怎么提取pdf的某一页?批量提取pdf的某一页的简单方法
怎么提取pdf的某一页?在日常工作与学习中,我们经常会遇到各式各样的PDF文件,它们以其良好的兼容性和稳定性,成为了信息传输和存储的首选格式。然而,在浩瀚的文档海洋中,有时某个PDF文件中的某一页内容尤为重要,它可能蕴含了关键数据、灵感笔记或是紧急任务的指示,急需我们从整份文件中单独提取出来,以便快速查阅或分享。面对这样的需求,我们无需手动复制粘贴或截图,这样既低效又可能遗漏信息。幸运的是,现代技术为我们提供了便捷的工具和方法。无论是专业的PDF文件处理软件,如星优PDF工具箱,还是轻量级的在线服务平台,都能轻松实现这一操作。用户只需打开目标PDF文件,利用“提取页面”或类似功能,指定需要分离的页码,几步简单的点击,即可将那一页宝贵的信息单独保存为一个新的PDF文件。
很多人不知道怎么提取,不过没关系,因为小编有解决办法,并且解决办法有好几个,并且每个解决办法还有详细的操作步骤,感兴趣的朋友赶紧试试看吧。

方法一:使用“星优PDF工具箱”软件提取pdf中的某一页
步骤1,假如你是第一次使用“星优PDF工具箱”这个软件,那就需要你先将它下载到电脑上并进行安装,安装完成后打开使用,请你点击左侧【PDF文件操作】,然后大家右侧【PDF提取页面】功能。

