如何设置 TORCH_CUDA_ARCH_LIST 环境变量以优化 PyTorch 性能
引言
在深度学习领域,PyTorch 是一个广泛使用的框架,它允许开发者高效地构建和训练模型。为了充分利用你的 GPU 硬件,正确设置 TORCH_CUDA_ARCH_LIST 环境变量至关重要。这个变量告诉 PyTorch 在构建过程中应该针对哪些 CUDA 架构版本进行优化。本文将指导你如何确定你的 GPU 的 CUDA 架构能力,并设置相应的环境变量。
确定你的 GPU 的 CUDA 架构能力
首先,你需要知道你的 GPU 支持的 CUDA 计算能力。你可以通过运行以下 Python 代码来获取这个信息:
import torch; print(torch.cuda.get_device_capability())或者,如果你更喜欢使用命令行,可以执行:
python -c "import torch; print(torch.cuda.get_device_capability())"这将返回一个元组,包含两个整数,分别代表你的 GPU 支持的 CUDA 架构的主版本号和次版本号。例如,如果输出是 (8, 9),则表示你的 GPU 支持 CUDA 架构 8.9。

设置 TORCH_CUDA_ARCH_LIST 环境变量
一旦你知道了你的 GPU 的 CUDA 架构能力,你就可以设置 TORCH_CUDA_ARCH_LIST 环境变量,以便 PyTorch 可以针对这些架构进行优化。这个列表告诉 PyTorch 你的 GPU 支持的 CUDA 版本,以便正确编译和优化 PyTorch 代码。
在 Linux 或 macOS 上设置环境变量
在终端中,你可以使用 export 命令来设置环境变量:
export TORCH_CUDA_ARCH_LIST="8.9"在 Windows 上设置环境变量
在命令提示符(CMD)中,你可以使用 set 命令:cmd
set TORCH_CUDA_ARCH_LIST=8.9在 PowerShell 中,你可以使用:
$env:TORCH_CUDA_ARCH_LIST="8.9"构建优化的 PyTorch 版本
设置好环境变量后,你就可以开始构建针对特定 CUDA 架构优化的 PyTorch 版本了。这对于确保你的深度学习模型能够充分利用 GPU 的性能至关重要。
结论
正确设置 TORCH_CUDA_ARCH_LIST 环境变量可以显著提高你的 PyTorch 应用的性能。通过遵循上述步骤,你可以确保你的深度学习模型在 GPU 上运行得更快、更高效。如果你在设置过程中遇到任何问题,不要犹豫,查阅 PyTorch 官方文档或寻求社区的帮助。
相关文章:
如何设置 TORCH_CUDA_ARCH_LIST 环境变量以优化 PyTorch 性能
引言 在深度学习领域,PyTorch 是一个广泛使用的框架,它允许开发者高效地构建和训练模型。为了充分利用你的 GPU 硬件,正确设置 TORCH_CUDA_ARCH_LIST 环境变量至关重要。这个变量告诉 PyTorch 在构建过程中应该针对哪些 CUDA 架构版本进行优…...

CSS的三个重点
目录 1.盒模型 (Box Model)2.位置 (position)3.布局 (Layout)4.低代码中的这些概念 在学习CSS时,有三个概念需要重点理解,分别是盒模型、定位、布局 1.盒模型 (Box Model) 定义: CSS 盒模型是指每个 HTML 元素在页面上被视为一个矩形盒子。…...

【笔记】前后端互通中前端登录无响应
后来的前情提要 : 后端的ip地址在本地测试阶段应该设置为localhost 前端中写cors的配置 后端也要写cors的配置 且两者的url都要为localhost 前端写的baseUrl是指定对应的后端的ip地址以及端口号 很重要 在本地时后端的IP的地址也必须为本地的 F12的网页报错是&a…...

