Mysql 竟然还有这么多不为人知的查询优化技巧,还不看看?
前言
Mysql 我随手造200W条数据,给你们讲讲分页优化
MySql 索引失效、回表解析
今天再聊聊一些我想分享的查询优化相关点。
正文
准备模拟数据。
首先是一张 test_orde 表:
CREATE TABLE `test_order` (`id` INT(11) NOT NULL AUTO_INCREMENT,`p_sn` VARCHAR(50) NULL DEFAULT NULL COLLATE 'utf8_general_ci',`t_sn` VARCHAR(50) NULL DEFAULT NULL COLLATE 'utf8_general_ci',`type` TINYINT(4) NULL DEFAULT NULL,`create_time` DATETIME NULL DEFAULT NULL,PRIMARY KEY (`id`) USING BTREE
)然后是一个存储过程 :
BEGIN DECLARE num INT DEFAULT 2000000; DECLARE i INT DEFAULT 0; WHILE i < num DO INSERT INTO test_order(`p_sn`,`t_sn`,`type`,`create_time`) VALUES(CONCAT('SN',i),UUID(),1,now());SET i = i + 1;END WHILE;
END执行存储过程,看下模拟数据:
开始。
① 使用 count 、 group by 注意点
比如, 我们想统计一下 当前 表里面, 根据type维度 分别有多少 数据 :
SELECT COUNT(*) ,type
FROM test_order GROUP BY TYPE ;
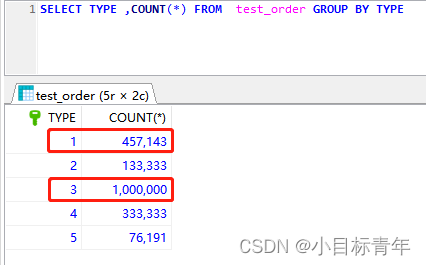
目前可以看到我们现在数据库表 里面,其实type 就 1个 , 就是 1 。
真实场景,我们 肯定不止一个type。
改造出模拟数据(尽量使数据更随机,真实业务场景也许会更加更加散乱):
将数据里面 id 是 7的 倍数的数据 的type 改成 5;
将数据里面 id 是 5 的 倍数的数据 的type 改成 2;
将数据里面 id 是 3 的 倍数的数据 的type 改成 4;
将数据里面 id 是 2 的 倍数的数据 的type 改成 3;
sql:
UPDATE test_order a
INNER JOIN test_order b ON b.id % 7=0 AND a.id=b.id SET a.TYPE =5
UPDATE test_order a
INNER JOIN test_order b ON b.id % 5=0 AND a.id=b.id SET a.TYPE =2
UPDATE test_order a
INNER JOIN test_order b ON b.id % 3=0 AND a.id=b.id SET a.TYPE =4
UPDATE test_order a
INNER JOIN test_order b ON b.id % 2=0 AND a.id=b.id SET a.TYPE =3
看看效果 :
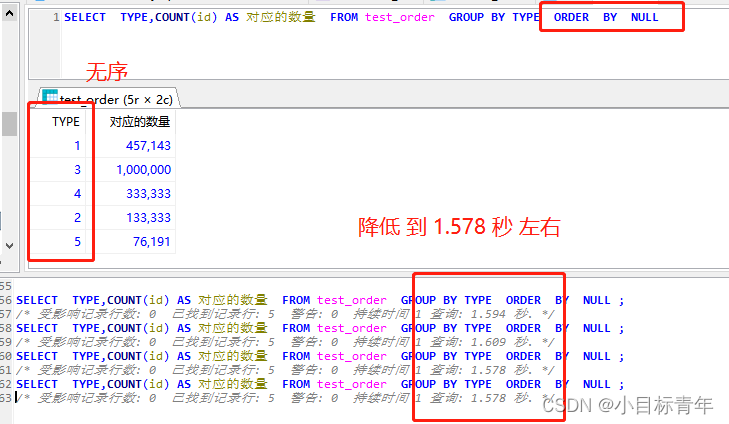
统计出 表里面 不同 type 类型 的 数据分别有多少条 ,且看看时间用了多久:

看看 EXPLAIN :
Using filesort : 通过表的索引或全表扫描,读取满足条件的数据行,然后在排序缓冲区sort buffer中完成排序操作,所以并不是通过索引直接返回排序结果的排序都叫 FileSort 排序
可以看到,分析里面 出现了一个 using filesort , 这个玩意就是慢的原因。
可以看到 用到了 group by type , 返回来的数据 TYPE 是 1,2,3,4,5 默认 升序排好的。
是的,相当于 mysql 默认帮我们执行了排序, 无疑 这是需要花时间的。
所以说,当我们仅仅要的是 不同 type 数据的 统计数量结果, 那么我们是可以优化掉这个排序的耗时的。
优化技巧 :
order by null
我们在 group by 后面 加上 ORDER BY NULL , 强制禁止排序 ,
看看效果 :
那有没有更加快的优化?
有的, 加索引。 group by 是能命中索引的。
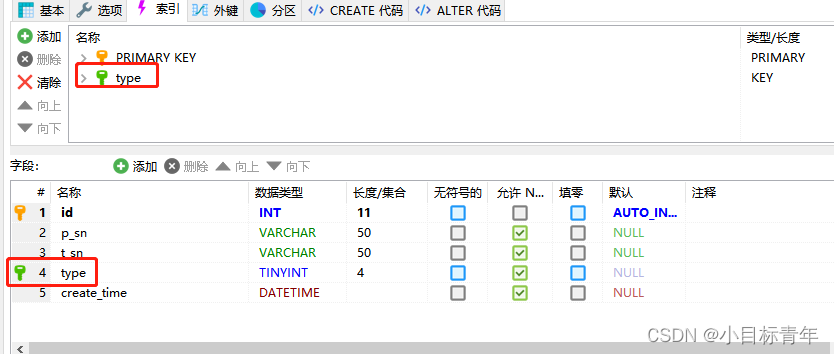
加完索引效果:

②使用 left join / right join 的注意点
关联查询, 比如 有 A 、 B 两个表 。
A表即是 我们的 test_order 表 200W条数据:
而B 表 是 test_order_detail 表 5W 条数据:
这两个表通过id、order_id 关联(简单举个例子)。
注意点:
1.当使用left join时,左表是驱动表,右表是被驱动表
2.当使用right join时,右表是驱动表,左表是被驱动表
3.当使用inner join时,mysql会默认自动选择数据量比较小的表作为驱动表,大表作为被驱动表
我们尽量要保证 小表 驱动 大表, 大小指的是数据量。
那么我们看 left join 来看看效果, A表 test_order 目前是大表 B表 test_order_detail是小表 效果:
我们使用 left join , 故意把 大数据表放在 左, 小数据表放在右, 这时候 左大驱右小 ,
发现用了13秒,返回的是 200万条数据
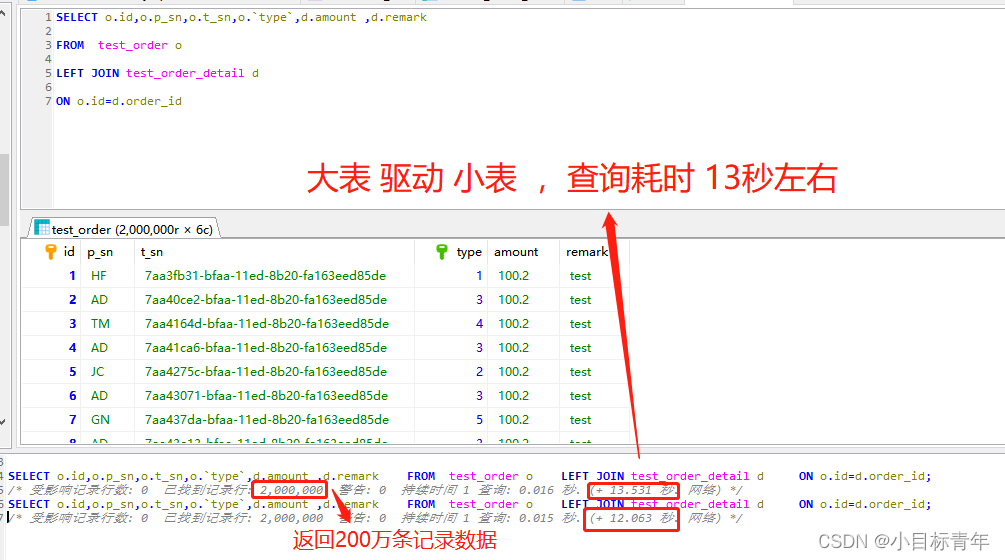
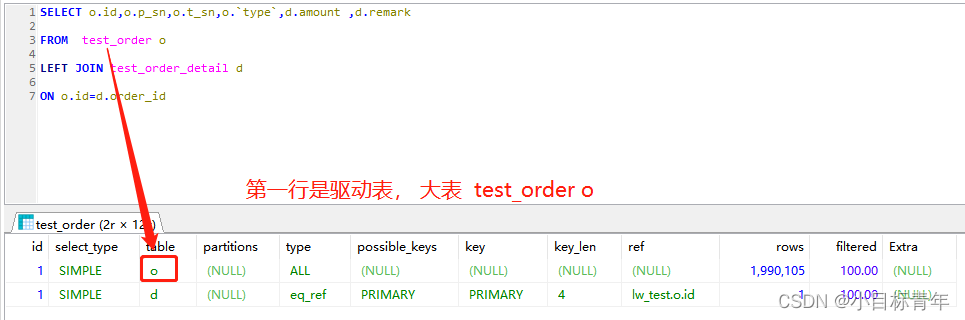
看看EXPLAIN分析情况:
ps :
当查询引擎完成对行的计数时,结果集的其余部分出现。所以Heidi所谓的“网络时间”是计算行数的时间。这对于MyISAM来说实际上是瞬间的,而InnoDB需要一段时间。(heidiSQL编辑器)
那么如果我们反过来, 左小驱右大 :
发现用了0.29秒,返回的是 5万条数据

看看EXPLAIN分析情况:

可以看到 小表驱动大表的情况,时间效果的差距所在。
所以根据业务情况,必须要清晰地使用上 这个优化技巧 ,尽可能保证小表驱动大表。
为什么 ?
其实这个道理很简单, 驱动表 和 被 驱动表 , 就相当于 2层 for 循环遍历。
比如 大表200万数据 驱动 小表 5万数据 ,就是 :
for(int 驱动表行数=0 ; 驱动表行数 <20000000; 驱动表行数++){for (int 被驱动表行数=0 ; 被驱动表行数<50000; 被驱动表行数++){找出 驱动表行记录 条件 等于 被驱动表行记录 条件值}}那可能很多初学者还是不明白, 放外面是 200W 循环,里面再嵌套 5W 是 200 乘以 5 ?
那跟反过来5 乘以 200 有什么区别?
简析:
可以看到上述的 EXPLAIN 大表驱动小表 或是 小表驱动大表, 可以看到 驱动表的索引都是不生效的, 生效的是 被驱动表的索引 。
索引是b+树,在索引上等值查询的时间复杂度为logN。
因为驱动表不走索引,需要全表扫描,而被驱动表可以建立索引加速查找。
若小表驱动大表,则时间复杂度为 5W*log200W
若大表驱动小表,则时间复杂度为 200W*log5W
所以 为什么 时间耗时久 ,也就显然得知了。
是因为被驱动表又能命中索引,而且时间查找又快啊。
③ 对字段进行表达式操作 的注意点
比如 我们 想查出来 type 是 2 的 2倍 的数据 (这里简单用type举例, 可能业务上更多是 传入一个参数,然后触发某某计算倍数的概念):
当我们 把 字段 type 融入到 表达式 里面时,可以看到 耗时 是 2.45+秒 (因为索引失效了):
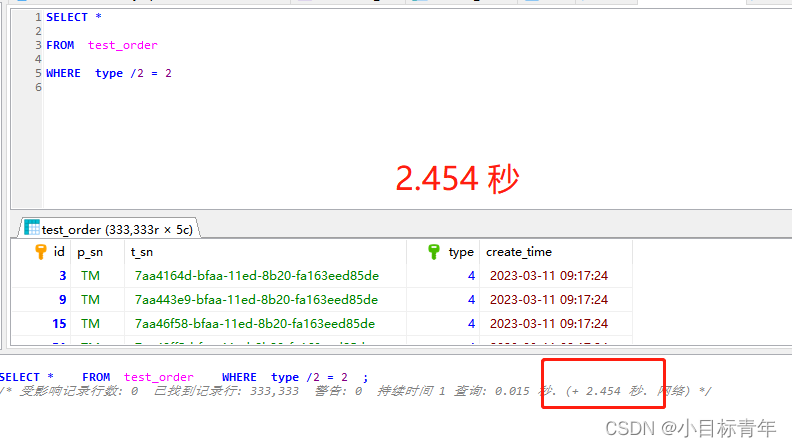
看看EXPLAIN分析情况:

而我们把 type 字段 抽出来,不参与 表达式操作,我们发现效果一样,但是耗时只有 1.3 秒(因为能命中索引) :
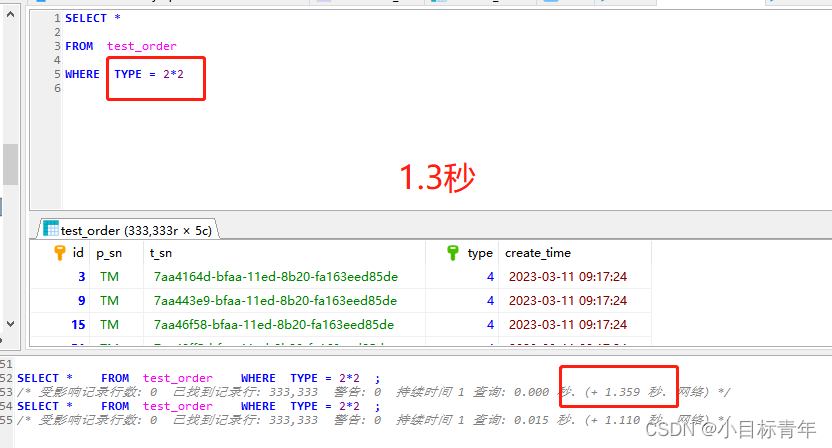
看看EXPLAIN分析情况:
④ 对明确知道的条件值 使用 or 查询 还是 UNION ALL ,有说法
比如我们想查出表里面 type 是1 或者 type 是 5的 数据 , 如果我们使用 or 去实现 ,大家知道的,使用or 是命中不了索引的,会全表扫描 。
很多这种时候,大家可能就会想, 遇到or 慢查询, 就换成 UNION ALL 呗 。
其实并不然 。
你可以理解为,当你使用or 查询 发现慢的时候, 你可以尝试使用UNION ALL 去替代调试 , 注意,是调试, 如果性能确实优化了,你就可以替代。
直接眼见为实 :
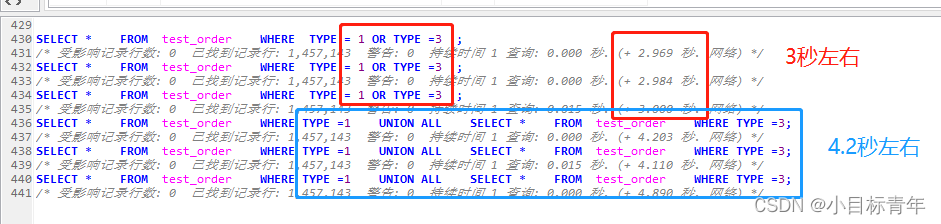
首先可以看到 union all 比 or 还要慢 。
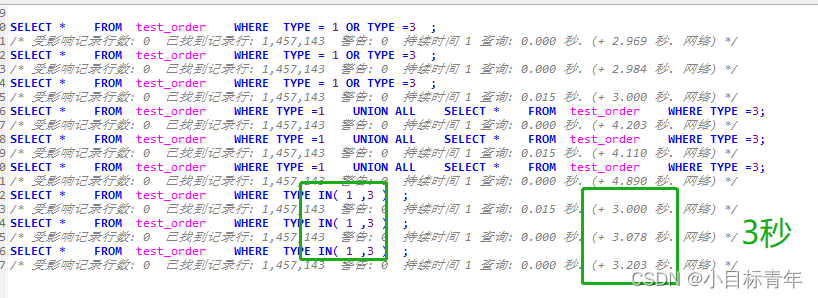
甚至 还可以看看 in 的效果 ,也是跟 or 基本一致 也是 3秒 左右 。
我们看看 使用 in的 EXPLAIN :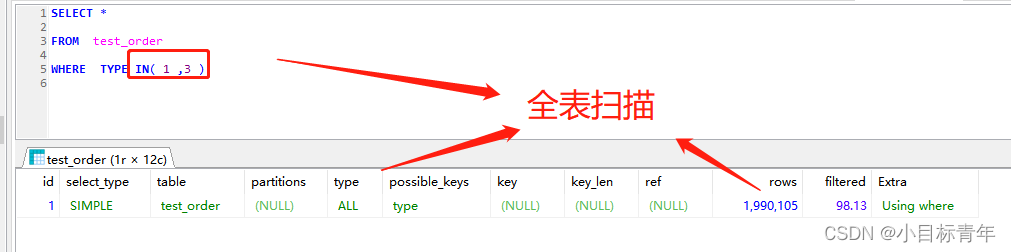
再看看 使用 or 的 EXPLAIN :
or 和 in 几乎是一样的 在不中索引的时候。
那看看 union all 的 EXPLAIN :
可以看到命中了 索引的。
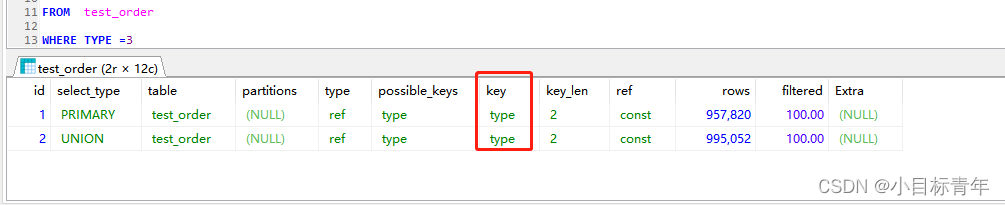
但是为什么这时候 union all 反而慢呢?
原因 :
1. 其实我们可以关注到 rows 和 filtered
2. 数据量情况 以及散乱程度
当全表扫描 98% 的数据 都是需要的, 一次扫描拿出结果。
而 union all 进行了 2次 扫描,虽然扫的是索引,但是扫了96万 + 99 万 数据, 我们一共才200W数据。
2次加起来 跟我们 全部扫描看到的row 199万 基本没区别。
这时候就是看 数据的分布情况了。
继续看看 查询 三个 type :
使用 OR :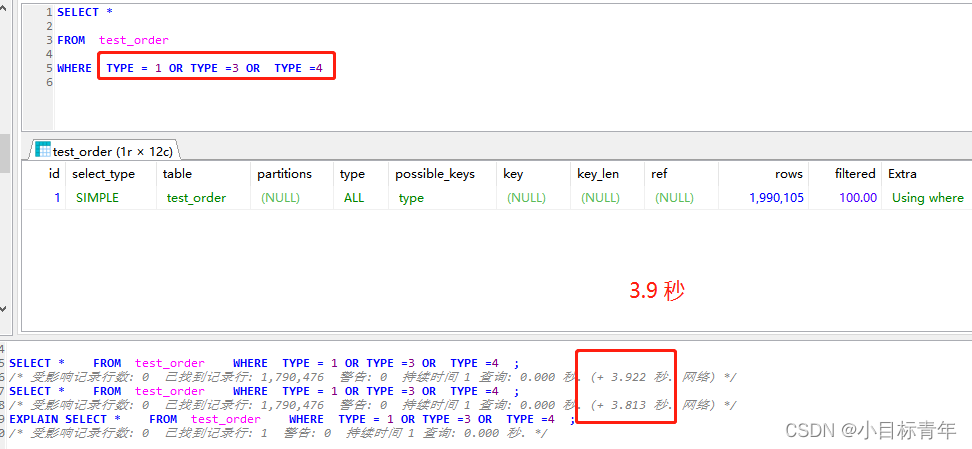
使用 union all :

