Hadoop大数据集群搭建
一、虚拟机配置网络
1、配置文件
进入“/etc/sysconfig/network-scripts”目录,查看当前目录下的“ifcfg-ens33”文件

对“ens33”文件进行配置

2、重启网络
systemctl restart network3、测试网络
Ping www.baidu.com
4、设置虚拟机主机名称

5、绑定主机名和IP地址
vi /etc/hosts
6、查看ssh状态

7、关闭防火墙
Hadoop 可以使用 Web 页面进行管理,但需要关闭防火墙,否则打不开 Web 页 面。同时不关闭防火墙也会造成 Hadoop 后台运行脚本出现莫名其妙的错误。关闭命令如下:
systemctl stop firewalld关闭防火墙后要查看防火墙的状态,确认一下。

可以看到防火墙是开启的,需要执行命令关闭

看到 inactive (dead)就表示防火墙已经关闭。不过这样设置后,Linux 系 统如果重启,防火墙仍然会重新启动。执行如下命令可以永久关闭防火墙。
systemctl disable firewalld8、创建普通用户
在 Linux 系统中 root 用户为超级管理员,具有全部权限,使用 root 用户在 Linux 系统中进行操作,很可能因为误操作而对 Linux 系统造成损害。正常的作 法是创建一个普通用户,平时使用普通用户在系统进行操作,当用户需要使用管 理员权限,可以使用两种方法达到目的:一种方法是使用 su 命令,从普通用户 切换到 root 用户,这需要知道 root 用户的密码。另一种方法是使用 sudo 命令。 用户的 sudo 可以执行的命令由 root 用户事先设置好。 在本教材中使用 root 用户来安装 Hadoop 的运行环境,当 Hadoop 运行环境 都安装配置好后,使用 hadoop 用户(这只是一个用户名,也可以使用其他的用 户名)来运行 Hadoop实际工作中也是这样操作的。因此需要创建一个 hadoop 用户来使用 Hadoop。创建命令如下:
useradd zxb
passwd xiaozhu
二、安装JAVA环境
1、检查虚拟机是否自带安装好的OpenJDK,若有则需要进行删除。

并没有存在(可能我的版本是最小安装的吧)
2、在/opt目录下创建两个文件夹,一个名为software,用来存放资源,一个名为module用来作为资源的安装路径。
cd /opt
mkdir software module 
3、使用xftp工具上传下载好的jdk文件到/opt/software目录

4、解压到安装目录:/opt/module
tar -zxf /opt/software/jdk-8u371-linux-x64.tar.gz -C /opt/module/
5、配置JAVA环境
在 Linux 中设置环境变量的方法比较多,较常见的有两种:一是配置 /etc/profile 文件,配置结果对整个系统有效,系统所有用户都可以使用;二是配置~/bashrc 文件,配置结果仅对当前用户有效。这里使用第一种方法。
vi /etc/profile在末尾添加一段内容来指定JAVA的安装目录:
export JAVA_HOME=/opt/module/jdk1.8.0_371export PATH=$PATH:$JAVA_HOME/bin # 将 JAVA 安装目录加入 PATH 路径6、刷新配置
source /etc/profile 7、检测是否已经安装成功

三、安装Hadoop
1、用xftp将安装包拉进 /opt/software目录中

2、将其解压到 /opt/module文件夹中。
tar -zxf /opt/software/hadoop-2.7.1.tar.gz -C /opt/module/
3、配置Hadoop环境变量
vi /etc/profile配置环境:
# HADOOP_HOME 指向 JAVA 安装目录
export HADOOP_HOME=/opt/module/hadoop-2.7.1
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin# 执行 source 使用设置生效:
[root@master ~]# source /etc/profile4、检验是否安装成功

出现上述 Hadoop 帮助信息就说明 Hadoop 已经安装好了。
5、修改/opt/module目录的所有者跟所有者组
上述安装完成的 Hadoop 软件只能让 root 用户使用,要让 zxb 用户能够运行 Hadoop 软件,需要将目录 /opt/module的所有者改为 zxb 用户

/opt/module目录的所有者已经改为 zxb了。
6、配置Hadoop的配置文件
进入 Hadoop 目录
[root@master ~]# cd /opt/module/hadoop-2.7.1/
配置 hadoop-env.sh 文件,目的是告诉 Hadoop 系统 JDK 的安装目录。
[root@master ~]# vi etc/hadoop/hadoop-env.sh
在文件中查找 export JAVA_HOME 这行,将其改为如下所示内容。
export JAVA_HOME=/opt/module/jdk1.8.0_371
这样就设置好 Hadoop 的本地模式.
(在 vim 中,按下 / 键,然后输入你想要搜索的字段,按下回车键。vim 将会跳转到第一个匹配的字段所在的位置。如果你想继续查找下一个匹配项,可以按下 n 键。如果要向上查找,则按下 Shift + n 键。)

7、测试Hadoop
(1)切换到zxb用户,使用zxb用户来测试运行Hadoop软件

(2)创建输入数据存放目录
将输入数据存放在~/input 目录(zxb用户主目录下的 input 目录中)。
[zxb@master ~]$ mkdir ~/input

(3)创建输入数据文件
创建数据文件 data.txt,将要测试的数据内容输入到 data.txt 文件中。
[zxb@master ~]$ vi ~/input/data.txt# 输入如下内容,保存退出。
Hello World
Hello Hadoop
Hello Wangzaixiaozhu(4)测试MapReduce
运行 WordCount 官方案例,统计 data.txt 文件中单词的出现频度。这个案例可以用来统计年度十大热销产品、年度风云人物、年度最热名词等。命令如下:
hadoop jar /opt/module/hadoop- 2.7.1/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.1.jar wordcount ~/input/data.txt ~/output

