二、ElasticSearch基础语法
目录
- 一、简单了解ik分词器(分词效果)
- 1.standard(单字分词器,es默认分词器)
- 2.ik_smart分词(粗粒度的拆分)
- 3.ik_max_word分词器(最细粒度拆分)
- 二、指定默认分词器
- 1.为索引指定默认分词器
- 三、ES操作数据
- 1.概述
- 2.创建索引
- 3.查询索引
- 4.删除索引
- 5.添加文档
- 6.查询索引库
- 6.1查询索引库中所有内容
- 6.2简单等值查询
- 6.3简单范围查询
- 6.4 通过id进行in查询
- 6.5分页查询
- 6.6对查询结果只显示指定字段
- 6.7排序查询
- 7.修改索引内容
- 8.删除索引内容
- 9.PUT和POST区别
一、简单了解ik分词器(分词效果)
这个是底层自带的不属于ik分词,ik分词器属于第三方分词器
1.standard(单字分词器,es默认分词器)
POST _analyze
{"analyzer":"standard","text":"我爱学搜索引擎"
}
效果(把每一个字都拆分,每个字都被分词了)
{"tokens" : [{"token" : "我","start_offset" : 0,"end_offset" : 1,"type" : "<IDEOGRAPHIC>","position" : 0},{"token" : "爱","start_offset" : 1,"end_offset" : 2,"type" : "<IDEOGRAPHIC>","position" : 1},{"token" : "学","start_offset" : 2,"end_offset" : 3,"type" : "<IDEOGRAPHIC>","position" : 2},{"token" : "搜","start_offset" : 3,"end_offset" : 4,"type" : "<IDEOGRAPHIC>","position" : 3},{"token" : "索","start_offset" : 4,"end_offset" : 5,"type" : "<IDEOGRAPHIC>","position" : 4},{"token" : "引","start_offset" : 5,"end_offset" : 6,"type" : "<IDEOGRAPHIC>","position" : 5},{"token" : "擎","start_offset" : 6,"end_offset" : 7,"type" : "<IDEOGRAPHIC>","position" : 6}]
}2.ik_smart分词(粗粒度的拆分)
和单字分词器的区别,就是按照比较粗的粒度去分词,把搜索引擎当成一个词来分词
POST _analyze
{"analyzer":"ik_smart","text":"我爱学搜索引擎"
}
效果
{"tokens" : [{"token" : "我","start_offset" : 0,"end_offset" : 1,"type" : "CN_CHAR","position" : 0},{"token" : "爱","start_offset" : 1,"end_offset" : 2,"type" : "CN_CHAR","position" : 1},{"token" : "学","start_offset" : 2,"end_offset" : 3,"type" : "CN_CHAR","position" : 2},{"token" : "搜索引擎","start_offset" : 3,"end_offset" : 7,"type" : "CN_WORD","position" : 3}]
}
3.ik_max_word分词器(最细粒度拆分)
按照最细粒度进行分词,把认为能组成一个词的情况都拆分。
POST _analyze
{"analyzer":"ik_max_word","text":"我爱学搜索引擎"
}
效果
{"tokens" : [{"token" : "我","start_offset" : 0,"end_offset" : 1,"type" : "CN_CHAR","position" : 0},{"token" : "爱","start_offset" : 1,"end_offset" : 2,"type" : "CN_CHAR","position" : 1},{"token" : "学","start_offset" : 2,"end_offset" : 3,"type" : "CN_CHAR","position" : 2},{"token" : "搜索引擎","start_offset" : 3,"end_offset" : 7,"type" : "CN_WORD","position" : 3},{"token" : "搜索","start_offset" : 3,"end_offset" : 5,"type" : "CN_WORD","position" : 4},{"token" : "索引","start_offset" : 4,"end_offset" : 6,"type" : "CN_WORD","position" : 5},{"token" : "引擎","start_offset" : 5,"end_offset" : 7,"type" : "CN_WORD","position" : 6}]
}二、指定默认分词器
1.为索引指定默认分词器
创建一个索引(mysql中对应database),名为test_index_database
指定默认分词器为:ik_max_word
PUT /test_index_database
{"settings":{"index":{"analysis.analyzer.default.type":"ik_max_word"}}
}
三、ES操作数据
在7.x版本以后类型默认为_doc
1.概述
es是面向文档的,它可以储存整个对象或者文档,对该文档进行索引、搜索、排序、过滤。
使用json作为文档序列化格式
2.创建索引
PUT /test_index01
3.查询索引
GET /test_index01
查询信息如下
其中number_of_shards(分片数量)
number_of_replicas(副本数量)
es7.6.1版本默认的分片和副本数量为1,这个默认数量和你es的版本有关系。可能其他版本默认不是1
