HBase Java基础操作
Apache HBase 是一个开源的、分布式的、可扩展的大数据存储系统,它基于 Google 的 Bigtable 模型。使用 Java 操作 HBase 通常需要借助 HBase 提供的 Java API。以下是一个基本的示例,展示了如何在 Java 中连接到 HBase 并执行一些基本的操作,如创建表、插入数据、扫描表以及删除数据。
一、前提条件
HBase 安装和配置:确保 HBase 已经在你的环境中正确安装和配置。
Hadoop 环境:HBase 依赖于 Hadoop,因此 Hadoop 也需要正确安装和配置。
HBase Java 客户端库:你需要将 HBase 的客户端库添加到你的 Java 项目中。通常,这可以通过 Maven 或 Gradle 来完成。
二、Maven 依赖
使用 Maven 来管理项目依赖,可以在 pom.xml 文件中添加以下依赖:
<dependencies><dependency><groupId>org.apache.hbase</groupId><artifactId>hbase-client</artifactId><version>2.4.9</version> <!-- 请根据你的 HBase 版本选择合适的版本 --></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-common</artifactId><version>3.3.1</version> <!-- 请根据你的 Hadoop 版本选择合适的版本 --></dependency>
</dependencies>
三、建立连接
在使用HBase Java API之前,首先需要建立与HBase的连接。这通常涉及到配置HBase的连接信息,如Zookeeper的地址和端口等。
Configuration configuration = HBaseConfiguration.create();
configuration.set("hbase.zookeeper.quorum", "your_zookeeper_quorum"); // 设置Zookeeper的地址
configuration.set("hbase.zookeeper.property.clientPort", "your_zookeeper_port"); // 设置Zookeeper的端口
Connection connection = ConnectionFactory.createConnection(configuration);
四、对表的操作
- 创建表
创建表需要指定表名和列族。HBase中的表是由列族构成的,每个列族下可以包含多个列。
Admin admin = connection.getAdmin();
if (!admin.tableExists(TableName.valueOf("your_table_name"))) {HTableDescriptor tableDescriptor = new HTableDescriptor(TableName.valueOf("your_table_name"));tableDescriptor.addFamily(new HColumnDescriptor("your_column_family"));admin.createTable(tableDescriptor);
}
- 删除表
在删除表之前,需要先禁用该表。
if (admin.tableExists(TableName.valueOf("your_table_name"))) {admin.disableTable(TableName.valueOf("your_table_name"));admin.deleteTable(TableName.valueOf("your_table_name"));
}
- 判断表是否存在
boolean exists = admin.tableExists(TableName.valueOf("your_table_name"));
- 列出所有表
HTableDescriptor[] tables = admin.listTables();
for (HTableDescriptor table : tables) {System.out.println(table.getNameAsString());
}
五、对数据的操作
- 添加数据
添加数据需要指定表名、行键、列族、列名以及对应的值。
Table table = connection.getTable(TableName.valueOf("your_table_name"));
Put put = new Put(Bytes.toBytes("your_row_key"));
put.addColumn(Bytes.toBytes("your_column_family"), Bytes.toBytes("your_column"), Bytes.toBytes("your_value"));
table.put(put);
table.close();
- 获取数据
获取数据可以使用Get类来指定要获取的行键和列。
Table table = connection.getTable(TableName.valueOf("your_table_name"));
Get get = new Get(Bytes.toBytes("your_row_key"));
get.addColumn(Bytes.toBytes("your_column_family"), Bytes.toBytes("your_column"));
Result result = table.get(get);
byte[] value = result.getValue(Bytes.toBytes("your_column_family"), Bytes.toBytes("your_column"));
String valueStr = Bytes.toString(value);
table.close();
- 扫描数据
扫描数据可以使用Scan类来指定要扫描的表、列族、列等条件。
Scan scan = new Scan();
scan.setCaching(500); // 设置每次扫描的缓存大小
scan.setCacheBlocks(false); // 设置是否缓存数据块
scan.addFamily(Bytes.toBytes("your_column_family")); // 添加要扫描的列族ResultScanner scanner = table.getScanner(scan);
for (Result result : scanner) {// 处理扫描结果byte[] rowKey = result.getRow();String rowKeyStr = Bytes.toString(rowKey);// 获取指定列的值byte[] value = result.getValue(Bytes.toBytes("your_column_family"), Bytes.toBytes("your_column"));String valueStr = Bytes.toString(value);// 输出结果System.out.println("RowKey: " + rowKeyStr + ", Value: " + valueStr);
}
scanner.close();
table.close();
- 删除数据
删除数据需要指定表名、行键以及要删除的列(可选)。
Table table = connection.getTable(TableName.valueOf("your_table_name"));
Delete delete = new Delete(Bytes.toBytes("your_row_key"));
delete.addColumn(Bytes.toBytes("your_column_family"), Bytes.toBytes("your_column")); // 可选,指定要删除的列
table.delete(delete);
table.close();
六、关闭连接
在完成所有操作后,需要关闭与HBase的连接以释放资源。
connection.close();
七、示例代码
