pytorch-模型训练
目录
- 1. 模型训练的基本步骤
- 1.1 train、test数据下载
- 1.2 train、test数据加载
- 1.3 Lenet5实例化、初始化loss函数、初始化优化器
- 1.4 开始train和test
- 2. 完整代码
1. 模型训练的基本步骤
以cifar10和Lenet5为例
1.1 train、test数据下载
使用torchvision中的datasets可以方便下载cifar10数据
cifar_train = datasets.CIFAR10('cifa', True, transform=transforms.Compose([transforms.Resize((32, 32)),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225])]), download=True)
transforms.Resize((32, 32)) 将数据图形数据resize为32x32,这里可不用因为cifar10本身就是32x32
transforms.ToTensor()是将numpy或者numpy数组或PIL图像)转换为PyTorch的Tensor格式,以便输入网络。
transforms.Normalize()根据指定的均值和标准差对每个颜色通道进行图像归一化,可以提高神经网络训练过程中的收敛速度
1.2 train、test数据加载
使用pytorch torch.utils.data中的DataLoader用来加载数据
cifar_train = DataLoader(cifar_train, batch_size=batchz, shuffle=True)
batch_size=batchz: 这里batchz是一个变量,代表每个批次的样本数量。
shuffle=True: 这个参数设定为True意味着在每次训练循环(epoch)开始前,数据集中的样本会被随机打乱顺序。这样做可以增加训练过程中的随机性,帮助模型更好地泛化,避免过拟合特定的样本排列顺序。
1.3 Lenet5实例化、初始化loss函数、初始化优化器
device = torch.device('cuda')model = Lenet5().to(device)crition = nn.CrossEntropyLoss().to(device)optimizer = optim.Adam(model.parameters(), lr=1e-3)
注意:网络和模型一定要搬到GPU上
1.4 开始train和test
- 循环epoch
- 加载train数据、输入模型、计算loss、backward、调用优化器
- 加载test数据、输入模型、计算prediction、计算正确率
- 输出正确率
for epoch in range(1000):model.train()for batch, (x, label) in enumerate(cifar_train):x, label = x.to(device), label.to(device)logits = model(x)loss = crition(logits, label)optimizer.zero_grad()loss.backward()optimizer.step()# testmodel.eval()with torch.no_grad():total_correct = 0total_num = 0for x, label in cifar_test:x, label = x.to(device), label.to(device)logits = model(x)pred = logits.argmax(dim=1)correct = torch.eq(pred, label).float().sum().item()total_correct += correcttotal_num += x.size(0)acc = total_correct / total_numprint(epoch, 'test acc:', acc)
2. 完整代码
import torch
from torchvision import datasets
from torch.utils.data import DataLoader
from torchvision import transforms
from torch import nn, optim
import syssys.path.append('.')
from Lenet5 import Lenet5def main():batchz = 128cifar_train = datasets.CIFAR10('cifa', True, transform=transforms.Compose([transforms.Resize((32, 32)),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225])]), download=True)cifar_train = DataLoader(cifar_train, batch_size=batchz, shuffle=True)cifar_test = datasets.CIFAR10('cifa', False, transform=transforms.Compose([transforms.Resize((32, 32)),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225])]), download=True)cifar_test = DataLoader(cifar_test, batch_size=batchz, shuffle=True)device = torch.device('cuda')model = Lenet5().to(device)crition = nn.CrossEntropyLoss().to(device)optimizer = optim.Adam(model.parameters(), lr=1e-3)for epoch in range(1000):model.train()for batch, (x, label) in enumerate(cifar_train):x, label = x.to(device), label.to(device)logits = model(x)loss = crition(logits, label)optimizer.zero_grad()loss.backward()optimizer.step()# testmodel.eval()with torch.no_grad():total_correct = 0total_num = 0for x, label in cifar_test:x, label = x.to(device), label.to(device)logits = model(x)pred = logits.argmax(dim=1)correct = torch.eq(pred, label).float().sum().item()total_correct += correcttotal_num += x.size(0)acc = total_correct / total_numprint(epoch, 'test acc:', acc)if __name__ == '__main__':main()model.train()和model.eval()的区别和作用
model.train()
作用:当调用模型的model.train()方法时,模型会进入训练模式。这意味着:
启用 Dropout层和BatchNorm层:在训练模式下,Dropout层会按照设定的概率随机“丢弃”一部分神经元以防止过拟合,而Batch Normalization(批规范化)层会根据当前批次的数据动态计算均值和方差进行归一化。
梯度计算:允许梯度计算,这是反向传播和权重更新的基础。
应用场景:在模型的训练循环中,每次迭代开始之前调用,以确保模型处于正确的训练状态。
model.eval()
作用:调用model.eval()方法后,模型会进入评估模式。此时:
禁用 Dropout层:Dropout层在评估时不发挥作用,所有的神经元都会被保留,以确保预测的确定性和可重复性。
固定 BatchNorm层:BatchNorm层使用训练过程中积累的统计量(全局均值和方差)进行归一化,而不是当前批次的统计量,这有助于模型输出更加稳定和一致。
应用场景:在验证或测试模型性能时使用,确保模型输出是确定性的,不受训练时特有的随机操作影响,以便于准确评估模型的泛化能力。
相关文章:

pytorch-模型训练
目录 1. 模型训练的基本步骤1.1 train、test数据下载1.2 train、test数据加载1.3 Lenet5实例化、初始化loss函数、初始化优化器1.4 开始train和test 2. 完整代码 1. 模型训练的基本步骤 以cifar10和Lenet5为例 1.1 train、test数据下载 使用torchvision中的datasets可以方便…...

Linux /proc目录总结
1、概念 在Linux系统中,/proc目录是一个特殊的文件系统,通常被称为"proc文件系统"或"procfs"。这个文件系统以文件系统的方式为内核与进程之间的通信提供了一个接口。/proc目录中的文件大多数都提供了关于系统状态的信息࿰…...
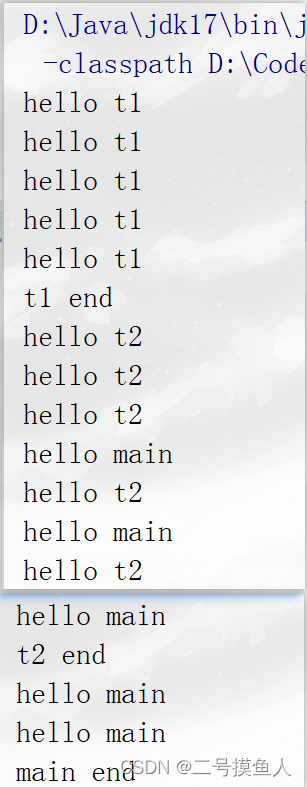
【JavaEE】浅谈线程(二)
线程 线程的常见属性 线程属性可以通过下面的表格查看。 •ID 是线程的唯⼀标识,不同线程不会重复 • 名称是各种调试⼯具⽤到(如jconsoloe) • 状态表示线程当前所处的⼀个情况,下⾯我们会进⼀步说明 • 优先级高的线程理论上来…...
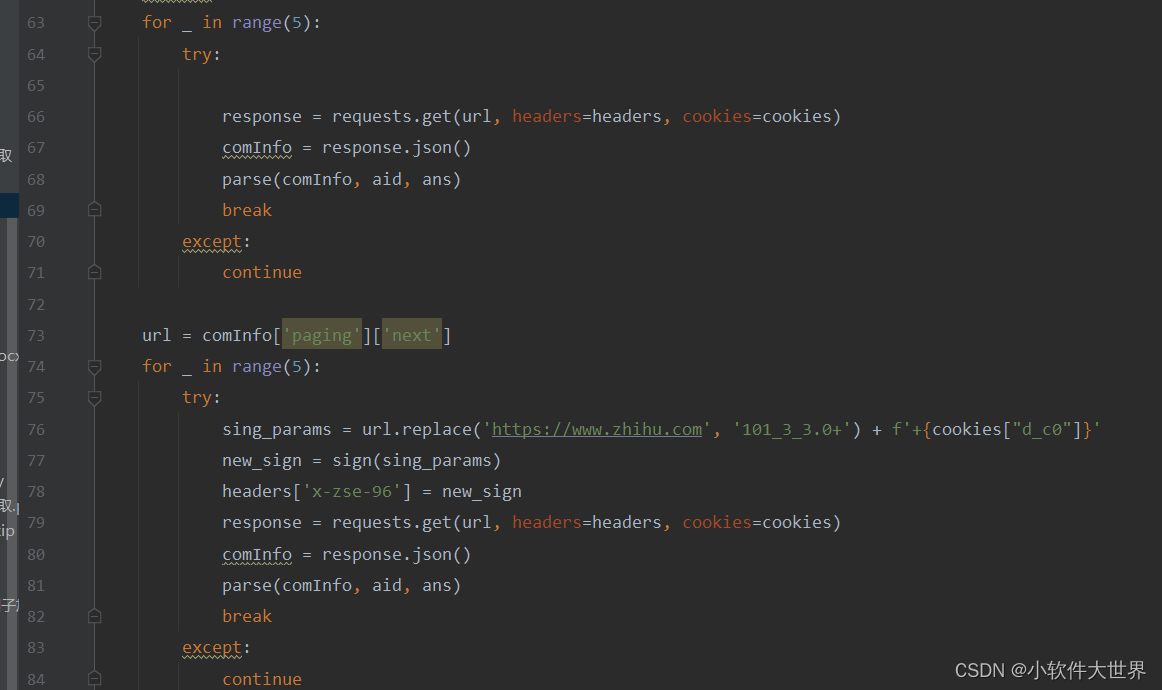
爬虫:爬取知乎热榜一级评论及回答2024不包含翻页
一、先上结果(注:本文仅为兴趣爱好探究,请勿进行商业利用或非法研究,负责后果自负,与作者无关) 1、爬标题及其具体内容 2、抓标题下的对应回答 3、爬取对应一级评论 二、上流程 1、获取cookies(相信哥哥姐姐…...

