【机器学习】强化学习(1)——强化学习原理浅析(区分强化学习、监督学习和启发式算法)
文章目录
- 强化学习介绍
- 强化学习和监督学习比较
- 监督学习
- 强化学习
- 强化学习的数学和过程表达
- 动作空间
- 序列决策
- 策略(policy)
- 价值函数(value function)
- 模型(model)
- 强化学习和启发式算法比较
- 强化学习步骤
- 代码走查
- 总结
- 标准强化学习和深度强化学习
- 标准强化学习
- 深度强化学习
写在前面:最近在了解马尔科夫决策,学习了很多启发式算法,对它的过程和原理大概有了一些了解和掌握,然而在看到一篇关于强化学习的文章时,搜索了相关知识,发现强化学习的概念和启发式算法很像,所以这里尽可能通俗、清晰地区分一下强化学习、深度强化学习、监督学习、启发式算法。由于之前对深度学习有了一些研究,所以本文的重点是结合其他方法的异同深入了解强化学习,文章的结构和路线就是我的思考路线。
强化学习介绍
强化学习(reinforcement learning,RL) 讨论的问题是智能体(agent)怎么在复杂、不确定的环境(environment)中最大化它能获得的奖励。强化学习由两部分组成:智能体和环境。在强化学习过程中,智能体与环境一直在交互。智能体在环境中获取某个状态后,它会利用该状态输出一个动作 (action),这个动作也称为决策(decision)。然后这个动作会在环境中被执行,环境会根据智能体采取的动作,输出下一个状态以及当前这个动作带来的奖励。智能体的目的就是尽可能多地从环境中获取奖励。

“强化学习研究的问题是智能体与环境交互的问题”,如下图,左边的智能体右边的环境进行交互。智能体把它的动作输出给环境,环境取得这个动作后会进行下一步,把下一步的观测与这个动作带来的奖励返还给智能体。这样的交互会产生很多观测,智能体的目的是从这些观测之中学到能最大化奖励的策略。

很早之前看过的一个博主发布的关于使用强化学习玩贪吃蛇游戏的视频印象特别深,也算是给我打开了强化学习的大门(链接:我用30天写了一个完美的贪吃蛇AI ),博主通过不断地添加奖励和惩罚方式训练贪吃蛇。
刚开始的奖惩机制是吃到果子+1、撞到墙或身体-1,贪吃蛇为了避免撞墙不停地转圈圈(up:“这是由于稀疏奖励问题,就是它拿到奖励的概率太低,AI如果乱走撞墙的可能性比吃到果子的概率大多了”)针对此问题添加了步长限制,在560步之内未吃到果子就扣分,蛇刚开始的吃果子表现很好,但是在蛇身长度变长之后,由于撞墙的概率很大,还是存在转圈圈的问题。添加规则“计算蛇头与果子的举例,接近果子加分、远离果子扣分”,分数比吃果子和撞墙的分值小很多,从而引导AI朝着果子走,同时具有允许绕路的长线思维,同时将原来的固定奖励改成动态的,“蛇越长,吃到果子的奖励越多,输掉游戏的扣分越少”……

强化学习和监督学习比较
监督学习
通常假设样本空间中全体样本服从一个未知分布,我们获得的每个样本都是独立地从这个分布上采样获得的,即独立同分布(independent and identically distributed,简称 i.i.d.)。输入的数据(标注的数据)都应是没有关联的。因为如果输入的数据有关联,学习器(learner)是不好学习的。需要告诉学习器正确的标签是什么,这样它可以通过正确的标签来修正自己的预测。
强化学习
强化学习得到的观测(observation)不是独立同分布的,上一帧与下一帧间有非常强的连续性。
以雅达利(Atari)游戏 Breakout 为例,这是一个打砖块的游戏,控制木板左右移动从而把球反弹到上面来消除砖块。智能体得到的数据是相关的时间序列数据,不满足独立同分布。另外,我们并没有立刻获得反馈,游戏没有告诉我们哪个动作是正确动作。比如现在把木板往右移,这只会使得球往上或者往左一点儿,我们并不会得到即时的反馈。因此,强化学习之所以困难,是因为智能体不能得到即时的反馈,然而我们依然希望智能体在这个环境中学习。

