通过Go示例理解函数式编程思维
一个孩子要尝试10次、20次才肯接受一种新的食物,我们接受一种新的范式,大概不会比这个简单。-- 郭晓刚 《函数式编程思维》译者
函数式编程(Functional Programming, 简称fp)是一种编程范式,与命令式编程(Imperative Programming)、面向对象编程(OOP)、泛型编程(Generics Programming)、逻辑编程(logic Programming)[1]等是一类的概念。
注:尽管面向对象范式引入了新的编程思想和技术,但它本质上与命令式编程一样,都关注程序的状态和如何通过改变状态来控制程序的执行流程,因此,OOP仍然属于命令式编程的一个分支。OOP可以看作是命令式编程的一种扩展和补充,它增强了代码的模块化、复用性和可维护性。在接下来,我会统一使用命令式编程范式来指代它们。
但几十年的编程语言的演进和实践已经证明:函数式编程并非银弹,它有优势,更有不足。从编程社区的实际反映来看,纯函数式编程语言(比如:CLisp[2]、Haskell[3]、Scala、Clojure、Erlang等)始终处于小众地位。此外,即便很多主流命令式编程语言在近些年融入了一些函数式编程的语法特性,采用函数式风格的代码依旧比例极低,且不易被广泛接受。许多程序员在面对复杂的状态管理和副作用时,依然倾向于使用传统的命令式编程风格(包括OOP)。。
注:Go就原生提供了一些支持函数式范式编程的语法特性,比如:函数是一等公民(first-class)、高阶函数、闭包[4]、函数迭代器[5]以及泛型[6]等。
造成这种局面的原因众说纷纭,但我认为有如下几个:
首先从人类这个物种的大脑的认知和思维方式来看,命令式编程更接近于人类的自然思维方式,其逻辑与人类解决问题时的逻辑思维相似,即都是以步骤的形式理解问题,且有明确的控制流:命令式语言的控制结构(如条件语句、选择语句和循环)使得程序的执行路径清晰可见,符合人类的直觉理解,这也使得命令式语言更容易被人类大脑所掌握。
其次,命令式编程强调状态的变化,程序员可以直接看到和控制变量的变化,这与人类处理现实世界事物的方式相似。
在上面原因的驱使下,久而久之,程序员便形成习惯与传统,有了积淀,便可以促进命令式编程语言在教育和产业中的广泛应用,使得大多数程序员习惯于这种编程方式(间接挤压了函数式编程的使用空间)。进而使得命令式语言有更丰富的学习资源和社区支持,程序员也更容易找到帮助和示例。
也就是说,命令式编程范式占据主流的根本原因是人类的大脑本身就是命令式的,而不是函数式的。不过也有极少数大脑是函数式思维的,比如发明了TLA+这门形式化建模和验证语言[7]的Leslie Lamport老先生[8]。
那么问题来了!既然学习函数式编程思维是违反人类大脑直觉的,且较为困难,那为什么还是有很多人学习函数式编程思维,并在实际开发中应用函数式编程范式呢?关于这个问题,我们可以从两方面来看。
从主观上说,程序员经常有探索新技术和新范式的内在动力,这种好奇心驱使他们尝试函数式编程,也就是我们俗称的“玩腻了,尝尝鲜儿”。并且,许多程序员视学习函数式编程为一种智力挑战,一种来自舒适区之外的挑战,这种挑战能带来成就感和个人成长。此外,在竞争激烈的IT行业,掌握多种编程范式可以使得个人技能多样化,增加个人的职业竞争力。
从客观上看,函数式编程也确实能帮助程序员提高抽象思维和系统设计能力,这种能力的提升不仅限于函数式编程,还能应用到其他编程范式中。并且,函数式编程为程序员提供了一个新的解决问题的视角和方法,特别是在处理并发和并行计算、复杂数据转换和流处理方面。
学习函数式编程范式,并不是说抛弃命令式范式(或其他范式),而是融合,从主流编程语言对函数式编程的语法特性的支持也可窥见这般。
那么,到底什么是函数式编程范式?它与命令式范式对比又有怎么样的差异与优劣呢?在这篇文章中,我就来说说我的体会,并辅以Go示例来帮助大家理解。
1. 思维差异:命令式编程 vs. 函数式编程
在看过很多函数式编程的资料后(见文后的参考资料一节),我问了自己一个问题:面对同一个实际的问题,用命令式编程范式和用函数式编程范式的核心思维差异在哪里?为此,我基于现实世界的一个典型问题模型(数据输入 -> 数据处理 -> 处理结果输出),并根据自己的理解画了下面两幅图:
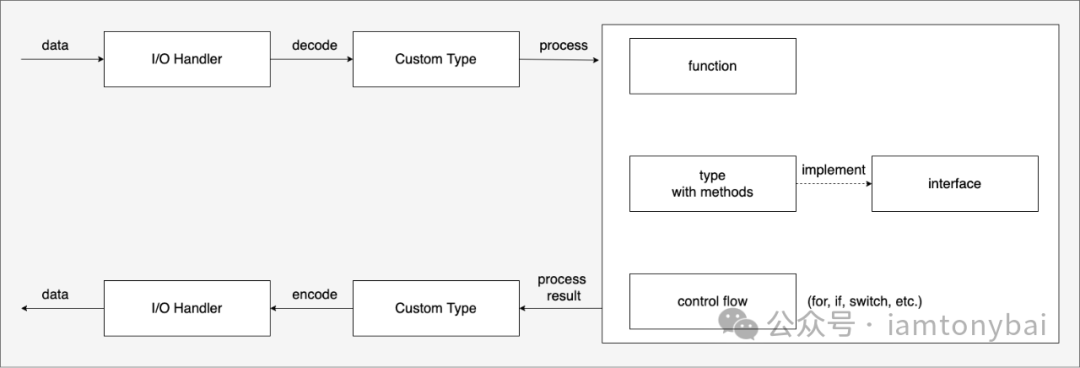
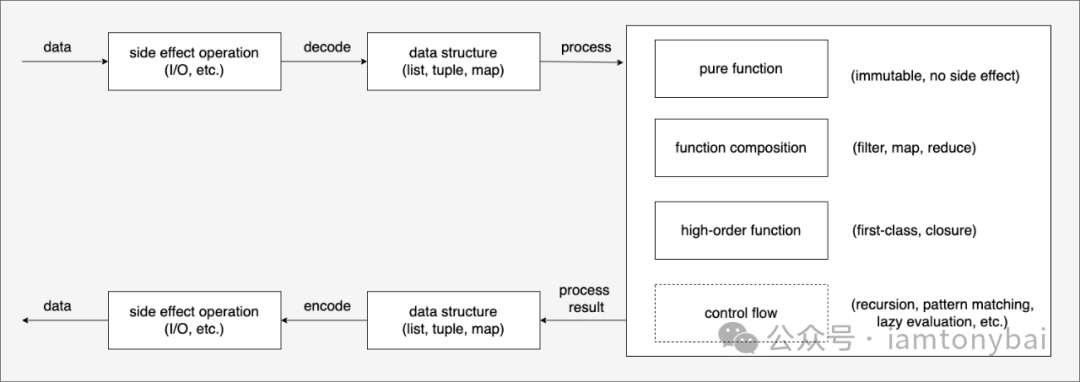
我们先来描述一下上面两幅图中的数据处理流程:
命令式编程:通过I/O操作获取数据,然后解码为自定义类型进行处理,再编码为自定义类型以便I/O操作输出。处理过程中使用函数、带方法的类型和控制流结构(如for、if、switch等)。
函数式编程:通过带有副作用的操作(如I/O操作)获取数据,然后解码数据放入通用数据结构(如列表、元组、映射)进行处理,再放入通用数据结构以便通过副作用操作输出。处理过程中会使用纯函数、高阶函数以及它们的函数组合。
基于上述流程的说明,我们可以看出两种范式核心关注点的差异:
命令式编程范式:更关注类型的封装、类型间的耦合关系、行为集合的抽象(接口)以及对数据在类型实例间的传递的显式控制(if/for/switch)。
函数式编程范式:弱化类型的概念,使用通用数据结构,专注于通过纯函数/高阶函数、不可变数据和函数组合来实现对数据的处理逻辑。“控制流”更加隐含,比如会通过递归、模式匹配和惰性求值等方式实现。建立专门的抽象来应对与真实世界交互时的带有副作用(side effect)的操作。
下面我们通过一个具体的问题来大致体会一下不同编程泛型在解决问题的实现上的思维差异。这个问题很简单:编写一个程序从input.txt文件中读取数字(每行一个数字),将每个数字乘以2,然后将结果写入output.txt文件中。
我们先来用命令式编程范式实现:
// fp-in-go/double/go/main.go// NumberData represents the input data
type NumberData struct {numbers []int
}// ProcessedData represents the processed output data
type ProcessedData struct {numbers []int
}// NewNumberData creates and returns a new NumberData instance
func NewNumberData() *NumberData {return &NumberData{numbers: []int{}}
}// AddNumber adds a number to NumberData
func (nd *NumberData) AddNumber(num int) {nd.numbers = append(nd.numbers, num)
}// Process doubles all numbers in NumberData and returns ProcessedData
func (nd *NumberData) Process() ProcessedData {processed := ProcessedData{numbers: make([]int, len(nd.numbers))}for i, num := range nd.numbers {processed.numbers[i] = num * 2}return processed
}// FileProcessor handles file operations and data processing
type FileProcessor struct {inputFile stringoutputFile string
}// NewFileProcessor creates and returns a new FileProcessor instance
func NewFileProcessor(input, output string) *FileProcessor {return &FileProcessor{inputFile: input,outputFile: output,}
}// ReadAndDeserialize reads data from input file and deserializes it into NumberData
func (fp *FileProcessor) ReadAndDeserialize() (*NumberData, error) {file, err := os.Open(fp.inputFile)if err != nil {return nil, fmt.Errorf("error opening input file: %w", err)}defer file.Close()data := NewNumberData()scanner := bufio.NewScanner(file)for scanner.Scan() {num, err := strconv.Atoi(scanner.Text())if err != nil {return nil, fmt.Errorf("error converting to number: %w", err)}data.AddNumber(num)}if err := scanner.Err(); err != nil {return nil, fmt.Errorf("error reading input file: %w", err)}return data, nil
}// SerializeAndWrite serializes ProcessedData and writes it to output file
func (fp *FileProcessor) SerializeAndWrite(data ProcessedData) error {file, err := os.Create(fp.outputFile)if err != nil {return fmt.Errorf("error creating output file: %w", err)}defer file.Close()writer := bufio.NewWriter(file)defer writer.Flush()for _, num := range data.numbers {_, err := writer.WriteString(fmt.Sprintf("%d\n", num))if err != nil {return fmt.Errorf("error writing to output file: %w", err)}}return nil
