Linux驱动之并发与竞争
文章目录
- 并发与竞争的概念
- 原子操作
- 原子整形操作 API 函数
- 原子位操作 API 函数
- 自旋锁
- 自旋锁简介
- 自旋锁结构体
- 自旋锁 API 函数
- 自旋锁的注意事项
- 读写自旋锁
- 读写自旋锁的API
- 顺序锁
- 顺序锁的API
- RCU(Read-Copy-Update)
- RCU的API
- 信号量
- 信号量API
- 互斥体
- 互斥体的API
- 完成量(Completion)
- 完成量的API
并发与竞争的概念
Linux 系统是个多任务操作系统,会存在多个任务同时访问同一片内存区域,这些任务可
能会相互覆盖这段内存中的数据,造成内存数据混乱。
针对这个问题必须要做处理,严重的话可能会导致系统崩溃。
linux存在以下并发访问:
①、多线程并发访问,Linux 是多任务(线程)的系统,所以多线程访问是最基本的原因。
②、抢占式并发访问,从 2.6 版本内核开始,Linux 内核支持抢占,也就是说调度程序可以
在任意时刻抢占正在运行的线程,从而运行其他的线程。
③、中断程序并发访问,这个无需多说,学过 STM32 应该知道,硬件中断的权利可
是很大的。
④、SMP(多核)核间并发访问,现在 ARM 架构的多核 SOC 很常见,多核 CPU 存在核间并
发访问。
原子操作
原子操作就是指不能再进一步分割的操作
Linux 内核提供了一些原子操作 API 函数来完成此功能
这些API分为对整型数据操作, 以及位运算操作
原子整形操作 API 函数
| 函数 | 描述 |
|---|---|
| ATOMIC_INIT(int i) | 定义原子变量的时候对其初始化。 |
| int atomic_read(atomic_t *v) | 读取 v 的值,并且返回。 |
| void atomic_set(atomic_t *v, int i) | 向 v 写入 i 值。 |
| void atomic_add(int i, atomic_t *v) | 给 v 加上 i 值。 |
| void atomic_sub(int i, atomic_t *v) | 从 v 减去 i 值。 |
| void atomic_inc(atomic_t *v) | 给 v 加 1,也就是自增。 |
| void atomic_dec(atomic_t *v) | 从 v 减 1,也就是自减 |
| int atomic_dec_return(atomic_t *v) | 从 v 减 1,并且返回 v 的值。 |
| int atomic_inc_return(atomic_t *v) | 给 v 加 1,并且返回 v 的值。 |
| int atomic_sub_and_test(int i, atomic_t *v) | 从 v 减 i,如果结果为 0 就返回真,否则返回假 |
| int atomic_dec_and_test(atomic_t *v) | 从 v 减 1,如果结果为 0 就返回真,否则返回假 |
| int atomic_inc_and_test(atomic_t *v) | 给 v 加 1,如果结果为 0 就返回真,否则返回假 |
| int atomic_add_negative(int i, atomic_t *v) | 给 v 加 i,如果结果为负就返回真,否则返回假 |
原子位操作 API 函数
| 函数 | 描述 |
|---|---|
| void set_bit(int nr, void *p) | 将 p 地址的第 nr 位置 1。 |
| void clear_bit(int nr,void *p) | 将 p 地址的第 nr 位清零。 |
| void change_bit(int nr, void *p) | 将 p 地址的第 nr 位进行翻转。 |
| int test_bit(int nr, void *p) | 获取 p 地址的第 nr 位的值。 |
| int test_and_set_bit(int nr, void *p) | 将 p 地址的第 nr 位置 1,并且返回 nr 位原来的值。 |
| int test_and_clear_bit(int nr, void *p) | 将 p 地址的第 nr 位清零,并且返回 nr 位原来的值。 |
| int test_and_change_bit(int nr, void *p) | 将 p 地址的第 nr 位翻转,并且返回 nr 位原来的值。 |
自旋锁
自旋锁简介
当一个线程要访问某个共享资源的时候首先要先获取相应的锁,锁只能被一个线程持有,
只要此线程不释放持有的锁,那么其他的线程就不能获取此锁。对于自旋锁而言,如果自旋锁
正在被线程 A 持有,线程 B 想要获取自旋锁,那么线程 B 就会处于忙循环-旋转-等待状态,线
程 B 不会进入休眠状态或者说去做其他的处理,而是会一直傻傻的在那里“转圈圈”的等待锁可用。
从这里我们可以看到自旋锁的一个缺点:那就等待自旋锁的线程会一直处于自旋状态,这样会浪
费处理器时间,降低系统性能,所以自旋锁的持有时间不能太长。所以自旋锁适用于短时期的轻
量级加锁,如果遇到需要长时间持有锁的场景那就需要换其他的方法了
自旋锁结构体
typedef struct spinlock {union {struct raw_spinlock rlock;#ifdef CONFIG_DEBUG_LOCK_ALLOC# define LOCK_PADSIZE (offsetof(struct raw_spinlock, dep_map))struct {u8 __padding[LOCK_PADSIZE];struct lockdep_map dep_map;};#endif};} spinlock_t;
Linux 内核使用结构体 spinlock_t 表示自旋锁
自旋锁 API 函数
| 函数 | 描述 |
|---|---|
| DEFINE_SPINLOCK(spinlock_t lock) | 定义并初始化一个自旋变量。 |
| int spin_lock_init(spinlock_t *lock) | 初始化自旋锁。 |
| void spin_lock(spinlock_t *lock) | 获取指定的自旋锁,也叫做加锁。 |
| void spin_unlock(spinlock_t *lock) | 释放指定的自旋锁。 |
| int spin_trylock(spinlock_t *lock) | 尝试获取指定的自旋锁,如果没有获取到就返回 0 |
| int spin_is_locked(spinlock_t *lock) | 检查指定的自旋锁是否被获取,如果没有被获取就返回非 0,否则返回 0。 |
