从零开始实现大语言模型(二):文本数据处理
1. 前言
神经网络不能直接处理自然语言文本,文本数据处理的核心是做tokenization,将自然语言文本分割成一系列tokens。
本文介绍tokenization的基本原理,OpenAI的GPT系列大语言模型使用的tokenization方法——字节对编码(BPE, byte pair encoding),并构建训练大语言模型的Dataset及DataLoader。
2. Tokenization
Tokenization的目标是将自然语言文本分割成一系列tokens。在英文自然语言处理领域,最常用的tokenization方法是将英文文本分割成单词及标点符号。在中文自然语言处理领域,往往会将一个字或一个标点符号作为一个token。
如下面的代码所示,可以使用Python自带的正则表达式库re将英文文本分割成不同的单词及标点符号:
import resentence = "Hello, world. This, is a test."
tokens = re.split(r'([,.?_!"()\']|\s)', sentence)
tokens = [item for item in tokens if item.strip()]
print(tokens)
执行上面代码,打印结果如下:
['Hello', ',', 'world', '.', 'This', ',', 'is', 'a', 'test', '.']
上面的tokenization示例代码删除掉了文本中的空格。在实际应用中,也可以将空格视为一个单独的字符。删除空格可以显著减少分割文本产生的tokens数量,减少内存消耗,降低计算资源需求。但是在构建代码生成模型等应用场景中,必须将文本中的空格视为一个单独的字符,并编码成相应的token。
3. 将Token转换成数字ID
绝大部分处理自然语言文本的神经网络都包含Embedding层(embedding layer)torch.nn.Embedding。Embedding层存储了不同tokens对应的embedding向量,输入一系列tokens对应的索引列表,Embedding层输出相应tokens对应的embedding向量。
对自然语言文本做tokenization,将文本分割成不同的tokens。Tokens不能直接输入神经网络的Embedding层,需要将tokens转换成数字ID(token ID)。将tokens转换成数字ID首先要构造词汇表(vocabulary)。词汇表定义了不同tokens与数字索引的一一对应关系,可以使用词汇表将分割自然语言文本产生的一系列tokens转换成数字ID列表,也可以通过词汇表将数字ID列表还原成自然语言文本。
如下图所示,构造词汇表需要对训练数据集中全部文本数据做tokenization,获取所有不同的tokens,并一一添加到字典(dict)中。字典的key为训练数据集中的不同tokens,字典的value为相应token添加到字典中的顺序。