步骤2,此时软件会跳转到软件内页,随后点击左上角【添加文件】文字按键,将需要提取页面的pdf文件添加到软件里。

步骤3,如下图所示,点击【全部页码】黄色按键,随后通过弹出的窗口选择要提取的页面页码,加入你要提取第2页,那就选择“2”。
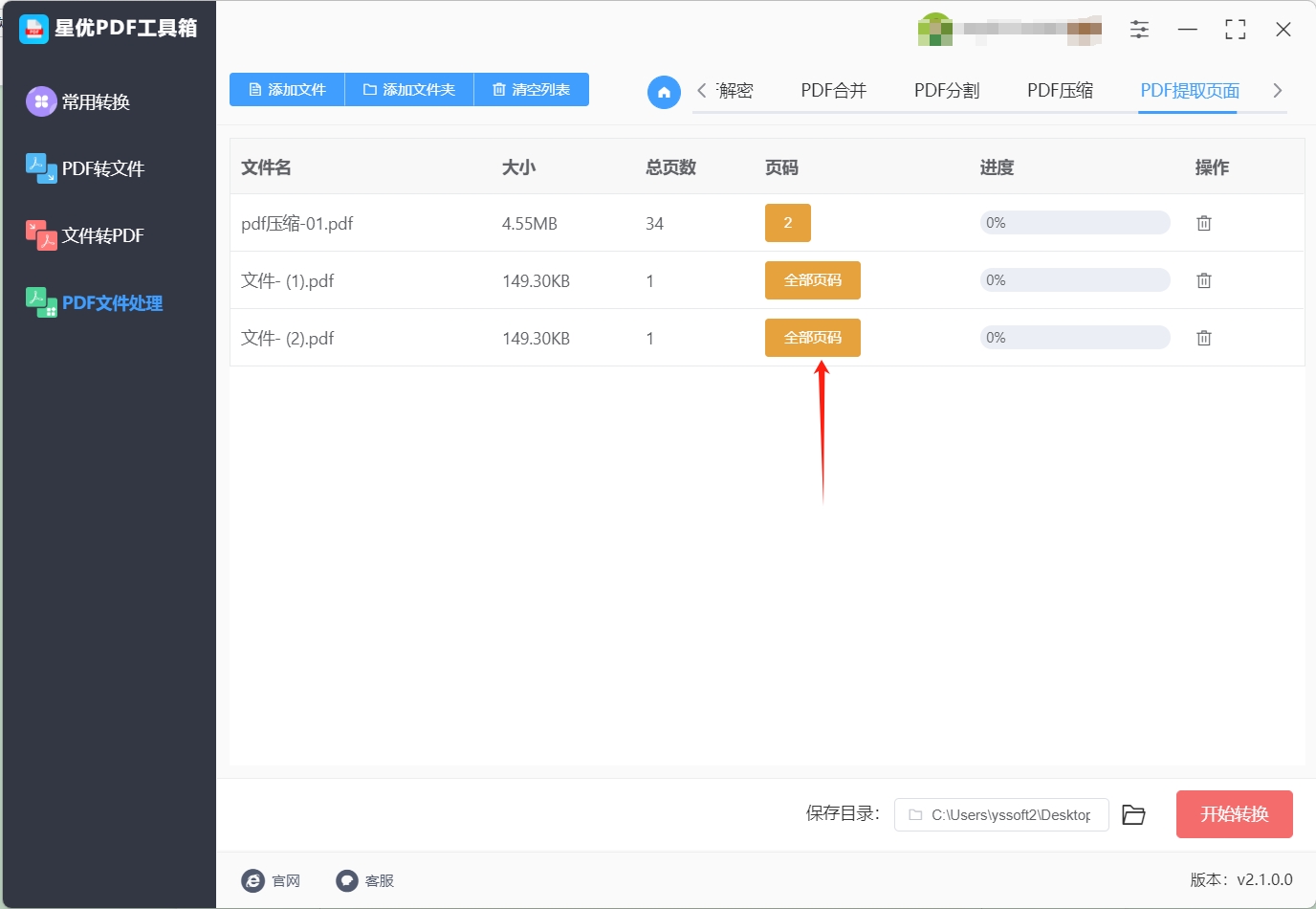
步骤4,设置好后点击右下角【开始转换】红色按键启动提取程序,提取速度是十分迅速的。
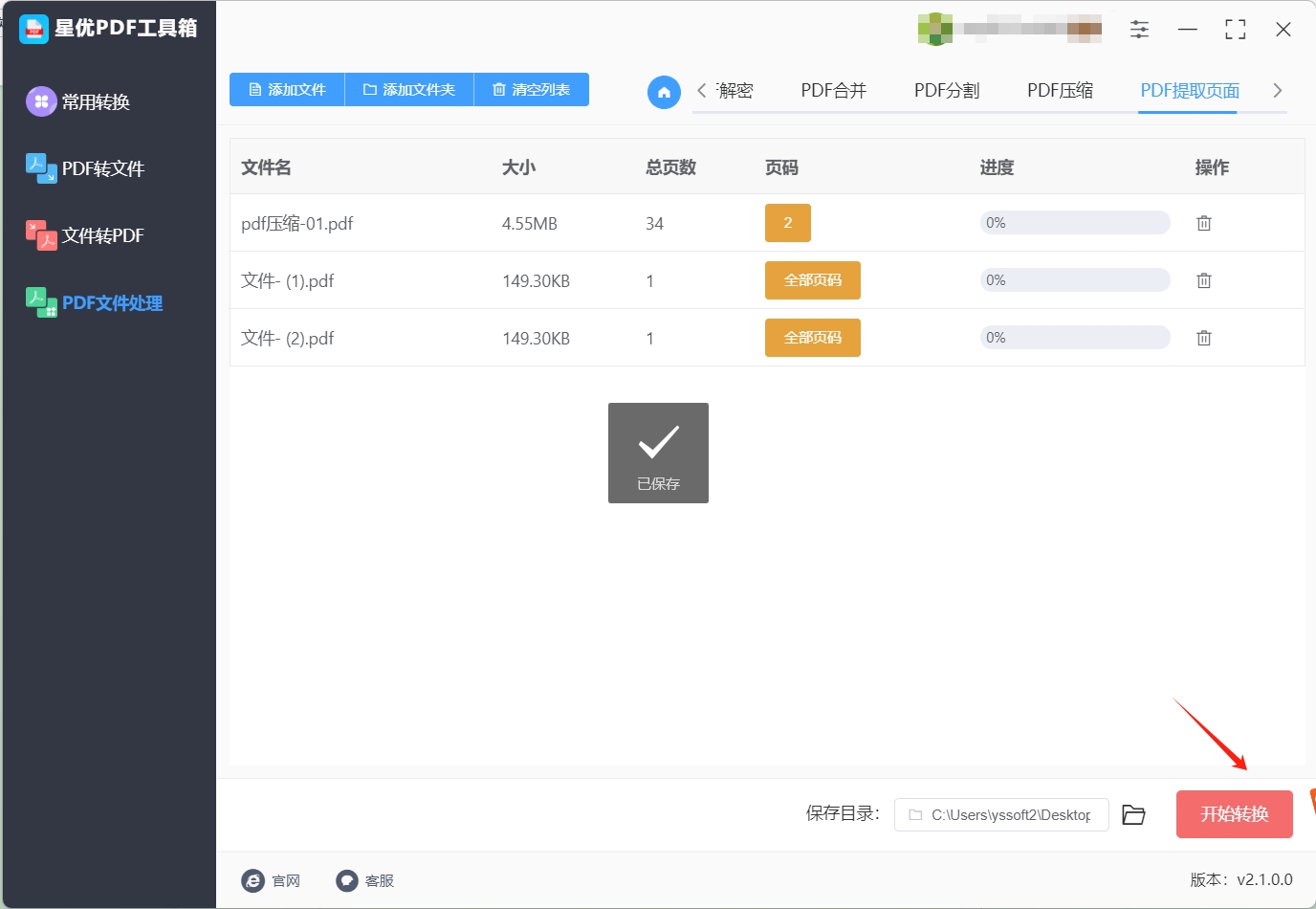
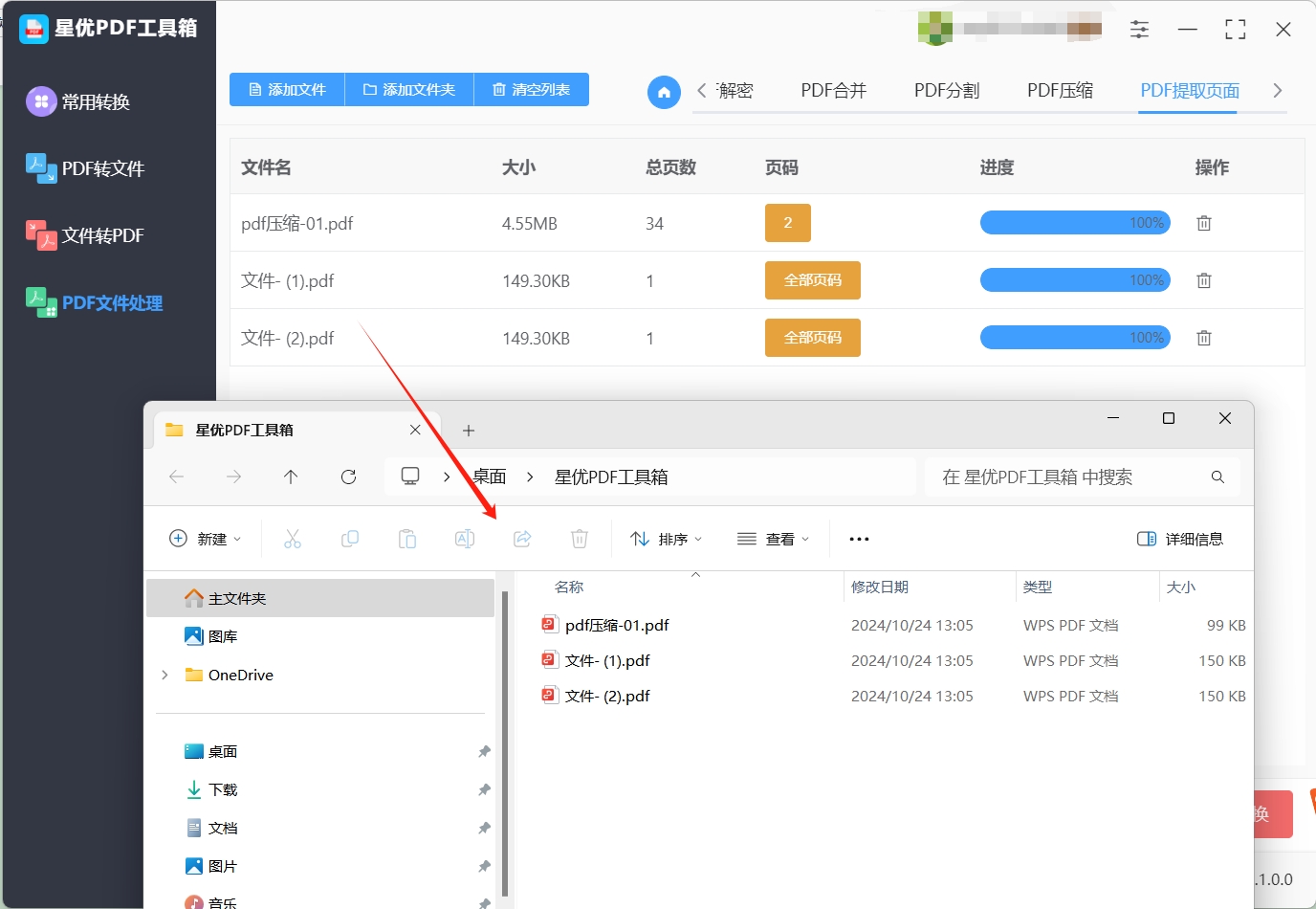
步骤5,等待一会后软件会弹出输出文件夹,这代表页面提取操作结束,在输出文件夹里你可以找到提取出来的pdf页面。
方法二:使用“Adobe Acrobat Reader DC”软件提取pdf中的某一页
启动Adobe Acrobat Reader DC并加载PDF文件
打开程序:首先,双击桌面上的Adobe Acrobat Reader DC图标,或者通过开始菜单找到并启动该应用程序。
加载PDF文件:在程序界面的顶部工具栏中,点击“文件”菜单,选择“打开”选项,浏览到存储PDF文件的位置,选中该文件并点击“打开”按钮。此时,所选的PDF文档将会在Adobe Acrobat Reader DC中显示。
导出PDF为JPEG格式
访问文件菜单:在程序界面的顶部工具栏中,找到并点击“文件”菜单。这将显示一个下拉菜单,其中包含多个选项。
