政安晨:【Keras机器学习示例演绎】(五十四)—— 使用神经决策森林进行分类
目录
导言
数据集
设置
准备数据
定义数据集元数据
为训练和验证创建 tf_data.Dataset 对象
创建模型输入
输入特征编码
深度神经决策树
深度神经决策森林
实验 1:训练决策树模型
实验 2:训练森林模型
政安晨的个人主页:政安晨
欢迎 👍点赞✍评论⭐收藏
收录专栏: TensorFlow与Keras机器学习实战
希望政安晨的博客能够对您有所裨益,如有不足之处,欢迎在评论区提出指正!
本文目标:如何为深度神经网络的端到端学习训练可微分决策树。
导言
本示例提供了 P. Kontschieder 等人提出的用于结构化数据分类的深度神经决策林模型的实现。 它演示了如何建立一个随机可变的决策树模型,对其进行端到端训练,并将决策树与深度表示学习统一起来。
数据集
本示例使用加州大学欧文分校机器学习资料库提供的美国人口普查收入数据集。 该数据集包含 48,842 个实例,其中有 14 个输入特征(如年龄、工作级别、教育程度、职业等): 5 个数字特征和 9 个分类特征。
设置
import keras
from keras import layers
from keras.layers import StringLookup
from keras import opsfrom tensorflow import data as tf_data
import numpy as np
import pandas as pdimport math准备数据
CSV_HEADER = ["age","workclass","fnlwgt","education","education_num","marital_status","occupation","relationship","race","gender","capital_gain","capital_loss","hours_per_week","native_country","income_bracket",
]train_data_url = ("https://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.data"
)
train_data = pd.read_csv(train_data_url, header=None, names=CSV_HEADER)test_data_url = ("https://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.test"
)
test_data = pd.read_csv(test_data_url, header=None, names=CSV_HEADER)print(f"Train dataset shape: {train_data.shape}")
print(f"Test dataset shape: {test_data.shape}")Train dataset shape: (32561, 15)
Test dataset shape: (16282, 15)删除第一条记录(因为它不是一个有效的数据示例)和类标签中的尾部 "点"。
test_data = test_data[1:]
test_data.income_bracket = test_data.income_bracket.apply(lambda value: value.replace(".", "")
)我们将训练数据和测试数据分割成 CSV 文件存储在本地。
train_data_file = "train_data.csv"
test_data_file = "test_data.csv"train_data.to_csv(train_data_file, index=False, header=False)
test_data.to_csv(test_data_file, index=False, header=False)定义数据集元数据
在此,我们定义了数据集的元数据,这些元数据将有助于读取、解析和编码输入特征。
# A list of the numerical feature names.
NUMERIC_FEATURE_NAMES = ["age","education_num","capital_gain","capital_loss","hours_per_week",
]
# A dictionary of the categorical features and their vocabulary.
CATEGORICAL_FEATURES_WITH_VOCABULARY = {"workclass": sorted(list(train_data["workclass"].unique())),"education": sorted(list(train_data["education"].unique())),"marital_status": sorted(list(train_data["marital_status"].unique())),"occupation": sorted(list(train_data["occupation"].unique())),"relationship": sorted(list(train_data["relationship"].unique())),"race": sorted(list(train_data["race"].unique())),"gender": sorted(list(train_data["gender"].unique())),"native_country": sorted(list(train_data["native_country"].unique())),
}
# A list of the columns to ignore from the dataset.
IGNORE_COLUMN_NAMES = ["fnlwgt"]
# A list of the categorical feature names.
CATEGORICAL_FEATURE_NAMES = list(CATEGORICAL_FEATURES_WITH_VOCABULARY.keys())
# A list of all the input features.
FEATURE_NAMES = NUMERIC_FEATURE_NAMES + CATEGORICAL_FEATURE_NAMES
# A list of column default values for each feature.
COLUMN_DEFAULTS = [[0.0] if feature_name in NUMERIC_FEATURE_NAMES + IGNORE_COLUMN_NAMES else ["NA"]for feature_name in CSV_HEADER
]
# The name of the target feature.
TARGET_FEATURE_NAME = "income_bracket"
# A list of the labels of the target features.
TARGET_LABELS = [" <=50K", " >50K"]为训练和验证创建 tf_data.Dataset 对象
我们创建了一个输入函数来读取和解析文件,并将特征和标签转换为 tf_data.Dataset 用于训练和验证。 我们还通过将目标标签映射到索引对输入进行预处理。
target_label_lookup = StringLookup(vocabulary=TARGET_LABELS, mask_token=None, num_oov_indices=0
)lookup_dict = {}
for feature_name in CATEGORICAL_FEATURE_NAMES:vocabulary = CATEGORICAL_FEATURES_WITH_VOCABULARY[feature_name]# Create a lookup to convert a string values to an integer indices.# Since we are not using a mask token, nor expecting any out of vocabulary# (oov) token, we set mask_token to None and num_oov_indices to 0.lookup = StringLookup(vocabulary=vocabulary, mask_token=None, num_oov_indices=0)lookup_dict[feature_name] = lookupdef encode_categorical(batch_x, batch_y):for feature_name in CATEGORICAL_FEATURE_NAMES:batch_x[feature_name] = lookup_dict[feature_name](batch_x[feature_name])return batch_x, batch_ydef get_dataset_from_csv(csv_file_path, shuffle=False, batch_size=128):dataset = (tf_data.experimental.make_csv_dataset(csv_file_path,batch_size=batch_size,column_names=CSV_HEADER,column_defaults=COLUMN_DEFAULTS,label_name=TARGET_FEATURE_NAME,num_epochs=1,header=False,na_value="?",shuffle=shuffle,).map(lambda features, target: (features, target_label_lookup(target))).map(encode_categorical))return dataset.cache()
创建模型输入