}// Process orchestrates the entire data processing workflow
func (fp *FileProcessor) Process() error {// Read and deserialize input datainputData, err := fp.ReadAndDeserialize()if err != nil {return err}// Process dataprocessedData := inputData.Process()// Serialize and write output dataerr = fp.SerializeAndWrite(processedData)if err != nil {return err}return nil
}func main() {processor := NewFileProcessor("input.txt", "output.txt")if err := processor.Process(); err != nil {fmt.Fprintf(os.Stderr, "Error: %v\n", err)os.Exit(1)}fmt.Println("Processing completed successfully.")
}这段代码十分容易理解,在这段代码中,我们建立了三个类型:NumberData、ProcessedData和FileProcessor。前两个分别代表解码后的输入数据和编码前的输出数据,FileProcessor则是封装了文件操作和数据处理的逻辑的自定义类型。这段代码将文件I/O、数据处理和主要流程控制分离到不同的方法中。在读取和写入过程中,数据经历了字符串 -> NumberData -> ProcessedData -> 字符串的转换过程,同时数据也是在不同类型的方法间传递和变换状态。
接下来我们再来看看函数式范式版本,Go虽然提供了一些函数式编程的基础支持,比如一等公民的函数、支持高阶函数、闭包等,但一些像monad、monoid等高级概念还需要手工实现。IBM开源了一个Go的函数式编程基础库fp-go[9],这里就借用fp-go的便利实现上面的同等功能,我们看看风格上有何不同:
// fp-in-go/double/fp-go/main.gopackage mainimport ("bufio""fmt""os""strconv""strings""github.com/IBM/fp-go/either""github.com/IBM/fp-go/ioeither"
)// 读取文件内容
func readFile(filename string) ioeither.IOEither[error, string] {return ioeither.TryCatchError(func() (string, error) {content, err := os.ReadFile(filename)return string(content), err})
}// 将字符串转换为数字列表
func parseNumbers(content string) either.Either[error, []int] {numbers := []int{}scanner := bufio.NewScanner(strings.NewReader(content))for scanner.Scan() {num, err := strconv.Atoi(scanner.Text())if err != nil {return either.Left[[]int](err "[]int")}numbers = append(numbers, num)}return either.Right[error](numbers "error")
}// 将数字乘以2
func multiplyBy2(numbers []int) []int {result := make([]int, len(numbers))for i, num := range numbers {result[i] = num * 2}return result
}// 将结果写入文件
func writeFile(filename string, content string) ioeither.IOEither[error, string] {return ioeither.TryCatchError(func() (string, error) {return "", os.WriteFile(filename, []byte(content), 0644)})
}func main() {program := ioeither.Chain(func(content string) ioeither.IOEither[error, string] {return ioeither.FromEither(either.Chain(func(numbers []int) either.Either[error, string] {multiplied := multiplyBy2(numbers)result := []string{}for _, num := range multiplied {result = append(result, strconv.Itoa(num))}return either.Of[error](strings.Join(result, "\n"))})(parseNumbers(content)),)})(readFile("input.txt"))program = ioeither.Chain(func(content string) ioeither.IOEither[error, string] {return writeFile("output.txt", content)})(program)result := program()err := either.ToError(result)if err != nil {fmt.Println("Program failed:", err)} else {fmt.Println("Program completed successfully")}
}相对于前面使用命令式范式风格的代码,这段函数式范式的代码理解起来就要难上不少。
不过,这段代码很好地诠释了函数式编程中的函数组合理念,我们看到函数被当作值来传递和使用。例如,在ioeither.Chain中,我们传递了匿名函数作为参数,这体现了函数式编程中函数作为一等公民的概念。multiplyBy2函数是一个纯函数的例子,它没有副作用,对于相同的输入总是产生相同的输出。这种纯函数更容易测试和推理。
代码中最明显的函数组合例子是在main函数中,我们使用ioeither.Chain来组合多个函数操作。并且在这里,我们将文件读取、内容处理和文件写入操作串联在一起,形成一个更大的操作。而ioeither.Chain和either.Chain又都是高阶函数的例子,它们接受其他函数作为参数并返回新的函数。Either和IOEither类型也是函数式编程中用于错误处理的主流方式,允许我们以更函数式的方式处理错误,将错误处理集成到函数组合中。
很多人好奇如果用纯函数式编程语言实现这个示例会是什么样子的,下面我就贴一段Haskell语言的代码,大家简单了解一下,这里就不对代码进行解释了:
// fp-in-go/double/fp-haskell/Main.hsimport System.IO
import Control.Monad (when)
import Text.Read (readMaybe)
import Data.Maybe (catMaybes)-- Define a custom type for the result
data DoubledNumbers = DoubledNumbers { doubledNumbers :: [Int] } deriving (Show)-- Function to read numbers from a file
readNumbers :: FilePath -> IO (Either String [Int])
readNumbers filePath = docontent <- readFile filePathlet numbers = catMaybes (map readMaybe (lines content))return $ if null numbersthen Left "No valid numbers found."else Right numbers-- Function to write result to a file
writeResult :: FilePath -> DoubledNumbers -> IO (Either String ())
writeResult filePath result = dolet resultString = unlines (map show (doubledNumbers result))writeFile filePath resultStringreturn $ Right ()-- Function to double the numbers
doubleNumbers :: [Int] -> DoubledNumbers
doubleNumbers numbers = DoubledNumbers { doubledNumbers = map (* 2) numbers }main :: IO ()
main = do-- Read numbers from input.txtreadResult <- readNumbers "input.txt"case readResult ofLeft err -> putStrLn $ "Error: " ++ errRight numbers -> dolet result = doubleNumbers numbers-- Write result to output.txtwriteResultResult <- writeResult "output.txt" resultcase writeResultResult ofLeft err -> putStrLn $ "Error: " ++ errRight () -> putStrLn "Successfully written the result to output.txt."注:安装ghc后,执行ghc --make Main就可以将上面Main.hs编译为一个可执行程序。更多关于haskell编译器的信息可以到haskell官网[10]查看。
