Java NIO 核心知识总结
在学习 NIO 之前,需要先了解一下计算机 I/O 模型的基础理论知识。还不了解的话,可以参考我写的这篇文章:Java IO 模型详解。
一、NIO 简介
在传统的 Java I/O 模型(BIO)中,I/O 操作是以阻塞的方式进行的。也就是说,当一个线程执行一个 I/O 操作时,它会被阻塞直到操作完成。这种阻塞模型在处理多个并发连接时可能会导致性能瓶颈,因为需要为每个连接创建一个线程,而线程的创建和切换都是有开销的。
为了解决这个问题,在 Java1.4 版本引入了一种新的 I/O 模型 — NIO (New IO,也称为 Non-blocking IO) 。NIO 弥补了同步阻塞 I/O 的不足,它在标准 Java 代码中提供了非阻塞、面向缓冲、基于通道的 I/O,可以使用少量的线程来处理多个连接,大大提高了 I/O 效率和并发。
下图是 BIO、NIO 和 AIO 处理客户端请求的简单对比图(关于 AIO 的介绍,可以看我写的这篇文章:Java IO 模型详解,不是重点,了解即可)。

⚠️需要注意:使用 NIO 并不一定意味着高性能,它的性能优势主要体现在高并发和高延迟的网络环境下。当连接数较少、并发程度较低或者网络传输速度较快时,NIO 的性能并不一定优于传统的 BIO
二、工作原理
-
非阻塞模式
-
Java NIO的非阻塞模式使得一个线程可以从某个通道发送或读取数据,但它仅能得到当前可用的数据。如果没有数据可用,线程不会被阻塞,而是可以继续做其他事情。
-
这种非阻塞模式提高了线程的利用率和应用的性能。
-
-
缓冲区操作
-
在NIO中,数据总是从通道读取到缓冲区中,或者从缓冲区写入到通道中。
-
缓冲区提供了对数据读写的灵活性和高效性。通过缓冲区的position、limit和capacity属性,可以精确地控制数据的读写操作。
-
-
选择器监听
-
选择器通过监听多个通道的事件来管理多个输入和输出通道。
-
当某个通道的事件发生时(如连接请求、数据到达等),选择器会返回并告知哪些通道的事件已经就绪。
-
线程可以根据选择器返回的信息来处理相应的事件。
-
三、NIO 核心组件
NIO 主要包括以下三个核心组件:
-
Buffer(缓冲区):
-
NIO 读写数据都是通过缓冲区进行操作的。读操作的时候将 Channel 中的数据填充到 Buffer 中,而写操作时将 Buffer 中的数据写入到 Channel 中。
-
缓冲区是一个容器对象,它实质上是一个数组。在NIO中,所有数据都是用缓冲区处理的。缓冲区提供了对数据读写的灵活性和高效性。
-
常用的缓冲区类型包括:ByteBuffer(字节缓冲区)、CharBuffer(字符缓冲区)、IntBuffer(整数缓冲区)、LongBuffer(长整型缓冲区)、DoubleBuffer(双精度浮点缓冲区)和FloatBuffer(单精度浮点缓冲区)。
-
缓冲区有三个关键属性:capacity(容量)、position(位置)和limit(限制)。capacity表示缓冲区的总大小,position表示当前读写操作的位置,limit表示当前可以操作的最大位置。
-
-
Channel(通道):
-
Channel 是一个双向的、可读可写的数据传输通道,NIO 通过 Channel 来实现数据的输入输出。通道是一个抽象的概念,它可以代表文件、套接字或者其他数据源之间的连接。
-
通道是NIO中用于读写数据的通道,它类似于传统的流,但提供了更高的性能和更多的功能。
-
通道可以是双向的,这意味着它既可以从通道读取数据,也可以向通道写入数据。
-
常用的通道类型包括:FileChannel(文件通道)、SocketChannel(套接字通道)、ServerSocketChannel(服务器套接字通道)和DatagramChannel(数据报通道)。
-
-
Selector(选择器):
-
允许一个线程处理多个 Channel,基于事件驱动的 I/O 多路复用模型。所有的 Channel 都可以注册到 Selector 上,由 Selector 来分配线程来处理事件。
-
选择器是NIO中的一个重要组件,它允许一个线程监视多个通道的事件(如连接请求、数据到达等)。
-
通过选择器,一个线程可以管理多个输入和输出通道,从而提高了网络应用的性能和响应速度。
-
使用选择器时,需要先将通道注册到选择器上,并指定感兴趣的事件类型。然后,通过调用选择器的select()方法来等待事件的发生。一旦有事件发生,选择器就会返回并告知哪些通道的事件已经就绪。
-
三者的关系如下图所示(暂时不理解没关系,后文会详细介绍):

