MySQL原理简介—10.SQL语句和执行计划
大纲
1.什么是执行计划
2.执行计划包含哪些内容
3.SQL语句和执行计划的总结
4.SQL语句使用多个二级索引
5.多表关联的SQL语句如何执行
6.全表扫描执行计划的成本计算方法
7.索引的成本计算方法
8.MySQL如何优化执行计划
9.explain的参数说明
1.什么是执行计划
(1)什么是SQL优化
一般开发一个系统,都是先设计表结构,表结构必须满足业务需求。然后写代码,代码写完后,根据代码是如何查询表来设计表的索引,需要考虑设计几个索引,选择哪些字段作索引,是不是联合索引,以及如何排列索引字段的顺序才能让查询语句都用上索引。
普通的SQL优化就是设计好索引,让不太复杂的普通查询都能用上索引。但针对复杂表结构和大数据量的上百行的复杂的SQL优化,必须要理解复杂SQL是怎么执行的,而这就涉及到执行计划。
(2)什么是执行计划
执行SQL语句时,面对磁盘上的大量数据表、聚簇索引和二级索引:如何检索查询、如何筛选过滤、如何使用函数、如何进行排序、如何进行分组、怎样把数据按照SQL查出来,这个过程就是执行计划。
也就是说,每次提交一个SQL语句给MySQL。它的查询优化器,都会针对这个SQL语句的语义去生成一个执行计划,这个执行计划会包含如何查各个表、用到哪些索引、如何做排序和分组,一般基于执行计划来进行SQL优化。
(3)什么是SQL调优
根据SQL语句执行计划,去想办法改写SQL语句,改良表的索引设计,进而优化SQL语句的执行计划,最终提升SQL的执行性能。
2.执行计划包含哪些内容
(1)const
如果可以直接通过聚簇索引或者二级索引+回表聚簇索引,轻松查出数据。那么这种根据主键索引就能直接查出数据的过程,在执行计划里称为const。类似如下的SQL,建立的索引是key(id)和key(name)。
mysql> select * from table where id=x;
mysql> select * from table where name=x;执行计划里的count,代表的意思是性能超高的常量级。所以执行计划里出现const,表明SQL会通过索引查询数据,速度极快。
但需要注意的是:二级索引必须是唯一索引才是属于const方式。即必须建立unique key唯一索引,保证二级索引的每一个值都是唯一的,这时根据二级索引查询才是const。
(2)ref
如果查询时使用的普通的二级索引只有一列,并且不是唯一索引,那么查询的速度也很快,它在执行计划里叫做ref。类似如下SQL,建立的索引是key(name)。
mysql> select * from table where name=x;如果查询时使用的普通的二级索引包含多列,那么必须从索引最左侧开始连续多个列都是等值比较才是属于ref方式。类似如下SQL,建立的索引是key(name,age,sex)。
mysql> select * from table where
name=x and age=x and sex=x;如果使用name is null这种查询,即使name是主键或者唯一索引,还是只能通过ref方式来查询。
(3)ref_or_null
如果查询时使用了普通的二级索引而且还限定了is null,类似如下SQL,那么在执行计划里就是ref_or_null。
mysql> select * from table where
name=x or name is null;所以,当我们在分析执行计划时:看到了const,表明肯定是通过主键/唯一索引访问的,速度超高。看到了ref,表明用了普通索引,或主键/唯一索引使用is not null。看到了ref_or_null,表明用了普通索引,而且还限定了is null。
(4)range
如果SQL里面对索引有范围查询,那么就会用这个range方式。类似如下SQL语句,假设age就是一个普通索引,此时必然通过索引来进行范围筛选。一旦利用索引范围筛选,那么这种方式就是range。
mysql> select * from table where
age > x and age < y;(5)index
假设有一个表,里面有个联合索引key(x1, x2, x3),现在有如下SQL语句。这个SQL是没办法直接从联合索引的索引树根节点开始二分查找的。但这个SQL里要查的几个字段,恰好就是联合索引里的几个字段。
mysql> select x1, x2, x3 from table where x2=xxx;因为聚簇索引的叶子节点放的是完整的数据页,联合索引的叶子节点放的数据页只包含索引字段的值和主键的值。所以这种SQL的查询,会直接遍历这个联合索引的索引树的叶子节点。一个个遍历,找到x2=xxx的那条数据。然后把x1,x2,x3三个字段的值提取出来即可,不需要回源到聚簇索引。
遍历二级索引的过程,要比遍历聚簇索引快得多。毕竟二级索引叶子节点只包含几个字段值,比聚簇索引叶子节点小很多。
这种只需要遍历二级索引就可获取想要查询的数据,而不需要回表到聚簇索引的查询方式,就叫做index。
(6)all
全表扫描,扫描聚簇索引的所有子节点。
(7)总结
const、ref和range,都是基于索引树进行二分查找和多层跳转来查询的。所以const、ref和range的性能一般都很高,然后index的速度就比前面这三种要差一些,因为index是通过遍历二级索引的叶子节点的方式来执行,所以index肯定比二分查找慢但比全表扫描好。
3.SQL语句和执行计划的总结
(1)const、ref和range本质都是基于索引查询
只要索引查出来的数据量不是特别大,一般性能都极为高效。
(2)index稍微次一点,需要遍历某个二级索引
但是因为二级索引比较小,所以遍历性能也还可以。
(3)最差的就是all,意味着全表扫描
即扫描聚簇索引的所有叶子节点,一个表一行一行数据去扫描。如果数据量很大,全表扫描就很危险了。
(4)SQL语句的执行计划案例
案例一:
mysql> select * from table where
x1 = xxx and x2 > xx;这个SQL语句要查一个表,用了x1和x2两个字段。如果给x1和x2建立联合索引,那么是可以直接通过索引去扫描的。但如果现在建了只有(x1, x3)和(x2, x4)这两个联合索引,此时MySQL只能选择其中一个索引去用,会选哪个?这时MySQL负责生成执行计划的查询优化器,一般会选择在索引里扫描行数比较少的那个。
比如x1 = xx,在索引里只要做等值比较,扫描数据比较少。那么可能就会挑选x1的索引,然后基于其索引树进行查找。在执行计划里,对应于ref的方式,找到几条数据后再接着进行回表。回到聚簇索引里去查出每条数据的完整信息,然后把这些信息加载到内存,根据x2 > xx条件进行筛选。
案例二:
mysql> select * from table where
x1=xx and c1=xx and c2>xx and c3 is not null;我们经常会写出类似上述这样的SQL,就是SQL的所有筛选条件里,只有一个x1有索引,其他字段都没索引。这种情况还是很常见的,因为不可能针对所有SQL的where字段都加索引,我们一般只能抽取部分经常在where里用到的字段来设计两三个联合索引。