从上面的示例我们大致也能感受到两种范式在思维层面的差异,正如Robert Martin在《函数式设计》一书中说道的那样:函数式程序更倾向于铺设调节数据流转换的管道结构,而可变的命令式程序更倾向于迭代地处理一个个类型对象。
我们很难在一个例子中体现出函数式编程的所有概念和思维特点,接下来,我们就来逐个说说函数式编程范式中的要素,你也可以对应前面的图中的内容,反复感受函数式编程的思维特点。
2. 函数式编程的要素
面向对象的编程通过封装不确定因素来使代码能被人理解,而函数式编程通过尽量减少不确定因素来使代码能被人理解。—— Michael Feathers 《修改代码的艺术[11]》一书作者
函数式编程建立在几个核心要素之上,这些要素共同构成了函数式编程的基础。让我们逐一探讨这些要素。
2.1 纯函数 (Pure Functions)
纯函数是函数式编程的基石。一个纯函数具有以下特性:
对于相同的输入,总是产生相同的输出;
不会产生副作用(不会修改外部状态);
不依赖外部状态。
例如,前面fp-go示例中的multiplyBy2就是一个纯函数:
func multiplyBy2(numbers []int) []int {result := make([]int, len(numbers))for i, num := range numbers {result[i] = num * 2}return result
}这个函数总是为相同的输入返回相同的结果,并且不会修改任何外部状态。
2.2 不可变性 (Immutability)
Robert Martin在《函数式设计》一书为函数式编程下一个理想的定义:没有赋值语句的编程。实质是其强调了不可变性在函数式编程范式中的重要意义。在没有赋值语句的情况下,代码通常基于对原状态的计算而得到新的状态,而对原状态没有任何修改。
在Go语言中,由于不支持不可变变量(很多语言用val关键字来声明不可变变量,但Go并不支持),我们通常通过复制对象来实现不可变性,这可以帮助我们避免状态变化带来的复杂性,但也因为复制而增加了内存开销和性能成本。
// 定义一个不可变的结构体
type Point struct {x, y int
}// 创建一个新的 Point,模拟不可变性
func NewPoint(x, y int) Point {return Point{x, y}
}// 移动Point的方法,返回一个新的Point
func (p Point) Move(dx, dy int) Point {return NewPoint(p.x+dx, p.y+dy)
}2.3 高阶函数 (Higher-Order Functions)与函数组合(Function Composition)
Go语言的一个内置特性让它具备了使用函数式编程范式的前提,那就是在Go中,函数是一等公民。这意味着函数可以像其他类型变量一样,被赋值、传参和返回。
而接受其他函数作为参数或返回函数的函数,被称为高阶函数,这也是函数式编程的基石,如下面的applyOperation函数就是一个高阶函数:
func applyOperation(x int, operation func(int) int) int {return operation(x)
}func double(x int) int {return x * 2
}result := applyOperation(5, double) // 结果为10而有了对高阶函数的支持,我们才能运用函数式思维中的核心思维:函数组合,来铺设调节数据流转换的管道结构:
// fp-in-go/high-order-func/main.gopackage mainimport ("fmt"
)// 定义一个类型为函数的别名
type IntTransformer func(int) int// 将多个转换函数组合成一个管道
func pipe(value int, transformers ...IntTransformer) int {for _, transformer := range transformers {value = transformer(value)}return value
}// 定义一些转换函数
func addOne(x int) int {return x + 1
}func square(x int) int {return x * x
}func main() {// 使用管道处理数据result := pipe(3, addOne, square)fmt.Println("Result:", result) // 输出 Result: 16
}这个示例中的pipe函数接受一个初始值和多个转换函数,并将其串联执行。main函数调用pipe函数,将addOne和square两个转换函数连接起来并执行输出结果。
前面那个使用fp-go编写的示例中,使用ioeither.Chain构建的program也是一个函数调用组合。
此外,链式调用也是一种在日常开发中常见的函数组合的使用形式,它融合了命令式的类型和函数式编程的函数组合,特别适用于集合类型数据的处理,通过链式调用,可以以更简洁和直观的方式进行数据转换和处理。下面是一个基于泛型实现的通用的链式调用(filter -> map -> reduce)的示例:
// fp-in-go/func-composition/main.gopackage mainimport "fmt"// Collection 接口定义了通用的集合操作
type Collection[T any] interface {Filter(predicate func(T) bool) Collection[T]Map(transform func(T) T) Collection[T]Reduce(initialValue T, reducer func(T, T) T) T
}// SliceCollection 是基于切片的集合实现
type SliceCollection[T any] struct {data []T
}// NewSliceCollection 创建一个新的 SliceCollection
func NewSliceCollection[T any](data []T "T any") *SliceCollection[T] {return &SliceCollection[T]{data: data}
}// Filter 实现了 Collection 接口的 Filter 方法
func (sc *SliceCollection[T]) Filter(predicate func(T) bool) Collection[T] {result := make([]T, 0)for _, item := range sc.data {if predicate(item) {result = append(result, item)}}return &SliceCollection[T]{data: result}
}// Map 实现了 Collection 接口的 Map 方法
func (sc *SliceCollection[T]) Map(transform func(T) T) Collection[T] {result := make([]T, len(sc.data))for i, item := range sc.data {result[i] = transform(item)}return &SliceCollection[T]{data: result}
}// Reduce 实现了 Collection 接口的 Reduce 方法
func (sc *SliceCollection[T]) Reduce(initialValue T, reducer func(T, T) T) T {result := initialValuefor _, item := range sc.data {result = reducer(result, item)}return result
}// SetCollection 是基于 map 的集合实现
type SetCollection[T comparable] struct {data map[T]struct{}
}// NewSetCollection 创建一个新的 SetCollection
func NewSetCollection[T comparable]( "T comparable") *SetCollection[T] {return &SetCollection[T]{data: make(map[T]struct{})}
}// Add 向 SetCollection 添加元素
func (sc *SetCollection[T]) Add(item T) {sc.data[item] = struct{}{}
}// Filter 实现了 Collection 接口的 Filter 方法
func (sc *SetCollection[T]) Filter(predicate func(T) bool) Collection[T] {result := NewSetCollection[T]( "T")for item := range sc.data {if predicate(item) {result.Add(item)}}return result
}// Map 实现了 Collection 接口的 Map 方法
func (sc *SetCollection[T]) Map(transform func(T) T) Collection[T] {result := NewSetCollection[T]( "T")for item := range sc.data {result.Add(transform(item))}return result
}// Reduce 实现了 Collection 接口的 Reduce 方法
