图神经网络(GNN)入门笔记(2)——从谱域理解图卷积,ChebNet和GCN实现
一、谱域图卷积(Spectral Domain Graph Convolution)
与谱域图卷积(Spectral Domain Graph Convolution)对应的是空间域(Spatial Domain)图卷积。本节学习的谱域图卷积指的是通过频率来理解卷积的方法。
二、ChebNet
上一节结尾,我们将谱域图卷积写作:
( g ∗ g f ) = U W U T f (g *_g f)= U W U^T f (g∗gf)=UWUTf
这其实已经可以做一些任务了,例如对于一个三维点云图,特征为每个点的坐标或者法向量,进行低通滤波可以把这个三维模型变得更加平滑。
而对于另一些任务,就不大合适。例如,我们有一张论文互相引用图,特征为每篇论文的种类,想要预测其中一些未标记的论文的种类。这时,这种图卷积就暴露了一些问题,例如,参数量和图规模相关以至于不适合处理不同的图,以及该处理方法过于全局,缺乏局部信息。
于是我们重新考虑拉普拉斯矩阵。乘一次拉普拉斯矩阵,相当于每个点聚合一次邻居的信息。那么乘两次,就是聚合2跳邻居的信息。乘k次,是k-hop信息。而:
L k = ( U Λ U T ) k = U Λ k U T L^k = (U\Lambda U^T)^k = U\Lambda^kU^T Lk=(UΛUT)k=UΛkUT
因此,我们可以这样修改信号处理方法。我们学习参数 θ 0 , . . . , θ k − 1 \theta_0,...,\theta_{k-1} θ0,...,θk−1,代表不同距离邻居的重要程度,令 W = θ 0 Λ 0 + . . . + θ k − 1 Λ k − 1 W=\theta_0 \Lambda^0 +...+\theta_{k-1} \Lambda^{k-1} W=θ0Λ0+...+θk−1Λk−1,就是一个对这个任务不错的滤波函数。
不过ChebNet之所以叫ChebNet,就是因为它出于种种复杂的原因使用了一个名为Chebyshev polynomial的技巧来拟合上述的 W W W。具体地:
W ≈ ∑ k = 0 K − 1 θ k T k ( Λ ~ ) W \approx \sum_{k=0}^{K-1} \theta_k T_k(\tilde \Lambda) W≈k=0∑K−1θkTk(Λ~)
其中 T 0 ( x ) = 1 , T 1 ( x ) = x , T k ( x ) = 2 x T k − 1 ( x ) − T k − 2 ( x ) T_0(x)=1,T_1(x)=x,T_k(x)=2xT_{k-1}(x)-T_{k-2}(x) T0(x)=1,T1(x)=x,Tk(x)=2xTk−1(x)−Tk−2(x)
为什么要使用切比雪夫多项式?我看网上有些人说是为了降低复杂度,但实际上计算 T k ( L ) T_k(L) Tk(L)应该并不会比计算 L k L^k Lk复杂度更低。实际上应该和切比雪夫多项式在信号处理中的性质有关,由于我相关知识不足,所以暂且略过。总之,目前需要学到的是ChebNet引入的把参数量从和图中点数有关的 O ( n ) O(n) O(n)减少到 O ( 1 ) O(1) O(1)级别的思想。
而 Λ ~ \tilde \Lambda Λ~是对原 Λ \Lambda Λ进行放缩的值,因为切比雪夫多项式要求参数取值在 [ − 1 , 1 ] [-1,1] [−1,1]之间,所以对其进行了一个 Λ ~ = 2 Λ λ m a x − I \tilde \Lambda=\frac{2\Lambda}{\lambda_{max}}-I Λ~=λmax2Λ−I这样的缩放。接着代回到原式,得:
( g ∗ g f ) = ∑ k = 0 K − 1 θ k T k ( L ~ ) f (g*_g f)=\sum_{k=0}^{K-1} \theta_kT_k(\tilde L)f (g∗gf)=k=0∑K−1θkTk(L~)f
其中 L ~ = 2 L λ m a x − I \tilde L = \frac{2L}{\lambda_{max}}-I L~=λmax2L−I
不过等等,这么说我们还是得花费高额复杂度求特征值吗?其实也不必,因为我们可以相信神经网络参数对规模缩放的自适应性(或许也可以使用一些估计方法?),取 l m a x ≈ 2 l_{max} \approx 2 lmax≈2即可。那么此时, L ~ = D − 1 2 A D − 1 2 \tilde L=D^{-\frac{1}{2}}AD^{-\frac{1}{2}} L~=D−21AD−21。
至此,我们已经解决了上一章讨论的所有问题:
- W W W不再与图结构相关。
- 不需要计算特征向量。
- 因为不需要计算特征向量,不需求对称性保证正交基存在,可以扩展用于有向图)。
- 可以拟合局部信息。
三、ChebNet的实现
接下来我们尝试实现一个简单的ChebNet。
在此我使用了小规模论文类别-引用关系数据集Cora,可以使用torch_geometric.datasets来下载这个数据集。下载时如果出现超时问题,可以参考这篇博客。
另外,实际问题中的图一般都是稀疏图,拉普拉斯矩阵也是稀疏矩阵,可以用一些稀疏矩阵乘法方法加速过程。因为本篇笔记尚未讨论相关问题(我还没学会),此处给出使用邻接矩阵进行完整矩阵乘法的实现。
卷积核:
class ChebConv(nn.Module):def __init__(self, in_channels, out_channles, K=2,use_bias=True):super(ChebConv, self).__init__()self.in_channels = in_channelsself.out_channles = out_channlesself.K = Kself.use_bias = use_biasself.weights = nn.Parameter(torch.Tensor(K, 1, in_channels, out_channles))nn.init.xavier_normal_(self.weights)if(use_bias):self.bias = nn.Parameter(torch.FloatTensor(out_channles))else:self.register_parameter('bias', None)# 切比雪夫多项式,其实可以提前实现而不必在卷积核里每次都重算一遍# 放在此处只是为了演示清晰def cheb_polynomial(self, laplacian):N = laplacian.size(0)terms = torch.zeros([self.K, N, N], device=laplacian.device, dtype=torch.float32)terms[0] = torch.eye(N, device=device, dtype=torch.float32)if(self.K == 1):return termsterms[1] = laplacianfor k in range(2, self.K):terms[k] = 2.0 * torch.mm(laplacian, terms[k-1]) - terms[k-2]return terms # [K, N, N]def forward(self, inputs, laplacian):# inputs: [B, N, in_channels]# outputs: [B, N, out_channels]terms = self.cheb_polynomial(laplacian).unsqueeze(1) # [K, 1, N, N]outputs = torch.matmul(terms, inputs) # [K, B, N, in_channels]outputs = torch.matmul(outputs, self.weights) # [K, B, N, out_channels]outputs = torch.sum(outputs, dim=0) #[B, N, out_channels]if(self.use_bias):outputs += self.biasreturn outputs
