类和对象(下):点亮编程星河的类与对象进阶之光
再探构造函数
在实现构造函数时,对成员变量进行初始化主要有两种方式:
- 一种是常见的在函数体内赋值进行初始化;
- 另一种则是通过初始化列表来完成初始化。
之前我们在构造函数中经常采用在函数体内对成员变量赋值的方式来给予它们初始值。例如:
class Date { public:// 构造函数Date(int year = 1, int month = 1, int day = 1){_year = year;_month = month;_day = day;} private:int _year;int _month;int _day; };不过需要特别留意的是,尽管调用上述这样的构造函数后,对象中的每个成员变量都能获得一个初始值,但构造函数内的这些语句准确来讲只能算是赋初值,而非真正意义上的初始化。这是因为初始化原则上只能进行一次,而在构造函数体内却能够对成员变量进行多次赋值操作。就像下面这个修改后的
Date类构造函数示例:class Date { public:// 构造函数Date(int year = 1, int month = 1, int day = 1){_year = year; // 第一次赋值_year = 2024; // 第二次赋值//..._month = month;_day = day;} private:int _year;int _month;int _day; };初始化列表的好处在于能
- 满足引用、const 及无默认构造函数的类类型等特定成员变量的初始化要求、
- 提高自定义类型成员变量的初始化效率
- 明确成员变量按照在类中声明顺序进行初始化。
初始化列表
一、初始化列表的基本形式
初始化列表的使用方式是以一个冒号开始,接着是一个以逗号分隔的数据成员列表,每个 “成员变量” 后面跟一个放在括号中的初始值或表达式。以下是一个简单示例:
class Date { public:Date(int year = 1, int month = 1, int day = 1):_year(year), _month(month), _day(day){} private:int _year;int _month;int _day; };二、初始化列表的语法规则
- 每个成员变量在初始化列表中只能出现一次。从语法理解上来说,初始化列表可以看作是每个成员变量定义初始化的地方。
- 初始化列表中按照成员变量在类中声明顺序进行初始化,与成员在初始化列表出现的先后顺序无关。不过建议在编写代码时,让成员变量在类中的声明顺序和在初始化列表中的顺序保持一致,这样可以使代码的逻辑更加清晰,便于理解和维护。
面试题
下⾯程序的运⾏结果是什么()
A. 输出1 1
B. 输出2 2
C. 编译报错
D. 输出1 随机值
E. 输出1 2
F. 输出2 1
#include<iostream>using namespace std;class A { public:A(int a):_a1(a), _a2(_a1){}void Print() {cout << _a1 << " " << _a2 << endl;}private:int _a2 = 2;int _a1 = 2; };int main() {A aa(1);aa.Print(); }分析这道题需明确:初始化顺序按类中变量声明顺序,非初始化列表顺序。
先说选项,“存在 2” 不可选,因已显式初始化,一旦这样做了,那就和之前给变量设置的缺省值就没关系;选 “A” 也不可选,初始化是按变量声明顺序而非初始化列表顺序。
具体本题初始化过程:先初始化_a2,虽传参 a 值为 1,但按声明顺序此时其不受影响,_a2 (_a1) 这步因_a1 未初始化到传值 1,相当于用不确定值(类似随机值)初始化,所以_a2 初始化后是随机值。之后用传进的 1 初始化_a1。
综上,本题结果选 D。建议写代码时让成员变量声明顺序与初始化列表顺序一致,可使代码逻辑清晰、不易出错。
三、必须使用初始化列表初始化的情况
以下几种类型的成员变量必须放在初始化列表位置进行初始化,否则会导致编译报错:
- 引用成员变量:引用类型的变量在定义时就必须被赋予一个初始值,所以在类中的引用成员变量必须通过初始化列表来初始化。例如:
int a = 10; int& b = a; // 创建时就初始化class ClassWithRef { public:ClassWithRef(int& refValue) :refMember(refValue) {} private:int& refMember; };
- const 成员变量:被
const修饰的变量同样需要在定义时就给定初始值,因此也必须使用初始化列表进行初始化。比如:int a = 10; int& b = a; // 创建时就初始化class ClassWithRef { public:ClassWithRef(int& refValue) :refMember(refValue) {} private:int& refMember; };
- 没有默认构造的类类型成员变量:若一个类没有默认构造函数(默认构造函数是指不用传参就可以调用的构造函数,包括编译器自动生成的构造函数、无参的构造函数以及全缺省的构造函数),那么在实例化该类对象作为另一个类的成员变量时,就必须使用初始化列表对其进行初始化。例如:
class A { public:A(int val) {_val = val;} private:int _val; };class B { public:B() :_a(2024) {} private:A _a; };在上述示例中,
A类没有默认构造函数,所以在B类的构造函数中,对于成员变量_a(类型为A)就必须通过初始化列表来初始化。总结
这些成员变量在定义或者实例化相关情境下,自身都存在一些特殊要求使得它们必须在特定时刻就被赋予初始值。
- 对于引用成员变量,其类型特性决定了定义时就得有初始值;
- const 成员变量由于被 const 修饰,按规定一开始就要确定值;
- 而没有默认构造函数的类类型成员变量,在作为另一个类的成员被实例化时,因为无法依靠默认构造函数来完成初始化,
所以都需要通过初始化列表这种方式来明确地给它们设定初始值,否则程序在编译阶段就会报错,无法正常进行下去。
四、C++11 关于成员变量缺省值的规定
C++11 支持在成员变量声明的位置给缺省值,这个缺省值主要是供那些没有显式在初始化列表初始化的成员使用的。例如:
class SomeClass { public:SomeClass() {} private:int memberVariable = 10; // 这里给成员变量声明了缺省值 };在上述
SomeClass类中,成员变量memberVariable声明时被赋予了缺省值10,当在构造函数中没有显式通过初始化列表对其进行初始化时,就会使用这个缺省值。尽量使用初始化列表初始化成员变量,原因如下:
- 无论是否在初始化列表中显式地对成员变量进行初始化,每个成员变量实际上都要走初始化列表这个流程。如果某个成员在声明位置给了缺省值,那么初始化列表会用这个缺省值来初始化该成员。
- 对于没有在初始化列表中显式初始化的情况:
- 内置类型成员:如果没有给缺省值,对于没有显式在初始化列表初始化的内置类型成员是否初始化取决于编译器,C++ 并没有对此作出明确规定。
- 自定义类型成员:对于没有显式在初始化列表初始化的自定义类型成员,会调用这个成员类型的默认构造函数,如果该成员类型没有默认构造函数则会导致编译错误。
class Time { public:Time(int hour = 0) {_hour = hour;} private:int _hour; };class Test { public:// 使用初始化列表Test(int hour):_t(12) // 调用一次Time类的构造函数{} private:Time _t; };// 对比不使用初始化列表的情况 class TestWithoutList { public:TestWithoutList(int hour) {Time t(hour);_t = t;} private:Time _t; };在上述示例中,通过对比
Test类(使用初始化列表)和TestWithoutList类(不使用初始化列表)可以看出,不使用初始化列表在实例化TestWithoutList类对象时,会多进行一些不必要的构造函数调用和赋值操作,从而影响效率。五、关于初始化列表的总结要点
- 无论是否显式地写出初始化列表,每个构造函数实际上都拥有一个隐含的初始化列表。
- 无论是否在初始化列表中显式地对成员变量进行初始化,每个成员变量都要走初始化列表这个初始化流程。
综上所述,初始化列表在构造函数对成员变量的初始化过程中扮演着重要的角色,理解并正确运用它对于编写高效、正确的 C++ 代码至关重要。