选择另存为其他:在下拉菜单中,寻找“另存为其他”选项,并将鼠标悬停在该选项上,会弹出一个子菜单。
选择图像类别:在子菜单中,选择“图像”类别,再从中选择“JPEG”选项。此时,将打开一个导出向导或对话框。
配置导出设置
勾选当前页面:在弹出的导出向导或对话框中,确保已勾选“当前页面”选项。这样只会将当前显示的PDF页面转换为JPEG格式,而不是整个文档。
调整图像参数:根据需要,您可以调整图像质量、分辨率等参数。例如,您可以选择高质量以确保图像清晰,或选择较低的分辨率以减小文件大小。通常,图像质量的选项可能以滑块或下拉菜单的形式出现。
完成保存操作
选择保存位置:完成所有必要的设置后,点击“保存”按钮。接着,您将被要求选择保存图像的文件夹和文件名。
保存文件:选择合适的文件夹,输入文件名,然后点击“保存”按钮,完成JPEG文件的导出。
方法三:使用“飞跃PDF处理器”软件提取pdf中的某一页
在使用飞跃PDF处理器软件来提取PDF中的某一页时,你可以按照以下详细步骤进行操作:
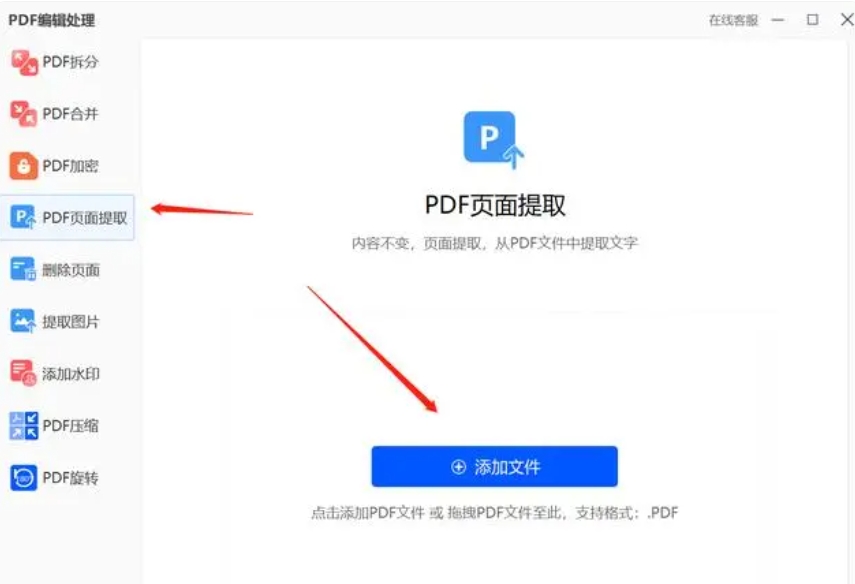
首先,打开飞跃PDF处理器软件。在软件的主界面中,你可能会看到一个包含多个选项的菜单或工具栏。在这些选项中,找到并点击“PDF处理”或与之类似的选项。这个选项通常会包含一系列与PDF文件处理相关的功能。