这种SQL语句,where后的条件有好几个,但只有一个字段可用到索引。此时查询优化器生成的执行计划,只会针对x1字段执行ref方式的查询,也就是通过x1字段的索引树快速找到符合x1=xx的一大堆数据。接着会根据这一大堆数据回表到聚簇索引里,查出每条数据的完整字段。然后将这些包含完整字段的数据加载到内存里去。接着就可以在内存针对这些数据的c1,c2,c3字段按条件进行筛选和过滤。最后便可以拿到符合条件的数据。
因此为了保证后续的查询性能比较高,所以针对x1索引的设计,需要尽可能让x1=xx这个条件在索引树里查找出来的数据量比较少。
4.SQL语句使用多个二级索引
一般一个SQL语句只会用到一个二级索引,但是一些特殊的情况下,可能一个SQL语句会用到多个二级索引。比如有SQL语句:
mysql> select * from table where x1=xx and x2=xx;其中x1和x2分别有一个索引,查询优化器会生成如下这样的执行计划:先对x1的索引树查找出一批数据,再对x2的索引树查找出另一批数据,然后两批数据按主键值做交集,这个交集就是符合两个条件的数据了,最后再回表到聚簇索引去获取完整的数据。
什么情况下会对两个字段的两个索引一起查,然后取交集再回表呢?什么情况下会查多个索引树呢?
如果同时查两个索引树再取交集后的数据量很小,那么根据这少量数据回表到聚簇索引查询,就可以提升性能。所以是否会查多个索引树的标准是,能否提升性能。因此执行计划里出现了intersection交集、union并集等,意思就是查询时使用了多个索引,最后对结果集做交集或并集。
5.多表关联的SQL语句如何执行
(1)多表关联的基本原理
如下SQL语句在from后接了两个表,表示对两个表的数据关联起来查询。如果多表关联查询时没有限定多表连接条件,那么会直接进行笛卡尔积。比如"select * from t1,t2;"就会使用笛卡尔积,但一般会加限定关联条件。
mysql> select * from t1,t2 where
t1.x1=xx and t1.x2=t2.x2 and t2.x3=xx;上面SQL语句的关联条件是"t1.x2=t2.x2",所以其执行过程是:首先根据t1.x1=xx这个筛选条件去t1表里查询,可能使用了const、ref、index、all,具体要看索引如何建的。然后将筛选出来的结果,根据结果中x2的值,去t2表查询,也就是去t2表里查找t2.x2等于这些x2的值以及t2.x3=xx都匹配的数据。
这就是多表关联的基本原理,先查的表叫驱动表,根据先查出的数据再去查的另外一张表叫被驱动表。
(2)几种连接
一.内连接inner join
两个表里的数据必须是完全能关联上,才能将数据返回来。
二.左外连接left join
左侧表的某条数据在右侧表关联不到任何数据,也把左侧表该数据返回。
三.右外连接right join
右侧表的某条数据在左侧表关联不到任何数据,也把右侧表该数据返回。
四.语法限制
如果是内连接,那么连接条件可放在where语句里。如果是外连接,那么连接条件需放在on字句里。
(3)嵌套循环关联
假设有两个表要一起执行关联,此时会先在一个驱动表里根据它的where筛选条件找出一批数据。接着对这批数据进行循环,用每条数据都到另外一个被驱动表里,根据ON连接条件和where里的被驱动表筛选条件去查找数据。
假设从驱动表找出1000条数据,那么就要到被驱动表查询1000次。所以很多时候多表关联是很慢的。
因此针对多表查询的语句,尽量给两个表都加上索引。索引要确保从驱动表里查询是通过驱动表的索引去查找,接着对被驱动表查询也是通过被驱动表的索引去查找。
6.全表扫描执行计划的成本计算方法
(1)MySQL如何根据成本估算选择执行计划
(2)执行一个SQL语句的IO成本
(3)执行一个SQL语句的CPU成本
(4)评估SQL语句执行成本的案例
(1)MySQL如何根据成本估算选择执行计划
MySQL在执行单表查询时:对应的一些执行计划是诸如const、ref、range、index、all之类的。
MySQL在执行多表关联时:本质就是先查驱动表,接着根据连接条件再去被驱动表循环查询。
MySQL是如何对一个查询语句的多个执行计划评估成本的?MySQL如何根据成本评估选择一个成本最低的执行计划的?
执行一个SQL语句的成本一般分成两部分:IO成本和CPU成本。
(2)执行一个SQL语句的IO成本
首先这些数据需要从磁盘里读出来,从磁盘读数据到内存就是IO成本。而且MySQL里都是一页一页读的,读一页的IO成本约定为1.0。
(3)执行一个SQL语句的CPU成本
然后内存拿到数据后,需要对数据进行操作,比如验证是否符合搜索条件或者排序分组等,这些属于CPU成本。一般约定读取和检测一条数据是否符合条件的成本是0.2。
(4)评估SQL语句执行成本的案例
比如执行如下SQL语句:
mysql> select * from t where x1=xx and x2=xx;步骤一:假设该表有两个索引分别是针对x1和x2建立的,那么MySQL会先看这个SQL可以用到哪几个索引。由于发现x1和x2都有可能,于是possible_keys。
步骤二:接着会针对这个SQL计算一下全表扫描的成本,全表扫描需要进行磁盘IO把聚簇索引里的叶子节点上的数据页读到内存,所以磁盘文件上有多少的数据页就会耗费多少的IO成本。然后还需要对内存里的每一条数据都判断是否符合搜索条件,读取到内存里有多少条数据就需要耗费多少CPU成本。
(5)如何计算执行成本
可以使用命令show table status like "表名"拿到表的统计信息。MySQL在对表进行增删改的时候,MySQL会维护这个表的统计信息。比如rows记录表的记录数,data_length记录表的聚簇索引的字节数大小。
使用data_length除以1024就是KB大小,再除以16就是数据页的数量。通过估算数据页的数量和rows记录数,就可以计算全表扫描的成本了。
IO成本就是:数据页数量 * 1.0 + 微调值;CPU成本就是:行记录数 * 0.2 + 微调值;两者相加就是一个总成本。比如一个表有100个数据页,记录数有2万条。那么执行总成本值大致就是 100 + 4000 = 4100。
7.索引的成本计算方法
如果是根据主键查,那么直接通过聚簇索引查询就可以了。
如果是根据非主键字段查,该字段也建了索引。那么一般会首先从二级索引查一批数据,然后再根据这批数据的主键去聚簇索引回表查。最后对比全表扫描的估算成本和索引的估算成本,选成本低的执行计划。所以有时候出现不用索引而用全表扫描,就是因为索引的估算成本更高。
8.MySQL如何优化执行计划
(1)优化SQL语句的清晰语义
(2)子查询的优化
(1)优化SQL语句的清晰语义