类型转换
隐式类型转换是 C++ 中由编译器自动完成的一种类型转换机制,通常在不同类型的变量之间进行操作时发生。
- 支持隐式转换:单个参数构造函数除构造初始化对象外,还支持隐式转换,如
Date类单参构造函数,Date d1 = 2021可将2021转为Date类对象。- 早期处理:早期编译器遇
Date d1 = 2021,先构造临时对象Date tmp(2021),再拷贝构造d1。- 现代优化:现在编译器遇此代码按
Date d1(2021)处理,仍属隐式转换。- 对比常见情况:类似
int a = 10; double b = a的常见隐式转换,会构建临时变量传值,函数返回局部变量值成功也因隐式转换产生的临时变量未销毁。
一、类类型相关隐式转换
1.内置类型到类类型
C++ 支持内置类型隐式转换为类类型对象,但需要有以相关内置类型为参数的构造函数。例如,我们有一个
A类,其构造函数接受一个int参数:class A { public:A(int a1) :_a1(a1) {} private:int _a1; };当我们编写
A aa1 = 1;时,编译器会自动调用A类的这个构造函数,将1转换为A类的对象aa1。这里实际上发生了隐式类型转换,先构造了一个临时的A类对象,然后再用这个临时对象拷贝构造aa1(在一些现代编译器中,可能会进行优化,直接构造aa1)。完整使用代码(水果篮):
class FruitBasket { public:FruitBasket(int numFruits) : _numFruits(numFruits) {} private:int _numFruits; }; int main() {// 5隐式转换为FruitBasket类对象FruitBasket myBasket = 5; return 0; }2.类类型之间
- 类类型的对象之间也可以进行隐式转换,这同样需要相应的构造函数支持。假设有
A类和B类,B类有一个以A类对象为参数的构造函数:class B { public:B(const A& a) :_b(a.Get()) {} private:int _b; };当我们编写
B b = aa3;(假设aa3是A类的对象)时,就会发生从A类对象到B类对象的隐式转换,调用B类的相应构造函数来创建b对象。完整使用代码:
class FruitBasket { public:FruitBasket(int numFruits) : _numFruits(numFruits) {}int GetNumFruits() { return _numFruits; } private:int _numFruits; }; class FruitShopInventory { public:FruitShopInventory(const FruitBasket& basket) : _stock(basket.GetNumFruits()) {} private:int _stock; }; int main() {FruitBasket myBasket = 8;// myBasket隐式转换为FruitShopInventory类对象FruitShopInventory inventory = myBasket; return 0; }3.控制隐式转换(
explicit)如果我们不想让这种隐式类型转换发生,可以在构造函数前面加上
explicit关键字。例如,如果将A类的构造函数修改为explicit A(int a1),那么A aa1 = 1;这样的隐式转换语句将不再被允许,编译器会报错。class SpecialFruitBasket { public:explicit SpecialFruitBasket(int numFruits) : _numFruits(numFruits) {} private:int _numFruits; }; int main() {// 加explicit后,此行隐式转换报错,应改为SpecialFruitBasket specialBasket(3);// SpecialFruitBasket specialBasket = 3; return 0; }二、一般隐式转换情况及问题
在基本类型之间,隐式转换也很常见。例如,当我们进行
int和double的运算时,如int a = 10; double b = 5.5; double c = a + b;,编译器会自动将int类型的a转换为double类型,以便与b进行运算。然而,隐式转换虽然方便,但也可能会带来一些问题,比如精度丢失。当double转换为int时,小数部分会被截断,这可能导致数据不准确。int main() {int numApples = 5;double pricePerApple = 2.5;// numApples隐式转换为double计算总价double totalPrice = numApples * pricePerApple; double totalMoney = 12.8;// totalMoney隐式转换为int算能买苹果个数,可能精度丢失int numBoughtApples = totalMoney / pricePerApple; return 0; }再举一个结合例子
#include<iostream> using namespace std;// 定义类A class A { public:// 构造函数,若声明为explicit则不再支持隐式类型转换// 这里未声明为explicit,所以支持隐式类型转换// 接受一个int参数的构造函数,用于初始化成员变量_a1// explicit A(int a1)A(int a1):_a1(a1) // 在初始化列表中将传入的参数a1赋值给成员变量_a1{}// 接受两个int参数的构造函数,分别用于初始化成员变量_a1和_a2// explicit A(int a1, int a2)A(int a1, int a2):_a1(a1) // 在初始化列表中将第一个参数a1赋值给成员变量_a1, _a2(a2) // 在初始化列表中将第二个参数a2赋值给成员变量_a2{}// 成员函数,用于输出成员变量_a1和_a2的值void Print(){cout << _a1 << " " << _a2 << endl;}// 常成员函数,用于返回成员变量_a1和_a2的和int Get() const{return _a1 + _a2;}private:int _a1 = 1; // 定义并初始化成员变量_a1,默认值为1int _a2 = 2; // 定义并初始化成员变量_a2,默认值为2 };// 定义类B class B { public:// 构造函数,接受一个A类的常引用作为参数// 通过调用传入的A类对象的Get函数获取值,用于初始化成员变量_bB(const A& a):_b(a.Get()){}private:int _b = 0; // 定义并初始化成员变量_b,默认值为0 };int main() {// 1. 创建对象aa1并涉及隐式类型转换// 构造一个A的临时对象,再用这个临时对象拷贝构造aa1// 编译器遇到连续构造 + 拷贝构造的情况,会优化为直接构造// 这里利用A类接受一个int参数的构造函数,将整数1隐式转换为A类对象并赋值给aa1A aa1 = 1;aa1.Print(); // 调用aa1的Print函数输出_a1和_a2的值// 2. 创建一个指向临时A类对象的常引用aa2// 同样是利用隐式类型转换,将整数1转换为临时的A类对象,并将该临时对象的引用赋值给aa2const A& aa2 = 1;// 3. 创建对象aa3并使用多参数初始化(C++11之后支持的方式)// 使用接受两个int参数的构造函数创建A类对象aa3,并通过初始化列表初始化成员变量_a1和_a2A aa3 = { 2, 2 };// 4. 从A类对象aa3隐式转换创建B类对象b// 原理和前面将整数隐式转换为A类对象类似,这里是将A类对象aa3作为参数传递给B类的构造函数// 从而隐式地将aa3转换为B类对象并赋值给bB b = aa3;// 5. 创建一个指向B类对象b的常引用rbconst B& rb = aa3;return 0; }