网络架构:
class ChebNet(nn.Module):def __init__(self, in_channels, hidden_channels, out_channles, K=2, droput=0.5):super(ChebNet, self).__init__()self.conv1 = ChebConv(in_channels, hidden_channels, K)self.conv2 = ChebConv(hidden_channels, out_channles, K)self.dropout = droputdef forward(self, x, laplacian):outputs1 = self.conv1(x, laplacian)outputs1 = outputs1.relu()outputs1 = F.dropout(outputs1, p=self.dropout, training=self.training) outputs2 = self.conv2(outputs1, laplacian)outputs2 = outputs2.relu()return outputs2
数据集处理及训练和测试:
# 获取数据集,Cora只有一组数据,且不分训练和测试
dataset = Planetoid(root='./Cora', name='Cora', transform=NormalizeFeatures())
data = dataset[0]device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')# 定义模型
model = ChebNet(in_channels=dataset.num_node_features,hidden_channels=16,out_channles=dataset.num_classes,K=3, droput=0).to(device)# 邻接矩阵
def edge_index_to_adj(edge_index, num_nodes): # 构建一个大小为 (num_nodes, num_nodes) 的零矩阵 adj = torch.zeros(num_nodes, num_nodes, dtype=torch.float32)# 使用索引广播机制,一次性将边索引映射到邻接矩阵的相应位置上 adj[edge_index[0], edge_index[1]] = 1.adj[edge_index[1], edge_index[0]] = 1.return adjdef get_laplacian(adj, use_normalize=True):I = torch.eye(adj.size(0), device=adj.device, dtype=adj.dtype)if(use_normalize):D = torch.diag(torch.sum(adj, dim=-1) ** (-1 / 2))L = I - torch.mm(torch.mm(D, adj), D)else:D = torch.diag(torch.sum(adj, dim=-1))L = D - adjL -= Ireturn L# 提前计算拉普拉斯矩阵
adj = edge_index_to_adj(data.edge_index, data.num_nodes)
laplacian = get_laplacian(adj).to(device)# 定义损失函数和优化器
loss = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(params=model.parameters(), lr = 0.001, weight_decay=5e-4)def train():model.train()optimizer.zero_grad() # 梯度清理y_hat = model(data.x.unsqueeze(0).to(device), laplacian).squeeze(0)l = loss(y_hat[data.train_mask].to(device), data.y[data.train_mask].to(device))l.backward() # 误差反向传播optimizer.step()return ldef test():model.eval()pred = model(data.x.unsqueeze(0).to(device), laplacian).squeeze(0)pred = pred.argmax(dim=1)test_correct = pred[data.test_mask] == data.y[data.test_mask].to(device)test_acc = int(test_correct.sum()) / int(data.test_mask.sum())return test_accepoch = 501
for epoch in range(1, epoch):train_loss = train()test_acc = test()if epoch % 10 == 0:print(f"epoch:{epoch} loss:{train_loss} test_acc:{test_acc}")
四、从ChebNet的first-order近似到GCN:从谱域理解GCN
对于ChebNet,在 K = 2 K=2 K=2的情况下,卷积的定义为:
g θ ∗ f = θ 0 f − θ 1 D − 1 2 A D − 1 2 g_\theta * f=\theta_0 f - \theta_1 D^{-\frac{1}{2}}AD^{-\frac{1}{2}} gθ∗f=θ0f−θ1D−21AD−21
如果我们进一步减少参数量,取 θ 1 = − θ 0 \theta_1=-\theta_0 θ1=−θ0,则此时有:
g θ ∗ f = θ ( I + D − 1 2 A D − 1 2 ) f g_\theta * f=\theta (I+D^{-\frac{1}{2}}AD^{-\frac{1}{2}})f gθ∗f=θ(I+D−21AD−21)f
到这一步已经离GCN很近了,只缺少最后一点:Renormalization Trick。
