Hadoop运行模块
二、Hadoop运行模式
1)Hadoop官方网站:http://hadoop.apache.org
2)Hadoop运行模式包括:本地模式、伪分布式模式以及完全分布式模式。
- 本地模式:单机运行,只是用来演示一下官方案例。生产环境不用。
- 伪分布式模式:也是单机运行,但是具备Hadoop集群的所有功能,一台服务器模拟一个分布式的环境。个别缺钱的公司用来测试,生产环境不用。
- 完全分布式模式:多台服务器组成分布式环境。生产环境使用。
2.1 完全分布式运行模式(开发重点)
分析:
- 1.准备3台虚拟机(
关闭防火墙、静态IP、主机名称) - 2.安装JDK
- 3.配置环境变量
- 4.安装Hadoop
- 5.配置环境变量
- 6.配置集群
- 7.单点启动
- 8.配置ssh
- 9.群起并测试集群
2.2.1 虚拟机准备
详见1.1、1.2两节。
2.2.2 编写集群分发脚本xsync
1)scp(secure copy)安全拷贝
scp定义:scp可以实现服务器与服务器之间的数据拷贝。(from server1 to server2)
-
1.基本语法(
重要!!!)scp-r$pdir/$fname$user@$host:$pdir/$fname命令 递归 要拷贝的文件路径/名称 目的地用户@主机:目的地路径/名称 -
2.案例实操
前提:在hadoop102、hadoop103、hadoop104都已经创建好的/opt/module、 /opt/software两个目录,并且已经把这两个目录修改为ovo:ovo
[ovo@hadoop102 ~]$ sudo chown ovo:ovo -R /opt/module效果如图:

(a)在hadoop102上,将hadoop102中/opt/module/jdk1.8.0_212目录拷贝到hadoop103上。
[ovo@hadoop102 ~]$ scp -r /opt/module/jdk1.8.0_212 ovo@hadoop103:/opt/module(b)在hadoop103上,将hadoop102中/opt/module/hadoop-3.1.3目录拷贝到hadoop103上。
[ovo@hadoop103 ~]$ scp -r ovo@hadoop102:/opt/module/hadoop-3.1.3 /opt/module/(c)在hadoop103上操作,将hadoop102中/opt/module目录下所有目录拷贝到hadoop104上。
[ovo@hadoop103 opt]$ scp -r ovo@hadoop102:/opt/module/* ovo@hadoop104:/opt/module
2)rsync远程同步工具
rsync主要用于备份和镜像。具有速度快、避免复制相同内容和支持符号链接的优点。
rsync和scp区别:用rsync做文件的复制要比scp的速度快,rsync只对差异文件做更新。scp是把所有文件都复制过去。
-
1.基本语法
rsync-av$pdir/$fname$user@$host:$pdir/$fname命令 递归 要拷贝的文件路径/名称 目的地用户@主机:目的地路径/名称 选项参数说明:
选项 功能 -a 归档拷贝 -v 显示复制过程 -
2.案例实操
(a)删除hadoop103中/opt/module/hadoop-3.1.3/wcinput
[ovo@hadoop103 hadoop-3.1.3]$ rm -rf wcinput/(b)同步hadoop102中的/opt/module/hadoop-3.1.3到hadoop103
[ovo@hadoop102 module]$ rsync -av hadoop-3.1.3/ ovo@hadoop103:/opt/module/hadoop-3.1.3/
3)xsync集群分发脚本
-
1.需求:循环复制文件到所有节点的相同目录下
-
2.需求分析:
(a)rsync命令原始拷贝:rsync -av /opt/module ovo@hadoop103:/opt/(b)期望脚本:xsync要同步的文件名称
(c)期望脚本在任何路径都能使用(脚本放在声明了全局环境变量的路径)[ovo@hadoop102 ~]$ echo $PATH /usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/home/ovo/.local/bin:/home/ovo/bin:/opt/module/jdk1.8.0_212/bin -
3.脚本实现
(a)在/home/ovo/bin目录下创建xsync文件
[ovo@hadoop102 opt]$ cd /home/ovo [ovo@hadoop102 ~]$ mkdir bin [ovo@hadoop102 ~]$ cd bin [ovo@hadoop102 bin]$ vim xsync在该文件中编写如下代码
#!/bin/bash#1. 判断参数个数 if [ $# -lt 1 ] thenecho Not Enough Arguement!exit; fi#2. 遍历集群所有机器 for host in hadoop102 hadoop103 hadoop104 doecho ==================== $host ====================#3. 遍历所有目录,挨个发送for file in $@do#4. 判断文件是否存在if [ -e $file ]then#5. 获取父目录pdir=$(cd -P $(dirname $file); pwd)#6. 获取当前文件的名称fname=$(basename $file)ssh $host "mkdir -p $pdir"rsync -av $pdir/$fname $host:$pdirelseecho $file does not exists!fidone done(b)修改脚本 xsync 具有执行权限
[ovo@hadoop102 bin]$ chmod +x xsync(c)测试脚本
[ovo@hadoop102 ~]$ xsync /home/ovo/bin(d)将脚本复制到/bin中,以便全局调用
[ovo@hadoop102 bin]$ sudo cp xsync /bin/(e)同步环境变量配置(root所有者)
[ovo@hadoop102 ~]$ sudo ./bin/xsync /etc/profile.d/my_env.sh注意:如果用了sudo,那么xsync一定要给它的路径补全。
让环境变量生效[ovo@hadoop103 bin]$ source /etc/profile [ovo@hadoop104 opt]$ source /etc/profile
2.2.3 SSH无密登录配置
1)配置ssh
-
1.基本语法:
ssh 另一台电脑的主机名 -
2.ssh连接时出现Host key verification failed的解决方法
[ovo@hadoop102 ~]$ ssh hadoop103如果出现如下内容
Are you sure you want to continue connecting (yes/no)?输入yes,并回车
-
3.退回到hadoop102
[ovo@hadoop103 ~]$ exit
2)无密钥配置
-
1.免密登录原理
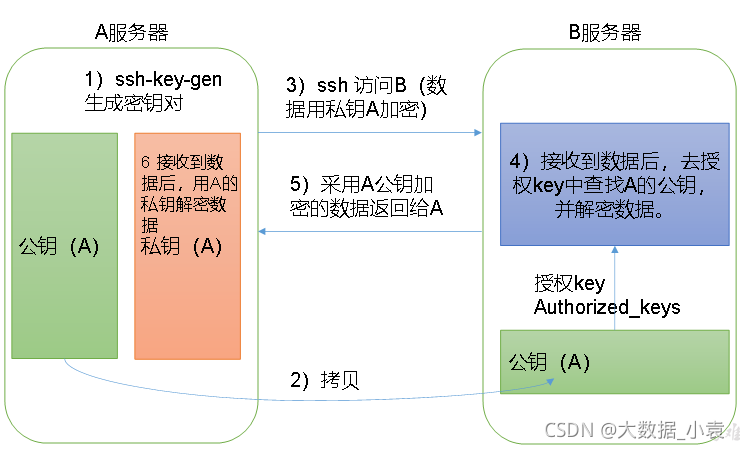
-
2.生成公钥和私钥
[ovo@hadoop102 .ssh]$ pwd /home/ovo/.ssh[ovo@hadoop102 .ssh]$ ssh-keygen -t rsa然后敲(三个回车),就会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)
-
3.将公钥拷贝到要免密登录的目标机器上
[ovo@hadoop102 .ssh]$ ssh-copy-id hadoop102 [ovo@hadoop102 .ssh]$ ssh-copy-id hadoop103 [ovo@hadoop102 .ssh]$ ssh-copy-id hadoop104注意:
- 还需要在hadoop103上采用ovo账号配置一下无密登录到hadoop102、hadoop103、hadoop104服务器上。
- 还需要在hadoop104上采用ovo账号配置一下无密登录到hadoop102、hadoop103、hadoop104服务器上。
- 还需要在hadoop102上采用root账号,配置一下无密登录到hadoop102、hadoop103、hadoop104;
2.2.4 集群配置
1)集群部署规划
注意:
- NameNode 和 SecondaryNameNode不要安装在同一台服务器
- ResourceManager也很消耗内存,不要和NameNode、SecondaryNameNode配置在同一台机器上。

