计算机前沿技术-人工智能算法-大语言模型-最新研究进展-2024-10-21
计算机前沿技术-人工智能算法-大语言模型-最新研究进展-2024-10-21
目录
文章目录
- 计算机前沿技术-人工智能算法-大语言模型-最新研究进展-2024-10-21
- 目录
- 1. The Fair Language Model Paradox
- 摘要
- 研究背景
- 问题与挑战
- 如何解决
- 创新点
- 算法模型
- 实验效果
- 重要数据与结论
- 推荐阅读指数:★★★★☆
- 推荐理由
- 2. DISP-LLM: Dimension-Independent Structural Pruning for Large Language Models
- 摘要
- 研究背景
- 问题与挑战
- 如何解决
- 创新点
- 算法模型
- 实验效果
- 重要数据与结论
- 推荐阅读指数:★★★★☆
- 推荐理由
- 3. Holistic Reasoning with Long-Context LMs: A Benchmark for Database Operations on Massive Textual Data
- 摘要
- 研究背景
- 问题与挑战
- 如何解决
- 创新点
- 算法模型
- 实验效果
- 重要数据与结论
- 推荐阅读指数:★★★★☆
- 推荐理由
- 4. Impacts of Continued Legal Pre-Training and IFT on LLMs' Latent Representations of Human-Defined Legal Concepts
- 摘要
- 研究背景
- 问题与挑战
- 如何解决
- 创新点
- 算法模型
- 实验效果
- 重要数据与结论
- 推荐阅读指数:★★★★☆
- 推荐理由
- 5. Toolken+: Improving LLM Tool Usage with Reranking and a Reject Option
- 摘要
- 研究背景
- 问题与挑战
- 如何解决
- 创新点
- 算法模型
- 实验效果
- 重要数据与结论
- 推荐阅读指数:★★★★☆
- 推荐理由
- 后记
1. The Fair Language Model Paradox
Authors: Andrea Pinto and Tomer Galanti and Randall Balestriero
https://arxiv.org/abs/2410.11985
大型语言模型的公平性悖论
摘要
本文研究了大型语言模型(LLMs)在训练过程中的token级动态,特别是权重衰减对不同频率token性能的影响。研究发现,随着权重衰减的增加,模型对低频token的性能影响更大,这在大多数语言中构成了词汇的绝大多数。这一发现对于确保所有可用token的公平性至关重要,需要开发新的正则化技术。
研究背景
大型语言模型(LLMs)在现实世界的应用中广泛部署,但对其在token级别训练动态的了解甚少。通常的评估依赖于在批量级别测量的聚合训练损失,这忽略了由token级动态和超参数引入的结构偏差所产生的微妙的每个token的偏差。

问题与挑战
- 权重衰减虽然常用于稳定训练,但研究发现它在token级别上引入了性能偏差。
- 在不同数据集大小、模型架构和参数量(从2.7亿到30亿参数)的模型中,随着权重衰减的增加,低频token受到不成比例的贬低。
- 这些被忽视的低频token在大多数语言的token分布中占绝大多数,这对模型的公平性提出了挑战。
如何解决
研究者们通过实验展示了权重衰减对不同频率token的影响,并提出了需要新的正则化技术来确保所有token的公平性。
创新点
- 揭示了权重衰减在token级别上引入的偏差,这种偏差在传统的基于批量的评估中是检测不到的。
- 提出了需要新的正则化技术,以确保在不平衡的token分布上训练的LLMs中所有token的公平性。
算法模型
研究中使用了不同的模型架构和大小,包括Apple OpenELM模型(2.7亿和30亿参数)和Qwen2模型(0.5亿和1.5亿参数)。这些模型在IMDB数据集及其扩展版本上进行了训练,使用了不同的权重衰减水平。
实验效果
- 实验结果表明,随着权重衰减的增加,模型在低频token上的性能显著下降,而高频token的性能基本不受影响。
- 通过对比不同权重衰减水平下的每个token的交叉熵损失,研究者们发现低频token在更高的权重衰减下遭受了更高的损失。
- 研究还发现,随着权重衰减的增加,高频token的学习速度比低频token快,这表明正则化可能对罕见token不利。