在上式中, I + D − 1 2 A D − 1 2 I+D^{-\frac{1}{2}}AD^{-\frac{1}{2}} I+D−21AD−21的特征值范围在 [ 0 , 2 ] [0,2] [0,2]之间(可以使用盖尔圆理论进行估计),大于1的数反复相乘有可能引起数值不稳定和梯度爆炸的问题。而Renormalization Trick就是通过对图中所有点添加自环,然后再统一归一化,来估计一个特征值在 [ − 1 , 1 ] [-1,1] [−1,1]之间的 L ~ \tilde L L~。具体地:
A ~ = A + I , D ~ i i = ∑ j A ~ i j , L ~ = D ~ − 1 2 A ~ D ~ − 1 2 \tilde A = A+I, \tilde D_{ii}=\sum_j \tilde A_{ij}, \tilde L =\tilde D^{-\frac{1}{2}}\tilde A\tilde D^{-\frac{1}{2}} A~=A+I,D~ii=j∑A~ij,L~=D~−21A~D~−21
盖尔圆理论
若 A = ( a i j ) ∈ C A=(a_{ij}) \in \mathbb{C} A=(aij)∈C,则第 i i i的盖尔圆为以 a i i a_{ii} aii为圆心,以 R i = ∑ j ≠ i ∣ a i j ∣ R_i=\sum_{j \not=i} |a_{ij}| Ri=∑j=i∣aij∣为半径的圆。 A A A的所有特征值落在盖尔圆的并集之内。
I + D − 1 2 A D − 1 2 I+D^{-\frac{1}{2}}AD^{-\frac{1}{2}} I+D−21AD−21的每一个盖尔圆都是以1为圆心,以1为半径,特征值取值范围: [ 0 , 2 ] [0,2] [0,2]。而 L ~ \tilde L L~的盖尔圆是以 1 D i i \frac{1}{D_{ii}} Dii1为圆心,以 1 − 1 D i i 1-\frac{1}{D_{ii}} 1−Dii1为半径的,特征值取值范围: [ − 1 , 1 ] [-1,1] [−1,1]。
好的,恭喜你也学会GCN了,让我们来实现吧!
五、GCN的实现
卷积核:
class GCNConv(nn.Module):def __init__(self, in_channels, out_channles, use_bias=True):super(GCNConv, self).__init__()self.in_channels = in_channelsself.out_channles = out_channlesself.use_bias = use_biasself.weights = nn.Parameter(torch.Tensor(in_channels, out_channles))nn.init.xavier_normal_(self.weights)if(use_bias):self.bias = nn.Parameter(torch.FloatTensor(out_channles))else:self.register_parameter('bias', None)def forward(self, inputs, laplacian):# inputs: [B, N, in_channels]# outputs: [B, N, out_channels]outputs = torch.matmul(inputs, self.weights) # [B, N, out_channels]outputs = torch.matmul(laplacian, outputs) # [B, N, out_channels]if(self.use_bias):outputs += self.biasreturn outputs
网络:
class GCN(nn.Module):def __init__(self, in_channels, hidden_channels, out_channles, droput=0.5):super(GCN, self).__init__()self.conv1 = GCNConv(in_channels, hidden_channels)self.conv2 = GCNConv(hidden_channels, out_channles)self.dropout = droputdef forward(self, x, laplacian):outputs1 = self.conv1(x, laplacian)outputs1 = outputs1.relu()outputs1 = F.dropout(outputs1, p=self.dropout, training=self.training) outputs2 = self.conv2(outputs1, laplacian)outputs2 = F.softmax(outputs2, dim=2)return outputs2
renormalization trick后的拉普拉斯矩阵计算:
def get_laplacian(adj):I = torch.eye(adj.size(0), device=adj.device, dtype=adj.dtype)adj = adj + ID = torch.diag(torch.sum(adj, dim=-1) ** (-1 / 2))L = torch.mm(torch.mm(D, adj), D)return L
除了自己手写GCN卷积核以外,还可以使用torch_geometric中的GCNConv实现,此时传入的不再是拉普拉斯矩阵,而是所有的边集(edge index),包中会用一些针对拉普拉斯矩阵的稀疏性质的方法加速计算:
class GCN(nn.Module):def __init__(self, in_channels, hidden_channels, out_channles, droput=0.5):super(GCN, self).__init__()self.conv1 = GCNConv(in_channels, hidden_channels)self.conv2 = GCNConv(hidden_channels, out_channles)self.dropout = droputdef forward(self, x, edge_index):outputs1 = self.conv1(x, edge_index)outputs1 = outputs1.relu()outputs1 = F.dropout(outputs1, p=self.dropout, training=self.training) outputs2 = self.conv2(outputs1, edge_index)outputs2 = F.softmax(outputs2, dim=2)return outputs2
相关文章:
入门笔记(2)——从谱域理解图卷积,ChebNet和GCN实现)
图神经网络(GNN)入门笔记(2)——从谱域理解图卷积,ChebNet和GCN实现
一、谱域图卷积(Spectral Domain Graph Convolution) 与谱域图卷积(Spectral Domain Graph Convolution)对应的是空间域(Spatial Domain)图卷积。本节学习的谱域图卷积指的是通过频率来理解卷积的方法。 …...