AI 编程探索- iOS动态标签控件
需求分析: 标签根据文字长度,自适应标签居中显示扩展 超过内容显示范围,需要换行显示,且保持居中显示 AI实现过程 提问: 回答: import UIKit import SnapKitclass DynamicLabelsContainerView: UIView…...
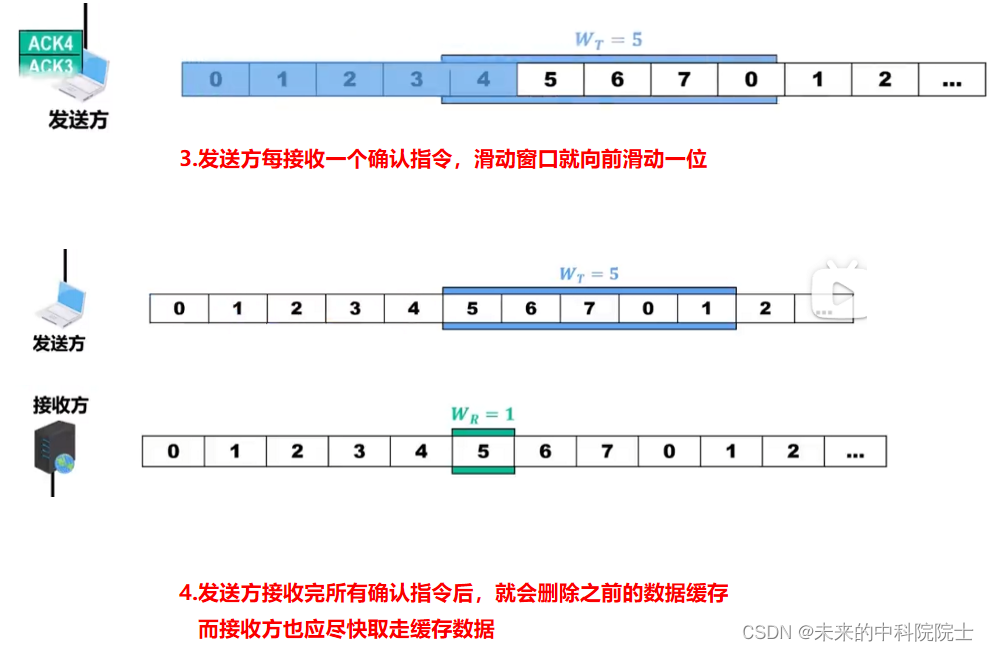
计算机网络——数据链路层(数据链路层概述及基本问题)
链路、数据链路和帧的概念 数据链路层在物理层提供服务的基础上向网络层提供服务,其主要作用是加强物理层传输原始比特流的功能,将物理层提供的可能出错的物理连接改造为逻辑上无差错的数据链路,使之对网络层表现为一条无差错的链路。 链路(…...

