【智能大数据分析 | 实验四】Spark实验:Spark Streaming

【作者主页】Francek Chen
【专栏介绍】 ⌈ ⌈ ⌈智能大数据分析 ⌋ ⌋ ⌋ 智能大数据分析是指利用先进的技术和算法对大规模数据进行深入分析和挖掘,以提取有价值的信息和洞察。它结合了大数据技术、人工智能(AI)、机器学习(ML)和数据挖掘等多种方法,旨在通过自动化的方式分析复杂数据集,发现潜在的价值和关联性,实现数据的自动化处理和分析,从而支持决策和优化业务流程。与传统的人工分析相比,智能大数据分析具有自动化、深度挖掘、实时性和可视化等特点。智能大数据分析广泛应用于各个领域,包括金融服务、医疗健康、零售、市场营销等,帮助企业做出更为精准的决策,提升竞争力。
【GitCode】专栏资源保存在我的GitCode仓库:https://gitcode.com/Morse_Chen/Intelligent_bigdata_analysis。
文章目录
- 一、实验目的
- 二、实验要求
- 三、实验原理
- (一)Spark Streaming 架构
- (二)Spark Streaming 编程模型
- (三)Spark Streaming 典型案例
- 四、实验环境
- 五、实验步骤
- (一)启动 Hadoop 集群和 Spark 集群
- (二)编写 SparkStreaming 代码
- (三)运行 Sparksteaming JAR包
- 六、实验结果
- 七、实验心得
一、实验目的
- 了解 Spark Streaming 版本的 WordCount 和 MapReduce 版本的 WordCount 的区别;
- 理解 Spark Streaming 的工作流程;
- 理解 Spark Streaming 的工作原理。
二、实验要求
要求实验结束时,每位学生能正确运行成功本实验中所写的 jar 包程序,能正确的计算出单词数目。
三、实验原理
(一)Spark Streaming 架构
计算流程:Spark Streaming 是将流式计算分解成一系列短小的批处理作业。这里的批处理引擎是 Spark,也就是把 Spark Streaming 的输入数据按照 batch size(如1秒)分成一段一段的数据(Discretized Stream),每一段数据都转换成 Spark 中的 RDD(Resilient Distributed Dataset),然后将 Spark Streaming 中对 DStream 的 Transformation 操作变为针对 Spark 中对 RDD 的 Transformation 操作,将 RDD 经过操作变成中间结果保存在内存中。整个流式计算根据业务的需求可以对中间的结果进行叠加,或者存储到外部设备。如图1所示:

容错性:对于流式计算来说,容错性至关重要。首先我们要明确一下 Spark 中 RDD 的容错机制。每一个 RDD 都是一个不可变的分布式可重算的数据集,其记录着确定性的操作继承关系(lineage),所以只要输入数据是可容错的,那么任意一个 RDD 的分区(Partition)出错或不可用,都是可以利用原始输入数据通过转换操作而重新算出的。
对于 Spark Streaming 来说,其 RDD 的传承关系如下图所示,图中的每一个椭圆形表示一个 RDD,椭圆形中的每个圆形代表一个 RDD 中的一个 Partition,图中的每一列的多个 RDD 表示一个 DStream(图中有三个 DStream),而每一行最后一个 RDD 则表示每一个 Batch Size 所产生的中间结果 RDD。我们可以看到图中的每一个 RDD 都是通过 lineage 相连接的,由于 Spark Streaming 输入数据可以来自于磁盘,例如 HDFS(多份拷贝)或是来自于网络的数据流(Spark Streaming 会将网络输入数据的每一个数据流拷贝两份到其他的机器)都能保证容错性。所以 RDD 中任意的 Partition 出错,都可以并行地在其他机器上将缺失的 Partition 计算出来。这个容错恢复方式比连续计算模型(如 Storm)的效率更高。 如图2所示:

实时性:对于实时性的讨论,会牵涉到流式处理框架的应用场景。Spark Streaming 将流式计算分解成多个 Spark Job,对于每一段数据的处理都会经过 Spark DAG 图分解,以及 Spark 的任务集的调度过程。对于目前版本的 Spark Streaming 而言,其最小的 Batch Size 的选取在0.5~2秒钟之间(Storm 目前最小的延迟是100ms左右),所以 Spark Streaming 能够满足除对实时性要求非常高(如高频实时交易)之外的所有流式准实时计算场景。
扩展性与吞吐量:Spark 目前在 EC2 上已能够线性扩展到100个节点(每个节点4Core),可以以数秒的延迟处理6GB/s的数据量(60M records/s),其吞吐量也比流行的 Storm 高2~5倍,图3是 Berkeley 利用 WordCount 和 Grep 两个用例所做的测试,在 Grep 这个测试中,Spark Streaming 中的每个节点的吞吐量是 670k records/s,而 Storm 是 115k records/s。如图3所示:

(二)Spark Streaming 编程模型
Spark Streaming 的编程和 Spark 的编程如出一辙,对于编程的理解也非常类似。对于 Spark 来说,编程就是对于 RDD 的操作;而对于 Spark Streaming 来说,就是对 DStream 的操作。下面将通过一个大家熟悉的 WordCount 的例子来说明 Spark Streaming 中的输入操作、转换操作和输出操作。
Spark Streaming 初始化:在开始进行 DStream 操作之前,需要对 Spark Streaming 进行初始化生成 StreamingContext。参数中比较重要的是第一个和第三个,第一个参数是指定 Spark Streaming 运行的集群地址,而第三个参数是指定 Spark Streaming 运行时的 batch 窗口大小。在这个例子中就是将1秒钟的输入数据进行一次 Spark Job 处理。
val ssc = new StreamingContext("Spark://…", "WordCount", Seconds(1), [Homes], [Jars])
Spark Streaming 的输入操作:目前 Spark Streaming 已支持了丰富的输入接口,大致分为两类:一类是磁盘输入,如以 batch size 作为时间间隔监控 HDFS 文件系统的某个目录,将目录中内容的变化作为 Spark Streaming 的输入;另一类就是网络流的方式,目前支持 Kafka、Flume、Twitter 和 TCP socket。在 WordCount 例子中,假定通过网络 socket 作为输入流,监听某个特定的端口,最后得出输入 DStream(lines)。
val lines = ssc.socketTextStream("localhost",8888)
Spark Streaming 的转换操作:与 Spark RDD 的操作极为类似,Spark Streaming 也就是通过转换操作将一个或多个 DStream 转换成新的 DStream。常用的操作包括 map、filter、flatmap 和 join,以及需要进行 shuffle 操作的 groupByKey/reduceByKey 等。在 WordCount 例子中,我们首先需要将 DStream(lines) 切分成单词,然后将相同单词的数量进行叠加, 最终得到的 wordCounts 就是每一个 batch size 的(单词,数量)中间结果。
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _)
另外,Spark Streaming 有特定的窗口操作,窗口操作涉及两个参数:一个是滑动窗口的宽度(Window Duration);另一个是窗口滑动的频率(Slide Duration),这两个参数必须是 batch size 的倍数。例如以过去5秒钟为一个输入窗口,每1秒统计一下 WordCount,那么我们会将过去5秒钟的每一秒钟的 WordCount 都进行统计,然后进行叠加,得出这个窗口中的单词统计。
val wordCounts = words.map(x => (x, 1)).reduceByKeyAndWindow(_ + _, Seconds(5s),seconds(1))
但上面这种方式还不够高效。如果我们以增量的方式来计算就更加高效,例如,计算 t+4 秒这个时刻过去5秒窗口的 WordCount,那么我们可以将 t+3 时刻过去5秒的统计量加上 [t+3,t+4] 的统计量,在减去 [t-2,t-1] 的统计量,这种方法可以复用中间三秒的统计量,提高统计的效率。如图4所示:
val wordCounts = words.map(x => (x, 1)).reduceByKeyAndWindow(_ + _, _ - _, Seconds(5s),seconds(1))

