[C++] 容器适配器:深入理解Stack与Queue的底层原理

文章目录
- 容器适配器简介
- `deque`的缺陷
- 为什么使用`deque`作为`stack`和`queue`的底层默认容器
- `stack`和`queue`的简单讲解
- Stack(栈)
- 栈的操作图示
- 栈的相关接口
- Queue(队列)
- `Stack`和`Queue`的模拟实现
- Stack(栈)
- 作为容器适配器的特性
- 模拟实现
- Queue(队列)
- 作为容器适配器的特性
- 模拟实现
- `PriorityQueue`(优先级队列)
- 优先级队列的特性
- `priority_queue`的使用
- 常用接口
- 传入自定义类型的注意事项
- 使用自定义类型传入应用示例
- `priority_queue`的模拟实现
- `deque`的实际应用
- 仿函数(Functor)
- 什么是仿函数?
- 仿函数的定义
- 仿函数的特性
- 状态保存
- 参数化
- 灵活性
- 仿函数的使用场景


容器适配器简介
适配器(Adapter)是一种设计模式,其主要作用是将一个类的接口转换为另一个客户希望的接口。在STL(Standard Template Library)中,适配器用来封装底层容器,提供特定的接口和行为。这种封装可以使得不同的底层容器在接口上保持一致,从而简化代码的使用和维护。
本文所涉及的stack、queue和priority_queue都是容器适配器,在底层都可以通过在接口传入的容器类型来进行底层的容器实现。

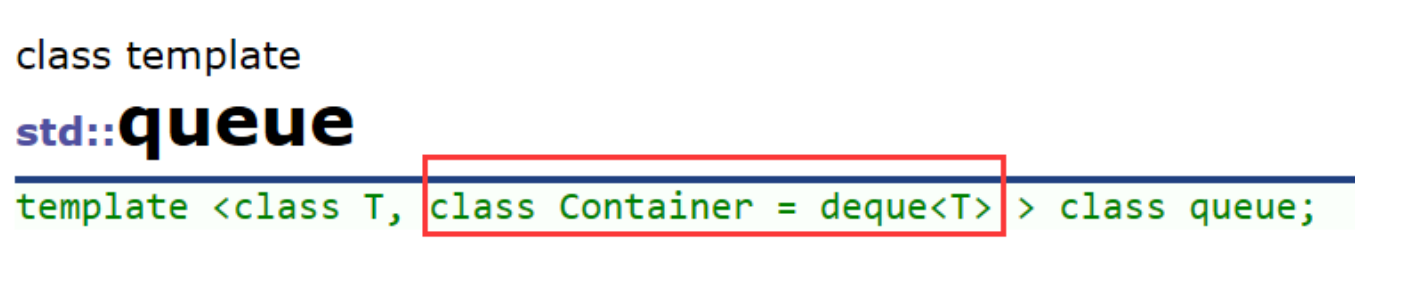

以上官方接口图示中,
Container就是适配器初始化时容器类型的指定,Compare是仿函数,也可以实现相关的适配。
deque的缺陷
与vector比较,deque的优势是:头部插入和删除时,不需要搬移元素,效率特别高,而且在扩容时,也不需要搬移大量的元素,因此其效率是必vector高的。
与list比较,其底层是连续空间,空间利用率比较高,不需要存储额外字段。
但是,deque有一个致命缺陷:不适合遍历,因为在遍历时,deque的迭代器要频繁的去检测其是否移动到某段小空间的边界,导致效率低下,而序列式场景中,可能需要经常遍历,因此在实际中,需要线性结构时,大多数情况下优先考虑vector和list,deque的应用并不多,而目前能看到的一个应用就是,STL用其作为stack和queue的底层数据结构。
为什么使用deque作为stack和queue的底层默认容器
stack是一种后进先出的特殊线性数据结构,因此只要具有push_back()和pop_back()操作的线性结构,都可以作为stack的底层容器,比如vector和list都可以;queue是先进先出的特殊线性数据结构,只要具有push_back和pop_front操作的线性结构,都可以作为queue的底层容器,比如list。但是STL中对stack和queue默认选择deque作为其底层容器,主要是因为:
stack和queue不需要遍历(因此stack和queue没有迭代器),只需要在固定的一端或者两端进行操作。- 在
stack中元素增长时,deque比vector的效率高(扩容时不需要搬移大量数据);queue中的
元素增长时,deque不仅效率高,而且内存使用率高。结合了deque的优点,而完美的避开了其缺陷。
关于deque的详细讲解:
[C++] vector对比list & deque的引出-CSDN博客