func (sc *SetCollection[T]) Reduce(initialValue T, reducer func(T, T) T) T {result := initialValuefor item := range sc.data {result = reducer(result, item)}return result
}// ToSlice 实现了 Collection 接口的 ToSlice 方法
func (sc *SetCollection[T]) ToSlice() []T {result := make([]T, 0, len(sc.data))for item := range sc.data {result = append(result, item)}return result
}func main() {// 使用 SliceCollectionnumbers := NewSliceCollection([]int{1, 2, 3, 4, 5, 6, 7, 8, 9, 10})result := numbers.Filter(func(n int) bool { return n%2 == 0 }).Map(func(n int) int { return n * 2 }).Reduce(0, func(acc, n int) int { return acc + n })fmt.Println(result) // 输出: 60// 使用 SetCollectionset := NewSetCollection[int]( "int")for _, n := range []int{1, 2, 2, 3, 3, 3, 4, 5} {set.Add(n)}uniqueSum := set.Filter(func(n int) bool { return n > 2 }).Map(func(n int) int { return n * n }).Reduce(0, func(acc, n int) int { return acc + n })fmt.Println(uniqueSum) // 输出: 50 (3^2 + 4^2 + 5^2)
}这段代码定义的泛型接口类型Collection包含三个方法:
Filter:根据条件过滤集合中的元素。
Map:对集合中的每个元素应用转换函数。
Reduce:对集合中的元素进行归约操作,比如求和。
其中Filtre、Map都是返回集合自身,这样便允许实现Collection接口的集合类型(如上面的SetCollection和SliceCollection)使用链式调用,代码看起来也十分易于理解。
2.4 递归(Recursion)
递归是函数式编程中常用的控制结构,常用来替代循环。例如下面是计算阶乘的函数实现:
func factorial(n int) int {if n <= 1 {return 1}return n * factorial(n-1)
}递归的优点十分明显,代码简洁,易于理解(相对于循环),特别适合处理分解问题(如树结构、图遍历等)。但不足也很突出,比如可能导致栈溢出(尤其是对那些不支持尾递归优化的语言,比如Go),特别是对于较大的输入。此外,由于每次递归调用都需要创建新栈帧,维护栈状态,递归会有额外的性能开销。调试递归函数也可能比循环更复杂,因为需要跟踪多个函数调用。
2.5 惰性求值 (Lazy Evaluation)
惰性求值是指延迟计算表达式的值,直到真正需要它的时候。这样可以避免不必要的计算并有效管理内存,特别是在处理大集合或无限集合时。下面是用惰性求值实现迭代集合元素的示例:
注:Go原生并不支持惰性求值的语法,但我们可以使用闭包来模拟。
// fp-in-go/lazy-evaluation/lazy-range/main.gopackage mainimport "fmt"func lazyRange(start, end int) func() (int, bool) {current := startreturn func() (int, bool) {if current >= end {return 0, false}result := currentcurrent++return result, true}
}
func main() {next := lazyRange(1, 5)for {value, hasNext := next()if !hasNext {break}fmt.Println(value)}
}我们看到这段代码通过惰性求值方式生成从1到4的数字,避免了预先生成整个范围的集合元素,节省了内存,并避免了不必要的计算。
我们再来看一个用惰性求值生成前N个斐波那契数列的示例:
// fp-in-go/lazy-evaluation/fibonacci/main.gopackage mainimport ("fmt"
)// Fibonacci 返回一个生成无限斐波那契数列的函数
func Fibonacci() func() int {a, b := 0, 1return func() int {a, b = b, a+breturn a}
}func main() {fib := Fibonacci()for i := 0; i < 10; i++ { // 打印前10个斐波那契数fmt.Println(fib())}
}我们看到Fibonacci函数返回一个闭包,每次调用时生成下一个斐波那契数,这样我们在需要时生成下一个斐波那契数,而无需生成所有。
虽然函数式编程强调纯函数和不可变性,但在实际应用中,我们不可避免地需要处理副作用,如I/O操作、数据库交互等。接下来,我们就来看看在函数式编程范式中是如何处理带有副作用的操作的。
3. 函数式编程对副作用操作的处理
3.1 理解副作用
在函数式编程中,副作用是指函数或表达式在执行过程中对其周围环境产生的任何可观察到的变化。这些变化包括但不限于:
修改全局变量或静态局部变量
修改函数参数
执行I/O操作(读写文件、网络通信等)
抛出异常或错误
调用其他具有副作用的函数
副作用使得程序的行为变得难以预测和测试,因为函数的输出不仅依赖于其输入,还依赖于程序的状态和外部环境。函数式编程通过最小化副作用来提高程序的可预测性和可测试性。
3.2 Monad: 函数式编程中处理副作用的核心抽象
在函数式编程中,Monad是一种用于处理副作用的核心抽象。它提供了一种结构化的方式来处理计算中的状态、异常、输入输出等副作用,使得程序更加模块化和可组合。
在范畴论中,Monad被定义为一个自函子(endofunctor)加上两个自然变换(有点抽象了):
return (也称为unit):将一个值封装到Monad中。
bind (也称为flatMap或>>=):将一个Monad中的值应用到一个函数中,并返回一个新的Monad。
注:要入门范畴论,可以参考《Category Theory for Programmers[12]》这本书。
Monad可以通过以下策略来处理副作用:
延迟执行:将副作用操作封装在Monad中,但不立即执行,这样可以将副作用推迟到程序的边缘。
显式表示:使副作用成为类型系统的一部分,迫使开发者显式地处理这些效果。
组合性:提供了一种方式来组合包含副作用的操作,而不破坏函数的纯粹性。
错误处理:提供了一种统一的方式来处理可能失败的操作。
状态管理:允许在一系列操作中传递和修改状态,而不需要使用可变变量。
在实际应用中,我们可以根据具体需求选择使用不同的Monad实现。每种Monad都有其适用场景,比如:
使用Option(Maybe) Monad处理可能缺失的值,避免空指针异常。
使用Result(Either) Monad 处理可能失败的操作,提供更丰富的错误信息。
使用IO Monad封装所有的I/O操作,将副作用推迟到程序的边缘。
接下来,我们就结合Go示例来逐一探讨这三种Monad实现。
3.3 Option (Maybe)
Option 用于表示一个值可能存在或不存在,避免了使用null或undefined带来的问题。
// fp-in-go/side-effect/option/main.gopackage mainimport "fmt"type Option[T any] struct {value Tpresent bool
}func Some[T any](x T "T any") Option[T] {return Option[T]{value: x, present: true}
}func None[T any]( "T any") Option[T] {return Option[T]{present: false}
}func (o Option[T]) Bind(f func(T) Option[T]) Option[T] {if !o.present {return None[T]( "T")}return f(o.value)
}// 使用示例
func safeDivide(a, b int) Option[int] {if b == 0 {return None[int]( "int")}return Some(a / b)
}func main() {result := Some(10).Bind(func(x int) Option[int] {return safeDivide(x, 2)})fmt.Println(result) // {5 true}result = Some(10).Bind(func(x int) Option[int] {return safeDivide(x, 0)})fmt.Println(result) // {0 false}
}这段示例程序定义了一个Option结构体:包含一个值和一个表示值是否存在的布尔变量。Some和None函数是Option的创建函数,Some函数:返回一个包含值的Option。None函数返回一个不包含值的Option。Bind方法对Option中的值应用一个函数,如果值不存在则返回None。
3.4 Result (Either)
Result可用于处理可能产生错误的操作,它比Option提供了更多的信息,它可以可以携带错误信息。
// fp-in-go/side-effect/result/main.gopackage mainimport ("fmt""os""strings"
)type Result[T any] struct {value Terr errorisOk bool
}func Ok[T any](value T "T any") Result[T] {return Result[T]{value: value, isOk: true}
