【chatgpt】两层gcn提取最后一层节点输出特征,如何自定义简单数据集
文章目录
- 两层gcn,提取最后一层节点输出特征,10个节点,每个节点8个特征,连接关系随机生成(无全连接层)
- 如何计算MSE
- 100个样本,并且使用批量大小为32进行训练
- 第一个版本定义数据集出错,添加super()并修改为__len__和__getitem__
- idx的作用
- 使用super()方法
- 再次解释一遍定义数据集的代码
- 另外一个值得注意的错误:定义数据集部分修改之后还是报obj = super().__new__(cls)TypeError: Can't instantiate abstract class MyDataset with abstract methods get, len错误
- from torch.utils.data import Dataset 与 from torch_geometric.data import Data 和 Dataset是不一样的
- from torch_geometric.data import Data的作用
- 验证 MyDataset 类生成的样本和批次数据的形状
- 完整代码
两层gcn,提取最后一层节点输出特征,10个节点,每个节点8个特征,连接关系随机生成(无全连接层)
如果没有全连接层(fc层),那么输出将是每个节点的特征。这样的话,标签需要对应每个节点的输出特征。在这种情况下,标签的维度应该是节点数乘以输出特征数。
如果我们将输出特征数设为1,并且没有全连接层,那么每个节点的输出将是一个标量。标签的维度将与节点数相同。例如,假设有10个节点,每个节点的输出是一个标量,那么标签的维度应该是 (10,)。
以下是一个没有全连接层的双层GCN实现,其中标签数和节点数相同:
import torch
import torch.nn.functional as F
from torch_geometric.nn import GCNConv
from torch_geometric.data import Dataclass GCN(torch.nn.Module):def __init__(self, in_channels, hidden_channels, out_channels):super(GCN, self).__init__()self.conv1 = GCNConv(in_channels, hidden_channels)self.conv2 = GCNConv(hidden_channels, out_channels)def forward(self, x, edge_index):print(x.shape)x = self.conv1(x, edge_index)print(x.shape)x = F.relu(x)x = self.conv2(x, edge_index)print(x.shape)return x# 定义图数据
num_nodes = 10
num_node_features = 8
edge_index = torch.tensor([[0, 1, 2, 3, 4, 5, 6, 7, 8, 9],[1, 2, 3, 4, 5, 6, 7, 8, 9, 0]], dtype=torch.long)
x = torch.randn((num_nodes, num_node_features))data = Data(x=x, edge_index=edge_index)# 定义并训练模型
model = GCN(in_channels=num_node_features, hidden_channels=16, out_channels=1)
print(model)
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
criterion = torch.nn.MSELoss()# 假设我们有一些训练标签,每个节点一个标签
labels = torch.randn((num_nodes, 1))# 简单的训练循环
model.train()
for epoch in range(1):optimizer.zero_grad()out = model(data.x, data.edge_index)loss = criterion(out, labels)print(f"loss {loss}")loss.backward()optimizer.step()# 提取最后一层节点输出特征
model.eval()
with torch.no_grad():out = model(data.x, data.edge_index)print(out)在这个示例中:
- 模型输出的形状是
(num_nodes, 1),即每个节点有一个输出特征。 - 标签的形状也是
(num_nodes, 1),即每个节点有一个对应的标签。 - 损失函数使用均方误差损失(MSELoss),并计算每个节点输出与对应标签之间的误差。
这样,我们确保输出与标签的维度一致,从而正确计算损失并进行训练。
如何计算MSE
在没有全连接层的情况下,每个节点都有一个输出特征,标签也是每个节点一个标签。损失函数(如MSELoss)会计算每个节点输出特征与对应标签之间的误差,然后将这些误差进行平均或求和,得到总体损失。
以下是一个更详细的说明:
- 模型输出:形状为
(num_nodes, 1),表示每个节点的输出特征。 - 标签:形状为
(num_nodes, 1),表示每个节点的对应标签。
在训练过程中,损失函数会计算每个节点的输出与对应标签之间的误差,并将所有节点的误差进行汇总(通常是求平均),得到一个标量损失值。优化器会根据这个损失值更新模型的参数。
我们使用均方误差损失(MSELoss),其计算公式为:
MSE = 1 N ∑ i = 1 N ( y i − y ^ i ) 2 \text{MSE} = \frac{1}{N} \sum_{i=1}^N (y_i - \hat{y}_i)^2 MSE=N1∑i=1N(yi−y^i)2
其中 N N N是节点数, y i y_i yi 是第 i i i 个节点的标签, y ^ i \hat{y}_i y^i是第 i i i 个节点的预测值。
在这个示例中:
- 模型输出:每个节点的输出特征(形状为
(num_nodes, 1))。 - 标签:每个节点的对应标签(形状为
(num_nodes, 1))。 - 损失函数:均方误差损失(MSELoss),计算每个节点输出与对应标签之间的误差,并将这些误差进行平均,得到总体损失。
这个过程确保了每个节点的输出特征与其对应的标签进行比较,从而计算损失并优化模型。
100个样本,并且使用批量大小为32进行训练
第一个版本定义数据集出错,添加super()并修改为__len__和__getitem__
# 定义数据集类
class MyDataset(Dataset):def __init__(self, num_samples, num_nodes, num_node_features):self.num_samples = num_samplesself.num_nodes = num_nodesself.num_node_features = num_node_featuresdef len(self):return self.num_samplesdef get(self, idx):edge_index = torch.tensor([[i for i in range(self.num_nodes)],[(i + 1) % self.num_nodes for i in range(self.num_nodes)]], dtype=torch.long)x = torch.randn((self.num_nodes, self.num_node_features))y = torch.randn((self.num_nodes, 1)) # 每个节点一个标签return Data(x=x, edge_index=edge_index, y=y)
当你遇到 AttributeError: can't set attribute 错误时,通常是因为你试图在一个类的实例上设置一个属性,但该类不允许直接设置属性。在Python中,某些类,特别是那些继承自某些基类(比如 torch.utils.data.Dataset)的类,限制了直接属性赋值的操作,这是为了安全或一致性考虑。
要解决这个问题,你应该在你的 MyDataset 类的 __init__ 方法中正确地初始化属性。以下是如何修复这个问题的方法:
from torch.utils.data import Dataset
from torch_geometric.data import Data# 定义数据集类
class MyDataset(Dataset):def __init__(self, num_samples, num_nodes, num_node_features):super(MyDataset, self).__init__() # Initialize base class if inheritingself.num_samples = num_samplesself.num_nodes = num_nodesself.num_node_features = num_node_features# 创建固定的边索引,这里简单使用环形图self.edge_index = torch.tensor([[i for i in range(self.num_nodes)],[(i + 1) % self.num_nodes for i in range(self.num_nodes)]], dtype=torch.long)def __len__(self):return self.num_samplesdef __getitem__(self, idx):# 创建随机特征和标签,这里仅作示例x = torch.randn((self.num_nodes, self.num_node_features))y = torch.randn((self.num_nodes, 1)) # 每个节点一个标签# 返回一个包含图数据的 Data 对象,保持相同的边索引return Data(x=x, edge_index=self.edge_index, y=y)# 创建数据集和数据加载器
