Linux -- 共享内存(1)
目录
共享内存
共享内存相关函数
ftok 函数 -- 获取 key 值
什么是 key?
如何生成 key ?
参数:
返回值:
封装:
shmget 函数 -- 获取 shmid 值
什么是 shmid?
shmid 和 key 的区别?
如何获取 shmid ?
参数:
返回值:
封装:
shmctl 函数 -- 控制共享内存
参数:
返回值:
封装:
删除共享内存:
获得共享内存的状态:
shmat 函数 -- 将共享内存挂接到进程地址空间
参数:
返回值:
封装:
shmdt 函数 -- 取消挂接
参数:
返回值:
封装:
共享内存
共享内存是一种在计算机系统中允许多个进程访问同一块内存区域的机制。它是进程间通信(IPC, Inter-Process Communication)的一种方式,可以让不同的进程通过读写同一个内存段来交换数据。这种方式非常高效,因为它避免了数据复制的过程,直接在内存中进行数据的传递。
在操作系统层面,当一个进程创建了一个共享内存区后,其他被授权的进程可以映射这个共享内存到自己的地址空间,并且可以像访问普通内存一样访问这块共享内存。这种机制对于需要频繁交换大量数据的应用程序特别有用,比如数据库管理系统、多媒体应用程序等。
共享内存相关函数
ftok 函数 -- 获取 key 值
什么是 key?
因为两个进程访问同一块共享内存,而且操作系统不止一块共享内存,怎么保证两个或者不同的进程看到的是同一块共享内存呢?操作系统如何管理所有的共享内存?
我们给共享内存提供内核中的唯一性的标识,称为 key ,主要用于在创建或访问共享内存段时标识这个内存段。
如何生成 key ?
#include <sys/ipc.h>key_t ftok(const char *pathname, int proj_id);参数:
pathname:指向一个字符串的指针,该字符串包含了一个路径名。这个路径名可以是任何文件或目录的路径,甚至可以是一个不存在的文件路径。其主要目的是为了生成一个唯一的键值。
proj_id:一个整数,用于进一步区分不同的共享内存段或信号量集。proj_id通常是一个较小的整数,因为ftok函数返回的 key 值是由路径名和proj_id组合计算得出的。过大的proj_id可能会影响到 key 值的分布。这个值通常由程序员根据应用程序的需要自行选择。通常情况下,开发者会根据项目的实际需求来选择一个合适的
proj_id。例如,可以使用一个固定的数字,或者是某种有意义的编码,只要保证它是唯一且一致的即可。
返回值:
- 如果成功,
ftok函数返回一个非负的键值(key_t类型)。- 如果失败,返回 -1,并且会设置
errno来表明错误的原因。
封装:
key_t GetShmKeyOrDie(const char* pathname,const int pro_jid)
{key_t k=ftok(pathname,pro_jid);//得到key值if(k<0)//获取失败{cerr<<" ftok failed,errno:"<<errno<<", errstring:"<<strerror(errno)<<endl;exit(1);//直接终止程序}return k;//获取成功
}shmget 函数 -- 获取 shmid 值
什么是 shmid?
shmid是一个整数,用于标识一个已创建的共享内存段。一旦获取了shmid,进程就可以通过它来进一步操作共享内存段(如附着、分离等)。类似于文件描述符。
shmid 和 key 的区别?
- key用于标识共享内存段的逻辑键值,而
shmid则是操作系统分配给这个共享内存段的一个内部标识符,用来管理具体共享内存段。两者共同作用于共享内存机制,确保多个进程能够正确地共享同一块内存。key是一个逻辑上的标识符,用于创建或查找共享内存段;而shmid是一个物理上的标识符,用于具体的操作共享内存段。key是静态的,一旦生成就不会改变;而shmid是动态的,每次创建共享内存段时,操作系统都会返回一个新的shmid。key用于解决“找到”共享内存的问题,而shmid用于解决“操作”共享内存的问题。
如何获取 shmid ?
