CodeFormer——基于代码本查找变换器的鲁棒盲人脸修复翻译
文章目录
- 原文翻译
- 摘要
- 1 Introduction
- 2 Related Work
- 3 Methodology
- 3.1 Codebook Learning (Stage I)
- 3.2 Codebook Lookup Transformer Learning (Stage II)
- 3.3 Controllable Feature Transformation (Stage III)
- 4 Experiments
- 4.1 Datasets
- 4.2 Experimental Settings and Metrics
- 4.3 Comparisons with State-of-the-Art Methods
- 4.4 Ablation Studies
- 4.5 Running time
- 4.6 Extensions
- 4.7 Limitation
- 5 Conclusion
原文翻译

paper:https://arxiv.org/pdf/2206.11253
github:https://github.com/sczhou/CodeFormer
摘要
盲人脸修复是一个高度不适定的问题,通常需要辅助指导来 1) 改善从降质输入到期望输出的映射,或 2) 补充输入中丢失的高质量细节。本文展示了一种在小型代理空间中学习的离散代码本先验,通过将盲人脸修复视为一个代码预测任务,极大地减少了修复映射的复杂性和模糊性,同时提供了丰富的视觉原子用于生成高质量的人脸。在这一范式下,我们提出了一种基于变换器的预测网络,称为 CodeFormer,用于建模低质量人脸的全局组成和上下文,以便进行代码预测,从而发现即使在输入严重降质的情况下也能与目标人脸紧密接近的自然人脸。为了增强对不同降质情况的适应性,我们还提出了一个可控特征转换模块,允许在真实感和质量之间灵活权衡。得益于表现力强的代码本先验和全局建模,CodeFormer 在质量和真实感方面均优于当前最先进的技术,并表现出对降质的优越鲁棒性。大量关于合成和真实世界数据集的实验结果验证了我们方法的有效性。
1 Introduction
在野外捕获的人脸图像经常受到各种退化的影响,如压缩、模糊和噪声。由于退化引起的信息丢失导致给定低质量 (LQ) 输入无限合理的高质量 (HQ) 输出,因此恢复此类图像是高度不适定的。在盲恢复中,不适定性进一步提高,其中特定的退化是未知的。尽管随着深度学习的出现取得了进展,但在巨大的图像空间中没有额外指导的情况下学习LQ-HQ映射仍然是难以处理的,导致早期方法的恢复质量次优。为了提高输出质量,1)降低LQ-HQ映射的不确定性和2)补充高质量细节的辅助信息是必不可少的。
各种先验已被用于缓解这个问题的不适定性,包括几何先验[5,6,31,45]、参考先验[24-26]和生成先验[2,38,44]。虽然观察到改进的纹理和细节,但这些方法往往对退化或有限的先验表达能力有很高的敏感性。这些先验为人脸恢复提供了不充分的指导,因此它们的网络本质上求助于通常高度损坏的LQ输入图像的信息。因此,LQ-HQ映射不确定性仍然存在,输出质量因输入图像的退化而恶化。最近,基于生成先验,一些方法通过迭代潜在优化[27]或直接潜在编码[29]将退化的人脸投影到连续的无限空间中。尽管输出的真实性很大,但在严重退化的情况下很难找到准确的潜在向量,从而导致低保真结果(图 1(d))。为了提高保真度,这种方法通常需要编码器和解码器之间的跳跃连接[38,44,2],如图1(a)(上)所示,然而,这样的设计同时在输入严重退化时会在结果中引入伪影,如图1(e)所示。

