分类模型评估:混淆矩阵、准确率、召回率、ROC
1. 混淆矩阵
在二分类问题中,混淆矩阵被用来度量模型的准确率。因为在二分类问题中单一样本的预测结果只有Yes or No,即:真或者假两种结果,所以全体样本的经二分类模型处理后,处理结果不外乎四种情况,每种情况都有一个专门称谓,如果用一个2行2列表格描述,得到的就是“混淆矩阵”,以下是遵循sklearn规范的混淆矩阵布局(本文地址:https://laurence.blog.csdn.net/article/details/129006571,转载请注明出处!):
| 预测为’假’ | 预测为’真’ | |
|---|---|---|
| 实际为’假’ | 真阴性 / TN (True Negative) | 假阳性 / FP (False Positive) |
| 实际为’真’ | 假阴性 / FN (False Negative) | 真阳性 / TP (True Positive) |
助记:
- 行:实际值,第1行:假,第2行:真;
- 列:预测值,第1列:假,第2列:真
- 主对角线:真阴、真阳,均以T开头
- 副对角线:假阳、假阴,均以F开头
| 名称 | 缩写 | 解释(1) | 解释(2) |
|---|---|---|---|
| 真阴性 | TN | 预测为阴,实测也为阴 | 预测为假,实测也为假 |
| 假阳性 | FP | 预测为阳,实测为阴(错报) | 预测为真,实测为假 |
| 假阴性 | FN | 预测为阴,实测为阳(漏报) | 预测为假,实测为真 |
| 真阳性 | TP | 预测为阳,实测也为阳 | 预测为真,实测也为真 |
其中,假阳性(FP)又被称为“Type 1 Error”,就是“错报”,假阴性(FN)又被称为“Type 2 Error”,就是“漏报”。混淆矩阵的4个值定义清晰,没有任何歧义,容易让人搞混的是混淆矩阵的布局,因为业界没有统一规定过在混淆矩阵中实际值和预测值谁应该是行谁应该是列,也没规定真假值/正负值谁应是第一行谁应是第二行,所以在不同的资料和程序库中就会出现行列结构或顺序相反的情况,所以要特别留意一下混淆矩阵的布局。本文遵循的是sklearn中定义的混淆矩阵结构,使用公式描述就是:
ConfusionMatrix=[TNFPFNTP]Confusion\ Matrix = \begin{bmatrix} {TN}&{FP}\\ {FN}&{TP}\\ \end{bmatrix}Confusion Matrix=[TNFNFPTP]
在《Hands-On ML》一书的第三章,就计算过针对图片(数字5)的二分类模型处理结果的混淆矩阵:

