语音语言模型最新综述! 关于GPT-4o背后技术的尝试
近期,大型语言模型(LLMs)在生成文本和执行各种自然语言处理任务方面展现出了卓越的能力,成为了强大的AI驱动语言理解和生成的基础模型。然而,仅依赖于基于文本模态的模型存在显著局限性。这促使了基于语音的生成模型的发展,使其能够更自然、直观地与人类互动。
为了实现语音交互,OpenAI前阵子发布的GPT-4o,它可以直接与用户进行低时延,高质量语音对话,并具有多种不同的能力,如对说话人的识别,语音情感的识别,甚至是生成特定风格的语音,如唱歌。语音语言模型 (SpeechLMs)正是朝着这个方向的一种尝试,近期也成为了研究热点。本文是对SpeechLMs研究的一篇全面综述。
论文链接:https://arxiv.org/abs/2410.03751
Motivation
由于基于文本的大语言模型的成功,一般的语音交互方案通常采用"自动语音识别(ASR) +大型语言模型(LLM) +文本到语音合成(TTS)"的级联式架构。这种方法需要将语音信号转换为文本,并通过LLM基于文本进行回答,最后再将回答的语音进行生成。然而,这种方法存在两大主要的局限性:
-
整个流程是基于文本语言模型的,所以首先需要将音频转换为文本再进行处理。这种方式会丢失掉很多包含在音频中但不包含在文本中的信息,导致了音频信息的部分丢失。
-
整个流程是将三个独立的模块拼接在一起的,因此三个阶段在处理时候的错误会进行累积。
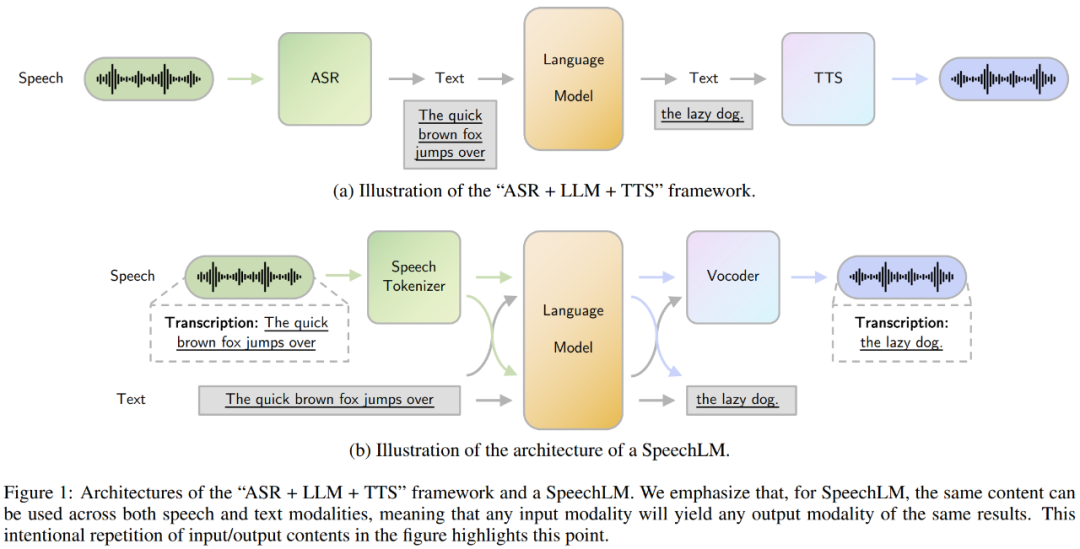
为了解决这些问题,SpeechLMs作为一种端到端的语音交互模型应运而生,它无需将语音转换为文本就能直接生成语音输出。SpeechLMs不仅可以执行传统的ASR、TTS任务,还能直接进行端到端的语音对话,以及实现更多复杂的功能,如编码说话人的音色信息和语音情感的细微差别。

那么,什么是SpeechLM呢?SpeechLM是一种自回归的基础模型(foundation model),能够处理和生成语音数据,利用上下文理解来生成连贯的序列。它通常支持语音,或语音和文本两个模态,如语音输入文本输出、文本输入语音输出或语音输入语音输出。这使其可以进行广泛的任务和具有上下文感知的能力。
以下是SpeechLMs的分类框架:

SpeechLM的组成部分
SpeechLM主要由三个核心组件构成:
-
语音分词器(Speech Tokenizer):将连续的音频信号编码为离散的token。
-
语言模型(Language Model):对语音token进行自回归建模。
-
Token到语音合成器(Vocoder):将生成的token合成为语音波形。

