Yolov8添加ConvNetV1和V2模块
Yolov8添加ConvNet模块
1 ConvNet系列相关内容
(1)2022 论文地址:A ConvNet for the 2020s
Code Link
如下图所示,精度、效率、尺寸都很不错。

论文的摘要如下:
视觉识别的“咆哮的 20 年代”始于视觉注意力 (ViT) 的引入,它迅速取代了 ConvNets 成为最先进的图像分类模型。另一方面,vanilla ViT 在应用于一般计算机视觉任务(如对象检测和语义分割)时面临困难。正是分层 Transformer(例如 Swin Transformers)重新引入了几个 ConvNet 先验,使 Transformer 实际上可以作为通用视觉骨干,并在各种视觉任务中表现出卓越的性能。然而,这种混合方法的有效性仍然在很大程度上归功于 Transformer 的固有优势,而不是卷积固有的归纳偏置。在这项工作中,我们重新审视了设计空间,并测试了纯ConvNet可以达到的极限。我们逐步将标准 ResNet “现代化”现代化,以设计视觉转换器,并发现导致性能差异的几个关键组件。这次探索的结果是一系列被称为 ConvNeXt 的纯 ConvNet 模型。ConvNeXts 完全由标准 ConvNet 模块构建,在精度和可扩展性方面与 Transformer 竞争,实现了 87.8% 的 ImageNet top-1 准确率,在 COCO 检测和 ADE20K 分割方面优于 Swin Transformers,同时保持了标准 ConvNet 的简单性和效率。
(2)2023论文地址:ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders
Code link
如下图所示,2023年改进的ConvNeXt比之前的更好了:

论文的摘要如下:
在改进的架构和更好的表示学习框架的推动下,视觉识别领域在 2020 年代初期实现了快速的现代化和性能提升。例如,以ConvNeXt [52]为代表的现代ConvNets在各种场景中都表现出了强大的性能。虽然这些模型最初是为使用ImageNet标签的监督学习而设计的,但它们也可能从自监督学习技术中受益,如蒙版自动编码器(MAE)[31]。然而,我们发现,简单地将这两种方法结合起来会导致性能不佳。在本文中,我们提出了一种全卷积掩码自编码器框架和一种新的全局响应归一化(GRN)层,可以将其添加到ConvNeXt架构中以增强通道间的特征竞争。这种自监督学习技术和架构改进的协同设计产生了一个名为 ConvNeXt V2 的新模型系列,该模型系列显着提高了纯 ConvNet 在各种识别基准上的性能,包括 ImageNet 分类、COCO 检测和 ADE20K 分割。我们还提供各种尺寸的预训练 ConvNeXt V2 模型,模型的范围有在 ImageNet 上准确率为 76.7% 的高效 3.7M 参数 Atto 模型,到仅使用公共训练数据即可达到 88.9% 准确率的 650M Huge 模型。
2 添加ConvNeXt的代码到ultralytics/nn/modules/conv.py文件末尾
网络模型代码参考地址:https://blog.csdn.net/Orange_sparkle/article/details/126827461?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522172267585216800182132305%2522%252C%2522scm%2522%253A%252220140713.130102334…%2522%257D&request_id=172267585216800182132305&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2allsobaiduend~default-1-126827461-null-null.142v100pc_search_result_base5&utm_term=convnext%E6%A8%A1%E5%9E%8B%E4%BB%A3%E7%A0%81&spm=1018.2226.3001.4187
"""
original code from facebook research:
https://github.com/facebookresearch/ConvNeXt
"""import torch
import torch.nn as nn
import torch.nn.functional as Fdef drop_path(x, drop_prob: float = 0., training: bool = False):"""Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).This is the same as the DropConnect impl I created for EfficientNet, etc networks, however,the original name is misleading as 'Drop Connect' is a different form of dropout in a separate paper...See discussion: https://github.com/tensorflow/tpu/issues/494#issuecomment-532968956 ... I've opted forchanging the layer and argument names to 'drop path' rather than mix DropConnect as a layer name and use'survival rate' as the argument."""if drop_prob == 0. or not training:return xkeep_prob = 1 - drop_probshape = (x.shape[0],) + (1,) * (x.ndim - 1) # work with diff dim tensors, not just 2D ConvNetsrandom_tensor = keep_prob + torch.rand(shape, dtype=x.dtype, device=x.device)random_tensor.floor_() # binarizeoutput = x.div(keep_prob) * random_tensorreturn outputclass DropPath(nn.Module):"""Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks)."""def __init__(self, drop_prob=None):super(DropPath, self).__init__()self.drop_prob = drop_probdef forward(self, x):return drop_path(x, self.drop_prob, self.training)class LayerNorm(nn.Module):r""" LayerNorm that supports two data formats: channels_last (default) or channels_first.The ordering of the dimensions in the inputs. channels_last corresponds to inputs withshape (batch_size, height, width, channels) while channels_first corresponds to inputswith shape (batch_size, channels, height, width)."""# channels_first (batch_size, channels, height, width) pytorch官方默认使用# channels_last (batch_size, height, width, channels)def __init__(self, normalized_shape, eps=1e-6, data_format="channels_last"):super().__init__()self.weight = nn.Parameter(torch.ones(normalized_shape), requires_grad=True) # weight bias对应γ βself.bias = nn.Parameter(torch.zeros(normalized_shape), requires_grad=True)self.eps = epsself.data_format = data_formatif self.data_format not in ["channels_last", "channels_first"]:raise ValueError(f"not support data format '{self.data_format}'")self.normalized_shape = (normalized_shape,)def forward(self, x: torch.Tensor) -> torch.Tensor:if self.data_format == "channels_last":return F.layer_norm(x, self.normalized_shape, self.weight, self.bias, self.eps)elif self.data_format == "channels_first":# [batch_size, channels, height, width]# 对channels 维度求均值mean = x.mean(1, keepdim=True)# 方差var = (x - mean).pow(2).mean(1, keepdim=True)# 减均值,除以标准差的操作x = (x - mean) / torch.sqrt(var + self.eps)x = self.weight[:, None, None] * x + self.bias[:, None, None]return x# ConvNeXt Block
class ConvNeXt_Block(nn.Module):r""" ConvNeXt Block. There are two equivalent implementations:(1) DwConv -> LayerNorm (channels_first) -> 1x1 Conv -> GELU -> 1x1 Conv; all in (N, C, H, W)(2) DwConv -> Permute to (N, H, W, C); LayerNorm (channels_last) -> Linear -> GELU -> Linear; Permute backWe use (2) as we find it slightly faster in PyTorchArgs:dim (int): Number of input channels.drop_rate (float): Stochastic depth rate. Default: 0.0layer_scale_init_value (float): Init value for Layer Scale. Default: 1e-6."""def __init__(self, dim, drop_rate=0., layer_scale_init_value=1e-6):super().__init__()self.dwconv = nn.Conv2d(dim, dim, kernel_size=7, padding=3, groups=dim) # depthwise convself.norm = LayerNorm(dim, eps=1e-6, data_format="channels_last")self.pwconv1 = nn.Linear(dim, 4 * dim) # pointwise/1x1 convs, implemented with linear layersself.act = nn.GELU()self.pwconv2 = nn.Linear(4 * dim, dim)# gamma 针对layer scale的操作self.gamma = nn.Parameter(layer_scale_init_value * torch.ones((dim,)),requires_grad=True) if layer_scale_init_value > 0 else Noneself.drop_path = DropPath(drop_rate) if drop_rate > 0. else nn.Identity() # nn.Identity() 恒等映射def forward(self, x: torch.Tensor) -> torch.Tensor:shortcut = xx = self.dwconv(x)x = x.permute(0, 2, 3, 1) # [N, C, H, W] -> [N, H, W, C]x = self.norm(x)x = self.pwconv1(x)x = self.act(x)x = self.pwconv2(x)if self.gamma is not None:x = self.gamma * xx = x.permute(0, 3, 1, 2) # [N, H, W, C] -> [N, C, H, W]x = shortcut + self.drop_path(x)return xclass ConvNeXt(nn.Module):r""" ConvNeXtA PyTorch impl of : `A ConvNet for the 2020s` -https://arxiv.org/pdf/2201.03545.pdfArgs:in_chans (int): Number of input image channels. Default: 3num_classes (int): Number of classes for classification head. Default: 1000depths (tuple(int)): Number of blocks at each stage. Default: [3, 3, 9, 3]dims (int): Feature dimension at each stage. Default: [96, 192, 384, 768]drop_path_rate (float): Stochastic depth rate. Default: 0.layer_scale_init_value (float): Init value for Layer Scale. Default: 1e-6.head_init_scale (float): Init scaling value for classifier weights and biases. Default: 1."""def __init__(self, in_chans: int = 3, num_classes: int = 1000, depths: list = None,dims: list = None, drop_path_rate: float = 0., layer_scale_init_value: float = 1e-6,head_init_scale: float = 1.):super().__init__()# 最初下采样部分self.downsample_layers = nn.ModuleList() # stem and 3 intermediate downsampling conv layers# Conv2d k4, s4# LayerNormstem = nn.Sequential(nn.Conv2d(in_chans, dims[0], kernel_size=4, stride=4),LayerNorm(dims[0], eps=1e-6, data_format="channels_first"))self.downsample_layers.append(stem)# 对应stage2-stage4前的3个downsamplefor i in range(3):downsample_layer = nn.Sequential(LayerNorm(dims[i], eps=1e-6, data_format="channels_first"),nn.Conv2d(dims[i], dims[i + 1], kernel_size=2, stride=2))self.downsample_layers.append(downsample_layer)self.stages = nn.ModuleList() # 4 feature resolution stages, each consisting of multiple blocks# 等差数列,初始值0,到drop path rate,总共depths个数dp_rates = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))]cur = 0# 构建每个stage中堆叠的blockfor i in range(4):stage = nn.Sequential(*[ConvNeXt_Block(dim=dims[i], drop_rate=dp_rates[cur + j], layer_scale_init_value=layer_scale_init_value)for j in range(depths[i])])self.stages.append(stage)cur += depths[i]self.norm = nn.LayerNorm(dims[-1], eps=1e-6) # final norm layerself.head = nn.Linear(dims[-1], num_classes)self.apply(self._init_weights)self.head.weight.data.mul_(head_init_scale)self.head.bias.data.mul_(head_init_scale)def _init_weights(self, m):if isinstance(m, (nn.Conv2d, nn.Linear)):nn.init.trunc_normal_(m.weight, std=0.2)nn.init.constant_(m.bias, 0)def forward_features(self, x: torch.Tensor) -> torch.Tensor:for i in range(4):x = self.downsample_layers[i](x)x = self.stages[i](x)return self.norm(x.mean([-2, -1])) # global average pooling, (N, C, H, W) -> (N, C)def forward(self, x: torch.Tensor) -> torch.Tensor:x = self.forward_features(x)x = self.head(x)return xdef convnext_tiny(num_classes: int):# https://dl.fbaipublicfiles.com/convnext/convnext_tiny_1k_224_ema.pthmodel = ConvNeXt(depths=[3, 3, 9, 3],dims=[96, 192, 384, 768],num_classes=num_classes)return modeldef convnext_small(num_classes: int):# https://dl.fbaipublicfiles.com/convnext/convnext_small_1k_224_ema.pthmodel = ConvNeXt(depths=[3, 3, 27, 3],dims=[96, 192, 384, 768],num_classes=num_classes)return modeldef convnext_base(num_classes: int):# https://dl.fbaipublicfiles.com/convnext/convnext_base_1k_224_ema.pth# https://dl.fbaipublicfiles.com/convnext/convnext_base_22k_224.pthmodel = ConvNeXt(depths=[3, 3, 27, 3],dims=[128, 256, 512, 1024],num_classes=num_classes)return modeldef convnext_large(num_classes: int):# https://dl.fbaipublicfiles.com/convnext/convnext_large_1k_224_ema.pth# https://dl.fbaipublicfiles.com/convnext/convnext_large_22k_224.pthmodel = ConvNeXt(depths=[3, 3, 27, 3],dims=[192, 384, 768, 1536],num_classes=num_classes)return modeldef convnext_xlarge(num_classes: int):# https://dl.fbaipublicfiles.com/convnext/convnext_xlarge_22k_224.pthmodel = ConvNeXt(depths=[3, 3, 27, 3],dims=[256, 512, 1024, 2048],num_classes=num_classes)return modelclass CNeB(nn.Module):# CSP ConvNextBlock with 3 convolutons by is cyy/yoloairdef __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansionsuper(CNeB, self).__init__()c_ = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, c_, 1, 1)self.cv2 = Conv(c1, c_, 1, 1)self.cv3 = Conv(2 * c_, c2, 1) # act=FReLU(c2)self.m = nn.Sequential(*(ConvNeXt_Block(c_) for _ in range(n))) #ConvNeXt_Block与bilibili讲解的ConvNextblock的一致def forward(self, x):return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), dim=1))
在ultralytics/nn/modules/conv.py中的__all__中加入’CNeB’模块名称:

