万字长文详解数据结构:树 | 第6章 | Java版大话数据结构 | 二叉树 | 哈夫曼树 | 二叉树遍历 | 构造二叉树 | LeetCode练习
📌本篇分享的大话数据结构中🎄树🎄这一章的知识点,在此基础上,增加了练习题帮助大家理解一些重要的概念✅;同时,由于原文使用的C语言代码,不利于学习Java语言的同学实践,毛毛张这里将C语言代码转化成了Java代码✅
文章目录
- 1.前言
- 2.树的基本概念
- 2.1 树的定义
- 2.2 基本术语
- 2.3 树的基本性质
- 2.4 树的抽象数据结构
- 3.树的存储结构
- 3.1 概述
- 3.2 双亲表示法
- 3.2 孩子表示法
- 3.3 孩子兄弟表示法(常用)
- 3.4 总结
- 4.二叉树的定义
- 4.1 二叉树的特点
- 4.2 特殊的二叉树
- 4.2.1 斜树
- 4.2.2 满二叉树
- 4.2.3 完全二叉树
- 4.2.4 二叉排序树
- 4.2.5 平衡二叉树
- 4.3 二叉树的性质
- 4.3.0 性质0
- 4.3.1 性质1
- 4.4.2 性质2
- 4.5.3 性质3
- 4.3.4 性质4
- 4.3.5 性质5
- 4.4 基础练习
- 5.二叉树的存储结构
- 5.1 顺序存储结构
- 5.2 链式存储结构
- 5.2.1 二叉链表
- 5.2.2 三叉链表
- 6.遍历二叉树
- 6.1 二叉树的遍历
- 6.2 深度优先遍历
- 6.2.1 前序遍历(PreOrder)
- 遍历规则
- 算法实现
- LeetCode链接
- 6.2.2 中序遍历
- 遍历规则
- 算法实现
- LeetCode链接
- 6.2.3 后序遍历
- 遍历规则
- 算法实现
- LeetCode链接:
- 6.2.4 总结
- 6.3 广度优先遍历
- 6.3.1 层序遍历
- 遍历规则
- 算法逻辑及其实现
- LeetCode
- 6.4 总结
- 7.二叉树的建立
- 7.1 根据扩展二叉树构造二叉树
- 7.1.1 原理
- 7.1.2 代码实现
- 7.2 由遍历序列构造二叉树
- 7.2.1 性质
- 7.2.2 巩固练习
- 7.3 LeetCode练习
- 1.[106. 从中序与后序遍历序列构造二叉树](https://leetcode.cn/problems/construct-binary-tree-from-inorder-and-postorder-traversal/)
- 1.1 题目描述
- 1.2 题解
- 1.2.1 递归法
- 1.2.1.1 方法1
- 1.2.1.2 方法2
- 1.2.1.3 方法3
- 1.2.2 迭代法
- 2.[105. 从前序与中序遍历序列构造二叉树](https://leetcode.cn/problems/construct-binary-tree-from-preorder-and-inorder-traversal/)
- 2.1 题目描述
- 2.2 题解
- 2.2.1 递归法
- 2.2.1.1 方法1
- 2.2.1.2 方法2
- 2.2.1.3 方法3
- 2.2.2 迭代法
- 8.线索二叉树
- 8.1 线索二叉树的原理
- 8.2 线索二叉树的存储结构
- 8.3 二叉树的线索化
- 8.3.1 中序线索二叉树
- 8.3.2 前序和后序线索二叉树
- 9.树、森林与二叉树的转化
- 9.1 树转换为二叉树
- 9.2 森林转化为二叉树
- 9.3 二叉树转换为树
- 9.4 二叉树转换为森林
- 9.5 树和森林的遍历
- 9.5.1 树的遍历
- 9.5.2 森林的遍历
- 10 哈夫曼树及其应用
- 10.1 哈夫曼树的定义和原理
- 10.2 哈夫曼树的构造
- 10.3 哈夫曼编码
- 10.3.1 哈夫曼编码引入
- 10.3.2 哈夫曼编码定义
- 参考文献
1.前言
- 线性结构是1️⃣对1️⃣的关系,如果处理1️⃣对多的情况,则需要使用树形结构
- 🌲树形结构包括:二叉树、 A V L AVL AVL树、B树、红黑树等,而二叉树是学其它树的基础,学好了二叉树才能在后续更难的树时得心应手🫱
- 在介绍二叉树之前同时还需要整体的介绍一下树这个数据结构
2.树的基本概念
2.1 树的定义
- **定义:**🌳树是 n ( n ≥ 0 ) n(n≥0) n(n≥0)个结点的有限集。当 n = 0 n = 0 n=0时,称为空树。在任意一棵非空树中应满足:
- 有且仅有一个特定的称为根(Root)的结点;
- 当 n > 1 n>1 n>1时,其余节点可分为 m ( m > 0 ) m(m>0) m(m>0)个互不相交的有限集 T 、 T 2 、 … 、 T m T、T~2~、…、T_m T、T 2 、…、Tm,其中每个集合本身又是一棵树,并且称为根的子树(SubTree)
- 图解:

- 从上面的定义中可以发现树的定义是递归的,即在树的定义中又用到了自身,树是一种递归的数据结构
- 树作为一种逻辑结构,同时也是一种分层结构,具有以下两个特点:
- 树的根结点没有前驱,除根结点外的所有结点有且只有一个前驱
- 树中所有结点可以有零个或多个后继
- 注意:
- n > 0 n>0 n>0时根节点是唯一的,不可能存在多个根节点
- m > 0 m>0 m>0时,子树的个数没有限制,但他们一定是互不相交的,下面两个图均不符合树的定义

2.2 基本术语

- 节点的分类
- 根节点: 一棵树中没有双亲结点的结点,如上图:A结点
- 结点的度: 结点拥有的子树,如上图:D结点的度为3
- 树的度: 是树内各节点的度的最大值,如上图:树的度为3
- 叶子结点(Leaf): 度为0的结点,如上图:G、H、I等结点均为叶结点
- 分支结点(非终端结点): 度不为0的结点,如上图:B、C、D等节点为分支结点
- 除根节点之外,分支节点也称为内部节点
- 节点间的关系
- 子节点(孩子结点Child): 一个结点的子树的根节点称为该结点的孩子节点,如上图:B是A的孩子结点
- 父节点(双亲结点Parent): 若一个结点含有子节点,则这个结点称为其子节点的父节点,如上图:A是B的父结点
- 兄弟结点(Sibling): 同一个双亲的孩子结点之间互称为兄弟,如上图:B、C是兄弟结点
- 节点的祖先:从根节点到该节点所经分支上的所有结点,如上图:A是所有结点的祖先, B是 G、H、I 的祖先
- 结点的子孙:以某结点为根的子树中的任一结点都称为该节点的子孙,如上图:所有结点都是A的子孙
- 树的其它相关概念
- 结点的层次(Level): 从根开始定义起,根为第一层,根的孩子为第二层,以此类推
- 堂兄弟:双亲在同一层的结点互为堂兄弟,图中结点J与G、H、I互为堂兄弟
- 树的高度(深度Depth): 树中结点的最大层,如上图:树的深度为4
- 有序树与无序树:如果将树中结点的各子树看成从左至右是有次序的,不能互换的,则称该树为有序树,否则为无序树
- 森林(Forest):是m(m≥0)棵互不相交的树的集合
- 结点的路径:是由这两个结点之间所经过的结点序列构成的
- 路径长度:是路径上所经过的边的个数
注意:上述概念无须刻意记忆, 根据实例理解即可
2.3 树的基本性质
- n n n个结点的树中有 n − 1 n-1 n−1条边
- 树中的结点数等于所有结点的度数加 1 1 1
- 度为 m m m的树中第 i i i层上至多有 m i − 1 {{m}}^{i-1} mi−1个结点( i ≥ 1 i ≥1 i≥1)
- 高度为 h h h的 m m m叉树至多有 m h − 1 m − 1 \frac{m^h-1}{m-1} m−1mh−1个结点
- 具有 n n n个结点的 m m m叉树的最小高度为 h = ⌈ log m ( n ( m − 1 ) + 1 ) ⌉ h=\lceil\log_m(n(m-1)+1)\rceil h=⌈logm(n(m−1)+1)⌉ (向上取整)
2.4 树的抽象数据结构
ADT 树(tree)
Data树是由一个根结点和若干棵子树构成。树中结点具有相同数据类型及层次关系。
OperationInitTree(*T):构造空树TDestroyTree(*T):销毁树TCreateTree(*T,definition):按definition中给出树的定义来构造树ClearTree(*T):若树T存在,则将树T情空为空树TreeEmpty(T):若T为空树,返回true,否则返回falseTreeDepth(T):返回T的深度Root(T):返回T的根结点Value(T,cur_e):cur_e是树T中的一个结点,返回此结点的值Assign(T,cur_e,value):给树T的结点cur_e赋值为valueParent(T,cur_e):若cur_e是树T的非根结点,则返回它的双亲,否则返回空LeftChild(T,cur_e):若cur_e是树T的非叶结点,则返回它的最左孩子,否则返回空RightSibling(T,cur_e):若cur_e有右兄弟,则返回它的右兄弟,否则返回空InsertChild(*T,*p,i,c):其中p指向树T的某个结点,i为所指结点p的度上加1,非空树c与T不相交,操作结果为插入c为树T中p指结点的第i棵子树DeleteChild(*T,*p,i):其中p指向树T的某个结点,i为所指结点p的度,操作结果为删除T中p所指结点的第i棵子树
endADT
3.树的存储结构
3.1 概述
- 简单的顺序存储是不能满足树的实现要求的,因此我们需要充分利用顺序存储和链式存储结构的特点来表述树的存储结
- 树的存储结构有三种不同的表示法:双亲表示法、孩子表示法和孩子兄弟表示法,其中孩子兄弟表示法最常用
- 在介绍以上三种存储结构的过程中,都以下面这个树为例子

3.2 双亲表示法
- 我们假设以一组连续空间存储树的结点,同时在每个结点中,附设一个指示器指示其双亲结点到链表中的位置。也就是说,每个结点除了知道自已是谁以外,还知道它的双亲在哪里。
- 它的节点结构如下所示,其中
data是数据域,存储结点的数据信息;而parent是指针域,存储该结点的双亲在数组中的下标

- 上图树结构可用下表中的树双亲表示如下图:

- 结点结构定义Java代码:
/*结点结构*/ public class PTNode {int data; // 节点数据 数据域int parent; // 双亲位置 指针域// 默认构造方法public PTNode() {this.data = 0;this.parent = -1;}// 参数构造方法public PTNode(int data, int parent) {this.data = data;this.parent = parent;} }/*树结构*/ public class PTree {private static final int MAX_TREE_SIZE = 100; // 最大树的大小PTNode[] nodes; // 节点数组int root; // 根的位置int nodeCount; // 节点数public PTree() {nodes = new PTNode[MAX_TREE_SIZE];root = -1; // 初始根节点位置,-1表示还没有根节点nodeCount = 0;} } - 分析:
- 通过上述存储结构,我们可以根据结点的
parent指针很容易找到它的双亲结点,所用的时间复杂度为 O ( 1 ) O(1) O(1),直到parent为 − 1 -1 −1时,表示找到了树结点的根 - 可如果我们要知道结点的孩子是什么,需要遍历整个结构才行,所以我们可以把此结构扩展为有双亲域、长子域、再有右兄弟域
- 存储结构的设计是一个非常灵活的过程,一个存储结构设计得是否合理,取决于基于该存储结构的运算是否适合、是否方便,时间复杂度好不好等
- 通过上述存储结构,我们可以根据结点的
3.2 孩子表示法
- 把每个结点的孩子结点排列起来,以单链表作存储结构,则n个结点有n个孩子链表,如果是叶子结点则此单链表为空。然后n个头指针又组成一个线性表,采用顺序存储结构,存放进一个一维数组中,如下图所示

