RocketMQ: 专业术语以及相关问题解决
概述
- 要了解 RocketMQ 的多个关键特性的实现原理,并对消息中间件遇到的各种问题进行解决
- 我们引用 JMS 规范 与 CORBA Notification 规范,规范为我们设计系统指明了方向
- 但是仍有不少问题规范没有提及,对于消息中间件又至关重要
- RocketMQ 并不遵循任何规范,但是参考了各种规范不同类产品的设计思想
产品发展历史
大约经历了5个主要版本迭代
一、Metaq(Metamorphosis) 1.x
- 由开源社区 killme2008 维护,开源社区非常活跃
- https://github.com/killme2008/Metamorphosis
二、Metaq 2.x
- 于 2012 年 10 月份上线,在淘宝内部被广泛使用
三、RocketMQ 3.x
- 基于公司内部开源共建原则, RocketMQ 项目只维护核心功能,且去除了所有其他运行时依赖,核心功能最简化
- 每个Business Unit (业务单元/业务部门简称 BU)个性化需求都在 RocketMQ 项目之上进行深度定制。RocketMQ 向其他 BU 提供的仅仅是 Jar 包,例如要定制一个 Broker,那只需要依赖 rocketmq-broker 返个 jar 包即可,可通过 API 迕行交互。如果定制 client,则依赖 rocketmq-client 返个 jar 包,对其提供的 api 进行再封装
- 开源社区地址:https://github.com/alibaba/RocketMQ
- 在 RocketMQ 项目基础上衍生的项目如下
- com.taobao.metaq v3.0 = RocketMQ + 淘宝个性化需求为淘宝应用提供消息服务
- com.alipay.zpullmsg v1.0 = RocketMQ + 支付宝个性化需求 为支付宝应用提供消息服务
- com.alibaba.commonmq v1.0 = Notify + RocketMQ + B2B 个性化需求为 B2B 应用提供消息服务
四、RocketMQ 4.x
- 发布日期:2016年
- 主要特点:
- 全面开源:RocketMQ 4.x 版本正式对外全面开源,成为阿里巴巴集团的重要开源项目之一。
- 高可用性:增强了系统的高可用性和稳定性,引入了主从同步、多副本机制等,确保数据的可靠性和一致性
- 分布式事务支持:增加了对分布式事务的支持,提供了全局事务的能力,解决了分布式系统中的一致性问题
- 社区支持:开源社区非常活跃,吸引了大量开发者和企业的贡献和支持,形成了丰富的生态。
- 插件化架构:引入了插件化架构,使得扩展和定制变得更加灵活和方便
- 多语言客户端:除了 Java 客户端,还支持多种编程语言的客户端,如 C++、Python、Go 等。
- 开源社区地址:https://github.com/apache/rocketmq
五、RocketMQ 5.x
- 发布日期:2021年
- 主要特点:
- 云原生支持:全面支持 Kubernetes 和云原生架构,使得 RocketMQ 更容易部署和管理在云环境中。
- 流处理能力:增强了流处理能力,支持实时数据处理和分析,提供了更强大的数据处理引擎。
- 性能优化:进一步优化了性能,提升了消息处理的速度和吞吐量,降低了延迟。
- 安全增强:加强了安全特性,支持更细粒度的权限管理和认证机制,确保数据的安全传输。
- 多租户支持:引入了多租户支持,使得一个 RocketMQ 集群可以同时服务于多个不同的租户,提高了资源利用率。
- 自动化运维:提供了更多的自动化运维工具和监控指标,简化了运维工作,提高了系统的可维护性。
- 社区和生态:继续扩大社区影响力,吸引了更多企业和开发者参与,形成了更加完善的生态系统。
- 开源社区地址:https://github.com/apache/rocketmq
六、补充说明
- 版本演进:从 Metaq 1.x 到 RocketMQ 5.x,RocketMQ 经历了多次重大版本迭代,逐步从一个内部使用的消息中间件发展成为全球知名的开源项目
- 社区贡献:随着版本的演进,RocketMQ 的开源社区越来越活跃,吸引了大量的开发者和企业参与贡献,形成了丰富的生态体系
- 企业应用:RocketMQ 不仅在阿里巴巴集团内部广泛应用,还在众多企业中得到了广泛的应用,成为消息中间件领域的佼佼者
专业术语
- Producer
- 消息生产者,负责产生消息,一般由业务系统负责产生消息
- Consumer
- 消息消费者,负责消费消息,一般是后台系统负责异步消费
- Push Consumer
- Consumer 的一种,应用通常向 Consumer 对象注册一个 Listener 接口
- 一旦收到消息,Consumer 对象立刻回调 Listener 接口方法
- Pull Consumer
- Consumer 的一种,应用通常主劢调用 Consumer 的拉消息方法从 Broker 拉消息
- 主动权由应用控制
- Producer Group
- 一类 Producer 的集合名称,这类 Producer 通常发送一类消息,且发送逻辑一致
- Consumer Group