def create_model_inputs():inputs = {}for feature_name in FEATURE_NAMES:if feature_name in NUMERIC_FEATURE_NAMES:inputs[feature_name] = layers.Input(name=feature_name, shape=(), dtype="float32")else:inputs[feature_name] = layers.Input(name=feature_name, shape=(), dtype="int32")return inputs输入特征编码
def encode_inputs(inputs):encoded_features = []for feature_name in inputs:if feature_name in CATEGORICAL_FEATURE_NAMES:vocabulary = CATEGORICAL_FEATURES_WITH_VOCABULARY[feature_name]# Create a lookup to convert a string values to an integer indices.# Since we are not using a mask token, nor expecting any out of vocabulary# (oov) token, we set mask_token to None and num_oov_indices to 0.value_index = inputs[feature_name]embedding_dims = int(math.sqrt(lookup.vocabulary_size()))# Create an embedding layer with the specified dimensions.embedding = layers.Embedding(input_dim=lookup.vocabulary_size(), output_dim=embedding_dims)# Convert the index values to embedding representations.encoded_feature = embedding(value_index)else:# Use the numerical features as-is.encoded_feature = inputs[feature_name]if inputs[feature_name].shape[-1] is None:encoded_feature = keras.ops.expand_dims(encoded_feature, -1)encoded_features.append(encoded_feature)encoded_features = layers.concatenate(encoded_features)return encoded_features深度神经决策树
神经决策树模型有两组权重需要学习。 第一组是 pi,代表树叶中类别的概率分布。 第二组是路由层 decision_fn 的权重,代表前往每个树叶的概率。 该模型的前向传递工作原理如下:
该模型希望将输入特征作为一个单一的向量,对批次中某个实例的所有特征进行编码。 该向量可以由应用于图像的卷积神经网络(CNN)生成,也可以由应用于结构化数据特征的密集变换生成。
模型首先应用已用特征掩码随机选择要使用的输入特征子集。
然后,模型通过在树的各个层级迭代执行随机路由,计算输入实例到达树叶的概率(mu)。
最后,将到达树叶的概率与树叶上的类概率相结合,生成最终输出。
class NeuralDecisionTree(keras.Model):def __init__(self, depth, num_features, used_features_rate, num_classes):super().__init__()self.depth = depthself.num_leaves = 2**depthself.num_classes = num_classes# Create a mask for the randomly selected features.num_used_features = int(num_features * used_features_rate)one_hot = np.eye(num_features)sampled_feature_indices = np.random.choice(np.arange(num_features), num_used_features, replace=False)self.used_features_mask = ops.convert_to_tensor(one_hot[sampled_feature_indices], dtype="float32")# Initialize the weights of the classes in leaves.self.pi = self.add_weight(initializer="random_normal",shape=[self.num_leaves, self.num_classes],dtype="float32",trainable=True,)# Initialize the stochastic routing layer.self.decision_fn = layers.Dense(units=self.num_leaves, activation="sigmoid", name="decision")def call(self, features):batch_size = ops.shape(features)[0]# Apply the feature mask to the input features.features = ops.matmul(features, ops.transpose(self.used_features_mask)) # [batch_size, num_used_features]# Compute the routing probabilities.decisions = ops.expand_dims(self.decision_fn(features), axis=2) # [batch_size, num_leaves, 1]# Concatenate the routing probabilities with their complements.decisions = layers.concatenate([decisions, 1 - decisions], axis=2) # [batch_size, num_leaves, 2]mu = ops.ones([batch_size, 1, 1])begin_idx = 1end_idx = 2# Traverse the tree in breadth-first order.for level in range(self.depth):mu = ops.reshape(mu, [batch_size, -1, 1]) # [batch_size, 2 ** level, 1]mu = ops.tile(mu, (1, 1, 2)) # [batch_size, 2 ** level, 2]level_decisions = decisions[:, begin_idx:end_idx, :] # [batch_size, 2 ** level, 2]mu = mu * level_decisions # [batch_size, 2**level, 2]begin_idx = end_idxend_idx = begin_idx + 2 ** (level + 1)mu = ops.reshape(mu, [batch_size, self.num_leaves]) # [batch_size, num_leaves]probabilities = keras.activations.softmax(self.pi) # [num_leaves, num_classes]outputs = ops.matmul(mu, probabilities) # [batch_size, num_classes]return outputs深度神经决策森林
神经决策森林模型由一组同时训练的神经决策树组成。 森林模型的输出是各树的平均输出。
class NeuralDecisionForest(keras.Model):def __init__(self, num_trees, depth, num_features, used_features_rate, num_classes):super().__init__()self.ensemble = []# Initialize the ensemble by adding NeuralDecisionTree instances.# Each tree will have its own randomly selected input features to use.for _ in range(num_trees):self.ensemble.append(NeuralDecisionTree(depth, num_features, used_features_rate, num_classes))def call(self, inputs):# Initialize the outputs: a [batch_size, num_classes] matrix of zeros.batch_size = ops.shape(inputs)[0]outputs = ops.zeros([batch_size, num_classes])# Aggregate the outputs of trees in the ensemble.for tree in self.ensemble:outputs += tree(inputs)# Divide the outputs by the ensemble size to get the average.outputs /= len(self.ensemble)return outputs最后,让我们来设置训练和评估模型的代码。
learning_rate = 0.01
batch_size = 265