自旋锁API函数适用于SMP或支持抢占的单CPU下线程之间的并发访问
中断里面可以使用自旋锁,但是在中断里面使用自旋锁的时候,在获取锁之前一定要先禁止本地中断(也就是本 CPU 中断,对于多核 SOC来说会有多个 CPU 核),否则可能导致锁死现象的发生
SMP是指多个核心运行一个操作系统,该操作系统同等的管理多个内核,这种运行模式就是简单提高运行性能。目前支持该运行模式的操作系统有:Linux,Windows,Vxworks。
AMP的运行模式基本不会存在开销问题,尤其是在运行裸机程序时,甚至没有开销,这种模式比较适合实时性高的应用。但是两个核心之间的通信与资源共享需要有一套优秀的处理机制。
BMP运行模式与 SMP类似,同样也是一个OS管理所有的核心,但开发者可以指定将某个任务仅在某个指定内核上执行 。
| 函数 | 描述 |
|---|---|
| void spin_lock_irq(spinlock_t *lock) | 禁止本地中断,并获取自旋锁。 |
| void spin_unlock_irq(spinlock_t *lock) | 激活本地中断,并释放自旋锁。 |
| void spin_lock_irqsave(spinlock_t *lock, unsigned long flags) | 保存中断状态,禁止本地中断,并获取自旋锁。 |
| void spin_unlock_irqrestore(spinlock_t *lock, unsigned long flags) | 将中断状态恢复到以前的状态,并且激活本地中断,释放自旋锁。 |
自旋锁的注意事项
①、因为在等待自旋锁的时候处于“自旋”状态,因此锁的持有时间不能太长,一定要
短,否则的话会降低系统性能。如果临界区比较大,运行时间比较长的话要选择其他的并发处
理方式,比如稍后要讲的信号量和互斥体。
②、自旋锁保护的临界区内不能调用任何可能引起进程调度 API函数,否则的话可能
导致死锁。 如调用copy_from_user(), copy_to_user(), kmalloc(), msleep()等函数, 有可能导致内核崩溃
③、不能递归申请自旋锁,因为一旦通过递归的方式申请一个你正在持有的锁,那么你就
必须“自旋”,等待锁被释放,然而你正处于“自旋”状态,根本没法释放锁。结果就是自己
把自己锁死了!
④、在编写驱动程序的时候我们必须考虑到驱动的可移植性,因此不管你用的是单核的还
是多核的 SOC,都将其当做多核 SOC来编写驱动程序。 在单核的情况下, 若中断和进程可能访问同一临界
区, 进程里调用spin_lock_irqsave()是安全的, 在中断里其实不调用spin_lock()也没问题, 因为spin_
lock_irqsave()可以保证这个cpu的中断服务不被执行. 但是, 如果cpu变成多核, spin_lock_irqsave()不能屏蔽
另一个cpu的中断, 所以另一个核就可能造成并发问题, 因此无论如何, 我们在中断服务程序里也应该调用spin_lock().
读写自旋锁
自旋锁不关心锁定的临界区究竟在进行什么操作, 不管是读还是写
实际上, 对共享资源并发访问, 多个执行单元同时读取是不会有问题的, 自旋锁衍生的读写自旋锁(rwlock)可允许读
的操作并发.
读写自旋锁的API
读写锁操作 API函数分为两部分,一个是给读使用的,一个是给写使用的
| 函数 | 描述 |
|---|---|
| DEFINE_RWLOCK(rwlock_t lock) | 定义并初始化读写锁 |
| void rwlock_init(rwlock_t *lock) | 初始化读写锁。 |
读锁
| 函数 | 描述 |
|---|---|
| void read_lock(rwlock_t *lock) | 获取读锁。 |
| void read_unlock(rwlock_t *lock) | 释放读锁。 |
| void read_lock_irq(rwlock_t *lock) | 禁止本地中断,并且获取读锁。 |
| void read_unlock_irq(rwlock_t *lock) | 打开本地中断,并且释放读锁。 |
| void read_lock_irqsave(rwlock_t *lock, unsigned long flags) | 保存中断状态,禁止本地中断,并获取读锁。 |
| void read_unlock_irqrestore(rwlock_t *lock, unsigned long flags) | 将中断状态恢复到以前的状态,并且激活本地中断,释放读锁。 |
| void read_lock_bh(rwlock_t *lock) | 关闭下半部,并获取读锁。 |
| void read_unlock_bh(rwlock_t *lock) | 打开下半部,并释放读锁。 |
写锁
| 函数 | 描述 |
|---|---|
| void write_lock(rwlock_t *lock) | 获取写锁。 |
| void write_unlock(rwlock_t *lock) | 释放写锁。 |
| void write_lock_irq(rwlock_t *lock) | 禁止本地中断,并且获取写锁。 |
| void write_unlock_irq(rwlock_t *lock) | 打开本地中断,并且释放写锁。 |
| void write_lock_irqsave(rwlock_t *lock, unsigned long flags) | 保存中断状态,禁止本地中断,并获取写锁。 |
| void write_unlock_irqrestore(rwlock_t *lock, unsigned long flags) | 将中断状态恢复到以前的状态,并且激活本地中断,释放读锁。 |
| void write_lock_bh(rwlock_t *lock) | 关闭下半部,并获取读锁。 |
| void write_unlock_bh(rwlock_t *lock) | 打开下半部,并释放读锁。 |
顺序锁
顺序锁是对读写锁的一种优化, 若使用顺序锁, 读执行单元不会被写执行单元阻塞, 也就是说, 读执行单元在写执行单元对被顺序锁保护的共享资源进行写操作时仍然可以继续读, 而不必等待写执行单元完成写操作, 写执行单元也不需要等待读执行单元完成读操作再进行写操作.
但是写执行单元与写执行单元之间仍然互斥.
尽管读写之间不互斥, 但是如果读执行单元操作期间, 写执行单元已经发生了写操作, 那么, 读执行单元必需重新读取数据. 以便确保数据时完整的. 所以, 这种情况下, 读端可能反复读多次同样的区域才能得到有效的数据.
顺序锁的API
获取顺序锁