下面详细介绍一下这三个组件。
1、Buffer(缓冲区)
在传统的 BIO 中,数据的读写是面向流的, 分为字节流和字符流。
在 Java 1.4 的 NIO 库中,所有数据都是用缓冲区处理的,这是新库和之前的 BIO 的一个重要区别,有点类似于 BIO 中的缓冲流。NIO 在读取数据时,它是直接读到缓冲区中的。在写入数据时,写入到缓冲区中。 使用 NIO 在读写数据时,都是通过缓冲区进行操作。
Buffer 的子类如下图所示。其中,最常用的是 ByteBuffer,它可以用来存储和操作字节数据。

你可以将 Buffer 理解为一个数组,IntBuffer、FloatBuffer、CharBuffer 等分别对应 int[]、float[]、char[] 等。
为了更清晰地认识缓冲区,我们来简单看看Buffer 类中定义的四个成员变量:
public abstract class Buffer {// Invariants: mark <= position <= limit <= capacityprivate int mark = -1;private int position = 0;private int limit;private int capacity;
}这四个成员变量的具体含义如下:
-
容量(
capacity):Buffer可以存储的最大数据量,Buffer创建时设置且不可改变; -
界限(
limit):Buffer中可以读/写数据的边界。写模式下,limit代表最多能写入的数据,一般等于capacity(可以通过limit(int newLimit)方法设置);读模式下,limit等于 Buffer 中实际写入的数据大小。 -
位置(
position):下一个可以被读写的数据的位置(索引)。从写操作模式到读操作模式切换的时候(flip),position都会归零,这样就可以从头开始读写了。 -
标记(
mark):Buffer允许将位置直接定位到该标记处,这是一个可选属性;
并且,上述变量满足如下的关系:0 <= mark <= position <= limit <= capacity 。
另外,Buffer 有读模式和写模式这两种模式,分别用于从 Buffer 中读取数据或者向 Buffer 中写入数据。Buffer 被创建之后默认是写模式,调用 flip() 可以切换到读模式。如果要再次切换回写模式,可以调用 clear() 或者 compact() 方法。


Buffer 对象不能通过 new 调用构造方法创建对象 ,只能通过静态方法实例化 Buffer。
这里以 ByteBuffer为例进行介绍:
// 分配堆内存
public static ByteBuffer allocate(int capacity);
// 分配直接内存
public static ByteBuffer allocateDirect(int capacity);Buffer 最核心的两个方法:
-
get: 读取缓冲区的数据 -
put:向缓冲区写入数据
除上述两个方法之外,其他的重要方法:
-
flip:将缓冲区从写模式切换到读模式,它会将limit的值设置为当前position的值,将position的值设置为 0。 -
clear: 清空缓冲区,将缓冲区从读模式切换到写模式,并将position的值设置为 0,将limit的值设置为capacity的值。
Buffer 中数据变化的过程:
import java.nio.*;public class CharBufferDemo {public static void main(String[] args) {// 分配一个容量为8的CharBufferCharBuffer buffer = CharBuffer.allocate(8);System.out.println("初始状态:");printState(buffer);// 向buffer写入3个字符buffer.put('a').put('b').put('c');System.out.println("写入3个字符后的状态:");printState(buffer);// 调用flip()方法,准备读取buffer中的数据,将 position 置 0,limit 的置 3buffer.flip();System.out.println("调用flip()方法后的状态:");printState(buffer);// 读取字符while (buffer.hasRemaining()) {System.out.print(buffer.get());}// 调用clear()方法,清空缓冲区,将 position 的值置为 0,将 limit 的值置为 capacity 的值buffer.clear();System.out.println("调用clear()方法后的状态:");printState(buffer);}// 打印buffer的capacity、limit、position、mark的位置private static void printState(CharBuffer buffer) {System.out.print("capacity: " + buffer.capacity());System.out.print(", limit: " + buffer.limit());System.out.print(", position: " + buffer.position());System.out.print(", mark 开始读取的字符: " + buffer.mark());System.out.println("\n");}
}输出:
初始状态:
capacity: 8, limit: 8, position: 0写入3个字符后的状态:
capacity: 8, limit: 8, position: 3准备读取buffer中的数据!
调用flip()方法后的状态:
capacity: 8, limit: 3, position: 0读取到的数据:abc
调用clear()方法后的状态:
capacity: 8, limit: 8, position: 0
为了帮助理解,我绘制了一张图片展示 capacity、limit和position每一阶段的变化。