static成员
一、静态成员的概念
声明为
static的类成员被称为类的静态成员。其中,用static修饰的成员变量,就是静态成员变量;而用static修饰的成员函数,则被叫做静态成员函数。需要特别注意的是,静态成员变量一定要在类外进行初始化哦。二、静态成员的特点
1.共享性
静态成员变量为所有类对象所共享,不属于某个具体的对象,不存在对象中,存放在静态区。
这意味着什么呢?我们来看下面这段代码:
#include <iostream> using namespace std; class Test { private:static int _n; }; int main() {cout << sizeof(Test) << endl;return 0; }在这个例子中,计算
Test类的大小结果为 1。这是因为静态成员_n是存储在静态区的,它属于整个类,也属于类的所有对象。所以在计算类的大小或是类对象的大小时,静态成员并不计入其总大小之和呢。2.必须在类外定义
静态成员变量必须在类外定义,而且定义时不添加
static关键字。例如:class A{public:private:// 类⾥⾯声明 static int _scount;};// 类外⾯初始化 int A::_scount = 0;注意:这里静态成员变量_scount虽然是私有,但是我们在类外突破类域直接对其进行了访问。这是一个特例,不受访问限定符的限制,否则就没办法对静态成员变量进行定义和初始化了。
3.静态成员函数没有隐藏的
this指针⽤static修饰的成员函数,称之为静态成员函数,静态成员函数没有this指针。静态成员函数中可以访问其他的静态成员,但是不能访问⾮静态的,因为没有this指针。
注意:⾮静态的成员函数,可以访问任意的静态成员变量和静态成员函数。
class Test { public:static void Fun(){cout << _a << endl; //error不能访问非静态成员cout << _n << endl; //correct} private:int _a; //非静态成员static int _n; //静态成员 };这里的静态成员函数
Fun试图访问非静态成员_a就会报错,因为它没有this指针来指向具体的对象呀。不过它是可以访问静态成员_n的哦。小贴士:通常含有静态成员变量的类,一般会含有一个静态成员函数,专门用于访问静态成员变量呢。
三、访问静态成员变量的方法
突破类域就可以访问静态成员,可以通过类名::静态成员或者对象.静态成员来访问静态成员变量 和静态成员函数。
1.公有静态成员变量的访问方式
当静态成员变量为公有时,有以下几种访问方式哦:
class Test { public:static int _n; //公有 }; // 静态成员变量的定义初始化 int Test::_n = 0; int main() {Test test;cout << test._n << endl; //1.通过类对象突破类域进行访问cout << Test()._n << endl; //3.通过匿名对象突破类域进行访问cout << Test::_n << endl; //2.通过类名突破类域进行访问return 0; }我们既可以通过类对象、匿名对象来突破类域访问公有静态成员变量,也可以直接通过类名来访问呢。(匿名对象下面有讲)
2.私有静态成员变量的访问方式
当静态成员变量为私有时,情况就不太一样啦,得通过成员函数来访问哦:
#include <iostream> using namespace std; class Test { public:static int GetN(){return _n;} private:static int _n; }; // 静态成员变量的定义初始化 int Test::_n = 0; int main() {Test test;cout << test.GetN() << endl; //1.通过对象调用成员函数进行访问cout << Test().GetN() << endl; //2.通过匿名对象调用成员函数进行访问cout << Test::GetN() << endl; //3.通过类名调用静态成员函数进行访问return 0; }在这里,我们通过定义一个获取静态成员变量值的静态成员函数
GetN,然后利用对象、匿名对象或者直接通过类名调用这个函数来间接访问私有静态成员变量哦。3.静态成员的访问级别
静态成员也是类的成员,受public、protected、private访问限定符的限制。
所以当静态成员变量设置为
private时,就算我们突破了类域,也不能直接对其进行访问呢,得按照上面说的私有静态成员变量的访问方式来操作哦。两个问题
(一)静态成员函数能否调用非静态成员函数?
答案是不可以哦。因为非静态成员函数的第一个形参默认为
this指针,而静态成员函数中没有this指针呀,所以静态成员函数没办法调用非静态成员函数呢。(二)非静态成员函数能否调用静态成员函数?
这个是可以的哦。因为静态成员函数和非静态成员函数都在类中,在类里面是不受访问限定符的限制的,所以非静态成员函数可以自由地调用静态成员函数啦。
4、静态成员变量的特殊性
静态成员变量不能在声明位置给缺省值初始化,因为缺省值是个构造函数初始化列表的,静态成员 变量不属于某个对象,不⾛构造函数初始化列表。
非静态量申明赋缺省值:
class Class { public:Class() {} private:int memberVariable = 10; // 这里给成员变量声明了缺省值 };静态成员变量属整个类,存于静态存储区且被所有对象共享,不依赖具体对象创建,不走构造函数初始化列表,所以不能像普通成员变量那样在声明时赋缺省值初始化,需在类外单独按“类名::静态成员变量名 = 值;”方式初始化
class AnotherClass { public:AnotherClass() {} private:static int staticMemberVariable; }; // 必须在类外进行初始化,如下所示 int AnotherClass::staticMemberVariable = 20;总结
由于静态成员变量的这种特殊性质 —— 属于整个类且不与具体对象的创建绑定,导致它不能使用针对具体对象的构造函数初始化列表那种方式来在声明位置给缺省值进行初始化。
5、两道面试题
求1+2+3+...+n (牛客网)
https://www.nowcoder.com/practice/7a0da8fc483247ff8800059e12d7caf1?tpId=13&tqId=11200&tPage=3&rp=3&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking
// 定义Sum类 class Sum { public:// Sum类的默认构造函数Sum(){// 每次创建Sum类的对象时,将当前的_i值累加到_ret中_ret += _i;// 然后将_i的值自增1,以便下次累加时使用更新后的_i值++_i;}// 静态成员函数,用于获取静态成员变量_ret的值static int GetRet(){return _ret;} private:// 声明静态成员变量_i,用于在每次构造Sum类对象时进行累加操作,初始值将在类外定义static int _i;// 声明静态成员变量_ret,用于存储累加的结果,初始值将在类外定义static int _ret; };// 在类外对Sum类的静态成员变量_i进行初始化,初始值设为1 int Sum::_i = 1; // 在类外对Sum类的静态成员变量_ret进行初始化,初始值设为0 int Sum::_ret = 0;// 定义Solution类 class Solution { public:// 函数Sum_Solution,用于根据传入的参数n计算累加结果并返回int Sum_Solution(int n) {// 创建一个变长数组arr,数组元素类型为Sum类,数组大小为n// 这里创建Sum类对象数组的过程会多次调用Sum类的默认构造函数,从而实现累加操作Sum arr[n];// 返回Sum类中存储的累加结果,通过调用Sum类的静态成员函数GetRet来获取return Sum::GetRet();} };这段代码的主要功能是通过创建
Sum类的对象数组来实现累加操作,最后通过Sum类的静态成员函数获取累加的结果。其中利用了静态成员变量在类的多个对象间共享数据的特性,以及静态成员函数可以直接通过类名调用的特点。设已经有A,B,C,D4个类的定义,程序中A,B,C,D构造函数调⽤顺序为?()
设已经有A,B,C,D4个类的定义,程序中A,B,C,D析构函数调⽤顺序为?()
- A : D B A C
- B : B A D C
- C : C D B A
- D : A B D C
- E : C A B D
- F : C D A B
C c;int main(){A a;B b;static D d;}return 0 ;构造函数调用顺序思路:
- 全局对象(
C c;)构造函数在main函数前调用。main函数里局部对象按定义顺序调用构造函数(先A a;,再B b;)。- 静态局部对象(
static D d;)构造函数在全局及同函数非静态局部对象构造完后,首次执行到其定义语句时调用。顺序为C A B D,选E。析构函数调用顺序思路:
main函数结束时,局部对象按定义逆序析构(先B b;,再A a;)。- 静态局部对象(
static D d;)析构函数在同函数非静态局部对象析构完后,程序结束时调用。- 全局对象(
C c;)析构函数最后在程序完全结束时调用。顺序为B A D C。