强化学习的训练数据就是一个玩游戏的过程。我们从第 1 步开始,采取一个动作,比如我们把木板往右移,接到球。第 2 步我们又做出动作,得到的训练数据是一个玩游戏的序列。比如现在是在第 3 步,我们把这个序列放进网络,希望网络可以输出一个动作,即在当前的状态应该输出往右移或者往左移。这里有个问题,我们没有标签来说明现在这个动作是正确还是错误的,必须等到游戏结束才可能知道,这个游戏可能 10s 后才结束。现在这个动作到底对最后游戏是否能赢有无帮助,我们其实是不清楚的。这里我们就面临延迟奖励(delayed reward)的问题,延迟奖励使得训练网络非常困难。
智能体获得自己能力的过程,其实是不断地试错探索(trial-and-error exploration)的过程。探索 (exploration)和利用(exploitation)是强化学习里面非常核心的问题。其中,探索指尝试一些新的动作, 这些新的动作有可能会使我们得到更多的奖励,也有可能使我们“一无所有”;利用指采取已知的可以获得最多奖励的动作,重复执行这个动作,因为我们知道这样做可以获得一定的奖励。因此,我们需要在探索和利用之间进行权衡,这也是在监督学习里面没有的情况。
到这里我有个问题,我们通过训练得到的是一种决策方式吗?
贪吃蛇的例子将强化学习和卷积神经网络结合起来,看起来更像是深度强化学习,通过训练得到一种通用决策。
上述的雅达利游戏也是,似乎是训练出来了一个聪明的玩家,从而能够在所有的弹球游戏中都有很好的表现。
那么标准强化学习究竟是在作什么工作?
而且得到的玩家以及他的通用决策究竟是如何训练和表示的呢?
强化学习的数学和过程表达
动作空间
不同的环境允许不同种类的动作。在给定的环境中,有效动作的集合经常被称为动作空间(action space)。贪吃蛇的环境有离散动作空间(discrete action space),在这个动作空间里,智能体的动作数量是有限的。在其他环境可能有连续动作空间(continuous action space),在连续动作空间中,动作是实值的向量。
例如,走迷宫机器人如果只有往东、往南、往西、往北这4种移动方式,则其动作空间为离散动作空 间;如果机器人可以向 360°中的任意角度进行移动,则其动作空间为连续动作空间。
序列决策
在一个强化学习环境里面,智能体的目的就是选取一系列的动作来最大化奖励,所以这些选取的动作 必须有长期的影响。但在这个过程里面,智能体的奖励其实是被延迟了的,就是我们现在选取的某一步动作,可能要等到很久后才知道这一步到底产生了什么样的影响。 比如在贪吃蛇游戏中,我们在游戏结束时才能得到最后的得分,过程中采取的“向前”、“向左”、“向右”的动作,并不会直接决定最后的总分。
在于环境交互的过程中,智能体会获得很多观测,针对每一个观测,智能体会采取一个动作,也会得到一个奖励。 比如贪吃蛇每次吃到果子都会加分或每距离果子更近一步就会加分,就是每个观测采取动作得到的奖励。所以强化学习里面有一个重要的课题就是近期奖励和远期奖励的权衡(trade-off),研究怎么让智能体取得更多的远期奖励。
(ps: 下图是我在参考文章的图基础上改的)