2、Channel(通道)
Channel 是一个通道,它建立了与数据源(如文件、网络套接字等)之间的连接。我们可以利用它来读取和写入数据,就像打开了一条自来水管,让数据在 Channel 中自由流动。
BIO 中的流是单向的,分为各种 InputStream(输入流)和 OutputStream(输出流),数据只是在一个方向上传输。通道与流的不同之处在于通道是双向的,它可以用于读、写或者同时用于读写。
Channel 与前面介绍的 Buffer 打交道,读操作的时候将 Channel 中的数据填充到 Buffer 中,而写操作时将 Buffer 中的数据写入到 Channel 中。

另外,因为 Channel 是全双工的,所以它可以比流更好地映射底层操作系统的 API。特别是在 UNIX 网络编程模型中,底层操作系统的通道都是全双工的,同时支持读写操作。
Channel 的子类如下图所示。

其中,最常用的是以下几种类型的通道:
-
FileChannel:文件访问通道; -
SocketChannel、ServerSocketChannel:TCP 通信通道; -
DatagramChannel:UDP 通信通道;

Channel 最核心的两个方法:
-
read:读取数据并写入到 Buffer 中。 -
write:将 Buffer 中的数据写入到 Channel 中。
这里我们以 FileChannel 为例演示一下是读取文件数据的。
RandomAccessFile reader = new RandomAccessFile("/Users/guide/Documents/test_read.in", "r"))
FileChannel channel = reader.getChannel();
ByteBuffer buffer = ByteBuffer.allocate(1024);
channel.read(buffer);3、Selector(选择器)
Selector(选择器) 是 NIO 中的一个关键组件,它允许一个线程处理多个 Channel。Selector 是基于事件驱动的 I/O 多路复用模型,主要运作原理是:通过 Selector 注册通道的事件,Selector 会不断地轮询注册在其上的 Channel。当事件发生时,比如:某个 Channel 上面有新的 TCP 连接接入、读和写事件,这个 Channel 就处于就绪状态,会被 Selector 轮询出来。Selector 会将相关的 Channel 加入到就绪集合中。通过 SelectionKey 可以获取就绪 Channel 的集合,然后对这些就绪的 Channel 进行相应的 I/O 操作。

