数据库系统概论:数据库系统的锁机制
引言
锁是计算机协调多个进程或线程并发访问某一资源的机制。在数据库中,数据作为一种共享资源,其并发访问的一致性和有效性是数据库必须解决的问题。锁机制通过对数据库中的数据对象(如表、行等)进行加锁,以确保在同一时间只有一个事务可以对该数据对象进行修改或访问,从而保证数据的一致性和完整性。
锁机制
产生并发不一致性问题主要原因是破坏了事务的隔离性,解决方法是通过并发控制来保证隔离性。并发控制可以通过封锁(锁机制)来实现。
封锁(Locking)是一种并发控制机制,用于在多个事务并发地访问共享资源时保持数据的一致性和完整性。
封锁机制通过给予事务对共享资源的独占权或共享权来实现。当一个事务获取了资源的锁定权限后,其他事务就需要等待或按照规定的方式进行访问控制。
封锁粒度
封锁粒度是指锁定资源时所考虑的资源范围或细微程度。封锁粒度的不同会影响并发性能和封锁效果。
封锁对象可以很大也可以很小,例如对整个数据库加锁、对某个属性值加锁;可以是逻辑单元,也可以是物理单元。
-
逻辑单元: 属性值、属性值集合、元组、关系、索引项、整个索引、整个数据库等。 -
物理单元:页(数据页或索引页)、块等。
封锁粒度与系统并发度和并发控制的开销密切相关,一般来说,封锁粒度越大,数据库所能封锁的数据单元就越少,并发度越小,开销越小
选择封锁的原则
-
需要处理多个关系的大量元组的用户事务时以数据库为封锁单位
-
需要处理大量元组的用户事务时以关系为封锁单元
-
只处理少量元组的用户事务时以元组为封锁单位
封锁类别
表级封锁
表级锁(Table-Level Locking)是封锁机制的一种类型,该类型的锁是在表级别上应用的。当一个事务获得了表级锁之后,它对整个表的所有数据具有排他访问权限,其他事务在此期间无法对该表进行读取或修改操作。
应用场景
表级锁可以用于不同的应用场景,例如:
-
数据库备份:当进行数据库备份时,可以对整个表进行加锁,防止其他事务对数据进行修改,保证备份数据的一致性。
-
表结构变更:当需要对表的结构进行变更,如添加列、删除列等操作时,可以对整个表进行锁定,以防止其他事务的读取和写入操作干扰变更过程。
-
特定业务场景的串行处理:在某些特定的业务流程中,可能需要对某个表实现串行处理,以确保数据的一致性和正确性。
缺点
-
并发性能:表级锁锁定了整个表,其他事务无法并发地执行读取和写入操作,可能导致并发性能下降。在高并发的场景下,应尽量避免过多地使用表级锁。
-
粒度过大:表级锁的粒度是最大的,无法实现细粒度的并发控制。如果只是针对某几行或特定条件的数据进行操作,表级锁会导致大量不必要的锁等待和资源浪费。
-
锁冲突和死锁:当多个事务同时请求对整个表的锁定时,可能会出现死锁和锁冲突的情况。需要谨慎设计事务和锁定策略,以避免这些问题。
行级封锁
行级锁(Row-Level Locking)是封锁机制的一种类型,该类型的锁是在数据行级别上应用的。当一个事务获得了行级锁之后,它对该行的数据具有排他性访问权限,其他事务只能在该行上获取共享锁或等待锁释放。
优势
-
并发性能:相比表级锁,行级锁的粒度更小,可以允许多个事务并发地访问同一张表的不同行,提高并发性能和系统吞吐量。
-
数据一致性:行级锁可以保证每个事务对数据的独占性访问,防止不同事务之间的数据冲突,确保数据的一致性和完整性。
-
细粒度控制:行级锁可以精确地选择需要锁定的数据行,而不是锁定整个表,可以避免锁冲突和资源浪费。
-
并发度高:由于不同事务可以并发地访问不同行,行级锁可以提供更高的并发度,支持更多的用户并发操作。
缺点
-
锁开销:由于行级锁是细粒度的,需要对数据行进行锁定和释放,加强对象间调度控制,可能会带来额外的开销。在高并发的场景下,需要综合考虑锁开销和并发性能的折衷。
-
锁冲突和死锁:在使用行级锁时,由于事务需要等待其他事务释放锁才能进行操作,容易导致死锁和锁冲突的问题。需要合理设计事务和锁定策略,以减少锁冲突的概率。
-
行级锁不适用于大规模数据更新、删除等导致的性能问题。
页级封锁
页级锁(Page-Level Locking)是封锁机制的一种类型,该类型的锁是在数据页级别上应用的。数据页是数据库管理系统中用于存储数据的基本单位,每个数据页通常包含多行数据。
在页级锁下,锁是在数据页上进行的,一个事务获取了某个数据页的锁后,它可以对该数据页中的所有行进行读取或修改操作。其他事务可以在相同数据页上获取共享锁,但若有事务请求互斥锁,则需要等待当前事务释放锁。
数据页
在关系型数据库中,数据页(Data Page)代表表中的一部分数据的物理存储单位。它是数据库中分配给每个表的存储空间的一部分。
具体来说,数据页是数据库管理系统将表的数据存储在磁盘上的方式。数据库中的数据被组织成一个个的数据页,每个数据页可以存储多行数据。通常,一个数据页的大小是固定的,例如 4KB 或 8KB,具体大小取决于数据库系统的配置和限制。
当数据库要存储表的数据时,它将数据划分为适当大小的数据页,并将这些数据页分配给表。每个表可能由多个数据页组成,数据页之间可能是连续的、不连续的或者散乱的,根据数据库系统的实现。
数据页包含了表中的实际数据行,以及可能的索引、元数据和管理信息。它通常由一个页表来管理,该页表记录了每个数据页的位置、状态和其他相关信息。
通过将表的数据划分为数据页,数据库系统可以更高效地管理和访问表中的数据。它提供了对数据的物理存储层面的管理和优化,以保证数据的持久性和高效访问。
特点
-
中等粒度的控制:相比表级锁,页级锁的粒度更小一些,可以将一组相关数据行封锁在同一个页中,提供了比表级锁更细粒度的并发控制。
-
并发性能和系统吞吐量:页级锁允许多个事务在同一表中的不同页上并发执行读取或修改操作,相较于表级锁,可以提高并发性能和系统的吞吐量。
-
锁开销:相比行级锁,页级锁的开销较小,因为锁定和释放页级锁所需的时间和资源开销比行级锁要少。
-
减少锁冲突:由于锁定的粒度较大,页级锁可以减少锁冲突和锁竞争,从而减少死锁的可能性。特别适合全表扫描、范围查询等操作
缺点
-
粒度过大:页级锁锁定的范围是整个数据页,而非具体的数据行,因此会导致一些不必要的锁等待,降低了并发性能。
-
锁竞争:当不同事务并发访问同一数据页时,可能会出现锁竞争的情况,造成资源的浪费和性能下降。
-
数据分布不平衡:如果数据的分布不均匀,即某些数据页中包含的行数远多于其他数据页,那么锁竞争可能会更加严重。
表分区封锁
表分区锁(Table Partition Locking)是一种针对表分区进行的封锁机制。表分区是将表分割为更小的逻辑单元,每个分区可独立存储和管理数据。在使用表分区锁时,锁是在表的分区级别而非整个表上进行的。
表分区
表分区(Table Partitioning)是一种数据库设计技术,用于将大型表划分为更小的、更易于管理和查询的部分。它将一张表的数据水平分割成多个子集,每个子集称为分区(Partition),每个分区包含的数据量通常相等。
表分区是为了解决存储大量数据时,表的性能下降而设计的。它可以帮助优化大型数据库的性能,减轻对磁盘I/O的压力,同时也可以更好地支持备份、灾难恢复等管理操作。
表分区可以按照固定的规则或键进行分区,例如分区日期、地域、用户ID等。每个分区都是一个独立的物理结构,分区之间没有重叠,可以像普通表一样进行查询、更新等操作。分区可以选择不同的存储格式和存储位置,也可以为每个分区单独指定不同的索引等。
对于常规查询,数据库系统可以选择在单个分区中执行,而不必扫描整个表。这减少了I/O操作的数量,大大提高了查询性能。此外,表分区还可以帮助平衡数据的负载并更好地利用集群实现分布式处理。
表分区技术也有一些局限性,例如增加了管理和维护的复杂性、编程难度增加等。但总体上,表分区作为一种常见的数据库设计技术,已经被广泛地应用于大型数据仓库、物联网数据存储、金融数据存储等场景。
特点
-
并发性能:相比整个表级锁,表分区锁的粒度更小,可以允许多个事务并发地访问不同分区,提高并发性能和系统吞吐量。
-