重要数据与结论
- 在IMDB数据集上,95%的总token被词汇表中顶部0.01%的token捕获,表明了token频率的极端不平衡。
- 随着权重衰减的增加,模型在低频token上的交叉熵损失显著增加,而高频token的损失增加较少。
- 研究强调了在LLMs训练实践中一个重大的疏忽:权重衰减虽然可以改善整体损失指标的收敛和稳定性,但可能会严重影响模型处理低频token的能力。
推荐阅读指数:★★★★☆
推荐理由
这篇文章对于理解大型语言模型在训练过程中的内在偏差以及权重衰减对模型性能的影响提供了深刻的见解。它对于自然语言处理领域的研究人员和工程师来说是非常有价值的,因为它揭示了在设计和训练LLMs时需要考虑的新挑战和潜在的改进方向。此外,这项研究还强调了开发新的正则化技术以确保模型公平性的重要性。
2. DISP-LLM: Dimension-Independent Structural Pruning for Large Language Models
Authors: Shangqian Gao and Chi-Heng Lin and Ting Hua and Tang Zheng and Yilin
Shen and Hongxia Jin and Yen-Chang Hsu
https://arxiv.org/abs/2410.11988

DISP-LLM: 大型语言模型的维度无关结构性剪枝
摘要
本文提出了一种新的结构性剪枝方法,用于压缩大型语言模型(LLMs),而不需要额外的后处理步骤。该方法通过打破传统结构性剪枝方法中的结构依赖,允许不同层选择不同的特征子集,并且可以自由调整每层的宽度,从而显著提高了结构剪枝的灵活性。实验结果表明,该方法在多种LLMs上的表现超过了其他最先进的方法,并首次展示了结构性剪枝可以达到与半结构性剪枝相似的准确性。
研究背景
大型语言模型(LLMs)在自然语言处理任务中取得了显著的成功,但是这些模型的内存和计算成本对于资源受限的设备来说是一个挑战。为了在不牺牲性能的情况下部署这些模型,需要有效的压缩技术。
问题与挑战
现有的结构性剪枝方法要么限制了剪枝的灵活性,要么通过引入额外的投影矩阵增加了模型的参数量。这些方法在减少模型大小和计算成本方面存在局限性。
如何解决
文章提出了一种新的维度无关结构性剪枝方法,该方法通过索引选择和索引添加操作来剪枝,而不是修改残差连接,从而避免了传统方法中的限制。
创新点
- 提出了一种新的结构性剪枝方法,打破了传统方法中的结构依赖,提高了剪枝的灵活性。
- 通过超网络和基于梯度的优化方法来学习每层的宽度,而不是引入额外的参数。
- 实验表明,该方法能够在保持低计算成本的同时,超越现有的结构性和半结构性剪枝方法。
算法模型
文章中提出了DISP-LLM方法,该方法通过在注意力层和MLP层中应用不同的选择矩阵,实现了在不增加额外参数的情况下,对不同层进行不同特征子集的选择。此外,该方法还通过学习每层的宽度来进一步提高灵活性。


实验效果
- 在WikiText-2数据集上的实验结果表明,DISP-LLM在不同的剪枝比例下,都能取得比现有方法更好的性能。
- 在零样本任务上,DISP-LLM也展现出了优越的性能,与半结构性剪枝方法相当。
- 文章还提供了关于模型在不同剪枝比例下的困惑度(PPL)和准确率的详细数据。

