第100+13步 ChatGPT学习:R实现决策树分类
基于R 4.2.2版本演示
一、写在前面
有不少大佬问做机器学习分类能不能用R语言,不想学Python咯。
答曰:可!用GPT或者Kimi转一下就得了呗。
加上最近也没啥内容写了,就帮各位搬运一下吧。
二、R代码实现决策树分类
(1)导入数据
我习惯用RStudio自带的导入功能:
(2)建立决策树模型(默认参数)
# Load necessary libraries
library(caret)
library(pROC)
library(ggplot2)# Assume 'data' is your dataframe containing the data
# Set seed to ensure reproducibility
set.seed(123)# Split data into training and validation sets (80% training, 20% validation)
trainIndex <- createDataPartition(data$X, p = 0.8, list = FALSE)
trainData <- data[trainIndex, ]
validData <- data[-trainIndex, ]# Convert the target variable to a factor for classification
trainData$X <- as.factor(trainData$X)
validData$X <- as.factor(validData$X)# Define control method for training with cross-validation
trainControl <- trainControl(method = "cv", number = 10)
# Fit Decision Tree model on the training set
model <- train(X ~ ., data = trainData, method = "rpart", trControl = trainControl)# Print the best parameters found by the model
best_params <- model$bestTune
cat("The best parameters found are:\n")
print(best_params)# Predict on the training and validation sets
trainPredict <- predict(model, trainData, type = "prob")[,2]
validPredict <- predict(model, validData, type = "prob")[,2]# Convert true values to factor for ROC analysis
trainData$X <- as.factor(trainData$X)
validData$X <- as.factor(validData$X)# Calculate ROC curves and AUC values
trainRoc <- roc(response = trainData$X, predictor = trainPredict)
validRoc <- roc(response = validData$X, predictor = validPredict)# Plot ROC curves with AUC values
ggplot(data = data.frame(fpr = trainRoc$specificities, tpr = trainRoc$sensitivities), aes(x = 1 - fpr, y = tpr)) +geom_line(color = "blue") +geom_area(alpha = 0.2, fill = "blue") +geom_abline(slope = 1, intercept = 0, linetype = "dashed", color = "black") +ggtitle("Training ROC Curve") +xlab("False Positive Rate") +ylab("True Positive Rate") +annotate("text", x = 0.5, y = 0.1, label = paste("Training AUC =", round(auc(trainRoc), 2)), hjust = 0.5, color = "blue")ggplot(data = data.frame(fpr = validRoc$specificities, tpr = validRoc$sensitivities), aes(x = 1 - fpr, y = tpr)) +geom_line(color = "red") +geom_area(alpha = 0.2, fill = "red") +geom_abline(slope = 1, intercept = 0, linetype = "dashed", color = "black") +ggtitle("Validation ROC Curve") +xlab("False Positive Rate") +ylab("True Positive Rate") +annotate("text", x = 0.5, y = 0.2, label = paste("Validation AUC =", round(auc(validRoc), 2)), hjust = 0.5, color = "red")# Calculate confusion matrices based on 0.5 cutoff for probability
confMatTrain <- table(trainData$X, trainPredict >= 0.5)
confMatValid <- table(validData$X, validPredict >= 0.5)# Function to plot confusion matrix using ggplot2
plot_confusion_matrix <- function(conf_mat, dataset_name) {conf_mat_df <- as.data.frame(as.table(conf_mat))colnames(conf_mat_df) <- c("Actual", "Predicted", "Freq")p <- ggplot(data = conf_mat_df, aes(x = Predicted, y = Actual, fill = Freq)) +geom_tile(color = "white") +geom_text(aes(label = Freq), vjust = 1.5, color = "black", size = 5) +scale_fill_gradient(low = "white", high = "steelblue") +labs(title = paste("Confusion Matrix -", dataset_name, "Set"), x = "Predicted Class", y = "Actual Class") +theme_minimal() +theme(axis.text.x = element_text(angle = 45, hjust = 1), plot.title = element_text(hjust = 0.5))print(p)
}
# Now call the function to plot and display the confusion matrices
plot_confusion_matrix(confMatTrain, "Training")
plot_confusion_matrix(confMatValid, "Validation")# Extract values for calculations
a_train <- confMatTrain[1, 1]
b_train <- confMatTrain[1, 2]