细粒度控制:表分区锁可以实现对特定分区的锁定和解锁,可以避免全表锁定带来的锁冲突和资源浪费。
-
灵活性:通过使用表分区锁,可以实现对不同分区的不同操作,例如读取、修改或删除,灵活地控制对分区的访问权限。适合在大规模数据处理环境和大规模数据挖掘等场景中使用。
缺点
-
锁冲突:当多个事务需要同时访问同一分区时,可能会出现锁冲突的情况,需要适当的设计事务和锁定策略,以减少冲突的概率。
-
数据一致性:表分区锁只能保证在同一分区内的数据的一致性,不同分区之间的数据可能存在一定的延迟或不一致性,需要在应用设计中考虑。
多粒度封锁
多粒度封锁(multiple granularity locking):如果在一个系统中同时支持多种封锁粒度供不同的事务选择是比较理想的。选择封锁粒度时应该同时考虑封锁开销和并发度两个因素,适当选择封锁粒度以求得最优的效果。
采用多粒度封锁的方式,可以定义一个多粒度树,其根结点是整个数据库,表示最大的数据粒度。叶结点表示最小的数据粒度。
多粒度封锁协议允许多粒度树中的每个结点被独立地加锁。对一个结点加锁意味着,这个结点的所有后裔结点也被加以同样类型的锁。
在多粒度封锁中一个数据对象可能以两种方式封锁,显式封锁和隐式封锁:
-
显式封锁:应事务的要求直接加到数据对象上的锁
-
隐式封锁:该数据对象没有被独立加锁,是由于其上级结点加锁而使该数据对象加上了锁。
检查封锁冲突时,需要同时检查上下级的显式封锁和隐式封锁
乐观锁与悲观锁
悲观锁
悲观锁是一种并发控制机制,它基于悲观的假设,即并发冲突会时常发生,因此在访问共享资源(如数据库记录或共享变量)之前,会先获取独占性的锁,以防止其他线程对资源的并发读写。
工作流程
悲观锁的工作流程通常包括以下几个步骤:
-
获取锁:线程在访问共享资源之前,尝试获取独占性的锁机制,通常使用
互斥锁(Mutex Lock)或自旋锁(Spin Lock)等。 -
访问资源:获取到锁后,线程可以安全地访问共享资源,其他线程无法同时进行读写操作。
-
释放锁:线程完成对共享资源的读写操作后,释放锁,允许其他线程获取锁并继续访问资源。
悲观锁的特点是在整个访问过程中,资源始终被一个线程独占,其他线程需要等待获取锁才能继续执行相应操作。由于频繁地加锁和解锁操作以及可能的线程挂起和恢复,悲观锁可能会导致较大的性能开销和线程切换的开销。
常见的悲观锁机制
常见的悲观锁机制包括:
-
互斥锁(Mutex):使用信号量或互斥量实现,同一时间只允许一个线程获取锁。 -
读写锁(Read and Write Lock):支持并发读、独占写的锁机制,允许多个线程同时读取共享资源,但在写操作时需要独占锁。 -
自旋锁(Spin Lock):线程在获取锁时,会忙等待(自旋)直到锁被释放,适用于锁持有时间短暂和线程并发度较高的场景。
适用场景
悲观锁适用于写操作频繁、读操作较少的场景,能够确保数据一致性,但会引入较大的开销和线程切换的开销。
因此,在选择锁的时候需要根据实际情况对读写比例、并发度和性能需求进行综合考虑。
乐观锁
乐观锁是一种并发控制机制,相对于悲观锁(如互斥锁)而言,它更倾向于假设并发冲突不会发生,从而减少锁的使用,提高并发性能。
工作流程
乐观锁的工作流程通常包括以下几个步骤:
-
读取数据:线程从数据库或内存中读取需要操作的数据,并将版本信息一并读取。
-
执行操作:线程对数据进行修改或计算,但此时并不对数据进行加锁。
-
提交更新:线程尝试将修改后的数据提交到数据库或内存中,同时将之前读取到的版本信息作为条件一并提交。
-
校验版本:系统校验提交的数据与实际数据之间的版本是否一致,若一致则说明没有其他线程修改过数据,操作成功;若不一致则意味着其他线程已经修改了数据,操作失败。
-
处理冲突:若操作失败,根据实际需求进行冲突处理,可以选择重试操作、放弃操作或采取其他策略。
乐观锁通常借助于数据的版本控制来实现。每个数据都会有一个版本标识,例如时间戳或计数器,用于标识数据的版本。
在执行更新操作时,会比较当前操作使用的版本与实际数据的版本,若一致则提交成功,否则表示有其他线程已经修改了数据,需要进行冲突处理。
适用场景
乐观锁的优点是减少了锁的竞争和线程的阻塞,适用于读操作远多于写操作的场景,能够提高并发性能。但有一定的风险,因为在提交操作时可能会发生数据冲突,需要根据实际情况处理冲突。
封锁类型
读写锁
读写锁(Reader-Writer Lock)是一种更复杂的锁机制,它在数据库系统中应用广泛,旨在提高并发性能,减少锁争用和死锁的发生。它允许多个读操作同时进行,但只允许一个写操作进行,可以有效地提高系统的并发处理性能和吞吐量。
共享锁 Shared Lock
共享锁(Shared Lock),也称为读锁(Read Lock),简写为 S锁,是数据库管理系统中一种常见的封锁机制,用于确保资源的共享读取访问。当一个事务获取了共享锁时,其他事务也可以获取共享锁,实现并发读取操作。
特点
共享锁的特点包括:
-
共享性访问:多个事务可以同时获取
S锁,相互之间不会互斥。S锁允许多个事务并发读取相同的资源。 -
读操作可并发:共享锁不会互斥地阻塞其他事务的读操作,多个事务可以同时持有共享锁并进行读操作。
-
写操作阻塞:当一个事务持有
S锁时,其他事务如果尝试获取X锁,则会被共享锁阻塞,直到共享锁释放。
常见应用场景
共享锁的应用场景包括但不限于:
-
数据读取:当多个事务需要同时读取某些数据时,可以获取共享锁,避免互斥地阻塞读取操作。
-
数据查询:查询操作通常不会修改数据,所以可以使用共享锁来允许并发的读取操作,提高系统的并发性能。
对于只读操作或读取密集型的场景,适当地使用共享锁可以提高系统的并发能力。然而,在并发写操作较多的情况下,仍需要谨慎使用共享锁,以避免出现数据不一致或性能瓶颈的问题。
排他锁 Exclusive Lock
排他锁(Exclusive Lock),也称为写锁(Write Lock),简写为 X锁,是数据库管理系统中一种常见的封锁机制,用于确保资源的独占性修改访问。当一个事务获取了排他锁时,其他事务无法同时获取排他锁或共享锁,只能等待该锁释放。
排他锁应谨慎使用,避免锁定过多的资源,以避免可能的死锁和性能问题。
特点
排他锁的特点包括:
-
独占性访问:一个事务持有排他锁时,其他事务无法同时进行读取或修改操作,保证了数据的一致性和完整性。
-
写操作互斥:多个事务同时尝试获取排他锁时,只有一个事务能够成功获取,其他事务需要等待。
-
读操作阻塞:当一个事务持有排他锁时,其他事务如果尝试获取共享锁,会被排他锁阻塞,直到排他锁释放。
-
隔离事务:排他锁常用于事务中的写操作,确保事务对资源的修改不会被其他事务所干扰。
常见应用场景
排他锁的应用场景包括但不限于:
-
数据修改:当一个事务需要对某行或某些行进行修改时,可以获取排他锁,防止其他事务同时对同一行进行修改。
-
数据删除:当一个事务需要删除某行或某些行时,可以获取排他锁,防止其他事务同时对同一行进行读取或写入。
-
数据加载:当一个事务需要将数据加载到表中,并防止其他事务对该表进行读写操作时,可以获取排他锁。
在并发环境中,合理使用排他锁可以确保数据的一致性和完整性,但也要考虑并发性能和优化。因此,开发人员需要根据具体的应用需求和场景,合理选择封锁粒度和封锁级别,以实现良好的并发控制。
互斥性
需要注意的是,共享锁与排他锁(Exclusive Lock)是互斥的。当一个事务持有共享锁时,其他事务无法获取排他锁,只能等待共享锁释放。这是为了保证在并行读操作的情况下,不会出现数据不一致的情况。
锁的兼容关系如下:
| 可获取锁 | X锁 | S锁 |
|---|---|---|
X锁 | × | × |
S锁 | × | √ |
意向锁
在存在行级锁和表级锁的情况下,事务 T 想要对表 A 加 X 锁,就需要先检测是否有其它事务对表 A 或者表 A 中的任意一行加了锁,那么就需要对表 A 的每一行都检测一次,这是非常耗时的。
意向锁(Intention Lock)是一种在数据库管理系统中使用的封锁机制,用于提高并发性能和减少资源竞争。它是一种针对表、页或行的封锁级别的辅助锁定机制,可以更容易地支持多粒度封锁。