重要数据与结论
- DISP-LLM在50%的剪枝比例下,对于LLaMA-2 7B模型,其在WikiText-2上的困惑度为9.84,与未剪枝的模型相比,性能损失极小。
- 在零样本任务中,DISP-LLM在50%剪枝比例下的平均准确率为51.05%,与半结构性剪枝方法相当。
推荐阅读指数:★★★★☆
推荐理由
该方法不仅提高了剪枝的灵活性,而且在保持模型性能的同时减少了计算成本。
3. Holistic Reasoning with Long-Context LMs: A Benchmark for Database Operations on Massive Textual Data
Authors: Seiji Maekawa, Hayate Iso, Nikita Bhutani
https://arxiv.org/abs/2410.11996
整体推理与长文本语境的语言模型:大规模文本数据上的数据库操作基准测试
摘要
随着文本信息的快速增长,我们需要更高效的方法来筛选、组织和理解这些信息。虽然检索增强型生成(RAG)模型在访问大型文档集合中的信息方面表现出色,但它们在处理需要跨多个文档聚合和推理的复杂任务时存在困难,这就是所谓的整体推理。长文本语境的语言模型(LCLMs)在处理大规模文档方面具有很大的潜力,但它们在这方面的能力仍然不清楚。在这项工作中,我们介绍了HoloBench,这是一个新的框架,它将数据库推理操作引入基于文本的上下文中,使系统地评估LCLMs在处理大型文档的整体推理能力变得更加容易。我们的方法调整了上下文长度、信息密度、信息分布和查询复杂性等关键因素,以全面评估LCLMs。我们的实验表明,上下文中的信息量对LCLM性能的影响大于实际的上下文长度。此外,查询的复杂性对性能的影响超过了信息量,特别是对于不同类型的查询。有趣的是,涉及寻找最大值或最小值的查询对LCLMs来说更容易,并且受上下文长度的影响较小,尽管它们对RAG系统构成了挑战。然而,需要聚合多条信息的任务随着上下文长度的增加而准确度明显下降。此外,我们发现,尽管分组相关信息通常会提高性能,但最佳定位因模型而异。我们的发现揭示了在实现长上下文的整体理解方面的进步和持续存在的挑战。这些可以指导未来LCLM的发展,并为创建更强大的语言模型以应用于现实世界的应用奠定基础。
研究背景
随着文本数据的爆炸性增长,需要有效的方法来处理、组织和理解大型文档集合。检索增强型生成(RAG)模型虽然在访问这些庞大资源中的信息方面取得了进展,但在执行需要跨多个文档进行聚合和推理的复杂任务时,它们的能力受限。

问题与挑战
现有的RAG模型依赖于局部上下文检索,这使得它们在处理需要整体推理的复杂任务时效果不佳。此外,对于长文本的整体推理能力的评价还存在空白,需要一个能够系统评估LCLMs在处理大型文档时的整体推理能力的基准测试。
如何解决
文章提出了HoloBench,这是一个新的评估框架,专门设计用来评估LCLMs在处理长文本数据时的整体推理能力。HoloBench利用数据库操作来创建需要模型聚合和综合分布在广泛上下文中的信息的复杂推理任务。
创新点
- 提出了HoloBench,一个基于数据库操作的评估框架,用于系统评估LCLMs处理大规模文本数据的整体推理能力。
- 设计了能够控制影响LCLM性能的关键因素的评估方法,包括上下文长度、信息密度、信息分布和查询复杂性。
- 实现了自动化和可扩展的评估过程,无需人工注释,提高了评估的效率和可扩展性。
算法模型
HoloBench框架基于文本到SQL的基准测试构建,通过调整上下文长度、信息密度和查询复杂性等因素,动态生成评估数据。该框架利用SQL查询在数据库上执行以生成动态的基准答案,同时控制上下文大小和信息分布。

实验效果
实验结果表明,上下文中的信息量对模型性能的影响大于上下文的实际长度。查询的复杂性对性能的影响超过了信息量,特别是对于不同类型的查询。涉及寻找最大值或最小值的查询对LCLMs来说更容易,并且受上下文长度的影响较小。然而,需要聚合多条信息的任务随着上下文长度的增加而准确度明显下降。
重要数据与结论
- 上下文中的信息量对LCLM性能的影响大于上下文的实际长度。
- 查询的复杂性对性能的影响超过了信息量。
- 涉及寻找最大值或最小值的查询对LCLMs来说更容易。
- 需要聚合多条信息的任务随着上下文长度的增加而准确度明显下降。