图 1:动机的说明。(a) 连续生成先验(顶部)和我们的离散码本先验(底部)的恢复框架。(b) HQ/LQ 人脸特征和码本项目的 t-SNE [36] 可视化。© LQ 输入。(d-e) 具有连续先验 (PULSE [27] 和 GFP-GAN [38]) 的现有方法的结果。(f-g)离散先验的结果(最近邻[11,35]和CodeFormer)。(h) 代码序列基本事实的重建结果。(i) HQ 基本事实。如图所示,(d) 没有跳跃连接的 PULSE 显示出低保真度。(e) 带有跳跃连接的 GFP-GAN 缓解了身份问题,但引入了显着的伪影。(f) 与 (d-e) 相比,利用最近邻匹配进行代码查找可以恢复更准确的面部结构,但无法恢复眼镜等一些细节,可能会引入一些伪影。(g) 使用 Transformer 进行代码预测,我们的 CodeFormer 以高质量和保真度生成最佳结果。
与上述方法不同,这项工作将盲人脸恢复作为学习离散码本先验的小有限代理空间中的代码预测任务,显示出对退化的鲁棒性和丰富的表现力。码本是通过使用矢量量化自动编码器自重建HQ人脸来学习的,解码器存储丰富的HQ细节进行人脸恢复。与连续生成先验[11,38,44]相比,码本项的组合形成了一个具有有限基数的离散先验空间。通过将LQ图像映射到更小的代理空间(例如1024个代码),LQ-HQ映射的不确定性显著减弱,促进了对不同退化的鲁棒性,如图1(d-g)所示。此外,码本空间具有更强的表现力,在感知上近似于图像空间,如图1(h)所示。这种性质允许网络减少对输入的依赖,甚至没有跳过连接。
虽然基于码本的离散表示已被部署用于图像生成[4,11,35],但图像恢复的准确代码组合仍然是一个不平凡的挑战。现有的工作通过最近邻(NN)特征匹配查找码本,这对于图像恢复来说是不可行的,因为LQ输入的内在纹理通常被破坏。LQ图像中的信息丢失和多样性退化不可避免地扭曲特征分布,禁止准确的特征匹配。如图1(b)(右)所示,即使在对LQ图像上的编码器进行微调后,LQ特征不能很好地聚类到精确的代码,而是扩散到其他附近的代码集群中,因此在这种情况下最近邻匹配是不可靠的。
为恢复量身定制,我们提出了一种基于 Transformer 的代码预测网络 CodeFormer,以利用 LQ 人脸的全局组合和远程依赖关系来更好地进行代码预测。具体来说,Transformer 模块将 LQ 特征作为输入,预测代码标记序列,该序列被视为码本空间中人脸图像的离散表示。由于全局建模来弥补LQ图像中的局部信息损失,所提出的CodeFormer对严重退化的鲁棒性,并保持整体一致性。比较图1(f-g)所示的结果,所提出的CodeFormer能够恢复比最近邻匹配更多的细节,如眼镜,提高恢复的质量和保真度。
此外,我们提出了一个具有可调系数的可控特征变换模块,用于控制从 LQ 编码器到解码器的信息流。这样的设计允许在恢复质量和保真度之间进行灵活的权衡,从而实现它们之间的连续图像转换。该模块增强了CodeFormer在不同退化下的自适应性,例如,在严重退化的情况下,可以手动减少携带退化的LQ特征的信息流,生成高质量的结果。
配备上述组件,所提出的CodeFormer在现有数据集中表现出了优越的性能,以及我们新引入的WIDER-Test数据集,该数据集由从WIDER-Face数据集[43]收集的970个严重退化的人脸组成。除了人脸恢复之外,我们的方法还证明了它在人脸修复等其他具有挑战性的任务上的有效性,其中需要来自其他区域的远程线索。进行了系统的研究和实验,以证明我们的方法相对于以前的工作的优点。
2 Related Work
盲人脸恢复。由于人脸是高度结构化的,人脸的几何先验被用于盲人脸恢复。一些方法在他们的设计中引入了面部标志 [6]、人脸解析图 [5, 31, 42]、面部成分热图 [45] 或 3D 形状 [16, 28, 49]。然而,这种先验信息无法从退化的人脸中准确获取。此外,几何先验无法为高质量的人脸恢复提供丰富的细节。
已经提出了基于参考的方法[9,24 - 26]来规避上述限制。这些方法通常需要参考与输入退化人脸具有相同的身份。例如,Li等人[26]提出了一种由翘曲子网络和重建子网络组成的引导人脸恢复网络,并使用与输入具有相同身份的高质量图像来更好地恢复面部细节。但是,此类引用并不总是可用的。DFDNet[24]预先构建了由高质量面部成分特征组成的字典。然而,特定于组件的字典特征仍然不足以获得高质量的人脸恢复,特别是对于字典范围之外的区域(例如皮肤、头发)。为了缓解这个问题,最近的基于 VQGAN 的方法 [40,47] 探索了一个学习的 HQ 字典,其中包含更通用和更丰富的细节人脸恢复。
最近,来自预训练生成器(例如 StyleGAN2 [21])的生成面部先验已被广泛研究用于盲人脸恢复。它通过不同的迭代潜在优化策略来实现有效的 GAN 反演 [12, 27] 或退化人脸的直接潜在编码 [29]。然而,当将退化的人脸投影到连续的无限潜在空间中时,保持恢复的人脸的高保真度是具有挑战性的。为了缓解这个问题,GLEAN [2, 3]、GPEN [44] 和 GFPGAN [38] 将生成先验嵌入到编码器-解码器网络结构中,并将输入图像的额外结构信息作为指导。尽管保真度有所提高,但这些方法高度依赖于跳过连接的输入,当输入严重损坏时,这可能会给结果引入伪影。
字典学习。使用学习字典的稀疏表示已经证明了它在图像恢复任务中的优越性,例如超分辨率[13,33,34,41]和去噪[10]。然而,这些方法通常需要迭代优化来学习字典和稀疏编码,计算成本高。尽管效率低下,但它们对探索HQ字典的高级洞察启发了基于参考的恢复网络,如LUT[18]和自参考[48],以及合成方法[11,35]。Jo 和 Kim [18] 通过将网络输出值转移到 LUT 来构建一个查找表 (LUT),以便在推理过程中只需要一个简单的值检索。然而,将HQ纹理存储在图像域通常需要巨大的LUT,限制了其实用性。VQVAE[35]首先引入矢量量化自编码器模型学习的高度压缩码本。VQGAN[11]进一步采用对抗性损失和感知损失,以较高的压缩率提高感知质量,在不牺牲码本表达能力的情况下显著降低码本大小。与大型手工字典[18,24]不同,可学习码本自动学习HQ图像重建的最优元素,提供卓越的效率和表现力,并规避费力的字典设计。受码本学习的启发,本文研究了一种用于盲人脸恢复的离散代理空间。与最近的基于VQGAN的方法不同[40,47],我们通过全局建模预测代码序列来利用离散码本,并通过固定编码器来保证先验的有效性。这样的设计允许我们的方法充分利用码本,使其不依赖于与LQ线索的特征融合,显著提高了人脸恢复的鲁棒性。
3 Methodology
这项工作的主要重点是利用离散表示空间来减少恢复映射的不确定性,并为退化的输入补充高质量的细节。由于局部纹理和细节在低质量的输入中丢失和损坏,我们使用 Transformer 模块对自然人脸的全局组合进行建模,从而弥补局部信息损失,从而实现高质量的恢复。整个框架如图2所示。