#include <sys/shm.h>int shmget(key_t key, size_t size, int shmflg);参数:
key:用于标识共享内存段的键值。这个键值通常通过ftok函数生成。
size:共享内存段的大小(以字节为单位)。如果key对应的一个共享内存段已经存在,那么这个参数将被忽略。在内核中,共享内存的大小以 4KB 为基本单位,且你只能用你申请的大小,为了避免空间浪费,建议 size 的大小是 n*4KB。
shmflg:一组标志位,用于控制创建和访问共享内存段的行为。
常见的标志位包括:
IPC_CREAT:如果指定的key对应的共享内存段不存在,则创建一个新的共享内存段;如果存在,则直接获取该共享内存。传该参数得到的共享内存不一定是新的,可能是之前创建的。IPC_EXCL:独自使用时没有意义。IPC_EXCL|IPC_CREAT:key对应的共享内存段如果不存在,就会创建一个新的共享内存;如果已经存在,则shmget会失败并返回EEXIST错误。传该参数得到的共享内存一定是新的!- 权限位:如
0666,用于设置共享内存段的访问权限。
返回值:
- 如果成功,
shmget返回一个非负整数,即shmid。- 如果失败,返回 -1,并且设置
errno以指示失败的原因。
封装:
int CreateShmOrDie(key_t key, int size, int flag)
{//得到共享内存的shmidint shmid=shmget(key,size,flag);if(shmid<0)//创建失败{cerr<<" shmget failed, errno:"<<errno<<", errstring:"<<strerror(errno)<<endl;exit(2);}return shmid;//创建成功
}int CreateShm(key_t key,int size)
{//创建一个新的共享内存,并设置权限return CreateShmOrDie(key,size,IPC_CREAT|IPC_EXCL|0666);
}int GetShm(key_t key,int size)
{return CreateShmOrDie(key,size,IPC_CREAT);
}shmctl 函数 -- 控制共享内存
#include <sys/shm.h>int shmctl(int shmid, int cmd, struct shmid_ds *buf);参数:
shmid:共享内存段的标识符,通常通过shmget函数获得。
cmd:命令代码,用于指定要执行的操作。
cmd参数的常用值:
IPC_STAT:获取共享内存段的状态信息,并存储在buf指向的结构体中。IPC_RMID:删除共享内存段。
buf:指向struct shmid_ds类型的指针,struct shmid_ds包含有关共享内存段的各种信息,包括权限、所有者等。若不需要该参数,可以传 NULL 。
返回值:
- 如果shmctl函数成功执行,它返回 0。
- 如果shmctl函数执行失败,它返回 -1,并且会设置 errno 以指示失败的原因。
封装:
删除共享内存:
void DeleteShm(int shmid)
{int n=shmctl(shmid,IPC_RMID,nullptr);if(n<0)cerr<<" Delete failed,errno:"<<errno<<", errstring:"<<strerror(errno)<<endl;elsecout<<" Delete success, shmid:"<<shmid<<endl;
}获得共享内存的状态:
string ToHex(key_t k)//将 key 值转为十六进制
{char buffer[1024];//用C语言方便用 %x 直接转为十六进制snprintf(buffer,sizeof(buffer),"0x%x",k);return buffer;
}void DebugShm(int shmid)
