科普文:深入理解负载均衡(四层负载均衡、七层负载均衡)
概叙
网络模型:OSI七层模型、TCP/IP四层模型、现实的五层模型

应用层:对软件提供接口以使程序能使用网络服务,如事务处理程序、文件传送协议和网络管理等。(HTTP、Telnet、FTP、SMTP)
表示层:程序和网络之间的翻译官,管理数据的解密加密数据转换、格式化和文本压缩。(JPEG、ASCII、GIF、DES、MPEG)
会话层:负责在网络中的两节点之间建立和维持通信,以及提供交互会话的管理功能。(RPC、SQL、NFS)
传输层:提供建立、维护和拆除传送连接的功能;选择网络层提供最合适的服务;在系统之间提供可靠的透明的数据传送,提供端到端的错误恢复和流量控制。(TCP、UDP、SPX)
网络层:将网络地址(ip地址)翻译成对应物理地址(网卡地址),并决定如何将数据从发送方路由到接收方。(IP、ICMP、IGMP、IPX、ARP、RARP)
数据链路层:物理地址寻址、数据的成帧、流量控制、数据的检错、重发。(IEEE 802.3/.2、HDLC、PPP、ATM)
物理层:物理连网媒介,如电缆连线连接器。(RS232、V.35、RJ-45、FDDI)
为什么要有负载均衡?
在高并发的业务场景下,解决单个节点压力过大,导致Web服务响应过慢,特别是严重的情况下导致服务瘫痪,无法正常提供服务的问题,目的就是为了维护系统稳定可靠。而负载均衡技术通过将负载(工作任务)平衡、分摊到多个操作单元上进行运行,如FTP服务器、Web服务器等,从而协同完成工作任务。这种技术构建在原有网络结构之上,提供了一种透明且廉价有效的方法来扩展服务器和网络设备的带宽,加强网络数据处理能力,增加吞吐量,提高网络的可用性和灵活性。
负载均衡的主要作用是为了保证系统的可用性、可靠性、性能和响应时间。
具体来说,负载均衡的作用包括:
- 提高系统性能:通过将负载分发到多个资源上,系统能够处理更多的并发请求,从而提高整体的处理能力和性能。
- 实现高可用性:当其中一个资源发生故障或不可用时,负载均衡可以自动将请求转发到其他可用的资源,降低单点故障的风险,提高系统的可靠性和容错性。
- 提高系统可伸缩性:随着业务的增长,负载均衡技术可以动态地增加或减少资源的数量,根据实际负载情况进行扩展或收缩,实现水平扩展,满足不断增长的需求。
- 优化资源利用:根据资源的性能、可用性和负载情况,合理地分配请求或任务,最大限度地利用资源,避免资源的空闲或过载。
此外,负载均衡还可以与其他云服务进行集成,例如容器编排、数据库、网络服务等,为用户提供更全面的云服务。通过实现这些功能,负载均衡确保了系统的持续运行,优化了系统的性能和响应时间,从而提高了系统的整体效率和用户体验
什么是负载均衡?
负载均衡(Load Balance)的指将负载(工作任务)进行平衡、分摊到多个操作单元上进行运行,例如FTP服务器、Web服务器、企业核心应用服务器和其它主要任务服务器等,从而协同完成工作任务。负载均衡构建在原有网络结构之上,它提供了一种透明且廉价有效的方法扩展服务器和网络设备的带宽、加强网络数据处理能力、增加吞吐量、提高网络的可用性和灵活性。
负载均衡重点在于由原来的单个节点承接流量,变成多个节点分担流量,减少请求响应时间,提高应用程序的可用性和可伸缩性。
负载均衡是指将传入的网络流量高效分发到一组后端服务器,也称为“服务器群”或“服务器池”。现代高流量网站必须满足来自用户或客户端的数十万甚至数百万的并发请求,并快速、可靠地返回正确的文本、图像、视频或应用数据。为了经济高效地进行扩展以满足这些海量数据需求,现代计算最佳实践通常要求添加更多的服务器。
负载均衡有两方面的含义:
首先,大量的并发访问或数据流量分担到多台节点设备上分别处理,减少用户等待响应的时间;
其次,单个重负载的运算分担到多台节点设备上做并行处理,每个节点设备处理结束后,将结果汇总,返回给用户,系统处理能力得到大幅度提高。
通过这种方式,负载均衡器可执行以下功能:
- 在多台服务器之间高效分配客户端请求或网络负载
- 仅向在线服务器发送请求,确保高可用性和可靠性
- 提供按需增减服务器的灵活性