意向锁的含义是如果对一个结点加意向锁,则说明该结点的下层结点正在被加锁;对任一结点加锁时,必须先对它的上层结点加意向锁。
意向锁的目的是指示其他事务对相同资源的封锁意图,以避免不必要的锁冲突和资源浪费。当一个事务需要对某个资源进行封锁时,它会首先请求获取适当级别的意向锁,然后再获取实际的读锁或写锁。
它的存在使得事务可以在不阻塞其他事务的情况下,更高效地执行读写操作。意向锁机制在多用户并发操作时特别有用,可以避免不必要的锁等待和轮询,提高数据库的吞吐量和效率,提高并发性能。
意向锁本身并不直接作用于数据行,它只表示事务对表、页或行的意向。实际的读锁或写锁仍然会被应用在数据行上,以保证数据操作的一致性和完整性。
-
一个事务在获得某个数据行对象的
S锁之前,必须先获得表的IS锁或者更强的锁; -
一个事务在获得某个数据行对象的
X锁之前,必须先获得表的IX锁。
意向共享锁(IS锁)
意向共享锁(Intention Shared Lock,IS锁):指示事务对某一资源(如表、页)具有共享读取的意图。一个事务获取了 IS锁 后,其他事务可以继续获取 IS锁,但不能获取排他锁。
意向共享锁的存在可以提前通知其他事务的意向,它不直接限制其他事务的锁获取,而是对事务之间的资源访问进行协调。
如果对一个数据对象加 IS锁,表示它的后裔结点拟(意向)加 S锁。例如,事务 T 要对 R 中某个元组加 S锁,则要首先对关系 R 和 数据库 加 IS锁。
意向共享锁的使用可以减少锁争用和死锁的可能性,提高并发性能。在读多写少的场景下,通过使用意向共享锁可以允许多个读操作同时进行,而写操作会独占资源,便于提高系统性能,避免不必要的阻塞。
意向排他锁(IX锁)
意向排他锁(Intention Exclusive Lock,IX锁):指示事务对某一资源具有修改的意图,但不排斥其他事务的共享读取。一个事务获取了 IX锁 后,其他事务仍可以获取 IS锁,但不能获取排他锁。
意向排他锁的存在可以提前通知其他事务的意向,并表示它的后裔结点拟(意向)加 X锁。以协调对资源的独占访问,避免不必要的阻塞和资源争用,提高并发性能。例如,事务 T 要对 R 中某个元组加 X锁,则要首先对关系 R 和数据库加 IX锁。
事务 T 想要对表 A 加 X锁,只需要先检测是否有其它事务对表 A 加了 X/IX/S/IS 锁,如果加了就表示有其它事务正在使用这个表或者表中某一行的锁,因此事务 T 加 X锁 失败。
共享排他意向锁(SIX锁)
如果对一个数据对象加 SIX锁,表示对它加 S锁 ,再加X锁,即 S I X = S + I X SIX=S+IX SIX=S+IX。例如对某个表加 SIX锁,则表示该事务要读整个表(所以要对该表加 S锁),同时会更新个别元组(所以要对该表加 IX锁)。
兼容关系
| 持有锁 | X | IX | S | IS |
|---|---|---|---|---|
| X | × | × | × | × |
| IX | × | √ | × | √ |
| S | × | × | √ | √ |
| IS | × | √ | √ | √ |
-
任意 IS/IX 锁之间都是兼容的,其只表示想要对表加锁的意向,而不是真正加锁;
-
S锁只与S锁和IS锁兼容,也就是说事务 T 想要对数据行加S锁,其它事务可以已经获得对表或者表中的行的S锁。
活锁与死锁
封锁技术可以有效地解决并发操作的一致性问题,但是会带来新的问题:活锁与死锁:
-
活锁:事务 T 1 T_1 T1 封锁数据 R R R,事务 T 2 T_2 T2 又请求封锁数据 R R R,事务 T 2 T_2 T2 需要等待 T 1 T_1 T1 释放锁,此时,事务 T 3 T_3 T3 也请求封锁数据 R R R,事务 T 3 T_3 T3 也需要等待 T 1 T_1 T1 释放锁。当事务 T 1 T_1 T1 释放锁后,系统却首先批准了 事务 T 3 T_3 T3 的请求,事务 T 2 T_2 T2 继续等待然后,又有别的事务到来,由于事务 T 2 T_2 T2 的优先级可能较低,所以导致它长时间得不到服务,产生饥饿现象。
避免活锁可以废除特权,采用先来先服务算法
-
两个或两个以上事务均处于等待状态,每个事务都在等待其中另一个事务封锁的数据,导致任何事务都不能向前推进的现象
封锁协议
封锁协议(Locking Protocol)是一种在并发环境中管理资源访问的规范或机制,定义了事务在访问资源时应该遵循的规则和约束。它确保在多个并发事务之间对共享资源的访问具有一致性和正确性,以避免竞态条件、数据不一致和其他并发访问问题。
三级封锁协议
一级封锁协议
事务T 在修改 数据R 之前必须先对其加 X锁,这些锁在整个事务期间均不会释放,直到事务结束( COMMIT / ROLLBACK )一次性释放。
一级封锁协议可以防止丢失修改,并保证事务T是可恢复的。使用一级封锁协议可以解决丢失修改问题。但如果仅仅是读数据不对其进行修改,是不需要加锁的,它不能保证可重复读和不读“脏”数据。
由于锁的持有时间过长,可能会导致死锁问题,因此一级封锁协议不再被大多数数据库系统使用。
- 写:
加 X锁 -> 修改 数据R -> 成功或失败 -> 释放 X锁 - 读:不加锁,导致读到别的事务未提交数据,且多次读结果不一致
![![[Pasted image 20231214192306.png]]](https://i-blog.csdnimg.cn/direct/bca734f52b4b459888664ef796526e36.png)
二级封锁协议
在一级封锁协议的基础上,要求 事务T 读取 数据R 时必须加 S锁,读取完马上释放 S锁。由于读完数据后即可释放 S锁,所以它不能保证可重复读。
可以解决读脏数据问题,因为如果一个事务在对数据 A 进行修改,根据 一级封锁协议,会加 X 锁,那么就不能再加 S 锁了,也就是不会读入数据。
-
写:
加 X锁 -> 修改 数据R -> 成功或失败 -> 释放X锁 -
读:
加 S锁 -> 读 数据R -> 读完释放 S锁,不会读到别的事务未提交的数据,但不能保证可重复读
在数据R加了X锁之后,不能再加其它锁(其它事务的X锁和S锁);在数据R加了S锁之后,其它锁还能加S锁,但不能加X锁
![![[Pasted image 20231214192813.png]]](https://i-blog.csdnimg.cn/direct/2d7d2ed689674347a3a436514b3ec3db.png)
三级封锁协议
在二级封锁协议的基础上,要求读取数据 R 时必须加 S锁,直到事务结束了才能释放 S锁。
防止了丢失修改和不读“脏”数据外,还可以解决不可重复读的问题,因为读 R 时,其它事务不能对 R 加 X锁,从而避免了在读的期间数据发生改变
-
写:
加 X锁 -> 修改 数据R ->成功或失败 -> 释放X锁 -
读:
加 S锁 -> 读 数据R -> 再读 数据R -> 事务完成 -> 释放 S锁,多次读结果一致。
![![[Pasted image 20231214192913.png]]](https://i-blog.csdnimg.cn/direct/78c55c976e6245b0a88c81580b9ffae2.png)
二段封锁协议
二段封锁协议(Two-Phase Locking Protocol,2PL)是一种常见的并发控制协议,用于管理多个事务对共享资源的并发访问。它通过加锁和解锁的两个阶段来确保事务的隔离性和一致性,并防止数据不一致的问题。
两段锁协议是三级封锁协议的特例,目前 DBMS 普遍采用该种协议实现并发调度的可串行性。
二段封锁协议分为两个阶段:
-
加锁阶段(Growing Phase):在这个阶段,事务可以获取所需的锁,这通常包括
共享锁(S锁)和排他锁(X锁)。事务在执行读操作时可以获取共享锁,而在执行写操作时需要获取排他锁。一旦事务释放了锁,它就不能再重新申请或获取锁。 -