推荐阅读指数:★★★★☆
推荐理由
这篇文章提供了一个全面的评估框架来测试和改进LCLMs在处理大规模文本数据时的整体推理能力。
4. Impacts of Continued Legal Pre-Training and IFT on LLMs’ Latent Representations of Human-Defined Legal Concepts
Authors: Shaun Ho
https://arxiv.org/abs/2410.12001
继续法律预训练和指令微调对大型语言模型在人类定义的法律概念的潜在表示的影响
摘要
本文旨在为人工智能与法律领域的研究人员和实践者提供更详细的理解,即在法律语料上继续预训练和指令微调(IFT)是否以及如何增加大型语言模型(LLMs)在开发输入序列的全局上下文表示时对人类定义的法律概念的利用。我们比较了三个模型:Mistral 7B、SaulLM-7B-Base(在法律语料上继续预训练的Mistral 7B)和SaulLM-7B-Instruct(进一步IFT)。这个初步评估检查了7个不同的文本序列,每个序列都包含了一个人类定义的法律概念。我们首先比较了模型分配给代表法律概念的标记子集的总注意力的比例。然后,我们可视化了原始注意力分数变化的模式,评估法律训练是否引入了与人类法律知识结构相对应的新颖注意力模式。这项调查揭示了(1)法律训练的影响在各种人类定义的法律概念之间不均匀分布,以及(2)在法律训练中学到的法律知识上下文表示与人类定义的法律概念的结构不相符。我们以进一步调查法律LLM训练动态的建议结束。
研究背景
在法律任务中使用大型语言模型(LLMs)面临挑战,因为许多法律术语与一般语言中的相同词汇具有不同的含义,并且法律语料的统计数据与一般语料不同。虽然在法律语料上的继续预训练和微调(统称为“法律训练”)提高了法律基准的性能,但这些模型在从注释、修辞角色预测到事实模式编码等多样化的实际应用中的表现仍然不确定。
问题与挑战
法律训练数据稀缺且成本高昂,其质量高度依赖于注释者的专业知识和一致性。此外,文献还对微调是否以模型稳定性为代价引入表面改进提出了质疑。需要更深入地理解法律训练的潜在动态,以阐明法律LLMs的优势和劣势,以便它们可以被谨慎和适当地部署。
如何解决
通过分析注意力分数和结构,研究者们可以独立于数据集评估LLMs利用法律概念的程度,从而排除了上述数据质量问题的影响。
创新点
- 提出了一种新的方法来评估法律训练对LLMs的影响,特别是在处理人类定义的法律概念时。
- 通过比较不同模型在法律语料上的预训练和微调,揭示了法律训练对模型注意力分配的影响。
- 可视化了注意力分数变化的模式,以评估法律训练是否引入了与人类法律知识结构相对应的新颖注意力模式。
算法模型
研究比较了三个模型:Mistral 7B、SaulLM-7B-Base和SaulLM-7B-Instruct。这些模型使用相同的架构,为隔离法律训练对通用LLMs的影响提供了理想的比较基础。
实验效果
实验结果表明:
- 法律训练的影响在各种人类定义的法律概念之间不均匀分布。
- 在法律训练中学到的法律知识上下文表示与人类定义的法律概念的结构不相符。
- 法律训练通常减少了对大多数人类定义的法律概念的注意力,有时甚至到了极端程度。额外的IFT调节了这种行为,导致偏斜值更接近零或甚至为正(即更多地关注人类定义的法律概念)。
重要数据与结论
- 法律训练对模型在开发输入序列的全局上下文表示时利用不同法律概念的程度有不均匀的影响。
- 法律训练和IFT对模型的注意力分配有显著影响,但这些影响并不总是与人类定义的法律概念结构一致。

推荐阅读指数:★★★★☆
推荐理由
这篇文章研究结果揭示了法律训练对LLMs注意力分配的影响,这对于优化法律LLMs的设计和应用具有重要意义。
5. Toolken+: Improving LLM Tool Usage with Reranking and a Reject Option
Authors: Konstantin Yakovlev, Sergey Nikolenko, Andrey Bout
https://arxiv.org/abs/2410.12004
Toolken+: 通过重新排名和拒绝选项改进大型语言模型的工具使用
摘要
最近提出的工具学习范式ToolkenGPT展示了有希望的性能,但存在两个主要问题:首先,它无法从工具文档中受益;其次,它经常在是否使用工具上犯错误。我们介绍了Toolken+,通过重新排名ToolkenGPT选择的前k个工具来缓解第一个问题,并通过特殊的“拒绝”选项解决第二个问题,以便当“拒绝”排名第一时,模型将生成一个词汇标记。我们在多步骤数值推理和工具选择任务上展示了Toolken+的有效性。
研究背景
大型语言模型(LLM)通过允许访问外部工具(如符号计算引擎、作为外部内存的数据库等)被扩展。Tool learning paradigms可以分为两类:一类是监督微调以利用工具,另一类是在上下文中学习,提供示例。ToolkenGPT旨在结合这两种方法的优点,通过可训练的嵌入和扩展词汇表来表示每个工具。