num_samples = 100
num_nodes = 10
num_node_features = 8
batch_size = 32dataset = MyDataset(num_samples, num_nodes, num_node_features)
print(dataset[0].edge_index)idx的作用
在PyTorch中,特别是在使用 torch.utils.data.Dataset 和 torch.utils.data.DataLoader 构建数据加载和处理管道时,idx(或者通常命名为 index)代表着数据集中样本的索引。具体来说:
-
__getitem__方法中的idx:- 在自定义的数据集类中,通常会实现
__getitem__方法。这个方法接收一个参数idx,它表示你要获取的样本在数据集中的索引。 - 例如,在一个图像分类任务中,
idx就是每张图像在数据集中的位置。通过这个索引,你可以从数据集中加载并返回对应位置的样本数据。
- 在自定义的数据集类中,通常会实现
-
作用:
idx的作用是定位和访问数据集中特定样本的数据。在训练过程中,DataLoader会使用__getitem__方法迭代数据集,根据给定的idx获取每个样本,然后将它们组织成批量供模型训练。- 在使用
DataLoader加载数据时,idx通常会被DataLoader内部迭代器管理,你无需手动传递它,只需实现好__getitem__方法即可。
-
示例:
- 假设你有一个自定义的数据集类
MyDataset,实现了__getitem__方法来根据idx加载图像数据。当你使用DataLoader加载这个数据集时,DataLoader会自动处理索引的管理和批量数据的组织,你只需要关注数据集类的实现和模型的训练过程。
- 假设你有一个自定义的数据集类
总结来说,idx 是用来在数据集中定位和访问特定样本的索引参数,它在自定义数据集类中的作用是非常重要的,能够帮助你有效地管理和处理数据集中的样本数据。
使用super()方法
如果在使用 super() 调用时出现错误,通常是因为类的初始化方法(__init__)中没有正确地调用父类的初始化方法。这可能会导致 Python 报告类的属性无法设置的错误。让我们来看看如何正确使用 super() 并初始化属性。
在你的 MyDataset 类中,确保按照以下方式使用 super() 和正确初始化属性:
super()函数:在 Python 中,super()函数用于调用父类的方法。在MyDataset类的__init__方法中,super(MyDataset, self).__init__()调用了Dataset类的初始化方法,确保正确初始化了Dataset类中的属性和方法。- 属性初始化:在
MyDataset的__init__方法中,通过self.num_samples、self.num_nodes和self.num_node_features初始化了数据集的属性。这些属性用于定义数据集的特征和样本数量。 - 数据加载:
__getitem__方法用于按照给定的idx加载数据集中的样本,并返回一个包含图数据的Data对象。
通过这样的方式,你可以确保 MyDataset 类正确地继承了 Dataset 类,并正确初始化了属性,避免了 AttributeError 错误的发生。
再次解释一遍定义数据集的代码
在PyTorch中,torch.utils.data.Dataset 是一个抽象基类,要求自定义的数据集类必须实现 __len__ 和 __getitem__ 方法。这些方法分别用于确定数据集的长度和获取数据集中的一个样本。
__init__方法:在__init__方法中,创建了一个固定的边索引self.edge_index,这里使用简单的环形图示例。这个边索引在数据集初始化时被创建,并在每次调用__getitem__方法时被重复使用,从而确保每个样本的图数据保持相同的连接关系。__len__方法:这个方法返回数据集的长度,即数据集中样本的数量。在这里,它返回了num_samples,表示数据集中有多少个样本。__getitem__方法:这个方法根据给定的索引idx返回数据集中的一个样本。在这里,它返回一个包含随机节点特征、固定边索引和随机节点标签的Data对象,确保了图连接关系的不变性。
你可以正确地实现并使用 MyDataset 类来创建多个数据集样本,并确保每个样本的图连接关系保持不变。
另外一个值得注意的错误:定义数据集部分修改之后还是报obj = super().new(cls)TypeError: Can’t instantiate abstract class MyDataset with abstract methods get, len错误
from torch.utils.data import Dataset 与 from torch_geometric.data import Data 和 Dataset是不一样的
torch.utils.data.Dataset 和 torch_geometric.data.Dataset 是两个不同的类,分别来自于不同的模块,功能和用途也略有不同。
-
torch.utils.data.Dataset:- 这是 PyTorch 提供的一个抽象基类,用于创建自定义数据集。它要求用户继承并实现
__len__和__getitem__方法,以便能够使用torch.utils.data.DataLoader进行数据加载和批处理。 - 主要用途是在通用的机器学习任务中加载和处理数据集,例如图像分类、文本处理等。
- 这是 PyTorch 提供的一个抽象基类,用于创建自定义数据集。它要求用户继承并实现
-
torch_geometric.data.Dataset:- 这是 PyTorch Geometric 提供的一个特定数据集类,用于处理图数据。它继承自
torch.utils.data.Dataset,并额外提供了一些方法和功能,使得可以更方便地处理图数据集。 - 主要用途是在图神经网络中加载和处理图数据,包括节点特征、边索引等。
- 这是 PyTorch Geometric 提供的一个特定数据集类,用于处理图数据。它继承自
-
功能特点:
torch.utils.data.Dataset适用于通用的数据加载和处理,可以处理各种类型的数据集。torch_geometric.data.Dataset专门用于处理图数据,提供了额外的功能来处理节点和边的特征。
-
使用场景:
- 如果你处理的是普通的数据集(如图像、文本等),可以使用
torch.utils.data.Dataset来创建自定义的数据加载器。 - 如果你处理的是图数据(如节点和边具有特定的连接关系和属性),建议使用
torch_geometric.data.Dataset来利用其专门针对图数据设计的功能。
- 如果你处理的是普通的数据集(如图像、文本等),可以使用
如果你想要处理图数据,可以使用 torch_geometric.data.Dataset 的子类,例如 torch_geometric.datasets.Planetoid,用来加载图数据集,例如 Planetoid 数据集:
from torch_geometric.datasets import Planetoid
import torch_geometric.transforms as Tdataset = Planetoid(root='/your/data/path', name='Cora', transform=T.NormalizeFeatures())
这里使用了 Planetoid 数据集类,它继承自 torch_geometric.data.Dataset,专门用于加载和处理图数据集,例如 Cora 数据集。
from torch_geometric.data import Data的作用
在 PyTorch Geometric 中,torch_geometric.data.Data 是一个用于表示图数据的核心数据结构之一。它主要用来存储图中的节点特征、边索引以及可选的图级别特征,具有以下作用:
-
存储节点特征和边索引:
Data对象可以存储节点特征矩阵(通常是一个二维张量)和边索引(通常是一个二维长整型张量)。节点特征矩阵的每一行表示一个节点的特征向量,边索引描述了节点之间的连接关系。
-
支持图级别的特征:
- 除了节点特征和边索引外,
Data对象还可以存储图级别的特征,例如全局图特征(如图的标签或属性)。
- 除了节点特征和边索引外,
-
作为输入输出的载体:
- 在图神经网络中,
Data对象通常作为输入数据的载体。例如,在进行图分类、节点分类或图生成任务时,模型的输入通常是Data对象。
- 在图神经网络中,
-
与其他 PyTorch Geometric 函数和类的兼容性:
Data对象与 PyTorch Geometric 中的其他函数和类高度兼容,例如数据转换、数据集加载等。它们共同支持创建、处理和转换图数据。
-
用于数据集的表示:
- 在自定义的数据集中,你可以使用
Data对象来表示每个样本的图数据。通过组织和存储节点特征、边索引和图级别特征,可以更方便地加载和处理复杂的图结构数据集。
- 在自定义的数据集中,你可以使用
下面是一个简单的示例,展示如何使用 Data 对象创建和操作图数据:
from torch_geometric.data import Data
import torch# 创建节点特征和边索引
x = torch.tensor([[1, 2], [3, 4], [5, 6]], dtype=torch.float) # 3个节点,每个节点2个特征
edge_index = torch.tensor([[0, 1, 1, 2], [1, 0, 2, 1]], dtype=torch.long) # 边索引表示节点之间的连接关系# 创建一个 Data 对象
data = Data(x=x, edge_index=edge_index)# 访问和操作 Data 对象中的属性
print(data)
print("Number of nodes:", data.num_nodes)
print("Number of edges:", data.num_edges)
print("Node features shape:", data.x.shape)
print("Edge index shape:", data.edge_index.shape)
在这个示例中,我们首先创建了节点特征矩阵 x 和边索引 edge_index,然后使用它们来实例化一个 Data 对象 data。通过访问 data 对象的属性,可以获取节点数、边数以及节点特征和边索引的形状信息。
总之,torch_geometric.data.Data 在 PyTorch Geometric 中扮演着关键的角色,用于表示和处理图数据,是构建图神经网络模型的重要基础之一。
验证 MyDataset 类生成的样本和批次数据的形状
为了实现一个自定义数据集 MyDataset,可以创建一个包含 100 个样本的数据集,每个样本包含一个形状为 (32, 8) 的节点特征矩阵。需要注意的是,MyDataset 类中的 __getitem__ 方法应该返回每个样本的数据,包括节点特征、边索引等。
我们可以通过打印 MyDataset 中每个样本的数据形状来验证数据的形状。以下是实现和验证的示例代码:
dataset = MyDataset(num_samples, num_nodes, num_node_features)
print(len(dataset))# 查看数据集中的前几个样本的形状
for i in range(3):data = dataset[i]print(f"Sample {i} - Node features shape: {data.x.shape}, Edge index shape: {data.edge_index.shape}, Labels shape: {data.y.shape}")dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
# 从 DataLoader 中获取一个批次的数据
for batch in dataloader:print("Batch node features shape:", batch.x.shape)print("Batch edge index shape:", batch.edge_index.shape)print("Batch labels shape:", batch.y.shape)break # 仅查看第一个批次的形状
数据格式是展平的 (batch_size * num_nodes, num_features)
使用DenseDataLoader数据格式为(batch_size , num_nodes, num_features)
DenseDataLoader 和 DataLoader 在处理数据的方式上有所不同。DenseDataLoader 是专门用于处理稠密图数据的,而 DataLoader 通常用于处理稀疏图数据。在你的案例中,如果所有图的节点数和边数是固定的,可以使用 DenseDataLoader 进行更高效的批处理。
完整代码
import torch
import torch.nn.functional as F
from torch_geometric.nn import GCNConvfrom torch.utils.data import Dataset
from torch_geometric.data import Data
from torch_geometric.loader import DataLoader, DenseDataLoader# 定义数据集类
class MyDataset(Dataset):def __init__(self, num_samples, num_nodes, num_node_features):super(MyDataset, self).__init__() # Initialize base class if inheritingself.num_samples = num_samplesself.num_nodes = num_nodesself.num_node_features = num_node_features# 创建固定的边索引,这里简单使用环形图self.edge_index = torch.tensor([[i for i in range(self.num_nodes)],[(i + 1) % self.num_nodes for i in range(self.num_nodes)]], dtype=torch.long)def __len__(self):return self.num_samplesdef __getitem__(self, idx):# 创建随机特征和标签,这里仅作示例x = torch.randn((self.num_nodes, self.num_node_features))y = torch.randn((self.num_nodes, 1)) # 每个节点一个标签# 返回一个包含图数据的 Data 对象,保持相同的边索引return Data(x=x, edge_index=self.edge_index, y=y)# 创建数据集和数据加载器
num_samples = 100
num_nodes = 10
num_node_features = 8
batch_size = 32dataset = MyDataset(num_samples, num_nodes, num_node_features)
# data_list = [dataset[i] for i in range(num_samples)]
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
# 从 DataLoader 中获取一个批次的数据
for batch in dataloader:print("Batch node features shape:", batch.x.shape)print("Batch edge index shape:", batch.edge_index.shape)print("Batch labels shape:", batch.y.shape)break # 仅查看第一个批次的形状# 定义GCN模型
class GCN(torch.nn.Module):def __init__(self, in_channels, hidden_channels, out_channels):super(GCN, self).__init__()self.conv1 = GCNConv(in_channels, hidden_channels)self.conv2 = GCNConv(hidden_channels, out_channels)def forward(self, x, edge_index):print(f"first {x.shape}")x = self.conv1(x, edge_index)print(f"conv1 {x.shape}")x = F.relu(x)x = self.conv2(x, edge_index)print(f"conv2 {x.shape}")return xmodel = GCN(in_channels=num_node_features, hidden_channels=16, out_channels=1)
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
criterion = torch.nn.MSELoss()# 训练模型
model.train()
for epoch in range(2):for data in dataloader:optimizer.zero_grad()out = model(data.x, data.edge_index)loss = criterion(out, data.y)loss.backward()optimizer.step()# 评估模型
model.eval()
with torch.no_grad():for batch in dataloader:out = model(batch.x, batch.edge_index)print(out.shape) # 待实现把batch中所有features都拼接起来写得比较乱,最后densedataloader和dataloader都可以专门来写一篇了
相关文章:

【chatgpt】两层gcn提取最后一层节点输出特征,如何自定义简单数据集
文章目录 两层gcn,提取最后一层节点输出特征,10个节点,每个节点8个特征,连接关系随机生成(无全连接层)如何计算MSE 100个样本,并且使用批量大小为32进行训练第一个版本定义数据集出错࿰…...

Java面试题:讨论你如何保持对Java生态系统中新技术的了解
保持对Java生态系统中新技术的了解可以通过以下几种方法: 官方资源: Oracle的官方博客和新闻:Oracle是Java的主要维护者,其官方网站和博客会定期发布Java的新版本、功能更新和最佳实践。Java SE Documentation:Java官方…...
深度学习之Transformer模型的Vision Transformer(ViT)和Swin Transformer
Transformer 模型最初由 Vaswani 等人在 2017 年提出,是一种基于自注意力机制的深度学习模型。它在自然语言处理(NLP)领域取得了巨大成功,并且也逐渐被应用到计算机视觉任务中。以下是两种在计算机视觉领域中非常重要的 Transformer 模型:Vision Transformer(ViT)和 Swi…...
玩个游戏 找以下2个wordpress外贸主题的不同 你几找到几处
Aitken艾特肯wordpress外贸主题 适合中国产品出海的蓝色风格wordpress外贸主题,产品多图展示、可自定义显示产品详细参数。 https://www.jianzhanpress.com/?p7060 Ultra奥创工业装备公司wordpress主题 蓝色风格wordpress主题,适合装备制造、工业设备…...

