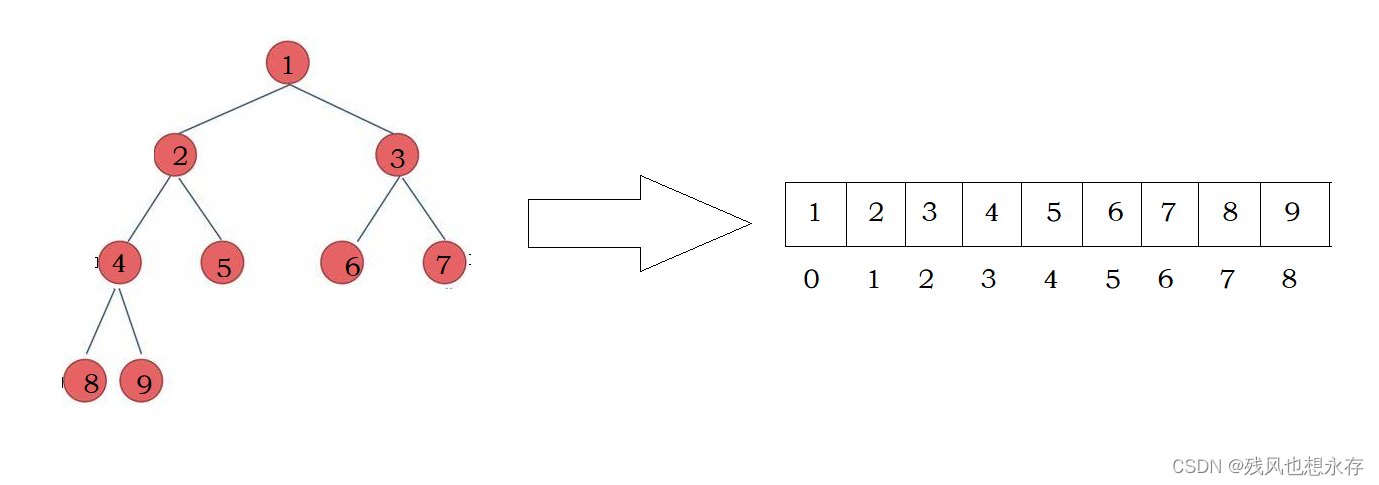
二叉树第一期:树与二叉树的概念
一、树 1.树的定义 与线性表不同,树是一种非线性的数据结构,由N(N>0)个结点组成的具有层次关系的集合;因其形状类似生活中一颗倒挂着的树,故将其数据结构称为树。 2.树的相关概念 根结点 没有前驱的结点,称为根…...

vue跨域问题,请注意你的项目是vue2还是vue3
uniapp跨域设置了,但还是有问题 uniapp设置代理后还是无法请求后端接口vue2项目设置代理vue3项目设置代理 uniapp设置代理后还是无法请求后端接口 如果你在possman,apifox上测试接口都没有问题,但是在hbuild项目中设置代理后,还是…...
大厂晋升学习方法一:海绵学习法
早晨 30 分钟 首先,我们可以把起床的闹钟提前 30 分钟,比如原来 07:30 的闹钟可以改为 07:00。不用担心提前 30 分钟起床会影响休息质量,习惯以后,早起 30 分钟不但不会影响一天的精力,甚至可能反而让人更有精神。早起…...

【ARMv8/v9 GIC 系列 4.2 -- GIC CPU Interface 详细介绍】
文章目录 GIC CPU Interface 介绍CPU Interface 主要寄存器 GIC CPU Interface 介绍 A 系列处理器提供 5个管脚来实现中断,分别是: nIRQ:物理普通中断nFIQ:物理快速中断nVIRQ:虚拟普通中断nVFIQ:虚拟快速…...

小抄 20240619
1 一个人内心充满恐惧的时候,就会开始信仰一个至高的东西来追求道德上的确定感。 然后会向外看,去指责那些自己不敢做但别人做到的,在他看来不道德的事。 2 之前说租房有不可能三角:房租低,离公司近,住着…...