接下来,在左侧的功能栏中,你需要选择“PDF页面提取”功能。这个功能专门用于从PDF文件中提取特定的页面。
一旦选择了“PDF页面提取”功能,你就可以开始添加要处理的PDF文件了。点击页面左上方的“添加文件”按钮,这通常是一个带有加号(+)图标或文件夹图标的按钮。另外,你也可以直接将PDF文件拖拽到软件界面中,这样软件会自动识别并添加该文件。
在弹出的文件选择窗口中,浏览你的计算机,找到并选中需要提取页面的PDF文件。然后,点击窗口下方的“打开”按钮,将文件添加到软件中。
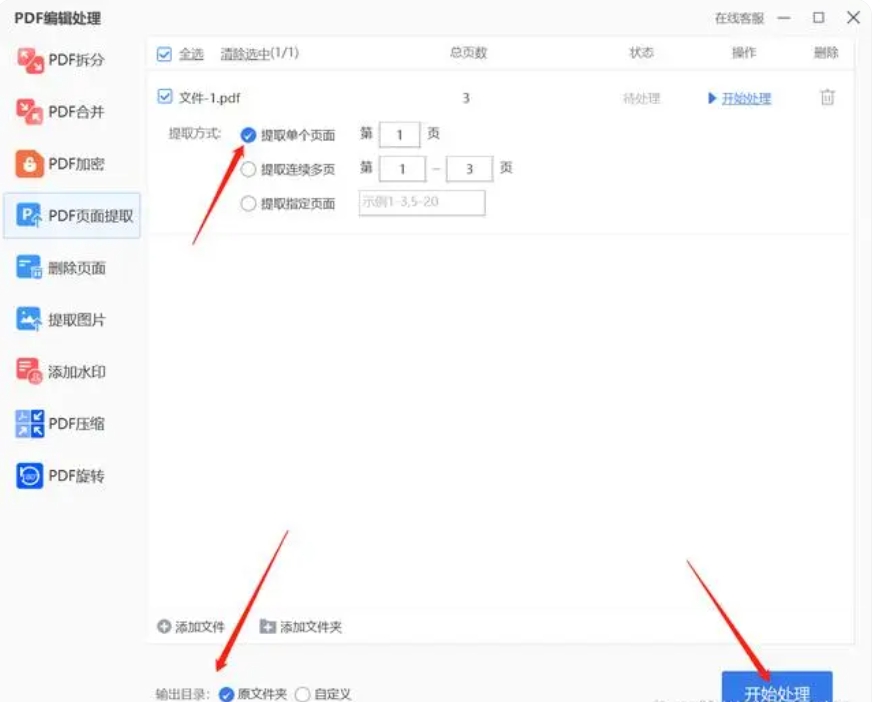
现在,你可以在软件界面中看到已添加的PDF文件的缩略图或列表。接下来,你需要找到“页码选择”选项。这个选项可能会以不同的形式出现,如输入框、下拉菜单或复选框等。根据你的需求,自定义选择需要提取的页面范围。你可以输入具体的页码,或选择起始页码和结束页码来定义一个范围。
在提取页面之前,你还需要设置输出方式和输出目录。输出方式通常指的是提取后的页面是以新的PDF文件保存,还是以其他格式(如图像)保存。输出目录则是你希望保存提取后文件的文件夹路径。你可以点击相应的设置按钮或选项来选择输出方式和指定输出目录。
最后,一切准备就绪后,点击界面上的“开始提取”按钮。软件将开始处理文件,并按照你的要求提取指定的页面。处理完成后,你可以在指定的输出目录中找到提取后的文件。
方法四:使用在线PDF工具(如lelepdf)提取pdf中的某一页