{"test_index01" : {"aliases" : { },"mappings" : { },"settings" : {"index" : {"creation_date" : "1678969193239","number_of_shards" : "1","number_of_replicas" : "1","uuid" : "n6tD0dyxTB2aOQjqyDK0QQ","version" : {"created" : "7060199"},"provided_name" : "test_index01"}}}
}4.删除索引
DELETE /test_index01
5.添加文档
格式: PUT /索引名称/类型/id
PUT /test_index01/_doc/1
{
"name": "张三",
"sex": 1,
"age": 25,
"address": "北京",
"remark": "java"
}
执行结果
_index:索引名称
_type:类型
_id:id
_version:版本(因为这条数据可能会被修改,所以版本可能不是1)
result:结果(操作结果,创建,更新等)
{"_index" : "test_index01","_type" : "_doc","_id" : "1","_version" : 1,"result" : "created","_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"_seq_no" : 0,"_primary_term" : 1
}
6.查询索引库
查询格式:GET /索引名称/类型/id
GET /test_index01/_doc/1
查询结果
{"_index" : "test_index01","_type" : "_doc","_id" : "1","_version" : 1,"_seq_no" : 0,"_primary_term" : 1,"found" : true,"_source" : {"name" : "张三","sex" : 1,"age" : 25,"address" : "北京","remark" : "java"}
}
6.1查询索引库中所有内容
格式: GET /索引名称/类型/_search
GET /test_index01/_doc/_search
相当于mysql中的 select *
结果(我这里只有一条数据)
#! Deprecation: [types removal] Specifying types in search requests is deprecated.
{"took" : 1,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 1,"relation" : "eq"},"max_score" : 1.0,"hits" : [{"_index" : "test_index01","_type" : "_doc","_id" : "1","_score" : 1.0,"_source" : {"name" : "秀儿","sex" : 1,"age" : 25,"address" : "上海","remark" : "java"}}]}
}
6.2简单等值查询
格式: GET /索引名称/类型/_search?q=:**
GET /test_index01/_doc/_search?q=age:25
6.3简单范围查询
格式: GET /索引名称/类型/_search?q=***[left TO tight]
GET /test_index01/_doc/_search?q=age[25 TO 26]
6.4 通过id进行in查询
格式: GET /索引名称/类型/_mget
GET /test_index01/_doc/_mget
{
"ids":["1","2"]
}
6.5分页查询
GET /索引名称/类型/_search?from=0&size=1
GET /索引名称/类型/_search?q=条件&from=0&size=1
GET /test_index01/_doc/_search?from=0&size=1
GET /test_index01/_doc/_search?q=age[25 TO 26]&from=0&size=1
6.6对查询结果只显示指定字段
GET /索引名称/类型/_search?_source=字段,字段
GET /test_index01/_doc/_search?_source=name,age
6.7排序查询
GET /索引名称/类型/_search?sort=字段 desc
GET /test_index01/_doc/_search?sort=age:desc
GET /test_index01/_doc/_search?sort=age:asc
7.修改索引内容
格式:PUT /索引名称/类型/id
PUT /test_index01/_doc/1
{
"name": "秀儿",
"sex": 1,
"age": 25,
"address": "上海",
"remark": "java"
}
结果
{"_index" : "test_index01","_type" : "_doc","_id" : "1","_version" : 2,"result" : "updated","_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"_seq_no" : 1,"_primary_term" : 1
}
8.删除索引内容
格式: DELETE /索引名称/类型/id
DELETE /test_index01/_doc/1
结果
{"_index" : "test_index01","_type" : "_doc","_id" : "1","_version" : 3,"result" : "deleted","_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"_seq_no" : 2,"_primary_term" : 1
}9.PUT和POST区别
post和put都能实现创建和更新操作
①PUT:
(1)需要对一个具体的资源进行操作,所以必须要有id才能更新和创建操作。没有就会执行失败
(2)只会将json数据全都进行替换
(3)与delete都是幂等操作,无论操作多少次结果都一样
②POST:
(1)针对整个资源集合进行操作,如果不写id就会由es生成一个唯一的id进行创建文档,如果指定id则会对应创建或者更新文档。
(2)只会更新相同字段的值
相关文章:

二、ElasticSearch基础语法
目录一、简单了解ik分词器(分词效果)1.standard(单字分词器,es默认分词器)2.ik_smart分词(粗粒度的拆分)3.ik_max_word分词器(最细粒度拆分)二、指定默认分词器1.为索引指定默认分词器三、ES操作数据1.概述2.创建索引3.查询索引4.删除索引5.添…...
Yolov8详解与实战
文章目录摘要模型详解C2F模块Losshead部分模型实战训练COCO数据集下载数据集COCO转yolo格式数据集(适用V4,V5,V6,V7,V8)配置yolov8环境训练测试训练自定义数据集Labelme数据集摘要 YOLOv8 是 ultralytics …...
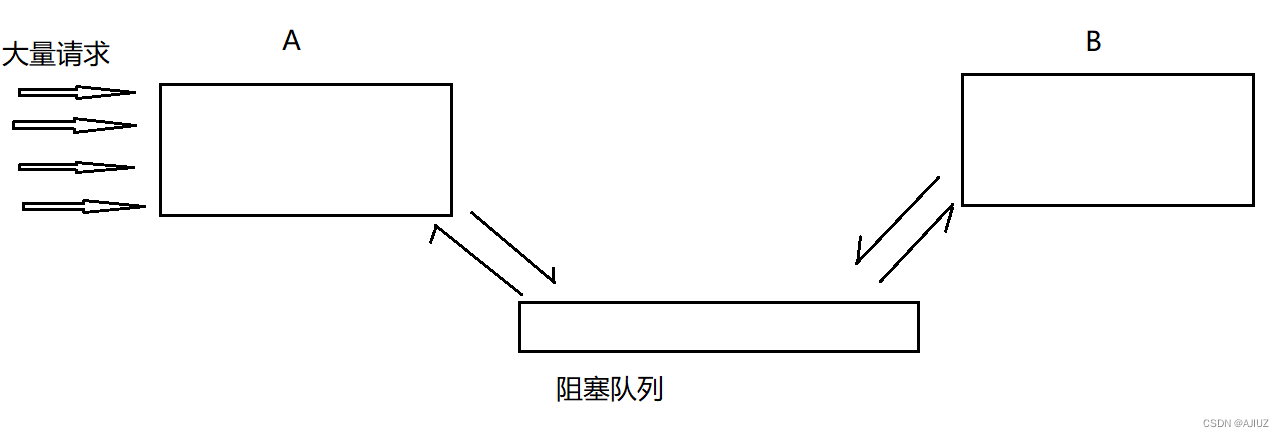
多线程案例——阻塞队列
目录 一、阻塞队列 1. 生产者消费者模型 (1)解耦合 (2)“削峰填谷” 2. 标准库中的阻塞队列 3. 自己实现一个阻塞队列(代码) 4. 自己实现生产者消费者模型(代码) 一、阻塞队列…...