| 函数 | 描述 |
|---|---|
| void write_seqlock(seqlock_t *sl) | 获取顺序锁 |
| void write_seqlock_irqsave(seqlock_t *lock, unsigned long flags) | 保存中断状态,禁止本地中断,并获取顺序锁。 |
| void write_seqlock_irq(seqlock_t *lock) | 禁止本地中断,并且获取顺序锁 |
| void write_seqlock_bh(seqlock_t *lock) | 关闭下半部,并获取顺序锁 |
释放顺序锁
| 函数 | 描述 |
|---|---|
| void write_sequnlock(seqlock_t *sl) | 释放顺序锁 |
| void wirte_sequnlock_irqrestore(seqlock *sl, unsigned long flags) | 将中断状态恢复到以前的状态,并且激活本地中断,释放顺序锁 |
| void write_sequnlock_irq(seqlock *sl) | 打开本地中断,并且释放顺序锁。 |
| void write_sequnlock_bh(seqlock *sl) | 打开下半部,并释放顺序锁。 |
读开始
| 函数 |
|---|
| unsigned read_seqbegin(const seqlock_t *sl) |
| unsigned read_seqbegin_irqsave(const seqlock_t *sl, flags) |
读执行单在对被顺序锁sl保护的共享资源进行访问前需要调用该函数, 该函数返回顺序锁sl的当前顺序号.
重读
| 函数 |
|---|
| int read_seqretry(const seqlock_t *sl, unsigned iv) |
| int read_seqretry_irqrestore(const seqlock_t *sl, flags) |
读执行单元在访问完被顺序锁sl保护的共享资源后需要调用该函数来检查, 在读访问期间是否有写操作, 如果有写操作, 读执行单元就需要重新进行读操作
顺序锁的使用模式如下:
do{seqnum = read_seqbegin(&seqlock_a);读操作代码
}while(read_seqretry(&seqlock_a, seqnum));
RCU(Read-Copy-Update)
RCU工作原理:
不同于自旋锁, 使用RCU的读端没有锁, 内存屏障, 原子指令类的开销, 几乎可以认为是直接读(知识简单的标明开始和结束), 而RCU的写执行单元在访问它的共享资源前复制一个副本, 然后对副本进行修改, 最后使用一个回调机制在适当的时机把指向原来数据的指针重新指向新的被修改的数据, 这个时机就是所有引用该数据的CPU都退出对共享数据读操作的时候, 等待适当的时机这一时期称为宽限期.
例子:
进程A通过RCU修改某链表的N节点内容, RCU通过构造一个新的M节点, 在M节点中修改内容, 并用M节点代替N节点, 之后进程A等待在链表前期已经存在的所有读端结束后(即宽限期, 通过synchronize_rcu()API完成), 再释放原来的N节点.
假设存在一个链表:
struct foo{struct list_head list;int a;int b;int c;
};
LIST_HEAD(head)
...
p = search(head, key);
if(p == NULL){//...
}
q = kmalloc(sizeof(*p), GFP_KERNEL);
*q = *p;
q->b = 2;
q->c = 3;
list_replace_rcu(&p->list, &q->list);
synchronize_rcu();
kfree(p);
RCU的API
读锁定
rcu_read_lock()
rcu_read_lock_bh()
读解锁
rcu_read_unlock()
rc_read_unlock_bh()
同步RCU
synchronize_rcu()
该函数由RCU写执行单元调用, 它将阻塞写执行单元, 直到当前CPU上所有的已经存在的读执行单元完成读临界区, 写执行单元才可以继续下一步操作.synchronize_rcu()并不需要等待后续读临界区的完成.
挂接回调
void call_rcu(struct rcu_head* head, void (*func)(struct rcu_head *rcu));
call_rcu()由RCU写执行单元调用, 与synchronize_rcu()不同的是, 它不会使写执行单元阻塞, 因而可以再中断上下文或软中断中使用. 该函数把函数func挂接到rcu回调函数链上, 然后立即返回, 挂接的回调函数会在一个宽限期结束后被执行.
rcu_assign_pointer(p, v)
给RCU保护的指针赋一个新的值
rcu_dereference(p)
读端使用rcu_dereference()获取一个RCU保护的指针, 之后既可以安全的引用它, 一般需要在rcu_read_lock()/rcu_read_unlock()保护的区间引用这个指针
rcu_access_pointer(p)
读端使用rcu_access_pointer()获取一个RCU保护的指针, 之后并不引用它, 这种情况下, 我们只关心指针本身的值, 比如可以使用该函数判断指针是否为NULL
ex:
把rcu_assign_pointer() rcu_dereference()结合, 写端分配一个新的 struct foo内存, 初始化其中的成员, 之后把该结构体的地址赋值给全局的gp指针:
struct foo{int a;int b;int c;
};
struct foo *gp = NULL;p = kmalloc(sizeof(*p), GFP_KERNEL);
p->a = 1;
p->b = 2;
p->c = 3;
rcu_assign_pointer(gp, p);读端访问该片区:
rcu_read_lock();
p = rcu_dereference(gp);
if(p != NULL){do_something_with(p->a, p->b, p->c);
}
rcu_read_unlock();
对于链表数据结构而言, Linux内核增加了专门给RCU保护的链表操作API
static inline void list_add_rcu(struct list_head *new, struct list_head *head);
该函数把链表元素new插入RCU保护的链表head的开头