然后在ultralytics/nn/modules/init.py中添加模块名CNeB,并在下面的__all__中也添加CNeB,这样CNeB就封装成了ultralytics.nn.modules库函数:


3 在ultralytics/nn/tasks.py的parse_model函数中解析模型yaml文件,判断是否有CNeB模块,在pare_model函数中添加的代码如下:
elif m is CNeB:c1, c2 = ch[f], args[0]if c2 != nc: # if c2 not equal to number of classes (i.e. for Classify() output) c2 = make_divisible(min(c2, max_channels) * width, 8)args = [c1, c2, *args[1:]]if m is CNeB:args.insert(2, n)n = 1


4 修改一个yolov8-seg.yaml文件
复制ultralytics/cfg/models/v8/yolov8-seg.yaml文件,在位置ultralytics/cfg/models/v8/中新建yolov8-CNeBseg.yaml文件,在backbone和head部分都添加CNeB模块。
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8-seg instance segmentation model. For Usage examples see https://docs.ultralytics.com/tasks/segment# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n-seg.yaml' will call yolov8-seg.yaml with scale 'n'# [depth, width, max_channels]n: [0.33, 0.25, 1024]s: [0.33, 0.50, 1024]m: [0.67, 0.75, 768]l: [1.00, 1.00, 512]x: [1.00, 1.25, 512]# YOLOv8.0n backbone
backbone:# [from, repeats, module, args]- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4- [-1, 3, C2f, [128, True]] #2- [-1, 3, CNeB, [128] #-->3- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8-->4- [-1, 6, C2f, [256, True]] #4-->5- [-1, 6, CNeB, [256] #-->6- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16-->7- [-1, 6, C2f, [512, True]] #6-->8- [-1, 6, CNeB, [512] #-->9- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32-->10- [-1, 3, C2f, [1024, True]] #8-->11- [-1, 3, CNeB, [1024] #-->12- [-1, 1, SPPF, [1024, 5]] # 9-->13# YOLOv8.0n head
head:- [-1, 1, nn.Upsample, [None, 2, "nearest"]] #10-->14- [[-1, 9], 1, Concat, [1]] # cat backbone P4-->15- [-1, 3, C2f, [512]] # 12-->16- [-1, 3, CNeB, [512] #-->17- [-1, 1, nn.Upsample, [None, 2, "nearest"]] #13-->18- [[-1, 6], 1, Concat, [1]] # cat backbone P3-->19- [-1, 3, C2f, [256]] # 15 (P3/8-small)-->20- [-1, 3, CNeB, [256] #-->21- [-1, 1, Conv, [256, 3, 2]] #16-->22- [[-1, 17], 1, Concat, [1]] # cat head P4-->23- [-1, 3, C2f, [512]] # 18 (P4/16-medium)-->24- [-1, 3, CNeB, [512] #-->25- [-1, 1, Conv, [512, 3, 2]] #19-->26- [[-1, 13], 1, Concat, [1]] # cat head P5-->27- [-1, 3, C2f, [1024]] # 21 (P5/32-large)-->28- [-1, 3, CNeB, [1024] #-->29# - [[15, 18, 21], 1, Segment, [nc, 32, 256]] # Segment(P3, P4, P5)- [[21, 25, 29], 1, Segment, [nc, 32, 256]] # Segment(P3, P4, P5)注意在需要引用前面的序号部分要重新更新,“–>”符号指向新的序号
,backbone部分没有引用前面的序号,head部分有,就要相应的修改。
5 测试和训练
复制一份tests/test_python.py文件中的测试代码,新建文件命名为test_yolov8_CNeB_model.py,只保留下方代码:
# Ultralytics YOLO 🚀, AGPL-3.0 licenseimport contextlib
import urllib
from copy import copy
from pathlib import Pathimport cv2
import numpy as np
import pytest
import torch
import yaml
from PIL import Imagefrom tests import CFG, IS_TMP_WRITEABLE, MODEL, SOURCE, TMP
from ultralytics import RTDETR, YOLO
from ultralytics.cfg import MODELS, TASK2DATA, TASKS
from ultralytics.data.build import load_inference_source
from ultralytics.utils import (ASSETS,DEFAULT_CFG,DEFAULT_CFG_PATH,LOGGER,ONLINE,ROOT,WEIGHTS_DIR,WINDOWS,checks,
)
from ultralytics.utils.downloads import download
from ultralytics.utils.torch_utils import TORCH_1_9CFG = 'ultralytics/cfg/models/v8/yolov8l-CNeBseg.yaml' #使用l模型加一个l字母
SOURCE = ASSETS / "bus.jpg"
def test_model_forward():"""Test the forward pass of the YOLO model."""model = YOLO(CFG)model(source=SOURCE, imgsz=[512,512], augment=True) # also test no source and augment先在ultralytics/nn/tasks.py的parse_model函数中增加一行代码用于查看模型结构:
print(f"{i:>3}{str(f):>20}{n_:>3}{m.np:10.0f} {t:<45}{str(args):<30}")

