大数据学习之Flink基础(补充)
Flink基础
1、系统时间与事件时间
系统时间(处理时间)
在Sparksreaming的任务计算时,使用的是系统时间。
假设所用窗口为滚动窗口,大小为5分钟。那么每五分钟,都会对接收的数据进行提交任务.
但是,这里有个要注意的点,有个概念叫时间轴对齐。若我们在12:12开始接收数据,按道理我们会在12:17进行提交任务。事实上我们会在12:20进行提交任务,因为会进行时间轴对齐,将一天按照五分钟进行划分,会对应到12:20。在此时提交任务,后面每个五分钟提交任务,都会对应到我们所划分的时间轴。
事件时间
flink支持带有事件时间的窗口(Window)操作
事件时间区别于系统时间,如下举例:
flink处理实时数据,对数据进行逐条处理。设定事件时间为5分钟,12:00开始接收数据,接收的第一条数据时间为12:01,接收的第二条数据为12:02。假设从此时起没有收到数据,那么将不会进行提交任务。**到了12:06,接收到了第三条数据。第三条数据的接收时间自12:00起,已经超过了五分钟,**那么此时便会进行任务提交。
2、wordcount简单案例的实现
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;public class Demo01StreamWordCount {public static void main(String[] args) throws Exception {// 1、构建Flink环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 2、通过Socket模拟无界流环境,方便FLink处理// 虚拟机启动:nc -lk 8888// 从Source构建第一个DataStream// TODO C:\Windows\System32\drivers\etc\hosts文件中配置了master与IP地址的映射,所以这里可以使用masterDataStream<String> lineDS = env.socketTextStream("master", 8888);// 统计每个单词的数量// 第一步:将每行数据的每个单词切出来并进行扁平化处理DataStream<String> wordsDS = lineDS.flatMap(new FlatMapFunction<String, String>() {/***FlatMapFunction<String, String>: 表示输入、输出数据的类型* @param line DS中的一条数据* @param out 通过collect方法将数据发送到下游* @throws Exception*/@Overridepublic void flatMap(String line, Collector<String> out) throws Exception {for (String word : line.split(",")) {// 将每个单词发送到下游out.collect(word);}}});// 第二步:将每个单词变成 KV格式,V置为1;返回的数据是一个二元组Tuple2DataStream<Tuple2<String, Integer>> wordKVDS = wordsDS.map(new MapFunction<String, Tuple2<String, Integer>>() {@Overridepublic Tuple2<String, Integer> map(String word) throws Exception {return Tuple2.of(word, 1);}});/*** 第三步:按每一个单词进行分组; 无法再使用其父类DataStream进行定义(无法向上转型)* KeyedStream<T, K> 是 DataStream<T> 的一个特殊化版本,它添加了与键控操作相关的特定方法(如 reduce、aggregate、window 等)。* 由于 KeyedStream 提供了额外的功能和方法,它不能简单地被视为 DataStream 的一个简单实例,* 因为它实现了额外的接口(如 KeyedOperations<T, K>)并可能覆盖了某些方法的行为以支持键控操作。*/KeyedStream<Tuple2<String, Integer>, String> keyedDS = wordKVDS.keyBy(new KeySelector<Tuple2<String, Integer>, String>() {@Overridepublic String getKey(Tuple2<String, Integer> tuple2) throws Exception {// 对Key进行分组return tuple2.f0;}});// 第四步:对1进行聚合sum,下标是从0开始的DataStream<Tuple2<String, Integer>> wordCntDS = keyedDS.sum(1);// 3、打印结果:将DS中的内容Sink到控制台wordCntDS.print();// 执行任务env.execute();}
}
3、设置任务执行的并行度
本机为8核,可并行16的线程
手动改变任务的并行度,若不设置则会显示1-16,设置后只会显示1-2
env.setParallelism(2);
setBufferTimeout():设置输出缓冲区刷新的最大时间频率(毫秒)。
env.setBufferTimeout(200);
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;public class Demo01StreamWordCount {public static void main(String[] args) throws Exception {// 1、构建Flink环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 手动改变任务的并行度,默认并行度为最大,env.setParallelism(2);// setBufferTimeout():设置输出缓冲区刷新的最大时间频率(毫秒)。env.setBufferTimeout(200);// 2、通过Socket模拟无界流环境,方便FLink处理// 虚拟机启动:nc -lk 8888// 从Source构建第一个DataStreamDataStream<String> lineDS = env.socketTextStream("master", 8888);System.out.println("lineDS并行度:" + lineDS.getParallelism());// 统计每个单词的数量// 第一步:将每行数据的每个单词切出来并进行扁平化处理DataStream<String> wordsDS = lineDS.flatMap(new FlatMapFunction<String, String>() {/**** @param line DS中的一条数据* @param out 通过collect方法将数据发送到下游* @throws Exception*/@Overridepublic void flatMap(String line, Collector<String> out) throws Exception {for (String word : line.split(",")) {// 将每个单词发送到下游out.collect(word);}}});System.out.println("wordsDS并行度:" + wordsDS.getParallelism());// 第二步:将每个单词变成 KV格式,V置为1DataStream<Tuple2<String, Integer>> wordKVDS = wordsDS.map(new MapFunction<String, Tuple2<String, Integer>>() {@Overridepublic Tuple2<String, Integer> map(String word) throws Exception {return Tuple2.of(word, 1);}});System.out.println("wordKVDS并行度:" + wordKVDS.getParallelism());// 第三步:按每一个单词进行分组// keyBy之后数据流会进行分组,相同的key会进入同一个线程中被处理// 传递数据的规则:hash取余(线程总数,默认CPU的总线程数)原理KeyedStream<Tuple2<String, Integer>, String> keyedDS = wordKVDS.keyBy(new KeySelector<Tuple2<String, Integer>, String>() {@Overridepublic String getKey(Tuple2<String, Integer> tuple2) throws Exception {return tuple2.f0;}});System.out.println("keyedDS并行度:" + keyedDS.getParallelism());// 第四步:对1进行聚合sumDataStream<Tuple2<String, Integer>> wordCntDS = keyedDS.sum(1);System.out.println("wordCntDS并行度:" + wordCntDS.getParallelism());// 3、打印结果:将DS中的内容Sink到控制台keyedDS.print();env.execute();}
}
4、设置批/流处理方式,使用Lambda表达式,使用自定类实现接口中抽象的方法
package com.shujia.flink.core;import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;public class Demo02BatchWordCount {public static void main(String[] args) throws Exception {// 1、构建环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 设置Flink程序的处理方式:默认是流处理/*** BATCH:批处理,只能处理有界流,底层是MR模型,可以进行预聚合* STREAMING:流处理,可以处理无界流,也可以处理有界流,底层是持续流模型,数据一条一条处理* AUTOMATIC:自动判断,当所有的Source都是有界流则使用BATCH模式,当Source中有一个是无界流则会使用STREAMING模式*/env.setRuntimeMode(RuntimeExecutionMode.BATCH);// 2、获得第一个DS// 通过readTextFile可以基于文件构建有界流DataStream<String> wordsFileDS = env.readTextFile("flink/data/words.txt");// 3、DS之间的转换// 统计每个单词的数量// 第一步:将每行数据的每个单词切出来并进行扁平化处理// Flink处理逻辑传入的方式// new XXXFunction 使用匿名内部类
// DataStream<String> wordsDS = wordsFileDS.flatMap(new FlatMapFunction<String, String>() {
// /**
// * @param line DS中的一条数据
// * @param out 通过collect方法将数据发送到下游
// * @throws Exception
// * Type parameters:
// * FlatMapFunction<T, O>
// * <T> – Type of the input elements. <O> – Type of the returned elements.
// */
// @Override
// public void flatMap(String line, Collector<String> out) throws Exception {
// for (String word : line.split(",")) {
// // 将每个单词发送到下游
// out.collect(word);
// }
// }
// });/*** 使用Lambda表达式* 使用时得清楚FlatMapFunction中所要实现的抽象方法flatMap的两个参数的含义* ()->{}* 通过 -> 分隔,左边是函数的参数,右边是函数实现的具体逻辑* 并且需要给出 flatMap函数的输出类型,Types.STRING* line: 输入数据类型, out: 输出数据类型*/DataStream<String> wordsDS = wordsFileDS.flatMap((line, out) -> {for (String word : line.split(",")) {out.collect(word);}}, Types.STRING);//TODO 使用自定类实现接口中抽象的方法,一般不使用这种方法wordsFileDS.flatMap(new MyFunction()).print();// 第二步:将每个单词变成 KV格式,V置为1
// DataStream<Tuple2<String, Integer>> wordKVDS = wordsDS.map(new MapFunction<String, Tuple2<String, Integer>>() {
// @Override
// public Tuple2<String, Integer> map(String word) throws Exception {
// return Tuple2.of(word, 1);