上述案例使用的是MNIST数据集,训练数据6万张图片(使用6万张图片训练,同时再使用它们进行评估),根据红框中的混淆矩阵可知:
- 实际不是数字5,模型预测也不是数字5(预测正确)的图片有:53892张
- 实际不是数字5,模型预测是数字5(预测错误)的图片有:687张
- 实际是数字5,模型预测不是数字5(预测错误)的图片有:1891张
- 实际是数字5,模型预测也是数字5(预测正确)的图片有:3530张
2. 准确率与召回率
在混淆矩阵的四个数据基础之上,人们还设计了两种常用的度量指标,分别是准确率和召回率:
-
准确率 ( Precision )
在所有“预测为真”(TP+FP)的样本中,有多少是“预测对了”(TP)的? 这个百分比叫准确率 ( Precision ),计算公式:
Precision=TPTP+FPPrecision=\frac{TP}{TP + FP}Precision=TP+FPTP -
召回率 ( Recall )
在所有“实际为真”(TP + FN)的样本中,有多少是“预测对了”(TP)的? 这个百分比叫召回率 ( Recall ),计算公式:
Recall=TPTP+FNRecall=\frac{TP}{TP + FN}Recall=TP+FNTP
在《Hands-On ML》一书的第三章,给出了一张图,清晰明了地阐述了混淆矩阵、准确率、召回率三者之间的关系:
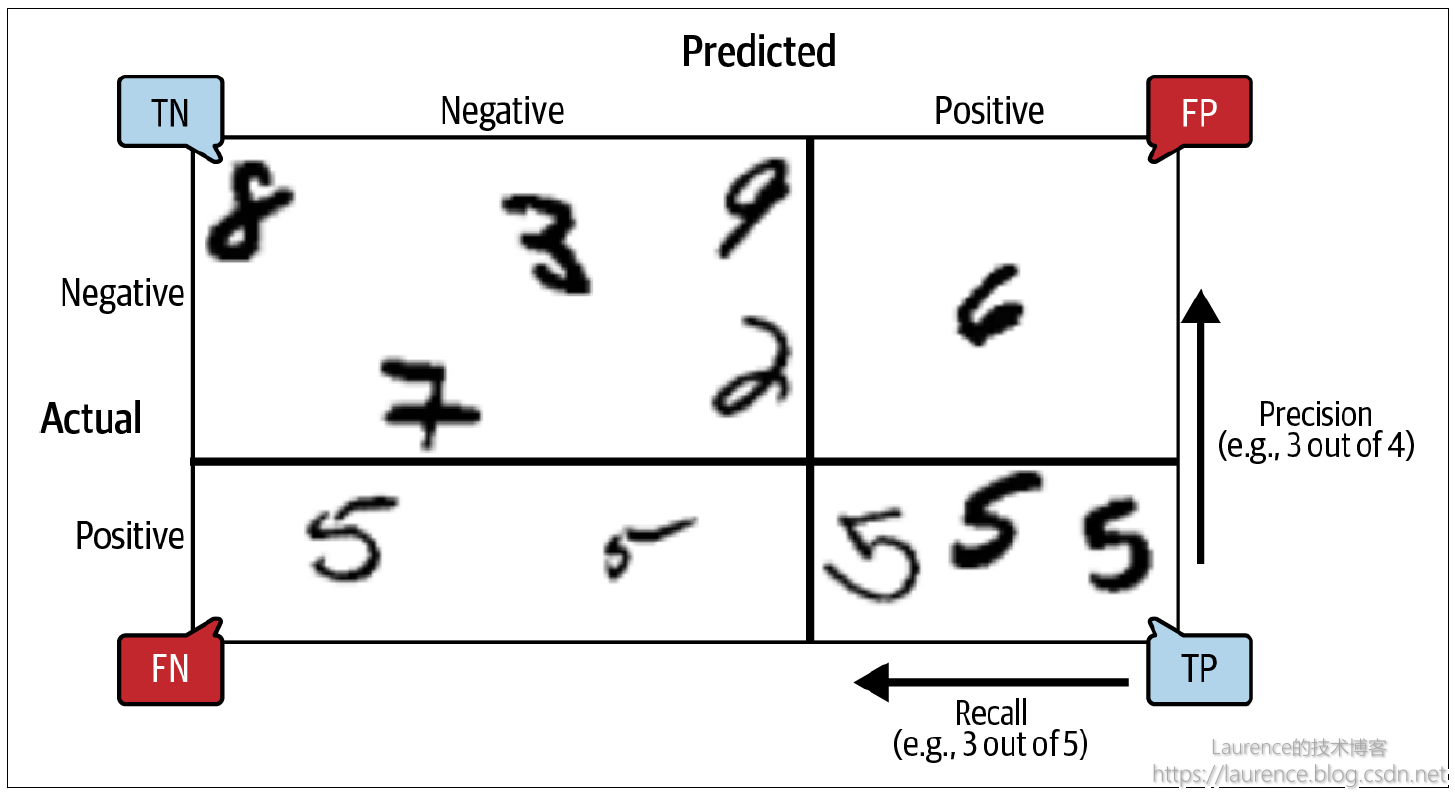
注意:该图4个象限的布局对应Sklearn中的混淆矩阵的布局。网上有的资料介绍混淆矩阵使用的4象限图表
未必与本图一致,它们对于行列是实际值还是预测值的定义可能是反的,对于真假值/正负值谁是第一行谁是二行的定义可能是反的,请一定注意区分!
3. 准确率与召回率之间的权衡
人们之所以会定义“准确率”和“召回率”这两个概念,是因为它们能从两个不同的维度(或者说角度)度量二分类模型的准确性,且在不同的场景里,人们对这两个指标的看重程度是不一样的。引用《Hands-On ML》一书给出的两个例子:
-
案例一: 过滤少儿不宜的视频
在这个场景中,模型的任务是:判定视频是否适合儿童观看,True表示健康视频,False表示少儿不宜。在该场景下模型应该追求的是:宁可将部分健康视频错误地认定为少儿不宜,也要最大限度地保证认定为健康的视频一定是健康的,这是典型的“优先保证高准确率,允许牺牲一定召回率”的场景。
-
案例二:识别商超监控中的盗窃行为
在这个场景中,模型的任务是:判定视频中的人是否有盗窃行为,True表示有,False表示无。在该场景下模型应该追求的是:宁可将部分正常行为的视频错误地认定为了盗窃,也要最大限度地保证所有盗窃行为都能被识别出来,这是典型的“优先保证高召回率,允许牺牲一定准确率”的场景。
很多时候,鱼和熊掌不可兼得,在模型调至最优状态时,依然要在“准确率”与“召回率”之间作出“权衡”,它们之间是“此消彼长”的博弈关系,通过调整阈值是可以调节两者的大小的。我们以《Hands-On ML》第三章“识别数字5”的图片二分类结果为例解释的“准确率”与“召回率”之间的“权衡”或者“博弈”关系:
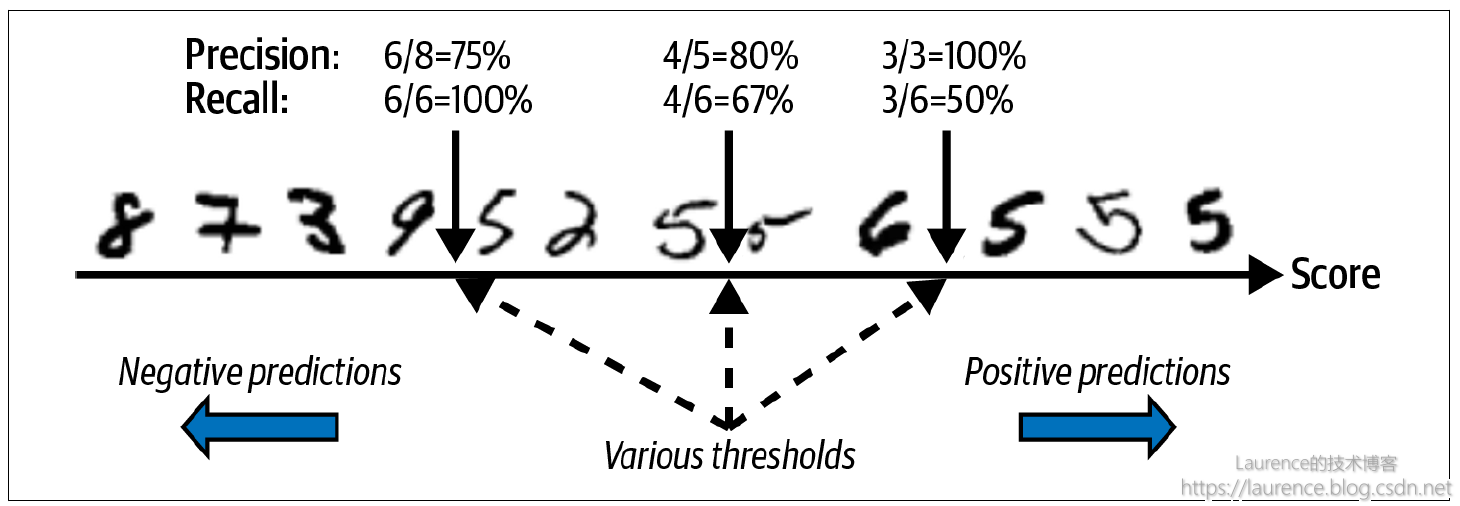
首先,图中12张数字图片的排序不是随机的,而是根据模型给它们的“评分”按从小到大的顺序在Score数轴上依次排列的。这里是“准确率”与“召回率”之间可调的关键,因为虽然二分类模型给出的是一个Yes or No的二元结果,但在模型内部其实为维护的是一个“量值”,通过调节“阈值”的大小,可以决定最终输出的是Yes还是No,这会影响一个“不是很容易分辨的样本”最后被划定成FP还是FN(TP和TN的分值一般会很高或很低,受阈值调整的影响不大,这很容易理解)。以图示的情况为例:
-
情形一:阈值设定在数轴左侧图片9和5的得分之间(暂不考虑具体数值),则右侧8张图片均会被判定为True,8张图片中实际有两个数字2和6被错误判定了,所以
准确率=6/8=75%;同时,在总计6张的数字5图片中,该阈值设定下,全部6张数字5的图片都被判定为True,所以召回率=6/6=100% -
情形二:阈值设定在数轴中间两张图片5的得分之间(暂不考虑具体数值),则右侧5张图片均会被判定为True,5张图片中实际有1个数字6被错误判定了,所以
准确率=4/5=80%;同时,在总计6张的数字5图片中,该阈值设定下,只有4张数字5的图片都被判定为True,所以召回率=4/6=67% -
情形三:阈值设定在在数轴右侧图片6和5的得分之间(暂不考虑具体数值),则右侧3张图片均会被判定为True,3张图片全部正确判定,所以
准确率=3/3=100%;同时,在总计6张的数字5图片中,该阈值设定下,只有3张数字5的图片都被判定为True,所以召回率=3/6=50%
从上述三次阈值的调节中我们可以清晰观察到:“准确率”和“召回率”之间此消彼长的博弈关系。
关于上述解释中所说的“评分”,专业名称叫“Confidence Score”,分值越高表示结果为True的可能性越大。在Sklearn中使用SGDClassifier.decision_function(X)方法可以计算出给定样本的评分,下图是书中针对某一个数字5的图片计算score的示例代码:

4. 如何设定期望的准确率与召回率?
就像前面介绍的两个案例一样,不同的情形下,人们对于模型的准确率与召回率的期望是不同的,而通过设定Score的阈值,我们就可以调整模型预测的准确率和召回率。我们可以自行推导一下寻找期望的准确率和召回率组合的方法:
假设有1000个样本,首先,计算出所有样本的Confidence Score,按分值从小到大排好,以每一个score作为阈值,计算对应的准确率和召回率,这样就会得出准确率和召回率伴随阈值变化的曲线,可以想见:当阈值取最小的score时,全部样本都会被判定为True,所以召回率将是100%,而准确率会非常低,而当阈值取到最大的score时,全部样本都会被判定为False,此时召回率将降为0,准确率会趋向于无穷大。为此,Sklearn专门提供了一个函数sklearn.metrics.precision_recall_curve(官方文档)用于计算一组样本+对应成绩的准确率和召回率曲线,下图是《Hands-On ML》一书利用这个函数绘制的数字5的准确率和召回率变化曲线:
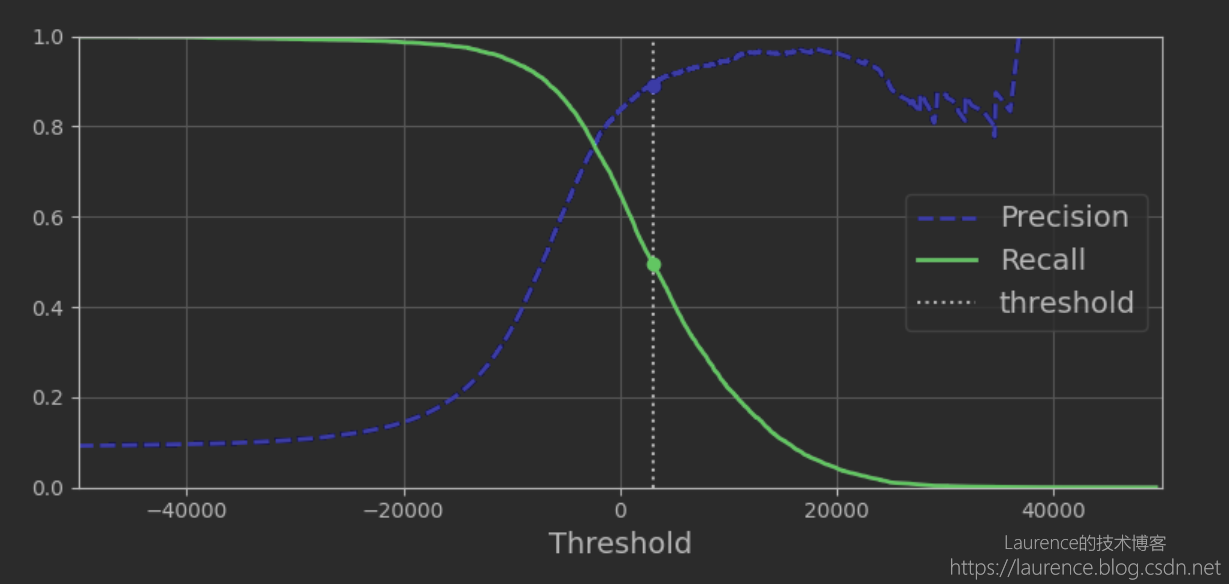
这张图已经把阈值变化对准确率和召回率的影响描述地非常清晰了,从这张图上也能清晰地看出准确率和召回率之间的“此消彼长”的博弈关系。此外,我们还可以观察准确率和召回率之间的变化关系,就是以Recall为横坐标,Precision为纵坐标绘制的曲线,一般称之为Precision-Recall曲线,下图是《Hands-On ML》针对上述准确率和召回率数据绘制的两者变化关系,这张图提供了一些额外的“信息”,我们可以从中发现:一但准确率低于80%以后就会急剧下降,当然,这也意味着召回率是在急剧上升。

