MOE混合专家模型总结(面试)
目录
1. MOE介绍
2.MOE出现的背景
3.有哪些MOE模型
4.门控网络或路由
5.为什么门控网络要引入噪声
6.如何均衡专家间的负载
7.“专家”指什么
8.专家的数量对预训练有何影响
9.什么是topk门控
10.MOE模型的主要特点
11.MOE和稠密模型的对比
12.MOE的优势
13.MOE的挑战
14.微调MOE的方法
15.MOE的并行计算
1. MOE介绍
MOE,全称Mixture of Experts,即混合专家模型,是一种基于神经网络领域开发的集成学习技术和机器学习方法。它最早于1991年被提出,最初应用于计算机视觉领域,目前在自然语言处理领域也备受推崇。MOE模型通过集成多个专家模型(通常是神经网络),利用稀疏的门控机制来选择性地激活最相关的专家来处理输入数据,从而在不牺牲精度的前提下,显著降低计算成本并提高推理性能。
2.MOE出现的背景
随着人工智能技术的不断发展,大模型在各个领域的应用越来越广泛。然而,大模型的训练和推理成本也越来越高,成为制约其进一步发展的瓶颈。为了降低计算成本并提高推理性能,研究人员开始探索新的模型架构,MOE混合专家模型就是在这种背景下应运而生的。
3.有哪些MOE模型
典型的MOE架构的大语言模型包括Switch Transformers、Mixtral、DBRX、Jamba DeepSeekMoE等。这些模型都采用了MOE的架构,通过集成多个专家模型来提高模型的性能和效率。
4.门控网络或路由
MOE模型中的门控网络负责决定每个输入应该由哪个专家来处理。它接收输入数据并执行一系列学习的非线性变换,产生一组权重,这些权重表示了每个专家对当前输入的贡献程度。门控网络的设计对于MOE模型的性能至关重要,它需要确保输入数据能够被正确地路由到最相关的专家进行处理。
5.为什么门控网络要引入噪声
在门控网络中引入噪声是为了增加模型的鲁棒性和泛化能力。通过引入噪声,模型能够更好地处理输入数据中的不确定性,避免过拟合,并提高对新样本的泛化能力。
6.如何均衡专家间的负载
为了均衡专家间的负载,可以采用以下策略:
引入噪声:通过噪声的引入,使得每个专家都有机会处理不同的输入数据,避免某个专家被过度使用而其他专家闲置的情况。
引入辅助损失:通过添加辅助损失函数,鼓励门控网络在给定输入时选择多个专家进行处理,以实现负载均衡。
引入随机路由:在路由过程中引入随机性,使得输入数据有可能被路由到不同的专家进行处理。
设置专家处理token数量上限:限制每个专家能够处理的token数量,以避免某个专家处理过多的数据而其他专家处理不足的情况。
7.“专家”指什么
在MOE模型中,“专家”通常指的是前馈网络(FFN)或其他类型的神经网络。每个专家负责处理输入数据的不同部分或不同特征,并产生相应的输出。这些输出将在后续的步骤中进行加权聚合,以形成最终的模型输出。
8.专家的数量对预训练有何影响
专家的数量对MOE模型的预训练过程有重要影响。增加专家数量可以提升处理样本的效率和加速模型的运算速度,但这些优势随着专家数量的增加而递减。同时,更多的专家也意味着在推理过程中需要更多的显存来加载整个模型。因此,在选择专家数量时需要权衡计算资源和模型性能之间的关系。
9.什么是topk门控