具体来说,SpeechLM在工作时,会先将输入的音频信号通过语音分词器处理成离散的token,再通过语言模型对这些语音token进行自回归建模,生成后续的语音token。最后,这些由语言模型生成出的语音token会经过语音合成器,再恢复成语音。
接下来让我们详细了解这三个组件:
-
语音分词器:语音分词器的核心目标是如何有效的将语音信号通过离散的token进行表示。这些token需要包含语音里面的多种信息。语音分词器的设计遵循有三类目标 - 语义理解、声学生成和混合目标。
-
语义理解型分词器,如HuBERT,专注于捕捉语音内容和含义。
-
声学生成型分词器,如SoundStream,侧重保留生成高质量语音所需的声学特征。
-
混合型分词器,如SpeechTokenizer,则平衡了语义理解和声学生成。
-
-
语言模型:大多采用Transformer或Decoder-Only架构,如OPT、LLaMA等。它们以自回归方式生成语音。SpeechLM中的语言模型通常可以将语音和文本的词表进行拼接,从而联合建模文本和语音模态。
-
语音合成器:主要有GAN-based、Flow-based等多种类型。GAN-based如HiFi-GAN,是在SpeechLM中最为广泛使用的一类vocoder,因为其以快速且高保真的生成而著称。
SpeechLM的训练配方
在训练方面,SpeechLMs的"配方"包括:
建模特征:这里表示的是SpeechLM的语言模型在训练时选择使用哪一类特征进行建模。一般可分为离散特征和连续特征。
-
离散特征:这是最主要的SpeechLM所建模的特征,一般以token形式存在。这里一般主要包含语义token,副语言学(paralinguistic)token,和声学token。
-
语义token:主要包含了语音里面语义信息。
-
副语言学token:主要包含了语音里面出语义信息以外的信息,如音高,韵律等。
-
声学token:主要包含语音信号中的声学信息。这些信息有助于将token恢复出高质量高保真语音。
-
-
连续特征:当然也有极少部分SpeechLM选择对连续信号进行建模,如梅尔谱(mel-spectrogram)
训练阶段:包括语言模型预训练和指令微调两个主要阶段。
-
语言模型预训练:此阶段主要关注如何让SpeechLM中的语言模型有效学习到语音token之间的上下文关系,从而让模型能够输出上下文相关的且连贯的语音。此阶段可以选择使用随机初始化的参数开始训练,但研究人员一般会更愿意选择基于文本训练好的LLM checkpoint进行继续预训练。研究人员发现采用文本预训练的checkpoint继续预训练使得SpeechLM效果更好,且能够更快拟合。
-
语言模型指令微调:此阶段主要关注让SpeechLM中的语音模型能够有效的进行指令跟随,从而更好的与人类对话或回答人类提出的问题。
语音生成范式:除传统生成方式外,还包括实时交互和静默模式等高级语音交互技能。
-
实时交互:一般的语言模型在交互时遵循回合制(turn-based),即每一轮的输入输出需要等上一轮的输入输出结束后才能进行。然而,这并不符合人类说话(语音交互)的范式。人类语音交互时,通常可以不等待上一个人说话结束后就会说话,或者在他人说话时自己同时开始说。这催生了SpeechLM的实时交互模式的探索。
-
静默模式:静默模式指的是当模型识别到,当人类没有与其对话的时候(如在和其他人对话时),选择不进行回应的能力。
下游任务与能力