再再再顺便再贴一个 示例 (查询不同字段条件值的场景),让大家知道 or 和 union all 就是需要看实际情况调试使用的 :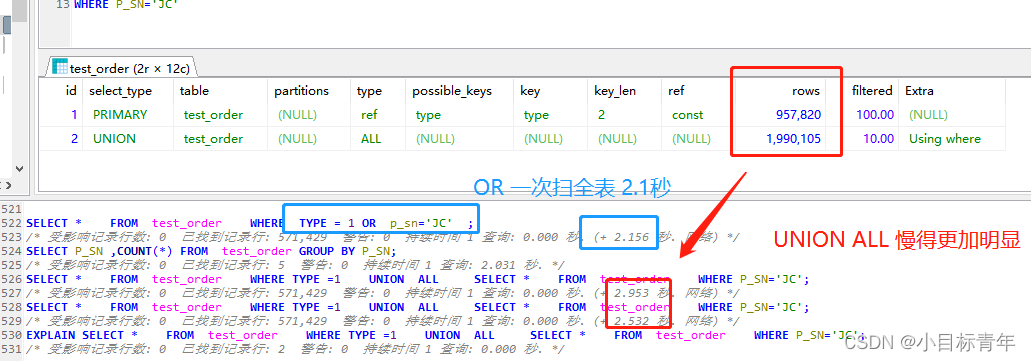
所以 什么时候用 or 什么时候 用 union all , 非绝对, 要调试为准(特别是当你的union all 条件的字段也没索引的时候 ,你想想扫描多次表的效率)!
⑤ order by 的效能 提升
先改造一下表 :
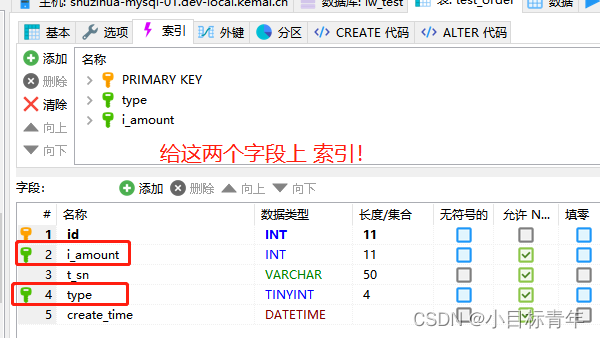
平时我们写代码,很多时候,我们一些复杂的业务sql拆分,我们很愿意去拆,提高效率。
但是遇到排序, 我个人就很懒,基本 就是 丢到sql上面 order by 了。
那么 这就有说法了。
模拟点数据 :
UPDATE test_order a
INNER JOIN test_order b ON b.id % 7=0 AND a.id=b.id SET a.i_amount =99;
UPDATE test_order a
INNER JOIN test_order b ON b.id % 5=0 AND a.id=b.id SET a.i_amount =66;
UPDATE test_order a
INNER JOIN test_order b ON b.id % 3=0 AND a.id=b.id SET a.i_amount =588;
UPDATE test_order a
INNER JOIN test_order b ON b.id % 2=0 AND a.id=b.id SET a.i_amount =88; 可以看到现在 数据 有那么一些些乱了,可以来讲讲 order by 排序了 :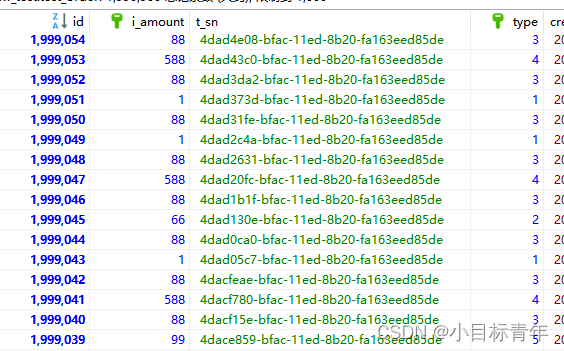
这时,如果我们 进行 组合 排序, 按照 i_amount 排序 然后再按照 type 排序, 我们会发现 ,引擎有脾气,没有中索引,但是 在 extra上面 有说 用了 using filesort 。
时间肯定是没有 直接用上 index 快的 :

所以我们给它整活, 我们升级成组合索引 :

这时候我们再执行,发现 可以命中了index 了:
好了,就先讲到这吧, 有空再讲其他。
相关文章:
Mysql 竟然还有这么多不为人知的查询优化技巧,还不看看?
前言 Mysql 我随手造200W条数据,给你们讲讲分页优化 MySql 索引失效、回表解析 今天再聊聊一些我想分享的查询优化相关点。 正文 准备模拟数据。 首先是一张 test_orde 表: CREATE TABLE test_order (id INT(11) NOT NULL AUTO_INCREMENT,p_sn VARCHA…...
 (附MATLAB和python代码实现))
MATLAB算法实战应用案例精讲-【智能优化算法】海洋捕食者算法(MPA) (附MATLAB和python代码实现)
目录 前言 知识储备 Lvy 飞行 布朗运动 算法原理 算法思想 数学模型...