stack和queue的简单讲解
Stack(栈)
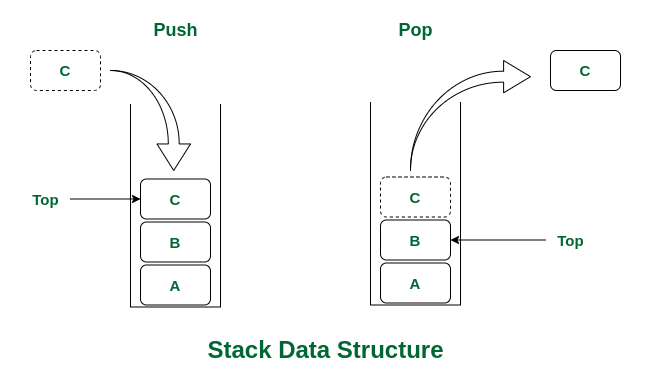
栈的操作图示
栈的相关接口
栈是一种后进先出(LIFO, Last In First Out)的数据结构,通常用于存储临时数据或实现递归。其基本操作包括:
| 接口函数 | 说明 |
|---|---|
push(x) | 将元素x压入栈顶 |
pop() | 移除并返回栈顶元素 |
top() | 返回栈顶元素 |
empty() | 判断栈是否为空 |
size() | 返回栈中元素个数 |
Queue(队列)
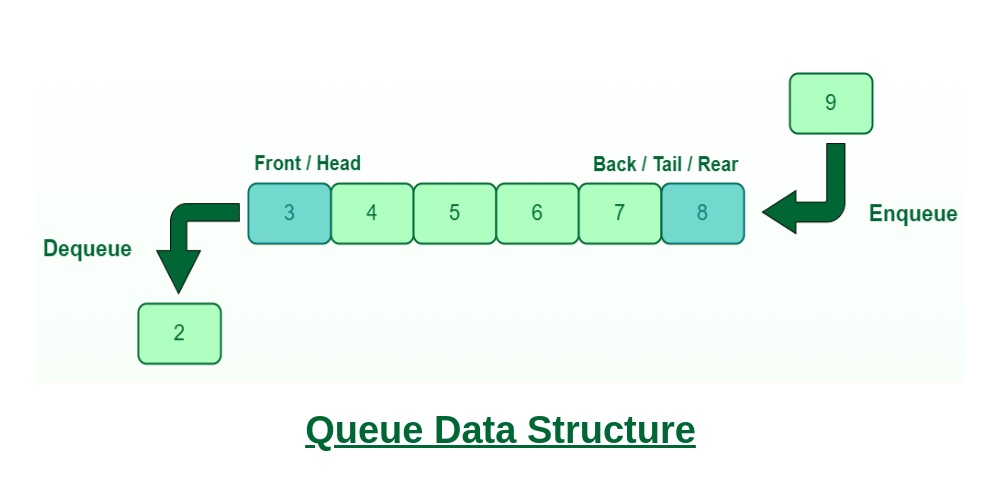
队列是一种先进先出(FIFO, First In First Out)的数据结构,适用于需要顺序处理数据的场景。其基本操作包括:
| 接口函数 | 说明 |
|---|---|
push(x) | 将元素x加入队尾 |
pop() | 移除并返回队头元素 |
front() | 返回队头元素 |
back() | 返回队尾元素 |
empty() | 判断队列是否为空 |
size() | 返回队列中元素个数 |

