【Linux学习】进程间通信——system V(共享内存 | 消息队列 | 信号量)
🐱作者:一只大喵咪1201
🐱专栏:《Linux学习》
🔥格言:你只管努力,剩下的交给时间!

进程间通信——共享内存 | 消息队列 | 信号量
- 🏀共享内存
- ⚽系统调用shmget
- key值
- ⚽系统调用shmctl
- ⚽系统调用shmat和shmdt
- ⚽共享内存的进程间通信
- 特性
- ⚽共享内存的内核数据结构
- 🏀消息队列(了解)
- ⚽系统调用
- 🏀信号量(了解)
- 🏀总结
system V是一种进程间通信策略,它包括共享内存,消息队列以及信号量。
🏀共享内存
共享内存区是最快的IPC(进程间通信)形式。一旦这样的内存映射到共享它的进程的地址空间,这些进程间数据传递不再涉及到内核,换句话说是进程不再通过执行进入内核的系统调用来传递彼此的数据。
- 共享内存也是由操作系统维护的共享资源。
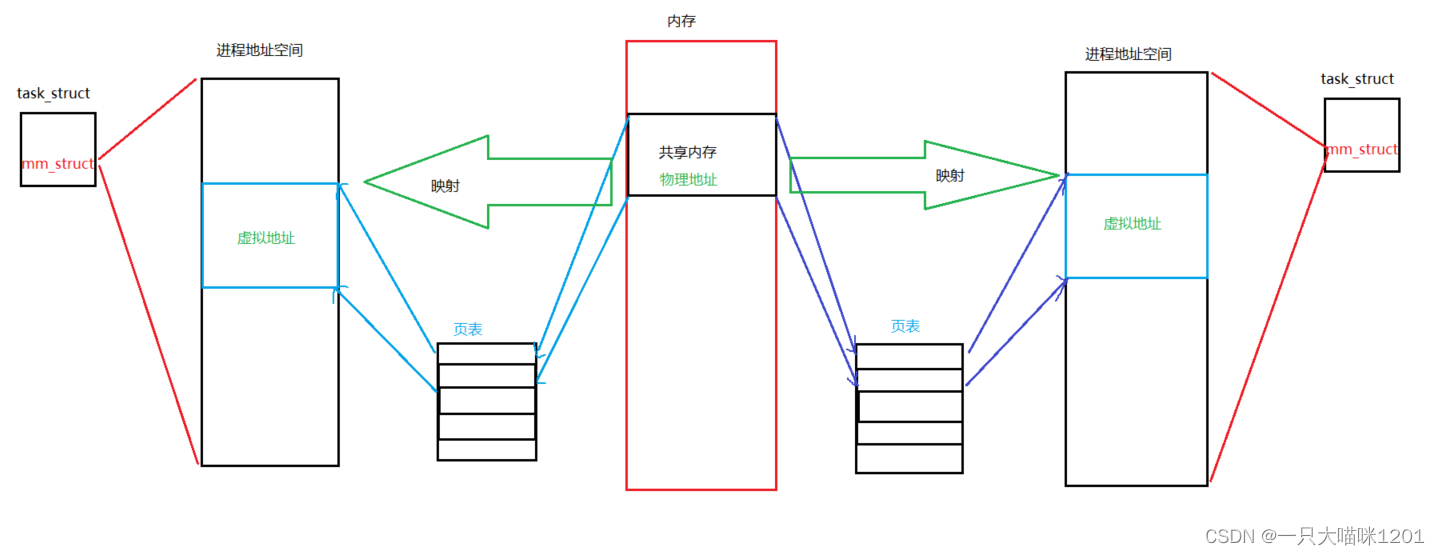
两个进程的PCB各自维护着一个进程地址空间。当两个进程要进行通信时:
- 操作系统在内存中开辟一个内存块。
- 通过两个进程的页表,将内存中的内存块映射到两个进程的进程地址空间中。
- 此时两个进程便建立了连接。
- 进行通信时,两个进程只需要访问自己的进程地址空间即可,操作系统会通过页表访问内存中的内存块。
所以说,共享内存就是让不同的进程,看到同一块内存块。
在维持通信关系中,还涉及到几个概念:
- 挂接:将内存中创建好的内存块映射到进程的地址空间中。
- 去关联:不想通信时,取消进程和内存的映射关系。
注意: 去关联后,共享内存仍然存在,只是和去关联的进程没有了映射关系。
⚽系统调用shmget
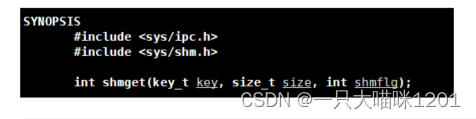
该系统调用接口就是用来在内存中创建共享内存的。它们的参数意义非凡,下面本喵来详细解释一下。
key值
关于共享内存,首先需要理解几件事情:
- 共享内存是专门设计的ipc方式,是用来进行进程间通信的。
- 所有想通信的进程都可以用共享内存的方式来通信。
- 所以操作系统中注定不止一块共享内存。
共享内存多了,就需要有一个标识,让要通信的进程找到正确的共享内存。
key值就是共享内存的标识,让想要通信的进程双方看到同一块公共资源。
系统中既然存在很多个共享内存,操作系统势必要将它们管理起来,管理也是使用先描述再组织的方式。
管理共享内存并不是在管理内存块本身,而是在管理共享内存对应的结构体:
struct shm
{key_t key;size_t size;//....
}
结构体类似与上面代码,包含许多共享内存的属性,最重要的是,结构体中有key值。
- 每创建一个共享内存,就会创建一个结构体对象,并且赋一个不同的key值。
- 所以这个key值就代表着一块唯一的共享内存。
问题又来了,怎么保证这个key值是唯一的呢?
从shmget函数的声明中可以看到,这个key值是我们传给操作系统的,也就是用我们传的key值来标定共享内存。
函数ftok()
这就需要用到另一个函数ftok(),来生成一个独一无二的key值。

- pathname:文件路径名,可以随意写,一般我们都写成当前路径"."。
- proj_id:项目ID,同样可以自定义,但是不能为0。
- 返回值:独一无二的key值。
该函数会根据我们传的路径名和项目id值生成一个key值,具体实现是通过一些算法实现的,我们不需要在意,只需要得到key值就行。
所以,在开辟共享内存之前,必须先使用ftok函数来生成一个独一无二的key值,这样才能保证我们内存块的标识是唯一的。
当两个进程通过key值和共享内存挂接起来后,就可以进行通信了。
结论:key值就是用来标识共享内存的唯一性的。
size
size是用来指定开辟的共享内存是多大的,以字节为单位。
- 一般指定的大小是4KB的整数倍。
- 也可以是任意值。
操作系统在开辟共享内存的时候是以4KB为单位的。每次开辟的共享内存,最小也是4KB的。
- 假设我们指定4097字节大小的共享内存,但是在内存中实际开辟的共享内存是2*4KB的。
- 但是在使用的时候只能使用4097字节的空间,剩下的空间用户无法使用,操作系统也不会用,就浪费掉了。
所以,即使用不了那么大的空间,我们也要指定4KB的整数倍。
shmflg
这是一个标志位,和之前使用的open用法相似,也是一个int类型的数据,根据比特位不同,用法也不同。
常用的两个选项:
- IPC_CREAT:创建共享内存,如果不存在,创建新的,如果存在,获取相关信息。
- IPC_EXCL:无法单独使用,必须与其他标志组合使用。
IPC_CREAT | IPC_EXCL:创建共享内存,如果不存在,则创建,如果存在,错误返回。
IPC_CREAT | IPC_EXCL是专门给用户使用的,就是为了保证创建的共享内存是一块新的内存块。
返回值

- 创建成功返回共享内存的标识符,注意不是key值。
- 创建失败,返回-1。
来看看返回的值是什么样子:

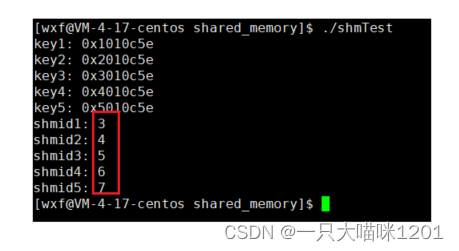
- shmid也是连续的小整数,它和文件描述符fd一样,也是让用户使用的。
- 但是它和文件描述符代表的意义又不一样。
又存在一个问题,为什么返回的不是key值,而是shmid呢?key值也是唯一的啊。
在设计上是可以的,都是唯一的数字,用户在语言层和在系统使用的标识相同是没有问题的。
- 如果写好了一份代码,代码中使用的是key值。
- 当系统的底层发生了变化,key值也会变化。
- 但是代码中的key值没有变化,此时继续使用原理的代码就会出错。
所以说,用户层使用shmid而不是key值是为了让用户层和系统层解耦。
结论:shmid是供用户使用的共享内存标识符。
shmget系统调用就是用来让通信双方获取同一块共享内存的。
⚽系统调用shmctl
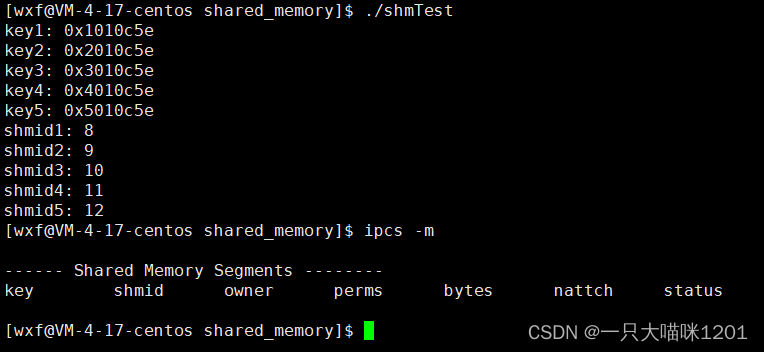
刚刚我们使用shmget时创建了五个共享内存:
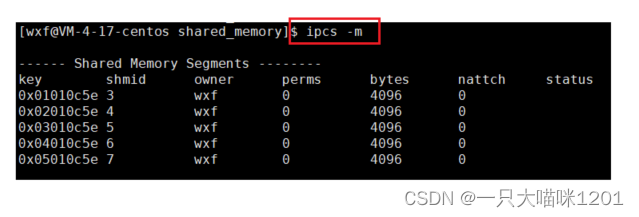
此时创建的5个共享内存就显示出来了。
此时,进程早已经结束了,但是共享内存还是存在,没有随进程的结束而消失。
所以说,共享内存的生命周期随内核,不随进程。
如果不想要这几个共享内存了,怎么删除呢?同样有指令:
- 指令:ipcrm -m shimd
- 功能:删除指定shimd标识的共享内存。
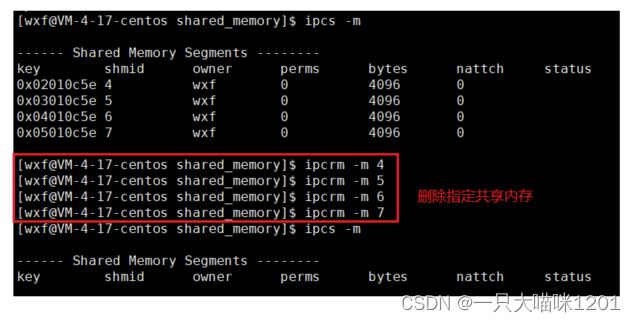
此时所有的共享内存就被删除了,但是需要我们手动的一个个去删除。
由于指令也是shell上运行的进程,也是属于用户层,所以操作共享内存时,使用的时shmid,而不是key值。
用命令行的形式未免也太麻烦了,所以有系统调用shmctl也可以用来删除共享内存,而且是自动的。
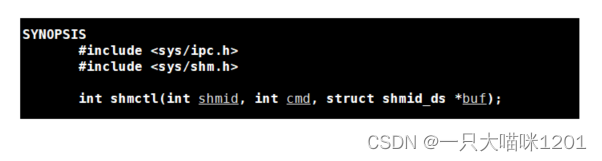
- shmid:获取共享内存后返回的标识符。
- cmd:指定控制共享内存的方式。
- buf:描述共享内存的数据结构指针。
cmd:IPC_RMID
删除是最常用的选项。
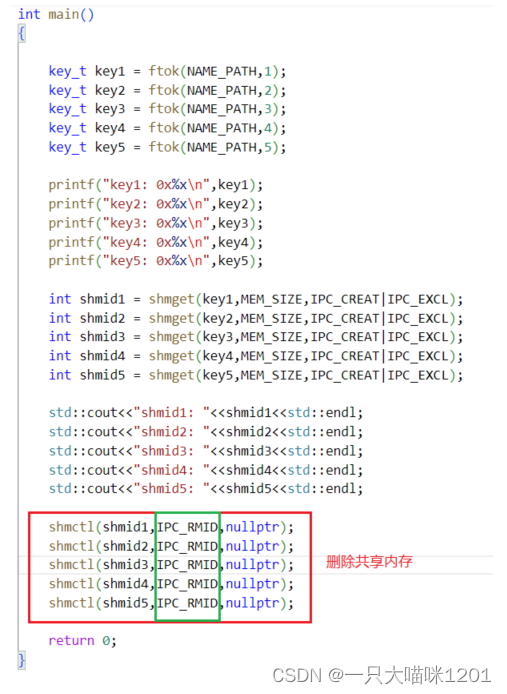
key值和shmid也打印了,说明共享内存创建成功了,但是使用ipcs查看时,发现什么都没有,证明shmctl将创建的共享内存删除了。
cmd:IPC_STAT
用来查看共享内存内核数据结构中的属性,不常用。
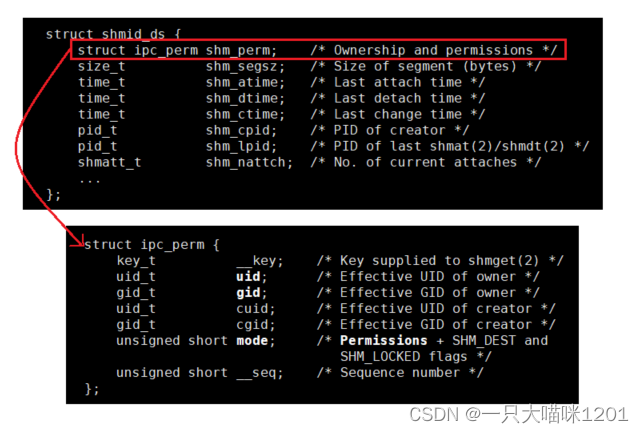
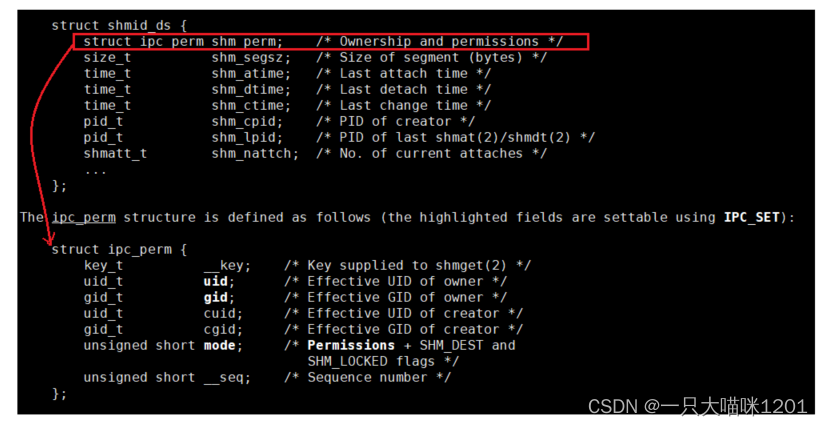
上图所示就是共享内存的数据结构struct_shmid_ds,也就是用来描述共享内存的数据结构,这只是其中的一部分。
该结构体的第一个成员变量是struct ipc_prem shm_prem,具体内容如红色箭头所指。可以看到,key值就在这里,共享内存就是通过它来标识唯一性的。
当cmd是IPC_STAT时,我们就可以获取到共享内存的属性:
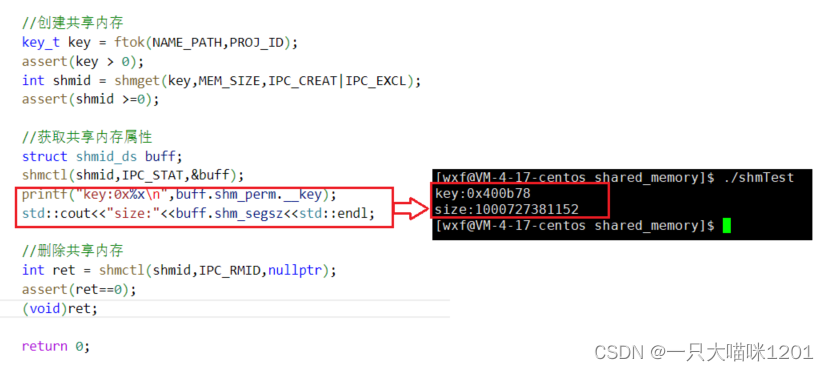
此时共享内存内核数据结构中的属性信息就被我们看到了。
cmd可以传的值有很多,分别对应这不同的操作,但是最常用的还是删除。
⚽系统调用shmat和shmdt
shmat
shmat是让进程和共享内存挂接:
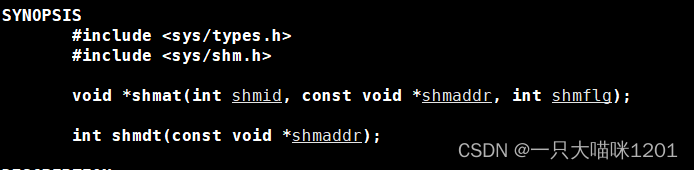
- shmid:创建共享内存后返回的标识符。