学习优秀博文(【国产MCU移植】手把手教你使用RT-Thread制作GD32系列BSP)有感 | 文末赠书5本
学习优秀博文(【guo产MCU移植】手把手教你使用RT-Thread制作GD32系列BSP)有感 一篇优秀的博文是什么样的?它有什么规律可循吗?优秀的guo产32位单片机处理器是否真的能成功替换掉stm32的垄断地位? 本文博主以亲身经历聊…...

写用例写的焦头烂额?看看摸鱼5年的老点工是怎么写的...
给你个需求,你要怎么转变成最终的用例? 直接把需求文档翻译一下就完事了。 老点工拿到需求后的标准操作: 第一步:解析需求 先解析需求-找出所有需求中的动词,再列出所有测试点。测试点过程不断发散,对于…...

基于深度学习的鸟类检测识别系统(含UI界面,Python代码)
摘要:鸟类识别是深度学习和机器视觉领域的一个热门应用,本文详细介绍基于YOLOv5的鸟类检测识别系统,在介绍算法原理的同时,给出Python的实现代码以及PyQt的UI界面。在界面中可以选择各种鸟类图片、视频以及开启摄像头进行检测识别…...

零基础搭建Tomcat集群(超详细)
💗推荐阅读文章💗 🌸JavaSE系列🌸👉1️⃣《JavaSE系列教程》🌺MySQL系列🌺👉2️⃣《MySQL系列教程》🍀JavaWeb系列🍀👉3️⃣《JavaWeb系列教程》…...
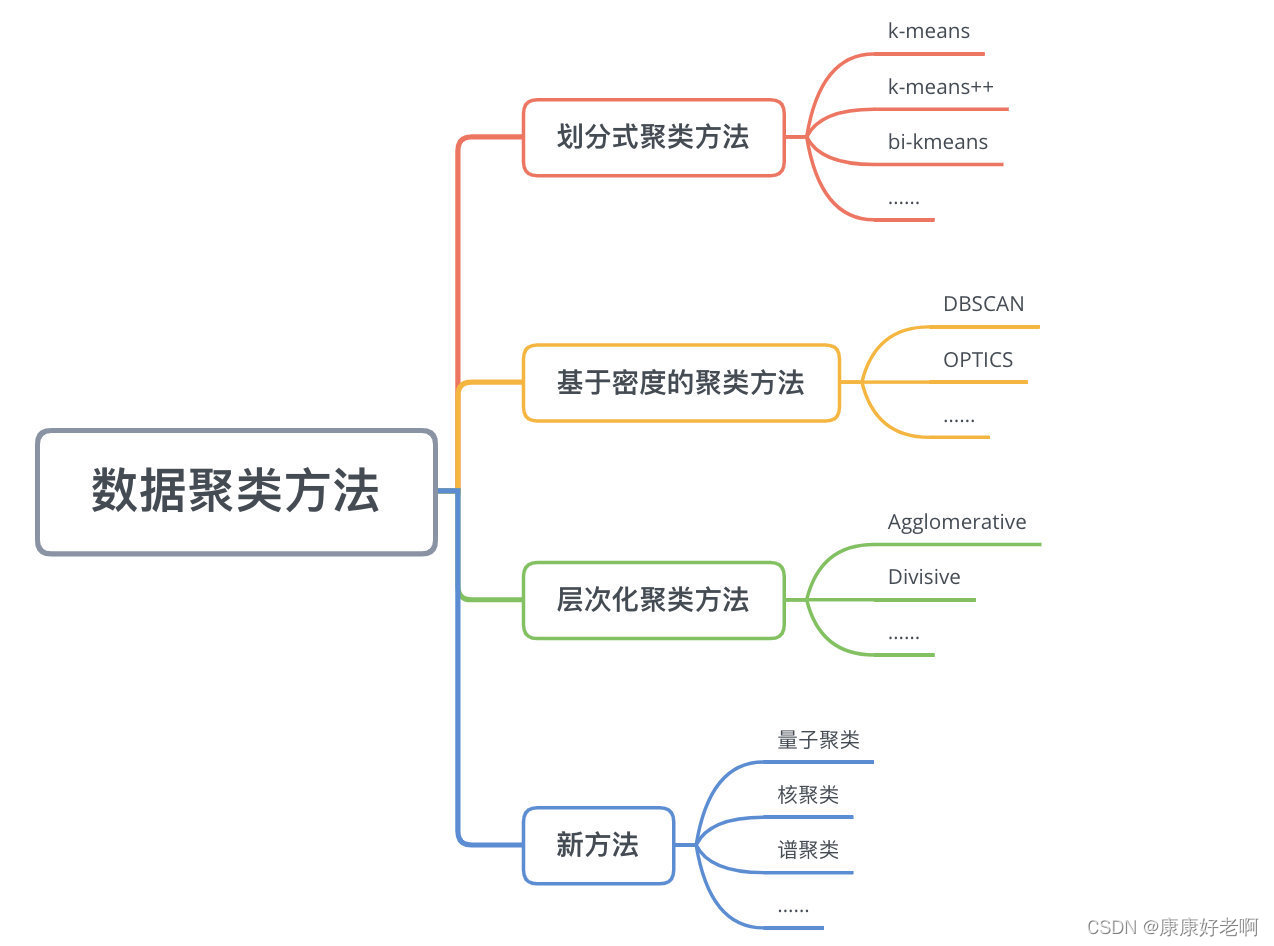
机器学习自学笔记——聚类
聚类的基本概念 聚类,顾名思义,就是将一个数据集中各个样本点聚集成不同的“类”。每个类中的样本点都有某些相似的特征。比如图书馆中,会把成百上千的书分成不同的类别:科普书、漫画书、科幻书等等,方便人们查找。每…...
注意下C语言整形提升
C语言整形提升 C语言整形提升是指在表达式中使用多种类型的数据时,编译器会自动将较小的类型转换为较大的类型,以便进行运算。在C语言中,整型提升规则如下: 如果表达式中存在short类型,则将其自动转换为int类型。 如…...