// }
// });// TODO 此处需要给出 map函数的输出类型,Types.TUPLE(Types.STRING, Types.INT),是一个二元组DataStream<Tuple2<String, Integer>> wordKVDS = wordsDS.map(word -> Tuple2.of(word, 1), Types.TUPLE(Types.STRING, Types.INT));/*** 第三步:按每一个单词进行分组* keyBy之后数据流会进行分组,相同的key会进入同一个线程中被处理* 传递数据的规则:hash取余(线程总数,默认CPU的总线程数,本机为16)原理*/
// KeyedStream<Tuple2<String, Integer>, String> keyedDS = wordKVDS.keyBy(new KeySelector<Tuple2<String, Integer>, String>() {
// @Override
// public String getKey(Tuple2<String, Integer> tuple2) throws Exception {
// return tuple2.f0;
// }
// });// TODO 此处的Types.STRING 并不是直接表示某个方法的输出类型,而是用来指定 keyBy 方法中键(key)的类型。这里可以省略!KeyedStream<Tuple2<String, Integer>, String> keyedDS = wordKVDS.keyBy(kv -> kv.f0, Types.STRING);// 第四步:对1进行聚合sum,无需指定返回值类型DataStream<Tuple2<String, Integer>> wordCntDS = keyedDS.sum(1);// 4、最终结果的处理(保存/输出打印)wordCntDS.print();env.execute();}
}class MyFunction implements FlatMapFunction<String,String>{@Overridepublic void flatMap(String line, Collector<String> out) throws Exception {for (String word : line.split(",")) {// 将每个单词发送到下游out.collect(word);}}
}
5、source
Flink 在流处理和批处理上的 source 大概有 4 类:
基于本地集合的 source、
基于文件的 source、
基于网络套接字的 source、
自定义的 source。自定义的 source 常见的有 Apache kafka、Amazon Kinesis Streams、RabbitMQ、Twitter Streaming API、Apache NiFi 等,当然你也可以定义自己的 source。
1、从本地集合source中读取数据
package com.shujia.flink.source;import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import java.util.ArrayList;public class Demo01ListSource {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 本地集合SourceArrayList<String> arrList = new ArrayList<>();arrList.add("flink");arrList.add("flink");arrList.add("flink");arrList.add("flink");//TODO 有界流,fromCollectionDataStream<String> listDS = env.fromCollection(arrList);listDS.print();env.execute();}
}
2、新版本从本地文件中读取数据,有界流和无界流两种方式
package com.shujia.flink.source;import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.connector.file.src.FileSource;
import org.apache.flink.connector.file.src.reader.TextLineInputFormat;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import java.io.File;
import java.time.Duration;public class Demo02FileSource {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();//TODO 历史版本读文件的方式,有界流DataStream<String> oldFileDS = env.readTextFile("flink/data/words.txt");
// oldFileDS.print();//TODO 读取案例一: 新版本加载文件的方式:FileSource,默认是有界流FileSource<String> fileSource = FileSource.forRecordStreamFormat(new TextLineInputFormat(), new Path("flink/data/words.txt")).build();//TODO 从Source加载数据构建DS,使用自带source类,使用 fromSourceDataStream<String> fileSourceDS = env.fromSource(fileSource, WatermarkStrategy.noWatermarks(), "fileSource");fileSourceDS.print();//TODO 读取案例二: 将读取文件变成无界流FileSource<String> fileSource2 = FileSource.forRecordStreamFormat(new TextLineInputFormat(), new Path("flink/data/words"))//TODO 使成为无界流读取一个文件夹中的数据,类似Flume中的spool dir,可以监控一个目录下文件的变化// Duration.ofSeconds(5) 以5秒为间隔持续监控.monitorContinuously(Duration.ofSeconds(5)).build();DataStream<String> fileSourceDS2 = env.fromSource(fileSource2,WatermarkStrategy.noWatermarks(),"fileSource2");fileSourceDS2.print();env.execute();}
}
3、自定义source类,区分有界流与无界流
- 只有在Source启动时会执行一次
run方法如果会结束,则Source会得到一个有界流run方法如果不会结束,则Source会得到一个无界流
package com.shujia.flink.source;import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.SourceFunction;public class Demo03MySource {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// TODO 使用自定义source类,通过addSource对其进行添加DataStream<String> mySourceDS = env.addSource(new MySource());mySourceDS.print();env.execute();}
}class MySource implements SourceFunction<String>{/*** 只有在Source启动时会执行一次* run方法如果会结束,则Source会得到一个有界流* run方法如果不会结束,则Source会得到一个无界流* 下面的例子Source会得到一个无界流*/@Overridepublic void run(SourceContext<String> ctx) throws Exception {System.out.println("run方法启动了");// ctx 可以通过collect方法向下游发送数据long cnt = 0L;while(true){ctx.collect(cnt+"");cnt ++;// 休眠一会Thread.sleep(1000);}}// Source结束时会执行@Overridepublic void cancel() {System.out.println("Source结束了");}
}
4、自定义source类,读取MySQL中的数据,并进行处理
package com.shujia.flink.source;import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.SourceFunction;import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;public class Demo04MyMySQLSource {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStream<Students> studentDS = env.addSource(new MyMySQLSource());// 统计班级人数DataStream<Tuple2<String, Integer>> clazzCntDS = studentDS.map(stu -> Tuple2.of(stu.clazz, 1), Types.TUPLE(Types.STRING, Types.INT)).keyBy(t2 -> t2.f0).sum(1);clazzCntDS.print();// 统计性别人数DataStream<Tuple2<String, Integer>> genderCntDS = studentDS.map(stu -> Tuple2.of(stu.gender, 1), Types.TUPLE(Types.STRING, Types.INT)).keyBy(t2 -> t2.f0).sum(1);genderCntDS.print();env.execute();}
}// TODO 自定义source类从MySQL中读取数据
class MyMySQLSource implements SourceFunction<Students> {@Overridepublic void run(SourceContext<Students> ctx) throws Exception {//TODO run方法只会执行一次创建下列对象的操作// 建立连接Connection conn = DriverManager.getConnection("jdbc:mysql://master:3306/bigdata_30", "root", "123456");// 创建StatementStatement st = conn.createStatement();// 执行查询ResultSet rs = st.executeQuery("select * from students2");// 遍历rs提取每一条数据while (rs.next()) {long id = rs.getLong("id");String name = rs.getString("name");int age = rs.getInt("age");String gender = rs.getString("gender");String clazz = rs.getString("clazz");Students stu = new Students(id, name, age, gender, clazz);ctx.collect(stu);/*** 16> (文科四班,1)* 15> (女,1)* 15> (女,2)* 2> (男,1)* 7> (文科六班,1)* 15> (女,3)* 2> (男,2)* 17> (理科六班,1)* 17> (理科六班,2)* 13> (理科五班,1)* 20> (理科二班,1)* 13> (理科四班,1)*/}rs.close();st.close();conn.close();}@Overridepublic void cancel() {}
}// TODO 创建一个类,用于存储从MySQL中取出的数据
class Students {Long id;String name;Integer age;String gender;String clazz;public Students(Long id, String name, Integer age, String gender, String clazz) {this.id = id;this.name = name;this.age = age;this.gender = gender;this.clazz = clazz;}
}
6、sink
Flink 将转换计算后的数据发送的地点 。
Flink 常见的 Sink 大概有如下几类:
写入文件、
打印出来、
写入 socket 、
自定义的 sink 。自定义的 sink 常见的有 Apache kafka、RabbitMQ、MySQL、ElasticSearch、Apache Cassandra、Hadoop FileSystem 等,同理你也可以定义自己的 sink。