React Native优质开源项目推荐与解析
目录 2. React Native的优势 2.1. 跨平台开发 2.2. 热更新 2.3. 丰富的社区资源 2.4. 优秀的性能 3. 优质开源项目推荐 3.1. React Navigation 3.1.1 项目简介 3.1.2 特点和优势 3.1.3 应用场景 3.2. Redux 3.2.1 项目简介 3.2.2 特点和优势 3.2.3 应用场景 3.3…...
树莓派安装windows系统
第1步: https://uupdump.net/下载对应的系统文件,所有选择项都默认选择。 第2步: 解压下载后的文件,双击运行下面文件。等待下载完成,等待过程很漫长,很考验耐心。 第3步: 提示已经finish了&…...
CSS-position/transform
1 需求 2 语法 在CSS中,positioning 和 transform 是两个非常重要的概念,它们分别用于控制元素在页面上的布局和变换。 Positioning CSS中的position属性用于设置元素的定位类型。它有几个值,包括: static:这是默认…...

面试题之一
路由的两种模式:hash模式和 history模式。 两种的区别、如何实现。 hash模式中#的作用 vue性能优化。具体如何实现(回答了一个可以函数引入的方法引入路由。问) keep-alive 说一下EventBus CSS: flex布局 css新特性 盒子模型 J…...

