大数据面试题之Flume
目录
介绍下Flume
Flume架构
Flume有哪些Source
说下Flume事务机制
介绍下Flume采集数据的原理?底层实现?
Flume如何保证数据的可靠性
Flume传输数据时如何保证数据一致性(可靠性)
Flume拦截器
如何监控消费型Flume的消费情况
Kafka和Flume是如何对接的?
为什么要使用Flume进行数据采集
介绍下Flume
Apache Flume是一个分布式的、可靠的、高可用的系统,专门设计用于收集、聚合并传输大量日志数据。Flume最初是由Cloudera开发,
并于2009年贡献给Apache软件基金会,成为Hadoop生态系统的一部分。它特别适用于大数据环境下的日志数据采集,能够从多个来源高效地
收集数据,并将其传输到集中式存储或处理系统中,如Hadoop的HDFS、数据库、消息队列等。Flume的特点
1、分布式架构:
Flume支持在分布式环境中部署,能够从多个节点收集数据,非常适合大规模的日志采集场景。
2、可靠性:
Flume具有内置的容错机制,能够处理数据传输中的故障,并在失败情况下重试,确保数据的完整性。
3、灵活性:
Flume提供了高度的配置灵活性,支持多种数据源(sources)、数据通道(channels)和数据接收端(sinks),可以根据具体需求定制数
据流。
4、可扩展性:
Flume的架构设计使得添加新的数据源、通道和接收端相对简单,便于系统根据需求进行扩展。
5、简单数据模型:
Flume使用简单且可扩展的数据模型,数据以事件(events)的形式传输,事件包含一个头部(header)和一个主体(body),头部可以携
带元数据信息。
6、批处理与流处理:
Flume支持批处理和流处理模式,能够适应不同的数据处理需求。Flume的架构组件Flume的核心架构由三个主要组件构成:
1、Source(数据源):
Source负责从数据产生点收集数据。数据源可以是本地文件系统、网络流、系统日志、JMS消息等。
2、Channel(通道):
Channel作为缓冲区存储从Source接收到的数据,直到数据被Sink处理。通道可以是内存中的、文件系统的或者
JDBC数据库中的。
3、Sink(接收端):
Sink将数据从Channel中取出并发送到最终目的地,如HDFS、HBase、Solr、数据库或其他Flume Agent。除了这三个主要组件,Flume还支持Interceptors(拦截器)用于过滤和修改事件,Selectors(选择器)用于在多Sink配置中决定数据
流向哪个Sink,以及Processors(处理器)用于实现更复杂的事件处理逻辑。Flume广泛应用于日志管理和监控系统中,特别是在大数据处理领域,是构建实时数据管道和日志基础设施的重要工具。Flume架构
Apache Flume 的架构围绕着几个关键组件设计,这些组件协同工作来实现数据的收集、聚合和传输。Flume 的核心架构组件包括:1、Agent:
Agent 是 Flume 的基本运行单元,它是一个 Java 进程,负责从数据源收集数据,处理数据,并将数据传送到目的地。每个 Agent 包含
一个或多个 Source、Channel 和 Sink 组件。
2、Source:
Source 是数据的入口点,负责监听或主动从数据产生点拉取数据。数据源可以是多种类型,如文件系统、网络流、消息队列、JMS、Avro、
Thrift 等。Source 接收到数据后,将其转换为 Flume 事件,并将事件推送到 Channel。
3、Channel:
Channel 是一个临时存储区域,用于在 Source 和 Sink 之间缓冲数据。Channel 可以是内存中的,也可以是基于磁盘的,甚至可以是
事务性的,以确保数据的持久性和可靠性。Channel 在数据传输过程中起到中介作用,确保数据在从 Source 到 Sink 的移动过程中不会
丢失。
4、Sink:
Sink 是数据的出口点,负责将数据从 Channel 中取出并发送到目的地,如 HDFS、HBase、Solr、数据库或其他 Flume Agent。Sink
可以是多种类型,以适应不同的数据存储或处理需求。
5、Interceptor:
Interceptor 是可选的组件,用于在数据流经 Channel 之前对事件进行过滤或修改。它可以添加、删除或修改事件头或事件体,以实现数
据的预处理。
6、Selector:
Selector 是用于在多 Sink 配置中决定数据流向哪个 Sink 的组件。这允许数据根据不同的条件被路由到不同的目的地。
7、Processor:
Processor 是一个可选组件,用于在数据从 Channel 到 Sink 的过程中执行更复杂的逻辑。它能够对事件进行过滤、修改或重新路由。
8、Master:
在一些较新的 Flume 架构中提到了 Master 的概念,它负责管理协调 Agent 和 Collector 的配置和状态,但这个组件并非 Flume
的核心组成部分,而是特定实现或配置中可能存在的。Flume 的架构设计允许组件之间的松耦合,使得系统高度可配置和可扩展。通过不同的 Source、Channel 和 Sink 的组合,Flume 可
以适应各种数据收集和传输的场景,从而满足大规模数据处理的需求。Flume有哪些Source
Flume提供了多种Source类型以支持各种数据源的接入,这些Source类型包括但不限于:1、AvroSource:Flume中使用较多的一种数据源类型,它能够将消息数据在不同节点之间进行安全可靠地传输,可以从另一个AvroSource或AvroSink中接收消息。
2、ExecSource:可以调用外部程序,并将其输出作为消息体进行采集。这种Source类型可以启动一个用户所指定的Linux shell命令,
并采集该命令的标准输出作为数据。
3、SpoolingDirectorySource:监控特定目录下的新文件,读取这些新文件中的信息,并将其数据转换成消息体,传输到指定的sink。
4、NetcatSource:能够接受TCP/UDP协议的流量,并将其内容转换为消息体进行采集。它启动一个socket服务,监听一个端口,将端口上
收到的数据转成event写入channel。
5、SyslogTcpSource:专门用于接收syslog方式协议的日志流量,并将其内容转换为消息体进行采集。
6、JMS Source:专门用于接收JMS(Java Messaging Service)方式协议的消息流量,并将其内容转换为消息体进行采集,用于数据中
心之间的数据传输。
7、Sequence Generator Source:它可以生成多个消息流,每个消息体中都包含当前的有序索引。
8、Kafka Source:专门用于接收Kafka协议的消息,并将其内容转换为消息体进行采集。Kafka是一种分布式发布-订阅消息系统,能够很
好地解决大规模消息传输的需求。
9、TwitterSource(Alpha版本):专门用于从Twitter流中提取消息。需要注意的是,Flume的早期版本中可能没有直接处理Twitter
API消息的源。
10、Morphline Source:可以对任何数据源进行抽取,并将其内容转换为消息体进行采集,不仅能够处理结构化的数据,还能处理未结构
化的数据。
11、IRC Source:专门用于接收Internet Relay Chat (IRC)协议的消息,并将其内容转换为消息体进行采集,用于建立即时聊天系
统。除了上述列举的Source类型外,Flume还支持自定义Source的实现,以满足特定的数据接入需求。在自定义Source时,可以根据具体的数
据源特点,编写相应的代码来接收数据,并将其转换为Flume的Event进行传输。说下Flume事务机制
Flume的事务机制是其核心功能之一,确保了数据可靠地从源到目的地传输,并且在失败时能够进行恢复。以下是Flume事务机制的详细说
明:1、事务概念:
Flume中的事务是一个逻辑单位,表示一次数据传输操作。每个事务包含一组事件(events),这些事件通常代表了需要从源到目的地传输的
数据。
2、事件和通道:
事件是Flume中的基本数据单元,通常代表一个日志条目或其他数据项。Flume通过通道(Channel)来缓冲事件,通道充当了事务的存储区
域。
3、事务处理流程:
当Flume接收到数据(事件)时,它会将这些数据写入一个事务中,并将事务存储在通道中。每个事务都有一个唯一的事务ID,用于标识和跟
踪事务。
4、事务提交:
当一个事务达到一定的大小或者一定的时间间隔时,Flume可以选择提交事务。提交事务意味着将其中的事件发送到下游(例如,到目的地或
者另一个Flume agent)。
5、事务回滚:
如果在提交之前发生故障(例如,目的地不可用),Flume可以选择回滚事务。事务回滚将撤销该事务,事件将保留在通道中等待下一次提交。
6、事务保证:
Flume提供了事务保证,确保了事件在传输过程中不会丢失。即使在提交前发生失败,事件也不会丢失,因为它们仍然保留在通道中。
7、事务恢复:
当Flume Agent重新启动或者恢复后,它会检查通道中的未提交事务并尝试重新提交它们。这确保了即使在Agent故障后,数据也能够最终到
达目的地。
8、可配置性:
Flume允许用户配置事务的大小、提交间隔、事务的最大尝试次数等参数,以满足不同应用场景的需求。
9、具体处理过程:
Source读取数据并将其封装成事件,然后将事务主动推入Channel中。Sink从Channel中拉取事务,并进行处理。在Put事务流程中,如果