图2:CodeFormer的框架。(a) 我们首先学习一个离散的码本和一个解码器,通过自重构学习存储人脸图像的高质量视觉部分。(b) 在固定码本和解码器的情况下,我们引入了一个用于代码序列预测的 Transformer 模块,对低质量输入的全局人脸组成进行建模。此外,利用可控特征变换模块控制从LQ编码器到解码器的信息流。请注意,此连接是可选的,当输入严重退化时,可以禁用此连接以避免不利影响,并且可以调整标量权重 w 以在质量和保真度之间进行权衡。
我们首先结合矢量量化[11,35]的思想,通过自重构预训练量化自编码器,得到离散码本和相应的解码器(第3.1节)。然后使用码本组合和解码器的先验进行人脸恢复。基于这个码本先验,我们使用 Transformer 从低质量输入(第 3.2 节)中准确预测代码组合。此外,引入了一个可控的特征变换模块来利用恢复质量和保真度之间的灵活权衡(第 3.3 节)。我们方法的训练相应地分为三个阶段。
3.1 Codebook Learning (Stage I)
为了减少LQ-HQ映射的不确定性,并补充高质量的恢复细节,我们首先预训练量化自编码器来学习一个上下文丰富的码本,提高了网络的表达能力以及对退化的鲁棒性。
如图2(a)所示,首先将HQ人脸图像 I h ∈ R H × W × 3 I_{h}∈R^{H×W×3} Ih∈RH×W×3嵌入到编码器 E H E_{H} EH的压缩特征 Z h ∈ R m × n × d Z_{h}∈R^{m×n×d} Zh∈Rm×n×d中。在VQVAE[35]和VQGAN[11]之后,我们将 Z h Z_{h} Zh中的每个“像素”替换为可学习码本 C = { c k ∈ R d } k = 0 N C =\{ c_{k}∈R^{d} \}^{N}_{k=0} C={ck∈Rd}k=0N中最近的项,得到量化特征 Z c ∈ R m × n × d Z_{c}∈R^{m×n×d} Zc∈Rm×n×d和相应的代码标记序列 s ∈ { 0 , 1 } m ⋅ n s∈\{0,1\}^{m·n} s∈{0,1}m⋅n:

然后解码器 D H D_{H} DH在给定 Z c Z_{c} Zc的情况下重建高质量的人脸图像 I r e c I_{rec} Irec。m · n 个代码标记序列 s 形成一个新的潜在离散表示,它指定学习码本的相应代码索引,即当 s ( i , j ) s^{(i,j)} s(i,j) = k 时, Z c ( i , j ) = c k Z^{(i,j)}_{c} = c_{k} Zc(i,j)=ck。
训练目标。为了用码本训练量化自编码器,我们采用了三种图像级重建损失:L1损失L1、感知损失[19,46] L p e r L_{per} Lper和对抗性损失[11] L a d v L_{adv} Ladv:

其中Φ表示VGG19[32]的特征提取器。由于在更新码本项时,图像级损失受到约束,我们还采用了中间码级损失[11,35] L c o d e f e a t L^{feat}_{code} Lcodefeat来减少码本C与输入特征嵌入 Z h Z_{h} Zh之间的距离:

其中 sg(·) 代表停止梯度算子,β = 0.25 是编码器和码本更新率的权重权衡。由于Eq.(1)中的量化操作是不可微的,我们采用直通梯度估计器[11,35]将梯度从解码器复制到编码器。码本先验学习 L c o d e b o o k L_{codebook} Lcodebook 的完整目标是:

在我们的实验中, λ a d v λ_{adv} λadv 设置为 0.8。
码本设置。我们的编码器 E H E_{H} EH 和解码器 D H D_{H} DH 由 12 个残差块和 5 个调整大小层组成,分别用于下采样和上采样。因此,我们获得了 r = H/n = W/m = 32 的大压缩比,这导致了对退化的鲁棒性和第二阶段全局建模的可处理计算成本。尽管更多的码本项目可以减轻重建,但冗余元素可能会导致后续代码预测的模糊性。因此,我们将码本的项目数 N 设置为 1024,足以进行准确的人脸重建。此外,代码维度 d 设置为 256。
3.2 Codebook Lookup Transformer Learning (Stage II)
由于LQ人脸纹理的破坏,Eq.(1)中的最近邻(NN)匹配通常无法找到准确的代码进行人脸恢复。如图1(b)所示,具有不同退化的LQ特征可能会偏离正确的代码,并分组到附近的集群中,导致不良的恢复结果,如图1(f)所示。为了缓解这个问题,我们使用 Transformer 对全局相互关系进行建模以获得更好的代码预测。
基于第 3.1 节中介绍的学习自动编码器,如图 2(b) 所示,我们在编码器之后插入一个包含九个自注意力块的 Transformer [37] 模块。我们固定码本 C 和解码器 D H D_{H} DH 并对编码器 E H E_{H} EH 进行微调以恢复。微调后的编码器表示为 E L E_{L} EL。为了通过 E L E_{L} EL 获得 L Q L_{Q} LQ 特征 Z l ∈ R m × n × d Z_{l} ∈ R^{m×n×d} Zl∈Rm×n×d,我们首先将特征展开为 m · n 个向量 Z l v Z^{v}_{l} Zlv ∈ R ( m ⋅ n ) × d R^{(m·n)×d} R(m⋅n)×d,然后将它们馈送到 Transformer 模块。Transformer 的第 s 个自注意力块计算如下:

其中 X 0 = Z l v X_{0} = Z^{v}_{l} X0=Zlv。查询 Q、键 K 和值 V 是通过线性层从 X s X_{s} Xs 获得的。我们在查询 Q 和键 K 上添加了一个正弦位置嵌入 P ∈ R ( m ⋅ n ) × d P ∈ R^{(m·n)×d} P∈R(m⋅n)×d [1, 7],以增加对序列表示建模的表达能力。在自注意力块之后,采用线性层将特征投影到 (m · n) × N 的维度。总体而言,以编码特征 Z l v Z^{v}_{l} Zlv 作为输入,Transformer 以 N 个代码项的概率以 m · n 个代码序列 s ^ ∈ 0 , ⋅ ⋅ , ∣ N ∣ − 1 m ⋅ n \hat s ∈ {0, · · , |N | − 1}^{m·n} s^∈0,⋅⋅,∣N∣−1m⋅n 的形式预测 m · n 个代码序列 s ^ ∈ 0 , ⋅ ⋅ , ∣ N ∣ − 1 m ⋅ n \hat s ∈ {0, · · , |N | − 1}^{m·n} s^∈0,⋅⋅,∣N∣−1m⋅n。然后,预测的代码序列从学习的码本中检索m·n个各自的代码项,形成量化特征 Z ^ c ∈ R m × n × d \hat Z_{c}∈R^{m×n×d} Z^c∈Rm×n×d,通过固定的解码器DH生成高质量的人脸图像。由于我们的大压缩比(即 32),我们的 Transformer 在建模 LQ 人脸图像的全局相关性方面是有效的和高效。
训练目标。我们训练 Transformer 模块 T 并微调编码器 E L E_{L} EL 以进行恢复,而码本 C 和解码器 D H D_{H} DH 保持固定。在这个阶段只需要代码级损失,而不是在图像级别使用重建损失和对抗性损失:1)用于代码令牌预测监督的交叉熵损失 L t o k e n L_{token} Ltoken 代码,以及 2)L2 loss L c o d e f e a t ′ L^{feat'}_{code} Lcodefeat′ 来强制LQ特征 Z l Z_{l} Zl 从码本中接近量化的特征 Z c Z_{c} Zc,这减轻了令牌预测学习的难度:

其中潜在代码 s 的地面实况是从阶段 I(第 3.1 节)中预训练的自动编码器获得的,因此然后根据 s 从码本中检索量化特征 Z c Z_{c} Zc。Transformer 学习的最终目标是:

其中在我们的方法中 λ t o k e n λ_{token} λtoken 设置为 0.5。请注意,在这个阶段之后的网络已经具备了人脸恢复中优越的鲁棒性和有效性,特别是对于严重退化的人脸。
3.3 Controllable Feature Transformation (Stage III)
尽管我们的第二阶段获得了一个很好的人脸恢复模型,但我们也研究了人脸恢复的质量和保真度之间的灵活权衡。因此,我们提出了可控特征变换 (CFT) 模块来控制从LQ编码器 E L E_{L} EL 到解码器 D H D_{H} DH 的信息流。具体来说,如图 2 所示,LQ特征 F e F_{e} Fe 用于通过空间特征变换 [39] 稍微调整解码器特征 F d F_{d} Fd,仿射参数为 α 和 β。然后使用可调系数 w ∈ [0, 1] 来控制输入的相对重要性:

其中 P θ P_{θ} Pθ 表示一堆卷积,它从 c ( F e , F d ) c(F_{e}, F_{d}) c(Fe,Fd) 的连接特征预测 α 和 β。我们在编码器和解码器之间采用多个尺度 s ∈ {32, 64, 128, 256} 的 CFT 模块。这样的设计允许我们的网络保持高保真度的轻度退化和高质量的严重退化。具体来说,可以使用一个小的 w 来减少对退化严重的输入 LQ 图像的依赖,从而产生高质量的输出。w越大,从LQ图像中引入更多的信息,在轻度退化的情况下提高保真度。
训练目标。为了训练可控模块并在这个阶段微调编码器 E L E_{L} EL,我们保持第二阶段 L t f L_{tf} Ltf 的代码级损失,并添加 L1、 L p e r L_{per} Lper 和 L a d v L_{adv} Ladv 的图像级损失,这与第一阶段相同,只是 I r e c I_{rec} Irec 被恢复输出 I r e s I_{res} Ires 替换。这一阶段的完整损失是上述损失的总和,加权其原始权重因子。在这个阶段的训练期间,我们将 w 设置为 1,然后允许网络在推理过程中通过调整 [0, 1] 中的 w 来实现结果的连续转换。对于推理,除非另有说明,我们默认设置 w = 0.5 以在输出的质量和保真度之间做出良好的平衡。
4 Experiments
4.1 Datasets
训练数据集。我们在FFHQ数据集[21]上训练模型,该数据集包含70,000张高质量的(HQ)图像,所有图像都被调整为512×512进行训练。为了形成训练对,我们用以下退化模型从HQ对应Ih合成LQ图像Il[24,38,44]:

其中HQ图像Ih首先与高斯核kσ进行卷积,然后对尺度r进行下采样。之后,在图像中添加加性高斯噪声 nδ,然后应用质量因子 q 的 JPEG 压缩。最后,LQ 图像被调整为 512×512。我们分别从 [1, 15]、[1, 30]、[0, 20] 和 [30, 90] 中随机采样 σ、r、δ 和 q。
测试数据集。我们在合成数据集CelebA-Test和三个真实数据集上评估我们的方法:LFW-Test、WebPhoto-Test和我们提出的WIDER-Test。CelebA-Test 包含从 CelebA-HQ 数据集 [20] 中选择的 3,000 张图像,其中 LQ 图像是在与我们的训练设置相同的退化范围内合成的。这三个真实世界的数据集分别包含三个不同的退化程度,即轻度(LFW-Test)、中等(WebPhoto-Test)和重度(WIDER-Test)。LFW-Test 由 LFW 数据集 [17] 中每个人的第一个图像组成,包含 1,711 张图像。WebPhoto-Test [38] 由从 Internet 收集的 407 个低质量人脸组成。我们的WIDER-Test包括来自WIDER Face数据集[43]的970张严重退化的人脸图像,提供了一个更具挑战性的数据集来评估盲人脸恢复方法的泛化性和鲁棒性。
4.2 Experimental Settings and Metrics
设置。我们将 512 × 512 × 3 的人脸图像表示为 16 × 16 代码序列。对于训练阶段,我们使用批量大小为 16 的 Adam [23] 优化器。我们将阶段 I 和 II 的学习率设置为 8 × 1 0 − 5 8×10^{−5} 8×10−5,阶段 III 的学习率为 2 × 1 0 − 5 2×10^{−5} 2×10−5。这三个阶段分别使用 1.5M、200K 和 20K 次迭代进行训练。我们的方法是使用 PyTorch 框架实现的,并使用四个 NVIDIA Tesla V100 GPU 进行训练。
指标。为了对具有基本事实的CelebA-Test进行评估,我们采用PSNR、SSIM和LPIPS[46]作为指标。我们还使用ArcFace网络[8]的特征的余弦相似度来评估身份保存,记为IDS。对于没有基本事实的真实数据集的评估,我们采用了广泛使用的非参考感知指标:FID [15] 和 MUSIIQ (KonIQ) [22]。
4.3 Comparisons with State-of-the-Art Methods
我们将提出的CodeFormer与最先进的方法进行了比较,包括PULSE[27]、DFDNet[24]、PSFRGAN[5]、GLEAN[3]、GFP-GAN[38]和GPEN[44]。我们对合成数据集和真实数据集进行了广泛的比较。
合成数据集的评估。我们首先在表1中展示了CelebA-Test的定量比较。在图像质量指标LPIPS、FID和MUSIIQ方面,我们的CodeFormer取得了比现有方法最好的分数。此外,它还忠实地保留了身份,这反映在最高的 IDS 分数和 PSNR 中。此外,我们在图3中给出了定性比较。比较方法不能产生令人愉快的恢复结果,例如DFDNet[24]、PSFRGAN[5]、GFP-GAN [38] 和 GPEN [44] 引入了明显的伪影,GLEAN [3] 产生了缺乏面部细节的过度平滑结果。此外,所有比较方法都无法保留身份。由于富有表现力的码本先验和全局建模,CodeFormer不仅产生高质量的人脸,而且很好地保留了身份,即使输入高度退化。