c_train <- confMatTrain[2, 1]
d_train <- confMatTrain[2, 2]a_valid <- confMatValid[1, 1]
b_valid <- confMatValid[1, 2]
c_valid <- confMatValid[2, 1]
d_valid <- confMatValid[2, 2]# Training Set Metrics
acc_train <- (a_train + d_train) / sum(confMatTrain)
error_rate_train <- 1 - acc_train
sen_train <- d_train / (d_train + c_train)
sep_train <- a_train / (a_train + b_train)
precision_train <- d_train / (b_train + d_train)
F1_train <- (2 * precision_train * sen_train) / (precision_train + sen_train)
MCC_train <- (d_train * a_train - b_train * c_train) / sqrt((d_train + b_train) * (d_train + c_train) * (a_train + b_train) * (a_train + c_train))
auc_train <- roc(response = trainData$X, predictor = trainPredict)$auc# Validation Set Metrics
acc_valid <- (a_valid + d_valid) / sum(confMatValid)
error_rate_valid <- 1 - acc_valid
sen_valid <- d_valid / (d_valid + c_valid)
sep_valid <- a_valid / (a_valid + b_valid)
precision_valid <- d_valid / (b_valid + d_valid)
F1_valid <- (2 * precision_valid * sen_valid) / (precision_valid + sen_valid)
MCC_valid <- (d_valid * a_valid - b_valid * c_valid) / sqrt((d_valid + b_valid) * (d_valid + c_valid) * (a_valid + b_valid) * (a_valid + c_valid))
auc_valid <- roc(response = validData$X, predictor = validPredict)$auc# Print Metrics
cat("Training Metrics\n")
cat("Accuracy:", acc_train, "\n")
cat("Error Rate:", error_rate_train, "\n")
cat("Sensitivity:", sen_train, "\n")
cat("Specificity:", sep_train, "\n")
cat("Precision:", precision_train, "\n")
cat("F1 Score:", F1_train, "\n")
cat("MCC:", MCC_train, "\n")
cat("AUC:", auc_train, "\n\n")cat("Validation Metrics\n")
cat("Accuracy:", acc_valid, "\n")
cat("Error Rate:", error_rate_valid, "\n")
cat("Sensitivity:", sen_valid, "\n")
cat("Specificity:", sep_valid, "\n")
cat("Precision:", precision_valid, "\n")
cat("F1 Score:", F1_valid, "\n")
cat("MCC:", MCC_valid, "\n")
cat("AUC:", auc_valid, "\n")在R语言中,还是使用caret包来训练决策树模型,可以调整多种参数来优化模型的性能:
①cp (Complexity Parameter): 用来控制树的生长。cp 值越大,生成的模型越简单。如果 cp 设置得太高,可能导致模型欠拟合。
②maxdepth: 决定了树的最大深度。较深的树可以更好地捕捉数据中的复杂关系,但也可能导致过拟合。
③minsplit: 定义了节点在尝试分裂之前所需的最小样本数。增加这个值可以让树更加稳健,但也可能导致欠拟合。
④minbucket: 叶节点最少包含的样本数。这个参数可以帮助防止模型过于复杂,从而避免过拟合。
结果输出(默认参数):
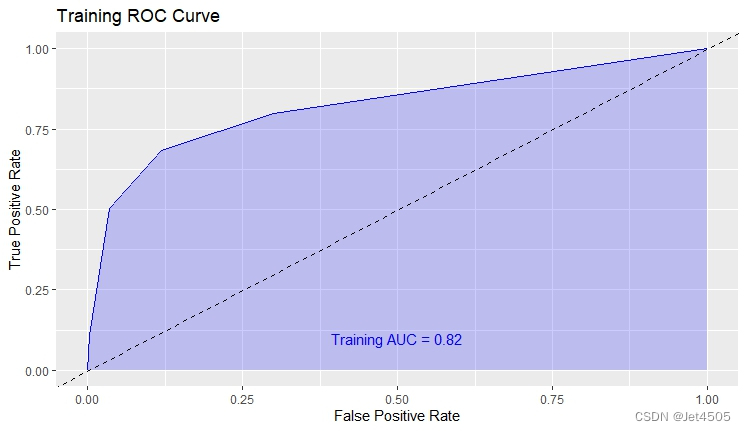
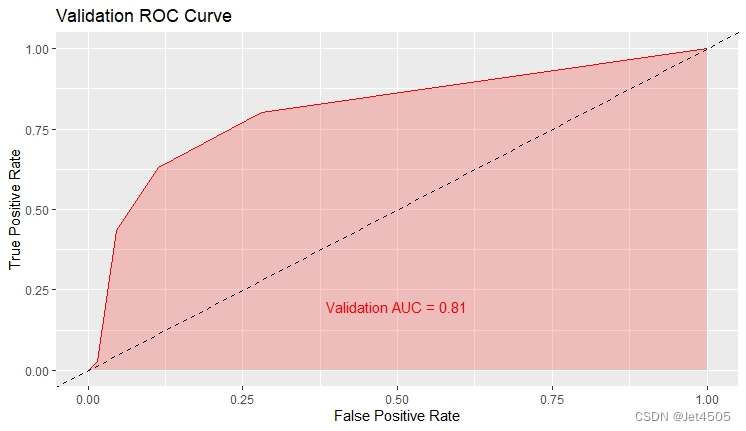
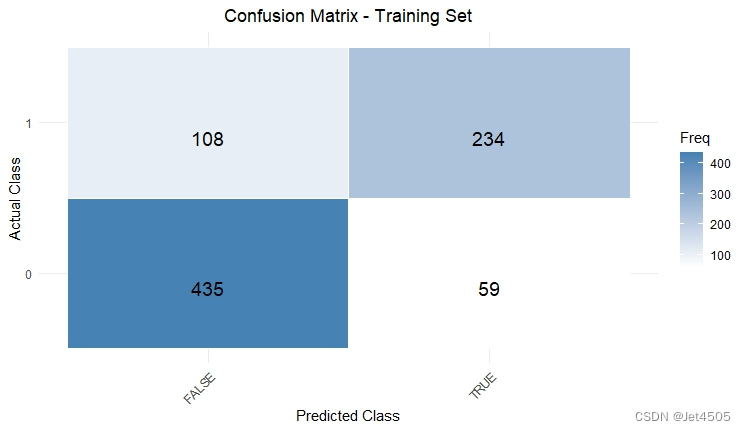
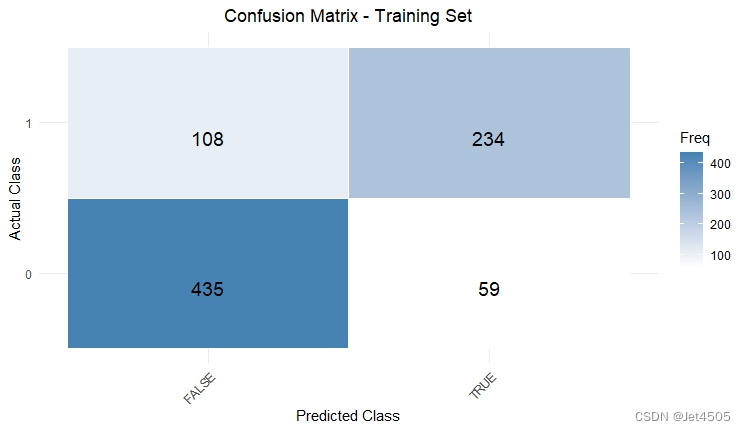
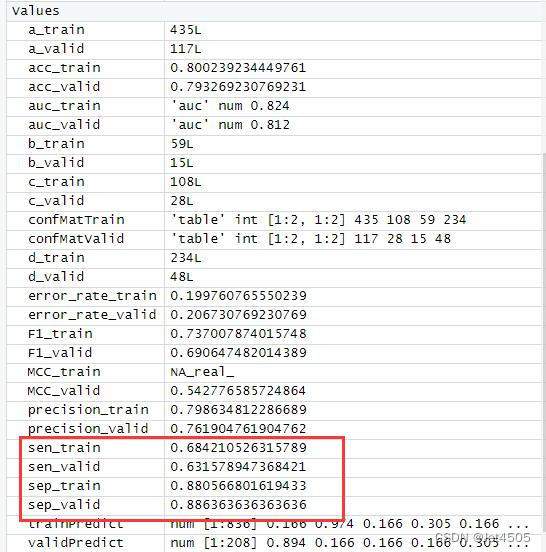
在默认参数中,caret包只会默默帮我们找几个合适的cp值进行测试。其他三个参数就一个默认值。
三、决策树调参方法(仅cp值)
如前所述,决策树的关键参数就是有4个,但是caret包做网格搜索的话,只能提供对于cp值的遍历,其余三个不提供。
比如我设置cp值从0.001到0.1,步长是0.001;而maxdepth = 20, minsplit = 10, minbucket = 10:
# Load necessary libraries
library(caret)
library(pROC)
library(ggplot2)
library(rpart)# Assume 'data' is your dataframe containing the data
# Set seed to ensure reproducibility
set.seed(123)# Split data into training and validation sets (80% training, 20% validation)
trainIndex <- createDataPartition(data$X, p = 0.8, list = FALSE)
trainData <- data[trainIndex, ]
validData <- data[-trainIndex, ]# Convert the target variable to a factor for classification
trainData$X <- as.factor(trainData$X)
validData$X <- as.factor(validData$X)# 定义交叉验证控制方法
trainControl <- trainControl(method = "cv", number = 10)# 定义参数网格,只包括 cp
tuneGrid <- expand.grid(cp = seq(0.001, 0.1, by = 0.001))# 定义 rpart.control,固定其他参数
rpartControl <- rpart.control(maxdepth = 20, minsplit = 10, minbucket = 10)# 使用 rpart 方法训练决策树模型
model <- train(X ~ ., data = trainData, method = "rpart", trControl = trainControl, tuneGrid = tuneGrid,control = rpartControl)# 打印找到的最佳参数
best_params <- model$bestTune
cat("The best parameters found are:\n")