static inline void list_add_tail_rcu(struct list_head *new, struct list_head *head);
该函数将元素new添加到被RCU保护的链表的尾部
static inline void list_del_rcu(struct list_head *entry);
该函数从RCU保护的链表中删除指定的元素entry.
static inline void list_replace_rcu(struct list_head *old, struct list_head *new);
它使用新的链表元素new取代旧的链表元素old
list_for_each_entry_rcu(pos, head)
该宏用于遍历由RCU保护的链表head, 只要在读执行单元临界区使用该函数, 它就可以安全的和其他RCU保护的链表操作函数(如list_add_rcu())并发运行.
ex:
链表写端代码
struct foo{struct list_head list;int a;int b;int c;
};
LIST_HEAD(head);p = kmalloc(sizeof(*p), GFP_KERNEL);
p->a = 1;
p->b = 2;
p->c = 3;
list_add(&p->list, &head);链表读端代码
rcu_read_lock();
list_for_each_entry_rcu(p, head, list)
if(p != NULL){do_something_with(p->a, p->b, p->c);
}
rcu_read_unlock();信号量
相比于自旋锁,信号量可以使线程进入休眠状态,信号量的开销要比自旋锁大,因为信号量使
线程进入休眠状态以后会切换线程,切换线程就会有开销。
①、因为信号量可以使等待资源线程进入休眠状态,因此适用于那些占用资源比较久的场
合。
②、因此信号量不能用于中断中,因为信号量会引起休眠,中断不能休眠。 (也有不休眠的信号量API)
③、如果共享资源的持有时间比较短,那就不适合使用信号量了,因为频繁的休眠、切换
线程引起的开销要远大于信号量带来的那点优势。
信号量结构体:
struct semaphore { raw_spinlock_t lock; unsigned int count; struct list_head wait_list;
};
信号量API
| 函数 | 描述 |
|---|---|
| DEFINE_SEAMPHORE(name) | 定义一个信号量,并且设置信号量的值为 1。 |
| void sema_init(struct semaphore *sem, int val) | 初始化信号量 sem,设置信号量值为 val。 |
| void down(struct semaphore *sem) | 获取信号量,因为会导致休眠,因此不能在中断中使用。 |
| int down_trylock(struct semaphore *sem); | 尝试获取信号量,如果能获取到信号量就获取,并且返回 0。如果不能就返回非 0,并且不会进入休眠。 |
| int down_interruptible(struct semaphore *sem) | 获取信号量,和 down类似,只是使用 down进入休眠状态的线程不能被信号打断。而使用此函数进入休眠以后是可以被信号打断的。 |
| void up(struct semaphore *sem) | 释放信号量 |
互斥体
将信号量的值设置为 1就可以使用信号量进行互斥访问了,虽然可以通过信号量实现互斥,但是 Linux提供了一个比信号量更专业的机制来进行互斥,它就是互斥体—mutex。互斥访问表示一次只有一个线程可以访问共享资源,不能递归申请互斥体。在我们编写 Linux驱动的时候遇到需要互斥访问的地方建议使用 mutex。Linux内核使用 mutex结构体表示互斥体,定义如下:
struct mutex { /* 1: unlocked, 0: locked, negative: locked, possible waiters */ atomic_t count; spinlock_t wait_lock;
};
在使用 mutex之前要先定义一个 mutex变量。在使用 mutex的时候要注意如下几点:
①、mutex可以导致休眠,因此不能在中断中使用 mutex,中断中只能使用自旋锁。
②、和信号量一样,mutex保护的临界区可以调用引起阻塞的 API函数。
③、因为一次只有一个线程可以持有 mutex,因此,必须由 mutex的持有者释放 mutex。并且 mutex不能递归上锁和解锁。
互斥体的API
| 函数 | 描述 |
|---|---|
| DEFINE_MUTEX(name) | 定义并初始化一个 mutex变量。 |
| void mutex_init(mutex *lock) | 初始化 mutex。 |
| void mutex_lock(struct mutex *lock) | 获取 mutex,也就是给 mutex上锁。如果获取不到就进休眠。 |
| void mutex_unlock(struct mutex *lock) | 释放 mutex,也就给 mutex解锁。 |
| int mutex_trylock(struct mutex *lock) | 尝试获取 mutex,如果成功就返回 1,如果失败就返回 0。 |
| int mutex_is_locked(struct mutex *lock) | 判断 mutex是否被获取,如果是的话就返回1,否则返回 0。 |
| int mutex_lock_interruptible(struct mutex *lock) | 使用此函数获取信号量失败进入休眠以后可以被信号打断。 |
完成量(Completion)
用于一个执行单元等待另一个执行单元执行完某事
完成量的API
定义完成量
struct completion my_completion;
初始化完成量
初始化或者重新初始化my_completion这个完成量的值为0(即没有完成的状态)
init_completion(&my_completion);
reinit_completion(&my_completion)
等待完成量
等待一个完成量被唤醒:
void wait_for_completion(struct completion *c);
唤醒完成量
void complete(struct completion *c);
只唤醒一个等待的执行单元
void complete_all(struct completion *c);
释放所有等待同一完成量的执行单元
相关文章:

Linux驱动之并发与竞争
文章目录并发与竞争的概念原子操作原子整形操作 API 函数原子位操作 API 函数自旋锁自旋锁简介自旋锁结构体自旋锁 API 函数自旋锁的注意事项读写自旋锁读写自旋锁的API顺序锁顺序锁的APIRCU(Read-Copy-Update)RCU的API信号量信号量API互斥体互斥体的API完成量(Completion)完成…...

【密码学复习】第四讲分组密码(三)
AES算法的整体结构 AES算法的轮函数 1)字节代换(SubByte) 2)行移位(ShiftRow) 3)列混合(MixColumn) 4)密钥加(AddRoundKey)1-字节代换…...

JVM(内存划分,类加载,垃圾回收)
JVMJava程序,是一个名字为Java 的进程,这个进程就是所说的“JVM”1.内存区域划分JVM会先从操作系统这里申请一块内存空间,在这个基础上再把这个内存空间划分为几个小的区域在一个JVM进程中,堆和方法区只有一份;栈和程序…...

工作中遇到的问题 -- 你见过哪些写的特别好的代码
strPtr : uintptr((*(*stringStruct)(unsafe.Pointer(&str))).str)代码解析: 这是一段 Go 代码,它的作用是获取一个字符串变量 str 的底层指针,即字符串数据的起始地址。 这段代码涉及到了 Go 语言中的指针、类型转换和内存布局等概念&…...

基于chatGPT设计卷积神经网络
1. 简介 本文主要介绍基于chatGPT,设计一个针对骁龙855芯片设计的友好型神经网络。 提问->跑通总共花了5min左右,最终得到的网络在Cifar100数据集上与ResNet18的精度对比如下。 模型flopsparamstrain acc1/5test acc1/5ResNet18(timm)1.8211.18~98…...

java.sql.Date和java.util.Date的区别
参考答案 java.sql.Date 是 java.util.Date 的子类java.util.Date 是 JDK 中的日期类,精确到时、分、秒、毫秒java.sql.Date 与数据库 Date 相对应的一个类型,只有日期部分,时分秒都会设置为 0,如:2019-10-23 00:00:0…...
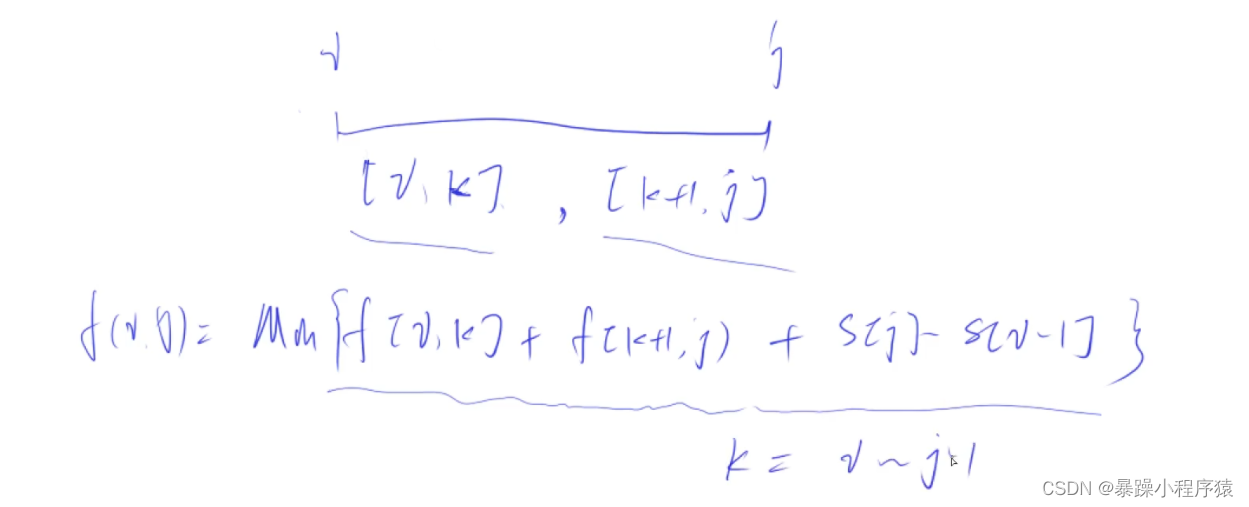
动态规划---线性dp和区间dp
动态规划(三) 目录动态规划(三)一:线性DP1.数字三角形1.1数字三角形题目1.2代码思路1.3代码实现(正序and倒序)2.最长上升子序列2.1最长上升子序列题目2.2代码思路2.3代码实现3.最长公共子序列3.1最长公共子序列题目3.2代码思路3.3代码实现4.石子合并4.1题目如下4.2代…...

