【3.17】MySQL索引整理、回溯(分割、子集问题)
3.1 索引常见面试题
索引的分类
-
什么是索引?
索引是一种数据结构,可以帮助MySQL快速定位到表中的数据。使用索引,可以大大提高查询的性能。
-
按「数据结构」分类:B+tree索引、Hash索引、Full-text索引。
InnoDB 存储引擎创建的聚簇索引或者二级索引默认使用的都是 B+Tree 这种数据结构。
-
按「存储类型」分类:聚簇索引(主键索引)、二级索引(辅助索引)。术语“聚簇”表示数据行和相邻的键值聚簇地存储在一起。这也形象地说明了聚簇索引叶子节点的特点,保存表的完整数据。
对于B + 树来说,每个节点都是一个数据页。B + 树只有叶子节点才会存放数据,非叶子节点仅用来存放目录项作为索引。所有节点按照索引键大小排序,构成双向链表,便于顺序查找和范围查找。
而B + Tree索引又可以分成聚簇索引和二级索引(非聚簇索引),它们区别就在于叶子节点存放的是什么数据。
-
聚簇索引的叶子节点存放的是实际数据,所有完整的用户记录都存放在叶子节点。
-
InnoDB存储引擎一定会为表创建一个聚簇索引,一般情况下会使用主键作为聚簇索引,且一张表只允许存在一个聚簇索引。
-
如果没有主键,就选择第一个不包含 NULL 值的唯一列作为聚簇索引的索引键;
-
在上面两个都没有的情况下,InnoDB 将自动生成一个隐式自增 id 列作为聚簇索引的索引键;
-
-
-
由于一张表只能有一个聚簇索引,为了实现非主键字段的快速搜索,就引出了二级索引(非聚簇索引/辅助索引),它也是利用了 B+ 树的数据结构,但是二级索引的叶子节点存放的是主键值,不是实际数据。
-
回表,就是先检索二级索引,找到叶子节点并获取主键值,通过聚簇索引查询到对应的叶子节点,也就是要查两个 B+Tree 才能查到数据。
-
索引覆盖,就是当查询的数据是主键值时,那么在二级索引就能查询到,不用再去聚簇索引查,就表示发生了索引覆盖,也就是只需要查一个 B+Tree就能找到数据。
-
-
-
按「字段特性」分类:主键索引、唯一索引、普通索引、前缀索引。
- 主键索引也叫聚簇索引,就是建立在主键字段上的索引,在创建表的时候一起创建,一张表最多只有一个主键索引,索引列的值不允许有空值。
- 唯一索引建立在 UNIQUE 字段上的索引,表示索引列的值必须唯一,允许有空值。一张表可以有多个唯一索引。
- 普通索引就是建立在普通字段上的索引,既不要求字段为主键,也不要求字段为 UNIQUE。
- 前缀索引是指对字符型字段的前几个字符建立的索引。使用前缀索引的目的是为了减少索引占用的存储空间,提升查询效率。
-
按「字段个数」分类:单列索引、联合索引。
-
单列索引:一个字段的索引。
-
联合索引:将多个字段组合成一个索引。
-
联合索引按照最左匹配原则,如果创建了一个 (a, b, c) 联合索引,查询条件存在a就可以匹配上联合索引,比如where a=1;
联合索引的最左匹配原则会一直向右匹配直到遇到范围查询(>、<)就会停止使用联合索引。也就是范围查询的字段可以用到联合索引,但是在范围查询字段之后的字段无法用到联合索引。注意,对于 >=、<=、BETWEEN、like 前缀匹配,这类范围查询,并不会停止使用索引,两个字段都会用到联合索引查询,但是只是 = 的部分用到了。
-
索引下推优化**(index condition pushdown,ICP), 是针对联合索引的一种优化。可以在联合索引遍历过程中,对联合索引中包含的字段先做判断**,直接过滤掉不满足条件的记录,从而减少回表次数。
- 因为二级索引存储字段和主键值,联合索引在二级索引中的形态是存储联合索引中的所有字段和主键值。所以可以优先对联合索引中包含的字段先做判断
-
实际开发工作中在建立联合索引时,建议把区分度大的字段排在前面,区分度越大,搜索的记录越少。 UUID 这类字段就比较适合做索引或排在联合索引列的靠前的位置。
比如,性别的区分度就很小,字段的值分布均匀,那么无论搜索哪个值都可能得到一半的数据。
-
-
什么时候需要 / 不需要创建索引?
-
索引的缺点
-
索引是一种数据结构,也需要占用磁盘空间。
-
创建、维护索引要耗费时间,这种时间随着数据量的增加而增大;
-
索引有可能失效。
-
-
什么时候适用索引?
- 字段有唯一性限制,比如商品编码。
- 经常用于 WHERE 查询条件、GROUP BY 和 ORDER BY 的字段。
- 在查询的时候就不需要再去做一次排序了,因为 B+Tree 的记录都是有序的。
-
什么时候不需要创建索引?
- WHERE 条件,GROUP BY,ORDER BY 里用不到的字段。
- 因为索引的价值是快速定位,如果起不到定位作用的字段不需要创建索引。
- 字段中存在大量重复数据,不需要创建索引。
- MySQL 有一个查询优化器,查询优化器发现某个值出现在表的数据行中的百分比很高的时候,它一般会忽略索引,进行全表扫描。
- 表数据太少的时候,不需要创建索引。
- 如果字段经常更新,不需要创建索引。
- 维护B + 树的结构,就需要频繁重建索引,影响数据库性能。
- WHERE 条件,GROUP BY,ORDER BY 里用不到的字段。
有什么优化索引的方法?
-