接口类和抽象类在设计模式中的一些应用
C设计模式中,有些模式需要使用接口类(Interface Class)和抽象类(Abstract Class)来实现特定的设计目标。以下是一些常见的设计模式及其需要的原因,并附上相应的代码片段。 1. 策略模式(Strateg…...

【系统架构】如何演变系统架构:从单体到微服务
引言 随着企业的发展,网站架构必须不断演变以应对日益增长的用户流量和复杂性需求。本文将详细探讨从单体架构到微服务架构的演变过程,尤其关注订单和支付服务的实现方式,帮助您打造一个高效、可扩展的在线平台。 步骤1:分离应用…...

Neo4j入门:详解Cypher查询语言中的MATCH语句
Neo4j入门:详解Cypher查询语言中的MATCH语句 引言什么是MATCH语句?示例数据1. 基础节点查询查询所有节点按标签查询节点 2. 关系查询基础关系查询指定关系方向指定关系类型 3. 使用WHERE子句4. 使用参数5. 多重MATCH和WITH子句实用技巧总结 引言 大家好…...

CPP贪心算法示例
设有n个正整数(n ≤ 20),将它们联接成一排,组成一个最大的多位整数。 例如:n3时,3个整数13,312,343联接成的最大整数为:34331213 又如:n4时,4个整…...

GPT对NLP的冲击
让我来详细解释张俊林对GPT冲击NLP领域的分析: 中间任务(脚手架)的消失: 传统NLP中间任务: - 分词 - 词性标注 - 命名实体识别 - 句法分析 - 词向量学习为什么会消失: - GPT直接进行端到端学习 - 不需要人工定义的中间步骤 - 模…...