运行test_yolov8_CNeB_model.py的结果如下:
============================= test session starts ==============================
collected 1 item test_yolov8_CBAM_model.py::test_model_forward PASSED [100%] 0 -1 1 1856 ultralytics.nn.modules.conv.Conv [3, 64, 3, 2] 1 -1 1 73984 ultralytics.nn.modules.conv.Conv [64, 128, 3, 2] 2 -1 3 279808 ultralytics.nn.modules.block.C2f [128, 128, 3, True] 3 -1 3 142720 ultralytics.nn.modules.conv.CNeB [128, 128, 3] 4 -1 1 295424 ultralytics.nn.modules.conv.Conv [128, 256, 3, 2] 5 -1 6 2101248 ultralytics.nn.modules.block.C2f [256, 256, 6, True] 6 -1 6 963072 ultralytics.nn.modules.conv.CNeB [256, 256, 6] 7 -1 1 1180672 ultralytics.nn.modules.conv.Conv [256, 512, 3, 2] 8 -1 6 8396800 ultralytics.nn.modules.block.C2f [512, 512, 6, True] 9 -1 6 3761152 ultralytics.nn.modules.conv.CNeB [512, 512, 6] 10 -1 1 2360320 ultralytics.nn.modules.conv.Conv [512, 512, 3, 2] 11 -1 3 4461568 ultralytics.nn.modules.block.C2f [512, 512, 3, True] 12 -1 3 2143744 ultralytics.nn.modules.conv.CNeB [512, 512, 3] 13 -1 1 656896 ultralytics.nn.modules.block.SPPF [512, 512, 5] 14 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest'] 15 [-1, 9] 1 0 ultralytics.nn.modules.conv.Concat [1] 16 -1 3 4723712 ultralytics.nn.modules.block.C2f [1024, 512, 3] 17 -1 3 2143744 ultralytics.nn.modules.conv.CNeB [512, 512, 3] 18 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest'] 19 [-1, 6] 1 0 ultralytics.nn.modules.conv.Concat [1] 20 -1 3 1247744 ultralytics.nn.modules.block.C2f [768, 256, 3] 21 -1 3 547584 ultralytics.nn.modules.conv.CNeB [256, 256, 3] 22 -1 1 590336 ultralytics.nn.modules.conv.Conv [256, 256, 3, 2] 23 [-1, 17] 1 0 ultralytics.nn.modules.conv.Concat [1] 24 -1 3 4592640 ultralytics.nn.modules.block.C2f [768, 512, 3] 25 -1 3 2143744 ultralytics.nn.modules.conv.CNeB [512, 512, 3] 26 -1 1 2360320 ultralytics.nn.modules.conv.Conv [512, 512, 3, 2] 27 [-1, 13] 1 0 ultralytics.nn.modules.conv.Concat [1] 28 -1 3 4723712 ultralytics.nn.modules.block.C2f [1024, 512, 3] 29 -1 3 2143744 ultralytics.nn.modules.conv.CNeB [512, 512, 3] 30 [21, 25, 29] 1 7950688 ultralytics.nn.modules.head.Segment [80, 32, 256, [256, 512, 512]]image 1/1 /XXXXXXXX/ultralyticsv8_2-main/ultralytics/assets/bus.jpg: 640x480 (no detections), 135.6ms
Speed: 2.1ms preprocess, 135.6ms inference, 0.5ms postprocess per image at shape (1, 3, 640, 480)
模型修改完成,选择自己的分割数据进行训练,结果如下:

如上图,这里使用“l”大模型,只需yolov8-CBAMseg.yaml中加一个“l”变成yolov8l-CNeBseg.yaml,优化器为上一篇博客yolov8更改的Lion优化器。可以看到arguments参数按照“l”模型发生了调整,模型开始训练。

6 添加ConvNeXtV2模块
如果添加ConvNeXtV2模块ultralytics/nn/modules/conv.py文件末尾,后面还有新模块的话,conv.py会越来越长,一种整洁的方法时,在conv.py 的同级目录中新建一个自定义模块的py文件,然后在conv.py中引用并按照前面的添加过程也是可以的。
如下图:

convnextv2.py的代码如下:
# coding=gbk
# 来源:https://blog.csdn.net/qq_42076902/article/details/129938723?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522172268630316800207028360%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=172268630316800207028360&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~first_rank_ecpm_v1~rank_v31_ecpm-4-129938723-null-null.142^v100^pc_search_result_base5&utm_term=convnext-V2%E7%BD%91%E7%BB%9C%E4%BB%A3%E7%A0%81&spm=1018.2226.3001.4187
# cited from: https://github.com/facebookresearch/ConvNeXt-V2/blob/main/models/convnextv2.py
import torch
import torch.nn as nn
import torch.nn.functional as F
from timm.models.layers import trunc_normal_, DropPathclass ConvNeXtV2_Block(nn.Module):""" ConvNeXtV2 Block.Args:dim (int): Number of input channels.drop_path (float): Stochastic depth rate. Default: 0.0"""def __init__(self, dim, drop_path=0.):super().__init__()self.dwconv = nn.Conv2d(dim, dim, kernel_size=7, padding=3, groups=dim) # depthwise convself.norm = LayerNorm(dim, eps=1e-6)self.pwconv1 = nn.Linear(dim, 4 * dim) # pointwise/1x1 convs, implemented with linear layersself.act = nn.GELU()self.grn = GRN(4 * dim)self.pwconv2 = nn.Linear(4 * dim, dim)self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()def forward(self, x):input = xx = self.dwconv(x)x = x.permute(0, 2, 3, 1) # (N, C, H, W) -> (N, H, W, C)x = self.norm(x)x = self.pwconv1(x)x = self.act(x)x = self.grn(x)x = self.pwconv2(x)x = x.permute(0, 3, 1, 2) # (N, H, W, C) -> (N, C, H, W)x = input + self.drop_path(x)return xclass LayerNorm(nn.Module):""" LayerNorm that supports two data formats: channels_last (default) or channels_first.The ordering of the dimensions in the inputs. channels_last corresponds to inputs withshape (batch_size, height, width, channels) while channels_first corresponds to inputswith shape (batch_size, channels, height, width)."""def __init__(self, normalized_shape, eps=1e-6, data_format="channels_last"):super().__init__()self.weight = nn.Parameter(torch.ones(normalized_shape))self.bias = nn.Parameter(torch.zeros(normalized_shape))self.eps = epsself.data_format = data_formatif self.data_format not in ["channels_last", "channels_first"]:raise NotImplementedErrorself.normalized_shape = (normalized_shape,)def forward(self, x):if self.data_format == "channels_last":return F.layer_norm(x, self.normalized_shape, self.weight, self.bias, self.eps)elif self.data_format == "channels_first":u = x.mean(1, keepdim=True)s = (x - u).pow(2).mean(1, keepdim=True)x = (x - u) / torch.sqrt(s + self.eps)x = self.weight[:, None, None] * x + self.bias[:, None, None]return xclass GRN(nn.Module):""" GRN (Global Response Normalization) layer"""def __init__(self, dim):super().__init__()self.gamma = nn.Parameter(torch.zeros(1, 1, 1, dim))self.beta = nn.Parameter(torch.zeros(1, 1, 1, dim))def forward(self, x):Gx = torch.norm(x, p=2, dim=(1, 2), keepdim=True)Nx = Gx / (Gx.mean(dim=-1, keepdim=True) + 1e-6)return self.gamma * (x * Nx) + self.beta + xclass ConvNeXtV2(nn.Module):""" ConvNeXt V2Args:in_chans (int): Number of input image channels. Default: 3num_classes (int): Number of classes for classification head. Default: 1000depths (tuple(int)): Number of blocks at each stage. Default: [3, 3, 9, 3]dims (int): Feature dimension at each stage. Default: [96, 192, 384, 768]drop_path_rate (float): Stochastic depth rate. Default: 0.head_init_scale (float): Init scaling value for classifier weights and biases. Default: 1."""def __init__(self, in_chans=3, num_classes=1000,depths=[3, 3, 9, 3], dims=[96, 192, 384, 768],drop_path_rate=0., head_init_scale=1.):super().__init__()self.depths = depthsself.downsample_layers = nn.ModuleList() # stem and 3 intermediate downsampling conv layersstem = nn.Sequential(nn.Conv2d(in_chans, dims[0], kernel_size=4, stride=4),LayerNorm(dims[0], eps=1e-6, data_format="channels_first"))self.downsample_layers.append(stem)for i in range(3):downsample_layer = nn.Sequential(LayerNorm(dims[i], eps=1e-6, data_format="channels_first"),nn.Conv2d(dims[i], dims[i + 1], kernel_size=2, stride=2),)self.downsample_layers.append(downsample_layer)self.stages = nn.ModuleList() # 4 feature resolution stages, each consisting of multiple residual blocksdp_rates = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))]cur = 0for i in range(4):stage = nn.Sequential(*[ConvNeXtV2_Block(dim=dims[i], drop_path=dp_rates[cur + j]) for j in range(depths[i])])self.stages.append(stage)cur += depths[i]self.norm = nn.LayerNorm(dims[-1], eps=1e-6) # final norm layerself.head = nn.Linear(dims[-1], num_classes)self.apply(self._init_weights)self.head.weight.data.mul_(head_init_scale)self.head.bias.data.mul_(head_init_scale)def _init_weights(self, m):if isinstance(m, (nn.Conv2d, nn.Linear)):trunc_normal_(m.weight, std=.02)nn.init.constant_(m.bias, 0)def forward_features(self, x):for i in range(4):x = self.downsample_layers[i](x)x = self.stages[i](x)return self.norm(x.mean([-2, -1])) # global average pooling, (N, C, H, W) -> (N, C)def forward(self, x):x = self.forward_features(x)print(x.size())x = self.head(x)return xdef convnextv2_atto(num_classes=100, **kwargs):model = ConvNeXtV2(depths=[2, 2, 6, 2], dims=[40, 80, 160, 320], num_classes=num_classes, **kwargs)return modeldef convnextv2_femto(num_classes=100, **kwargs):model = ConvNeXtV2(depths=[2, 2, 6, 2], dims=[48, 96, 192, 384], num_classes=num_classes, **kwargs)return modeldef convnext_pico(num_classes=100, **kwargs):model = ConvNeXtV2(depths=[2, 2, 6, 2], dims=[64, 128, 256, 512], num_classes=num_classes, **kwargs)return modeldef convnextv2_nano(num_classes=100, **kwargs):model = ConvNeXtV2(depths=[2, 2, 8, 2], dims=[80, 160, 320, 640], num_classes=num_classes, **kwargs)return modeldef convnextv2_tiny(num_classes=100, **kwargs):model = ConvNeXtV2(depths=[3, 3, 9, 3], dims=[96, 192, 384, 768], num_classes=num_classes, **kwargs)return modeldef convnextv2_base(num_classes=100, **kwargs):model = ConvNeXtV2(depths=[3, 3, 27, 3], dims=[128, 256, 512, 1024], num_classes=num_classes, **kwargs)return modeldef convnextv2_large(num_classes=100, **kwargs):model = ConvNeXtV2(depths=[3, 3, 27, 3], dims=[192, 384, 768, 1536], num_classes=num_classes, **kwargs)return modeldef convnextv2_huge(num_classes=100, **kwargs):model = ConvNeXtV2(depths=[3, 3, 27, 3], dims=[352, 704, 1408, 2816], num_classes=num_classes, **kwargs)return modelclass CNeB(nn.Module):# CSP ConvNextBlock with 3 convolutons by is cyy/yoloairdef __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansionsuper(CNeB, self).__init__()c_ = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, c_, 1, 1)self.cv2 = Conv(c1, c_, 1, 1)self.cv3 = Conv(2 * c_, c2, 1) # act=FReLU(c2)self.m = nn.Sequential(*(ConvNeXtV2_Block(c_) for _ in range(n))) #ConvNeXtV2_Blockdef forward(self, x):return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), dim=1))if __name__ == "__main__":m = convnextv2_atto(num_classes=3)params = sum(p.numel() for p in m.parameters())print(params)input = torch.randn(1, 3, 256, 256)out = m(input)print(out.shape)然后在conv.py 中引用ConvNeXtV2_Block模块

from .covnextv2 import ConvNeXtV2_Block
class CNeBV2(nn.Module):# CSP ConvNextBlock with 3 convolutons by is cyy/yoloairdef __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansionsuper(CNeBV2, self).__init__()c_ = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, c_, 1, 1)self.cv2 = Conv(c1, c_, 1, 1)self.cv3 = Conv(2 * c_, c2, 1) # act=FReLU(c2)self.m = nn.Sequential(*(ConvNeXtV2_Block(c_) for _ in range(n))) #ConvNeXtV2_Blockdef forward(self, x):return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), dim=1))
covnext的ConvNeXt_Block也可以改成上面的这种方式。
然后在conv.py前面申明模块名