Channel内存队列空间不足,Flume会执行回滚操作。在Take事务流程中,如果数据发送过程中出现异常,Flume会执行回滚操作,将数据归
还给Channel内存队列。综上所述,Flume的事务机制是为了确保数据在传输过程中的可靠性和可恢复性而设计的。通过将事件存储在通道中,并在提交和回滚时进行
控制,Flume能够有效地处理大规模日志数据,并保证即使在出现故障情况下也不会丢失重要的数据。这种事务机制使得Flume成为了数据收
集和传输领域的重要工具之一。介绍下Flume采集数据的原理?底层实现?
Apache Flume 的数据采集原理和底层实现围绕其核心组件展开,即 Agent、Source、Channel 和 Sink。下面是对 Flume 如何采集
数据的详细解释,以及其底层实现的一些细节。Flume 数据采集原理
1、Agent:
Flume的基础单位是Agent,它是一个独立的 Java 进程,负责执行数据的收集、处理和传输任务。Agent 可以在多个主机上分布部署,形
成一个数据采集网络。
2、Source:
Source是数据进入Flume Agent的入口点,它负责监听或主动从数据产生源拉取数据。数据源可以是多种类型的,例如日志文件、网络流、
消息队列等。Source将数据转化为Flume Event,并将Event发送到 Channel。
3、Channel:
Channel 是一个临时的存储层,用于在 Source 和 Sink 之间传递数据。Channel 提供了一个缓冲区域,确保数据在从 Source 到
Sink 的传输过程中不会丢失。Channel 可以是内存中的,也可以是基于磁盘的,支持事务性操作,以确保数据的可靠传输。
4、Sink:
Sink是数据离开Flume Agent的出口点,负责将数据从Channel中取出并发送到目的地,如HDFS、HBase、Kafka或者其他Flume
Agent。Sink的选择取决于数据的最终存储位置或处理需求。
5、Event:
Flume中的数据以Event形式存在,每个Event包含一个Body和一个Header。Body存储实际的数据内容,Header 存储元数据信息,如事件
的时间戳、源地址等。底层实现
Flume 的底层实现涉及以下几个关键点:1、插件化架构:
Flume 的 Source、Channel 和 Sink 都是插件化的,这意味着用户可以根据需要选择或编写自己的组件。这种设计提供了极高的灵活性
和可扩展性。
2、数据传输的事务性:
Flume 的数据传输过程使用事务机制来保证数据的一致性和完整性。在数据从 Source 到 Channel 的传输过程中,以及从 Channel 到
Sink 的传输过程中,都实现了事务性操作。如果数据传输失败,事务会回滚,数据保留在 Channel 中,直到成功传输。
3、线程模型:
Flume 使用多线程模型来处理数据的输入和输出。Source 和 Sink 通常在一个单独的线程中运行,而 Channel 则可能使用多个线程来
处理数据的入队和出队操作。
4、配置文件:
Flume Agent 的配置通过一个配置文件来定义,该文件指定了 Source、Channel 和 Sink 的类型和参数。配置文件的格式通常是简单
的键值对,易于阅读和修改。
5、监控和管理:
Flume 提供了监控和管理功能,允许用户查看 Agent 的状态,监控数据传输速率,以及管理配置变更。Flume 的设计和实现旨在处理大规模数据流的采集和传输,其灵活的架构和强大的功能使其成为构建实时数据管道和日志基础设施的理想选
择。Flume如何保证数据的可靠性
Apache Flume 设计了一系列机制来保证数据采集、传输和存储过程中的可靠性。以下是 Flume 保证数据可靠性的主要方式:1、事务机制:
Flume 使用事务机制来确保数据从 Source 到 Channel,再到 Sink 的传输过程中数据的完整性和一致性。事务确保了数据至少被送达
一次,但可能在某些情况下多次送达(at-least-once delivery)。如果数据发送失败,Flume 会自动重试,直到数据成功发送或达到配
置的最大重试次数。
2、Channel 存储:
Flume 的 Channel 可以配置为持久化的存储,如基于文件系统的 Channel 或 JDBC Channel。这意味着如果 Channel 中的数据未能
及时被 Sink 处理,数据将被持久化存储在磁盘上,从而防止数据丢失。
3、故障恢复:
Flume 支持故障恢复机制,当主节点或组件发生故障时,数据处理可以从故障点恢复。例如,如果 Sink 发生故障,数据会保留在
Channel 中,直到 Sink 恢复或数据被转发到备用的 Sink。
4、数据校验和:
Flume 支持数据校验和的生成和验证,以确保数据在传输过程中的完整性和正确性。如果数据在传输过程中被损坏,校验和可以帮助检测错
误。
5、异常处理:
Flume 提供了异常处理机制,可以捕获和处理在数据处理过程中遇到的任何异常。这有助于防止故障扩散,并允许系统在遇到问题时采取补救
措施。
6、多点冗余:
Flume 支持主从模式和多点冗余配置,这意味着如果主节点发生故障,可以自动切换到备用节点继续工作,确保数据传输的连续性。
7、Sink 多路复用:
Flume 允许配置多个 Sink,这样即使其中一个 Sink 出现问题,数据也可以被发送到其他的 Sink,从而提高数据传输的可靠性。
8、数据流重定向:
如果某个数据处理路径失败,Flume 可以配置为将数据流重定向到另一个路径,确保数据不会丢失。
9、配置和监控:
Flume 提供了详细的配置选项和监控工具,允许管理员调整和监控数据处理流程,以便在问题出现时迅速响应。通过上述机制,Flume 能够在复杂的分布式环境下保证数据的可靠传输,是大数据平台中日志数据收集和传输的可靠解决方案。Flume传输数据时如何保证数据一致性(可靠性)
在Apache Flume中,数据一致性(可靠性)主要通过其事务机制和一些关键组件的设计来保证。下面是一些核心概念和步骤,解释了Flume
是如何确保数据在传输过程中的可靠性和一致性的:1、事务机制:
Flume采用了一个双阶段的事务机制来处理数据的流动。这意味着数据从Source到Channel的传输和从Channel到Sink的传输都是原子操
作,即要么完全成功,要么完全失败。
当Source向Channel写入数据时,它会启动一个事务,将数据写入Channel。如果事务成功,数据被提交;如果失败,事务将回滚,数据会
被再次尝试写入,直到成功。
同样,当Sink从Channel读取数据时,它也启动一个事务。如果数据成功被Sink处理,Channel中的数据将被删除;如果失败,数据会保留
在Channel中,直到下一次读取尝试。
2、Channel持久化:
Flume的Channel可以配置为持久化存储,如File Channel或JDBC Channel。这意味着如果系统崩溃或重启,Channel中的数据不会丢
失,可以继续传输到Sink。
这种持久化机制保证了即使在系统故障的情况下,数据也不会丢失,从而保证了数据的一致性。
3、容错与恢复:
Flume设计有容错机制,当组件(如Source、Channel或Sink)出现故障时,Flume可以自动恢复并重试数据传输。
如果Sink不可用,数据将继续保留在Channel中,直到Sink恢复或数据被转发到其他可用的Sink。
4、数据校验:
Flume可以配置数据校验功能,如计算和验证校验和,以确保数据在传输过程中的完整性和正确性。
5、多Sink配置:
Flume允许配置多个Sink,如果主Sink失败,数据可以被路由到备份Sink,这提高了数据传输的可靠性。
6、监控与报警:
Flume提供了监控工具和接口,可以实时查看数据流的状态,如果检测到异常或故障,可以触发报警,以便快速响应。通过这些机制,Flume能够确保在复杂的大数据环境中数据的传输是可靠和一致的。这使得Flume成为日志聚合、数据流处理等场景下的一个
强大工具。Flume拦截器
Flume拦截器(Interceptor)是Flume中的一个重要组件,它位于Source与Channel之间,可以在事件(events)传输过程中进行拦
截、处理和修改。以下是关于Flume拦截器的详细解释:1、定义与位置:
拦截器是一种可配置的组件,位于Source与Channel之间。在事件写入Channel之前,拦截器可以对事件进行转换、提取或删除操作,以满
足特定的数据处理需求。2、作用:
数据处理和转换:拦截器可以对事件数据进行各种处理和转换,例如数据清洗、格式转换、数据重构等。
过滤:通过配置拦截器,可以实现对数据流的过滤操作,确保只有符合要求的数据流被传递到下一个组件。3、配置与使用:
Flume支持多种类型的拦截器,例如TimestampInterceptor、Host Interceptor、StaticInterceptor等。每个拦截器只处理同一
个Source接收到的事件,也可以同时配置多个拦截器,它们会按照配置的顺序执行。拦截器的配置包括指定拦截器的类型、设置相关参数
等。4、常见拦截器:
TimestampInterceptor:为事件添加或更新时间戳信息。
Host Interceptor:为事件添加或更新主机名或IP地址信息。
StaticInterceptor:为事件添加静态的头部信息或内容。
UUID Interceptor:为事件生成唯一的UUID。
Morphline Interceptor:使用Morphline库对事件进行复杂的转换和处理。
