昇思25天学习打卡营第11天 | LLM原理和实践:基于MindSpore实现BERT对话情绪识别
1. 基于MindSpore实现BERT对话情绪识别
1.1 环境配置
# 实验环境已经预装了mindspore==2.2.14,如需更换mindspore版本,可更改下面mindspore的版本号
!pip uninstall mindspore -y
!pip install -i https://pypi.mirrors.ustc.edu.cn/simple mindspore==2.2.14# 该案例在 mindnlp 0.3.1 版本完成适配,如果发现案例跑不通,可以指定mindnlp版本,执行`!pip install mindnlp==0.3.1`
!pip install mindnlp
!pip show mindspore
Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple
Collecting mindnlp==0.3.1Downloading https://pypi.tuna.tsinghua.edu.cn/packages/72/37/ef313c23fd587c3d1f46b0741c98235aecdfd93b4d6d446376f3db6a552c/mindnlp-0.3.1-py3-none-any.whl (5.7 MB)━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 5.7/5.7 MB 18.8 MB/s eta 0:00:00a 0:00:01
...
Requirement already satisfied: tzdata>=2022.7 in /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages (from pandas->datasets->mindnlp==0.3.1) (2024.1)
Building wheels for collected packages: jiebaBuilding wheel for jieba (setup.py) ... doneCreated wheel for jieba: filename=jieba-0.42.1-py3-none-any.whl size=19314459 sha256=9ddea89911261cc55a74d51c5bd604e293e2c08b73a29597c8fde9ed0dc8dfc7Stored in directory: /home/nginx/.cache/pip/wheels/1a/76/68/b6d79c4db704bb18d54f6a73ab551185f4711f9730c0c15d97
Successfully built jieba
Installing collected packages: sortedcontainers, sentencepiece, pygtrie, jieba, addict, xxhash, safetensors, regex, pytest, pyarrow-hotfix, pyarrow, multiprocess, multidict, ml-dtypes, hypothesis, fsspec, frozenlist, async-timeout, yarl, pyctcdecode, aiosignal, tokenizers, aiohttp, datasets, evaluate, mindnlpAttempting uninstall: pytestFound existing installation: pytest 8.0.0Uninstalling pytest-8.0.0:Successfully uninstalled pytest-8.0.0Attempting uninstall: fsspecFound existing installation: fsspec 2024.6.0Uninstalling fsspec-2024.6.0:Successfully uninstalled fsspec-2024.6.0
Successfully installed addict-2.4.0 aiohttp-3.9.5 aiosignal-1.3.1 async-timeout-4.0.3 datasets-2.20.0 evaluate-0.4.2 frozenlist-1.4.1 fsspec-2024.5.0 hypothesis-6.105.0 jieba-0.42.1 mindnlp-0.3.1 ml-dtypes-0.4.0 multidict-6.0.5 multiprocess-0.70.16 pyarrow-16.1.0 pyarrow-hotfix-0.6 pyctcdecode-0.5.0 pygtrie-2.5.0 pytest-7.2.0 regex-2024.5.15 safetensors-0.4.3 sentencepiece-0.2.0 sortedcontainers-2.4.0 tokenizers-0.19.1 xxhash-3.4.1 yarl-1.9.4
Name: mindspore
Version: 2.2.14
Summary: MindSpore is a new open source deep learning training/inference framework that could be used for mobile, edge and cloud scenarios.
Home-page: https://www.mindspore.cn
Author: The MindSpore Authors
Author-email: contact@mindspore.cn
License: Apache 2.0
Location: /home/nginx/miniconda/envs/jupyter/lib/python3.9/site-packages
Requires: asttokens, astunparse, numpy, packaging, pillow, protobuf, psutil, scipy
Required-by: mindnlp
1.2 模型简介
BERT全称是来自变换器的双向编码器表征量(Bidirectional Encoder Representations from Transformers),它是Google于2018年末开发并发布的一种新型语言模型。与BERT模型相似的预训练语言模型例如问答、命名实体识别、自然语言推理、文本分类等在许多自然语言处理任务中发挥着重要作用。模型是基于Transformer中的Encoder并加上双向的结构,因此一定要熟练掌握Transformer的Encoder的结构。
BERT模型的主要创新点都在pre-train方法上,即用了Masked Language Model和Next Sentence Prediction两种方法分别捕捉词语和句子级别的representation。
在用Masked Language Model方法训练BERT的时候,随机把语料库中15%的单词做Mask操作。对于这15%的单词做Mask操作分为三种情况:80%的单词直接用[Mask]替换、10%的单词直接替换成另一个新的单词、10%的单词保持不变。
因为涉及到Question Answering (QA) 和 Natural Language Inference (NLI)之类的任务,增加了Next Sentence Prediction预训练任务,目的是让模型理解两个句子之间的联系。与Masked Language Model任务相比,Next Sentence Prediction更简单些,训练的输入是句子A和B,B有一半的几率是A的下一句,输入这两个句子,BERT模型预测B是不是A的下一句。
BERT预训练之后,会保存它的Embedding table和12层Transformer权重(BERT-BASE)或24层Transformer权重(BERT-LARGE)。使用预训练好的BERT模型可以对下游任务进行Fine-tuning,比如:文本分类、相似度判断、阅读理解等。
对话情绪识别(Emotion Detection,简称EmoTect),专注于识别智能对话场景中用户的情绪,针对智能对话场景中的用户文本,自动判断该文本的情绪类别并给出相应的置信度,情绪类型分为积极、消极、中性。 对话情绪识别适用于聊天、客服等多个场景,能够帮助企业更好地把握对话质量、改善产品的用户交互体验,也能分析客服服务质量、降低人工质检成本。
下面以一个文本情感分类任务为例子来说明BERT模型的整个应用过程。
- 导入依赖
# 导入os模块,提供了一种方便的方式来使用操作系统相关的功能。
import os# 导入mindspore模块,这是一个面向AI的深度学习框架。
import mindspore# 从mindspore.dataset子模块中导入text、GeneratorDataset和transforms,这些都是用于数据处理的工具。
# text用于处理文本数据,GeneratorDataset用于创建自定义的数据集,transforms用于数据增强和预处理。
from mindspore.dataset import text, GeneratorDataset, transforms# 从mindspore模块中导入nn和context。