友元
友元提供了⼀种突破类访问限定符封装的⽅式,友元分为:友元函数和友元类,在函数声明或者类 声明的前⾯加friend,并且把友元声明放到⼀个类的⾥⾯。
一、友元函数
1.友元函数的基本特性
友元函数可以直接访问类的私有成员,这一点打破了类的封装限制,为我们在某些特定场景下提供了便利。
但需要注意的是,它是定义在类外部的普通函数,并不属于任何类哦。不过呢,要想让它具备访问类私有成员的 “特权”,就需要在类的内部进行声明,并且声明时要加上
friend关键字。2.友元函数在运算符重载中的应用
以日期类为例,重载
operator<<和operator>>时:
- 若将
operator<<重载为成员函数,cout与隐含的this指针会争占首参位置(this默认为首参,但cout需为首参才好用),所以只能重载为全局函数,可这又导致类外无法访问日期类成员,此时友元函数就有用了(operator>>同理)。- C++ 的
<<和>>能自动识别类型,是因库中已对内置类型重载,自定义日期类要实现此功能得写对应重载函数,像这样:在Date类内声明operator<<和operator>>为友元函数,之后的重载函数就能访问Date类私有成员,实现正确输入输出操作。
class Date {// 友元函数的声明friend ostream& operator<<(ostream& out, const Date& d);friend istream& operator>>(istream& in, Date& d); public:Date(int year = 0, int month = 1, int day = 1){_year = year;_month = month;_day = day;} private:int _year;int _month;int _day; };// <<运算符重载 ostream& operator<<(ostream& out, const Date& d) {out << d._year << "-" << d._month << "-" << d._day << endl;return out; }// >>运算符重载 istream& operator>>(istream& in, Date& d) {in >> d._year >> d._month >> d._day;return in; }在这个例子中,通过在
Date类内部声明operator<<和operator>>为友元函数,它们就可以顺利访问Date类的私有成员变量_year、_month和_day,从而实现了对日期类对象的正确输入输出操作。3.友元函数的其他注意事项
- 友元函数虽然可以访问类的私有和保护成员,但它可不是类的成员函数哦,这一点要牢记呢。
- 友元函数不能用
const修饰,这是因为它本身并不属于类的成员函数体系,不存在通过const来限定对象状态不变的情况。- 友元函数可以在类定义的任何地方声明,完全不受访问限定符的限制,这为我们在编写代码时提供了一定的灵活性。
- 一个函数还可以是多个类的友元函数呢,比如我们可以有一个通用的函数,根据不同的类对象进行不同的操作,并且都能访问它们各自的私有成员。
- 友元函数的调用与普通函数的调用原理相同,都是通过函数名加上合适的参数来进行调用的。
二、友元类
1.友元类的基本特性
友元类中的成员函数都可以是另⼀个类的友元函数,都可以访问另⼀个类中的私有和保护成员。
我们来看一个简单的例子:
class A {// 声明B是A的友元类friend class B; public:A(int n = 0):_n(n){} private:int _n; };class B { public:void Test(A& a){// B类可以直接访问A类中的私有成员变量cout << a._n << endl;} };在这个例子中,因为
B是A的友元类,所以B类中的Test函数就可以直接访问A类的私有成员变量_n啦。2.友元类的关系特性
- 友元关系是单向的,不具有交换性。就像上面的例子中,
B是A的友元,所以在B类中可以直接访问A类的私有成员变量,但是在A类中可不能访问B类中的私有成员变量呢。这一点在使用友元类时要特别注意,不要误以为友元关系是双向的哦。- 友元关系不能传递。也就是说,如果
A是B的友元,B是C的友元,我们可不能就此推出A是C的友元呀。这种非传递性也限制了友元关系的扩散范围,使得我们在设计类之间的友元关系时需要更加谨慎地考虑其必要性和影响范围。
三、友元机制的利弊权衡
友元机制的优势:
特定场景下便利,处理需频繁访问他类私有成员的复杂逻辑时,友元函数或类可直取数据,免复杂接口或间接访问,使代码简洁、编程效率提高。
友元机制的劣势:
- 增加类间耦合度,友元关系下类或函数联系紧密,一类变可能影响相关友元,增代码出错风险。
- 一定程度破坏封装性,私有成员不再绝对 “私有”,与封装原则相悖。
总之,实际编程要谨慎用友元,权衡利弊后确需突破封装实现特定功能时才用。