负载均衡适用场景

负载均衡策略
目前有许多不同的负载均衡技术用以满足不同的应用需求,下面从负载均衡所采用的设备对象(软、硬件负载均衡),应用的OSI网络层次(网络层次上的负载均衡),及应用的地理结构(客户端和服务端负载均衡)等来分类。
硬件与软件负载均衡
负载均衡器通常有两种形式:基于硬件和基于软件。基于硬件的解决方案的厂商将专有软件加载到其提供的机器(通常搭载专用处理器)上。
为了处理日益增加的网站流量,您必须从厂商处购买更多或更大的机器。而软件解决方案通常在商用硬件上运行,因此更为经济、更加灵活。您可将软件安装到所选硬件上,或者安装在 AWS EC2 等云环境中。
软件负载均衡
软件负载均衡解决方案是指在一台或多台服务器相应的操作系统上安装一个或多个附加软件来实现负载均衡,如DNS Load Balance,Check Point Firewall-1 Connect Control,Keepalive+ IPVS、Nginx、apache、LVS等,它的优点是基于特定环境,配置简单,使用灵活,成本低廉,可以满足一般的负载均衡需求。
软件解决方案缺点也较多,因为每台服务器上安装额外的软件运行会消耗系统不定量的资源,越是功能强大的模块,消耗得越多,所以当连接请求特别大的时候,软件本身会成为服务器工作成败的一个关键;软件可扩展性并不是很好,受到操作系统的限制;由于操作系统本身的Bug,往往会引起安全问题。
硬件负载均衡
硬件负载均衡解决方案是直接在服务器和外部网络间安装负载均衡设备,这种设备通常是一个独立于系统的硬件,我们称之为负载均衡器。由于专门的设备完成专门的任务,独立于操作系统,整体性能得到大量提高,加上多样化的负载均衡策略,智能化的流量管理,可达到最佳的负载均衡需求。
负载均衡器有多种多样的形式,除了作为独立意义上的负载均衡器外,有些负载均衡器集成在交换设备中,置于服务器与Internet链接之间,有些则以两块网络适配器将这一功能集成到PC中,一块连接到Internet上,一块连接到后端服务器群的内部网络上。
软、硬件负载均衡的对比
软件负载均衡的优点是需求环境明确,配置简单,操作灵活,成本低廉,效率不高,能满足普通的企业需求;缺点是依赖于系统,增加资源开销;软件的优劣决定环境的性能;系统的安全,软件的稳定性均会影响到整个环境的安全。
硬件负载均衡优点是独立于系统,整体性能大量提升,在功能、性能上优于软件方式;智能的流量管理,多种策略可选,能达到最佳的负载均衡效果;缺点是价格昂贵(F5硬件服务器不低于20万/台)。
OSI网络层次负载均衡

按照OSI七层模型划分方式:根据采用的设备对象区分、根据位于OSI中不同层次的划分,这里我们主要讲根据OSI中的层次划分。

二层负载均衡(mac地址):数据链路层,使用虚拟MAC地址方式,外部请求流量经过虚拟MAC地址,负载均衡收到流量请求后分配后端实际的MAC地址进行响应。
三层负载均衡(ip地址):网络层,使用虚拟ip地址方式,外部请求流量经过虚拟IP地址,负载均衡收到流量请求后分配后端实际的IP地址进行响应。
四层负载均衡(tcp、udp):传输层,使用IP+PORT接收外部流量请求,转发到对应的机器上。
七层负载均衡(http):应用层,使用虚拟的URL或IP地址接收外部流量请求,转发到对应的处理服务器。1)二层负载均衡(一般是用虚拟mac地址方式,外部对虚拟MAC地址请求,负载均衡接收后分配后端实际的MAC地址响应);2)三层负载均衡(一般采用虚拟IP地址方式,外部对虚拟的ip地址请求,负载均衡接收后分配后端实际的IP地址响应);3)四层负载均衡(在三次负载均衡的基础上,用 ip+port 接收请求,再转发到对应的机器);4)七层负载均衡(根据虚拟的url或是IP,主机名接收请求,再转向相应的处理服务器)。二层负载均衡
二层负债均衡是基于数据链路层的负债均衡,即让负债均衡服务器和业务服务器绑定同一个虚拟IP(即VIP),客户端直接通过这个VIP进行请求。
那么如何区分相同IP下的不同机器呢?没错,通过MAC物理地址,每台机器的MAC物理地址都不一样,当负载均衡服务器接收到请求之后,通过改写HTTP报文中以太网首部的MAC地址,按照某种算法将请求转发到目标机器上,实现负载均衡。
这种方式负载方式虽然控制粒度比较粗,但是优点是负载均衡服务器的压力会比较小,负载均衡服务器只负责请求的进入,不负责请求的响应(响应是有后端业务服务器直接响应给客户端),吞吐量会比较高。

三层负载均衡
三层负载均衡是基于网络层的负载均衡,通俗的说就是按照不同机器不同IP地址进行转发请求到不同的机器上。
这种方式虽然比二层负载多了一层,但从控制的颗粒度上看,并没有比二层负载均衡更有优势,并且,由于请求的进出都要经过负载均衡服务器,会对其造成比较大的压力,性能也比二层负载均衡要差。

四层负载均衡
四层的负载均衡就是基于IP+端口的负载均衡:在三层负载均衡的基础上,通过发布三层的IP地址(VIP),然后加四层的端口号,来决定哪些流量需要做负载均衡,对需要处理的流量进行NAT处理,转发至后台服务器,并记录下这个TCP或者UDP的流量是由哪台服务器处理的,后续这个连接的所有流量都同样转发到同一台服务器处理。
对应的负载均衡器称为四层交换机(L4 switch),主要分析IP层及TCP/UDP层,实现四层负载均衡。
此种负载均衡器不理解应用协议(如HTTP/FTP/MySQL等等),常见例子有:LVS,F5。

七层负载均衡
七层的负载均衡就是基于虚拟的URL或主机IP的负载均衡:在四层负载均衡的基础上(没有四层是绝对不可能有七层的),再考虑应用层的特征,比如同一个Web服务器的负载均衡,除了根据VIP加80端口辨别是否需要处理的流量,还可根据七层的URL、浏览器类别、语言来决定是否要进行负载均衡。
举个例子,如果你的Web服务器分成两组,一组是中文语言的,一组是英文语言的,那么七层负载均衡就可以当用户来访问你的域名时,自动辨别用户语言,然后选择对应的语言服务器组进行负载均衡处理。
对应的负载均衡器称为七层交换机(L7 switch),除了支持四层负载均衡以外,还有分析应用层的信息,如HTTP协议URI或Cookie信息,实现七层负载均衡。此种负载均衡器能理解应用协议,常见例子有: haproxy,MySQL Proxy、Nginx、apache。