访问lelepdf的官方网站。
在首页找到并点击“Split PDF”(拆分PDF)工具。
上传包含目标页面的PDF文件。
在缩略图列表中浏览并找到想要提取的那一页。
确认无误后,点击“Extract Page”(提取页面)按钮。
提取完成后,下载并保存生成的PDF文件。
方法五:使用PDFill PDF Tools提取pdf中的某一页
从PDFill官方网站下载并安装PDFill PDF Tools
访问官方网站:打开浏览器,前往PDFill的官方网站。
下载软件:在网站上,找到“PDFill PDF Tools”部分,点击“下载”按钮。选择合适的版本,通常为Windows版本,进行下载。
安装程序:下载完成后,双击安装文件以启动安装向导。按照屏幕上的提示,选择安装位置并接受软件许可协议,完成安装。
打开PDFill PDF Tools
启动软件:安装完成后,找到桌面上的PDFill PDF Tools图标,双击以打开该软件。您也可以通过开始菜单找到它并启动。
打开源PDF文件
选择文件菜单:在软件界面的顶部工具栏中,点击“文件”菜单。
打开PDF文件:在下拉菜单中选择“打开”选项,浏览到您希望提取页面的源PDF文件位置,选择该文件并点击“打开”按钮。此时,所选的PDF文档将会在软件中加载。
选择页面操作选项
访问页面操作选项卡:在软件主界面的选项卡中,找到并选择“页面操作”选项。这一选项卡包含了多个与页面处理相关的功能。
选择分割、提取或插入PDF页面:在“页面操作”选项卡中,寻找“分割、提取或插入PDF页面”选项。这将引导您进入处理页面的相关功能。
提取页面
点击提取页面按钮:在相关选项中,找到并点击“提取页面”按钮。这会弹出一个新的窗口,允许您配置提取设置。
设置提取参数
配置页面提取参数:在弹出的窗口中,您可以设置提取页面的参数,例如:
页面范围:输入要提取的页面范围(例如,1-5表示提取第一页到第五页)。
单独提取:如果您只想提取特定的页面,可以选择输入单独的页面编号(如2, 4, 6)。
调整其他选项:根据需要,您还可以选择是否提取空白页,或者设置提取后的文件名称。
执行提取操作
点击继续按钮:设置好所有参数后,点击“继续”按钮,软件将开始执行页面提取操作。根据PDF文件的大小和所提取的页面数量,此过程可能需要几秒钟到几分钟不等。
保存新生成的PDF文件
完成提取:提取完成后,软件会提示您保存新生成的PDF文件。您可以选择合适的保存位置,输入文件名称。
保存文件:点击“保存”按钮,确认保存位置和文件名,完成PDF页面提取操作。
方法六:使用PDF-XChange Editor提取pdf中的某一页
一、启动 PDF-XChange Editor 并打开 PDF 文件
首先,在电脑桌面上找到 PDF-XChange Editor 的图标,或者通过 “开始” 菜单等途径找到并启动该软件。软件启动过程可能需要几秒钟的时间,耐心等待直至软件完全加载,呈现出其专业且功能丰富的主界面。
主界面通常会有菜单栏、工具栏以及文档显示区域等部分。在菜单栏中,找到并点击 “文件” 选项。点击后,会弹出一个下拉菜单,在这个下拉菜单中,选择 “打开” 选项。
此时,会弹出一个文件选择对话框。通过浏览电脑的存储路径,准确地找到需要提取页面的 PDF 文件所在的位置。仔细查找目标文件,选中它后,点击 “打开” 按钮。软件会迅速读取并加载这个 PDF 文件,将其显示在文档显示区域中,准备进行后续的操作。
二、在页面缩略图中选择要提取的页面
查看左侧面板:在 PDF-XChange Editor 的主界面中,通常会在左侧有一个面板,其中显示了 PDF 文件的页面缩略图。这个面板可以帮助用户快速浏览和选择 PDF 文件中的各个页面。
选择页面:在页面缩略图中,仔细查找需要提取的特定页面。可以通过滚动鼠标滚轮或者使用面板上的滚动条来浏览不同的页面。当找到要提取的页面时,点击该页面的缩略图,使其被选中。选中后,页面缩略图可能会有一个高亮显示或者边框显示,以表示该页面已被选中。
三、选择 “提取页面” 功能
点击 “页面” 菜单:在软件的菜单栏中,找到并点击 “页面” 菜单。这个菜单包含了与 PDF 页面操作相关的各种功能选项。
选择 “提取页面” 选项:点击 “页面” 菜单后,会弹出一个下拉菜单。在这个下拉菜单中,找到并选择 “提取页面” 选项。这个选项通常会用特定的图标或文字来突出显示,方便用户快速识别和选择。
选择 “提取页面” 选项后,软件会弹出一个对话框,用于设置提取页面的相关参数。
四、设置提取页面的保存位置和文件名
弹出对话框:选择 “提取页面” 选项后,会弹出一个对话框,这个对话框通常会有多个选项卡或区域,用于设置提取页面的不同参数。
设置保存位置:在对话框中,找到保存位置设置的区域。这个区域可能会有一个 “浏览” 按钮或者一个输入框,用于指定提取页面后保存的位置。点击 “浏览” 按钮,会弹出一个文件选择对话框,通过浏览电脑的存储路径,选择一个合适的文件夹作为保存提取页面的位置。或者在输入框中直接输入保存位置的路径。
设置文件名:在对话框中,还会有一个文件名设置的区域。这个区域可能会有一个默认的文件名,也可以根据需要输入一个新的文件名。文件名可以根据提取的页面内容或者其他特征来命名,以便于识别和管理。
五、保存提取的页面
确认设置:在设置好提取页面的保存位置和文件名后,仔细检查设置是否正确。确保保存位置是你想要保存的文件夹,文件名也符合你的需求。
点击 “保存” 按钮:当一切确认无误后,在对话框中找到并点击 “保存” 按钮。点击这个按钮后,软件会开始提取选中的页面,并将其保存到指定的位置。
在提取页面的过程中,可能会看到进度条显示提取的进度,或者有提示信息显示提取的状态。请耐心等待提取过程完成。提取的时间长短会因 PDF 文件的大小、复杂程度以及电脑的性能而有所不同。
当提取完成后,可以在指定的保存位置找到提取的页面文件。打开这个文件,可以用 PDF 阅读器检查提取的页面是否正确。
方法七:使用“优速PDF工厂”软件提取pdf中的某一页
下载并打开优速PDF工厂软件。
在软件主界面选择“PDF文件操作”选项。
点击左侧的“PDF页面提取”功能。
点击软件左上角的“添加文件”按钮来选择想提取页面的PDF文件。
文件导入成功后,点击文件右侧的“全部页码”按钮来选择想提取的那一页。
页面选择完成后,点击软件右上角的“开始转换”按钮来启动软件的PDF页面提取程序。
软件完成页面提取操作后,打开输出目录以找到提取后的PDF文件。
方法八:使用Python中的PyPDF2库提取pdf中的某一页
确保已安装PyPDF2库(如未安装,可使用pip进行安装)。
编写Python脚本,使用PyPDF2库打开输入PDF文件。
创建一个PdfWriter对象用于写入提取的页面。
遍历指定的页面列表,将每个页面从PdfReader对象中提取并添加到PdfWriter对象中。
将提取的页面写入到新的PDF文件中。
以下是一个使用PyPDF2库的示例代码:
python
import PyPDF2
def extract_pages(input_pdf, output_pdf, page_numbers):
with open(input_pdf, "rb") as infile:
reader = PyPDF2.PdfReader(infile)
writer = PyPDF2.PdfWriter()
for page_num in page_numbers:
if 0 <= page_num < len(reader.pages):
page = reader.pages[page_num]
writer.add_page(page)
else:
print(f"页面编号 {page_num} 超出范围")
with open(output_pdf, "wb") as outfile:
writer.write(outfile)
# 示例用法
input_pdf_path = "example.pdf" # 输入PDF文件路径
output_pdf_path = "extracted_pages.pdf" # 输出PDF文件路径
pages_to_extract = [0] # 要提取的页面编号列表(0-based index)
extract_pages(input_pdf_path, output_pdf_path, pages_to_extract)
单独提取PDF页面不仅提高了工作效率,还便于信息的保密与安全传输。比如,在分享敏感数据时,我们只需传递包含关键信息的那一页,避免了整个文档泄露的风险。此外,对于制作报告或演示文稿时,也能灵活选取最精彩的部分进行展示,使内容更加聚焦、专业。总之,当PDF文件中某个页面变得至关重要时,掌握快速提取页面的技巧显得尤为重要。它不仅能够满足我们即时的信息需求,更是提升个人工作效率、优化信息处理方式的一大利器。在这个数字化时代,善用科技工具,让信息处理变得更加高效与便捷,无疑是我们每个人应当掌握的技能之一。上面小编为大家讲解了几个“怎么提取pdf的某一个”的操作方法,相信对大家是有帮助的,因为介绍的方法真的非常简单,赶紧去试试看吧。
相关文章:
怎么提取pdf的某一页?批量提取pdf的某一页的简单方法
怎么提取pdf的某一页?在日常工作与学习中,我们经常会遇到各式各样的PDF文件,它们以其良好的兼容性和稳定性,成为了信息传输和存储的首选格式。然而,在浩瀚的文档海洋中,有时某个PDF文件中的某一页内容尤为重…...
Github优质项目推荐(第八期)
文章目录 Github优质项目推荐 - 第八期一、【manim】,66.5k stars - 创建数学动画的 Python 框架二、【siyuan】,19.5k stars - 个人知识管理软件三、 【GetQzonehistory】,1.3k stars - 获取QQ空间发布的历史说说四、【SecLists】࿰…...