Stack和Queue的模拟实现
Stack(栈)
作为容器适配器的特性
- 后进先出(LIFO):栈是一种遵循 LIFO 原则的数据结构,这意味着最后被添加到栈中的元素将是第一个被移除的元素。
- 受限的接口:与完整的容器不同,栈的接口限制了用户只能通过栈顶进行操作,不允许直接访问栈中的其他元素。
- 主要操作:
push:向栈顶添加一个元素。pop:移除栈顶的元素。top:访问栈顶的元素(不移除它)。- 空栈检查:可以检查栈是否为空,以便在尝试访问或移除元素之前确保栈不为空。
- 大小限制:可以查询栈中元素的数量,但不允许直接通过索引访问元素。
- 迭代器:虽然栈的迭代器功能有限,但栈仍然提供了迭代器,允许遍历栈中的元素,尽管只能从栈顶开始。
- 异常中立性:栈的操作(如
push和pop)保证不抛出异常,除非是底层容器的操作抛出异常。- 底层容器:栈通常使用
deque或vector作为底层容器来存储元素。选择哪种容器取决于具体的实现和性能要求。- 模板类:栈是一个模板类,可以存储任意类型的元素。
- 不提供排序:栈不提供元素排序功能,它只提供了基本的 LIFO 操作。
- 不提供元素删除:除了
pop操作外,栈不提供从栈中删除任意位置元素的功能。- 不提供直接访问:不能直接访问或修改栈中的元素,除了栈顶元素。
模拟实现
template<class T, class Container = std::deque<T>>
class stack {
public:// 向栈顶添加一个元素void push(const T& x) {_con.push_back(x); // 使用底层容器的 push_back 方法}// 移除栈顶元素void pop() {if (empty()) {throw std::out_of_range("Stack<>::pop: empty stack");}_con.pop_back(); // 使用底层容器的 pop_back 方法}// 获取栈顶元素的引用const T& top() const {if (empty()) {throw std::out_of_range("Stack<>::top: empty stack");}return _con.back(); // 使用底层容器的 back 方法}// 获取栈中元素的数量size_t size() const {return _con.size();}// 检查栈是否为空bool empty() const {return _con.empty();}private:Container _con; // 底层容器
};
Queue(队列)
作为容器适配器的特性
- 队列是一种容器适配器,专门用于在FIFO上下文(先进先出)中操作,其中从容器一端插入元素,另一端提取元素。
- 队列作为容器适配器实现,容器适配器即将特定容器类封装作为其底层容器类,queue提供一组特定的成员函数来访问其元素。元素从队尾入队列,从队头出队列。
- 底层容器可以是标准容器类模板之一,也可以是其他专门设计的容器类。该底层容器应至少支持以下操作:
empty:检测队列是否为空size:返回队列中有效元素的个数front:返回队头元素的引用back:返回队尾元素的引用push_back:在队列尾部入队列pop_front:在队列头部出队列- 标准容器类
deque和list满足了这些要求。默认情况下,如果没有为queue实例化指定容器
类,则使用标准容器deque
模拟实现
template<class T, class Container = std::deque<T>>
class queue {
public:// 向队列尾部添加一个元素void push(const T& x) {_con.push_back(x); // 使用底层容器的 push_back 方法}// 移除队列头部的元素void pop() {if (empty()) {throw std::out_of_range("Queue<>::pop: empty queue");}_con.pop_front(); // 使用底层容器的 pop_front 方法}// 获取队列头部元素的引用const T& front() const {if (empty()) {throw std::out_of_range("Queue<>::front: empty queue");}return _con.front(); // 使用底层容器的 front 方法}// 获取队列尾部元素的引用const T& back() const {if (empty()) {throw std::out_of_range("Queue<>::back: empty queue");}return _con.back(); // 使用底层容器的 back 方法}// 获取队列中元素的数量size_t size() const {return _con.size();}// 检查队列是否为空bool empty() const {return _con.empty();}private:Container _con; // 底层容器,默认为 deque
};