可以看出统计结果正确,说明 Hadoop 本地模式运行正常。
四、克隆两个虚拟机作为子节点,一个为slave1,另一个为slave2




对克隆后的虚拟机进行修改IP、MAC信息以及主机名等信息。
1、Slave1、2信息修改:

2、重启网咯

3、修改主机名以及绑定主机名和IP地址
hostnamectl set-hostname slave1![]()
[root@slave1 ~]# vi /etc/hosts
在其中增加如下一行内容:
192.168.229.101 slave1
4、查看ssh状态

5、关闭防火墙
systemctl stop firewalldslave2重复同样的操作即可。
五、集群网络配置
1、分别修改主机配置文件“/etc/hosts”,在命令终端输入如下命令
[root@master ~]# vi /etc/hosts
# 输入内容:
192.168.229.100 master
192.168.229.101 slave1
192.168.229.102 slave2 (三台虚拟机都要)
配置完毕,执行“reboot”命令重新启动系统。
六、配置ssh无密钥验证
1、每个节点安装和启动 SSH 协议
实现 SSH 登录需要 openssh 和 rsync 两个服务,一般情况下默认已经安装,可以通过下面命令查看结果
[root@master ~]# rpm -qa | grep openssh 
[root@master ~]# rpm -qa | grep rsync
并没有rsync,那么需要安装
yum install rsync
2、切换到zxb用户,每个节点额生成密钥树
#在 master 上生成密钥
[zxb@master ~]$ ssh-keygen -t rsa -P ''
#slave1 生成密钥
[zxb@slave1 ~]$ ssh-keygen -t rsa -P ''
#slave2 生成密钥
[zxb@slave2 ~]$ ssh-keygen -t rsa -P ''
3、查看"/home/hadoop/"下是否有".ssh"文件夹,且".ssh"文件下是否有两个刚生产的无密码密钥对。(三台机都要)



4、将 id_rsa.pub 追加到授权 key 文件中
#master
[zxb@master .ssh]$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
[zxb@master .ssh]$ ls ~/.ssh/
#slave1
[zxb@slave1 ~]$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
[zxb@slave1 .ssh]$ ls ~/.ssh/
#slave2
[zxb@slave2 ~]$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
[zxb@slave2 .ssh]$ ls ~/.ssh/


5、修改文件"authorized_keys"权限
通过 ll 命令查看,可以看到修改后 authorized_keys 文件的权限为“rw-------”,表示所有者可读写,其他用户没有访问权限。如果该文件权限太大,ssh 服务会拒绝工作,出现无法通过密钥文件进行登录认证的情况
#master
[zxb@master .ssh]$ chmod 600 ~/.ssh/authorized_keys
[zxb@master .ssh]$ ll ~/.ssh/ 
#slave1
[zxb@slave1 .ssh]$ chmod 600 ~/.ssh/authorized_keys
[zxb@slave1 .ssh]$ ll ~/.ssh/
#slave2
[zxb@slave2 .ssh]$ chmod 600 ~/.ssh/authorized_keys
[zxb@slave2 .ssh]$ ll ~/.ssh/
6、配置SSH服务
使用 root 用户登录,修改 SSH 配置文件"/etc/ssh/sshd_config"的下列内容,需要将该配置字段前面的#号删除,启用公钥私钥配对认证方式。
#master
[zxb@master .ssh]$ su - root
[root@master ~]# vi /etc/ssh/sshd_config
PubkeyAuthentication yes
#slave1
[zxb@slave1 .ssh]$ su - root
[root@slave1 ~]# vi /etc/ssh/sshd_config
PubkeyAuthentication yes
#slave2
[zxb@slave2 .ssh]$ su - root
[root@slave2 ~]# vi /etc/ssh/sshd_config
PubkeyAuthentication yes
7、重启SSH服务
设置完后需要重启 SSH 服务,才能使配置生效。
systemctl restart sshd 8、切换到 zxb 用户,验证 SSH 登录本机
在 zxb 用户下验证能否嵌套登录本机,若可以不输入密码登录,则本机通过密钥登

首次登录时会提示系统无法确认 host 主机的真实性,只知道它的公钥指纹,询问用户是否还想继续连接。需要输入“yes”,表示继续登录。第二次再登录同一个主机,则不会再 出现该提示,可以直接进行登录。
读者需要关注是否在登录过程中是否需要输入密码,不需要输入密码才表示通过密钥认证成功

配置成功。
9、交换 SSH 密钥
步骤一:将 Master 节点的公钥 id_rsa.pub 复制到每个 Slave 点
[zxb@master ~]$ scp ~/.ssh/id_rsa.pub zxb@slave1:~/
[zxb@master ~]$ scp ~/.ssh/id_rsa.pub zxb@slave2:~/ 

首次远程连接时系统会询问用户是否要继续连接。需要输入“yes”,表示继续。因为目前尚未完成密钥认证的配置,所以使用 scp 命令拷贝文件需要输入 slave1 节点 hadoop用户的密码
步骤二:在每个 Slave 节点把 Master 节点复制的公钥复制到 authorized_keys 文件
[zxb@slave1 ~]$ cat ~/id_rsa.pub >>~/.ssh/authorized_keys
[zxb@slave2 ~]$ cat ~/id_rsa.pub >>~/.ssh/authorized_keys

步骤三:在每个 Slave 节点删除 id_rsa.pub 文件
[zxb@slave1 ~]$ rm -f ~/id_rsa.pub
[zxb@slave2 ~]$ rm -f ~/id_rsa.pub

步骤四:将每个 Slave 节点的公钥保存到 Master
(1)将 Slave1 节点的公钥复制到 Master
[zxb@slave1 ~]$ scp ~/.ssh/id_rsa.pub zxb@master:~/ 
(2)在 Master 节点把从 Slave 节点复制的公钥复制到 authorized_keys 文件
[zxb@master ~]$ cat ~/id_rsa.pub >>~/.ssh/authorized_keys (3)在 Master 节点删除 id_rsa.pub 文件
[zxb@master ~]$ rm -f ~/id_rsa.pub