状态是对世界的完整描述,不会隐藏世界的信息。观测是对状态的部分描述,可能会遗漏一些信息。在深度强化学习中,我们几乎总是用实值的向量、矩阵或者更高阶的张量来表示状态和观测。例如,我们可以用RGB像素值的矩阵来表示一个视觉的观测,可以用机器人关节的角度和速度来表示一个机器人的状态。
- 历史是观测、动作、奖励的序列: H t = o 1 , a 1 , r 1 , . . . , o t , a t , r t H_{t}=o_{1}, a_{1}, r_{1}, ..., o_{t}, a_{t}, r_{t} Ht=o1,a1,r1,...,ot,at,rt,其中 o o o、 a a a、 r r r分别对应观测、动作、奖励。
- 智能体在采取当前动作的时候会依赖于它之前得到的历史,所以可以把整个游戏的状态看成关于这个历史的函数: S t = f ( H t ) S_{t}=f(H_{t}) St=f(Ht)
- 关于环境状态更新的函数: S t e = f e ( H t ) S_{t}^{e}=f^{e}(H_{t}) Ste=fe(Ht),表示当前环境的状态
- 智能体内部存在一个函数: S t a = f a ( H t ) S_{t}^{a}=f^{a}(H_{t}) Sta=fa(Ht),表示智能体所认识的当前环境的状态
当智能体能够观察到环境的所有状态时,我们称这个环境是完全可观测的(fully observed)。在这种情况下,强化学习通常被建模成一个马尔可夫决策过程(Markov decision process,MDP)的问题。即在马尔可夫决策过程中, o t = S t e = S t a o_{t}=S_{t}^{e}=S_{t}^{a} ot=Ste=Sta。
但是有一种情况是智能体得到的观测并不能包含环境运作的所有状态,因为在强化学习的设定里面, 环境的状态才是真正的所有状态。比如智能体在玩black jack(21点)游戏,它能看到的其实只有牌面上的牌。当智能体只能看到部分的状态,我们就称这个环境是部分可观测的(partially observed)。在这种情况下,强化学习通常被建模成部分可观测马尔可夫决策过程(partially observable Markov decision process, POMDP)的问题。部分可观测马尔可夫决策过程依然具有马尔可夫性质。部分可观测马尔可夫决策过程可以用一个七元组描述: ( S , A , T , R , Ω , O , γ ) (S,A,T,R,Ω,O,γ) (S,A,T,R,Ω,O,γ)。其中 S S S表示状态空间,为隐变量, A A A为动作空间, T ( s ′ ∣ s , a ) T(s′∣s,a) T(s′∣s,a)为状态转移概率, R R R为奖励函数, Ω ( o ∣ s , a ) Ω(o∣s,a) Ω(o∣s,a)为观测概率, O O O为观测空间, γ γ γ为折扣系数。
策略(policy)
策略是智能体的动作模型,决定了智能体的动作。它其实是一个函数,用于把输入的状态变成动作。
策略 π \pi π表示智能体在每个状态下选择行为的概率分布:
π ( a ∣ s ) = P [ a t = a ∣ s t = s ] \pi(a|s)=P[a_{t}=a|s_{t}=s] π(a∣s)=P[at=a∣st=s]
策略可分为两种:随机性策略和确定性策略。
- 随机性策略(stochastic policy)
输入一个状态 s s s,输出一个概率。这个概率是智能体所有动作的概率,然后对这个概率分布进行采样,可得到智能体将采取的动作。比如可能是有0.7的概率往左,0.3的概率往右,那么通过采样就可以得到智能体将采取的动作。 - 确定性策略(deterministic policy)
就是智能体直接采取最有可能的动作。
通常情况下,强化学习一般使用随机性策略,随机性策略有很多优点。比如,在学习时可以通过引入一定的随机性来更好地探索环境;随机性策略的动作具有多样性,这一点在多个智能体博弈时非常重要。采用确定性策略的智能体总是对同样的状态采取相同的动作,这会导致它的策略很容易被对手预测。
价值函数(value function)
智能体的目标是找到最优策略 π ∗ \pi^* π∗ ,使得从任意状态 s s s开始行动时,累积的期望回报 G t G_{t} Gt最大。
- 对于无折扣的情况,总回报为:
G t = R t + 1 + R t + 2 + R t + 3 + . . . = ∑ k = 0 ∞ R t + k + 1 G_{t}=R_{t+1}+R_{t+2}+R_{t+3}+...=\sum_{k=0}^{\infty}R_{t+k+1} Gt=Rt+1+Rt+2+Rt+3+...=∑k=0∞Rt+k+1 - 对于有折扣的情况,使用折扣因子 γ γ γ(其中 0 ≤ γ ≤ 1 0≤γ≤1 0≤γ≤1)来表示未来奖励的重要性,总回报为:
G t = R t + 1 + γ R t + 2 + γ 2 R t + 3 + . . . = ∑ k = 0 ∞ γ k R t + k + 1 G_{t}=R_{t+1}+γR_{t+2}+γ^{2}R_{t+3}+...=\sum_{k=0}^{\infty}γ^{k}R_{t+k+1} Gt=Rt+1+γRt+2+γ2Rt+3+...=∑k=0∞γkRt+k+1
这里, γ γ γ控制了未来奖励对当前回报的影响程度。当 γ γ γ越接近1,越重视长期奖励;当 γ γ γ越接近0,则更加关注短期奖励。
价值函数的值是对未来奖励的预测,用它来评估状态的好坏。价值函数有两种主要形式:
- 状态价值函数(State Value Function):表示在状态 s s s下,按照某一策略 π \pi π行动时,未来回报的期望值
V π ( s ) ≈ E π [ G t ∣ s t = s ] = E π [ ∑ k = 0 ∞ γ k R t + k + 1 ∣ s t = s ] V_{π}(s)≈\mathbb{E}_\pi[G_{t}|s_{t}=s]=\mathbb{E}_{\pi}\left[\sum_{k=0}^{\infty}γ^{k}R_{t+k+1}|s_{t}=s\right] Vπ(s)≈Eπ[Gt∣st=s]=Eπ[k=0∑∞γkRt+k+1∣st=s] - 动作价值函数(Action Value Function):表示在状态 s s s下采取动作 a a a并且随后按照某一策略 π \pi π行动时,未来回报的期望值
Q π ( s , a ) ≈ E π [ G t ∣ s t = s , a t = a ] = E π [ ∑ k = 0 ∞ γ k R t + k + 1 ∣ s t = s , a t = a ] Q_{π}(s, a)≈\mathbb{E}_\pi[G_{t}|s_{t}=s, a_{t}=a]=\mathbb{E}_{\pi}\left[\sum_{k=0}^{\infty}γ^{k}R_{t+k+1}|s_{t}=s, a_{t}=a\right] Qπ(s,a)≈Eπ[Gt∣st=s,at=a]=Eπ[k=0∑∞γkRt+k+1∣st=s,at=a]
利用Q函数,可以通过比较不同的 π \pi π和 a a a对应的 Q Q Q值知道进入某个状态后要采取的最优动作。
V π ( s ) V_{π}(s) Vπ(s)可以被视为在当前状态下所有可能动作的 Q π ( s , a ) Q_{π}(s, a) Qπ(s,a)的加权平均。
贝尔曼期望方程(Bellman Expectation Equation) 将价值函数表示为当前奖励与未来状态的价值之间的关系,即状态s下的价值等于当前行动得到的即时奖励加上下一未来状态的折扣价值。
模型(model)
模型表示智能体对环境的状态进行理解,它决定了环境中世界的运行方式。下一步的状态取决于当前的状态以及当前采取的动作,它由状态转移概率和奖励函数两个部分组成。(我的理解是,模型指的就是强化学习的学习过程,由奖励函数和状态转移概率来表示智能体是如何进行学习的)
- 状态转移概率: p s s ′ a = p ( s t + 1 = s ′ ∣ s t = s , a t = a ) p^{a}_{ss'}=p(s_{t+1}=s'|s_{t}=s, a_{t}=a) pss′a=p(st+1=s′∣st=s,at=a)
- 奖励函数: R ( s , a ) = E [ r t + 1 ∣ s t = s , a t = a ] R(s,a)=\mathbb{E}[r_{t+1}|s_{t}=s, a_{t}=a] R(s,a)=E[rt+1∣st=s,at=a]
价值函数是对某个决策状态下的行动价值进行估计的函数,它反映了在特定状态下采取某个动作的潜在汇报。而奖励函数是为了引导学习过程,给智能体在特定状态下采取某个动作提供立即的评估。奖励函数通常是通过人工定义的,而价值函数则可以通过学习得到。
强化学习和启发式算法比较
强化学习步骤
对数学表达有了进一步认识之后,下面来解决“强化学习学到的是什么”的问题。
为什么会有这个疑惑:因为神经网络最重要的就是每个隐藏层的表达式,通过学习更新权重和偏置参数到表现较好的值。学习的结果就是得到一个确定的(无未知数的)表达式,输入不同的数据到网络,经“表达式”处理,最终输出结果。
那么强化学习对应的“表达式”是什么?它更新的未知数又是什么?上述提到的概念是被如何使用的?
强化学习模型通过以下步骤工作:
- 环境状态:智能体在时刻 t t t的环境状态表示为 s t s_{t} st。
- 选择行为:智能体根据当前状态 s t s_{t} st选择一个行为 a t a_{t} at。
- 获得奖赏:智能体执行行为 a t a_{t} at后获得即时奖赏 r t r_{t} rt。
- 状态转移:智能体转移到下一个状态 s t + 1 s_{t+1} st+1。
- 策略更新:根据获得的奖赏和状态转移,更新策略 π \pi π,使得未来的奖赏最大化。
其实,我们最后学习到的“固定表达式”就是策略,存储了经学习后每个状态对应每个动作的概率。
举个走迷宫的例子,如下图:要求智能体从起点(start)开始,然后到达终点(goal)的位置。每走一步,我们就会得到 -1 的奖励。我们可以采取的动作是往上、下、左、右走。用智能体所在的位置来描述当前状态(因为迷宫游戏的特点就是,不需要关注前面路径的顺序,在某一个格子中总是有一个到达终点的最好选择,类似动态规划问题)。