494. 目标和 Medium
给你一个非负整数数组 nums 和一个整数 target 。 向数组中的每个整数前添加 或 - ,然后串联起所有整数,可以构造一个 表达式 : 例如,nums [2, 1] ,可以在 2 之前添加 ,在 1 之前添加 - ,然…...

如何实现灌区闸门控制自动化?宏电“灌区哨兵”为灌区闸门控制添“智慧”动能
闸门控制站是节水灌溉工程中的重要组成部分。随着科技的不断进步和农田水利现代化的发展,传统的闸门控制和管理手段已经不能满足现代农业的发展要求。以宏电“灌区哨兵”为核心的闸门自动化控制系统,能有效解决灌区闸门距离远、数量多、不易操作、不好监…...

PHP电商系统开发指南数据库管理
回答:数据库管理是电商系统开发的关键,涉及数据的存储、管理和检索。选择合适的数据库引擎,如mysql或 postgresql。创建数据库架构,定义数据的组织方式(如产品表、订单表)。进行数据建模,考虑实…...

基于Vue.js的电商前端模板:Vue-Dashboard-Template的设计与实现
摘要 随着电子商务的飞速发展,前端页面的设计和实现变得愈发重要。本文介绍了一个基于Vue.js的电商前端模板——Vue-Dashboard-Template,旨在提供一个高性能、易扩展的电商平台前端解决方案。该模板遵循响应式设计、模块化、组件化开发等设计原则&#…...