print(best_params)# Predict on the training and validation sets
trainPredict <- predict(model, trainData, type = "prob")[,2]
validPredict <- predict(model, validData, type = "prob")[,2]# Convert true values to factor for ROC analysis
trainData$X <- as.factor(trainData$X)
validData$X <- as.factor(validData$X)# Calculate ROC curves and AUC values
trainRoc <- roc(response = trainData$X, predictor = trainPredict)
validRoc <- roc(response = validData$X, predictor = validPredict)# Plot ROC curves with AUC values
ggplot(data = data.frame(fpr = trainRoc$specificities, tpr = trainRoc$sensitivities), aes(x = 1 - fpr, y = tpr)) +geom_line(color = "blue") +geom_area(alpha = 0.2, fill = "blue") +geom_abline(slope = 1, intercept = 0, linetype = "dashed", color = "black") +ggtitle("Training ROC Curve") +xlab("False Positive Rate") +ylab("True Positive Rate") +annotate("text", x = 0.5, y = 0.1, label = paste("Training AUC =", round(auc(trainRoc), 2)), hjust = 0.5, color = "blue")ggplot(data = data.frame(fpr = validRoc$specificities, tpr = validRoc$sensitivities), aes(x = 1 - fpr, y = tpr)) +geom_line(color = "red") +geom_area(alpha = 0.2, fill = "red") +geom_abline(slope = 1, intercept = 0, linetype = "dashed", color = "black") +ggtitle("Validation ROC Curve") +xlab("False Positive Rate") +ylab("True Positive Rate") +annotate("text", x = 0.5, y = 0.2, label = paste("Validation AUC =", round(auc(validRoc), 2)), hjust = 0.5, color = "red")# Calculate confusion matrices based on 0.5 cutoff for probability
confMatTrain <- table(trainData$X, trainPredict >= 0.5)
confMatValid <- table(validData$X, validPredict >= 0.5)# Function to plot confusion matrix using ggplot2
plot_confusion_matrix <- function(conf_mat, dataset_name) {conf_mat_df <- as.data.frame(as.table(conf_mat))colnames(conf_mat_df) <- c("Actual", "Predicted", "Freq")p <- ggplot(data = conf_mat_df, aes(x = Predicted, y = Actual, fill = Freq)) +geom_tile(color = "white") +geom_text(aes(label = Freq), vjust = 1.5, color = "black", size = 5) +scale_fill_gradient(low = "white", high = "steelblue") +labs(title = paste("Confusion Matrix -", dataset_name, "Set"), x = "Predicted Class", y = "Actual Class") +theme_minimal() +theme(axis.text.x = element_text(angle = 45, hjust = 1), plot.title = element_text(hjust = 0.5))print(p)
}
# Now call the function to plot and display the confusion matrices
plot_confusion_matrix(confMatTrain, "Training")
plot_confusion_matrix(confMatValid, "Validation")# Extract values for calculations
a_train <- confMatTrain[1, 1]
b_train <- confMatTrain[1, 2]
c_train <- confMatTrain[2, 1]
d_train <- confMatTrain[2, 2]a_valid <- confMatValid[1, 1]
b_valid <- confMatValid[1, 2]
c_valid <- confMatValid[2, 1]
d_valid <- confMatValid[2, 2]# Training Set Metrics
acc_train <- (a_train + d_train) / sum(confMatTrain)
error_rate_train <- 1 - acc_train
sen_train <- d_train / (d_train + c_train)
sep_train <- a_train / (a_train + b_train)
precision_train <- d_train / (b_train + d_train)
F1_train <- (2 * precision_train * sen_train) / (precision_train + sen_train)
MCC_train <- (d_train * a_train - b_train * c_train) / sqrt((d_train + b_train) * (d_train + c_train) * (a_train + b_train) * (a_train + c_train))
auc_train <- roc(response = trainData$X, predictor = trainPredict)$auc# Validation Set Metrics
acc_valid <- (a_valid + d_valid) / sum(confMatValid)
error_rate_valid <- 1 - acc_valid
sen_valid <- d_valid / (d_valid + c_valid)
sep_valid <- a_valid / (a_valid + b_valid)
precision_valid <- d_valid / (b_valid + d_valid)
F1_valid <- (2 * precision_valid * sen_valid) / (precision_valid + sen_valid)