Topk门控是一种门控策略,它选择权重最高的k个专家来处理输入数据。这种策略可以确保最相关的专家被优先激活,从而提高模型的性能和效率。然而,topk门控也可能导致某些专家被过度使用而其他专家闲置的情况,因此需要在实际应用中进行权衡。
10.MOE模型的主要特点
MOE模型的主要特点包括:
高效性:通过选择性地激活最相关的专家来处理输入数据,MOE模型能够在不牺牲精度的前提下显著降低计算成本并提高推理性能。
扩展性:MOE模型的架构具有良好的扩展性,可以通过增加专家的数量来处理更复杂的任务。
并行性:不同的专家可以并行处理数据,这有助于提高模型的计算效率。
11.MOE和稠密模型的对比
与稠密模型相比,MOE模型具有以下优势:
更低的计算成本:MOE模型通过选择性地激活专家来处理输入数据,减少了不必要的计算开销。
更高的推理性能:由于MOE模型能够集中处理关键信息,因此其推理性能通常优于传统的稠密模型。
更好的扩展性:MOE模型的架构具有良好的扩展性,可以适应更大规模的数据和更复杂的任务。
然而,MOE模型也存在一些挑战,如如何设计有效的专家选择和激活机制、如何平衡训练和推理过程中的专家激活数量等。
12.MOE的优势
MOE模型的优势主要包括:
训练优势:MOE模型具有更快的预训练速度,能够在相同的计算资源条件下更快地达到相同的性能水平。
推理优势:MOE模型在推理过程中具有更高的吞吐量和更低的延迟,能够更快地处理输入数据并产生输出。
13.MOE的挑战
MOE模型面临的挑战主要包括:
训练挑战:在微调阶段,MOE模型可能出现泛化能力不足、容易过拟合的问题。这需要通过合理的正则化方法和数据增强技术来缓解。
推理挑战:MOE模型在推理过程中对显存的要求更高,需要更多的计算资源来加载整个模型。这可以通过优化模型结构和提高计算效率来解决。
14.微调MOE的方法
微调MOE模型的方法主要包括:
冻结所有非专家层的权重,专门只训练专家层。这种方法可以确保专家层能够适应新的任务和数据分布,同时保持其他层的稳定性。
只冻结MOE层参数,训练其他层的参数。这种方法可以使得模型在保持MOE层不变的情况下,对其他层进行微调以适应新的任务和数据。
15.MOE的并行计算
让 MoE 起飞
最初的混合专家模型 (MoE) 设计采用了分支结构,这导致了计算效率低下。这种低效主要是因为 GPU 并不是为处理这种结构而设计的,而且由于设备间需要传递数据,网络带宽常常成为性能瓶颈。在接下来的讨论中,我们会讨论一些现有的研究成果,旨在使这些模型在预训练和推理阶段更加高效和实用。我们来看看如何优化 MoE 模型,让 MoE 起飞。
并行计算
让我们简要回顾一下并行计算的几种形式:
- 数据并行: 相同的权重在所有节点上复制,数据在节点之间分割。
- 模型并行: 模型在节点之间分割,相同的数据在所有节点上复制。
- 模型和数据并行: 我们可以在节点之间同时分割模型和数据。注意,不同的节点处理不同批次的数据。
- 专家并行: 专家被放置在不同的节点上。如果与数据并行结合,每个节点拥有不同的专家,数据在所有节点之间分割。
在专家并行中,专家被放置在不同的节点上,每个节点处理不同批次的训练样本。对于非 MoE 层,专家并行的行为与数据并行相同。对于 MoE 层,序列中的令牌被发送到拥有所需专家的节点。