AI引领PPT创作:迈向“免费”时代的新篇章?
AI引领PPT创作:迈向“免费”时代的新篇章? 在信息爆炸的时代,演示文稿(PPT)作为传递信息和展示观点的重要工具,其制作效率和质量直接关系到演讲者的信息传递效果。随着人工智能(AI)…...

HTB:Perfection[WriteUP]
目录 连接至HTB服务器并启动靶机 1.What version of OpenSSH is running? 使用nmap对靶机TCP端口进行开放扫描 2.What programming language is the web application written in? 使用浏览器访问靶机80端口页面,并通过Wappalyzer查看页面脚本语言 3.Which e…...

鸿蒙next打包流程
目录 下载团结引擎 添加开源鸿蒙打包支持 打包报错 路径问题 安装DevEcoStudio 可以在DevEcoStudio进行打包hap和app 包结构 没法直接用previewer运行 真机运行和测试需要配置签名,DevEcoStudio可以自动配置, 模拟器安装hap提示报错 安装成功,但无法打开 团结1.3版本新增工具…...

uni-app 实现自定义底部导航
原博:https://juejin.cn/post/7365533404790341651 在开发微信小程序,通常会使用uniapp自带的tabBar实现底部图标和导航,但现实有少量应用使用uniapp自带的tabBar无法满足需求,这时需要自定义底部tabBar功能。 例如下图的需求&am…...

Vue前端开发:animate.css第三方动画库
在实际的项目开发中,如果自定义元素的动画,不仅效率低下,代码量大,而且还存在浏览器的兼容性问题,因此,可以借助一些优秀的第三动画库来协助完成动画的效果,如animate.css和gsap动画库ÿ…...

Java中的I/O模型——BIO、NIO、AIO
1. BIO(Blocking I/O) 1. 1 BIO(Blocking I/O)模型概述 BIO,即“阻塞I/O”(Blocking I/O),是一种同步阻塞的I/O模式。它的主要特点是,当程序发起I/O请求(比如…...
)
【软考知识】敏捷开发与统一建模过程(RUP)
敏捷开发模式 概述敏捷开发的主要特点包括:敏捷开发的常见实践包括:敏捷开发的优势:敏捷开发的挑战:敏捷开发的方法论: ScrumScrum 的核心概念Scrum 的执行过程Scrum 的适用场景 极限编程(XP)核…...
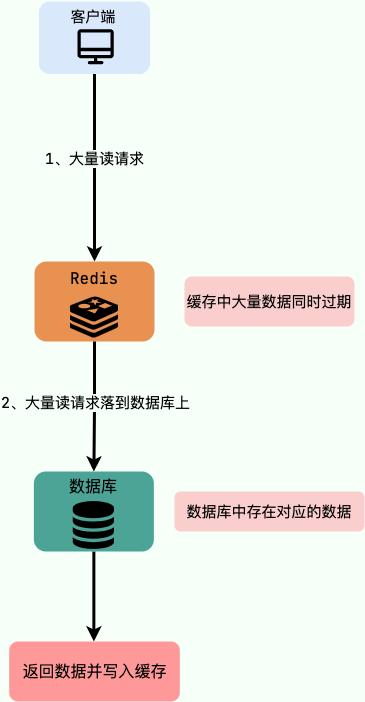
Redis常见面试题(二)
Redis性能优化 Redis性能测试 阿里Redis性能优化 使用批量操作减少网络传输 Redis命令执行步骤:1、发送命令;2、命令排队;3、命令执行;4、返回结果。其中 1 与 4 消耗时间 --> Round Trip Time(RTT,…...
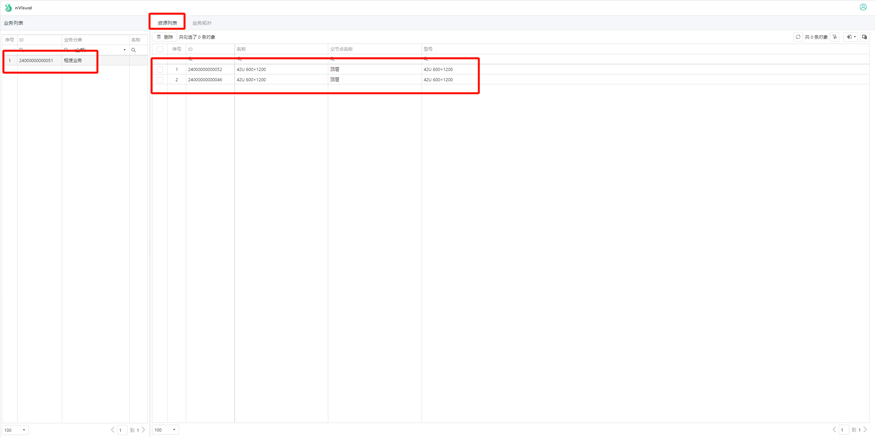
业务模块部署
一、部署前端 1.1 window部署 下载业务模块前端包。 (此包为耐威迪公司发布,请联系耐威迪客服或售后获得) 包名为:业务-xxxx-business (注:xxxx为发布版本号) 此文件部署位置为:……...