MCC_valid <- (d_valid * a_valid - b_valid * c_valid) / sqrt((d_valid + b_valid) * (d_valid + c_valid) * (a_valid + b_valid) * (a_valid + c_valid))
auc_valid <- roc(response = validData$X, predictor = validPredict)$auc# Print Metrics
cat("Training Metrics\n")
cat("Accuracy:", acc_train, "\n")
cat("Error Rate:", error_rate_train, "\n")
cat("Sensitivity:", sen_train, "\n")
cat("Specificity:", sep_train, "\n")
cat("Precision:", precision_train, "\n")
cat("F1 Score:", F1_train, "\n")
cat("MCC:", MCC_train, "\n")
cat("AUC:", auc_train, "\n\n")cat("Validation Metrics\n")
cat("Accuracy:", acc_valid, "\n")
cat("Error Rate:", error_rate_valid, "\n")
cat("Sensitivity:", sen_valid, "\n")
cat("Specificity:", sep_valid, "\n")
cat("Precision:", precision_valid, "\n")
cat("F1 Score:", F1_valid, "\n")
cat("MCC:", MCC_valid, "\n")
cat("AUC:", auc_valid, "\n")结果输出:
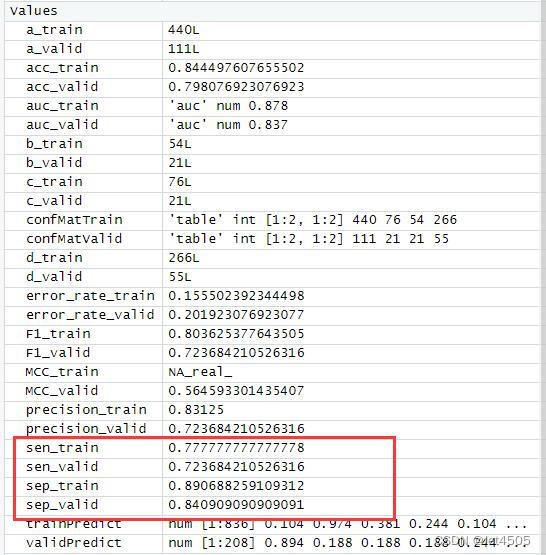
似乎好了一点了,那么,如果我先把其余三个参数也纳入遍历呢?那只能用循环语句了。
四、决策树调参方法(4个值)
设置cp值从0.001到0.1,步长是0.001;maxdepth从10到30,步长是5;minsplit取值10、20、30、40;minbucket取值5、10、15、20:
# Load necessary libraries
library(caret)
library(pROC)
library(ggplot2)
library(rpart)# Assume 'data' is your dataframe containing the data
# Set seed to ensure reproducibility
set.seed(123)# Split data into training and validation sets (80% training, 20% validation)
trainIndex <- createDataPartition(data$X, p = 0.8, list = FALSE)
trainData <- data[trainIndex, ]
validData <- data[-trainIndex, ]# Convert the target variable to a factor for classification
trainData$X <- as.factor(trainData$X)
validData$X <- as.factor(validData$X)# 参数网格定义
cp_values <- seq(0.001, 0.01, by = 0.001)
maxdepth_values <- seq(10, 30, by = 5)
minsplit_values <- c(10, 20, 30, 40)
minbucket_values <- c(5, 10, 15, 20)# 用于存储结果的列表
results <- list()# 网格搜索实现
for (cp in cp_values) {for (maxdepth in maxdepth_values) {for (minsplit in minsplit_values) {for (minbucket in minbucket_values) {# 训练模型model <- rpart(X ~ ., data = trainData, control = rpart.control(cp = cp, maxdepth = maxdepth,minsplit = minsplit, minbucket = minbucket))# 预测验证集predictions <- predict(model, validData, type = "class")# 计算性能指标,这里使用准确度accuracy <- sum(predictions == validData$X) / nrow(validData)# 存储结果results[[length(results) + 1]] <- list(cp = cp, maxdepth = maxdepth, minsplit = minsplit, minbucket = minbucket,accuracy = accuracy)}}}
}# 找到最高准确度的模型参数
best_model <- results[[which.max(sapply(results, function(x) x$accuracy))]]
print(best_model)# Predict on the training and validation sets
trainPredict <- predict(model, trainData, type = "prob")[,2]
validPredict <- predict(model, validData, type = "prob")[,2]# Convert true values to factor for ROC analysis
trainData$X <- as.factor(trainData$X)
validData$X <- as.factor(validData$X)# Calculate ROC curves and AUC values
trainRoc <- roc(response = trainData$X, predictor = trainPredict)
validRoc <- roc(response = validData$X, predictor = validPredict)# Plot ROC curves with AUC values
ggplot(data = data.frame(fpr = trainRoc$specificities, tpr = trainRoc$sensitivities), aes(x = 1 - fpr, y = tpr)) +geom_line(color = "blue") +geom_area(alpha = 0.2, fill = "blue") +geom_abline(slope = 1, intercept = 0, linetype = "dashed", color = "black") +ggtitle("Training ROC Curve") +xlab("False Positive Rate") +ylab("True Positive Rate") +annotate("text", x = 0.5, y = 0.1, label = paste("Training AUC =", round(auc(trainRoc), 2)), hjust = 0.5, color = "blue")ggplot(data = data.frame(fpr = validRoc$specificities, tpr = validRoc$sensitivities), aes(x = 1 - fpr, y = tpr)) +geom_line(color = "red") +geom_area(alpha = 0.2, fill = "red") +geom_abline(slope = 1, intercept = 0, linetype = "dashed", color = "black") +ggtitle("Validation ROC Curve") +xlab("False Positive Rate") +ylab("True Positive Rate") +annotate("text", x = 0.5, y = 0.2, label = paste("Validation AUC =", round(auc(validRoc), 2)), hjust = 0.5, color = "red")# Calculate confusion matrices based on 0.5 cutoff for probability