Switch Transformers 论文中展示如何使用不同的并行技术在节点上分割数据和模型的插图
参考:https://zhuanlan.zhihu.com/p/674698482
相关文章:
MOE混合专家模型总结(面试)
目录 1. MOE介绍 2.MOE出现的背景 3.有哪些MOE模型 4.门控网络或路由 5.为什么门控网络要引入噪声 6.如何均衡专家间的负载 7.“专家”指什么 8.专家的数量对预训练有何影响 9.什么是topk门控 10.MOE模型的主要特点 11.MOE和稠密模型的对比 12.MOE的优势 13.MOE的挑…...

第8次CCF CSP认证真题解
1、最大波动 题目链接:https://sim.csp.thusaac.com/contest/8/problem/0 100分代码: #include <iostream> #include <algorithm> using namespace std; int main(int argc, char *argv[]) {int n;cin >> n;int a[1010];for(int i …...
)
2024昆明ICPC A. Two-star Contest(直观命名+详细注释)
Problem - A - Codeforces 思路: 按照等级排序,维护同等级最大评分,每个等级的总评分至少比其第前一个等级的最大评分大1分 吐槽: 思路不难,但坑好多,感觉全踩了一遍 坑:(按解决…...

【算法刷题指南】双指针
🌈个人主页: 南桥几晴秋 🌈C专栏: 南桥谈C 🌈C语言专栏: C语言学习系列 🌈Linux学习专栏: 南桥谈Linux 🌈数据结构学习专栏: 数据结构杂谈 🌈数据…...
HTML,CSS,JavaScript三件套
前言 1.HTML 就是用来写网页的 就是超文本标记语言 1.1快速入门 标签是根标签,就是开始的地方 head就是头,加载一些资源信息,和展示title标题的地方,比如html快速入门那几个字就是title标题标签 body是身体,就是正…...
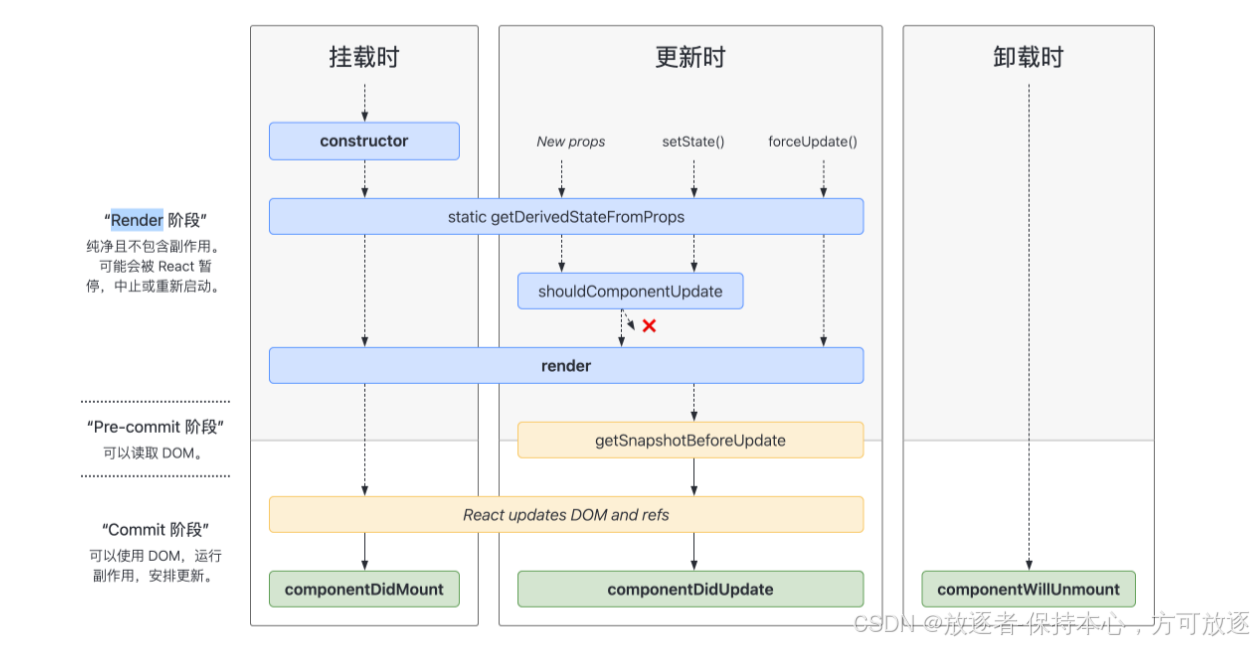
react 总结+复习+应用加深
文章目录 一、React生命周期1. 挂载阶段(Mounting)补充2. 更新阶段(Updating)补充 static getDerivedStateFromProps 更新阶段应用补充 getSnapshotBeforeUpdate3. 卸载阶段(Unmounting) 二、React组件间的…...

关于 API
关于 API $set 问法:有没有遇到过数据更新了但视图没有更新的情况? <template><div>{{arr}}<button click"btn"></button></div> </template><script> export default {name:"Home"da…...