Spark Streaming 的输出操作:对于输出操作,Spark 提供了将数据打印到屏幕及输入到文件中。在 WordCount 中我们将 DStream wordCounts 输入到 HDFS 文件中。
wordCounts = saveAsHadoopFiles("WordCount")
Spark Streaming 启动:经过上述的操作,Spark Streaming 还没有进行工作,我们还需要调用 Start 操作,Spark Streaming 才开始监听相应的端口,然后收取数据,并进行统计。
ssc.start()
(三)Spark Streaming 典型案例
在互联网应用中,网站流量统计作为一种常用的应用模式,需要在不同粒度上对不同数据进行统计,既有实时性的需求,又需要涉及到聚合、去重、连接等较为复杂的统计需求。传统上,若是使用 Hadoop MapReduce 框架,虽然可以容易地实现较为复杂的统计需求,但实时性却无法得到保证;反之若是采用 Storm 这样的流式框架,实时性虽可以得到保证,但需求的实现复杂度也大大提高了。Spark Streaming 在两者之间找到了一个平衡点,能够以准实时的方式容易地实现较为复杂的统计需求。 下面介绍一下使用 Kafka 和 Spark Streaming 搭建实时流量统计框架。
数据暂存:Kafka 作为分布式消息队列,既有非常优秀的吞吐量,又有较高的可靠性和扩展性,在这里采用Kafka作为日志传递中间件来接收日志,抓取客户端发送的流量日志,同时接受 Spark Streaming 的请求,将流量日志按序发送给 Spark Streaming 集群。
数据处理:将 Spark Streaming 集群与 Kafka 集群对接,Spark Streaming 从 Kafka 集群中获取流量日志并进行处理。Spark Streaming 会实时地从 Kafka 集群中获取数据并将其存储在内部的可用内存空间中。当每一个 batch 窗口到来时,便对这些数据进行处理。
结果存储:为了便于前端展示和页面请求,处理得到的结果将写入到数据库中。
相比于传统的处理框架,Kafka+Spark Streaming 的架构有以下几个优点。Spark 框架的高效和低延迟保证了 Spark Streaming 操作的准实时性。利用 Spark 框架提供的丰富 API 和高灵活性,可以精简地写出较为复杂的算法。编程模型的高度一致使得上手 Spark Streaming 相当容易,同时也可以保证业务逻辑在实时处理和批处理上的复用。
Spark Streaming 提供了一套高效、可容错的准实时大规模流式处理框架,它能和批处理及即时查询放在同一个软件栈中。如果你学会了 Spark 编程,那么也就学会了 Spark Streaming 编程,如果理解了 Spark 的调度和存储,Spark Streaming 也类似。按照目前的发展趋势,Spark Streaming 一定将会得到更大范围的使用。
四、实验环境
- 云创大数据实验平台:

- Java 版本:jdk1.7.0_79
- Hadoop 版本:hadoop-2.7.1
- Spark 版本:spark-1.6.0
- ZooKeeper 版本:zookeeper-3.4.6
- Kafka 版本:kafka_2.10-0.9.0.1
- IntelliJ IDEA 版本:IntelliJ IDEA Community Edition 2016.3.1
五、实验步骤
(一)启动 Hadoop 集群和 Spark 集群
具体部署 Hadoop 和 Spark 集群的步骤可参考:【智能大数据分析 | 实验二】Spark实验:部署Spark集群
这里,登录大数据实验一体机,启动实验,并点击右上方的一键搭建按钮,等待一键搭建完成。
使用jps检验 Hadoop 集群和 Spark 集群是否成功启动。成功启动 Hadoop 集群和 Spark 集群的情况使用jps命令能成功看到以下 java 进程。
jps



(二)编写 SparkStreaming 代码
打开 IntelliJ IDEA 准备编写 Spark-streaming 代码。点击 File -> New -> Module -> Maven -> Next -> 输入 GroupId 和 AriifactId -> Next -> 输入 Module name 新建一个 maven 的 Module。


打开项目录,点击目录下的pom.xml文件,在标签中输入 maven 的依赖。然后右键 -> maven -> Reimport 导入 maven 依赖, 效果如下:

<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>com.cstor.sparkstreaming</groupId><artifactId>nice</artifactId><version>1.0-SNAPSHOT</version><build><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><configuration><source>1.6</source><target>1.6</target></configuration></plugin></plugins></build><!-- https://mvnrepository.com/artifact/org.apache.spark/Spark Streaming_2.10 --><dependencies><dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming_2.10</artifactId><version>1.6.0</version></dependency></dependencies>
</project>
在src/main/java的目录下,点击java目录新建一个 package 命名为spark.streaming.test,然后在包下新建一个SparkStreaming的 java class。在SparkStreaming中键入代码。

package spark.streaming.test;import scala.Tuple2;
import com.google.common.collect.Lists;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.api.java.StorageLevels;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaPairDStream;
import org.apache.spark.streaming.api.java.JavaReceiverInputDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import java.util.Iterator;
import java.util.regex.Pattern;public class SparkStreaming {private static final Pattern SPACE = Pattern.compile(" ");public static void main(String[] args) throws InterruptedException {if (args.length < 2) {System.err.println("Usage: JavaNetworkWordCount <hostname> <port>");System.exit(1);}SparkConf sparkConf = new SparkConf().setAppName("JavaNetworkWordCount");JavaStreamingContext ssc = new JavaStreamingContext(sparkConf, Durations.seconds(1));JavaReceiverInputDStream<String> lines = ssc.socketTextStream(args[0], Integer.parseInt(args[1]), StorageLevels.MEMORY_AND_DISK_SER);JavaDStream<String> words = lines.flatMap(new FlatMapFunction<String, String>() {@Overridepublic Iterable<String> call(String x){return Lists.newArrayList(SPACE.split(x));}});JavaPairDStream<String, Integer> wordCounts = words.mapToPair(new PairFunction<String, String, Integer>() {@Overridepublic Tuple2<String, Integer> call(String s) {return new Tuple2<String, Integer>(s, 1);}}).reduceByKey(new Function2<Integer, Integer, Integer>() {@Overridepublic Integer call(Integer i1, Integer i2) {return i1 + i2;}});wordCounts.print();ssc.start();ssc.awaitTermination();}
}
附:由于原程序运行后,每1秒刷新一次(即从监听入口接收一次信息)很难即时截到图,所以将程序中ssc的刷新时间适当提高,便很容易截到。