可以用不同的强化学习方法来解这个环境。
如果我们采取 基于策略的强化学习(policy-based RL) 方法,当学习好了这个环境后,在每一个状态,都会得到一个最佳的动作。比如我们现在在起点位置,我们知道最佳动作是往右走;在第二格的时候,得到的最佳动作是往上走;第三格是往右走…通过最佳的策略,我们可以最快地到达终点。

如果换成 基于价值的强化学习(value-based RL) 方法,利用价值函数作为导向,会得到另外一种表征,每一个状态会返回一个价值。比如我们在起点位置的时候,价值是-16,表示我们最快可以 16步到达终点。因为每走一步会减1,所以这里的价值是-16。当我们快接近终点的时候,这个数字变得越来越大。在拐角的时候,比如现在在第二格,价值是-15,智能体会看上、下两格,它看到上面格子的价值变大了,变成 -14 了,下面格子的价值是 -16,那么智能体就会采取一个往上走的动作。

我以前一直因为觉得保存每个状态的数据量太太太太太太大了,存储成本很高,所以下意识以为将这些庞大的排列组合结果都存下来应该是不可能的,所以对于强化学习的结果一直不太理解。
实际上,神经网络的参数量也是非常庞大的。所以没什么需要担心的。
强化学习学习到的策略可以通过多种方式进行存储,主要包括使用经验缓存池(experience buffer)和利用数据结构如list、deque、dataset和dict进行数据管理。
- On-policy方法中通常使用list来存储数据。例如,在每个episode中,将状态、动作和奖励分别存储在列表中,训练时从列表中随机采样数据进行训练。
- Off-policy方法:可以使用经验缓存池(experience buffer),这种方法通过将多个episodes的经验存储在一个大的buffer中,使得数据可以被重复利用,从而提高学习效率和稳定性。
“episodes”(回合、情节)指的是智能体与环境之间的一系列交互,从初始状态开始,到终止状态结束。一个episode通常包含以下特点:
- 起始点:每个episode都是从一个初始状态开始,这个状态可以是随机选择的,也可以是固定的。
- 序列动作:智能体在每个状态下选择一个动作,然后环境根据这个动作和当前状态给出反馈。
- 反馈:智能体执行动作后,环境会提供一个反馈,包括立即奖励(instant reward)和新的状态。
- 终止条件:一个episode会在达到某个终止条件时结束。这个条件可以是达到一个特定的状态(比如目标状态),或者在episode中执行了一定数量的动作。
- 累积奖励:在episode过程中,智能体的目的是最大化累积奖励,即从初始状态到终止状态过程中获得的所有奖励之和。
- 经验学习:智能体在每个episode中通过与环境的交互学习,更新其策略或价值函数,以便在未来的episode中表现得更好。
On-policy方法 指的是智能体(Agent)在学习过程中,只使用当前策略生成的数据来更新策略。换句话说,智能体在生成数据(即选择动作和观察结果)时使用的策略与评估或改进策略时使用的策略是同一个。这种方法的优点是简单直观,因为它直接针对当前的策略进行优化,但缺点是可能较慢地探索到最优策略,因为它完全依赖于当前策略的行为。特点:
- 数据一致性:只使用当前策略生成的数据。
- 探索与利用:需要在探索(尝试新动作)和利用(重复已知的好动作)之间平衡。
- 代表性算法:SARSA(State-Action-Reward-State-Action)是典型的On-policy算法。
Off-policy方法 指的是智能体在学习过程中,可以使用与当前策略不同的策略生成的数据来更新策略。这意味着智能体可以利用过去的行为策略(behavior policy)生成的数据来改进目标策略(target policy)。这种方法的优点是可以更有效地利用数据,因为它允许智能体从不同的策略中学习,从而可能更快地收敛到最优策略。缺点是可能需要更复杂的算法来处理数据的偏差问题。特点:
- 数据灵活性:可以使用不同策略生成的数据。
- 目标策略与行为策略分离:目标策略是智能体想要学习的策略,而行为策略是智能体实际遵循的策略。
- 代表性算法:Q-learning和Deep Q-Networks(DQN)是典型的Off-policy算法。
代码走查
即便已经了解了上述概念,还是非常抽象。比如我是如何更新策略的?在我某一次的episode结束之后,我发现向上走更好,如何更新策略函数?
以“冰冻湖”(Frozen Lake)问题为例,智能体需要从起点出发,避开冰洞(hole),到达目标(goal)。使用Q学习(Q-Learning)算法解决。注意,这里的问题和代码均由AI生成,只是为了便于理解过程,我忽略了是否存在代码错误。
问题描述 :环境是一个4×4的网格,每个格子可以是“起始”、“目标”、“冰洞”或“冰面”。智能体每次可以向上、下、左、右移动。如果智能体掉入冰洞,它会得到-1的奖励,并回到起始的位置;如果智能体到达目标,它会得到+1的奖励,并结束游戏。智能体每次移动都会得到-0.01的惩罚,以鼓励更短的路径。
import gym # gym库用于强化学习
import numpy as np
import random# 创建冰冻湖环境
env = gym.make('FrozenLake-v0')# 初始化Q表,所有值设置为0
Q = np.zeros([env.observation_space.n, env.action_space.n])
"""
Q表包含了智能体在给定状态下采取不同行动的预期回报值。Q表的每一行代表一个状态,每一列代表在该状态下可以采取的一个行动,表格中的每个单元格Q[s,a]代表在状态s下采取行动a的Q值(行动值函数)。
"""# 设置学习参数
learning_rate = 0.8 # 学习率决定了新信息的权重(新信息对现有估计的影响程度)
discount_factor = 0.95 # 折扣因子,用于计算未来奖励的现值
epsilon = 0.1 # 探索率,决定了智能体随机探索的概率# 训练过程