- 一类 Consumer 的集合名称,这类 Consumer 通常消费一类消息,且消费逻辑一致
- Broker
- 消息中转角色,负责存储消息,转发消息,一般也称为 Server
- 在 JMS 规范中称为 Provider
- 广播消费
- 一条消息被多个 Consumer 消费,即使这些 Consumer 属于同一个 Consumer Group
- 消息也会被 Consumer Group 中的每个 Consumer 都消费一次
- 广播消费中的 Consumer Group 概念可以认为在消息划分方面无意义
- 在 CORBA Notification 规范中,消费方式都属于广播消费
- 在 JMS 规范中,相当于 JMS publish/subscribe model
- 集群消费
- 一个 Consumer Group 中的 Consumer 实例平均分摊消费消息
- 例如某个 Topic 有 9 条消息,其中一个 Consumer Group 有 3 个实例
- 可能是 3 个进程,或者 3 台机器,那么每个实例只消费其中的 3 条消息
- 在 CORBA Notification 规范中,无此消费方式
- 在 JMS 规范中,JMS point-to-point model 与之类似,但是 RocketMQ 的集群消费功能大等于 PTP 模型
- 因为 RocketMQ 单个 Consumer Group 内的消费者类似于 PTP,但是一个 Topic/Queue 可以被多个 Consumer Group 消费
- 顺序消息
- 消费消息的顺序要同发送消息的顺序一致,在 RocketMQ 中,主要指的是局部顺序
- 即一类消息为满足顺序性,必须 Producer 单线程顺序发送,且发送到同一个队列
- 这样 Consumer 就可以按照 Producer 发送的顺序去消费消息
- 普通顺序消息
- 顺序消息的一种,正常情况下可以保证完全的顺序消息,但是一旦发生通信异常
- Broker 重启,由于队列总数发生发化,哈希取模后定位的队列会发化
- 产生短暂的消息顺序不一致
- 如果业务能容忍在集群异常情况(如某个 Broker 宕机或者重启)下
- 消息短暂的乱序,使用普通顺序方式比较合适
- 严格顺序消息
- 顺序消息的一种,无论正常异常情况都能保证顺序
- 但是牺牲了分布式 Failover 特性,即 Broker 集群中只要有一台机器不可用
- 则整个集群都不可用,服务可用性大大降低
- 如果服务器部署为同步双写模式,此缺陷可通过备机自动切换为主避免
- 不过仍然会存在几分钟的服务不可用(依赖同步双写,主备自动切换)
- 目前已知的应用只有数据库 binlog 同步强依赖严格顺序消息
- 其他应用绝大部分都可以容忍短暂乱序,推荐使用普通的顺序消息
- 在 RocketMQ 中,所有消息队列都是持久化,长度无限的数据结构
- 所谓长度无限是指队列中的每个存储单元都是定长
- 访问其中的存储单元使用 Offset 来访问,offset 为 java long 类型,64 位
- 理论上在 100 年内不会溢出,所以认为是长度无限,另外队列中只保存最近几天的数据
- 之前的数据会按照过期时间来删除
- 也可以认为 Message Queue 是一个长度无限的数组,offset 就是下标
消息中间件解决的问题
1 ) Publish/Subscribe
- 发布订阅是消息中间件的最基本功能,也是相对于传统 RPC 通信而言。在此不再详述
2 )Message Priority
- 规范中描述的优先级是指在一个消息队列中,每条消息都有不同的优先级,一般用整数来描述,优先级高的消息优先投递,如果消息完全在一个内存队列中,那在投递前可以按照优先级排序,令优先级高的先投递
- 由于 RocketMQ 所有消息都是持久化的,所以如果按照优先级来排序,开销会非常大,因此 RocketMQ 没有特意支持消息优先级,但是可以通过变通的方式实现类似功能,即单独配置一个优先级高的队列,和一个普通优先级的队列, 将不同优先级发送到不同队列即可
- 对于优先级问题,可以归纳为 2 类
- 1 )只要达到优先级目的即可,不是严格意义上的优先级,通常将优先级划分为高、中、低
- 或者再多几个级别。每个优先级可以用不同的 topic 表示,发消息时,指定不同的 topic 来表示优先级
- 这种方式可以解决绝大部分的优先级问题,但是对业务的优先级精确性做了妥协
- 2 )严格的优先级,优先级用整数表示,例如 0 ~ 65535,返种优先级问题一般使用不同 topic 解决就非常不合适
- 如果要让 MQ 解决此问题,会对 MQ 的性能造成非常大的影响
- 这里要确保一点,业务上是否确实需要返种严格的优先级
- 如果将优先级压缩成几个,对业务的影响有多大?
3 ) Message Order
- 消息有序指的是一类消息消费时,能挄照収送的顺序来消费
- 例如:一个订单产生了 3 条消息,分别是订单创建,订单付款,订单完成
- 消费时,要按照这个顺序消费才能有意义
- 但是同时订单之间是可以并行消费的,RocketMQ 可以严格的保证消息有序
4 )Message Filter
-
Broker 端消息过滤
- 在 Broker 中,按照 Consumer 的要求做过滤