使用前缀索引:使用字段中字符串的前几个字符建立索引,可以减小索引字段大小,节省空间。可以增加一个索引页存储前缀索引值,从而提高索引查询速度。
-
前缀索引的局限性
order by 就无法使用前缀索引,因为前缀字符无法排序。
无法把前缀索引用作覆盖索引,因为一般只有查询主键值时会用到覆盖索引。
-
-
使用覆盖索引:争取 SQL 中查询的所有字段,都能从二级索引中查询得到记录,避免回表的操作。
-
主键索引最好是自增的:如果我们使用主键自增,就不需要频繁改变B + 树的结构,直接按顺序插入。
- 如果我们使用非自增主键,每次主键值都是随机的,插入新的数据时,有可能产生数据页分裂,导致索引结构不紧凑,从而影响查询效率。
-
索引列最好设置为NOT NULL(非空)约束:索引列存在 NULL 就会导致优化器在做索引选择的时候更加复杂,更加难以优化。因为可为 NULL 的列会使索引、索引统计、值的比较,都更复杂。比如进行索引统计时,count 会省略值为NULL 的行。
并且NULL 值是一个没意义的值,行格式会至少使用1字节空间存储NULL 值列表,会占用物理空间。
3.2 从数据页的角度看B + 树
数据页的组成
InnoDB的数据是按照数据页为单位来读写的,默认的大小是16KB。
数据页由七个部分组成:文件头(File Header)、页头(Page Header)、用户空间(UserRecords) 、最大、最小记录(Infimum + Supermum)、空闲空间(Free + Space)、页目录(PageDirectory)、文件尾(File Trailer)。
- 文件头:文件头有两个指针,分别指向上一个和下一个数据页,连接起来的数据页相当于一个双向链表。实现逻辑上的连续存储。
- 页目录:页目录起到数据的索引作用。数据页中的数据**按照主键的顺序组成单向链表。**页目录由多个槽组成,**槽相当于分组数据的索引。**我们通过槽查找记录时,可以使用二分法快速定位要查询的记录在哪个槽(哪个记录分组),随后遍历槽内的所有记录,找到对应的记录。每个槽对应的值都是这个组的主键最大的记录。
- 用户空间:在页的 7 个组成部分中,我们自己存储的记录会按照我们指定的行格式存储到 用户空间(User Records) 部分。一开始生成页的时候,并没有这个部分,每当我们插入一条记录,都会从 Free Space 部分申请一个记录大小的空间划分到User Records部分。当 Free Space 部分的空间全部被 User Records 部分替代掉之后,也就意味着这个页使用完了,如果还有新的记录插入的话,就需要去申请新的页了。
B + 树是如何进行查询的?
在进行查询时,B + 树通过二分法快速定位到包含该记录的页。定位到该页后,又会在该页内进行二分法快速定位记录所在的分组(槽号),最后在分组内进行遍历查找。
3.3 为什么MySQL采用B + 树作为索引?
怎样的索引的数据结构是好的?
-
读取数据时,先读取索引到内存,再通过索引找到磁盘中的某行数据,然后读到内存中,磁盘I/O操作次数越多,所消耗的时间也越大。所以MySQL的索引应该要尽可能减少磁盘I/O次数,并且能够高效地查找某一个记录,也要能高效的范围查找。
-
为什么不用二叉查找树?
- 二叉查找树的特点是一个节点的左子树的所有节点都小于这个节点,右子树的所有节点都大于这个节点。
- 二叉查找树的搜索速度快,解决了插入新节点的问题,但是如果每次插入的元素都是二叉查找树中最大的元素,二叉查找树就会退化成了一条链表,查找数据的时间复杂度变成了 O(n)。随着元素插入越多,树的高度越高,磁盘IO操作也就越多,查询性能严重下降。
-
为什么不用自平衡二叉树(AVL树)?
- 自平衡二叉树在二叉查找树的基础上增加了一些条件约束:每个节点的左子树和右子树的高度差不能超过 1。
- 但是和二叉查找树一样,随着插入的元素变多,会导致树的高度变高,磁盘IO操作次数就会变多,影响整体数据查询效率。
-
为什么不用B树?
- B树解决了树的高度问题,但是B树的每个节点都包含数据(索引+记录),而用户记录的数据大小有可能远远超过索引数据,就要花费更多的IO来读取到有用的索引数据。
-
B + 树对B树进行了升级,与B树的区别主要是以下几点
- 叶子节点才会存放实际数据(索引+记录),非叶子节点只会存放索引;
- 叶子节点之间构成一个有序链表,叶子结点本身依关键字的大小自小而大顺序链接。对于范围查找可以提高效率;
- 非叶子节点的索引也会同时存在在子节点中,并且是在子节点中所有索引的最大(或最小)。
- 非叶子节点中有多少个子节点,就有多少个索引;
-
Innodb 使用的 B+ 树有一些特别的点,比如:
- B+ 树的叶子节点之间是用「双向链表」进行连接,这样的好处是既能向右遍历,也能向左遍历。
- B+ 树节点的内容是数据页,数据页里存放了用户的记录以及各种信息,每个数据页默认大小是 16 KB。
为什么MySQL使用B + 树作为索引?
MySQL 默认的存储引擎 InnoDB 采用的是 B+ 树作为索引的数据结构,原因有如下几点:
-
B+ 树的非叶子节点仅存放索引。
- 在数据量相同的情况下,相比既存索引又存记录的 B 树,B+树的非叶子节点可以存放更多的索引,因此 B+ 树可以比 B 树更「矮胖」,查询底层节点的磁盘 I/O次数会更少。