一个多路复用器 Selector 可以同时轮询多个 Channel,由于 JDK 使用了 epoll() 代替传统的 select 实现,所以它并没有最大连接句柄 1024/2048 的限制。这也就意味着只需要一个线程负责 Selector 的轮询,就可以接入成千上万的客户端。
Selector 可以监听以下四种事件类型:
-
SelectionKey.OP_ACCEPT:表示通道接受连接的事件,这通常用于ServerSocketChannel。 -
SelectionKey.OP_CONNECT:表示通道完成连接的事件,这通常用于SocketChannel。 -
SelectionKey.OP_READ:表示通道准备好进行读取的事件,即有数据可读。 -
SelectionKey.OP_WRITE:表示通道准备好进行写入的事件,即可以写入数据。
Selector是抽象类,可以通过调用此类的 open() 静态方法来创建 Selector 实例。Selector 可以同时监控多个 SelectableChannel 的 IO 状况,是非阻塞 IO 的核心。
一个 Selector 实例有三个 SelectionKey 集合:
-
所有的
SelectionKey集合:代表了注册在该 Selector 上的Channel,这个集合可以通过keys()方法返回。 -
被选择的
SelectionKey集合:代表了所有可通过select()方法获取的、需要进行IO处理的 Channel,这个集合可以通过selectedKeys()返回。 -
被取消的
SelectionKey集合:代表了所有被取消注册关系的Channel,在下一次执行select()方法时,这些Channel对应的SelectionKey会被彻底删除,程序通常无须直接访问该集合,也没有暴露访问的方法。
简单演示一下如何遍历被选择的 SelectionKey 集合并进行处理:
Set<SelectionKey> selectedKeys = selector.selectedKeys();
Iterator<SelectionKey> keyIterator = selectedKeys.iterator();
while (keyIterator.hasNext()) {SelectionKey key = keyIterator.next();if (key != null) {if (key.isAcceptable()) {// ServerSocketChannel 接收了一个新连接} else if (key.isConnectable()) {// 表示一个新连接建立} else if (key.isReadable()) {// Channel 有准备好的数据,可以读取} else if (key.isWritable()) {// Channel 有空闲的 Buffer,可以写入数据}}keyIterator.remove();
}Selector 还提供了一系列和 select() 相关的方法:
-
int select():监控所有注册的Channel,当它们中间有需要处理的IO操作时,该方法返回,并将对应的SelectionKey加入被选择的SelectionKey集合中,该方法返回这些Channel的数量。 -
int select(long timeout):可以设置超时时长的select()操作。 -
int selectNow():执行一个立即返回的select()操作,相对于无参数的select()方法而言,该方法不会阻塞线程。 -
Selector wakeup():使一个还未返回的select()方法立刻返回。
使用 Selector 实现网络读写的简单示例:
import java.io.IOException;
import java.net.InetSocketAddress;
import java.nio.ByteBuffer;
import java.nio.channels.SelectionKey;
import java.nio.channels.Selector;
import java.nio.channels.ServerSocketChannel;
import java.nio.channels.SocketChannel;
import java.util.Iterator;
import java.util.Set;public class NioSelectorExample {public static void main(String[] args) {try {ServerSocketChannel serverSocketChannel = ServerSocketChannel.open();serverSocketChannel.configureBlocking(false);serverSocketChannel.socket().bind(new InetSocketAddress(8080));Selector selector = Selector.open();// 将 ServerSocketChannel 注册到 Selector 并监听 OP_ACCEPT 事件serverSocketChannel.register(selector, SelectionKey.OP_ACCEPT);while (true) {int readyChannels = selector.select();if (readyChannels == 0) {continue;}Set<SelectionKey> selectedKeys = selector.selectedKeys();Iterator<SelectionKey> keyIterator = selectedKeys.iterator();while (keyIterator.hasNext()) {SelectionKey key = keyIterator.next();if (key.isAcceptable()) {// 处理连接事件ServerSocketChannel server = (ServerSocketChannel) key.channel();SocketChannel client = server.accept();client.configureBlocking(false);// 将客户端通道注册到 Selector 并监听 OP_READ 事件client.register(selector, SelectionKey.OP_READ);} else if (key.isReadable()) {// 处理读事件SocketChannel client = (SocketChannel) key.channel();ByteBuffer buffer = ByteBuffer.allocate(1024);int bytesRead = client.read(buffer);if (bytesRead > 0) {buffer.flip();System.out.println("收到数据:" +new String(buffer.array(), 0, bytesRead));// 将客户端通道注册到 Selector 并监听 OP_WRITE 事件client.register(selector, SelectionKey.OP_WRITE);} else if (bytesRead < 0) {// 客户端断开连接client.close();}} else if (key.isWritable()) {// 处理写事件SocketChannel client = (SocketChannel) key.channel();ByteBuffer buffer = ByteBuffer.wrap("Hello, Client!".getBytes());client.write(buffer);// 将客户端通道注册到 Selector 并监听 OP_READ 事件client.register(selector, SelectionKey.OP_READ);}keyIterator.remove();}}} catch (IOException e) {e.printStackTrace();}}
}在示例中,我们创建了一个简单的服务器,监听 8080 端口,使用 Selector 处理连接、读取和写入事件。当接收到客户端的数据时,服务器将读取数据并将其打印到控制台,然后向客户端回复 "Hello, Client!"。
四、NIO 零拷贝
零拷贝是提升 IO 操作性能的一个常用手段,像 ActiveMQ、Kafka 、RocketMQ、QMQ、Netty 等顶级开源项目都用到了零拷贝。
零拷贝是指计算机执行 IO 操作时,CPU 不需要将数据从一个存储区域复制到另一个存储区域,从而可以减少上下文切换以及 CPU 的拷贝时间。也就是说,零拷贝主要解决操作系统在处理 I/O 操作时频繁复制数据的问题。零拷贝的常见实现技术有: mmap+write、sendfile和 sendfile + DMA gather copy 。
下图展示了各种零拷贝技术的对比图:
| CPU 拷贝 | DMA 拷贝 | 系统调用 | 上下文切换 | |
|---|---|---|---|---|
| 传统方法 | 2 | 2 | read+write | 4 |
| mmap+write | 1 | 2 | mmap+write | 4 |
| sendfile | 1 | 2 | sendfile | 2 |
| sendfile + DMA gather copy | 0 | 2 | sendfile | 2 |
可以看出,无论是传统的 I/O 方式,还是引入了零拷贝之后,2 次 DMA(Direct Memory Access) 拷贝是都少不了的。因为两次 DMA 都是依赖硬件完成的。零拷贝主要是减少了 CPU 拷贝及上下文的切换。
Java 对零拷贝的支持:
MappedByteBuffer是 NIO 基于内存映射(mmap)这种零拷⻉⽅式的提供的⼀种实现,底层实际是调用了 Linux 内核的mmap系统调用。它可以将一个文件或者文件的一部分映射到内存中,形成一个虚拟内存文件,这样就可以直接操作内存中的数据,而不需要通过系统调用来读写文件。FileChannel的transferTo()/transferFrom()是 NIO 基于发送文件(sendfile)这种零拷贝方式的提供的一种实现,底层实际是调用了 Linux 内核的sendfile系统调用。它可以直接将文件数据从磁盘发送到网络,而不需要经过用户空间的缓冲区。关于FileChannel的用法可以看看这篇文章:Java NIO 文件通道 FileChannel 用法。
代码示例:
private void loadFileIntoMemory(File xmlFile) throws IOException {FileInputStream fis = new FileInputStream(xmlFile);// 创建 FileChannel 对象FileChannel fc = fis.getChannel();// FileChannel.map() 将文件映射到直接内存并返回 MappedByteBuffer 对象MappedByteBuffer mmb = fc.map(FileChannel.MapMode.READ_ONLY, 0, fc.size());xmlFileBuffer = new byte[(int)fc.size()];mmb.get(xmlFileBuffer);fis.close();
}总结
这篇文章我们主要介绍了 NIO 的核心知识点,包括 NIO 的核心组件和零拷贝。
如果我们需要使用 NIO 构建网络程序的话,不建议直接使用原生 NIO,编程复杂且功能性太弱,推荐使用一些成熟的基于 NIO 的网络编程框架比如 Netty。Netty 在 NIO 的基础上进行了一些优化和扩展比如支持多种协议、支持 SSL/TLS 等等
相关文章:
Java NIO 核心知识总结
在学习 NIO 之前,需要先了解一下计算机 I/O 模型的基础理论知识。还不了解的话,可以参考我写的这篇文章:Java IO 模型详解。 一、NIO 简介 在传统的 Java I/O 模型(BIO)中,I/O 操作是以阻塞的方式进行的。…...