服务端负载均衡 和 客户端负载均衡
服务端负载均衡
服务端负载均衡可通过硬件设备或软件来实现,硬件比如:F5、Array等,软件比如:LVS、Nginx等。通过硬件或软件实现负载均衡均会维护一个服务端清单,利用心跳检测等手段进行清单维护,保证清单中都是可以正常访问的服务节点。当用户发送请求时,会先到达负载均衡器(也相当于一个服务),负载均衡器根据负载均衡算法(轮训、随机、加权轮训)从可用的服务端列表中取出一台服务端的地址,接着进行转发,降低系统的压力。

服务端负载均衡分类
- DNS负载均衡
- 链路层负载均衡
- IP负载均衡
- HTTP负载均衡
- 反向代理负载均衡
DNS域名解析负载均衡

利用DNS处理域名解析请求的同时进行负载均衡是一种常用的方案。在DNS服务器中配置多个A记录,每次域名解析请求都会根据负载均衡算法计算一个不同的IP地址返回,这样A记录中配置的多个服务器就构成一个集群,并可以实现负载均衡。
DNS域名解析负载均衡的优点是将负载均衡工作交给DNS,省略掉了网络管理的麻烦,缺点就是DNS可能缓存A记录,不受网站控制。事实上,大型网站总是部分使用DNS域名解析,作为第一级负载均衡手段,然后再在内部做第二级负载均衡。
数据链路层负载均衡(LVS)

数据链路层负载均衡是指在通信协议的数据链路层修改mac地址进行负载均衡。
这种数据传输方式又称作三角传输模式,负载均衡数据分发过程中不修改IP地址,只修改目的的mac地址,通过配置真实物理服务器集群所有机器虚拟IP和负载均衡服务器IP地址一样,从而达到负载均衡,这种负载均衡方式又称为直接路由方式(DR)。
在上图中,用户请求到达负载均衡服务器后,负载均衡服务器将请求数据的目的mac地址修改为真实WEB服务器的mac地址,并不修改数据包目标IP地址,因此数据可以正常到达目标WEB服务器,该服务器在处理完数据后可以经过网关服务器而不是负载均衡服务器直接到达用户浏览器。
使用三角传输模式的链路层负载均衡是目前大型网站所使用的最广的一种负载均衡手段。在linux平台上最好的链路层负载均衡开源产品是LVS(linux virtual server)。
IP负载均衡

IP负载均衡:即在网络层通过修改请求目标地址进行负载均衡。
用户请求数据包到达负载均衡服务器后,负载均衡服务器在操作系统内核进行获取网络数据包,根据负载均衡算法计算得到一台真实的WEB服务器地址,然后将数据包的IP地址修改为真实的WEB服务器地址,不需要通过用户进程处理。真实的WEB服务器处理完毕后,相应数据包回到负载均衡服务器,负载均衡服务器再将数据包源地址修改为自身的IP地址发送给用户浏览器。
这里的关键在于真实WEB服务器相应数据包如何返回给负载均衡服务器,一种是负载均衡服务器在修改目的IP地址的同时修改源地址,将数据包源地址改为自身的IP,即源地址转换(SNAT),另一种方案是将负载均衡服务器同时作为真实物理服务器的网关服务器,这样所有的数据都会到达负载均衡服务器。
IP负载均衡在内核进程完成数据分发,较反向代理均衡有更好的处理性能。但由于所有请求响应的数据包都需要经过负载均衡服务器,因此负载均衡的网卡带宽成为系统的瓶颈。
HTTP重定向负载均衡

HTTP重定向服务器是一台普通的应用服务器,其唯一的功能就是根据用户的HTTP请求计算一台真实的服务器地址,并将真实的服务器地址写入HTTP重定向响应中(响应状态吗302)返回给浏览器,然后浏览器再自动请求真实的服务器。
这种负载均衡方案的优点是比较简单,缺点是浏览器需要每次请求两次服务器才能拿完成一次访问,性能较差;使用HTTP302响应码重定向,可能是搜索引擎判断为SEO作弊,降低搜索排名。重定向服务器自身的处理能力有可能成为瓶颈。因此这种方案在实际使用中并不见多。
反向代理负载均衡

传统代理服务器位于浏览器一端,代理浏览器将HTTP请求发送到互联网上。而反向代理服务器则位于网站机房一侧,代理网站web服务器接收http请求。
反向代理的作用是保护网站安全,所有互联网的请求都必须经过代理服务器,相当于在web服务器和可能的网络攻击之间建立了一个屏障。
除此之外,代理服务器也可以配置缓存加速web请求。当用户第一次访问静态内容的时候,静态内存就被缓存在反向代理服务器上,这样当其他用户访问该静态内容时,就可以直接从反向代理服务器返回,加速web请求响应速度,减轻web服务器负载压力。
另外,反向代理服务器也可以实现负载均衡的功能。
由于反向代理服务器转发请求在HTTP协议层面,因此也叫应用层负载均衡。优点是部署简单,缺点是可能成为系统的瓶颈。
客户端负载均衡
对于客户端负载均衡来说,与服务端负载均衡的主要区分点在于服务清单的存放位置。在客户端负载均衡中,客户端自己会存储一份服务端清单,它是通过从注册中心进行抓取得到的,同时也需要对此进行维护。
在如今的微服务架构中,基本都是采用的这种客户端负载均衡。相比于服务器端负载均衡,它有一个显著的优点,就是可以一定程度避免load balancer单点故障。