num_epochs = 10def run_experiment(model):model.compile(optimizer=keras.optimizers.Adam(learning_rate=learning_rate),loss=keras.losses.SparseCategoricalCrossentropy(),metrics=[keras.metrics.SparseCategoricalAccuracy()],)print("Start training the model...")train_dataset = get_dataset_from_csv(train_data_file, shuffle=True, batch_size=batch_size)model.fit(train_dataset, epochs=num_epochs)print("Model training finished")print("Evaluating the model on the test data...")test_dataset = get_dataset_from_csv(test_data_file, batch_size=batch_size)_, accuracy = model.evaluate(test_dataset)print(f"Test accuracy: {round(accuracy * 100, 2)}%")实验 1:训练决策树模型
在本实验中,我们使用所有输入特征训练一个神经决策树模型。
num_trees = 10
depth = 10
used_features_rate = 1.0
num_classes = len(TARGET_LABELS)def create_tree_model():inputs = create_model_inputs()features = encode_inputs(inputs)features = layers.BatchNormalization()(features)num_features = features.shape[1]tree = NeuralDecisionTree(depth, num_features, used_features_rate, num_classes)outputs = tree(features)model = keras.Model(inputs=inputs, outputs=outputs)return modeltree_model = create_tree_model()
run_experiment(tree_model)Start training the model...
Epoch 1/10123/123 ━━━━━━━━━━━━━━━━━━━━ 5s 26ms/step - loss: 0.5308 - sparse_categorical_accuracy: 0.8150
Epoch 2/10123/123 ━━━━━━━━━━━━━━━━━━━━ 1s 11ms/step - loss: 0.3476 - sparse_categorical_accuracy: 0.8429
Epoch 3/10123/123 ━━━━━━━━━━━━━━━━━━━━ 1s 11ms/step - loss: 0.3312 - sparse_categorical_accuracy: 0.8478
Epoch 4/10123/123 ━━━━━━━━━━━━━━━━━━━━ 1s 11ms/step - loss: 0.3247 - sparse_categorical_accuracy: 0.8495
Epoch 5/10123/123 ━━━━━━━━━━━━━━━━━━━━ 1s 10ms/step - loss: 0.3202 - sparse_categorical_accuracy: 0.8512
Epoch 6/10123/123 ━━━━━━━━━━━━━━━━━━━━ 1s 11ms/step - loss: 0.3158 - sparse_categorical_accuracy: 0.8536
Epoch 7/10123/123 ━━━━━━━━━━━━━━━━━━━━ 1s 11ms/step - loss: 0.3116 - sparse_categorical_accuracy: 0.8572
Epoch 8/10123/123 ━━━━━━━━━━━━━━━━━━━━ 1s 11ms/step - loss: 0.3071 - sparse_categorical_accuracy: 0.8608
Epoch 9/10123/123 ━━━━━━━━━━━━━━━━━━━━ 1s 11ms/step - loss: 0.3026 - sparse_categorical_accuracy: 0.8630
Epoch 10/10123/123 ━━━━━━━━━━━━━━━━━━━━ 1s 10ms/step - loss: 0.2975 - sparse_categorical_accuracy: 0.8653
Model training finished
Evaluating the model on the test data...62/62 ━━━━━━━━━━━━━━━━━━━━ 1s 13ms/step - loss: 0.3279 - sparse_categorical_accuracy: 0.8463
Test accuracy: 85.08%实验 2:训练森林模型
在本实验中,我们使用 num_trees 树训练神经决策森林,每棵树随机使用 50%的输入特征。 通过设置 used_features_rate 变量,可以控制每棵树使用的特征数量。 此外,与之前的实验相比,我们将深度设置为 5,而不是 10。
num_trees = 25
depth = 5
used_features_rate = 0.5def create_forest_model():inputs = create_model_inputs()features = encode_inputs(inputs)features = layers.BatchNormalization()(features)num_features = features.shape[1]forest_model = NeuralDecisionForest(num_trees, depth, num_features, used_features_rate, num_classes)outputs = forest_model(features)model = keras.Model(inputs=inputs, outputs=outputs)return modelforest_model = create_forest_model()run_experiment(forest_model)Start training the model...
Epoch 1/10123/123 ━━━━━━━━━━━━━━━━━━━━ 47s 202ms/step - loss: 0.5469 - sparse_categorical_accuracy: 0.7915
Epoch 2/10123/123 ━━━━━━━━━━━━━━━━━━━━ 1s 10ms/step - loss: 0.3459 - sparse_categorical_accuracy: 0.8494
Epoch 3/10123/123 ━━━━━━━━━━━━━━━━━━━━ 1s 10ms/step - loss: 0.3268 - sparse_categorical_accuracy: 0.8523
Epoch 4/10123/123 ━━━━━━━━━━━━━━━━━━━━ 1s 10ms/step - loss: 0.3195 - sparse_categorical_accuracy: 0.8524
Epoch 5/10123/123 ━━━━━━━━━━━━━━━━━━━━ 1s 10ms/step - loss: 0.3149 - sparse_categorical_accuracy: 0.8539
Epoch 6/10123/123 ━━━━━━━━━━━━━━━━━━━━ 1s 10ms/step - loss: 0.3112 - sparse_categorical_accuracy: 0.8556
Epoch 7/10123/123 ━━━━━━━━━━━━━━━━━━━━ 1s 10ms/step - loss: 0.3079 - sparse_categorical_accuracy: 0.8566
Epoch 8/10123/123 ━━━━━━━━━━━━━━━━━━━━ 1s 9ms/step - loss: 0.3050 - sparse_categorical_accuracy: 0.8582
Epoch 9/10123/123 ━━━━━━━━━━━━━━━━━━━━ 1s 9ms/step - loss: 0.3021 - sparse_categorical_accuracy: 0.8595
Epoch 10/10123/123 ━━━━━━━━━━━━━━━━━━━━ 1s 9ms/step - loss: 0.2992 - sparse_categorical_accuracy: 0.8617
Model training finished
Evaluating the model on the test data...62/62 ━━━━━━━━━━━━━━━━━━━━ 5s 39ms/step - loss: 0.3145 - sparse_categorical_accuracy: 0.8503
Test accuracy: 85.55%
相关文章:
政安晨:【Keras机器学习示例演绎】(五十四)—— 使用神经决策森林进行分类
目录 导言 数据集 设置 准备数据 定义数据集元数据 为训练和验证创建 tf_data.Dataset 对象 创建模型输入 输入特征编码 深度神经决策树 深度神经决策森林 实验 1:训练决策树模型 实验 2:训练森林模型 政安晨的个人主页:政安晨 欢…...
洞察消费者心理:Transformer模型在消费者行为分析的创新应用
洞察消费者心理:Transformer模型在消费者行为分析的创新应用 在数字化时代,消费者行为分析对于企业理解市场动态、制定营销策略至关重要。Transformer模型,以其在处理序列数据方面的优势,为消费者行为分析提供了新的视角和工具。…...