【前端】前端权限管理的实现方式:基于Vue项目的详细指南
前端权限管理的实现方式:基于Vue项目的详细指南 在Web开发中,前端权限管理是一个确保应用安全性和优化用户体验的关键部分。本文将详细介绍前端权限管理的几种实现方式,并通过Vue项目中的代码示例来演示具体实现方法。 前端权限管理的基本实…...
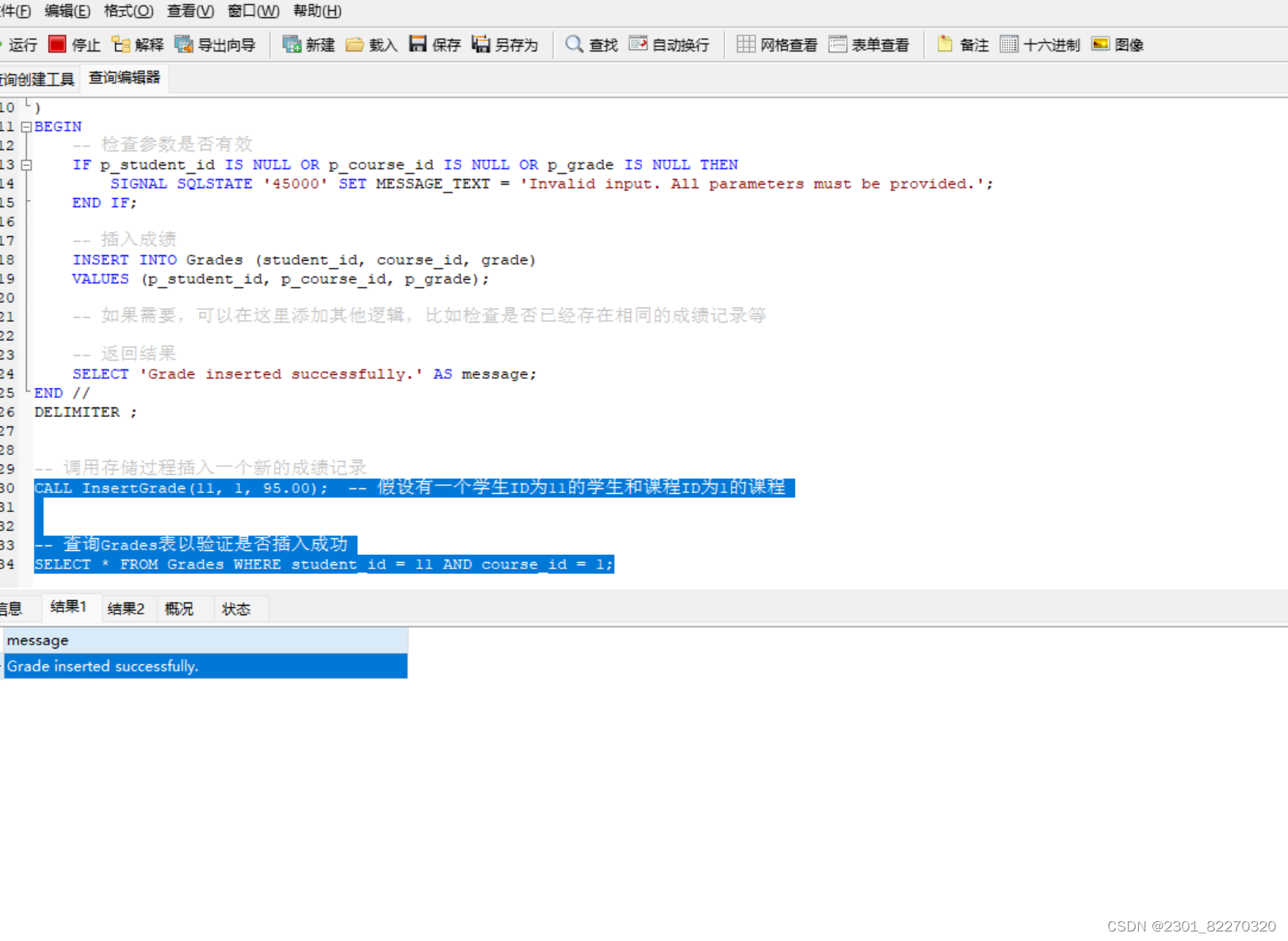
MySQL数据库基础练习系列——教务管理系统
项目名称与项目简介 教务管理系统是一个旨在帮助学校或教育机构管理教务活动的软件系统。它涵盖了学生信息管理、教师信息管理、课程管理、成绩管理以及相关的报表生成等功能。通过该系统,学校可以更加高效地处理教务数据,提升教学质量和管理水平。 1.…...