疑难Tips:NextCloud域名访问登录时卡住,显示违反内容安全策略
[ 知识是人生的灯塔,只有不断学习,才能照亮前行的道路 ] 1使用域名访问Nextcloud用户登录时卡住,显示违反内容安全策略 我使用官方Docker镜像来部署NextCloud 28.0.5,并通过Openresty反向代理Nextcloud,但是在安装后无法稳定工作,每次登录后,页面会卡死在登录界面,无法…...

C 语言学习-06【指针】
1、目标单元与简介存取 直接访问和间接访问 #include <stdio.h>int main(void) {int a 3, *p;p &a;printf("a %d, *p %d\n", a, *p);*p 10;printf("a %d, *p %d\n", a, *p);printf("Enter a: ");scanf("%d", &a)…...
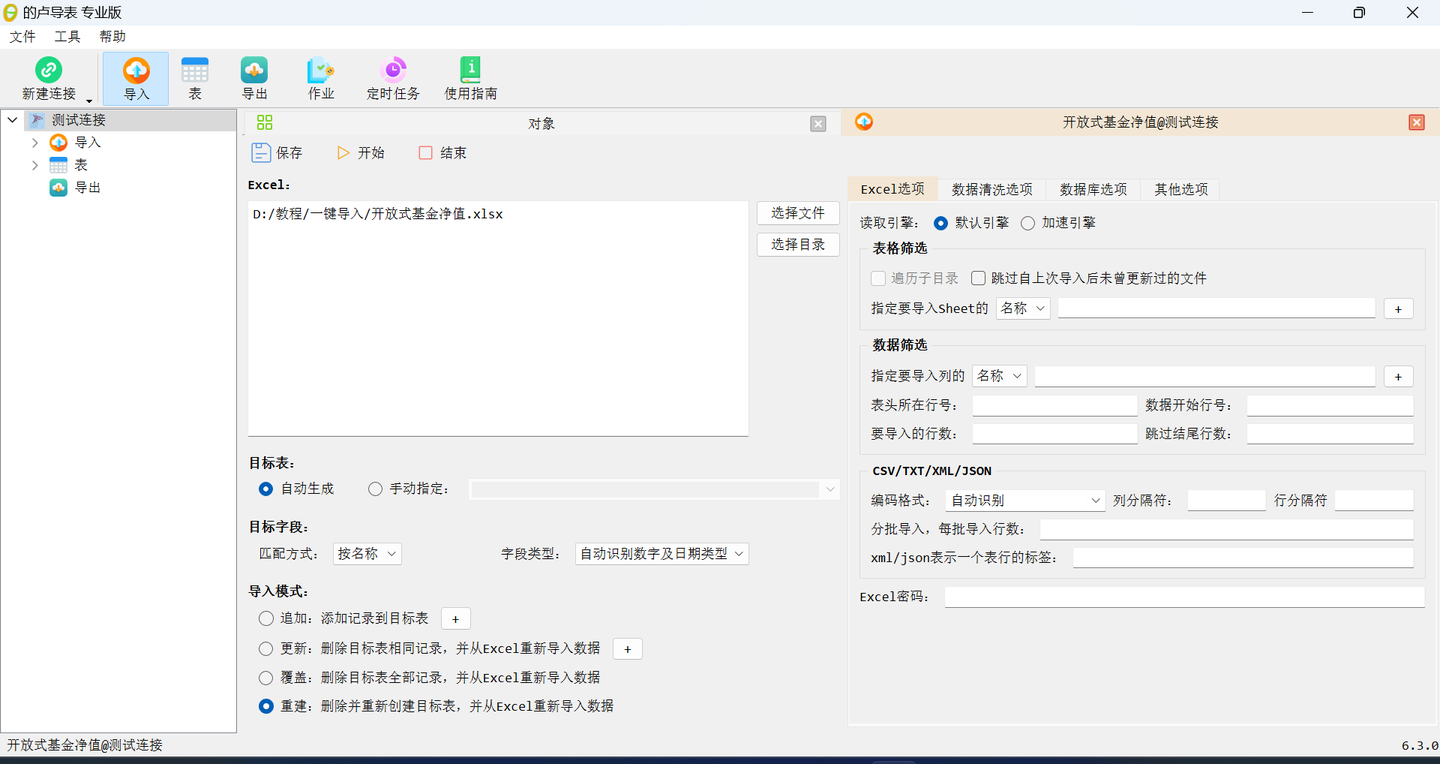
如何快速将Excel数据导入到SQL Server数据库
工作中,我们经常需要将Excel数据导入到数据库,但是对于数据库小白来说,这可能并非易事;对于数据库专家来说,这又可能非常繁琐。 这篇文章将介绍如何帮助您快速的将Excel数据导入到sql server数据库。 准备工作 这里&…...