如何安全使用代理ip
1、选择可靠的代理服务提供商:选择知名的、信誉良好的代理服务提供商,避免使用免费的代理服务,因为免费的代理服务可能存在安全隐患。 2、使用HTTPS代理:使用HTTPS代理可以加密你的网络流量,保护你的隐私和安全。 3、…...

机器学习——LR、GBDT、SVM、CNN、DNN、RNN、Word2Vec等模型的原理和应用
LR(逻辑回归) 原理: 逻辑回归模型(Logistic Regression, LR)是一种广泛应用于分类问题的统计方法,尤其适用于二分类问题。其核心思想是通过Sigmoid函数将线性回归模型的输出映射到(0,1)区间,从…...

揭秘SQL Server数据库选项:性能与行为的调控者
揭秘SQL Server数据库选项:性能与行为的调控者 在SQL Server的世界中,数据库选项是那些可以调整以优化数据库性能和行为的设置。它们是数据库管理员和开发者的得力助手,通过精细调控,可以显著提升数据库的响应速度和资源利用率。…...
】)
【排序 - 选择排序优化版(利用堆排序)】
结合选择排序和堆排序的思路,可以通过利用堆数据结构来优化选择排序的过程,使得排序算法更加高效。在这种结合中,我们利用堆的特性来快速定位和选择未排序部分的最小元素,避免了选择排序中每次线性搜索的开销。 选择排序和堆排序…...