图 3:CelebA-Test 的定性比较。尽管输入人脸严重退化,但我们的CodeFormer产生了高质量的人脸,细节忠实。(详见 Zoom)
对真实世界数据集的评估。如表 2 所示,我们的 CodeFormer 在具有轻微和中等退化的真实世界测试数据集上实现了与比较方法相当的 FID 分数感知质量,并且测试数据集的最佳分数严重退化。虽然PULSE[27]也获得了良好的感知MUSIIQ评分,但它不能保留输入图像的身份,如表1和图4所示。从图4的视觉比较可以看出,我们的方法对真实重退化表现出了卓越的鲁棒性,产生了视觉上最令人愉悦的结果。值得注意的是,CodeFormer成功地保留了身份,产生了具有丰富细节的自然结果。

表2:真实世界LFW-Test、WebPhoto-Test和WIDER-Test的定量比较。红色和蓝色分别表示最佳和次最佳性能。

表 1:CelebATest 的定量比较。红色和蓝色分别表示最佳和次最佳性能。Code GT的结果是CodeFormer的上界。

图4:真实世界人脸的定性比较。我们的CodeFormer能够恢复高质量的人脸,显示出对严重退化的鲁棒性。(详见 Zoom)
4.4 Ablation Studies
码本空间的有效性。我们首先研究码本空间的有效性。如 Exp(a) 表 3 所示,删除码本(即直接将编码器特征 Z l Z_{l} Zl 馈送到解码器)会导致 LPIPS 和 IDS 分数更差。结果表明,码本的离散空间是保证模型的鲁棒性和有效性的关键。

表 3:CelebA-Test 上变体网络和代码查找方法的烧蚀研究。删除“码本”意味着网络是一个通用的编码器-解码器结构。w是 CFT 模块的可调系数,用于控制来自编码器的信息流。
基于 Transformer 的代码预测的优越性。为了验证我们基于 Transformer 的代码预测对码本查找的优越性,我们将其与两种不同的解决方案进行比较,即最近邻 (NN) 匹配,即 Exp。(b) 和基于 CNN 的代码预测模块,即 Exp。©,它采用线性层进行编码器 EL 之后的预测。如表 3 所示,Exps 的比较。(b) 和 © 表明采用代码预测进行码本查找比 NN 特征匹配更有效。然而,CNN卷积运算的局部性质限制了其对长码序列预测的建模能力。与纯基于 CNN 的方法相比,即 Exp。©,我们基于 Transformer 的解决方案在 LPIPS 和 IDS 分数方面产生了更好的保真度结果,以及在所有退化程度下代码预测的准确性更高,如图 6 所示。此外,CodeFormer 的优越性也显示在图 5 和图 9 所示的视觉比较中。

图 6:代码序列预测精度的曲线比较。

图 5:不同码本查找方法的定性比较。

图9:在具有挑战性的情况下与最先进的人脸修复方法的视觉比较。
固定解码器的重要性。与DFDNet[24]中旨在存储大量面部细节的大型字典(~3.2G)不同,我们故意采用紧凑的码本 C ∈ R N × d C∈R^{N ×d} C∈RN×d,N =1024和d=256,只保留人脸恢复的基本代码,然后激活存储在预训练解码器中的详细线索。因此,码本必须与解码器一起使用,以充分释放其潜力。为了证明我们的设计,我们进行了两项研究:1)修复码本和解码器,即 Exp.(g) 和 2) 修复码本但微调解码器,即 Exp.(e)。表 3 显示了微调解码器会降低性能,验证了我们的陈述。这是因为微调解码器会破坏预训练的码本和解码器持有的学习先验,从而导致性能次优。因此,我们在我们的方法中保持解码器固定。
可控特征变换模块的灵活性。考虑到真实世界LQ人脸图像的退化程度不同,我们提供了一个可控的特征变换模块(CFT),以允许质量和保真度之间的灵活权衡。如图 7 所示,较小的 w 往往会产生高质量的结果,而较大的 w 提高了保真度。虽然在之前的工作中很少探索这种灵活性,但在这里我们表明,提高我们的方法在不同场景下的适应性是一种很有吸引力的策略。如表 3 所示,Exp。(f),即将系数 w 设置为 1 会增加重建和身份分数,但会降低视觉质量。在这项工作中,我们在质量和保真度之间进行权衡,默认情况下将系数 w 设置为 0.5。