Slave2:
(1)将 Slave2 节点的公钥复制到 Master[zxb@slave2 ~]$ scp ~/.ssh/id_rsa.pub zxb@master:~/

(2)在 Master 节点把从 Slave2 节点复制的公钥复制到 authorized_keys 文件
[zxb@master ~]$ cat ~/id_rsa.pub >>~/.ssh/authorized_keys


(3)在 Master 节点删除 id_rsa.pub 文件
[zxb@master ~]$ rm -f ~/id_rsa.pub

10、验证 SSH 无密码登录
步骤一:查看 Master 节点 authorized_keys 文件
[zxb@master .ssh]$ cat ~/.ssh/authorized_keys
可以看到 Master 节点 authorized_keys 文件中包括 master、slave1、slave2 三个节点
的公钥

步骤二:查看 Slave 节点 authorized_keys 文件
[zxb@slave1.ssh]$ cat ~/.ssh/authorized_keys
[zxb@slave2.ssh]$ cat ~/.ssh/authorized_keys
可以看到 Slave 节点 authorized_keys 文件中包括 Master、当前 Slave 两个节点的公
钥


步骤三:验证 Master 到每个 Slave 节点无密码登录
zxb 用户登录 master 节点,执行 SSH 命令登录 slave1 和 slave2 节点。可以观察到
不需要输入密码即可实现 SSH 登录




七、Hadoop全局配置
1、配置 hdfs-site.xml 文件参数
[root@master ~]# cd /opt/module/hadoop/etc/hadoop/执行以下命令修改 hdfs-site.xml 配置文件。
[root@master hadoop]# vi hdfs-site.xml #在文件中<configuration>和</configuration>一对标签之间追加以下配置信息
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/module/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/module/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
在相应的路径下创建 dfs/data 和 dfs/name 目录。这些目录分别用于存储Hadoop分布式文件系统(HDFS)的数据节点(DataNode)数据和名称节点(NameNode)的元数据。

2、配置 core-site.xml 文件参数
执行以下命令修改 core-site.xml 配置文件。
[root@master hadoop]# vi core-site.xml
#在文件中<configuration>和</configuration>一对标签之间追加以下配置信息
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.229.100:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/opt/module/hadoop/tmp</value>
</property>
</configuration>

3、配置 mapred-site.xml
在“/opt/module/hadoop/etc/hadoop”目录下有一个 mapred-site.xml.template,需要修改文件名称,把它重命名为 mapred-site.xml,然后把 mapred-site.xml 文件配置成 如下内容。 执行以下命令修改 mapred-site.xml 配置文件。
#确保在该路径下执行此命令
[root@master hadoop]# cd /opt/module/hadoop/etc/hadoop
[root@master hadoop]# cp mapred-site.xml.template mapred-site.xml
[root@master hadoop]# vi mapred-site.xml
#在文件中<configuration>和</configuration>一对标签之间追加以下配置信息
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
</configuration>

4、配置 yarn-site.xml
# 执行以下命令修改 yarn-site.xml 配置文件。
[root@master hadoop]# vi yarn-site.xml
#在文件中<configuration>和</configuration>一对标签之间追加以下配置信息
<configuration>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>5、配置 masters 文件
# 执行以下命令修改 masters 配置文件。
# 加入以下配置信息
[root@master hadoop]# vi masters
#master 主机 IP 地址
192.168.229.100
6、配置 slaves 文件
需要把所有数据节点的主机名写入该文件,每行一个,默认为 localhost(即把本机作为数据节点),所以,在伪分布式配置时,就采用了这种默认的配,使得节点既作为名称 节点也作为数据节点。在进行分布式配置时,可以保留 localhost,让 Master 节点同时充当名称节点和数据节点,或者也可以删掉 localhost 这行,让 Master 节点仅作为名称节点 使用。 本教材 Master 节点仅作为名称节点使用,因此将 slaves 文件中原来的 localhost 删
除,并添加 slave1、slave2 节点的 IP 地址。
# 执行以下命令修改 slaves 配置文件。
# 删除 localhost,加入以下配置信息
[root@master hadoop]# vi slaves
#slave1 主机 IP 地址
192.168.229.101
#slave2 主机 IP 地址
192.168.229.1027、将slave1、slave2原本的hadoop软件删除,再从master节点复制过去
[zxb@master ~]$ scp -r /opt/module/hadoop/ zxb@slave1:/opt/module/
[zxb@master ~]$ scp -r /opt/module/hadoop/ zxb@slave2:/opt/module/
修改环境变量
vi /etc/profile
source /etc/profile刷新配置即可。
八、Hadoop集群运行
1、配置Hadoop格式化
步骤一:NameNode 格式化
将 NameNode 上的数据清零,第一次启动 HDFS 时要进行格式化,以后启动无需再格式 化,否则会缺失 DataNode 进程。另外,只要运行过 HDFS,Hadoop 的工作目录(本书设置为/opt/module/hadoop/tmp)就会有数据,如果需要重新格式化,则在格式化之前一定要先删除工作目录下的数据,否则格式化时会出问题。
执行如下命令,格式化 NameNode
[root@master ~]# su – hadoop
[zxb@master ~]$ cd /opt/module/hadoop/
[zxb@master hadoop]$ bin/hdfs namenode –format
步骤二:启动 NameNode
执行如下命令,启动 NameNode:
[zxb@master hadoop]$ hadoop-daemon.sh start namenode
2、查看Java进程
启动完成后,可以使用 JPS 命令查看是否成功。JPS 命令是 Java 提供的一个显示当前 所有 Java 进程 pid 的命令

