Python学习从0到1 day26 第三阶段 Spark ④ 数据输出
半山腰太挤了,你该去山顶看看
—— 24.11.10
一、输出为python对象
1.collect算子
功能:
将RDD各个分区内的数据,统一收集到Driver中,形成一个List对象
语法:
rdd.collect()返回值是一个list列表
示例:
from pyspark import SparkConf,SparkContext
import osconf = SparkConf().setMaster("local").setAppName("test_spark")
os.environ['PYSPARK_PYTHON'] = "E:/python.learning/pyt/scripts/python.exe"
sc = SparkContext(conf = conf)Set = {"小明","小红","小强"}
Tuple = ("小明","小红","小强")set_rdd = sc.parallelize(Set)
tuple_rdd = sc.parallelize(Tuple)print(set_rdd.collect())
print(tuple_rdd.collect())
2.reduce算子
功能:
对RDD数据集按照你传入的逻辑进行聚合
语法:
rdd.reduce(func)rdd = sc.parallelize(range(1 , 10))
# 将rdd的数据进行累加求和
print(rdd.reduce(lambda a , b : a + b))返回值等同于计算函数的返回值
示例:
from pyspark import SparkContext,SparkConf
import os
import jsonos.environ['PYSPARK_PYTHON'] = "E:/python.learning/pyt/scripts/python.exe"conf = SparkConf().setMaster("local").setAppName("test_spark")
sc = SparkContext(conf = conf)List = [1,2,3,4,5,6,7,8,9]
rdd = sc.parallelize(List)
print(rdd.reduce(lambda x, y : x + y))

3.take算子
功能:
取RDD的前N个元素,组合成list返回
语法:
sc.parallelize([3,2,1,4,5,6]).take(5) # [3,2,1,4,5]返回前n个元素组成的list
示例:
from pyspark import SparkContext,SparkConf
import os
import jsonos.environ['PYSPARK_PYTHON'] = "E:/python.learning/pyt/scripts/python.exe"
conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
sc = SparkContext(conf=conf)
List = (1,2,3,4,5,6,7,8,9)
rdd = sc.parallelize(List)
res = rdd.take(4)
print("前四个元素为:"+res)
4.count算子
功能:
计算RDD有多少条数据
语法:
sc.parallelize([3,2,1,4,5,6]).count()返回值是一个数字
示例:
from pyspark import SparkConf,SparkContext
import os
import jsonos.environ['PYSPARK_PYTHON'] = "E:/python.learning/pyt/scripts/python.exe"
conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
sc = SparkContext(conf=conf)rdd = sc.parallelize(["yyh","hl","grq","zxj","cby","wfe","mrr","qjy"])
print(rdd.count())
二、输出到文件中
1.saveAsTextFile算子
功能:
将RDD的数据写入文本文件中
支持本地写出、 hdfs等文件系统
语法:
rdd = sc.parallelize([1,2,3,4,5])
rdd.saveAsTextFile("../data/output/test.txt")2.配置Hadoop相关依赖
调用保存文件的算子,需要配置Hadoop依赖
① 下载Hadoop安装包
http://archive.apache.org/dist/hadoop/common/hadoop-3.0.0/hadoop-3.0.0.tar.gz② 解压到电脑任意位置

③ 在Python代码中使用os模块配置:
os.environ['HADOOP HOME']='HADOOP解压文件夹路径'
E:\python.learning\hadoop分布式相关\hadoop-3.0.0④ 下载winutils.exe,并放入Hadoop解压文件夹的bin目录内
https://raw.githubusercontent.com/steveloughran/winutils/master/hadoop-3.0.0/bin/winutils.exe
⑤ 下载hadoop.dll,并放入:C:/Windows/System32 文件夹内
https://raw.githubusercontent.com/steveloughran/winutils/master/hadoop-3.0.0/bin/hadoop.dll