SpeechLMs能够执行多种下游任务,大致可分为三类:
-
语义相关应用:如口语对话、语音翻译、自动语音识别等;
-
说话人相关应用:如说话人识别、验证、分离等。此能力可以让SpeechLM分辨出多个说话人,从而可以处理更加复杂的场景,如在参与会议并与多人同时进行讨论;
-
语音学应用:如情感识别、语音分离、增强语音学生成等。此能力能使得SpeechLM识别并生成带有特定风格的语音,如使用不同情感说话,甚至是唱歌。
评 估
在评估方面,SpeechLMs采用自动(客观)评估和人工(主观)评估两种方法。
-
自动(客观)评估:通过自动化指标来评判SpeechLM的好坏。自动评估通常从多个角度去衡量SpeechLM的性能:
-
特征评估:衡量SpeechLM所输出的特征;
-
语言学评估:衡量SpeechLM对于词法,句法,语义的理解与生成;
-
副语言学评估:衡量SpeechLM对于副语言学特征的理解与生成质量。
-
-
人工(主观)评估:通过人工评估来评判SpeechLM的好坏。人工评估主要依赖平均意见得分(MOS)。
未来研究方向
尽管SpeechLMs展现出令人印象深刻的能力,但这一领域的研究仍处于起步阶段。未来的研究方向包括:
-
深入理解不同组件(语音分词器,语言模型,语音合成器)选择的优劣;
-
探索端到端训练方法:当前的SpeechLM在训练时通常会选择分开对三个组件训练,而将三个组件合在一起进行端到端训练的策略值得研究;
-
继续增强SpeechLM的实时语音生成能力;
-
解决SpeechLMs中的安全风险:语音生成模型中同时有与文本生成模型相似的和独立的安全风险。例如,SpeechLM可能会生成有毒性的文本(制作炸弹的教学),不合规的语音(如色情语音),和对说话人的偏见(对不同口音的语音输入产生不同的输出)。因此,解决SpeechLM中的安全风险至关重要;
-
提升在稀有语言上的表现:对于稀有语言(小语种)来说,通常在互联网上能够获取到的文本资料很少,但语音数据却相对较多。因此,研究者可以关注如何提升SpeechLM在稀有语言上的表现。
总结
SpeechLMs作为一种新兴的语音交互技术,展现出了巨大的潜力。它不仅能够克服传统ASR+LLM+TTS方案的局限性,还能实现更自然、更丰富的人机语音交互。随着研究的深入,我们有理由相信SpeechLMs将在未来的AI语音交互中扮演越来越重要的角色。
相关文章:
语音语言模型最新综述! 关于GPT-4o背后技术的尝试
近期,大型语言模型(LLMs)在生成文本和执行各种自然语言处理任务方面展现出了卓越的能力,成为了强大的AI驱动语言理解和生成的基础模型。然而,仅依赖于基于文本模态的模型存在显著局限性。这促使了基于语音的生成模型的发展,使其能够更自然、直观地与人类互动。 为了…...

根据用户选择的行和列数据构造数据结构(跨行跨列)
方案一 这段代码的功能是根据用户选择的行和列数据,生成一个适合复制粘贴的字符串表格。代码会先按列的 id 从小到大排序,再根据行列的选择关系将数据按顺序填入表格,每行之间使用换行符分隔,每列之间使用制表符分隔。如果某一行…...

Spark教程5-基本结构化操作
加载csv文件 df spark.read.format("json").load("/data/flight-data/json/2015-summary.json")Schema 输出Schema df.printSchema()使用Schema读取csv文件,以指定数据类型 from pyspark.sql.types import StructField, StructType, Strin…...

内置数据类型、变量名、字符串、数字及其运算、数字的处理、类型转换
内置数据类型 python中的内置数据类型包括:整数、浮点数、布尔类型(以大写字母开头)、字符串 变量名 命名变量要见名知意,确保变量名称具有描述性和意义,这样可以使得代码更容易维护,使用_可以使得变量名…...

Win/Mac/Android/iOS怎麼刪除代理設置?
設置代理設置的主要構成 IP 地址和端口 這些是代理伺服器配置的最基本組件。代理伺服器的IP地址引導互聯網流量,而端口號指定伺服器上的通信通道。 為什麼要刪除代理設置? 刪除代理設置通常是為了解決網路問題、提高速度、恢復安全性或過渡到新的網路…...

数据结构------手撕顺序表
文章目录 线性表顺序表的使用及其内部方法ArrayList 的扩容机制顺序表的几种遍历方式顺序表的优缺点顺序表的模拟实现洗牌算法 线性表 线性表(linear list)是n个具有相同特性的数据元素的有限序列。 线性表是一种在实际中广泛使用的数据结构,…...

UDP(用户数据报协议)端口监控
随着网络的扩展,确保高效的设备通信对于优化网络功能变得越来越重要。在这个过程中,端口发挥着重要作用,它是实现外部设备集成的物理连接器。通过实现数据的无缝传输和交互,端口为网络基础设施的顺畅运行提供了保障。端口使数据通…...

【Java小白图文教程】-05-数组和排序算法详解
精品专题: 01.《C语言从不挂科到高绩点》课程详细笔记 https://blog.csdn.net/yueyehuguang/category_12753294.html?spm1001.2014.3001.5482 02. 《SpringBoot详细教程》课程详细笔记 https://blog.csdn.net/yueyehuguang/category_12789841.html?spm1001.20…...