内部类
一、内部类的概念
如果一个类定义在另一个类的内部,那么这个类就被称作内部类啦。
这里有几个需要特别注意的点哦:
1.独立性
虽说它在另一个类的内部,但此时的内部类可是一个独立的类哦,它并不属于外部类呢。而且要记住,不能通过外部类的对象去调用内部类哦,它们在本质上还是相互独立的个体,只是存在着特殊的关联关系。
2.访问权限关系
外部类对内部类并没有任何优越的访问权限哦,它们各自有着自己的访问规则和限制。不过呢,内部类是外部类的友元类哦,这意味着内部类可以通过外部类的对象参数来访问外部类中的所有成员呢。但反过来,外部类可不是内部类的友元哦,这种友元关系是单向的呢。
二、内部类的特性
1.定义区域灵活性
内部类可以定义在外部类的
public、private以及protected这三个区域中的任一区域哦。这就给我们在设计代码结构时提供了很大的灵活性,我们可以根据具体的需求和想要实现的封装程度,来选择合适的区域放置内部类呢。2.访问外部类成员的便利性
内部类有着很方便的访问外部类成员的能力哦。它可以直接访问外部类中的
static、枚举成员,而且不需要借助外部类的对象或者类名呢。这使得内部类在处理与外部类相关的业务逻辑时,能够更加顺畅地获取所需的信息啦。3.大小独立性
还有一个很重要的特性就是,外部类的大小与内部类的大小是无关的哦。就像下面这个例子:
#include <iostream> using namespace std; class A //外部类 { public:class B //内部类{private:int _b;}; private:int _a; }; int main() {cout << sizeof(A) << endl; //外部类的大小return 0; }在这个例子中,外部类
A的大小为 4(这里假设int类型占 4 个字节),它仅仅取决于自身的成员变量_a,和内部类B的大小没有任何关系哦。三、用内部类优化上面的面试题
class Solution {class Sum{public:// Sum类的默认构造函数// 每次创建Sum类的对象时,会执行以下操作Sum(){// 将当前的_i值累加到_ret中,实现累加功能_ret += _i;// 将_i的值自增1,以便下次创建Sum类对象时进行新的累加操作++_i;}};// 声明静态成员变量_i,用于在Sum类的构造函数中进行累加操作的计数等相关用途// 其初始值将在类外进行初始化static int _i;// 声明静态成员变量_ret,用于存储累加的结果// 其初始值将在类外进行初始化static int _ret;public:// 函数Sum_Solution,用于根据传入的参数n计算累加结果并返回int Sum_Solution(int n) {// 创建一个变长数组arr,数组元素类型为内部类Sum// 这里通过创建Sum类对象数组的方式,多次调用Sum类的默认构造函数来实现累加操作// 数组大小为n,即会创建n个Sum类的对象,每个对象的构造函数都会对_i和_ret进行相应操作Sum arr[n];// 返回累加的最终结果,即静态成员变量_ret的值return _ret;} };// 在类外对Solution类的静态成员变量_i进行初始化,初始值设为1 int Solution::_i = 1; // 在类外对Solution类的静态成员变量_ret进行初始化,初始值设为0 int Solution::_ret = 0;

匿名对象
一、匿名对象的生命周期概念
⽤类型(实参)定义出来的对象叫做匿名对象,相⽐之前我们定义的类型对象名(实参)定义出来的叫有名对象
int main() {// 这就是匿名对象的定义啦,没有给它取名字哦A(1);A();return 0; }匿名对象就是这样直接在创建的地方使用,不需要像有名对象那样有一个特定的名字来指代它。
二、匿名对象的生命周期
匿名对象⽣命周期只在当前⼀⾏,⼀般临时定义⼀个对象当前⽤⼀下即可,就可以定义匿名对象。
比如说我们在
main函数里定义了匿名对象A();或者A(1);,当这一行代码运行结束之后,紧接着下一行就会看到输出~A() (如果自己在析构函数里写了打印函数的话),这就说明它的析构函数已经被调用啦,它的使命也就完成咯。而且要注意哦,即使匿名对象参数无参的时候,我们也是需要将括号带着的呢,比如
A()这样的写法才是正确的哦。三、有名对象与匿名对象调用类中函数的区别
1.有名对象调用函数
int main() {// 先创建有名对象s1Solution s1;// 通过有名对象s1调用Sum_Solution函数cout << s1.Sum_Solution(10) << endl;return 0; }2.匿名对象调用函数
int main() {// 创建匿名对象Solution()的同时调用Sum_Solution函数cout << Solution().Sum_Solution(10) << endl;return 0; }四、匿名对象在其他方面的特性及注意事项
1.匿名对象在函数缺省值设置中的应用
在给函数进行缺省值的设置的时候,我们是可以用到匿名对象的哦。比如在函数定义中可以这样写:
void func(A aa = A(1)) {}这里就利用了匿名对象
A(1)来给函数参数aa设置了缺省值呢。2.匿名对象的引用操作
匿名对象也是可以进行引用操作的哦,不过要注意啦,因为匿名对象是具有常性的,所以我们需要在左边添加
const哦。就像这样:int main() {const A& r = A();return 0; }当匿名对象被引用之后,它的生命周期是会被延长的哦,此时这个匿名对象的生命周期就跟着引用走啦,是伴随着引用的销毁而销毁的呢。如果这个匿名对象销毁之后,但是引用还在,那这个引用就变成了野引用了,这可是要特别注意避免的情况哦。
匿名对象的特点
没有名称:匿名对象没有明确的变量名,它们直接在创建的地方使用。
短生命周期:通常,它们的生命周期很短,通常仅限于创建它们的上下文。
简化代码:匿名对象有助于避免为临时对象命名,减少不必要的代码。
五、匿名对象的常见使用场景及优点
常见使用场景
- 方法参数:在传递对象作为方法参数时,直接创建匿名对象而不需要事先定义它哦。就像在其他编程语言中的这个例子一样:
public class Demo {public void printData(Person person) {System.out.println(person.getName());}public static void main(String[] args) {Demo demo = new Demo();demo.printData(new Person("Jean", 30)); // 直接创建匿名对象} }
- 短暂的计算:在需要临时对象来执行某些逻辑时,使用匿名对象是很方便的哦。比如在 C++ 里可以这样:
int result = new Calculator().add(10, 20); // 创建匿名Calculator对象执行加法
- 初始化列表:在某些语言中,匿名对象还用于在构造函数中初始化对象或集合呢,比如在 JavaScript 中的类似用法。
优点
- 简洁性:匿名对象最大的优点之一就是能避免为短暂的对象创建冗余变量,从而简化代码哦。让代码看起来更加简洁明了,尤其是在一些只需要临时使用对象的场景下。
- 更好的性能:在某些情况下,匿名对象可能避免了不必要的对象引用,这样有助于垃圾回收更快地回收内存呢,从而在一定程度上提升了程序的性能。
六、匿名对象的注意事项
虽然匿名对象能简化代码,但也可能让代码变得难以调试或维护哦,因为没有明确的对象引用嘛。所以如果多个地方需要使用相同的对象,建议还是使用具名对象哦,这样在调试和维护代码的时候会更加方便清晰呢。
对象拷⻉时的编译器优化
一、编译器优化的背景与原则
现代编译器始终秉持着一个重要目标:在确保程序正确性不受影响的前提下,竭尽全力提高程序的运行效率。在对象拷贝相关的操作中,比如传参和传返回值过程,编译器会想尽办法减少那些可有可无的拷贝操作。毕竟,每一次不必要的拷贝都可能消耗额外的时间和内存资源,而通过优化,就能让程序在运行过程中更加轻盈高效。
值得注意的是,关于具体该如何进行这些优化,C++ 标准并没有给出严格的规定哦。这就好比给了各个编译器充分的自由发挥空间,它们会依据自身的情况和算法来制定相应的优化策略。目前主流的相对新一点的编译器,以及一些更为 “激进” 的编译器,都有着各自独特的优化手段呢。