1、构建FileSink,监控一个端口中的数据并将其写入到本地文件夹中
package com.shujia.flink.sink;import org.apache.flink.api.common.serialization.SimpleStringEncoder;
import org.apache.flink.configuration.MemorySize;
import org.apache.flink.connector.file.sink.FileSink;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.filesystem.rollingpolicies.DefaultRollingPolicy;import java.time.Duration;
public class Demo01FileSink {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStreamSource<String> lineDS = env.socketTextStream("master", 8888);// 构建FileSinkFileSink<String> fileSink = FileSink.<String>forRowFormat(new Path("flink/data/fileSink"), new SimpleStringEncoder<String>("UTF-8")).withRollingPolicy(DefaultRollingPolicy.builder()// 这个设置定义了滚动的时间间隔。.withRolloverInterval(Duration.ofSeconds(10))// 这个设置定义了一个不活动间隔。.withInactivityInterval(Duration.ofSeconds(10))// 这个设置定义了单个日志文件可以增长到的最大大小。在这个例子中,每个日志文件在被滚动之前可以增长到最多1MB。.withMaxPartSize(MemorySize.ofMebiBytes(1)).build()).build();lineDS.sinkTo(fileSink);env.execute();}
}
2、自定义sink类
package com.shujia.flink.sink;import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.SinkFunction;import java.util.ArrayList;public class Demo02MySink {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();ArrayList<String> arrList = new ArrayList<>();arrList.add("flink");arrList.add("flink");arrList.add("flink");arrList.add("flink");DataStreamSource<String> ds = env.fromCollection(arrList);ds.addSink(new MySinkFunction());env.execute();/*** 进入了invoke方法* flink* 进入了invoke方法* flink* 进入了invoke方法* flink* 进入了invoke方法* flink*/}
}class MySinkFunction implements SinkFunction<String>{@Overridepublic void invoke(String value, Context context) throws Exception {System.out.println("进入了invoke方法");// invoke 每一条数据会执行一次// 最终数据需要sink到哪里,就对value进行处理即可System.out.println(value);}
}
7、Transformation:数据转换的常用操作
1、Map
package com.shujia.flink.tf;import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;public class Demo01Map {public static void main(String[] args) throws Exception {// 传入一条数据返回一条数据StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStream<String> ds = env.socketTextStream("master", 8888);// 1、使用匿名内部类DataStream<Tuple2<String, Integer>> mapDS = ds.map(new MapFunction<String, Tuple2<String, Integer>>() {@Overridepublic Tuple2<String, Integer> map(String word) throws Exception {return Tuple2.of(word, 1);}});// mapDS.print();// 2、使用lambda表达式DataStream<Tuple2<String, Integer>> mapDS2 =ds.map(word -> Tuple2.of(word, 1), Types.TUPLE(Types.STRING, Types.INT));mapDS2.print();env.execute();}
}
2、FlatMap
package com.shujia.flink.tf;import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;public class Demo02FlatMap {public static void main(String[] args) throws Exception {// 传入一条数据返回多条数据,类似UDTF函数StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStream<String> ds = env.socketTextStream("master", 8888);// 1、使用匿名内部类SingleOutputStreamOperator<Tuple2<String, Integer>> flatMapDS01 = ds.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {@Overridepublic void flatMap(String line, Collector<Tuple2<String, Integer>> out) throws Exception {for (String word : line.split(",")) {out.collect(Tuple2.of(word, 1));}}});flatMapDS01.print();// 2、使用lambda表达式SingleOutputStreamOperator<Tuple> flatMapDS02 = ds.flatMap((line, out) -> {for (String word : line.split(",")) {out.collect(Tuple2.of(word, 1));}}, Types.TUPLE(Types.STRING, Types.INT));flatMapDS02.print();env.execute();}
}
3、Filter
package com.shujia.flink.tf;import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;public class Demo03Filter {public static void main(String[] args) throws Exception {// 过滤数据,注意返回值必须是布尔类型,返回true则保留数据,返回false则过滤数据StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStream<String> ds = env.socketTextStream("master", 8888);/*** Integer.valueOf:该方法将字符串参数转换为 Integer 对象。返回的是 Integer 类型,即 java.lang.Integer 的一个实例。* Integer.parseInt:该方法将字符串参数解析为基本数据类型 int 的值。返回的是 int 类型的值,而不是对象。* 无需指定返回值类型*/// 只输出大于10的数字SingleOutputStreamOperator<String> filterDS = ds.filter(new FilterFunction<String>() {@Overridepublic boolean filter(String value) throws Exception {return Integer.parseInt(value) > 10;}});filterDS.print();ds.filter(value -> Integer.parseInt(value) > 10).print();env.execute();}
}
4、KeyBy
// 两种不同的简写方式
ds.keyBy(value -> value.toLowerCase(), Types.STRING).print();
ds.keyBy(String::toLowerCase, Types.STRING).print();
package com.shujia.flink.tf;import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;public class Demo04KeyBy {public static void main(String[] args) throws Exception {// 用于就数据流分组,让相同的Key进入到同一个任务中进行处理,后续可以跟聚合操作StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStream<String> ds = env.socketTextStream("master", 8888);KeyedStream<String, String> keyByDS = ds.keyBy(new KeySelector<String, String>() {@Overridepublic String getKey(String value) throws Exception {return value;}});keyByDS.print();// 两种不同的简写方式ds.keyBy(value -> value.toLowerCase(), Types.STRING).print();ds.keyBy(String::toLowerCase, Types.STRING).print();env.execute();}
}
5、Reduce
package com.shujia.flink.tf;import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;public class Demo05Reduce {public static void main(String[] args) throws Exception {// 用于对KeyBy之后的数据流进行聚合计算StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStream<String> ds = env.socketTextStream("master", 8888);// 统计班级的平均年龄/** 文科一班,20* 文科一班,22* 文科一班,21* 文科一班,20* 文科一班,22** 理科一班,20* 理科一班,21* 理科一班,20* 理科一班,21* 理科一班,20**/SingleOutputStreamOperator<Tuple3<String, Integer, Integer>> kvDS = ds.map(line -> {String[] split = line.split(",");String clazz = split[0];int age = Integer.parseInt(split[1]);return Tuple3.of(clazz, age, 1);}, Types.TUPLE(Types.STRING, Types.INT, Types.INT));KeyedStream<Tuple3<String, Integer, Integer>, String> keyByDS = kvDS.keyBy(kv -> kv.f0, Types.STRING);keyByDS.reduce(new ReduceFunction<Tuple3<String, Integer, Integer>>() {@Overridepublic Tuple3<String, Integer, Integer> reduce(Tuple3<String, Integer, Integer> value1, Tuple3<String, Integer, Integer> value2) throws Exception {return Tuple3.of(value1.f0, value1.f1 + value2.f1, value1.f2 + value2.f2);}}).map(t3 -> Tuple2.of(t3.f0, (double) t3.f1 / t3.f2),Types.TUPLE(Types.STRING,Types.DOUBLE)).print();keyByDS.reduce((v1,v2)->Tuple3.of(v1.f0, v1.f1 + v2.f1, v1.f2 + v2.f2)).map(t3 -> Tuple2.of(t3.f0, (double) t3.f1 / t3.f2),Types.TUPLE(Types.STRING,Types.DOUBLE)).print();env.execute();}