在ultralytics/nn/modules/init.py中申明模块名

在ultralytics/nn/tasks.py中parse_model函数内解析yaml模型文件,添加如下语句:

上面将两个ConvNeXt版本合在一起处理,并开启了print,解析时会打印模块信息。
7 修改一个yaml文件
这里用之前修改的yolov8-CNeBseg.yaml文件复制一份,命名为yolov8-CNeBV2seg.yaml,然后将CNeB模块名改成CNeBV2即可:
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8-seg instance segmentation model. For Usage examples see https://docs.ultralytics.com/tasks/segment# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n-seg.yaml' will call yolov8-seg.yaml with scale 'n'# [depth, width, max_channels]n: [0.33, 0.25, 1024]s: [0.33, 0.50, 1024]m: [0.67, 0.75, 768]l: [1.00, 1.00, 512]x: [1.00, 1.25, 512]# YOLOv8.0n backbone
backbone:# [from, repeats, module, args]- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4- [-1, 3, C2f, [128, True]] #2- [-1, 3, CNeBV2, [128]] #-->3- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8-->4- [-1, 6, C2f, [256, True]] #4-->5- [-1, 6, CNeBV2, [256]] #-->6- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16-->7- [-1, 6, C2f, [512, True]] #6-->8- [-1, 6, CNeBV2, [512]] #-->9- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32-->10- [-1, 3, C2f, [1024, True]] #8-->11- [-1, 3, CNeBV2, [1024]] #-->12- [-1, 1, SPPF, [1024, 5]] # 9-->13# YOLOv8.0n head
head:- [-1, 1, nn.Upsample, [None, 2, "nearest"]] #10-->14- [[-1, 9], 1, Concat, [1]] # cat backbone P4-->15- [-1, 3, C2f, [512]] # 12-->16- [-1, 3, CNeBV2, [512]] #-->17- [-1, 1, nn.Upsample, [None, 2, "nearest"]] #13-->18- [[-1, 6], 1, Concat, [1]] # cat backbone P3-->19- [-1, 3, C2f, [256]] # 15 (P3/8-small)-->20- [-1, 3, CNeBV2, [256]] #-->21- [-1, 1, Conv, [256, 3, 2]] #16-->22- [[-1, 17], 1, Concat, [1]] # cat head P4-->23- [-1, 3, C2f, [512]] # 18 (P4/16-medium)-->24- [-1, 3, CNeBV2, [512]] #-->25- [-1, 1, Conv, [512, 3, 2]] #19-->26- [[-1, 13], 1, Concat, [1]] # cat head P5-->27- [-1, 3, C2f, [1024]] # 21 (P5/32-large)-->28- [-1, 3, CNeBV2, [1024]] #-->29# - [[15, 18, 21], 1, Segment, [nc, 32, 256]] # Segment(P3, P4, P5)- [[21, 25, 29], 1, Segment, [nc, 32, 256]] # Segment(P3, P4, P5)
8 测试
与第5步一样的测试代码,将其中CFG变量改成如下代码:
CFG = 'ultralytics/cfg/models/v8/yolov8l-CNeBV2seg.yaml' #使用l模型加一个l字母
运行test_yolov8_CNeB_model.py,可以测试通过,接下来就可以拿去训练了。🚀🚀🚀

相关文章:
Yolov8添加ConvNetV1和V2模块
Yolov8添加ConvNet模块 1 ConvNet系列相关内容 (1)2022 论文地址:A ConvNet for the 2020s Code Link 如下图所示,精度、效率、尺寸都很不错。 论文的摘要如下: 视觉识别的“咆哮的 20 年代”始于视觉注意力 &…...
)
十个常见的 Python 脚本 (详细介绍 + 代码举例)
1. 批量重命名文件 介绍: 该脚本用于批量重命名指定目录下的文件,例如将所有 ".txt" 文件重命名为 ".md" 文件。 import osdef batch_rename(directory, old_ext, new_ext):"""批量重命名文件扩展名。Args:directory: 要处理…...

【C语言】详解feof函数和ferror函数
文章目录 前言1. feof1.1 feof函数原型1.2 正确利用函数特性读写文件1.2.1 针对文本文件1.2.2 针对二进制文件 1.3 feof函数的原理1.4 feof函数实例演示 2. ferror2.1 ferror函数原型 前言 或许我们曾在网络上看过有关于feof函数,都说这个函数是检查文件是否已经读…...

ValueListenableBuilder 和 addListener 在 ChangeNotifier的区别
1、前言 ValueListenableBuilder 和 addListener 在 ChangeNotifier 中有不同的用途和用法,适用于不同的场景。它们的主要区别在于它们如何监听和响应状态变化,以及它们的用法和特性。 2、ValueListenableBuilder用法 ValueListenableBuilder 是一个 …...
ScriptEcho:AI赋能的前端代码生成神器
ScriptEcho:AI赋能的前端代码生成神器 在前端开发中,如果你总是觉得写代码太费时费力,那么 ScriptEcho 将成为你的救星。这个 AI 代码生成平台不仅能帮你省下大量时间,还能让你轻松愉快地写出生产级代码。本文将带你了解 ScriptEc…...

TypeError: ‘float’ object is not iterable 深度解析
TypeError: ‘float’ object is not iterable 深度解析与实战指南 在Python编程中,TypeError: float object is not iterable是一个常见的错误,通常发生在尝试对浮点数(float)进行迭代操作时。这个错误表明代码中存在类型使用不…...