【06】数据模型和工作量证明-工作量证明
1. 工作量证明的背景 比特币是通过工作量证明来竞争记账权,并获得比特币奖励。简单来讲就是谁能够根据区块数据更快的计算得到满足条件的哈希值,谁就可以胜出,这个块才会被添加到区块链中。我们把这个过程称为挖矿。比特币每10分钟产生1个区块。 2. 工作量证明算法 1. 获…...
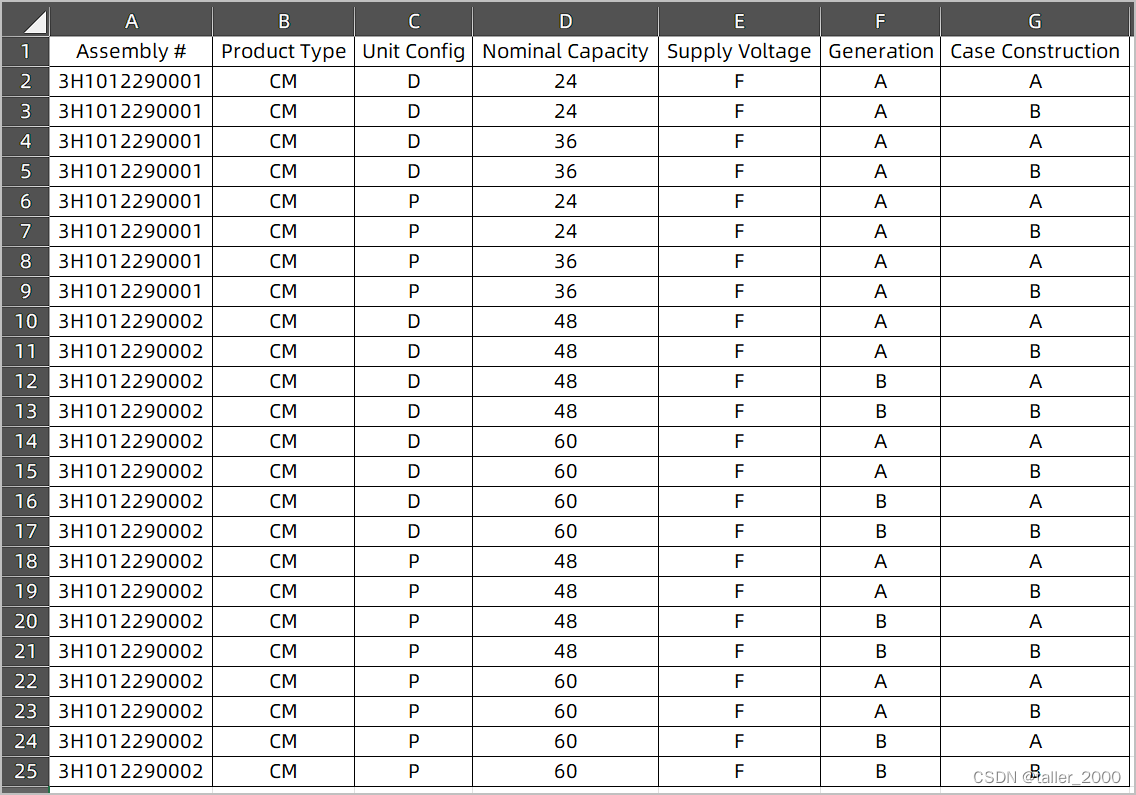
VBA递归过程快速组合数据
实例需求:数据表包含的列数不固定,有的列(数量和位置不固定)包含组合数据,例如C2单元格为D,P,说明Unit Config有两种分别为D和P,如下图所示。 现在需要将所有的组合罗列出来,如下所示…...
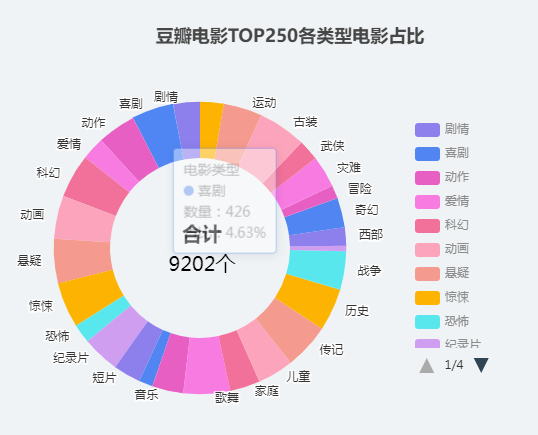
基于豆瓣电影TOP250的可视化设计
本文要完成的目的,实现豆瓣电影TOP250的可视化 思路 讲解思路,采用倒推的方式, 首先确定可视化图表,也就是最终的效果。这样就能确定需要那些基础数据根据需要的数据进行按需爬取存储。 本篇文章完成前两步。可视化图表设计 和 …...