点击 File -> Project Structure -> Aritifacts -> 点击加号 -> JAR -> from modules with dependences -> 选择刚才新建的 module -> 选择 Main Class -> Ok -> 选择 Output directory -> 点击 Ok。

去掉除guava-14.0.1.jar和guice-3.0.jar以外所有的 JAR 包,点击 Apply,再点击 Ok。

点击 Build -> Build Aritifacts 。


然后,就可以在类似该路径下D:\DELL\AppData\IdealWorkSpace\out\artifacts\sparkstreaming_jar找到刚才生成的 jar 包。

选择刚才设置的 jar 包,上传到 master 上去。

(三)运行 Sparksteaming JAR包
新建一个 SSH 连接,登录 master 服务器,使用命令nc -lk 9999设置路由器。
nc -lk 9999

注:如果系统只没有nc这个命令,可以使用yum install nc安装nc命令。
进入 spark 的安装目录,执行下面的命令。
cd /usr/cstor/spark
bin/spark-submit --class spark.streaming.test.SparkStreaming ~/sparkstreaming.jar localhost 9999
在网络流中输入单词。按回车结束一次输出。
在命令提交的 xshell 连接中观察程序输出。按 Ctrl+C 可终止程序运行。
六、实验结果
在提交任务之后应该能看到以下结果(因屏幕刷新很快,所以只能看到部分结果)。在nc -lk 9999命令下输入:

所示结果中应该立刻显示出如下内容:

七、实验心得
- 深入理解 Spark Streaming 的工作原理: 通过本次实验,我对 Spark Streaming 的流处理机制有了更直观的理解。实验让我看到,Spark Streaming 通过将流式数据划分成一系列的批处理任务,将实时数据按指定时间窗口转换为 RDD,并对 RDD 进行一系列的转换操作。这种批处理方式较好地平衡了实时性和容错性,能够处理大规模的数据流并确保系统的稳定运行。
- 不同于传统 MapReduce 的实时性处理: 实验中,我们使用了类似 WordCount 的例子,直观地体会到 Spark Streaming 相比 MapReduce 在实时处理方面的优势。传统的 MapReduce 虽然适合处理大批量数据,但实时性表现较差。而 Spark Streaming 能将数据按时间窗口进行切片处理,几乎能做到准实时的计算,这对于需要快速响应的应用场景非常适用。
- Kafka与Spark Streaming的结合: 实验提到了通过 Kafka 进行流数据传输的典型应用案例。这让我意识到,Kafka 作为消息队列与 Spark Streaming 的结合,不仅提高了系统的数据吞吐量,还能保证数据的可靠性和扩展性。在现代大数据处理环境中,这种组合能更好地满足高效处理实时数据的需求。
- 编程实践中的挑战与收获: 实验过程中,我实际编写并运行了 Spark Streaming 程序。在编程实践中,我学会了如何通过 Java 编写流处理任务,如何通过 socket 监听数据流,并通过 RDD 转换和窗口操作处理数据。实验对编码要求较高,我在调试过程中也遇到了一些问题,比如依赖包的导入、环境配置等,这些问题的解决过程让我对大数据编程环境的搭建有了更多的实战经验。
- 系统的扩展性与容错性: 实验中,Spark Streaming 展示了其在扩展性和容错性方面的优势。通过对 RDD lineage 的追踪机制,即使在某些节点发生故障时,系统也能够通过重新计算 RDD 的分区来恢复数据。这种容错机制相较于其他实时流处理框架如 Storm 更加高效可靠。
总的来说,本次实验让我更好地理解了 Spark Streaming 的工作机制和实际应用场景,同时也强化了我的编程能力和对大数据处理框架的认识。
附:以上文中的数据文件及相关资源下载地址:
链接:https://pan.quark.cn/s/920b281a115e
提取码:4yCn
相关文章:
【智能大数据分析 | 实验四】Spark实验:Spark Streaming
【作者主页】Francek Chen 【专栏介绍】 ⌈ ⌈ ⌈智能大数据分析 ⌋ ⌋ ⌋ 智能大数据分析是指利用先进的技术和算法对大规模数据进行深入分析和挖掘,以提取有价值的信息和洞察。它结合了大数据技术、人工智能(AI)、机器学习(ML&a…...

es实现自动补全
目录 自动补全 拼音分词器 安装拼音分词器 第一步:下载zip包,并解压缩 第二步:去docker找到es-plugins数据卷挂载的位置,并进入这个目录 第三步:把拼音分词器的安装包拖到这个目录下 第四步:重启es 第…...