Go panic的学习
一、前言 我们的应用程序常常会出现异常,包括由运行时检测到的异常或者应用开发者自己抛出的异常。 异常在一些其他语言中,如c、java,被叫做Exception,主要由抛出异常和捕获异常两部分组成。异常在go语言中,叫做pani…...

讲解Linux中samba理论讲解及Linux共享访问
♥️作者:小刘在C站 ♥️个人主页:小刘主页 ♥️每天分享云计算网络运维课堂笔记,努力不一定有收获,但一定会有收获加油!一起努力,共赴美好人生! ♥️夕阳下,是最美的绽放࿰…...
【C++笔试强训】第三十二天
🎇C笔试强训 博客主页:一起去看日落吗分享博主的C刷题日常,大家一起学习博主的能力有限,出现错误希望大家不吝赐教分享给大家一句我很喜欢的话:夜色难免微凉,前方必有曙光 🌞。 💦&a…...

OpenAI GPT-4震撼发布:多模态大模型
OpenAI GPT-4震撼发布:多模态大模型发布要点GPT4的新功能GPT-4:我能玩梗图GPT4:理解图片GPT4:识别与解析图片内容怎样面对GPT4申请 GPT-4 API前言: 🏠个人主页:以山河作礼。 📝📝:本文章是帮助大家更加了…...

手把手教你 在linux上安装kafka
目录 1. 准备服务器 2. 选一台服务器配置kafka安装包 2.1 下载安装包 2.2 解压安装包 2.3 修改配置文件 3. 分发安装包到其他机器 4. 修改每台机器的broker.id 5. 配置环境变量 6. 启停kafka服务 6.1 启动kafak服务 6.2 停止kafka服务 1. 准备服务器 1.买几台云服务…...

Spring Cloud(微服务)学习篇(五)
Spring Cloud(微服务)学习篇(五) 1 nacos配置文件的读取 1.1 访问localhost:8848/index.html并输入账户密码后进入nacos界面并点击配置列表 1.2 点击右侧的号 1.3 点击加号后,进入新建配置界面,并做好如下配置 1.4 往下翻动,点击发布按钮 1.5 发布成功后的界面 1.6 在pom.xml…...