episodes = 2000 # 训练的回合数
for i in range(episodes):state = env.reset() # 重置环境,获取初始状态done = False # 标志位,表示回合是否结束total_reward = 0 # 当前回合的总奖励while not done:# epsilon-greedy策略选择行动if random.uniform(0, 1) < epsilon:action = env.action_space.sample() # 探索:随机选择一个行动else:action = np.argmax(Q[state, :]) # 利用:选择Q值最大的行动# 执行行动,观察下一个状态和奖励next_state, reward, done, _ = env.step(action)"""这里没有定义next_state、reward、done的计算方式,需要按照问题描述中的规则新建类重写step方法。"""# 更新Q表Q[state, action] = (1 - learning_rate) * Q[state, action] + learning_rate * (reward + discount_factor * np.max(Q[next_state, :]))"""上式表示为:Q[s,a]=(1-α)*Q[s,a]+α*(r+γ*max(Q[s',*]))=Q[s,a]+α*(r+γ*max(Q[s',*])-Q[s,a])即原始Q表的基础上,加上新信息的影响。新信息的影响又根据当前的即时奖励+未来可能获得的最大Q值的影响-现有的总Q值。"""state = next_state # 更新状态total_reward += reward # 累加奖励if i % 100 == 0:print(f"Episode {i}: Total Reward = {total_reward}") # 每100个回合打印一次# 测试训练好的策略
test_episodes = 100 # 测试的回合数
wins = 0 # 获胜次数
for _ in range(test_episodes):state = env.reset() # 重置环境done = Falsewhile not done:action = np.argmax(Q[state, :]) # 使用训练好的策略state, reward, done, _ = env.step(action) # 执行行动if reward == 1:wins += 1 # 如果获胜,增加获胜次数print(f"Winning percentage after training = {wins/test_episodes * 100}%") # 打印训练后的获胜百分比更新策略部分的代码截取如下:
# 更新Q表Q[state, action] = (1 - learning_rate) * Q[state, action] + learning_rate * (reward + discount_factor * np.max(Q[next_state, :]))"""上式表示为:Q[s,a]=(1-α)*Q[s,a]+α*(r+γ*max(Q[s',*]))=Q[s,a]+α*(r+γ*max(Q[s',*])-Q[s,a])即原始Q表的基础上,加上新信息的影响。新信息的影响又根据当前的即时奖励+未来可能获得的最大Q值的影响-现有的总Q值。"""
从代码可以看出,策略是如何综合历史表现和新的学习。上述Q-Learning更新规则的依据有:
- 即时奖励( r r r):这是智能体在当前时间步获得的奖励,反映了采取当前行动的直接后果。
- 最大未来奖励的估计( m a x ( Q ( s ’ , ∗ ) ) max(Q(s’, *)) max(Q(s’,∗))):这是基于下一个状态 s ’ s’ s’,对所有可能行动的Q值取最大值。这个值代表了在下一个状态采取最优行动所能获得的期望回报。
- 折扣因子( γ γ γ):因为未来的奖励是不确定的,所以我们需要通过折扣因子来减少未来奖励对当前决策的影响。 γ γ γ接近1表示智能体更看重长期奖励,而 γ γ γ接近0则表示更看重短期奖励。
- 学习率( α α α):学习率决定了我们如何平衡旧Q值和新获得的信息。 α α α接近1表示我们更相信新的信息,而 α α α接近0则表示我们更相信旧的Q值。
总结
根据上述学习可以看出,强化学习是机器学习的一个子领域,可以通过训练得到一个“通用方法”,在多次训练之后,使得面对相同的问题,能够直接找到最好的策略。而启发式算法在每次运用的时候,都要执行算法的迭代过程,从而找到当前最优的结果。
启发式算法
启发式算法(Heuristic Algorithm)是基于直观或经验构造的算法,旨在在可接受的花费下给出待解决组合优化问题的可行解,但无法保证最优解。启发式算法通常依赖于特定的规则,适用于有明确规则的问题,但在处理动态优化问题时效果较差。
具体区别
- 问题建模:强化学习通过智能体与环境的交互学习最优策略,而启发式算法依赖于特定的规则。
- 反馈信号:强化学习通过长期的奖励信号进行优化,而启发式算法通常依赖于短期的反馈信号。
- 探索与开发:强化学习在探索和开发之间找到平衡,通过试错学习最优策略,而启发式算法更多地依赖于预设的规则进行探索和开发。
- 适用场景:强化学习适用于高维、复杂的状态和动作空间,而启发式算法更适用于有明确规则的问题。
- 实际应用场景:强化学习适用于需要长期优化和自适应的场景,如自动驾驶、机器人控制等。启发式算法:适用于有明确规则和短期优化的场景,如最短路径问题、调度问题等。
标准强化学习和深度强化学习
由于时间限制,以及资源有限,我凭借自己的理解解释一下二者的区别(还是以Q-Learning为例)。
标准强化学习
策略可以用Q表查询, Q [ s , a ] Q[s,a] Q[s,a]存储了每个状态和动作对应的Q值。在学习的过程中,最终得到一个这样的图。