解锁阶段(Shrinking Phase):在这个阶段,事务开始释放已经持有的锁。一旦锁被释放,事务无法再获取该锁。解锁的操作通常发生在事务结束之前,以确保其他事务可以访问被锁定的资源。
二段封锁协议的原则是对于一个事务来说,它在加锁阶段获取的锁必须在解锁阶段之前全部释放。这个协议的使用可以确保事务之间的隔离性,避免数据的不一致性。
需要注意的是,二段封锁协议并不能完全消除并发访问带来的问题,比如死锁。因此,在实际使用时,需要根据具体情况和需求,选择适当的并发控制机制来提高系统性能和数据一致性。
其他封锁协议
哨兵封锁协议
哨兵封锁协议(Sentinel Locking Protocol)是一种事务并发控制方法,它是二段封锁协议的变种。哨兵封锁协议通过引入哨兵,实现更高效的锁管理。
在哨兵封锁协议中,每个事务会被赋予一个哨兵,哨兵的任务是监测资源并发访问情况。
每个资源会有一个锁状态的集合:
- 未加锁,已经被某个事务锁定
- 被某个事务锁定且已经被该事务的哨兵标记。
当某个事务需要锁定某个资源时,它的哨兵就会把哨兵标记设置在相应的锁状态上。
随着事务的进行,哨兵不断地移动锁状态的标记,直到所有事务完成操作。一旦事务释放了锁,相应的哨兵也会标记的自己的位置远离锁状态集合并接近下一个锁状态集合,以确保其他的事务可以尽快获得所需的锁。
哨兵封锁协议相对于二段封锁协议而言,可以更加高效地管理锁,并且可以更好地支持分布式事务处理。
但是,哨兵封锁协议的实现较为复杂,需要额外的开销来维护哨兵标记和状态,同时哨兵的移动可能会增加锁的等待时间。因此,在实际环境中,需要根据具体应用场景,选择哨兵封锁协议或其它适合的并发控制策略。
高级封锁协议
高级封锁协议(Advanced Locking Protocol)是一系列相对复杂和灵活的事务并发控制协议,旨在提供更高级的功能和性能优化。
具体来说,高级封锁协议可以包括以下一些技术和策略:
-
多粒度锁定(Multigranularity Locking):允许事务在不同层级上获取锁,比如表级锁、页级锁或者行级锁,以提高并发性能和减少锁冲突。 -
间隙锁(Gap Locking):对于范围查询操作,可以在两个现有的键值之间创建一个间隙锁,防止其他事务插入新的键值对,从而保持查询结果的一致性。 -
快照隔离(Snapshot Isolation):事务可以读取一致的数据快照,而不受其他事务并发修改的干扰,从而提供更高的隔离级别和读取性能。 -
乐观并发控制(Optimistic Concurrency Control):事务在读取数据时不会加锁,而是在提交时检查是否有冲突,如果有冲突则进行回滚。这种机制适用于读多写少的情况,可以提高并发性能。 -
时间戳排序(Timestamp Ordering):为每个事务分配唯一的时间戳,在事务提交时按照时间戳的先后顺序进行排序,从而保证并发事务之间的一致性和隔离性。
这些高级封锁协议和技术可以根据不同的数据库系统和应用场景进行组合和优化,以提供更高的并发性能、数据一致性和隔离级别。在实际应用中,选择适当的高级封锁协议需要综合考虑系统的需求、数据访问模式和负载情况。
MySQL 的隐式与显式封锁
MySQL 的 InnoDB 存储引擎采用两段封锁协议,会根据隔离级别在需要的时候自动加锁,并且所有的锁都是在同一时刻被释放,这被称为隐式锁定。
隐式封锁
隐式锁定(Implicit Locking):在使用事务的情况下自动应用的锁定机制,由于其上级结点加锁而使该数据对象加上了锁。MySQL 默认采用隐式锁定,通过数据库管理系统来管理和控制锁定。隐式锁定包括共享锁(Shared Lock)和排他锁(Exclusive Lock),用于控制并发事务之间的读取和写入操作。
显式封锁
显式锁定(Explicit Locking):使用 LOCK TABLES 和 UNLOCK TABLES 语句显式地管理锁定。使用显示锁定可以在事务中对指定的表或数据集进行锁定操作。显示锁定可以是共享锁,也可以是排他锁,具体取决于锁定语句的参数。
-
LOCK TABLES语句用于获取锁定,指定表和锁定模式(共享锁或排他锁)。该语句会阻塞其他事务对同一表的并发读取和写入操作。 -
UNLOCK TABLES语句用于释放锁定,将之前锁定的表解锁。解锁后,其他事务可以对该表进行操作。
显示锁定需要开发人员显式地管理和控制锁定操作,更灵活但也更容易出错。通常情况下,隐式锁定是推荐的方式,因为它由数据库管理系统自动处理,并确保数据的一致性和完整性。而显示锁定则适用于特定的需求或特殊的并发控制操作。
Next-Key Locks
Next-Key Locks(下一关键字锁)也是在数据库事务中用于并发控制的一种锁机制。它是一种组合了记录锁和间隙锁的方式,不仅锁定一个记录上的索引,也锁定索引之间的间隙。
Next-Key Locks 通常在数据库的并发控制及隔离级别的实现中使用,如常见的隔离级别中的可重复读(Repeatable Read)和串行化(Serializable)级别。它有助于提供更高的并发性和数据的一致性。
Next-Key Locks 主要用于防止幻读(Phantom Read)的发生。Next-Key Locks 通过在查询过程中对范围内的索引键加锁,同时还包括对范围之后的下一个索引键加上间隙锁(Gap Lock),从而避免了幻读的发生。
记录锁
Record Locks(记录锁)锁定一个记录上的索引,而不是记录本身。如果表没有设置索引,InnoDB 会自动在主键上创建隐藏的聚簇索引,因此 Record Locks 依然可以使用。
间隙锁
Gap Locks(间隙锁)用于锁定一个索引键之间的间隔,但不包含索引本身,以避免其他事务在该间隔中插入或更新数据。
例如,在进行一个范围查询时,如果对范围中的每一个索引键进行加锁,就可以防止其他事务在查询结果中插入或更新数据,但是不会阻止其他事务在范围之外的位置插入新的数据。
SELECT c FROM t WHERE c BETWEEN 10 and 20 FOR UPDATE;
如果还想避免这种情况的发生,就需要使用间隙锁。当以间隙锁的方式锁住索引键之间的间隔时,任何其他事务都不能插入新的数据或者更新已有数据,从而保证了数据的完整性和一致性。
间隙锁会影响并发性能,因为其他事务在范围之外的位置进行插入或者更新操作时也会受到限制。因此,使用间隙锁需要权衡好数据的一致性和并发性能之间的平衡。
总结
在实际的数据库应用中,需要选择合适的锁机制取决于应用场景和性能要求。例如,在并发读操作较多的场景下,可以选择使用共享锁和行级锁来提高并发性能;而在并发写操作较多的场景下,则可能需要考虑使用排他锁和表级锁来确保数据的一致性。
相关文章:
数据库系统概论:数据库系统的锁机制
引言 锁是计算机协调多个进程或线程并发访问某一资源的机制。在数据库中,数据作为一种共享资源,其并发访问的一致性和有效性是数据库必须解决的问题。锁机制通过对数据库中的数据对象(如表、行等)进行加锁,以确保在同…...
-- ADB获取设备信息)
Django+vue自动化测试平台(28)-- ADB获取设备信息
概述 adb的全称为Android Debug Bridge,就是起到调试桥的作用。通过adb可以在Eclipse中通过DDMS来调试Android程序,说白了就是调试工具。 adb的工作方式比较特殊,采用监听Socket TCP 5554等端口的方式让IDE和Qemu通讯,默认情况下…...
RESTful API设计指南:构建高效、可扩展和易用的API
文章目录 引言一、RESTful API概述1.1 什么是RESTful API1.2 RESTful API的重要性 二、RESTful API的基本原则2.1 资源导向设计2.2 HTTP方法的正确使用 三、URL设计3.1 使用名词而非动词3.2 使用复数形式表示资源集合 四、请求和响应设计4.1 HTTP状态码4.2 响应格式4.2.1 响应实…...