Search and Replace Interceptor:在事件内容中进行搜索和替换操作。
Regex Filtering Interceptor:使用正则表达式对事件进行过滤。
Regex Extractor Interceptor:使用正则表达式从事件中提取信息。5、示例配置(以Host Interceptor和Timestamp Interceptor为例):
agent_lxw1234.sources.sources1.interceptors = i1 i2
agent_lxw1234.sources.sources1.interceptors.i1.type = host
agent_lxw1234.sources.sources1.interceptors.i1.useIP = false
agent_lxw1234.sources.sources1.interceptors.i1.hostHeader = agentHost
agent_lxw1234.sources.sources1.interceptors.i2.type = timestamp
在上述配置中,i1是Host Interceptor,它将为主机名添加或更新一个名为agentHost的头部信息,而不使用IP地址。i2是Timestamp
Interceptor,它将为事件添加或更新时间戳信息。总结:
Flume拦截器是Flume中用于在事件传输过程中进行数据处理和转换的重要组件。通过配置和使用不同类型的拦截器,可以满足各种数据处理
需求,提高数据处理的效率和准确性。如何监控消费型Flume的消费情况
监控消费型Flume Agent的消费情况通常涉及到监控数据的吞吐量、延迟、错误率以及资源使用情况等。Flume提供了多种监控方法,可以让
你了解Agent的运行状态和性能。以下是一些常见的监控方法:1、JMX (Java Management Extensions) 监控:
Flume利用JMX来暴露其内部状态和性能指标。你可以在flume-env.sh配置文件中启用JMX监控,通过设置JAVA_OPTS环境变量来开启JMX
远程访问。
一旦启用了JMX,你可以使用如JConsole或VisualVM这样的工具来远程监控Flume Agent的运行状态,包括内存使用、CPU使用率、线程
信息等。
2、HTTP监控:
Flume支持通过HTTP协议来暴露监控信息。在启动Agent时,可以通过参数-Dflume.monitoring.type=http和-
Dflume.monitoring.port=<port>来开启HTTP监控服务。
这个HTTP服务会提供关于Agent、Source、Channel和Sink的统计信息,包括事件的数量、速率、延迟和错误等。
3、Ganglia监控:
如果你的环境已经部署了Ganglia监控系统,Flume可以配置成将监控数据报告给Ganglia的metanode。这需要在启动Agent时指定相应的
参数。
Ganglia能够提供图形化的监控界面,展示Flume Agent的实时和历史性能指标。
4、Log4j监控:
Flume使用Log4j作为日志框架,你可以配置Log4j来记录详细的运行日志,包括错误、警告和调试信息。这有助于诊断问题和监控Agent的
行为。
5、自定义监控:
Flume允许开发自定义的监控插件,如果你有特定的监控需求,可以编写自己的插件来收集和报告数据。为了监控消费型Flume的消费情况,你应当关注以下指标:事件的吞吐量:每秒处理的事件数量。
事件延迟:事件从Source到达Sink的时间。
错误和失败事件数:由于各种原因未成功处理的事件数量。
资源使用情况:CPU、内存、磁盘I/O和网络I/O的使用情况。通过这些监控方法和指标,你可以深入了解Flume Agent的运行状况,确保数据流的健康和性能。在配置监控时,记得根据实际的网络环境和
安全策略来适当配置远程访问权限。Kafka和Flume是如何对接的?
Kafka和Flume的对接主要通过Flume的KafkaSink组件实现,以下是详细的对接步骤和要点:1. 准备工作
安装与配置Kafka:安装Kafka服务器,配置server.properties文件,并启动Kafka Broker。创建Topic:在Kafka中创建用于接收
Flume数据的Topic,例如命名为flume_logs的Topic。2. 配置Flume Agent
安装Flume:安装Flume服务,并确保其与Kafka版本兼容。
编写Flume配置文件(如flume-kafka.conf):
定义Flume Agent:每个Agent包含Source、Channel和Sink组件。
配置Source:根据数据源类型选择合适的Source,如exec从命令行输出收集日志,spooling-directory监听指定目录的文件变动,
http通过HTTP接口接收日志等。
配置Channel:选择合适的Channel类型,如memory(内存队列,适用于短时、低延迟场景)或file(文件队列,适用于持久化、高吞吐场
景)。配置KafkaSink:
使用kafka类型的Sink。
指定Kafka服务器地址(如a1.sinks.k1.kafka.bootstrap.servers =
node2:9092,node3:9092,node4:9092)。
指定Topic名称(如a1.sinks.k1.kafka.topic = flumetopic)。
配置生产者参数(如a1.sinks.k1.kafka.producer.acks = -1)。3. 配置文件示例
以下是一个简单的配置文件示例,展示了Flume如何配置以将数据发送到Kafka:# Named
a1.sources = r1
a1.channels = c1
a1.sinks = k1# Source
a1.sources.r1.type = netcat
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 6666# Channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 10000
a1.channels.c1.transactionCapacity = 100# Sink
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.bootstrap.servers = node2:9092,node3:9092,node4:9092
a1.sinks.k1.kafka.topic = flumetopic
a1.sinks.k1.kafka.flumeBatchSize = 100
a1.sinks.k1.useFlumeEventFormat = true
a1.sinks.k1.kafka.producer.acks = -1# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c14. 启动与验证
启动Flume Agent,并观察其日志输出,确保没有错误发生。
发送数据到Flume的Source(如通过telnet连接到配置的netcat端口),并检查Kafka中的Topic是否接收到了这些数据。通过以上步骤,
Kafka和Flume就可以成功对接,实现数据的实时收集与传输。为什么要使用Flume进行数据采集
Apache Flume 成为数据采集的首选工具之一,主要是因为它在处理大规模、分布式日志数据和其他数据流时所具有的优势。以下是一些使
用 Flume 进行数据采集的主要原因:1、高可用性与可靠性:
Flume 设计为高可用和高可靠性的系统,它能够处理数据传输中的故障并提供数据持久性,确保数据不会因为系统故障而丢失。
2、分布式架构:
Flume 支持分布式部署,可以轻松地在多台服务器上部署 Agent,以处理大规模的数据流,这非常适合处理来自多个源的日志数据。
3、灵活的数据流模型:
Flume 提供了基于流的数据流模型,允许数据从多个源采集,并通过复杂的路由和过滤规则传输到多个目的地,如 HDFS、HBase、Kafka 等。
4、可插拔的组件:
Flume 的 Source、Channel 和 Sink 都是可插拔的,这意味着你可以根据需要选择不同的组件,甚至可以开发自定义组件来适应特定的
数据源或目标。
5、数据预处理能力:
Flume 支持 Interceptor 和 Processor,可以对数据进行预处理,如过滤、格式转换、数据增强等,这在数据进入下游系统前是非常有
用的。
6、低延迟:
Flume 能够以较低的延迟处理数据,这对于实时数据分析和监控系统非常重要。
7、可配置性:
Flume 非常容易配置和管理,可以通过简单的配置文件来定义数据流和处理逻辑,无需编程即可实现复杂的数据流处理。
8、容错机制:
Flume 提供了丰富的容错和数据恢复机制,即使在组件故障的情况下也能确保数据的完整性和一致性。
9、监控与管理:
Flume 提供了监控工具,可以查看数据流的状态,这对于运维人员来说是非常重要的,他们可以监控数据处理的性能和故障。
10、成熟稳定:
Flume 是一个成熟的技术,由 Apache 软件基金会维护,有大量的社区支持和文档,可以确保长期的稳定性和技术支持。综上所述,Flume 是一个强大且灵活的工具,特别适合用于大数据环境中的日志数据采集和传输,以及需要高可用性和可靠性的数据流处理场
景。引用:https://www.nowcoder.com/discuss/353159520220291072
通义千问、文心一言
相关文章:

大数据面试题之Flume
目录 介绍下Flume Flume架构 Flume有哪些Source 说下Flume事务机制 介绍下Flume采集数据的原理?底层实现? Flume如何保证数据的可靠性 Flume传输数据时如何保证数据一致性(可靠性) Flume拦截器 如何监控消费型Flu…...

js文件的执行和变量初始化缓存
js文件和变量初始化 全局变量举例js文件加载 全局变量举例 import * as turf from "turf/turf"; import earcut from "earcut"; import * as THREE from "three"; import { TextGeometry } from "three/addons/geometries/TextGeometry.js…...
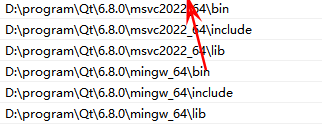
无法定位程序输入点Z9 qt assertPKcS0i于动态链接库F:\code\projects\06_algorithm\main.exe
解决方法: 这个报错,是因为程序在运行时没要找到所需的dll库,如果把这个程序方法中对应库的目录下执行,则可正常执行。即使将图中mingw_64\bin 环境变量上移到msvc2022_64\bin 之前也不可以。 最终的解决方法是在makefile中设置环…...

GoLand 2024 for Mac GO语言集成开发工具环境
Mac分享吧 文章目录 效果一、下载软件二、开始安装1、双击运行软件(适合自己的M芯片版或Intel芯片版),将其从左侧拖入右侧文件夹中,等待安装完毕2、应用程序显示软件图标,表示安装成功3、打开访达,点击【文…...
)
Protocol Buffer 基础(c++)
本教程提供了使用协议缓冲区的基本介绍。通过逐步创建一个简单的示例应用程序,介绍以下内容: 1.在.proto文件中定义消息格式。 2.使用 protocol buffer 编译器。 3.使用c protocol buffer API来写入和读取消息。 一、问题描述 将要使用的示例是…...
上位机网络通讯
目录 一 设计原型 二 后台源码 一 设计原型 二 后台源码 using System; using System.Net.Sockets; using System.Text; using System.Threading.Tasks; using System.Windows.Forms;namespace 上位机网络通讯 {public partial class Form1 : Form{public Form1(){Initializ…...