问题与挑战
ToolkenGPT面临的挑战包括:
- 无法利用对LLMs有帮助的工具文档。
- 在判断何时使用工具时经常出错,调用工具过于频繁。
如何解决
Toolken+通过以下方式解决这些问题:
- 引入工具嵌入的副本来重新排名检索到的工具。
- 引入一个额外的“拒绝”工具,以便在不需要调用任何工具时切换回文本生成。
创新点
- 引入重新排名机制,使模型能够根据工具文档选择最相关的工具。
- 引入“拒绝”选项,减少不必要的工具调用,提高模型的鲁棒性。
算法模型
Toolken+模型扩展了工具集,包括一个特殊的“拒绝”工具,并在推理过程中重新排名前k个工具。该模型使用softmax函数来计算下一个标记的概率,并在工具选择过程中引入掩码向量。

实验效果
实验结果表明,Toolken+在GSM8K、MetaTool和VirtualHome数据集上的表现显著优于ToolkenGPT。具体数据包括:
- 在MetaTool数据集上,Toolken+在所有考虑的LLM上都显著提高了结果。
- 在GSM8K数据集上,Toolken+通过拒绝机制显著提高了准确性。
- 在VirtualHome数据集上,Toolken+在生成动作序列的任务中一致性地优于ToolkenGPT。


重要数据与结论
Toolken+通过引入重新排名和拒绝选项,显著提高了模型在工具使用过程中的鲁棒性和准确性。这使得基于现代LLM的AI代理和用户面向工具更加可靠。
推荐阅读指数:★★★★☆
推荐理由
Toolken+通过重新排名和拒绝选项解决了ToolkenGPT的局限性,提高了模型在使用外部工具时的准确性和鲁棒性。此外,该研究还为未来在更广泛的任务和数据集上测试和改进Toolken+框架提供了基础。
后记
如果您对我的博客内容感兴趣,欢迎三连击(点赞、收藏、关注和评论),我将持续为您带来计算机人工智能前沿技术(尤其是AI相关的大语言模型,深度学习和计算机视觉相关方向)最新学术论文及工程实践方面的内容分享,助力您更快更准更系统地了解 AI前沿技术。
相关文章:
计算机前沿技术-人工智能算法-大语言模型-最新研究进展-2024-10-21
计算机前沿技术-人工智能算法-大语言模型-最新研究进展-2024-10-21 目录 文章目录 计算机前沿技术-人工智能算法-大语言模型-最新研究进展-2024-10-21目录1. The Fair Language Model Paradox摘要研究背景问题与挑战如何解决创新点算法模型实验效果重要数据与结论推荐阅读指数&…...

安全芯片 OPTIGA TRUST M 使用介绍与示例(基于STM32裸机)
文章目录 目的资料索引硬件电路软件框架介绍数据存储框架移植框架使用 使用示例示例地址与硬件连接通讯测试功能测试 总结 目的 OPTIGA TRUST M 是英飞凌推出的安全芯片,芯片通提供了很多 slot ,用于存放各类安全证书、密钥、用户数据等,内置…...

【AI换装整合及教程】CatVTON:时尚与科技的完美融合
在当今数字化时代,时尚行业正经历着一场前所未有的变革,而 CatVTON 作为一款由中山大学、Pixocial 等机构联合研发的轻量化 AI 虚拟换装工具,无疑是这场变革中的璀璨明星。 一、独特的技术架构 CatVTON 基于 Stable Diffusion v1.5 inpainit…...

接口测试(七)jmeter——参数化(RandomString函数)
一、RandomString函数 需求:模拟10个用户注册 1. 【工具】–>【函数助手对话框】 2. 选择RandomString函数 假设手机号码前3位设置为固定数值136,后8位可用RandomString函数随机产生数值 ① Random string length:8(随机长度…...

simple_php
访问靶场 这里传入a和b参数,绕过三个if即可拿到flag a a a_GET[ a’ ];中是抑制报错信息的。 第一个if非常的抽象, if($a0 and $a){echo $flag1; }处理a 要输出flag1,a0,但是,在php中0被视为假也就是Flase 如果a0࿰…...

网络搜索引擎Shodan(4)
声明:学习视频来自b站up主 泷羽sec,如涉及侵权马上删除文章 声明:本文主要用作技术分享,所有内容仅供参考。任何使用或依赖于本文信息所造成的法律后果均与本人无关。请读者自行判断风险,并遵循相关法律法规。 感谢泷…...