图中主要包含三个部分:API Gateway、Service Registry Server、微服务。一般来说,为了提高并发处理能力,API Gateway和微服务都需要有多个instance。
基于上面的架构图,设想两个典型的场景:
- API Gateway收到一个请求,在完成 认证 和 授权校验 之后,需要把请求转发到微服务A去处理,而微服务A有多个instance,那么API Gateway应该如何把请求转发到微服务A的哪个instance呢?
- 微服务A收到一个请求,处理这个请求时它需要发一个同步请求给微服务B以获取一些数据,那么这时微服务A应该如何把请求发送到微服务B的哪个instance呢?
对于这两个问题,我们可以利用服务注册和服务发现模块(比如说zookeeper、eureka等)来实现。一般来说,服务注册和服务发现是微服务架构里面非常重要的一个模块,它主要是用于解决微服务架构内部大量微服务之间相互依赖的问题。通过这个模块,可以使微服务之间的相互依赖变得简单和容易维护;同时,也可以实现微服务的负载均衡。
服务注册和服务发现模块是如何应用到上面两个场景的呢?
服务注册的角度:
每个微服务的instance在启动阶段就自动地把自己的IP和端口注册到Service Registry Server;当shutdown的时候,Service Registry Server就自动地把这个instance的IP和端口删除掉。
服务发现的角度:
针对场景1,API Gateway首先去Service Registry Server获取微服务A所有的instance列表(IP+端口),然后利用某种负载均衡策略选择一个instance,这时就可以直接把请求转发到微服务A的这个instance。
针对场景2,流程也是类似,微服务A首先去Service Registry Server获取微服务B所有的instance列表(IP+端口),然后利用某种负载均衡策略选择一个instance,这时就可以直接把请求转发到微服务B的这个instance。
客户端负载均衡是如何避免单点故障的?答:缓存服务端实例列表
从负载均衡角度可以看到,负载均衡的逻辑是运行在客户端的,顾名思义,这就是一种典型的客户端负载均衡。回到上面提到的,客户端负载均衡可以避免load balancer的单点故障,如何实现呢?以上面场景2为例,微服务A获取到微服务B的所有instance列表之后可以缓存到内存中,接下来当微服务A请求微服务B时,都直接从内存中获取微服务B的所有instance列表,这样即使Service Registry Server挂了,也不影响微服务A和微服务B正常通讯。
API Gateway的负载均衡

什么是API Gateway?

网关是系统的唯一对外的入口,介于客户端和服务器端之间的中间层,处理非业务功能,提供路由请求、鉴权、监控、缓存、限流、日志记录等功能。这样,不同的微服务之间无需重复实现限流、认证等功能,让微服务每个服务的功能实现更加纯粹,减少研发成本。无论你查看任何一个微服务项目架构,你都会发现在客户端和服务器端之间有一个网关,移动端的任何请求都必须经过网关才能到达服务端。它包括但不限于以下这些特点:
- 丰富的路由策略:API Gateway 工作在七层,所以它可以解析到 HTTP/HTTPS 层的数据。因此它可以根据请求的 Path 或 Domain 甚至是 Header 作为条件,将请求转发到不同的上游服务器。
- 认证:可以在 API 层面支持多种多样的认证方式来避免非法请求,比如 OAuth2、JWT 等等,直接将认证这部分服务独立出来,不侵入或者少侵入业务代码。
- 限流:支持对不同程度的路由进行细粒度的限流,防止恶意攻击,防止后端服务雪崩。
- 可观测性:可观测性是指从系统外部观察系统内部程序的运行状态和资源使用情况的能力。 API Gateway 支持将日志对接到 Kafka、 Google Cloud Logging Service、Elasticsearch 等,支持将相关 metrics 接入到 prometheus、datadog 等。
- 扩展:因为 API Gateway 自身是网关身份,这就注定对它要求是能适配各家公司不同应用场景,比如不同的鉴权、灰度、安全策略、日志收集等,必须允许用户自由选择所需扩展或者自定义开发,因此扩展性很强,允许选择的扩展种类也十分丰富。以 Apache APISIX 举例,光是认证的扩展就有 13 款,几乎涵盖了市面上常见的认证需求。
目前市面上有许多 API Gateway,比如 Apache APISIX、Kong、Tyk、Zuul 等,开发者可以根据自己的需求选择合适的 API Gateway。
go-zero中负载均衡的实现
go-zero中的网关
go-zero推荐使用 nginx 做为网关,使用 nginx 的 auth_request 模块作为统一鉴权,业务内部不做鉴权。由nginx统一接收外部请求,通过匹配 location 将请求转发到不同的api服务,此时如果需要鉴权,则先调用鉴权api,鉴权通过后,再去调用对应的rpc服务。

Nginx负载均衡
高可用nginx集群
为了防止nginx宕机导致整个服务不可用,也可以使用 Keepalived+Nginx 来实现nginx双机热备。Master和Backup两边都开启nginx服务,无论Master还是Backup,当其中的一个keepalived服务停止后,vip都会漂移到keepalived服务还在的节点上。对外只暴露一个vip。
具体实现原理:
- Master没挂,则Master占有vip且nginx运行在Master上
- Master挂了,则backup抢占vip且在backup上运行nginx服务
- 如果master服务器上的nginx服务挂了,则vip资源转移到backup服务器上
- 检测后端服务器的健康状态