图 7:CFT 模块能够生成图像质量和保真度之间的连续转换。
4.5 Running time
我们比较了最先进的方法[27,24,5,2,38,44]和提出的CodeFormer的运行时间。所有现有方法都使用公开可用的代码在 51 2 2 512^{2} 5122 张人脸图像上进行评估。如表 5 所示,所提出的 CodeFormer 与 PSFRGAN [5] 和 GPEN [44] 具有相似的运行时间,可以在 0.1s 内推断一张图像。同时,我们的方法在Celeb-Test数据集上的LPIPS方面取得了最好的性能。

表 5:不同网络的运行时间。所有方法都使用 NVIDIA Tesla V100 GPU 在 51 2 2 512^{2} 5122 个输入图像上进行评估。'_'表示每个测试图像的运行时间小于 0.1s。
4.6 Extensions
人脸颜色增强。我们使用与 GFP-GAN (v1) [38] 相同的颜色增强(随机颜色抖动和灰度转换)在人脸颜色增强上微调我们的模型。我们在真实世界的旧照片(来自 CelebChild-Test 数据集 [38])上将我们的方法与 GFP-GAN (v1) [38] 进行比较,并带有颜色损失。所提出的CodeFormer生成具有更自然的颜色和忠实细节的高质量人脸图像。

图8:人脸颜色增强对真实世界旧人脸照片的视觉比较。
人脸修复。所提出的Codeformer可以很容易地扩展到人脸修复,即使在较大的掩码比率下也表现出出色的性能。为了构建训练对,我们使用公开可用的脚本 [44] 随机绘制不规则折线掩码以生成掩码人脸。我们将我们的方法与两种最先进的人脸修复方法 CTSDG [14] 和 GPEN [44] 以及用于码本查找的最近邻匹配进行比较。如图 9 所示,CTSDG 和 GPEN 在具有大掩码的情况下挣扎。在我们的框架中使用最近邻匹配大致重建人脸结构,但它也未能恢复眼镜和眼睛等完整的视觉部分。相比之下,我们的CodeFormer生成高质量的自然面孔,没有笔画和工件。

图9:在具有挑战性的情况下与最先进的人脸修复方法的视觉比较。
4.7 Limitation
我们的方法建立在带有码本的预训练自动编码器之上。因此,自动编码器的能力和表现力可能会影响我们方法的性能。1)虽然 Transformer 的全局建模显着缓解了身份不一致问题,但一些罕见的视觉部分仍然存在不一致,例如配件,其中当前的码本空间无法无缝表示图像空间。在码本空间中使用多个尺度来探索更细粒度的视觉量化可能是一种解决方案。2)虽然CodeFormer在大多数情况下表现出了很强的鲁棒性,但在人脸方面,CodeFormer比其他方法提供了有限的优势,也不能产生良好的结果,如图10所示的故障情况。这是意料之中的,因为在FFHQ训练数据集中只有少数侧面,因此,在这种情况下,码本无法学习到足够的代码,导致重建和恢复的有效性降低。

图10:失败案例往往发生在侧脸上,这可能是由于FFHQ训练数据集中侧人脸图像数量有限造成的。
5 Conclusion
本文旨在解决盲人脸恢复的基本挑战。通过学习的小离散但富有表现力的码本空间,我们将人脸恢复转化为代码令牌预测,显著降低了恢复映射的不确定性,简化了恢复网络的学习。为了解决局部损失,我们通过富有表现力的 Transformer 模块探索退化人脸的全局组合和依赖性,以实现更好的代码预测。得益于这些设计,我们的方法在严重退化方面表现出很强的表现力和强大的鲁棒性。为了提高我们的方法对不同退化的适应性,我们还提出了一个可控的特征变换模块,该模块允许在保真度和质量之间进行灵活的权衡。实验结果表明我们的方法的优越性和有效性。
相关文章:
CodeFormer——基于代码本查找变换器的鲁棒盲人脸修复翻译
文章目录 原文翻译摘要1 Introduction2 Related Work3 Methodology3.1 Codebook Learning (Stage I)3.2 Codebook Lookup Transformer Learning (Stage II)3.3 Controllable Feature Transformation (Stage III) 4 Experiments4.1 Datasets4.2 Experimental Settings and Metri…...

监控场景下,视频SDK的应用策略
在当今数字化、智能化的时代背景下,音视频技术的快速发展正深刻改变着各行各业。特别是在监控领域,音视频SDK的应用不仅极大地提升了监控系统的性能与效率,还推动了监控技术的智能化转型。 一、音视频SDK 音视频SDK是一套集成了音视频编解码…...

前端面试必备!HTML 超实用考点全解析
在前端开发的广阔领域中,面试是检验开发者能力的关键环节。而 HTML 作为前端开发的基础,在面试中常常占据重要地位。无论是初入前端领域的新人,还是经验丰富的开发者,都可能在 HTML 的相关问题上遭遇挑战。今天,就让我…...

自动驾驶系统研发系列—避免事故的利器:AEB自动紧急制动系统详解
🌟🌟 欢迎来到我的技术小筑,一个专为技术探索者打造的交流空间。在这里,我们不仅分享代码的智慧,还探讨技术的深度与广度。无论您是资深开发者还是技术新手,这里都有一片属于您的天空。让我们在知识的海洋中一起航行,共同成长,探索技术的无限可能。 🚀 探索专栏:学…...

zabbix 6.0 监控clickhouse(单机)
zabbix 6.0 LTS已经包含了clickhouse的监控模板,所以我们可以直接使用自带的模板来监控clickhouse了。 0.前置条件 clickhouse 已经安装,我安装的是24.3.5.47zabbix-agent 已经安装并配置。系统是ubuntu 2204 server 1. 新建监控用户 使用xml的方式为…...