中值定理类证明题中对‘牛顿插值法’的应用
牛顿插值法是一种使用多项式插值的方法,它通过构造一个多项式来近似一组数据点。这种方法是由艾萨克牛顿提出的。牛顿插值法的一个优点是,当需要添加更多的数据点时,它不需要重新计算整个多项式,只需要对现有的多项式进行修改。...

HTMLCSS:3D 旋转卡片的炫酷动画
效果演示 这段代码是一个HTML和CSS的组合,用于创建一个具有3D效果的动画卡片。 HTML <div class"obj"><div class"objchild"><span class"inn6"><h3 class"text">我是谁?我在那<…...

Node.js 全栈开发进阶篇
🌈个人主页:前端青山 🔥系列专栏:node.js篇 🔖人终将被年少不可得之物困其一生 依旧青山,本期给大家带来node.js篇专栏内容:node.js- 全栈开发进阶篇 前言 大家好,我是青山。在上一篇文章中,…...

SQL语句-MySQL
数据定义声明 改变数据库语句 ALTER {DATABASE | SCHEMA} [db_name]alter_option ... ALTER {DATABASE | SCHEMA} db_nameUPGRADE DATA DIRECTORY NAMEalter_option: {[DEFAULT] CHARACTER SET [] charset_name| [DEFAULT] COLLATE [] collation_name } ALTER DATABASE使您能…...

Tencent Hunyuan3D
一、前言 腾讯于2024年11月5日正式开源了最新的MoE模型“混元Large”以及混元3D生成大模型“Hunyuan3D-1.0”,支持企业及开发者在精调、部署等不同场景下的使用需求。 GitHub - Tencent/Hunyuan3D-1 二、技术与原理 Hunyuan3D-1.0 是一款支持文本生成3D(…...

[ABC239E] Subtree K-th Max
[ABC239E] Subtree K-th Max 题面翻译 给定一棵 n n n 个节点的树,每个节点的权值为 x i x_i xi。 现有 Q Q Q 个询问,每个询问给定 v , k v,k v,k,求节点 v v v 的子树第 k k k 大的数。 0 ≤ x i ≤ 1 0 9 , 2 ≤ n ≤ 1 0 5 , …...
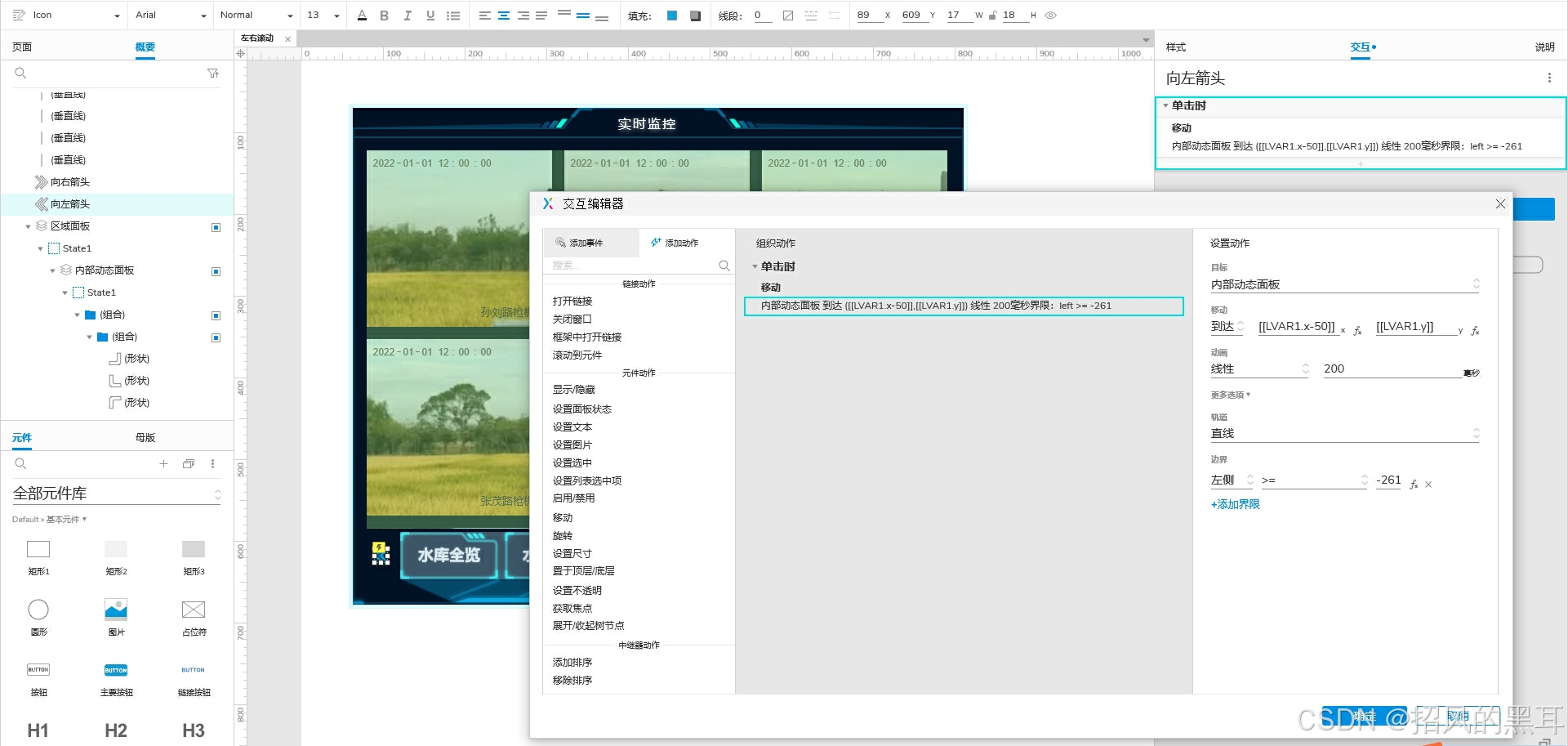
Axure设计之左右滚动组件教程(动态面板)
很多项目产品设计经常会遇到左右滚动的导航、图片展示、内容区域等,接下来我们用Axure来实现一下左右滚动的菜单导航。通过案例我们可以举一反三进行其他方式的滚动组件设计,如常见的上下滚动、翻页滚动等等。 一、效果展示: 1、点击“向左箭…...