以下是一个完整的 Java 示例代码,展示了如何连接到 HBase 并执行基本的操作:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.util.Bytes;import java.io.IOException;public class HBaseExample {public static void main(String[] args) {// 创建 HBase 配置对象Configuration config = HBaseConfiguration.create();config.set("hbase.zookeeper.quorum", "localhost"); // 设置 Zookeeper 地址config.set("hbase.zookeeper.property.clientPort", "2181"); // 设置 Zookeeper 端口// 创建连接对象try (Connection connection = ConnectionFactory.createConnection(config);Admin admin = connection.getAdmin()) {// 创建表createTable(admin, "my_table", "my_column_family");// 插入数据insertData(connection, "my_table", "row1", "my_column_family", "column1", "value1");// 扫描表scanTable(connection, "my_table");// 删除数据deleteData(connection, "my_table", "row1", "my_column_family", "column1");// 删除表(可选)// deleteTable(admin, "my_table");} catch (IOException e) {e.printStackTrace();}}private static void createTable(Admin admin, String tableName, String columnFamily) throws IOException {TableName table = TableName.valueOf(tableName);if (!admin.tableExists(table)) {HTableDescriptor tableDescriptor = new HTableDescriptor(table);HColumnDescriptor columnDescriptor = new HColumnDescriptor(columnFamily);tableDescriptor.addFamily(columnDescriptor);admin.createTable(tableDescriptor);System.out.println("Table created: " + tableName);} else {System.out.println("Table already exists: " + tableName);}}private static void insertData(Connection connection, String tableName, String rowKey, String columnFamily, String column, String value) throws IOException {TableName table = TableName.valueOf(tableName);try (Table table = connection.getTable(table)) {Put put = new Put(Bytes.toBytes(rowKey));put.addColumn(Bytes.toBytes(columnFamily), Bytes.toBytes(column), Bytes.toBytes(value));table.put(put);System.out.println("Data inserted: " + rowKey + ", " + column + " = " + value);}}private static void scanTable(Connection connection, String tableName) throws IOException {TableName table = TableName.valueOf(tableName);try (Table table = connection.getTable(table);ResultScanner scanner = table.getScanner(new Scan())) {for (Result result : scanner) {System.out.println("Scanned row: " + Bytes.toString(result.getRow()));result.getNoVersionMap().forEach((family, familyMap) -> {familyMap.forEach((qualifier, value) -> {System.out.println("Family: " + Bytes.toString(family) + ", Qualifier: " + Bytes.toString(qualifier) + ", Value: " + Bytes.toString(value.get()));});});}}}private static void deleteData(Connection connection, String tableName, String rowKey, String columnFamily, String column) throws IOException {TableName table = TableName.valueOf(tableName);try (Table table = connection.getTable(table)) {Delete delete = new Delete(Bytes.toBytes(rowKey));delete.addColumn(Bytes.toBytes(columnFamily), Bytes.toBytes(column));table.delete(delete);System.out.println("Data deleted: " + rowKey + ", " + column);}}private static void deleteTable(Admin admin, String tableName) throws IOException {TableName table = TableName.valueOf(tableName);if (admin.tableExists(table)) {admin.disableTable(table);admin.deleteTable(table);System.out.println("Table deleted: " + tableName);} else {System.out.println("Table does not exist: " + tableName);}}
}
说明
- 创建配置对象:使用 HBaseConfiguration.create() 创建 HBase 配置对象,并设置 Zookeeper 的地址和端口。
- 创建连接对象:使用 ConnectionFactory.createConnection(config) 创建 HBase 连接对象。
- 创建表:通过 Admin 接口的 createTable 方法创建表。
- 插入数据:使用 Put 对象将数据插入到指定的表中。
- 扫描表:使用 Scan 对象扫描表并获取数据。
- 删除数据:使用 Delete 对象删除指定的数据。
- 删除表:如果需要删除表,可以先禁用表,然后删除表(此操作在示例中是注释掉的,以防止意外删除)。
注意事项
- 确保 HBase 和 Zookeeper 正在运行,并且配置正确。
- 根据你的 HBase 和 Hadoop 版本调整依赖版本。
- 在生产环境中,务必进行充分的错误处理和资源管理(如关闭连接和释放资源)。
相关文章:

HBase Java基础操作
Apache HBase 是一个开源的、分布式的、可扩展的大数据存储系统,它基于 Google 的 Bigtable 模型。使用 Java 操作 HBase 通常需要借助 HBase 提供的 Java API。以下是一个基本的示例,展示了如何在 Java 中连接到 HBase 并执行一些基本的操作,…...

关于一次开源java spring快速开发平台项目RuoYi部署的记录
关于一次开源java spring快速开发平台项目RuoYi部署的记录 本次因为需要一些练习环境,想要快速搭建一个javaweb 项目作为练习环境,经过查询和实验找到一个文档详细,搭建简单,架构也相对比较新的开源项目RuoYi。 项目介绍…...

【AI编程实战】安装Cursor并3分钟实现Chrome插件(保姆级)
Cursor介绍 https://www.cursor.com/ 一句话介绍:AI代码编辑器,当前最火的AI编程器 软件下载与安装 下载 打开Cursor官网下载,会根据操作系统的差别进行选择 https://www.cursor.com/ 这里下载的内容很小,是个安装器&#x…...

【Chatgpt】如何通过分层Prompt生成更加细致的图文内容
如何通过分层Prompt生成更加细致的图文内容 利用ChatGPT和类似的生成式AI模型,通过分层Prompt设计可以生成更具层次感和细节的图文内容。分层Prompt的核心在于将需求分解成多层次的指令,从宏观到微观逐步细化,最终形成高质量的内容输出。 一…...

中间件--laravel进阶篇
laravel版本11.31,这中间件只有3种,分别是全局中间件,路由中间件,控制器中间件。相比thinkphp8,少了一个应用中间件。 一、创建中间件 laravel创建中间件可以使用命令的方式创建,非常方便。比如php artisan make:middleware EnsureTokenIsValid。EnsureTokenIsValid是中间…...

【vue】vue中.sync修饰符如何使用--详细代码对比
.sync修饰符作用 .sync修饰符是一个语法糖,可以简化父子组件通信操作,当子组件想改变父组件数值时,父组件只需要使用.sync修饰符,子组件使用props接收属性,再使用this.$emit(update:属性, 值);就可以实现子组件更新父…...
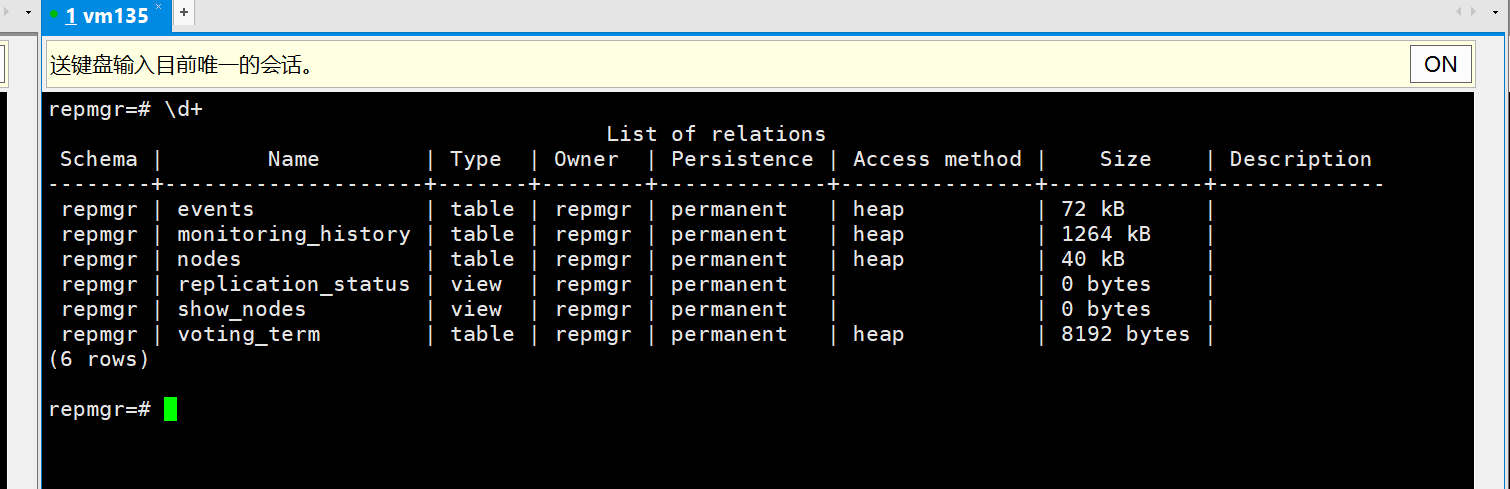
repmgr安装及常用运维指令
简介 repmgr 由 EDB 与其他个人和组织的贡献一起开发,安装部署相对较为简单 安装 repmgr官网上传对应的安装到服务器上 安装前/etc/hosts IP映射、始终同步、免密通信本文忽略 repmgr的安装相对较为简单,目前repmgr-5仅仅支持到postgresql-15 postgresql必要参数…...