}func Err[T any](err error "T any") Result[T] {return Result[T]{err: err, isOk: false}
}func (r Result[T]) Bind(f func(T) Result[T]) Result[T] {if !r.isOk {return Err[T](r.err "T")}return f(r.value)
}// 使用示例
func readFile(filename string) Result[string] {content, err := os.ReadFile(filename)if err != nil {return Err[string](err "string")}return Ok(string(content))
}func processContent(content string) Result[string] {// 处理内容...return Ok(strings.ToUpper(content))
}func main() {result := readFile("input.txt").Bind(processContent)fmt.Println(result) // {HELLO, GOLANG <nil> true}result = readFile("input1.txt").Bind(processContent)fmt.Println(result) // { 0xc0000a0420 false}
}这段示例程序定义了一个Result结构体:包含一个值、一个错误信息和一个表示操作是否成功的布尔变量。Ok和Err函数是Result的创建函数,Ok函数返回一个成功的Result。Err函数返回一个失败的Result。Bind方法对成功的Result中的值应用一个函数,如果操作失败则返回错误。
在示例中,我们分别用读取input.txt和不存在的input1.txt来演示成功和错误的两个情况,具体输出结果见上面代码中的注释。
3.5 IO Monad
IO Monad用于封装所有的带有副作用的输入/输出操作,使得这些操作在类型系统中可见,并且可以被推迟执行。
// fp-in-go/side-effect/io-monad/main.gopackage mainimport ("fmt""os""strings"
)// IO represents an IO operation that, when run, produces a value of type any or an error
type IO struct {run func() (any, error)
}// NewIO creates a new IO monad
func NewIO(f func() (any, error)) IO {return IO{run: f}
}// Bind chains IO operations, allowing for type changes
func (io IO) Bind(f func(any) IO) IO {return NewIO(func() (any, error) {v, err := io.run()if err != nil {return nil, err}return f(v).run()})
}// Map transforms the value inside IO
func (io IO) Map(f func(any) any) IO {return io.Bind(func(v any) IO {return NewIO(func() (any, error) {return f(v), nil})})
}// Pure lifts a value into the IO context
func Pure(x any) IO {return NewIO(func() (any, error) { return x, nil })
}// ReadFile is an IO operation that reads a file
func ReadFile(filename string) IO {return NewIO(func() (any, error) {content, err := os.ReadFile(filename)if err != nil {return nil, fmt.Errorf("failed to read file: %w", err)}return string(content), nil})
}// WriteFile is an IO operation that writes to a file
func WriteFile(filename string, content string) IO {return NewIO(func() (any, error) {err := os.WriteFile(filename, []byte(content), 0644)if err != nil {return nil, fmt.Errorf("failed to write file: %w", err)}return true, nil})
}// Print is an IO operation that prints to stdout
func Print(x any) IO {return NewIO(func() (any, error) {fmt.Println(x)return x, nil})
}func main() {// Example: Read a file, transform its content, and write it backprogram := ReadFile("input.txt").Map(func(v any) any {return strings.ToUpper(v.(string))}).Bind(func(v any) IO {return WriteFile("output.txt", v.(string))}).Bind(func(v any) IO {success := v.(bool)if success {return Pure("File processed successfully")}return Pure("Failed to process file")}).Bind(func(v any) IO {return Print(v)})// Run the IO operationresult, err := program.run()if err != nil {fmt.Printf("An error occurred: %v\n", err)} else {fmt.Printf("Program completed: %s\n", result)}
}这个示例提供了一个非泛型版本的IO Monad的Go实现,它允许我们链式组合带有副作用的IO操作,同时保持了一定程度的类型安全(尽管需要类型断言)。在实际使用中,你完全不用自己实现IO Monad,可以直接使用IBM/fp-go中的ioeither,就像本文初那个示例那样。
4. 小结
到这里,关于函数式编程思维的入门介绍就告一段落了!
通过上面的介绍,我们看到函数式编程提供了一种不同于传统命令式编程的思维方式。它强调不可变性、纯函数和函数的组合,为数据流的处理搭建管道,这些特性使得代码更易于理解、测试和并行化。然而,函数式编程也带来了一些挑战,如处理副作用和状态管理的复杂性和难于理解。
学习函数式编程不仅可以扩展我们的编程技能,还能帮助我们以新的方式思考问题和设计解决方案。正如《函数式编程思维》一书中译者所说,接受一种新的编程范式可能需要时间和耐心,但最终会带来新的见解和能力。
在实际应用中,纯粹的函数式编程并不常见,更常见的是将函数式编程的概念和技术与其他编程范式(主要就是命令式范式)相结合。
Go语言虽然不是一个纯函数式语言,但它提供了足够的特性来支持函数式编程风格,如一等公民的函数、闭包和高阶函数等。
最后要记住,编程范式是工具,而不是教条。好的程序员应该能够根据具体问题和场景,灵活地选择和组合不同的编程范式,以创造出最优雅、高效的解决方案。
本文涉及的源码可以在这里[13]下载 - https://github.com/bigwhite/experiments/blob/master/fp-in-go
本文部分源代码由Claude 3.5 sonnet和GPT-4o生成。
5. 参考资料
《函数式设计:原则、模式与实践[14]》- https://book.douban.com/subject/36974785/
《函数式编程思维[15]》- https://book.douban.com/subject/26587213/
《计算机程序的构造和解释[16]》- https://book.douban.com/subject/36787585/
《Learning Functional Programming in Go[17]》 - https://book.douban.com/subject/30165168/
Introduction to fp-go, functional programming for golang[18] - https://www.youtube.com/watch?v=Jif3jL6DRdw
Investigate Functional Programming Concepts in Go[19] - https://betterprogramming.pub/investigate-functional-programming-concepts-in-go-1dada09bc913
Investigating the I/O Monad in Go[20] - https://medium.com/better-programming/investigating-the-i-o-monad-in-go-3c0fabbb4b3d
Gopher部落知识星球[21]在2024年将继续致力于打造一个高品质的Go语言学习和交流平台。我们将继续提供优质的Go技术文章首发和阅读体验。同时,我们也会加强代码质量和最佳实践的分享,包括如何编写简洁、可读、可测试的Go代码。此外,我们还会加强星友之间的交流和互动。欢迎大家踊跃提问,分享心得,讨论技术。我会在第一时间进行解答和交流。我衷心希望Gopher部落可以成为大家学习、进步、交流的港湾。让我相聚在Gopher部落,享受coding的快乐! 欢迎大家踊跃加入!