步骤一:slave 启动 DataNode
执行如下命令,启动 DataNode:
[zxb@slave2 hadoop]$ hadoop-daemon.sh start datanode
[zxb@slave1 hadoop]$ hadoop-daemon.sh start datanode 
步骤二:启动 SecondaryNameNode
执行如下命令,启动 SecondaryNameNode:


查看到有 NameNode 和 SecondaryNameNode 两个进程,就表明 HDFS 启动成功。
步骤三:查看 HDFS 数据存放位置:
执行如下命令,查看 Hadoop 工作目录:
[zxb@master hadoop]$ ll dfs/3、查看HDFS报告




4、使用浏览器查看节点状态
在浏览器的地址栏输入http://master:50070,进入页面可以查看NameNode和DataNode信息

在浏览器的地址栏输入 http://master:50090,进入页面可以查看 SecondaryNameNode信息

可以使用 start-dfs.sh 命令启动 HDFS。这时需要配置 SSH 免密码登录,否则在启动过程中系统将多次要求确认连接和输入 Hadoop 用户密码
[zxb@master hadoop]$ stop-dfs.sh
[zxb@master hadoop]$ start-dfs.sh步骤一:在 HDFS 文件系统中创建数据输入目录
确保 dfs 和 yarn 都启动成功
[zxb@master hadoop]$ start-yarn.sh
[zxb@master hadoop]$ jps 
如果是第一次运行 MapReduce 程序,需要先在 HDFS 文件系统中创建数据输入目录,存放输入数据。这里指定/input 目录为输入数据的存放目录。执行如下命令,在 HDFS 文件系统中创建/input 目录:
[zxb@master hadoop]$ hdfs dfs -mkdir /input
[zxb@master hadoop]$ hdfs dfs -ls / 
此处创建的/input 目录是在 HDFS 文件系统中,只能用 HDFS 命令查看和操作。
步骤二:将输入数据文件复制到 HDFS 的/input 目录中
测试用数据文件仍然是上一节所用的测试数据文件~/input/data.txt,内容如下所示。

# 执行如下命令,将输入数据文件复制到 HDFS 的/input 目录中:
[zxb@master hadoop]$ hdfs dfs -put ~/input/data.txt /input
# 确认文件已复制到 HDFS 的/input 目录:
[zxbmaster hadoop]$ hdfs dfs -ls /input
步骤三:运行 WordCount 案例,计算数据文件中各单词的频度。
运行 MapReduce 命令需要指定数据输出目录,该目录为 HDFS 文件系统中的目录,会自
动生成。如果在执行 MapReduce 命令前,该目录已经存在,则执行 MapReduce 命令会出错。
例如 MapReduce 命令指定数据输出目录为/output,/output 目录在 HDFS 文件系统中已经存
在,则执行相应的 MapReduce 命令就会出错。所以如果不是第一次运行 MapReduce,就要先
查看HDFS中的文件,是否存在/output目录。如果已经存在/output目录,就要先删除/output
目录,再执行上述命令。
自动创建的/output 目录在 HDFS 文件系统中,使用 HDFS 命令查看和操作。
[zxb@master hadoop]$ hdfs dfs -mkdir /output# 先执行如下命令查看 HDFS 中的文件:
[zxb@master hadoop]$ hdfs dfs -ls /
上述目录中/input 目录是输入数据存放的目录,/output 目录是输出数据存放的目录。执行如下命令,删除/output 目录。
[zxb@master hadoop]$ hdfs dfs -rm -r -f /output 
执行如下命令运行 WordCount 案例:
[zxb@master hadoop]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.1.jar wordcount /input/data.txt /outputMapReduce 程序运行过程中的输出信息如下所示:

由上述信息可知 MapReduce 程序提交了一个作业,作业先进行 Map,再进行 Reduce 操
作。
MapReduce 作业运行过程也可以在 YARN 集群网页中查看。在浏览器的地址栏输入:
http://master:8088,页面如图 所示,可以看到 MapReduce 程序刚刚完成了一个作业

除了可以用 HDFS 命令查看HDFS文件系统中的内容,也可使用网页查看 HDFS 文件系统。
在浏览器的地址栏输入 http://master:50070,进入页面,在 Utilities 菜单中选择 Browse the file system,可以查看 HDFS 文件系统内容。如图 5-5 所示,查看 HDFS 的根目录,可以看到 HDFS 根目录中有三个目录,input、output 和 tmp。

查看 output 目录,如图 所示,发现有两个文件。文件_SUCCESS 表示处理成功,处
理的结果存放在 part-r-00000 文件中。在页面上不能直接查看文件内容,需要下载到本地
系统才行。

可以使用 HDFS 命令直接查看 part-r-00000 文件内容,结果如下所示
[zxb@master hadoop]$ hdfs dfs -cat /output/part-r-00000
可以看出统计结果正确,说明 Hadoop 运行正常。
5、停止Hadoop
步骤一:停止 yarn
[zxb@master hadoop]$ stop-yarn.sh
步骤二:停止 DataNode
[zxb@slave1 hadoop]$ hadoop-daemon.sh stop datanode
[zxb@slave2 hadoop]$ hadoop-daemon.sh stop datanode
步骤三:停止 NameNode
[zxb@master hadoop]$ hadoop-daemon.sh stop namenode
步骤三:停止 SecondaryNameNode
[zxb@master hadoop]$ hadoop-daemon.sh stop secondarynamenode
步骤四:查看 JAVA 进程,确认 HDFS 进程已全部关闭
[zxb@master hadoop]$ jps
九、Mapreduce实战
使用Mapreduce统计‘基于EVE-NG的网络工程实践平台.txt’里面的 eve-ng 的个数
1、使用xftp将这个文件上传 ~/input目录下
[zxb@master hadoop]$ hdfs dfs -ls / 
将/output、/tmp先行删除。

删除之后上传文件:

2、将输入数据文件复制到 HDFS 的/input 目录中:
[zxb@master hadoop]$ hdfs dfs -put ~/input/基于EVE-NG的网络工程实践平台.txt /input
3、执行如下命令运行案例:
[zxb@master hadoop]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.1.jar wordcount /input/基于EVE-NG的网络工程实践平台.txt /output
4、浏览器访问,下载
http://192.168.229.100:50070/Utilities->Browse the file system/wordcount/outputpart-r-00000.统计之后的结果:


十、Hive导入数据计算
1、使用xftp工具上次hive(1.2.1版本),并进行解压到/opt/module

2、配置环境变量

3、启动hive

4、创建数据库
create database labone;
use labone;5、创建表
CREATE TABLE `stugr` (`stuid` string,`class` string,`grade` int
);6、导入数据
source /opt/module/stugr.sql;7、查询数据
select * from stugr;8、导入后计算命令
SELECT stuid, stugr.class, avg_grade, grade- avg_grade diff
FROM stugr,(select class,AVG( grade)avg_grade
FROM stugr
GROUP BY class
)avg_stugr
WHERE stugr.class = avg_stugr.class;十一、Zookeeper安装
1、ZooKeeper 的安装包 zookeeper-3.4.8.tar.gz 已放置在 Linux 系统/opt/software目录下。

2、解压安装包到指定目标,在 Master 节点执行如下命令。
[root@master ~]# tar -zxvf /opt/software/zookeeper-3.4.8.tar.gz -C
/opt/module
[root@master ~]# mv /opt/module/zookeeper-3.4.8
/opt/module/zookeeper
3、ZooKeeper 的配置选项
步骤一:Master 节点配置
(1)在 ZooKeeper 的安装目录下创建 data 和 logs 文件夹。
[root@master ~]# cd /opt/module/zookeeper
[root@master zookeeper]# mkdir data && mkdir logs(2)在每个节点写入该节点的标识编号,每个节点编号不同,master 节点写入 1,
slave1 节点写入 2,slave2 节点写入 3。 [root@master zookeeper]# echo 1 > /opt/module/zookeeper/data/myid (3)修改配置文件 zoo.cfg [root@master zookeeper]# cp /opt/module/zookeeper/conf/zoo_sample.cfg
/opt/module/zookeeper/conf/zoo.cfg
[root@master zookeeper]# vi /opt/module/zookeeper/conf/zoo.cfg
修改 dataDir 参数内容如下:
dataDir=/opt/module/zookeeper/data(4)在 zoo.cfg 文件末尾追加以下参数配置,表示三个 ZooKeeper 节点的访问端口号。
server.1=master:2888:3888
server.2=slave1:2888:3888
server.3=slave2:2888:3888(5)修改 ZooKeeper 安装目录的归属用户为 zxb 用户。
[root@master zookeeper]# chown -R zxb:zxb /opt/module/zookeeper步骤二:Slave 节点配置
(1)从 Master 节点复制 ZooKeeper 安装目录到两个 Slave 节点。
[root@master ~] # cd ~
[root@master ~] # scp -r /opt/module/zookeeper slave1:/opt/module
[root@master ~] # scp -r /opt/module/zookeeper slave2:/opt/module(2)在 slave1 节点上修改 zookeeper 目录的归属用户为 zxb 用户。
[root@slave1 ~] # chown -R zxb:zxb /opt/module/zookeeper
(3)在 slave1 节点上配置该节点的 myid 为 2。
[root@slave1 ~] # echo 2 > /opt/module/zookeeper/data/myid(4)在 slave2 节点上修改 zookeeper 目录的归属用户为 zxb 用户。
[root@slave2 ~] # chown -R zxb:zxb /opt/module/zookeeper
(5)在 slave2 节点上配置该节点的 myid 为 3。
[root@slave2 ~] # echo 3 > /opt/module/zookeeper/data/myid步骤三:系统环境变量配置
在 master、slave1、slave2 三个节点增加环境变量配置。
# vi /etc/profile
# 在文件末尾追加
# set zookeeper environment
# ZooKeeper 安装目录
export ZOOKEEPER_HOME=/opt/module/zookeeper
# ZooKeeper 可执行程序目录
export PATH=$PATH:$ZOOKEEPER_HOME/bin重启环境变量
Source /etc/profile4、启动zookeeper
启动 ZooKeeper 需要使用 Hadoop 用户进行操作。
(1)分别在 master、slave1、slave2 三个节点使用 zkServer.sh start 命令启动
ZooKeeper。



(2)三个节点都启动完成后,再统一查看 ZooKeeper 运行状态。
分别在 master、slave1、slave2 三个节点使用 zkServer.sh status 命令查看
ZooKeeper 状态。可以看到三个节点的状态分别为 follower、leader、follower。三个节
点会包括一个 leader 和两个 follower,每个节点地位均等,leader 是根据 ZooKeeper 内
部算法进行选举,每个节点的具体状态不固定



十二、Hbase安装
1、解压HBase安装包
[root@master ~]# tar -zxvf /opt/software/hbase-1.2.1-bin.tar.gz -C
/opt/module 