npm下载的依赖包版本号怎么看
npm下载的依赖包版本号怎么看 版本号一般分三个部分,主版本号、次版本号、补丁版本号。 主版本号:一般依赖包发生重大更新时,主版本号才回发生变化,如Vue2.x到Vue3.x。次版本号:当依赖包中发生了一些小变化ÿ…...
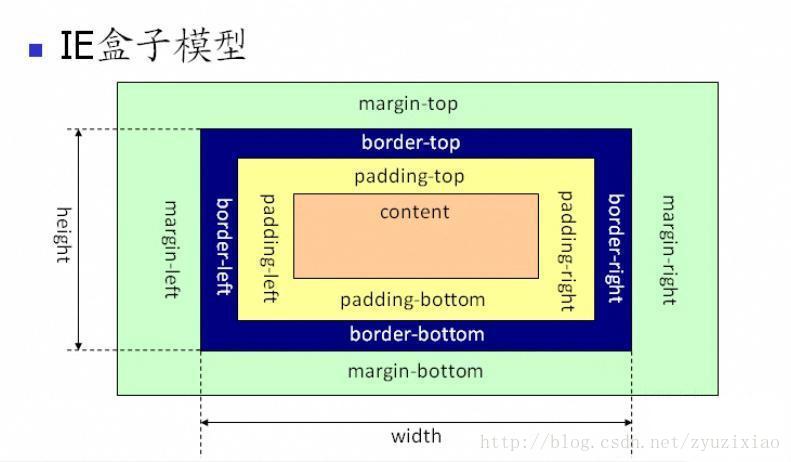
css前端面试题
1.什么是css盒子模型? 盒子模型包含了元素内容(content)、内边距(padding)、边框(border)、外边距(margin)几个要素。 标准盒子模型和IE盒子模型的区别在于其对元素的w…...