灵茶八题 - 子序列 +w+
灵茶八题 - 子序列 w 题目描述 给你一个长为 n n n 的数组 a a a,输出它的所有非空子序列的元素和的元素和。 例如 a [ 1 , 2 , 3 ] a[1,2,3] a[1,2,3] 有七个非空子序列 [ 1 ] , [ 2 ] , [ 3 ] , [ 1 , 2 ] , [ 1 , 3 ] , [ 2 , 3 ] , [ 1 , 2 , 3 ] [1],[…...

为什么美元债务会越来越多?
美元债务规模持续膨胀,其背后原因复杂多样,可归结为以下几个主要因素: 财政赤字和刺激政策是导致美元债务增加的重要原因。美国政府长期面临财政赤字问题,支出远超收入,为弥补这一缺口,政府不得不大量发行…...

二维凸包算法 Julia实现
问题描述:给定平面上 n n n 个点的集合 Q Q Q,求其子集 P P P 构成 Q Q Q 的凸包,即 ∀ p ∈ Q , ∃ p 0 , p 1 , p 2 ∈ P \forall p \in Q, \exist p_0, p_1, p_2 \in P ∀p∈Q,∃p0,p1,p2∈P 使得点 p p p 在以点 p 0 , p 1 …...
python dash框架
Dash 是一个用于创建数据分析型 web 应用的 Python 框架。它由 Plotly 团队开发,并且可以用来构建交互式的 web 应用程序,这些应用能够包含图表、表格、地图等多种数据可视化组件。 Dash 的特点: 易于使用:Dash 使用 Python 语法…...

2.外部中断(EXTI)
理论 NVIC:嵌套向量中断控制器(解释教程) 外部通用中断线(EXTI0~EXTI15):每个GPIO设置成中断模式,与中断控制器连接的线 外部中断触发方式 上升沿触发、下降沿触发、双边沿触发 外部中断触发函数 在stm32f1xx_it.c文件…...

Python | SyntaxError: invalid syntax 深度解析
Python | SyntaxError: invalid syntax 深度解析 在Python编程中,SyntaxError: invalid syntax是一个常见的错误,它表明Python解释器在尝试解析代码时遇到了语法问题。这个错误通常是由于代码中存在拼写错误、缺少符号(如括号、冒号或逗号&a…...
付费进群系统源码原版最新修复全开源版
付费进群,和平时所见到的别人拉你进群是不一样的,付费进群需要先缴费以后,才会看到群的二维码,扫码进群或者是长按二维码图片识别进群,付费进群这个功能广泛应用于拼多多的砍价群,活动的助力群,…...

Docker容器部署的SpringBoot项目jar包,上传文件但是找不到路径的问题
在docker容器内部署的jar包运行后,请求访问都没有问题,在文件上传时,发现上传图片接口响应成功,但是图片路径报404错误,发现找不到路径。 在服务器上查看也没有找到相关图片。 原因: 启动docker镜像时没…...
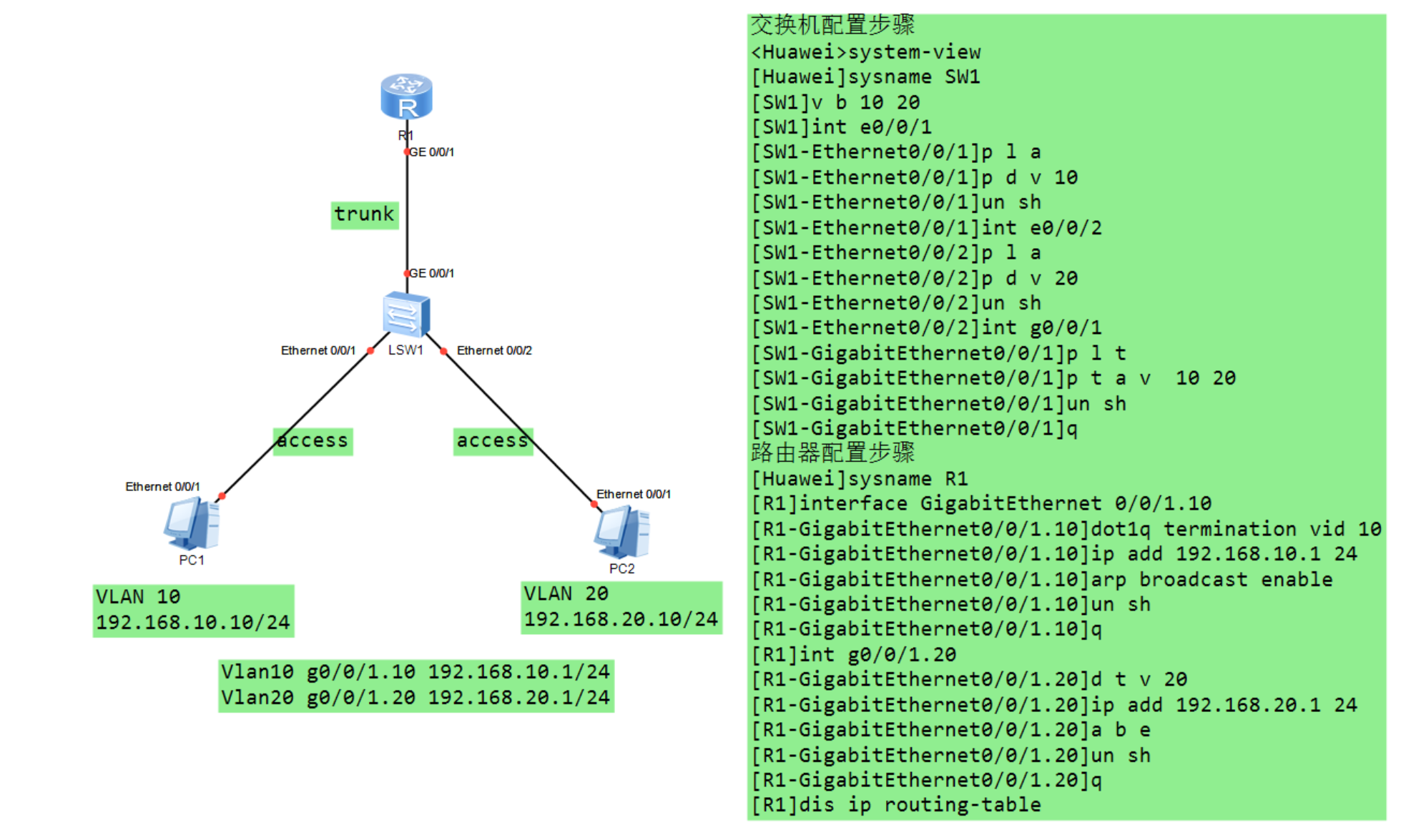
云计算学习——5G网络技术
系列文章目录 提示:仅用于个人学习,进行查漏补缺使用。 Day1 网络参考模型 Day2 网络综合布线与应用 Day3 IP地址 Day4 华为eNSP网络设备模拟器的基础安装及简单使用 Day5 交换机的基本原理与配置 Day6 路由器的原理与配置 Day7 网络层协议介绍一 Day8 传…...