【LeetCode】【算法】48. 旋转图像
LeetCode 48. 旋转图像 题目描述 给定一个 n n 的二维矩阵 matrix 表示一个图像。请你将图像顺时针旋转 90 度。 你必须在 原地 旋转图像,这意味着你需要直接修改输入的二维矩阵。请不要 使用另一个矩阵来旋转图像。 思路 思路:再次拜见K神…...

【STM32F1】——9轴姿态模块JY901与串口通信(上)
【STM32F1】——9轴姿态模块JY901与串口通信(上) 一、简介 本篇主要对调试JY901模块的过程进行总结,实现了以下功能。 串口普通收发:使用STM32F103C8T6的USART2实现9轴姿态模块JY901串口数据的读取,并利用USART1发送到串口助手。 串口DMA收发:使用STM32F103C8T6的USART…...

Docker网络概述
1. Docker 网络概述 1.1 网络组件 Docker网络的核心组件包括网络驱动程序、网络、容器以及IP地址管理(IPAM)。这些组件共同工作,为容器提供网络连接和通信能力。 网络驱动程序:Docker支持多种网络驱动程序,每种驱动程…...

Vite与Vue Cli的区别与详解
它们的功能非常相似,都是提供基本项目脚手架和开发服务器的构建工具。 主要区别 Vite在开发环境下基于浏览器原生ES6 Modules提供功能支持,在生产环境下基于Rollup打包; Vue Cli不区分环境,都是基于Webpack。 在生产环境下&…...

深究JS底层原理
一、JS中八种数据类型判断方法 在JavaScript中,数据类型分为两大类:基本(原始)数据类型和引用(对象)数据类型。 基本数据类型(Primitive Data Types) 基本数据类型是表示简单的数…...

数据分析-41-时间序列预测之机器学习方法XGBoost
文章目录 1 时间序列1.1 时间序列特点1.1.1 原始信号1.1.2 趋势1.1.3 季节性和周期性1.1.4 噪声1.2 时间序列预测方法1.2.1 统计方法1.2.2 机器学习方法1.2.3 深度学习方法2 XGBoost2.1 模拟数据2.2 生成滞后特征2.3 切分训练集和测试集2.4 封装专用格式2.5 模型训练和预测3 参…...

json转java对象 1.文件读取为String 2.String转为JSONObject 3.JSONObject转为Class
一.参考王广帅的 服务器起服时的加载 private void readConfigFile(String configDir, Class<?> clazz) throws Exception {String fileName getConfigFileName(clazz);File configFile new File(configDir, fileName);// 读取所有的行,因此,应…...