-
B+ 树有大量的冗余节点。
- 这些冗余索引让 B+ 树在插入、删除的效率都更高,比如删除根节点的时候,不会像 B 树那样会发生复杂的树的变化;
-
B+ 树将数据按照顺序存储在叶子节点中,叶子节点之间用双向链表连接,既能向右遍历,也能向左遍历,在排序操作和范围查询中有很高的效率。
- B+Tree 存储千万级数据只需要 3-4 层高度就可以满足,从千万级的表查询目标数据最多需要 3-4 次磁盘 I/O。
- 而 B 树要实现范围查询,因此只能通过树的遍历来完成范围查询,这会涉及多个节点的磁盘 I/O 操作,范围查询效率不如 B+ 树。
综上所述,B+树是一种非常高效的数据结构,可以在大规模数据的情况下提供高效的索引支持,因此MySQL选择使用B+树作为索引。
3.4 MySQL单表不要超过2000W行,靠谱吗?
InnoDB存储引擎的表数据存放在一个.idb(innodb data)的文件中,也叫做表空间。
索引结构不会影响单表最大行数,2000W 也只是推荐值,超过了这个值可能会导致 B + 树层级更高,影响查询性能。
但是,当单表数据库到达某个量级的上限时,导致内存无法存储其索引,使得之后的 SQL 查询会产生磁盘 IO,从而导致性能下降,所以增加硬件配置,可能会带来立竿见影的性能提升。
3.5 索引失效有哪些?
-
当我们使用左或者左右模糊匹配的时候,也就是 like %xx 或者 like %xx% 这两种方式都会造成索引失效。
- 因为索引 B+ 树是按照「索引值」有序排列存储的,只能根据前缀进行比较。
-
对索引列进行表达式计算、使用函数,这些情况下都会造成索引失效。
- 因为索引保存的是索引字段的原始值,而不是经过计算后的值。
-
索引列发生隐式类型转换。MySQL 在遇到字符串和数字比较的时候,会自动把字符串转为数字,然后再进行比较。如果字符串是索引列,而输入的参数是数字的话,那么索引列会发生隐式类型转换。
- 由于隐式类型转换是通过 CAST 函数实现的,等同于对索引列使用了函数,所以就会导致索引失效。
-
联合索引没有遵循最左匹配原则,也就是按照最左边的索引优先的方式进行索引的匹配,就会导致索引失效。
-
在 WHERE 子句中,如果在 OR 前的条件列是索引列,而在 OR 后的条件列不是索引列,那么索引会失效。
- 因为 OR 的含义就是两个只要满足一个即可,只要有条件列不是索引列,就会进行全表扫描。
3.6 MySQL使用like “%x”,索引一定会失效吗?
-
当数据库表中的字段只有主键+二级索引时,使用左模糊匹配(like “%x”),不会走全表扫描(索引不会生效),而是走全扫描二级索引树。
- 因为查二级索引的B + 树就可以查到全部结果,MySQL 优化器认为直接遍历二级索引树要比遍历聚簇索引树的成本要小的多,因此 MySQL 选择了「全扫描二级索引树」的方式查询数据。
-
附加题:不遵循联合索引的最左匹配原则,索引一定会失效吗?
- 如果数据库表中的字段都是索引的话,即使查询过程中,没有遵循联合索引的最左匹配原则,也是走全扫描二级索引树(type=index)。
3.7 count(*)和count(1)有什么区别?哪个性能好?
-
性能:count(*) = count(1) > count(主键字段) > count(字段)。
-
count()是什么?
-
count()是一个聚合函数,函数的参数不仅可以是字段名,也可以是其他任意的表达式,作用是统计函数指定的参数不为 NULL 的记录有多少个。
-
比如count(name):统计name不为NULL的字段有多少。
count(1):统计1不为NULL的字段有多少。1永远不可能是NULL,所以其实是在统计一共有多少条记录。
-
-
-
count(主键字段)执行过程是怎样的?
-
如果表中只有主键索引,没有二级索引,InnoDB在遍历时就会遍历聚簇索引,将读取到的记录返回给server层(server层维护了一个count的变量),然后读取记录中的主键值,如果为NULL,就将count变量 + 1。
如果表中有二级索引,InnoDB就会遍历二级索引,通过二级索引获取主键值,进一步统计个数。
-
-
count(1)执行过程是怎样的?
- 如果表中只有主键索引,没有二级索引,InnoDB遍历时会遍历聚簇索引,将读取到的记录返回给server层,但是不会读取记录中的任何字段的值。因为 count 函数的参数是 1,不是字段,所以不需要读取记录中的字段值。如果表中有二级索引,InnoDB就会遍历二级索引。
- 因为 count 函数的参数是 1,不是字段,所以不需要读取记录中的字段值。
- 如果表中只有主键索引,没有二级索引,InnoDB遍历时会遍历聚簇索引,将读取到的记录返回给server层,但是不会读取记录中的任何字段的值。因为 count 函数的参数是 1,不是字段,所以不需要读取记录中的字段值。如果表中有二级索引,InnoDB就会遍历二级索引。
-
count(*)执行过程是怎样的?
- count(
*) 其实等于 count(0),也就是说,当你使用 count(*) 时,MySQL 会将*参数转化为参数 0 来处理。
- count(
-