某一时刻需要做出决策,使用Q表:

深度强化学习
深度强化学习就是把当前状态输入神经网络(策略网络),然后输出得到当前最优策略。学习过程就是训练神经网络参数的过程。其实策略网络的表达可以省略,但是这里为了更好地理解这个过程,我还是认真模拟了一下。仍以上面的某一时刻举例,假设输入的是5×5的矩阵,0表示无路、-1表示非当前位置,1表示当前位置。

选择下一步的动作时,将状态输入策略网络:

省略最后的SoftMax操作,输出得到移动到每个位置的概率,存储在形状为[1, 25]的矩阵中。(由于太久没有看深度学习了,不知道这里步骤有没有搞错的地方)。假设计算得到的矩阵为:

那么下一步的移动方案是向右一步。
【个人理解,欢迎指正】
参考来源:
我用30天写了一个完美的贪吃蛇AI
强化学习深入学习(一):价值函数和贝尔曼方程
什么是强化学习
什么是深度强化学习(DRL)?【知多少】
劝退强化学习/劝退一波研一入学想搞强化学习的同学/RL
关于我的强化学习模型不收敛这件事
她的强化学习模型终于收敛了
相关文章:
【机器学习】强化学习(1)——强化学习原理浅析(区分强化学习、监督学习和启发式算法)
文章目录 强化学习介绍强化学习和监督学习比较监督学习强化学习 强化学习的数学和过程表达动作空间序列决策策略(policy)价值函数(value function)模型(model) 强化学习和启发式算法比较强化学习步骤代码走…...

【SoC设计指南 基于Arm Cortex-M】学习笔记1——AMBA
AMBA简介 先进微控制器总线架构(Advanced Microcontroller Bus Architecture,AMBA)是用在arm处理器上的片上总线协议规范集。 AMBA总线协议规范集包含AHB、APB、AXI等。 AHB:先进高性能总线(Advanced High-performance Bus) APB&…...
)
flutter鸿蒙模拟器 Win环境调试报错问题记录(暂未解决)
前情提要: 1、flutter项目已经正确生成了ohos项目 2、flutter和鸿蒙的环境变量配置正确 3、ohos项目执行flutter build hap成功 4、没有真机,使用win环境创建的x86模拟器 问题状态 使用模拟器运行ohos,控制台提示“安装HAP 报 code:9568347错…...

详解Rust标准库:HashSet
## 查看本地官方文档安装rust后运行 rustup doc查看The Standard Library即可获取标准库内容 std::collections::hash_set::HashSet定义 HashSet是一种集合数据结构,它只存储唯一的元素。它主要用于检查元素是否存在于集合中,或者对元素进行去重操作&…...