2)配置文件说明
Hadoop配置文件分两类:默认配置文件和自定义配置文件,只有用户想修改某一默认配置值时,才需要修改自定义配置文件,更改相应属性值。
- 默认配置文件:

- 自定义配置文件:core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml四个配置文件存放在
$HADOOP_HOME/etc/hadoop这个路径上,用户可以根据项目需求重新进行修改配置。
3)配置集群
-
1.核心配置文件:
core-site.xml[ovo@hadoop102 ~]$ cd $HADOOP_HOME/etc/hadoop [ovo@hadoop102 hadoop]$ vim core-site.xml文件内容如下:
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><!-- 指定NameNode的地址 --><property><name>fs.defaultFS</name><value>hdfs://hadoop102:8020</value></property><!-- 指定hadoop数据的存储目录 --><property><name>hadoop.tmp.dir</name><value>/opt/module/hadoop-3.1.3/data</value></property><!-- 配置HDFS网页登录使用的静态用户为ovo --><property><name>hadoop.http.staticuser.user</name><value>ovo</value></property> </configuration> -
2.HDFS配置文件:
hdfs-site.xml[ovo@hadoop102 hadoop]$ vim hdfs-site.xml文件内容如下:
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><!-- nn web端访问地址--><property><name>dfs.namenode.http-address</name><value>hadoop102:9870</value></property><!-- 2nn web端访问地址--><property><name>dfs.namenode.secondary.http-address</name><value>hadoop104:9868</value></property> </configuration> -
3.YARN配置文件:
yarn-site.xml[ovo@hadoop102 hadoop]$ vim yarn-site.xml文件内容如下:
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><!-- 指定MR走shuffle --><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><!-- 指定ResourceManager的地址--><property><name>yarn.resourcemanager.hostname</name><value>hadoop103</value></property><!-- 环境变量的继承 --><property><name>yarn.nodemanager.env-whitelist</name><value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value></property> </configuration> -
4.MapReduce配置文件:
mapred-site.xml[ovo@hadoop102 hadoop]$ vim mapred-site.xml文件内容如下:
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><!-- 指定MapReduce程序运行在Yarn上 --><property><name>mapreduce.framework.name</name><value>yarn</value></property> </configuration>
4)在集群上分发配置好的Hadoop配置文件
[ovo@hadoop102 hadoop]$ xsync /opt/module/hadoop-3.1.3/etc/hadoop/
5)去103和104上查看文件分发情况
[ovo@hadoop103 ~]$ cat /opt/module/hadoop-3.1.3/etc/hadoop/core-site.xml
[ovo@hadoop104 ~]$ cat /opt/module/hadoop-3.1.3/etc/hadoop/core-site.xml
2.2.5 群起集群
1)配置workers
[ovo@hadoop102 hadoop]$ vim /opt/module/hadoop-3.1.3/etc/hadoop/workers
在该文件中增加如下内容:
hadoop102
hadoop103
hadoop104
注意:该文件中添加的内容结尾不允许有空格,文件中不允许有空行。
同步所有节点配置文件
[ovo@hadoop102 hadoop]$ xsync /opt/module/hadoop-3.1.3/etc
2)启动集群
-
1.如果集群是第一次启动,需要在hadoop102节点格式化NameNode
注意:格式化NameNode,会产生新的集群id,导致NameNode和DataNode的集群id不一致,集群找不到已往数据。
重点:如果集群在运行过程中报错,需要重新格式化NameNode的话,一定要先停止namenode和datanode进程,并且要删除所有机器的data和logs目录,然后再进行格式化。
[ovo@hadoop102 hadoop-3.1.3]$ hdfs namenode -format -
2.启动HDFS
[ovo@hadoop102 hadoop-3.1.3]$ sbin/start-dfs.sh -
3.在配置了ResourceManager的节点(注意:hadoop103上)启动YARN
[ovo@hadoop103 hadoop-3.1.3]$ sbin/start-yarn.sh -
4.Web端查看HDFS的NameNode
(a)浏览器中输入:http://hadoop102:9870
(b)查看HDFS上存储的数据信息 -
5.Web端查看YARN的ResourceManager
(a)浏览器中输入:http://hadoop103:8088
(b)查看YARN上运行的Job信息
2.2.6 配置历史服务器
为了查看程序的历史运行情况(
集群重新格式化后访问之前的数据),需要配置一下历史服务器。具体配置步骤如下:
1)配置mapred-site.xml
[ovo@hadoop102 hadoop]$ vim mapred-site.xml
在该文件里面增加如下配置。
<!-- 历史服务器端地址 -->
<property><name>mapreduce.jobhistory.address</name><value>hadoop102:10020</value>
</property><!-- 历史服务器web端地址 -->
<property><name>mapreduce.jobhistory.webapp.address</name><value>hadoop102:19888</value>
</property>
2)分发配置
[ovo@hadoop102 hadoop]$ xsync $HADOOP_HOME/etc/hadoop/mapred-site.xml
3)在hadoop102启动历史服务器
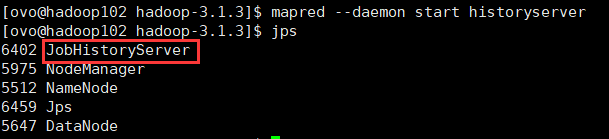
[ovo@hadoop102 hadoop]$ mapred --daemon start historyserver
4)查看历史服务器是否启动
[ovo@hadoop102 hadoop]$ jps
5)查看JobHistory:http://hadoop102:19888/jobhistory
2.2.7 配置日志的聚集
日志聚集概念:应用运行完成以后,将程序运行日志信息上传到HDFS系统上。