【人工智能】Python在机器学习与人工智能中的应用
Python因其简洁易用、丰富的库支持以及强大的社区,被广泛应用于机器学习与人工智能(AI)领域。本教程通过实用的代码示例和讲解,带你从零开始掌握Python在机器学习与人工智能中的基本用法。 1. 机器学习与AI的Python生态系统 Pyth…...

使用八爪鱼爬虫抓取汽车网站数据,分析舆情数据
我是做汽车行业的,可以用八爪鱼爬虫抓取汽车之家和微博上的汽车文章内容,分析各种电动汽车口碑数据。 之前,我写过很多Python网络爬虫的案例,使用requests、selenium等技术采集数据,这次尝试去采集小米SU7在微博、汽车…...

什么是事务?事务有哪些特性?
在数据库管理中,事务是一个核心概念,它确保了数据操作的完整性和一致性。本文将探讨事务的定义及其四大特性。 一、事务的定义 事务是数据库操作的最小工作单元,是作为单个逻辑工作单元执行的一系列操作。这些操作作为一个整体一起向系统提…...
)
玩转合宙Luat教程 基础篇④——程序基础(库、线程、定时器和订阅/发布)
文章目录 一、前言二、库三、线程四、定时器五、订阅/发布5.1 回调函数5.2 堵塞等待一、前言 教程目录大纲请查阅:玩转合宙Luat教程——导读 写一写Lua程序基础的东西。 包括如何调用库,如何创建线程、如何创建定时器,如何使用订阅/发布事件。 二、库 程序从main.lua开始通…...