Spring @Profile
1. Overview In this tutorial, we’ll focus on introducing Profiles in Spring. Profiles are a core feature of the framework — allowing us to map our beans to different profiles — for example, dev, test, and prod. We can then activate different profiles…...

Vue3电商项目实战-个人中心模块4【09-订单管理-列表渲染、10-订单管理-条件查询】
文章目录09-订单管理-列表渲染10-订单管理-条件查询09-订单管理-列表渲染 目的:完成订单列表默认渲染。 大致步骤: 定义API接口函数抽取单条订单组件获取数据进行渲染 落的代码: 1.获取订单列表API借口 /*** 查询订单列表* param {Number…...

【十二天学java】day01-Java基础语法
day01 - Java基础语法 1. 人机交互 1.1 什么是cmd? 就是在windows操作系统中,利用命令行的方式去操作计算机。 我们可以利用cmd命令去操作计算机,比如:打开文件,打开文件夹,创建文件夹等。 1.2 如何打…...
【面试题】闭包是什么?this 到底指向谁?
一通百通,其实函数执行上下文、作用域链、闭包、this、箭头函数是相互关联的,他们的特性并不是孤立的,而是相通的。因为内部函数可以访问外层函数的变量,所以才有了闭包的现象。箭头函数内没有 this 和 arguments,所以…...
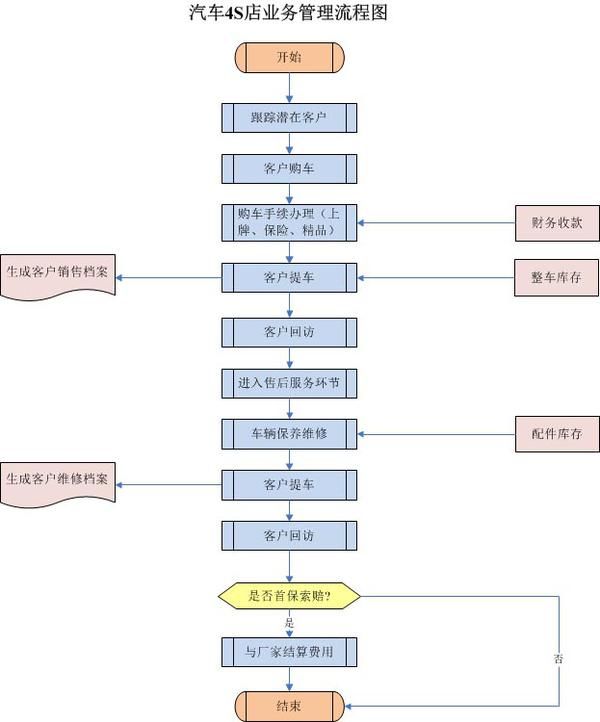
汽车4S店业务管理软件
一、产品简介 它主要提供给汽车4S商店,用于管理各种业务,如汽车销售、售后服务、配件、精品和保险。整个系统以客户为中心,以财务为基础,覆盖4S商店的每一个业务环节,不仅可以提高服务效率和客户满意度,…...
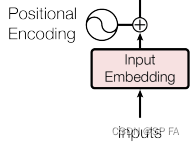
基于 pytorch 的手写 transformer + tokenizer
先放出 transformer 的整体结构图,以便复习,接下来就一个模块一个模块的实现它。 1. Embedding Embedding 部分主要由两部分组成,即 Input Embedding 和 Positional Encoding,位置编码记录了每一个词出现的位置。通过加入位置编码可以提高模型的准确率,因为同一个词出现在…...

算法小抄6-二分查找
二分查找,又名折半查找,其搜索过程如下: 从数组中间的元素开始,如果元素刚好是要查找的元素,则搜索过程结束如果搜索元素大于或小于中间元素,则排除掉不符合条件的那一半元素,在剩下的数组中进行查找由于每次需要排除掉一半不符合要求的元素,这需要数组是已经排好序的或者是有…...
大学四年..就混了毕业证的我,出社会深感无力..辞去工作,从头开始
时间如白驹过隙,一恍就到了2023年,今天最于我来说是一个值得纪念的日子,因为我收获了今年的第一个offer背景18年毕业,二本。大学四年,也就将就混了毕业证和学位证。毕业后,并未想过留在湖南,就回…...

C语言数据结构初阶(6)----链表常见OJ题
CSDN的uu们,大家好!编程能力的提高不仅需要学习新的知识,还需要大量的练习。所以,C语言数据结构初阶的第六讲邀请uu们一起来看看链表的常见oj题目。移除链表元素原题链接:203. 移除链表元素 - 力扣(Leetcod…...