从而方便后续在索引和数据页里进行查找,比如类似"i=5 and j>i"这样的会常量替换成"i=5 and j>5",比如类似"x=y and y=k and k=3"会常量替换成"x=3 and y=3 and k=3",比如类似"b=b and a=a"这种没意义的就直接删掉条件了。
(2)子查询的优化
如下SQL执行时会分两步:先执行子查询,再执行select * from t1 where...
mysql> select * from t1 where
x1=(select x1 from t2 where id = xxx);像上述这种单表查询可以直接用上索引还好,但有时用不上索引就会基于内存或者临时文件执行。
如下SQL会先通过子查询先查一批结果,然后判断t1表里哪些数据的x1值在这个结果集里。
mysql> select * from t1 where
x1 in (select x2 from t2 where x3 = xxx);如果先执行子查询,然后对t1表再进行全表扫描,而全表扫描会判断每条数据是否在该子查询的结果集里,那么效率就会非常低。
因此对于上述子查询,执行计划会被优化为:先执行子查询,然后再把子查询查出来的数据写入临时表。临时表也叫物化表,即把中间结果集进行物化。
这个物化表可能会基于memory存储引擎来通过内存存放。如果结果集太大,则可能采用普通B+树聚簇索引的方式放在磁盘里。这个物化表都会建立索引,所以这种中间结果写入物化表都是有索引的。
如果t1表的数据量很大比如10万,但物化表结果集的数据量只有500条。那么此时会由全表扫描t1表改成全表扫描物化表,这也是其中一种子查询的优化。
9.explain的参数说明
(1)id
select查询的序列号,包含一组数字,表示查询中执行select子句或者操作表的顺序。
(2)select_type
主要用来分辨查询的类型,是普通查询还是联合查询还是子查询。
(3)table
对应行正在访问哪一个表,表名或者别名,可能是临时表或者union合并结果集。
(4)type
type显示的是访问类型,访问类型表示以何种方式去访问数据。比如全表扫描,直接遍历一张表去寻找需要的数据,效率非常低下。
访问的类型有很多,效率从最好到最坏依次是:system > const > eq_ref > ref > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > all
一般情况下,得保证查询至少达到range级别,最好能达到ref。
--all:全表扫描,一般情况下出现这样的sql语句而且数据量比较大的话那么就需要进行优化。
explain select * from emp;--index:全索引扫描这个比all的效率要好;
--主要有两种情况,一种是当前的查询时覆盖索引,即我们需要的数据在索引中就可以索取,或者是使用了索引进行排序,这样就避免数据的重排序
explain select empno from emp;--range:表示利用索引查询的时候限制了范围,在指定范围内进行查询,这样避免了index的全索引扫描;
--适用的操作符:=, <>, >, >=, <, <=, IS NULL, BETWEEN, LIKE, or IN()
explain select * from emp where empno between 7000 and 7500;--index_subquery:利用索引来关联子查询,不再扫描全表
explain select * from emp where emp.job in (select job from t_job);--unique_subquery:该连接类型类似与index_subquery,使用的是唯一索引
explain select * from emp e where e.deptno in (select distinct deptno from dept); --index_merge:在查询过程中需要多个索引组合使用,没有模拟出来--ref_or_null:对于某个字段即需要关联条件,也需要null值的情况下,查询优化器会选择这种访问方式
explain select * from emp e where e.mgr is null or e.mgr=7369;--ref:使用了非唯一性索引进行数据的查找
create index idx_3 on emp(deptno);
explain select * from emp e,dept d where e.deptno = d.deptno;--eq_ref :使用唯一性索引进行数据查找
explain select * from emp,emp2 where emp.empno = emp2.empno;--const:这个表至多有一个匹配行
explain select * from emp where empno = 7369; --system:表只有一行记录(等于系统表),这是const类型的特例,平时不会出现(5)possible_keys
显示可能应用在这张表中的索引,一个或多个。查询涉及到的字段上若存在索引,则该索引将被列出。但这些列出的索引,不一定会被查询实际使用。
(6)key
实际使用的索引,如果为null,则没有使用索引。查询中若使用了覆盖索引,则该索引和查询的select字段重叠。
(7)key_len
表示索引中使用的字节数,可以通过key_len计算查询中使用的索引长度,在不损失精度的情况下长度越短越好。
(8)ref
显示索引的哪一列被使用了,如果可能的话,是一个常数。
(9)rows
根据表的统计信息及索引使用情况,大致估算找出所需记录要读取的行数。此参数很重要,直接反应SQL找了多少数据,当然其数值越少越好。
(10)extra
包含额外的信息:
--using filesort:说明mysql无法利用索引进行排序,只能利用排序算法进行排序,会消耗额外的位置
explain select * from emp order by sal;--using temporary:建立临时表来保存中间结果,查询完成之后把临时表删除
explain select ename,count(*) from emp where deptno = 10 group by ename;--using index:这个表示当前的查询时覆盖索引的,直接从索引中读取数据,而不用访问数据表。
--如果同时出现using where 表名索引被用来执行索引键值的查找,如果没有,表面索引被用来读取数据,而不是真的查找
explain select deptno,count(*) from emp group by deptno limit 10;--using where:使用where进行条件过滤
explain select * from t_user where id = 1;--using join buffer:使用连接缓存,情况没有模拟出来--impossible where:where语句的结果总是false
explain select * from emp where empno = 7469;相关文章:

MySQL原理简介—10.SQL语句和执行计划
大纲 1.什么是执行计划 2.执行计划包含哪些内容 3.SQL语句和执行计划的总结 4.SQL语句使用多个二级索引 5.多表关联的SQL语句如何执行 6.全表扫描执行计划的成本计算方法 7.索引的成本计算方法 8.MySQL如何优化执行计划 9.explain的参数说明 1.什么是执行计划 (1)什么…...

wordpress二开-WordPress新增页面模板-说说微语
微语说说相当于一个简单的记事本,使用还是比较方便的。这个版本的说说微语CSS样式不兼容,可能有些主题无法适配,但是后台添加内容,前端显示的逻辑已经实现。可以当作Word press二开中自定义页面模板学习~ 一、后台添加说说微语模…...

001 MATLAB介绍
前言: 软件获取渠道有很多,难点也就是百度网盘下载慢; 线上版本每月有时间限制。 01 MATLAB介绍 性质: MATLAB即Matrix Laboratory 矩阵实验室的意思,是功能强大的计算机高级语言, 已广泛应用于各学科研究部门、…...
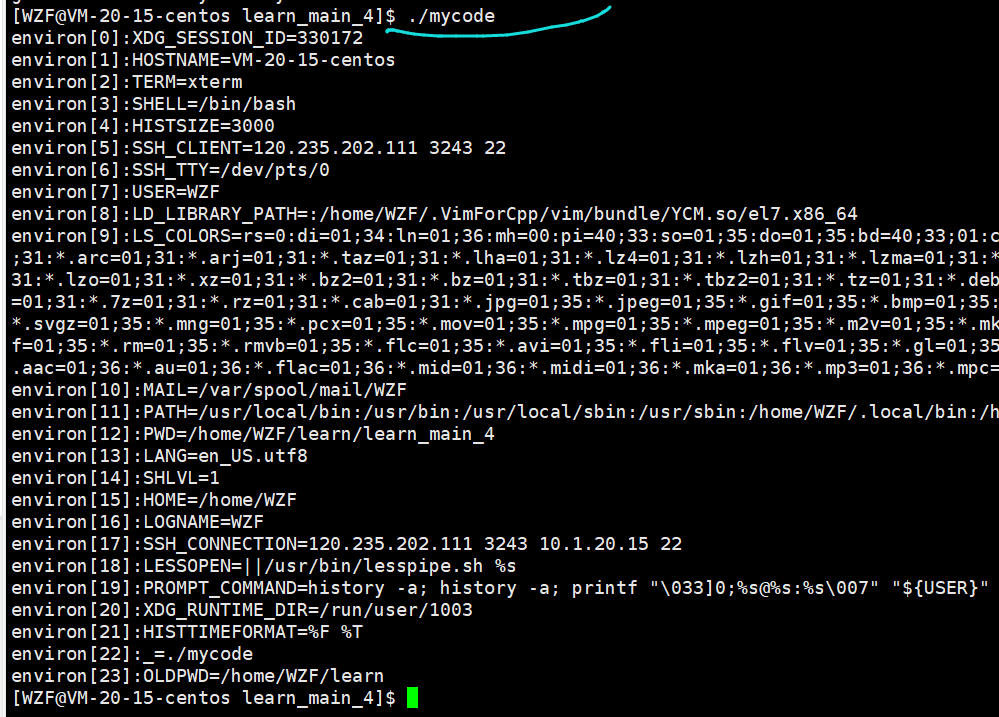
Linux—进程概念学习-03
目录 Linux—进程学习—31.进程优先级1.1Linux中的进程优先级1.2修改进程优先级—top 2.进程的其他概念3.进程切换4.环境变量4.0环境变量的理解4.1环境变量的基本概念4.2添加环境变量—export4.3Linux中环境变量的由来4.4常见环境变量4.5和环境变量相关的命令4.6通过系统调用获…...