confMatTrain <- table(trainData$X, trainPredict >= 0.5)
confMatValid <- table(validData$X, validPredict >= 0.5)# Function to plot confusion matrix using ggplot2
plot_confusion_matrix <- function(conf_mat, dataset_name) {conf_mat_df <- as.data.frame(as.table(conf_mat))colnames(conf_mat_df) <- c("Actual", "Predicted", "Freq")p <- ggplot(data = conf_mat_df, aes(x = Predicted, y = Actual, fill = Freq)) +geom_tile(color = "white") +geom_text(aes(label = Freq), vjust = 1.5, color = "black", size = 5) +scale_fill_gradient(low = "white", high = "steelblue") +labs(title = paste("Confusion Matrix -", dataset_name, "Set"), x = "Predicted Class", y = "Actual Class") +theme_minimal() +theme(axis.text.x = element_text(angle = 45, hjust = 1), plot.title = element_text(hjust = 0.5))print(p)
}
# Now call the function to plot and display the confusion matrices
plot_confusion_matrix(confMatTrain, "Training")
plot_confusion_matrix(confMatValid, "Validation")# Extract values for calculations
a_train <- confMatTrain[1, 1]
b_train <- confMatTrain[1, 2]
c_train <- confMatTrain[2, 1]
d_train <- confMatTrain[2, 2]a_valid <- confMatValid[1, 1]
b_valid <- confMatValid[1, 2]
c_valid <- confMatValid[2, 1]
d_valid <- confMatValid[2, 2]# Training Set Metrics
acc_train <- (a_train + d_train) / sum(confMatTrain)
error_rate_train <- 1 - acc_train
sen_train <- d_train / (d_train + c_train)
sep_train <- a_train / (a_train + b_train)
precision_train <- d_train / (b_train + d_train)
F1_train <- (2 * precision_train * sen_train) / (precision_train + sen_train)
MCC_train <- (d_train * a_train - b_train * c_train) / sqrt((d_train + b_train) * (d_train + c_train) * (a_train + b_train) * (a_train + c_train))
auc_train <- roc(response = trainData$X, predictor = trainPredict)$auc# Validation Set Metrics
acc_valid <- (a_valid + d_valid) / sum(confMatValid)
error_rate_valid <- 1 - acc_valid
sen_valid <- d_valid / (d_valid + c_valid)
sep_valid <- a_valid / (a_valid + b_valid)
precision_valid <- d_valid / (b_valid + d_valid)
F1_valid <- (2 * precision_valid * sen_valid) / (precision_valid + sen_valid)
MCC_valid <- (d_valid * a_valid - b_valid * c_valid) / sqrt((d_valid + b_valid) * (d_valid + c_valid) * (a_valid + b_valid) * (a_valid + c_valid))
auc_valid <- roc(response = validData$X, predictor = validPredict)$auc# Print Metrics
cat("Training Metrics\n")
cat("Accuracy:", acc_train, "\n")
cat("Error Rate:", error_rate_train, "\n")
cat("Sensitivity:", sen_train, "\n")
cat("Specificity:", sep_train, "\n")
cat("Precision:", precision_train, "\n")
cat("F1 Score:", F1_train, "\n")
cat("MCC:", MCC_train, "\n")
cat("AUC:", auc_train, "\n\n")cat("Validation Metrics\n")
cat("Accuracy:", acc_valid, "\n")
cat("Error Rate:", error_rate_valid, "\n")
cat("Sensitivity:", sen_valid, "\n")
cat("Specificity:", sep_valid, "\n")
cat("Precision:", precision_valid, "\n")
cat("F1 Score:", F1_valid, "\n")
cat("MCC:", MCC_valid, "\n")
cat("AUC:", auc_valid, "\n")结果输出:
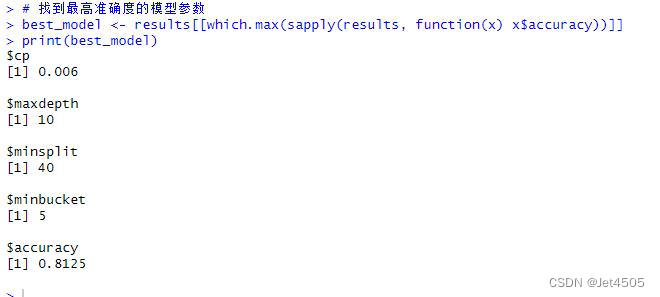
以上是找到的相对最优参数组合,看看具体性能:
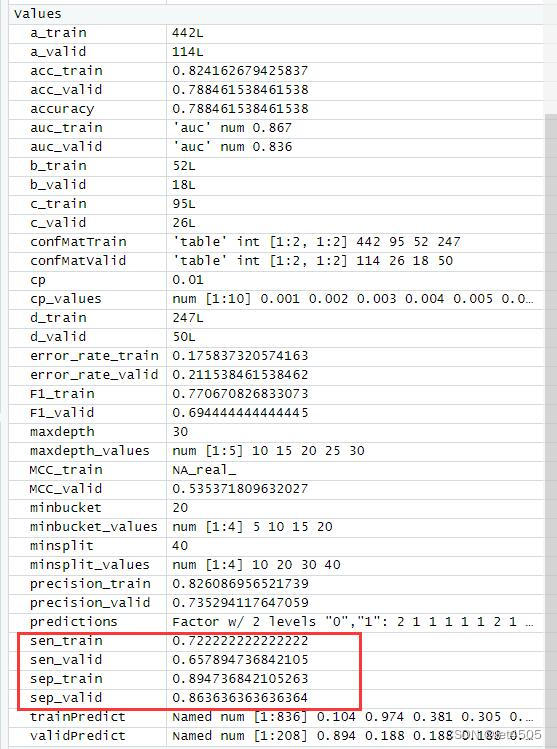
哈哈,又给调回去了,矫枉过正。思路就是这么个思路,大家自行食用了。
五、最后
看到这里,我觉得还是Python的sk-learn提供的调参简单些,至少不用写循环。
数据嘛:
链接:https://pan.baidu.com/s/1rEf6JZyzA1ia5exoq5OF7g?pwd=x8xm
提取码:x8xm
相关文章:
第100+13步 ChatGPT学习:R实现决策树分类
基于R 4.2.2版本演示 一、写在前面 有不少大佬问做机器学习分类能不能用R语言,不想学Python咯。 答曰:可!用GPT或者Kimi转一下就得了呗。 加上最近也没啥内容写了,就帮各位搬运一下吧。 二、R代码实现决策树分类 (…...