常见的2D与3D碰撞检测算法
分离轴分离轴定理(Separating Axis Theorem)是用于解决2D或3D物体碰撞检测问题的一种方法。其基本思想是,如果两个物体未发生碰撞,那么可以找到一条分离轴(即一条直线或平面),两个物体在该轴上的…...

STM32 10个工程篇:1.IAP远程升级(二)
一直提醒自己要更新CSDN博客,但是确实这段时间到了一个项目的关键节点,杂七杂八的事情突然就一涌而至。STM32、FPGA下位机代码和对应Labview的IAP升级助手、波形设置助手上位机代码笔者已经调试通过,因为不想去水博客、凑数量,复制…...
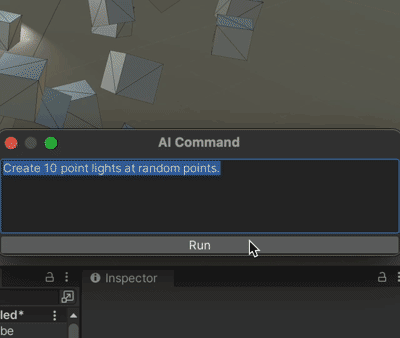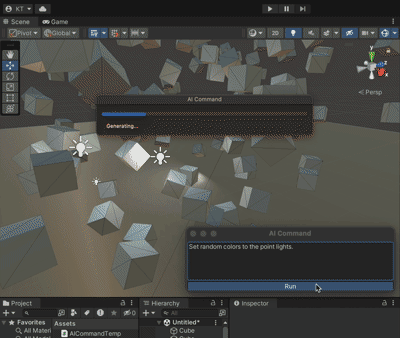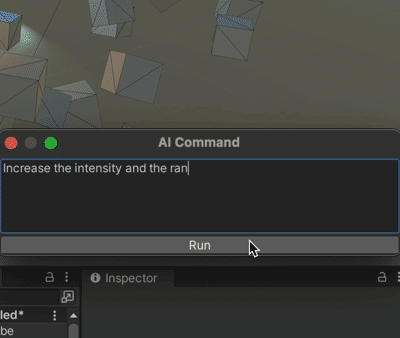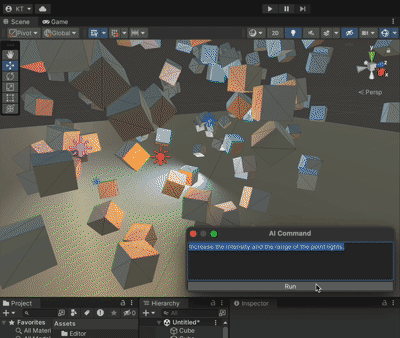
Unity+ChatGpt的联动 AICommand
果然爱是会消失的,对吗 chatGpt没出现之前起码还看人家的文章,现在都是随便你。 本着师夷长技以制夷的思路,既然打不过,那么我就加入 github地址:https://github.com/keijiro/AICommand 文档用chatGpt翻译如下&#…...
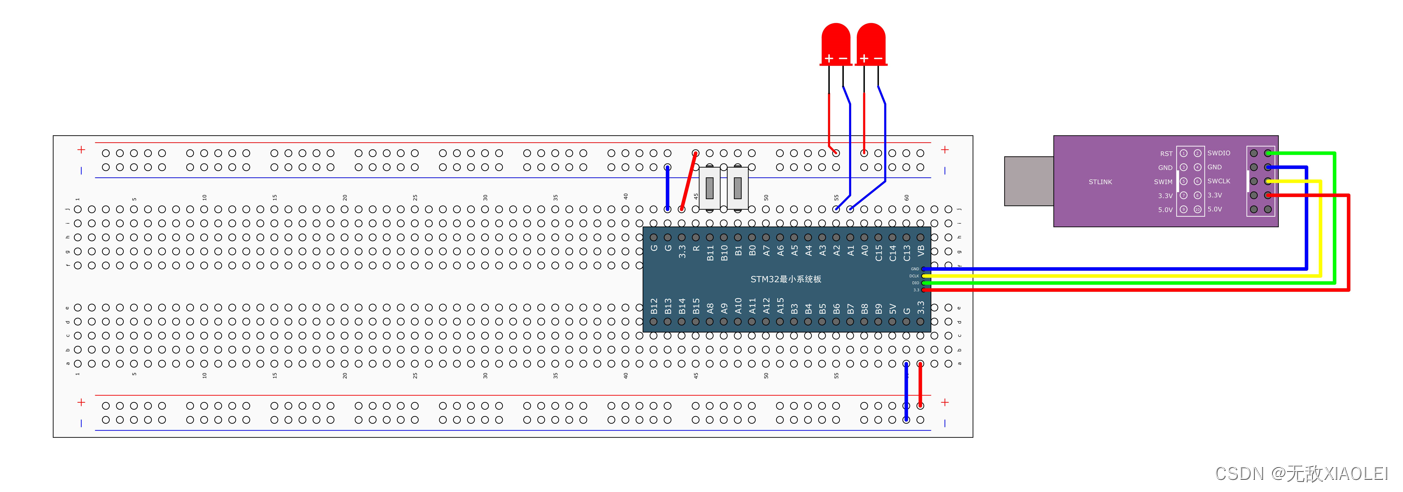
STM-32:按键控制LED灯 程序详解
目录一、基本原理二、接线图三、程序思路3.1库函数3.2程序代码注:一、基本原理 左边是STM322里电路每一个端口均可以配置的电路部分,右边部分是外接设备 电路图。 配置为 上拉输入模式的意思就是,VDD开关闭合,VSS开关断开。 浮空…...
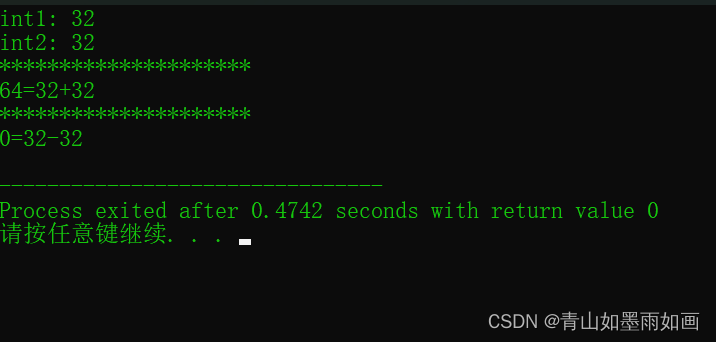
北邮22信通:(8)实验1 题目五:大整数加减法(搬运官方代码)
北邮22信通一枚~ 跟随课程进度每周更新数据结构与算法的代码和文章 持续关注作者 解锁更多邮苑信通专属代码~ 上一篇文章: 北邮22信通:(7)实验1 题目四:一元多项式(节省内存版)_青山如…...