快读快写模板
原理 众所周知,在c中,用putchar和getchar输入输出字符的速度是很快的,因此,我们可以考虑把数字转化为字符,按位输出;把字符读入后转化为数字的每一位。 该快读快写可以实现对所有整数类型的输入。 templ…...

make_blobs函数
make_blobs 是 scikit-learn 库中用于生成聚类(或分类)数据集的函数。它通常用于生成多个高斯分布的簇状数据,以便进行分类或聚类算法的测试和验证。make_blobs 非常灵活,可以控制簇的数量、样本数量、每个簇的标准差、中心点等参…...

特斯拉Optimus:展望智能生活新篇章
近日,特斯拉举办了 "WE ROBOT" 发布会,发布会上描绘的未来社会愿景,让无数人为之向往。在这场吸引全球无数媒体的直播中,特斯拉 Optimus 人形机器人一出场就吸引了所有观众的关注。从多家媒体现场拍摄的视频可以看出来&…...
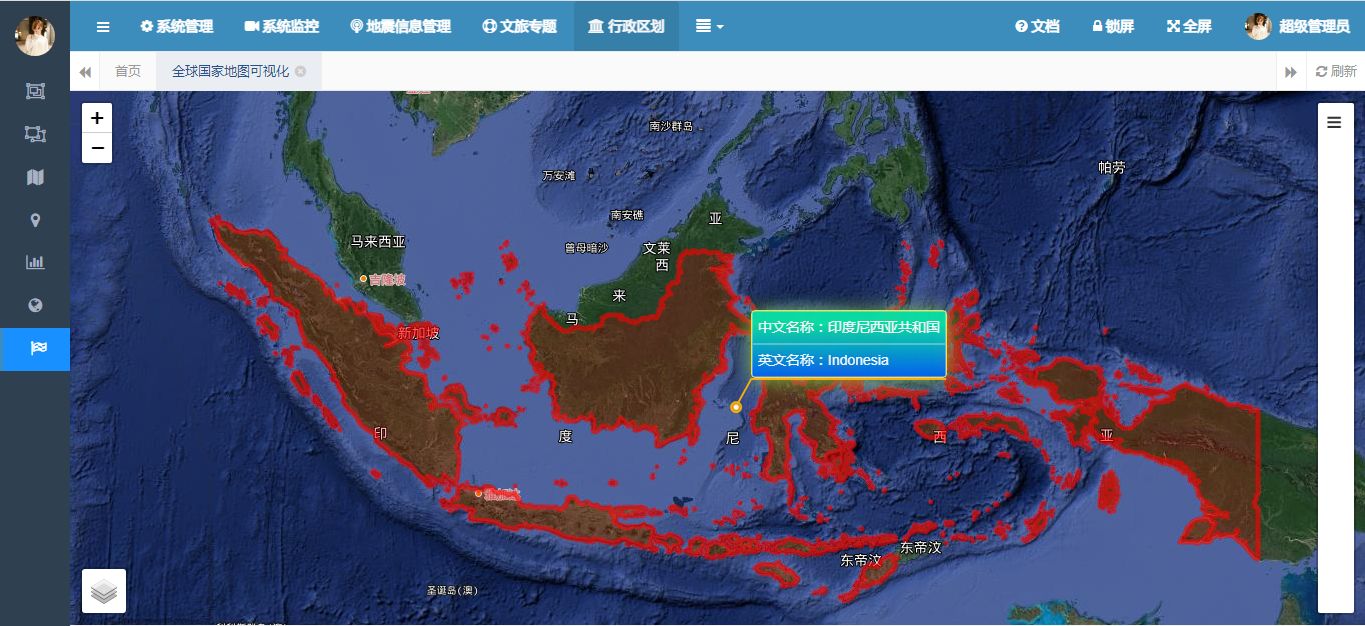
基于Leaflet和SpringBoot的全球国家综合检索WebGIS可视化
目录 前言 一、Java后台程序设计 1、业务层设计 2、控制层设计 二、WebGIS可视化实现 1、侧边栏展示 2、空间边界信息展示 三、标注成果展示 1、面积最大的国家 2、国土面积最小的国家 3、海拔最低的国家 4、最大的群岛国家 四、总结 前言 在前面的博文中ÿ…...

【Linux】/usr/share目录
在Linux和类Unix操作系统中,/usr/share 目录是一个用于存放共享数据文件的目录。这个目录遵循Filesystem Hierarchy Standard (FHS),它定义了Linux系统中文件和目录的组织结构。/usr 代表 “user”,而 share 表示这些文件可以被系统上的多个用…...

Java中如何应用序列化 serialVersionUID 版本号呢?
文章目录 示例1:没有 serialVersionUID 的类输出结果:示例2:类修改后未定义 serialVersionUID可能出现的问题:示例3:显式定义 serialVersionUID总结最佳实践推荐阅读文章 为了更好地理解 serialVersionUID 的使用&…...

面部识别技术:AI 如何识别人脸
在科技飞速发展的今天,面部识别技术已经广泛应用于各个领域,从手机解锁到安防监控,从金融支付到门禁系统,面部识别技术正在改变着我们的生活方式。那么,AI 究竟是如何识别人脸的呢?让我们一起来揭开面部识别…...
及其操作(DOM的概念与结构、操作DOM节点、描述DOM树的形成过程、用DOMParser解析字符串为DOM对象))
全面解析文档对象模型(DOM)及其操作(DOM的概念与结构、操作DOM节点、描述DOM树的形成过程、用DOMParser解析字符串为DOM对象)
1. 引言 文档对象模型(DOM)是Web开发中的核心概念,它提供了一种结构化的方法来表示和操作HTML和XML文档。通过DOM,开发者可以动态地访问和更新文档的内容、结构和样式。本文将深入探讨DOM的概念与结构、操作DOM节点的方法、DOM树…...

字符串使用方法:
字符串: -- 拼接字符串 SELECT CONCAT(糯米,啊啊啊撒,删掉); -- 字符长度 SELECT LENGTH(asssssssggg); -- 转大写 SELECT UPPER(asdf); -- 转小写 SELECT LOWER(ASDFG); -- 去除左边空格 SELECT LTRIM( aaaasdrf ); -- 去除右边空格 SELECT RTRIM( aaaasdff ); -- 去除两端…...
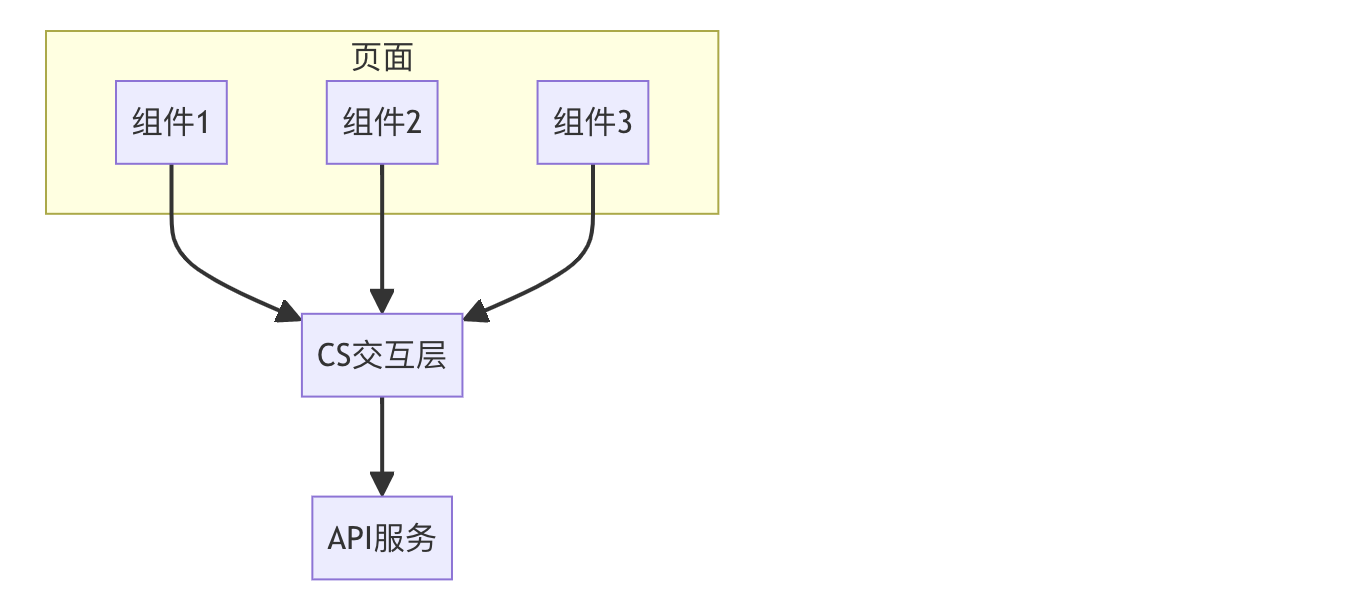
想让前后端交互更轻松?alovajs了解一下?
作为一个前端开发者,我最近发现了一个超赞的请求库 alovajs,它真的让我眼前一亮!说实话,我感觉自己找到了前端开发的新大陆。大家知道,在前端开发中,处理 Client-Server 交互一直是个老大难的问题ÿ…...