- 优点是减少了对于 Consumer 无用消息的网络传输
- 缺点是增加了 Broker 的负担,实现相对复杂
- (1). 淘宝 Notify 支持多种过滤方式,包含直接按照消息类型过滤
- 灵活的语法表达式过滤,几乎可以满足最苛刻的过滤需求
- (2). 淘宝 RocketMQ 支持按照简单的 Message Tag 过滤
- 也支持按照 Message Header、body 进行过滤
- (3). CORBA Notification 规范中也支持灵活的语法表达式过滤
-
Consumer 端消息过滤
- 这种过滤方式可由应用完全自定义实现,但是缺点是很多无用的消息要传输到 Consumer 端
5 ) Message Persistence
-
消息中间件通常采用的几种持久化方式:
- (1). 持久化到数据库,例如 Mysql
- (2). 持久化到 KV 存储,例如 levelDB、伯克利 DB 等 KV 存储系统
- (3). 文件记录形式持久化,例如 Kafka,RocketMQ
- (4). 对内存数据做一个持久化镜像,例如 beanstalkd,VisiNotify
-
(1)、(2)、(3)三种持久化方式都具有将内存队列 Buffer 迕行扩展的能力
-
(4)只是一个内存的镜像,作用是当 Broker挂掉重启后仍然能将之前内存的数据恢复出来
-
JMS 与 CORBA Notification 规范没有明确说明如何持久化
-
但是持久化部分的性能直接决定了整个消息中间件的性能
-
RocketMQ 参考了 Kafka 的持久化方式,充分利用 Linux 文件系统内存 cache 来提高性能
.6 )Message Reliablity
- 影响消息可靠性的几种情况:
- (1). Broker 正常关闭
- (2). Broker 异常 Crash
- (3). OS Crash
- (4). 机器掉电,但是能立即恢复供电情况
- (5). 机器无法开机(可能是 cpu、主板、内存等关键设备损坏)
- (6). 磁盘设备损坏
- (1)、(2)、(3)、(4)四种情况都属于硬件资源可立即恢复情况
- RocketMQ 在返四种情况下能保证消息不丢,或者丢失少量数据(依赖刷盘方式是同步还是异步)
- (5)、(6)属于单点故障,且无法恢复,一旦发生,在此单点上的消息全部丢失
- RocketMQ 在这两种情况下,通过异步复制,可保证 99%的消息不丢,但是仍然会有极少量的消息可能丢失
- 通过同步双写技术可以完全避免单点,同步双写势必会影响性能,适合对消息可靠性要求极高的场合,例如与 Money 相关的应用,RocketMQ 从 3.0 版本开始支持同步双写
7 )Low Latency Messaging
- 在消息不堆积情况下,消息到达 Broker 后,能立刻到达 Consumer
- RocketMQ 使用长轮询 Pull 方式,可保证消息非常实时,消息实时性不低于 Push
8 )At least Once
- 是指每个消息必须投递一次 RocketMQ Consumer 先 pull 消息到本地
- 消费完成后,才向服务器返回 ack,如果没有消费一定不会 ack 消息
- 所以 RocketMQ 可以很好的支持此特性
9 )Exactly Only Once
- (1). 发送消息阶段,不允许发送重复的消息
- (2). 消费消息阶段,不允许消费重复的消息
- 只有以上两个条件都满足情况下,才能认为消息是 “Exactly Only Once”
- 而要实现以上两点,在分布式系统环境下,不可避免要产生巨大的开销
- 所以 RocketMQ 为了追求高性能,并不保证此特性,要求在业务上进行去重
- 也就是说消费消息要做到幂等性
- RocketMQ 虽然不能严格保证不重复,但是正常情况下很少会出现重复发送、消费情况
- 只有网络异常,Consumer 启停等异常情况下会出现消息重复
- 此问题的本质原因是网络调用存在不确定性,即既不成功也不失败的第三种状态
- 所以才产生了消息重复性问题
10 )Broker 的 Buffer 满了怎么办?
- Broker 的 Buffer 通常指的是 Broker 中一个队列的内存 Buffer 大小
- 这类 Buffer 通常大小有限,如果 Buffer 满了以后怎么办?
- 下面是 CORBA Notification 规范中处理方式:
- (1). RejectNewEvents 拒绝新来的消息,向 Producer 返回 RejectNewEvents 错误码
- (2). 按照特定策略丢弃已有消息
- a ) AnyOrder - Any event may be discarded on overflow. This is the default setting for this
property. - b ) FifoOrder - The first event received will be the first discarded.
- c ) LifoOrder - The last event received will be the first discarded.