{struct shmid_ds shmds;int n = shmctl(shmid, IPC_STAT, &shmds);if (n < 0)cerr << " shmctl failed " << endl;else{std::cout << "shmds.shm_segsz: " << shmds.shm_segsz << std::endl;//共享内存的大小std::cout << "shmds.shm_nattch:" << shmds.shm_nattch << std::endl;//有多少个进程挂接std::cout << "shmds.shm_ctime:" << shmds.shm_ctime << std::endl;//上一次挂接或取消挂接的时间std::cout << "shmds.shm_perm.__key:" << ToHex(shmds.shm_perm.__key) << std::endl;//对应的key}
}shmat 函数 -- 将共享内存挂接到进程地址空间
上面的 shmget 函数只是创建了一个共享内存,但是这个共享内存并没有映射到进程的地址空间,还不属于进程,所以需要调用函数,把该共享内存挂接到进程地址空间中。
#include <sys/shm.h>void *shmat(int shmid, const void *shmaddr, int shmflg);参数:
shmid:共享内存段的标识符,通常通过shmget函数获得。
shmaddr:指定共享内存段在进程地址空间中的起始地址。如果设置为NULL,则由系统选择一个合适的地址。
shmflg:一组标志位,用于控制共享内存段的映射行为。
常用的标志位包括:
SHM_RDONLY:只读方式映射共享内存段。SHM_RND:映射地址将是 4K 对齐的随机地址。SHM_REMAP:如果共享内存段已经存在于进程地址空间中,则重新映射共享内存段。
当
shmflg设为 0 时,意味着不使用任何特定的标志位,默认按照系统默认的方式进行映射。具体来说:
- 默认映射方式:系统会选择一个适合的地址来映射共享内存段。
- 读写模式:默认情况下,映射是以读写模式进行的,而不是只读模式。
- 无特殊要求:不强制使用特定的映射地址,也不要求重新映射已经存在的共享内存段。
返回值:
- 如果成功,
shmat返回一个指向共享内存段的指针。- 如果失败,返回
(void *)-1,并且会设置errno以指示失败的原因。void*(空指针类型)是C语言中的一种指针类型,表示一个未指定类型的指针。void* 可以存储任何类型的指针值,并且在使用时需要显式转换为目标类型的指针。
封装:
void *ShmAttach(int shmid)
{void* addr=shmat(shmid,nullptr,0);if((long long int)addr==-1){//挂接失败cerr<<" attach failed,errno:"<<errno<<", errstring:"<<strerror(errno)<<endl;return nullptr;}else{//挂接成功return addr;}
}shmdt 函数 -- 分离
shmdt(shared memory detach)函数用于将先前通过shmat函数映射到进程地址空间的共享内存段分离(detach)出来。分离后,共享内存段仍然存在于系统中,只是不再映射到当前进程的地址空间中。这意味着进程不能再直接访问这块共享内存中的数据。
#include <sys/shm.h>int shmdt(const void *shmaddr);参数:
shmaddr:指向先前通过shmat函数映射到进程地址空间的共享内存段的指针。
返回值:
- 如果
shmdt函数成功执行,它返回 0。- 如果
shmdt函数执行失败,它返回 -1,并设置errno以指示失败的原因。
封装:
void ShmDetach(void *addr)
{int n=shmdt(addr);if(n<0){cerr<<" Detach failed,errno:"<<errno<<", errstring:"<<strerror(errno)<<endl;}
}相关文章:
)
Linux -- 共享内存(1)
目录 共享内存 共享内存相关函数 ftok 函数 -- 获取 key 值 什么是 key? 如何生成 key ? 参数: 返回值: 封装: shmget 函数 -- 获取 shmid 值 什么是 shmid? shmid 和 key 的区别? …...