PriorityQueue(优先级队列)
优先级队列是一种特殊的队列,元素按照优先级排列。其基本操作类似于堆,主要用于调度算法、路径搜索等需要频繁获取最高优先级元素的场景。
优先级队列的特性
- 优先队列是一种容器适配器,根据严格的弱排序标准,它的第一个元素总是它所包含的元素中最大的。
- 此上下文类似于堆,在堆中可以随时插入元素,并且只能检索最大堆元素(优先队列中位于顶部的元素)。
- 优先队列被实现为容器适配器,容器适配器即将特定容器类封装作为其底层容器类,queue提供一组特定的成员函数来访问其元素。元素从特定容器的“尾部”弹出,其称为优先队列的顶部。
- 底层容器可以是任何标准容器类模板,也可以是其他特定设计的容器类。容器应该可以通过随机访问迭代器访问,并支持以下操作:
empty():检测容器是否为空size():返回容器中有效元素个数front():返回容器中第一个元素的引用push_back():在容器尾部插入元素pop_back():删除容器尾部元素- 标准容器类
vector和deque满足这些需求。默认情况下,如果没有为特定的priority_queue
类实例化指定容器类,则使用vector。- 需要支持随机访问迭代器,以便始终在内部保持堆结构。容器适配器通过在需要时自动调用
算法函数make_heap、push_heap和pop_heap来自动完成此操作。
priority_queue的使用
优先级队列默认使用vector作为其底层存储数据的容器,在vector上又使用了堆算法将vector中元素构造成堆的结构,因此priority_queue就是堆,所有需要用到堆的位置,都可以考虑使priority_queue。
注意:默认情况下
priority_queue是大堆。
常用接口
| 接口函数 | 说明 |
|---|---|
push(x) | 插入元素x |
pop() | 移除并返回最大(或最小)元素 |
top() | 返回最大(或最小)元素但不移除 |
empty() | 判断队列是否为空 |
size() | 返回队列中元素个数 |
emplace(x) | 就地构造元素x并插入队列 |
swap(q) | 交换当前优先级队列与q中的元素 |
std::less<T> | 默认仿函数,构建最大堆 |
std::greater<T> | 自定义仿函数,构建最小堆(需自定义仿函数参数) |
传入自定义类型的注意事项
当你使用 std::priority_queue 时,它默认使用 < 运算符来确定元素之间的优先级关系,即默认情况下,较小的元素会被认为是具有较高优先级的。然而,std::priority_queue 也允许用户指定一个自定义的比较函数,这使得你可以定义自己的优先级规则。
所以:如果在
priority_queue中放自定义类型的数据,需要在自定义类型中提供>或者<的重载。
如果你要将自定义类型的对象放入 std::priority_queue 中,并且希望使用不同于默认的优先级规则(例如,你可能希望较大的元素具有较高的优先级),你需要提供一个自定义的比较函数。这个比较函数可以是:
- 一个函数对象(functor)。
- 一个普通的函数。
- 一个 lambda 表达式。
这就是仿函数的基本用法。当使用自定义类型时,传入std::greater<T>或std::less<T>会自动调用自定义类型重载的<和>来构建优先级队列。
使用自定义类型传入应用示例
class Date {
public:// 构造函数,初始化日期Date(int year = 1900, int month = 1, int day = 1): _year(year), _month(month), _day(day) {}// 重载小于运算符,用于比较两个日期bool operator<(const Date& d) const {return (_year < d._year) ||(_year == d._year && _month < d._month) ||(_year == d._year && _month == d._month && _day < d._day);}// 重载大于运算符,用于比较两个日期bool operator>(const Date& d) const {return (_year > d._year) ||(_year == d._year && _month > d._month) ||(_year == d._year && _month == d._month && _day > d._day);}// 友元函数,重载输出流运算符,用于输出日期friend std::ostream& operator<<(std::ostream& os, const Date& d) {os << d._year << "-" << d._month << "-" << d._day;return os;}private:int _year;int _month;int _day;
};void TestPriorityQueue() {// 使用默认的 priority_queue 创建最大堆std::priority_queue<Date> q1;q1.push(Date(2018, 10, 29));q1.push(Date(2018, 10, 28));q1.push(Date(2018, 10, 30));std::cout << "Max heap top: " << q1.top() << std::endl;// 使用自定义比较对象 greater<Date> 创建最小堆std::priority_queue<Date, std::vector<Date>, std::greater<Date>> q2;q2.push(Date(2018, 10, 29));q2.push(Date(2018, 10, 28));q2.push(Date(2018, 10, 30));std::cout << "Min heap top: " << q2.top() << std::endl;
}int main() {TestPriorityQueue();return 0;
}
TestPriorityQueue函数展示了如何使用std::priority_queue来创建最大堆和最小堆。最大堆q1使用Date类的<运算符来确定元素的优先级,而最小堆q2使用std::greater<Date>来实现,它将Date类型的>运算符作为比较函数。函数最后输出了两个堆的顶部元素。
priority_queue的模拟实现
template<class T>
class Less {
public:bool operator()(const T& x, const T& y) const { return x < y;}
};template<class T>
class Greater {
public:bool operator()(const T& x, const T& y) const { return x > y;}
};namespace bee {template<class T, class Container = std::vector<T>, class Compare = Less<T>>class priority_queue {public:void adjustUp(int child) {while (child > 0) {int parent = (child - 1) / 2;if (_compare(_con[child], _con[parent])) {std::swap(_con[child], _con[parent]);child = parent;} else {break;}}}void push(const T& x) {_con.push_back(x);adjustUp(static_cast<int>(_con.size()) - 1);}void adjustDown(int parent) {int child = parent * 2 + 1;while (child < _con.size()) {int right_child = child + 1;if (right_child < _con.size() && _compare(_con[child], _con[right_child])) {child = right_child;}if (_compare(_con[child], _con[parent])) {std::swap(_con[child], _con[parent]);parent = child;child = parent * 2 + 1;} else {break;}}}void pop() {std::swap(_con[0], _con.back());_con.pop_back();adjustDown(0);}T top() const { // 添加 const 并移除 return 关键字return _con[0];}size_t size() const {return _con.size();}bool empty() const {return _con.empty();}private:Container _con;Compare _compare; // 存储比较函数对象};
}
在底层使用堆进行维护,符合了deque的逻辑。
deque的实际应用
struct Task {int priority;std::string name;// 重载运算符,用于比较任务的优先级(priority),越小优先级越高bool operator<(const Task& other) const {return priority > other.priority; // priority值越小优先级越高}
};int main() {std::priority_queue<Task> taskQueue;// 添加任务到队列taskQueue.push(Task{3, "Task A"});taskQueue.push(Task{1, "Task B"});taskQueue.push(Task{2, "Task C"});// 处理任务while (!taskQueue.empty()) {Task currentTask = taskQueue.top();std::cout << "Processing " << currentTask.name << " with priority " << currentTask.priority << std::endl;taskQueue.pop();}
在这个例子中,我们定义了一个
Task结构体,每个任务有一个优先级和名称。我们使用std::priority_queue来管理这些任务,并通过重载operator<来定义任务的优先级比较规则。优先级最高的任务(priority值最小)会首先被处理。