- d ) PriorityOrder - Events should be discarded in priority order, such that lower priority events will be discarded before higher priority events.
- e) DeadlineOrder - Events should be discarded in the order of shortest expiry deadline first.
- a ) AnyOrder - Any event may be discarded on overflow. This is the default setting for this
- RocketMQ 没有内存 Buffer 概念,RocketMQ 的队列都是持久化磁盘,数据定期清除
- 对于此问题的解决思路,RocketMQ 同其他 MQ 有非常显著的区别
- RocketMQ 的内存 Buffer 抽象成一个无限长度的队列,不管有多少数据进来都能装得下
- 这个无限是有前提的,Broker 会定期删除过期的数据,例如 Broker 只保存 3 天的消息
- 那这个 Buffer 虽然长度无限,但是 3 天前的数据会被从队尾删除
11 )回溯消费
- 回溯消费是指 Consumer 已经消费成功的消息,由于业务上需求需要重新消费,要支持此功能
- Broker 在向Consumer 投递成功消息后,消息仍然需要保留
- 并且重新消费一般是按照时间维度,例如由于 Consumer 系统故障
- 恢复后需要重新消费 1 小时前的数据,那 Broker 要提供一种机制,可以按照时间维度来回退消费进度
- RocketMQ 支持按照时间回溯消费,时间维度精确到毫秒,可以向前回溯,也可以向后回溯
12 )消息堆积
- 消息中间件的主要功能是异步解耦,还有个重要功能是挡住前端的数据洪峰,保证后端系统的稳定性
- 这就要求消息中间件具有一定的消息堆积能力,消息堆积分以下两种情况:
- (1). 消息堆积在内存 Buffer,一旦超过内存 Buffer,可以根据一定的丢弃策略来丢弃消息,如 CORBA Notification 规范中描述。
- 适合能容忍丢弃消息的业务,这种情况消息的堆积能力主要在于内存 Buffer 大小,而且消息
堆积后,性能下降不会太大,因为内存中数据多少对于对外提供的访问能力影响有限 - (2). 消息堆积到持久化存储系统中,例如 DB,KV 存储,文件记录形式
- 当消息不能在内存 Cache 命中时,要丌可避免的访问磁盘,会产生大量读 IO
- 读 IO 的吞吐量直接决定了消息堆积后的访问能力
- 评估消息堆积能力主要有以下四点:
- (1). 消息能堆积多少条,多少字节?即消息的堆积容量
- (2). 消息堆积后,发消息的吞吐量大小,是否会受堆积影响?
- (3). 消息堆积后,正常消费的 Consumer 是否会受影响?
- (4). 消息堆积后,访问堆积在磁盘的消息时,吞吐量有多大?
13 ) 分布式事务
- 已知的几个分布式事务规范,如 XA,JTA 等。其中 XA 规范被各大数据库厂商广泛支持,如 Oracle,Mysql 等
- 其中 XA 的 TM 实现佼佼者如 Oracle Tuxedo,在金融、电信等领域被广泛应用
- 分布式事务涉及两阶段提交问题,在数据存储方面必然需要 KV 存储的支持,因为第二阶段的提交回滚需要修改消息状态,一定涉及到根据 Key 去查找 Message 的动作
- RocketMQ 在第二阶段绕过了根据 Key 去查找 Message 的问题,采用第一阶段发送 Prepared 消息时,拿到了消息的 Offset,第二阶段通过 Offset 去访问消息,并修改状态,Offset 就是数据的地址
- RocketMQ 返种实现事务方式,没有通过 KV 存储做,而是通过 Offset 方式,存在一个显著缺陷,即通过 Offset 更改数据,会令系统的脏页过多,需要特别关注
14 )定时消息
- 定时消息是指消息发到 Broker 后,不能立刻被 Consumer 消费,要到特定的时间点或者等待特定的时间后才能被消费
- 如果要支持任意的时间精度,在 Broker 局面,必须要做消息排序,如果再涉及到持久化,那消息排序要不可避免的产生巨大性能开销
- RocketMQ 支持定时消息,但是不支持任意时间精度,支持特定的 level,例如定时 5s,10s,1m 等
15 )消息重试
- Consumer 消费消息失败后,要提供一种重试机制,令消息再消费一次
- Consumer 消费消息失败通常可以认为有以下几种情况
- 1.由于消息本身的原因,例如反序列化失败,消息数据本身无法处理(例如话费充值,当前消息的手机号被注销,无法充值)等
- 这种错误通常需要跳过这条消息,再消费其他消息,而这条失败的消息即使立刻重试消费,99%也不成功,所以最好提供一种定时重试机制,即过 10s 秒后再重试
- 2.由于依赖的下游应用服务不可用,例如 db 连接不可用,外系统网络不可达等
- 遇到这种错误,即使跳过当前失败的消息,消费其他消息同样也会报错
- 这种情况建议应用 sleep 30s,再消费下一条消息,这样可以减轻 Broker 重试消息的压力
相关文章:

RocketMQ: 专业术语以及相关问题解决
概述 要了解 RocketMQ 的多个关键特性的实现原理,并对消息中间件遇到的各种问题进行解决我们引用 JMS 规范 与 CORBA Notification 规范,规范为我们设计系统指明了方向但是仍有不少问题规范没有提及,对于消息中间件又至关重要RocketMQ 并不遵…...

C++ 类和对象中的 拷贝构造 和 运算符重载
构造函数中可以添加参数并添加默认值构成缺省构造,如果我们在构造函数的参数中加上自身类型类的引用和其他给出默认值的参数则会构成一种特殊的构造函数叫做———拷贝构造函数 1.拷贝构造 拷贝构造的特点: 1.拷贝构造函数是构造函数的一个重载 2.拷…...

el-table最大高度无法滚动
解决el-table同时使用fixed和计算的最大高度时固定右边的列无法跟随滚动的问题 原因:el-table组件会根据传入的 max-height 计算表格内容部分 和 fixed部分的最大高度,以此来生成滚动条和产生滚动效果,当传入的 max-height 为一个计算的高度…...

Vscode写markdown快速插入python代码
如图当我按下快捷键CRTLSHIFTK 自动出现python代码片段 配置方法shortcuts’ 打开这个json文件 输入 {"key": "ctrlshiftk","command": "editor.action.insertSnippet","when": "editorTextFocus","args&…...

基于 NCD 与优化函数结合的非线性优化 PID 控制
基于 NCD 与优化函数结合的非线性优化 PID 控制 1. 引言 NCD(Normalized Coprime Factorization Distance)优化是一种用于非线性系统的先进控制方法。通过将 NCD 指标与优化算法结合,可以在动态调整控制参数的同时优化控制器性能。此方法特别…...

【数据分析】基于GEE实现大津算法提取洞庭湖流域水体
大津算法提取水体 1.写在前面2.洞庭湖水体识别1.写在前面 最大类间方差法,也称为Otsu或大津法,是一种高效的图像二值化算法,由日本学者Otsu于1979年提出。该算法基于图像的频率分布直方图,假设图像包含两类像素(前景和背景),并计算出一个最佳阈值,以最大化类间方差,从…...
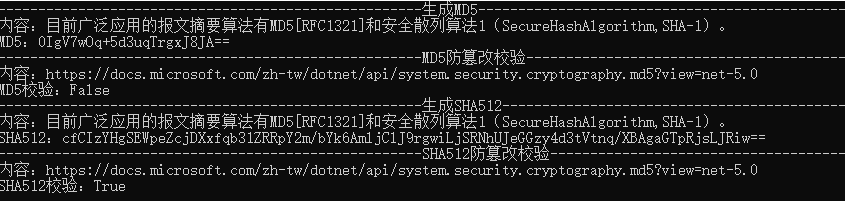
计算机网络安全 —— 报文摘要算法 MD5
一、报文摘要算法基本概念 使用加密通常可达到报文鉴别的目的,因为伪造的报文解密后一般不能得到可理解的内容。但简单采用这种方法,计算机很难自动识别报文是否被篡改。另外,对于不需要保密而只需要报文鉴别的网络应用,对整个…...

