N4 - Pytorch实现中文文本分类
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
目录
- 任务描述
- 步骤
- 环境设置
- 数据准备
- 模型设计
- 模型训练
- 模型效果展示
- 总结与心得体会
任务描述
在上周的任务中,我们使用torchtext下载了托管的英文的AG News数据集 进行了分类任务。本周我们来对中文的自定义数据集来进行分类任务。
自定义数据集的格式是csv格式,我们先用pandas进行读取,创建数据集对象。然后后面的步骤就和上周基本上一致了。
步骤
环境设置
import torch
import warningswarnings.filterwarnings('ignore') # 忽略警告# 创建全局设备对象
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
device

数据准备
使用pandas读取数据
import pandas as pd
train_data = pd.read_csv('train.csv', sep='\t', header=None)
train_data.head()

可以看到数据有两列,第一列是文字内容,第二列是所属的标签。
接下来编写一个迭代器函数,每次迭代返回一对内容和标签
def custom_data_iter(texts, labels):for x, y in zip(texts, labels):yield x, y
train_iter = custom_data_iter(train_data[0].values[:], train_data[1].values[:])
然后创建词典,使用torchtext中的build_vocab_from_iterator工具函数
from torchtext.vocab import build_vocab_from_iterator
import jieba# 使用jieba库来做分词器
tokenizer = jieba.lcut # lcut直接返回列表, cut 返回一个迭代器# 编写一个迭代函数,每次返回一句内容的分词结果
def yield_tokens(data_iter):for text, _ in data_iter: # 每次返回一句内容和对应标签yield tokenizer(text) # 返回该句内容的分词列表# 创建词典
vocab = build_vocab_from_iterator(yield_tokens(train_iter), specials=['<unk>'])
vocab.set_default_index(vocab['<unk>'])# 测试词典
vocab(['我', '想', '看', '和平', '精英', '上', '战神', '必备', '技巧', '的', '游戏', '视频'])

获取所有的标签名
label_name = list(set(train_data[1].values[:]))
print(label_name)

编写函数,将内容和标签分别转换成数值
text_pipeline = lambda x: vocab(tokenizer(x))
label_pipeline = lambda x: label_name.index(x)print(text_pipeline("我想看和平精英上战神必备技巧的游戏视频"))
print(label_pipeline('Video-Play'))

编写文本的批处理函数,用于数据集与模型之间,将一个批次的文本数据转换为数值,还需要生成EmbeddingBag输入时的offsets参数。
from torch.utils.data import DataLoaderdef collate_batch(batch):label_list, text_list, offsets = [], [], [0]for (_text, _label) in batch:# 标签列表label_list.append(label_pipeline(_label))# 文本列表processed_text = torch.tensor(text_pipeline(_text), dtype=torch.int64)text_list.append(processed_text)# 偏移列表offsets.append(len(processed_text))label_list = torch.tensor(label_list, dtype=torch.int64)text_list = torch.cat(text_list)offsets = torch.tensor(offsets[:-1]).cumsum(dim=0)return text_list.to(device), label_list.to(device), offsets.to(device)dataloader = DataLoader(train_iter, batch_size=8, shuffle=False, collate_fn=collate_batch)
模型设计
和上节一样,一个EmbeddingBag层跟着一个全连接层就可以了
from torch import nnclass TextClassificationModel(nn.Module):# 参数随后设置def __init__(self, vocab_size, embed_dim, num_classes):super().__init__()self.embedding = nn.EmbeddingBag(vocab_size, embed_dim, sparse=False)self.fc = nn.Linear(embed_dim, num_classes)self.init_weights()# 自定义的权重初始化操作def init_weights(self):initrange = 0.5self.embedding.weight.data.uniform_(-initrange, initrange)self.fc.weight.data.uniform_(-initrange, initrange)self.fc.bias.data.zero_()# 向前传播def forward(self, text, offsets):embedded = self.embedding(text, offsets)return self.fc(embedded)
创建模型对象
num_classes = len(label_name) # 分类数量
vocab_size = len(vocab) # 词典大小
embedding_size = 64 # 嵌入向量的维度
model = TextClassificationModel(vocab_size, embedding_size, num_classes).to(device)
model