仿函数(Functor)
什么是仿函数?
仿函数(Functor)是指实现了operator()的对象。在C++中,仿函数是一种能够像普通函数一样被调用的对象。它们通过重载函数调用运算符operator()来实现这一点,因此可以像函数一样使用。
通过重载operator(),仿函数可以模拟函数的行为,使得对象不仅可以保存状态,还可以执行操作。这种机制在C++中非常有用,特别是在STL(标准模板库)中,它允许用户自定义排序准则、筛选条件等。
仿函数的定义
仿函数是一个类或者结构体,通过重载operator()来实现。基本形式如下:
class Functor {
public:void operator()(/* 参数列表 */) {// 函数体}
};
仿函数的特性
状态保存
仿函数可以有成员变量,这允许它们在调用时保存状态。这是与普通函数的一个重要区别,因为普通函数没有状态。仿函数可以应用在需要保留上下文信息的场景。例如,计数器仿函数可以记录被调用的次数:
class Counter {
public:Counter() : count(0) {}void operator()() {++count;std::cout << "Called " << count << " times" << std::endl;}private:int count;
};int main() {Counter countCalls;countCalls(); // 输出 "Called 1 times"countCalls(); // 输出 "Called 2 times"return 0;
}
在这个例子中,Counter仿函数保存了调用次数,并在每次调用时输出当前的调用次数。
参数化
仿函数可以通过构造函数参数传递数据,使得调用operator()时可以使用这些数据进行操作,也就是在上文适配器中关于仿函数的使用方式。
灵活性
仿函数可以重载operator()来实现不同的功能,比如比较、操作等,提供了很大的灵活性。结合灵活性与参数化,可以灵活的控制相关容器的底层存储。
template<class T, class Container = std::vector<T>, class Compare = Less<T>>
通过传递仿函数,用户可以自定义优先级队列的元素排列规则
例如在上文实现优先级队列的模拟实现代码中,就使用的仿函数作为模板参数:
在
priority_queue中,仿函数Compare决定了元素的优先级顺序。默认情况下,Less<T>会将较小的元素放在堆顶,形成最小堆。如果使用Greater<T>,则会形成最大堆。仿函数的灵活性允许用户根据需要自定义优先级队列的行为。仿函数的使用使得priority_queue能够支持多种排列规则,而不需要修改底层容器的实现。
仿函数的使用场景
- 排序:在STL算法(如
std::sort)中,可以使用仿函数自定义排序准则。 - 筛选:在STL算法(如
std::remove_if)中,可以使用仿函数定义筛选条件。 - 优先级队列:在
std::priority_queue中,仿函数用于定义元素的优先级排序。 - 延迟计算:通过在仿函数中保存状态,用户可以实现延迟计算的逻辑。
具体的应用请通过上文优先级队列理解。

相关文章:
[C++] 容器适配器:深入理解Stack与Queue的底层原理
文章目录 容器适配器简介deque的缺陷为什么使用deque作为stack和queue的底层默认容器 stack和queue的简单讲解Stack(栈)栈的操作图示栈的相关接口 Queue(队列) Stack和Queue的模拟实现Stack(栈)作为容器适配…...

Eclipse maven 的坑
在使用 eclipse 时, eclipse 的右下角 一直在提示 “JPA java change event handler” ,eclipse使用起来很卡,解决办法 问题描述: 在使用 eclipse时, eclipse 的右下角 一直在提示 “JPA java change event handler”…...

多模态视觉大语言模型——LLaVA
论文题目:Visual Instruction Tuning 论文地址:https://arxiv.org/abs/2304.08485 github: https://github.com/haotian-liu/LLaVA 1. Abstract 本文首次尝试使用GPT-4生成多模态指令数据,并基于这些数据训练了LLaVA(Large Language and Vision Assistant)模型,这是一种结…...

服务注册到nacos上,不能点击下线的问题处理
nacos不能下线: 修改 /usr/local/mid/nacos/data 文件夹下 protocol 文件重命名为 protocol_bak,然后再重启nacos nacos单机启动命令:cd sh startup.sh -m standalone nginx启动命令:cd /usr/local/mid/nginx/sbin ./…...