count(字段)执行过程是怎样的?
- 会采用全表扫描的方式来计数,所以它的执行效率是比较差的。
-
count(1)、 count(
*)、 count(主键字段)在执行的时候,如果表里存在二级索引,优化器就会选择二级索引进行扫描。所以,如果要执行 count(1)、 count(*)、 count(主键字段) 时,尽量在数据表上建立二级索引,这样优化器会自动采用 key_len 最小的二级索引进行扫描,相比于扫描主键索引效率会高一些。 -
为什么InnoDB存储引擎要通过遍历索引的方式计数?
- InnoDB 存储引擎是支持事务的,同一个时刻的多个查询,由于多版本并发控制(MVCC)的原因,InnoDB 表“应该返回多少行”也是不确定的。
-
如何优化count(*) ?
- 使用近似值。如果业务对于统计个数不需要很精确,可以使用explain 命令来进行估算。
- 使用额外表保存计数值。将这个计数值保存到单独的一张计数表中,在数据表插入一条记录的同时,将计数表中的计数字段 + 1。但是在新增和删除操作时,我们需要额外维护这个计数表。
分割回文串
切割问题类似组合问题。对于字符串abcdef
-
组合问题:选取一个a之后,在bcdef中再去选取第二个,选取b之后在cdef中再选取第三个…。
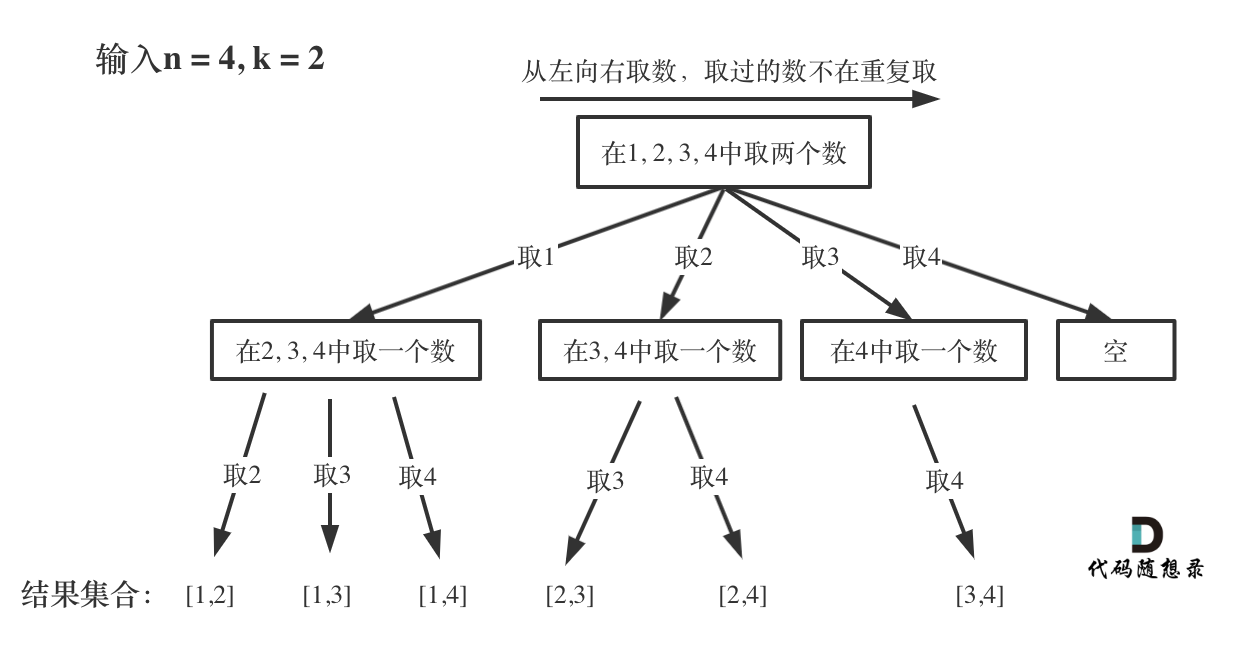
-
切割问题:切割一个a之后,在bcdef中再去切割第二段,切割b之后在cdef中再切割第三段…。
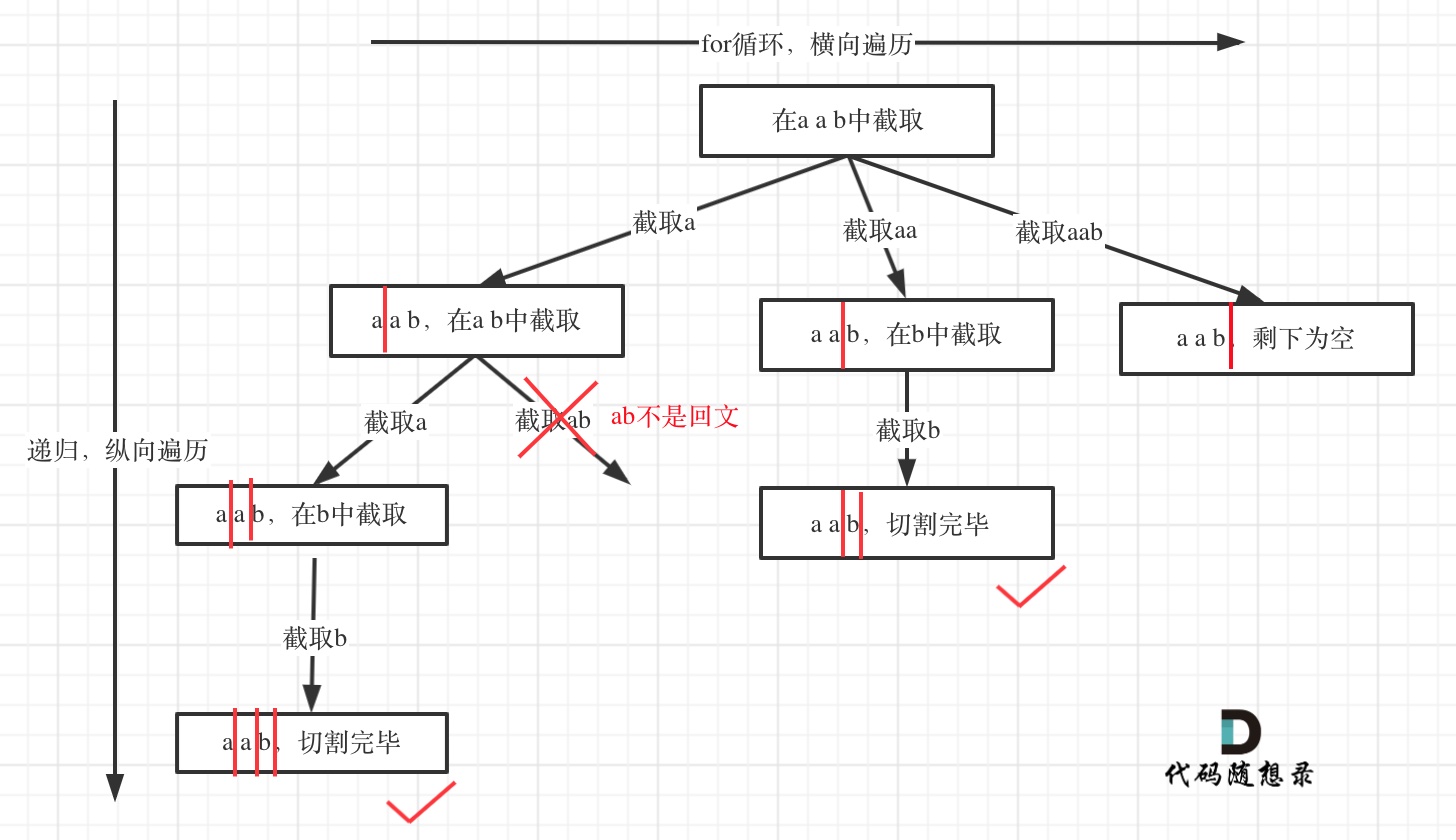
class Solution {List<List<String>> ans = new ArrayList<>();Deque <String> path = new LinkedList<>();public List<List<String>> partition(String s) {StringBuffer sb = new StringBuffer(s);breaktracking(sb , 0);return ans;}void breaktracking(StringBuffer sb , int index){// 开始位置大于 sb的大小,说明找到了一组。if(index >= sb.length()){ans.add(new ArrayList<>(path));return ;}for(int i = index ; i < sb.length() ; i++){//每次切割下来的s子串。String s = sb.substring(index , i + 1);//判断是否回文if(isBack(s)){path.add(s);}else{continue;}//切割过的位置不重复切割breaktracking(sb , i + 1);path.removeLast();}}boolean isBack(String s){StringBuffer sb = new StringBuffer(s);// System.out.println(sb.toString());if(sb.toString().equals(sb.reverse().toString())){return true;}return false;}
}
复原IP地址
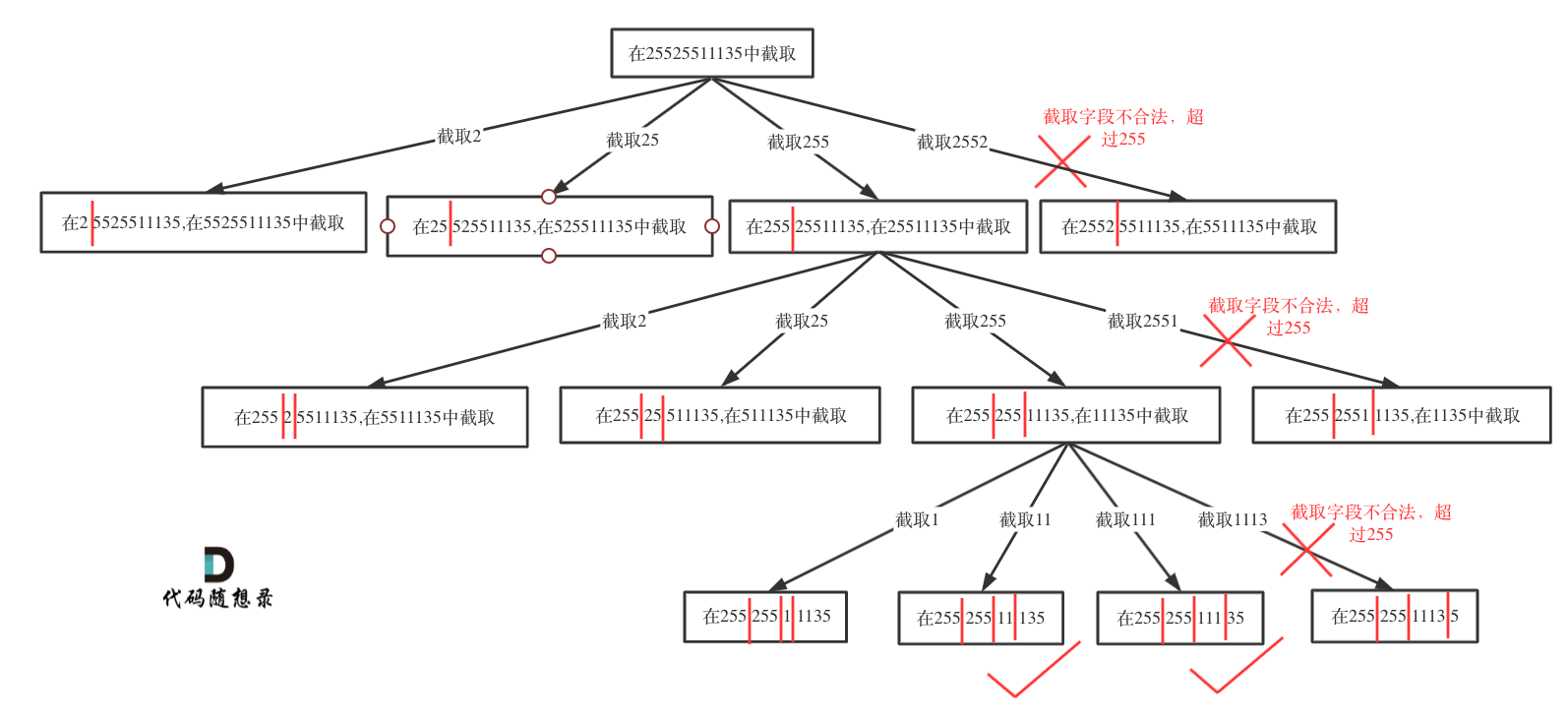
截取操作都在原字符串上操作,找到一个合法stage即为:在s中当前合法stage后面加一个'.'即可。
删除操作删除'.'
class Solution {List<String> ans = new ArrayList<>();String stage;int pointsNum = 0;public List<String> restoreIpAddresses(String s) {if(s.length() > 12) return ans;breaktracking(s , 0);return ans;}void breaktracking(String s , int index){stage = s.substring(index);if(pointsNum == 3 && isLeagel(stage)){ans.add(s);}for(int i = index ; i < s.length() ; i++){stage = s.substring(index , i + 1);if(isLeagel(stage)){s = s.substring(0 , i + 1) + "." + s.substring(i + 1);pointsNum ++;breaktracking(s , i + 2);pointsNum -- ;s = s.substring(0 , i + 1) + s.substring(i + 2);}else break;}}boolean isLeagel(String s){if(s.length() <= 0){return false;}if(s.length() > 1 && s.charAt(0) == '0'){return false;}int num = 0;for(int i = 0 ; i < s.length() ; i ++){if (s.charAt(i) > '9' || s.charAt(i) < '0') { // 遇到⾮数字字符不合法return false;}num = num * 10 + (s.charAt(i) - '0');if (num > 255) { // 如果⼤于255了不合法return false;}}return true;}