# nn是构建神经网络层的模块,context是用于设置运行环境的模块,如硬件设备、运行模式等。
from mindspore import nn, context# 从mindnlp._legacy.engine子模块中导入Trainer和Evaluator。
# Trainer是训练模型的类,Evaluator是评估模型的类。
from mindnlp._legacy.engine import Trainer, Evaluator# 从mindnlp._legacy.engine.callbacks子模块中导入CheckpointCallback和BestModelCallback。
# CheckpointCallback用于在训练过程中保存模型的权重,BestModelCallback用于保存评估结果最好的模型。
from mindnlp._legacy.engine.callbacks import CheckpointCallback, BestModelCallback# 从mindnlp._legacy.metrics子模块中导入Accuracy,这是一个用于计算准确率的评估指标。
from mindnlp._legacy.metrics import Accuracy输出:
Building prefix dict from the default dictionary ...
Dumping model to file cache /tmp/jieba.cache
Loading model cost 1.032 seconds.
Prefix dict has been built successfully.
大意为:
正在从默认词典构建前缀词典…
正在将模型转储到文件缓存 /tmp/jieba.cache
加载模型耗时1.032秒。
前缀词典已成功构建。
# 准备数据集
class SentimentDataset:"""情感数据集"""def __init__(self, path):self.path = path # 初始化数据集路径self._labels, self._text_a = [], [] # 初始化标签和文本列表self._load() # 调用加载函数def _load(self):# 以只读模式打开指定路径的文件,并指定编码为utf-8with open(self.path, "r", encoding="utf-8") as f:dataset = f.read() # 读取文件内容lines = dataset.split("\n") # 按行分割文件内容for line in lines[1:-1]: # 跳过标题行和最后一个空行label, text_a = line.split("\t") # 按制表符分割每行,获取标签和文本self._labels.append(int(label)) # 将标签转换为整数并添加到标签列表self._text_a.append(text_a) # 将文本添加到文本列表def __getitem__(self, index):# 实现getitem方法,以便能够通过索引访问数据集的元素return self._labels[index], self._text_a[index] # 返回对应索引的标签和文本def __len__(self):# 实现len方法,以便能够获取数据集的大小return len(self._labels) # 返回标签列表的长度,即数据集的大小1.3 数据集
这里提供一份已标注的、经过分词预处理的机器人聊天数据集,来自于百度飞桨团队。数据由两列组成,以制表符(‘\t’)分隔,第一列是情绪分类的类别(0表示消极;1表示中性;2表示积极),第二列是以空格分词的中文文本,如下示例,文件为 utf8 编码。
label–text_a
0–谁骂人了?我从来不骂人,我骂的都不是人,你是人吗 ?
1–我有事等会儿就回来和你聊
2–我见到你很高兴谢谢你帮我
这部分主要包括数据集读取,数据格式转换,数据 Tokenize 处理和 pad 操作。
# 使用wget命令从百度NLP的官方网站下载情感检测数据集的压缩文件
# 并将下载的文件重命名为emotion_detection.tar.gz
!wget https://baidu-nlp.bj.bcebos.com/emotion_detection-dataset-1.0.0.tar.gz -O emotion_detection.tar.gz# 使用tar命令解压下载的emotion_detection.tar.gz文件
!tar xvf emotion_detection.tar.gz
输出:
--2024-07-04 23:28:31-- https://baidu-nlp.bj.bcebos.com/emotion_detection-dataset-1.0.0.tar.gz
Resolving baidu-nlp.bj.bcebos.com (baidu-nlp.bj.bcebos.com)... 119.249.103.5, 113.200.2.111, 2409:8c04:1001:1203:0:ff:b0bb:4f27
Connecting to baidu-nlp.bj.bcebos.com (baidu-nlp.bj.bcebos.com)|119.249.103.5|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 1710581 (1.6M) [application/x-gzip]
Saving to: ‘emotion_detection.tar.gz’emotion_detection.t 100%[===================>] 1.63M 10.9MB/s in 0.2s 2024-07-04 23:28:31 (10.9 MB/s) - ‘emotion_detection.tar.gz’ saved [1710581/1710581]data/
data/test.tsv
data/infer.tsv
data/dev.tsv
data/train.tsv
data/vocab.txt
1.3.1 数据加载和数据预处理
新建 process_dataset 函数用于数据加载和数据预处理,具体内容可见下面代码注释。
import numpy as np# 定义一个处理数据集的函数,它接受源数据、分词器、最大序列长度、批处理大小和是否打乱数据集的参数
def process_dataset(source, tokenizer, max_seq_len=64, batch_size=32, shuffle=True):# 判断当前设备是否为Ascend AI处理器is_ascend = mindspore.get_context('device_target') == 'Ascend'# 定义数据集中的列名column_names = ["label", "text_a"]# 创建一个生成器数据集,使用指定的列名和是否打乱数据集的参数dataset = GeneratorDataset(source, column_names=column_names, shuffle=shuffle)# 定义类型转换操作,将数据类型转换为mindspore.int32type_cast_op = transforms.TypeCast(mindspore.int32)# 定义一个函数,用于对文本进行分词和填充def tokenize_and_pad(text):# 如果是Ascend设备,则使用特定的分词参数if is_ascend:tokenized = tokenizer(text, padding='max_length', truncation=True, max_length=max_seq_len)else:tokenized = tokenizer(text)# 返回输入ID和注意力掩码return tokenized['input_ids'], tokenized['attention_mask']# 对数据集进行映射操作,应用分词和填充函数,并指定输入和输出列dataset = dataset.map(operations=tokenize_and_pad, input_columns="text_a", output_columns=['input_ids', 'attention_mask'])# 对数据集进行映射操作,应用类型转换操作,并指定输入和输出列dataset = dataset.map(operations=[type_cast_op], input_columns="label", output_columns='labels')# 如果是Ascend设备,则直接批处理数据集if is_ascend:dataset = dataset.batch(batch_size)else:# 如果不是Ascend设备,则使用填充的批处理,并指定填充信息dataset = dataset.padded_batch(batch_size, pad_info={'input_ids': (None, tokenizer.pad_token_id),'attention_mask': (None, 0)})# 返回处理后的数据集return dataset昇腾NPU环境下暂不支持动态Shape,数据预处理部分采用静态Shape处理:
# 从mindnlp.transformers模块中导入BertTokenizer类
from mindnlp.transformers import BertTokenizer# 使用BertTokenizer的from_pretrained静态方法创建一个分词器实例
# 该方法会根据预训练模型的名称加载预训练的权重和配置
# 在这个例子中,加载的是'bert-base-chinese'模型的分词器
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')输出:
100%49.0/49.0 [00:00<00:00, 3.10kB/s]107k/0.00 [00:00<00:00, 103kB/s]263k/0.00 [00:00<00:00, 161kB/s]624/? [00:00<00:00, 62.9kB/s]
from_pretrained方法会从互联网上下载预训练的模型权重和配置,如果已经下载过,则会从本地缓存中加载。
tokenizer.pad_token_id
输出:
0
# 使用SentimentDataset类创建训练数据集,传入训练数据的路径
dataset_train = process_dataset(SentimentDataset("data/train.tsv"), tokenizer)# 使用SentimentDataset类创建验证数据集,传入验证数据的路径
dataset_val = process_dataset(SentimentDataset("data/dev.tsv"), tokenizer)# 使用SentimentDataset类创建测试数据集,传入测试数据的路径,并且指定shuffle参数为False,表示不进行数据打乱
dataset_test = process_dataset(SentimentDataset("data/test.tsv"), tokenizer, shuffle=False)# 调用dataset_train对象的get_col_names方法
# 这个方法会返回数据集中的列名列表
dataset_train.get_col_names()输出:
['input_ids', 'attention_mask', 'labels']
# 调用dataset_train数据集的create_tuple_iterator()方法,创建一个元组迭代器
# 使用next()函数获取迭代器的下一个元素,即数据集中的第一个元素
# 并将该元素的内容打印出来,这将显示数据集中的一个样本,包括其特征和标签
print(next(dataset_train.create_tuple_iterator()))输出:
[Tensor(shape=[32, 64], dtype=Int64, value=
[[ 101, 1914, 1568 ... 0, 0, 0],[ 101, 872, 812 ... 0, 0, 0],[ 101, 5314, 872 ... 0, 0, 0],...[ 101, 6929, 872 ... 0, 0, 0],[ 101, 1343, 6859 ... 0, 0, 0],[ 101, 2428, 677 ... 0, 0, 0]]), Tensor(shape=[32, 64], dtype=Int64, value=
[[1, 1, 1 ... 0, 0, 0],[1, 1, 1 ... 0, 0, 0],[1, 1, 1 ... 0, 0, 0],...[1, 1, 1 ... 0, 0, 0],[1, 1, 1 ... 0, 0, 0],[1, 1, 1 ... 0, 0, 0]]), Tensor(shape=[32], dtype=Int32, value= [2, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 0, 0, 1, 0, 1, 1, 0, 0, 1, 1, 1, 1, 2, 2, 2, 1, 1])]
1.4 模型构建
通过 BertForSequenceClassification 构建用于情感分类的 BERT 模型,加载预训练权重,设置情感三分类的超参数自动构建模型。后面对模型采用自动混合精度操作,提高训练的速度,然后实例化优化器,紧接着实例化评价指标,设置模型训练的权重保存策略,最后就是构建训练器,模型开始训练。
# 从mindnlp.transformers模块中导入BertForSequenceClassification和BertModel类
from mindnlp.transformers import BertForSequenceClassification, BertModel# 从mindnlp._legacy.amp模块中导入auto_mixed_precision函数
from mindnlp._legacy.amp import auto_mixed_precision# 使用BertForSequenceClassification的from_pretrained静态方法加载预训练的BERT模型
# 指定num_labels参数为3,因为情感分类任务有3个标签
model = BertForSequenceClassification.from_pretrained('bert-base-chinese', num_labels=3)# 使用auto_mixed_precision函数对模型进行自动混合精度训练
# 'O1'表示使用16位浮点数进行部分训练,以提高训练速度和减少内存消耗
model = auto_mixed_precision(model, 'O1')# 创建一个Adam优化器实例,传入模型的训练参数和学习率
# 学习率设置为2e-5,这是一个常见的BERT模型学习率
optimizer = nn.Adam(model.trainable_params(), learning_rate=2e-5)输出:
The following parameters in checkpoint files are not loaded:
['cls.predictions.bias', 'cls.predictions.transform.dense.bias', 'cls.predictions.transform.dense.weight', 'cls.seq_relationship.bias', 'cls.seq_relationship.weight', 'cls.predictions.transform.LayerNorm.bias', 'cls.predictions.transform.LayerNorm.weight']
The following parameters in models are missing parameter:
['classifier.weight', 'classifier.bias']
模型有一堆参数没有加载…不知道是否影响…
# 创建一个Accuracy指标实例,用于评估模型的准确性
metric = Accuracy()# 定义用于保存检查点的回调函数
# CheckpointCallback将在每个epoch结束时保存检查点,并指定保存路径和检查点文件名
# keep_checkpoint_max参数指定最多保留的检查点文件数
ckpoint_cb = CheckpointCallback(save_path='checkpoint', ckpt_name='bert_emotect', epochs=1, keep_checkpoint_max=2)# BestModelCallback将在验证集上评估模型性能,并在性能提升时保存最佳模型的检查点
# auto_load参数设置为True,表示在训练结束后自动加载最佳模型的检查点
best_model_cb = BestModelCallback(save_path='checkpoint', ckpt_name='bert_emotect_best', auto_load=True)# 创建一个Trainer实例,用于训练模型
# network参数指定要训练的模型
# train_dataset参数指定训练数据集
# eval_dataset参数指定验证数据集
# metrics参数指定评估模型性能的指标
# epochs参数指定训练的轮数
# optimizer参数指定优化器
# callbacks参数指定训练过程中使用的回调函数列表
trainer = Trainer(network=model, train_dataset=dataset_train,eval_dataset=dataset_val, metrics=metric,epochs=5, optimizer=optimizer, callbacks=[ckpoint_cb, best_model_cb])
# 打印时间
%%time
# 使用Trainer的run方法启动模型训练
# tgt_columns参数指定目标列名,即模型需要预测的标签列名
trainer.run(tgt_columns="labels")输出:
The train will start from the checkpoint saved in 'checkpoint'.