Hi3861 OpenHarmony嵌入式应用入门--LiteOS MessageQueue
CMSIS 2.0接口中的消息(Message)功能主要涉及到实时操作系统(RTOS)中的线程间通信。在CMSIS 2.0标准中,消息通常是通过消息队列(MessageQueue)来进行处理的,以实现不同线程之间的信息…...

ffmpeg编码图象时报错Invalid buffer size, packet size * < expected frame_size *
使用ffmpeg将单个yuv文件编码转为jpg或其他图像格式时,报错: Truncating packet of size 11985408 to 3585 [rawvideo 0x1bd5390] Packet corrupt (stream 0, dts 1). image_3264_2448_0.yuv: corrupt input packet in stream 0 [rawvideo 0x1bd7c60…...

解决类重复的问题
1.针对AndroidX 类重复问题 解决办法: android.useAndroidXtrue android.enableJetifiertrue2.引用其他sdk出现类重复的问题解决办法:configurations {all { // You should exclude one of them not both of themexclude group: "com.enmoli"…...

使用 shell 脚本 统计app冷启动耗时
下面是一个 shell 脚本,它使用 参数将包名称作为参数--app,识别相应应用程序进程的 PID,使用 终止该进程adb shell kill,最后使用 重新启动该应用程序adb shell am start: #!/bin/bash# Check if package name is pro…...
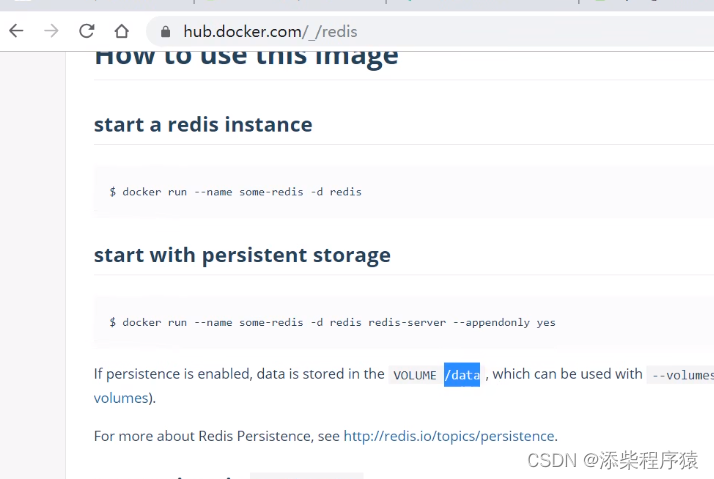
使用容器部署redis_设置配置文件映射到本地_设置存储数据映射到本地_并开发java应用_连接redis---分布式云原生部署架构搭建011
可以看到java应用的部署过程,首先我们要准备一个java应用,并且我们,用docker,安装一个redis 首先我们去start.spring.io 去生成一个简单的web项目,然后用idea打开 选择以后下载 放在这里,然后我们去安装redis 在公共仓库中找到redis . 可以看到它里面介绍说把数据放到了/dat…...