低速接口项目之串口Uart开发(二)——FIFO实现串口数据的收发回环测试
本节目录 一、设计思路 二、loop环回模块 三、仿真模块 四、仿真验证 五、上板验证 六、往期文章链接本节内容 一、设计思路 串口数据的收发回环测试,最简单的硬件测试是把Tx和Rx连接在一起,然后上位机进行发送和接收测试,但是需要考虑到串…...

java: itext8.05 create pdf
只能调用windows 已安装的字体,这样可以在系统中先预装字体,5.0 可以调用自配文件夹的字体文件。CSharp donetItext8.0 可以调用。 /*** encoding: utf-8* 版权所有 2024 ©涂聚文有限公司 言語成了邀功盡責的功臣,還需要行爲每日來值班…...

如何用通义灵码快速绘制流程图?
使用通义灵码快速绘制流程图?新功能体验 不想读前人“骨灰级”代码,不想当“牛马”程序员,想像看图片一样快速读复杂代码和架构? 通义灵码已经支持代码逻辑可视化,可以把你的每段代码画成流程图。像个脑图工具一样帮你…...

vue 预览pdf 【@sunsetglow/vue-pdf-viewer】开箱即用,无需开发
sunsetglow/vue-pdf-viewer 开箱即用的pdf插件sunsetglow/vue-pdf-viewer, vue3 版本 无需多余开发,操作简单,支持大文件 pdf 滚动加载,缩放,左侧导航,下载,页码,打印,文本复制&…...

Java NIO 核心知识总结
在学习 NIO 之前,需要先了解一下计算机 I/O 模型的基础理论知识。还不了解的话,可以参考我写的这篇文章:Java IO 模型详解。 一、NIO 简介 在传统的 Java I/O 模型(BIO)中,I/O 操作是以阻塞的方式进行的。…...