Fiddler抓取https史上最强教程
有任何疑问建议观看下面视频 2023最新Fiddler抓包工具实战,2小时精通十年技术!!!对于想抓取HTTPS的测试初学者来说,常用的工具就是fiddler。 但是初学时,大家对于fiddler如何抓取HTTPS难免走歪路ÿ…...
STM32开发基础知识入门
C语言基础 位操作 对基本类型变量可以在位级别进行操作。 1) 不改变其他位的值的状况下,对某几个位进行设值。 先对需要设置的位用&操作符进行清零操作,然后用|操作符设值。 2) 移位操作提高代码的可读性。 3) ~取反操作使用技巧 可用于对某…...

学习操作系统的必备教科书《操作系统:原理与实现》| 文末赠书4本
使用了6年的实时操作系统,是时候梳理一下它的知识点了 摘要: 本文简单介绍了博主学习操作系统的心路历程,同时还给大家总结了一下当下流行的几种实时操作系统,以及在工程中OSAL应该如何设计。希望对大家有所启发和帮助。 文章目录…...
)
大数据的常用算法(分类、回归分析、聚类、关联规则、神经网络方法、web数据挖掘)
在大数据时代,数据挖掘是最关键的工作。大数据的挖掘是从海量、不完全的、有噪声的、模糊的、随机的大型数据库中发现隐含在其中有价值的、潜在有用的信息和知识的过程,也是一种决策支持过程。其主要基于人工智能,机器学习,模式学…...
【数据结构】详解二叉树与堆与堆排序的关系
🌇个人主页:平凡的小苏 📚学习格言:别人可以拷贝我的模式,但不能拷贝我不断往前的激情 🛸C语言专栏:https://blog.csdn.net/vhhhbb/category_12174730.html 🚀数据结构专栏ÿ…...
【Pandas】数据分析入门
文章目录前言一、Pandas简介1.1 什么是Pandas1.2 Pandas应用二、Series结构2.1 Series简介2.2 基本使用三、DataFrame结构3.1 DataFrame简介3.2 基本使用四、Pandas-CSV4.1 CSV简介4.2 读取CSV文件4.3 数据处理五、数据清洗5.1 数据清洗的方法5.2 清洗案例总结前言 大家好&…...
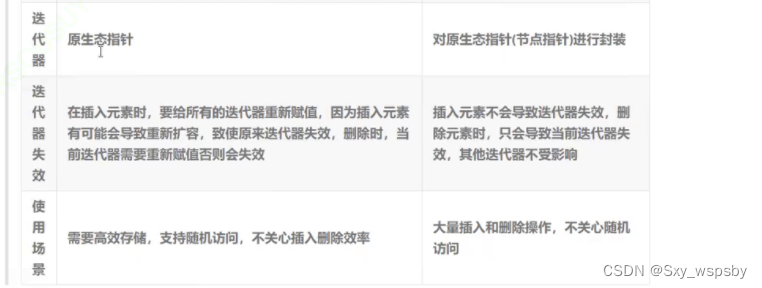
【c++】:list模拟实现“任意位置插入删除我最强ƪ(˘⌣˘)ʃ“
文章目录 前言一.list的基本功能的使用二.list的模拟实现总结前言 1. list是可以在常数范围内在任意位置进行插入和删除的序列式容器,并且该容器可以前后双向迭代。2. list的底层是双向链表结构,双向链表中每个元素存储在互不相关的独立节点中࿰…...