冒泡排序和二分查找--go
冒泡排序的逻辑 二分查找的逻辑 func bubbleSort(arr *[5]int){//冒泡排序fmt.Println(*arr)temp : 0for j : len(*arr); j > 0; j-- {for i : 0; i < j-1; i {temp (*arr)[i]if((*arr)[i] > (*arr)[i1]){(*arr)[i] (*arr)[i1](*arr)[i1] temp}}} }func binaryF…...

springboot RedisTemplate支持多个序列化方式
前提纪要:因为业务变动,需要在原先只支持protobuf的前提序列化的前提下,新增正常的序列化读取数据所以在原先的基础上进行优化。文章用于记忆。 话不多说直接上代码 Configuration AutoConfigureAfter(RedisAutoConfiguration.class) Import…...

开源项目-拍卖管理系统
哈喽,大家好,今天主要给大家带来一个开源项目-拍卖管理系统 拍卖管理系统主要有拍卖品管理,我的拍卖,拍卖详情,拍卖品信息修改,发布拍卖品等功能 登录 拍卖商品管理 主要用于查看、竞拍拍卖商品的信息 我…...
Python小游戏14——雷霆战机
首先,你需要确保安装了Pygame库。如果你还没有安装,可以使用pip来安装: bash pip install pygame 代码如下: python import pygame import sys import random # 初始化Pygame pygame.init() # 设置屏幕大小 screen_width 800 scr…...
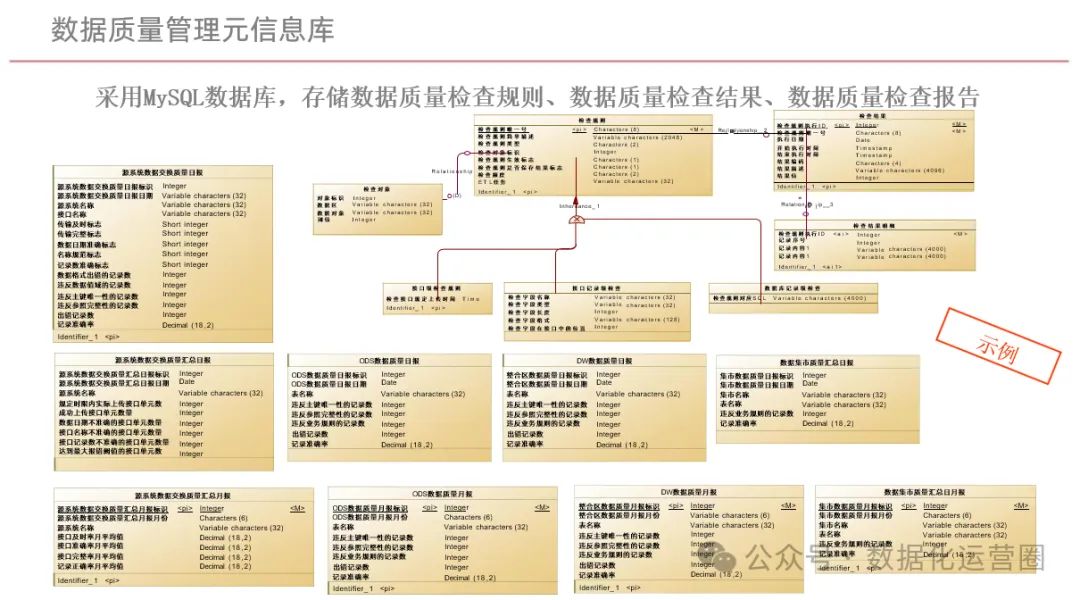
81页PPT | 企业数字化底座与数字化转型方案
方案内容涵盖了企业数字化转型的议程、集团管理分析类应用建设的现状与问题、数字化建设的目标、预期收益、总体架构、数据产生层、数据交换层、数据存储层、数据应用层、数据管控层等多个方面。方案详细描述了数据从产生、交换、存储到应用的全过程,以及如何通过数…...

R语言笔记(五):Apply函数
文章目录 一、Apply Family二、apply(): rows or columns of a matrix or data frame三、Applying a custom function四、Applying a custom function "on-the-fly"五、Applying a function that takes extra arguments六、Whats the return argument?七、Optimized…...

Newsqueak:在 Go 之前的一门语言
写在前面 学习一个东西的一种很好的方法,就是去了解这个东西的历史。在我们学习 Go 的过程中,同样也可以去了解下在 Go 之前的一些事情。 内容 Rob Pike 是 Go 语言的作者之一,早年他在贝尔实验室工作,也是 Unix 团队的成员。 …...