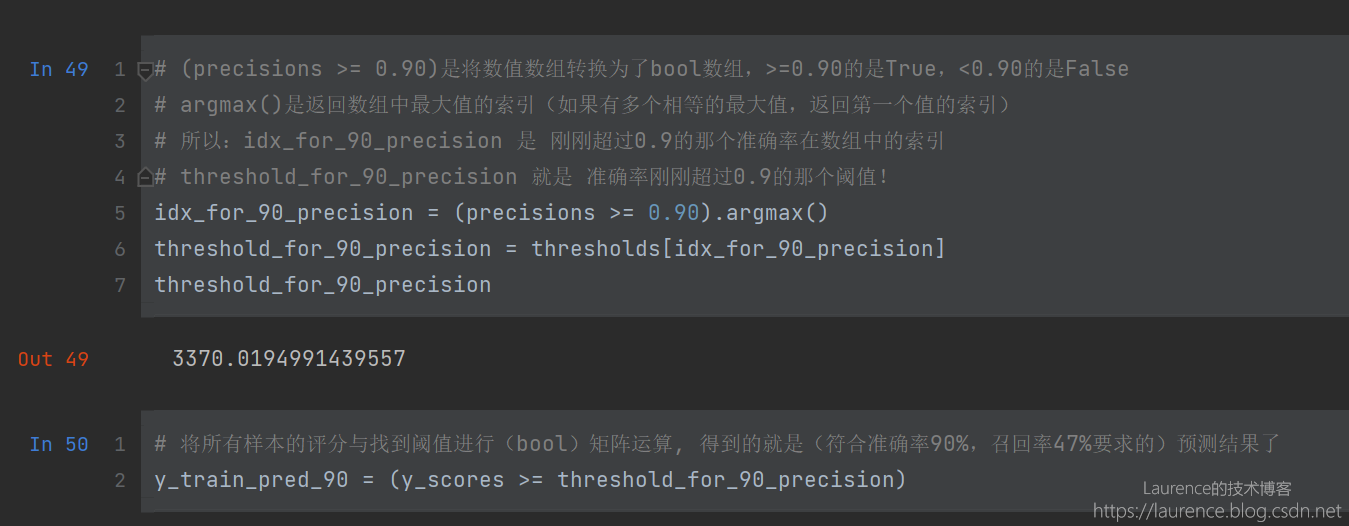
假设我们最终选择了:准确率90% + 召回率50% 的组合,接下来的工作就是找出它们所对应的阈值,然后将这个阈值设置给模型产出符合预期的预测结果。但是,这里有一个不问题,那就是:Sklearn其实并不提供修改其内部阈值的接口(不允许用户直接修改),怎么办呢?非常简单,我们只需要拿到score数组,然后和自己设定的threshold值进行矩阵逻辑计算,就可以轻松获得最终的判定结果:布尔数组,就是下面的做法:
5. ROC
ROC的全称是“受试者工作特征”(Receiver Operating Characteristic)曲线,是另一种评判分类模型结果好坏的一方法。ROC曲线与Precision-Recall曲线类似,也是用两个比值作为横纵坐标绘制的曲线,这两个比值分别是:
-
假阳性率 ( False Positice Rate,FPR )
在所有“实际为假”(FP+TN)的样本中,有多少是“预测错了”(FP)的? 这个百分比叫假阳性率(FPR),计算公式:
FalsePositiveRate(FPR)=FPFP+TNFalse\ Positive \ Rate\ (FPR)= \frac{FP}{FP+TN}False Positive Rate (FPR)=FP+TNFP -
真阳性率 ( True Positive Rate,TPR )
在所有“实际为真”(TP + FN)的样本中,有多少是“预测对了”(TP)的? 这个百分比叫真阳性率(TPR),其实也就是召回率(Recall),计算公式:
TruePositiveRate(TPR)=TPTP+FNTrue \ Positive \ Rate\ (TPR)= \frac{TP}{TP+FN}True Positive Rate (TPR)=TP+FNTP
而ROC曲线就是以假阳性率(FPR)为横坐标,真阳性率(TPR)为纵坐标绘制的曲线:

其实前面已经介绍过好几种度量分类模型效果的指标了,ROC有什么特别之处呢?
TBD…
6. 概念汇总
-
准确率 ( Precision )
在所有“预测为真”(TP+FP)的样本中,有多少是“预测对了”(TP)的? 这个百分比叫准确率 ( Precision ),计算公式:
Precision=TPTP+FPPrecision=\frac{TP}{TP + FP}Precision=TP+FPTP -
召回率 ( Recall )
在所有“实际为真”(TP + FN)的样本中,有多少是“预测对了”(TP)的? 这个百分比叫召回率 ( Recall ),其实也就是真阳性率 ( True Positive Rate,TPR ),计算公式:
Recall=TPTP+FNRecall=\frac{TP}{TP + FN}Recall=TP+FNTP -
真阳性率 ( True Positive Rate,TPR )
在所有“实际为真”(FN + TP)的样本中,有多少是“预测对了”(TP)的? 这个百分比叫真阳性率(TPR),其实也就是召回率(Recall),计算公式:
TruePositiveRate(TPR)=TPFN+TPTrue \ Positive \ Rate\ (TPR)= \frac{TP}{FN + TP}True Positive Rate (TPR)=FN+TPTP -
真阴性率 ( True Negative Rate,TNR )
在所有“实际为假”(TN + FP)的样本中,有多少是“预测对了”(TN)的? 这个百分比叫真阴性率(TNR),计算公式:
TrueNegativeRate(TPR)=TNTN+FPTrue \ Negative \ Rate\ (TPR)= \frac{TN }{TN + FP}True Negative Rate (TPR)=TN+FPTN -
假阳性率 ( False Positice Rate,FPR )
在所有“实际为假”(TN + FP)的样本中,有多少是“预测错了”(FP)的? 这个百分比叫假阳性率(FPR),计算公式:
FalsePositiveRate(FPR)=FPTN+FPFalse\ Positive \ Rate\ (FPR)= \frac{FP}{TN + FP}False Positive Rate (FPR)=TN+FPFP -
假阴性率 ( False Negative Rate,FNR )
在所有“实际为真”(FN + TP)的样本中,有多少是“预测错了”(FN)的? 这个百分比叫假阴性率(TNR)
FalseNegativeRate(FNR)=FNFN+TPFalse\ Negative \ Rate\ (FNR)= \frac{FN}{FN+TP}False Negative Rate (FNR)=FN+TPFN
以上所有概念,只有准确率是以预测数据为参照(作分母)进行度量的,真阳性率、真阴性率、假阳性率、假阴性率都是以实际数据为参照(作分母)进行度量的。以下是它们之间存在的一些关系:
召回率(Recall)=真阳性率(TPR)召回率 ( Recall ) = 真阳性率 ( TPR ) 召回率(Recall)=真阳性率(TPR)
真阳性率(TPR)+假阴性率(FNR)=1真阳性率 ( TPR ) + 假阴性率( FNR )= 1 真阳性率(TPR)+假阴性率(FNR)=1
真阴性率(TNR)+假阳性率(FPR)=1真阴性率 ( TNR ) + 假阳性率( FPR )= 1 真阴性率(TNR)+假阳性率(FPR)=1
参考资料:
机器学习之分类性能度量指标 : ROC曲线、AUC值、正确率、召回率
相关文章:
分类模型评估:混淆矩阵、准确率、召回率、ROC
1. 混淆矩阵 在二分类问题中,混淆矩阵被用来度量模型的准确率。因为在二分类问题中单一样本的预测结果只有Yes or No,即:真或者假两种结果,所以全体样本的经二分类模型处理后,处理结果不外乎四种情况,每种…...
算法 ——世界 一
个人简介:云计算网络运维专业人员,了解运维知识,掌握TCP/IP协议,每天分享网络运维知识与技能。个人爱好: 编程,打篮球,计算机知识个人名言:海不辞水,故能成其大;山不辞石…...