第15次CCF CSP真题解
1、小明上学 题目链接:https://sim.csp.thusaac.com/contest/15/problem/0 本题是模拟红绿灯计时的题,根据红绿灯转换规则可知,红灯后面通常是绿灯,绿灯后面是黄灯,黄灯过后又是红灯。根据题意,当k 0时&…...
STM32硬件平台
STM32 系列是 STMicroelectronics 设计的高度灵活、广泛应用的微控制器(MCU)系列,支持从低功耗应用到高性能处理的需求,适用于工业、汽车、消费电子和物联网等广泛领域。STM32 系列具有广泛的硬件种类和丰富的功能,以下…...

一文讲明白大模型分布式逻辑(从GPU通信原语到Megatron、Deepspeed)
1. 背景介绍 如果你拿到了两台8卡A100的机器(做梦),你的导师让你学习部署并且训练不同尺寸的大模型,并且写一个说明文档。你意识到,你最需要学习的就是关于分布式训练的知识,因为你可是第一次接触这么多卡…...

【人工智能-初级】第6章 决策树和随机森林:浅显易懂的介绍及Python实践
文章目录 一、决策树简介二、决策树的构建原理2.1 决策树的优缺点优点缺点 三、随机森林简介3.1 随机森林的构建过程3.2 随机森林的优缺点优点缺点 四、Python实现决策树和随机森林4.1 导入必要的库4.2 加载数据集并进行预处理4.3 创建决策树模型并进行训练4.4 可视化决策树4.5…...
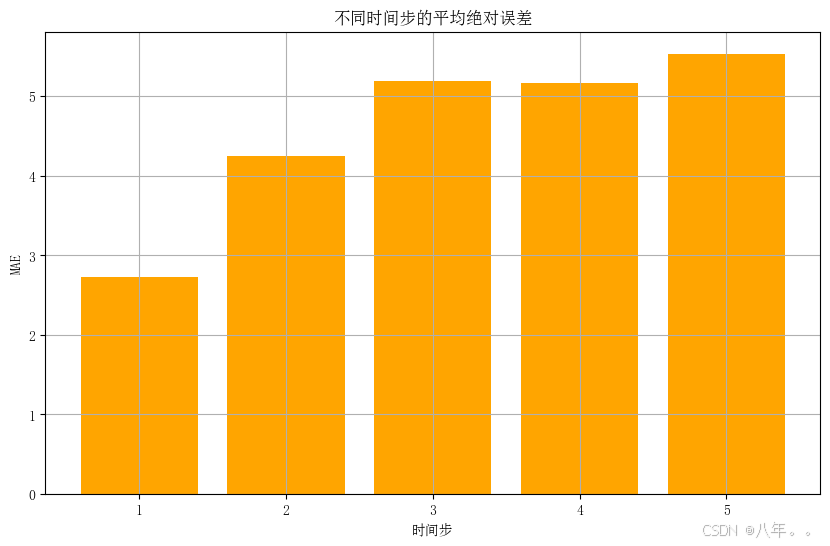
时间序列预测(九)——门控循环单元网络(GRU)
目录 一、GRU结构 二、GRU核心思想 1、更新门(Update Gate):决定了当前时刻隐藏状态中旧状态和新候选状态的混合比例。 2、重置门(Reset Gate):用于控制前一时刻隐藏状态对当前候选隐藏状态的影响程度。…...

李东生牵手通力股份IPO注册卡关,三年近10亿“清仓式分红”引关注
《港湾商业观察》施子夫 9月27日,通力科技股份有限公司(以下简称,通力股份)再度提交了注册申请,实际上早在去年11月6日公司已经提交过注册,看起来公司注册环节面临卡关。公开信息显示,通力股份…...