【日志】Unity3D模型导入基本问题以及浅谈游戏框架
2024.10.22 真正的谦逊从来不是人与人面对时的谦卑,而是当你回头看那个曾经的自己时,依旧保持肯定与欣赏。 【力扣刷题】 暂无 【数据结构】 暂无 【Unity】 导入外部模型资源报错问题 在导入外部资源包的时候一般都会报错,不是这个资源模…...

1.8K Star,简洁易用 Web 端创意画板
Hi,骚年,我是大 G,公众号「GitHub 指北」会推荐 GitHub 上有趣有用的项目,一分钟 get 一个优秀的开源项目,挖掘开源的价值,欢迎关注。 在数字创作的时代,找到一款功能强大且易于使用的绘图工具…...

WPF中的<Style.Triggers>
Triggers介绍 在XAML中,Triggers是Style元素的一部分,用于定义在特定条件触发时应用的样式更改。这些触发器可以响应各种事件和属性值的变化,例如控件的状态变化(如鼠标悬停、焦点状态)、数据绑定值的变化等。 以下是…...
)
pod相关面试题总结(持续更新)
1:当一个Pod有多个容器时,如果连接到指定的容器? #查看当前空间下的pod [rootmaster210 pods]# kubectl get pods NAME READY STATUS RESTARTS AGE linux85-nginx-tomcat 2/2 Running 0 63s [rootmaster210 …...

Matlab学习03-符号的替换及运算(接上一篇)
在上一篇的学习中,我知道了符号变量的声明👇 Matlab学习02-matlab中的数据显示格式及符号变量-CSDN博客 接下来开始学习符号运算相关的内容,并学习最为核心的matlab程序设计。之前的学习都是为了程 序设计做铺垫,程序设计又是为了…...

Windows中API-磁盘管理笔记
硬盘是由一组堆积的盘片组成类似于圆柱体组成,每个盘片的数据都以电磁方式存储在同心圆或轨道中,轨道的最小可寻址单元是扇区;基本磁盘:最常用于windows的存储类型,指的是**包含分区的磁盘。**在基本磁盘上只能创建和删…...

010 操作符详解 上
写代码的实质是在写方法体 —— 刘铁猛 操作符概览 操作符本质 操作符的本质是函数的“简记法” 操作符 简写Add函数 34 等同Add(3,4)操作符不能脱离与它关联的数据类型可以说操作符就是与固定数据类型关联的一套算法的简记法 如下图所示算法的简记法 操作符的优先级 可以使…...
)
【贪心算法】(第十篇)
目录 加油站(medium) 题目解析 讲解算法原理 编写代码 单调递增的数字(medium) 题目解析 讲解算法原理 编写代码 加油站(medium) 题目解析 1.题目链接:. - 力扣(LeetCode&a…...

029.爬虫专用浏览器-抓取跨域#document下的内容
一、iframe下的#document是什么 #document 是一个特殊的 HTML 元素,表示 <iframe> 元素内部的文档对象。当你在 HTML 页面中嵌入一个 <iframe> 元素时,浏览器会创建一个新的文档对象来表示 <iframe> 内部的内容。这 个文档对象就是 #…...

SIP 业务举例之 Call Hold(呼叫保持)
目录 1. Call Hold(呼叫保持)简介 2. 信令流程 呼叫保持 呼叫恢复开始 恢复通话完成 3. 本例 Call Hold 建立了几个 Dialog? 博主wx:yuanlai45_csdn 博主qq:2777137742 想要 深入学习 5GC IMS 等通信知识(加入 51学通信),或者想要 cpp 方向修改简历,模拟面试,学习…...

eks节点的网络策略配置机制解析
参考链接 vpc-cni网络策略最佳实践,https://aws.github.io/aws-eks-best-practices/security/docs/network/#additional-resourcesvpc cni网络策略faq,https://github.com/aws/amazon-vpc-cni-k8s/blob/0703d03dec8afb8f83a7ff0c9d5eb5cc3363026e/docs/…...