世界酒中国菜与另可数字平台达成战略合作
世界酒中国菜与另可数字平台达成战略合作,共推行业发展新高度 近日,在行业内引起广泛关注的“世界酒中国菜”项目,与“另可”数字平台成功举行了战略合作签约仪式。这一重要合作不仅是双方发展历程中的重要里程碑,更是继世界酒中…...

ElasticSearch基础篇——概念讲解,部署搭建,使用RestClient操作索引库和文档数据
目录 一、概念介绍 二、Elasticsearch的Docker容器安装 2.1拉取elasticsearch的镜像文件 2.2运行docker命令启动容器 2.3通过访问端口地址查看部署情况 三、安装Kibana容器 3.1拉取Kibana镜像容器指令(默认拉取最新版本): 3.2拉取完…...
k8s 二进制部署安装(一)
目录 环境准备 初始化操作系统 部署docker 引擎 部署 etcd 集群 准备签发证书环境 部署 Master01 服务器相关组件 apiserver scheduler controller-manager.sh admin etcd 存储了 Kubernetes 集群的所有配置数据和状态信息,包括资源对象、集群配置、元数据…...
115页PPT华为管理变革:制度创新与文化塑造的核心实践
集成供应链(ISC)体系 集成供应链(ISC)体系是英文Integrated Supply Chain的缩写,是一种先进的管理思想,它指的是由相互间提供原材料、零部件、产品和服务的供应商、合作商、制造商、分销商、零售商、顾客等…...

ubuntu限制网速方法
sudo apt-get install trickle sudo trickle -d <下载速度> -u <上传速度> <命令>例如git clone sudo trickle -d 1024 git clone http://xxxxxxxxxx.git如果想简化指令可以在bashrc中添加如下指令 alias gitttrickle -u 1024 gitgitt为自定义 使用方法&am…...

三品PLM研发管理系统:企业产品研发过程的得力助手
三品PLM系统:全方位赋能企业产品生命周期管理的优选方案 在当今竞争激烈的市场环境中,产品生命周期管理PLM系统已成为企业实现高效、灵活和创新产品开发的关键工具。PLM系统集成了信息技术、先进管理思想与企业业务流程,旨在帮助企业优化产品…...
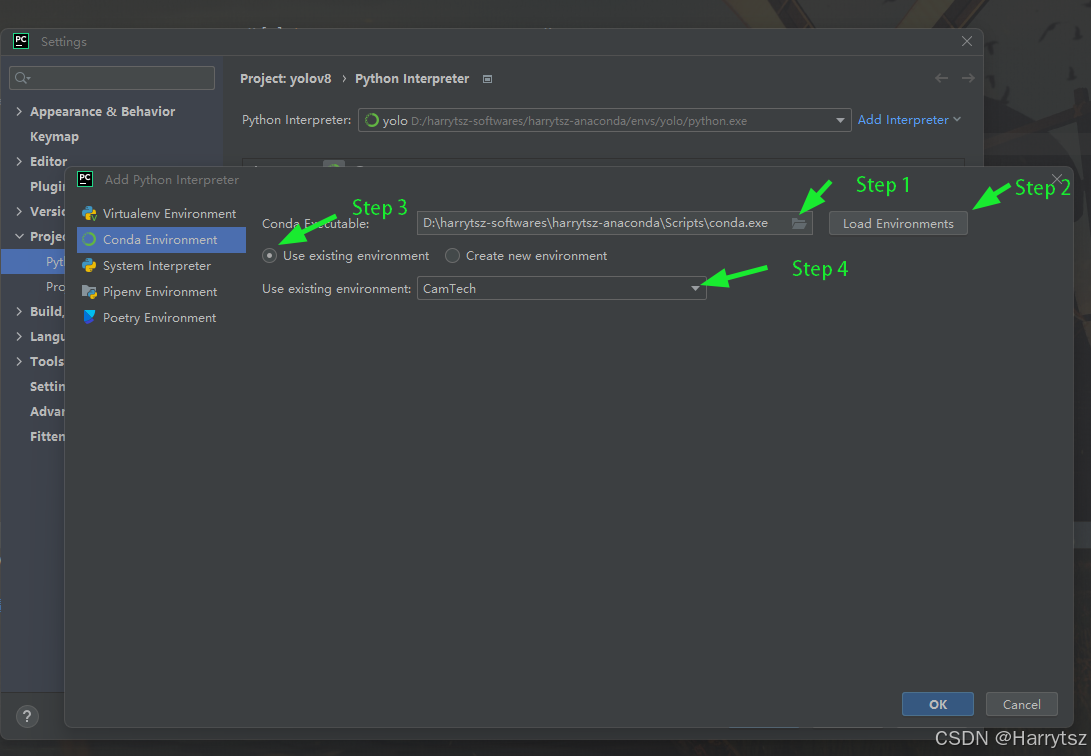
PyCharm 添加不了 Anaconda 环境
经常会遇到 PyCharm 无法添加新创建的 Anaconda 环境, Setting --> Python Interpreter --> Add Python Interperter --> Conda Environment 中为空,即使打开右侧文件夹路径按钮,选择新创建的 conda 环境,也无法找到 pyt…...