- 实现该存储结构需要设计两种结点结构:孩子链表的孩子结点和表头数组的表头结点
- 孩子链表的孩子结点: 其中
child是数据域,用来存储某个结点在表头数组中的下标;next是指针域,用来存储指向某结点的下一个孩子结点的指针

- 表头数组的表头结点: 其中
data是数据域,存储某结点的数据信息;firstchild是头指针域,存储该结点的孩子链表的头指针

- 孩子表示法的结构定义Java代码:
/*孩子结点*/ public class CTNode {int child; // 子节点的位置CTNode next; // 下一个子节点的引用public CTNode() {this.child = -1; // 默认初始化为-1this.next = null;}public CTNode(int child) {this.child = child;this.next = null;} }/*表头结点*/ public class CTBox {int data; // 节点数据CTNode firstChild; // 第一个子节点的引用public CTBox() {this.data = -1; // 默认初始化为-1this.firstChild = null;}public CTBox(int data) {this.data = data;this.firstChild = null;} }/*树结构*/ public class CTree {private static final int MAX_TREE_SIZE = 100; // 最大树的大小CTBox[] nodes; // 节点数组int root; // 根的位置int nodeCount; // 节点数public CTree() {nodes = new CTBox[MAX_TREE_SIZE];root = -1; // 初始根节点位置,-1表示还没有根节点nodeCount = 0;} } - 分析:
- 这样的结构对于我们要查找某个结点的某个孩子,或者找某个结点的兄弟,只需要查找这个结点的孩子单链表即可。对于遍历整棵树也是很方便的,对头结点的数组循环即可
- 但是,这也存在着问题,我如何知道某个结点的双亲是谁呢?比较麻烦,需要整棵树遍历才行,难道就不可以把双亲表示法和孩子表示法综合一下吗?当然是可以,这个读者可自己尝试结合一下,在此不做赘述
3.3 孩子兄弟表示法(常用)
- 刚才我们分别从双亲的角度和从孩子的角度研究树的存储结构,如果我们从树结点的兄弟的角度又会如何呢?当然,对于树这样的层级结构来说,只研究结点的兄弟是不行的。
- 我们观察后发现,任意一棵树, 它的结点的第一个孩子如果存在就是唯一的,它的右兄弟如果存在也是唯一的。 因此,我们设置两个指针,分别指向该结点的第一个孩子和此结点的右兄弟。
- 结点的结构如下:其中
data是数据域;firstchild为指针域,存储该结点的第一个孩子结点的存储地址;rightsib是指针域,存储该结点的右兄弟结点的存储地址

- 孩子兄弟表示法的结构定义代码如下:
public class TreeNode {int value; // 树中存储的数据TreeNode firstChild; // 第一个孩子引用TreeNode nextBrother; // 下一个兄弟引用 } - 分析:
- 这种表示法,给查找某个结点的某个孩子带来了方便。
- 通过这种结构,我们就把原来的树变成下图所示:其实这种表示法最大的好处就是把一颗复杂的树变成了一棵二叉树

3.4 总结
- 线性表中,存储结构都相对简单,但树形结构的存储结构比较复杂,并且有很多种:双亲表示法,孩子表示法、孩子双亲表示法、孩子兄弟表示法等等,这里先了解即可
4.二叉树的定义
- 定义:二叉树 (Binary Tree) 是 n n n ( n ≥ 0 n≥0 n≥0) 个结点的有限集合,该集合或者为空集(称为空二叉树),即 n = 0 n=0 n=0;或者由一个根结点和两颗互不相交的、分别被被称为根节点的左子树和右子树的二叉树组成。
- 二叉树的定义可以通过递归来描述,对于包含 n n n ( n ≥ 0 n≥0 n≥0) 个节点的有限集合:
- 当 n = 0 n=0 n=0时,该二叉树为空二叉树。
- 当 n ≠ 0 n≠0 n=0时,该二叉树由一个根节点和两个互不相交的子树组成,分别称为根的左子树和右子树。而这两个子树又分别是二叉树。
- 图例:

4.1 二叉树的特点
- 二叉树是一种特殊的树形结构,具有以下特点:
- 每个节点最多只有两个子节点,即不存在度大于 2 2 2的节点。
- 子树有左右之分,且次序不能任意颠倒。即使节点只有一棵子树,也需区分其为左子树还是右子树。
- 二叉树的五种基本形态如下图所示,任意二叉树都可以由以下几种情况组合而成:

4.2 特殊的二叉树
4.2.1 斜树
- 定义: 所有的结点都只有左子树的二叉树叫左斜树;所有结点都是只有右子树的二叉树叫右斜树;这两者统称为斜树
4.2.2 满二叉树
- 定义: 在一棵二叉树中,如果所有分支节点都存在左子树和右子树,并且所有叶子都在一层上,这样的二叉树称为满二叉树
- 如果一棵二叉树的层数为 k k k,且结点总数是 2 k − 1 2^{k} - 1 2k−1,则它就是满二叉树
- 图解:

- 特点:
- 叶子节点只能出现在最下一层
- 非叶子节点的度一定是 2 2 2
- 在同样深度的二叉树中,满二叉树的节点个数最多,叶子树最多
4.2.3 完全二叉树
- 定义: 对一颗具有 n n n个节点的二叉树按层序编号,如果编号 i ( 1 ≤ i ≤ n ) i (1≤i≤n) i(1≤i≤n)的结点与同样深度的满二叉树中编号为i的节点在二叉树中位置完全相同,则这颗二叉树称为完全二叉树。完全二叉树是效率很高的数据结构,完全二叉树是由满二叉树而引出来的,要注意的是满二叉树是一种特殊的完全二叉树。
- 特点:
- 叶子节点只能出现在最下层
- 最下层的叶子一定集中在左部连续位置
- 倒数第二层,所有叶子节点,一定都在右部连续位置
- 如果节点度为 1 1 1,则该结点只有左孩子,即不存在只有右子树的情况
- 同样结点数的二叉树,完全二叉树的深度最小
- 图解:

4.2.4 二叉排序树
- 定义:
- 左子树上所有结点的关键字均小于根结点的关键字;
- 右子树上的所有结点的关键字均大于根结点的关键字;
- 左子树和右子树又各是一棵二叉排序树。
4.2.5 平衡二叉树
- 定义: 树上任一结点的左子树和右子树的深度之差不超过 1 1 1
4.3 二叉树的性质
4.3.0 性质0
- 性质0: 任意一棵树,若结点数量为 n n n,则边的数量为 n − 1 n − 1 n−1
4.3.1 性质1
- 性质1: 在二叉树的第i层至多有 2 i − 1 2^{i-1} 2i−1个节点( i ≥ 1 i≥1 i≥1)
4.4.2 性质2
- 性质2: 深度为 k k k的二叉树至多有 2 k − 1 2^{k}-1 2k−1个节点( k ≥ 1 k≥1 k≥1)
4.5.3 性质3
-
性质3: 对任何一颗二叉树T,假设有N个结点,如果其终端节点数为n0,度为2的结点数为n2,度为1的结点数n1,则n0 = n2 + 1
-
推导:
-
结论1:一颗二叉树的结点数等于度为0的结点、度为1的结点和度为2的结点的数之和
- 即: N = n 0 + n 1 + n 2 \mathrm{N=n_0+n_1+n_2} N=n0+n1+n2(式1)
-
结论2:一个有N个节点的树,应该有N-1条边
- 边的总数:
- 度为0的节点,能产生多少条边?—> 0
- 度为1的节点,向下只能产生1条边,如果有n1个节点,能产生多少条边? —> n1 条边
- 度为2的节点,向下只能产生1条边,如果有n2个节点,能产生多少条边? —> 2*n2 条边
- 根据结点总数相等建立方程:N - 1 = n0 * 0 + n1 * 1 + n2 * 2 (式2)
- 边的总数:
-
联合公式1和公式2: n0 + n1 + n2 = 1 + n0 * 0 + n1 * 1 + n2 * 2
- 化简得:n0 = n2 + 1
-
4.3.4 性质4
- 性质4: 具有 n n n个节点的完全二叉树的深度为: h = ⌊ l o g 2 n ⌋ + 1 = ⌈ l o g 2 ( n + 1 ) ⌉ h = ⌊log_2n⌋+1 = ⌈log_2(n+1)⌉ h=⌊log2n⌋+1=⌈log2(n+1)⌉
4.3.5 性质5
- 性质5: 如果对一棵有 n n n个节点的完全二叉树(其深度为 ⌊ l o g 2 n ⌋ + 1 ⌊log_2n⌋+1 ⌊log2n⌋+1)的结点按层序编号(从第 1 1 1层到第 ⌊ l o g 2 n ⌋ + 1 ⌊log_2n⌋+1 ⌊log2n⌋+1层,每层从左到右),对任一节点 i i i( 1 ≤ i ≤ n 1≤i≤n 1≤i≤n)有:
- 如果 i = 1 i=1 i=1,则结点 i i i是二叉树的根,无双亲;如果 i > 1 i>1 i>1,则其双亲是结点$\lfloor\frac{i}{2}\rfloor $
- 如果 2 i > n 2i > n 2i>n,则结点i无左孩子(结点i为叶子结点);否则其左孩子是结点 2 i 2i 2i
- 如果 2 i + 1 > n 2i + 1 > n 2i+1>n,则结点 i i i无右孩子(结点 i i i为叶子结点);否则其左孩子是结点 2 i + 1 2i+1 2i+1
- 图解:

4.4 基础练习
选择题: 下面的题目均可根据上面的性质或者定义来作答,大家可以先做,然后再看后面的答案
- 某二叉树共有399个结点,其中有199个度为2的结点,则该二叉树中的叶子结点数为( )
- A:不存在这样的二叉树
- B:200
- C:198
- D:199
- 在具有2n个结点的完全二叉树中,叶子结点个数为( )
- A:n
- B:n+1
- C:n-1
- D:n/2
- 一个具有767个节点的完全二叉树,其叶子节点个数为()
- A:383
- B:384
- C:385
- D:386
- 一棵完全二叉树的节点数为531个,那么这棵树的高度为( )
- A:11
- B:10
- C:8
- D:12
答案:
1.B
2.A
3.B
4.B
5.二叉树的存储结构
5.1 顺序存储结构
- 二叉树的顺序存储是指用一组地址连续的存储单元依次自上而下、自左至右存储完全二叉树上的结点元素,即将完全二叉树上编号为 i i i的结点元素存储在一维数组下标为 i − 1 i−1 i−1的分量中,二叉树的顺序存储结构如图所示,其中 0 0 0表示并不存在的空结点