记录学习react的一些内容
由于是在公司实际项目中学习,所以不是很完整 需要一点一点的学 1.React.useState 类似于vue中的ref 可以修改状态 但是是异步的 感觉不好用 const [wishData, setWishData] React.useState<any>(null); 只能使用setxxx来修改 2.useEffect(()>{},[]) 类…...

json绘制热力图
首先需要一段热力信息的json,我放在头部了。 然后就是需要de-geo库了。 实现代码如下: import * as d3geo from d3-geoimport trafficJSON from ../assets/json/traffic.jsonlet geoFun;// 地理投影函数// let info {max: Number.MIN_SAFE_INTEGER,mi…...

linux 下查看程序启动的目录
以azkaban为例 第一步、ps -ef | grep azkaban 查询出进程号 第二步、cd /proc/ 第三步 、cd 进程号 第四部 ll 查看详情 查看jar 位置 查看jar 启动命令...

书生浦语第四期基础岛L1G2000-玩转书生「多模态对话」与「AI搜索」产品
文章目录 一、MindSearch二、书生浦语三、书生万象四、进阶任务 一、MindSearch MindSearch 是一个开源的 AI 搜索引擎。它会对你提出的问题进行分析并拆解为数个子问题,在互联网上搜索、总结得到各个子问题的答案,最后通过模型总结得到最终答案。书生浦…...

保护Kubernetes免受威胁:容器安全的有效实践
安全并非“放之四海而皆准”的解决方案,相反地,它更多的是一个范围,受其应用的特定上下文的影响。安全领域的专业人士很少宣称什么产品是完全安全的,但总有方法可以实现更强的安全性。在本文中,我们将介绍各种方法来支…...

【客观理性深入讨论国产中间件及数据库-科创基础软件】
随着国产化的进程,越来越多的国企央企开始要求软件产品匹配过程化的要求, 最近有一家银行保险的科技公司对行为验证码产品就要求匹配国产中间件, 于是开始了解国产中间件都有哪些厂家 一:国产中间件主要产品及厂商 1 东方通&…...

MFC中Excel的导入以及使用步骤
参考地址 在需要对EXCEL表进行操作的类中添加以下头文件:若出现大量错误将其放入stdafx.h中 #include "resource.h" // 主符号 #include "CWorkbook.h" //单个工作簿 #include "CRange.h" //区域类,对Excel大…...

AWS S3在客户端应用不能使用aws-sdk场景下的文件上传与下载
简介 通常情况下,应用程序上传文件到AWS S3,会使用aws-sdk,但是有些情况下,客户端应用会有安装限制,比如不能安装aws-sdk,此时我们就需要通过其他方式实现文件上传与下载。 这里我们提供一个服务端&#…...

深入解析 Transformers 框架(四):Qwen2.5/GPT 分词流程与 BPE 分词算法技术细节详解
前面我们已经通过三篇文章,详细介绍了 Qwen2.5 大语言模型在 Transformers 框架中的技术细节,包括包和对象加载、模型初始化和分词器技术细节: 深入解析 Transformers 框架(一):包和对象加载中的设计巧思与…...

【Python-AI篇】K近邻算法(KNN)
0. 前置----机器学习流程 获取数据集数据基本处理特征工程机器学习模型评估在线服务 1. KNN算法概念 如果一个样本在特征空间中的K个最相似(即特征空间中最邻近)的样本中大多数属于某一个类别,则该样本也属于这一个类别 1.1 KNN算法流程总…...

aws xray如何实现应用log和trace的关联关系
参考资料 https://community.aws/tutorials/solving-problems-you-cant-see-using-aws-x-ray-and-cloudwatch-for-user-level-observability-in-your-serverless-microservices-applicationshttps://stackoverflow.com/questions/76000811/search-cloudwatch-logs-for-aws-xra…...

centos服务器登录失败次数设定
实现的效果 一台centos服务,如果被别人暴力或者登录次数超过多少次,就拒绝或者在规定时间内拒绝ip登录。这里使用的是fail2ban 安装fail2ban sudo yum install epel-release -y # 先安装 EPEL 源 sudo yum install fail2ban -y配置fail2ban # 复制默…...

实时高效,全面测评快递100API的物流查询功能
一、引言 你是否曾经在网购后焦急地等待包裹,频繁地手动刷新订单页面以获取最新的物流信息?或者作为一名开发者,正在为如何在自己的应用程序中高效地实现物流查询功能而发愁?其实,有一个非常好用的解决方案——快递10…...

第14张 GROUP BY 分组
一、分组功能介绍 使用group by关键字通过某个字段进行分组,对分完组的数据分别 “SELECT 聚合函数”查询结果。 1.1 语法 SELECT column, group_function(column) FROM table [WHERE condition] [GROUP BY group_by_expression] [ORDER BY column]; 明确&#…...
input子系统与相关框架)
笔记整理—linux驱动开发部分(10)input子系统与相关框架
关于输入类设备的系统有touch、按键、鼠标等,在系统中,命令行也是输入类系统。但是GUI的引入,不同输入类设备数量不断提升,带来麻烦,所以出现了struct input_event。 struct input_event {struct timeval time;//内核…...

[算法初阶]埃氏筛法与欧拉筛
素数的定义: 首先我们明白:素数的定义是只能整除1和本身(1不是素数)。 我们判断一个数n是不是素数时,可以采用试除法,即从i2开始,一直让n去%i,直到i*i<n c语言: #include<…...