二、常见的编译器优化策略及示例
1.连续拷贝的合并优化
许多编译器对于连续一个表达式步骤中的连续拷贝操作会进行合并优化,就像我们常见的以下几种情况:
首先,来看一个简单的类
A的定义:#include<iostream> using namespace std;class A { public:A(int a = 0): _a1(a){cout << "A(int a)" << endl;}A(const A& aa): _a1(aa._a1){cout << "A(const A& aa)" << endl;}A& operator=(const A& aa){cout << "A& operator=(const A& aa)" << endl;if (this!= &aa){_a1 = aa._a1;}return *this;}~A(){cout << "~A()" << endl;} private:int _a1 = 1; };
2.返回值优化(RVO)
当函数返回一个对象时,编译器可以施展一种很厉害的优化手段 —— 返回值优化(RVO)。具体来说,编译器可以直接在调用方的内存空间中构造返回的对象,而不是依照常规先在函数内部构造好,然后再拷贝到调用方。这样一来,就能够巧妙地避免一次不必要的对象拷贝啦
举个例子:
MyClass createObject() {return MyClass(); }在没有开启返回值优化(RVO)时,
MyClass()会先在函数内部创建,然后再拷贝到调用方。而一旦开启了 RVO,MyClass就可以直接在调用方的内存空间中构造,大大节省了拷贝的开销呢。3.移动语义(C++11 及之后版本)
在 C++11 及之后的版本中,引入了移动语义这一强大的优化利器。当对象被移动时,编译器会通过一种 “偷取” 资源的方式来避免深拷贝哦。移动构造函数和移动赋值运算符赋予了编译器从源对象中 “偷取” 资源的能力,而不是傻乎乎地去复制它们。这种优化在处理临时对象或者对象需要从另一个作用域转移的情况时,显得尤为有用呢。
MyClass obj1; MyClass obj2 = std::move(obj1); // 通过移动语义“偷取”资源,而不是拷贝这里通过
std::move函数,触发了移动语义,使得obj2可以直接获取obj1的资源,而无需进行繁琐的拷贝操作。4.拷贝省略(C++17 引入)
C++17 版本引入了强制的拷贝省略规则哦。这意味着在某些特定情况下,即使没有定义移动构造函数或移动赋值运算符,编译器也会跳过拷贝操作,直接构造目标对象呢。
就像下面这个例子:
MyClass createObject() {MyClass obj;return obj; // 编译器可以省略拷贝或移动 }5.内联优化(Inline Expansion)
对于那些小巧且频繁被调用的函数,编译器可能会选择内联展开函数代码哦。这样做不仅能够减少函数调用所带来的开销,而且还能让编译器在内联的上下文中进行更多的对象优化呢。
inline MyClass createObject() {return MyClass(); }通过将函数内联展开,编译器在处理这个函数返回对象的过程中,就有更多机会施展它的优化魔法啦。
6.对象合并与内存重用
编译器还会进行一种对象合并的优化操作哦。它会仔细分析多个对象的生命周期,如果发现它们不会同时存在于内存中,那么编译器就会聪明地将它们分配在同一块内存空间中,从而有效减少内存的占用呢。
7.懒惰拷贝(写时拷贝,COW)
还有一种有趣的优化策略叫做懒惰拷贝,也称为写时拷贝(Copy on Write,COW)。当多个对象引用同一资源时,编译器会选择延迟执行真正的拷贝操作,直到有一个对象尝试修改该资源时才会进行拷贝。这样就能巧妙地避免不必要的深拷贝啦,节省了大量的内存和时间开销呢。
8.循环展开与向量化优化
在对象拷贝的循环操作中,编译器也不会闲着哦。它可能会进行循环展开和向量化优化,将循环中的多个对象拷贝操作合并或者并行化处理,以此来提高程序的性能呢。

相关文章:

类和对象(下):点亮编程星河的类与对象进阶之光
再探构造函数 在实现构造函数时,对成员变量进行初始化主要有两种方式: 一种是常见的在函数体内赋值进行初始化;另一种则是通过初始化列表来完成初始化。 之前我们在构造函数中经常采用在函数体内对成员变量赋值的方式来给予它们初始值。例如&…...

42.接雨水
目录 题目过程解法 题目 给定 n 个非负整数表示每个宽度为 1 的柱子的高度图,计算按此排列的柱子,下雨之后能接多少雨水。 过程 发现有特殊情况就是,最高峰的地方,如果右边小于他,然后再右边也都很小的话,…...
:Kafka消费 offset API,包含指定 Offset 消费以及指定时间消费)
使用Java代码操作Kafka(五):Kafka消费 offset API,包含指定 Offset 消费以及指定时间消费
文章目录 1、指定 Offset 消费2、指定时间消费 1、指定 Offset 消费 auto.offset.reset earliest | latest | none 默认是 latest (1)earliest:自动将偏移量重置为最早的偏移量,–from-beginning (2)lates…...