疑难Tips:NextCloud域名访问登录时卡住,显示违反内容安全策略
[ 知识是人生的灯塔,只有不断学习,才能照亮前行的道路 ] 1使用域名访问Nextcloud用户登录时卡住,显示违反内容安全策略 我使用官方Docker镜像来部署NextCloud 28.0.5,并通过Openresty反向代理Nextcloud,但是在安装后无法稳定工作,每次登录后,页面会卡死在登录界面,无法…...

C 语言学习-06【指针】
1、目标单元与简介存取 直接访问和间接访问 #include <stdio.h>int main(void) {int a 3, *p;p &a;printf("a %d, *p %d\n", a, *p);*p 10;printf("a %d, *p %d\n", a, *p);printf("Enter a: ");scanf("%d", &a)…...
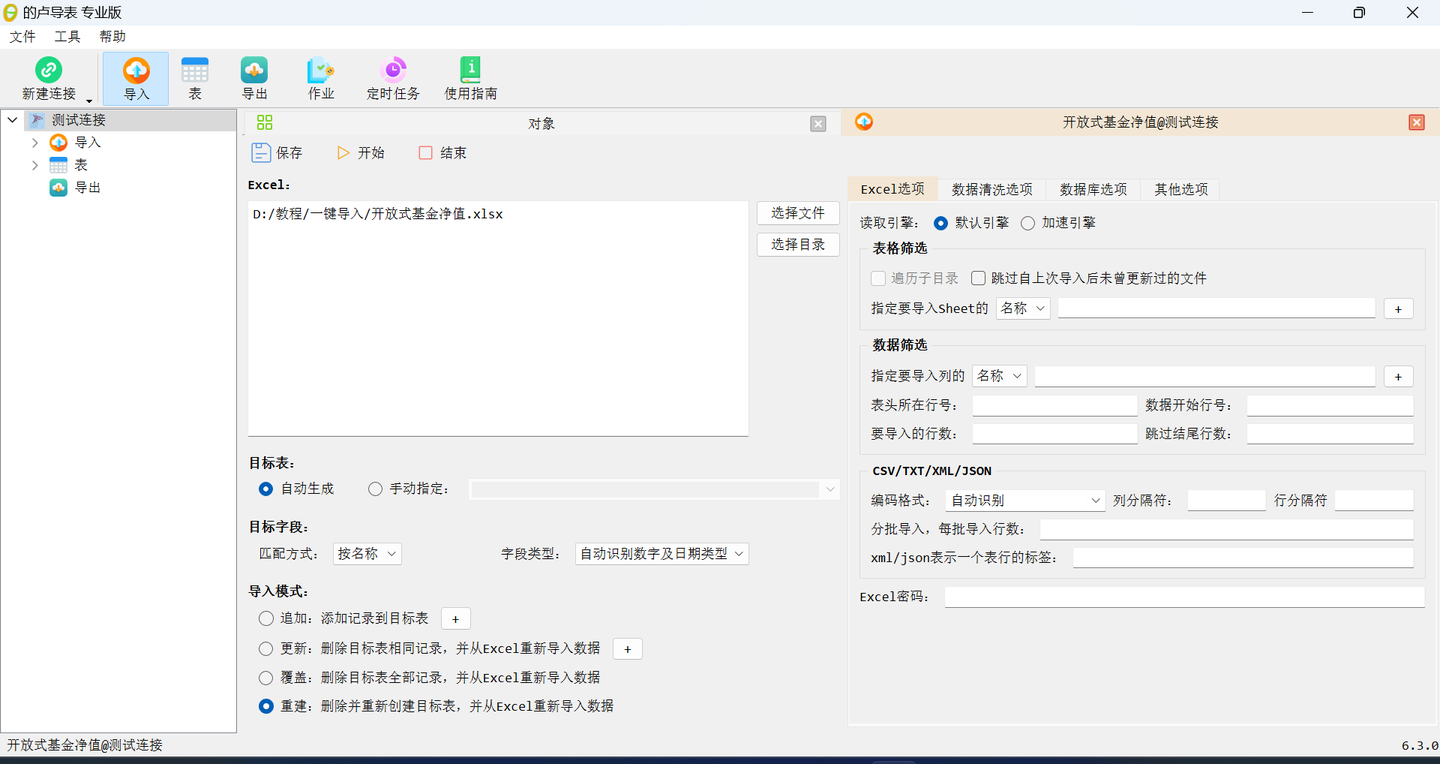
如何快速将Excel数据导入到SQL Server数据库
工作中,我们经常需要将Excel数据导入到数据库,但是对于数据库小白来说,这可能并非易事;对于数据库专家来说,这又可能非常繁琐。 这篇文章将介绍如何帮助您快速的将Excel数据导入到sql server数据库。 准备工作 这里&…...