未来3-5年,哪些工作会被AI取代
一篇由高盛经济学家约瑟夫布里格斯 (Joseph Briggs)和德维西科德纳尼 (Devesh Kodnani)撰写的报告指出,全球预计将有3亿个工作岗位被生成式AI取代。 报告称:“最近出现的生成式人工智能将降低劳动力成本和…...

鸿蒙系统开发【网络管理】
网络管理 介绍 此Demo展示如何查询网络详情、域名解析、网络状态监听等功能。 效果预览: 使用说明: 1.启动应用,在点击检查网络、网络详情、网络连接信息后,展示对应的信息; 2.在域名解析的模块下,输入…...

nginx如何处理请求
nginx如何处理请求 注:内容翻译自Nginx官网文档 How nginx processes a request。 基于名称的虚拟服务器 nginx首先要决定哪个服务器应该处理请求。让我们从一个简单的配置开始,三个虚拟服务器都监听在端口*:80: server {listen 80;server_name e…...

换地不换IP?揭秘微博IP地址的奥秘
在这个信息飞速传递的时代,社交媒体成为我们生活中不可或缺的一部分。微博,作为其中的佼佼者,不仅是我们获取资讯的重要渠道,也是展现自我、分享生活的重要平台。然而,你有没有遇到过这样的情况:明明已经换…...

数据库事务处理技术——故障恢复
1. 数据故障恢复的宏观思路 我们知道DBMS是利用内存(主存)和外存(辅存)这样的存储体系进行数据库的管理,其中内存也就是我们常说的缓存是易失的。而事务时DBMS对数据库进行控制的基本单元,宏观上是由程序设…...

Java零基础之多线程篇:性能考虑篇
哈喽,各位小伙伴们,你们好呀,我是喵手。运营社区:C站/掘金/腾讯云;欢迎大家常来逛逛 今天我要给大家分享一些自己日常学习到的一些知识点,并以文字的形式跟大家一起交流,互相学习,一…...

CSP 初赛复习 :计算机网络基础
计算机网络的基础和网络的拓扑结构是计算机网络设计和实施的关键要素。 计算机网络的基础涉及多个方面,包括网络层协议(如IP、ICMP、IGMP等)、传输层协议(TCP、UDP等)以及应用层协议(…...
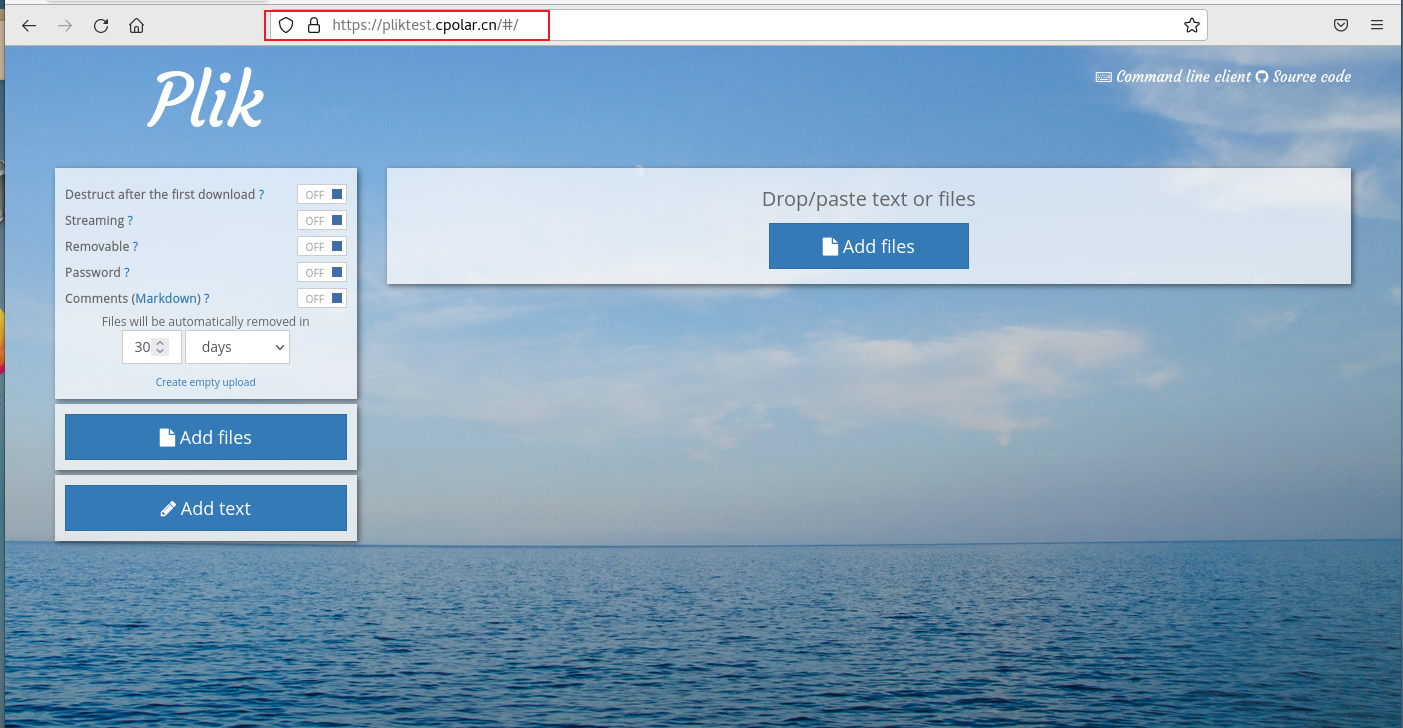
【Docker应用】快速搭建Plik服务结合内网穿透无公网IP远程访问传输文件
文章目录 前言1. Docker部署Plik2. 本地访问Plik3. Linux安装Cpolar4. 配置Plik公网地址5. 远程访问Plik6. 固定Plik公网地址7. 固定地址访问Plik 前言 本文介绍如何使用Linux docker方式快速安装Plik并且结合Cpolar内网穿透工具实现远程访问,实现随时随地在任意设…...