可以使用如下代码构造词汇表:
diff_tokens = sorted(set(tokens))
vocabulary = {token: idx for idx, token in enumerate(diff_tokens)}for item in vocabulary.items():print(item)
执行上面代码,打印结果如下:
(',', 0)
('.', 1)
('Hello', 2)
('This', 3)
('a', 4)
('is', 5)
('test', 6)
('world', 7)
4. 常用的特殊Tokens
上述对训练数据集中全部文本数据做tokenization,获取所有不同的tokens,并构造将token映射成数字ID的词汇表的文本数据处理方法无法将训练数据集中不存在的token转换成数字ID。在自然语言处理项目实践中,往往会在词汇表中增加一些特殊tokens,以增强模型理解自然语言文本结构等信息的能力。常用的特殊tokens如下所示:
<|unk|>(unknown):该token一般用于表示不在构建的词汇表中的单词或字符<|endoftext|>(end of text):该token一般用于分割两个不相关的文本。训练大语言模型的文本数据一般由许多文本拼接而成,不同文本之间使用<|endoftext|>分隔,使大语言模型可以理解训练数据的组织方式[BOS](beginning of sequence):该token通常位于一段文本的开头,用于给模型提供输入文本的组织结构信息[EOS](end of sequence):该token通常位于一段文本的末尾,用于拼接多个不相关的文本,其作用与<|endoftext|>类似[PAD](padding):训练大语言模型每次会使用一个batch的训练样本,构成一个张量(tensor),张量内所有训练样本token数量必须相同。如果batch中包含不同长度的训练样本,一般会使用[PAD]将较短的训练样本填充至batch中最长训练样本长度
GPT-2系列大语言模型只在词汇表中增加了
<|endoftext|>这个特殊token。其使用了一种被称为字节对编码(byte pair encoding)的tokenization方法,该方法分割文本不会产生词汇表不包含的新token。
可以将上述tokenization方法封装成一个Tokenizer类,其中encode函数用于将自然语言文本分割成一系列tokens,并转换成数字ID列表。decode函数用于将数字ID列表还原成自然语言文本:
class Tokenizer:def __init__(self, vocabulary):self.str_to_int = vocabularyself.int_to_str = list(vocabulary.keys())def encode(self, text):preprocessed = re.split(r'([,.?_!"()\']|\s)', text)preprocessed = [item for item in preprocessed if item.strip()]preprocessed = [item if item in self.str_to_int else "<|unk|>" for item in preprocessed]ids = [self.str_to_int[s] for s in preprocessed]return idsdef decode(self, ids):text = " ".join([self.int_to_str[i] for i in ids])text = re.sub(r'\s+([,.?!"()\'])', r'\1', text)return text
可以使用如下代码实例化Tokenizer类对象,并调用encode及decode函数,打印示例文本对应的tokens及相应文本内容:
vocabulary.update({"<|unk|>": len(vocabulary), "<|endoftext|>": len(vocabulary) + 1})
text = "Hello world. <|endoftext|> This is a test dataset."tokenizer = Tokenizer(vocabulary)
print(tokenizer.encode(text))
print(tokenizer.decode(tokenizer.encode(text)))
执行上面代码,打印结果如下:
[2, 7, 1, 9, 3, 5, 4, 6, 8, 1]
Hello world. <|endoftext|> This is a test <|unk|>.
5. 字节对编码(Byte Pair Encoding)
字节对编码(BPE)是大语言模型GPT-2、GPT-3以及ChatGPT使用的tokenization方法。BPE会将所有单个字符(如"a","b"等)以及频繁出现的字符组合(subtoken)添加到词汇表中(如字符"d"和"e"的组合"de"在许多英文单词中很常见,因此会将"de"添加到词汇表中作为一个token)。
如下图所示,BPE可以将不在其词汇表中的单词分解成粒度更小的字符或字符组合,因此OpenAI的GPT系列模型不用<|unk|>等特殊token来处理不在其词汇表中的单词。

OpenAI开源了其使用Rust语言实现的非常高效的BPE算法tiktoken库,可以使用如下命令安装tiktoken:
!pip install tiktoken==0.5.1
使用tiktoken.encoding_for_model方法创建tokenizer对象,加载大语言模型GPT-2所使用的词汇表,并调用encode及decode函数,测试BPE算法:
import tiktokentokenizer = tiktoken.encoding_for_model("gpt2")
text = "Hello, do you like tea? <|endoftext|> In the sunlit terraces of someunknownPlace."
integers = tokenizer.encode(text, allowed_special={"<|endoftext|>"})
print(integers)
strings = tokenizer.decode(integers)
print(strings)
执行上面代码,打印结果如下:
[15496, 11, 466, 345, 588, 8887, 30, 220, 50256, 554, 262, 4252, 18250, 8812, 2114, 286, 617, 34680, 27271, 13]
Hello, do you like tea? <|endoftext|> In the sunlit terraces of someunknownPlace.
创建tokenizer对象并加载大语言模型GPT-3.5所使用的词汇表,可以使用
tokenizer = tiktoken.encoding_for_model("gpt-3.5-turbo")方法。加载大语言模型GPT-4所使用的词汇表,可以使用tokenizer = tiktoken.encoding_for_model("gpt-4")。查看tiktoken的内部源码可知,大语言模型GPT-3.5及GPT-4所使用的词汇表完全相同。
6. 构建训练大语言模型的Dataset及DataLoader
6.1 大语言模型的训练样本
预训练大语言模型的数据集包含许多自然语言文档,不同文档的内容使用<|endoftext|>拼接,构成一个非常长的文本字符串,使用上述BPE算法可以将该字符串转变成数字ID列表。
使用下一个token预测任务预训练大语言模型,从数字ID列表中随机抽取一个长度为context_len的子列表输入大语言模型。大语言模型可以执行context_len次下一个token预测任务,共预测输出context_len个tokens。
如下图所示,假设context_len等于8,则第一次下一个token预测任务大模型根据输入LLMs预测learn,第二次根据输入LLMs learn预测to。依此类推,第八次根据输入LLMs learn to predict one word at a预测time。