}
子集
组合问题和分割问题都是手机树的叶子节点,但是子集问题是找树的所有节点。
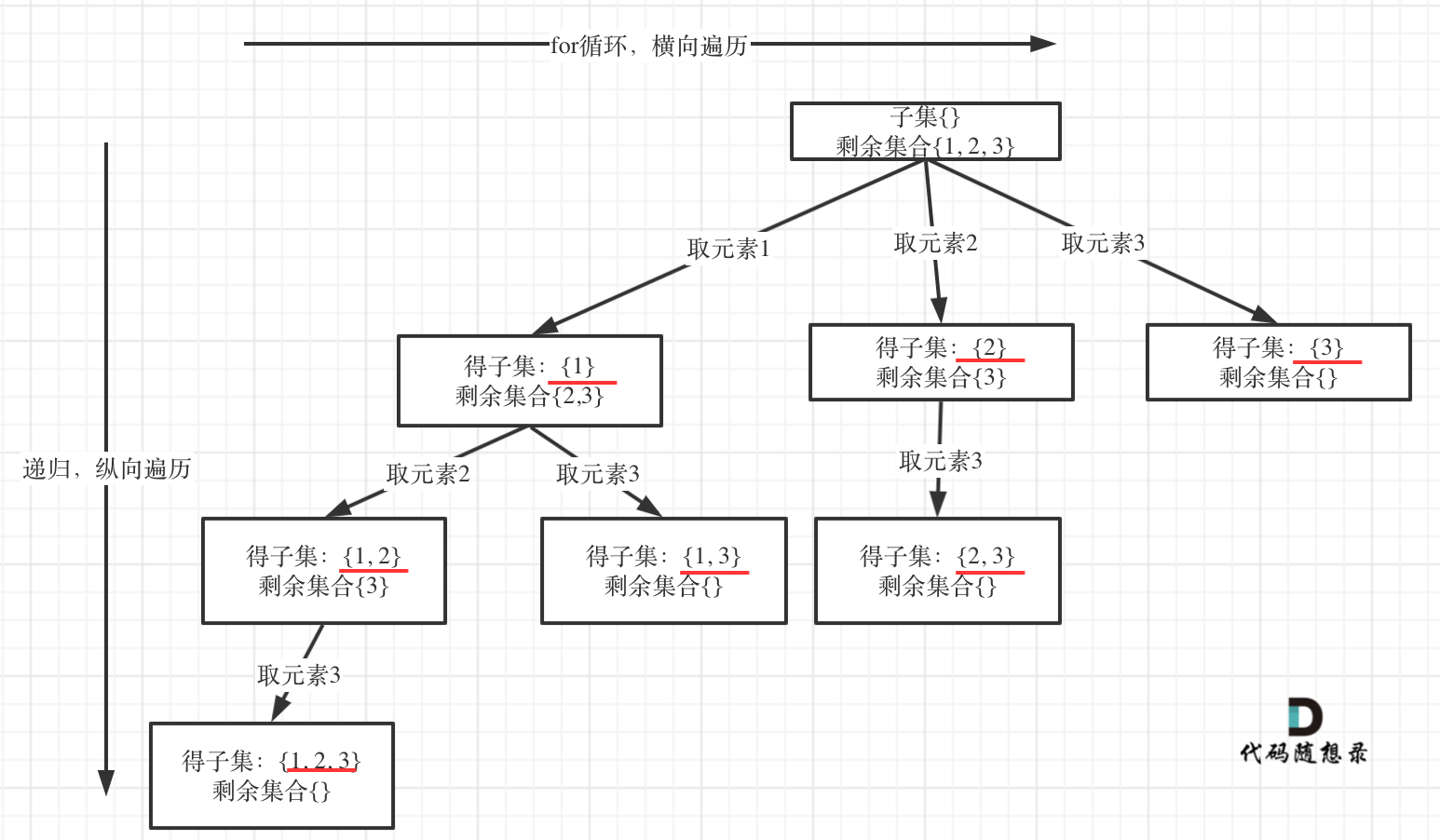
递归终止条件:剩余集合为空,就是叶子节点,此时递归应该终止。
if (startIndex >= nums.size()) {return;
}
其实可以不需要加终止条件,因为startIndex >= nums.size(),本层for循环本来也结束了。
单层逻辑
for (int i = startIndex; i < nums.size(); i++) {path.push_back(nums[i]); // 子集收集元素backtracking(nums, i + 1); // 注意从i+1开始,元素不重复取path.pop_back(); // 回溯
}
最终代码如下:
class Solution {List<List<Integer>> ans = new ArrayList<>();LinkedList<Integer> path = new LinkedList<>();public List<List<Integer>> subsets(int[] nums) {ans.add(new ArrayList<>(path));breaktracking(nums , 0);return ans;}void breaktracking(int [] nums , int index){if(index >= nums.length){return;}for(int i = index ; i < nums.length ; i ++){path.offer(nums[i]);//每一个节点都要加入。ans.add(new ArrayList<>(path));breaktracking(nums , i + 1);path.removeLast();}}
}
子集II
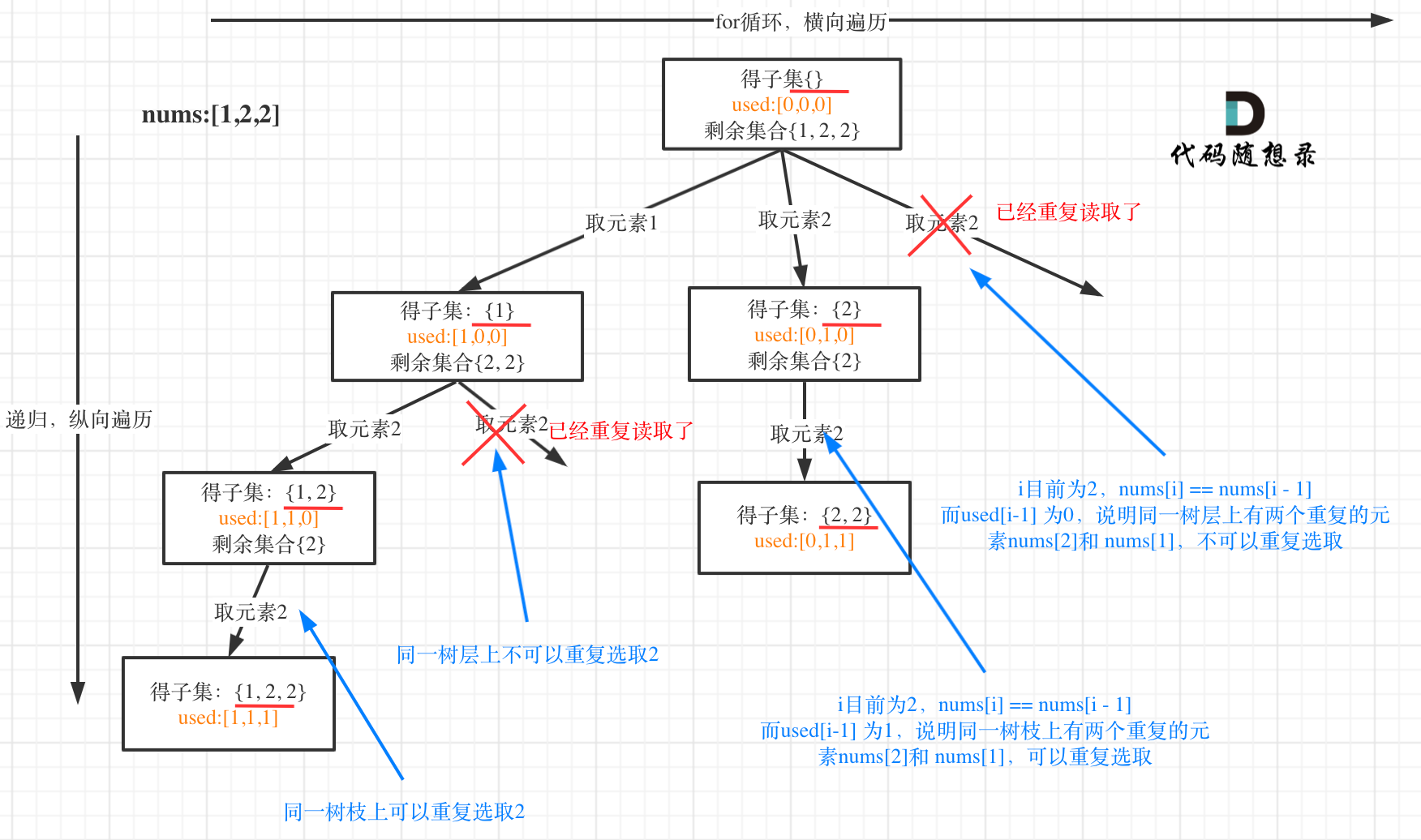
去重时,要先对集合排序,同一树层上,不能重复选取元素。
class Solution {Deque <Integer> path = new LinkedList<>();List<List<Integer>> ans = new ArrayList<>();boolean [] used ; public List<List<Integer>> subsetsWithDup(int[] nums) {Arrays.sort(nums);used = new boolean [nums.length];ans.add(new ArrayList<>(path));breaktarcking(nums , 0);return ans;}void breaktarcking(int [] nums , int index){if(index >= nums.length){return;}for(int i = index ; i < nums.length ; i ++){//说明在本树层被用过了。if( i > 0 && nums[i] == nums[i - 1] && used[i - 1] == false){continue;}path.offer(nums[i]);ans.add(new ArrayList<>(path));used[i] = true;breaktarcking(nums , i + 1);used[i] = false;path.removeLast();}}
}
相关文章:
【3.17】MySQL索引整理、回溯(分割、子集问题)
3.1 索引常见面试题 索引的分类 什么是索引? 索引是一种数据结构,可以帮助MySQL快速定位到表中的数据。使用索引,可以大大提高查询的性能。 按「数据结构」分类:Btree索引、Hash索引、Full-text索引。 InnoDB 存储引擎创建的聚簇…...
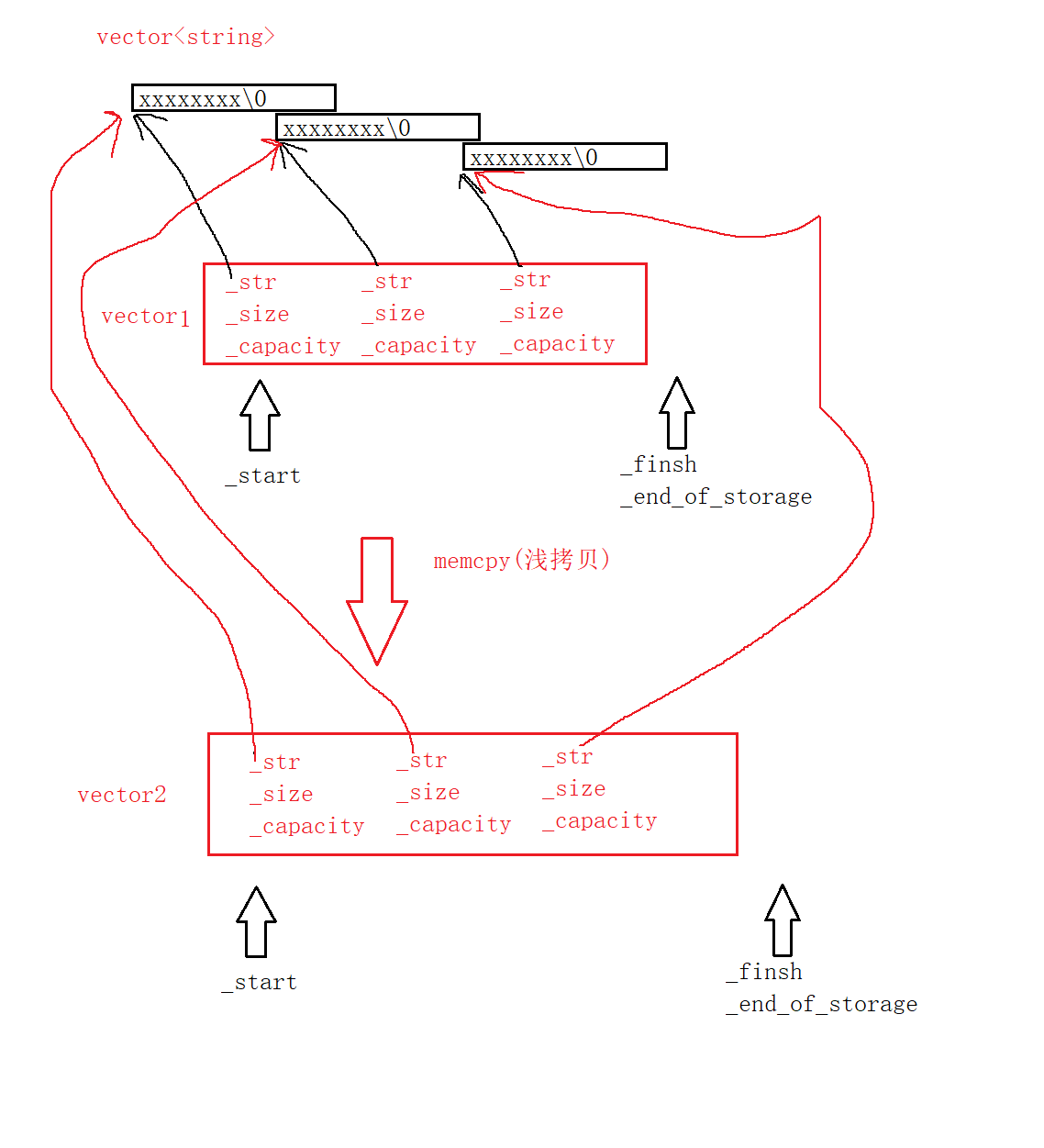
转解疑难杂症,详解vector迭代器失效和深浅拷贝的问题
前文http://t.csdn.cn/kVeVX——vector模拟实现本篇文章主要是针对vector中的两个比较经典的问题同时也是上一篇文章遗留下来的问题进行详细解释,第一个就是迭代器失效的问题,第二个是深浅拷贝的问题。ps:注意本文演示用的代码是上一篇vector…...
质量工具之头脑风暴法
云质QMS原创 转载请注明来源 作者:王洪石 1. 什么是头脑风暴法 头脑风暴最早是精神病理学上的用语,指的是精神病患者的精神错乱状态,后来拓展为无限制的自由联想和讨论,其目的在于产生新创意、激发新设想,或通过找到新…...