- shmaddr:指定共享内存映射到进程地址空间中的地址,一般设置成NULL,让系统自动来设置。
- shmflg:不用管它是啥,直接给0。
- 返回值:共享内存映射到进程地址空间中的地址。不成功返回-1,但是是void*类型的。
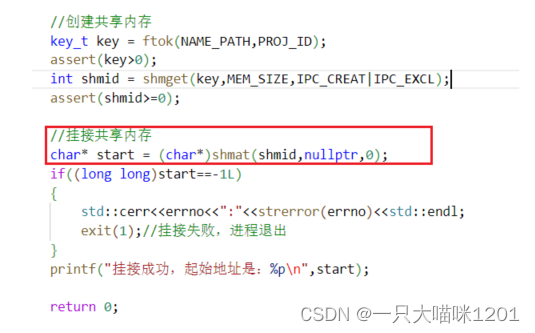
让该进程挂接共享内存,挂接成功打印映射到进程地址空间中的起始地址。
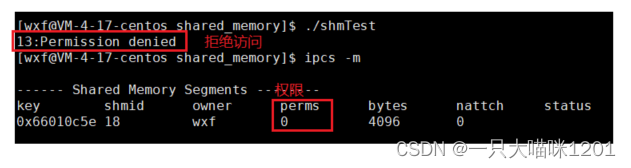
在运行的时候发现报错了,说我们没有权限,再查看共享内存,发现确实是创建了,但是共享内存的权限是0,也就是我们谁都不能访问。
解决办法就让给共享内存开发相应的权限:
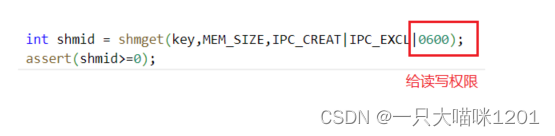
- 在创建共享内存的时候,让其开发对拥有者的读写权限。
- 将0600和IPC_CREAT已经IPC_EXCL或在一起。
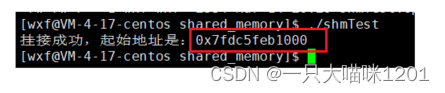
此时便挂接成功了,并且成功打印出了共享内存映射在进程地址空间中的起始地址。
shmdt
shmdt是让进程和共享内存去关联。
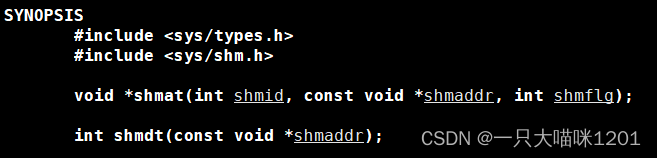
- shmaddr:要去关联的共享内存映射在进程地址空间中的起始地址。
- 返回值:成功返回0,不成功返回-1。
nattch值
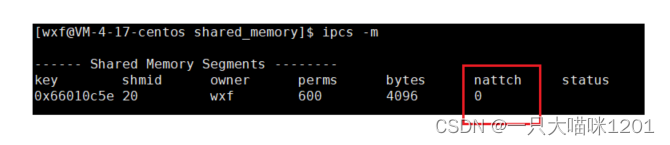
在使用ipcs查看共享内存的时候,有一栏是nattch。
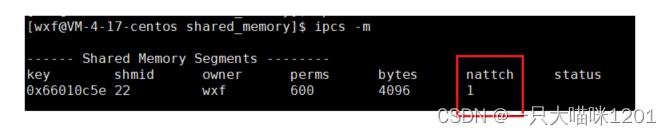
在进程和共享内存挂接后,查看共享内存信息,发现这个共享内存的nattch变成了1。
- nattch:表示和这块共享内存挂接的进程数量。
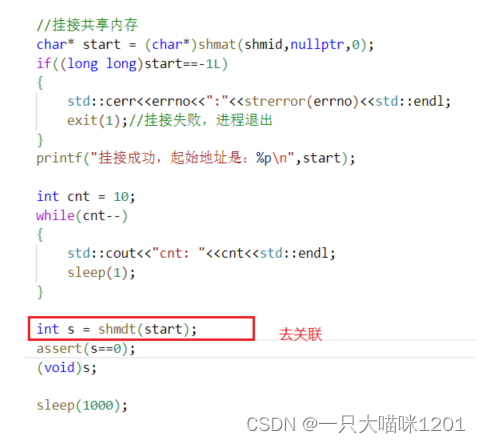
在和共享内存挂接以后,进行10s的延时,时间到进行去关联。
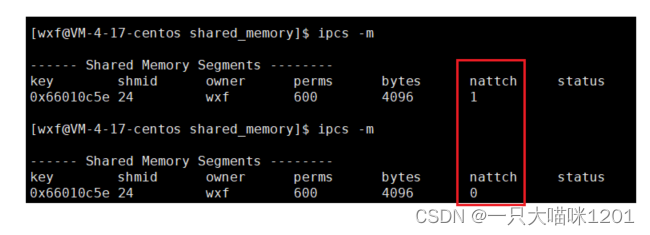
可以看到,在计时到之前,nattch的值是1,等计时到了,nattch的值变成了0,此时就将该进程和共享内存去关联了。
注意: 去关联后,共享内存还在,只是和进程没有联系了。
共享内存方式的进程间通信,用到的系统调用为shmget,shmctl,shmat,shmdt四个。
⚽共享内存的进程间通信
使用共享内存的方式,实现进程server和client之间的通信:
- server负责创建共享内存,删除共享内存
- server从共享内存中读数据。
- client向共享内存中写数据。
shmget,shmctl,shmat,shmdt四个系统调用通信双方都会使用,而且会对返回值进行严格判断,所以我们将这些共用的代码放在一个头文件中。
comm.h:
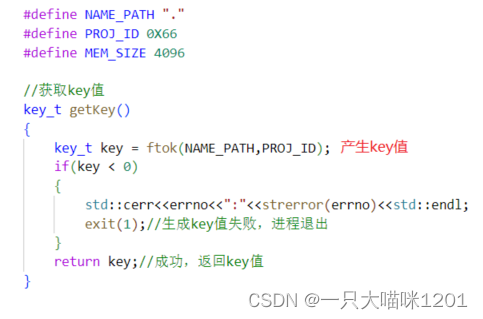
使用ftok生成key值,如果成功的话,返回key值,失败的话之间退出进程。
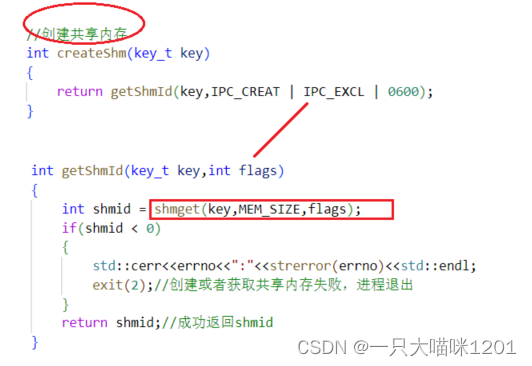
server方需要负责维护共享内存,所以就由它来创建,将创建的具体过程封装在一个函数里,只需要调用创建函数,传入一个key值就可以创建。
创建成功返回共享内存标识符shmid,失败的话退出进程。
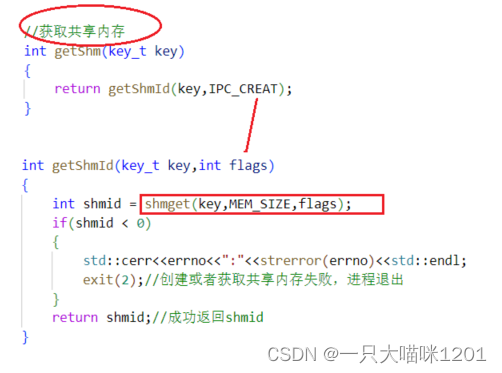
client方只需获取共享内存的shmid即可,同样将具体实现封装,只需要调用获取函数,传入一个key值就可以,获取成功返回共享内存标识符,失败退出进程。