Leetcode 二叉树的右视图
好的,我来用中文详细解释这段代码的算法思想。 问题描述 题目要求给定一个二叉树的根节点,从树的右侧看过去,按从上到下的顺序返回看到的节点值。即,我们需要找到每一层的最右侧节点并将其加入结果中。 算法思想 这道题可以通…...

console.log(“res.data = “ + JSON.stringify(res.data));
res.data[object Object] 说明你在控制台打印 res.data 时,它是一个 JavaScript 对象,而不是字符串。这种情况下,console.log 输出的 [object Object] 表示它无法直接显示对象的内容。 要查看 res.data 的实际内容,你需要将其转换…...

node和npm
背景(js) 1、为什么js能操作DOM和BOM? 原因:每个浏览器都内置了DOM、BOM这样的API函数 2、浏览器中的js运行环境? v8引擎:负责解析和执行js代码 内置API:由运行环境提供的特殊接口,只能在所…...

通过四元数求机器人本体坐标旋转量
是的,通过两次姿态数据(以四元数表示)的差值,可以确定机器人在两个时刻之间的旋转角度变化。具体步骤如下: 获取四元数:假设两个时刻的四元数分别为 ( q_1 ) 和 ( q_2 )。计算四元数的差值: 将…...
-QL语法(递归))
CodeQL学习笔记(2)-QL语法(递归)
最近在学习CodeQL,对于CodeQL就不介绍了,目前网上一搜一大把。本系列是学习CodeQL的个人学习笔记,根据个人知识库笔记修改整理而来的,分享出来共同学习。个人觉得QL的语法比较反人类,至少与目前主流的这些OOP语言相比&…...

376. Wiggle Subsequence
376. Wiggle Subsequence 代码 class Solution { public:int wiggleMaxLength(vector<int>& nums) {int n nums.size();int res 1;int prediff 0;int curdiff 0;for(int i 0;i < n-1;i){curdiff nums[i1] - nums[i];if( (prediff > 0 && curdif…...

深入解析C++中的extern关键字:跨文件共享变量与函数的终极指南
🚀 C extern 关键字深度解析:跨文件编程的终极指南 📅 更新时间:2025年6月5日 🏷️ 标签:C | extern关键字 | 多文件编程 | 链接与声明 | 现代C 文章目录 前言🔥一、extern 是什么?&…...

html-<abbr> 缩写或首字母缩略词
定义与作用 <abbr> 标签用于表示缩写或首字母缩略词,它可以帮助用户更好地理解缩写的含义,尤其是对于那些不熟悉该缩写的用户。 title 属性的内容提供了缩写的详细说明。当用户将鼠标悬停在缩写上时,会显示一个提示框。 示例&#x…...
)
Angular微前端架构:Module Federation + ngx-build-plus (Webpack)
以下是一个完整的 Angular 微前端示例,其中使用的是 Module Federation 和 npx-build-plus 实现了主应用(Shell)与子应用(Remote)的集成。 🛠️ 项目结构 angular-mf/ ├── shell-app/ # 主应用&…...