Vue从零到实战
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 非常期待和您一起在这个小…...

【Chatgpt大语言模型医学领域中如何应用】
随着人工智能技术 AI 的不断发展和应用,ChatGPT 作为一种强大的自然语言处理技术,无论是 自然语言处理、对话系统、机器翻译、内容生成、图像生成,还是语音识别、计算机视觉等方面,ChatGPT 都有着广泛的应用前景。特别在临床医学领…...
)
ES6 正则的扩展(十九)
1. 正则表达式字面量改进 特性:在 ES6 中,正则表达式字面量允许在字符串中使用斜杠(/)作为分隔符。 用法:简化正则表达式的书写。 const regex1 /foo/; const regex2 /foo/g; // 全局搜索2. u 修饰符(U…...

<数据集>钢铁缺陷检测数据集<目标检测>
数据集格式:VOCYOLO格式 图片数量:1800张 标注数量(xml文件个数):1800 标注数量(txt文件个数):1800 标注类别数:6 标注类别名称:[crazing, patches, inclusion, pitted_surface, rolled-in_scale, scr…...

Kafka系列之:Kafka存储数据相关重要参数理解
Kafka系列之:Kafka存储数据相关重要参数理解 一、log.segment.bytes二、log.retention.bytes三、日志段四、log.retention.check.interval.ms五、数据底层文件六、index、log、snapshot、timeindex、leader-epoch-checkpoint、partition.metadata一、log.segment.bytes 参数lo…...