转让5000万无区域能源公司要求和流程
国家局的公司,也就是无地域无区域性的公司名称。这样的公司是还可以继续注册的,但是想要拥有国家局无区域的名称就不是那么容易的了。总局的企业要求高,也是实力的体现。对字号有保护。所以有很多人都对无地域的名称一直情有独钟。现有一家名…...
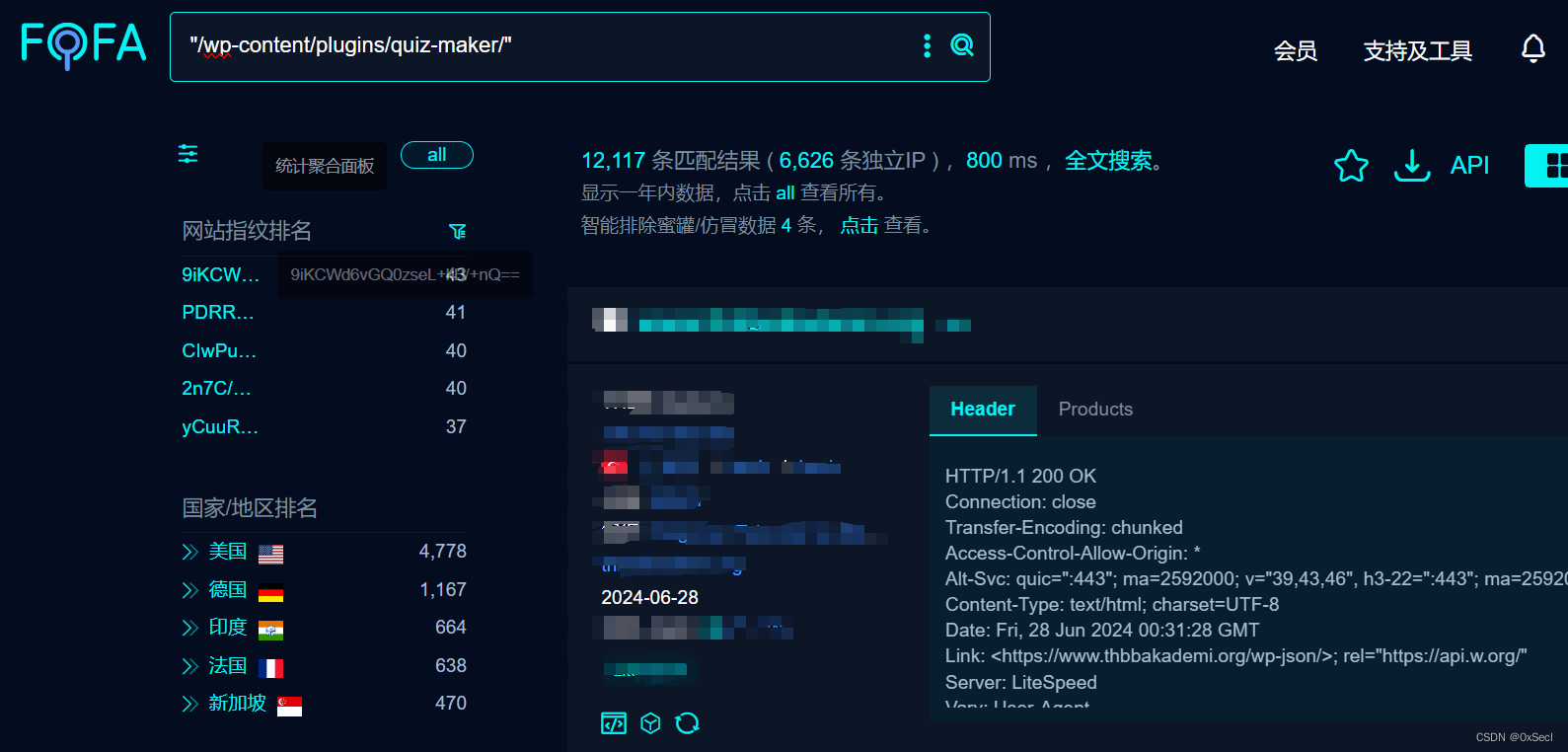
WordPress Quiz Maker插件 SQL注入漏洞复现(CVE-2024-6028)
0x01 产品简介 WordPress Quiz Maker插件是一款功能强大的测验生成工具,旨在帮助用户轻松、快速地构建复杂的测验和考试。插件支持多种问题类型,包括单选框(MCQ)、复选框(MCQ)、下拉列表(MCQ)、文本、短文本、数字、日期等。还支持横幅(HTML)显示信息性消息、填空题…...