2、重命名 HBase 安装文件夹
[rootp@master]#mv hbase-1.2.1 hbase3、在master节点添加环境变量
[root@master ~]# vi /etc/profile
# set hbase environment
export HBASE_HOME=/opt/module/hbase
export PATH=$HBASE_HOME/bin:$PATH 重启环境变量
source /etc/profile4、在 master 节点进入配置文件目录
[root@master ~]# cd /opt/module/hbase/conf/#在文件中修改
[root @master conf]# vi hbase-env.sh
#Java 安装位置
export JAVA_HOME=/opt/module/jdk1.8.0_371
#值为 true 使用 HBase 自带的 ZooKeeper,值为 false 使用在 Hadoop 上装的 ZooKeeper
export HBASE_MANAGES_ZK=false
#HBase 类路径
export HBASE_CLASSPATH=/opt/module/hadoop/etc/hadoop/ 5、在 master 节点配置 hbase-site.xml
[zxb @master conf]# vi hbase-site.xml
<property>
<name>hbase.rootdir</name>
<value>hdfs://master:9000/hbase</value> # 使用 9000 端口
<description>The directory shared by region servers.</description>
</property>
<property>
<name>hbase.master.info.port</name>
<value>60010</value>
# 使用 master 节点 60010 端口
</property>
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2181</value>
# 使用 master 节点 2181 端口
<description>Property from ZooKeeper's config zoo.cfg. The port at
which the clients will connect.
</description>
</property>
<property>
<name>zookeeper.session.timeout</name>
<value>120000</value>
# ZooKeeper 超时时间
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>master,slave1,slave2</value>
# ZooKeeper 管理节点
</property>
<property>
<name>hbase.tmp.dir</name>
<value>/opt/module/hbase/tmp</value>
# HBase 临时文件路径
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
# 使用分布式 HBase
</property> 6、在 master 节点修改 regionservers 文件
#删除 localhost,每一行写一个 slave 节点主机机器名
[zxb @master conf]$ vi regionservers
slave1
slave27、在 master 节点创建 hbase.tmp.dir 目录
[zxb @master ~]# mkdir /opt/module/hbase/tmp8、将 master 上的 hbase 安装文件同步到 slave1 slave2
[zxb @master ~]# scp -r /opt/module/hbase/ zxb@slave1:/opt/module
[zxb @master ~]# scp -r /opt/module/hbase/ zxb@slave2:/opt/module9、在所有节点修改 hbase 目录权限
master 节点修改权限 (用zxb用户操作可以不用)
[root @master ~]# chown -R hadoop:hadoop /opt/module/hbase/
slave1 节点修改权限
[root @slave1 ~]# chown -R hadoop:hadoop /opt/module/hbase/
slave2 节点修改权限
[root @slave2 ~]# chown -R hadoop:hadoop /opt/module/hbase/ 10、在所有节点配置环境和重启环境
vi /etc/profile
Source /etc/profile11、启动hbase
先启动hadoop(start-all.sh),然后启动zookeeper(zkServer.sh start),最后启动Hbase(start-hbase.sh)

12、进入HBASE命令:hbase shell

13、先创建一个表(score_list),且列族为info

导入数据,将文件先导入到/opt/modul目录下

使用以下命令上传文件
[zxb@master module]$ hdfs dfs -put "/opt/module/score.csv" /input导入hbase
[zxb@master module]$ hbase org.apache.hadoop.hbase.mapreduce.ImportTsv -Dimporttsv.separator="," -Dimporttsv.columns=HBASE_ROW_KEY,info:student_ID,info:Process_score,info:Final_Score,info:Total_Mark score_list hdfs://192.168.229.100:9000/input/score.csvHBase 客户端命令行中查看是否导入成功
hbase(main):003:0> scan 'score_list'
相关文章:
Hadoop大数据集群搭建
一、虚拟机配置网络 1、配置文件 进入“/etc/sysconfig/network-scripts”目录,查看当前目录下的“ifcfg-ens33”文件 对“ens33”文件进行配置 2、重启网络 systemctl restart network 3、测试网络 Ping www.baidu.com 4、设置虚拟机主机名称 5、绑定主机名和…...

【技术前沿】MetaGPT入门安装部署——用多个大语言模型解决任务!一键安装,只需填写OpenAI API
项目简介 MetaGPT 是一个多智能体框架,旨在构建全球首家 “AI 软件公司”。该项目通过为 GPT 分配不同的角色,模拟产品经理、架构师、工程师等职业,协同完成复杂的软件开发任务。MetaGPT 将一个简单的需求转化为完整的软件开发流程ÿ…...

#compsoer基本使用01#
Composer 是 PHP 的依赖管理工具,它允许开发人员管理和安装项目所需的依赖包。 1:查看Compsoer的全局配置命令 composer config -g --list --verbose 这个可以查看composer的镜像地址。例如 [repositories.packagist.org] type (string) : composer [repositor…...
)
基于c++的yolov5推理之前处理详解及代码(一)
目录 一、前言: 二、关于环境安装: 三、首先记录下自己的几个问题 问题:c部署和python部署的区别? 四、正文开始 4.1 图像预处理讲解 1、BGR---->RBG 2、等比例放缩图片(涉及到短边的填充) 3、归一化…...
什么是并行查询(Parallel Query)?)
Oracle(55)什么是并行查询(Parallel Query)?
并行查询(Parallel Query)是数据库管理系统中的一种查询优化技术,它允许数据库引擎同时使用多个处理器或线程来执行查询操作。通过将查询任务分解为多个子任务,并在多个处理器上同时执行这些子任务,可以显著提高查询的…...

关于 Lora中 Chirp Spread Spectrum(CSS)调制解调、发射接收以及同步估计的分析
本文结合相关论文对CSS信号的数学形式、调制解调、发射接收以及同步估计做了全面分析,希望有助于更好地理解lora信号 long-range (LoRa) modulation, also known as chirp spread spectrum (CSS) modulation, in LoRaWAN to ensure robust transmission over long d…...

Java - API
API全称"Application Programming Interface",指应用程序编程接口 API(JDK17.0)链接如下 : Overview (Java SE 17 & JDK 17) (oracle.com)https://docs.oracle.com/en/java/javase/17/docs/api/中文版: Java17中…...

力扣 3152. 特殊数字Ⅱ
题目描述 queries二维数组是nums数组待判断的索引区间(左闭右闭)。需要判断每个索引区间中的nums相邻元素奇偶性是否不同,如果都不同则该索引区间的搜索结果为True,否则为False。 暴力推演:也是我最开始的思路 遍历q…...