著名云主机服务厂商DigitalOcean发布最新的主机计划,入门级Droplet配置升级为:1 core CPU、1G内存、25G高速SSD,价格5$/月。有使用DigitalOcean需求的朋友,可以打开这个链接地址[22]:https://m.do.co/c/bff6eed92687 开启你的DO主机之路。
Gopher Daily(Gopher每日新闻) - https://gopherdaily.tonybai.com
我的联系方式:
微博(暂不可用):https://weibo.com/bigwhite20xx
微博2:https://weibo.com/u/6484441286
博客:tonybai.com
github: https://github.com/bigwhite
Gopher Daily归档 - https://github.com/bigwhite/gopherdaily
Gopher Daily Feed订阅 - https://gopherdaily.tonybai.com/feed

商务合作方式:撰稿、出书、培训、在线课程、合伙创业、咨询、广告合作。
参考资料
[1]
逻辑编程(logic Programming): https://tonybai.com/2012/05/08/translate-seven-languages-in-seven-weeks/
[2]CLisp: https://tonybai.com/2011/08/30/c-programers-tame-common-lisp-series-introduction/
[3]Haskell: https://www.haskell.org
[4]闭包: https://tonybai.com/2021/08/09/when-variables-captured-by-closures-are-recycled-in-go
[5]函数迭代器: https://tonybai.com/2024/06/24/range-over-func-and-package-iter-in-go-1-23/
[6]泛型: https://tonybai.com/2022/05/20/solving-problems-in-generic-function-implementation-using-named-return-values
[7]TLA+这门形式化建模和验证语言: https://tonybai.com/2024/08/05/formally-verify-concurrent-go-programs-using-tla-plus/
[8]Leslie Lamport老先生: https://lamport.azurewebsites.net
[9]IBM开源了一个Go的函数式编程基础库fp-go: https://github.com/IBM/fp-go
[10]haskell官网: https://www.haskell.org
[11]修改代码的艺术: https://book.douban.com/subject/2248759/
[12]Category Theory for Programmers: https://book.douban.com/subject/30357114/
[13]这里: https://github.com/bigwhite/experiments/blob/master/fp-in-go
[14]函数式设计:原则、模式与实践: https://book.douban.com/subject/36974785/
[15]函数式编程思维: https://book.douban.com/subject/26587213/
[16]计算机程序的构造和解释: https://book.douban.com/subject/36787585/
[17]Learning Functional Programming in Go: https://book.douban.com/subject/30165168/
[18]Introduction to fp-go, functional programming for golang: https://www.youtube.com/watch?v=Jif3jL6DRdw
[19]Investigate Functional Programming Concepts in Go: https://betterprogramming.pub/investigate-functional-programming-concepts-in-go-1dada09bc913
[20]Investigating the I/O Monad in Go: https://medium.com/better-programming/investigating-the-i-o-monad-in-go-3c0fabbb4b3d
[21]Gopher部落知识星球: https://public.zsxq.com/groups/51284458844544
[22]链接地址: https://m.do.co/c/bff6eed92687
相关文章:
通过Go示例理解函数式编程思维
一个孩子要尝试10次、20次才肯接受一种新的食物,我们接受一种新的范式,大概不会比这个简单。-- 郭晓刚 《函数式编程思维》译者 函数式编程(Functional Programming, 简称fp)是一种编程范式,与命令式编程(Imperative Programming)、面向对象编…...