Android13、14特殊权限-应用安装权限适配
Android13、14特殊权限-应用安装权限适配 文章目录 Android13、14特殊权限-应用安装权限适配一、前言二、权限适配三、其他1、特殊权限-应用安装权限适配小结2、dumpsys package查看获取到了应用安装权限3、Android权限系统:应用操作管理类AppOpsManager(…...
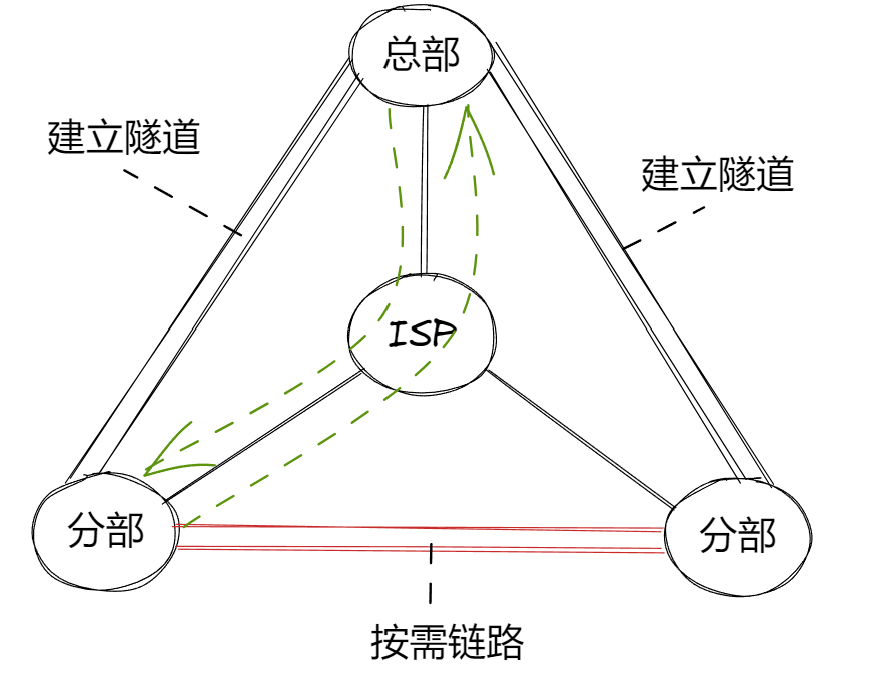
DMVPN协议
DMVPN(Dynamic Multipoint VPN)动态多点VPN 对于分公司和分总公司内网实现通信环境下,分公司是很多的。我们不可能每个分公司和总公司都挨个建立ipsec隧道 ,而且如果是分公司和分公司建立隧道,就会很麻烦。此时我们需…...
-零钱兑换II)
leetcode动态规划(十八)-零钱兑换II
题目 322.零钱兑换II 给你一个整数数组 coins ,表示不同面额的硬币;以及一个整数 amount ,表示总金额。 计算并返回可以凑成总金额所需的 最少的硬币个数 。如果没有任何一种硬币组合能组成总金额,返回 -1 。 你可以认为每种硬…...

2024 CSP-J 题解
2024 CSP-J题解 扑克牌 题目给出了一整套牌的定义,但是纯粹在扯淡,完全没有必要去判断给出的牌的花色和点数,我们用一个循环来依次读入每一张牌,如果这个牌在之前出现过,我们就让答案减一。这里建议用map、unorde…...

GPU 服务器厂家:中国加速计算服务器市场的前瞻洞察
科技的飞速发展,让 GPU 服务器在加速计算服务器领域的地位愈发凸显。中国加速计算服务器市场正展现出蓬勃的生机,而 GPU 服务器厂家则是这场科技盛宴中的关键角色。 从市场预测的趋势来看,2023 年起,中国加速计算服务器市场便已展…...

Hadoop集群修改yarn队列
1.修改默认的default队列参数 注意: yarn.scheduler.capacity.root.队列名.capacity总和不能超过100 <property><name>yarn.scheduler.capacity.root.queues</name><value>default,hive,spark,flink</value><description>The…...

【GPIO】2.ADC配置错误,还是能得到电压数据
配置ADC功能时,GPIO引脚弄错了,P1写成P2,但还是配置成功,能得到电压数据。 首先一步步排查: 既然引脚弄错了,那引脚改为正确的引脚,能得到数据通过第一步判断,GPIO配置似乎是不起作…...