【C】用c写贪吃蛇
1.输入正确的账号密码及其用户名,登录成功进入贪吃蛇游戏界面, 2.随机生成蛇头★、食物▲的位置(x,y),并使用□打印地图 3.使用w s a d按键,完成蛇头的上下左右移动 4.蛇头碰撞到食物后,吃下食物变成蛇身的一部分●…...

qt QLineEdit详解
一、概述 QLineEdit 是 Qt 框架中用于创建单行文本输入框的类。它非常适合用于接收用户输入,例如用户名、密码或其他简单的文本信息。它提供了许多有用的编辑功能,支持多种输入模式和文本限制,并支持撤销、重做、剪切、粘贴以及拖放等功能。…...

DevEco Studio的使用 习题答案<HarmonyOS第一课>
一、判断题 1. 如果代码中涉及到一些网络、数据库、传感器等功能的开发,均可使用预览器进行预览。 正确(True)错误(False) 错误(False)回答正确 2. module.json5文件中的deviceTypes字段中,配置了phone,tablet,2in1等多种设备类型,才能进行多设备预览。 正确(True)…...
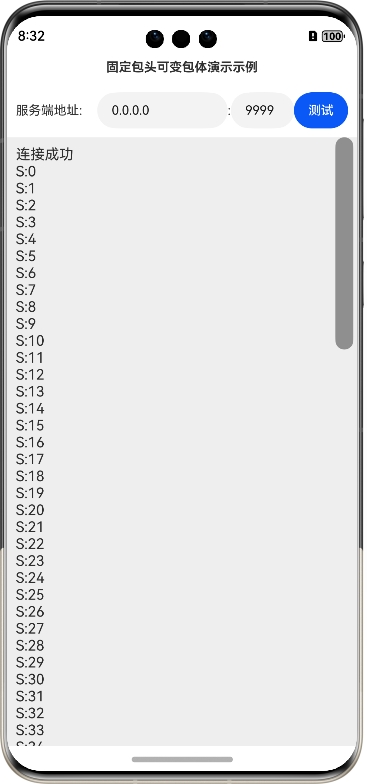
鸿蒙网络编程系列36-固定包头可变包体解决TCP粘包问题
1. TCP数据传输粘包简介 在本系列的第6篇文章《鸿蒙网络编程系列6-TCP数据粘包表现及原因分析》中,我们演示了TCP数据粘包的表现,如图所示: 随后解释了粘包背后的可能原因,并给出了解决TCP传输粘包问题的两种思路,第一…...

【华为路由】OSPF多区域配置
网络拓扑 设备接口地址 设备 端口 IP地址 RTA Loopback 0 1.1.1.1/32 G0/0/0 10.1.1.1/24 RTB Loopback 0 2.2.2.2/32 G0/0/0 10.1.1.2/24 G0/0/1 10.1.2.1/24 RTC Loopback 0 3.3.3.3/32 G0/0/0 10.1.2.2/24 G0/0/1 10.1.3.1/24 RTD Loopback 0 4.4.4…...

【C++初阶】一文讲通C++内存管理
文章目录 1. C/C内存分布2. C语言中动态内存管理方式3. C内存管理方式3. 1 new/delete操作内置类型3. 2 new和delete操作自定义类型 4. new与delete的原理4. 1 operator new与operator delete函数4. 2 内置类型4. 3 自定义类型 5. 定位new表达式(placement-new)6. malloc/free和…...
)
Vue学习笔记(九、简易计算器)
在这个案例中,我们使用v-model分别双向绑定了n1、n2操作数,op操作选项和result计算结果,同时用绑定了等号按钮事件。 由于是双向绑定,当input和select通过外部输入内容时,vm内部的数值也会改变,所以calcula…...
)
论文解读:交大港大上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化学习框架(二)
HoST框架核心实现方法详解 - 论文深度解读(第二部分) 《Learning Humanoid Standing-up Control across Diverse Postures》 系列文章: 论文深度解读 + 算法与代码分析(二) 作者机构: 上海AI Lab, 上海交通大学, 香港大学, 浙江大学, 香港中文大学 论文主题: 人形机器人…...

突破不可导策略的训练难题:零阶优化与强化学习的深度嵌合
强化学习(Reinforcement Learning, RL)是工业领域智能控制的重要方法。它的基本原理是将最优控制问题建模为马尔可夫决策过程,然后使用强化学习的Actor-Critic机制(中文译作“知行互动”机制),逐步迭代求解…...