第五节:如何使用其他注解方式从IOC中获取bean(自学Spring boot 3.x的第一天)
大家好,我是网创有方,上节我们实践了通过Bean方式声明Bean配置。咱们这节通过Component和ComponentScan方式实现一个同样功能。这节实现的效果是从IOC中加载Bean对象,并且将Bean的属性打印到控制台。 第一步:创建pojo实体类studen…...

Paragon NTFS与Tuxera NTFS有何区别 Mac NTFS 磁盘读写工具选哪个好
macOS系统虽然以稳定、安全系数高等优点著称,但因其封闭性,不能对NTFS格式磁盘写入数据常被人们诟病。优质的解决方案是使用磁盘管理软件Paragon NTFS for Mac(点击获取激活码)和Tuxera NTFS(点击获取激活码࿰…...

EtherCAT主站IGH-- 2 -- IGH之coe_emerg_ring.h/c文件解析
EtherCAT主站IGH-- 2 -- IGH之coe_emerg_ring.h/c文件解析 0 预览一 该文件功能coe_emerg_ring.c 文件功能函数预览 二 函数功能介绍coe_emerg_ring.c 中主要函数的作用1. ec_coe_emerg_ring_init2. ec_coe_emerg_ring_clear3. ec_coe_emerg_ring_size4. ec_coe_emerg_ring_pus…...

psensor 的手势功能
psensor 的手势功能的移植过程 有时间再来写下...
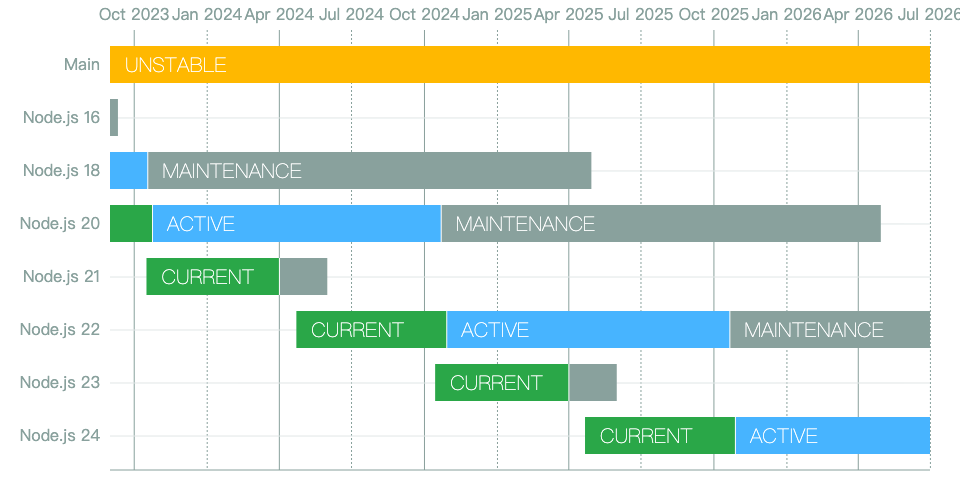
使用 nvm 管理 Node 版本及 pnpm 安装
文章目录 GithubWindows 环境Mac/Linux 使用脚本进行安装或更新Mac/Linux 环境变量nvm 常用命令npm 常用命令npm 安装 pnpmNode 历史版本 Github https://github.com/nvm-sh/nvm Windows 环境 https://nvm.uihtm.com/nvm.html Mac/Linux 使用脚本进行安装或更新 curl -o- …...
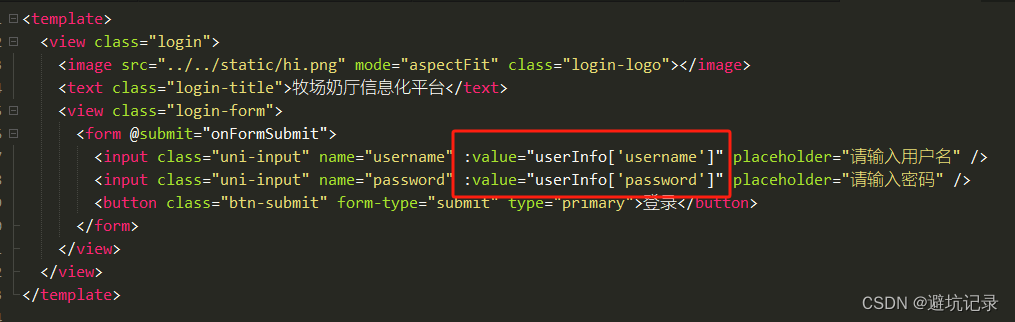
uni-appx使用form表单页面初始化报错
因为UniFormSubmitEvent的类型时 e-->detail-->value,然后没有了具体值。所以页面初始化的时候 不能直接从value取值,会报错找不到 所以form表单里的数据我们要设置成一个对象来存放 这个问题的关键在于第22行代码 取值: 不能按照点的方式取值 …...

TiDB-从0到1-数据导出导入
TiDB从0到1系列 TiDB-从0到1-体系结构TiDB-从0到1-分布式存储TiDB-从0到1-分布式事务TiDB-从0到1-MVCCTiDB-从0到1-部署篇TiDB-从0到1-配置篇TiDB-从0到1-集群扩缩容 一、数据导出 TiDB中通过Dumpling来实现数据导出,与MySQL中的mysqldump类似,其属于…...
代码实践 -卷积神经网络-16自定义层)
动手学深度学习(Pytorch版)代码实践 -卷积神经网络-16自定义层
16自定义层 import torch import torch.nn.functional as F from torch import nnclass CenteredLayer(nn.Module):def __init__(self):super().__init__()#从其输入中减去均值#X.mean() 计算的是整个张量的均值#希望计算特定维度上的均值,可以传递 dim 参数。#例如…...

树莓派4设置
使用sudo命令时要求输入密码 以 sudo 为前缀的命令以超级用户身份运行。默认情况下,超级用户不需要密码。不过,您可以要求所有以 sudo 运行的命令都输入密码,从而提高 Raspberry Pi 的安全性。 要强制 sudo 要求输入密码,请为你…...