【Flask】一、安装与第一个测试程序
目录 Flask简介 安装Flask 安装pip(Python包管理器) 使用pip安装Flask 验证安装 创建Flask程序 创建应用 运行 访问测试 Flask简介 Flask是一个用Python编写的轻量级Web应用框架。它被设计为易于使用和扩展,使其成为构建简单网站或复…...
:向量)
R语言笔记(二):向量
文章目录 一、Data structure: vectors二、Indexing vectors三、Re-assign values to vector elements四、Generic function for vectors五、Vector of random samples from a distribution六、Vector arithmetic七、Recycling八、Element-wise comparisons of vectors九、Comp…...

信息安全工程师(71)隐私保护技术与应用
前言 隐私保护技术是指通过一系列的技术手段来保护人们的隐私不被公开泄露。随着数字化和网络化社会的发展,个人隐私的保护变得尤为重要,隐私保护技术也因此得到了广泛的应用和发展。 一、隐私保护技术概述 隐私保护技术主要包括数据加密技术、身份认证技…...

层和块学习
1.生成一个网络,其中包含一个具有256个单元和ReLU激活函数的全连接隐藏层,然后是一个具有10个隐藏单元且不带激活函数的全连接输出层。 import torch from torch import nn from torch.nn import functional as Fnet nn.Sequential(nn.Linear(20, 256)…...

Zookeeper面试整理-源码及实现细节
Zookeeper 的源码和实现细节是理解其高可用性、分布式一致性和高效性的关键。以下是 Zookeeper 的核心实现细节,涵盖其架构、关键模块、以及具体的代码实现机制。 1. Zookeeper 架构 Zookeeper 采用 Leader-Follower 架构,集群由多个节点组成。主要分为三种角色:Leader、Fol…...

岭回归的MATLAB步骤
MATLAB 实现框架,它涵盖了从数据导入到岭回归的步骤,包括计算共线性、使用 MAE、MSE、R、MAPE 进行评价,以及绘制相应的可视化图表。 1. 数据导入 首先,导入你的 Excel 文件 data.xlsx。假设前面的列是因变量(特征&a…...
)
智能指针(unique_ptr,shared_ptr,weak_ptr)
在实际的C开发中,我们经常会遇到诸如程序运行中突然崩溃,程序运行所用内存越来越多最终不得不重启等问题,这些问题往往都是内存资源管理不当造成的(内存泄漏) 比如: 有些内存资源已经被释放,但指向它的指针并没有改变指…...

Sql执行较慢的排查方式
SQL执行较慢的排查方式涉及多个方面,包括检查SQL语句本身、数据库配置、硬件资源等。以下是一些具体的排查步骤和优化建议: 一、检查SQL语句 启用慢查询日志: 大多数数据库管理系统(如MySQL、PostgreSQL)都支持慢查询…...

CesiumJS 案例 P6:添加图片图层、添加图片图层并覆盖指定区域
CesiumJS CesiumJS API:https://cesium.com/learn/cesiumjs/ref-doc/index.html CesiumJS 是一个开源的 JavaScript 库,它用于在网页中创建和控制 3D 地球仪(地图) 一、添加图片图层 <!DOCTYPE html> <html lang"…...

Python画笔案例-094 绘制 神奇彩条动画
1、绘制 神奇彩条动画 通过 python 的turtle 库绘制 神奇彩条动画,如下图: 2、实现代码 绘制 神奇彩条动画,以下为实现代码: """神奇彩条动画.py一个用海龟画图的图章功能配合颜色渐变和动画原理做成的动画。 """ from random import randi…...

javaScript整数反转
function _reverse(number) { // 补全代码 return (number ).split().reverse().join(); } number :首先,将数字 number 转换为字符串。在 JavaScript 中,当你将一个数字与一个字符串相加时,JavaScript 会自动将数字转换为字符串…...

Zookeeper面试整理-故障排查和调试
在使用 Zookeeper 的过程中,可能会遇到各种问题,如性能下降、节点失效、集群不可用等。为了保持系统的稳定性和高可用性,掌握 Zookeeper 的故障排查和调试方法至关重要。以下是一些常见的故障排查技巧和调试方法: 1. 日志分析 Zookeeper 的日志是最直接的调试和故障排查工具…...