24.<Spring博客系统①(数据库+公共代码+持久层+显示博客列表+博客详情)>
项目整体预览 登录页面 主页 查看全文 编辑 写博客 PS:Service.impl(现在流行写法) 推荐写法。后续完成项目。会尝试这样写。 接口可以有多个实现。每个实现都可以不同。 这也算一种设计模式。叫做(策略模式)。 我们…...
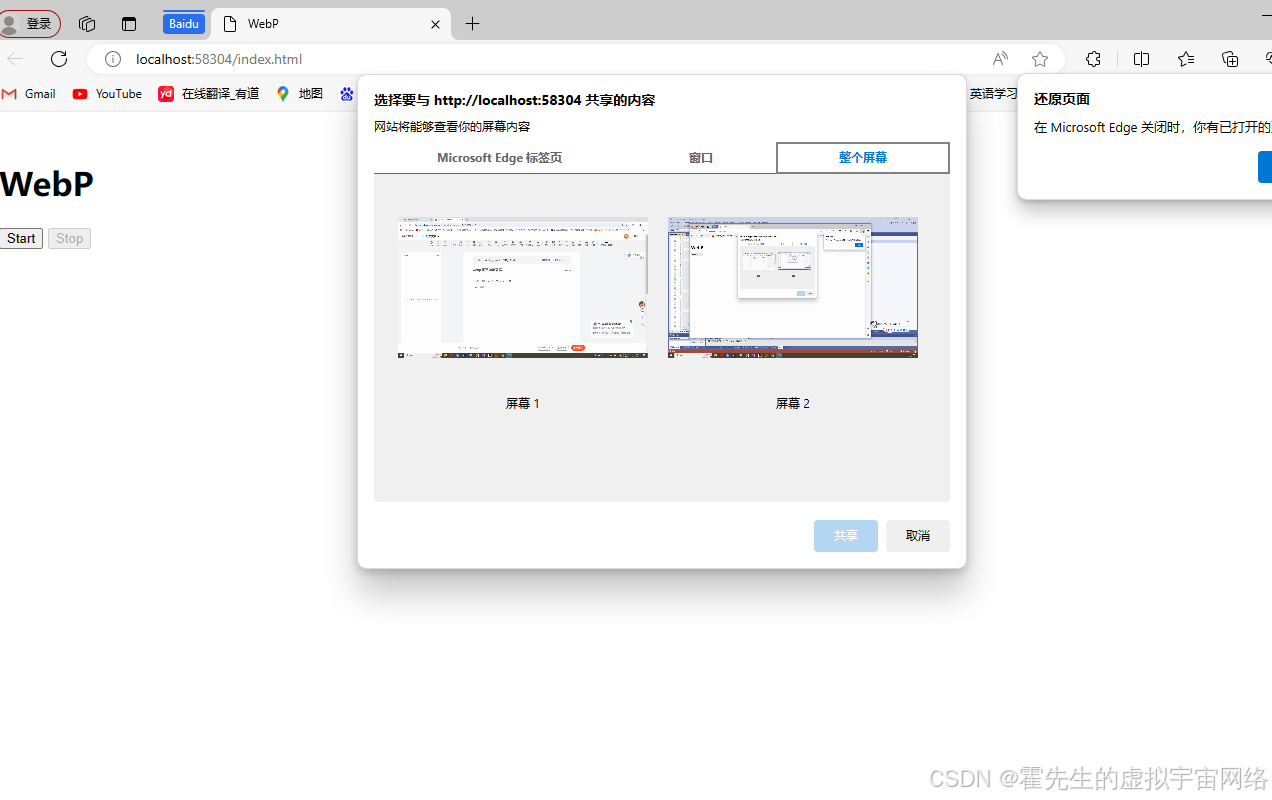
webp 网页如何录屏?
工作中正好研究到了一点:记录下这里: 先看下效果: 具体实现代码:  <!DOCTYPE html> <html lang"zh-CN"> <head><meta charset"UTF-8"><meta name"viewport&qu…...

丹摩征文活动|实现Llama3.1大模型的本地部署
文章目录 1.前言2.丹摩的配置3.Llama3.1的本地配置4. 最终界面 丹摩 1.前言 Llama3.1是Meta 公司发布的最新开源大型语言模型,相较于之前的版本,它在规模和功能上实现了显著提升,尤其是最大的 4050亿参数版本,成为开源社区中非常…...

Spring Boot 2 和 Spring Boot 3 中使用 Spring Security 的区别
文章目录 Spring Boot 2 和 Spring Boot 3 中使用 Spring Security 的区别1. Jakarta EE 迁移2. Spring Security 配置方式的变化3. PasswordEncoder 加密方式的变化4. permitAll() 和 authenticated() 的变化5. 更强的默认安全设置6. Java 17 支持与语法提升7. PreAuthorize、…...

【数据结构与算法】 LeetCode:回溯
文章目录 回溯算法组合组合总和(Hot 100)组合总和 II电话号码的字母组合(Hot 100)括号生成(Hot 100)分割回文串(Hot 100)复原IP地址子集(Hot 100)全排列&…...

SpringBoot线程池的使用
SpringBoot线程池的使用 在现代Web应用开发中,特别是在使用Spring Boot框架时,合理使用线程池可以显著提高应用的性能和响应速度。线程池不仅能够减少线程创建和销毁的开销,还能有效地控制并发任务的数量,避免因线程过多而导致的…...
Neural Magic 发布 LLM Compressor:提升大模型推理效率的新工具
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…...

HttpServletRequest req和前端的关系,req.getParameter详细解释,req.getParameter和前端的关系
HttpServletRequest 对象在后端和前端之间起到了桥梁的作用,它包含了来自客户端的所有请求信息。通过 HttpServletRequest 对象,后端可以获取前端发送的请求参数、请求头、请求方法等信息,并根据这些信息进行相应的处理。以下是对 HttpServle…...

React-useEffect的使用
useEffect react提供的一个常用hook,用于在函数组件中执行副作用操作,比如数据获取、订阅或手动更改DOM。 基本用法: 接受2个参数: 一个包含命令式代码的函数(副作用函数)。一个依赖项数组,用…...

MySQL数据库与Informix:能否创建同名表?
MySQL数据库与Informix:能否创建同名表? 一、MySQL数据库中的同名表创建1. 使用CREATE TABLE ... SELECT语句2. 使用CREATE TABLE LIKE语句3. 复制表结构并选择性复制数据4. 使用同义词(Synonym)二、Informix数据库中的同名表创建1. 使用不同所有者2. 使用不同模式3. 复制表…...