善用Git LFS来降低模型文件对磁盘的占用
将讲一个实际的例子:对于模型文件,动辄就是好几个G,而有的仓库更是高达几十G,拉一个仓库到本地,稍不注意直接磁盘拉满都有可能。 比如:meta-llama-3.1-8b-instruct,拉到本地后发现居然占用了60G…...

Oracle RAC的thread
参考文档: Real Application Clusters Administration and Deployment Guide 3 Administering Database Instances and Cluster Databases Initialization Parameter Use in Oracle RAC Table 3-3 Initialization Parameters Specific to Oracle RAC THREAD Sp…...

如何创建备份设备以简化 SQL Server 备份过程?
SQL Server 中的备份设备是什么? 在 SQL Server 中,备份设备是用于存储备份数据的物理或逻辑介质。备份设备可以是文件、设备或其他存储介质。主要类型包括: 文件备份设备:通常是本地文件系统中的一个或多个文件。可以是 .bak 文…...

DeBiFormer实战:使用DeBiFormer实现图像分类任务(一)
摘要 一、论文介绍 研究背景:视觉Transformer在计算机视觉领域展现出巨大潜力,能够捕获长距离依赖关系,具有高并行性,有利于大型模型的训练和推理。现有问题:尽管大量研究设计了高效的注意力模式,但查询并…...

【go从零单排】迭代器(Iterators)
🌈Don’t worry , just coding! 内耗与overthinking只会削弱你的精力,虚度你的光阴,每天迈出一小步,回头时发现已经走了很远。 📗概念 在 Go 语言中,迭代器的实现通常不是通过语言内置的迭代器类型&#x…...

Java与HTML:构建静态网页
在Web开发领域,HTML是构建网页的基础标记语言,而Java作为一种强大的编程语言,也能够在创建HTML内容方面发挥重要作用。今天,我们就来探讨一下如何使用Java来制作一个不那么简单的静态网页。 一、项目准备 首先,我们需…...

软件测试:测试用例详解
🍅 点击文末小卡片,免费获取软件测试全套资料,资料在手,涨薪更快 一、通用测试用例八要素 1、用例编号; 2、测试项目; 3、测试标题; 4、重要级别; 5、预置…...
。】2022-5-15)
【根据当天日期输出明天的日期(需对闰年做判定)。】2022-5-15
缘由根据当天日期输出明天的日期(需对闰年做判定)。日期类型结构体如下: struct data{ int year; int month; int day;};-编程语言-CSDN问答 struct mdata{ int year; int month; int day; }mdata; int 天数(int year, int month) {switch (month){case 1: case 3:…...