YOLOv8中的C2f模块
文章目录 一、结构概述二、模块功能 一、结构概述 C2f块:首先由一个卷积块(Conv)组成,该卷积块接收输入特征图并生成中间特征图特征图拆分:生成的中间特征图被拆分成两部分,一部分直接传递到最终的Concat块,另一部分传递到多个Botleneck块进…...
)
ESP32 双线汽车接口 (TWAI)
一:TWAI概述 双线汽车接口 (TWAI) 是一种适用于汽车和工业应用的实时串行通信协议。它兼容 ISO11898-1 经典帧(CAN2.0),因此可以支持标准帧格式(11 位 ID)和扩展帧格式(29 位 ID&#x…...
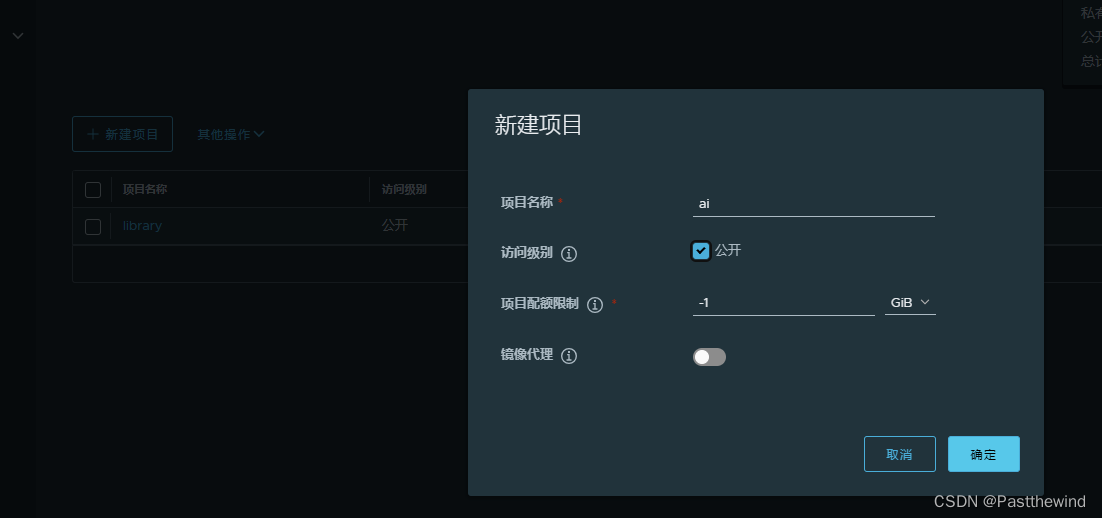
docker-compose离线安装harbor
1、下载harbor goharbor下载:Releases goharbor/harbor GitHub harbor-offline-installer-v2.11.0.tgz 2、解压 tar -xvf harbor-offline-installer-v2.11.0.tgz 3、创建一个卷目录,并复制一份配置文件 cd harbor; mkdir data;cp harbor.yml.tmp…...
)
服务器“雪崩”的常见原因和解决方法 (C++)
在C服务器编程中,"雪崩"现象指的是服务器在高并发请求的情况下,由于资源(如线程、文件描述符、内存等)耗尽或锁争用等问题,导致服务器性能急剧下降,甚至完全失去响应的情况。这种现象会连带影响其…...

详解ES6中的类、对象和类的继承
在ES6(ECMAScript 2015)之前,JavaScript 并没有像其他面向对象的编程语言那样的类(class)的概念。相反,它使用了一种基于原型的继承模型来实现面向对象编程。然而,这种模型对于许多开发者来说可…...

游戏遇到攻击有什么办法能解决?
随着网络技术的飞速发展,游戏行业在迎来繁荣的同时,也面临着日益严峻的网络威胁。黑客攻击、数据泄露、DDoS攻击等安全事件频发,给游戏服务器带来了极大的挑战。面对愈演愈烈的网络威胁,寻找一个能解决游戏行业攻击问题的安全解决…...
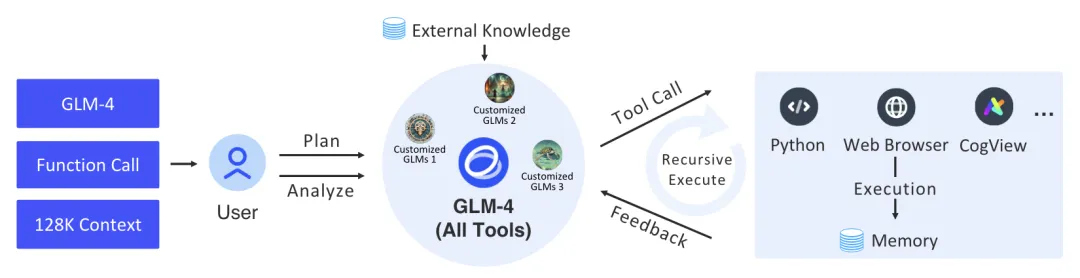
【LLM】GLM系列模型要点
note 文章目录 noteGLM一、数据层面1. 预训练数据 二、GLM4模型层面三、GLM-4 All Tools四、GLM的其他技术Reference GLM Paper:https://arxiv.org/abs/2406.12793 GitHub:https://github.com/THUDM HF:https://huggingface.co/THUDM 经过…...