在实际训练大语言模型时,会输入长度为
context_len的数字ID列表,每个数字对应一个token,而不是输入一个字符串。
因此可以使用如下规则构建训练大语言模型的训练样本。每个训练样本包含一个input-target pair,其中:
- input:从训练数据集对应的数字ID列表中随机抽取的长度为
context_len的子列表 - target:将input子列表向后移一个token对应的子列表,其中target中第 i i i个token ID为input中第 i − 1 i-1 i−1个token ID
理论上,长度为 n n n的token ID列表对应的训练数据集最多可以构造出 n − context_len + 1 n-\text{context\_len}+1 n−context_len+1个不同的训练样本。实际上,会使用stride控制两个相邻训练样本之间的重叠tokens数量。如果 stride = = 1 \text{stride}==1 stride==1,则两个相邻的训练样本存在个 context_len − 1 \text{context\_len}-1 context_len−1重叠的tokens,第 i i i个训练样本的target即为第 i + 1 i+1 i+1个训练样本的input。如果 stride = = context_len \text{stride}==\text{context\_len} stride==context_len,则两个相邻训练样本之间不存在重叠的tokens。stride越小,则可以构造出更多训练样本,但是模型更容易过拟合。stride越大,模型越不容易过拟合,但是同一个训练数据集中构造的训练样本数会更少。
6.2 构建Dataset
Pytorch提供的高效组织及加载训练数据的模块由Dataset及DataLoader类构成,其中Dataset类用于定义如何加载每个训练样本,DataLoader类用于随机打乱训练数据集,并将训练数据集划分到不同的batch。
构建训练数据集对应的Dataset,需要实现一个Dataset的子类,并重写__init__构造方法,__getitem__方法,以及__len__方法。__init__方法用于初始化与访问训练数据相关的属性,如文件路径、数据库连接器等等。如果训练数据集不是特别大,可以在__init__方法中将整个训练数据集全部读取到内存中。如果训练数据集特别大,无法一次全部加载进内存,一般只会在__init__方法中初始化数据文件路径,后续实际要用到相应数据时才会去读取。__getitem__中实现了根据索引返回相应训练样本的方法。在DataLoader类的实例化对象获取一个batch的训练样本时,__getitem__方法会被调用batch_size次,共传入batch_size个不同的索引,返回batch_size个不同的训练样本,构成一个训练大语言模型的batch。__len__方法定义了训练数据集的大小,假设__len__方法返回训练数据集的大小为10,则每次调用__getitem__方法传入的索引均为0-9之间(包括0和9)的整数。
综上所述,可以使用如下代码构建训练大语言模型的Dataset:
import os
import json
import randomimport torch
import tiktoken
from torch.utils.data import Datasetclass LLMDataset(Dataset):def __init__(self, data_path, file_index_dir, vocabulary, special_token_id, context_len, stride):self.tokenizer = tiktoken.encoding_for_model(vocabulary)self.special_token_id = special_token_idself.context_len = context_lenself.stride = strideif not os.path.exists(file_index_dir):os.makedirs(file_index_dir, exist_ok=True)file_index_path = os.path.join(file_index_dir, "file_index.json")if not os.path.isfile(file_index_path):support_file_paths = []for root, dirs, files in os.walk(data_path):for file in files:if file.endswith((".txt", ".md")):file_path = os.path.join(root, file)support_file_paths.append(file_path)random.shuffle(support_file_paths)file_indexes, total_tokens = dict(), 0for file_path in support_file_paths:with open(file_path, "rt", encoding="utf-8") as f:file_token = self.tokenizer.encode(f.read(), allowed_special=self.tokenizer.special_tokens_set)file_indexes[file_path] = [total_tokens, total_tokens + len(file_token)]total_tokens += len(file_token) + 1with open(file_index_path, "wt", encoding="utf-8") as f:json.dump(file_indexes, f, ensure_ascii=False)with open(file_index_path, "rt", encoding="utf-8") as f:self.file_index = json.load(f)max_token_index = list(self.file_index.values())[-1][1]self.num_sample = (max_token_index - context_len) // stride + 1def __getitem__(self, index):index_files = self._index_files(index)start_index = index * self.stridestop_index = start_index + self.context_lensample = []for file_path in index_files:index_range = self.file_index[file_path]file_start, file_end = 0, index_range[1] - index_range[0] + 1if index_range[0] <= start_index <= index_range[1]:file_start = start_index - index_range[0]if index_range[0] <= stop_index <= index_range[1]:file_end = stop_index - index_range[0] + 1with open(file_path, "rt", encoding="utf-8") as f:tokens = self.tokenizer.encode(f.read(), allowed_special=self.tokenizer.special_tokens_set)tokens.append(self.special_token_id)sample.extend(tokens[file_start: file_end])return torch.tensor(sample[:-1]), torch.tensor(sample[1:])def __len__(self):return self.num_sampledef _index_files(self, index):index_files = []start_file, stop_file = None, Nonestart_index = index * self.stridestop_index = start_index + self.context_lenfor file_path, index_range in self.file_index.items():if index_range[0] <= start_index <= index_range[1]:start_file = file_pathif start_file is not None:index_files.append(file_path)if index_range[0] <= stop_index <= index_range[1]:stop_file = file_pathif stop_file is not None:breakreturn index_files
LLMDataset类的__init__方法中通过self.tokenizer = tiktoken.encoding_for_model(vocabulary)初始化了将文本转换为token ID的BPE tokenizer。遍历整个训练数据集中的.txt及.md文件,初始化了一个key为文件路径,value为文件中全部token的[起始索引, 终止索引]列表的字典self.file_index,用于在__getitem__方法中根据索引找到相应训练样本所在文件。初始化了记录训练数据集中可构造训练样本总数的变量self.num_sample。
__getitem__方法调用self._index_files(index)函数,返回index对应的训练样本所分布的文件路径。遍历文件路径列表index_files,从各个文件中取出属于index对应训练样本部分的tokens,并组合成训练样本sample。
上述训练大语言模型的
LLMDataset并没有将训练数据一次全部加载进内存,只在__init__方法中记录了训练数据文件,并在调用__getitem__方法时根据index实时读取所需文件,构造训练样本。这种方法可以不用将全部训练数据加载进内存,但是需要耗费一定时间完成训练样本构造。构建训练大语言模型的DataLoader时,可以通过设置
num_workers,使数据读取与模型训练并行进行。只要LLMDataset中的训练数据构造效率不是特别慢,一般不会影响模型训练效率。
如果训练大语言模型的计算服务器集群内存足够大到可以将整个训练数据集一次性全部加载进内存,构建训练大语言模型的Dataset时,可以在__init__方法中读取训练数据集中的全部.txt及.md文档,将不同文档的内容使用<|endoftext|>拼接,构成一个非常长的文本字符串,并使用BPE tokenizer分别将该字符串转变成token ID列表,存入计算服务器集群的内存。
虽然可以在构建训练大语言模型的DataLoader时,通过设置num_workers,使数据读取与模型训练并行进行,一定程度上避免训练数据构造效率对模型训练的影响。但是在内存资源充足的情况下,直接在__init__方法中将整个训练数据集全部加载进内存,从而提升__getitem__方法中根据指定index构造训练数据的速度,可以使模型训练的整体效率至少不比使用上面构建的Dataset差。具体代码如下所示:
class LLMDataset(Dataset):def __init__(self, data_path, vocabulary, special_token_id, context_len, stride):self.context_len = context_lenself.stride = stridesupport_file_paths = []for root, dirs, files in os.walk(data_path):for file in files:if file.endswith((".txt", ".md")):file_path = os.path.join(root, file)support_file_paths.append(file_path)random.shuffle(support_file_paths)self.tokens = []tokenizer = tiktoken.encoding_for_model(vocabulary)for file_path in support_file_paths:with open(file_path, "rt", encoding="utf-8") as f:file_token = tokenizer.encode(f.read(), allowed_special=tokenizer.special_tokens_set)file_token.append(special_token_id)self.tokens.extend(file_token)self.num_sample = (len(self.tokens) - context_len - 1) // stride + 1def __getitem__(self, index):start_index = index * self.stridex = self.tokens[start_index: start_index + self.context_len]y = self.tokens[start_index + 1: start_index + self.context_len + 1]return torch.tensor(x), torch.tensor(y)def __len__(self):return self.num_sample
6.3 构建DataLoader
构建分batch读取训练数据的DataLoader,只需要传入一个Dataset对象,并实例化DataLoader类对象。可以使用如下代码构建训练大语言模型的DataLoader:
from torch.utils.data import DataLoaderbatch_size = 16
random_seed = 123torch.manual_seed(random_seed)dataset = LLMDataset(data_path="some_data_folder_path")
train_loader = DataLoader(dataset=dataset,batch_size=batch_size,shuffle=True,num_workers=4,drop_last=True
)
shuffle参数用于控制是否随机打乱训练数据集。如果shuffle设置为False,DataLoader会依据索引从小到大的顺序依次生成不同batch的训练数据。如果shuffle设置为True,DataLoader会随机打乱所有训练样本的索引,并按照随机打乱后的索引顺序依次生成不同batch的训练数据。一般会将训练数据集对应DataLoader的shuffle参数设置为True,确保不同batch的训练数据是独立同分布的。测试数据集对应DataLoader的shuffle参数一般会设置为False,因为测试数据集中数据不被用于训练模型,保存数据测试顺序信息有助于分析数据测试结果。
通过torch.manual_seed(random_seed)指定随机数种子,可以使DataLoader在不同次训练流程中生成完全相同的训练样本索引随机排列,但是一次训练流程的对训练数据集的不同次迭代中,训练样本索引的随机排列会各不相同。设置随机数种子有助于神经网络训练结果复现,但是不会使得在训练过程中陷入重复的更新周期。
假设训练数据集共包含5个不同的训练样本,构建
DataLoader时设置shuffle参数为True,则在一次训练流程的前3次对训练数据集的遍历过程中,访问训练数据的顺序可能如下(不同随机数种子会产生不同的访问顺序):
- 第一次遍历训练数据集的顺序:[3, 4, 1, 0, 2]
- 第二次遍历训练数据集的顺序:[2, 1, 0, 3, 4]
- 第三次遍历训练数据集的顺序:[1, 4, 0, 3, 2]
保持随机数种子不变,第二次执行训练代码,在第二次训练流程中的前3次对训练数据集的遍历顺序必定与上面的遍历顺序相同。
如果在训练大语言模型时程序异常中断,从保存的断点(checkpoint)处恢复训练环境,需要特别注意随机数种子的设置与变更。如果从某个batch对应的checkpoint恢复训练环境,只需要使用同一个随机数种子,并跳过前 k k k个已经训练的batch即可。如果从某个epoch对应的checkpoint处继续训练模型,需要变更随机数种子,确保新的一轮训练遍历训练数据集的顺序与上一次遍历训练数据集的顺序不一致。在训练大语言模型时,建议不同epoch使用不同的随机数种子,并记录随机数种子的使用顺序。
batch_size是指训练大语言模型的一个batch中包含训练样本的数量。batch_size越小,则训练大语言模型要求的显卡最大内存越小,但是会导致计算出的更新大语言模型的梯度方差较大,影响大语言模型训练时的收敛速度及模型最终效果。batch_size的设置可以参考OpenAI训练GPT系列大语言模型的论文,或者设置成当前显卡内存资源允许的最大值。
在实际训练大语言模型时,训练数据集中的训练样本数量一般不太可能恰好构成整数个batch,最后一个batch很可能仅包含相对非常少的训练样本。在一个训练的epoch中,使用包含训练样本数量非常少的batch作为最后一个batch会引入一次噪声较大的更新梯度,影响训练大语言模型时的收敛效果。将drop_last设置为True,会将每个epoch中的最后一个batch丢弃,不参与模型参数更新。
num_workers参数用于控制数据并行加载及预处理。如下图所示,在使用GPU训练大语言模型时,CPU不仅要与GPU交互处理深度学习模型参数调度等任务,还要加载及预处理训练数据。如果num_workers=0,系统将使用主进程加载数据,数据处理与GPU任务调度时串行的,GPU在CPU加载及预处理训练数据时处于空闲状态,会明显降低模型训练速度及GPU利用率。如果num_workers大于0,系统将启动多个工作进程并行加载及预处理训练数据,使主进程专注于GPU资源及训练任务调度。num_workers必须根据系统计算资源及训练数据集情况来确定,根据实践经验,大部分情况下将num_workers设置为4可以比较高效地利用系统计算资源。