论文解读:【CVPR2024】DUSt3R: Geometric 3D Vision Made Easy
论文“”https://openaccess.thecvf.com/content/CVPR2024/papers/Wang_DUSt3R_Geometric_3D_Vision_Made_Easy_CVPR_2024_paper.pdf 代码:GitHub - naver/dust3r: DUSt3R: Geometric 3D Vision Made Easy DUSt3R是一种旨在简化几何3D视觉任务的新框架。作者着重于…...

springboot助农电商系统-计算机毕业设计源码08655
摘要 近年来,电子商务的快速发展引起了行业和学术界的高度关注。基于移动端的助农电商系统旨在为用户提供一个简单、高效、便捷的农产品购物体验,它不仅要求用户清晰地查看所需信息,而且还要求界面设计精美,使得功能与页面完美融合…...
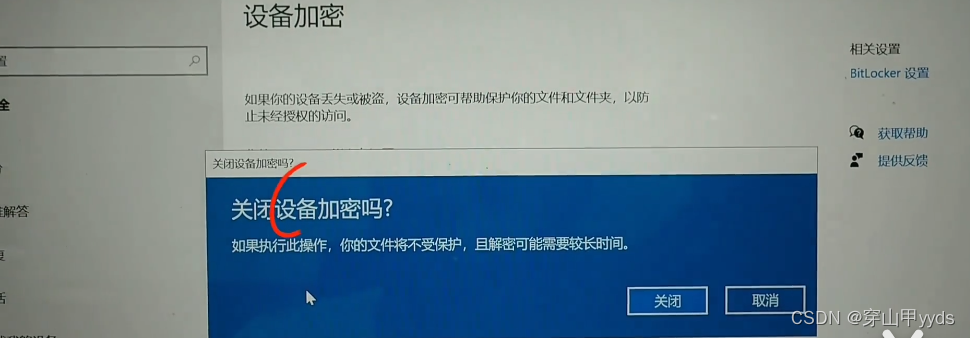
【windows】电脑如何关闭Bitlocker硬盘锁
如果你的硬盘显示这样的一把锁,说明开启了Bitlocker硬盘加密。 Bitlocker硬盘锁,可以保护硬盘被盗,加密防止打开查看数据。 方法一:进入“控制面板->BitLocker 驱动器加密”进行设置。或者“控制面板\系统和安全->BitLocke…...
vue-cli 搭建项目,ElementUI的搭建和使用
vue-cli 官方提供的一个脚手架,用于快速生成一个vue的项目模板;预先定义 好的目录结构及基础代码,就好比咱们在创建Maven项目时可以选择创建一个 骨架项目,这个骨架项目就是脚手架,我们的开发更加的快速; …...

SQL-DDL操作
数据库操作 登录MySQL PS D:\WorkSpace\MachineLearning\DL_learning> mysql -u root -p Enter password: ****** Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 12 Server version: 8.0.37 MySQL Community Server - GPLCopy…...

帮粉丝用gpt写代码生成一个文字视频
文章目录 使用网站ValueError: could not broadcast input array from shape (720,1280) into shape (720,1280,3) 定义文本内容和动画参数定义视频参数创建背景使用 PIL 创建文本图像创建文本剪辑使用函数创建文本剪辑合并所有剪辑导出视频1. 理解错误信息2. 确认图像数组形状…...

IP白名单及其作用解析
在网络安全领域,IP白名单是一项至关重要的策略,它允许特定的IP地址或地址范围访问网络资源,从而确保只有受信任的终端能够连接。下面,我们将深入探讨IP白名单的定义、作用以及实施时的关键考虑因素。 一、IP白名单的定义 IP白名单…...

【Android八股文】如何对ListView RecycleView进行局部刷新的?
文章目录 一、如何对ListView进行局部刷新的?1.1 方法一:更新对应view的内容1.2 方法二:通过ViewHolder去设置值1.3 方法三:调用一次getView()方法1.4 封装在万能适配器当中1.5 总结二、如何对RecyclerView 进行局部刷新的?2.0 为什么会有DiffUtil?2.1 讲解一下DiffUtil2…...