安卓开发,获取本机手机号
用免费云服务器,三丰云记录安卓开发过程 以下是使用 Android 开发获取本机手机号的示例代码(需要相关权限): java 复制 import android.content.Context; import android.content.pm.PackageManager; import android.os.Build; i…...

linux学习week1
linux学习 一.介绍 1.概述 linux的读法不下10种 linux是一个开源的操作系统,操作系统包括mac、windows、安卓等 linux的开发版:Ubuntu(乌班图)、RedHat(红帽)、CentOS linux的应用:linux在服…...

【React篇】父组件渲染时避免重复渲染子组件的3种处理方法
在 React 中,父组件渲染时要避免重复渲染子组件,可以使用以下方法: 使用 React.memo(仅适用于函数式组件)或 PureComponent(适用于类组件): 这些方法可以帮助你创建在接收到新的 pr…...

MPNet:旋转机械轻量化故障诊断模型详解python代码复现
目录 一、问题背景与挑战 二、MPNet核心架构 2.1 多分支特征融合模块(MBFM) 2.2 残差注意力金字塔模块(RAPM) 2.2.1 空间金字塔注意力(SPA) 2.2.2 金字塔残差块(PRBlock) 2.3 分类器设计 三、关键技术突破 3.1 多尺度特征融合 3.2 轻量化设计策略 3.3 抗噪声…...

synchronized 学习
学习源: https://www.bilibili.com/video/BV1aJ411V763?spm_id_from333.788.videopod.episodes&vd_source32e1c41a9370911ab06d12fbc36c4ebc 1.应用场景 不超卖,也要考虑性能问题(场景) 2.常见面试问题: sync出…...

【杂谈】-递归进化:人工智能的自我改进与监管挑战
递归进化:人工智能的自我改进与监管挑战 文章目录 递归进化:人工智能的自我改进与监管挑战1、自我改进型人工智能的崛起2、人工智能如何挑战人类监管?3、确保人工智能受控的策略4、人类在人工智能发展中的角色5、平衡自主性与控制力6、总结与…...
:にする)
日语学习-日语知识点小记-构建基础-JLPT-N4阶段(33):にする
日语学习-日语知识点小记-构建基础-JLPT-N4阶段(33):にする 1、前言(1)情况说明(2)工程师的信仰2、知识点(1) にする1,接续:名词+にする2,接续:疑问词+にする3,(A)は(B)にする。(2)復習:(1)复习句子(2)ために & ように(3)そう(4)にする3、…...

基于ASP.NET+ SQL Server实现(Web)医院信息管理系统
医院信息管理系统 1. 课程设计内容 在 visual studio 2017 平台上,开发一个“医院信息管理系统”Web 程序。 2. 课程设计目的 综合运用 c#.net 知识,在 vs 2017 平台上,进行 ASP.NET 应用程序和简易网站的开发;初步熟悉开发一…...

Mac软件卸载指南,简单易懂!
刚和Adobe分手,它却总在Library里给你写"回忆录"?卸载的Final Cut Pro像电子幽灵般阴魂不散?总是会有残留文件,别慌!这份Mac软件卸载指南,将用最硬核的方式教你"数字分手术"࿰…...

3-11单元格区域边界定位(End属性)学习笔记
返回一个Range 对象,只读。该对象代表包含源区域的区域上端下端左端右端的最后一个单元格。等同于按键 End 向上键(End(xlUp))、End向下键(End(xlDown))、End向左键(End(xlToLeft)End向右键(End(xlToRight)) 注意:它移动的位置必须是相连的有内容的单元格…...

佰力博科技与您探讨热释电测量的几种方法
热释电的测量主要涉及热释电系数的测定,这是表征热释电材料性能的重要参数。热释电系数的测量方法主要包括静态法、动态法和积分电荷法。其中,积分电荷法最为常用,其原理是通过测量在电容器上积累的热释电电荷,从而确定热释电系数…...

Spring AI Chat Memory 实战指南:Local 与 JDBC 存储集成
一个面向 Java 开发者的 Sring-Ai 示例工程项目,该项目是一个 Spring AI 快速入门的样例工程项目,旨在通过一些小的案例展示 Spring AI 框架的核心功能和使用方法。 项目采用模块化设计,每个模块都专注于特定的功能领域,便于学习和…...

深度学习之模型压缩三驾马车:模型剪枝、模型量化、知识蒸馏
一、引言 在深度学习中,我们训练出的神经网络往往非常庞大(比如像 ResNet、YOLOv8、Vision Transformer),虽然精度很高,但“太重”了,运行起来很慢,占用内存大,不适合部署到手机、摄…...