LeetCode 746. 使用最小花费爬楼梯 java题解
https://leetcode.cn/problems/min-cost-climbing-stairs/description/ 优化:可以不用dp数组,用变量,节省空间。 class Solution {public int minCostClimbingStairs(int[] cost) {int lencost.length;int[] dpnew int[len1];dp[0]0;//爬到0…...
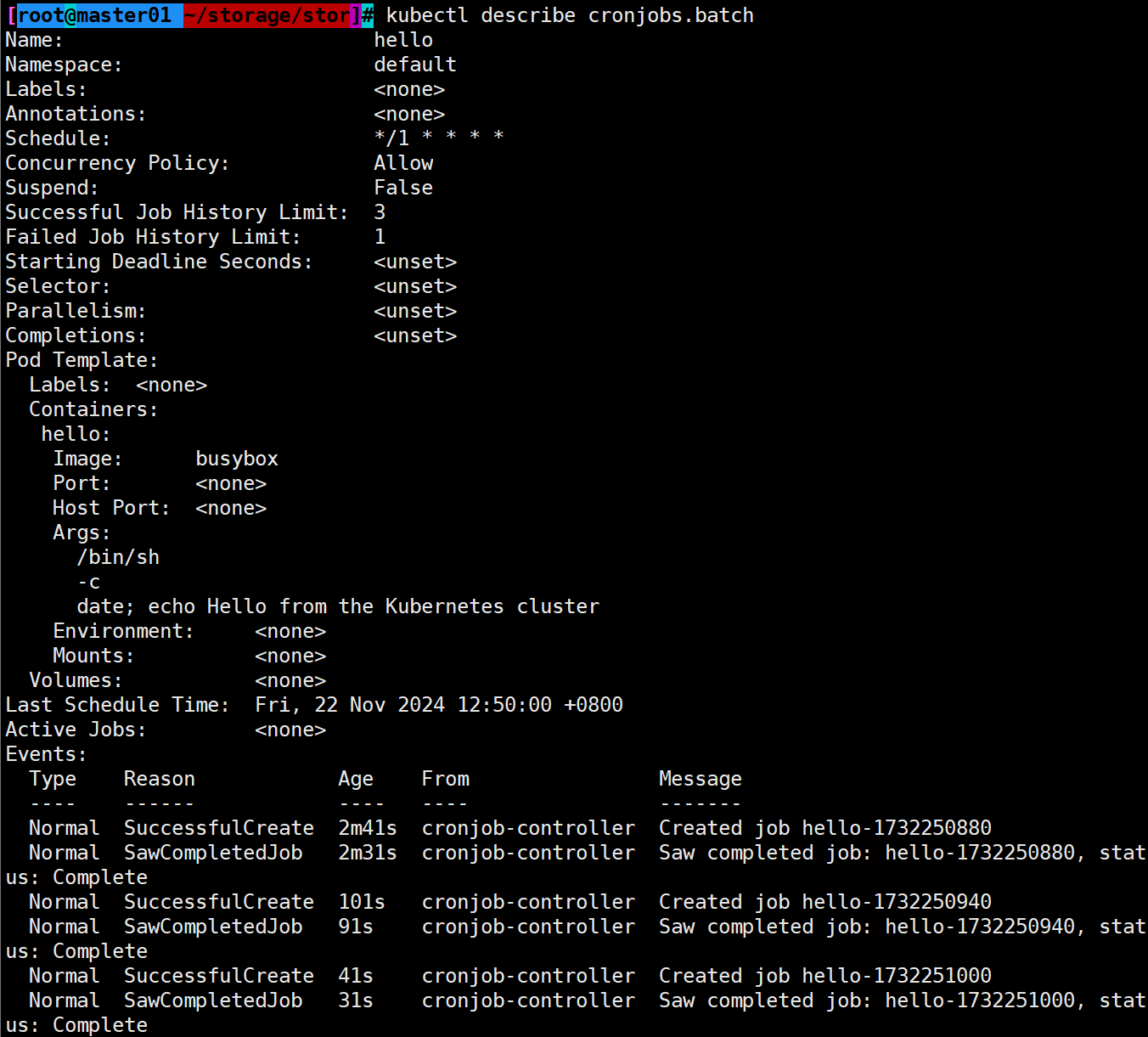
Kubernetes的pod控制器
文章目录 一,什么是pod控制器二,pod控制器类型(重点)1.ReplicaSet2.Deployment3.DaemonSet4.StatefulSet5.Job6.Cronjob 三,pod与控制器的关系1.Deployment2.SatefulSet2.1StatefulSet组成2.2headless的由来2.3有状态服…...
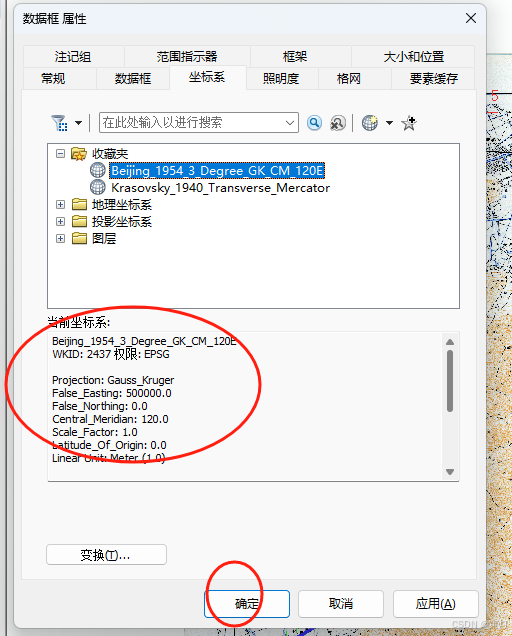
ArcMap 处理栅格数据地形图配准操作
ArcMap 处理栅格数据地形图配准操作今天分享 一、地形图配准 1、绘图 点击 开始绘制,四条线 2、地理配准 1)点击弹出 2)画控制点 关闭自动校正 画线 从焦点向外划线,然后邮件输入坐标弹出框,填写相应内容,…...