识别和缓解软件安全威胁的最佳工具
软件安全威胁会给企业带来重大损失,从经济损失到声誉受损。 企业必须主动识别和缓解这些威胁,防止它们造成危害。 幸运的是,有许多工具可以帮助企业识别和缓解软件安全威胁。 在本博客中,我们将探讨识别和缓解软件安全威胁的顶…...

Linux下的压缩与解压:掌握核心命令行工具
目录 一.前言 二.压缩文件概述 三.tar:Linux 的通用归档工具 常用 tar 命令 四.gzip:强大的压缩程序 常用 gzip 命令 五.zip 和 unzip:处理 ZIP 压缩文件 常用 zip 和 unzip 命令 实用技巧和最佳实践 六.结语 一.前言 在 Linux …...

BGP选路实验
要求: 1.如图连接网络,合理规格IP地址,AS200内IGP协议为OSPF; 2.R1属于AS 100;R2-R3-R4小AS234、R5-R6-R7小AS567,同时声明大AS 200,R8属于AS300; 3.R2-R5、R4-R7之间为联邦EBGP邻居…...

白骑士的C#教学高级篇 3.3 网络编程
网络编程是现代应用程序开发中至关重要的一部分。C# 提供了一套丰富的 API 来处理基本网络通信、Web请求与响应。在本节中,我们将深入探讨这些内容,帮助您掌握如何在 C# 中进行网络编程。 基本网络通信 基本网络通信通常涉及套接字(Socket&a…...

AI大模型赋能游戏:更智能、更个性化的NPC
参考论文:https://arxiv.org/abs/2403.10249 在传统游戏中,NPC(非玩家角色)的行为往往是预先设定好的,缺乏灵活性和变化性。然而,基于大模型的NPC可以利用其强大的推理和学习能力,实时生成对话…...

pymysql的上下文管理器:简化数据库操作
pymysql的上下文管理器:简化数据库操作 当我们使用 pymysql 操作数据库时,管理数据库连接和游标的生命周期是一项重要的任务。Python 的上下文管理器提供了一种优雅的方式来处理资源的获取和释放。在本文中,我们将探索如何创建一个简单的 py…...
)
AI秘境-墨小黑奇遇记 - 修炼成神经(二)
在解开了感知机和门电路的谜题后,墨小黑对人工智能的世界渐渐产生了浓厚的兴趣。他开始意识到,自己不仅是在学习一门复杂的技术,更是在探索一个充满未知与挑战的神秘领域。 入夜,墨小黑一脸无奈地盯着电脑屏幕,思考着自…...

计算机网络之分组交换时延的计算
一.类型 分组交换的时延包括一下几种: 1.1发送时延 发送时延,也叫传输时延,结点将分组的所有比特推向链路所需要的时间,即从发送分组的第一个比特算起,到该分组的最后一个比特发送完为止。 发送时延 分组长度 / 发…...
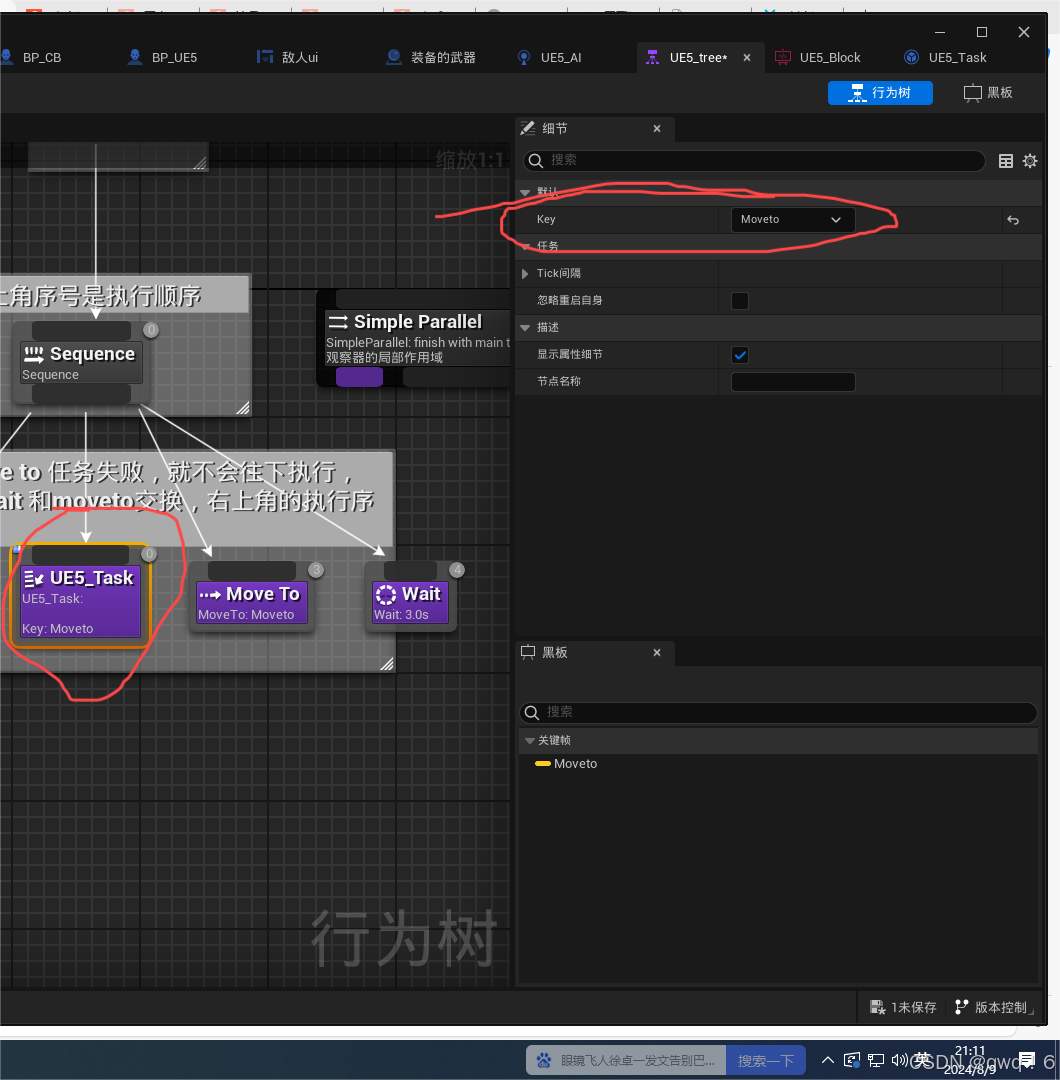
虚幻5|入门AI行为树,建立敌人
本章分成两块部分一块是第一点的制作一个简单的AI,后面第二点之后是第二部分建立ai行为树。这两个部分是一个衔接,最好不要跳看 一,制作一个简单的AI 1.首先,我们创建一个敌人的角色蓝图,添加一个场景组件widget用于…...