windowns server2016服务器配置php调用powerpoint COM组件
解决问题:windowns server2016服务器配置php调用powerpoint COM组件 环境: windows server2016 宝塔(nginxmysqlphp7.2) IIS 搭建宝塔: 下载地址:https://www.bt.cn/download/windows.html 安装使用&…...

Git之checkout/reset --hard/clean -f区别(四十二)
简介: CSDN博客专家,专注Android/Linux系统,分享多mic语音方案、音视频、编解码等技术,与大家一起成长! 优质专栏:Audio工程师进阶系列【原创干货持续更新中……】🚀 优质专栏:多媒…...

MySQL数据库基础练习系列:科研项目管理系统
DDL CREATE TABLE Users (user_id INT AUTO_INCREMENT PRIMARY KEY COMMENT 用户ID,username VARCHAR(50) NOT NULL UNIQUE COMMENT 用户名,password VARCHAR(255) NOT NULL COMMENT 密码,gender ENUM(男, 女) NOT NULL COMMENT 性别,email VARCHAR(100) UNIQUE COMMENT 邮箱 …...

算法设计与分析--考试真题
分布式算法试题汇总选择题简答题算法题 2013级试题2019级试题2021年秋考卷 根据考试范围找相应题目做。 分布式算法试题汇总 选择题 下述说法错误的是___ A 异步系统中的消息延迟是不确定的 B 分布式算法的消息复杂性是指在所有合法的执行上发送消息总数的最大值 C 在一个异步…...
【鸿蒙学习笔记】页面和自定义组件生命周期
官方文档:页面和自定义组件生命周期 目录标题 [Q&A] 都谁有生命周期? [Q&A] 什么是组件生命周期? [Q&A] 什么是组件?组件生命周期 [Q&A] 什么是页面生命周期? [Q&A] 什么是页面?页面生…...

ASPICE与ISO 21434:汽车软件与网络安全标准的协同与互补
ASPICE(Automotive SPICE)与ISO 21434在汽车行业中存在显著的相关性,主要体现在以下几个方面: 共同目标: ASPICE和ISO 21434都旨在提高汽车系统和软件的质量、可靠性和安全性。ASPICE关注汽车软件开发过程的成熟度和…...
视频格式转换方法:如何使用视频转换器软件转换视频
众所周知,目前存在许多不同的视频和音频格式。但我们的媒体播放器、移动设备、PC 程序等仅兼容少数特定格式。例如,如果不先将其转换为 MP4、MOV 或 M4V 文件,AVI、WMV 或 MKV 文件就无法在 iPhone 上播放。 视频转换器允许您将一种视频格式…...

vim操作小诀窍:快速多行添加注释
在使用vim编译python代码的时候,经常碰到需要将一段代码注释的情况,每次都要按“向下” “向左”按钮,将光标移到句首,然后再键入#井号键。如果行数较多,则操作相当繁琐。 vim里面有将一段文字前面加#注释的方法&#…...

无线麦克风领夹哪个牌子好,2024年领夹麦克风品牌排行榜推荐
随着短视频热潮的兴起,越来越多的人倾向于用vlog记录日常生活,同时借助短视频和直播平台开辟了副业。在这一过程中,麦克风在近两年内迅速发展,从最初的简单收音功能演变为拥有多样款式和功能,以满足视频创作的需求。…...

Mybatis入门——语法详解:基础使用、增删改查、起别名、解决问题、注释、动态查询,从入门到进阶
文章目录 1.基础使用1.添加依赖2.在resouces文件下新建xml文件db.properties3.在resouces文件下新建xml文件mybatis-config-xml4.创建一个MybatisUtils工具类5.创建xml文件XxxMapper.xml映射dao层接口6.添加日志5.测试 2.增删改查1.select2.delete3.update4.insert5.模糊查询6.…...