日志聚集功能好处:可以方便的查看到程序运行详情,方便开发调试。
注意:开启日志聚集功能,需要重新启动NodeManager 、ResourceManager和HistoryServer。
开启日志聚集功能具体步骤如下:
1)配置yarn-site.xml
[ovo@hadoop102 hadoop]$ vim yarn-site.xml
在该文件里面增加如下配置。
<!-- 开启日志聚集功能 -->
<property><name>yarn.log-aggregation-enable</name><value>true</value>
</property>
<!-- 设置日志聚集服务器地址 -->
<property> <name>yarn.log.server.url</name> <value>http://hadoop102:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为7天 -->
<property><name>yarn.log-aggregation.retain-seconds</name><value>604800</value>
</property>
2)分发配置
[ovo@hadoop102 hadoop]$ xsync $HADOOP_HOME/etc/hadoop/yarn-site.xml
3)关闭NodeManager 、ResourceManager和HistoryServer
[ovo@hadoop103 hadoop-3.1.3]$ sbin/stop-yarn.sh
[ovo@hadoop102 hadoop-3.1.3]$ mapred --daemon stop historyserver
4)启动NodeManager 、ResourceManage和HistoryServer
[ovo@hadoop103 ~]$ start-yarn.sh
[ovo@hadoop102 ~]$ mapred --daemon start historyserver
5)删除HDFS上已经存在的输出文件
[ovo@hadoop102 ~]$ hadoop fs -rm -r /output
6)执行WordCount程序(路径写自己任意一个文件路径)
[ovo@hadoop102 hadoop-3.1.3]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /input /output
7)查看日志
- 1.历史服务器地址:http://hadoop102:19888/jobhistory
- 2.历史任务列表
- 3.查看任务运行日志
- 4.运行日志详情
2.2.8 集群启动/停止方式总结
1)各个模块分开启动/停止(配置ssh是前提)常用
-
1.整体启动/停止HDFS
start-dfs.sh/stop-dfs.sh -
2.整体启动/停止YARN
start-yarn.sh/stop-yarn.sh
2)各个服务组件逐一启动/停止
-
1.分别启动/停止HDFS组件
hdfs --daemon start/stop namenode/datanode/secondarynamenode -
2.启动/停止YARN
yarn --daemon start/stop resourcemanager/nodemanager
2.2.9 编写Hadoop集群常用脚本
1)Hadoop集群启停脚本(包含HDFS,Yarn,Historyserver):myhadoop.sh
[ovo@hadoop102 ~]$ cd /home/ovo/bin
[ovo@hadoop102 bin]$ vim myhadoop.sh
输入如下内容
#!/bin/bashif [ $# -lt 1 ]
thenecho "No Args Input..."exit ;
ficase $1 in
"start")echo " =================== 启动 hadoop集群 ==================="echo " --------------- 启动 hdfs ---------------"ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/start-dfs.sh"echo " --------------- 启动 yarn ---------------"ssh hadoop103 "/opt/module/hadoop-3.1.3/sbin/start-yarn.sh"echo " --------------- 启动 historyserver ---------------"ssh hadoop102 "/opt/module/hadoop-3.1.3/bin/mapred --daemon start historyserver"
;;
"stop")echo " =================== 关闭 hadoop集群 ==================="echo " --------------- 关闭 historyserver ---------------"ssh hadoop102 "/opt/module/hadoop-3.1.3/bin/mapred --daemon stop historyserver"echo " --------------- 关闭 yarn ---------------"ssh hadoop103 "/opt/module/hadoop-3.1.3/sbin/stop-yarn.sh"echo " --------------- 关闭 hdfs ---------------"ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/stop-dfs.sh"
;;
*)echo "Input Args Error..."
;;
esac
保存后退出,然后赋予脚本执行权限
[ovo@hadoop102 bin]$ chmod +x myhadoop.sh
2)查看三台服务器Java进程脚本:jpsall