可以看到,这个模型简单的很。
模型训练
首先编写训练和评估函数
def train(dataloader):model.train()total_acc, train_loss, total_count = 0, 0, 0log_interval = 50start_time = time.time()for idx, (text, label, offsets) in enumerate(dataloader):predicted_label = model(text, offsets)optimizer.zero_grad()loss = criterion(predicted_label, label)loss.backward()nn.utils.clip_grad_norm_(model.parameters(), 0.1) #梯度裁剪optimizer.step()total_acc += (predicted_label.argmax(1) == label).sum().item()train_loss += loss.item()total_count += label.size(0)if idx % log_interval == 0 and idx > 0:elapsed = time.time() - start_timeprint('| epoch {:1d} | {:4d}/{:4d} batches ''| train_acc {:4.3f} train_loss {:4.5f}'.format(epoch, idx, len(dataloader), total_acc/total_count, train_loss, total_count))total_acc, train_loss, total_count = 0, 0, 0start_time = time.time()def evaluate(dataloader):model.eval()total_acc, train_loss, total_count = 0, 0, 0with torch.no_grad():for idx, (text, label, offsets) in enumerate(dataloader):predicted_label = model(text, offsets)loss = criterion(predicted_label, label)total_acc += (predicted_label.argmax(1) == label).sum().item()train_loss += loss.item()total_count += label.size(0)return total_acc/total_count, train_loss/total_count
开始训练
from torch.utils.data import random_split
from torchtext.data.functional import to_map_style_dataset# 迭代次数
EPOCHS = 20
# 学习率
LR = 5
# 批次大小
BATCH_SIZE = 64criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=LR)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, 1.0, gamma=0.1)total_accu = None
train_iter = custom_data_iter(train_data[0].values[:], train_data[1].values[:])
train_dataset = to_map_style_dataset(train_iter)train_size = int(len(train_dataset)*0.8)
split_train_, split_valid_ = random_split(train_dataset, [train_size, len(train_dataset) - train_size])train_dataloader = DataLoader(split_train_, batch_size=BATCH_SIZE, shuffle=True, collate_fn=collate_batch)
valid_dataloader = DataLoader(split_valid_, batch_size=BATCH_SIZE, shuffle=True, collate_fn=collate_batch)for epoch in range(1, EPOCHS+1):epoch_start_time = time.time()train(train_dataloader)val_acc, val_loss = evaluate(valid_dataloader)lr = optimizer.state_dict()['param_groups'][0]['lr']if total_accu is not None and total_accu > val_acc:scheduler.step()else:total_accu = val_accprint('-'*69)print('| epoch {:1d} | time: {:4.2f}s | ''valid_acc {:4.3f} valid_loss {:4.3f} | lr {:4.6f}'.format(epoch, time.time() - epoch_start_time, val_acc, val_loss, lr))print('-'*69)

训练结束后打印一下模型的准确度
model = model.to(device)
test_acc, test_loss = evaluate(valid_dataloader)
print('模型准确率为: {:5.4f}'.format(test_acc))

模型效果展示
自己写一句话让模型跑一下看看效果
def predict(text, text_pipeline):with torch.no_grad():text = torch.tensor(text_pipeline(text))output = model(text, torch.tensor([0]))return output.argmax(1).item()ex_text_str = '不要让一个男人听懂《水星记》'# 切换成CPU推理
model = model.to('cpu')
print('文本的分类是: %s' % label_name[predict(ex_text_str, text_pipeline)])

总结与心得体会
通过测试,发现这个模型的效果还是不错的。大部分的句子可以给出正确的分类。和上节相比,中文数据集的文本分类任务和英文数据集的文本分类主要差异在tokenizer(分词器)上。英文的分词非常简单,英文的词之间天然有间隔,所以可以直接使用标点和空格来分割。中文就不太一样,中文需要一个好的断句工具才行,jieba库就是这么一个工具。在大部分的中文自然语言处理任务中,都可以看到它的身影。我在想是不是可以直接使用深度学习来进行分词,来达到更好的效果,或者直接使用大语言模型,经过Prompt直接变成分词工具来使用(只不过成本太高了),希望有时间可以尝试一下。
相关文章:
N4 - Pytorch实现中文文本分类
🍨 本文为🔗365天深度学习训练营 中的学习记录博客🍖 原作者:K同学啊 目录 任务描述步骤环境设置数据准备模型设计模型训练模型效果展示 总结与心得体会 任务描述 在上周的任务中,我们使用torchtext下载了托管的英文的…...

centos 如何安装sox音视频处理工具
要在 CentOS 系统上安装 Sox 音频处理软件,你可以遵循以下步骤。请注意,这些说明适用于 CentOS 7,对于 CentOS 8 及更高版本,某些包管理命令可能略有不同。 第一步:安装所需的依赖库 首先,你需要安装一系列…...