2023年3月AMA-CDGA/CDGP数据治理认证考试这些城市可以报名
目前2023年3月5日CDGA&CDGP开放报名的城市有:北京、上海、广州、深圳、杭州、重庆,西安,成都,长沙,济南,更多考场正在增加中… DAMA认证为数据管理专业人士提供职业目标晋升规划,彰显了职业…...

Java变量和数据类型,超详细整理,适合新手入门
目录 一、什么是变量? 二、变量 变量值互换 三、基本数据类型 1、八种基本数据类型 2、布尔值 3、字符串 四、从控制台输入 一、什么是变量? 变量是一种存储值的容器,它可以在程序的不同部分之间共享;变量可以存储数字、字…...

Echarts 设置折线图拐点的颜色,边框等样式,hover时改变颜色
第014个点击查看专栏目录上一篇文章我们讲到了如何设置拐点大小,图形类型,旋转角度,缩放同比,位置偏移等,这篇文章介绍如何设置拐点的颜色、边框大小颜色等样式。hover轴线时候,拐点的填充颜色改变文章目录示例效果示例…...

做 SQL 性能优化真是让人干瞪眼
很多大数据计算都是用SQL实现的,跑得慢时就要去优化SQL,但常常碰到让人干瞪眼的情况。 比如,存储过程中有三条大概形如这样的语句执行得很慢: select a,b,sum(x) from T group by a,b where …; select c,d,max(y) from T grou…...

SpringBoot(3)之包结构
根据spring可知道,注解之所以可以使用,是因为通过包扫描器,扫描包,然后才能通过注解开发。 那么springboot需要扫描哪里呢? springboot的默认包扫描器,扫描的是自己所在的包和子包,例子如下 我…...

test2
物理层故障分析 一、传输介质故障 a.主要用途简述 传输介质主要分为 导向传输介质和非导向传输介质。前者包括双绞线(两根铜线并排绞合,距离过远会失真)、同轴电缆(铜质芯线屏蔽层,抗干扰性强,传输距离更…...