7. 结束语
本文详细讲解了文本数据处理的方法,并构建了训练大语言模型的Dataset及DataLoader。请坐好站稳,我们将要去深入了解大语言模型的神经网络架构了!
相关文章:
从零开始实现大语言模型(二):文本数据处理
1. 前言 神经网络不能直接处理自然语言文本,文本数据处理的核心是做tokenization,将自然语言文本分割成一系列tokens。 本文介绍tokenization的基本原理,OpenAI的GPT系列大语言模型使用的tokenization方法——字节对编码(BPE, byte pair en…...

生物分子生物学实验过程的自动化与智能监控系统设计
开题报告:生物分子生物学实验过程的自动化与智能监控系统设计 一、引言 随着生物科学技术的飞速发展,生物分子生物学实验在科研、医疗、农业等领域的应用日益广泛。然而,传统的生物分子生物学实验过程大多依赖于人工操作,存在操…...

linux的shell脚本编程详解
Shell 脚本是一种用于自动化任务的脚本语言,在 Linux 和其他类 Unix 操作系统中非常流行。它通常用于任务自动化、系统管理和批处理。编写 Shell 脚本并使其自动化编译过程(例如使用 gcc 编译 C/C 程序)是一种常见的任务。 以下是一个详细的…...

Redis 7.x 系列【11】数据类型之位图(Bitmap)
有道无术,术尚可求,有术无道,止于术。 本系列Redis 版本 7.2.5 源码地址:https://gitee.com/pearl-organization/study-redis-demo 文章目录 1. 概述2. 基本命令2.1 SETBIT2.2 GETBIT2.3 BITCOUNT2.4 BITPOS2.5 BITFIELD2.6 BITF…...

如何评定旅游卡的品质与服务?
评定旅游卡的品质与服务,可以从以下几个关键方面进行综合考量: 公司实力与资质:选择有实力、资质齐全的公司发行的旅游卡。查看公司背景,确认其是否长期稳定运营,是否具有旅游行业的专业资质,如旅行社许可证…...

适合学生暑假适用的护眼大路灯有哪些?五款好用护眼灯分享!
在护眼领域,护眼大路灯已经成为越来越多人的选择。这种具备实力的工具可以有效地缓解用眼疲劳、改善光线环境,是学生党和办公族的必备神器。然而,市面上的护眼大路灯品牌众多,如何选择一款性价比高、品质优良的产品呢?…...

linux服务器 部署jenkins
在 Linux 服务器上部署 Jenkins 通常包括以下几个步骤: 更新系统软件包: sudo apt update sudo apt upgrade 安装 Java: Jenkins 需要 Java 运行时环境。推荐使用 OpenJDK 11。 sudo apt install openjdk-11-jdk 添加 Jenkins 软件源并导入…...

电商控价:系统监测的必要性与优势
在品牌的发展进程中,会遭遇各种各样的渠道问题,控价乃是其中颇为关键的一环。品牌进行控价的目的无疑是为了妥善治理低价链接,低价链接的发现途径可以是人工,也可以是系统。力维网络在为上百个品牌提供服务的过程中察觉到…...

港股下半年能恢复上涨趋势吗?
今日港股两大指数涨跌不一,早盘盘初恒指冲高,涨幅一度扩大至1%。截至收盘,香港恒生指数涨0.57%。板块方面,电力、航空、石油、内险股、燃料电池、环保等板块涨幅居前;互动媒体与服务、生物科技、汽车零部件、新经济概念…...