Nginx实现四层负载均衡和七层负载均衡

负载均衡工作原理
-
负载均衡分为四层负载均衡和七层负载均衡。
-
四层负均衡是工作在七层协议的第四层-传输层,主要工作是转发。
-
它在接收到客户端的流量以后通过修改数据包的地址信息(目标地址和端口和源地址)将流量转发到应用服务器。
-
七层负载均衡是工作在七层协议的第七层-应用层,主要工作是代理。
-
它首先会与客户端建立一条完整的连接并将应用层的请求流量解析出来,再按照调度算法选择一个应用服务器,并与应用服务器建立另外一条连接将请求发送过去。
Nginx实现七层负载均衡
Nginx服务器:192.168.2.10
后端服务器1:192.168.2.20
后端服务器2:192.168.2.30
前端服务器主要配置upstream和proxy_pass:
upstream 主要是配置均衡池和调度方法。
proxy_pass 主要是配置代理服务器ip或服务器组的名字。
proxy_set_header 主要是配置转发给后端服务器的Host和前端客户端真实ip。
Nginx服务器配置
[root@bogon nginx]# vim /usr/local/ngin/conf/nginx.conf
# 在http指令块下配置upstream指令块
upstream web {
server 192.168.2.20;
server 192.168.2.30;
}
# 在location指令块配置proxy_pass
server {
listen 80;
server_name localhost;
location / {
proxy_pass http://web;
proxy_next_upstream error http_404 http_502;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
}
}
[root@bogon nginx]# /usr/local/nginx/sbin/nginx -s reload
proxy_next_upstream error http_404 http_502; 通过这个指令,可以处理后端返回404等报错时,直接将请求转发给其他服务器处理,而不是把报错返回客户端
proxy_set_header Host $host; 通过这个指令,把客户端请求的host,转发给后端
proxy_set_header X-Real-IP $remote_addr通过这个指令, 把客户端的IP转发给后端服务器, 在后端服务器的日志格式中,添加$http_x_real_ip即可获取原始客户端的IP了
后端服务器配置
创建两个静态页面,验证负载均衡效果在后端服务器192.168.2.20配置如下(配置文件不需要修改即可)
vim /usr/local/nginx/html/index.html
this is 2.20 page
在后端服务器192.168.2.30配置如下(配置文件不需要修改即可)
vim /usr/local/nginx/html/index.html
this is 2.30 page验证不同的负载均衡策略
1.轮询:
Nginx服务器 upstream web {
server 192.168.2.20;
server 192.168.2.30;}[root@bogon nginx]# /usr/local/nginx/sbin/nginx -s reload访问验证:
[root@localhost ~]# while true;do curl 192.168.2.10;sleep 2;done
this is 2.20 pagethis is 2.30 page
this is 2.20 pagethis is 2.30 page
this is 2.20 pagethis is 2.30 page
#可以看到后端服务器,非常平均的处理请求。2.轮询加权重:
upstream web {
server 192.168.2.20 weight=3;
server 192.168.2.30 weight=1;
}
默认是weight=1
[root@bogon nginx]# /usr/local/nginx/sbin/nginx -s reload访问验证:
[root@localhost ~]# while true;do curl 192.168.2.10;sleep 2;done
this is 2.20 page
this is 2.20 page
this is 2.20 pagethis is 2.30 page
this is 2.20 page
this is 2.20 page
this is 2.20 pagethis is 2.30 page
#后端服务,根据权重比例处理请求,适用于服务器性能不均的环境。3.最大错误连接次数:
-
错误的连接由proxy_next_upstream, fastcgi_next_upstream等指令决定,且默认情况下,后端某台服务器出现故障了,nginx会自动将请求再次转发给其他正常的服务器(因为默 proxy_next_upstream error timeout)。
-
所以即使我们没有配这个参数,nginx也可以帮我们处理error和timeout的相应,但是没法处理404等报错。
-
为了看清楚本质,可以先将proxy_next_upstream设置为off,也就是不将失败的请求转发给其他正常服务器,这样我们可以看到请求失败的结果。
vim /usr/local/nginx/conf/nginx.conf
upstream web {
server 192.168.2.20 weight=1 max_fails=3 fail_timeout=9s;
#先将2.20这台nginx关了。
server 192.168.2.30 weight=1;
}
server {
listen 80;
server_name localhost;
location / {
proxy_pass http://web;
#proxy_next_upstream error http_404 http_502;
proxy_next_upstream off;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
}
}
[root@bogon nginx]# /usr/local/nginx/sbin/nginx -s reload
# 在这里,我们将超时时间设置为9s,最多尝试3次,
这里要注意,尝试3次,依然遵循轮询的规则,并不是一个请求,连接3次,
而是轮询三次,有3次处理请求的机会访问验证:[root@localhost ~]# while true;do curl -I 192.168.2.10 2>/dev/null|grep HTTP/1.1 ;sleep 3;done
HTTP/1.1 502 Bad Gateway
HTTP/1.1 200 OK
HTTP/1.1 502 Bad Gateway
HTTP/1.1 200 OK
HTTP/1.1 502 Bad Gateway
HTTP/1.1 200 OK
HTTP/1.1 200 OK
HTTP/1.1 200 OK
HTTP/1.1 200 OK
HTTP/1.1 502 Bad Gateway
HTTP/1.1 200 OK
我们设置的超时时间为9s,我们是每3s请求一次。
我们可以看到后端一台服务器挂了后,请求没有直接转发给正常的服务器,
而是直接返回了502。尝试三次后,等待9s,才开始再次尝试(最后一个502)。
要注意,第二行的200响应,并不是客户端第一次的请求的响应码,而是客户端第二次新的请求。将proxy_next_upstream开启
vim /usr/local/nginx/conf/nginx.conf
upstream web {
server 192.168.2.20 weight=1 max_fails=3 fail_timeout=9s;
#先将2.20这台nginx关了。
server 192.168.2.30 weight=1;
}
server {
listen 80;
server_name localhost;
location / {
proxy_pass http://web;
proxy_next_upstream error http_404 http_502;
#proxy_next_upstream off;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
}
}
[root@bogon nginx]# /usr/local/nginx/sbin/nginx -s reload再次测试访问验证
[root@localhost ~]# while true;do curl -I 192.168.2.10 2>/dev/null|grep HTTP/1.1 ;sleep 3;done
HTTP/1.1 200 OK
HTTP/1.1 200 OK
HTTP/1.1 200 OK
HTTP/1.1 200 OK
HTTP/1.1 200 OK
HTTP/1.1 200 OK
HTTP/1.1 200 OK
HTTP/1.1 200 OK可以看到现在没有502报错,请求都处理了。因为错误的响应码被proxy_next_upstream 获取,这次请求
被转发给下一个正常的服务器了。
所以看到都是200,但是你应该清楚,哪个200是响应的上个服务器没有处理请求,哪个200是正常的响应。4.ip_hash
-
通过客户端ip进行hash,再通过hash值选择后端server 。
vim /usr/local/nginx/conf/nginx.conf
upstream web {
ip_hash;
server 192.168.2.20 weight=1 max_fails=3 fail_timeout=9s;