Swift中的二分查找:全面指南
Swift中的二分查找:全面指南 简介 二分查找是计算机科学中的经典算法,被广泛用于在已排序的数组中高效地搜索目标值。与线性查找逐个检查每个元素不同,二分查找不断将搜索区间减半,因此在处理大数据集时要快得多。 在这篇博客中…...
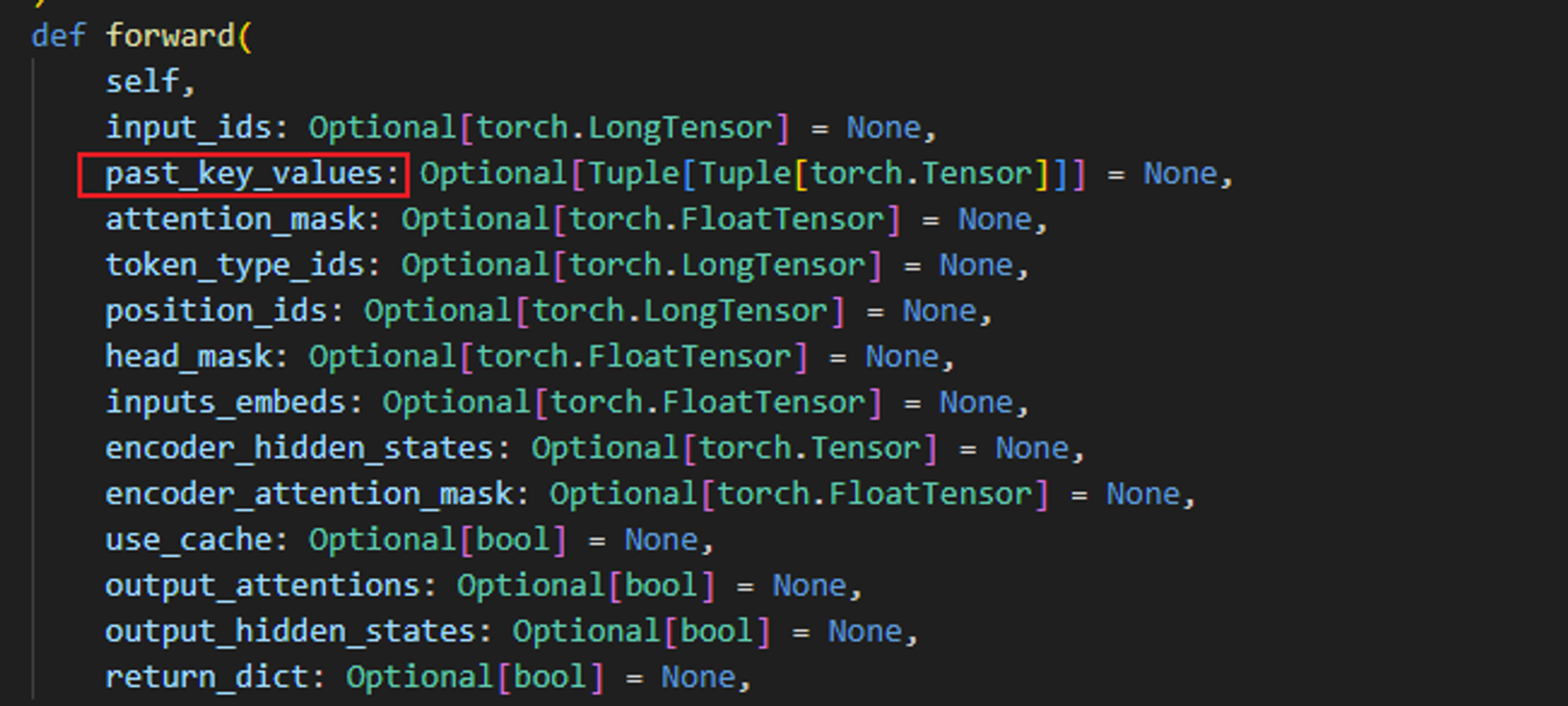
BUG TypeError: GPT2Model.forward() got an unexpected keyword argument ‘past’
TypeError: GPT2Model.forward() got an unexpected keyword argument past’ 环境 transformers 4.38.1详情 这是由于新版的transformers 对GPT2Model.forward() 参数进行了改变导致的错误。具体是past名称改为了 past_key_values 。 解决方法 找到错误语…...