MPNet:旋转机械轻量化故障诊断模型详解python代码复现
目录 一、问题背景与挑战 二、MPNet核心架构 2.1 多分支特征融合模块(MBFM) 2.2 残差注意力金字塔模块(RAPM) 2.2.1 空间金字塔注意力(SPA) 2.2.2 金字塔残差块(PRBlock) 2.3 分类器设计 三、关键技术突破 3.1 多尺度特征融合 3.2 轻量化设计策略 3.3 抗噪声…...

使用VSCode开发Django指南
使用VSCode开发Django指南 一、概述 Django 是一个高级 Python 框架,专为快速、安全和可扩展的 Web 开发而设计。Django 包含对 URL 路由、页面模板和数据处理的丰富支持。 本文将创建一个简单的 Django 应用,其中包含三个使用通用基本模板的页面。在此…...

Mybatis逆向工程,动态创建实体类、条件扩展类、Mapper接口、Mapper.xml映射文件
今天呢,博主的学习进度也是步入了Java Mybatis 框架,目前正在逐步杨帆旗航。 那么接下来就给大家出一期有关 Mybatis 逆向工程的教学,希望能对大家有所帮助,也特别欢迎大家指点不足之处,小生很乐意接受正确的建议&…...

深入理解JavaScript设计模式之单例模式
目录 什么是单例模式为什么需要单例模式常见应用场景包括 单例模式实现透明单例模式实现不透明单例模式用代理实现单例模式javaScript中的单例模式使用命名空间使用闭包封装私有变量 惰性单例通用的惰性单例 结语 什么是单例模式 单例模式(Singleton Pattern&#…...

Python实现prophet 理论及参数优化
文章目录 Prophet理论及模型参数介绍Python代码完整实现prophet 添加外部数据进行模型优化 之前初步学习prophet的时候,写过一篇简单实现,后期随着对该模型的深入研究,本次记录涉及到prophet 的公式以及参数调优,从公式可以更直观…...
)
python爬虫:Newspaper3k 的详细使用(好用的新闻网站文章抓取和解析的Python库)
更多内容请见: 爬虫和逆向教程-专栏介绍和目录 文章目录 一、Newspaper3k 概述1.1 Newspaper3k 介绍1.2 主要功能1.3 典型应用场景1.4 安装二、基本用法2.2 提取单篇文章的内容2.2 处理多篇文档三、高级选项3.1 自定义配置3.2 分析文章情感四、实战案例4.1 构建新闻摘要聚合器…...

2025 后端自学UNIAPP【项目实战:旅游项目】6、我的收藏页面
代码框架视图 1、先添加一个获取收藏景点的列表请求 【在文件my_api.js文件中添加】 // 引入公共的请求封装 import http from ./my_http.js// 登录接口(适配服务端返回 Token) export const login async (code, avatar) > {const res await http…...

BCS 2025|百度副总裁陈洋:智能体在安全领域的应用实践
6月5日,2025全球数字经济大会数字安全主论坛暨北京网络安全大会在国家会议中心隆重开幕。百度副总裁陈洋受邀出席,并作《智能体在安全领域的应用实践》主题演讲,分享了在智能体在安全领域的突破性实践。他指出,百度通过将安全能力…...

【Java_EE】Spring MVC
目录 Spring Web MVC 编辑注解 RestController RequestMapping RequestParam RequestParam RequestBody PathVariable RequestPart 参数传递 注意事项 编辑参数重命名 RequestParam 编辑编辑传递集合 RequestParam 传递JSON数据 编辑RequestBody …...

IoT/HCIP实验-3/LiteOS操作系统内核实验(任务、内存、信号量、CMSIS..)
文章目录 概述HelloWorld 工程C/C配置编译器主配置Makefile脚本烧录器主配置运行结果程序调用栈 任务管理实验实验结果osal 系统适配层osal_task_create 其他实验实验源码内存管理实验互斥锁实验信号量实验 CMISIS接口实验还是得JlINKCMSIS 简介LiteOS->CMSIS任务间消息交互…...