Epoch 0: 100%302/302 [04:14<00:00, 2.11s/it, loss=0.34553832]
Checkpoint: 'bert_emotect_epoch_0.ckpt' has been saved in epoch: 0.
Evaluate: 100%34/34 [00:16<00:00, 3.44s/it]
Evaluate Score: {'Accuracy': 0.9083333333333333}
---------------Best Model: 'bert_emotect_best.ckpt' has been saved in epoch: 0.---------------
Epoch 1: 100%302/302 [02:41<00:00, 1.91it/s, loss=0.19056101]
Checkpoint: 'bert_emotect_epoch_1.ckpt' has been saved in epoch: 1.
Evaluate: 100%34/34 [00:05<00:00, 6.80it/s]
Evaluate Score: {'Accuracy': 0.9611111111111111}
---------------Best Model: 'bert_emotect_best.ckpt' has been saved in epoch: 1.---------------
Epoch 2: 100%302/302 [02:41<00:00, 1.91it/s, loss=0.12954864]
The maximum number of stored checkpoints has been reached.
Checkpoint: 'bert_emotect_epoch_2.ckpt' has been saved in epoch: 2.
Evaluate: 100%34/34 [00:04<00:00, 8.05it/s]
Evaluate Score: {'Accuracy': 0.9833333333333333}
---------------Best Model: 'bert_emotect_best.ckpt' has been saved in epoch: 2.---------------
Epoch 3: 100%302/302 [02:41<00:00, 1.90it/s, loss=0.08371902]
The maximum number of stored checkpoints has been reached.
Checkpoint: 'bert_emotect_epoch_3.ckpt' has been saved in epoch: 3.
Evaluate: 100%34/34 [00:04<00:00, 7.65it/s]
Evaluate Score: {'Accuracy': 0.9916666666666667}
---------------Best Model: 'bert_emotect_best.ckpt' has been saved in epoch: 3.---------------
Epoch 4: 100%302/302 [02:41<00:00, 1.91it/s, loss=0.06113353]
The maximum number of stored checkpoints has been reached.
Checkpoint: 'bert_emotect_epoch_4.ckpt' has been saved in epoch: 4.
Evaluate: 100%34/34 [00:04<00:00, 7.82it/s]
Evaluate Score: {'Accuracy': 0.9935185185185185}
---------------Best Model: 'bert_emotect_best.ckpt' has been saved in epoch: 4.---------------
Loading best model from 'checkpoint' with '['Accuracy']': [0.9935185185185185]...
---------------The model is already load the best model from 'bert_emotect_best.ckpt'.---------------
CPU times: user 23min 36s, sys: 13min 1s, total: 36min 37s
Wall time: 15min 51s
5轮训练后,准确率达到了99.35%(相对于训练数据集来说)
1.5 模型验证
将验证数据集加再进训练好的模型,对数据集进行验证,查看模型在验证数据上面的效果,此处的评价指标为准确率。
# 创建一个Evaluator实例,用于评估模型性能
# network参数指定要评估的模型
# eval_dataset参数指定评估数据集
# metrics参数指定评估模型性能的指标
evaluator = Evaluator(network=model, eval_dataset=dataset_test, metrics=metric)# 使用Evaluator的run方法评估模型性能
# tgt_columns参数指定目标列名,即模型需要预测的标签列名
evaluator.run(tgt_columns="labels")输出:
Evaluate: 100%33/33 [00:08<00:00, 1.26s/it]
Evaluate Score: {'Accuracy': 0.9063706563706564}
在验证数据集上的准确率为90.64%
1.6 模型推理
遍历推理数据集,将结果与标签进行统一展示。
# 创建一个SentimentDataset实例,用于推理数据
# 传入推理数据的路径
dataset_infer = SentimentDataset("data/infer.tsv")# 定义一个预测函数,接受文本和标签(可选)作为输入
def predict(text, label=None):# 定义一个标签映射字典,将标签ID转换为对应的标签名称label_map = {0: "消极", 1: "中性", 2: "积极"}# 使用tokenizer对文本进行分词,并将结果转换为Tensor# Tensor是一个用于存储多维数组的类text_tokenized = Tensor([tokenizer(text).input_ids])# 使用模型对文本进行预测,获取logitslogits = model(text_tokenized)# 获取预测标签,即logits中最大值的索引predict_label = logits[0].asnumpy().argmax()# 构建信息字符串,包含输入文本、预测标签和(如果有的话)真实标签info = f"inputs: '{text}', predict: '{label_map[predict_label]}'"if label is not None:info += f" , label: '{label_map[label]}'"# 打印信息字符串print(info)# 导入Tensor类,用于存储多维数组
from mindspore import Tensor# 遍历dataset_infer数据集,使用predict函数对每个文本进行预测
# 并打印预测结果
for label, text in dataset_infer:predict(text, label)输出:
inputs: '我 要 客观', predict: '中性' , label: '中性'
inputs: 'KAO 你 真是 说 废话 吗', predict: '消极' , label: '消极'
inputs: '口嗅 会', predict: '中性' , label: '中性'
inputs: '每次 是 表妹 带 窝 飞 因为 窝路痴', predict: '中性' , label: '中性'
inputs: '别说 废话 我 问 你 个 问题', predict: '消极' , label: '消极'
inputs: '4967 是 新加坡 那 家 银行', predict: '中性' , label: '中性'
inputs: '是 我 喜欢 兔子', predict: '积极' , label: '积极'
inputs: '你 写 过 黄山 奇石 吗', predict: '中性' , label: '中性'
inputs: '一个一个 慢慢来', predict: '中性' , label: '中性'
inputs: '我 玩 过 这个 一点 都 不 好玩', predict: '消极' , label: '消极'
inputs: '网上 开发 女孩 的 QQ', predict: '中性' , label: '中性'
inputs: '背 你 猜 对 了', predict: '中性' , label: '中性'
inputs: '我 讨厌 你 , 哼哼 哼 。 。', predict: '消极' , label: '消极'
1.7 自定义推理数据集
自己输入推理数据,展示模型的泛化能力。
predict("家人们咱就是说一整个无语住了 绝绝子debuff")
predict("今天真是太倒霉了")
predict("今天天气不错")
输出:

2. 小结
本文主要介绍了用MindSpore实现BERT对话情绪识别的过程。主要包括环境配置、数据集下载、加载和预处理,模型构建和训练、模型验证、模型推理和模型泛化能力测试等方面。
相关文章:
昇思25天学习打卡营第11天 | LLM原理和实践:基于MindSpore实现BERT对话情绪识别
1. 基于MindSpore实现BERT对话情绪识别 1.1 环境配置 # 实验环境已经预装了mindspore2.2.14,如需更换mindspore版本,可更改下面mindspore的版本号 !pip uninstall mindspore -y !pip install -i https://pypi.mirrors.ustc.edu.cn/simple mindspore2.2…...

反向散射技术(backscatter communication)
智能反射表面辅助的反向散射通信系统研究综述(知网) 1 反向散射通信技术优势和应用场景 反向散射通信技术通过被动射频技术发送信号,不需要一定配有主动射频单元,被认为是构建绿色节能、低成本、可灵活部署的未来物联网规模化应用关键技术之一,是实现“…...

致远CopyFile文件复制漏洞
复现版本 V8.0SP2 漏洞范围 V5&G6_V6.1至V8.0SP2全系列版本、V5&G6&N_V8.1至V8.1SP2全系列版本。 漏洞复现 上传文件 POST /seeyon/ajax.do?methodajaxAction&managerNameportalCssManager&rnd57507 HTTP/1.1 Accept: */* Content-Type: applicatio…...