刷题DAY7
三角形面积 题目:已知三角形的边长a,b和从、,求其面积 输入:输入三个实数a,b,c,表示三边长 输出:输出面积,保留三位小数 输入:1 2 2.5 输出࿱…...
离线数据开发流程小案例-图书馆业务数据
参考 https://blog.csdn.net/m53931422/article/details/103633452 https://www.cnblogs.com/jasonlam/p/7928179.html https://cwiki.apache.org/confluence/display/Hive/LanguageManualUDF https://medium.com/jackgoettle23/building-a-hive-user-defined-function-f6abe9…...

GPT-5:未来已来,你准备好了吗
GPT-5:未来已来,你准备好了吗? 在人工智能的浩瀚星空中,自然语言处理(NLP)技术如同璀璨星辰,不断引领着技术革新的浪潮。而在这股浪潮中,OpenAI的GPT(Generative Pre-tr…...

白骑士的Matlab教学高级篇 3.2 并行计算
系列目录 上一篇:白骑士的Matlab教学高级篇 3.1 高级编程技术 并行计算是一种通过同时执行多个计算任务来加速程序运行的方法。在MATLAB中,并行计算工具箱(Parallel Computing Toolbox)提供了丰富的并行计算功能,使用…...

JS中【解构赋值】知识点解读
解构赋值(Destructuring Assignment)是 JavaScript 中一种从数组或对象中提取数据的简便方法,可以将其赋值给变量。这种语法可以让代码更加简洁、清晰。下面我会详细讲解解构赋值的相关知识点。 1. 数组解构赋值 数组解构赋值允许你通过位置…...

【Pyspark-驯化】一文搞懂Pyspark中对json数据处理使用技巧:get_json_object
【Pyspark-驯化】一文搞懂Pyspark中对json数据处理使用技巧:get_json_object 本次修炼方法请往下查看 🌈 欢迎莅临我的个人主页 👈这里是我工作、学习、实践 IT领域、真诚分享 踩坑集合,智慧小天地! 🎇 …...

第10章 无持久存储的文件系统 (1)
目录 前言 10.1 proc文件系统 10.1.1 /proc 内容 本专栏文章将有70篇左右,欢迎关注,查看后续文章。 前言 即存在于内存中的文件系统。如: proc: sysfs: 即/sys目录。 内容不一定是ASCII文本,可能是二进…...

如何把命令行创建python虚拟环境与pycharm项目管理更好地结合起来
1. 问题的提出 我在linux或windows下的某个目录如“X”下使用命令行的方式创建了一个python虚拟环境(参考文章),对应的目录为myvenv, 现在我想使用pycharm创建python项目myproject,并且利用虚拟环境myvenv,怎么办&…...

keepalived+lvs高可用负载均衡集群配置方案
配置方案 一、配置主备节点1. 在主备节点上安装软件2. 编写配置文件3. 启动keepalived服务 二、配置web服务器1. 安装并启动http服务2. 编写主页面3.配置虚拟地址4. 配置ARP 三、测试 服务器IP: 主负载均衡服务器 master 192.168.152.71备负载均衡服务器 backup 192…...

Azure OpenAI Swagger Validation Failure with APIM
题意:Azure OpenAI Swagger 验证失败与 APIM 问题背景: Im converting the Swagger for Azure OpenAI API Version 2023-07-01-preview from json to yaml 我正在将 Azure OpenAI API 版本 2023-07-01-preview 的 Swagger 从 JSON 转换为 YAML。 My S…...

haproxy高级功能配置
介绍HAProxy高级配置及实用案例 一.基于cookie会话保持 cookie value:为当前server指定cookie值,实现基于cookie的会话黏性,相对于基于 source 地址hash 调度算法对客户端的粒度更精准,但同时也加大了haproxy负载,目前此模式使用…...