挂接共享内存时,同样将具体实现封装起来,只需要调用挂接函数,传一个shmid即可,挂接成功返回映射后的虚拟地址,失败则退出进程。
- (long long)memp == -1L解释说明:
- memp是一个void类型的指针,即使失败返回的-1也是void的,所以在判断时要将其强转为整形。
- Linux是64位的机器,所以指针的大小是8个字节,所以为了不发生数据截断,需要强转成对应8个字节的long long类型。
- 常量-1默认是int类型的,加一个后缀L成为-1L就表示这是一个long long类型的常量。
- 此时相同类型的数据才可以进行判断。

将具体判断细节放在函数中,使用的时候只需要调用函数即可,不用再判断。若去关联失败则进程退出。
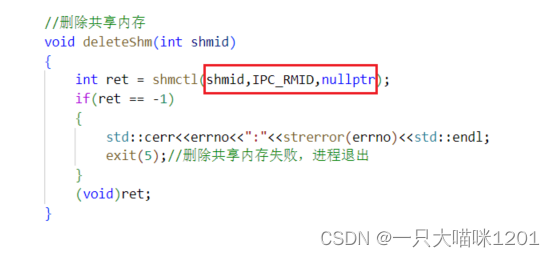
调用shmctl的具体传参细节在函数中实现,删除的时候只需要调用删除函数即可,删除失败则退出进程。
comm.h头文件中的各个函数,都是为了通信双方更方便通信而设计的。
server.cpp和client.cpp:
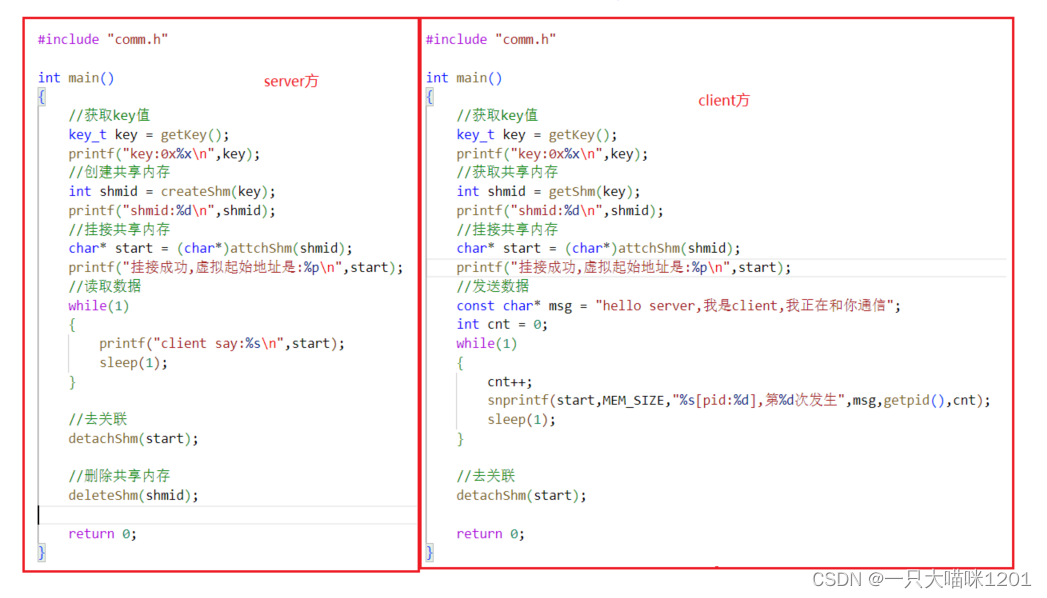
通信双方的通信框架都是按照:
- 获取key值
- 创建或获取共享内存(shmget)
- 和共享内存挂接
- 进行通信
- 和共享内存去关联
- 维护方伤处共享内存
双方数据传送:

发送方一秒发送一次,接收方一秒接收一次。
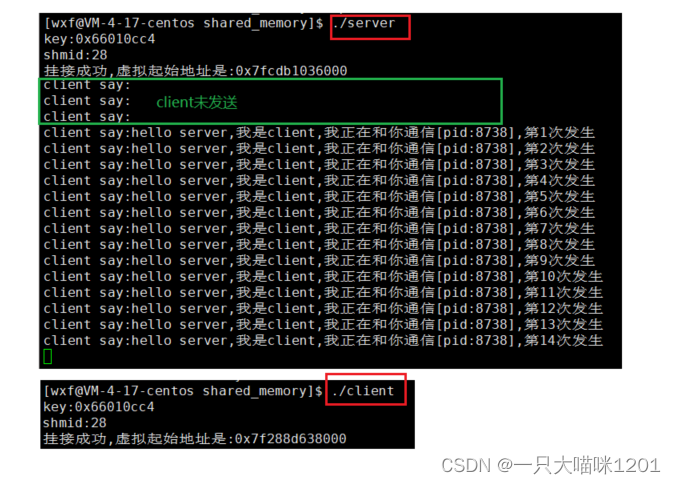
- 必须先执行server,因为server负责维护共享内存,只有共享内存创建了才能进行通信。
- 在client没有发数据之前,server就开始读取数据了,但此时什么都没有。
- 当client开始发送时,server才能读取到数据。
特性

- 通信双方获取的key值相同
因通信双方是通过这个key值在内存中找到同一块共享内存的,key值代表着唯一性,所以必须相同 - 标识符shmid相同
这个标识符和文件描述符不一样,具体是什么原因以后本喵再讲,现在只需要知道双方获取的shmid是相同的。 - 映射的虚拟地址不同
通信双方根据通过页表将共享内存映射到各自的进程地址空间时,除非指定地址,否则不同进程情况不同,内存使用也不同,所以得到的映射虚拟地址也不同。

可以看到,使用共享内存通信时,不像管道那样,通信双方是通过访问管道这个公共资源来实现数据交换的。
而是双方各自访问各自的虚拟地址就可以。
- 操作系统会通过各自的页表与共享内存建立联系。
- 所以双方各自访问自己进程地址空间中映射的起始地址时,就相当于访问到了同一块共享内存。
这样来看,双方各自管自己的就行,不用考虑对方,所以这种通信方式比较简单。
共享内存的优势:
考虑一个问题,通信双方一方写入,一方读取,采用管道和共享内存分别发生了几次数据拷贝。
管道:
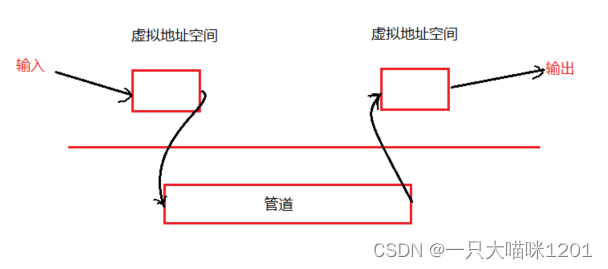
一共需要四次。
- 键盘->写入端进程地址空间->管道->写出端进程地址空间->显示器
共享内存:

一共需要两次。
- 键盘->共享内存(写入写出端进程地址空间)->显示器
由于共享内存在双方各自的进程地址空间中都有映射,相当于三者是一个整体。
*如果考虑用户层缓冲区的话,两种方式各自再增加两次拷贝。
当通信的数据量非常大时,共享内存的方式大大减少了拷贝次数。
- 所以说,共享内存是所有进程间通信速度最快的。
共享内存的劣势:
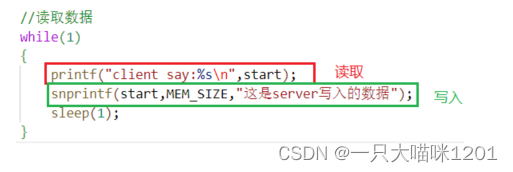
在发送方,有读取,有写入,每隔1秒发生一次。
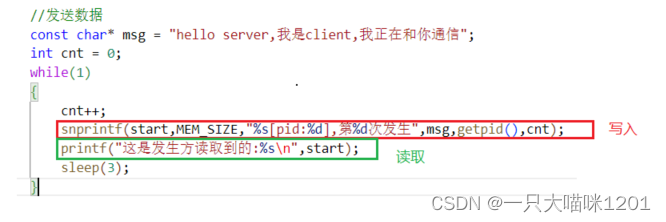
在写入方,有写入,有读取,每隔3秒发生一次。
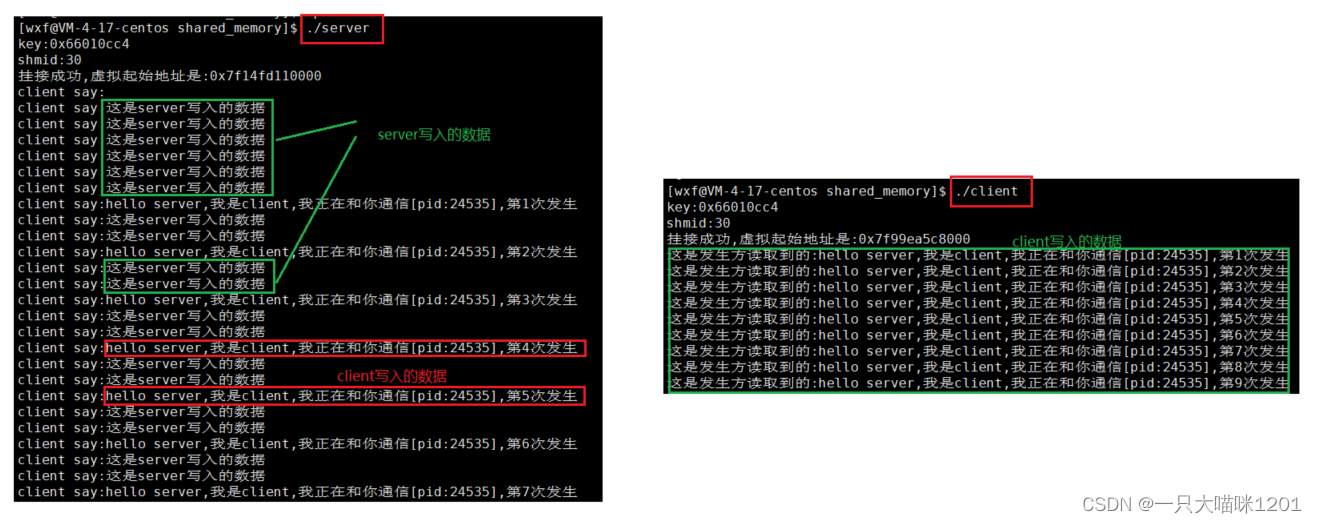
可以看到,结果非常混乱,两个进程想读就读,想写就写,这样就会导致数据混乱,通信的数据不准确。因为双方并不知道对方的存在。
- 原因是共享内存通信方式没有同步和互斥机制。
因为没有对公共资源的保护机制,所以就会导致通信混乱。
如果非要使用共享内存的方式,可以在通信双方之间再加入管道,利用管道的互斥机制来实现共享内存的互斥。有兴趣的小伙伴可以去试试。
共享内存的特征:
- 共享内存的生命周期随内核
- 共享内存是所有进程间通信速度最快的的方式
- 共享内存没有同步互斥机制,不对公共资源进行保护
⚽共享内存的内核数据结构
我们知道,操作系统中不仅有一块共享内存,它们是通过key值来进行唯一性标识的。
操作系统也要管理这些共享内存,上面本喵讲过采用的是先描述后组织的方式。
描述就是使用上图所示的结构体对象来描述的,该结构体中包含了共享内存的所有属性。
将这些描述共享内存的结构体对象组织成某一种数据结构,例如链表,这样操作系统就将共享内存管理起来了。
- 数据结构中存放的是描述共享内存结构体对象的指针。
这里这个指针有点特殊:
- 存放的并不是结构体struct shmid_ds对象的指针。
- 而是它的第一个成员变量struct ipc_perm shm_perm的指针。
由于结构体的地址和结构体中第一个成员的地址在数值上相等,所以在访问结构体的时候,将第一个成员的指针强转成结构体类型的指针就可以。
🏀消息队列(了解)
消息队列的公共资源是链表结构。
通信双方不会和消息队列进行挂接,而是像管道一样,访问内存中的消息队列。
- 消息队列由操作系统维护,但是由通信的某一方创建和删除
- 通信双方都需要获取到消息队列,和共享内存一样。
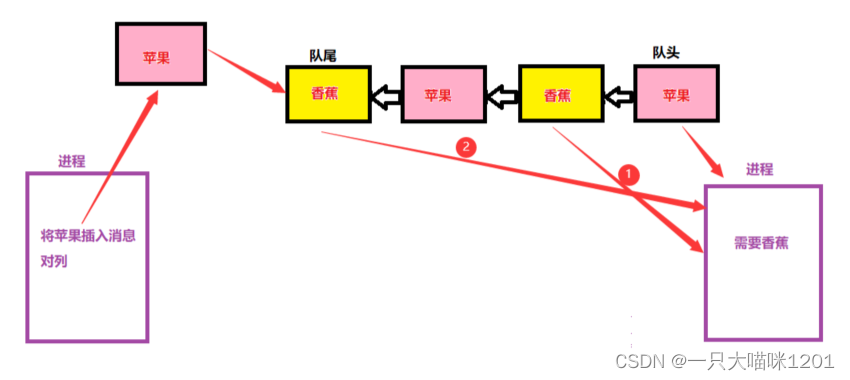
当发送方有数据发送时,将数据先打包成一个节点,然后尾插到内核中的消息队列中去。
当接收方接收数据时,从队列头部开始去找所需要的节点,然后进行解包得到数据。
- 消息队列和普通队列不一样,不是严格按照先进先出的规则。
- 读取方可以跳过队头寻找自己需要的数据。
- 但是相同的数据,必须先读取靠近队头的。
如上图中,当读取方需要的是香蕉,但是队头是苹果,此时就可以跳过苹果,读取香蕉,并且靠近队头的香蕉先被读取。
⚽系统调用
几乎和共享内存一样,本喵就不详细介绍了。
msgget()
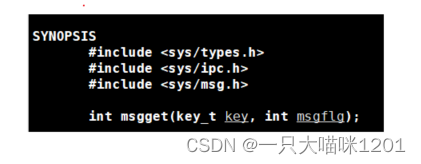
- key:和共享内存一样,也需要生成,是消息队列唯一性的标识符。
- msgflg:和共享内存一样,可以是IPC_CREAT或者IPC_EXCL或者是二者的组合。
- 返回值:返回消息队列的标识符,供用户层使用。
msgctl()
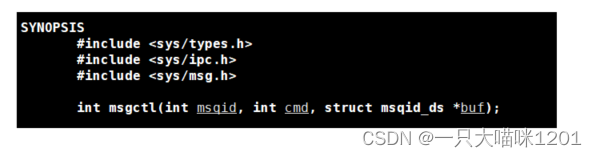
参数和共享内存的shmctl一样。
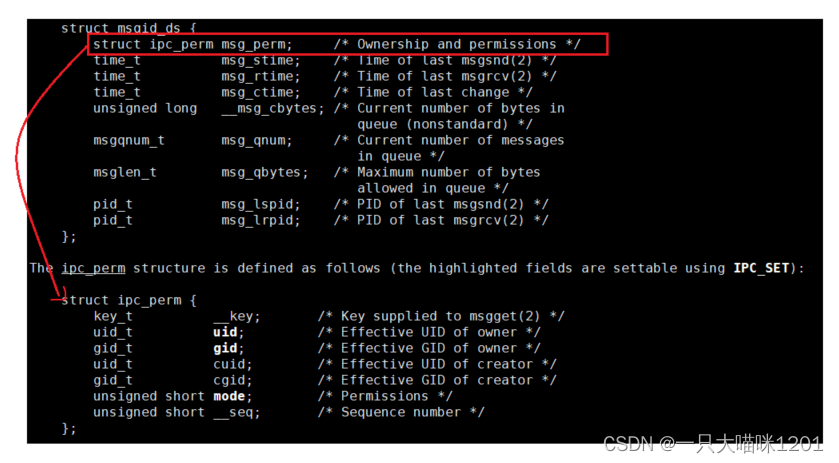
这是消息队列属性描述的结构体。
- 第一个成员变量的类型是struct ipc_perm,变量名是msg_perm,结构类型和共享内存的一样。
只要是采用system V的通信策略,描述共享资源的结构体都是这个结构,第一个变量类型都是struct ipc_perm。
msgsnd()
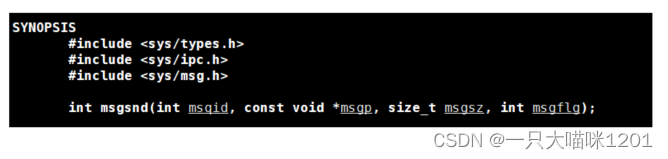
- msgid:消息队列标识符
- msgp:要发送数据所在的数组,元素类型是 struct msgbuf
- msgsz:要发生的数据大小,以字节为单位