}
6、Window
package com.shujia.flink.tf;import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.SlidingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;public class Demo06Window {public static void main(String[] args) throws Exception {// Flink窗口操作:时间、计数、会话StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStream<String> ds = env.socketTextStream("master", 8888);SingleOutputStreamOperator<Tuple2<String, Integer>> kvDS = ds.map(word -> Tuple2.of(word, 1), Types.TUPLE(Types.STRING, Types.INT));// 每隔5s统计每个单词的数量 ---> 滚动窗口实现(与spark中的定义相同)SingleOutputStreamOperator<Tuple2<String, Integer>> outputDS01 = kvDS// 按照Tuple2中的第一个元素进行分组.keyBy(kv -> kv.f0, Types.STRING)// 设置滚动时间.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))// 对Tuple2中的第二个元素(索引为1的元素,即Integer类型)进行求和.sum(1);// outputDS01.print();// 每隔5s统计最近10s内的每个单词的数量 ---> 滑动窗口实现(与spark中的定义相同)kvDS.keyBy(kv -> kv.f0, Types.STRING)// 设置窗口大小和滑动大小.window(SlidingProcessingTimeWindows.of(Time.seconds(10), Time.seconds(5))).sum(1).print();env.execute();}
}
7、Union
package com.shujia.flink.tf;import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;public class Demo07Union {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStream<String> ds01 = env.socketTextStream("master", 8888);DataStream<String> ds02 = env.socketTextStream("master", 9999);DataStream<String> unionDS = ds01.union(ds02);// union 就是将两个相同结构的DS合并成一个DS(上下合并)unionDS.print();env.execute();}
}
8、Process
通过processElement实现Map算子操作、flatMap算子操作(实现扁平化)、filter算子操作
package com.shujia.flink.tf;import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.ProcessFunction;
import org.apache.flink.util.Collector;public class Demo08Process {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStream<String> ds01 = env.socketTextStream("master", 8888);ds01.process(new ProcessFunction<String, Object>() {/** 每进来一条数据就会执行一次* value :一条数据* ctx:可以获取任务执行时的信息* out:用于输出数据* ProcessFunction<String, Object>.Context ctx:flink的上下文对象*/@Overridepublic void processElement(String value, ProcessFunction<String, Object>.Context ctx, Collector<Object> out) throws Exception {// 通过processElement实现Map算子操作out.collect(Tuple2.of(value, 1));// 通过processElement实现flatMap算子操作(实现扁平化)for (String word : value.split(",")) {out.collect(word);}// 通过processElement实现filter算子操作if("java".equals(value)){out.collect("java ok");}}}).print();env.execute();}
}
通过processElement实现KeyBy算子操作
package com.shujia.flink.tf;import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction;
import org.apache.flink.streaming.api.functions.ProcessFunction;
import org.apache.flink.util.Collector;import java.util.HashMap;public class Demo09KeyByProcess {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStream<String> ds01 = env.socketTextStream("master", 8888);KeyedStream<Tuple2<String, Integer>, String> keyedDS = ds01.process(new ProcessFunction<String, Tuple2<String, Integer>>() {@Overridepublic void processElement(String value, ProcessFunction<String, Tuple2<String, Integer>>.Context ctx, Collector<Tuple2<String, Integer>> out) throws Exception {for (String word : value.split(",")) {out.collect(Tuple2.of(word, 1));}}}).keyBy(t2 -> t2.f0, Types.STRING);// 基于分组之后的数据流同样可以调用process方法/*** KeyedProcessFunction<K, I, O>* Type parameters:* <K> – Type of the key. <I> – Type of the input elements. <O> – Type of the output elements.*/keyedDS.process(new KeyedProcessFunction<String, Tuple2<String, Integer>, String>() {HashMap<String, Integer> wordCntMap;// 当KeyedProcessFunction构建时只会执行一次,这样就避免了重复创建HashMap对象@Overridepublic void open(Configuration parameters) throws Exception {wordCntMap = new HashMap<String, Integer>();}// 每一条数据会执行一次@Overridepublic void processElement(Tuple2<String, Integer> value, KeyedProcessFunction<String, Tuple2<String, Integer>, String>.Context ctx, Collector<String> out) throws Exception {// 通过process实现word count// 判断word是不是第一次进入,通过HashMap查找word是否有count值String word = value.f0;int cnt = 1;if (wordCntMap.containsKey(word)) {//get 在集合中通过value来获取对应的值int newCnt = wordCntMap.get(word) + 1;wordCntMap.put(word, newCnt);cnt = newCnt;} else {wordCntMap.put(word, 1);}out.collect(word + ":" + cnt);}}).print();env.execute();}
}
8、Flink并行度
如何设置并行度?
1、考虑吞吐量
有聚合操作的任务:1w条/s 一个并行度
无聚合操作的任务:10w条/s 一个并行度
2、考虑集群本身的资源
注:
Task的数量由并行度以及有无Shuffle一起决定(可在shuffle之前观察是否有可合并的Task,可以来减少Task数量)
Task Slot数量 是由任务中最大的并行度决定
TaskManager的数量由配置文件中每个TaskManager设置的Slot数量及任务所需的Slot数量一起决定
FLink 并行度设置的几种方式:
1、通过env设置,不推荐,如果需要调整并行度得修改代码重新打包提交任务
2、每个算子可以单独设置并行度,视实际情况决定,一般不常用
3、还可以在提交任务的时候指定并行度,最常用 比较推荐的方式
命令行:flink run 可以通过 -p 参数设置全局并行度
4、配置文件flink-conf.yaml中设置
web UI:填写parallelism输入框即可设置,优先级:算子本身的设置 > env做的全局设置 > 提交任务时指定的 > 配置文件flink-conf.yaml
package com.shujia.flink.core;import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;public class Demo03Parallelism {public static void main(String[] args) throws Exception {/*** 如何设置并行度?* 1、考虑吞吐量* 有聚合操作的任务:1w条/s 一个并行度* 无聚合操作的任务:10w条/s 一个并行度* 2、考虑集群本身的资源** Task的数量由并行度以及有无Shuffle一起决定(可在shuffle之前观察是否有可合并的Task,可以来减少Task数量)* Task Slot数量 是由任务中最大的并行度决定* TaskManager的数量由配置文件中每个TaskManager设置的Slot数量及任务所需的Slot数量一起决定**/// FLink 并行度设置的几种方式StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 1、通过env设置,不推荐,如果需要调整并行度得修改代码重新打包提交任务env.setParallelism(3);// socketTextStream的并行度为1,无法调整DataStreamSource<String> ds = env.socketTextStream("master", 8888);// 2、每个算子可以单独设置并行度,视实际情况决定,一般不常用SingleOutputStreamOperator<Tuple2<String, Integer>> kvDS = ds.map(word -> Tuple2.of(word, 1), Types.TUPLE(Types.STRING, Types.INT)).setParallelism(4);SingleOutputStreamOperator<Tuple2<String, Integer>> wordCntDS2P =kvDS.keyBy(kv -> kv.f0).sum(1).setParallelism(2);// 如果算子不设置并行度则以全局为准wordCntDS2P.print();/*** 3、还可以在提交任务的时候指定并行度,最常用 比较推荐的方式* 命令行:flink run 可以通过 -p 参数设置全局并行度* * web UI:填写parallelism输入框即可设置,优先级:算子本身的设置 > env做的全局设置 > 提交任务时指定的 > 配置文件flink-conf.yaml*/env.execute();}
}
上述代码执行如下:


9、事件时间
事件时间:指的是数据产生的时间或是数据发生的时间。它是数据本身所携带的时间信息,代表了事件真实发生的时间。在Flink中,事件时间通过数据元素自身带有的时间戳来表示,这个时间戳具有业务含义,并与系统时间独立。
1、案例一:基于事件事件的滚动窗口的实现
窗口的触发条件:
1、水位线大于等于窗口的结束时间
2、窗口内有数据
水位线:某个线程中所接收到的数据中最大的时间戳
水位线设置1: 单调递增时间戳策略,不考虑数据乱序问题。所传入数据的最大事件时间作为水位线
.<Tuple2<String, Long>>forMonotonousTimestamps()
水位线设置2 设置水位线前移,容忍5s的数据乱序到达,本质上将水位线前移5s,缺点:导致任务延时变大.<Tuple2<String, Long>>forBoundedOutOfOrderness(Duration.ofSeconds(5))
package com.shujia.flink.core;import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.TimestampAssignerSupplier;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;import java.time.Duration;public class Demo04EventTime {public static void main(String[] args) throws Exception {// 事件时间:数据本身自带的时间StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 设置全局并行度env.setParallelism(1);/*数据格式:单词,时间戳(很大的整数,Long类型)a,1722233813000a,1722233814000a,1722233815000a,1722233816000a,1722233817000a,1722233818000a,1722233819000a,1722233820000a,1722233822000a,1722233827000*/DataStreamSource<String> wordTsDS = env.socketTextStream("master", 8888);SingleOutputStreamOperator<Tuple2<String, Long>> mapDS = wordTsDS.map(line -> Tuple2.of(line.split(",")[0], Long.parseLong(line.split(",")[1])), Types.TUPLE(Types.STRING, Types.LONG));// 指定数据的时间戳,告诉Flink,将其作为事件时间进行处理SingleOutputStreamOperator<Tuple2<String, Long>> assDS = mapDS.assignTimestampsAndWatermarks(WatermarkStrategy// 水位线:某个线程中所接收到的数据中最大的时间戳
// //水位线设置1: 单调递增时间戳策略,不考虑数据乱序问题。所传入数据的最大事件时间作为水位线
// .<Tuple2<String, Long>>forMonotonousTimestamps()//TODO :水位线设置2 设置水位线前移,容忍5s的数据乱序到达,本质上将水位线前移5s,缺点:导致任务延时变大.<Tuple2<String, Long>>forBoundedOutOfOrderness(Duration.ofSeconds(5))// 指定事件时间,可以提取数据的某一部分作为事件时间.withTimestampAssigner(new SerializableTimestampAssigner<Tuple2<String, Long>>() {@Overridepublic long extractTimestamp(Tuple2<String, Long> t2, long recordTimestamp) {return t2.f1;}}));// 不管是事件时间还是处理时间都需要搭配窗口操作一起使用assDS.map(kv -> Tuple2.of(kv.f0, 1), Types.TUPLE(Types.STRING, Types.INT)).keyBy(t2 -> t2.f0)/*** 窗口的触发条件* 1、水位线大于等于窗口的结束时间* 2、窗口内有数据*TumblingEventTimeWindows:滚动窗口*/.window(TumblingEventTimeWindows.of(Time.seconds(5))).sum(1).print();env.execute();}
}
2、案例二:自定义水平线策略
多并行度,map之后指定水位线生成策略
注:必须两个线程中的水位线都超过了窗口的大小,才能触发窗口的执行
当窗口满足执行条件:
1、所有线程的水位线都超过了窗口的结束时间 (依次每两个不同编号的线程为一组,该组均超过)
2、窗口有数据 触发一次process方法
package tfTest;import com.shujia.flink.event.MyEvent;
import org.apache.flink.api.common.eventtime.*;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;public class Demo05WaterMarkStrategy {public static void main(String[] args) throws Exception {// 自定义水位线策略// 参考链接:https://blog.csdn.net/zznanyou/article/details/121666563StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(2);DataStreamSource<String> eventDS = env.socketTextStream("master", 8888);// 将每条数据变成MyEvent类型eventDS.map(new MapFunction<String, MyEvent>() {@Overridepublic MyEvent map(String value) throws Exception {String[] split = value.split(",");return new MyEvent(split[0],Long.parseLong(split[1]));}})// TODO 设置事件时间和自定义水平线策略.assignTimestampsAndWatermarks(new WatermarkStrategy<MyEvent>() {@Overridepublic TimestampAssigner<MyEvent> createTimestampAssigner(TimestampAssignerSupplier.Context context) {return new SerializableTimestampAssigner<MyEvent>() {@Overridepublic long extractTimestamp(MyEvent element, long recordTimestamp) {return element.getTs();}};}@Overridepublic WatermarkGenerator<MyEvent> createWatermarkGenerator(WatermarkGeneratorSupplier.Context context) {return new MyMapWatermarkGenerator();}}).keyBy(my-> my.getWord()).window(TumblingEventTimeWindows.of(Time.seconds(5)))// 当窗口满足执行条件:1、所有线程的水位线都超过了窗口的结束时间 2、窗口有数据 触发一次process方法.process(new ProcessWindowFunction<MyEvent, String, String, TimeWindow>() {@Overridepublic void process(String s, ProcessWindowFunction<MyEvent, String, String, TimeWindow>.Context context, Iterable<MyEvent> elements, Collector<String> out) throws Exception {System.out.println("窗口触发执行了。");System.out.println("当前水位线为:" + context.currentWatermark() + ",当前窗口的开始时间:" + context.window().getStart() + ",当前窗口的结束时间:" + context.window().getEnd());// 基于elements做统计 通过out可以将结果发送到下游}}).print();env.execute();}
}// 用于map之后指定水位线生成策略
class MyMapWatermarkGenerator implements WatermarkGenerator<MyEvent> {private final long maxOutOfOrderness = 0;private long currentMaxTimeStamp;//TODO 每来一条数据会处理一次,若maxOutOfOrderness为0,则为单调递增时间戳策略;若不为0,则是水位线前移策略@Overridepublic void onEvent(MyEvent event, long eventTimestamp, WatermarkOutput output) {currentMaxTimeStamp = Math.max(currentMaxTimeStamp, eventTimestamp);System.out.println("当前线程编号为:" + Thread.currentThread().getId() + ",当前水位线为:" + (currentMaxTimeStamp - maxOutOfOrderness));}// 周期性的执行:env.getConfig().getAutoWatermarkInterval(); 默认是200ms@Overridepublic void onPeriodicEmit(WatermarkOutput output) {// 发送output.emitWatermark(new Watermark(currentMaxTimeStamp - maxOutOfOrderness));}
}
执行结果:

多并行度,source之后设置水位线策略
效果通线程并行度为1的情况
package com.shujia.flink.core;import com.shujia.flink.event.MyEvent;
import org.apache.flink.api.common.eventtime.*;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;public class Demo05WaterMarkStrategy {public static void main(String[] args) throws Exception {// 自定义水位线策略// 参考链接:https://blog.csdn.net/zznanyou/article/details/121666563StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(2);DataStreamSource<String> eventDS = env.socketTextStream("master", 8888);// 在Source之后就指定水位线策略eventDS.assignTimestampsAndWatermarks(new WatermarkStrategy<String>() {// 指定时间戳的提取策略@Overridepublic TimestampAssigner<String> createTimestampAssigner(TimestampAssignerSupplier.Context context) {return new SerializableTimestampAssigner<String>() {@Overridepublic long extractTimestamp(String element, long recordTimestamp) {return Long.parseLong(element.split(",")[1]);}};// 简写方式
// return (ele,ts)->Long.parseLong(ele.split(",")[1]);}// 指定水位线的策略@Overridepublic WatermarkGenerator<String> createWatermarkGenerator(WatermarkGeneratorSupplier.Context context) {return new MyWatermarkGenerator();}})// 将数据变成KV格式,即:单词,1.map(line -> Tuple2.of(line.split(",")[0], 1), Types.TUPLE(Types.STRING, Types.INT)).keyBy(t2 -> t2.f0).window(TumblingEventTimeWindows.of(Time.seconds(5)))// 当窗口满足执行条件:1、水位线超过了窗口的结束时间 2、窗口有数据 触发一次process方法.process(new ProcessWindowFunction<Tuple2<String, Integer>, Tuple2<String, Integer>, String, TimeWindow>() {@Overridepublic void process(String s, ProcessWindowFunction<Tuple2<String, Integer>, Tuple2<String, Integer>, String, TimeWindow>.Context context, Iterable<Tuple2<String, Integer>> elements, Collector<Tuple2<String, Integer>> out) throws Exception {System.out.println("窗口触发执行了。");System.out.println("当前水位线为:" + context.currentWatermark() + ",当前窗口的开始时间:" + context.window().getStart() + ",当前窗口的结束时间:" + context.window().getEnd());// 基于elements做统计 通过out可以将结果发送到下游}}).print();env.execute();}
}// 用于Source之后直接指定水位线生成策略
class MyWatermarkGenerator implements WatermarkGenerator<String> {private final long maxOutOfOrderness = 0;private long currentMaxTimeStamp;// 每来一条数据会处理一次@Overridepublic void onEvent(String event, long eventTimestamp, WatermarkOutput output) {currentMaxTimeStamp = Math.max(currentMaxTimeStamp, eventTimestamp);System.out.println("当前线程编号为:" + Thread.currentThread().getId() + ",当前水位线为:" + (currentMaxTimeStamp - maxOutOfOrderness));}// 周期性的执行:env.getConfig().getAutoWatermarkInterval(); 默认是200ms@Overridepublic void onPeriodicEmit(WatermarkOutput output) {output.emitWatermark(new Watermark(currentMaxTimeStamp - maxOutOfOrderness));}
}
10、窗口
1、时间窗口:滚动与滑动窗口
时间窗口:滚动、滑动
时间类型:处理时间、事件时间
package com.shujia.flink.window;import com.shujia.flink.event.MyEvent;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.SlidingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.assigners.SlidingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;import java.time.Duration;public class Demo01TimeWindow {public static void main(String[] args) throws Exception {/** 时间窗口:滚动、滑动* 时间类型:处理时间、事件时间*/StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);DataStream<MyEvent> myDS = env.socketTextStream("master", 8888).map(new MapFunction<String, MyEvent>() {@Overridepublic MyEvent map(String value) throws Exception {String[] split = value.split(",");return new MyEvent(split[0], Long.parseLong(split[1]));}});// 基于处理时间的滚动、滑动窗口SingleOutputStreamOperator<Tuple2<String, Integer>> processDS = myDS.map(e -> Tuple2.of(e.getWord(), 1), Types.TUPLE(Types.STRING, Types.INT)).keyBy(t2 -> t2.f0)// 滚动窗口 每隔5s统计一次
// .window(TumblingProcessingTimeWindows.of(Time.seconds(5)))// 滑动窗口 每隔5s统计最近10s内的数据.window(SlidingProcessingTimeWindows.of(Time.seconds(10), Time.seconds(5))).sum(1);// 基于事件时间的滚动、滑动窗口SingleOutputStreamOperator<MyEvent> assDS = myDS.assignTimestampsAndWatermarks(// 设置水位线策略、指定事件时间WatermarkStrategy// Duration.ofSeconds(5):水位线前移5s.<MyEvent>forBoundedOutOfOrderness(Duration.ofSeconds(5)).withTimestampAssigner((event, ts) -> event.getTs()));SingleOutputStreamOperator<Tuple2<String, Integer>> eventDS = assDS.map(e -> Tuple2.of(e.getWord(), 1), Types.TUPLE(Types.STRING, Types.INT)).keyBy(t2 -> t2.f0)// 滚动窗口,由于水位线前移了5s,整体有5s的延时
// .window(TumblingEventTimeWindows.of(Time.seconds(5)))// 滑动窗口.window(SlidingEventTimeWindows.of(Time.seconds(10),Time.seconds(5))).sum(1);// processDS.print();eventDS.print();env.execute();}
}
2、会话窗口
基于处理时间的会话窗口,当一段时间没有数据,那么就认定此次会话结束并触发窗口的执行
基于事件时间的会话窗口,连续接收的两条数据的事件时间之差要大于5s(窗口大小),才能触发窗口的执行
package com.shujia.flink.window;import com.shujia.flink.event.MyEvent;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.EventTimeSessionWindows;
import org.apache.flink.streaming.api.windowing.assigners.ProcessingTimeSessionWindows;
import org.apache.flink.streaming.api.windowing.assigners.SlidingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;public class Demo02Session {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);DataStream<MyEvent> myDS = env.socketTextStream("master", 8888).map(new MapFunction<String, MyEvent>() {@Overridepublic MyEvent map(String value) throws Exception {String[] split = value.split(",");return new MyEvent(split[0], Long.parseLong(split[1]));}});// 基于处理时间的会话窗口,当一段时间没有数据,那么就认定此次会话结束并触发窗口的执行SingleOutputStreamOperator<Tuple2<String, Integer>> processSessionDS = myDS.map(e -> Tuple2.of(e.getWord(), 1), Types.TUPLE(Types.STRING, Types.INT)).keyBy(t2 -> t2.f0)// 10秒内没有数据,则认定此次会话结束并触发窗口的执行.window(ProcessingTimeSessionWindows.withGap(Time.seconds(10))).sum(1);//TODO 基于事件时间的会话窗口,连续接收的两条数据的事件时间之差要大于5s(窗口大小),才能触发窗口的执行// 指定水位线策略并提供数据中的时间戳解析规则SingleOutputStreamOperator<MyEvent> assDS = myDS.assignTimestampsAndWatermarks(WatermarkStrategy.<MyEvent>forMonotonousTimestamps().withTimestampAssigner((e, ts) -> e.getTs()));SingleOutputStreamOperator<Tuple2<String, Integer>> eventSessionDS = assDS.map(e -> Tuple2.of(e.getWord(), 1), Types.TUPLE(Types.STRING, Types.INT)).keyBy(t2 -> t2.f0).window(EventTimeSessionWindows.withGap(Time.seconds(5))).sum(1);// processSessionDS.print();eventSessionDS.print();env.execute();}
}
3、计数窗口:滚动、滑动
滚动下:每同一个key的5条数据会统计一次
滑动下:每隔同一个key的5条数据,统计最近的同一个key的10条数据
package com.shujia.flink.window;import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;public class Demo03CountWindow {public static void main(String[] args) throws Exception {// 计数窗口:滚动、滑动StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStreamSource<String> ds = env.socketTextStream("master", 8888);ds.map(word-> Tuple2.of(word,1), Types.TUPLE(Types.STRING,Types.INT)).keyBy(t2->t2.f0)
// .countWindow(5) // 每同一个key的5条数据会统计一次.countWindow(10,5) // 每隔同一个key的5条数据,统计最近的同一个key的10条数据.sum(1).print();env.execute();/*** 每隔同一个key的5条数据,统计最近的同一个key的10条数据* 输入:* a* a* a* a* a* b* b* b* a* a* a* a* a* 输出:* 13> (a,5)* 13> (a,10)*/}
}
相关文章:
大数据学习之Flink基础(补充)
Flink基础 1、系统时间与事件时间 系统时间(处理时间) 在Sparksreaming的任务计算时,使用的是系统时间。 假设所用窗口为滚动窗口,大小为5分钟。那么每五分钟,都会对接收的数据进行提交任务. 但是,这里有…...