关键字 const
目录 一、符号常量与常变量 二、const的用法 2.1 const常用方法 2.2 const用于指针 2.2.1 p指针所指的对象值不能改变,但是p指针的指向可以改变 2.2.2 常指针p的指向不能改变,但是所指的对象的值可以改变 2.2.3 p所指对象的指向以及对象的值都不可…...
MybatisPlus------MyBatisX插件:快速生成代码以及快速生成CRUD(十二)
MybatisPlus------MyBatisX插件(十二) MyBatisX插件是IDEA插件,如果想要使用它,那么首先需要在IDEA中进行安装。 安装插件 搜索"MyBatisX",点击Install,之后重启IDEA即可。 插件基本用途&…...
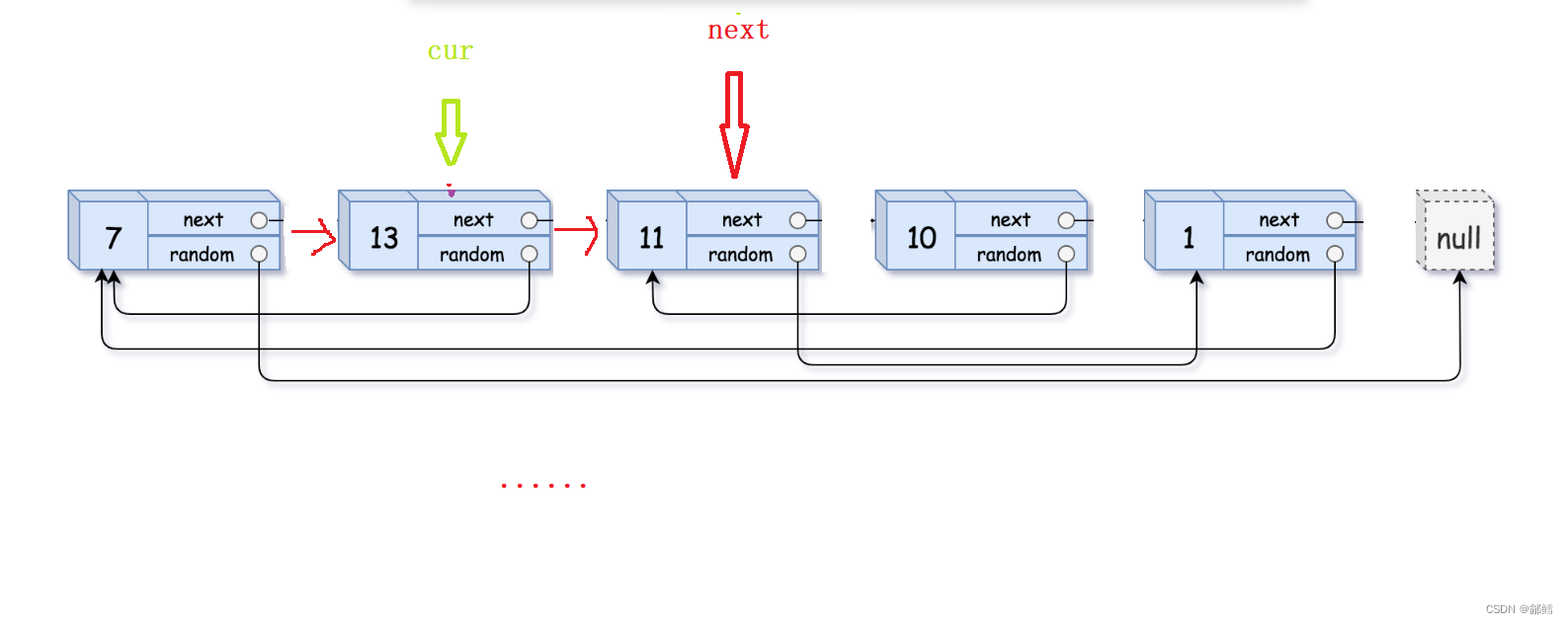
Leetcode138. 复制带随机指针的链表
复制带随机指针的链表 第一步 拷贝节点链接在原节点的后面 第二步拷贝原节点的random , 拷贝节点的 random 在原节点 random 的 next 第三步 将拷贝的节点尾插到一个新链表 ,并且将原链表恢复 从前往后遍历链表 ,将原链表的每个节点进行复制,并l链接到原…...
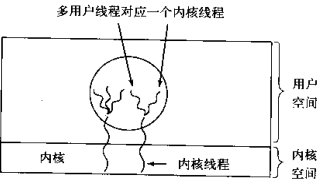
python并发编程多线程
在传统操作系统中,每个进程有一个地址空间,而且默认就有一个控制线程 线程顾名思义,就是一条流水线工作的过程,一条流水线必须属于一个车间,一个车间的工作过程是一个进程 车间负责把资源整合到一起,是一个…...

使用Maven实现Servlet程序
创建Maven项目我们打开idea的新建项目,选中里面Maven即可,如下图:创建完成之后,会看到这样的目录结构其中,main目录存放业务代码,其中的java目录存放的就是java代码,而resources目录存放是程序中依赖的文件,比如:图片,视频等.然后是 test目录,test目录存放的是测试代码.最后一个…...
百度的文心一言 ,没有想像中那么差
robin 的演示 我们用 robin 的演示例子来对比一下 文心一言和 ChatGPT 的真实表现(毕竟发布会上是录的)。 注意,我使用的 GPT 版本是 4.0 文学创作 1 三体的作者是哪里人? 文心一言: ChatGPT: 嗯&a…...