[ovo@hadoop102 ~]$ cd /home/ovo/bin
[ovo@hadoop102 bin]$ vim jpsall
输入如下内容
#!/bin/bashfor host in hadoop102 hadoop103 hadoop104
doecho =============== $host ===============ssh $host jps
done
保存后退出,然后赋予脚本执行权限
[ovo@hadoop102 bin]$ chmod +x jpsall
3)分发/home/ovo/bin目录,保证自定义脚本在三台机器上都可以使用
[ovo@hadoop102 ~]$ xsync /home/ovo/bin/
2.2.10 集群时间同步
如果服务器在公网环境(能连接外网),可以不采用集群时间同步,因为服务器会定期和公网时间进行校准;
如果服务器在内网环境,必须要配置集群时间同步,否则时间久了,会产生时间偏差,导致集群执行任务时间不同步。
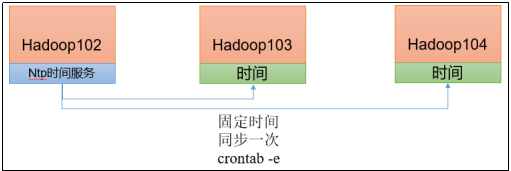
1)需求
找一个机器,作为时间服务器,所有的机器与这台集群时间进行定时的同步,生产环境根据任务对时间的准确程度要求周期同步。测试环境为了尽快看到效果,采用1分钟同步一次。
2)时间服务器配置(必须root用户)
-
1.查看所有节点ntpd服务状态和开机自启动状态
[ovo@hadoop102 ~]$ sudo systemctl status ntpd [ovo@hadoop102 ~]$ sudo systemctl start ntpd [ovo@hadoop102 ~]$ sudo systemctl is-enabled ntpd -
2.修改hadoop102的ntp.conf配置文件
[ovo@hadoop102 ~]$ sudo vim /etc/ntp.conf修改内容如下
(a)修改1(授权192.168.10.0-192.168.10.255网段上的所有机器可以从这台机器上查询和同步时间)
#restrict 192.168.1.0 mask 255.255.255.0 nomodify notrap为(
去掉了#号,改成了192.168.10.0)restrict 192.168.10.0 mask 255.255.255.0 nomodify notrap(b)修改2(集群在局域网中,不使用其他互联网上的时间)
server 0.centos.pool.ntp.org iburst server 1.centos.pool.ntp.org iburst server 2.centos.pool.ntp.org iburst server 3.centos.pool.ntp.org iburst为(
全部加上#号,注释掉)#server 0.centos.pool.ntp.org iburst #server 1.centos.pool.ntp.org iburst #server 2.centos.pool.ntp.org iburst #server 3.centos.pool.ntp.org iburst(c)添加3(当该节点丢失网络连接,依然可以采用本地时间作为时间服务器为集群中的其他节点提供时间同步)
server 127.127.1.0 fudge 127.127.1.0 stratum 10 -
3.修改hadoop102的/etc/sysconfig/ntpd 文件
[ovo@hadoop102 ~]$ sudo vim /etc/sysconfig/ntpd增加内容如下(让硬件时间与系统时间一起同步)
SYNC_HWCLOCK=yes -
4.重新启动ntpd服务
[ovo@hadoop102 ~]$ sudo systemctl start ntpd -
5.设置ntpd服务开机启动
[ovo@hadoop102 ~]$ sudo systemctl enable ntpd
3)其他机器配置(必须root用户)
-
1.关闭所有节点上ntp服务和自启动
[ovo@hadoop103 ~]$ sudo systemctl stop ntpd [ovo@hadoop103 ~]$ sudo systemctl disable ntpd [ovo@hadoop104 ~]$ sudo systemctl stop ntpd [ovo@hadoop104 ~]$ sudo systemctl disable ntpd -
2.在其他机器配置1分钟与时间服务器同步一次
[ovo@hadoop103 ~]$ sudo crontab -e编写定时任务如下:
*/1 * * * * /usr/sbin/ntpdate hadoop102 -
3.修改任意机器时间
[ovo@hadoop103 ~]$ sudo date -s "2022-9-11 11:11:11" -
4.1分钟后查看机器是否与时间服务器同步
[ovo@hadoop103 ~]$ sudo date
2.2.11 常考面试题
1)常用端口号
| 端口名称 | Hadoop2.x | hadoop3.x |
|---|---|---|
| HDFS NameNode 内部通信端口 | 8020/9000 | 8020/9000/9820 |
| HDFS NameNode 对用户的查询端口 | 50070 | 9870 |
| Yran 查看查看任务运行情况端口 | 8088 | 8088 |
| 历史服务器通信端口 | 19888 | 19888 |
| 2)常用配置文件 | ||
| hadoop2.x | core-site.xml | hadfs-size.xml |
| – | – | – |
| hadoop3.x | core-site.xml | hadfs-size.xml |
相关文章:
Hadoop运行模块
二、Hadoop运行模式 1)Hadoop官方网站:http://hadoop.apache.org 2)Hadoop运行模式包括:本地模式、伪分布式模式以及完全分布式模式。 本地模式:单机运行,只是用来演示一下官方案例。生产环境不用。伪分…...