ARM处理架构中的PMU(Performance Monitoring Unit)和 AMU(Activity Monitors Unit)简介
在 ARM 架构中,PMU(Performance Monitoring Unit)和 AMU(Activity Monitors Unit)是用于性能分析和监控的硬件单元,但它们的功能和应用场景有所不同。以下是它们的主要区别: 1. PMU (Performance Monitoring Unit) 功能:PMU 是一种用于监控处理器性能的硬件单元。它可…...

Service服务在Android中的使用
目录 一,Service简介 二,Service的两种启动方式 1,非绑定式启动Service 2,绑定式启动Service 三,Service的生命周期 1,非绑定式Service的生命周期 2,绑定式Service的生命周期 四…...

浅谈C语言位段
1、位段的定义 百度百科中是这样解释位段的: 位段,C语言允许在一个结构体中以位为单位来指定其成员所占内存长度,这种以位为单位的成员称为“位段”或称“位域”( bit field) 。利用位段能够用较少的位数存储数据。 以下,我们均在VS2022的…...

STM32F4基本定时器使用和原理详解
STM32F4基本定时器使用和原理详解 前言如何确定定时器挂载在哪条时钟线上配置及使用方法参数配置PrescalerCounter ModeCounter Periodauto-reload preloadTrigger Event Selection 中断配置生成的代码及使用方法初始化代码基本定时器触发DCA或者ADC的代码讲解中断代码定时启动…...

VTK如何让部分单位不可见
最近遇到一个需求,需要让一个vtkDataSet中的部分单元不可见,查阅了一些资料大概有以下几种方式 1.通过颜色映射表来进行,是最正规的做法 vtkNew<vtkLookupTable> lut; //值为0不显示,主要是最后一个参数,透明度…...

BCS 2025|百度副总裁陈洋:智能体在安全领域的应用实践
6月5日,2025全球数字经济大会数字安全主论坛暨北京网络安全大会在国家会议中心隆重开幕。百度副总裁陈洋受邀出席,并作《智能体在安全领域的应用实践》主题演讲,分享了在智能体在安全领域的突破性实践。他指出,百度通过将安全能力…...

鱼香ros docker配置镜像报错:https://registry-1.docker.io/v2/
使用鱼香ros一件安装docker时的https://registry-1.docker.io/v2/问题 一键安装指令 wget http://fishros.com/install -O fishros && . fishros出现问题:docker pull 失败 网络不同,需要使用镜像源 按照如下步骤操作 sudo vi /etc/docker/dae…...

vue3+vite项目中使用.env文件环境变量方法
vue3vite项目中使用.env文件环境变量方法 .env文件作用命名规则常用的配置项示例使用方法注意事项在vite.config.js文件中读取环境变量方法 .env文件作用 .env 文件用于定义环境变量,这些变量可以在项目中通过 import.meta.env 进行访问。Vite 会自动加载这些环境变…...

在web-view 加载的本地及远程HTML中调用uniapp的API及网页和vue页面是如何通讯的?
uni-app 中 Web-view 与 Vue 页面的通讯机制详解 一、Web-view 简介 Web-view 是 uni-app 提供的一个重要组件,用于在原生应用中加载 HTML 页面: 支持加载本地 HTML 文件支持加载远程 HTML 页面实现 Web 与原生的双向通讯可用于嵌入第三方网页或 H5 应…...

Java + Spring Boot + Mybatis 实现批量插入
在 Java 中使用 Spring Boot 和 MyBatis 实现批量插入可以通过以下步骤完成。这里提供两种常用方法:使用 MyBatis 的 <foreach> 标签和批处理模式(ExecutorType.BATCH)。 方法一:使用 XML 的 <foreach> 标签ÿ…...

20个超级好用的 CSS 动画库
分享 20 个最佳 CSS 动画库。 它们中的大多数将生成纯 CSS 代码,而不需要任何外部库。 1.Animate.css 一个开箱即用型的跨浏览器动画库,可供你在项目中使用。 2.Magic Animations CSS3 一组简单的动画,可以包含在你的网页或应用项目中。 3.An…...

【JVM面试篇】高频八股汇总——类加载和类加载器
目录 1. 讲一下类加载过程? 2. Java创建对象的过程? 3. 对象的生命周期? 4. 类加载器有哪些? 5. 双亲委派模型的作用(好处)? 6. 讲一下类的加载和双亲委派原则? 7. 双亲委派模…...

Xela矩阵三轴触觉传感器的工作原理解析与应用场景
Xela矩阵三轴触觉传感器通过先进技术模拟人类触觉感知,帮助设备实现精确的力测量与位移监测。其核心功能基于磁性三维力测量与空间位移测量,能够捕捉多维触觉信息。该传感器的设计不仅提升了触觉感知的精度,还为机器人、医疗设备和制造业的智…...