RedHat系统配置静态IP
1、执行nmtui命令进入字符配置界面如下图所示 2、选择编辑连接进入 3、选择编辑进入后,将IPv4设置为手动模式后,选择显示后进行ip地址、网关、DNS的配置,配置完成后选择确定退出编辑 4、进入主界面后选择启用连接进入后,选择启用&…...

nvm和nrm的安装与使用
NVM相关请跳转: Node版本管理器nvm的安装与使用 nrm 的安装与使用 nrm(NPM Registry Manager)是一个用于管理和切换 NPM 源的工具。它允许你在多个 NPM 源之间快速切换,以提高包管理的速度和效率。以下是 nrm 的安装和使用方法&…...

10大核心应用场景,解锁AI检测系统的智能安全之道
随着工业化和自动化的快速推进,高风险作业场景的安全管理需求日益增加。思通数科AI检测系统以深度学习、计算机视觉和多模态数据融合技术为基础,通过智能化监控和实时反馈,为企业提供全面的作业安全和流程管理解决方案。本文将详细解读该系统…...

香豆烤馍:传统美食中的烟火记忆
食家巷香豆烤馍,承载着甘肃人的乡愁与记忆。它那朴实的外表下,蕴含着丰富的口感和深厚的文化底蕴。烤馍的制作过程充满了烟火气息。选用优质的面粉,经过发酵、揉制等多道工序,再放入传统的烤炉中慢慢烘烤。这个过程需要经验丰富的…...

金融量化交易模型的探索与发展
随着全球金融市场的不断变化与技术进步,量化交易逐渐成为机构和个人投资者的重要选择。作为数据驱动的交易方式,量化交易通过科学建模和技术手段,有效提升了交易效率与决策精准度。本文将探讨金融量化交易模型的创新探索与未来发展方向。 量化…...
)
灾难恢复计划 (DRP)
灾难恢复计划 (DRP) 目录 灾难恢复计划 (DRP) 1 1. 简介 2 2. 目的 2 3. 范围 3 4. 风险评估 3 5. 容灾方案 3 6. 关键系统恢复优先级 4 7. 恢复流程 4 8. 测试与维护 5 9. 联系信息 5 10. 批准与分发 5 11. 附录 5 1. 简介 灾难恢复计…...

Makefile 之 wordlist
wordlist $(wordlist <s>,<e>,<text> ) 名称:取单词串函数——wordlist。 功能:从字符串<text>中取从<s>开始到<e>的单词串。<s>和<e>是一个数字。 返回:返回字符串<text>中从…...

半导体工艺与制造篇1 绪论
我们为什么要研究半导体?半导体凭什么可以成为电子信息行业的基础呢? 这就要说到半导体的一个重要特点:可以通过控制掺杂率来控制它的导电性 集成电路IC的生产 集成电路IC的生产包括: #mermaid-svg-rWB59zU4pI2cGloo {font-fami…...

接雨水
接雨水 1、 题目描述2、解题思路 1、 题目描述 给定 n 个非负整数表示每个宽度为 1 的柱子的高度图,计算按此排列的柱子,下雨之后能接多少雨水。 2、解题思路 本题使用了双指针,根据下图可以得出,下标 i 处能接的雨水量由左边…...

Python蓝桥杯刷题1
1.确定字符串是否包含唯一字符 题解:调用count函数计算每一个字符出现的次数,如果不等于1就输出no,并且结束循环,如果等于1就一直循环直到计算到最后一个字符,若最后一个字符也满足条件,则输出yes import…...

实习冲刺第二十七天
3.无重复字符的最长字串 给定一个字符串 s ,请你找出其中不含有重复字符的 最长 子串 的长度。 示例 1: 输入: s "abcabcbb" 输出: 3 解释: 因为无重复字符的最长子串是 "abc",所以其长度为 3。示例 2: 输入: s "bbbb…...

el-table-column自动生成序号在序号前插入图标
实现效果: 代码如下: 在el-table里加入这个就可以了,需要拿到值可以用scope.$index <el-table-column type"index" label"序号" show-overflow-tooltip"true" min-width"40">…...