【人工智能】Python在机器学习与人工智能中的应用
Python因其简洁易用、丰富的库支持以及强大的社区,被广泛应用于机器学习与人工智能(AI)领域。本教程通过实用的代码示例和讲解,带你从零开始掌握Python在机器学习与人工智能中的基本用法。 1. 机器学习与AI的Python生态系统 Pyth…...

使用八爪鱼爬虫抓取汽车网站数据,分析舆情数据
我是做汽车行业的,可以用八爪鱼爬虫抓取汽车之家和微博上的汽车文章内容,分析各种电动汽车口碑数据。 之前,我写过很多Python网络爬虫的案例,使用requests、selenium等技术采集数据,这次尝试去采集小米SU7在微博、汽车…...

什么是事务?事务有哪些特性?
在数据库管理中,事务是一个核心概念,它确保了数据操作的完整性和一致性。本文将探讨事务的定义及其四大特性。 一、事务的定义 事务是数据库操作的最小工作单元,是作为单个逻辑工作单元执行的一系列操作。这些操作作为一个整体一起向系统提…...
)
玩转合宙Luat教程 基础篇④——程序基础(库、线程、定时器和订阅/发布)
文章目录 一、前言二、库三、线程四、定时器五、订阅/发布5.1 回调函数5.2 堵塞等待一、前言 教程目录大纲请查阅:玩转合宙Luat教程——导读 写一写Lua程序基础的东西。 包括如何调用库,如何创建线程、如何创建定时器,如何使用订阅/发布事件。 二、库 程序从main.lua开始通…...

24.<Spring博客系统①(数据库+公共代码+持久层+显示博客列表+博客详情)>
项目整体预览 登录页面 主页 查看全文 编辑 写博客 PS:Service.impl(现在流行写法) 推荐写法。后续完成项目。会尝试这样写。 接口可以有多个实现。每个实现都可以不同。 这也算一种设计模式。叫做(策略模式)。 我们…...
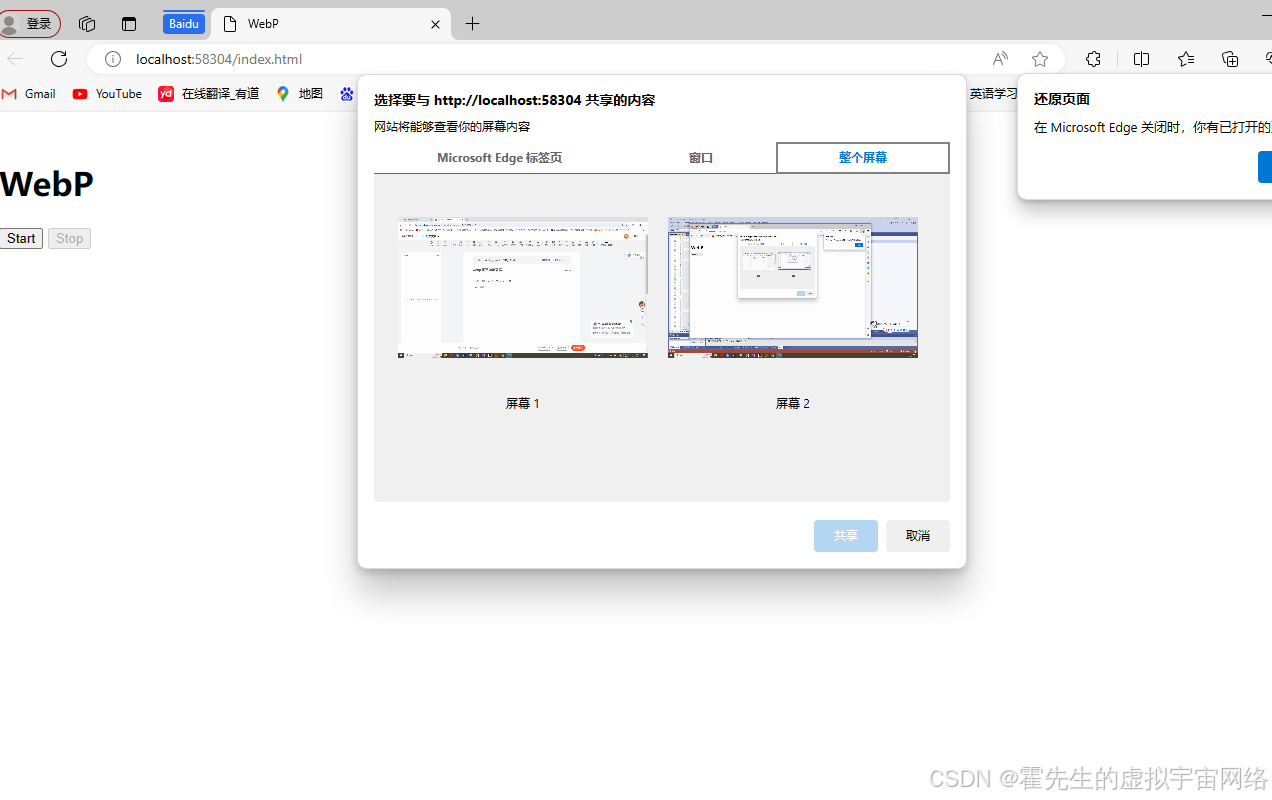
webp 网页如何录屏?
工作中正好研究到了一点:记录下这里: 先看下效果: 具体实现代码:  <!DOCTYPE html> <html lang"zh-CN"> <head><meta charset"UTF-8"><meta name"viewport&qu…...