C++基础语法:友元
前言 "打牢基础,万事不愁" .C的基础语法的学习."学以致用,边学边用",编程是实践性很强的技术,在运用中理解,总结. 以<C Prime Plus> 6th Edition(以下称"本书")的内容开展学习 引入 友元提供了一种特别的方式,访问对象私有数据. 友元有三…...

【大模型系列】Video-LaVIT(2024.06)
Paper:https://arxiv.org/abs/2402.03161Github:https://video-lavit.github.io/Title:Video-LaVIT: Unified Video-Language Pre-training with Decoupled Visual-Motional TokenizationAuthor:Yang Jin, 北大&#x…...

【总结】nacos作为注册中心-应用启动失败:NacosDiscoveryProperties{serverAddr=‘127.0.0.1:8848‘……
问题现象 启动springboot应用时报错,能够读取到nacos配置,但是使用nacos作为注册中心,应用注册到nacos失败。 应用配置bootstrap.properties如下: # 应用编码,安装时替换变量 spring.application.namedata-center #…...

C语言——数组和排序
C语言——数组和排序 数组数组的概念数组的初始化数组的特点 排序选择排序冒泡排序插入排序 二分查找 数组 数组的概念 数组是一组数据 ; 数组是一组相同类型的数据或变量的集合 ; 应用场景: 用于批量的处理多个数据 ; 语法&…...

QEMU 新增QMPHMP指令【原文阅读】
文章目录 0x0 QEMU原文0x10x11 How to write monitor commands0x12 Overview0x13 Testing 0x20x21 Writing a simple command: hello-world0x22 Arguments 0x30x31 Implementing the HMP command 0x40x41 Writing more complex commands0x42 Modelling data in QAPI0x43 User D…...

【Linux】全志Tina配置屏幕时钟的方法
一、文件位置 V:\f1c100s\Evenurs\f1c100s\tina\device\config\chips\c200s\configs\F1C200s\sys_config.fex 二、文件内容 三、介绍 在此处可以修改屏幕的频率,当前为21MHz。 四、总结 注意选择对应的屏幕的参数,sdk所支持的屏幕信息都在此文件夹中…...

探索WebKit的CSS表格布局:打造灵活的网页数据展示
探索WebKit的CSS表格布局:打造灵活的网页数据展示 CSS表格布局是一种在网页上展示数据的强大方式,它允许开发者使用CSS来创建类似于传统HTML表格的布局。WebKit作为许多流行浏览器的渲染引擎,提供了对CSS表格布局的全面支持。本文将深入探讨…...

信号的运算
信号实现运算,首先要明确,电路此时为负反馈电路,当处于深度负反馈时,可直接使用虚短虚断。负反馈相关内容可见:放大电路中的反馈_基极反馈-CSDN博客https://blog.csdn.net/qq_63796876/article/details/140438759 一、…...

Vue3知识点汇总
创建项目 npm init vuelatest // npm create vitelatestVue文件结构 <!-- 开关:经过语法糖的封装,容许在script中书写组合式API --> <!-- setup在beforeCreate钩子之前自动执行 --> <script setup><!-- 不再要求唯一根元素 -->…...

C++设计模式--单例模式
单例模式的学习笔记 单例模式是为了:在整个系统生命周期内,保证一个类只能产生一个实例,确保该类的唯一性 参见链接1,链接2 #include <iostream> #include <mutex>using namespace std;/*懒汉模式:只有在…...

数据驱动未来:构建下一代湖仓一体电商数据分析平台,引领实时商业智能革命
1.1 项目背景 本项目是一个创新的湖仓一体实时电商数据分析平台,旨在为电商平台提供深度的数据洞察和业务分析。技术层面,项目涵盖了从基础架构搭建到大数据技术组件的集成,采用了湖仓一体的设计理念,实现了数据仓库与数据湖的有…...

学习JavaScript第五天
文章目录 1.HTML DOM1.1 表单相关元素① form 元素② 文本输入框类和文本域(input 和 textarea)③ select 元素 1.2 表格相关元素① table 元素② tableRow 元素(tr 元素)③ tableCell 元素 (td 或 th) 1.3…...

pythonGame-实现简单的坦克大战
通过python简单复现坦克大战游戏。 使用到的库函数: import turtle import math import random import time 游戏源码: import turtle import math import random import time# 设置屏幕 screen turtle.Screen() screen.setup(800, 600) screen.tit…...

不太常见的asmnet诊断
asm侦听 [griddb1-[ASM1]-/home/grid]$ srvctl config asm ASM home: <CRS home> Password file: OCR/orapwASM Backup of Password file: OCRDG/orapwASM_backup ASM listener: LISTENER ASM instance count: 3 Cluster ASM listener: ASMNET1LSNR_ASM[rootdb1:/root]# …...
双指针-【3,4,5,6,7,8】
第三题:快乐数 . - 力扣(LeetCode). - 备战技术面试?力扣提供海量技术面试资源,帮助你高效提升编程技能,轻松拿下世界 IT 名企 Dream Offer。https://leetcode.cn/problems/happy-number/算法思想: 1.每个…...

react Vant中如何获取步进器的值
在React中使用Vant(一个轻量、可靠的移动端Vue组件库,虽然原生是为Vue设计的,但如果你在使用的是React版本的Vant,比如通过某些库或框架桥接Vue组件到React,或者是一个类似命名的React UI库),获…...