仓库选址问题【数学规划的应用(含代码)】阿里达院MindOpt
本文主要讲述使用MindOpt工具优化仓库选址的数学规划问题。 视频讲解👈👈👈👈👈👈👈👈👈 一、案例场景 仓库选址问题在现代物流和供应链管理中具有重要的应用。因为仓库…...
Docker Compose 一键快速部署 RocketMQ
Apache RocketMQ是一个开源的分布式消息中间件系统,最初由阿里巴巴开发并贡献给Apache软件基金会。RocketMQ提供了高性能、高可靠性、高扩展性和低延迟的消息传递服务,适用于构建大规模分布式系统中的消息通信和数据同步。 RocketMQ支持多种消息模型&am…...

Teensy 4.x驱动《钢铁战线》手柄的实时USB HID逆向通信库
1. 项目概述SBC(Steel Battalion Controller)驱动库是一个面向嵌入式平台的专用通信中间件,专为在NXP i.MX RT1062(Teensy 4.0/4.1)平台上实现与《钢铁战线》(Steel Battalion)原装游戏手柄的双…...

【技术干货】Google 全新 AI Studio Build Mode 深度解析:从多人与物理仿真到全栈应用的自动生成
摘要 Google 全新升级的 AI Studio(构建模式 / Agent 模式)已经从“写点前端 Demo”进化为“自动搭建可上线的全栈应用平台”:支持实时多人游戏、三维粒子交互、物理仿真、Firebase 深度集成、GitHub 自动发布等。本文结合视频内容࿰…...

CYBER-VISION模型部署:Anaconda创建虚拟环境,避免版本冲突
CYBER-VISION模型部署:Anaconda创建虚拟环境,避免版本冲突 1. 为什么需要虚拟环境? 在开发CYBER-VISION这类计算机视觉项目时,最令人头疼的问题莫过于"昨天还能跑通的代码,今天突然报错了"。这种情况十有八…...
)
控制四旋翼飞行器以进行多目标航点导航的MPC算法研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...
)
告别依赖烦恼:在Kylin V10桌面版一键部署Qt 5.12.3开发环境(附离线包制作方法)
告别依赖烦恼:在Kylin V10桌面版一键部署Qt 5.12.3开发环境(附离线包制作方法) 在团队协作开发中,开发环境的标准化部署一直是个令人头疼的问题。特别是当项目需要迁移到国产化平台时,如何快速、高效地为整个团队搭建统…...
并发编程实现:锁CAS)
Java JUC(一)并发编程实现:锁CAS
JUC Java 并发包 高级并发工具集合,是 Java 高性能并发编程的核心库,包括线程池、锁、原子类和并发集合等,让多线程开发更安全、高效、易维护。核心模块典型类线程池Executor, ExecutorService, ThreadPoolExecutor, ScheduledThreadPoolEx…...

无人棋牌室真正的核心,不是“无人”,而是这套系统逻辑
很多人第一次接触无人棋牌室,会把重点放在“无人”这两个字上。但如果从运营角度看,“无人”只是结果,不是本质。真正的核心是:👉 有没有一套稳定运行的系统逻辑一、无人只是表象,系统才是本质一个棋牌室能…...

NewStar CTF 2025 Week3-mirror_gate题解文件解析+上传漏
0x01 题目:文件上传解析漏洞0x02 思路:若是文件上传就要注意就算文件后缀过了,但是文件内容的恶意代码也会被识破<?php eval($_POST[cmd]); ?>这种木马肯定不行,用RIFFWEBPVP8<?cat /f*; ?>但是一开始我的思路并不…...

Qwen3-VL-8B与ComfyUI工作流结合:可视化编排多模态生成任务
Qwen3-VL-8B与ComfyUI工作流结合:可视化编排多模态生成任务 最近在折腾AI图像生成时,我总在想一个问题:能不能让整个创作过程更智能、更像一个闭环?比如,我生成了一张图,AI能不能自己看看,然后…...

2023年最新OWASP Top 10漏洞解析:这些安全陷阱你踩过吗?
2023年OWASP Top 10漏洞深度防御指南:从原理到实战 在数字化转型加速的今天,Web应用安全已成为企业防护体系中最薄弱的环节之一。根据Verizon《2023年数据泄露调查报告》,Web应用漏洞导致的入侵事件占比高达26%,平均修复周期长达2…...