爬虫实战:采集知乎XXX话题数据
目录 反爬虫的本意和其带来的挑战目标实战开发准备代码开发发现问题1. 发现问题[01]2. 发现问题[02] 解决问题1. 解决问题[01]2. 解决问题[02] 最终结果 结语 反爬虫的本意和其带来的挑战 在这个数字化时代社交媒体已经成为人们表达观点的重要渠道,对企业来说&…...

大数据新视界 -- Hive 数据桶原理:均匀分布数据的智慧(上)(9/ 30)
💖💖💖亲爱的朋友们,热烈欢迎你们来到 青云交的博客!能与你们在此邂逅,我满心欢喜,深感无比荣幸。在这个瞬息万变的时代,我们每个人都在苦苦追寻一处能让心灵安然栖息的港湾。而 我的…...

el-switch文字内置
el-switch文字内置 效果 vue <div style"color:#ffffff;font-size:14px;float:left;margin-bottom:5px;margin-right:5px;">自动加载</div> <el-switch v-model"value" active-color"#3E99FB" inactive-color"#DCDFE6"…...

CocosCreator 之 JavaScript/TypeScript和Java的相互交互
引擎版本: 3.8.1 语言: JavaScript/TypeScript、C、Java 环境:Window 参考:Java原生反射机制 您好,我是鹤九日! 回顾 在上篇文章中:CocosCreator Android项目接入UnityAds 广告SDK。 我们简单讲…...

Java 加密常用的各种算法及其选择
在数字化时代,数据安全至关重要,Java 作为广泛应用的编程语言,提供了丰富的加密算法来保障数据的保密性、完整性和真实性。了解这些常用加密算法及其适用场景,有助于开发者在不同的业务需求中做出正确的选择。 一、对称加密算法…...

鸿蒙中用HarmonyOS SDK应用服务 HarmonyOS5开发一个生活电费的缴纳和查询小程序
一、项目初始化与配置 1. 创建项目 ohpm init harmony/utility-payment-app 2. 配置权限 // module.json5 {"requestPermissions": [{"name": "ohos.permission.INTERNET"},{"name": "ohos.permission.GET_NETWORK_INFO"…...

WordPress插件:AI多语言写作与智能配图、免费AI模型、SEO文章生成
厌倦手动写WordPress文章?AI自动生成,效率提升10倍! 支持多语言、自动配图、定时发布,让内容创作更轻松! AI内容生成 → 不想每天写文章?AI一键生成高质量内容!多语言支持 → 跨境电商必备&am…...

深入解析C++中的extern关键字:跨文件共享变量与函数的终极指南
🚀 C extern 关键字深度解析:跨文件编程的终极指南 📅 更新时间:2025年6月5日 🏷️ 标签:C | extern关键字 | 多文件编程 | 链接与声明 | 现代C 文章目录 前言🔥一、extern 是什么?&…...
)
Typeerror: cannot read properties of undefined (reading ‘XXX‘)
最近需要在离线机器上运行软件,所以得把软件用docker打包起来,大部分功能都没问题,出了一个奇怪的事情。同样的代码,在本机上用vscode可以运行起来,但是打包之后在docker里出现了问题。使用的是dialog组件,…...
集成 Mybatis-Plus 和 Mybatis-Plus-Join)
纯 Java 项目(非 SpringBoot)集成 Mybatis-Plus 和 Mybatis-Plus-Join
纯 Java 项目(非 SpringBoot)集成 Mybatis-Plus 和 Mybatis-Plus-Join 1、依赖1.1、依赖版本1.2、pom.xml 2、代码2.1、SqlSession 构造器2.2、MybatisPlus代码生成器2.3、获取 config.yml 配置2.3.1、config.yml2.3.2、项目配置类 2.4、ftl 模板2.4.1、…...
【C++特殊工具与技术】优化内存分配(一):C++中的内存分配
目录 一、C 内存的基本概念 1.1 内存的物理与逻辑结构 1.2 C 程序的内存区域划分 二、栈内存分配 2.1 栈内存的特点 2.2 栈内存分配示例 三、堆内存分配 3.1 new和delete操作符 4.2 内存泄漏与悬空指针问题 4.3 new和delete的重载 四、智能指针…...
淘宝扭蛋机小程序系统开发:打造互动性强的购物平台
淘宝扭蛋机小程序系统的开发,旨在打造一个互动性强的购物平台,让用户在购物的同时,能够享受到更多的乐趣和惊喜。 淘宝扭蛋机小程序系统拥有丰富的互动功能。用户可以通过虚拟摇杆操作扭蛋机,实现旋转、抽拉等动作,增…...