QT表格控件实例(Table Widget 、Table View)
欢迎小伙伴的点评✨✨,相互学习🚀🚀🚀 博主🧑🧑 本着开源的精神交流Qt开发的经验、将持续更新续章,为社区贡献博主自身的开源精神👩🚀 文章目录前言一、图示实例二、列…...

深入浅出Asp.Net Core MVC应用开发系列-AspNetCore中的日志记录
ASP.NET Core 是一个跨平台的开源框架,用于在 Windows、macOS 或 Linux 上生成基于云的新式 Web 应用。 ASP.NET Core 中的日志记录 .NET 通过 ILogger API 支持高性能结构化日志记录,以帮助监视应用程序行为和诊断问题。 可以通过配置不同的记录提供程…...

ES6从入门到精通:前言
ES6简介 ES6(ECMAScript 2015)是JavaScript语言的重大更新,引入了许多新特性,包括语法糖、新数据类型、模块化支持等,显著提升了开发效率和代码可维护性。 核心知识点概览 变量声明 let 和 const 取代 var…...

centos 7 部署awstats 网站访问检测
一、基础环境准备(两种安装方式都要做) bash # 安装必要依赖 yum install -y httpd perl mod_perl perl-Time-HiRes perl-DateTime systemctl enable httpd # 设置 Apache 开机自启 systemctl start httpd # 启动 Apache二、安装 AWStats࿰…...
` 方法)
深入浅出:JavaScript 中的 `window.crypto.getRandomValues()` 方法
深入浅出:JavaScript 中的 window.crypto.getRandomValues() 方法 在现代 Web 开发中,随机数的生成看似简单,却隐藏着许多玄机。无论是生成密码、加密密钥,还是创建安全令牌,随机数的质量直接关系到系统的安全性。Jav…...

Linux简单的操作
ls ls 查看当前目录 ll 查看详细内容 ls -a 查看所有的内容 ls --help 查看方法文档 pwd pwd 查看当前路径 cd cd 转路径 cd .. 转上一级路径 cd 名 转换路径 …...

DIY|Mac 搭建 ESP-IDF 开发环境及编译小智 AI
前一阵子在百度 AI 开发者大会上,看到基于小智 AI DIY 玩具的演示,感觉有点意思,想着自己也来试试。 如果只是想烧录现成的固件,乐鑫官方除了提供了 Windows 版本的 Flash 下载工具 之外,还提供了基于网页版的 ESP LA…...

现代密码学 | 椭圆曲线密码学—附py代码
Elliptic Curve Cryptography 椭圆曲线密码学(ECC)是一种基于有限域上椭圆曲线数学特性的公钥加密技术。其核心原理涉及椭圆曲线的代数性质、离散对数问题以及有限域上的运算。 椭圆曲线密码学是多种数字签名算法的基础,例如椭圆曲线数字签…...

unix/linux,sudo,其发展历程详细时间线、由来、历史背景
sudo 的诞生和演化,本身就是一部 Unix/Linux 系统管理哲学变迁的微缩史。来,让我们拨开时间的迷雾,一同探寻 sudo 那波澜壮阔(也颇为实用主义)的发展历程。 历史背景:su的时代与困境 ( 20 世纪 70 年代 - 80 年代初) 在 sudo 出现之前,Unix 系统管理员和需要特权操作的…...

《基于Apache Flink的流处理》笔记
思维导图 1-3 章 4-7章 8-11 章 参考资料 源码: https://github.com/streaming-with-flink 博客 https://flink.apache.org/bloghttps://www.ververica.com/blog 聚会及会议 https://flink-forward.orghttps://www.meetup.com/topics/apache-flink https://n…...

【Android】Android 开发 ADB 常用指令
查看当前连接的设备 adb devices 连接设备 adb connect 设备IP 断开已连接的设备 adb disconnect 设备IP 安装应用 adb install 安装包的路径 卸载应用 adb uninstall 应用包名 查看已安装的应用包名 adb shell pm list packages 查看已安装的第三方应用包名 adb shell pm list…...