PHP编程开发工具有哪些?
PHP的开发工具种类繁多,涵盖了从集成开发环境(IDE)、代码编辑器、调试器到版本控制工具和数据库管理工具等多个方面。以下是一些常见的PHP开发工具: 1. 集成开发环境(IDE) PhpStorm:由JetBrai…...
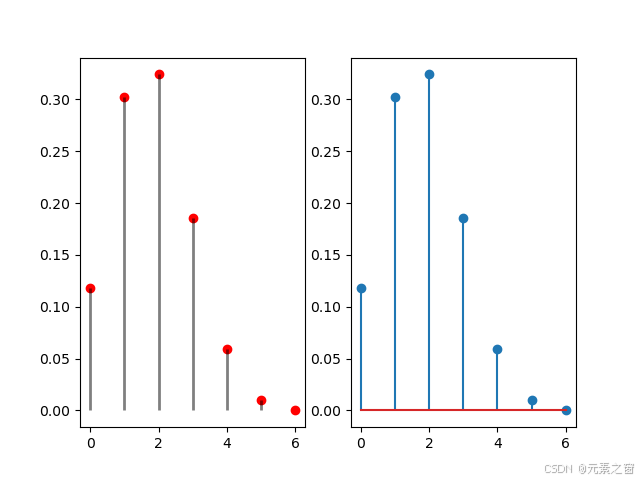
火柴棒图python绘画
使用Python绘制二项分布的概率质量函数(PMF) 在这篇博客中,我们将探讨如何使用Python中的scipy库和matplotlib库来绘制二项分布的概率质量函数(PMF)。二项分布是统计学中常见的离散概率分布,描述了在固定次…...