3.代码示例
from pyspark import SparkConf,SparkContext
import osconf = SparkConf().setMaster("local").setAppName("test_spark")
os.environ['PYSPARK_PYTHON'] = "E:/python.learning/pyt/scripts/python.exe"
sc = SparkContext(conf = conf)# 准备RDD1
rdd1 = sc.parallelize([1,2,3,4,5])# 准备RDD2
rdd2 = sc.parallelize([("Hello, 3"),("Spark", 5),("Hi", 7)])# 准备RDD3
rdd3 = sc.parallelize([[1, 3, 5],[6, 7, 9],[11, 13, 11]])# 输出到文件中
rdd1.saveAsTextFile("E:\python.learning\hadoop分布式相关\data\output1/rdd1")
rdd2.saveAsTextFile("E:\python.learning\hadoop分布式相关\data\output2/rdd2")
rdd3.saveAsTextFile("E:\python.learning\hadoop分布式相关\data\output3/rdd3")

注:如果输出路径的文件存在,代码将会报错
4.运行结果




创建几个文件取决于Hadoop上的分区数量
解决方式:修改rdd的分区
5.修改rdd分区为1个
方式1
Sparkconf对象设置属性全局并行度为1:
from pyspark import SparkConf, SparkContext
import os
os.environ['PYSPARK_PYTHON'] = "E:/python.learning/pyt/scripts/python.exe"
os.environ['HADOOP_HOME'] = "E:\python.learning\hadoop分布式相关\hadoop-3.0.0"
conf = SparkConf().setMaster("local").setAppName("test_spark")
conf.set("spark.default.parallelize", "1")
sc = SparkContext(conf = conf)# 准备RDD1
rdd1 = sc.parallelize([1,2,3,4,5])# 准备RDD2
rdd2 = sc.parallelize([("Hello, 3"),("Spark", 5),("Hi", 7)])# 准备RDD3
rdd3 = sc.parallelize([[1, 3, 5],[6, 7, 9],[11, 13, 11]])# 输出到文件中
rdd1.saveAsTextFile("E:\python.learning\hadoop分布式相关\data\output1/rdd1")
rdd2.saveAsTextFile("E:\python.learning\hadoop分布式相关\data\output2/rdd2")
rdd3.saveAsTextFile("E:\python.learning\hadoop分布式相关\data\output3/rdd3")
方式2
创建RDD的时候设置 parallelize方法传入numSlices参数为1:
rdd1 = sc.parallelize([1,2,3,4,5],1)相关文章:
Python学习从0到1 day26 第三阶段 Spark ④ 数据输出
半山腰太挤了,你该去山顶看看 —— 24.11.10 一、输出为python对象 1.collect算子 功能: 将RDD各个分区内的数据,统一收集到Driver中,形成一个List对象 语法: rdd.collect() 返回值是一个list列表 示例: from …...

AWTK fscript 中的 JSON 扩展函数
fscript 是 AWTK 内置的脚本引擎,开发者可以在 UI XML 文件中直接嵌入 fscript 脚本,提高开发效率。本文介绍一下 fscript 中的 ** JSON 扩展函数 ** 1.json_load 加载 json 数据。 原型 json_load(str) > object json_load(binary) > object js…...

动态规划 —— dp 问题-买卖股票的最佳时机III
1. 买卖股票的最佳时机III 题目链接: 123. 买卖股票的最佳时机 III - 力扣(LeetCode)https://leetcode.cn/problems/best-time-to-buy-and-sell-stock-iii/description/ 2. 题目解析 3. 算法原理 状态表示:以某一个位置为结尾或者…...

“绽放艺术风采、激发强国力量” 海南省第十一届中小学生艺术展演活动圆满开展
2024年11月1日,由省教育厅主办、琼台师范学院承办的海南省第十一届中小学生艺术展演省级展演活动在海口正式拉开帷幕。来自全省各市县、省属学校等共计4000余名师生参加本届中小学生艺术展演现场展演活动。 本届展演活动以“绽放艺术风采、激发强国力量”为主题&…...
)
Linux之文件和目录类命令详解(2)
Linux之文件和目录类命令详解(2) 1、mv-移动文件或重命名2、find-查找文件和目录3、locate-快速查找文件4、du-显示目录或文件的磁盘使用情况5、df-显示文件系统的磁盘空间使用情况6、chmod-更改文件或目录的权限7、chown-更改文件或目录的拥有者8、tree…...