Redis的RDB执行原理
文章目录 引入‘页表’的概念Copy-On-WriteRDB快照 引入‘页表’的概念 Linux里面每个进程都是无法直接操作物理内存的,每个进程只能用页表映射本进程的虚拟内存到物理内存的映射。 bgsave的时候,主进程会fork(复制)一个子进程&am…...
速度背!24下软考网工“经典100道母题来了”!
2024下软考已经迫在眉睫了,准备考下半年软考多媒体应用设计师的小伙伴们准备得怎么样了? 单单只啃书肯定不太够,今天给大家整理了多媒体100道经典题, 这些都是历年高频考点整理,包含24下软考80%以上考点,跟…...
、深度纹理(DepthTexture)、视频纹理(VideoTexture))
three.js 纹理(Texture)、深度纹理(DepthTexture)、视频纹理(VideoTexture)
纹理(Texture) 创建一个纹理贴图,将其应用到一个表面,或者作为反射/折射贴图。 构造函数 Texture( image, mapping, wrapS, wrapT, magFilter, minFilter, format, type, anisotropy, encoding ) // load a texture, set wrap…...

广东自闭症全托机构:提供高质量的康复服务
在广东这片充满活力的土地上,自闭症儿童的康复需求日益受到社会各界的关注。在众多自闭症全托机构中,位于广州的星贝育园自闭症儿童寄宿制学校以其专业的团队、全面的服务体系以及显著的康复成效,成为了众多家庭的信赖之选。 星贝育园&#…...

Nodejs安装配置及创建vue项目
文章目录 Node简介Node官网安装node.js验证是否安装成功 npm简介配置node远程拉取仓库安装cnpm(国内插件管理命令)npm相关参数解读 vue简介创建vue项目 Node 简介 Node.js 是一个免费、开源、跨平台的 JavaScript 运行时环境,它让开发人员能…...

浅析正交投影矩阵和透视投影矩阵的推导
先上矩阵的内容。在opengl中,分别通过glOrtho函数和glFrustum函数得到正交投影矩阵和透视投影矩阵。 glOrtho 函数描述生成正交投影矩阵。 (左、 下、 近) 和 (右、 上、 近) 参数分别指定近剪裁平面上映射到窗口左下角和右上角的点,假定眼睛位于 (0、0…...

python四舍五入保留两位小数不足补0
在 Python 中,当你想要对数字进行四舍五入并保留两位小数,同时确保当小数位数不足两位时能够补零,你可以继续使用 round() 函数进行四舍五入,然后在格式化输出时使用字符串格式化方法来确保小数位数。 round() 函数本身只会返回四…...

Mybatis-15.动态SQL-if
一.动态SQL 比如只想查询名字中带‘张’的,其他的都不进行条件筛查 会发现什么也查询不出来 我们希望SQL语句能够根据我们所输入的查询值进行动态的变化,就需要使用到动态SQL。动态SQL中有很多标签,其中用于条件判断的就是标签<if>。…...

gb28181-sip注册流程
gb28181-sip注册流程 当客户端第一次接入时,客户端将持续向Server端发送REGISTER消息,直到Server端回复"200 OK"后结束 它的注册流程如下图: 注册流程: 1 . SIP代理向SIP服务器发送Register请求: 第1行表…...

WEBRTC教程:局域网怎么调试,http://172.19.18.101:8080 ,无法访问摄像头和麦克风,请检查权限
在局域网中使用 WebRTC 时,无法访问摄像头和麦克风通常是因为浏览器的安全策略限制了 getUserMedia API 的使用。如果你在非 localhost 或非 HTTPS 环境下访问网页,浏览器会阻止访问摄像头和麦克风。 解决方案 在局域网中调试 WebRTC 时,你…...

Apache POI—读写Office格式文件
Apache POI 是一个开源的 Java 库,用于读写 Microsoft Office 格式的文件,主要包括 Excel、Word 和 PowerPoint 等文档。POI 对 Excel 文件的支持最为完善,通过 POI 可以方便地进行 Excel 文件的创建、编辑、读取等操作。 1. Apache POI 简介…...

3162. 优质数对的总数 I
3162. 优质数对的总数 I 题目链接:3162. 优质数对的总数 I 代码如下: class Solution { public:int numberOfPairs(vector<int>& nums1, vector<int>& nums2, int k){int res 0;for (int i 0; i < nums1.size(); i){for (int…...
(五)Web前端开发进阶2——AJAX
目录 2.Axios库 3.认识URL 4.Axios常用请求方法 5.HTTP协议——请求报文/响应报文 6.前后端分离开发 7.Element组件库 1.Ajax概述 AJAX 是异步的 JavaScript和XML(Asynchronous JavaScript And XML)。简单点说,就是使用XMLHttpRequest 对象与服务器通信。它可…...

数据结构(java)——数组的构建和插入
数组:地址连续,可以直接通过下标获取数组中的内容。(下标从0开始) 新建的数组都有默认值 //创建数组//Java是强类型 数组必须声明类型//以下是三种创建数组的方式 int[] arr {2,23,55,12,34,53};int[] brrnew int[5];int[] crrn…...

AI-CNN-验证码识别
1 需求 GitHub - xhh890921/cnn-captcha-pytorch: 小黑黑讲AI,AI实战项目《验证码识别》 2 接口 3 示例 config.json {"train_data_path": "./data/train-digit/","test_data_path": "./data/test-digit/","train_…...

前端倒计时误差!
提示:记录工作中遇到的需求及解决办法 文章目录 前言一、误差从何而来?二、五大解决方案1. 动态校准法(基础版)2. Web Worker 计时3. 服务器时间同步4. Performance API 高精度计时5. 页面可见性API优化三、生产环境最佳实践四、终极解决方案架构前言 前几天听说公司某个项…...

mongodb源码分析session执行handleRequest命令find过程
mongo/transport/service_state_machine.cpp已经分析startSession创建ASIOSession过程,并且验证connection是否超过限制ASIOSession和connection是循环接受客户端命令,把数据流转换成Message,状态转变流程是:State::Created 》 St…...