从零开始打造 OpenSTLinux 6.6 Yocto 系统(基于STM32CubeMX)(九)
设备树移植 和uboot设备树修改的内容同步到kernel将设备树stm32mp157d-stm32mp157daa1-mx.dts复制到内核源码目录下 源码修改及编译 修改arch/arm/boot/dts/st/Makefile,新增设备树编译 stm32mp157f-ev1-m4-examples.dtb \stm32mp157d-stm32mp157daa1-mx.dtb修改…...

解决本地部署 SmolVLM2 大语言模型运行 flash-attn 报错
出现的问题 安装 flash-attn 会一直卡在 build 那一步或者运行报错 解决办法 是因为你安装的 flash-attn 版本没有对应上,所以报错,到 https://github.com/Dao-AILab/flash-attention/releases 下载对应版本,cu、torch、cp 的版本一定要对…...

Matlab | matlab常用命令总结
常用命令 一、 基础操作与环境二、 矩阵与数组操作(核心)三、 绘图与可视化四、 编程与控制流五、 符号计算 (Symbolic Math Toolbox)六、 文件与数据 I/O七、 常用函数类别重要提示这是一份 MATLAB 常用命令和功能的总结,涵盖了基础操作、矩阵运算、绘图、编程和文件处理等…...

今日科技热点速览
🔥 今日科技热点速览 🎮 任天堂Switch 2 正式发售 任天堂新一代游戏主机 Switch 2 今日正式上线发售,主打更强图形性能与沉浸式体验,支持多模态交互,受到全球玩家热捧 。 🤖 人工智能持续突破 DeepSeek-R1&…...

关于 WASM:1. WASM 基础原理
一、WASM 简介 1.1 WebAssembly 是什么? WebAssembly(WASM) 是一种能在现代浏览器中高效运行的二进制指令格式,它不是传统的编程语言,而是一种 低级字节码格式,可由高级语言(如 C、C、Rust&am…...

Python ROS2【机器人中间件框架】 简介
销量过万TEEIS德国护膝夏天用薄款 优惠券冠生园 百花蜂蜜428g 挤压瓶纯蜂蜜巨奇严选 鞋子除臭剂360ml 多芬身体磨砂膏280g健70%-75%酒精消毒棉片湿巾1418cm 80片/袋3袋大包清洁食品用消毒 优惠券AIMORNY52朵红玫瑰永生香皂花同城配送非鲜花七夕情人节生日礼物送女友 热卖妙洁棉…...

push [特殊字符] present
push 🆚 present 前言present和dismiss特点代码演示 push和pop特点代码演示 前言 在 iOS 开发中,push 和 present 是两种不同的视图控制器切换方式,它们有着显著的区别。 present和dismiss 特点 在当前控制器上方新建视图层级需要手动调用…...

Qemu arm操作系统开发环境
使用qemu虚拟arm硬件比较合适。 步骤如下: 安装qemu apt install qemu-system安装aarch64-none-elf-gcc 需要手动下载,下载地址:https://developer.arm.com/-/media/Files/downloads/gnu/13.2.rel1/binrel/arm-gnu-toolchain-13.2.rel1-x…...

STM32---外部32.768K晶振(LSE)无法起振问题
晶振是否起振主要就检查两个1、晶振与MCU是否兼容;2、晶振的负载电容是否匹配 目录 一、判断晶振与MCU是否兼容 二、判断负载电容是否匹配 1. 晶振负载电容(CL)与匹配电容(CL1、CL2)的关系 2. 如何选择 CL1 和 CL…...
给网站添加live2d看板娘
给网站添加live2d看板娘 参考文献: stevenjoezhang/live2d-widget: 把萌萌哒的看板娘抱回家 (ノ≧∇≦)ノ | Live2D widget for web platformEikanya/Live2d-model: Live2d model collectionzenghongtu/live2d-model-assets 前言 网站环境如下,文章也主…...