XXL-JOB分布式定时任务框架快速入门
文章目录 前言定时任务分布式任务调度 1、XXL-JOB介绍1.1 XXL-JOB概述1.2 XXL-JOB特性1.3 整体架构 2、XXL-JOB任务中心环境搭建2.1 XXL-JOB源码下载2.2 IDEA导入xxljob工程2.3 初始化数据库2.4 Docker安装任务管理中心 3、XXL-JOB任务注册测试3.1 引入xxl-job核心依赖3.2 配置…...

直流电机及其驱动
直流电机是一种将电能转换为机械能的装置,有两个电极,当电极正接时,电机正转,当电极反接时,电机反转。 直流电机属于大功率器件,GPIO口无法直接驱动,需要配合电机驱动电路来操作 TB6612是一款双…...

Java-判断一个字符串是否为有效的JSON字符串
在 Java 中判断一个字符串是否为有效的 JSON 字符串,可以使用不同的库来进行验证。常见的库 包括 org.json、com.google.gson 和 com.alibaba.fastjson 等。这里我将展示如何使用 com.alibaba.fastjson 库来实现一个简单的工具类,用于判断给定的字符串…...

FPGA开发板的基本知识及应用
FPGA开发板是一种专门设计用于开发和测试现场可编程门阵列(Field-Programmable Gate Array, FPGA)的硬件平台。FPGA是一种高度可配置的集成电路,能够在制造后被编程以执行各种数字逻辑功能。FPGA开发板通常包含一个FPGA芯片以及一系列支持电路和接口,以便…...

JVM知识总结(性能调优)
文章收录在网站:http://hardyfish.top/ 文章收录在网站:http://hardyfish.top/ 文章收录在网站:http://hardyfish.top/ 文章收录在网站:http://hardyfish.top/ 性能调优 何时进行JVM调优? 遇到以下情况,…...

基于Ascend C的Matmul算子性能优化最佳实践
矩阵乘法是深度学习计算中的基础操作,对于提升模型训练和推理速度至关重要。昇腾AI处理器是一款专门面向AI领域的AI加速器,其AI Core采用达芬奇架构,以高性能Cube计算引擎为基础,针对矩阵运算进行加速,可大幅提高单位面…...

SQL注入之EVAL长度限制突破技巧
要求: PHP Eval函数参数限制在16个字符的情况下 ,如何拿到Webshell? widows小皮环境搭建: 使用phpstudy搭建一个网站。 随后在该eval文件夹下创建一个webshell.php文件,并在其输入代码环境 解题思路: 通…...
稀疏注意力:时间序列预测的局部性和Transformer的存储瓶颈
时间序列预测是许多领域的重要问题,包括对太阳能发电厂发电量、电力消耗和交通拥堵情况的预测。在本文中,提出用Transformer来解决这类预测问题。虽然在我们的初步研究中对其性能印象深刻,但发现了它的两个主要缺点:(1)位置不可知性:规范Tran…...

RestClient
什么是RestClient RestClient 是 Elasticsearch 官方提供的 Java 低级 REST 客户端,它允许HTTP与Elasticsearch 集群通信,而无需处理 JSON 序列化/反序列化等底层细节。它是 Elasticsearch Java API 客户端的基础。 RestClient 主要特点 轻量级ÿ…...

React 第五十五节 Router 中 useAsyncError的使用详解
前言 useAsyncError 是 React Router v6.4 引入的一个钩子,用于处理异步操作(如数据加载)中的错误。下面我将详细解释其用途并提供代码示例。 一、useAsyncError 用途 处理异步错误:捕获在 loader 或 action 中发生的异步错误替…...

基于大模型的 UI 自动化系统
基于大模型的 UI 自动化系统 下面是一个完整的 Python 系统,利用大模型实现智能 UI 自动化,结合计算机视觉和自然语言处理技术,实现"看屏操作"的能力。 系统架构设计 #mermaid-svg-2gn2GRvh5WCP2ktF {font-family:"trebuchet ms",verdana,arial,sans-…...
)
React Native 导航系统实战(React Navigation)
导航系统实战(React Navigation) React Navigation 是 React Native 应用中最常用的导航库之一,它提供了多种导航模式,如堆栈导航(Stack Navigator)、标签导航(Tab Navigator)和抽屉…...

Mybatis逆向工程,动态创建实体类、条件扩展类、Mapper接口、Mapper.xml映射文件
今天呢,博主的学习进度也是步入了Java Mybatis 框架,目前正在逐步杨帆旗航。 那么接下来就给大家出一期有关 Mybatis 逆向工程的教学,希望能对大家有所帮助,也特别欢迎大家指点不足之处,小生很乐意接受正确的建议&…...

SCAU期末笔记 - 数据分析与数据挖掘题库解析
这门怎么题库答案不全啊日 来简单学一下子来 一、选择题(可多选) 将原始数据进行集成、变换、维度规约、数值规约是在以下哪个步骤的任务?(C) A. 频繁模式挖掘 B.分类和预测 C.数据预处理 D.数据流挖掘 A. 频繁模式挖掘:专注于发现数据中…...

鸿蒙中用HarmonyOS SDK应用服务 HarmonyOS5开发一个医院查看报告小程序
一、开发环境准备 工具安装: 下载安装DevEco Studio 4.0(支持HarmonyOS 5)配置HarmonyOS SDK 5.0确保Node.js版本≥14 项目初始化: ohpm init harmony/hospital-report-app 二、核心功能模块实现 1. 报告列表…...

高效线程安全的单例模式:Python 中的懒加载与自定义初始化参数
高效线程安全的单例模式:Python 中的懒加载与自定义初始化参数 在软件开发中,单例模式(Singleton Pattern)是一种常见的设计模式,确保一个类仅有一个实例,并提供一个全局访问点。在多线程环境下,实现单例模式时需要注意线程安全问题,以防止多个线程同时创建实例,导致…...

android13 app的触摸问题定位分析流程
一、知识点 一般来说,触摸问题都是app层面出问题,我们可以在ViewRootImpl.java添加log的方式定位;如果是touchableRegion的计算问题,就会相对比较麻烦了,需要通过adb shell dumpsys input > input.log指令,且通过打印堆栈的方式,逐步定位问题,并找到修改方案。 问题…...

手机平板能效生态设计指令EU 2023/1670标准解读
手机平板能效生态设计指令EU 2023/1670标准解读 以下是针对欧盟《手机和平板电脑生态设计法规》(EU) 2023/1670 的核心解读,综合法规核心要求、最新修正及企业合规要点: 一、法规背景与目标 生效与强制时间 发布于2023年8月31日(OJ公报&…...