高危文件识别的常用算法:原理、应用与企业场景
高危文件识别的常用算法:原理、应用与企业场景 高危文件识别旨在检测可能导致安全威胁的文件,如包含恶意代码、敏感数据或欺诈内容的文档,在企业协同办公环境中(如Teams、Google Workspace)尤为重要。结合大模型技术&…...

大模型多显卡多服务器并行计算方法与实践指南
一、分布式训练概述 大规模语言模型的训练通常需要分布式计算技术,以解决单机资源不足的问题。分布式训练主要分为两种模式: 数据并行:将数据分片到不同设备,每个设备拥有完整的模型副本 模型并行:将模型分割到不同设备,每个设备处理部分模型计算 现代大模型训练通常结合…...

今日科技热点速览
🔥 今日科技热点速览 🎮 任天堂Switch 2 正式发售 任天堂新一代游戏主机 Switch 2 今日正式上线发售,主打更强图形性能与沉浸式体验,支持多模态交互,受到全球玩家热捧 。 🤖 人工智能持续突破 DeepSeek-R1&…...

IT供电系统绝缘监测及故障定位解决方案
随着新能源的快速发展,光伏电站、储能系统及充电设备已广泛应用于现代能源网络。在光伏领域,IT供电系统凭借其持续供电性好、安全性高等优势成为光伏首选,但在长期运行中,例如老化、潮湿、隐裂、机械损伤等问题会影响光伏板绝缘层…...

React---day11
14.4 react-redux第三方库 提供connect、thunk之类的函数 以获取一个banner数据为例子 store: 我们在使用异步的时候理应是要使用中间件的,但是configureStore 已经自动集成了 redux-thunk,注意action里面要返回函数 import { configureS…...

HashMap中的put方法执行流程(流程图)
1 put操作整体流程 HashMap 的 put 操作是其最核心的功能之一。在 JDK 1.8 及以后版本中,其主要逻辑封装在 putVal 这个内部方法中。整个过程大致如下: 初始判断与哈希计算: 首先,putVal 方法会检查当前的 table(也就…...

Mysql中select查询语句的执行过程
目录 1、介绍 1.1、组件介绍 1.2、Sql执行顺序 2、执行流程 2.1. 连接与认证 2.2. 查询缓存 2.3. 语法解析(Parser) 2.4、执行sql 1. 预处理(Preprocessor) 2. 查询优化器(Optimizer) 3. 执行器…...
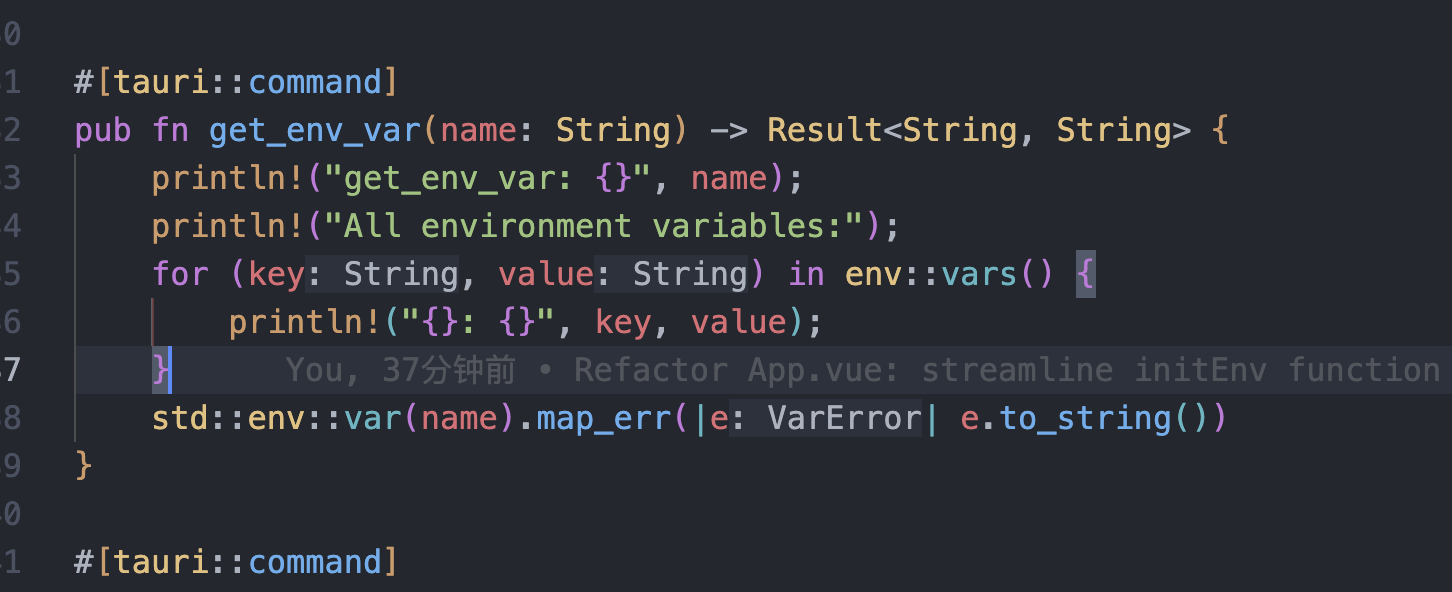
tauri项目,如何在rust端读取电脑环境变量
如果想在前端通过调用来获取环境变量的值,可以通过标准的依赖: std::env::var(name).ok() 想在前端通过调用来获取,可以写一个command函数: #[tauri::command] pub fn get_env_var(name: String) -> Result<String, Stri…...