丹摩征文活动|实现Llama3.1大模型的本地部署
文章目录 1.前言2.丹摩的配置3.Llama3.1的本地配置4. 最终界面 丹摩 1.前言 Llama3.1是Meta 公司发布的最新开源大型语言模型,相较于之前的版本,它在规模和功能上实现了显著提升,尤其是最大的 4050亿参数版本,成为开源社区中非常…...

Spring Boot 2 和 Spring Boot 3 中使用 Spring Security 的区别
文章目录 Spring Boot 2 和 Spring Boot 3 中使用 Spring Security 的区别1. Jakarta EE 迁移2. Spring Security 配置方式的变化3. PasswordEncoder 加密方式的变化4. permitAll() 和 authenticated() 的变化5. 更强的默认安全设置6. Java 17 支持与语法提升7. PreAuthorize、…...

LBE-LEX系列工业语音播放器|预警播报器|喇叭蜂鸣器的上位机配置操作说明
LBE-LEX系列工业语音播放器|预警播报器|喇叭蜂鸣器专为工业环境精心打造,完美适配AGV和无人叉车。同时,集成以太网与语音合成技术,为各类高级系统(如MES、调度系统、库位管理、立库等)提供高效便捷的语音交互体验。 L…...

AI-调查研究-01-正念冥想有用吗?对健康的影响及科学指南
点一下关注吧!!!非常感谢!!持续更新!!! 🚀 AI篇持续更新中!(长期更新) 目前2025年06月05日更新到: AI炼丹日志-28 - Aud…...

React 第五十五节 Router 中 useAsyncError的使用详解
前言 useAsyncError 是 React Router v6.4 引入的一个钩子,用于处理异步操作(如数据加载)中的错误。下面我将详细解释其用途并提供代码示例。 一、useAsyncError 用途 处理异步错误:捕获在 loader 或 action 中发生的异步错误替…...

【android bluetooth 框架分析 04】【bt-framework 层详解 1】【BluetoothProperties介绍】
1. BluetoothProperties介绍 libsysprop/srcs/android/sysprop/BluetoothProperties.sysprop BluetoothProperties.sysprop 是 Android AOSP 中的一种 系统属性定义文件(System Property Definition File),用于声明和管理 Bluetooth 模块相…...

ElasticSearch搜索引擎之倒排索引及其底层算法
文章目录 一、搜索引擎1、什么是搜索引擎?2、搜索引擎的分类3、常用的搜索引擎4、搜索引擎的特点二、倒排索引1、简介2、为什么倒排索引不用B+树1.创建时间长,文件大。2.其次,树深,IO次数可怕。3.索引可能会失效。4.精准度差。三. 倒排索引四、算法1、Term Index的算法2、 …...

鸿蒙中用HarmonyOS SDK应用服务 HarmonyOS5开发一个生活电费的缴纳和查询小程序
一、项目初始化与配置 1. 创建项目 ohpm init harmony/utility-payment-app 2. 配置权限 // module.json5 {"requestPermissions": [{"name": "ohos.permission.INTERNET"},{"name": "ohos.permission.GET_NETWORK_INFO"…...

LLM基础1_语言模型如何处理文本
基于GitHub项目:https://github.com/datawhalechina/llms-from-scratch-cn 工具介绍 tiktoken:OpenAI开发的专业"分词器" torch:Facebook开发的强力计算引擎,相当于超级计算器 理解词嵌入:给词语画"…...

06 Deep learning神经网络编程基础 激活函数 --吴恩达
深度学习激活函数详解 一、核心作用 引入非线性:使神经网络可学习复杂模式控制输出范围:如Sigmoid将输出限制在(0,1)梯度传递:影响反向传播的稳定性二、常见类型及数学表达 Sigmoid σ ( x ) = 1 1 +...

[Java恶补day16] 238.除自身以外数组的乘积
给你一个整数数组 nums,返回 数组 answer ,其中 answer[i] 等于 nums 中除 nums[i] 之外其余各元素的乘积 。 题目数据 保证 数组 nums之中任意元素的全部前缀元素和后缀的乘积都在 32 位 整数范围内。 请 不要使用除法,且在 O(n) 时间复杂度…...

项目部署到Linux上时遇到的错误(Redis,MySQL,无法正确连接,地址占用问题)
Redis无法正确连接 在运行jar包时出现了这样的错误 查询得知问题核心在于Redis连接失败,具体原因是客户端发送了密码认证请求,但Redis服务器未设置密码 1.为Redis设置密码(匹配客户端配置) 步骤: 1).修…...