- 完全二叉树和满二叉树采用顺序存储比较合适,树中结点的序号可以唯一地反映结点之间的逻辑关系,这样既能最大可能地节省存储空间,又能利用数组元素的下标值确定结点在二叉树中的位置,以及结点之间的关系。
- 对于一般的二叉树,为了让数组下标能反映二叉树中结点之间的逻辑关系,只能添加一些并不存在的空结点,让其每个结点与完全二叉树上的结点相对照,再存储到一维数组的相应分量中。
- 然而,考虑一种极端情况,一颗深度为 k k k的右斜树,它只有 k k k个节点(一个高度为 k k k且只有 k k k个结点的单支树),却需要分配 2 k − 1 2^{k}-1 2k−1个存储单元,这显然是对存储空间的浪费,所以,顺序存储结构一般只用于完全二叉树。
5.2 链式存储结构
5.2.1 二叉链表
- 既然顺序存储适用性不强,我们就要考虑链式存储结构。二叉树每个结点最多有两个孩子,所以为它设计一个数据域和两个指针域是比较自然的想法,我们称这样的链表叫做二叉链表,这种存储结构的本质就是树的存储结构中的孩子表示法
- 结点的结构如下: 其中
data是数据域,lchild和rchild都是指针域,分别存放指向左孩子和右孩子的指针

- 图解:

- 特点:在含有 n n n个结点的二叉链表中,含有 n + 1 n+1 n+1个空链域
- 二叉链表的结点结构定义代码:
//二叉链表 孩子表示法 public class TreeNode{public int val; //数据域public TreeNode left; //左孩子的引用,常常代表左孩子为根的整棵左子树public TreeNode right; //右孩子的引用,常常代表右孩子为根的整棵右子树public Treenode(){}public TreeNode(int val){this.val = val;}public TreeNode(int val,TreeNode left,TreeNode,right){this.val = val;this.left = left;this.right = right;} }
5.2.2 三叉链表
-
我们还可以在二叉链表的基础上,增加一个指向其双亲的指针域,那样就称之为三叉链表,这种存储结构的本质就是树的存储结构中的孩子双亲表示法
-
结点结构定义Java代码如下:
//三叉链表 孩子双亲表示法 public class TriTNode{public int val; //数据域public TriTNode left; //左孩子的引用,常常代表左孩子为根的整棵左子树public TriTNode right; //右孩子的引用,常常代表右孩子为根的整棵右子树public TriTNode parent; //当前节点的根节点(双亲结点)public TriTNode(int val){this.val = val;} }
6.遍历二叉树
6.1 二叉树的遍历
- 二叉树的遍历(
traversing binary tree):是指从根结点出发,按照某种次序依次访问二叉树中所有结点,使得每个结点被访问一次且仅被访问一次 - 二叉树的两类四种遍历方式:
- 深度优先遍历(DFS)
- 前序遍历
- 中序遍历
- 后序遍历
- 广度优先遍历(BFS)
- 层序遍历
- 深度优先遍历(DFS)
- 在学习二叉树的基本操作前,需先要创建一棵二叉树,然后才能学习其相关的基本操作。由于现在大家对二叉树结构掌握还不够深入,为了降低大家学习成本,此处手动快速创建一棵简单的二叉树,快速进入二叉树操作学习,等二叉树结构了解的差不多时,我们反过头再来研究二叉树真正的创建方式
/*二叉树的结点类*/ class BiTNode {public char val;public BiTNode left; // 左孩子的引用public BiTNode right; // 右孩子的引用public BiTNode(char val) {this.val = val;} } /*二叉树的基本操作类*/ class BinaryTree {public BiTNode createTree() {BiTNode A = new BiTNode('A');BiTNode B = new BiTNode('B');BiTNode C = new BiTNode('C');BiTNode D = new BiTNode('D');BiTNode E = new BiTNode('E');BiTNode F = new BiTNode('F');BiTNode G = new BiTNode('G');BiTNode H = new BiTNode('H');A.left = B;A.right = C;B.left = D;B.right = E;C.left = F;C.right = G;E.right = H;return A;}/*前序遍历*/public void preOrderTraverse(BiTNode root){}/*中序遍历*/public void inOrderTraverse(BiTNode root){}/*后序遍历*/public void postOrdeTraverse(BiTNode root){}/*层序遍历*/public void levelOrderTraverse(TreeNode root){} } /*二叉树的测试类*/ public class TestDemo {public static void main(String[] args) {BinaryTree binaryTree = new BinaryTree();BiTNode root = binaryTree.createTree();} }
6.2 深度优先遍历
6.2.1 前序遍历(PreOrder)
遍历规则
- 若二叉树为空,则空操作返回;否则先访问根结点;然后前序遍历左子树;再前序遍历右子树。如下图所示,遍历的顺序为:ABDGHCEIF

算法实现
/*二叉树的前序遍历递归算法*/
public void preOrderTraverse(BiTNode root) {if (root == null) {return;}System.out.print(root.val + " ");preOrderTraverse(root.left);preOrderTraverse(root.right);
}
LeetCode链接
- 大家看完上述代码可以点击右边链接跳转到LeetCode思考这题该如何解决:144. 二叉树的前序遍历
6.2.2 中序遍历
遍历规则
- 若二叉树为空,则空操作返回;否则从根节点开始(注意并不是先访问根节点),中序遍历根节点的左子树;然后访问根节点;最后中序遍历右子树。如下图所示,遍历的顺序:GDHBAEICF

算法实现
/*二叉树的中序遍历递归算法*/
public void inOrderTraverse(BiTNode root) {if(root == null) {return;}inOrderTraverse(root.left);System.out.print(root.val + " ");inOrderTraverse(root.right);
}
LeetCode链接
- 大家看完上述代码可以点击右边链接跳转到LeetCode思考这题该如何解决:94. 二叉树的中序遍历
6.2.3 后序遍历
遍历规则
- 若二叉树为空,则空操作返回;否则从左到右先叶子结点的方式遍历访问左右子树;最后是访问根节点。如下图所示,遍历的顺序为:GHDBIEFCA

算法实现
/*二叉树的后序遍历递归算法*/
public void postOrderTraverse(BiTNode root) {if(root == null) {return;}postOrderTraverse(root.left);postOrderTraverse(root.right);System.out.print(root.val + " ");
}
LeetCode链接:
- 大家看完上述代码可以点击右边链接跳转到LeetCode思考这题该如何解决:145. 二叉树的后序遍历
6.2.4 总结
算法分析:
- 前序、中序、后序遍历算法中,递归遍历左右子树的顺序都是固定的,只是访问根结点的顺序不同
- 不管采用哪种遍历算法,每个结点都访问一次且仅访问一次,故时间复杂度都是 O ( n ) O(n) O(n)
- 在递归遍历中,递归工作栈的栈深恰好为树的深度,所以在最坏情况下,二叉树是有 n n n个结点且深度为n的单支树,遍历算法的空间复杂度为 O ( n ) O(n) O(n)
6.3 广度优先遍历
6.3.1 层序遍历
遍历规则
- 若树为空,则返回空操作;否则从树的第一层,也就是根节点开始访问,从上而下逐层遍历;在同一层中,按从左到右的顺序对结点逐个访问。如下图所示,即按照箭头所指方向,按照1、2、3、4的层次顺序,对二叉树中的各个结点进行访问,遍历的结果为:ABCDEFGHI

算法逻辑及其实现
算法逻辑:
- 实现层次遍历,需要借助一个队列;先将二叉树根结点入队,然后出队,访问出队结点;若它有左子树,则将左子树根结点入队;若它有右子树,则将右子树根结点入队;然后出队,访问出队结… ,如此反复,直至队列为空。
代码:
public void levelOrderTraverse(BiTNode root) {//判断特殊情况if(root == null) return;//创建队列Queue<BiTNode> queue = new LinkedList<>();queue.offer(root);//开始迭代while(!queue.isEmpty()) {// 当前层有多少节点int size = queue.size(); //迭代每一层的结点for(int i = 0;i<size;i++){BiTNode cur = queue.poll(); // 弹出System.out.print(cur.val + " ");if(cur.left != null) { // 左queue.offer(cur.left);}if(cur.right != null) { // 右queue.offer(cur.right);}}}
}
LeetCode
- 大家看完上述代码可以点击右边链接跳转到LeetCode思考这题该如何解决:102. 二叉树的层序遍历
6.4 总结
- 大家看完前面的代码可以利用如下测试代码进行测试:
/*二叉树的测试类*/
public class TestDemo {public static void main(String[] args) {//实例化树类BinaryTree binaryTree = new BinaryTree();//创建二叉树BiTNode root = binaryTree.createTree();//前序遍历binaryTree.preOrderTraverse(root); //A B D E H C F GSystem.out.println();//中序遍历binaryTree.inOrderTraverse(root); //D B E H A F C GSystem.out.println();//后序遍历binaryTree.postOrderTraverse(root); //D H E B F G C ASystem.out.println();//层序遍历binaryTree.levelOrderTraverse(root); //A B C D E F G H I}
}
- 上面毛毛张介绍了二叉树的四种遍历方式以及涉及到的
LeetCode题目,但是具体的代码实现还远不止上面的这一种代码实现方法,更多的方法可以跳转到毛毛张的这篇文章进行学习:LeetCode刷题笔记:二叉树前序遍历、中序遍历、后序遍历和层序遍历 | 递归法 | 迭代法 | 统一迭代法 | 深度优先搜索 | 广度优先搜索
7.二叉树的建立
7.1 根据扩展二叉树构造二叉树
7.1.1 原理

- 如果我们要在内存中建立一个上图中左边这样的一颗二叉树,为了能让每个结点确认是否有左右孩子,我们对它进行了扩展,变成上图中右图的样子,也就是将二叉树中每个结点的空指针引出一个虚结点,其值为一特定值,比如
#,我们称这种处理后的二叉树为原二叉树的扩展二叉树。扩展二叉树就可以做到一个遍历序列确定一棵二叉树了。 - 上图的右边的扩展二叉树的前序遍历序列为
AB#D##C##,我们可以根据该序列来建立真正二叉树
7.1.2 代码实现
- Java代码实现:
class BinaryTree {private Scanner scanner;// 创建二叉树并返回其根节点public BiTNode createBiTree() {if (scanner == null) {System.out.println("请输入扩展二叉树的前序遍历序列:");scanner = new Scanner(System.in); // 初始化Scanner}if (!scanner.hasNext()) return null; // 如果没有更多输入,返回nullchar ch = scanner.next().charAt(0);if (ch == '#') {return null; // #表示当前结点为空} else {BiTNode node = new BiTNode(ch); // 创建当前结点node.left = createBiTree(); // 构造左子树node.right = createBiTree(); // 构造右子树return node;}}
}
- 测试输入案例:

- 其实建立二叉树,也是利用了递归的原理。只不过再原来应该是打印结点的地方改成了生成结点、给结点赋值的操作而已
7.2 由遍历序列构造二叉树
- 上面的方式只需要通过一个序列就能创建一个二叉树,但需要定义一个特殊的符号,来表示空结点
- 下面介绍的这种方式仅根据二叉树的遍历序列来构造二叉树,但是需要知道两个遍历序列,并且不是随便两个序列就可以的,下面一起来看一下吧!
7.2.1 性质
性质1:由二叉树的前序序列和中序序列可以唯一地确定一棵二叉树
逻辑分析:
- 在前序遍历序列中,第一个结点一定是二叉树的根结点
- 而在中序遍历中,根结点必然将中序序列分割成两个子序列,前一个子序列是根结点的左子树的中序序列,后一个子序列是根结点的右子树的中序序列
- 根据这两个子序列,在前序序列中找到对应的左子序列和右子序列
- 在前序序列中,左子序列的第一个结点是左子树的根结点,右子序列的第一个结点是右子树的根结点;
- 如此递归地进行下去,便能唯一地确定这棵二叉树
实例: 求前序序列( ABCDEFGH)和中序序列( BCAEDGHFI)所确定的二叉树
- 分析:
- 首先,由前序序列可知A为二叉树的根结点;
- 中序序列中A之前的BC为左子树的中序序列,EDGHFI为右子树的中序序列;
- 然后由前序序列可知B是左子树的根结点,D是右子树的根结点;
- 以此类推,就能将剩下的结点继续分解下去,最后得到的二叉树如图©所示

性质2:由二叉树的后序序列和中序序列也可以唯一地确定一棵二叉树
- 同理,因为后序序列的最后一个结点就如同前序序列的第一个结点,可以将中序序列分割成两个子序列,然后采用类似的方法递归地进行划分,进而得到一棵二叉树
性质3:由二叉树的层序序列和中序序列也可以唯一地确定一棵二叉树
- 同理,因为层序序列的最后一个结点就如同前序序列的第一个结点,可以将中序序列分割成两个子序列,然后采用类似的方法递归地进行划分,进而得到一棵二叉树
性质4:已知前序遍历和后序遍历,不能确定一颗二叉树
- 举例说明: 比如前序遍历:ABC;后序遍历:CBA
- 我们可以确定A一定是根节点,但接下来,我们无法知道,哪个结点是左子树,哪个结点是右子树
7.2.2 巩固练习
选择题:
1.某完全二叉树按层次输出(同一层从左到右)的序列为 ABCDEFGH 。该完全二叉树的前序序列为()
- A: ABDHECFG
- B: ABCDEFGH
- C: HDBEAFCG
- D: HDEBFGCA
2.二叉树的先序遍历和中序遍历如下:先序遍历:EFHIGJK;中序遍历:HFIEJKG.则二叉树根结点为()
- A: E
- B: F
- C: G
- D: H
3.设一课二叉树的中序遍历序列:badce,后序遍历序列:bdeca,则二叉树前序遍历序列为()
- A: adbce
- B: decab
- C: debac
- D: abcde
4.某二叉树的后序遍历序列与中序遍历序列相同,均为 ABCDEF ,则按层次输出(同一层从左到右)的序列为()
- A: FEDCBA
- B: CBAFED
- C: DEFCBA
- D: ABCDEF
题解:

答案:
1.A
2.A
3.D
4.A
7.3 LeetCode练习
- 上面毛毛张介绍了如何由遍历序列来构造二叉树,下面毛毛张将结合两道LeetCode算法题来分享代码实现,第一道题目是根据中序与后序遍历序列构造二叉树;第二道题目是根据前序与中序遍历序列构造二叉树
- 在上面的性质中我们从理论的角度分析了前序与中序遍历构造二叉树的步骤,下面毛毛张来仔细介绍一下根据中序和后序遍历序列构造二叉树的逻辑思路
- 逻辑思路: 以 后序数组的最后一个元素为切割点,先切中序数组,根据中序数组,反过来再切后序数组。一层一层切下去,每次后序数组最后一个元素就是节点元素。
- 图解:

- 实现步骤: 根据上面的逻辑思路和图解,很容易想到使用递归的方式来实现,利用递归实现,主要分为以下几步
- 第一步:如果数组大小为零的话,说明是空节点了。
- 第二步:如果不为空,那么取后序数组最后一个元素作为节点元素。
- 第三步:找到后序数组最后一个元素在中序数组的位置,作为切割点
- 第四步:切割中序数组,切成中序左数组和中序右数组 (顺序别搞反了,一定是先切中序数组)
- 第五步:切割后序数组,切成后序左数组和后序右数组
- 第六步:递归处理左区间和右区间
- 下面就让我们来看一下具体的代码实现吧!
1.106. 从中序与后序遍历序列构造二叉树
1.1 题目描述
给定两个整数数组 inorder 和 postorder ,其中 inorder 是二叉树的中序遍历, postorder 是同一棵树的后序遍历,请你构造并返回这颗 二叉树 。
示例 1:

输入:inorder = [9,3,15,20,7], postorder = [9,15,7,20,3]
输出:[3,9,20,null,null,15,7]
示例 2:
输入:inorder = [-1], postorder = [-1]
输出:[-1]
提示:
1 <= inorder.length <= 3000postorder.length == inorder.length-3000 <= inorder[i], postorder[i] <= 3000inorder和postorder都由 不同 的值组成postorder中每一个值都在inorder中inorder保证是树的中序遍历postorder保证是树的后序遍历
1.2 题解
- 递归法的方法1的实现没有重新创建其它函数,利用题目给定的函数作为递归函数,但是需要创建四个新的数组,比较耗费空间
- 递归法的方法2的实现正式因为由于方法1的缺陷,重新编写的一个递归函数,使用数组的索引作为参数,而避免了传递整个数组,减小了内存的消耗
- 递归法的方法3的实现是结合集合来实现,这种方式的实现依赖于题目中给定的条件:
inorder和postorder都由 不同 的值组成,仅适用于该题目 - 迭代法的实现没有递归法的思路简洁
- 毛毛张在这里推荐递归法的方法2
1.2.1 递归法
1.2.1.1 方法1
class Solution {//递归法 三步走//1.使用题目确定的形参和返回值public TreeNode buildTree(int[] inorder, int[] postorder) {//2.确定终止条件//①如果数组大小为零的话,说明是空节点了if(inorder == null || inorder.length == 0){return null;}//3.确定单层递归的逻辑//②如果数组不为空,那么取后序数组最后一个元素作为建立根节点int rootVal = postorder[postorder.length - 1];TreeNode root = new TreeNode(rootVal);//③找到后序数组最后一个元素在中序数组的位置,作为切割点int index;for(index = 0;index < inorder.length;index++){if(inorder[index] == rootVal) break;}int leftLength = index;int rightLength = inorder.length - index - 1;int[] inorderLeftArr = null;int[] postorderLeftArr = null;int[] inorderRightArr = null;int[] postorderRightArr = null;if(leftLength > 0){inorderLeftArr = new int[leftLength];postorderLeftArr = new int[leftLength];for(int i = 0;i<leftLength;i++){inorderLeftArr[i] = inorder[i];postorderLeftArr[i] = postorder[i];}}if(rightLength > 0){//中序右数组inorderRightArr = new int[rightLength];//后序右数组postorderRightArr = new int[rightLength];for(int i= 0;i<rightLength;i++){inorderRightArr[i] = inorder[index+1+i];postorderRightArr[i] = postorder[index+i];}}//⑥递归处理左区间和右区间root.left = buildTree(inorderLeftArr,postorderLeftArr);root.right = buildTree(inorderRightArr,postorderRightArr);return root;}
}
1.2.1.2 方法2
class Solution {public TreeNode buildTree(int[] inorder, int[] postorder) { 中序区间:[inBegin, inEnd),后序区间[postBegin, postEnd)return buildSubTree(inorder, 0,inorder.length,postorder,0,postorder.length);}//递归法 三步走//1.确定形参和返回值public TreeNode buildSubTree(int[] inorder, int inBegin,int inEnd,int[] postorder,int postBegin,int postEnd) {//2.确定终止条件//①如果数组大小为零的话,说明是空节点了if(inBegin == inEnd || postBegin == postEnd) return null;//3.确定单层递归逻辑//②如果不为空,那么取后序数组最后一个元素作为节点元素int rootVal = postorder[postEnd-1];TreeNode root = new TreeNode(rootVal);//③找到后序数组最后一个元素在中序数组的位置,作为切割点int index;for(index = inBegin;index < inEnd;index++){if(inorder[index] == rootVal) break; }//下面是本题的关键,获取切割之后的子树的开始索引和结束索引//中序:[9,3,15,20,7] 后序:[9,15,7,20,3]//④切割中序数组,切成中序左数组和中序右数组 int leftInBegin = inBegin;int leftInEnd = index;int rightInBegin = index + 1;int rightInEnd = inEnd;//⑤切割后序数组,切成后序左数组和后序右数组int leftPostBegin = postBegin;int leftPostEnd = postBegin + leftInEnd - leftInBegin;int rightPostBegin = postBegin + leftInEnd - leftInBegin;int rightPostEnd = postEnd - 1;//⑥递归处理左区间和右区间root.left = buildSubTree(inorder, leftInBegin,leftInEnd,postorder,leftPostBegin,leftPostEnd);root.right = buildSubTree(inorder, rightInBegin,rightInEnd,postorder,rightPostBegin,rightPostEnd);//返回结果return root;}
}
1.2.1.3 方法3
能使用这个方式是因为在题目的提示中说:
inorder和postorder都由 不同 的值组成
class Solution {Map<Integer, Integer> map = new HashMap<>();public TreeNode buildTree(int[] inorder, int[] postorder) {// inorder:左 -> 根 -> 右 postorder:左 -> 右 -> 根// 每次找到当前postorder中最后的元素作为当前节点,在inorder中找到这个节点划分成左子树和右子树后,重复这个过程。for(int i=0; i<inorder.length; i++){map.put(inorder[i], i);}return buildSubTree(inorder, 0, inorder.length, postorder, 0, postorder.length);}//递归法 三步走//1.确定形参和返回值public TreeNode buildSubTree(int[] inorder,int inBegin,int inEnd,int[] postorder,int postBegin,int postEnd){//2.确定终止条件//①如果数组大小为零的话,说明是空节点了if(inBegin == inEnd){return null;}//3.确定单层递归逻辑//②如果不为空,那么取后序数组最后一个元素作为节点元素int val = postorder[postEnd - 1];TreeNode root = new TreeNode(val);//③找到后序数组最后一个元素在中序数组的位置,作为切割点int index = map.get(val);//下面是本题的关键,获取切割之后的子树的开始索引和结束索引//中序:[9,3,15,20,7] 后序:[9,15,7,20,3]//⑥递归处理左区间和右区间root.left = buildSubTree(inorder, inBegin, index, postorder, postBegin, postBegin+(index - inBegin));root.right = buildSubTree(inorder, index+1, inEnd, postorder, postBegin+(index - inBegin), postEnd-1);//返回结果return root;}
}
1.2.2 迭代法
class Solution {public TreeNode buildTree(int[] inorder, int[] postorder) {//迭代法 借助栈 //首先判断特殊情况if (postorder == null || postorder.length == 0) {return null;}//创建栈,存储中间节点Stack<TreeNode> stack = new Stack<>();//创建根节点:根节点为前序数组的第一个元素TreeNode root = new TreeNode(postorder[postorder.length -1]);//根节点入栈stack.push(root);int inorderIndex = inorder.length - 1;for (int i = postorder.length - 2; i >= 0; i--) {int postorderVal = postorder[i];TreeNode node = stack.peek();if (node.val != inorder[inorderIndex]) {node.right = new TreeNode(postorderVal);stack.push(node.right);} else {while (!stack.isEmpty() && stack.peek().val == inorder[inorderIndex]) {node = stack.pop();inorderIndex--;}node.left = new TreeNode(postorderVal);stack.push(node.left);}}//返回结果return root;}
}
2.105. 从前序与中序遍历序列构造二叉树
2.1 题目描述
给定两个整数数组 preorder 和 inorder ,其中 preorder 是二叉树的先序遍历, inorder 是同一棵树的中序遍历,请构造二叉树并返回其根节点。
示例 1:

输入: preorder = [3,9,20,15,7], inorder = [9,3,15,20,7]
输出: [3,9,20,null,null,15,7]
示例 2:
输入: preorder = [-1], inorder = [-1]
输出: [-1]
提示:
1 <= preorder.length <= 3000inorder.length == preorder.length-3000 <= preorder[i], inorder[i] <= 3000preorder和inorder均 无重复 元素inorder均出现在preorderpreorder保证 为二叉树的前序遍历序列inorder保证 为二叉树的中序遍历序列\
2.2 题解
- 此题的思路与解法的分析可以参照上面
2.2.1 递归法
2.2.1.1 方法1
class Solution {//递归法 三步走//1.使用题目确定的形参和返回值public TreeNode buildTree(int[] preorder, int[] inorder) {//2.确定终止条件//①如果数组大小为零的话,说明是空节点了。if(inorder == null || inorder.length == 0){return null;}//3.确定单层递归的逻辑//②如果数组不为空,那么取后序数组最后一个元组作为节点元素int rootVal = preorder[0];TreeNode root = new TreeNode(rootVal);//③找到后序数组最后一个元素在中序数组的位置,作为切割点int index;for(index = 0;index < inorder.length;index++){//找到切割点if(inorder[index] == rootVal) break;}//左子树的长度int leftLength = index;//右子树的长度int rightLength = inorder.length - index - 1;//根据数组的长度建立数组int[] inorderLeftArr = null;int[] preorderLeftArr = null;int[] inorderRightArr = null;int[] preorderRightArr = null;if(leftLength > 0){inorderLeftArr = new int[leftLength];preorderLeftArr = new int[leftLength];for(int i = 0;i<leftLength;i++){inorderLeftArr[i] = inorder[i];preorderLeftArr[i] = preorder[i+1];}}if(rightLength > 0){//中序右数组inorderRightArr = new int[rightLength];//后序右数组preorderRightArr = new int[rightLength];for(int i= 0;i<rightLength;i++){inorderRightArr[i] = inorder[index+1+i];preorderRightArr[i] = preorder[index+1+i];}}//⑥递归处理左区间和右区间root.left = buildTree(preorderLeftArr,inorderLeftArr);root.right = buildTree(preorderRightArr,inorderRightArr);return root;}
}
2.2.1.2 方法2
class Solution {public TreeNode buildTree(int[] preorder, int[] inorder) {return buildSubTree(preorder ,0 ,preorder.length ,inorder ,0 ,inorder.length);}//递归法 三步走//1.确定形参和返回值public TreeNode buildSubTree(int[] preorder,int preBegin,int preEnd,int[] inorder,int inBegin,int inEnd){//2.确定终止条件//①如果数组大小为零的话,说明是空节点了if(preBegin == preEnd || inBegin == inEnd) return null;//3.确定单层递归逻辑//②如果不为空,那么取前序数组第一个元素作为节点元素int val = preorder[preBegin];TreeNode root = new TreeNode(val);//③找到前序数组第一个元素在中序数组的位置,作为切割点int index;for(index = inBegin;index < inEnd; index++) {if(inorder[index] == val) break;}//下面是本题的关键,获取切割之后的子树的开始索引和结束索引//前序:[3,9,20,15,7] 中序:[9,3,15,20,7]//⑥递归处理左区间和右区间int leftLen = index - inBegin;root.left = buildSubTree(preorder,preBegin+1,preBegin+leftLen+1,inorder,inBegin,index);root.right = buildSubTree(preorder,preBegin+leftLen+1,preEnd,inorder,index+1,inEnd);return root;}
}
2.2.1.3 方法3
class Solution {Map<Integer,Integer> map = new HashMap<>();public TreeNode buildTree(int[] preorder, int[] inorder) {//存储中序数组的元素和对应的索引for(int i=0;i<inorder.length;i++){map.put(inorder[i],i);}//开始递归return buildSubTree(preorder,0,preorder.length,inorder,0,inorder.length);}//递归法 三步走//1.确定形参和返回值public TreeNode buildSubTree(int[] preorder,int preBegin,int preEnd,int[] inorder,int inBegin,int inEnd){//2.确定终止条件//①如果数组大小为零的话,说明是空节点了if(preBegin == preEnd || inBegin == inEnd) return null;//3.确定单层递归逻辑//②如果不为空,那么取前序数组第一个元素作为节点元素int val = preorder[preBegin];TreeNode root = new TreeNode(val);//③找到前序数组第一个元素在中序数组的位置,作为切割点int index = map.get(val);int leftLen = index - inBegin;//下面是本题的关键,获取切割之后的子树的开始索引和结束索引//前序:[3,9,20,15,7] 中序:[9,3,15,20,7]//⑥递归处理左区间和右区间root.left = buildSubTree(preorder,preBegin+1,preBegin+leftLen+1,inorder,inBegin,index);root.right = buildSubTree(preorder,preBegin+leftLen+1,preEnd,inorder,index+1,inEnd);//返回结果return root;}
}
2.2.2 迭代法
class Solution {public TreeNode buildTree(int[] preorder, int[] inorder) {//迭代法 借助栈 //首先判断特殊情况if (preorder == null || preorder.length == 0) {return null;}//创建栈,存储中间节点Stack<TreeNode> stack = new Stack<>();//创建根节点:根节点为前序数组的第一个元素TreeNode root = new TreeNode(preorder[0]);//根节点入栈stack.push(root);int inorderIndex = 0;//开始迭代//前序:[3,9,20,15,7] 中序:[9,3,15,20,7]for (int i = 1; i < preorder.length; i++) {int preorderVal = preorder[i];TreeNode node = stack.peek();if (node.val != inorder[inorderIndex]) {//说明该节点肯定存在左子树node.left = new TreeNode(preorderVal);stack.push(node.left);} else {//不存在左子树,只存在右子树while (!stack.isEmpty() && stack.peek().val == inorder[inorderIndex]) {node = stack.pop();inorderIndex++;}node.right = new TreeNode(preorderVal);stack.push(node.right);}}//返回根节点return root;}
}
8.线索二叉树
8.1 线索二叉树的原理
- 我们首先可以看一下下图,对于一个有 n n n个结点的二叉链表,每个结点有指向左右孩子的两个指针域,所以一共是 2 n 2n 2n个指针域;而 n n n个结点的二叉树一共有 n − 1 n-1 n−1条分支线数,也就是说,其实是存在 2 n − ( n − 1 ) = n + 1 2n- (n-1) =n+1 2n−(n−1)=n+1个空指针域

- 遍历二叉树是以一定的规则将二叉树中的结点排列成一个线性序列,从而得到几种遍历序列,使得该序列中的每个结点(第一个和最后一个结点除外)都有一个直接前驱和直接后继;传统的二叉链表存储仅能体现一种父子关系,不能直接得到结点在遍历中的前驱或后继。
- 综合上面两个问题,由此设想能否利用这些空指针来存放指向其前驱或后继的指针?这样就可以像遍历单链表那样方便地遍历二叉树,如下图。引入线索二叉树正是为了加快查找结点前驱和后继的速度。我们把这种指向前驱和后继的指针称为线索,加上线索的二叉链表称为线索链表,相应的二叉树就称为线索二叉树(Threaded Binary Tree)。
- 我们把下面这棵二叉树进行中序遍历后,将所有的空指针域中的
rchild,改为指向它的后继结点。于是我们就可以通过指针知道H的后继是D(图中①),I的后继是B(图中②),J的后继是E(图中③),E的后继是A(图中④),F的后继是C(图中⑤),G的后继因为不存在而指向NULL(图中⑥)。此时共有6个空指针域被利用。
- 我们将下图这棵二叉树的所有空指针域中的
lchild,改为指向当前结点的前驱。因此H的前驱是NULL(图中①),Ⅰ的前驱是D(图中②),J的前驱是B(图中③),F的前驱是A(图中④),G的前驱是C(图中⑤)。一共5个空指针域被利用,正好和上面的后继加起来是11个。


- 对二叉树以某种次序遍历使其称为线索二叉树的过程称作是线索化。如下图,虚线为前驱,实线为后继。

8.2 线索二叉树的存储结构
- 在原本的二叉树的结点结构上对二叉树进行线索化,我们无法知道某一个结点的
lchild是指向左孩子还是指向前序?rchild是指向右孩子还是指向后继?因此我们需要在原本二叉树的结点结构的基础上增加两个标志域,如下图:lchild和rchild分别为左右孩子指针ltag为0时lchild指向该结点的左孩子,为1时lchild指向该结点的前驱rtag为0时rchild指向该结点的右孩子,为1时rchild指向该结点的后继

- 对于上图的二叉链表图可以修改为下图所示:

- 二叉树的线索存储结构代码如下:
class ThreadNode {int data; // 数据元素ThreadNode lchild, rchild; // 左、右孩子指针int ltag, rtag; // 左、右线索标志// 构造方法public ThreadNode(int data) {this.data = data;this.lchild = null;this.rchild = null;this.ltag = 0;this.rtag = 0;}
}
8.3 二叉树的线索化
- 二叉树的线索化 实质是将二叉链表中的空指针改为指向前驱或后继的线索。由于前驱或后继的信息只有在遍历该二叉树时才能得到,所以线索化的实质就是遍历一次二叉树,线索化的过程就是在遍历的过程中修改空指针的过程
8.3.1 中序线索二叉树
- 算法逻辑: 附设指针
pre指向刚刚访问过的结点,指针p指向正在访问的结点,即pre指向p的前驱。在中序遍历的过程中,检查p的左指针是否为空,若为空就将它指向pre;检查pre的右指针是否为空,若为空就将它指向p - 图解:

- 递归算法实现: 下面代码,除了中间的代码,和二叉树中序遍历的递归代码几乎完全一样,只不过将本是访问结点的功能改成了线索化的功能
class ThreadTree {private ThreadNode root;private ThreadNode pre; // 始终指向刚刚访问过的节点// 中序遍历进行中序线索化public void inThread(ThreadNode p) {if (p != null) {inThread(p.lchild); // 递归,线索化左子树if (p.lchild == null) { // 左子树为空,建立前驱线索p.lchild = pre;p.ltag = 1;}if (pre != null && pre.rchild == null) {pre.rchild = p; // 建立前驱结点的后继线索pre.rtag = 1;}pre = p; // 标记当前结点成为刚刚访问过的结点inThread(p.rchild); // 递归,线索化右子树}}
}
- 通过中序遍历建立中序线索二叉树的主过程算法如下:
// 创建中序线索化二叉树
public void createInThread() {pre = null; // 初始化pre为nullif (root != null) {inThread(root); // 线索化二叉树if (pre != null) {pre.rchild = null; // 处理遍历的最后一个结点pre.rtag = 1;}}
}
- 为了方便,可以在二叉树的线索链表上也添加一个头结点,令其
lchild域的指针指向二叉树的根结点,其rchild域的指针指向中序遍历时访问的最后一个结点;令二叉树中序序列中的第一个结点的lchild域指针和最后一个结点的rchild域指针均指向头结点,这好比为二叉树建立了一个双向线索链表,方便从前往后或从后往前对线索二叉树进行遍历,如下图所示

- 遍历的代码如下:
// 中序遍历二叉线索链表表示的二叉树
public void inOrderTraverse() {ThreadNode p = head.lchild; // p指向根结点// 空树或遍历结束时,p==head(最后一个结点指向根结点)while (p != head) {// 当ltag==0时循环到中序序列第一个结点while (p.ltag == 0) {p = p.lchild; // p指向p的左子树}visit(p); // 访问该结点// 后继线索为1且不是指向头指针while (p.rtag == 1 && p.rchild != head) {p = p.rchild; // p指向p的后继visit(p); // 访问该节点}// p进至其右子树根,开始对右子树根进行遍历p = p.rchild;}
}
- 说明:
- 从这段代码也可以看出,它等于是一个链表的扫描,所以时间复杂度为 O ( n ) O(n) O(n)
- 由于它充分利用了空指针域的空间(这等于节省了空间),又保证了创建时的一次遍历就可以终生受用前驱后继的信息(这意味着节省了时间)。
- 所以在实际问题中,如果所用的二叉树需经常遍历或查找结点时需要某种遍历序列中的前驱和后继,那么采用线索二叉链表的存储结构就是非常不错的选择。
8.3.2 前序和后序线索二叉树
- 上面给出了建立中序线索二叉树的代码,建立前序线索二叉树和后序线索二叉树的代码类似,只需变动线索化改造的代码段与调用线索化左右子树递归函数的位置
- 以图(a)的二叉树为例,其前序序列为ABCDF,后序序列为CDBFA,可得出其前序和后序线索二叉树分别如图(b)和©所示

- 如何在前序线索二叉树中找结点的后继?
- 如果有左孩子,则左孩子就是其后继;
- 如果无左孩子但有右孩子,则右孩子就是其后继;
- 如果为叶结点,则右链域直接指示了结点的后继。
- 在后序线索二叉树中找结点的后继较为复杂,可分3种情况:
- ①若结点x是二叉树的根,则其后继为空;
- ②若结点x是其双亲的右孩子,或是其双亲的左孩子且其双亲没有右子树,则其后继即为双亲;
- ③若结点x是其双亲的左孩子,且其双亲有右子树,则其后继为双亲的右子树上按后序遍历列出的第一个结点
- 图©中找结点B的后继无法通过链域找到,可见在后序线索二叉树上找后继时需知道结点双亲,即需采用带标志域的三叉链表作为存储结构
9.树、森林与二叉树的转化
- 在讲树的存储结构时,我们提到了树的孩子兄弟法可以将一棵树用二叉链表进行存储,所以借助二叉链表,树和二叉树可以相互进行转换。
- 从物理结构来看,它们的二叉链表也是相同的,只是解释不太一样而已。
- 因此,只要我们设定一定的规则,用二叉树来表示树,甚至表示森林都是可以的,森林与二叉树也可以互相进行转换。
9.1 树转换为二叉树
- 树转换为二义树的规则: 每个结点左指针指向它的第一个孩子,右指针指向它在树中的相邻右兄弟,这个规则又称“左孩子右兄弟”。
- 由于根结点没有兄弟,所以对应的二叉树没有右子树
- 树转换成二叉树的画法:
第一步:加线。在兄弟结点之间加一连线。
第二步:去线。对每个结点,只保留它与第一个孩子的连线,删除它与其他孩子结点之间的连线。
第三步:层次调整。以树的根结点为轴心,将整棵树顺时针旋转一定的角度,使之结构层次分明。注意第一个孩子是二叉树结点的左孩子,兄弟转换过来的孩子是结点的右孩子。 - 图解:

9.2 森林转化为二叉树
- 森林是由若干棵树组成的,所以完全可以理解为,森林中的每一棵树都是兄弟,可以按照兄弟的处理办法来操作。
- 森林转换成二叉树的画法:
第一步:把每个树转换为二叉树;
第二步:第一棵二叉树不动,从第二棵二叉树开始,依次把后一棵二叉树的根结点作为前一棵二叉树的根结点的右孩子,用线连接起来。当所有的二叉树连接起来后就得到了由森林转换来的二叉树。 - 图解:

9.3 二叉树转换为树
- 二叉树转换为树是树转换为二叉树的逆过程,也就是反过来做而已。
- 转换步骤:
第一步: 加线。若某结点的左孩子结点存在,则将这个左孩子的右孩子结点、右孩子的右孩子结点、右孩子的右孩子的右孩子结点……哈,反正就是左孩子的n个右孩子结点都作为此结点的孩子。将该结点与这些右孩子结点用线连接起来。
第二步: 去线。删除原二叉树中所有结点与其右孩子结点的连线。
第三步: 层次调整。使之结构层次分明。 - 图解:

9.4 二叉树转换为森林
- 判断一棵二叉树能够转换成一棵树还是森林,标准很简单,那就是只要看这棵二叉树的根结点有没有右孩子,有就是森林,没有就是一棵树。
- 步骤如下:
第一步: 从根结点开始,若右孩子存在,则把与右孩子结点的连线删除,再查看分离后的二叉树,若右孩子存在,则连线删除……,直到所有右孩子连线都删除为止,得到分离的二叉树。
第二步: 再将每棵分离后的二叉树转换为树即可。 - 图解:

9.5 树和森林的遍历
9.5.1 树的遍历
- 树的遍历是指用某种方式访问树中的每个结点,且仅访问一次。
- 树的遍历主要有两种方式:
- 方式1: 先根遍历。若树非空,先访问根结点,再依次遍历根结点的每棵子树,遍历子树时仍遵循先根后子树的规则。其遍历序列与这棵树相应二叉树的前序序列相同。
- 方式2: 后根遍历。若树非空,先依次遍历根结点的每棵子树,再访问根结点,遍历子树时仍遵循先子树后根的规则。其遍历序列与这棵树相应二叉树的中序序列相同。
- 示例: 下图的树的先根遍历序列为:
ABEFCDG,后根遍历序列为:EFBCGDA

- 另外,树也有层次遍历,与二叉树的层次遍历思想基本相同,即按层序依次访问各结点
9.5.2 森林的遍历
- 按照森林和树相互递归的定义,可得到森林的两种遍历方法:前序遍历和后序遍历
- 前序遍历森林。若森林为非空,则按如下规则进行遍历:
- 访问森林中第一棵树的根结点。
- 前序遍历第一棵树中根结点的子树森林。
- 前序遍历除去第一棵树之后剩余的树构成的森林。
- 后序遍历森林。森林为非空时,按如下规则进行遍历:
- 后序遍历森林中第一棵树的根结点的子树森林。
- 访问第一棵树的根结点。
- 后序遍历除去第一棵树之后剩余的树构成的森林。
- 示例: 森林的前序遍历序列为
ABCDEFGHI,后序遍历序列为BCDAFEHIG

- 说明:
- 当森林转换成二叉树时,其第一棵树的子树森林转换成左子树,剩余树的森林转换成右子树,可知森林的前序和后序遍历即为其对应二叉树的前序和中序遍历。
- 这也就告诉我们,当以二叉链表作树的存储结构时,树的先根遍历和后根遍历完全可以借用二叉树的前序遍历和中序遍历的算法来实现。这其实也就证实,我们找到了对树和森林这种复杂问题的简单解决办法。
10 哈夫曼树及其应用
- 美国数学家哈夫曼在 1952 年发明了哈夫曼编码,为了纪念他的成就,于是就把他在编码中用到的特殊的二叉树称为哈夫曼树,他的编码称之为哈夫曼编码
10.1 哈夫曼树的定义和原理
- 下面毛毛张将通过下面两个图引入哈夫曼树的定义与介绍:
- 前置概念:
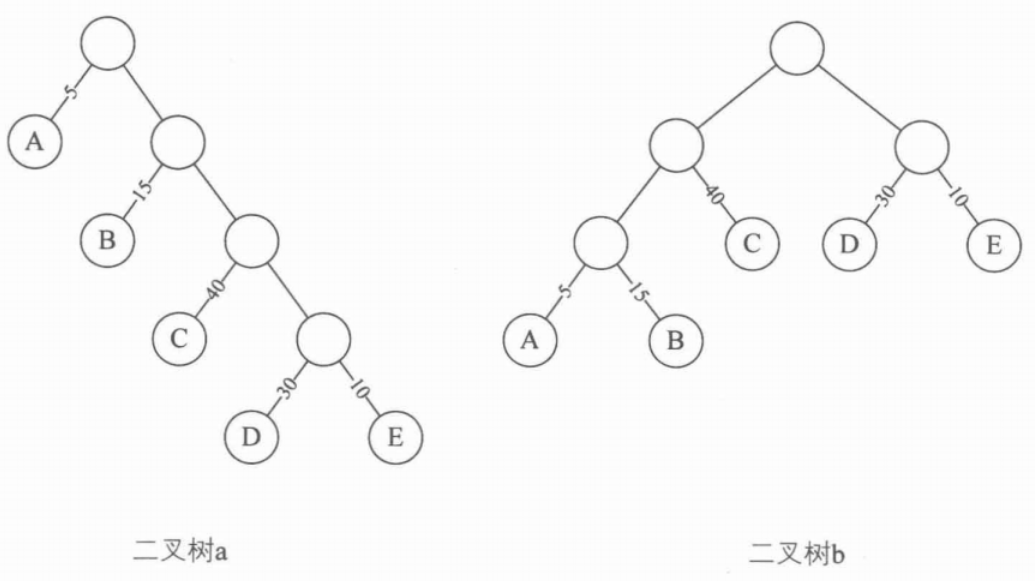
- 路径长度: 从树中一个结点到另一个结点之间的分支构成两个结点之间的路径,路径上的分支数目称作路径长度
- 树的路径长度: 就是从树根到每一结点的路径长度之和。如上图,二叉树a的路径长度就是: 1 + 1 + 2 + 2 + 3 + 3 + 4 + 4 = 20 1+1+2+2+3+3+4+4=20 1+1+2+2+3+3+4+4=20;二叉树b的路径长度就是: 1 + 2 + 3 + 3 + 2 + 1 + 2 + 2 = 16 1+2+3+3+2+1+2+2=16 1+2+3+3+2+1+2+2=16
- 权: 在许多应用中,树中结点常常被赋予一个表示某种意义的数值,称为该结点的权
- 带权路径长度: 如果考虑到带权的结点,结点的带权路径的长度为从该结点到树根之间的路径长度与结点上权的乘积;树的带权路径长度为树中所有叶子结点的带权路径长度之和( W P L WPL WPL)。
- 计算表达式: 假设有 n n n个权值 { w 1 , w 2 , … , w n } \{w_1,w_2,\ldots,w_n\} {w1,w2,…,wn},构造一棵有 n n n个叶子结点的二叉树,每个叶子结点带权 w k w_{k} wk,每个叶子结点的路径长度为 l k l_k lk,计算公式为 W P L = ∑ i = 1 n w i l i WPL=\sum_{i=1}^nw_il_i WPL=∑i=1nwili,则其中带权路径长度 W P L WPL WPL最小的二叉树称作哈夫曼树,也称最优二叉树
- 举例说明: 下图为三颗二叉树,它们的带权路径长度分别为:
- (a): W P L = 7 ∗ 2 + 5 ∗ 2 + 2 ∗ 2 + 4 ∗ 2 = 36 WPL = 7*2 + 5*2 + 2*2 + 4*2 = 36 WPL=7∗2+5∗2+2∗2+4∗2=36
- (b): W P L = 4 ∗ 2 + 7 ∗ 3 + 5 ∗ 3 + 2 ∗ 1 = 46 WPL = 4*2 + 7*3 + 5*3 + 2*1 = 46 WPL=4∗2+7∗3+5∗3+2∗1=46
- ©: W P L = 7 ∗ 1 + 5 ∗ 2 + 2 ∗ 3 + 4 ∗ 3 = 35 WPL = 7*1 + 5*2 + 2*3 + 4*3 = 35 WPL=7∗1+5∗2+2∗3+4∗3=35
- 其中,图©树的 W P L WPL WPL最小,可以验证,它恰好为哈夫曼树