文心一言发布的个人看法
文心一言发布宣传视频按照发布会上说的,文心一言并非属于百度赶工抄袭Chat-GPT的作品,而是十几年一直布局AI产业厚积薄发的成果,百度在芯片,机器学习,自然语言处理,知识图谱等方面均有相对深厚的积累。 国…...

【C5】111
文章目录bmc_wtd:syscpld.c中wd_en和wd_kick节点对应寄存器,crontab,FUNCNAMEAST2500/2600 WDT切换主备:BMC用WDT2作为主备切换的watchdog控制器AC后读取:bmc处于主primary flash(设完后:实际主…...

静态成员,友元函数
🐶博主主页:ᰔᩚ. 一怀明月ꦿ ❤️🔥专栏系列:线性代数,C初学者入门训练,题解C,C的使用文章,「初学」C 🔥座右铭:“不要等到什么都没有了,才下…...

Appium+python自动化(十六)- ADB命令
简介 Android 调试桥(adb)是多种用途的工具,该工具可以帮助你你管理设备或模拟器 的状态。 adb ( Android Debug Bridge)是一个通用命令行工具,其允许您与模拟器实例或连接的 Android 设备进行通信。它可为各种设备操作提供便利,如安装和调试…...

【Redis技术进阶之路】「原理分析系列开篇」分析客户端和服务端网络诵信交互实现(服务端执行命令请求的过程 - 初始化服务器)
服务端执行命令请求的过程 【专栏简介】【技术大纲】【专栏目标】【目标人群】1. Redis爱好者与社区成员2. 后端开发和系统架构师3. 计算机专业的本科生及研究生 初始化服务器1. 初始化服务器状态结构初始化RedisServer变量 2. 加载相关系统配置和用户配置参数定制化配置参数案…...

Cinnamon修改面板小工具图标
Cinnamon开始菜单-CSDN博客 设置模块都是做好的,比GNOME简单得多! 在 applet.js 里增加 const Settings imports.ui.settings;this.settings new Settings.AppletSettings(this, HTYMenusonichy, instance_id); this.settings.bind(menu-icon, menu…...
)
WEB3全栈开发——面试专业技能点P2智能合约开发(Solidity)
一、Solidity合约开发 下面是 Solidity 合约开发 的概念、代码示例及讲解,适合用作学习或写简历项目背景说明。 🧠 一、概念简介:Solidity 合约开发 Solidity 是一种专门为 以太坊(Ethereum)平台编写智能合约的高级编…...

HashMap中的put方法执行流程(流程图)
1 put操作整体流程 HashMap 的 put 操作是其最核心的功能之一。在 JDK 1.8 及以后版本中,其主要逻辑封装在 putVal 这个内部方法中。整个过程大致如下: 初始判断与哈希计算: 首先,putVal 方法会检查当前的 table(也就…...

JVM虚拟机:内存结构、垃圾回收、性能优化
1、JVM虚拟机的简介 Java 虚拟机(Java Virtual Machine 简称:JVM)是运行所有 Java 程序的抽象计算机,是 Java 语言的运行环境,实现了 Java 程序的跨平台特性。JVM 屏蔽了与具体操作系统平台相关的信息,使得 Java 程序只需生成在 JVM 上运行的目标代码(字节码),就可以…...

免费PDF转图片工具
免费PDF转图片工具 一款简单易用的PDF转图片工具,可以将PDF文件快速转换为高质量PNG图片。无需安装复杂的软件,也不需要在线上传文件,保护您的隐私。 工具截图 主要特点 🚀 快速转换:本地转换,无需等待上…...

华为OD机考-机房布局
import java.util.*;public class DemoTest5 {public static void main(String[] args) {Scanner in new Scanner(System.in);// 注意 hasNext 和 hasNextLine 的区别while (in.hasNextLine()) { // 注意 while 处理多个 caseSystem.out.println(solve(in.nextLine()));}}priv…...

【Linux系统】Linux环境变量:系统配置的隐形指挥官
。# Linux系列 文章目录 前言一、环境变量的概念二、常见的环境变量三、环境变量特点及其相关指令3.1 环境变量的全局性3.2、环境变量的生命周期 四、环境变量的组织方式五、C语言对环境变量的操作5.1 设置环境变量:setenv5.2 删除环境变量:unsetenv5.3 遍历所有环境…...

毫米波雷达基础理论(3D+4D)
3D、4D毫米波雷达基础知识及厂商选型 PreView : https://mp.weixin.qq.com/s/bQkju4r6med7I3TBGJI_bQ 1. FMCW毫米波雷达基础知识 主要参考博文: 一文入门汽车毫米波雷达基本原理 :https://mp.weixin.qq.com/s/_EN7A5lKcz2Eh8dLnjE19w 毫米波雷达基础…...