Nuxt.js 中的路由配置详解
Nuxt.js 通过其内置的路由系统简化了应用的路由配置,使得开发者可以轻松地管理页面导航和 URL 结构。路由配置主要涉及页面组件的组织、动态路由的设置以及路由元信息的配置。 自动路由生成 Nuxt.js 会根据 pages 目录下的文件结构自动生成路由配置。每个文件都会对…...

服务器--宝塔命令
一、宝塔面板安装命令 ⚠️ 必须使用 root 用户 或 sudo 权限执行! sudo su - 1. CentOS 系统: yum install -y wget && wget -O install.sh http://download.bt.cn/install/install_6.0.sh && sh install.sh2. Ubuntu / Debian 系统…...

HDFS分布式存储 zookeeper
hadoop介绍 狭义上hadoop是指apache的一款开源软件 用java语言实现开源框架,允许使用简单的变成模型跨计算机对大型集群进行分布式处理(1.海量的数据存储 2.海量数据的计算)Hadoop核心组件 hdfs(分布式文件存储系统)&a…...

三分算法与DeepSeek辅助证明是单峰函数
前置 单峰函数有唯一的最大值,最大值左侧的数值严格单调递增,最大值右侧的数值严格单调递减。 单谷函数有唯一的最小值,最小值左侧的数值严格单调递减,最小值右侧的数值严格单调递增。 三分的本质 三分和二分一样都是通过不断缩…...

CVPR2025重磅突破:AnomalyAny框架实现单样本生成逼真异常数据,破解视觉检测瓶颈!
本文介绍了一种名为AnomalyAny的创新框架,该方法利用Stable Diffusion的强大生成能力,仅需单个正常样本和文本描述,即可生成逼真且多样化的异常样本,有效解决了视觉异常检测中异常样本稀缺的难题,为工业质检、医疗影像…...