server 192.168.2.30 weight=1;
}
server {
listen 80;
server_name localhost;
location / {
proxy_pass http://web;
proxy_next_upstream error http_404 http_502;
#proxy_next_upstream off;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
}
}
[root@bogon nginx]# /usr/local/nginx/sbin/nginx -s reload访问验证:
[root@localhost ~]# while true;do curl 192.168.2.10;sleep 2;donethis is 2.30 pagethis is 2.30 pagethis is 2.30 pagethis is 2.30 pagethis is 2.30 pagethis is 2.30 page
[root@localhost ~]# curl 192.168.2.20
this is 2.20 page
#可以看到2.20的服务是正常的,但是却不转发给2.20了,请求固定在了2.30的服务器上。-
在使用负载均衡的时候会遇到会话保持的问题,常用的方法有:
-
ip hash,根据客户端的IP,将请求分配到不同的服务器上;
-
cookie,服务器给客户端下发一个cookie,具有特定cookie的请求会分配给它的发布者。
4.url_hash
vim /usr/local/nginx/conf/nginx.conf
upstream web {
hash $request_uri consistent;
server 192.168.2.20;
server 192.168.2.30;
}
[root@bogon nginx]# /usr/local/nginx/sbin/nginx -s reload根据响应时间均衡
# 下载模块:
wget https://github.com/gnosek/nginx-upstream-fair/archive/master.zip
# 解压:
unzip master.zip
# 修改源码bug:
sed -i 's/default_port/no_port/g' ngx_http_upstream_fair_module.c
# 预编译:
./configure --prefix=/usr/local/nginx --add-module=../echo-nginx-module --withhttp_stub_status_module --add-module=../nginx-upstream-fair-master
# 编译/安装:
make && make install
# 配置:
upstream web {
fair;
server 192.168.2.20 weight=1 max_fails=3 fail_timeout=9s;
server 192.168.2.30 weight=1;
}备用服务器
upstream web {
server 192.168.2.20 weight=1 max_fails=3 fail_timeout=9s;
server 192.168.2.30 weight=1 backup;
}
# 2.30的服务器做备用服务器,只有在2.30得服务器不能提供服务时,才会自动顶上,否则,默认是不提供服务的。Nginx实现四层负载均衡
前端服务器:192.168.2.10
后端服务器1:192.168.2.20
后端服务器2:192.168.2.30
-
前端服务器主要配置stream和upstream,注意该模块需要在预编译时指定,没有被默认编译进nginx。
#预编译:
./configure --prefix=/usr/local/nginx --add-module=../echo-nginx-module --withhttp_stub_status_module --with-stream
# 编译/安装:
make && make install
make upgrade
# 在main全局配置stream:
events {
worker_connections 1024;
}
stream {
upstream web {
# 必须要指定ip加port
server 192.168.2.20:80;
server 192.168.2.30:80;
}
server {
listen 80;
# 连接上游服务器超时间,超过则选择另外一个服务器
proxy_connect_timeout 3s;
# tcp连接闲置时间,超过则关闭
proxy_timeout 10s;
proxy_pass web;
}
log_format proxy '$remote_addr $remote_port $protocol $status
[$time_iso8601] '
'"$upstream_addr" "$upstream_bytes_sent"
"$upstream_connect_time"' ;
access_log /usr/local/nginx/logs/proxy.log proxy;
}后端服务器测试页面配置
在后端服务器192.168.2.20配置如下(配置文件不需要修改即可)
vim /usr/local/nginx/html/index.html
this is 2.20 page
在后端服务器192.168.2.30配置如下(配置文件不需要修改即可)
vim /usr/local/nginx/html/index.html
this is 2.30 page访问前端服务器IP测试- 在后端2.30上访问前端IP
[root@localhost ~]# curl 192.168.2.10
this is 2.20 page
- 查看后端2.20日志
[root@bogon nginx]# tail -1 /usr/local/nginx/logs/host.access.log
192.168.2.10 - - [26/Apr/2020:03:16:37 +0800] "GET / HTTP/1.1" 200 18 "-" "curl/7.29.0" "-"
-查看前端2.10日志
[root@bogon nginx]# tail -1 /usr/local/nginx/logs/proxy.log
192.168.2.30 45420 TCP 200 [2020-04-25T19:23:35+08:00] "192.168.2.20:80" "76""0.001"端口转发
#在前端2.10配置:
[root@bogon nginx]# vim conf/nginx.conf
events {worker_connections 1024;
}
stream {upstream web {server 192.168.2.20:22;
# server 192.168.2.30:80;
}server {listen 6666;proxy_connect_timeout 3s;proxy_timeout 10s;proxy_pass web;
}log_format proxy '$remote_addr $remote_port $protocol $status [$time_iso8601] ' '"$upstream_addr" "$upstream_bytes_sent""$upstream_connect_time"' ;
access_log /usr/local/nginx/logs/proxy.log proxy;
}
[root@bogon nginx]# /usr/local/nginx/sbin/nginx -s reload
#在另外一台服务器访问:
[root@localhost ~]# ssh 192.168.2.10 -p 6666
root@192.168.2.10's password:
Last login: Sun Apr 26 03:31:45 2020 from www.ys.com
#可以看到已经登上2.20服务器上了
[root@bogon ~]# ip add
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00inet 127.0.0.1/8 scope host lovalid_lft forever preferred_lft foreverinet6 ::1/128 scope host valid_lft forever preferred_lft forever
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000link/ether 00:0c:29:2c:72:99 brd ff:ff:ff:ff:ff:ffinet 192.168.2.20/24 brd 192.168.2.255 scope global noprefixroute ens33valid_lft forever preferred_lft foreverinet6 fe80::7e7a:cabd:3b11:a545/64 scope link noprefixroute valid_lft forever preferred_lft forever相关文章:
科普文:深入理解负载均衡(四层负载均衡、七层负载均衡)
概叙 网络模型:OSI七层模型、TCP/IP四层模型、现实的五层模型 应用层:对软件提供接口以使程序能使用网络服务,如事务处理程序、文件传送协议和网络管理等。(HTTP、Telnet、FTP、SMTP) 表示层:程序和网络之…...