力扣-35.搜索插入位置
题目描述 给定一个排序数组和一个目标值,在数组中找到目标值,并返回其索引。如果目标值不存在于数组中,返回它将会被按顺序插入的位置。 请必须使用时间复杂度为 O(log n) 的算法。 class Solution {public int searchInsert(int[] nums, …...

短视频矩阵系统文案创作功能开发实践,定制化开发
在短视频行业迅猛发展的当下,企业和个人创作者为了扩大影响力、提升传播效果,纷纷采用短视频矩阵运营策略,同时管理多个平台、多个账号的内容发布。然而,频繁的文案创作需求让运营者疲于应对,如何高效产出高质量文案成…...

安宝特案例丨Vuzix AR智能眼镜集成专业软件,助力卢森堡医院药房转型,赢得辉瑞创新奖
在Vuzix M400 AR智能眼镜的助力下,卢森堡罗伯特舒曼医院(the Robert Schuman Hospitals, HRS)凭借在无菌制剂生产流程中引入增强现实技术(AR)创新项目,荣获了2024年6月7日由卢森堡医院药剂师协会࿰…...

Java数值运算常见陷阱与规避方法
整数除法中的舍入问题 问题现象 当开发者预期进行浮点除法却误用整数除法时,会出现小数部分被截断的情况。典型错误模式如下: void process(int value) {double half = value / 2; // 整数除法导致截断// 使用half变量 }此时...

基于IDIG-GAN的小样本电机轴承故障诊断
目录 🔍 核心问题 一、IDIG-GAN模型原理 1. 整体架构 2. 核心创新点 (1) 梯度归一化(Gradient Normalization) (2) 判别器梯度间隙正则化(Discriminator Gradient Gap Regularization) (3) 自注意力机制(Self-Attention) 3. 完整损失函数 二…...

LLMs 系列实操科普(1)
写在前面: 本期内容我们继续 Andrej Karpathy 的《How I use LLMs》讲座内容,原视频时长 ~130 分钟,以实操演示主流的一些 LLMs 的使用,由于涉及到实操,实际上并不适合以文字整理,但还是决定尽量整理一份笔…...

[大语言模型]在个人电脑上部署ollama 并进行管理,最后配置AI程序开发助手.
ollama官网: 下载 https://ollama.com/ 安装 查看可以使用的模型 https://ollama.com/search 例如 https://ollama.com/library/deepseek-r1/tags # deepseek-r1:7bollama pull deepseek-r1:7b改token数量为409622 16384 ollama命令说明 ollama serve #:…...

解决:Android studio 编译后报错\app\src\main\cpp\CMakeLists.txt‘ to exist
现象: android studio报错: [CXX1409] D:\GitLab\xxxxx\app.cxx\Debug\3f3w4y1i\arm64-v8a\android_gradle_build.json : expected buildFiles file ‘D:\GitLab\xxxxx\app\src\main\cpp\CMakeLists.txt’ to exist 解决: 不要动CMakeLists.…...

华为OD机试-最短木板长度-二分法(A卷,100分)
此题是一个最大化最小值的典型例题, 因为搜索范围是有界的,上界最大木板长度补充的全部木料长度,下界最小木板长度; 即left0,right10^6; 我们可以设置一个候选值x(mid),将木板的长度全部都补充到x,如果成功…...
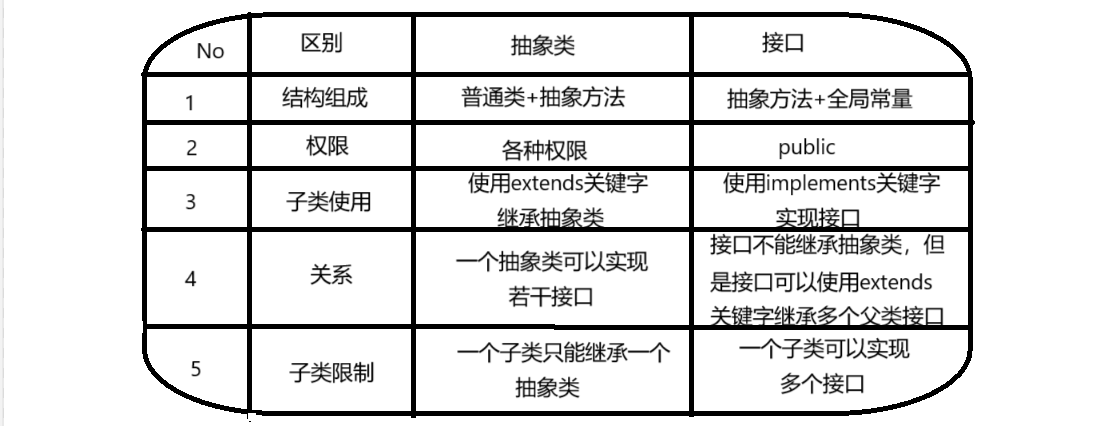
抽象类和接口(全)
一、抽象类 1.概念:如果⼀个类中没有包含⾜够的信息来描绘⼀个具体的对象,这样的类就是抽象类。 像是没有实际⼯作的⽅法,我们可以把它设计成⼀个抽象⽅法,包含抽象⽅法的类我们称为抽象类。 2.语法 在Java中,⼀个类如果被 abs…...