comprehension
1.读题---猜---文章主题 只读题目,不读选项 2.文章--定位 3.用文章对应选项 1 be based on be dependent upon 2 fruitful adj.富有成效的;硕果累累的; 3 unfruitful adj.徒然的,无益的,没有结果的 4 desperately adv.拼命地&#x…...

开源宝藏:Smart-Admin 重复提交防护的 AOP 切面实现详解
首先,说下重复提交问题,基本上解决方案,核心都是根据URL、参数、token等,有一个唯一值检验是否重复提交。 而下面这个是根据用户id,唯一值进行判定,使用两种缓存方式,redis和caffeineÿ…...

使用 npm 安装 Electron 作为开发依赖
好的,下面是一个使用 npm pack 和 npm install 命令来打包和安装离线版本的 npm 包的具体示例。我们将以 electron 为例,演示如何在有网络连接的机器上打包 electron,然后在没有网络连接的机器上安装它。 步骤 1: 在有网络连接的机器上打包 …...

JavaWeb之综合案例
前言 这一节讲一个案例 1. 环境搭建 然后就是把这些数据全部用到sql语句中执行 2.查询所有-后台&前台 我们先写后台代码 2.1 后台 2.2 Dao BrandMapper: 注意因为数据库里面的名称是下划线分割的,我们类里面是驼峰的,所以要映射 …...

MySQL 报错:1137 - Can‘t reopen table
MySQL 报错:1137 - Can’t reopen table 1. 问题 对临时表查询: select a.ts_code,a.tsnum,b.tsnum from (select t.ts_code ,count(*) tsnum from tmp_table t group by t.ts_code having count(*) > 20 and count(*)< 50 ) a ,(select t.ts_…...

Claude3.5-Sonnet和GPT-4o怎么选(附使用链接)
随着人工智能模型的不断进化,传统的评估标准已经逐渐变得陈旧和不再适用。以经典的“喝水测试”为例,过去广泛应用于检测模型能力,但现如今即便是国内的一些先进模型,也能够轻松答对这些简单的问题。因此,我们亟需引入…...