10.2 哈夫曼树的构造
哈夫曼树构造步骤
步骤1:先把有权值的叶子结点按照从大到小(从小到大也可以)的顺序排列成一个有序序列。
步骤2:取最后两个最小权值的结点作为一个新节点的两个子结点,注意相对较小的是左孩子。
步骤3:用第2步构造的新结点替掉它的两个子节点,插入有序序列中,保持从大到小排列。
步骤4:重复步骤2到步骤3,直到根节点出现。
图解:

10.3 哈夫曼编码
- 赫夫曼当前研究这种最优树的目的是为了解决当年远距离通信(主要是电报)的数据传输的最优化问题。
- 哈夫曼编码是一种被广泛应用而且非常有效的数据压缩编码
10.3.1 哈夫曼编码引入
- 情景介绍: 比如我们有一段文字内容为:BADCADFEED,要通过网络传输给别人,显然用二进制的数字(0和1)来表示是很自然的想法,现在这段文字只有六个字母:ABCDEF,那么我们可以用相应的二进制数据表示,如下表所示。这样按照固定长度编码编码后就是:001000011010000011101100100011,对方接收时可以按照3位一分来译码。
| 字母 | A | B | C | D | E | F |
|---|---|---|---|---|---|---|
| 二进制字符 | 000 | 001 | 010 | 011 | 100 | 101 |
- 问题分析: 如果一篇文章很长,这样的二进制串也将非常的可怕。而且事实上,不管是英文、中文或是其他语言,字母或汉字的出现频率是不相同的。假设六个字母的频率为A 27、B 8、C 15、D 15、E 30、F 5,合起来正好是 100 100% 100,那就意味着,我们完全可以重新按照赫夫曼树来规划它们。 下图中,左图为构造赫夫曼树的过程的权值显示;右图为将权值左分支改为 0 0 0,右分支改为 1 1 1后的赫夫曼树

- 此时,我们对这六个字母用其从树根到叶子所经过路径的 0 0 0或 1 1 1来编码,可以得到如下表所示这样的定义:

- 我们将文字内容”BADCADFEED”再次编码,对比可以看到结果串变小了
- 原编码二进制串:001000011010000011101100100011 (共 30 30 30个字符)
- 新编码二进制串:1001010010101001000111100 (共 25 25 25个字符)
- 也就是说,我们的数据被压缩了,节约了大约 17 % 17\% 17%的存储或传输成本。随着字符的增多和多字符权重的不同,这种压缩会更加显出其优势。上述的新编码二进制串就是哈夫曼编码
- 注意:
- 0 0 0和 1 1 1究竟是表示左子树还是右子树没有明确规定
- 左、右孩子结点的顺序是任意的,所以构造出的哈夫曼树并不唯一,但各哈夫曼树的带权路径长度 W P L WPL WPL相同且为最优
- 如有若干权值相同的结点,则构造出的哈夫曼树更可能不同,但 W P L WPL WPL必然相同且是最优的
10.3.2 哈夫曼编码定义
- 前缀编码: 若要设计长短不等的编码,则必须是任一字符的编码都不是另一个字符的编码的前缀,这种编码称作前缀编码
- 我们发现,前面经过哈夫曼树之后的编码,上表中的编码就不存在容易于
1001、1000混淆的“10”和“100”编码,当我们接收到1001010010101001000111100时,由预定好的哈夫曼树可知,1001得到第一个字母是B,接下来01意味着第二个字符是A,如下图所示,其余的也相应的可以得到,从而成功解码

- 我们发现,前面经过哈夫曼树之后的编码,上表中的编码就不存在容易于
- 哈夫曼编码: 一般地,设需要编码的字符集为 { d 1 , d 2 , . . . , d n } \{d_1,d_2,...,d_n\} {d1,d2,...,dn},各个字符在电文中出现的次数或频率集合 { w 1 , w 2 , . . . , w n } \{w_1,w_2,...,w_n\} {w1,w2,...,wn},以 d 1 , d 2 , . . . , d n d_1,d_2,...,d_n d1,d2,...,dn作为叶子结点,以 w 1 , w 2 , . . . , w n w_1,w_2,...,w_n w1,w2,...,wn作为相应叶子结点的权值来构造一颗哈夫曼树。规定哈夫曼树的左分支代表0,右分支代表1,则从根节点到叶子结点所经过的路径分支组成的 0 0 0和 1 1 1的序列便为该结点对应字符的编码,这就是哈夫曼编码
参考文献
- https://blog.csdn.net/yzhcjl_/article/details/128578171
- https://blog.csdn.net/qq_56884023/article/details/122531458
- https://blog.csdn.net/Real_Fool_/article/details/113930623
- 《大话数据结构》
相关文章:
万字长文详解数据结构:树 | 第6章 | Java版大话数据结构 | 二叉树 | 哈夫曼树 | 二叉树遍历 | 构造二叉树 | LeetCode练习
📌本篇分享的大话数据结构中🎄树🎄这一章的知识点,在此基础上,增加了练习题帮助大家理解一些重要的概念✅;同时,由于原文使用的C语言代码,不利于学习Java语言的同学实践,…...
NPOI入门指南:轻松操作Excel文件的.NET库
目录 引言 一、NPOI概述 二、NPOI的主要用途 三、安装NPOI库 四、NPOI基本使用 六、性能优化和内存管理 七、常见问题与解决方案 八、结论 附录 引言 Excel文件作为数据处理的重要工具,广泛应用于各种场景。然而,在没有安装Microsoft Office的…...
【高性能服务器】服务器概述
🔥博客主页: 我要成为C领域大神🎥系列专栏:【C核心编程】 【计算机网络】 【Linux编程】 【操作系统】 ❤️感谢大家点赞👍收藏⭐评论✍️ 本博客致力于知识分享,与更多的人进行学习交流 服务器概述 服…...

003 SSM框架整合
文章目录 整合web.xmlapplicationContext-dao.xmlapplicationContext-service.xmlspringmvc.xmldb.propertieslog4j.propertiespom.xml 测试sqlItemController.javaItemMapper.javaItem.javaItemExample.javaItemService.javaItemServiceImpl.javaItemMapper.xml 整合 将工程的…...
web刷题记录(7)
[HDCTF 2023]SearchMaster 打开环境,首先的提示信息就是告诉我们,可以用post传参的方式来传入参数data 首先考虑的还是rce,但是这里发现,不管输入那种命令,它都会直接显示在中间的那一小行里面,而实际的命令…...
【单片机毕业设计选题24037】-基于STM32的电力系统电力参数无线监控系统
系统功能: 系统上电后,OLED显示“欢迎使用电力监控系统请稍后”,两秒后显示“Waiting..”等待ESP8266初始化完成, ESP8266初始化成功后进入正常页面显示, 第一行显示电压值(单位V) 第二行显示电流值&am…...

Python使用彩虹表来尝试对MD5哈希进行破解
MD5是一种散列算法,它是不可逆的,无法直接解密。它的主要作用是将输入数据进行散列,生成一个固定长度的唯一哈希值。 然而,可以使用预先计算好的MD5哈希值的彩虹表(Rainbow Table)来尝试对MD5进行破解。彩…...
数据恢复篇: 如何在数据丢失后恢复照片
数据丢失的情况并不少见。如果您曾经遇到过图像丢失的情况,您可能想过照片恢复工具是如何工作的?可能会丢失多少数据图像?即使是断电也可能导致照片和媒体文件丢失。 话虽如此,如果你认为删除的照片无法恢复,那你就错…...

c++ 引用第三方库
文章目录 背景编写cmake代码里引用测试 背景 遇到一个c项目,想跑一些示例。了解下如何直接引用第三方库。 编写cmake 项目结构 myprojectincludexx.hmain.cppCMakeLists.txt CMakeLists.txt cmake_minimum_required(VERSION 3.28) project(velox_demo)set(CM…...

[数据集][目标检测]猪只状态吃喝睡站检测数据集VOC+YOLO格式530张4类别
数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):530 标注数量(xml文件个数):530 标注数量(txt文件个数):530 标注类别…...

Redis中设置验证码
限制一分钟内最多发送5次,且每次有效时间是5分钟! String 发送验证码(phoneNumber) {key "shortMsg:limit:" phoneNumber;// 设置过期时间为 1 分钟(60 秒)// 使⽤ NX,只在不存在 key 时才能设置成功bool…...

使用hadoop进行数据分析
Hadoop是一个开源框架,它允许分布式处理大数据集群上的大量数据。Hadoop由两个主要部分组成:HDFS(Hadoop分布式文件系统)和MapReduce。以下是使用Hadoop进行数据分析的基本步骤: 数据准备: 将数据存储在HDF…...

架构师篇-7、企业安全架构设计及实践
摘要: 认识企业安全架构企业安全案例分析及实践 内容: 为什么做企业安全架构怎么做好安全架构设计案例实践分析&随堂练 为什么要做企业安全架构 安全是麻烦制造者? 整天提安全需求增加开发工作增加运维要求增加不确定性延后业务上线…...

递归算法~快速排序、归并排序
递归排序是一种基于分治法的排序算法,最典型的例子就是快速排序和归并排序。这两种算法都利用递归将问题分解成更小的子问题,然后将子问题的解合并以得到原始问题的解。 1、快速排序(Quick Sort) 快速排序的基本思想是选择一个基…...