Java语言程序设计——篇十一(2)
🌿🌿🌿跟随博主脚步,从这里开始→博主主页🌿🌿🌿 欢迎大家:这里是我的学习笔记、总结知识的地方,喜欢的话请三连,有问题可以私信🌳🌳&…...

Linux 应急响应靶场练习 1
靶场在知攻善防实验室公众号中可以获取 前景需要:小王急匆匆地找到小张,小王说"李哥,我dev服务器被黑了",快救救我!! 挑战内容: (1)黑客的IP地址 (2࿰…...

AWS-Lambda的使用
介绍 Lambda 是一种无服务器(Serverless), 而且设计成事件驱动的计算服务器. 简单来说, 你可以将你的 code 上传, 当有事件产生(例如cronjob , 或者S3有新的文件被上传上來) , 你的code 就会在瞬间(零点几秒以內)被叫起來执行. 由于你不用管 Server如何维护, 或者自动扩展之类…...

python3.12 搭建MinerU 环境遇到的问题解决
报错: AttributeError: module pkgutil has no attribute ImpImporter. Did you mean: zipimporter? ERROR: Exception: Traceback (most recent call last):File "D:\ipa_workspace\MinerU\Lib\site-packages\pip\_internal\cli\base_command.py", …...

基于SpringBoot+Vue的流浪猫狗救助救援网站(带1w+文档)
基于SpringBootVue的流浪猫狗救助救援网站(带1w文档) 基于SpringBootVue的流浪猫狗救助救援网站(带1w文档) 该流浪猫狗救助救援网站在Windows平台下完成开发,采用java编程语言开发,将应用程序部署于Tomcat上,加之MySQL接口来实现交互式响应服…...

56_AOP
AOP使用案例 如何进行数据库和Redis中的数据同步?/ 你在项目的那些地方使用了aop?答:可以通过Aop操作来实现数据库和Redis中的数据同步。/ 通过Aop操作来实现数据库和Redis中的数据同步。可以定义一个切面类,通过对控制器下的所有…...

安装了h5py,使用报错ImportError: DLL load failed while importing _errors
使用pip 安装了h5py,但是运行代码报错; from . import _errorsImportError: DLL load failed while importing _errors: 找不到指定的程序。 原因: 可能和不正确安装h5py这个包有关系 解决: pip uninstall h5py 换成使用conda…...

BootStrap前端面试常见问题
在前端面试中,关于Bootstrap的问题通常围绕其基本概念、使用方式、特性以及实际应用等方面展开。以下是一些常见的问题及其详细解答: 1. Bootstrap是哪家公司研发的? 回答:Bootstrap是由Twitter的Mark Otto和Jacob Thornton合作…...

在linux运维中为什么第一道防线是云防火墙,而不是waf
在Linux运维和云计算环境中,第一道防线通常是云防火墙(Cloud Firewall),而不是Web应用防火墙(WAF),主要是因为云防火墙提供了更基础和广泛的网络层安全控制。以下是一些关键原因: 1…...
上海理工大学校内选拔赛)
2022年中国高校计算机大赛-团队程序设计天梯赛(GPLT)上海理工大学校内选拔赛
2022年中国高校计算机大赛-团队程序设计天梯赛(GPLT)上海理工大学校内选拔赛 2024.8.2 12:00————16:00 过题数790/1500 补题数943.33/1500 AB Problem Komorebi的数学课 次佛锅 Setsuna的K数列 Wiki下象棋 黄金律法 天气预报 叠硬币 AB Problem ag…...

多语言海外AEON抢单可连单加额外单源码,java版多语言抢单系统
多语言海外AEON抢单可连单加额外单源码,java版多语言抢单系统。此套是全新开发的java版多语言抢单系统。 后端java,用的若依框架,这套代码前后端是编译后的,测试可以正常使用,语言繁体,英文,日…...

文件上传——springboot大文件分片多线程上传功能,前端显示弹出上传进度框
一、项目搭建 创建 Spring Boot 项目: 创建一个新的 Spring Boot 项目,添加 Web 依赖。 添加依赖: 在 pom.xml 文件中添加以下依赖: <dependency><groupId>commons-fileupload</groupId><artifactId>commons-fileupload</artifactId&…...
每日学术速递8.2
1.A Scalable Quantum Non-local Neural Network for Image Classification 标题: 用于图像分类的可扩展量子非局部神经网络 作者: Sparsh Gupta, Debanjan Konar, Vaneet Aggarwal 文章链接:https://arxiv.org/abs/2407.18906 摘要&#x…...