【3】核心易中期刊推荐——人工智能计算机仿真
🚀🚀🚀NEW!!!核心易中期刊推荐栏目来啦 ~ 📚🍀 核心期刊在国内的应用范围非常广,核心期刊发表论文是国内很多作者晋升的硬性要求,并且在国内属于顶尖论文发表,具有很高的学术价值。在中文核心目录体系中,权威代表有CSSCI、CSCD和北大核心。其中,中文期刊的数…...

vFlash软件简介
🍅 我是蚂蚁小兵,专注于车载诊断领域,尤其擅长于对CANoe工具的使用🍅 寻找组织 ,答疑解惑,摸鱼聊天,博客源码,点击加入👉【相亲相爱一家人】🍅 玩转CANoe&…...
mysql-online-ddl是否需要rebuild
一、背景 DDL一直是DBA业务中的大项,看了TIDB的DDL讲解,恰巧我们的mysql业务大表也遇到了DDL的变更项,变更内容是将varchar(10)变更成varchar(20),这个变更通过官方文档很容易知道是不需要rebuild的(这里要注意下这个varchar(255…...

力扣-超过经理收入的员工
大家好,我是空空star,本篇带大家了解一道简单的力扣sql练习题。 文章目录前言一、题目:181. 超过经理收入的员工二、解题1.正确示范①提交SQL运行结果2.正确示范②提交SQL运行结果3.正确示范③提交SQL运行结果4.正确示范④提交SQL运行结果5.其…...
决策树基础知识点解读
目录 ID3算法 C4.5算法 CART树 ID3算法 定义:在决策树各个结点上应用信息增益准则选择特征,递归的构建决策树。该决策树是多分支分类。 信息增益 意义:给定特征X的条件下,使得类别Y的信息的不确定性减少的程度。取值越大越好。 定义&am…...