处理vxe-table 表尾数据是单独一个接口,表格tableData数据更新后,需要点击两下,表尾才是正确的
修改bug思路: 分别把 tabledata 和 表尾相关数据 console.log() 发现 更新数据先后顺序不对 settimeout延迟查询表格接口 ——测试可行 升级↑:async await 等接口返回后再开始下一个接口查询 ________________________________________________________…...
: 一刀斩断视频片头广告)
快刀集(1): 一刀斩断视频片头广告
一刀流:用一个简单脚本,秒杀视频片头广告,还你清爽观影体验。 1. 引子 作为一个爱生活、爱学习、爱收藏高清资源的老码农,平时写代码之余看看电影、补补片,是再正常不过的事。 电影嘛,要沉浸,…...
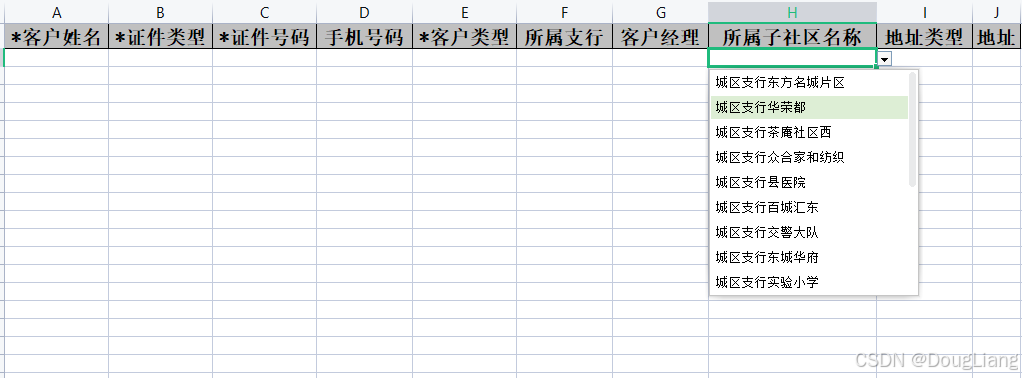
关于easyexcel动态下拉选问题处理
前些日子突然碰到一个问题,说是客户的导入文件模版想支持部分导入内容的下拉选,于是我就找了easyexcel官网寻找解决方案,并没有找到合适的方案,没办法只能自己动手并分享出来,针对Java生成Excel下拉菜单时因选项过多导…...

libfmt: 现代C++的格式化工具库介绍与酷炫功能
libfmt: 现代C的格式化工具库介绍与酷炫功能 libfmt 是一个开源的C格式化库,提供了高效、安全的文本格式化功能,是C20中引入的std::format的基础实现。它比传统的printf和iostream更安全、更灵活、性能更好。 基本介绍 主要特点 类型安全:…...

Spring Security 认证流程——补充
一、认证流程概述 Spring Security 的认证流程基于 过滤器链(Filter Chain),核心组件包括 UsernamePasswordAuthenticationFilter、AuthenticationManager、UserDetailsService 等。整个流程可分为以下步骤: 用户提交登录请求拦…...

小木的算法日记-多叉树的递归/层序遍历
🌲 从二叉树到森林:一文彻底搞懂多叉树遍历的艺术 🚀 引言 你好,未来的算法大神! 在数据结构的世界里,“树”无疑是最核心、最迷人的概念之一。我们中的大多数人都是从 二叉树 开始入门的,它…...