深入浅出Diffusion模型:从原理到实践的全方位教程
I. 引言:生成式AI的黎明 – Diffusion模型是什么? 近年来,生成式人工智能(Generative AI)领域取得了爆炸性的进展,模型能够根据简单的文本提示创作出逼真的图像、连贯的文本,乃至更多令人惊叹的…...
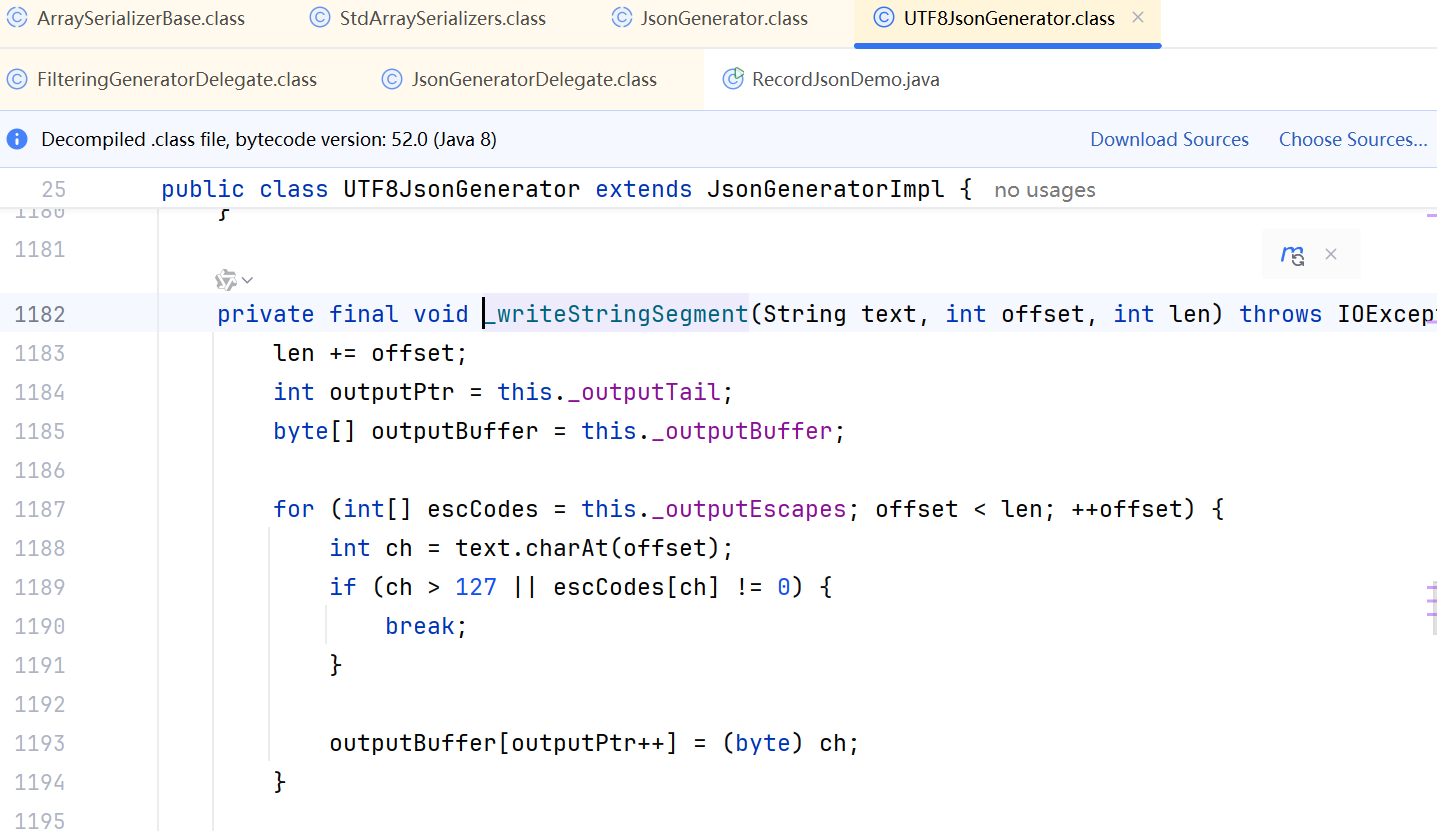
JDK 17 序列化是怎么回事
如何序列化?其实很简单,就是根据每个类型,用工厂类调用。逐个完成。 没什么漂亮的代码,只有有效、稳定的代码。 代码中调用toJson toJson 代码 mapper.writeValueAsString ObjectMapper DefaultSerializerProvider 一堆实…...
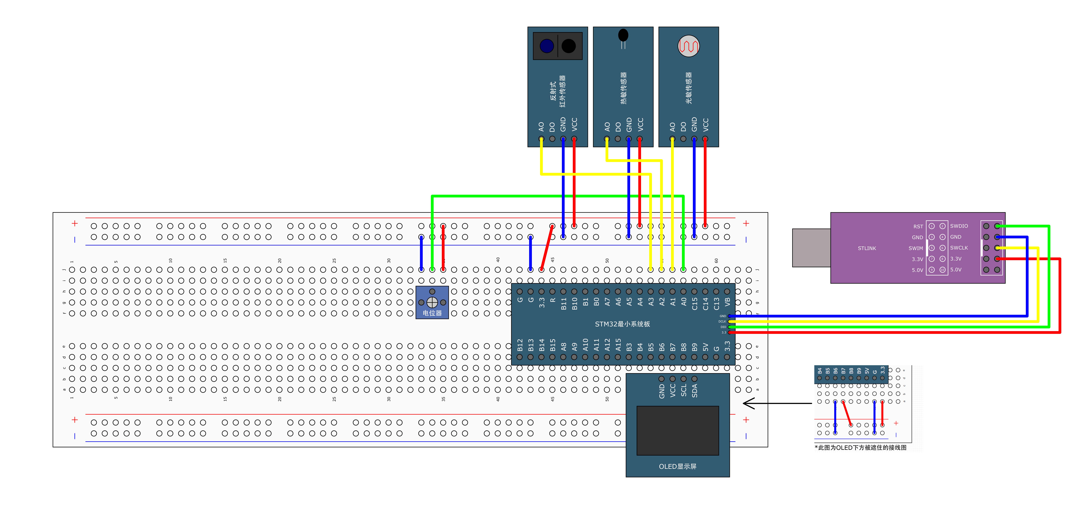
STM32标准库-ADC数模转换器
文章目录 一、ADC1.1简介1. 2逐次逼近型ADC1.3ADC框图1.4ADC基本结构1.4.1 信号 “上车点”:输入模块(GPIO、温度、V_REFINT)1.4.2 信号 “调度站”:多路开关1.4.3 信号 “加工厂”:ADC 转换器(规则组 注入…...
)
ArcPy扩展模块的使用(3)
管理工程项目 arcpy.mp模块允许用户管理布局、地图、报表、文件夹连接、视图等工程项目。例如,可以更新、修复或替换图层数据源,修改图层的符号系统,甚至自动在线执行共享要托管在组织中的工程项。 以下代码展示了如何更新图层的数据源&…...