DarkGPT:基于GPT-4-200k设计的人工智能OSINT助手
关于DarkGPT DarkGPT是一款功能强大的人工智能安全助手,该工具基于GPT-4-200k设计并实现其功能,可以帮助广大研究人员针对泄露数据库进行安全分析和数据查询相关的OSINT操作。 工具要求 openai1.13.3 requests python-dotenv pydantic1.10.12 工具安装 …...
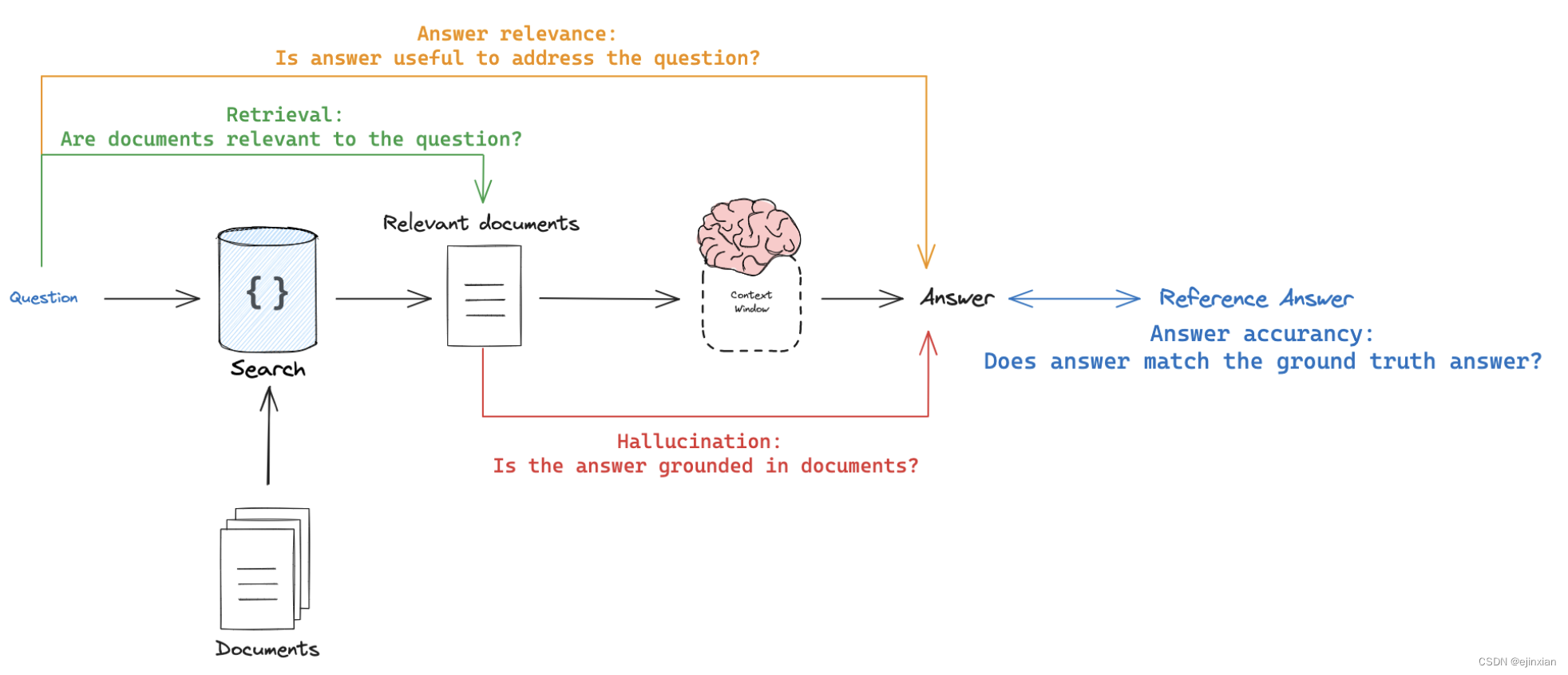
RAG 检索增强生成有效评估
我们将介绍RAG(检索增强生成)的评估工作流程 RAG工作流程的部分 数据集 这里是我们将要使用的LCEL (LangChain Expression Language)相关问题的数据集。 这个数据集是在LangSmith UI中使用csv上传创建的: https://smith.langchain.com/public/730d833b-74da-43e2-a614-4e2ca…...
Day38:LeedCode 1049. 最后一块石头的重量 II 494. 目标和 474.一和零
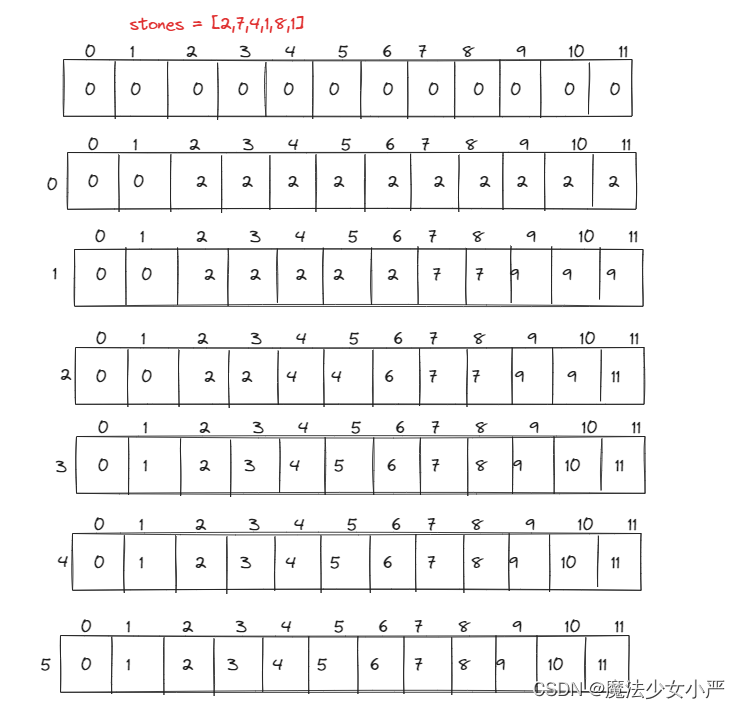
1049. 最后一块石头的重量 II 有一堆石头,用整数数组 stones 表示。其中 stones[i] 表示第 i 块石头的重量。 每一回合,从中选出任意两块石头,然后将它们一起粉碎。假设石头的重量分别为 x 和 y,且 x < y。那么粉碎的可能结果…...

sqlalchemy分页查询
sqlalchemy分页查询 在SQLAlchemy中,可以使用limit和offset方法实现分页查询 from sqlalchemy.orm import sessionmaker from sqlalchemy import create_engine from models import MyModel # 假设MyModel是你定义的模型# 连接数据库 engine = create_engine(sqlite:///myd…...

Java--常用类APl(复习总结)
前言: Java是一种强大而灵活的编程语言,具有广泛的应用范围,从桌面应用程序到企业级应用程序都能够使用Java进行开发。在Java的编程过程中,使用标准类库是非常重要的,因为标准类库提供了丰富的类和API,可以简化开发过…...

【股指期权投教】一手股指期权大概多少钱?
一手股指期权的权利金大概在几千人民币左右,如果是作为期权卖方还需要另外缴纳保证金的。国内的股指期权有三种,沪深300、上证50、中证1000股指期权,每点合约人民币100 元。 期权合约的价值计算可以通过此公式得出:权利金的支付或…...

vscode里如何用git
打开vs终端执行如下: 1 初始化 Git 仓库(如果尚未初始化) git init 2 添加文件到 Git 仓库 git add . 3 使用 git commit 命令来提交你的更改。确保在提交时加上一个有用的消息。 git commit -m "备注信息" 4 …...

应用升级/灾备测试时使用guarantee 闪回点迅速回退
1.场景 应用要升级,当升级失败时,数据库回退到升级前. 要测试系统,测试完成后,数据库要回退到测试前。 相对于RMAN恢复需要很长时间, 数据库闪回只需要几分钟。 2.技术实现 数据库设置 2个db_recovery参数 创建guarantee闪回点,不需要开启数据库闪回。…...

在鸿蒙HarmonyOS 5中实现抖音风格的点赞功能
下面我将详细介绍如何使用HarmonyOS SDK在HarmonyOS 5中实现类似抖音的点赞功能,包括动画效果、数据同步和交互优化。 1. 基础点赞功能实现 1.1 创建数据模型 // VideoModel.ets export class VideoModel {id: string "";title: string ""…...

江苏艾立泰跨国资源接力:废料变黄金的绿色供应链革命
在华东塑料包装行业面临限塑令深度调整的背景下,江苏艾立泰以一场跨国资源接力的创新实践,重新定义了绿色供应链的边界。 跨国回收网络:废料变黄金的全球棋局 艾立泰在欧洲、东南亚建立再生塑料回收点,将海外废弃包装箱通过标准…...

工业自动化时代的精准装配革新:迁移科技3D视觉系统如何重塑机器人定位装配
AI3D视觉的工业赋能者 迁移科技成立于2017年,作为行业领先的3D工业相机及视觉系统供应商,累计完成数亿元融资。其核心技术覆盖硬件设计、算法优化及软件集成,通过稳定、易用、高回报的AI3D视觉系统,为汽车、新能源、金属制造等行…...

企业如何增强终端安全?
在数字化转型加速的今天,企业的业务运行越来越依赖于终端设备。从员工的笔记本电脑、智能手机,到工厂里的物联网设备、智能传感器,这些终端构成了企业与外部世界连接的 “神经末梢”。然而,随着远程办公的常态化和设备接入的爆炸式…...

今日学习:Spring线程池|并发修改异常|链路丢失|登录续期|VIP过期策略|数值类缓存
文章目录 优雅版线程池ThreadPoolTaskExecutor和ThreadPoolTaskExecutor的装饰器并发修改异常并发修改异常简介实现机制设计原因及意义 使用线程池造成的链路丢失问题线程池导致的链路丢失问题发生原因 常见解决方法更好的解决方法设计精妙之处 登录续期登录续期常见实现方式特…...

代理篇12|深入理解 Vite中的Proxy接口代理配置
在前端开发中,常常会遇到 跨域请求接口 的情况。为了解决这个问题,Vite 和 Webpack 都提供了 proxy 代理功能,用于将本地开发请求转发到后端服务器。 什么是代理(proxy)? 代理是在开发过程中,前端项目通过开发服务器,将指定的请求“转发”到真实的后端服务器,从而绕…...

【分享】推荐一些办公小工具
1、PDF 在线转换 https://smallpdf.com/cn/pdf-tools 推荐理由:大部分的转换软件需要收费,要么功能不齐全,而开会员又用不了几次浪费钱,借用别人的又不安全。 这个网站它不需要登录或下载安装。而且提供的免费功能就能满足日常…...

DingDing机器人群消息推送
文章目录 1 新建机器人2 API文档说明3 代码编写 1 新建机器人 点击群设置 下滑到群管理的机器人,点击进入 添加机器人 选择自定义Webhook服务 点击添加 设置安全设置,详见说明文档 成功后,记录Webhook 2 API文档说明 点击设置说明 查看自…...