LoadRunner安装教程
备注:电脑最好安装有IE浏览器或者360极速版浏览器 一、下载安装包 提前下载安装文件,必须下载。 链接: https://pan.baidu.com/s/1blFiMIJcoE8s3uVhAxdzdA?pwdqhpt 提取码: qhpt 包含的文件有: 二、安装loadrunner 注意,以…...
VHDL语言基础-Testbech
目录 VHDL仿真概述: 基本结构: VHDL一般仿真过程: 仿真测试平台文件: 编写测试平台文件的语言: 一个测试平台文件的基本结构如下: 测试平台文件包含的基本语句: 产生激励信号的方式: 时钟信号: 复位信号: 周期信性信号: 使用延迟DELAYD: 一般的激励信号…...
机器学习基础总结
一,机器学习系统分类 机器学习系统分为三个类别,如下图所示: 二,如何处理数据中的缺失值 可以分为以下 2 种情况: 缺失值较多:直接舍弃该列特征,否则可能会带来较大噪声,从而对结果造成不良影…...
linux的三权分立设计思路和用户创建(安全管理员、系统管理员和审计管理员)
目录 一、三权分立设计思路 1、什么是三权 2、三员及权限的理解 3、三员之三权 4、权限划分 5、“三员”职责 6、“三员”配置要求 二、linux三权分立的用户创建 1、系统管理员 2、安全管理员 3、审计管理员 一、三权分立设计思路 1、什么是三权 三权指的是配置、…...

revit中如何创建有坡度的排水沟及基坑?
一、revit中如何创建有坡度的排水沟? 先分享一张有坡度排水沟的族的照片给大家加深一下印象,有了一个粗略的直观认识,小编就来说说做这个族的前期思路吧。 一、前期思路: 1、 用拼接的方式把这个族形状拼出来,先用放样࿰…...

Web自动化测试——selenium篇(一)
文章目录一、环境准备二、Web 自动化测试 Demo三、元素定位常用方法四、元素定位失败可能原因五、测试对象操作六、等待操作七、信息打印在学习 Web 自动化测试的过程中,selenium 是其中的常用工具。除了其开源免费,包含丰富的 API 以外,它还…...

认识 CSS pointer-events 属性
pointer-events 的基本信息 pointer-events 属性用来控制一个元素能否响应鼠标操作,常用的关键字有 auto 和 none pointer-events: none; // 让一个元素忽略鼠标操作 pointer-events: auto; // 还原浏览器设定的默认行为 规范定义 条目状态初始值auto可用值适用所…...

【java】springboot和springcloud区别
文章目录1、含义不同2、作用不同3、使用方式不同4、特征不同5、注释不同6、优势不同7、组件不同8、设计目的不同1、含义不同 springboot:一个快速开发框架,它简化了传统MVC的XML配置,使配置变得更加方便、简洁。 springcloud:是…...
网易游戏实时 HTAP 计费风控平台建设
本文整理自网易互娱资深工程师, Flink Contributor, CDC Contributor 林佳,在 FFA 实时风控专场的分享。本篇内容主要分为五个部分: 实时风控业务会话会话关联的 Flink 实现HTAP 风控平台建设提升风控结果数据能效发展历程与展望未来 众所周知ÿ…...
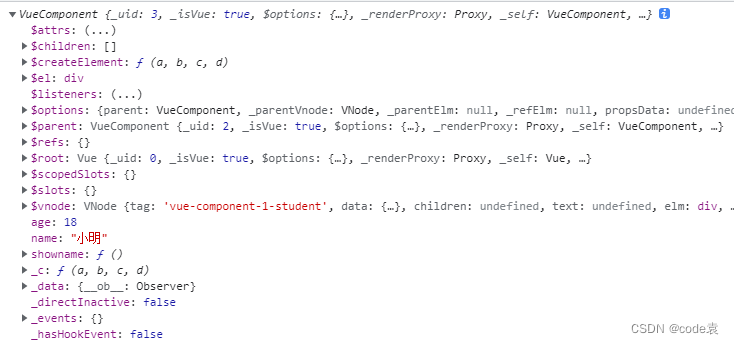
vue组件
文章目录1.vue组件2.非单文件组件2.1组件创建2.2祖册组件2.3使用组件3.组件的嵌套3.1 school组件嵌套student3.2 app组件嵌套school和hellozujain3.3 vm里面引入app组件4.VueCompent5.单文件组件1.vue组件 组件是实现应用中功能的局部代码和资源的集合 2.非单文件组件 2.1组件…...