记录使用FlinkSql进行实时工作流开发
使用FlinkSql进行实时工作流开发 引言Flink SQL实战常用的Connector1. MySQL-CDC 连接器配置2. Kafka 连接器配置3. JDBC 连接器配置4. RabbitMQ 连接器配置5. REST Lookup 连接器配置6. HDFS 连接器配置 FlinkSql数据类型1. 基本数据类型2. 字符串数据类型3. 日期和时间数据类…...
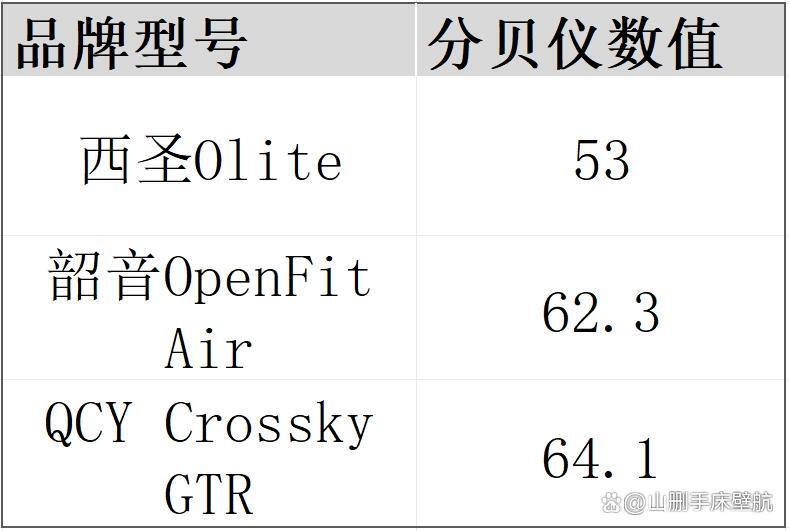
韶音开放式耳机怎么样?韶音、西圣、QCY热门款实测横评
开放式耳机是目前最火爆的的耳机市场细分赛道,开放式耳机的优点包括健康卫生,佩戴舒适性高,方便我们接收外部环境音等等,以上这些优势使得开放式耳机特别适配户外运动场景,在工作、日常生活等场景下使用也是绰绰有余。…...

求值(河南萌新2024)
我真的服了,注意数据范围!!!!!!!!!!!!!!!!!!&#…...

【Linux】文件描述符 fd
目录 一、C语言文件操作 1.1 fopen和fclose 1.2 fwrite和fread 1.3 C语言中的输入输出流 二、Linux的文件系统调用 2.1 open和文件描述符 2.2 close 2.3 read 2.4 write 三、Linux内核数据结构与文件描述符 一、C语言文件操作 在C语言中我们想要打开一个文件并对其进…...

带通采样定理
一、采样定理 1.1 低通采样定理(奈奎斯特采样) 低通采样定理(奈奎斯特采样)是要求大于信号的最高上限频率的两倍 1.2 带通采样定理 带通信号的采样频率在某个时间小于采样频率也能无失真恢复原信号 二、频谱混叠 对一个连续时域信号,采…...
运维工作中的事件、故障排查处理思路
一、运维工作中的事件 https://www.51cto.com/article/687753.html 二、运维故障排查 一)故障排查步骤 1、明确故障 故障现象的直接表现故障发生的时间、频率故障发生影响哪些系统故障发生是否有明确的触发条件 故障举例:无法通过ssh登录系统 影响…...