OpenCV视觉分析之目标跟踪(1)计算密集光流的类DISOpticalFlow的介绍
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 这个类实现了 Dense Inverse Search (DIS) 光流算法。更多关于该算法的细节可以在文献 146中找到。该实现包含了三个预设参数集,以提…...

Lucas带你手撕机器学习——套索回归
好的,下面我将详细介绍套索回归的背景、理论基础、实现细节以及在实践中的应用,同时还会讨论其优缺点和一些常见问题。 套索回归(Lasso Regression) 1. 背景与动机 在机器学习和统计学中,模型的复杂性通常会影响其在…...

面试中的一个基本问题:如何在数据库中存储密码?
面试中的一个基本问题:如何在数据库中存储密码? 在安全面试中,“如何在数据库中存储密码?”是一个基础问题,但反映了应聘者对安全最佳实践的理解。以下是安全存储密码的最佳实践概述。 了解风险 存储密码必须安全&am…...

XML HTTP Request
XML HTTP Request 简介 XMLHttpRequest(XHR)是一个JavaScript对象,它最初由微软设计,并在IE5中引入,用于在后台与服务器交换数据。它允许网页在不重新加载整个页面的情况下更新部分内容,这使得网页能够实现动态更新,大大提高了用户体验。虽然名字中包含“XML”,但XML…...

TLS协议基本原理与Wireshark分析
01背 景 随着车联网的迅猛发展,汽车已经不再是传统的机械交通工具,而是智能化、互联化的移动终端。然而,随之而来的是对车辆通信安全的日益严峻的威胁。在车联网生态系统中,车辆通过无线网络与其他车辆、基础设施以及云端服务进行…...
怎么办)
当遇到 502 错误(Bad Gateway)怎么办
很多安装雷池社区版的时候,配置完成,访问的时候可能会遇到当前问题,如何解决呢? 客户端,浏览器排查 1.刷新页面和清除缓存 首先尝试刷新页面,因为有时候 502 错误可能是由于网络临时波动导致服务器无法连…...
: 加油站)
学习记录:js算法(七十五): 加油站
文章目录 加油站思路一思路二思路三思路四思路五 加油站 在一条环路上有 n 个加油站,其中第 i 个加油站有汽油 gas[i] 升。 你有一辆油箱容量无限的的汽车,从第 i 个加油站开往第 i1 个加油站需要消耗汽油 cost[i] 升。你从其中的一个加油站出发…...

强心剂!EEMD-MPE-KPCA-LSTM、EEMD-MPE-LSTM、EEMD-PE-LSTM故障识别、诊断
强心剂!EEMD-MPE-KPCA-LSTM、EEMD-MPE-LSTM、EEMD-PE-LSTM故障识别、诊断 目录 强心剂!EEMD-MPE-KPCA-LSTM、EEMD-MPE-LSTM、EEMD-PE-LSTM故障识别、诊断效果一览基本介绍程序设计参考资料 效果一览 基本介绍 EEMD-MPE-KPCA-LSTM(集合经验模态分解-多尺…...

yarn的安装与使用以及与npm的区别(安装过程中可能会遇到的问题)
一、yarn的安装 使用npm就可以进行安装 但是需要注意的一点是yarn的使用和node版本是有关系的必须是16.0以上的版本。 输入以下代码就可以实现yarn的安装 npm install -g yarn 再通过版本号的检查来确定,yarn是否安装成功 yarn -v二、遇到的问题 1、问题描述…...

大数据行业预测
大数据行业预测 编译 李升伟 和所有预测一样,我们必须谨慎对待这些预测,因为其中一些预测可能成不了事实。当然,真正改变游戏规则的创新往往出乎意料,甚至让最警惕的预言家也措手不及。所以,如果在来年发生了一些惊天…...
打包成桌面端(nextron、electron、tauri)的最佳解决方式)
可能是NextJs(使用ssr、api route)打包成桌面端(nextron、electron、tauri)的最佳解决方式
可能是NextJs(使用ssr、api route)打包成桌面端(nextron、electron、tauri)的最佳解决方式 前言 在我使用nextron(nextelectron)写了一个项目后打包发现nextron等一系列桌面端框架在生产环境是不支持next的ssr也就是api route功能的这就导致我非常难受&…...

二百七十、Kettle——ClickHouse中增量导入清洗数据错误表
一、目的 比如原始数据100条,清洗后,90条正确数据在DWD层清洗表,10条错误数据在DWD层清洗数据错误表,所以清洗数据错误表任务一定要放在清洗表任务之后。 更关键的是,Hive中原本的SQL语句,放在ClickHouse…...