基于卷积神经网络的农作物病虫害识别系统(pytorch框架,python源码)
更多图像分类、图像识别、目标检测等项目可从主页查看 功能演示: 基于卷积神经网络的农作物病虫害检测(pytorch框架)_哔哩哔哩_bilibili (一)简介 基于卷积神经网络的农作物病虫害识别系统是在pytorch框架下实现的…...

以下是对华为 HarmonyOS NETX 5属性动画(ArkTS)文档的结构化整理,通过层级标题、表格和代码块提升可读性:
一、属性动画概述NETX 作用:实现组件通用属性的渐变过渡效果,提升用户体验。支持属性:width、height、backgroundColor、opacity、scale、rotate、translate等。注意事项: 布局类属性(如宽高)变化时&#…...

CMake基础:构建流程详解
目录 1.CMake构建过程的基本流程 2.CMake构建的具体步骤 2.1.创建构建目录 2.2.使用 CMake 生成构建文件 2.3.编译和构建 2.4.清理构建文件 2.5.重新配置和构建 3.跨平台构建示例 4.工具链与交叉编译 5.CMake构建后的项目结构解析 5.1.CMake构建后的目录结构 5.2.构…...

页面渲染流程与性能优化
页面渲染流程与性能优化详解(完整版) 一、现代浏览器渲染流程(详细说明) 1. 构建DOM树 浏览器接收到HTML文档后,会逐步解析并构建DOM(Document Object Model)树。具体过程如下: (…...

学习STC51单片机31(芯片为STC89C52RCRC)OLED显示屏1
每日一言 生活的美好,总是藏在那些你咬牙坚持的日子里。 硬件:OLED 以后要用到OLED的时候找到这个文件 OLED的设备地址 SSD1306"SSD" 是品牌缩写,"1306" 是产品编号。 驱动 OLED 屏幕的 IIC 总线数据传输格式 示意图 …...

数据库分批入库
今天在工作中,遇到一个问题,就是分批查询的时候,由于批次过大导致出现了一些问题,一下是问题描述和解决方案: 示例: // 假设已有数据列表 dataList 和 PreparedStatement pstmt int batchSize 1000; // …...

MySQL中【正则表达式】用法
MySQL 中正则表达式通过 REGEXP 或 RLIKE 操作符实现(两者等价),用于在 WHERE 子句中进行复杂的字符串模式匹配。以下是核心用法和示例: 一、基础语法 SELECT column_name FROM table_name WHERE column_name REGEXP pattern; …...

学习STC51单片机32(芯片为STC89C52RCRC)OLED显示屏2
每日一言 今天的每一份坚持,都是在为未来积攒底气。 案例:OLED显示一个A 这边观察到一个点,怎么雪花了就是都是乱七八糟的占满了屏幕。。 解释 : 如果代码里信号切换太快(比如 SDA 刚变,SCL 立刻变&#…...

JVM虚拟机:内存结构、垃圾回收、性能优化
1、JVM虚拟机的简介 Java 虚拟机(Java Virtual Machine 简称:JVM)是运行所有 Java 程序的抽象计算机,是 Java 语言的运行环境,实现了 Java 程序的跨平台特性。JVM 屏蔽了与具体操作系统平台相关的信息,使得 Java 程序只需生成在 JVM 上运行的目标代码(字节码),就可以…...

Linux 中如何提取压缩文件 ?
Linux 是一种流行的开源操作系统,它提供了许多工具来管理、压缩和解压缩文件。压缩文件有助于节省存储空间,使数据传输更快。本指南将向您展示如何在 Linux 中提取不同类型的压缩文件。 1. Unpacking ZIP Files ZIP 文件是非常常见的,要在 …...

push [特殊字符] present
push 🆚 present 前言present和dismiss特点代码演示 push和pop特点代码演示 前言 在 iOS 开发中,push 和 present 是两种不同的视图控制器切换方式,它们有着显著的区别。 present和dismiss 特点 在当前控制器上方新建视图层级需要手动调用…...