华为模拟器ensp中USG6000V防火墙web界面使用
防火墙需要配置 新建拓扑选择USG6000V型号 在防火墙中导包 忘记截图了 启动设备 输入用户名密码 默认用户名:admin 默认密码:Admin123 修改密码 然后他会提示你是否要修改密码,想改就改不想改就不改 进入命令行界面 进入系统视图开启web…...

使用Python绘制气泡图
使用Python绘制气泡图 气泡图效果代码 气泡图 气泡图通过气泡的大小表示数据的一个维度,用于展示三个维度的数据。例如,可以展示城市的人口、面积和GDP。 效果 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Mjj27sP7-1720…...

政安晨:【Keras机器学习示例演绎】(五十四)—— 使用神经决策森林进行分类
目录 导言 数据集 设置 准备数据 定义数据集元数据 为训练和验证创建 tf_data.Dataset 对象 创建模型输入 输入特征编码 深度神经决策树 深度神经决策森林 实验 1:训练决策树模型 实验 2:训练森林模型 政安晨的个人主页:政安晨 欢…...
洞察消费者心理:Transformer模型在消费者行为分析的创新应用
洞察消费者心理:Transformer模型在消费者行为分析的创新应用 在数字化时代,消费者行为分析对于企业理解市场动态、制定营销策略至关重要。Transformer模型,以其在处理序列数据方面的优势,为消费者行为分析提供了新的视角和工具。…...

如何安全使用代理ip
1、选择可靠的代理服务提供商:选择知名的、信誉良好的代理服务提供商,避免使用免费的代理服务,因为免费的代理服务可能存在安全隐患。 2、使用HTTPS代理:使用HTTPS代理可以加密你的网络流量,保护你的隐私和安全。 3、…...

机器学习——LR、GBDT、SVM、CNN、DNN、RNN、Word2Vec等模型的原理和应用
LR(逻辑回归) 原理: 逻辑回归模型(Logistic Regression, LR)是一种广泛应用于分类问题的统计方法,尤其适用于二分类问题。其核心思想是通过Sigmoid函数将线性回归模型的输出映射到(0,1)区间,从…...

揭秘SQL Server数据库选项:性能与行为的调控者
揭秘SQL Server数据库选项:性能与行为的调控者 在SQL Server的世界中,数据库选项是那些可以调整以优化数据库性能和行为的设置。它们是数据库管理员和开发者的得力助手,通过精细调控,可以显著提升数据库的响应速度和资源利用率。…...
】)
【排序 - 选择排序优化版(利用堆排序)】
结合选择排序和堆排序的思路,可以通过利用堆数据结构来优化选择排序的过程,使得排序算法更加高效。在这种结合中,我们利用堆的特性来快速定位和选择未排序部分的最小元素,避免了选择排序中每次线性搜索的开销。 选择排序和堆排序…...

PHP编程开发工具有哪些?
PHP的开发工具种类繁多,涵盖了从集成开发环境(IDE)、代码编辑器、调试器到版本控制工具和数据库管理工具等多个方面。以下是一些常见的PHP开发工具: 1. 集成开发环境(IDE) PhpStorm:由JetBrai…...
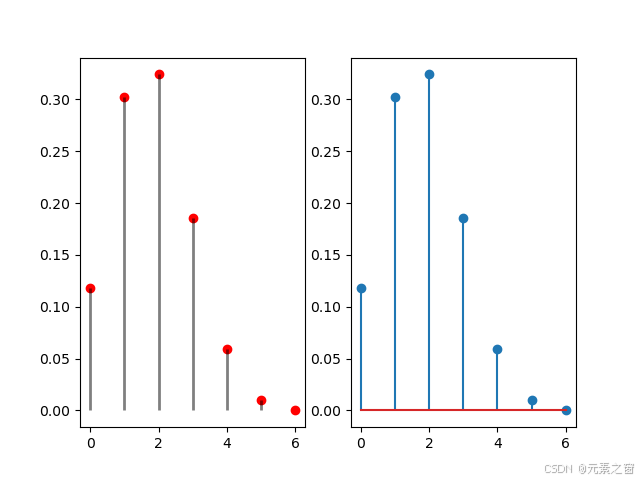
火柴棒图python绘画
使用Python绘制二项分布的概率质量函数(PMF) 在这篇博客中,我们将探讨如何使用Python中的scipy库和matplotlib库来绘制二项分布的概率质量函数(PMF)。二项分布是统计学中常见的离散概率分布,描述了在固定次…...

Nginx七层(应用层)反向代理:UWSGI代理uwsgi_pass篇
Nginx七层(应用层)反向代理 UWSGI代理uwsgi_pass篇 - 文章信息 - Author: 李俊才 (jcLee95) Visit me at CSDN: https://jclee95.blog.csdn.netMy WebSite:http://thispage.tech/Email: 291148484163.com. Shenzhen ChinaAddress of this a…...