- msgflg:创建标记,如果使用IPC_NOWAIT,失败就会立即返回。
0:阻塞发送
IPC_NOWAIT:非阻塞发送- 返回值:失败返回-1,成功返回0
在发送数据之前,需要先将数据进行打包:
struct msgbuf
{long mtype; //数据类型,必须大于0char mtext[1];//要发送的数据
};
- long mtype:该值是发送方用来表明数据的所属的。
- char mtext[1]:数组大小可以改变,和msgsend中的size是一个值。
在发送的时候,需要将数据进行打包,按照上面的规则。
msgrcv()
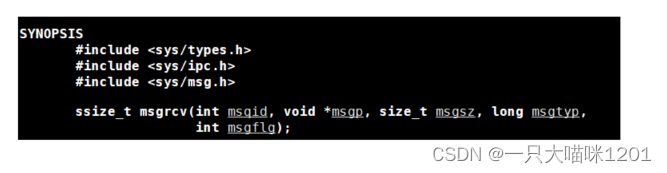
- msgid:消息队列标识符
- msgp:接收的数据后要存放的地址
- msgsz:要接收的数据大小
- msgtype:发送方设定的数据类型标识
- 0:读取队列中的第一条消息(不在乎当前队列头元素是什么消息类型,将他当作普通队列来处理)。
- 大于0(约定值):读取队列中类型为msgtyp 的第一条消息。(就是读取对列元素中第一个香蕉)
- 小于0:读取队列中最小类型小于或等于msgtyp 绝对值的第一条消息。
- msgflg:创建标记,如果指定IPC_ NOWAIT,获取失败会立刻返回
- 0:阻塞接收
- NOWAIT:非阻塞接收
- 返回值:成功返回读取数据的字节数,失败返回-1。
🏀信号量(了解)
信号量本质上就是资源计数器,能够保证多个进程之间访问临界资源,执行临界区代码时。
- 临界资源:多个进程都可以访问到的资源(例如:同一块内存)。
- 临界区:访问临界资源时的代码,所在区域称之为临界区。
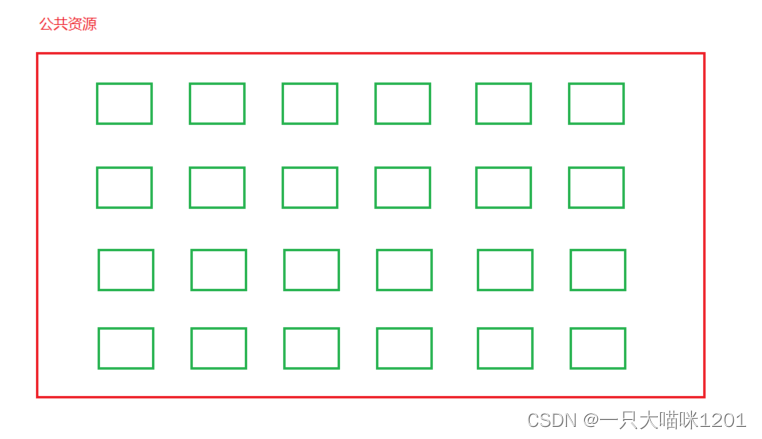
如上图,将一大块公共资源划分成了多个小块的公共资源,假设一个有100个小块。
- 这个100就是信号量,它用来计数公共资源的个数。
当进程想要访问某一小块资源的时候,首先要进行的就是申请信号量,一旦申请成功,信号量就会减1。
- 信号量申请成功进行减一的操作称为P操作。
当这个进程访问完这块小资源后,需要将资源释放,这时候信号量就会加1。
- 是否资源后信号量进行加一的操作称为V操作。
当信号量为0的时候,进程就不能再申请了。
此时再来看,所有进程在访问公共资源之前,都必须申请信号量,而申请信号量的前提是所有进程都能看到同一个信号量,所以这个信号量本身就是公共资源。
既然信号量是公共资源,就必须在很多进程对它进行PV操作时保证自身的安全。
- 试想,当一个进程正在申请,但是这个进程申请的比较慢,还有几个其他进程也在申请,但是申请的快。
- 后面几个进程把信号量都申请完了,当第一个进程申请完成以后,发现信号量没了,此时就会出错。
当然这是一种极端情况,在PV操作的时候,可能会因为时序问题,导致信号量有中间状态,从而导致数据不一致。
所以为了保证信号量的安全性:
- 申请信号量->计数器减1->P操作必须具有原子性。
- 释放信号量->计数器加1->B操作必须具有原子性。
- 原子性:要么不做,要做就做完。
- 也就是,信号量有互斥机制保护,当一个进程在申请信号量的时候,其他要申请信号量的进程处于阻塞状态。
信号量的具体使用,在后面用到的时候本喵会详细讲解,在这里只需要了解这些就可以。
🏀总结
重点介绍了system V通信策略的共享内存方式,包括它的原理及应该,至于消息队列和信号量仅做了解就行,在后面用到的时候本喵会详细讲解。
相关文章:
【Linux学习】进程间通信——system V(共享内存 | 消息队列 | 信号量)
🐱作者:一只大喵咪1201 🐱专栏:《Linux学习》 🔥格言:你只管努力,剩下的交给时间! 进程间通信——共享内存 | 消息队列 | 信号量🏀共享内存⚽系统调用shmgetkey值⚽系统…...
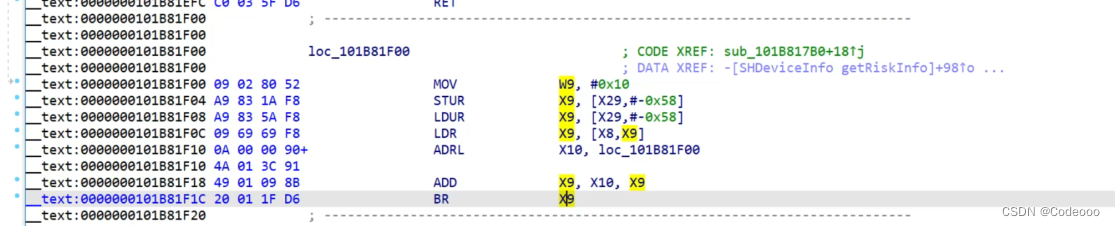
解决 IDA 防F5转伪C笔记
某app砸壳后放到IDA,根据堆栈查到该位置如下; G调到,0x1b81bcc 看下: BR 调到后面 x8 x9地址,汇编指令; 找到x9的地址,然后减去基地址也就是首地址,得到便宜地址; hook x9: var moduleAddr = Module.findBaseAddress("XX"); var line = moduleAddr.add...