深入理解JavaScript设计模式之单例模式
目录 什么是单例模式为什么需要单例模式常见应用场景包括 单例模式实现透明单例模式实现不透明单例模式用代理实现单例模式javaScript中的单例模式使用命名空间使用闭包封装私有变量 惰性单例通用的惰性单例 结语 什么是单例模式 单例模式(Singleton Pattern&#…...

vue3+vite项目中使用.env文件环境变量方法
vue3vite项目中使用.env文件环境变量方法 .env文件作用命名规则常用的配置项示例使用方法注意事项在vite.config.js文件中读取环境变量方法 .env文件作用 .env 文件用于定义环境变量,这些变量可以在项目中通过 import.meta.env 进行访问。Vite 会自动加载这些环境变…...

React---day11
14.4 react-redux第三方库 提供connect、thunk之类的函数 以获取一个banner数据为例子 store: 我们在使用异步的时候理应是要使用中间件的,但是configureStore 已经自动集成了 redux-thunk,注意action里面要返回函数 import { configureS…...

STM32HAL库USART源代码解析及应用
STM32HAL库USART源代码解析 前言STM32CubeIDE配置串口USART和UART的选择使用模式参数设置GPIO配置DMA配置中断配置硬件流控制使能生成代码解析和使用方法串口初始化__UART_HandleTypeDef结构体浅析HAL库代码实际使用方法使用轮询方式发送使用轮询方式接收使用中断方式发送使用中…...

数学建模-滑翔伞伞翼面积的设计,运动状态计算和优化 !
我们考虑滑翔伞的伞翼面积设计问题以及运动状态描述。滑翔伞的性能主要取决于伞翼面积、气动特性以及飞行员的重量。我们的目标是建立数学模型来描述滑翔伞的运动状态,并优化伞翼面积的设计。 一、问题分析 滑翔伞在飞行过程中受到重力、升力和阻力的作用。升力和阻力与伞翼面…...