前端工程化-node/npm/babel/polyfill/webpack 一文速通
文章主要介绍了前端工程化的相关内容,包括 Node 环境、npm 包管理器及其命令、配置和镜像,package.json 文件,babel 和 polyfill 用于解决 JavaScript 兼容性问题,以及 webpack 这一前端构建工具的作用、核心概念、构建流程、安装…...

溶液颜色-浓度线性关系分析系统
溶液颜色-浓度线性关系分析系统 下面是一个完整的Python解决方案,用于根据溶液颜色计算其与浓度的线性关系。该系统包含GUI界面、数据处理、回归分析和可视化功能。 import numpy as np import pandas as pd import matplotlib.pyplot as plt from matplotlib.backends.back…...

BetterNCM插件开发入门:从零开始创建你的第一个网易云音乐插件
BetterNCM插件开发入门:从零开始创建你的第一个网易云音乐插件 【免费下载链接】chromatic NCM 软件插件管理器 项目地址: https://gitcode.com/gh_mirrors/be/chromatic 想要为网易云音乐PC版添加个性化功能吗?BetterNCM插件管理器为你打开了一扇…...

如何为RetDec贡献翻译:为开源机器码反编译器构建国际化社区
如何为RetDec贡献翻译:为开源机器码反编译器构建国际化社区 【免费下载链接】retdec RetDec is a retargetable machine-code decompiler based on LLVM. 项目地址: https://gitcode.com/gh_mirrors/re/retdec RetDec是一个基于LLVM的可重定向机器码反编译器…...
)
GIS小白必看:5种全球人口数据下载指南(含百度云链接)
GIS初学者必备:5大全球人口数据集深度解析与高效获取指南 刚接触地理信息系统的朋友,常常会在第一步——数据获取上就遇到难题。面对五花八门的人口数据集,分辨率、年份、坐标系统这些专业术语让人眼花缭乱,更别提有些国际数据平…...

CLIP ViT-H-14图像特征提取实战:LAION-2B预训练模型在小样本场景表现
CLIP ViT-H-14图像特征提取实战:LAION-2B预训练模型在小样本场景表现 1. 引言 你有没有遇到过这样的问题?手头只有几十张、几百张图片,却想快速搭建一个靠谱的图片搜索系统,或者给图片打上智能标签。传统的深度学习方法往往需要…...
)
手把手教你用Yolov11-seg训练自己的番茄成熟度检测模型(附完整数据集+源码)
手把手教你用Yolov11-seg训练番茄成熟度检测模型(附完整数据集与实战代码) 在智慧农业领域,计算机视觉技术正逐渐成为提升作物管理效率的利器。以番茄种植为例,传统成熟度判断依赖人工观察,不仅效率低下且主观性强。本…...

深度学习项目训练环境实战案例:在预装环境中完成图像分类模型微调与剪枝
深度学习项目训练环境实战案例:在预装环境中完成图像分类模型微调与剪枝 1. 环境准备与快速上手 深度学习环境配置一直是让很多开发者头疼的问题,特别是对于刚入门的新手来说,各种依赖库的版本冲突、CUDA环境配置、框架安装等问题往往需要花…...

实测LingBot-Depth:一键将RGB图片变3D点云,效果惊艳
实测LingBot-Depth:一键将RGB图片变3D点云,效果惊艳 1. 引言:当照片“活”起来 你有没有想过,手机里的一张普通照片,其实隐藏着一个完整的三维世界?我们看到的只是颜色和光影,但丢失了最重要的…...

基于Chatbot Areda的AI辅助开发实践:从架构设计到性能优化
传统对话系统的困境与Chatbot Areda的破局 在构建智能对话系统的道路上,许多开发者都曾面临相似的困境。传统的对话系统,无论是基于规则引擎还是早期的机器学习模型,在应对真实世界的复杂交互时,常常显得力不从心。它们像是预先编…...

Phi-3-Mini-128K精彩案例分享:单次输入5万字技术文档精准定位核心段落
Phi-3-Mini-128K精彩案例分享:单次输入5万字技术文档精准定位核心段落 1. 工具核心能力解析 Phi-3-Mini-128K是基于微软最新Phi-3-mini-128k-instruct模型开发的轻量化对话工具,其最突出的能力是支持128K超长上下文处理。这意味着它可以一次性读取并理…...