Ubuntu安装不同版本的opencv,并任意切换使用
参考: opencv笔记:ubuntu安装opencv以及多版本共存 | 高深远的博客 https://zhuanlan.zhihu.com/p/604658181 安装不同版本opencv及共存、切换并验证。_pkg-config opencv --modversion-CSDN博客 Ubuntu下多版本OpenCV共存和切换_ubuntu20如同时安装o…...

突破内存限制:Mac Mini M2 服务器化实践指南
本篇文章,我们聊聊如何使用 Mac Mini M2 来实现比上篇文章性价比更高的内存服务器使用,分享背后的一些小的思考。 希望对有类似需求的你有帮助。 写在前面 在上文《ThinkPad Redis:构建亿级数据毫秒级查询的平民方案》中,我们…...

【排版教程】Word、WPS 分节符(奇数页等) 自动变成 分节符(下一页) 解决办法
毕业设计排版时,一般要求每章节的起始页为奇数页,空白页不显示页眉和页脚。具体做法如下: 1 Word 在一个章节的内容完成后,在【布局】中,点击【分隔符】,然后选择【奇数页】 这样在下一章节开始的时&…...

【在Linux世界中追寻伟大的One Piece】多线程(二)
目录 1 -> 分离线程 2 -> Linux线程互斥 2.1 -> 进程线程间的互斥相关背景概念 2.2 -> 互斥量mutex 2.3 -> 互斥量的接口 2.4 -> 互斥量实现原理探究 3 -> 可重入VS线程安全 3.1 -> 概念 3.2 -> 常见的线程不安全的情况 3.3 -> 常见的…...

flink学习(8)——窗口函数
增量聚合函数 ——指窗口每进入一条数据就计算一次 例如:要计算数字之和,进去一个12 计算结果为20, 再进入一个7 ——结果为27 reduce aggregate(aggregateFunction) package com.bigdata.day04;public class _04_agg函数 {public static …...

「实战应用」如何用图表控件LightningChart .NET实现散点图?(一)
LightningChart .NET完全由GPU加速,并且性能经过优化,可用于实时显示海量数据-超过10亿个数据点。 LightningChart包括广泛的2D,高级3D,Polar,Smith,3D饼/甜甜圈,地理地图和GIS图表以及适用于科…...
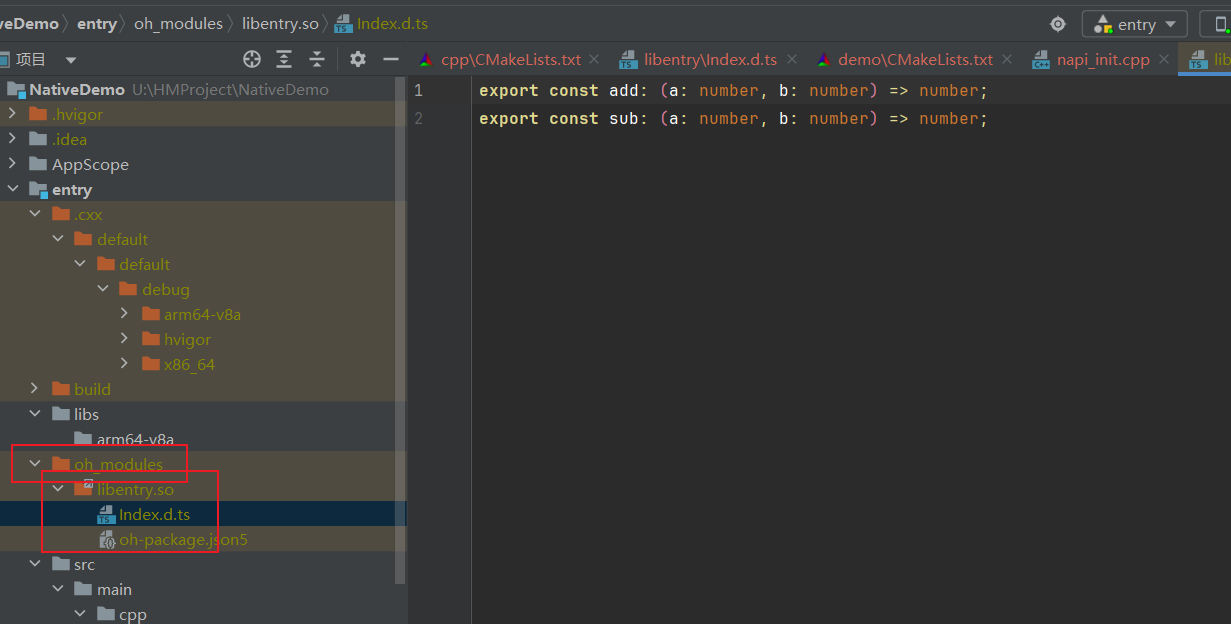
鸿蒙Native使用Demo
DevecoStudio使用Native 今天,给大家带来的是关于DevecoStudio中使用Native进行开发 个人拙见:为什么要使用Native?无论是JS还是TS在复杂的情况下运行速度,肯定不如直接操作内存的C/C的运行速度快,所以,会选择使用Native;这里面的过程是什么?通过映射转化,使用napi提供的接口…...

29.UE5蓝图的网络通讯,多人自定义事件,变量同步
3-9 蓝图的网络通讯、多人自定义事件、变量同步_哔哩哔哩_bilibili 目录 1.网络通讯 1.1玩家Pawn之间的同步 1.2事件同步 1.3UI同步 1.4组播 1.5变量同步 1.网络通讯 1.1玩家Pawn之间的同步 创建一个第三人称项目 将网络模式更改为监听服务器,即将房主作为…...

Scala—列表(可变ListBuffer、不可变List)用法详解
Scala集合概述-链接 大家可以点击上方链接,先对Scala的集合有一个整体的概念🤣🤣🤣 在 Scala 中,列表(List)分为不可变列表(List)和可变列表(ListBuffer&…...

【论文复现】偏标记学习+图像分类
📝个人主页🌹:Eternity._ 🌹🌹期待您的关注 🌹🌹 ❀ 偏标记学习图像分类 概述算法原理核心逻辑效果演示使用方式参考文献 概述 本文复现论文 Progressive Identification of True Labels for Pa…...

C嘎嘎探索篇:栈与队列的交响:C++中的结构艺术
C嘎嘎探索篇:栈与队列的交响:C中的结构艺术 前言: 小编在之前刚完成了C中栈和队列(stack和queue)的讲解,忘记的小伙伴可以去我上一篇文章看一眼的,今天小编将会带领大家吹奏栈和队列的交响&am…...