Vue 3 + WebSocket 实战:公司通知实时推送功能详解
📢 Vue 3 WebSocket 实战:公司通知实时推送功能详解 📌 收藏 点赞 关注,项目中要用到推送功能时就不怕找不到了! 实时通知是企业系统中常见的功能,比如:管理员发布通知后,所有用户…...
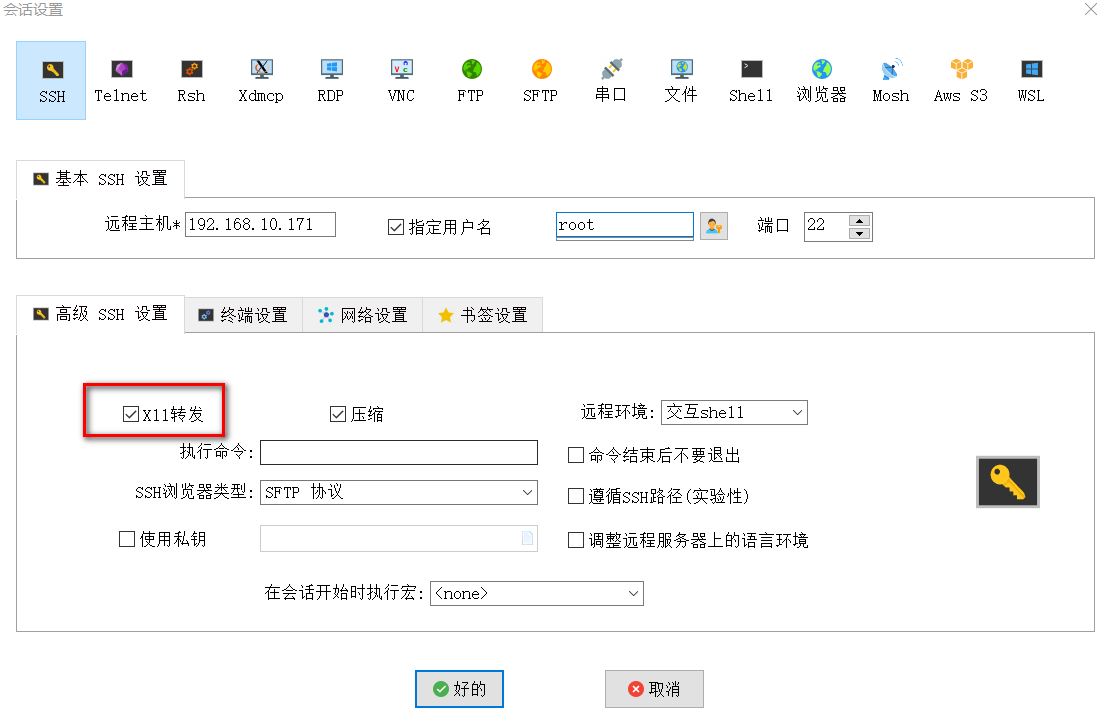
在MobaXterm 打开图形工具firefox
目录 1.安装 X 服务器软件 2.服务器端配置 3.客户端配置 4.安装并打开 Firefox 1.安装 X 服务器软件 Centos系统 # CentOS/RHEL 7 及之前(YUM) sudo yum install xorg-x11-server-Xorg xorg-x11-xinit xorg-x11-utils mesa-libEGL mesa-libGL mesa-…...
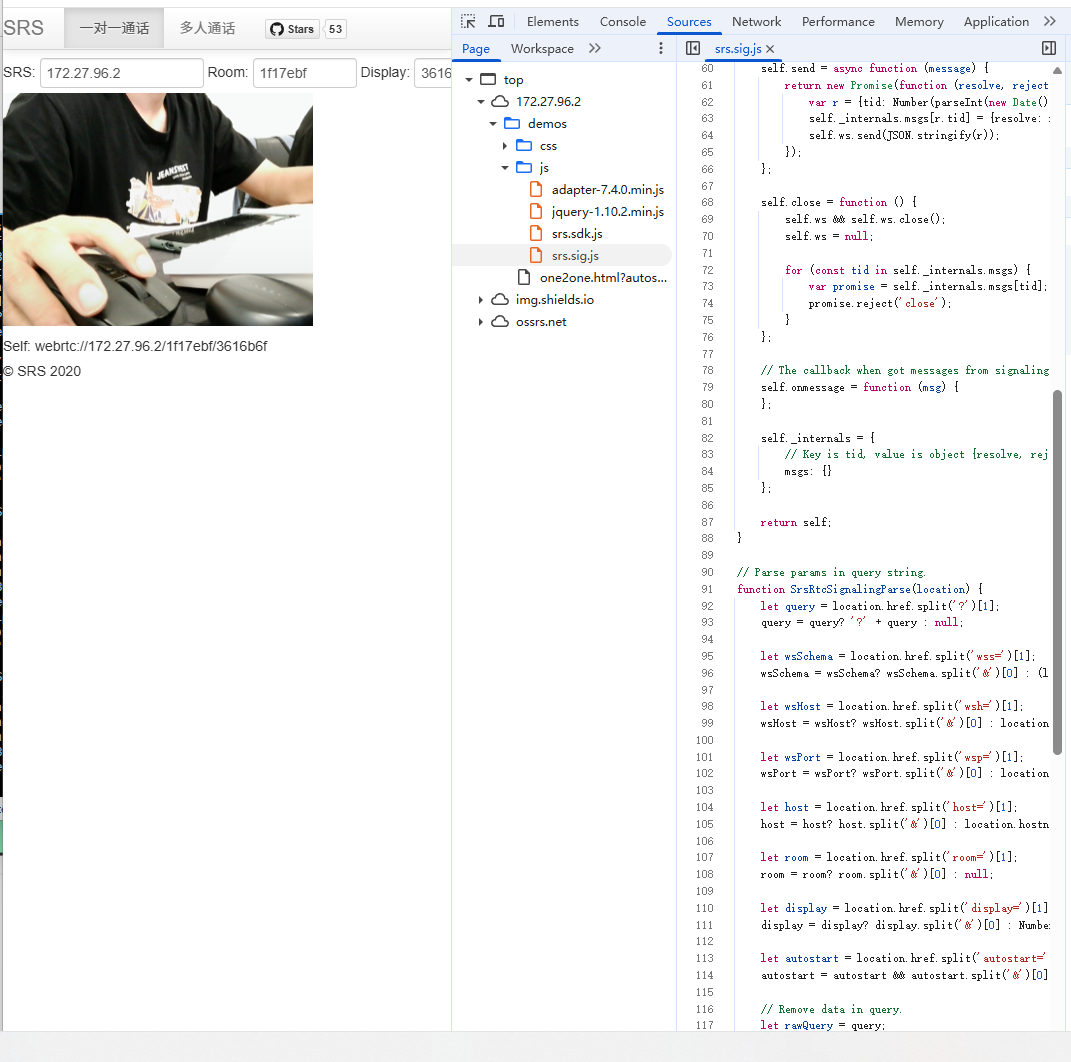
实现p2p的webrtc-srs版本
1. 基本知识 1.1 webrtc 一、WebRTC的本质:实时通信的“网络协议栈”类比 将WebRTC类比为Linux网络协议栈极具洞察力,二者在架构设计和功能定位上高度相似: 分层协议栈架构 Linux网络协议栈:从底层物理层到应用层(如…...