MySQL 创建数据库
MySQL 创建数据库 在当今的数据驱动世界中,数据库是任何应用程序的核心组成部分。MySQL,作为一个流行的开源关系数据库管理系统,因其可靠性、易用性和强大的功能而广受欢迎。本文将详细介绍如何在MySQL中创建数据库,包括基础知识和最佳实践。 什么是MySQL数据库? MySQL…...

AbyssFish单连通周期边界多孔结构2D软件
软件介绍 AbyssFish单连通周期边界多孔结构2D软件(以下简称软件)可用于生成具备周期性边界条件的单连通域多孔结构PNG图片,软件可设置生成模型的尺寸、孔隙率、孔隙尺寸、孔喉尺寸等参数,并且具备孔隙形态控制功能。 软件生成的…...

Linux驱动开发-03字符设备驱动框架搭建
一、字符设备驱动开发步骤 驱动模块的加载和卸载(将驱动编译模块,insmod加载驱动运行)字符设备注册与注销(我们的驱动实际上是去操作底层的硬件,所以需要向系统注册一个设备,告诉Linux系统,我有…...

Zynq系列FPGA实现SDI视频编解码+图像缩放+多路视频拼接,基于GTX高速接口,提供8套工程源码和技术支持
目录 1、前言工程概述免责声明 2、相关方案推荐本博已有的 SDI 编解码方案本博已有的FPGA图像缩放方案本方案的无缩放应用本方案在Xilinx--Kintex系列FPGA上的应用 3、详细设计方案设计原理框图SDI 输入设备Gv8601a 均衡器GTX 解串与串化SMPTE SD/HD/3G SDI IP核BT1120转RGB自研…...

VS2019使用C#写窗体程序技巧(1)
1、打开串口 private void button1_Click(object sender, EventArgs e){myPort cmb1.Text;mybaud Convert.ToInt32(cmb2.Text, 10);databit 8;parity Parity.None;stopBit StopBits.One;textBox9.Text "2";try{sp new SerialPort(myPort, mybaud, parity, dat…...

Python爬虫-requests模块
前戏: 1.你是否在夜深人静的时候,想看一些会让你更睡不着的图片却苦于没有资源... 2.你是否在节假日出行高峰的时候,想快速抢购火车票成功..。 3.你是否在网上购物的时候,想快速且精准的定位到口碑质量最好的商品. …...

适用于PyTorch 2.0.0的Ubuntu 22.04上CUDA v11.8和cuDNN 8.7安装指南
将下面内容保存为install.bash,直接用bash执行一把梭解决 #!/bin/bash### steps #### # verify the system has a cuda-capable gpu # download and install the nvidia cuda toolkit and cudnn # setup environmental variables # verify the installation ######…...

使用conda安装openturns
目录 1. 有效方法2. 整体分析使用pip安装使用conda安装验证安装安装过程中可能遇到的问题 1. 有效方法 conda install -c conda-forge openturns2. 整体分析 OpenTURNS是一个用于概率和统计分析的软件库,主要用于不确定性量化。你可以通过以下步骤在Python环境中安…...

Chameleon:动态UI框架使用详解
文章目录 引言Chameleon框架原理核心概念工作流程 基础使用安装与配置创建基础界面 高级使用自定义组件响应式布局数据流与状态管理 结论 引言 Chameleon,作为一种动态UI框架,旨在通过灵活、高效的方式帮助开发者构建跨平台、响应用户交互的图形用户界面…...

7.10飞书一面面经
问题描述 Redis为什么快? 这个问题我遇到过,但是没有好好总结,导致答得很乱。 答:Redis基于内存操作: 传统的磁盘文件操作相比减少了IO,提高了操作的速度。 Redis高效的数据结构:Redis专门设计…...

[数据结构] 归并排序快速排序 及非递归实现
()标题:[数据结构] 归并排序&&快速排序 及非递归实现 水墨不写bug (图片来源于网络) 目录 (一)快速排序 类比递归谋划非递归 快速排序的非递归实现: (二)归并排序 归…...