Template execution failed: ReferenceError: name is not defined
问题 我们使用了html-webpack-plugin(webpack)进行编译html,导致的错误。 排查结果 连接地址 html-webpack-plugin版本低(2.30.1),html模板里面不能有符号,注释都不行 // var reg new RegExp((^|&)${name}([^&…...

CVE-2024-24549 Apache Tomcat - Denial of Service
https://lists.apache.org/thread/4c50rmomhbbsdgfjsgwlb51xdwfjdcvg Apache Tomcat输入验证错误漏洞,HTTP/2请求的输入验证不正确,会导致拒绝服务,可以借助该漏洞攻击服务器。 https://mvnrepository.com/artifact/org.apache.tomcat.embed/…...

Linux下如何安装配置Graylog日志管理工具
Graylog是一个开源的日志管理工具,可以帮助我们收集、存储和分析大量的日志数据。它提供了强大的搜索、过滤和可视化功能,可以帮助我们轻松地监控系统和应用程序的运行情况。 在Linux系统下安装和配置Graylog主要包括以下几个步骤: 准备安装…...

「MQTT over QUIC」与「MQTT over TCP」与 「TCP 」通信测试报告
一、结论 在实车5G测试中「MQTT Over QUIC」整体表现优于「TCP」,可在系统架构升级时采用MQTT Over QUIC替换原有的TCP通讯;从实现原理上基于QUIC比基于TCP在弱网、网络抖动导致频繁重连场景延迟更低。 二、测试方案 网络类型:实车5G、实车…...