SAP-PLM创建物料主数据接口
FUNCTION zplm_d_0001_mm01. *"---------------------------------------------------------------------- *"*"本地接口: *" EXPORTING *" VALUE(EX_TOTAL) TYPE CHAR4 *" VALUE(EX_SUCCESSFUL) TYPE CHAR4 *" …...

超声波眼镜清洗机哪个品牌好?四款高性能超声波清洗机测评剖析
对于追求高生活质量的用户来说,眼镜的清洁绝对不能马虎。如果不定期清洁眼镜,时间久了,镜片的缝隙中会积累大量的灰尘和细菌,眼镜靠近眼部,对眼部健康有很大影响。在这种情况下,超声波清洗机显得尤为重要。…...
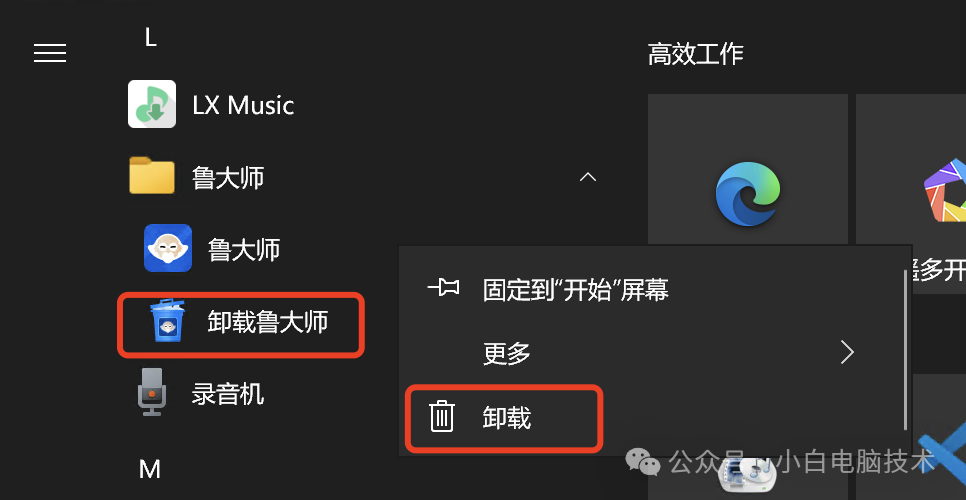
卸载Windows软件的正确姿势,你做对了吗?
前言 今天有小伙伴突然问我:她把软件都卸载了,但是怎么软件都还在运行? 这个问题估计很多小伙伴都是遇到过的,对于电脑小白来说,卸载Windows软件真的真的真的是一件很难的事情。所以,今天咱们就来讲讲&am…...
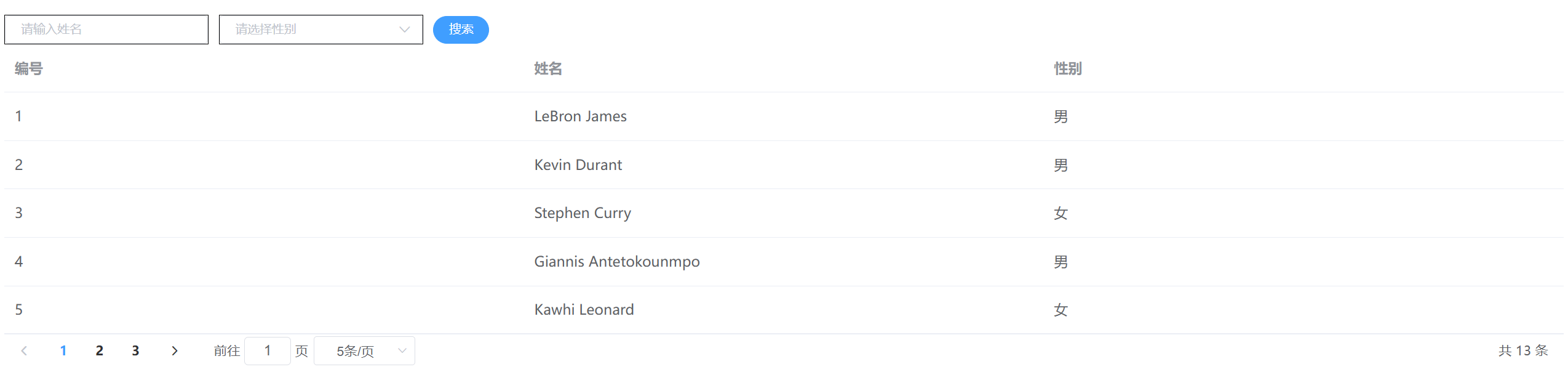
WEB前端14-Element UI(学生查询表案例/模糊查询/分页查询)
Vue2-Element UI 1.可重用组件的开发 可重用组件 我们一般将可重复使用的组件放在components目录之下,以便父组件的灵活调用 <!--可重用组件一般与css密切相关,使用可重用组件的目的是,将相似的组件放在一起,方便使用-->…...