解析Kotlin中的Lambda【笔记摘要】
先看实例: fun b(param: Int): String {return param.toString() }fun a(funParam: (Int) -> String): String {return funParam(1) }a(::b) val d ::b1.双冒号 ::method 到底是什么?答:一个指向和该函数具有相同功能的对象的引用 因为…...

rust单元测试顺序执行
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站。 存在的问题 有时候,不同单元测试之间可能会竞争相同的资源,比如读写相同的文件。在这种情况下,如果…...

力扣-744. 寻找比目标字母大的最小字母
文章目录 力扣题目代码工程 力扣题目 给你一个字符数组 letters,该数组按非递减顺序排序,以及一个字符 target。letters 里至少有两个不同的字符。 返回 letters 中大于 target 的最小的字符。如果不存在这样的字符,则返回 letters 的第一个…...

一篇文章搞懂弹性云服务器和轻量云服务器的区别
前言 在众多的云服务器类型中,弹性云服务器和轻量云服务器因其各自的特点和优势,受到了广大用户的青睐。那么,这两者之间到底有哪些区别呢?本文将为您详细解析。 弹性云服务器:灵活多变的计算资源池 弹性云服务器&…...

横穿自动驾驶
如果有一条线,可以穿起来所有自动驾驶的核心模块,那么我感觉它就是最优化,选择优化变量、构造优化问题、求解优化问题,这几个步骤贯穿了自动驾驶的始终。 先从我的自身接触顺序写起。最开始做个一点深度学习,那还是20…...