Effective C++笔记之二十一:One Definition Rule(ODR)
ODR细节有点复杂,跨越各种情况。基本内容如下: ●普通(非模板)的noninline函数和成员函数、noninline全局变量、静态数据成员在整个程序中都应当只定义一次。 ●class类型(包括structs和unions)、模板&…...
探索未来:Transformer模型在智能环境监测的革命性应用
探索未来:Transformer模型在智能环境监测的革命性应用 在当今数字化时代,环境监测正逐渐从传统的人工检测方式转变为智能化、自动化的系统。Transformer模型,作为深度学习领域的一颗新星,其在自然语言处理(NLP&#x…...

Nginx中文URL请求404
这两天正在搞我的静态网站。方案是:从思源笔记Markdown笔记,用MkOcs build成静态网站,上传到到Nginx服务器。遇到一个问题:URL含有中文会404,全英文URL则正常访问。 比如: 设置了utf-8 ht…...
介绍)
33. 动量法(Momentum)介绍
1. 背景知识 在深度学习的优化过程中,梯度下降法(Gradient Descent, GD)是最基本的方法。然而,基本的梯度下降法在实际应用中存在收敛速度慢、容易陷入局部最小值以及在高维空间中振荡较大的问题。为了解决这些问题,人…...

Python | Leetcode Python题解之第228题汇总区间
题目: 题解: class Solution:def summaryRanges(self, nums: List[int]) -> List[str]:def f(i: int, j: int) -> str:return str(nums[i]) if i j else f{nums[i]}->{nums[j]}i 0n len(nums)ans []while i < n:j iwhile j 1 < n …...

物联网应用,了解一点 WWAN全球网络标准
WWAN/蜂窝无线电认证,对跨地区应用场景,特别重要。跟随全球业务的脚步,我们像大唐先辈一样走遍全球业务的时候,了解一点全球化的 知识信息,就显得有那么点意义。 NA (北美):美国和加…...
如何指定多块GPU卡进行训练-数据并行
训练代码: train.py import torch import torch.nn as nn import torch.optim as optim from torch.utils.data import DataLoader, Dataset import torch.nn.functional as F# 假设我们有一个简单的文本数据集 class TextDataset(Dataset):def __init__(self, te…...

RK3568笔记三十三: helloworld 驱动测试
若该文为原创文章,转载请注明原文出处。 报着学习态度,接下来学习驱动是如何使用的,从简单的helloworld驱动学习起。 开始编写第一个驱动程序—helloworld 驱动。 一、环境 1、开发板:正点原子的ATK-DLRK3568 2、系统…...

vscode里如何用git
打开vs终端执行如下: 1 初始化 Git 仓库(如果尚未初始化) git init 2 添加文件到 Git 仓库 git add . 3 使用 git commit 命令来提交你的更改。确保在提交时加上一个有用的消息。 git commit -m "备注信息" 4 …...

相机Camera日志实例分析之二:相机Camx【专业模式开启直方图拍照】单帧流程日志详解
【关注我,后续持续新增专题博文,谢谢!!!】 上一篇我们讲了: 这一篇我们开始讲: 目录 一、场景操作步骤 二、日志基础关键字分级如下 三、场景日志如下: 一、场景操作步骤 操作步…...

条件运算符
C中的三目运算符(也称条件运算符,英文:ternary operator)是一种简洁的条件选择语句,语法如下: 条件表达式 ? 表达式1 : 表达式2• 如果“条件表达式”为true,则整个表达式的结果为“表达式1”…...

Keil 中设置 STM32 Flash 和 RAM 地址详解
文章目录 Keil 中设置 STM32 Flash 和 RAM 地址详解一、Flash 和 RAM 配置界面(Target 选项卡)1. IROM1(用于配置 Flash)2. IRAM1(用于配置 RAM)二、链接器设置界面(Linker 选项卡)1. 勾选“Use Memory Layout from Target Dialog”2. 查看链接器参数(如果没有勾选上面…...

VTK如何让部分单位不可见
最近遇到一个需求,需要让一个vtkDataSet中的部分单元不可见,查阅了一些资料大概有以下几种方式 1.通过颜色映射表来进行,是最正规的做法 vtkNew<vtkLookupTable> lut; //值为0不显示,主要是最后一个参数,透明度…...

[Java恶补day16] 238.除自身以外数组的乘积
给你一个整数数组 nums,返回 数组 answer ,其中 answer[i] 等于 nums 中除 nums[i] 之外其余各元素的乘积 。 题目数据 保证 数组 nums之中任意元素的全部前缀元素和后缀的乘积都在 32 位 整数范围内。 请 不要使用除法,且在 O(n) 时间复杂度…...

【Go语言基础【13】】函数、闭包、方法
文章目录 零、概述一、函数基础1、函数基础概念2、参数传递机制3、返回值特性3.1. 多返回值3.2. 命名返回值3.3. 错误处理 二、函数类型与高阶函数1. 函数类型定义2. 高阶函数(函数作为参数、返回值) 三、匿名函数与闭包1. 匿名函数(Lambda函…...

Python基于历史模拟方法实现投资组合风险管理的VaR与ES模型项目实战
说明:这是一个机器学习实战项目(附带数据代码文档),如需数据代码文档可以直接到文章最后关注获取。 1.项目背景 在金融市场日益复杂和波动加剧的背景下,风险管理成为金融机构和个人投资者关注的核心议题之一。VaR&…...

【Go语言基础【12】】指针:声明、取地址、解引用
文章目录 零、概述:指针 vs. 引用(类比其他语言)一、指针基础概念二、指针声明与初始化三、指针操作符1. &:取地址(拿到内存地址)2. *:解引用(拿到值) 四、空指针&am…...

使用Spring AI和MCP协议构建图片搜索服务
目录 使用Spring AI和MCP协议构建图片搜索服务 引言 技术栈概览 项目架构设计 架构图 服务端开发 1. 创建Spring Boot项目 2. 实现图片搜索工具 3. 配置传输模式 Stdio模式(本地调用) SSE模式(远程调用) 4. 注册工具提…...