面试题 12. 矩阵中的路径
矩阵中的路径 题目描述示例 题解 题目描述 给定一个 m x n 二维字符网格 board 和一个字符串单词 word 。如果 word 存在于网格中,返回 true ;否则,返回 false 。 单词必须按照字母顺序,通过相邻的单元格内的字母构成࿰…...

钉钉扫码登录第三方
钉钉文档 实现登录第三方网站 - 钉钉开放平台 (dingtalk.com) html页面 将html放在 <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8"><title>登录</title>// jquery<script src"http://code.jqu…...

多GPU系统中的CUDA设备不可用问题
我们在使用多GPU系统时遇到了CUDA设备不可用的问题,详细情况如下: 问题描述: 我们在一台配备有8块NVIDIA GeForce RTX 3090显卡的服务器上运行CUDA程序时,遇到了如下错误: cudaErrorDevicesUnavailable: CUDA-capabl…...

python的列表推导式
文章目录 前言一、解释列表推导式二、在这句代码中的应用三、示例四、使用 for 循环的等价代码总结 前言 看看这一行代码:questions [q.strip() for q in examples["question"]] ,问题是最外层的 中括号是做什么的? 最外层的中括…...

类与对象(2)
我们在了解了类的简单创建后,需要对类的创建与销毁有进一步的了解,也就是对于类的构造函数与析构函数的了解。 目录 注意: 构造函数的特性: 析构函数: 注意: 该部分内容为重难点内容,在正常…...

迂回战术:“另类“全新安装 macOS 15 Sequoia beta2 的极简方法
概述 随着 WWDC 24 的胜利闭幕,Apple 平台上各种 beta 版的系统也都“跃跃欲出”,在 mac 上自然也不例外。 本次全新的 macOS 15 Sequoia(红杉)包含了诸多重磅升级,作为秃头开发者的我们怎么能不先睹为快呢࿱…...

利用最小二乘法找圆心和半径
#include <iostream> #include <vector> #include <cmath> #include <Eigen/Dense> // 需安装Eigen库用于矩阵运算 // 定义点结构 struct Point { double x, y; Point(double x_, double y_) : x(x_), y(y_) {} }; // 最小二乘法求圆心和半径 …...

Docker 离线安装指南
参考文章 1、确认操作系统类型及内核版本 Docker依赖于Linux内核的一些特性,不同版本的Docker对内核版本有不同要求。例如,Docker 17.06及之后的版本通常需要Linux内核3.10及以上版本,Docker17.09及更高版本对应Linux内核4.9.x及更高版本。…...

大型活动交通拥堵治理的视觉算法应用
大型活动下智慧交通的视觉分析应用 一、背景与挑战 大型活动(如演唱会、马拉松赛事、高考中考等)期间,城市交通面临瞬时人流车流激增、传统摄像头模糊、交通拥堵识别滞后等问题。以演唱会为例,暖城商圈曾因观众集中离场导致周边…...

剑指offer20_链表中环的入口节点
链表中环的入口节点 给定一个链表,若其中包含环,则输出环的入口节点。 若其中不包含环,则输出null。 数据范围 节点 val 值取值范围 [ 1 , 1000 ] [1,1000] [1,1000]。 节点 val 值各不相同。 链表长度 [ 0 , 500 ] [0,500] [0,500]。 …...

全面解析各类VPN技术:GRE、IPsec、L2TP、SSL与MPLS VPN对比
目录 引言 VPN技术概述 GRE VPN 3.1 GRE封装结构 3.2 GRE的应用场景 GRE over IPsec 4.1 GRE over IPsec封装结构 4.2 为什么使用GRE over IPsec? IPsec VPN 5.1 IPsec传输模式(Transport Mode) 5.2 IPsec隧道模式(Tunne…...