44.商城系统(二十五):k8s基本操作,ingress域名访问,kubeSphere可视化安装
上一章我们已经配置好了k8s集群,如果没有配置好先去照着上面的配。 一、k8s入门操作 1.部署一个tomcat,测试容灾恢复 #在主机器上执行 kubectl create deployment tomcat6 --image=tomcat:6.0.53-jre8#查看k8s中的所有资源 kubectl get all kubectl get all -o wide#查看po…...

MySQL高级查询
MySQL 前言 文本源自微博客 (www.microblog.store),且已获授权. 一. mysql基础知识 1. mysql常用系统命令 启动命令 net start mysql停止命令 net stop mysql登录命令 mysql -h ip -P 端口 -u 用户名 -p 本机可以省略 ip mysql -u 用户名 -p 查看数据库版本 mysql --ve…...

聊聊啥项目适合做自动化测试
作为测试从业者,你是否遇到过这样的场景,某天公司大Boss找你谈话。 老板:小李,最近工作辛苦了 小李:常感谢您的认可,这不仅是对我个人的鼓励,更是对我们整个团队努力的认可。我们的成果离不开每…...

ROS2开发机器人移动
.创建功能包和节点 这里我们设计两个节点 example_interfaces_robot_01,机器人节点,对外提供控制机器人移动服务并发布机器人的状态。 example_interfaces_control_01,控制节点,发送机器人移动请求,订阅机器人状态话题…...
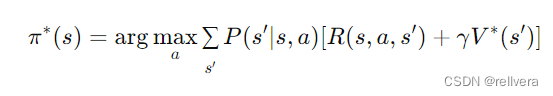
【强化学习】第02期:动态规划方法
笔者近期上了国科大周晓飞老师《强化学习及其应用》课程,计划整理一个强化学习系列笔记。笔记中所引用的内容部分出自周老师的课程PPT。笔记中如有不到之处,敬请批评指正。 文章目录 2.1 动态规划:策略收敛法/策略迭代法2.2 动态规划…...

第19节 Node.js Express 框架
Express 是一个为Node.js设计的web开发框架,它基于nodejs平台。 Express 简介 Express是一个简洁而灵活的node.js Web应用框架, 提供了一系列强大特性帮助你创建各种Web应用,和丰富的HTTP工具。 使用Express可以快速地搭建一个完整功能的网站。 Expre…...

应用升级/灾备测试时使用guarantee 闪回点迅速回退
1.场景 应用要升级,当升级失败时,数据库回退到升级前. 要测试系统,测试完成后,数据库要回退到测试前。 相对于RMAN恢复需要很长时间, 数据库闪回只需要几分钟。 2.技术实现 数据库设置 2个db_recovery参数 创建guarantee闪回点,不需要开启数据库闪回。…...

Zustand 状态管理库:极简而强大的解决方案
Zustand 是一个轻量级、快速和可扩展的状态管理库,特别适合 React 应用。它以简洁的 API 和高效的性能解决了 Redux 等状态管理方案中的繁琐问题。 核心优势对比 基本使用指南 1. 创建 Store // store.js import create from zustandconst useStore create((set)…...

中南大学无人机智能体的全面评估!BEDI:用于评估无人机上具身智能体的综合性基准测试
作者:Mingning Guo, Mengwei Wu, Jiarun He, Shaoxian Li, Haifeng Li, Chao Tao单位:中南大学地球科学与信息物理学院论文标题:BEDI: A Comprehensive Benchmark for Evaluating Embodied Agents on UAVs论文链接:https://arxiv.…...

Java如何权衡是使用无序的数组还是有序的数组
在 Java 中,选择有序数组还是无序数组取决于具体场景的性能需求与操作特点。以下是关键权衡因素及决策指南: ⚖️ 核心权衡维度 维度有序数组无序数组查询性能二分查找 O(log n) ✅线性扫描 O(n) ❌插入/删除需移位维护顺序 O(n) ❌直接操作尾部 O(1) ✅内存开销与无序数组相…...

从零开始打造 OpenSTLinux 6.6 Yocto 系统(基于STM32CubeMX)(九)
设备树移植 和uboot设备树修改的内容同步到kernel将设备树stm32mp157d-stm32mp157daa1-mx.dts复制到内核源码目录下 源码修改及编译 修改arch/arm/boot/dts/st/Makefile,新增设备树编译 stm32mp157f-ev1-m4-examples.dtb \stm32mp157d-stm32mp157daa1-mx.dtb修改…...

SpringCloudGateway 自定义局部过滤器
场景: 将所有请求转化为同一路径请求(方便穿网配置)在请求头内标识原来路径,然后在将请求分发给不同服务 AllToOneGatewayFilterFactory import lombok.Getter; import lombok.Setter; import lombok.extern.slf4j.Slf4j; impor…...

Unity | AmplifyShaderEditor插件基础(第七集:平面波动shader)
目录 一、👋🏻前言 二、😈sinx波动的基本原理 三、😈波动起来 1.sinx节点介绍 2.vertexPosition 3.集成Vector3 a.节点Append b.连起来 4.波动起来 a.波动的原理 b.时间节点 c.sinx的处理 四、🌊波动优化…...

今日学习:Spring线程池|并发修改异常|链路丢失|登录续期|VIP过期策略|数值类缓存
文章目录 优雅版线程池ThreadPoolTaskExecutor和ThreadPoolTaskExecutor的装饰器并发修改异常并发修改异常简介实现机制设计原因及意义 使用线程池造成的链路丢失问题线程池导致的链路丢失问题发生原因 常见解决方法更好的解决方法设计精妙之处 登录续期登录续期常见实现方式特…...

Docker 本地安装 mysql 数据库
Docker: Accelerated Container Application Development 下载对应操作系统版本的 docker ;并安装。 基础操作不再赘述。 打开 macOS 终端,开始 docker 安装mysql之旅 第一步 docker search mysql 》〉docker search mysql NAME DE…...