软件测试项目实战:银行贷款业务测试介绍-2
1、利息计算 正常利息贷款本金*借款天数*贷款年利率/360 罚息逾期本金*逾期天数*逾期年利率/360 复利逾期利息*逾期天数*逾期年利率/360 2、贷款五级分类 正常贷款:正常及逾期60天以内 关注贷款:逾期60天及以上,不足90天 次级贷款࿱…...

如何将Hive表的分区字段插入PG表对应的时间戳字段?
文章目录 1、背景描述2、场景分析 1、背景描述 数据仓库的建设通常是为业务和决策服务的。在数仓开发的应用层阶段,BI可以直接从主题层/业务层取数,而前端需要根据具体的作图需求通过后端查询数据库 作图的指标需要根据主题层/业务层做查询计算…...

Spring Boot与MyBatis的集成应用
Spring Boot与MyBatis的集成应用 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿!今天我们来聊聊Spring Boot与MyBatis的集成应用。MyBatis是一款优秀的持久层框…...
在昇腾服务器上使用llama-factory对baichuan2-13b模型进行lora微调
什么是lora微调 LoRA 提出在预训练模型的参数矩阵上添加低秩分解矩阵来近似每层的参数更新,从而减少适配下游任务所需要训练的参数。 环境准备 这次使用到的微调框架是llama-factory。这个框架集成了对多种模型进行各种训练的代码,少量修改就可使用。 …...

Kafka 管理TCP连接
生产者管理TCP连接 Kafka生产者程序概览 Kafka的Java生产者API主要的对象就是KafkaProducer。通常我们开发一个生产者的步骤有4步: 第1步:构造生产者对象所需的参数对象。 第2步:利用第1步的参数对象,创建KafkaProducer对象实例…...
electron教程(一)创建项目
一、方式① 根据官网描述将electron/electron-quick-start项目克隆下来并启动 electron/electron-quick-start地址: GitHub - electron/electron-quick-start: Clone to try a simple Electron app git clone https://github.com/electron/electron-quick-start…...

如何在Oracle、MySQL、PostgreSQL上终止会话或取消SQL查询
How to Kill session or Cancel SQL query on Oracle , MySQL, PostgreSQL 数据库维护过程中难免会遇到一些不正常的SQL或会话进程正在占用系统大量资源,临时需要终止查询或kill会话,在Oracle, MySQL, Postgresql数据库中不同的操作。 Oracle KILL会话…...
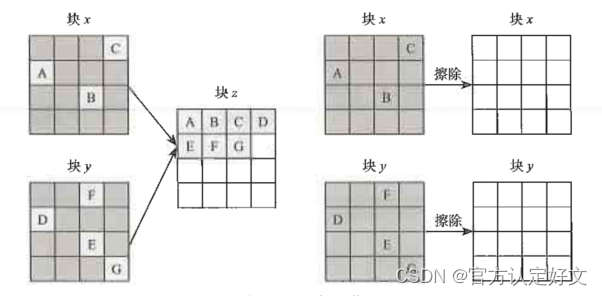
3、FTL基本工作过程
上文描述了FTL的四大功能,这里简述一下每个功能的含义。 地址转换简述 FTL要维护一个地址转换表,这个转换表是主机读/写硬盘的逻辑地址到硬盘实际物理地址的转换关系。 假如SSD的容量是128G,SSD逻辑块的大小是4KB,那SSD的逻辑块…...

微信小程序的跳转页面
在微信小程序中,要实现从当前页面返回到指定页面的功能,通常不直接使用“返回上一页”的逻辑,而是利用小程序的页面栈管理和navigateBack或者重新定向到目标页面的API。下面我将介绍两种主要的方法: 方法一:使用 navi…...
`, `notify()`, `notifyAll()`)
深入理解 Java 中的线程间通信:`wait()`, `notify()`, `notifyAll()`
引言 在多线程编程中,线程间通信是一个重要且复杂的主题。Java 提供了一套基本的机制来实现线程间通信,即使用 wait(), notify(), 和 notifyAll() 方法。这些方法由 Object 类提供,用于协调多个线程对共享资源的访问。本文将详细介绍这些方法…...