Nginx七层(应用层)反向代理:UWSGI代理uwsgi_pass篇
Nginx七层(应用层)反向代理 UWSGI代理uwsgi_pass篇 - 文章信息 - Author: 李俊才 (jcLee95) Visit me at CSDN: https://jclee95.blog.csdn.netMy WebSite:http://thispage.tech/Email: 291148484163.com. Shenzhen ChinaAddress of this a…...

Effective C++笔记之二十一:One Definition Rule(ODR)
ODR细节有点复杂,跨越各种情况。基本内容如下: ●普通(非模板)的noninline函数和成员函数、noninline全局变量、静态数据成员在整个程序中都应当只定义一次。 ●class类型(包括structs和unions)、模板&…...
探索未来:Transformer模型在智能环境监测的革命性应用
探索未来:Transformer模型在智能环境监测的革命性应用 在当今数字化时代,环境监测正逐渐从传统的人工检测方式转变为智能化、自动化的系统。Transformer模型,作为深度学习领域的一颗新星,其在自然语言处理(NLP&#x…...

Nginx中文URL请求404
这两天正在搞我的静态网站。方案是:从思源笔记Markdown笔记,用MkOcs build成静态网站,上传到到Nginx服务器。遇到一个问题:URL含有中文会404,全英文URL则正常访问。 比如: 设置了utf-8 ht…...
介绍)
33. 动量法(Momentum)介绍
1. 背景知识 在深度学习的优化过程中,梯度下降法(Gradient Descent, GD)是最基本的方法。然而,基本的梯度下降法在实际应用中存在收敛速度慢、容易陷入局部最小值以及在高维空间中振荡较大的问题。为了解决这些问题,人…...

Python | Leetcode Python题解之第228题汇总区间
题目: 题解: class Solution:def summaryRanges(self, nums: List[int]) -> List[str]:def f(i: int, j: int) -> str:return str(nums[i]) if i j else f{nums[i]}->{nums[j]}i 0n len(nums)ans []while i < n:j iwhile j 1 < n …...

物联网应用,了解一点 WWAN全球网络标准
WWAN/蜂窝无线电认证,对跨地区应用场景,特别重要。跟随全球业务的脚步,我们像大唐先辈一样走遍全球业务的时候,了解一点全球化的 知识信息,就显得有那么点意义。 NA (北美):美国和加…...
如何指定多块GPU卡进行训练-数据并行
训练代码: train.py import torch import torch.nn as nn import torch.optim as optim from torch.utils.data import DataLoader, Dataset import torch.nn.functional as F# 假设我们有一个简单的文本数据集 class TextDataset(Dataset):def __init__(self, te…...

RK3568笔记三十三: helloworld 驱动测试
若该文为原创文章,转载请注明原文出处。 报着学习态度,接下来学习驱动是如何使用的,从简单的helloworld驱动学习起。 开始编写第一个驱动程序—helloworld 驱动。 一、环境 1、开发板:正点原子的ATK-DLRK3568 2、系统…...

【智能制造-14】机器视觉软件
CCD相机和COMS相机? CCD(Charge-Coupled Device)相机和CMOS(Complementary Metal-Oxide-Semiconductor)相机是两种常见的数字图像传感器技术,用于捕捉和处理图像。 CCD相机: CCD相机使用一种称为CCD的光电…...
MVC分页
public ActionResult Index(int ? page){IPagedList<EF.ACCOUNT> userPagedList;using (EF.eMISENT content new EF.eMISENT()){第几页int pageNumber page ?? 1;每页数据条数,这个可以放在配置文件中int pageSize 10;//var infoslist.C660List.OrderBy(…...

webGL可用的14种3D文件格式,但要具体问题具体分析。
hello,我威斯数据,你在网上看到的各种炫酷的3d交互效果,背后都必须有三维文件支撑,就好比你网页的时候,得有设计稿源文件一样。WebGL是一种基于OpenGL ES 2.0标准的3D图形库,可以在网页上实现硬件加速的3D图…...