使用itextpdf进行pdf模版填充中文文本时部分字不显示问题
在网上找了很多种办法 都解决不了; 最后发现是文本域字体设置出了问题; 在这不展示其他的代码 只展示重要代码; 1 引入扩展包 <dependency><groupId>com.itextpdf</groupId><artifactId>itext-asian</artifactId><version>5.2.0</v…...

java-贪心算法
1. 霍夫曼编码(Huffman Coding) 描述: 霍夫曼编码是一种使用变长编码表对数据进行编码的算法,由David A. Huffman在1952年发明。它是一种贪心算法,用于数据压缩。霍夫曼编码通过构建一个二叉树(霍夫曼树&a…...

OpenCV和Qt坐标系不一致问题
“ OpenCV和QT坐标系导致绘图精度下降问题。” OpenCV和Qt常用的坐标系都是笛卡尔坐标系,但是细微处有些不同。 01 — OpenCV坐标系 OpenCV是图像处理库,是以图像像素为一个坐标位置,即一个像素对应一个坐标,所以其坐标系也叫图像…...

前端VUE项目启动方式
将VUE项目的前端项目运行起来,整个过程非常简单,预计5分钟就可以完成,取决于大家的网速。 项目运行先安装Node.js Windows 安装 Node.js 指南:http://www.iocoder.cn/NodeJS/windows-install(opens new window) Mac 安装 Node.js…...

龙虎榜——20250610
上证指数放量收阴线,个股多数下跌,盘中受消息影响大幅波动。 深证指数放量收阴线形成顶分型,指数短线有调整的需求,大概需要一两天。 2025年6月10日龙虎榜行业方向分析 1. 金融科技 代表标的:御银股份、雄帝科技 驱动…...

HTML 语义化
目录 HTML 语义化HTML5 新特性HTML 语义化的好处语义化标签的使用场景最佳实践 HTML 语义化 HTML5 新特性 标准答案: 语义化标签: <header>:页头<nav>:导航<main>:主要内容<article>&#x…...

RocketMQ延迟消息机制
两种延迟消息 RocketMQ中提供了两种延迟消息机制 指定固定的延迟级别 通过在Message中设定一个MessageDelayLevel参数,对应18个预设的延迟级别指定时间点的延迟级别 通过在Message中设定一个DeliverTimeMS指定一个Long类型表示的具体时间点。到了时间点后…...

前端倒计时误差!
提示:记录工作中遇到的需求及解决办法 文章目录 前言一、误差从何而来?二、五大解决方案1. 动态校准法(基础版)2. Web Worker 计时3. 服务器时间同步4. Performance API 高精度计时5. 页面可见性API优化三、生产环境最佳实践四、终极解决方案架构前言 前几天听说公司某个项…...

AI病理诊断七剑下天山,医疗未来触手可及
一、病理诊断困局:刀尖上的医学艺术 1.1 金标准背后的隐痛 病理诊断被誉为"诊断的诊断",医生需通过显微镜观察组织切片,在细胞迷宫中捕捉癌变信号。某省病理质控报告显示,基层医院误诊率达12%-15%,专家会诊…...

Go语言多线程问题
打印零与奇偶数(leetcode 1116) 方法1:使用互斥锁和条件变量 package mainimport ("fmt""sync" )type ZeroEvenOdd struct {n intzeroMutex sync.MutexevenMutex sync.MutexoddMutex sync.Mutexcurrent int…...

day36-多路IO复用
一、基本概念 (服务器多客户端模型) 定义:单线程或单进程同时监测若干个文件描述符是否可以执行IO操作的能力 作用:应用程序通常需要处理来自多条事件流中的事件,比如我现在用的电脑,需要同时处理键盘鼠标…...

群晖NAS如何在虚拟机创建飞牛NAS
套件中心下载安装Virtual Machine Manager 创建虚拟机 配置虚拟机 飞牛官网下载 https://iso.liveupdate.fnnas.com/x86_64/trim/fnos-0.9.2-863.iso 群晖NAS如何在虚拟机创建飞牛NAS - 个人信息分享...

【Linux】自动化构建-Make/Makefile
前言 上文我们讲到了Linux中的编译器gcc/g 【Linux】编译器gcc/g及其库的详细介绍-CSDN博客 本来我们将一个对于编译来说很重要的工具:make/makfile 1.背景 在一个工程中源文件不计其数,其按类型、功能、模块分别放在若干个目录中,mak…...
)
Leetcode33( 搜索旋转排序数组)
题目表述 整数数组 nums 按升序排列,数组中的值 互不相同 。 在传递给函数之前,nums 在预先未知的某个下标 k(0 < k < nums.length)上进行了 旋转,使数组变为 [nums[k], nums[k1], …, nums[n-1], nums[0], nu…...