E/MicroMsg.SDK.WXMediaMessage:checkArgs fail,thumbData is invalid 图片资源太大导致分享失败
1、微信分享报: 2、这个问题是因为图片太大导致: WXWebpageObject webpage new WXWebpageObject();webpage.webpageUrl qrCodeUrl;//用 WXWebpageObject 对象初始化一个 WXMediaMessage 对象WXMediaMessage msg new WXMediaMessage(webpage);msg.tit…...
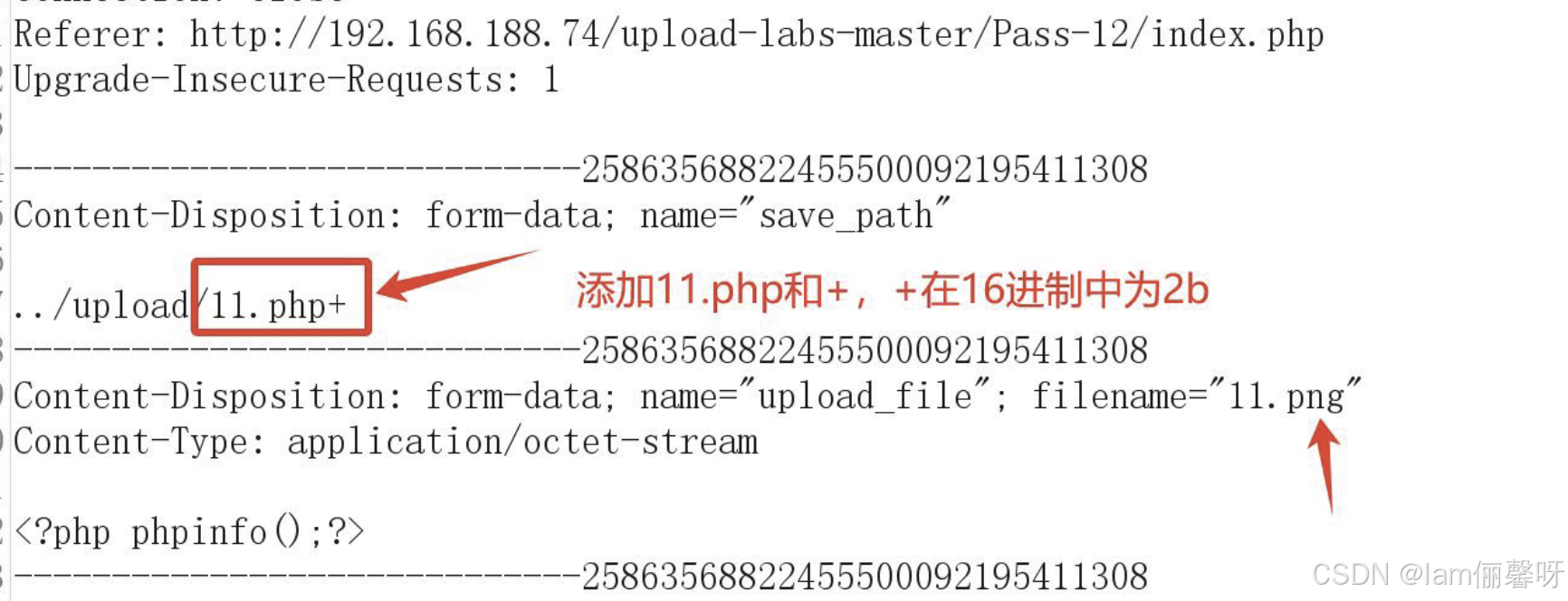
No.21 笔记 | WEB安全 - 任意文件绕过详解 part 3
(一)空格绕过 原理 Windows系统将文件名中的空格视为空,但程序检测代码无法自动删除空格,使攻击者可借此绕过黑名单限制。基于黑名单验证的代码分析 代码未对上传文件的文件名进行去空格处理,存在安全隐患。相关代码逻…...
咸鱼自动发货 免费无需授权
下载:(两个都可以下,自己选择) https://pan.quark.cn/s/1e3039e322ad https://pan.xunlei.com/s/VO9ww89ZNkEg_Fq1wRr-fk9ZA1?pwd8x9s# 不是闲管家 闲鱼自动发货(PC端) 暂不支持密,免费使…...
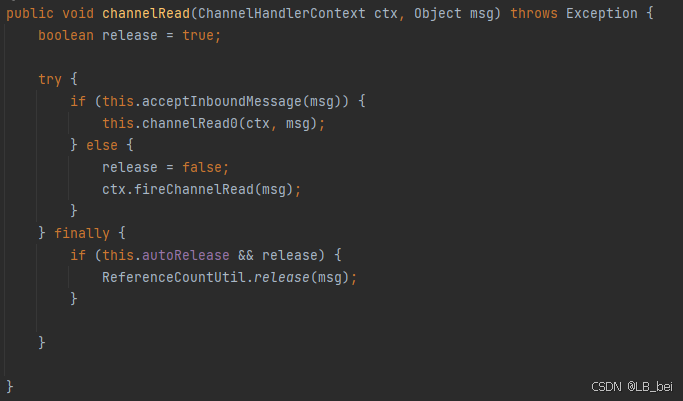
Netty核心组件
1.Channel Channel可以理解为是socket连接,在客户端与服务端连接的时候就会建立一个Channel,它负责基本的IO操作(binf()、connect()、rad()、write()等); 1.1 Channel的作用 通过Channel可获得当前网络连接的通道状态…...
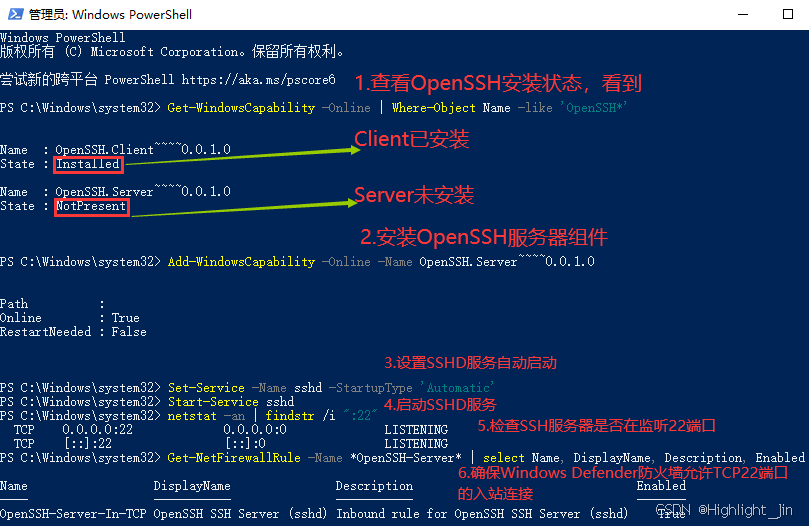
Windows中如何安装SSH
主要内容 一、参考资料二、主要过程法一:通过「设置」安装法二:使用 PowerShell进行安装在 Windows 中配置 OpenSSH 服务器过程截图 一、参考资料 Windows10 打开ssh服务,报错“The service name is invalid ” windows开启ssh服务教程 在 W…...
在linux上部署ollama+open-webu,且局域网访问教程
在linux上部署ollamaopen-webu,且局域网访问教程 运行ollamaopen-webui安装open-webui (待实现)下一期将加入内网穿透,实现外网访问功能 本文主要介绍如何在Windows系统快速部署Ollama开源大语言模型运行工具,并使用Op…...
基于大模型的招聘智能体:从创意到MVP
正在考虑下一个 SaaS 创意?以下是我在短短几个小时内从创意到 MVP 的过程。 以下是我将在这篇文章中介绍的内容概述: 为什么这个想法让我产生共鸣我是如何开始构建它的我现在的处境以及我是否会真正推出 获得 SaaS 创意并构建它并不容易。就是这样。 …...