23种设计模式【创建型模式】详细介绍之【单例模式】
23种设计模式【创建型模式】详细介绍之【单例模式】 设计模式的分类和应用场景总结单例模式1. 概述2. 实现方式2.1 饿汉式单例模式2.2 懒汉式单例模式(非线程安全)2.3 懒汉式单例模式(线程安全) 3. 单例模式的优缺点3.1 优点3.2 缺…...

label-studio的使用教程(导入本地路径)
文章目录 1. 准备环境2. 脚本启动2.1 Windows2.2 Linux 3. 安装label-studio机器学习后端3.1 pip安装(推荐)3.2 GitHub仓库安装 4. 后端配置4.1 yolo环境4.2 引入后端模型4.3 修改脚本4.4 启动后端 5. 标注工程5.1 创建工程5.2 配置图片路径5.3 配置工程类型标签5.4 配置模型5.…...

Zustand 状态管理库:极简而强大的解决方案
Zustand 是一个轻量级、快速和可扩展的状态管理库,特别适合 React 应用。它以简洁的 API 和高效的性能解决了 Redux 等状态管理方案中的繁琐问题。 核心优势对比 基本使用指南 1. 创建 Store // store.js import create from zustandconst useStore create((set)…...

基于Flask实现的医疗保险欺诈识别监测模型
基于Flask实现的医疗保险欺诈识别监测模型 项目截图 项目简介 社会医疗保险是国家通过立法形式强制实施,由雇主和个人按一定比例缴纳保险费,建立社会医疗保险基金,支付雇员医疗费用的一种医疗保险制度, 它是促进社会文明和进步的…...

CMake基础:构建流程详解
目录 1.CMake构建过程的基本流程 2.CMake构建的具体步骤 2.1.创建构建目录 2.2.使用 CMake 生成构建文件 2.3.编译和构建 2.4.清理构建文件 2.5.重新配置和构建 3.跨平台构建示例 4.工具链与交叉编译 5.CMake构建后的项目结构解析 5.1.CMake构建后的目录结构 5.2.构…...

YSYX学习记录(八)
C语言,练习0: 先创建一个文件夹,我用的是物理机: 安装build-essential 练习1: 我注释掉了 #include <stdio.h> 出现下面错误 在你的文本编辑器中打开ex1文件,随机修改或删除一部分,之后…...

MODBUS TCP转CANopen 技术赋能高效协同作业
在现代工业自动化领域,MODBUS TCP和CANopen两种通讯协议因其稳定性和高效性被广泛应用于各种设备和系统中。而随着科技的不断进步,这两种通讯协议也正在被逐步融合,形成了一种新型的通讯方式——开疆智能MODBUS TCP转CANopen网关KJ-TCPC-CANP…...

【git】把本地更改提交远程新分支feature_g
创建并切换新分支 git checkout -b feature_g 添加并提交更改 git add . git commit -m “实现图片上传功能” 推送到远程 git push -u origin feature_g...

Linux-07 ubuntu 的 chrome 启动不了
文章目录 问题原因解决步骤一、卸载旧版chrome二、重新安装chorme三、启动不了,报错如下四、启动不了,解决如下 总结 问题原因 在应用中可以看到chrome,但是打不开(说明:原来的ubuntu系统出问题了,这个是备用的硬盘&a…...

成都鼎讯硬核科技!雷达目标与干扰模拟器,以卓越性能制胜电磁频谱战
在现代战争中,电磁频谱已成为继陆、海、空、天之后的 “第五维战场”,雷达作为电磁频谱领域的关键装备,其干扰与抗干扰能力的较量,直接影响着战争的胜负走向。由成都鼎讯科技匠心打造的雷达目标与干扰模拟器,凭借数字射…...

关键领域软件测试的突围之路:如何破解安全与效率的平衡难题
在数字化浪潮席卷全球的今天,软件系统已成为国家关键领域的核心战斗力。不同于普通商业软件,这些承载着国家安全使命的软件系统面临着前所未有的质量挑战——如何在确保绝对安全的前提下,实现高效测试与快速迭代?这一命题正考验着…...