获取磁盘剩余容量-----c++
获取磁盘剩余容量 #include <filesystem>struct DiskSpaceInfo {double total;double free;double available; };DiskSpaceInfo getDiskSpace(const std::string& path) {std::filesystem::space_info si std::filesystem::space(path);DiskSpaceInfo info;info.…...

AI算法24-决策树C4.5算法
目录 决策树C4.5算法概述 决策树C4.5算法简介 决策树C4.5算法发展历史 决策树C4.5算法原理 信息熵(Information Entropy) 信息增益(Information Gain) 信息增益比(Gain Ratio) 决策树C4.5算法改进 …...
【云原生】Prometheus整合Alertmanager告警规则使用详解
目录 一、前言 二、Altermanager概述 2.1 什么是Altermanager 2.2 Altermanager使用场景 三、Altermanager架构与原理 3.1 Altermanager使用步骤 3.2 Altermanager工作机制 3.3 Altermanager在Prometheus中的位置 四、Altermanager部署与接入Prometheus 4.1 Altermana…...

C++ :友元类
友元类的概念和使用 (1)将类A声明为B中的friend class后,则A中所有成员函数都成为类B的友元函数了 (2)代码实战:友元类的定义和使用友元类是单向的 (3)友元类是单向的,代码实战验证 互为友元类 (1)2个类可以互为友元类,代码实战…...

【整理了一些关于使用swoole使用的解决方案】
目录 如何监控和分析 Swoole 服务器的性能瓶颈? 在进行 Swoole 服务器性能优化时,有哪些常见的错误和陷阱需要避免? 除了 Swoole,还有哪些 PHP 框架或技术可以用于构建高并发的 Web 应用? Swoole 同步请求在高并发…...

python selenium4 EdgeDriver动态页面爬取
截止至2024.7.16 chrome浏览器最新版本为126.0.6478.127 但对应的chromeDriver版本都低于此版本,因此,转用Edge浏览器 说明:仅记录自己使用过程中用到的一些代码和感受,看具体情况不定期更新。 selenium官方文档 1、安装selen…...
)
Spring Boot 实现流式响应(兼容 2.7.x)
在实际开发中,我们可能会遇到一些流式数据处理的场景,比如接收来自上游接口的 Server-Sent Events(SSE) 或 流式 JSON 内容,并将其原样中转给前端页面或客户端。这种情况下,传统的 RestTemplate 缓存机制会…...

遍历 Map 类型集合的方法汇总
1 方法一 先用方法 keySet() 获取集合中的所有键。再通过 gey(key) 方法用对应键获取值 import java.util.HashMap; import java.util.Set;public class Test {public static void main(String[] args) {HashMap hashMap new HashMap();hashMap.put("语文",99);has…...

vue3 字体颜色设置的多种方式
在Vue 3中设置字体颜色可以通过多种方式实现,这取决于你是想在组件内部直接设置,还是在CSS/SCSS/LESS等样式文件中定义。以下是几种常见的方法: 1. 内联样式 你可以直接在模板中使用style绑定来设置字体颜色。 <template><div :s…...

ESP32 I2S音频总线学习笔记(四): INMP441采集音频并实时播放
简介 前面两期文章我们介绍了I2S的读取和写入,一个是通过INMP441麦克风模块采集音频,一个是通过PCM5102A模块播放音频,那如果我们将两者结合起来,将麦克风采集到的音频通过PCM5102A播放,是不是就可以做一个扩音器了呢…...

屋顶变身“发电站” ,中天合创屋面分布式光伏发电项目顺利并网!
5月28日,中天合创屋面分布式光伏发电项目顺利并网发电,该项目位于内蒙古自治区鄂尔多斯市乌审旗,项目利用中天合创聚乙烯、聚丙烯仓库屋面作为场地建设光伏电站,总装机容量为9.96MWp。 项目投运后,每年可节约标煤3670…...
:滤镜命令)
ffmpeg(四):滤镜命令
FFmpeg 的滤镜命令是用于音视频处理中的强大工具,可以完成剪裁、缩放、加水印、调色、合成、旋转、模糊、叠加字幕等复杂的操作。其核心语法格式一般如下: ffmpeg -i input.mp4 -vf "滤镜参数" output.mp4或者带音频滤镜: ffmpeg…...

Java 二维码
Java 二维码 **技术:**谷歌 ZXing 实现 首先添加依赖 <!-- 二维码依赖 --><dependency><groupId>com.google.zxing</groupId><artifactId>core</artifactId><version>3.5.1</version></dependency><de…...

rnn判断string中第一次出现a的下标
# coding:utf8 import torch import torch.nn as nn import numpy as np import random import json""" 基于pytorch的网络编写 实现一个RNN网络完成多分类任务 判断字符 a 第一次出现在字符串中的位置 """class TorchModel(nn.Module):def __in…...

视觉slam十四讲实践部分记录——ch2、ch3
ch2 一、使用g++编译.cpp为可执行文件并运行(P30) g++ helloSLAM.cpp ./a.out运行 二、使用cmake编译 mkdir build cd build cmake .. makeCMakeCache.txt 文件仍然指向旧的目录。这表明在源代码目录中可能还存在旧的 CMakeCache.txt 文件,或者在构建过程中仍然引用了旧的路…...

JavaScript 数据类型详解
JavaScript 数据类型详解 JavaScript 数据类型分为 原始类型(Primitive) 和 对象类型(Object) 两大类,共 8 种(ES11): 一、原始类型(7种) 1. undefined 定…...