NVR管理平台EasyNVR多品牌NVR管理工具/设备摄像头开启ONVIF的方法
NVR小程序接入平台EasyNVR作为一款功能强大的安防视频监控平台,以其出色的兼容性和灵活性,在智慧校园、智慧工厂、智慧水利等多个场景中得到了广泛应用。本文将重点介绍如何为大华摄像头开启ONVIF协议,以便与EasyNVR进行无缝对接。 大华大部分…...

Pr 视频过渡:沉浸式视频
效果面板/视频过渡/沉浸式视频 Video Transitions/Immersive Video Adobe Premiere Pro 的视频过渡效果中,沉浸式视频 Immersive Video效果组主要用于 VR 视频剪辑之间的过渡。 自动 VR 属性 Auto VR Properties是所有 VR 视频过渡效果的通用选项。 默认勾选&#x…...

SwiftUI开发教程系列 - 第1章:简介与环境配置
1.1 SwiftUI简介 SwiftUI 是 Apple 于 2019 年推出的声明式用户界面框架,旨在简化 iOS、macOS、watchOS 和 tvOS 应用的 UI 开发。与 UIKit 的命令式编程方式不同,SwiftUI 提供了一种声明式语法,让开发者可以以更加直观、简洁的方式构建 UI。…...

gitlab ci/cd搭建及使用笔记
记录下使用gitlab的ci/cd的devops构建过程中,一些易忘点或者踩坑点: 官方文档中英文(建议英文) https://docs.gitlab.com/ee/ci/yaml/artifacts_reports.html https://gitlab.cn/docs/jh/ci/pipelines/schedules.html为什么创建了…...

Xcode 16 中 Swift Testing 的参数化(Parameterized)机制趣谈
概述 我们之前曾在 《用接地气的例子趣谈 WWDC 24 全新的 Swift Testing 入门》系列博文以及《WWDC24(Xcode 16)中全新的 Swift Testing 使用进阶》博文中较为系统地介绍了今年 WWDC 24 中全新的 Swift Testing 测试系统。 不过 Swift Testing 的本领远…...

Python自动化运维DevSecOps与安全自动化
Python自动化运维DevSecOps与安全自动化 目录 🛡️ DevSecOps概念与实践🔍 自动化安全扫描与漏洞修复🧰 基于Python的安全审计与合规性检查🐳 云平台与容器安全:基于Python的容器扫描工具⚠️ 自定义安全检测与漏洞修…...

2024下半年系统架构师考试【回忆版】
2024年11月10日,系统架构师考试如期举行,屡战屡败的参试倒是把北京的学校转了好几所。 本次考试时间 考试科目考试时间综合知识、案例分析8:30 - 12:30论文14:30 - 16:30 综合知识 1、1-1000以内包含5的数字个数 2、 案例分析 1、RESTful 对于前后…...

UE5.4 PCG 自定义PCG蓝图节点
ExecuteWithContext: PointLoopBody: 效果:点密度值与缩放成正比...

迁移学习相关基础
迁移学习 目标 将某个领域或任务上学习到的知识或模式应用到不同但相关的领域或问题中。 主要思想 从相关领域中迁移标注数据或者知识结构、完成或改进目标领域或任务的学习效果。 概述 Target data:和你的任务有直接关系的数据,但数据量少ÿ…...

华为云计算HCIE-Cloud Computing V3.0试验考试北京考场经验分享
北京试验考场 北京考场位置 1.试验考场地址 北京市海淀区北清路156号中关村环保科技示范园区M地块Q21楼 考试场选择北京,就是上面这个地址,在预约考试的时候会显示地址,另外在临近考试的时候也会给你发邮件,邮件内会提示你考试…...

数据分析——学习框架
✅作者简介:2022年博客新星 第八。热爱国学的Java后端开发者,修心和技术同步精进。 🍎个人主页:Java Fans的博客 🍊个人信条:不迁怒,不贰过。小知识,大智慧。 💞当前专栏…...

量化交易系统开发-实时行情自动化交易-3.4.2.Okex行情交易数据
19年创业做过一年的量化交易但没有成功,作为交易系统的开发人员积累了一些经验,最近想重新研究交易系统,一边整理一边写出来一些思考供大家参考,也希望跟做量化的朋友有更多的交流和合作。 接下来聊聊基于Okex交易所API获取行情数…...

pytorch实现深度神经网络DNN与卷积神经网络CNN
DNN概述 深度神经网络DNN来自人脑神经元工作的原理,通过在计算机中逻辑抽象出多个节点,接收处理并向后传递信息,实现计算机的自我学习,类比结构见下图: 该方法通过预测输出与实际值的差异不断调整节点参数࿰…...