Windows下Git Bash乱码问题解决
Windows下Git Bash乱码问题解决 缘起 个人用的电脑是Mac OS,系统和终端编码都是UTF-8,但公司给配发的电脑是Windows,装上Git Bash在使用 git commit -m "中文"时会乱码 解决 确认有以下配置 # 输入 git config --global --lis…...

HTML5 + CSS3
HTML 基础 准备开发环境 1.vscode 使用 新建文件夹 ---> 左键拖入 vscode 中 2.安装插件 扩展 → 搜索插件 → 安装打开网页插件:open in browser汉化菜单插件:Chinese 3.缩放代码字号 放大,缩小:Ctrl 加号,减号 4.设…...
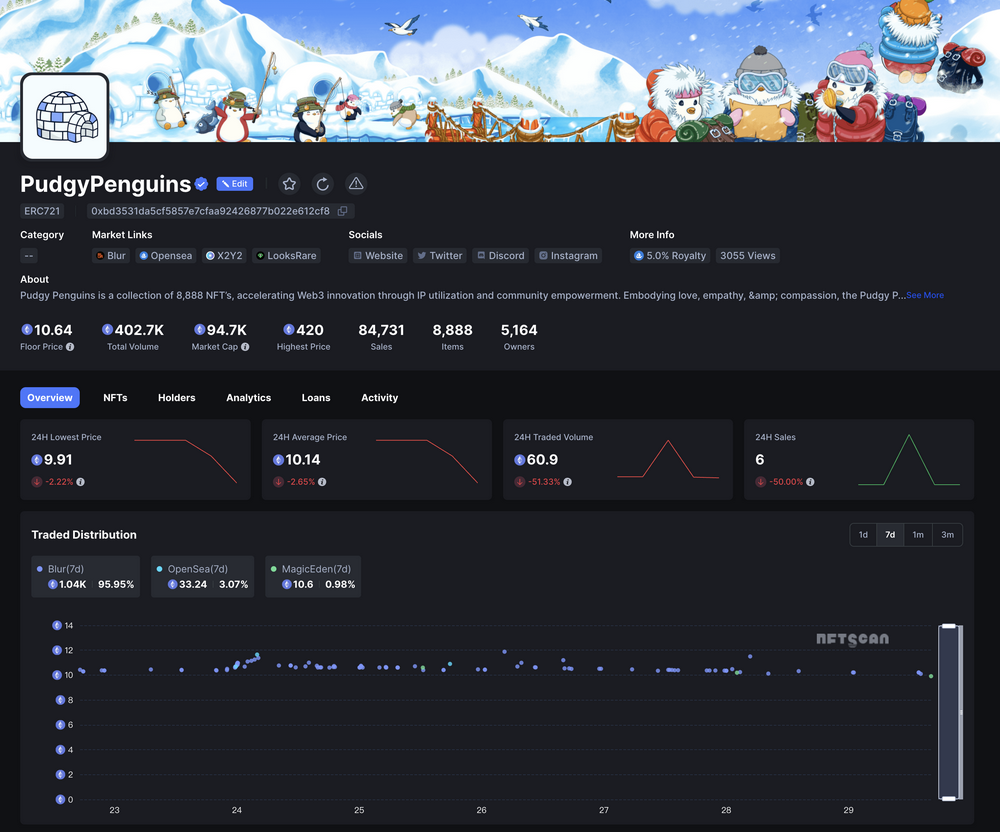
NFTScan | 07.22~07.28 NFT 市场热点汇总
欢迎来到由 NFT 基础设施 NFTScan 出品的 NFT 生态热点事件每周汇总。 周期:2024.07.22~ 2024.07.28 NFT Hot News 01/ 数据:NFT 系列 Liberty Cats 地板价突破 70000 MATIC 7 月 22 日,据 Magic Eden 数据,NFT 系列 Liberty C…...
)
【位运算】消失的两个数字(hard)
消失的两个数字(hard) 题⽬描述:解法(位运算):Java 算法代码:更简便代码 题⽬链接:⾯试题 17.19. 消失的两个数字 题⽬描述: 给定⼀个数组,包含从 1 到 N 所有…...

BCS 2025|百度副总裁陈洋:智能体在安全领域的应用实践
6月5日,2025全球数字经济大会数字安全主论坛暨北京网络安全大会在国家会议中心隆重开幕。百度副总裁陈洋受邀出席,并作《智能体在安全领域的应用实践》主题演讲,分享了在智能体在安全领域的突破性实践。他指出,百度通过将安全能力…...

【学习笔记】深入理解Java虚拟机学习笔记——第4章 虚拟机性能监控,故障处理工具
第2章 虚拟机性能监控,故障处理工具 4.1 概述 略 4.2 基础故障处理工具 4.2.1 jps:虚拟机进程状况工具 命令:jps [options] [hostid] 功能:本地虚拟机进程显示进程ID(与ps相同),可同时显示主类&#x…...

10-Oracle 23 ai Vector Search 概述和参数
一、Oracle AI Vector Search 概述 企业和个人都在尝试各种AI,使用客户端或是内部自己搭建集成大模型的终端,加速与大型语言模型(LLM)的结合,同时使用检索增强生成(Retrieval Augmented Generation &#…...

R语言速释制剂QBD解决方案之三
本文是《Quality by Design for ANDAs: An Example for Immediate-Release Dosage Forms》第一个处方的R语言解决方案。 第一个处方研究评估原料药粒径分布、MCC/Lactose比例、崩解剂用量对制剂CQAs的影响。 第二处方研究用于理解颗粒外加硬脂酸镁和滑石粉对片剂质量和可生产…...

【从零学习JVM|第三篇】类的生命周期(高频面试题)
前言: 在Java编程中,类的生命周期是指类从被加载到内存中开始,到被卸载出内存为止的整个过程。了解类的生命周期对于理解Java程序的运行机制以及性能优化非常重要。本文会深入探寻类的生命周期,让读者对此有深刻印象。 目录 …...
: 一刀斩断视频片头广告)
快刀集(1): 一刀斩断视频片头广告
一刀流:用一个简单脚本,秒杀视频片头广告,还你清爽观影体验。 1. 引子 作为一个爱生活、爱学习、爱收藏高清资源的老码农,平时写代码之余看看电影、补补片,是再正常不过的事。 电影嘛,要沉浸,…...

解析奥地利 XARION激光超声检测系统:无膜光学麦克风 + 无耦合剂的技术协同优势及多元应用
在工业制造领域,无损检测(NDT)的精度与效率直接影响产品质量与生产安全。奥地利 XARION开发的激光超声精密检测系统,以非接触式光学麦克风技术为核心,打破传统检测瓶颈,为半导体、航空航天、汽车制造等行业提供了高灵敏…...

Java求职者面试指南:Spring、Spring Boot、Spring MVC与MyBatis技术解析
Java求职者面试指南:Spring、Spring Boot、Spring MVC与MyBatis技术解析 一、第一轮基础概念问题 1. Spring框架的核心容器是什么?它的作用是什么? Spring框架的核心容器是IoC(控制反转)容器。它的主要作用是管理对…...

Netty自定义协议解析
目录 自定义协议设计 实现消息解码器 实现消息编码器 自定义消息对象 配置ChannelPipeline Netty提供了强大的编解码器抽象基类,这些基类能够帮助开发者快速实现自定义协议的解析。 自定义协议设计 在实现自定义协议解析之前,需要明确协议的具体格式。例如,一个简单的…...