道阻且长,未来可期,从GPT-4窥得通用人工智能时代的冰山一角!
大家这两天是不是又被满屏的ChatGPT相关的文章信息给轰炸得不轻,说实话,我真的对ChatGPT的热度如此经久不衰这个问题非常感兴趣。从去年刚面世时,小范围内造成的行业震荡,到今年二月份铺天盖地得铺舆论造势,引发全民热…...

百度将?百度已!
仿佛一夜之间,创业公司OpenAI旗下的ChatGPT就火遍全球。这是一场十分罕见的科技盛宴。下到普通用户,上到各科技大厂都在讨论ChatGPT的前景,国外的微软、谷歌,国内的百度、腾讯、阿里等等都在布局相关业务。比尔盖茨更是称ChatGPT与…...
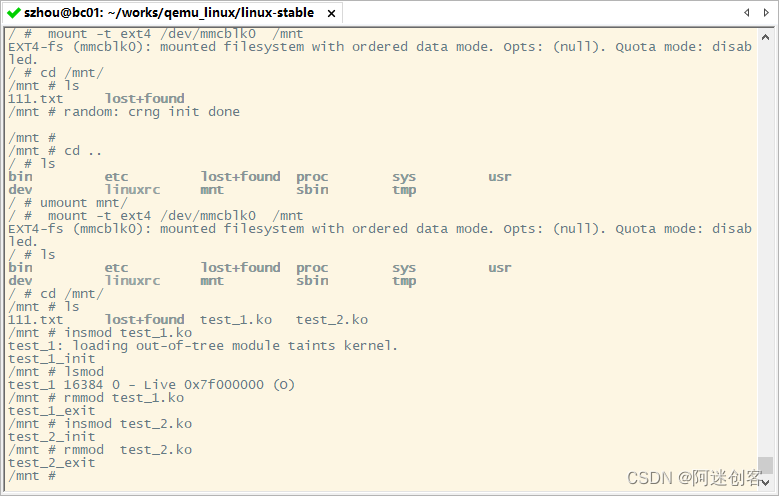
内核实验(三):编写简单Linux内核模块,使用Qemu加载ko做测试
文章目录一、篇头二、QEMU:挂载虚拟分区2.1 创建 sd.ext4.img 虚拟分区2.2 启动 Qemu2.3 手动挂载 sd.ext4.img三、实现一个简单的KO3.1 目录文件3.2 Makefile3.3 编译3.3.1 编译打印3.3.2 生成文件3.4 检查:objdump3.4.1 objdump -dS test\_1.ko3.4.2 o…...
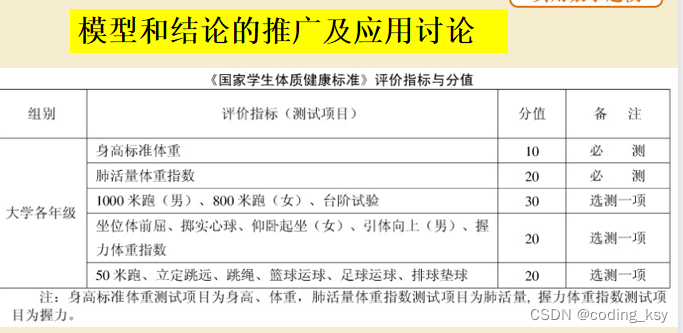
女子举重问题
一、问题的描述 问题及要求 1、搜集各个级别世界女子举重比赛的实际数据。分别建立女子举重比赛总成绩的线性模型、幂函数模型、幂函数改进模型,并最终建立总冠军评选模型。 应用以上模型对最近举行的一届奥运会女子举重比赛总成绩进行排名,并对模型及…...