【C++】入门知识之 命名空间与输入输出
前言C语言是结构化和模块化的语言,适合处理较小规模的程序。对于复杂的问题,规模较大的程序,需要高度的抽象和建模时,C语言则不合适。为了解决软件危机, 20世纪80年代, 计算机界提出了OOP(object oriented …...

redis持久化的几种方式
一、简介 Redis是一种高级key-value数据库。它跟memcached类似,不过数据可以持久化,而且支持的数据类型很丰富。有字符串,链表,集 合和有序集合。支持在服务器端计算集合的并,交和补集(difference)等,还支持…...
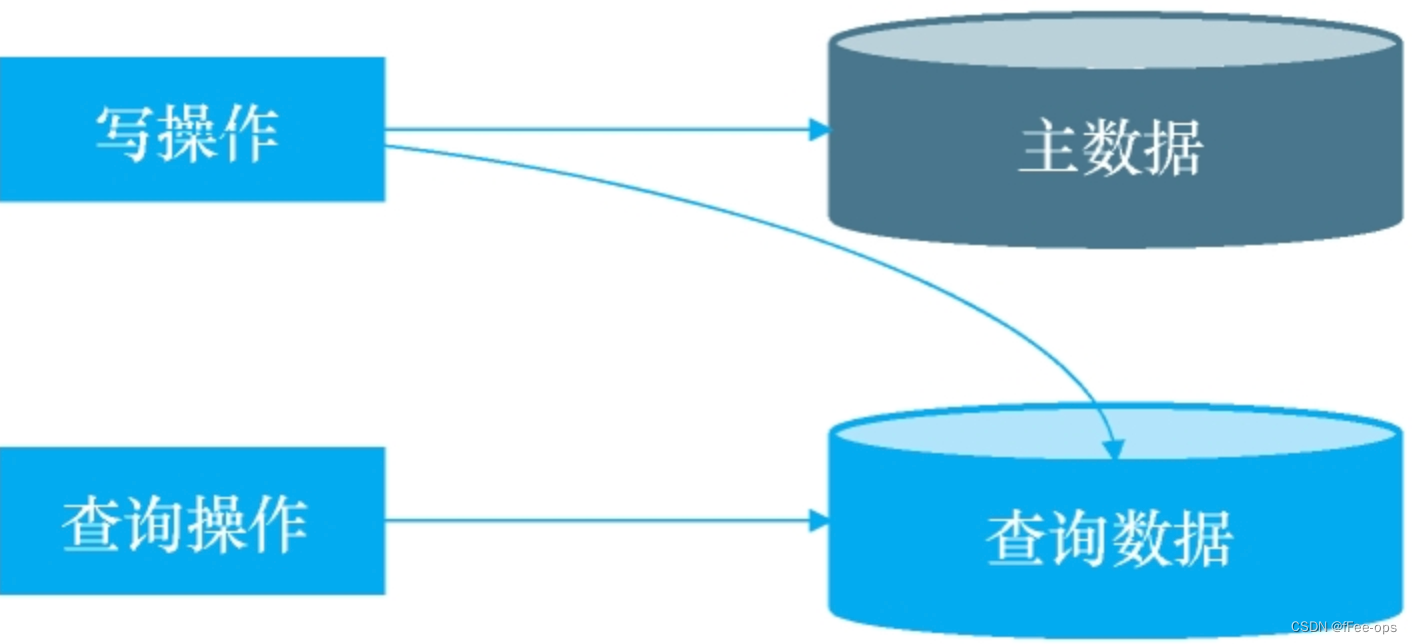
数据持久化层--查询分离
1. 业务场景 1)查询慢。当时工单数据库里面有1000万左右的客服工单时,每次查询时需要关联其他近10个表,一次查询平均花费13秒左右。 2)打开工单慢。工单打开以后需要调用多个接口,分别将用户信息、订单信息以及其他客服创建的单据信息列出来(如退款、赔偿、充值、投诉等…...