芯片测试-LDO测试
LDO测试 💢LDO的简介💢💢压降💢💢决定压降的主要因素💢 💢LDO的分类及原理💢💢PMOS LDO💢💢PMOS LDO工作过程💢💢PMOS LDO…...

期权懂|期权新手看过来:看跌期权该如何交易?
期权小懂每日分享期权知识,帮助期权新手及时有效地掌握即市趋势与新资讯! 期权新手看过来:看跌期权该如何交易? 一、可以直接购买看跌期权: (1)选择预期下跌的标的资产。 (2&#…...

深入剖析AI大模型:大模型时代的 Prompt 工程全解析
今天聊的内容,我认为是AI开发里面非常重要的内容。它在AI开发里无处不在,当你对 AI 助手说 "用李白的风格写一首关于人工智能的诗",或者让翻译模型 "将这段合同翻译成商务日语" 时,输入的这句话就是 Prompt。…...
)
进程地址空间(比特课总结)
一、进程地址空间 1. 环境变量 1 )⽤户级环境变量与系统级环境变量 全局属性:环境变量具有全局属性,会被⼦进程继承。例如当bash启动⼦进程时,环 境变量会⾃动传递给⼦进程。 本地变量限制:本地变量只在当前进程(ba…...

如何将联系人从 iPhone 转移到 Android
从 iPhone 换到 Android 手机时,你可能需要保留重要的数据,例如通讯录。好在,将通讯录从 iPhone 转移到 Android 手机非常简单,你可以从本文中学习 6 种可靠的方法,确保随时保持连接,不错过任何信息。 第 1…...

《基于Apache Flink的流处理》笔记
思维导图 1-3 章 4-7章 8-11 章 参考资料 源码: https://github.com/streaming-with-flink 博客 https://flink.apache.org/bloghttps://www.ververica.com/blog 聚会及会议 https://flink-forward.orghttps://www.meetup.com/topics/apache-flink https://n…...

dify打造数据可视化图表
一、概述 在日常工作和学习中,我们经常需要和数据打交道。无论是分析报告、项目展示,还是简单的数据洞察,一个清晰直观的图表,往往能胜过千言万语。 一款能让数据可视化变得超级简单的 MCP Server,由蚂蚁集团 AntV 团队…...

今日学习:Spring线程池|并发修改异常|链路丢失|登录续期|VIP过期策略|数值类缓存
文章目录 优雅版线程池ThreadPoolTaskExecutor和ThreadPoolTaskExecutor的装饰器并发修改异常并发修改异常简介实现机制设计原因及意义 使用线程池造成的链路丢失问题线程池导致的链路丢失问题发生原因 常见解决方法更好的解决方法设计精妙之处 登录续期登录续期常见实现方式特…...

【Go语言基础【13】】函数、闭包、方法
文章目录 零、概述一、函数基础1、函数基础概念2、参数传递机制3、返回值特性3.1. 多返回值3.2. 命名返回值3.3. 错误处理 二、函数类型与高阶函数1. 函数类型定义2. 高阶函数(函数作为参数、返回值) 三、匿名函数与闭包1. 匿名函数(Lambda函…...