试题 历届真题 循环小数【第十一届】【决赛】【Python】
试题 历届真题 循环小数【第十一届】【决赛】【Python】 题目来源:第十一届蓝桥杯决赛 http://lx.lanqiao.cn/problem.page?gpidT2891 资源限制 内存限制:256.0MB C/C时间限制:1.0s Java时间限制:3.0s Python时间限制ÿ…...

web vue 项目 Docker化部署
Web 项目 Docker 化部署详细教程 目录 Web 项目 Docker 化部署概述Dockerfile 详解 构建阶段生产阶段 构建和运行 Docker 镜像 1. Web 项目 Docker 化部署概述 Docker 化部署的主要步骤分为以下几个阶段: 构建阶段(Build Stage):…...

从WWDC看苹果产品发展的规律
WWDC 是苹果公司一年一度面向全球开发者的盛会,其主题演讲展现了苹果在产品设计、技术路线、用户体验和生态系统构建上的核心理念与演进脉络。我们借助 ChatGPT Deep Research 工具,对过去十年 WWDC 主题演讲内容进行了系统化分析,形成了这份…...

渗透实战PortSwigger靶场-XSS Lab 14:大多数标签和属性被阻止
<script>标签被拦截 我们需要把全部可用的 tag 和 event 进行暴力破解 XSS cheat sheet: https://portswigger.net/web-security/cross-site-scripting/cheat-sheet 通过爆破发现body可以用 再把全部 events 放进去爆破 这些 event 全部可用 <body onres…...

蓝桥杯 2024 15届国赛 A组 儿童节快乐
P10576 [蓝桥杯 2024 国 A] 儿童节快乐 题目描述 五彩斑斓的气球在蓝天下悠然飘荡,轻快的音乐在耳边持续回荡,小朋友们手牵着手一同畅快欢笑。在这样一片安乐祥和的氛围下,六一来了。 今天是六一儿童节,小蓝老师为了让大家在节…...

vue3 字体颜色设置的多种方式
在Vue 3中设置字体颜色可以通过多种方式实现,这取决于你是想在组件内部直接设置,还是在CSS/SCSS/LESS等样式文件中定义。以下是几种常见的方法: 1. 内联样式 你可以直接在模板中使用style绑定来设置字体颜色。 <template><div :s…...

BCS 2025|百度副总裁陈洋:智能体在安全领域的应用实践
6月5日,2025全球数字经济大会数字安全主论坛暨北京网络安全大会在国家会议中心隆重开幕。百度副总裁陈洋受邀出席,并作《智能体在安全领域的应用实践》主题演讲,分享了在智能体在安全领域的突破性实践。他指出,百度通过将安全能力…...

深入解析C++中的extern关键字:跨文件共享变量与函数的终极指南
🚀 C extern 关键字深度解析:跨文件编程的终极指南 📅 更新时间:2025年6月5日 🏷️ 标签:C | extern关键字 | 多文件编程 | 链接与声明 | 现代C 文章目录 前言🔥一、extern 是什么?&…...

多模态大语言模型arxiv论文略读(108)
CROME: Cross-Modal Adapters for Efficient Multimodal LLM ➡️ 论文标题:CROME: Cross-Modal Adapters for Efficient Multimodal LLM ➡️ 论文作者:Sayna Ebrahimi, Sercan O. Arik, Tejas Nama, Tomas Pfister ➡️ 研究机构: Google Cloud AI Re…...

AspectJ 在 Android 中的完整使用指南
一、环境配置(Gradle 7.0 适配) 1. 项目级 build.gradle // 注意:沪江插件已停更,推荐官方兼容方案 buildscript {dependencies {classpath org.aspectj:aspectjtools:1.9.9.1 // AspectJ 工具} } 2. 模块级 build.gradle plu…...

Go语言多线程问题
打印零与奇偶数(leetcode 1116) 方法1:使用互斥锁和条件变量 package mainimport ("fmt""sync" )type ZeroEvenOdd struct {n intzeroMutex sync.MutexevenMutex sync.MutexoddMutex sync.Mutexcurrent int…...