使用swiftui自定义圆形进度条实现loading
实现的代码如下: // // LoadingView.swift // SwiftBook // // Created by Song on 2024/8/2. //import SwiftUIstruct LoadingView: View {State var process 0.5var body: some View {VStack(spacing: 20) {ZStack {Circle().stroke(.gray.opacity(0.3), lin…...

Leetcode 3576. Transform Array to All Equal Elements
Leetcode 3576. Transform Array to All Equal Elements 1. 解题思路2. 代码实现 题目链接:3576. Transform Array to All Equal Elements 1. 解题思路 这一题思路上就是分别考察一下是否能将其转化为全1或者全-1数组即可。 至于每一种情况是否可以达到…...

Xshell远程连接Kali(默认 | 私钥)Note版
前言:xshell远程连接,私钥连接和常规默认连接 任务一 开启ssh服务 service ssh status //查看ssh服务状态 service ssh start //开启ssh服务 update-rc.d ssh enable //开启自启动ssh服务 任务二 修改配置文件 vi /etc/ssh/ssh_config //第一…...
)
Spring Boot 实现流式响应(兼容 2.7.x)
在实际开发中,我们可能会遇到一些流式数据处理的场景,比如接收来自上游接口的 Server-Sent Events(SSE) 或 流式 JSON 内容,并将其原样中转给前端页面或客户端。这种情况下,传统的 RestTemplate 缓存机制会…...
)
IGP(Interior Gateway Protocol,内部网关协议)
IGP(Interior Gateway Protocol,内部网关协议) 是一种用于在一个自治系统(AS)内部传递路由信息的路由协议,主要用于在一个组织或机构的内部网络中决定数据包的最佳路径。与用于自治系统之间通信的 EGP&…...

STM32+rt-thread判断是否联网
一、根据NETDEV_FLAG_INTERNET_UP位判断 static bool is_conncected(void) {struct netdev *dev RT_NULL;dev netdev_get_first_by_flags(NETDEV_FLAG_INTERNET_UP);if (dev RT_NULL){printf("wait netdev internet up...");return false;}else{printf("loc…...

Golang dig框架与GraphQL的完美结合
将 Go 的 Dig 依赖注入框架与 GraphQL 结合使用,可以显著提升应用程序的可维护性、可测试性以及灵活性。 Dig 是一个强大的依赖注入容器,能够帮助开发者更好地管理复杂的依赖关系,而 GraphQL 则是一种用于 API 的查询语言,能够提…...

Java-41 深入浅出 Spring - 声明式事务的支持 事务配置 XML模式 XML+注解模式
点一下关注吧!!!非常感谢!!持续更新!!! 🚀 AI篇持续更新中!(长期更新) 目前2025年06月05日更新到: AI炼丹日志-28 - Aud…...

Redis数据倾斜问题解决
Redis 数据倾斜问题解析与解决方案 什么是 Redis 数据倾斜 Redis 数据倾斜指的是在 Redis 集群中,部分节点存储的数据量或访问量远高于其他节点,导致这些节点负载过高,影响整体性能。 数据倾斜的主要表现 部分节点内存使用率远高于其他节…...

mysql已经安装,但是通过rpm -q 没有找mysql相关的已安装包
文章目录 现象:mysql已经安装,但是通过rpm -q 没有找mysql相关的已安装包遇到 rpm 命令找不到已经安装的 MySQL 包时,可能是因为以下几个原因:1.MySQL 不是通过 RPM 包安装的2.RPM 数据库损坏3.使用了不同的包名或路径4.使用其他包…...

重启Eureka集群中的节点,对已经注册的服务有什么影响
先看答案,如果正确地操作,重启Eureka集群中的节点,对已经注册的服务影响非常小,甚至可以做到无感知。 但如果操作不当,可能会引发短暂的服务发现问题。 下面我们从Eureka的核心工作原理来详细分析这个问题。 Eureka的…...