Python爬虫实战:研究MechanicalSoup库相关技术
一、MechanicalSoup 库概述 1.1 库简介 MechanicalSoup 是一个 Python 库,专为自动化交互网站而设计。它结合了 requests 的 HTTP 请求能力和 BeautifulSoup 的 HTML 解析能力,提供了直观的 API,让我们可以像人类用户一样浏览网页、填写表单和提交请求。 1.2 主要功能特点…...

变量 varablie 声明- Rust 变量 let mut 声明与 C/C++ 变量声明对比分析
一、变量声明设计:let 与 mut 的哲学解析 Rust 采用 let 声明变量并通过 mut 显式标记可变性,这种设计体现了语言的核心哲学。以下是深度解析: 1.1 设计理念剖析 安全优先原则:默认不可变强制开发者明确声明意图 let x 5; …...

黑马Mybatis
Mybatis 表现层:页面展示 业务层:逻辑处理 持久层:持久数据化保存 在这里插入图片描述 Mybatis快速入门 
【第二十一章 SDIO接口(SDIO)】
第二十一章 SDIO接口 目录 第二十一章 SDIO接口(SDIO) 1 SDIO 主要功能 2 SDIO 总线拓扑 3 SDIO 功能描述 3.1 SDIO 适配器 3.2 SDIOAHB 接口 4 卡功能描述 4.1 卡识别模式 4.2 卡复位 4.3 操作电压范围确认 4.4 卡识别过程 4.5 写数据块 4.6 读数据块 4.7 数据流…...

【配置 YOLOX 用于按目录分类的图片数据集】
现在的图标点选越来越多,如何一步解决,采用 YOLOX 目标检测模式则可以轻松解决 要在 YOLOX 中使用按目录分类的图片数据集(每个目录代表一个类别,目录下是该类别的所有图片),你需要进行以下配置步骤&#x…...

令牌桶 滑动窗口->限流 分布式信号量->限并发的原理 lua脚本分析介绍
文章目录 前言限流限制并发的实际理解限流令牌桶代码实现结果分析令牌桶lua的模拟实现原理总结: 滑动窗口代码实现结果分析lua脚本原理解析 限并发分布式信号量代码实现结果分析lua脚本实现原理 双注解去实现限流 并发结果分析: 实际业务去理解体会统一注…...

基于Java+VUE+MariaDB实现(Web)仿小米商城
仿小米商城 环境安装 nodejs maven JDK11 运行 mvn clean install -DskipTestscd adminmvn spring-boot:runcd ../webmvn spring-boot:runcd ../xiaomi-store-admin-vuenpm installnpm run servecd ../xiaomi-store-vuenpm installnpm run serve 注意:运行前…...

Vue ③-生命周期 || 脚手架
生命周期 思考:什么时候可以发送初始化渲染请求?(越早越好) 什么时候可以开始操作dom?(至少dom得渲染出来) Vue生命周期: 一个Vue实例从 创建 到 销毁 的整个过程。 生命周期四个…...
pgsql:还原数据库后出现重复序列导致“more than one owned sequence found“报错问题的解决
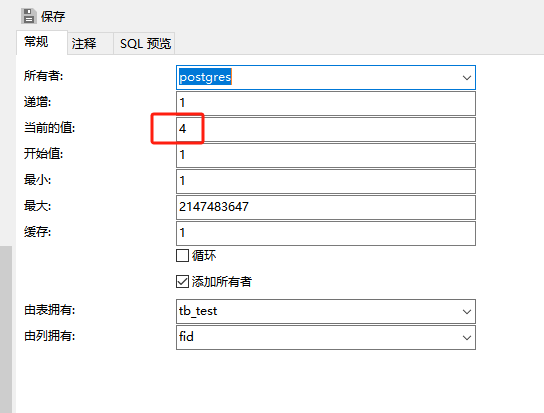
问题: pgsql数据库通过备份数据库文件进行还原时,如果表中有自增序列,还原后可能会出现重复的序列,此时若向表中插入新行时会出现“more than one owned sequence found”的报错提示。 点击菜单“其它”-》“序列”,…...

TCP/IP 网络编程 | 服务端 客户端的封装
设计模式 文章目录 设计模式一、socket.h 接口(interface)二、socket.cpp 实现(implementation)三、server.cpp 使用封装(main 函数)四、client.cpp 使用封装(main 函数)五、退出方法…...