AIGC-----AIGC在虚拟现实中的应用前景
AIGC在虚拟现实中的应用前景 引言 随着人工智能生成内容(AIGC)的快速发展,虚拟现实(VR)技术的应用也迎来了新的契机。AIGC与VR的结合为创造沉浸式体验带来了全新的可能性,这种组合不仅极大地降低了VR内容的…...

Django 路由层
1. 路由基础概念 URLconf (URL 配置):Django 的路由系统是基于 urls.py 文件定义的。路径匹配:通过模式匹配 URL,并将请求传递给对应的视图处理函数。命名路由:每个路由可以定义一个名称,用于反向解析。 2. 基本路由配…...
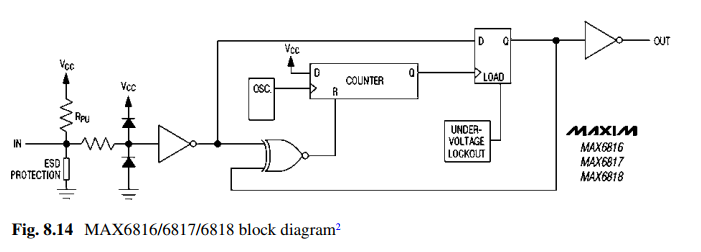
《硬件架构的艺术》笔记(八):消抖技术
简介 在电子设备中两个金属触点随着触点的断开闭合便产生了多个信号,这就是抖动。 消抖是用来确保每一次断开或闭合触点时只有一个信号起作用的硬件设备或软件。(就是每次断开闭合只对应一个操作)。 抖动在某些模拟和逻辑电路中可能产生问…...

Spring 与 Spring MVC 与 Spring Boot三者之间的区别与联系
一.什么是Spring?它解决了什么问题? 1.1什么是Spring? Spring,一般指代的是Spring Framework 它是一个开源的应用程序框架,提供了一个简易的开发方式,通过这种开发方式,将避免那些可能致使代码…...

【算法】连通块问题(C/C++)
目录 连通块问题 解决思路 步骤: 初始化: DFS函数: 复杂度分析 代码实现(C) 题目链接:2060. 奶牛选美 - AcWing题库 解题思路: AC代码: 题目链接:687. 扫雷 -…...

如何选择黑白相机和彩色相机
我们在选择成像解决方案时黑白相机很容易被忽略,因为许多新相机提供鲜艳的颜色,鲜明的对比度和改进的弱光性能。然而,有许多应用,选择黑白相机将是更好的选择,因为他们产生更清晰的图像,更好的分辨率&#…...

ChatGLM3-6B生成质量评估:对比原版模型的语义连贯性提升
ChatGLM3-6B生成质量评估:对比原版模型的语义连贯性提升 1. 引言:从“能回答”到“会聊天”的跨越 如果你用过早期的对话模型,可能有过这样的体验:你问一个问题,它答得还行;你再追问一句,它要…...

Youtu-VL-4B-InstructGPU利用率提升:通过batch_size=2+prefill优化,吞吐翻倍实测
Youtu-VL-4B-Instruct GPU利用率提升:通过batch_size2prefill优化,吞吐翻倍实测 1. 从单张到两张,一次简单的改变带来巨大收益 如果你正在使用腾讯优图开源的Youtu-VL-4B-Instruct模型,大概率会遇到这样一个问题:GPU…...

YOLOv8环境配置疑难解析:从‘No module named ultralytics‘到Git初始化失败的全面排错指南
1. 为什么你的YOLOv8环境总是报错? 最近很多朋友在搭建YOLOv8环境时遇到了各种奇怪的问题,从"找不到ultralytics模块"到"Git初始化失败",这些问题看似简单,但背后往往隐藏着复杂的系统环境问题。作为一个在计…...

用PyAutoGUI实现游戏自动化:从屏幕识图到自动点击的完整实战
用PyAutoGUI实现游戏自动化:从屏幕识图到自动点击的完整实战 游戏自动化一直是开发者们热衷探索的领域,而Python凭借其简洁的语法和丰富的库生态,成为了实现这一目标的理想工具。PyAutoGUI作为Python中最受欢迎的GUI自动化库之一,…...

TwinCAT3 Modbus-TCP双端通信实战:从环境配置到寄存器操作
1. TwinCAT3与Modbus-TCP通信基础 工业自动化领域最让人头疼的就是设备间的通信问题。我刚开始接触TwinCAT3时,面对各种通信协议也是一头雾水。直到掌握了Modbus-TCP这个"万能翻译官",才发现原来不同设备之间的对话可以如此简单。Modbus-TCP就…...

大数据领域数据服务的典型应用场景
大数据领域数据服务的典型应用场景关键词:大数据、数据服务、应用场景、商业决策、社会治理摘要:本文主要探讨了大数据领域数据服务的典型应用场景。通过深入分析不同行业中数据服务的具体应用,展现了大数据在当今社会的重要价值。从商业领域…...

轻量级CoAP库:面向Arduino/ESP32的嵌入式RESTful通信实现
1. 项目概述 CoAP Simple Library 是一款专为资源受限嵌入式平台设计的轻量级 Constrained Application Protocol(CoAP)协议实现,面向 Arduino 生态系统(包括 ESP32、ESP8266、Particle Photon/Core 等主流 MCU 平台)提…...

大数据基于Python的事业单位报考数据分析与可视化
目录数据采集与清洗数据存储与管理数据分析可视化实现自动化与部署关键注意事项项目技术支持源码获取详细视频演示 :文章底部获取博主联系方式!同行可合作数据采集与清洗 使用Python的requests或scrapy库爬取事业单位招聘网站数据(如各地人社…...
商用注意事项与合规建议)
AudioSeal入门必看:AudioSeal开源协议(MIT)商用注意事项与合规建议
AudioSeal入门必看:AudioSeal开源协议(MIT)商用注意事项与合规建议 1. AudioSeal概述 AudioSeal是Meta公司开源的一款专业级音频水印系统,专门用于AI生成音频的检测和溯源。这个工具在音频内容保护领域具有重要价值,…...

SenseVoice-small-onnx语音识别效果对比:中文普通话vs粤语识别差异
SenseVoice-small-onnx语音识别效果对比:中文普通话vs粤语识别差异 获取更多AI镜像 想探索更多AI镜像和应用场景?访问 CSDN星图镜像广场,提供丰富的预置镜像,覆盖大模型推理、图像生成、视频生成、模型微调等多个领域,…...