深入源码P3C-PMD:使用流程(1)
PMD开源组件启动流程介绍 在软件开发领域,代码质量是项目成功的关键因素之一。为了提升代码质量,开发者们常常借助各种工具进行代码分析和检查。PMD作为一款开源的静态代码分析工具,在Java、JavaScript、PLSQL等语言项目中得到了广泛应用。本…...

java~反射
反射 使用的前提条件:必须先得到代表的字节码的Class,Class类用于表示.class文件(字节码) 原理图 加载完类后,在堆中就产生了一个Class类型的对象(一个类只有一个Class对象),这个对…...

条件运算符
C中的三目运算符(也称条件运算符,英文:ternary operator)是一种简洁的条件选择语句,语法如下: 条件表达式 ? 表达式1 : 表达式2• 如果“条件表达式”为true,则整个表达式的结果为“表达式1”…...

基于Uniapp开发HarmonyOS 5.0旅游应用技术实践
一、技术选型背景 1.跨平台优势 Uniapp采用Vue.js框架,支持"一次开发,多端部署",可同步生成HarmonyOS、iOS、Android等多平台应用。 2.鸿蒙特性融合 HarmonyOS 5.0的分布式能力与原子化服务,为旅游应用带来…...

DeepSeek 技术赋能无人农场协同作业:用 AI 重构农田管理 “神经网”
目录 一、引言二、DeepSeek 技术大揭秘2.1 核心架构解析2.2 关键技术剖析 三、智能农业无人农场协同作业现状3.1 发展现状概述3.2 协同作业模式介绍 四、DeepSeek 的 “农场奇妙游”4.1 数据处理与分析4.2 作物生长监测与预测4.3 病虫害防治4.4 农机协同作业调度 五、实际案例大…...

Java线上CPU飙高问题排查全指南
一、引言 在Java应用的线上运行环境中,CPU飙高是一个常见且棘手的性能问题。当系统出现CPU飙高时,通常会导致应用响应缓慢,甚至服务不可用,严重影响用户体验和业务运行。因此,掌握一套科学有效的CPU飙高问题排查方法&…...

JavaScript基础-API 和 Web API
在学习JavaScript的过程中,理解API(应用程序接口)和Web API的概念及其应用是非常重要的。这些工具极大地扩展了JavaScript的功能,使得开发者能够创建出功能丰富、交互性强的Web应用程序。本文将深入探讨JavaScript中的API与Web AP…...

手机平板能效生态设计指令EU 2023/1670标准解读
手机平板能效生态设计指令EU 2023/1670标准解读 以下是针对欧盟《手机和平板电脑生态设计法规》(EU) 2023/1670 的核心解读,综合法规核心要求、最新修正及企业合规要点: 一、法规背景与目标 生效与强制时间 发布于2023年8月31日(OJ公报&…...
零知开源——STM32F103RBT6驱动 ICM20948 九轴传感器及 vofa + 上位机可视化教程
STM32F1 本教程使用零知标准板(STM32F103RBT6)通过I2C驱动ICM20948九轴传感器,实现姿态解算,并通过串口将数据实时发送至VOFA上位机进行3D可视化。代码基于开源库修改优化,适合嵌入式及物联网开发者。在基础驱动上新增…...

离线语音识别方案分析
随着人工智能技术的不断发展,语音识别技术也得到了广泛的应用,从智能家居到车载系统,语音识别正在改变我们与设备的交互方式。尤其是离线语音识别,由于其在没有网络连接的情况下仍然能提供稳定、准确的语音处理能力,广…...

【Linux】Linux安装并配置RabbitMQ
目录 1. 安装 Erlang 2. 安装 RabbitMQ 2.1.添加 RabbitMQ 仓库 2.2.安装 RabbitMQ 3.配置 3.1.启动和管理服务 4. 访问管理界面 5.安装问题 6.修改密码 7.修改端口 7.1.找到文件 7.2.修改文件 1. 安装 Erlang 由于 RabbitMQ 是用 Erlang 编写的,需要先安…...

规则与人性的天平——由高考迟到事件引发的思考
当那位身着校服的考生在考场关闭1分钟后狂奔而至,他涨红的脸上写满绝望。铁门内秒针划过的弧度,成为改变人生的残酷抛物线。家长声嘶力竭的哀求与考务人员机械的"这是规定",构成当代中国教育最尖锐的隐喻。 一、刚性规则的必要性 …...