Web自动化——前端基础知识(二)
1. Web前端开发三要素 web前端开发三要素 什么是HTMl? Html是超文本标记语言,是用来描述网页的一种标记语言HTML是一种标签规则的形式将内容呈现在浏览器中可以以任意编辑器创建,其文件扩展名为.html或.htm保存即可 什么是CSS?…...

NAS系列 硬件组装
转自我的博客文章https://blognas.hwb0307.com/nas/3260,内容更新仅在个人博客可见。欢迎关注! 前言 之前我在《NAS系列 硬件选择》里讲述了自己为了升级NAS如何选配硬件。本节我大概说一些我的新NAS硬件组装的注意事项。到目前为止,我只装过…...
IDAFrida
IDA&Frida 前言 偶然间发现了一本秘籍《IDA脚本开发之旅》,这是白龙的系列文章,主要是安卓平台,笔者只是根据他的知识点学习,拓展,可以会稍微提及别的平台。本文并不会贴出他的思路分析,只对于源码进…...
通过百度文心一言大模型作画尝鲜,感受国产ChatGPT的“狂飙”
3月16日下午,百度于北京总部召开新闻发布会,主题围绕新一代大语言模型、生成式AI产品文心一言。百度创始人、董事长兼首席执行官李彦宏,百度首席技术官王海峰出席,并展示了文心一言在文学创作、商业文案创作、数理推算、中文理解、…...

Nacos 注册中心 - 健康检查机制源码
目录 1. 健康检查介绍 2. 客户端健康检查 2.1 临时实例的健康检查 2.2 永久实例的健康检查 3. 服务端健康检查 3.1 临时实例的健康检查 3.2 永久实例服务端健康检查 1. 健康检查介绍 当一个服务实例注册到 Nacos 中后,其他服务就可以从 Nacos 中查询出该服务…...