【面试题】你需要知道的webpack高频面试题
大厂面试题分享 面试题库前后端面试题库 (面试必备) 推荐:★★★★★地址:前端面试题库谈谈你对webpack的看法webpack是一个模块打包工具,可以使用它管理项目中的模块依赖,并编译输出模块所需的静态文件。它…...

【YOLOv8/YOLOv7/YOLOv5/YOLOv4/Faster-rcnn系列算法改进NO.60】损失函数改进为wiou
前言作为当前先进的深度学习目标检测算法YOLOv8,已经集合了大量的trick,但是还是有提高和改进的空间,针对具体应用场景下的检测难点,可以不同的改进方法。此后的系列文章,将重点对YOLOv8的如何改进进行详细的介绍&…...
attack解析(详细))
2023年中职网络安全竞赛——数字取证调查(新版)attack解析(详细)
数字取证调查 任务环境说明: 服务器场景:FTPServer20221010(关闭链接)服务器场景操作系统:未知FTP用户名:attack817密码:attack817分析attack.pcapng数据包文件,通过分析数据包attack.pcapng找出恶意用户第一次访问HTTP服务的数据包是第几号,将该号数作为Flag值提交;…...

Cadence Allegro 导出Net Single Pin and No Pin报告详解
⏪《上一篇》 🏡《上级目录》 ⏩《下一篇》 目录 1,概述2,Net Single Pin and No Pin作用3,Net Single Pin and No Pin示例4,Net Single Pin and No Pin导出方法4.1,方法14.2,方法2B站关注“硬小二”浏览更多演示视频...
蓝桥冲刺31天之317
在这个时代,我们总是在比较,觉得自己不够好 其实不必羡慕别人的闪光点 每个人都是属于自己的限量版 做你喜欢并且擅长的事,做到极致 自然会找到自己独一无二的价值 鸟不跟鱼比游泳,鱼不跟鸟比飞翔 你我各有所长 A:组队…...
站上风口,文心一言任重道远
目录正式发布时机选择逻辑推理AI绘画用户选择总结自从OpenAI公司的chatGPT发布以来,吸引了全球目光,同时也引起了我们的羡慕,希望有国产的聊天机器人,盼星星盼月亮,终于等来了百度文心一言的发布。 正式发布 3月16日…...

Qt音视频开发24-视频显示QOpenGLWidget方式(占用GPU)
一、前言 采用painter的方式绘制解码后的图片,方式简单易懂,巨大缺点就是占CPU,一个两个通道还好,基本上CPU很低,但是到了16个64个通道的时候,会发现CPU也是很吃紧(当然强劲的电脑配置另当别论…...

百度发布文心一言,我想说几句
大家好,我是记得诚。 今天下午百度公司正式发布了文心一言,算是国内第一个交卷的互联网公司。 在ChatGPT和GPT-4的双重夹击下,可想而知百度的压力。 ChatGPT发布的时候,热度非常的高,大家对其都非常的感兴趣。 我是…...

简单了解JSP
JSP概念与原理概念: Java Server Pages,Java服务端页面一种动态的网页技术,其中既可以定义 HTML、JS、CSS等静态内容,还可以定义Java代码的动态内容JSP HTML Java, 用于简化开发JSP的本质上就是一个ServletJSP 在被访问时,由JSP容…...
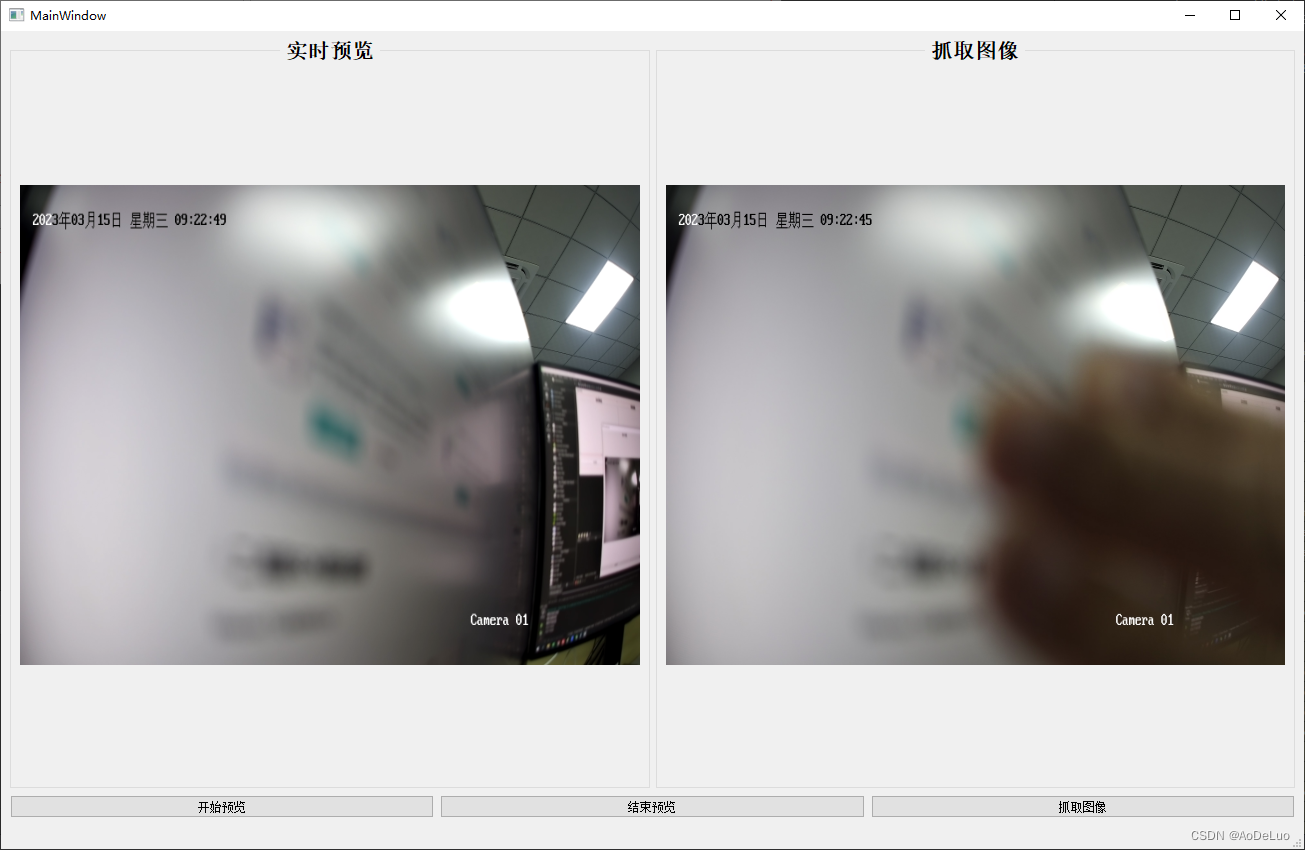
Qt(c++)调用海康威视监控摄像头
文章目录一.海康威视监控摄像头开发SDK介绍二.海康SDK模块说明三.Qt项目中海康威视SDK配置四.实时预览摄像头图像程序一.海康威视监控摄像头开发SDK介绍 设备网络SDK是基于设备私有网络通信协议开发的,为嵌入式网络硬盘录像机、NVR、网络摄像机、网络球机、视频服务…...
: CUDA_Run_Time_API_parallel_多流并行,以及多流之间互相同步等待的操作方式)
深度学习部署笔记(十五): CUDA_Run_Time_API_parallel_多流并行,以及多流之间互相同步等待的操作方式
// CUDA运行时头文件 #include <cuda_runtime.h>#include <chrono> #include <stdio.h> #include <string.h>using namespace std;#define checkRuntime(op) __check_cuda_runtime((op), #op, __FILE__, __LINE__)bool __check_cuda_runtime(cudaErro…...
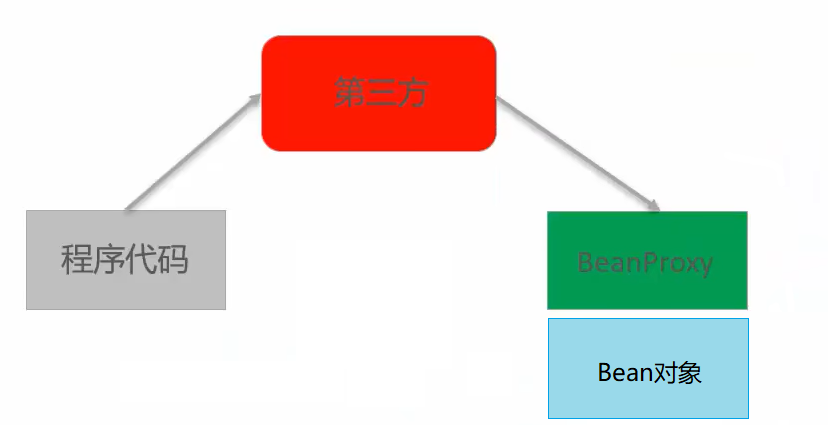
【Spring】spring框架简介
一、框架 1.框架的基本特点: 框架(Framework),是基于基础技术之上,从众多业务中抽取出的通用解决方案;框架是一个半成品,使用框架规定的语法开发可以提高开发效率,可以用简单的代码就能完成复杂的基础业务;框架内部使用大量的设…...