matlab仿真 信道编码和交织(上)
(内容源自详解MATLAB/SIMULINK 通信系统建模与仿真 刘学勇编著第八章内容,有兴趣的读者请阅读原书) clear all N10;%信息比特的行数 n7;%hamming码组长度n2^m-1 m3;%监督位长度 [H,G]hammgen(m);%产生(n,n-…...

基于YOLOv8的高压输电线路异物检测系统
基于YOLOv8的高压输电线路异物检测系统 (价格88) 包含 【“鸟窝”,“风筝”,“气球”,“垃圾”】 4个类 通过PYQT构建UI界面,包含图片检测,视频检测,摄像头实时检测。 (该系统可以根据数…...

23款奔驰GLS450加装原厂电吸门配置,提升车辆舒适性和便利性
今天是一台22款奔驰GLS450,车主是佛山的 以前被不良商家坑了 装了副厂的电吸门 刚开始就很正常 用了半年之后 就开始开不了门,被锁在里面,刚开始车主以为是零件坏了 后来越来越频繁,本来是为了家里老人小孩关门方便而升级的&#…...

git操作流程笔记
1、在本地项目文件夹右击鼠标点击Git Bash Here 2、输入git init,这个目录变成git可以管理的仓库,会出现一个.git文件夹,如果没出现的话需要选择“显示隐藏文件”(不会的同学自行百度一下) 3、绑定本地仓库与远程仓库…...

【QT】常用控件-上
欢迎来到Cefler的博客😁 🕌博客主页:折纸花满衣 目录 👉🏻QWidgetenabledgeometryrect制作上下左右按钮 window frame 的影响window titlewindowIcon代码示例: 通过 qrc 管理图片作为图标 windowOpacitycursor使用qrc自…...

2.Vue编写一个app
1.src中重要的组成 1.1main.ts // 引入createApp用于创建应用 import { createApp } from "vue"; // 引用App根组件 import App from ./App.vue;createApp(App).mount(#app)1.2 App.vue 其中要写三种标签 <template> <!--html--> </template>…...

转转集团旗下首家二手多品类循环仓店“超级转转”开业
6月9日,国内领先的循环经济企业转转集团旗下首家二手多品类循环仓店“超级转转”正式开业。 转转集团创始人兼CEO黄炜、转转循环时尚发起人朱珠、转转集团COO兼红布林CEO胡伟琨、王府井集团副总裁祝捷等出席了开业剪彩仪式。 据「TMT星球」了解,“超级…...

如何将联系人从 iPhone 转移到 Android
从 iPhone 换到 Android 手机时,你可能需要保留重要的数据,例如通讯录。好在,将通讯录从 iPhone 转移到 Android 手机非常简单,你可以从本文中学习 6 种可靠的方法,确保随时保持连接,不错过任何信息。 第 1…...

学习STC51单片机31(芯片为STC89C52RCRC)OLED显示屏1
每日一言 生活的美好,总是藏在那些你咬牙坚持的日子里。 硬件:OLED 以后要用到OLED的时候找到这个文件 OLED的设备地址 SSD1306"SSD" 是品牌缩写,"1306" 是产品编号。 驱动 OLED 屏幕的 IIC 总线数据传输格式 示意图 …...
)
【服务器压力测试】本地PC电脑作为服务器运行时出现卡顿和资源紧张(Windows/Linux)
要让本地PC电脑作为服务器运行时出现卡顿和资源紧张的情况,可以通过以下几种方式模拟或触发: 1. 增加CPU负载 运行大量计算密集型任务,例如: 使用多线程循环执行复杂计算(如数学运算、加密解密等)。运行图…...

GC1808高性能24位立体声音频ADC芯片解析
1. 芯片概述 GC1808是一款24位立体声音频模数转换器(ADC),支持8kHz~96kHz采样率,集成Δ-Σ调制器、数字抗混叠滤波器和高通滤波器,适用于高保真音频采集场景。 2. 核心特性 高精度:24位分辨率,…...

重启Eureka集群中的节点,对已经注册的服务有什么影响
先看答案,如果正确地操作,重启Eureka集群中的节点,对已经注册的服务影响非常小,甚至可以做到无感知。 但如果操作不当,可能会引发短暂的服务发现问题。 下面我们从Eureka的核心工作原理来详细分析这个问题。 Eureka的…...

智能AI电话机器人系统的识别能力现状与发展水平
一、引言 随着人工智能技术的飞速发展,AI电话机器人系统已经从简单的自动应答工具演变为具备复杂交互能力的智能助手。这类系统结合了语音识别、自然语言处理、情感计算和机器学习等多项前沿技术,在客户服务、营销推广、信息查询等领域发挥着越来越重要…...

MySQL 索引底层结构揭秘:B-Tree 与 B+Tree 的区别与应用
文章目录 一、背景知识:什么是 B-Tree 和 BTree? B-Tree(平衡多路查找树) BTree(B-Tree 的变种) 二、结构对比:一张图看懂 三、为什么 MySQL InnoDB 选择 BTree? 1. 范围查询更快 2…...
)
uniapp 集成腾讯云 IM 富媒体消息(地理位置/文件)
UniApp 集成腾讯云 IM 富媒体消息全攻略(地理位置/文件) 一、功能实现原理 腾讯云 IM 通过 消息扩展机制 支持富媒体类型,核心实现方式: 标准消息类型:直接使用 SDK 内置类型(文件、图片等)自…...