一文读懂Js中的this指向
前言 this关键字是一个非常重要的语法点。毫不夸张地说,不理解它的含义,大部分开发任务都无法完成。 简单说,this就是属性或方法“当前”所在的对象。 this.property上面代码中,this就代表property属性当前所在的对象。 下面是…...

零费用、零学习成本,用户快速可自定义json格式
随着物联网的发展,越来越多的设备被连接到互联网,数据量不断增加。这就需要有一种高效的方法来处理传输和处理这些数据。钡铼技术R40B边缘计算路由器,集成4G工业路由器、智能网关、RTU、DTU等产品多合一。支持边缘计算,它可以将计…...

2023年全国最新高校辅导员精选真题及答案25
百分百题库提供高校辅导员考试试题、辅导员考试预测题、高校辅导员考试真题、辅导员证考试题库等,提供在线做题刷题,在线模拟考试,助你考试轻松过关。 101.属于大学教师职业特征的是()。 A.教师劳动的复杂性 B.教师…...

二、数据结构-线性表
目录 🌻🌻一、线性表概述1.1 线性表的基本概念1.2 线性表的顺序存储1.2.1 线性表的基本运算在顺序表上的实现1.2.2 顺序表实现算法的分析1.2.3 单链表类型的定义1.2.4 线性表的基本运算在单链表上的实现1.3 其他运算在单链表上的实现1.3.1 建表1.3.2 删除…...
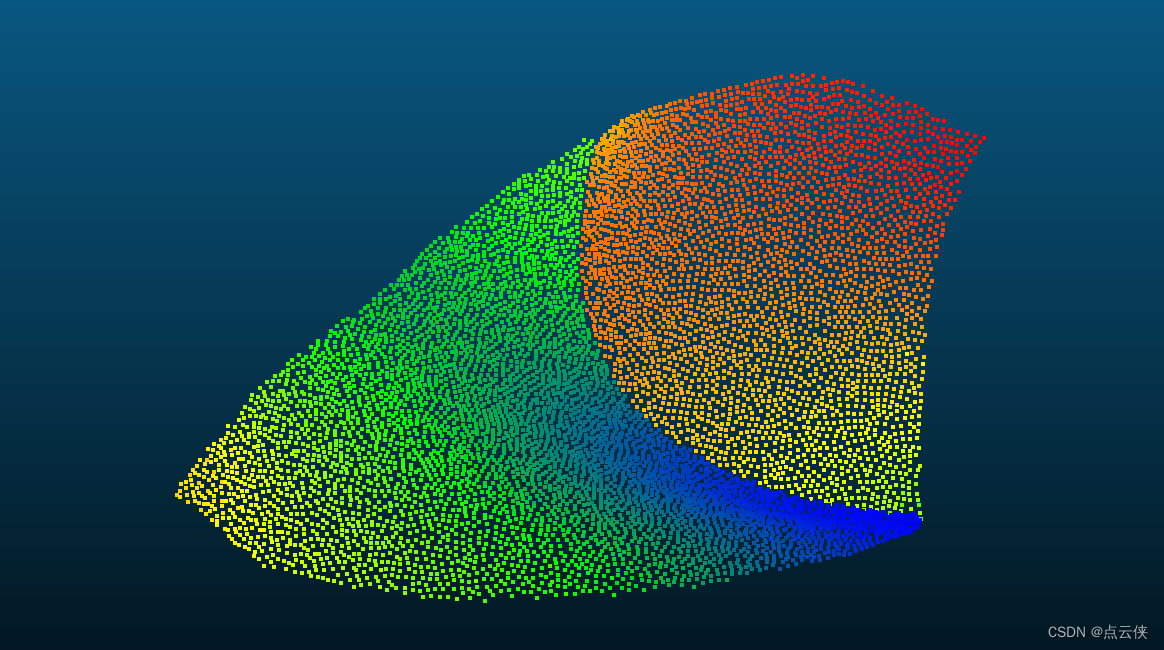
CGAL 点云上采样
目录一、算法原理1、主要函数2、参数解析二、代码实现三、结果展示一、算法原理 该方法对点集进行逐步上采样,同时根据法向量信息来检测边缘点,需要输入点云具有法线信息。在点云空洞填充和稀疏表面重建中具有较好的应用。 1、主要函数 头文件 #inclu…...
阿里云短信验证码实战
一、创建阿里云短信权限用户 1、登陆阿里云之后我们点击头像,接着点击AccessKey: 2、选择开始使用子用户 : 3、我们先要创建一个用户组: 4、依次点击新建的用户组——授权管理,给用户组授权,开通短信验证码服务…...

Android APP隐私合规检测工具Camille使用
目录一、简介二、环境准备常用使用方法一、简介 现如今APP隐私合规十分重要,各监管部门不断开展APP专项治理工作及核查通报,不合规的APP通知整改或直接下架。camille可以hook住Android敏感接口,检测是否第三方SDK调用。根据隐私合规的场景&a…...
手把手学会DFS (递归入门)
目录 算法介绍 递归实现指数型枚举 递归实现排列型枚举 递归实现组合型枚举 算法介绍 🧩DFS 即 Depth First Search ,中文又叫深度优先搜索,是一种沿着树的深度对其进行遍历,直到尽头之后再进行回溯,再走其他路线的…...

由《三体》太阳文明末日场景想到的……
《三体》电视剧正在热播,热度持续不退,豆瓣评分8.6,基本已经预定年度口碑最高的科幻题材剧;除了在国内多个平台播出外,还走出国门,成功“出海”,《人民日报》两会特刊都予以了高度赞扬。 上图红…...

铭豹扩展坞 USB转网口 突然无法识别解决方法
当 USB 转网口扩展坞在一台笔记本上无法识别,但在其他电脑上正常工作时,问题通常出在笔记本自身或其与扩展坞的兼容性上。以下是系统化的定位思路和排查步骤,帮助你快速找到故障原因: 背景: 一个M-pard(铭豹)扩展坞的网卡突然无法识别了,扩展出来的三个USB接口正常。…...

synchronized 学习
学习源: https://www.bilibili.com/video/BV1aJ411V763?spm_id_from333.788.videopod.episodes&vd_source32e1c41a9370911ab06d12fbc36c4ebc 1.应用场景 不超卖,也要考虑性能问题(场景) 2.常见面试问题: sync出…...

超短脉冲激光自聚焦效应
前言与目录 强激光引起自聚焦效应机理 超短脉冲激光在脆性材料内部加工时引起的自聚焦效应,这是一种非线性光学现象,主要涉及光学克尔效应和材料的非线性光学特性。 自聚焦效应可以产生局部的强光场,对材料产生非线性响应,可能…...
)
Java 语言特性(面试系列1)
一、面向对象编程 1. 封装(Encapsulation) 定义:将数据(属性)和操作数据的方法绑定在一起,通过访问控制符(private、protected、public)隐藏内部实现细节。示例: public …...

K8S认证|CKS题库+答案| 11. AppArmor
目录 11. AppArmor 免费获取并激活 CKA_v1.31_模拟系统 题目 开始操作: 1)、切换集群 2)、切换节点 3)、切换到 apparmor 的目录 4)、执行 apparmor 策略模块 5)、修改 pod 文件 6)、…...

JavaScript 中的 ES|QL:利用 Apache Arrow 工具
作者:来自 Elastic Jeffrey Rengifo 学习如何将 ES|QL 与 JavaScript 的 Apache Arrow 客户端工具一起使用。 想获得 Elastic 认证吗?了解下一期 Elasticsearch Engineer 培训的时间吧! Elasticsearch 拥有众多新功能,助你为自己…...

练习(含atoi的模拟实现,自定义类型等练习)
一、结构体大小的计算及位段 (结构体大小计算及位段 详解请看:自定义类型:结构体进阶-CSDN博客) 1.在32位系统环境,编译选项为4字节对齐,那么sizeof(A)和sizeof(B)是多少? #pragma pack(4)st…...

从零开始打造 OpenSTLinux 6.6 Yocto 系统(基于STM32CubeMX)(九)
设备树移植 和uboot设备树修改的内容同步到kernel将设备树stm32mp157d-stm32mp157daa1-mx.dts复制到内核源码目录下 源码修改及编译 修改arch/arm/boot/dts/st/Makefile,新增设备树编译 stm32mp157f-ev1-m4-examples.dtb \stm32mp157d-stm32mp157daa1-mx.dtb修改…...

鸿蒙中用HarmonyOS SDK应用服务 HarmonyOS5开发一个生活电费的缴纳和查询小程序
一、项目初始化与配置 1. 创建项目 ohpm init harmony/utility-payment-app 2. 配置权限 // module.json5 {"requestPermissions": [{"name": "ohos.permission.INTERNET"},{"name": "ohos.permission.GET_NETWORK_INFO"…...

html css js网页制作成品——HTML+CSS榴莲商城网页设计(4页)附源码
目录 一、👨🎓网站题目 二、✍️网站描述 三、📚网站介绍 四、🌐网站效果 五、🪓 代码实现 🧱HTML 六、🥇 如何让学习不再盲目 七、🎁更多干货 一、👨…...