GitHub加速完全指南:从诊断到优化的全方位解决方案
GitHub加速完全指南:从诊断到优化的全方位解决方案 【免费下载链接】gh-proxy github release、archive以及项目文件的加速项目 项目地址: https://gitcode.com/gh_mirrors/gh/gh-proxy GitHub作为全球最大的代码托管平台,其访问速度直接影响开发…...

科大奥锐虚拟仿真实验避坑指南:从85分到95分,我的密度测量实验复盘与代码优化
科大奥锐虚拟仿真实验提分实战:从85分到95分的密度测量实验深度优化 第一次接触科大奥锐的密度测量虚拟仿真实验时,我和大多数同学一样,以为按照指导手册操作就能轻松拿高分。直到连续三次实验分数卡在85-87分之间,才意识到这个看…...

Ultimate ASI Loader深度解析:构建Windows游戏插件生态系统的技术实践
Ultimate ASI Loader深度解析:构建Windows游戏插件生态系统的技术实践 【免费下载链接】Ultimate-ASI-Loader The Ultimate ASI Loader is a proxy DLL that loads custom .asi libraries into any game process. 项目地址: https://gitcode.com/gh_mirrors/ul/Ul…...

宝可梦随机化终极指南:Universal Pokemon Randomizer ZX 完全使用教程
宝可梦随机化终极指南:Universal Pokemon Randomizer ZX 完全使用教程 【免费下载链接】universal-pokemon-randomizer-zx Public repository of source code for the Universal Pokemon Randomizer ZX 项目地址: https://gitcode.com/gh_mirrors/un/universal-po…...

Keepass2Android密码库完整性验证终极指南:如何确保你的密码安全无虞
Keepass2Android密码库完整性验证终极指南:如何确保你的密码安全无虞 【免费下载链接】keepass2android Password manager app for Android 项目地址: https://gitcode.com/gh_mirrors/ke/keepass2android 在当今数字化时代,密码管理器已成为保护…...

forkrun:革新数据处理,突破传统并行工具性能瓶颈
【导语:forkrun 作为一款自调优工具,可直接替代 GNU Parallel 和 xargs -P。它在现代 CPU 上能显著提升基于 Shell 的数据准备速度,尤其在 NUMA 架构上表现出色,为数据处理领域带来了新的变革。】数据处理速度的飞跃:5…...

论计算机科学的本质是什么?编程么?
计算机科学的本质不是编程。编程只是实现计算机科学思想的工具和手段,而非其内核。计算机科学的核心是“计算”与“问题求解”计算机科学(Computer Science, CS)本质上是一门研究信息与计算的理论基础,以及如何通过算法高效、可靠…...

Qwen3-0.6B-FP8详细步骤:WebUI中max_new_tokens参数设置避坑指南
Qwen3-0.6B-FP8详细步骤:WebUI中max_new_tokens参数设置避坑指南 1. 引言:一个参数引发的“血案” 最近在折腾Qwen3-0.6B-FP8这个轻量级模型时,我遇到了一个挺有意思的问题。当时我正在测试它的“思考模式”——就是那个能展示模型内部推理…...

Qt6.10.1 + QCustomPlot 2.1.1 串口绘图实战:从Qt5老项目迁移到新版本的完整踩坑记录
Qt6.10.1与QCustomPlot 2.1.1串口绘图项目迁移实战指南 当Qt5项目需要升级到Qt6时,许多开发者都会面临兼容性挑战。特别是那些涉及串口通信和数据可视化的项目,往往隐藏着不少"坑"。本文将带你完整走一遍从Qt5老项目迁移到Qt6.10.1的全过程&am…...

【超详细】前端必备:从0到1吃透JavaScript闭包,附真实项目避坑指南
文章目录第一章 从“变量生命周期”开始,重新理解作用域链1.1 一个让新手困惑的面试题:循环中的var与let1.2 作用域链的形成:函数定义位置决定了一切第二章 闭包的工程价值:从封装到模块化2.1 数据私有化:用闭包实现真…...