PG数据库之索引详解
PostgreSQL数据库中的索引是一种用于提高查询性能的重要数据结构。通过索引,数据库可以快速定位到表中的特定行,而无需进行全表扫描。PostgreSQL支持多种索引类型,每种类型都有其特定的应用场景和性能特点。下面将详细介绍PostgreSQL中的索引…...

springboot项目测试环境构建出的依赖包比本地构建出的依赖包多
本地能够正常启动服务,但是测试环境启动报错。 上述druid是服务pom文件中之前引入的依赖包,后续由于某种原因而不需要该依赖包了,故已在pom文件中移除掉了该依赖包。 移除该依赖包之后,本地服务可正常构建和启动。 而测试环境却…...
:手搓截屏和帧率控制)
Python|GIF 解析与构建(5):手搓截屏和帧率控制
目录 Python|GIF 解析与构建(5):手搓截屏和帧率控制 一、引言 二、技术实现:手搓截屏模块 2.1 核心原理 2.2 代码解析:ScreenshotData类 2.2.1 截图函数:capture_screen 三、技术实现&…...

XCTF-web-easyupload
试了试php,php7,pht,phtml等,都没有用 尝试.user.ini 抓包修改将.user.ini修改为jpg图片 在上传一个123.jpg 用蚁剑连接,得到flag...

服务器硬防的应用场景都有哪些?
服务器硬防是指一种通过硬件设备层面的安全措施来防御服务器系统受到网络攻击的方式,避免服务器受到各种恶意攻击和网络威胁,那么,服务器硬防通常都会应用在哪些场景当中呢? 硬防服务器中一般会配备入侵检测系统和预防系统&#x…...

python如何将word的doc另存为docx
将 DOCX 文件另存为 DOCX 格式(Python 实现) 在 Python 中,你可以使用 python-docx 库来操作 Word 文档。不过需要注意的是,.doc 是旧的 Word 格式,而 .docx 是新的基于 XML 的格式。python-docx 只能处理 .docx 格式…...

EtherNet/IP转DeviceNet协议网关详解
一,设备主要功能 疆鸿智能JH-DVN-EIP本产品是自主研发的一款EtherNet/IP从站功能的通讯网关。该产品主要功能是连接DeviceNet总线和EtherNet/IP网络,本网关连接到EtherNet/IP总线中做为从站使用,连接到DeviceNet总线中做为从站使用。 在自动…...

Web后端基础(基础知识)
BS架构:Browser/Server,浏览器/服务器架构模式。客户端只需要浏览器,应用程序的逻辑和数据都存储在服务端。 优点:维护方便缺点:体验一般 CS架构:Client/Server,客户端/服务器架构模式。需要单独…...

SpringAI实战:ChatModel智能对话全解
一、引言:Spring AI 与 Chat Model 的核心价值 🚀 在 Java 生态中集成大模型能力,Spring AI 提供了高效的解决方案 🤖。其中 Chat Model 作为核心交互组件,通过标准化接口简化了与大语言模型(LLM࿰…...

鸿蒙HarmonyOS 5军旗小游戏实现指南
1. 项目概述 本军旗小游戏基于鸿蒙HarmonyOS 5开发,采用DevEco Studio实现,包含完整的游戏逻辑和UI界面。 2. 项目结构 /src/main/java/com/example/militarychess/├── MainAbilitySlice.java // 主界面├── GameView.java // 游戏核…...

C++--string的模拟实现
一,引言 string的模拟实现是只对string对象中给的主要功能经行模拟实现,其目的是加强对string的底层了解,以便于在以后的学习或者工作中更加熟练的使用string。本文中的代码仅供参考并不唯一。 二,默认成员函数 string主要有三个成员变量,…...
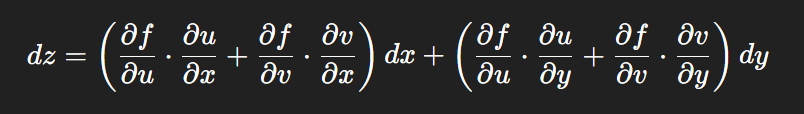
链式法则中 复合函数的推导路径 多变量“信息传递路径”
非常好,我们将之前关于偏导数链式法则中不能“约掉”偏导符号的问题,统一使用 二重复合函数: z f ( u ( x , y ) , v ( x , y ) ) \boxed{z f(u(x,y),\ v(x,y))} zf(u(x,y), v(x,y)) 来全面说明。我们会展示其全微分形式(偏导…...