虚拟电厂发展三大趋势:市场化、技术主导、车网互联
市场化:从政策驱动到多元盈利 政策全面赋能 2025年4月,国家发改委、能源局发布《关于加快推进虚拟电厂发展的指导意见》,首次明确虚拟电厂为“独立市场主体”,提出硬性目标:2027年全国调节能力≥2000万千瓦࿰…...
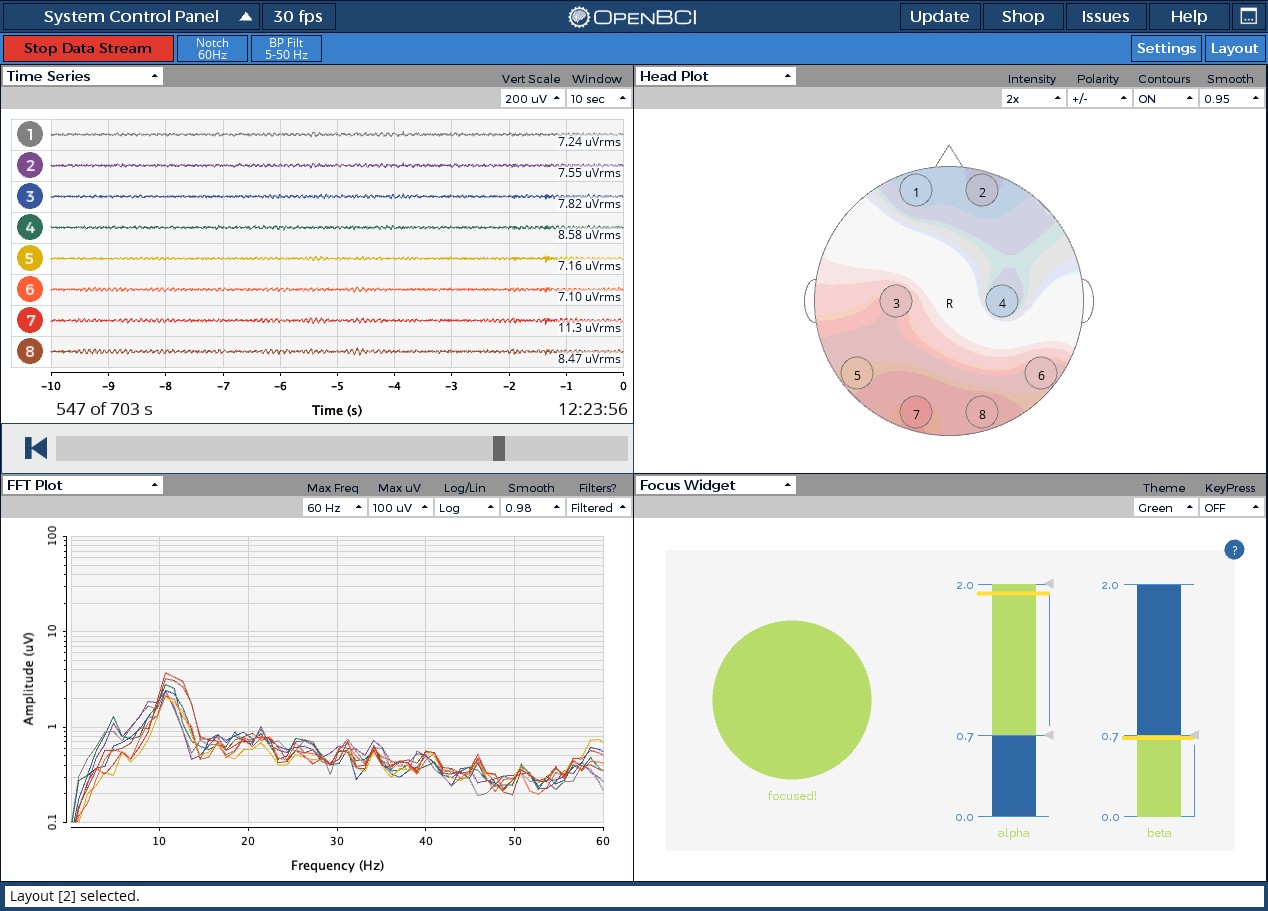
脑机新手指南(七):OpenBCI_GUI:从环境搭建到数据可视化(上)
一、OpenBCI_GUI 项目概述 (一)项目背景与目标 OpenBCI 是一个开源的脑电信号采集硬件平台,其配套的 OpenBCI_GUI 则是专为该硬件设计的图形化界面工具。对于研究人员、开发者和学生而言,首次接触 OpenBCI 设备时,往…...

【把数组变成一棵树】有序数组秒变平衡BST,原来可以这么优雅!
【把数组变成一棵树】有序数组秒变平衡BST,原来可以这么优雅! 🌱 前言:一棵树的浪漫,从数组开始说起 程序员的世界里,数组是最常见的基本结构之一,几乎每种语言、每种算法都少不了它。可你有没有想过,一组看似“线性排列”的有序数组,竟然可以**“长”成一棵平衡的二…...