Transformer在计算机视觉中的应用-VIT、TNT模型
上期介绍了Transformer的结构、特点和作用等方面的知识,回头看下来这一模型并不难,依旧是传统机器翻译模型中常见的seq2seq网络,里面加入了注意力机制,QKV矩阵的运算使得计算并行。 当然,最大的重点不是矩阵运算&…...
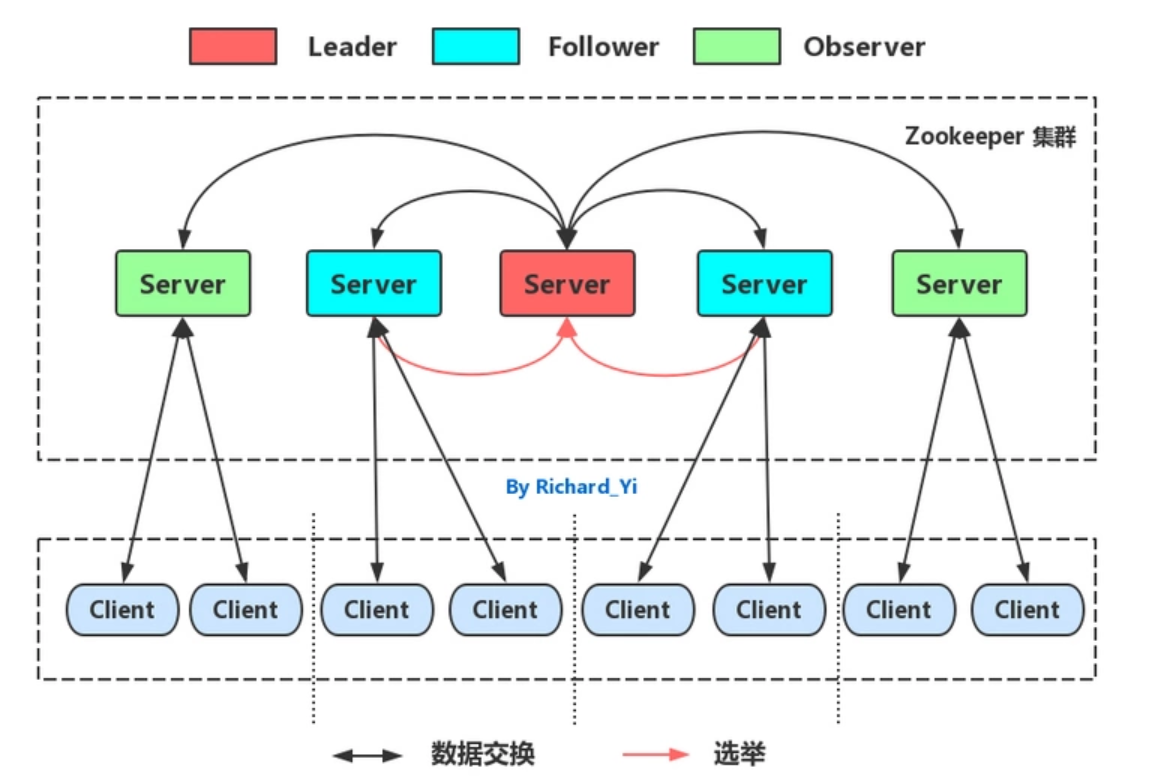
快速入门Zookeeper技术.黑马教程
快速入门Zookeeper技术.黑马教程一、初识 Zookeeper二、ZooKeeper 安装与配置三、ZooKeeper 命令操作1.Zookeeper 数据模型2.Zookeeper 服务端常用命令3.Zookeeper 客户端常用命令四、ZooKeeper JavaAPI 操作五、ZooKeeper JavaAPI 操作1.Curator 介绍2.Curator API 常用操作2.…...

网易C++实习一面
说下C11新特性 auto有没有效率上的问题?为什么?发生在什么时候? 说下单例模式 什么时候需要加锁,什么时候不需要加锁? 像printf这样的函数,自己本身不修改数据,但是其他人会修改数据&#x…...
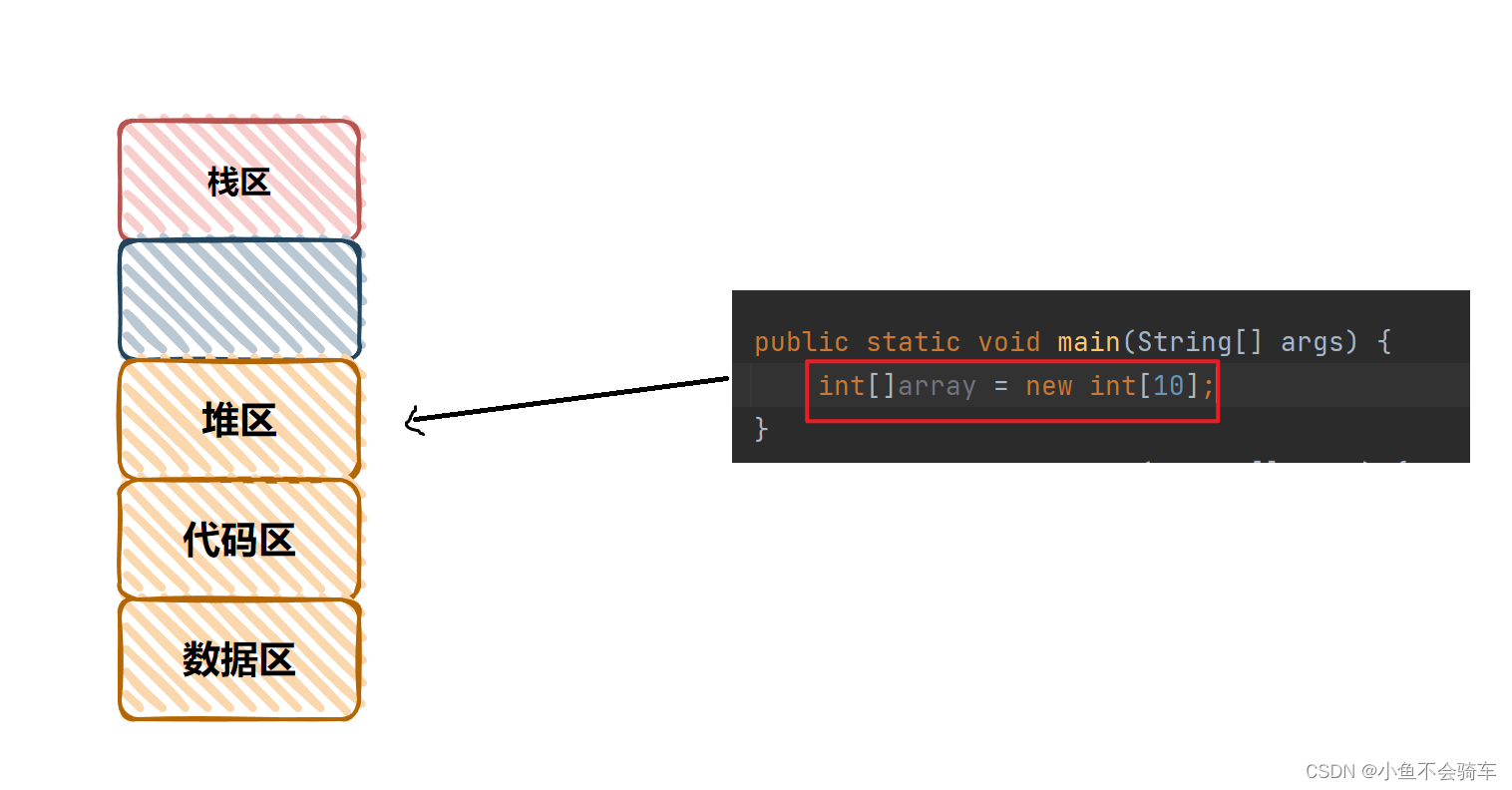
进程和线程的区别和联系
进程和线程的区别和联系1. 认识线程2. 进程和线程的关系3. 进程和线程的区别4. 线程共享了进程哪些资源1. 上下文切换2. 线程共享了进程哪些资源1.代码区2. 数据区3. 堆区1. 认识线程 线程是进程的一个实体,它被包含在进程中,一个进程至少包含一个线程,一个进程也可以包含多个…...