STM32F1+HAL库+FreeTOTS学习19——软件定时器
STM32F1HAL库FreeTOTS学习19——软件定时器 1 软件定时器1.1 FreeRTOS软件定时器简介1.2 FreeRTOS软件定时器服务任务1.3 FreeRTOS软件定时器服命令队列。1.4 软件定时器的状态1.5 复位定时器1.6 软件定时器结构体 2 软件定时器配置3 软件定时器API函数3.1 xTimerCreate()和xTi…...

微软PowerBI考试 PL300-选择 Power BI 模型框架【附练习数据】
微软PowerBI考试 PL300-选择 Power BI 模型框架 20 多年来,Microsoft 持续对企业商业智能 (BI) 进行大量投资。 Azure Analysis Services (AAS) 和 SQL Server Analysis Services (SSAS) 基于无数企业使用的成熟的 BI 数据建模技术。 同样的技术也是 Power BI 数据…...

【SpringBoot】100、SpringBoot中使用自定义注解+AOP实现参数自动解密
在实际项目中,用户注册、登录、修改密码等操作,都涉及到参数传输安全问题。所以我们需要在前端对账户、密码等敏感信息加密传输,在后端接收到数据后能自动解密。 1、引入依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId...

【网络安全产品大调研系列】2. 体验漏洞扫描
前言 2023 年漏洞扫描服务市场规模预计为 3.06(十亿美元)。漏洞扫描服务市场行业预计将从 2024 年的 3.48(十亿美元)增长到 2032 年的 9.54(十亿美元)。预测期内漏洞扫描服务市场 CAGR(增长率&…...

JVM垃圾回收机制全解析
Java虚拟机(JVM)中的垃圾收集器(Garbage Collector,简称GC)是用于自动管理内存的机制。它负责识别和清除不再被程序使用的对象,从而释放内存空间,避免内存泄漏和内存溢出等问题。垃圾收集器在Ja…...

学习STC51单片机31(芯片为STC89C52RCRC)OLED显示屏1
每日一言 生活的美好,总是藏在那些你咬牙坚持的日子里。 硬件:OLED 以后要用到OLED的时候找到这个文件 OLED的设备地址 SSD1306"SSD" 是品牌缩写,"1306" 是产品编号。 驱动 OLED 屏幕的 IIC 总线数据传输格式 示意图 …...

视频行为标注工具BehaviLabel(源码+使用介绍+Windows.Exe版本)
前言: 最近在做行为检测相关的模型,用的是时空图卷积网络(STGCN),但原有kinetic-400数据集数据质量较低,需要进行细粒度的标注,同时粗略搜了下已有开源工具基本都集中于图像分割这块,…...

力扣热题100 k个一组反转链表题解
题目: 代码: func reverseKGroup(head *ListNode, k int) *ListNode {cur : headfor i : 0; i < k; i {if cur nil {return head}cur cur.Next}newHead : reverse(head, cur)head.Next reverseKGroup(cur, k)return newHead }func reverse(start, end *ListNode) *ListN…...

MySQL JOIN 表过多的优化思路
当 MySQL 查询涉及大量表 JOIN 时,性能会显著下降。以下是优化思路和简易实现方法: 一、核心优化思路 减少 JOIN 数量 数据冗余:添加必要的冗余字段(如订单表直接存储用户名)合并表:将频繁关联的小表合并成…...

站群服务器的应用场景都有哪些?
站群服务器主要是为了多个网站的托管和管理所设计的,可以通过集中管理和高效资源的分配,来支持多个独立的网站同时运行,让每一个网站都可以分配到独立的IP地址,避免出现IP关联的风险,用户还可以通过控制面板进行管理功…...

LangFlow技术架构分析
🔧 LangFlow 的可视化技术栈 前端节点编辑器 底层框架:基于 (一个现代化的 React 节点绘图库) 功能: 拖拽式构建 LangGraph 状态机 实时连线定义节点依赖关系 可视化调试循环和分支逻辑 与 LangGraph 的深…...