让mybatis-plus支持null字段全量更新
文章目录背景方案一使用方案二方案二原理介绍背景 如果仅仅只是标题所列的目标,那么mybatis-plus 中可以通过设置 mybatis-plus.global-config.db-config.field-strategyignored 来忽略null判断,达到实体字段为null时也可以更新数据为null 但是一旦使用…...

MASA Stack 1.0 发布会讲稿——生态篇
2022年运营回顾 贡献者 首先感谢贡献者们为MASA Stack社区所作的积极贡献,这些贡献者给我们提出了很多宝贵的建议,更是积极的提交PR帮助我们一起让产品更健壮,更完善,还在各种场合推广我们的解决方案,非常给力&#x…...
)
JEECG Boot项目实战:如何优雅地移除登录验证码(前后端完整操作指南)
JEECG Boot项目实战:如何优雅地移除登录验证码(前后端完整操作指南) 在JEECG Boot的开发过程中,验证码功能虽然能有效防止恶意登录,但在某些特定场景下反而会成为效率瓶颈。想象一下这样的场景:开发团队正在…...

WiFi信号弱?5分钟搞懂dBi、dBm和dB的区别,选对天线不踩坑
WiFi信号弱?5分钟搞懂dBi、dBm和dB的区别,选对天线不踩坑 每次视频会议卡成PPT,游戏延迟飙红,或是刷剧总在关键时刻转圈——这些糟心体验八成是WiFi信号在作祟。很多人第一反应是升级千兆宽带,却忽略了无线信号从路由器…...

5个步骤掌握抖音批量下载高效解决方案:从需求到实战指南
5个步骤掌握抖音批量下载高效解决方案:从需求到实战指南 【免费下载链接】douyin-downloader 项目地址: https://gitcode.com/GitHub_Trending/do/douyin-downloader 在数字内容管理领域,短视频资源的高效获取已成为内容创作者、研究人员和普通用…...

PP-DocLayoutV3完整指南:支持弯曲/倾斜文档的布局分析实战
PP-DocLayoutV3完整指南:支持弯曲/倾斜文档的布局分析实战 1. 引言:告别平面文档的限制 想象一下这样的场景:你手头有一份古老的卷轴文献,或者一张被折叠多次的纸质文档,甚至是一本装订厚重的书籍内页。这些文档往往…...

别再死记硬背了!用‘快递寄送’和‘跨国通话’的比喻,5分钟搞懂OSI七层模型与TCP/IP五层模型
快递与越洋电话:用生活场景拆解网络分层模型 想象一下,你网购的商品从深圳工厂到北京家门口,要经过打包、装车、跨省运输、本地配送多个环节——这和网络数据传输的层层封装如出一辙。而当你给海外亲友视频通话时,双方手机自动协商…...

别再死记硬背了!用Vivado工具链图解FPGA底层:CLB、SLICE与LUT到底怎么连的?
用Vivado工具链图解FPGA底层:从代码到硬件的可视化之旅 当你在Vivado中编写完一段Verilog代码,点击综合按钮后,那些抽象的硬件描述究竟是如何变成FPGA芯片上实实在在的电路连接的?对于初学者来说,CLB、SLICE、LUT这些概…...

终极ViGEmBus虚拟手柄驱动:Windows游戏控制解决方案完全指南
终极ViGEmBus虚拟手柄驱动:Windows游戏控制解决方案完全指南 【免费下载链接】ViGEmBus Windows kernel-mode driver emulating well-known USB game controllers. 项目地址: https://gitcode.com/gh_mirrors/vi/ViGEmBus ViGEmBus是一款专业的Windows内核级…...

【20年ETL老兵亲授】Polars 2.0清洗Pipeline黄金架构:从schema-on-read校验→增量物化→自动fallback机制的闭环设计
第一章:Polars 2.0大规模数据清洗的范式演进与核心挑战Polars 2.0标志着声明式、惰性计算与零拷贝内存管理在数据清洗场景中的深度整合。相比传统Pandas的命令式逐行处理与隐式副本机制,Polars 2.0将整个清洗流水线建模为逻辑计划(Logical Pl…...

信创云渲染能支持远程设计与异地协同吗?
在信创推进深化的当下,企业对远程设计、异地协同的需求愈发迫切,传统本地工作站既难以适配国产软硬件环境,也无法满足跨地域高效协作需求。信创云渲染作为核心解决方案,能否同时支撑远程设计与异地协同?答案是肯定的&a…...

清华大学学位论文LaTeX模板:thuthesis完整使用指南
清华大学学位论文LaTeX模板:thuthesis完整使用指南 【免费下载链接】thuthesis LaTeX Thesis Template for Tsinghua University 项目地址: https://gitcode.com/gh_mirrors/th/thuthesis 清华大学thuthesis LaTeX模板是专为清华学子设计的学位论文写作工具&…...