Java学习笔记——集合
目录集合与数组的对比集合体系结构Collection——常见成员方法Collection——迭代器基本使用Collection——迭代器原理分析Collection——迭代器删除方法增强for——基本格式增强for——注意点Collection——练习集合与数组的对比 package top.xxxx.www.CollectionDemo;import …...
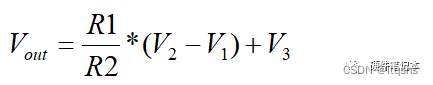
差分运放公式推导-运算放大器
不知道大家有没遇到这种情况,在计算电路的时候,有时候会突然的忘记一些公式啊啥的,需要回去翻看笔记或者查资料,知其然而不知其所以然。今天跟大家一起来一起推导一遍差分运放的计算过程。 计算过程其实归根结底还是根据运放的虚…...

金丹二层 —— 字符串长度求解的四种方法
前言: 1.CSDN由于我的排版不怎么好看,我的有道云笔记比较美观,请移步有道云笔记 2.修炼必备 1)入门必备:VS2019社区版,下载地址:Visual Studio 较旧的下载 - 2019、2017、2015 和以前的版本 (m…...

深入剖析Linux——进程信号
致前行的人: 要努力,但不着急,繁花锦簇,硕果累累都需要过程! 目录 1.信号概念 1.1生活角度的信号 2. 技术应用角度的信号 3.Linux操作系统中查看信号 4.常用信号发送 4.1通过键盘发送信号 4.2调用系统函数发送信号 4.3…...
API-Server的监听器Controller的List分页失效
前言 最近做项目,还是K8S的插件监听器(理论上插件都是通过API-server通信),官方的不同写法居然都能出现争议,争议点就是对API-Server的请求的耗时,说是会影响API-Server。实际上通过源码分析两着有差别&am…...

jupyter notebook 进阶使用:nbextensions,终极避坑
jupyter notebook 进阶使用:nbextensions,终极避坑吐槽安装 jupyter_contrib_nbextensions1. Install the python package(安装python包)方法一,PIP:方法二,Conda(推荐)&…...

C 语言编程 — Doxygen + Graphviz 静态项目分析
目录 文章目录目录安装配置解析Project related configuration optionsBuild related configuration optionsConfiguration options related to warning and progress messagesConfiguration options related to the input filesConfiguration options related to source brows…...
Mybatis报BindingException:Invalid bound statement (not found)异常
一、前言 本文的mybatis是与springboot整合时出现的异常,若使用的不是基于springboot,解决思路也大体一样的。 二、从整合mybatis的三个步骤排查问题 但在这之前,我们先要知道整合mybatis的三个重要的工作,如此才能排查&#x…...
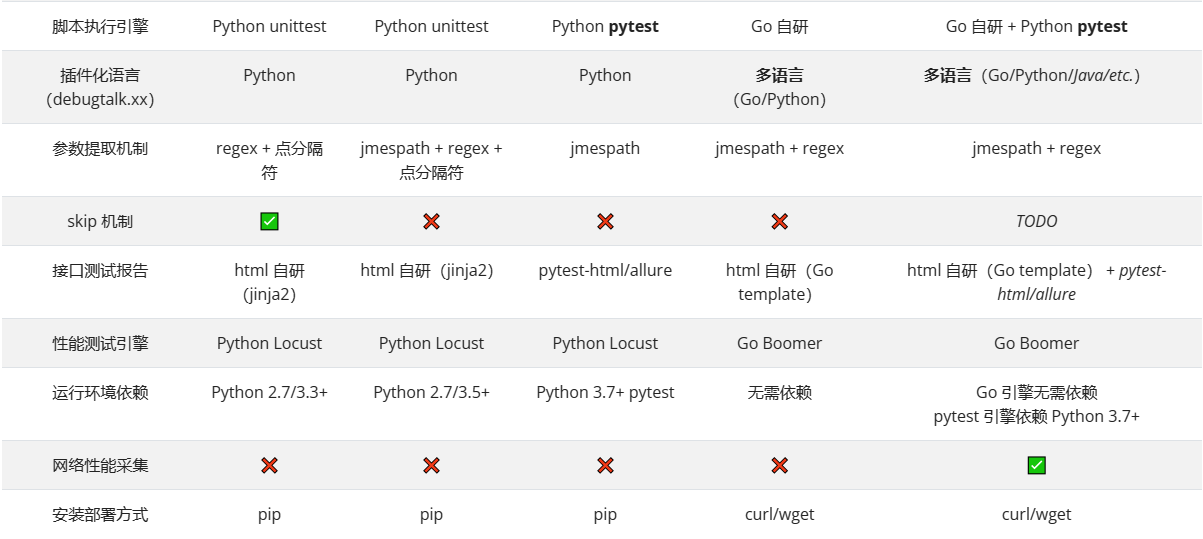
HttpRunner3.x(1)-框架介绍
HttpRunner 是一款面向 HTTP(S) 协议的通用测试框架,只需编写维护一份 YAML/JSON 脚本,即可实现自动化测试、性能测试、线上监控、持续集成等多种测试需求。主要特征继承的所有强大功能requests ,只需以人工方式获得乐趣即可处理HTTP…...