安宝特案例丨Vuzix AR智能眼镜集成专业软件,助力卢森堡医院药房转型,赢得辉瑞创新奖
在Vuzix M400 AR智能眼镜的助力下,卢森堡罗伯特舒曼医院(the Robert Schuman Hospitals, HRS)凭借在无菌制剂生产流程中引入增强现实技术(AR)创新项目,荣获了2024年6月7日由卢森堡医院药剂师协会࿰…...
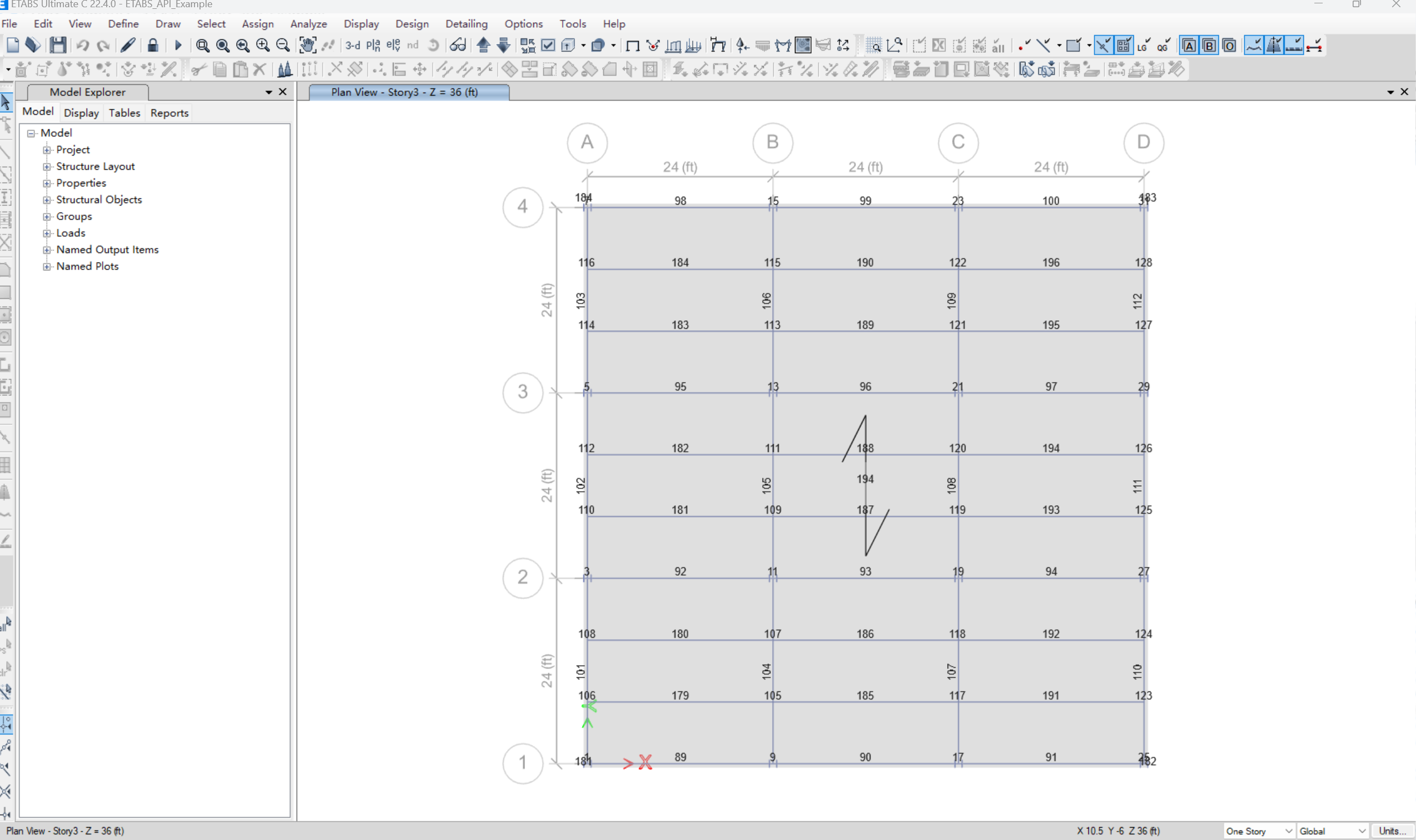
【Post-process】【VBA】ETABS VBA FrameObj.GetNameList and write to EXCEL
ETABS API实战:导出框架元素数据到Excel 在结构工程师的日常工作中,经常需要从ETABS模型中提取框架元素信息进行后续分析。手动复制粘贴不仅耗时,还容易出错。今天我们来用简单的VBA代码实现自动化导出。 🎯 我们要实现什么? 一键点击,就能将ETABS中所有框架元素的基…...

aardio 自动识别验证码输入
技术尝试 上周在发学习日志时有网友提议“在网页上识别验证码”,于是尝试整合图像识别与网页自动化技术,完成了这套模拟登录流程。核心思路是:截图验证码→OCR识别→自动填充表单→提交并验证结果。 代码在这里 import soImage; import we…...
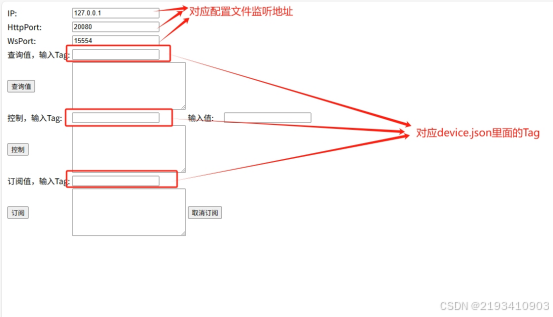
如何把工业通信协议转换成http websocket
1.现状 工业通信协议多数工作在边缘设备上,比如:PLC、IOT盒子等。上层业务系统需要根据不同的工业协议做对应开发,当设备上用的是modbus从站时,采集设备数据需要开发modbus主站;当设备上用的是西门子PN协议时…...
代理服务器-LVS的3种模式与调度算法
作者介绍:简历上没有一个精通的运维工程师。请点击上方的蓝色《运维小路》关注我,下面的思维导图也是预计更新的内容和当前进度(不定时更新)。 我们上一章介绍了Web服务器,其中以Nginx为主,本章我们来讲解几个代理软件:…...