为什么网上商店需要翻译成其他语言
网上商店不仅仅是一个可以买到商品的网站。它是一个完整的电子商务平台,为来自世界各地的用户提供购买所需物品的机会。但是,为了让这些用户舒适地使用网站,需要高质量的翻译和本地化。 本地化是指产品或服务适应特定文化或市场的过程。它包…...

【高考志愿】交通运输工程
目录 一、专业概述 二、课程设置 三、就业前景 四、报考注意 五、未来发展 六、交通运输工程专业排名 高考志愿选择交通运输工程专业,无疑是一个既具远见又富有挑战性的决定。这个专业以其综合性强、实用性高的特点,吸引了大批有志于投身交通事业的…...
【深度学习】【Lora训练3】StabelDiffusion,Lora训练过程,秋叶包,Linux,SDXL Lora训练
为了便于使用,构建一个docker镜像来使用秋叶包。2024年6月26日。 docker run -it --gpus all -v /ssd/xiedong:/datax --net host kevinchina/deeplearning:pytorch2.3.0-cuda12.1-cudnn8-devel-xformers bashgit clone --recurse-submodules https://github.com/A…...

ubuntu系统下如何安装python
在Ubuntu系统下安装Python,有多种方法可供选择。以下是两种常见的方法: 一、使用apt包管理器安装 安装步骤如下: 首先更新软件包列表 sudo apt update安装Python 3: 输入以下命令以安装Python 3(Ubuntu的默认Pyth…...

邦芒攻略:职场中学会这五种管好情绪的方法
我们在公司里面在跟同事的一些往来,或者说是工作的一些合作当中。相信很多人都会有与周围的一些人发生过一些各种的争执,或者说是一些分歧。当然作为每一个职场的人来说,每天都是工作很累的,也是都很辛苦的,所以说…...

业务系统对接大模型的基础方案:架构设计与关键步骤
业务系统对接大模型:架构设计与关键步骤 在当今数字化转型的浪潮中,大语言模型(LLM)已成为企业提升业务效率和创新能力的关键技术之一。将大模型集成到业务系统中,不仅可以优化用户体验,还能为业务决策提供…...

Qt Widget类解析与代码注释
#include "widget.h" #include "ui_widget.h"Widget::Widget(QWidget *parent): QWidget(parent), ui(new Ui::Widget) {ui->setupUi(this); }Widget::~Widget() {delete ui; }//解释这串代码,写上注释 当然可以!这段代码是 Qt …...

UDP(Echoserver)
网络命令 Ping 命令 检测网络是否连通 使用方法: ping -c 次数 网址ping -c 3 www.baidu.comnetstat 命令 netstat 是一个用来查看网络状态的重要工具. 语法:netstat [选项] 功能:查看网络状态 常用选项: n 拒绝显示别名&#…...

蓝牙 BLE 扫描面试题大全(2):进阶面试题与实战演练
前文覆盖了 BLE 扫描的基础概念与经典问题蓝牙 BLE 扫描面试题大全(1):从基础到实战的深度解析-CSDN博客,但实际面试中,企业更关注候选人对复杂场景的应对能力(如多设备并发扫描、低功耗与高发现率的平衡)和前沿技术的…...

【ROS】Nav2源码之nav2_behavior_tree-行为树节点列表
1、行为树节点分类 在 Nav2(Navigation2)的行为树框架中,行为树节点插件按照功能分为 Action(动作节点)、Condition(条件节点)、Control(控制节点) 和 Decorator(装饰节点) 四类。 1.1 动作节点 Action 执行具体的机器人操作或任务,直接与硬件、传感器或外部系统…...

鸿蒙中用HarmonyOS SDK应用服务 HarmonyOS5开发一个医院查看报告小程序
一、开发环境准备 工具安装: 下载安装DevEco Studio 4.0(支持HarmonyOS 5)配置HarmonyOS SDK 5.0确保Node.js版本≥14 项目初始化: ohpm init harmony/hospital-report-app 二、核心功能模块实现 1. 报告列表…...

2025盘古石杯决赛【手机取证】
前言 第三届盘古石杯国际电子数据取证大赛决赛 最后一题没有解出来,实在找不到,希望有大佬教一下我。 还有就会议时间,我感觉不是图片时间,因为在电脑看到是其他时间用老会议系统开的会。 手机取证 1、分析鸿蒙手机检材&#x…...

用机器学习破解新能源领域的“弃风”难题
音乐发烧友深有体会,玩音乐的本质就是玩电网。火电声音偏暖,水电偏冷,风电偏空旷。至于太阳能发的电,则略显朦胧和单薄。 不知你是否有感觉,近两年家里的音响声音越来越冷,听起来越来越单薄? —…...

Java毕业设计:WML信息查询与后端信息发布系统开发
JAVAWML信息查询与后端信息发布系统实现 一、系统概述 本系统基于Java和WML(无线标记语言)技术开发,实现了移动设备上的信息查询与后端信息发布功能。系统采用B/S架构,服务器端使用Java Servlet处理请求,数据库采用MySQL存储信息࿰…...

使用LangGraph和LangSmith构建多智能体人工智能系统
现在,通过组合几个较小的子智能体来创建一个强大的人工智能智能体正成为一种趋势。但这也带来了一些挑战,比如减少幻觉、管理对话流程、在测试期间留意智能体的工作方式、允许人工介入以及评估其性能。你需要进行大量的反复试验。 在这篇博客〔原作者&a…...