pytest学习和使用20-pytes如何进行分布式测试?(pytest-xdist)
20-pytes如何进行分布式测试?(pytest-xdist)1 什么是分布式测试?2 为什么要进行分布式测试?2.1 场景1:自动化测试场景2.2 场景2:性能测试场景3 分布式测试有什么特点?4 分布式测试关…...

超短脉冲激光自聚焦效应
前言与目录 强激光引起自聚焦效应机理 超短脉冲激光在脆性材料内部加工时引起的自聚焦效应,这是一种非线性光学现象,主要涉及光学克尔效应和材料的非线性光学特性。 自聚焦效应可以产生局部的强光场,对材料产生非线性响应,可能…...

基于距离变化能量开销动态调整的WSN低功耗拓扑控制开销算法matlab仿真
目录 1.程序功能描述 2.测试软件版本以及运行结果展示 3.核心程序 4.算法仿真参数 5.算法理论概述 6.参考文献 7.完整程序 1.程序功能描述 通过动态调整节点通信的能量开销,平衡网络负载,延长WSN生命周期。具体通过建立基于距离的能量消耗模型&am…...

sqlserver 根据指定字符 解析拼接字符串
DECLARE LotNo NVARCHAR(50)A,B,C DECLARE xml XML ( SELECT <x> REPLACE(LotNo, ,, </x><x>) </x> ) DECLARE ErrorCode NVARCHAR(50) -- 提取 XML 中的值 SELECT value x.value(., VARCHAR(MAX))…...

【VLNs篇】07:NavRL—在动态环境中学习安全飞行
项目内容论文标题NavRL: 在动态环境中学习安全飞行 (NavRL: Learning Safe Flight in Dynamic Environments)核心问题解决无人机在包含静态和动态障碍物的复杂环境中进行安全、高效自主导航的挑战,克服传统方法和现有强化学习方法的局限性。核心算法基于近端策略优化…...

Python基于历史模拟方法实现投资组合风险管理的VaR与ES模型项目实战
说明:这是一个机器学习实战项目(附带数据代码文档),如需数据代码文档可以直接到文章最后关注获取。 1.项目背景 在金融市场日益复杂和波动加剧的背景下,风险管理成为金融机构和个人投资者关注的核心议题之一。VaR&…...

Vue ③-生命周期 || 脚手架
生命周期 思考:什么时候可以发送初始化渲染请求?(越早越好) 什么时候可以开始操作dom?(至少dom得渲染出来) Vue生命周期: 一个Vue实例从 创建 到 销毁 的整个过程。 生命周期四个…...
 Module Federation:Webpack.config.js文件中每个属性的含义解释)
MFE(微前端) Module Federation:Webpack.config.js文件中每个属性的含义解释
以Module Federation 插件详为例,Webpack.config.js它可能的配置和含义如下: 前言 Module Federation 的Webpack.config.js核心配置包括: name filename(定义应用标识) remotes(引用远程模块࿰…...

【深度学习新浪潮】什么是credit assignment problem?
Credit Assignment Problem(信用分配问题) 是机器学习,尤其是强化学习(RL)中的核心挑战之一,指的是如何将最终的奖励或惩罚准确地分配给导致该结果的各个中间动作或决策。在序列决策任务中,智能体执行一系列动作后获得一个最终奖励,但每个动作对最终结果的贡献程度往往…...

EEG-fNIRS联合成像在跨频率耦合研究中的创新应用
摘要 神经影像技术对医学科学产生了深远的影响,推动了许多神经系统疾病研究的进展并改善了其诊断方法。在此背景下,基于神经血管耦合现象的多模态神经影像方法,通过融合各自优势来提供有关大脑皮层神经活动的互补信息。在这里,本研…...
未授权访问事件频发,我们应当如何应对?
在当下,数据已成为企业和组织的核心资产,是推动业务发展、决策制定以及创新的关键驱动力。然而,未授权访问这一隐匿的安全威胁,正如同高悬的达摩克利斯之剑,时刻威胁着数据的安全,一旦触发,便可…...