WuThreat身份安全云-TVD每日漏洞情报-2023-03-17
漏洞名称:TP-LINK Archer AX21 命令注入漏洞 漏洞级别:严重 漏洞编号:CVE-2023-1389,CNNVD-202303-1280 相关涉及:TP-LINK Archer AX21 1.1.4 Build 20230219之前的固件版本 漏洞状态:POC 参考链接:https://tvd.wuthreat.com/#/listDetail?TVD_IDTVD-2023-06347 漏洞名称:D-L…...

postman 调用webservice
有个外部接口需要提供古老的webservice 格式接口。1 设置格式按照xml 格式设置。2 消息体xml 封装不加envelope:<soap:Envelope xmlns:soap"" target"_blank">http://schemas.xmlsoap.org/soap/envelope/"><soap:Body><soap:Fault&…...
基于华为模拟器(ensp)的静态路由配置实验
一 实验需求静态路由实验,建立拓扑pc1>>R1>>R2>>R3>>pc2,使pc1与pc2能相互通信。二 实验拓扑三 ip地址规划设备接口ip地址AR1G0/0/0192.168.10.254/24G0/0/112.1.1.1/24AR2G0/0/012.1.1.2/24G0/0/123.1.1.2/24 AR3G0/0/023.1.1.…...
模拟实现字符串函数(长度受限制的详讲)
上次发布了长度不受限制的字符串函数的模拟实现方法,这次就给大家说说长度受限制的字符串函数。首先,长度受限制和不受限制有什么区别呢?其实从某种意义上来讲,长度受限制的字符串函数比长度不受限制的字符串安全,为什…...

分布式ID生成方案总结
什么是分布式 ID 分布式 ID 是指,在分布式环境下可用于对数据进行标识且易存储的全局唯一的 ID 标识。 为什么需要分布式 ID 对于单体系统来说,主键ID可能会常用主键自动的方式进行设置,这种ID生成方法在单体项目是可行的。 对于分布式系统…...

极智AI | 百度推出文心一言,对标ChatGPT功力几成
欢迎关注我,获取我的更多经验分享,极智传送《极智AI | 百度推出文心一言,对标 ChatGPT 功力几成》 大家好,我是极智视界,本文介绍一下 百度今日推出文心一言,对标ChatGPT功力几成。 邀您加入我的知识星球「极智视界」,星球内有超多好玩的项目实战源码下载,链接:https…...

使用docker在3台服务器上搭建基于redis 6.x的一主两从三台均是哨兵模式
一、环境及版本说明 如果服务器已经安装了docker,则忽略此步骤,如果没有安装,则可以按照一下方式安装: 1. 在线安装(有互联网环境): 请看我这篇文章 传送阵>> 点我查看 2. 离线安装(内网环境):请看我这篇文章 传送阵>> 点我查看 说明:假设每台服务器已…...

C++:std::is_convertible
C++标志库中提供is_convertible,可以测试一种类型是否可以转换为另一只类型: template <class From, class To> struct is_convertible; 使用举例: #include <iostream> #include <string>using namespace std;struct A { }; struct B : A { };int main…...

2025盘古石杯决赛【手机取证】
前言 第三届盘古石杯国际电子数据取证大赛决赛 最后一题没有解出来,实在找不到,希望有大佬教一下我。 还有就会议时间,我感觉不是图片时间,因为在电脑看到是其他时间用老会议系统开的会。 手机取证 1、分析鸿蒙手机检材&#x…...

初探Service服务发现机制
1.Service简介 Service是将运行在一组Pod上的应用程序发布为网络服务的抽象方法。 主要功能:服务发现和负载均衡。 Service类型的包括ClusterIP类型、NodePort类型、LoadBalancer类型、ExternalName类型 2.Endpoints简介 Endpoints是一种Kubernetes资源…...

虚拟电厂发展三大趋势:市场化、技术主导、车网互联
市场化:从政策驱动到多元盈利 政策全面赋能 2025年4月,国家发改委、能源局发布《关于加快推进虚拟电厂发展的指导意见》,首次明确虚拟电厂为“独立市场主体”,提出硬性目标:2027年全国调节能力≥2000万千瓦࿰…...

解析奥地利 XARION激光超声检测系统:无膜光学麦克风 + 无耦合剂的技术协同优势及多元应用
在工业制造领域,无损检测(NDT)的精度与效率直接影响产品质量与生产安全。奥地利 XARION开发的激光超声精密检测系统,以非接触式光学麦克风技术为核心,打破传统检测瓶颈,为半导体、航空航天、汽车制造等行业提供了高灵敏…...

Chrome 浏览器前端与客户端双向通信实战
Chrome 前端(即页面 JS / Web UI)与客户端(C 后端)的交互机制,是 Chromium 架构中非常核心的一环。下面我将按常见场景,从通道、流程、技术栈几个角度做一套完整的分析,特别适合你这种在分析和改…...

【Kafka】Kafka从入门到实战:构建高吞吐量分布式消息系统
Kafka从入门到实战:构建高吞吐量分布式消息系统 一、Kafka概述 Apache Kafka是一个分布式流处理平台,最初由LinkedIn开发,后成为Apache顶级项目。它被设计用于高吞吐量、低延迟的消息处理,能够处理来自多个生产者的海量数据,并将这些数据实时传递给消费者。 Kafka核心特…...

图解JavaScript原型:原型链及其分析 | JavaScript图解
忽略该图的细节(如内存地址值没有用二进制) 以下是对该图进一步的理解和总结 1. JS 对象概念的辨析 对象是什么:保存在堆中一块区域,同时在栈中有一块区域保存其在堆中的地址(也就是我们通常说的该变量指向谁&…...

鸿蒙HarmonyOS 5军旗小游戏实现指南
1. 项目概述 本军旗小游戏基于鸿蒙HarmonyOS 5开发,采用DevEco Studio实现,包含完整的游戏逻辑和UI界面。 2. 项目结构 /src/main/java/com/example/militarychess/├── MainAbilitySlice.java // 主界面├── GameView.java // 游戏核…...